In the following section, we describe our methodology for constructing our two-stage model for predicting spatiotemporal PM2.5 pollutants over Los Angeles county. Our motivations for using multisource meteorological data, wildfire data, remote-sensing satellite imagery, and ground-based air pollution sensor data are that these data sources are interrelated, and including data from all sources provides the necessary depth of clarity to accurately predict spatiotemporal air pollution.
2.1. Model Architecture
The Graph Convolutional Network (GCN) is a complex deep-learning architecture applied upon graphs [
13]. Graphs are a valuable and effective method of modeling air pollution and weather forecasting, since the bulk of open-access air pollution and meteorological data are in the form of stationary ground-based sensors. Thus, it is intuitive to draw a parallel between these ground-based sensors and nodes in a weighted directed graph. A weighted directed graph provides the additional functionality to preserve the spatial and distance-based correlations among sensors. The goal of the Graph Convolutional Network is to learn the feature embeddings and patterns of nodes and edges in a graph. The GCN learns the features of an input graph
typically expressed with an adjacency matrix
A as well as a feature vector
for every node
i in the graph expressed in a matrix of size
where
V is the number of vertices in the graph and
D is the number of input features for each vertex. The output of the GCN is an
matrix where
F is the number of output features for each vertex. We can then construct a deep neural network with an initial layer embedding of
to perform convolution neighborhoods of nodes, similar to a Convolutional Neural Network (CNN). Then, the
k-th layer of the neural network’s embedding on vertices
is
where
is some non-linear activation function,
is the previous layer embedding of
v,
is a transformation matrix for self and neighbor embeddings, and
is the average of a neighbor’s previous layer embeddings. The neural network can be trained efficiently through sparse batch operations on a layer wise propagation rule
where
I is the identity matrix,
, and
D is the diagonal node degree matrix defined as
[
14]. In this way, the GCN can train a neural network to output a graph with feature vectors for each node in the graph. In our implementation, we extend the GCN model’s capabilities further by providing a feature matrix constructed of feature vectors for each edge in the graph such that the GCN outputs a graph with an output feature matrix for all nodes and edges in the graph.
The second stage of our model uses the highly effective Convolutional Long Short-Term Memory (ConvLSTM) deep-learning architecture which learns and predicts for data considering both spatial and temporal correlations. The ConvLSTM model is a variant of the traditional Long Short-Term Memory (LSTM) model, a time-series Recurrent Neural Network (RNN).
Traditional LSTM models rely on a single-dimensional input vector parameterized by time. The structure of the LSTM model relies on a recurrent sequential architecture of gates and cells which retain and propagate certain information from previous cells and data. For a traditional FC-LSTM (Fully Connected Long Short-Term Memory), the time-parameterized input gates
, forget gates
, cell states
, output gates
, and hidden gates
are defined as
where
W denotes the weight matrix and ∘ denotes the Hadamard matrix multiplication product [
15]. In a traditional FC-LSTM, both the inputs and outputs are single-dimensional time-series vectors. As a result, LSTM models do not allow for or use spatial correlations in data. More generally, the traditional FC-LSTM architecture does not allow image or video-like inputs.
The ConvLSTM model improves upon the FC-LSTM by applying convolution within the cells and gates of the LSTM to allow for multidimensional video-like inputs and outputs. This can be achieved by replacing the Hadamard products used to define the key equations for the FC-LSTM with the convolution operation. Intuitively, this replacement effectively serves as an intermediary processing layer between the video-like input and the traditional LSTM model by transforming the video-like input frames to single-dimensional vectors through convolution at each cell of the FC-LSTM. The key equations for the ConvLSTM are
where * denotes the convolution operation [
16].
Please note that there are two methods to induce convolution in a traditional LSTM model. One such method is denoted as the ConvLSTM model and uses the convolution operation within the cells and gates of the LSTM, thus directly allowing the inputs and outputs of the ConvLSTM to be time-series multidimensional data. Another method of inducing convolution is to perform convolution prior to and separately from the LSTM model. By modularizing the convolution operation and first training a Convolutional Neural Network (CNN) to transform video-like inputs to single-dimensional time-parameterized output vectors and then using the CNN’s output in a traditional FC-LSTM, we can achieve a similar level of learning and prediction based on spatial and temporal correlations. This approach is succinctly presented as a standalone deep-learning model denoted the Convolutional Neural Network—Long Short-Term Memory (CNN-LSTM), which, as the name suggests, uses a CNN and LSTM run in series to learn and predict video-like inputs. We perform spatiotemporal air pollution prediction using the ConvLSTM model; however, there is prior research on alternatively using the CNN-LSTM model to predict spatiotemporal air pollution [
17,
18,
19,
20].
More specifically, we find that including meteorological features is essential to an accurate prediction of ambient air pollution. Air pollutants are closely correlated with meteorological data. A recent study found that of the 896 government-monitored air pollution sensors in China, 675 ground-based sensors reported an increase in carbon monoxide (
), sulfur dioxide (
), nitrogen dioxide (
), and PM2.5 when there was a greater than 10% increase in wind speed at the same location [
21].
In the geographical setting of Los Angeles county, it comes as no surprise that wildfire/heat data can provide useful insights into the structures and patterns of atmospheric air pollutants. We find that including remote-sensing satellite imagery and ground-based grid sensor data information on the wildfire, smoke, and heat patterns in Los Angeles county greatly improved the accuracy of our predictive model for forecasting PM2.5. In fact, Burke et al. [
22] found that wildfire smoke now accounts for up to half of all fine-particle pollution including PM2.5 in the Western U.S and up to 25% of fine-particle pollution nationwide. Thus, a major focus of our model is fixated on effectively using the wildfire/smoke information for the reliable and accurate prediction of PM2.5 in Los Angeles county.
We find that including a mixture of both remote-sensing satellite imagery of air pollution and ground-based sensor air pollution data is necessary for a robust and multifaceted approach to spatiotemporal air pollution prediction. Remote-sensing satellite imagery provides information on atmospheric air pollution and its general structures, while ground-based sensors provide finer-grained information on air pollution at sea level or within cities. Since the level of air pollution may vary greatly with respect to altitude, we use both remote-sensing satellite imagery and ground-based sensor data as input to our model to fully understand and predict air pollution.
Finally, we find that including remote-sensing satellite imagery and ground-based sensor data from other air pollutants prove to be beneficial when predicting for a particular pollutant—in our case PM2.5. For example, although the goal of our model is to predict PM2.5, we include imagery and sensor data of nitrogen dioxide (
), carbon monoxide (
CO), ozone (
), and methane (
) atmospheric air pollutants because these pollutants are closely linked to PM2.5 [
23]. According to Jiao and Frey [
24], the main source of both PM2.5 and atmospheric carbon monoxide is vehicle exhausts and emissions. Thus, it serves only benefit to include additional air pollutant data when predicting for spatiotemporal PM2.5.
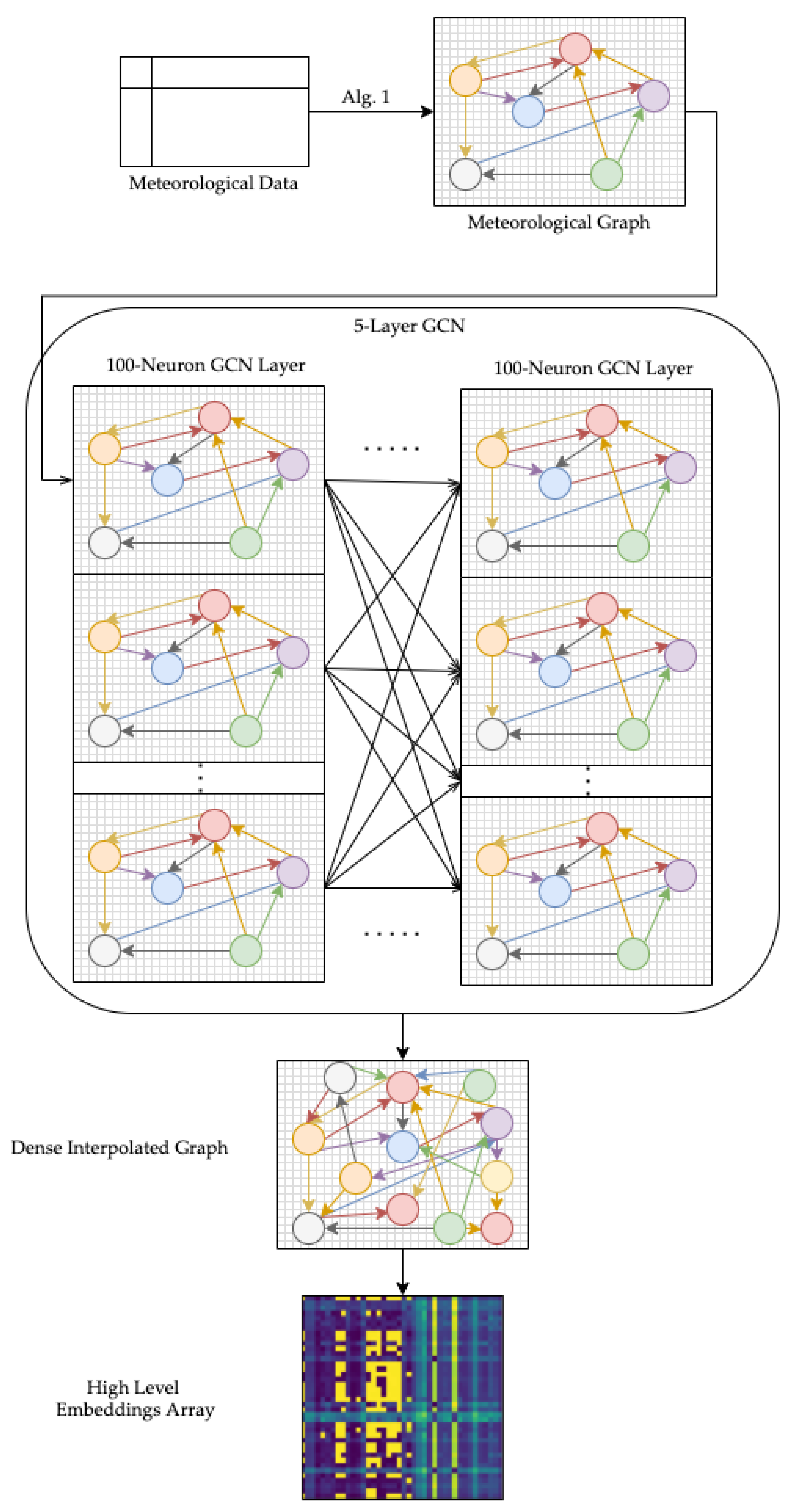
The first stage of our model uses the Graph Convolutional Network architecture to learn patterns of meteorological data through a graph representation. We first construct a weighted directed graph representation with the meteorological data. The goal of the GCN architecture is to interpolate a denser meteorological graph with more nodes and connecting edges than the input graph. The primary issue with high-quality validated ground-based meteorological sensor data is that for a geographic area as fine-grained as Los Angeles county, the number of site locations and meteorological features are sparse. Basic interpolation techniques such as distance-weighted interpolation and nearest neighbor interpolation fail to accurately map the spatiotemporal correlations of meteorological data. The task of interpolation is inherently an effective task to obtain high-level learned feature embeddings. By applying a GCN architecture for spatial interpolation, we can train a deep-learning model to predict meteorological trends in areas not provided by the input graph. We can later use these interpolated correlations as inputs to construct a video-like sequence of spatially continuous predicted meteorological features over time in our geographical area. For our model, we adapt previous work on spatiotemporal kriging with Graph Convolutional Networks to interpolate our nodes and edges of the meteorological graph [
25]. We train the GCN for this interpolation task by systematically hiding a small percentage of node and edges and their corresponding attribute vectors. The GCN model learns to predict for the hidden meteorological node and edge feature values using the ground truth data from a neighborhood of nodes and edges surrounding the missing information. By iteratively training the interpolation process using the loss function between the ground truth hidden attribute values and the predicted values, the GCN can interpolate a sparse meteorological graph into a dense graph containing various meteorological features. The GCN will create a dense meteorological graph for each sample parameterized by time. In the case of our model, the GCN interpolates the sparse meteorological graph into a dense graph for every hour of the hourly meteorological dataset.
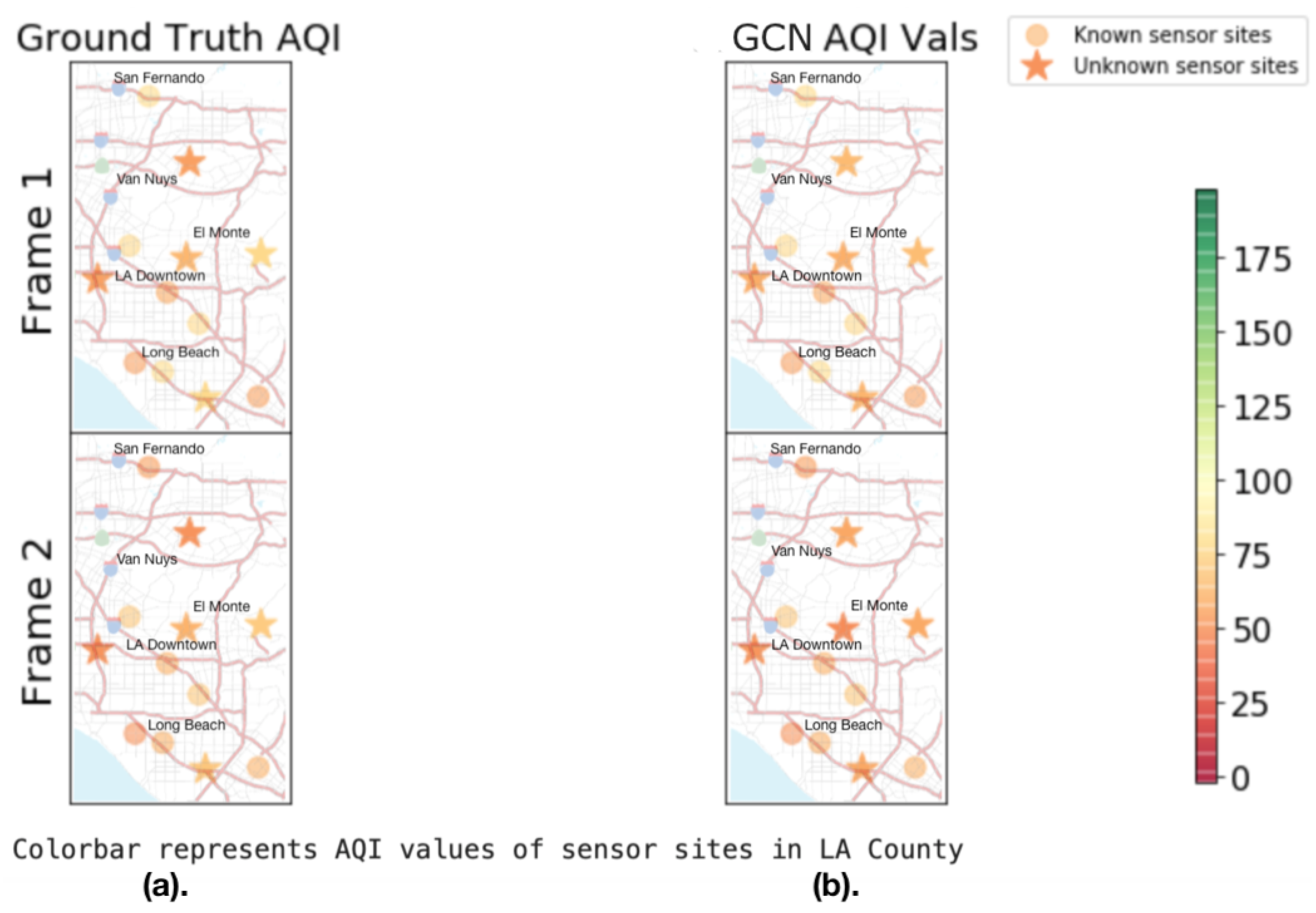
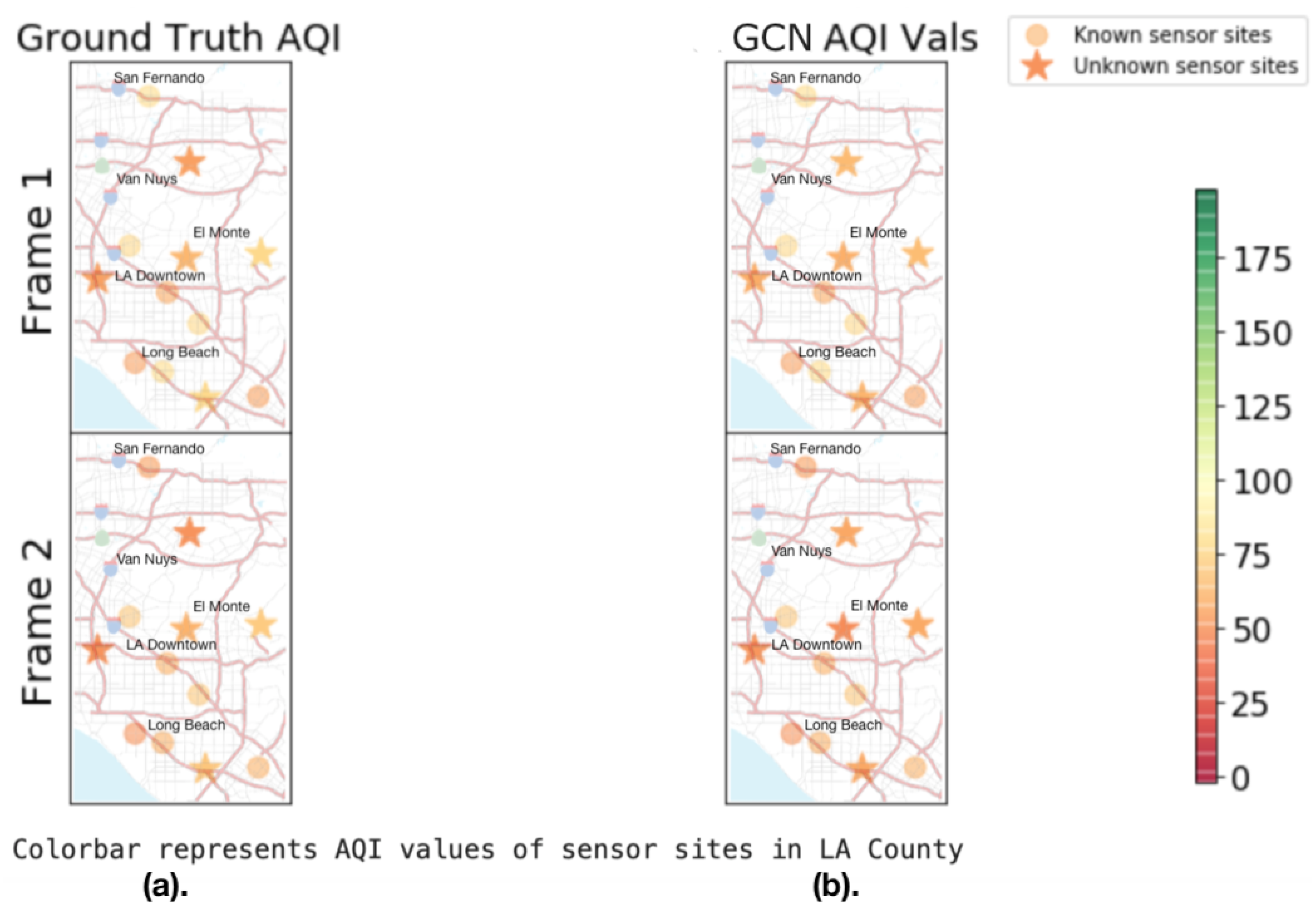
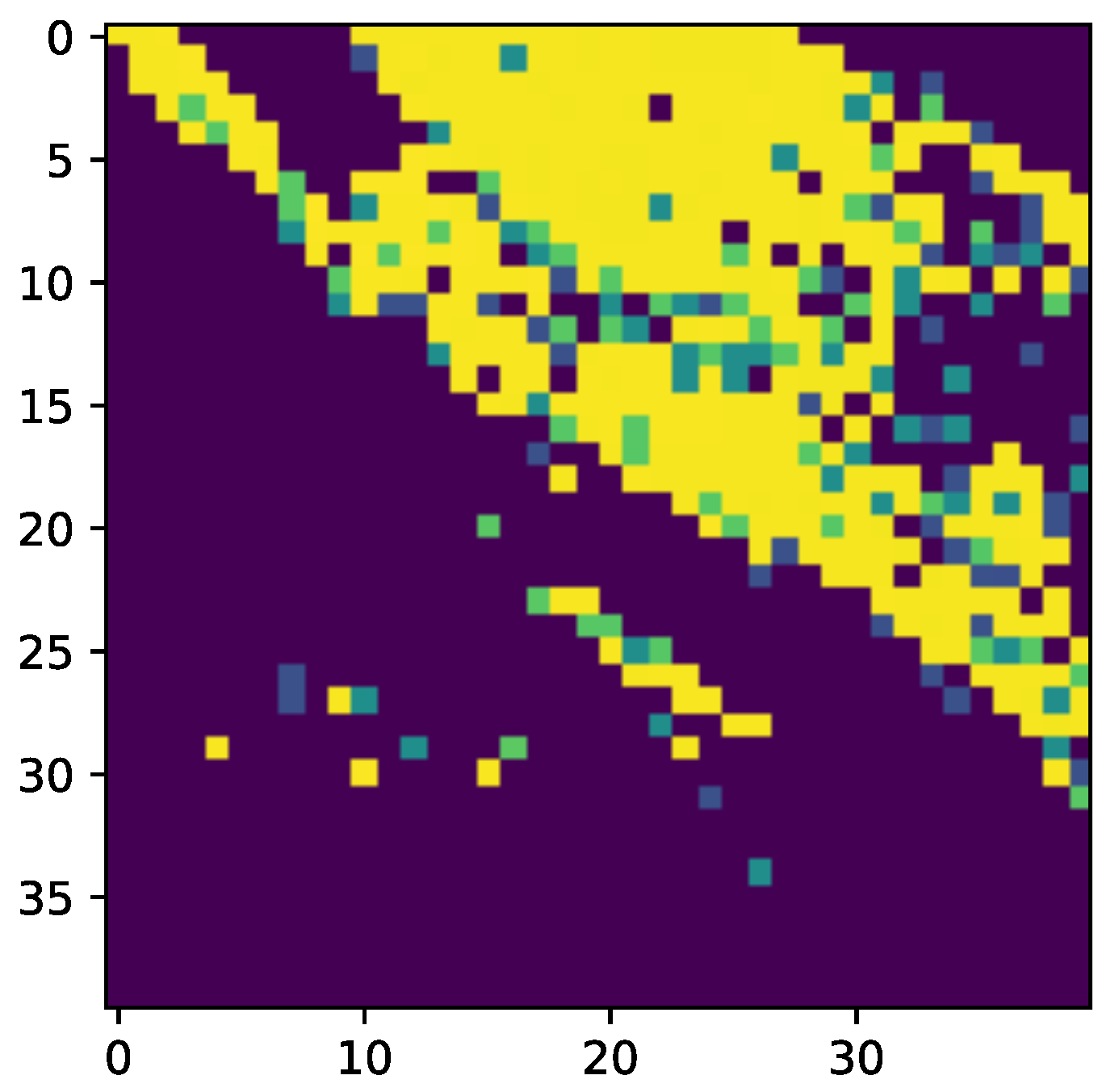
We provide a visualization of this interpolation training process in
Figure 1. We visualize two frames of the interpolation training process on the meteorological graph structure for a single stationary attribute of AQI.
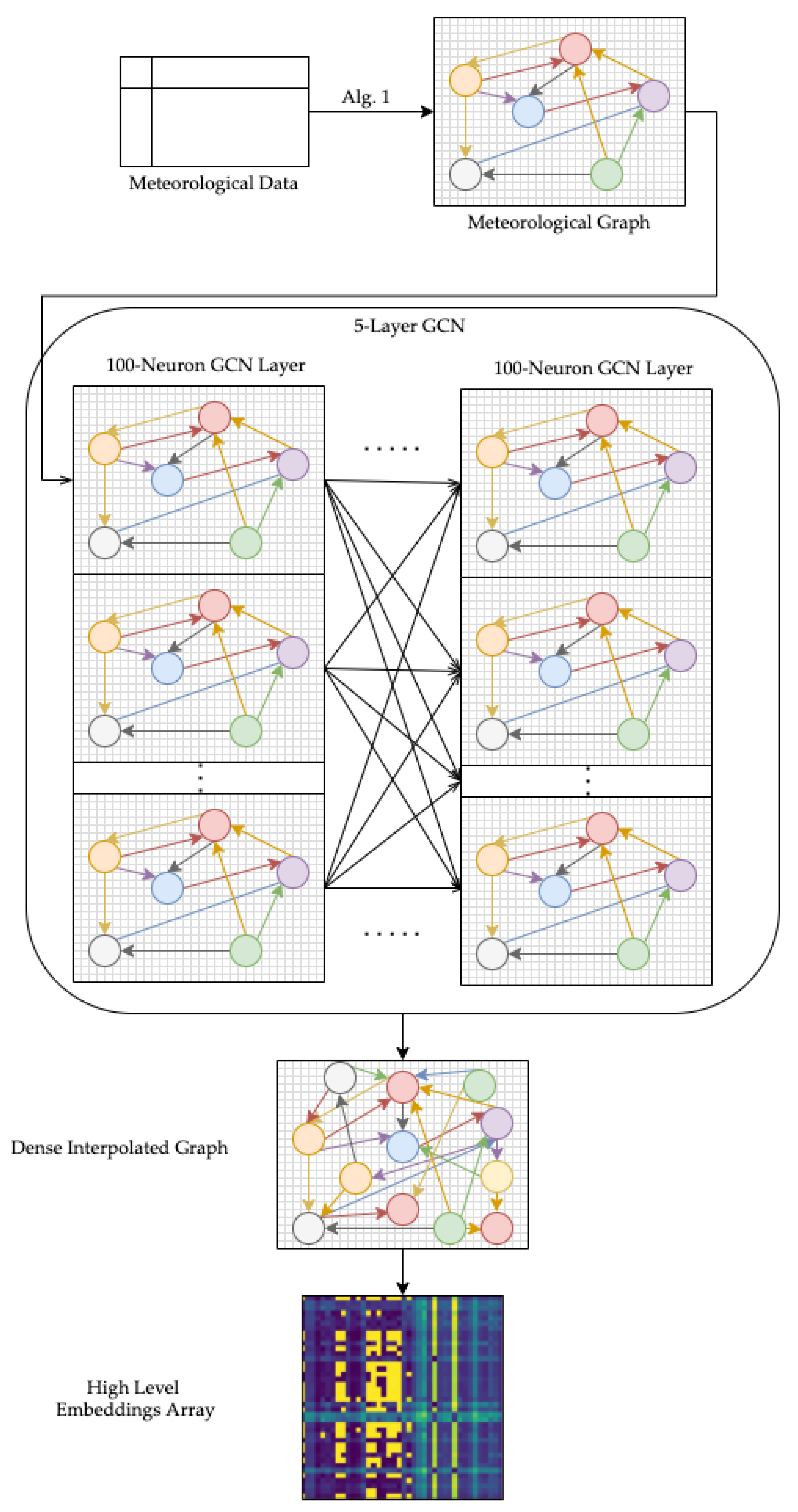
An intermediate step in our model converts the GCN-interpolated dense meteorological graph into an image-based format and concatenates many time-series samples into a video-like input to the ConvLSTM model. We apply an unsupervised learning graph representation learning approach to create a matrix of high-level weights corresponding to the representations of nodes and edges in the meteorological graph. This set of weights is bounded by the geographic area we have defined, and as a result, the high-level embedding weight array is calculated for each timestep of the meteorological dataset. By converting the dense meteorological graphs into spatiotemporal embeddings in a video-like input, we can pass the learned meteorological information as input to the second stage of our model. A visualization of the first stage and the intermediate step to convert raw meteorological data into high-level embeddings from dense interpolated graphs is described in
Figure 2.
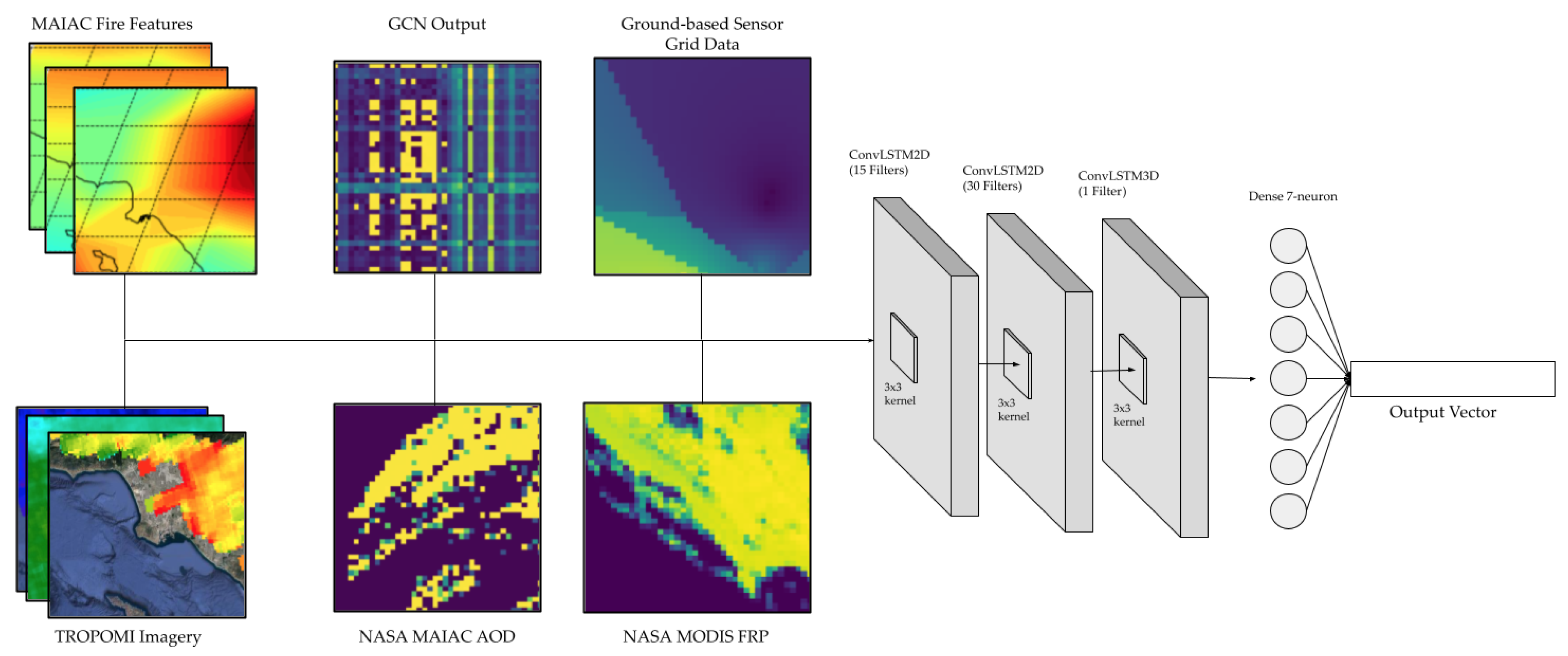
The second stage of our model uses the ConvLSTM architecture to predict spatiotemporal PM2.5. The inputs to the ConvLSTM model are all video-like in format: all input data are formatted as frames of images or arrays parameterized over time. The inputs to the ConvLSTM model are the learned meteorological information outputs from the first stage of the model, the remote-sensing satellite imagery of air pollutants, the wildfire heat data, and the ground-based sensor data of air pollutants. The output of the ConvLSTM model is a set of predicted ground-based PM2.5 sensor values around Los Angeles county for multiple days in the future.
Figure 3 displays a visualization of the ConvLSTM architecture which makes up the second module of our model.
2.2. Dataset
Our geographical bounds for prediction is a square region of roughly 2500 of northwest Los Angeles county. More specifically, we select the square region with corner coordinates ranging from N to N and W to W. We format all input data to fit these geographical bounds. For remote-sensing satellite imagery in our dataset, we crop the satellite images to fit the geographic boundaries we defined. For the ground-based sensors, we use the data from all sensors within the latitude and longitude range of our geographic boundary.
Our temporal bound for prediction is three years of data from 1 January 2018 to 31 December 2020. Each sample of our dataset has an hourly temporal frequency. This hourly frequency is standard across all input data and prediction results. For each of our data sources, we collect 26,304 samples corresponding to 24 hourly samples for the 1096 days of data from 1 January 2018 to 31 December 2020.
Our meteorological data are collected from the Iowa State University Environmental Mesonet database [
26]. The Environmental Mesonet database collects and records hourly Meteorological Aerodrome (METAR) Reports from Automated Surface Observing Systems (ASOS) located near various airports and municipal airstrips within the continental United States. The ASOS data are primarily used by airlines and air traffic controllers to monitor meteorological features near and around airport runways. The METAR data provides comprehensive hourly reports of 17 ground-level meteorological features including wind speed, wind direction, relative humidity, dew point, precipitation, Air Quality Index (AQI), air pressure, and air temperature. The complete list of meteorological features collected from each site is presented in the
Appendix A (
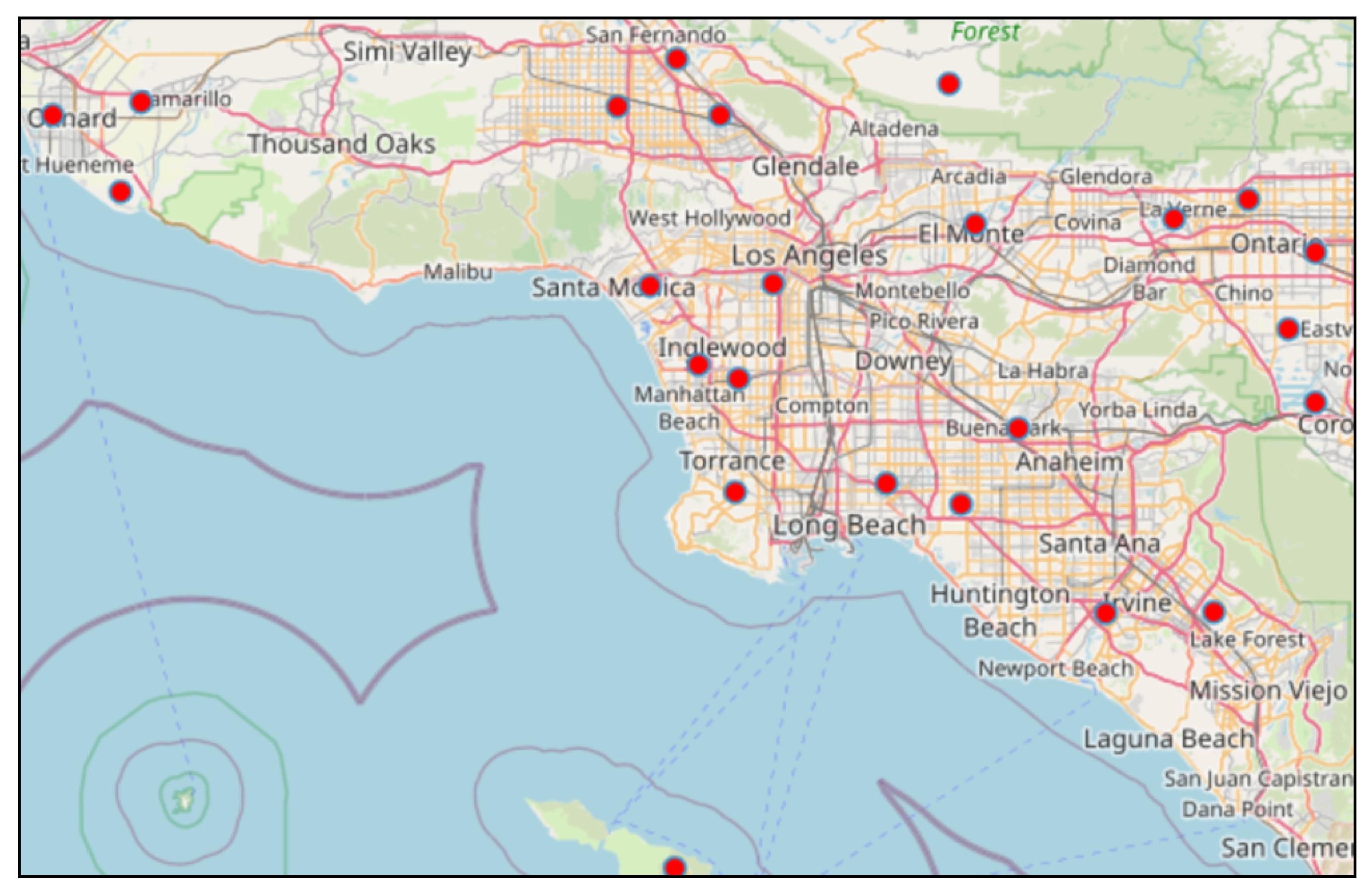
Table A2). Within our geographic boundaries, there are 24 ASOS sensors providing comprehensive, validated, and quality checked METAR reports.
Figure 4 describes the geographical area of interest and site locations for the raw meteorological features we collected.
To use these meteorological features within the model, we must transform the array format of the meteorological features into hourly meteorological graphs for the GCN model. First, since each of the meteorological features are recorded in terms of their respective units, we normalize the various units of these meteorological features. To normalize the units, we calculate each data point’s percentile value with respect to the previous day’s maximum value. This percentile value is calculated for each hourly sample and is the ratio between the current sample’s raw value and the metric’s maximum value across all 24 samples for the previous day. In this way, we retain the important meteorological information relative to each metric without relying on the domain-specific units of each meteorological feature.
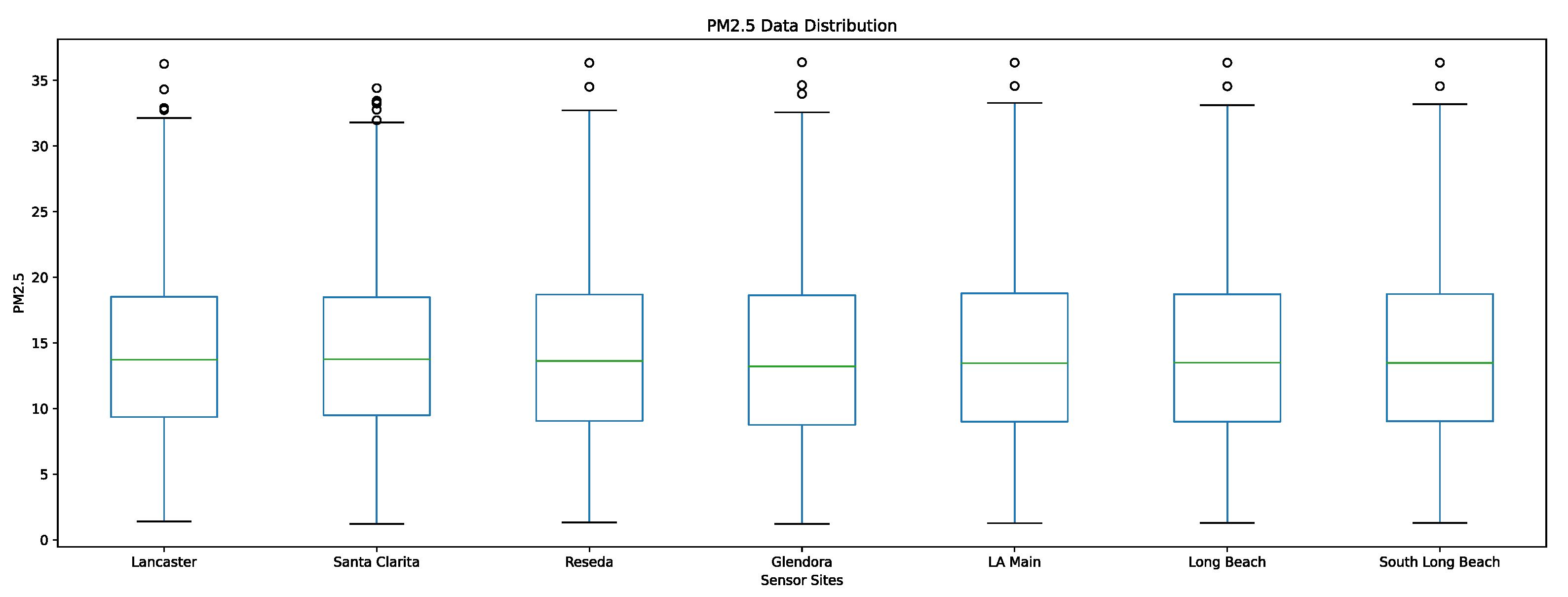
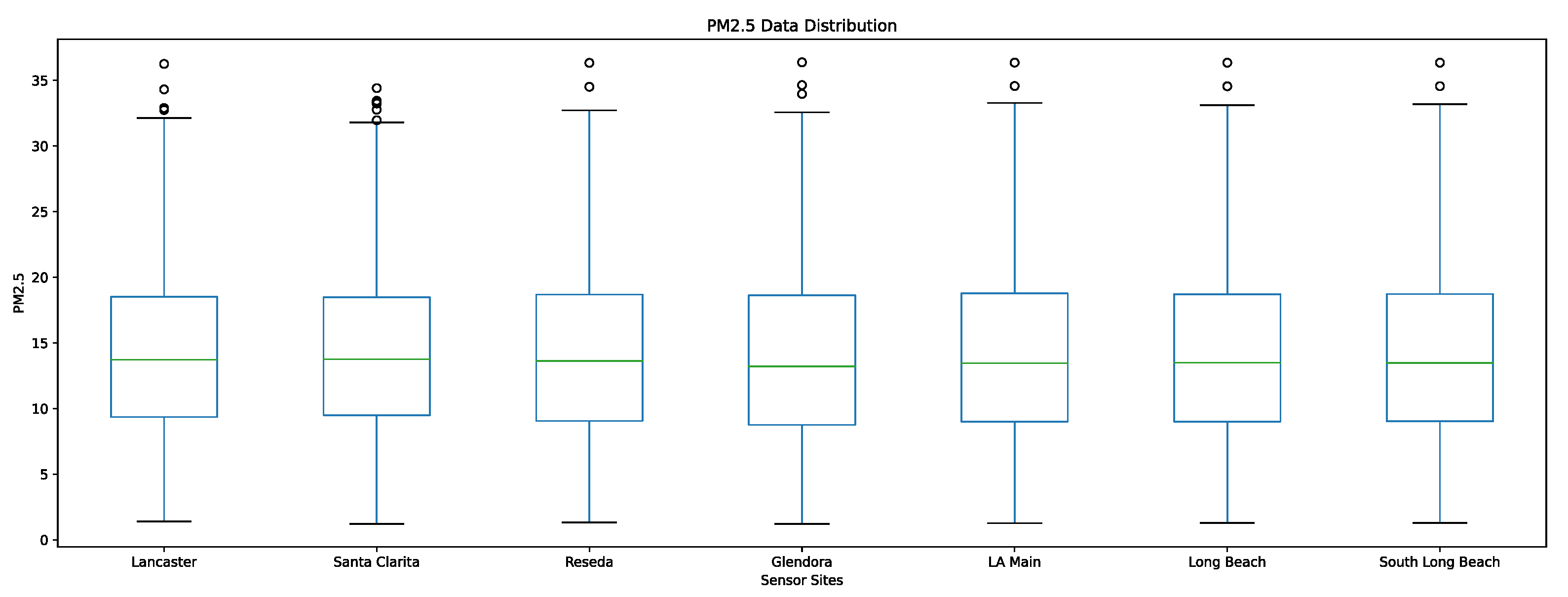
Our ground-based sensor PM2.5 dataset is collected from the Southern California Air Resources Board AQMIS2 portal [
27]. For the geographic range we have defined, there are seven quality-assured, validated PM2.5 monitoring sites collecting hourly data in the following locations: Lancaster, Santa Clarita, Reseda, Glendora, Los Angeles—North Main St, Long Beach, and Long Beach—Rt 710. These seven PM2.5 sensors are the only government-maintained PM2.5 sensors within the geographical bounds; however, there are various low-cost privately maintained sensors we did not use in our predictive model. To effectively validate the performance of our model, we select only highly regulated and closely maintained sensors to ensure that the error uncertainty for the raw sensor measurements is as low as possible. We use historical PM2.5 data at these locations while training the model and validate the accuracy of our model by measuring the error between our predicted PM2.5 values for future timesteps at these locations against the ground truth PM2.5 values.
Our remote-sensing data of various air pollutants is collected from the NASA Multi-Angle Implementation of Atmospheric Correction (MAIAC) algorithm and the ESA TROPOspheric Monitoring Instrument (TROPOMI) data sources [
28,
29]. The MAIAC algorithm is a preprocessing algorithm performed on imagery collected by the NASA Moderate Resolution Imaging Spectroradiometer (MODIS) instrument onboard the NASA Terra and Aqua satellites [
30]. The Terra and Aqua provide imagery over 36 spectral bands using the MODIS imaging instrument. The MAIAC algorithm is a complex data-preprocessing algorithm that converts raw MODIS imagery to data analytics ready samples by retrieving atmospheric aerosol and air pollutant data from MODIS images, normalizing pixel values, interpolating daily data for hourly use, and removing cloud cover masks.
In our model, one of the remote-sensing satellite imagery collections we use is the MAIAC MODIS/Terra+Aqua Daily Aerosol Optical Depth (AOD) dataset. AOD is a measure of the direct amount of sunlight blocked by atmospheric aerosols and air pollutants. This measure is perhaps the most comprehensive measure of ambient air pollution, and years of research has shown a strong correlation between AOD readings and PM2.5 concentrations in both atmospheric and ground-level settings [
31,
32]. The MAIAC MODIS AOD dataset we use in our predictive model records the blue-band Aerosol Optical Depth at a central wavelength of 0.47
m. The raw MAIAC MODIS AOD dataset provides a spatial resolution of 1 km/pixel for an area of 1200 km by 1200 km. For our implementation, we crop the imagery to fit our defined geographic bounds within Los Angeles county.
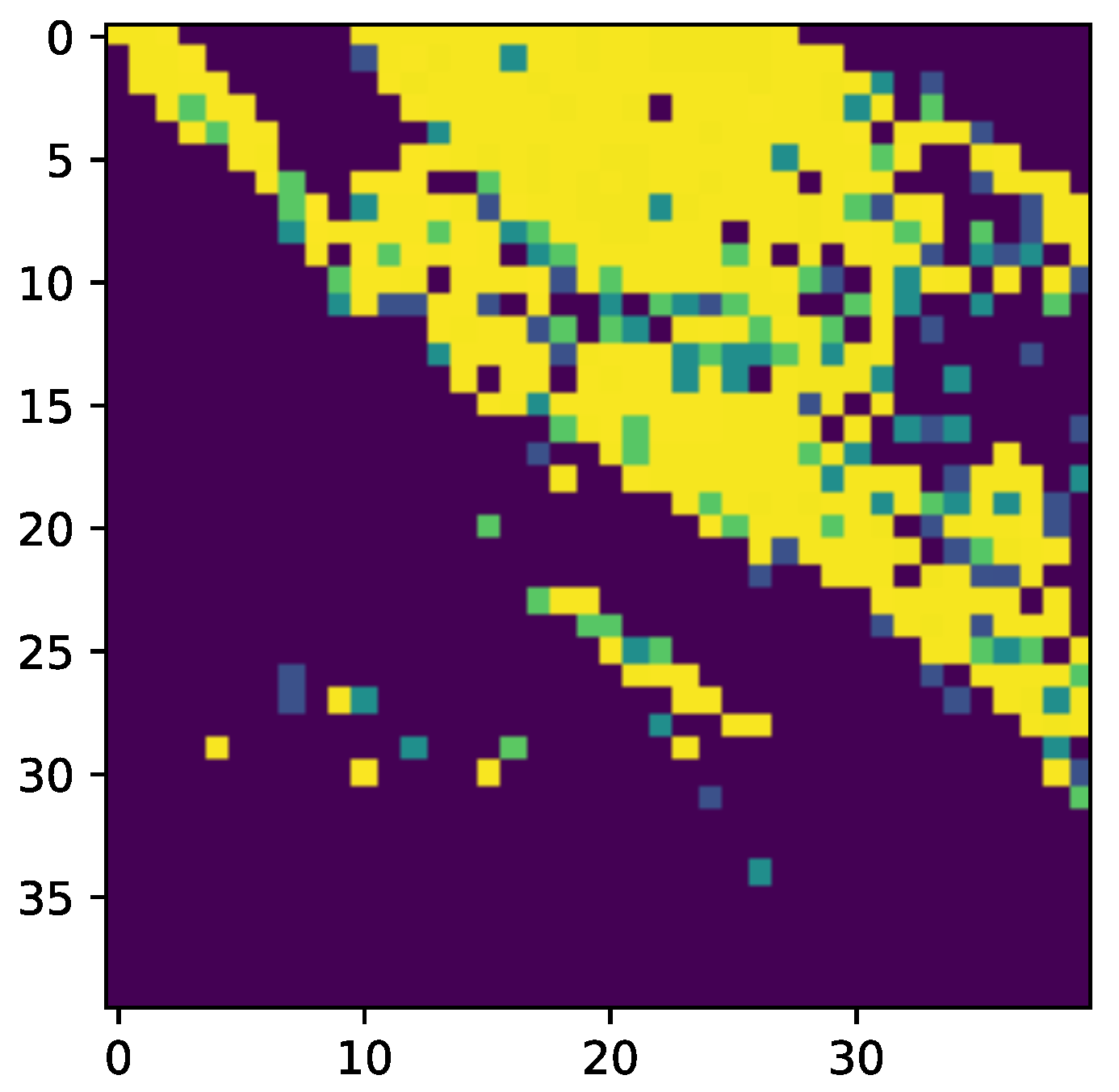
Figure 5 describes a sample of NASA MODIS AOD imagery after preprocessing from the MAIAC algorithm. We also apply an additional preprocessing step to downsample the MAIAC output to a grid of 40 by 40 pixels within our geographic bounds. This down sampling is performed to normalize the sample sizes across all input sources. Please note that the figure provides a visualization of the raw grid-like data of the MAIAC AOD imagery, and thus the color values of the visualization correspond to AOD values, not raw RGB values. As such, this visualization’s color values should be interpreted as a color map, not as a visual indicator of true AOD values. The brighter-colored pixels in the visualization correspond to higher AOD values.
We also collect remote-sensing data from the TROPOMI instrument onboard the ESA Sentinel-5P satellite. The Sentinel-5P satellite launched on 13 October 2017, orbiting at a height of 512 miles above sea level, with an orbital swath of 2600 km, and a mission length of seven years (2017–2024). The Sentinel-5P TROPOspheric Monitoring Instrument (TROPOMI) is a spectrometer capable of sensing ultraviolet (UV), visible (VIS), near (NIR) and short-wavelength infrared (SWIR) light. TROPOMI provides high-resolution global hourly data of atmospheric ozone, methane, formaldehyde, aerosol, carbon monoxide, nitrogen dioxide, and sulfur dioxide. For our model, we use remote-sensing data of methane (
), nitrogen dioxide (
), and carbon monoxide (
). We chose these air pollutants based on its correlation to PM2.5 and the spatial resolution of TROPOMI data. For these features, we apply additional downsampling to the TROPOMI data to generate hourly 40-by-40-pixel grids of data for each air pollutant.
Figure 6 describes examples of the downsampled methane, nitrogen dioxide, and carbon monoxide data used in our model.
We use ground-based and atmospheric wildfire and heat data to predict spatiotemporal PM2.5 in Los Angeles county. We collect wildfire and heat data from two sources: NASA MODIS data and NASA MERRA-2 data. We collect Fire Radiative Power (FRP) imagery from the NASA MODIS/Terra Land Surface Temperature and Emissivity collection [
33]. Fire Radiative Power (FRP) is a measure of the radiant heat output from a fire. The main contributors to increased levels of FRP include smoke from wildfires and emissions from the burning of carbon-based fuel, such as carbon monoxide (
) and carbon dioxide (
) emissions. Thus, there is a strong positive correlation between wildfires and FRP values as well as a weaker positive correlation between carbon emissions (
,
) and FRP values. FRP is measured in megawatts (MW) and can be collected using an imaging instrument onboard a remote-sensing satellite aircraft. The wavelength of light needed to image FRP is in the range of 2070
m to 3200
m.
In our model, we find that including FRP imagery drastically improves our model’s performance during the wildfire seasons such as months from June through November when predicting for spatiotemporal PM2.5 in Los Angeles. We also see improvements in our model’s performance in non-winter months after including FRP, since during these months, the imagery provides information on carbon-based fuel emissions, which is highly correlated with the movement and structure of PM2.5 [
34].
Figure 7 describes a 40-by-40-pixel downsampled visualization of FRP values over various times of the year. Again, note that the figure provides visualizations of the raw grid-like data of the MODIS FRP imagery, and thus the color values of the visualization correspond to FRP values, not raw RGB values.
We also use wildfire and heat data from the NASA MERRA-2 data source. The Modern-Era Retrospective analysis for Research and Applications, version 2 (MERRA-2) is a global atmospheric reanalysis produced by the NASA Global Modeling and Assimilation Office (GMAO). It spans the satellite observing era from 1980 to the present. The goals of MERRA-2 are to provide a regularly gridded, homogeneous record of the global atmosphere, and to incorporate additional aspects of the climate system including trace gas constituents (stratospheric ozone), and improved land surface representation, and cryospheric processes [
35]. All the MERRA-2 features we use in our predictive model are in the format of multidimensional arrays of grid-based raw values throughout Los Angeles over time.
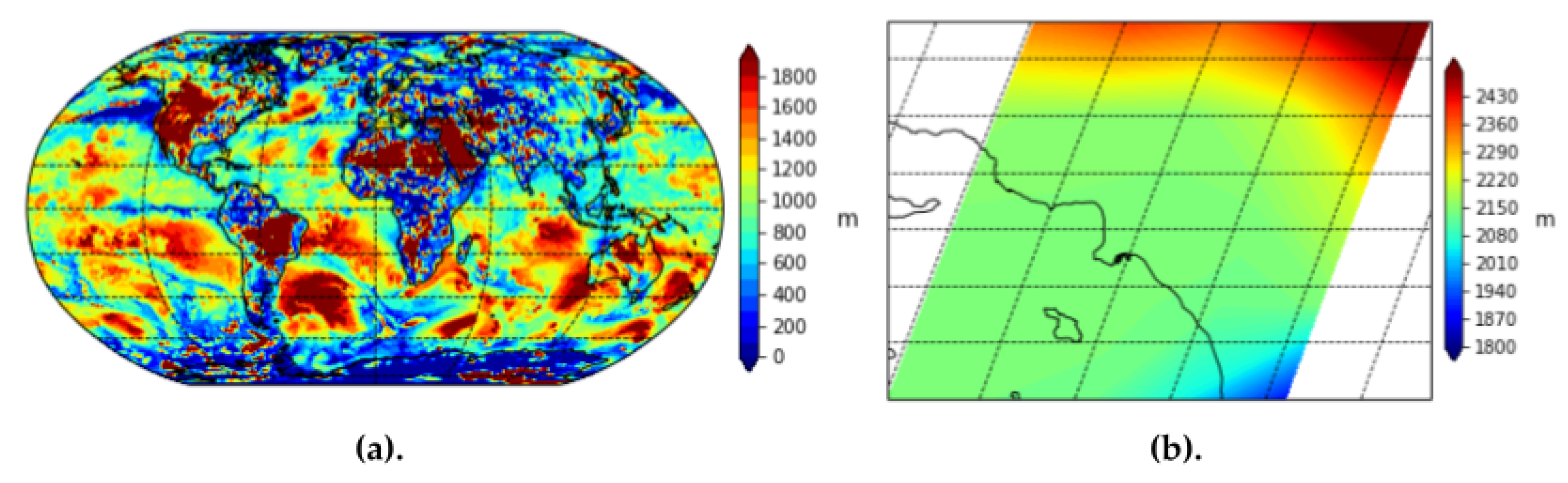
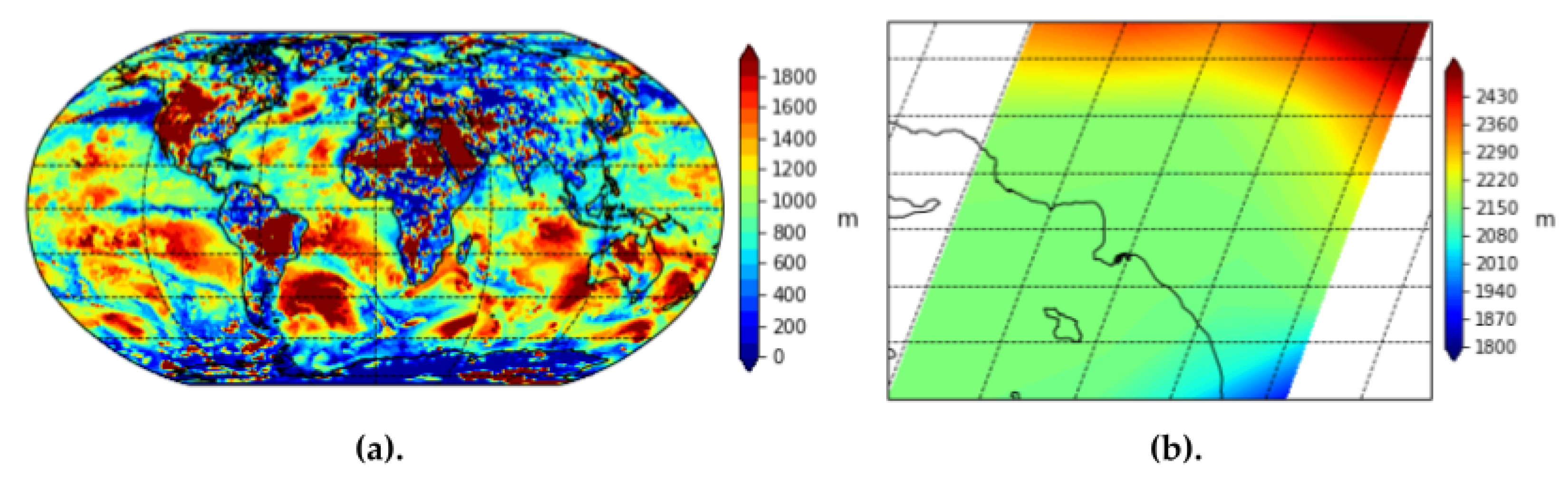
We use MERRA-2 imagery of three wildfire/heat features: Planetary Boundary Layer (PBL) height, surface air temperature, and surface exchange coefficient for heat. Planetary Boundary Layer Height is a measure of the distance from ground level of the lowest part of the atmosphere. The lowest part of the atmosphere, or the peplosphere, is directly influenced by the changing surface temperature of Earth, various aerosols in the atmosphere, and is especially influenced by smoke or ash from a fire. PBL height is also influenced by precipitation and changes in surface pressure. Over deserts or areas of dry, warm climates that may be caused by fires burning in the area, the PBL may extend up to 4000 to 5000 m above sea level. Over cooler, more humid temperatures with little aerosols, dust, or smoke in the atmosphere, the PBL may be less than 1000 m above sea level. Thus, intuitively, a low PBL height means that there are no fires burning in the area and the atmosphere is relatively clear of aerosols.
Figure 8 provides a visualization of the MERRA-2 imagery for PBL height globally and over Los Angeles county.
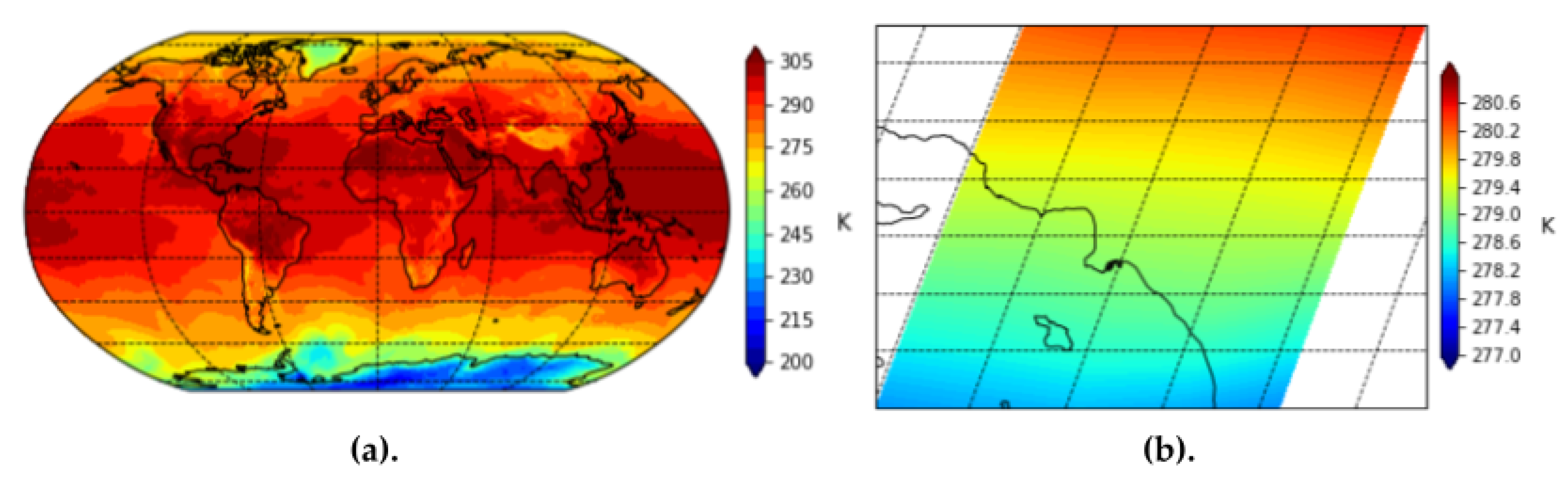
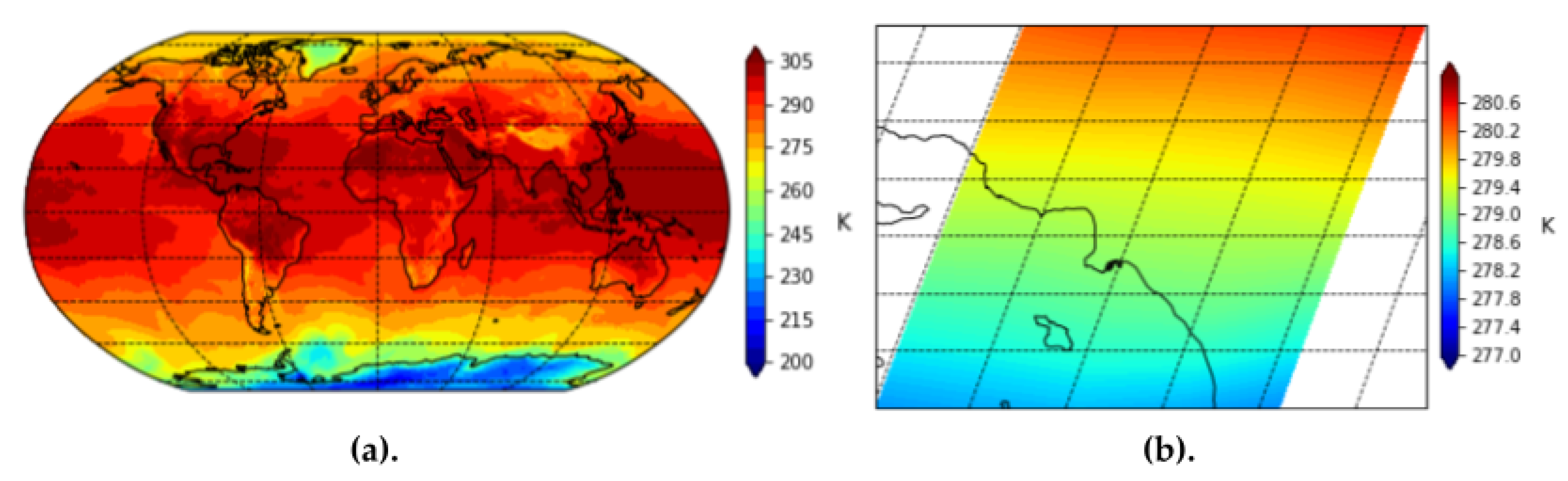
We also use the surface air temperature feature collection from MERRA-2 to provide general information about heat. We find that wildfires, smoke plumes, and industrial exhausts will all influence surface air temperature.
Figure 9 provides a visualization of the MERRA-2 imagery for surface air temperature globally and over Los Angeles county.
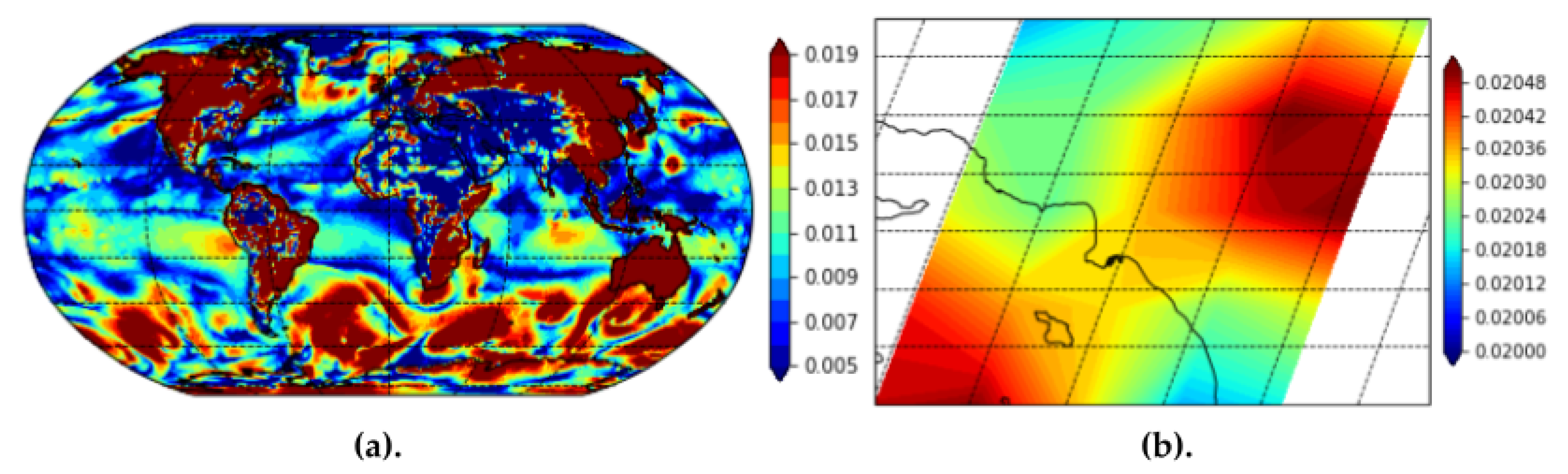
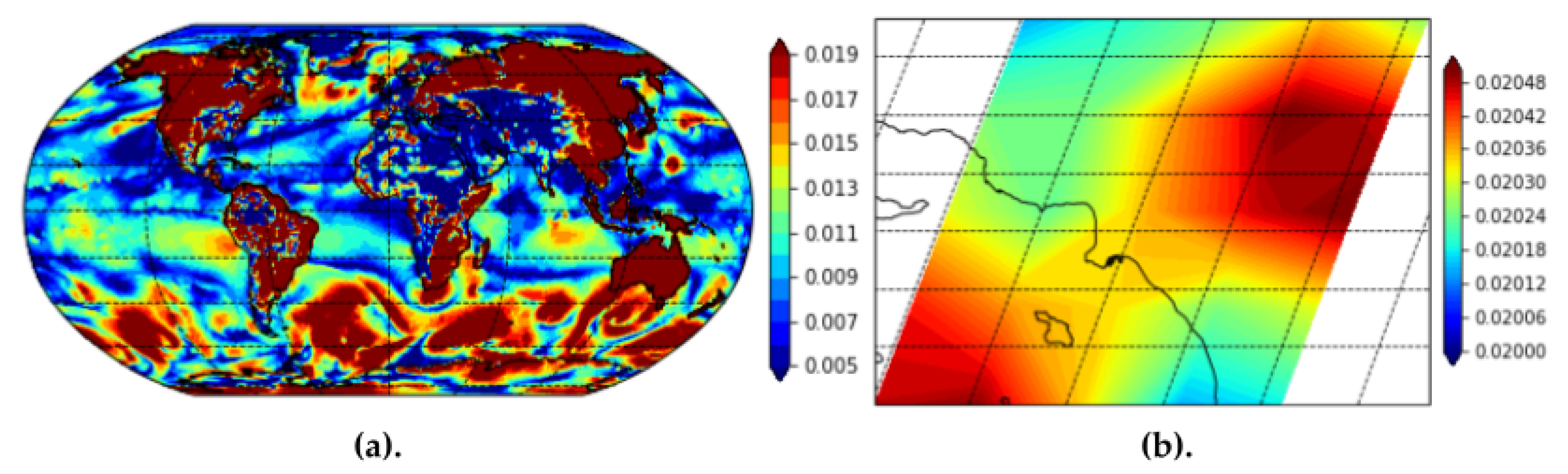
Finally, we use the MERRA-2 surface exchange coefficient for heat features. Surface exchange coefficient for heat provides insights into the effects of wildfires, heat, and smoke plumes over non-terrain regions as well, such as oceans and rivers. The surface exchange coefficient for heat feature provides especially useful information since our geographical area of interest is Los Angeles. For example, we find that including surface exchange coefficient for heat helped the model understand atmospheric PM2.5 over the Pacific Ocean near the Port of Los Angeles and Port of Long Beach.
Figure 10 provides a visualization of the MERRA-2 imagery for surface exchange coefficient for heat globally and over Los Angeles county. We provide the full summary of input data used, the datasets we collected them from, the instruments used to capture the data, and the data source types in the
Appendix A (
Table A1).
2.3. Implementation
In our GCN architecture which uses meteorological data to create dense interpolated high-level embeddings of meteorological features, we must preprocess raw meteorological data into weighted directed graphs with node and edge attribute vectors. That is, for each timestep of the meteorological dataset, we create a weighted directed graph denoting the nodes of the graph as “stationary” meteorological features pertaining to a sensor location and the edges denoting “non-stationary” meteorological features. We define “stationary” features as scalar measurements of individual meteorological features at a sensor location. For example, the node attributes for our meteorological graph include relative humidity, AQI, temperature, air pressure, dew point, and heat index. We describe the full dichotomy of “stationary” and “non-stationary” attributes in the
Appendix A (
Table A2). Edge attributes consist of “non-stationary” meteorological features that rely on or connect multiple sensors. For example, the edge attributes consist of the physical distance in miles from meteorological sensor locations, the wind speed, and the wind direction. For each timestep, we can create a multidimensional weighted directed graph containing the spatial and distance-based information of all meteorological sensors and their recorded features. We then repeat this process to create these multidimensional weighted directed graphs for each hourly sample in the dataset. Algorithm 1 describes a step-by-step procedure of creating these weighted directed meteorological graphs for a single timestep.
To implement the ConvLSTM architecture, we use the Keras ConvLSTM layer [
36]. This implementation requires the input data to be in the form of a five-dimensional tensor with dimensions (sample, frame, row, column, filter). For the remote-sensing satellite imagery in our dataset, we set the row, column, and filter dimensions as the 2D image along with the RGB color values as the filter. All remote-sensing satellite imagery data sets are downsampled to 40-by-40-pixel resolutions, which correspond to a 40 row by 40 column array for the 5D tensor input. For the ground-based sensor data, we create a 40-by-40-pixel grid and use the latitude and longitude coordinates of the monitoring sites to set the location of the sensor values within the array, similar to the process described in Algorithm 1.
| Algorithm 1. Meteorological Graph Construction |
Input: Meteorological site features , where each contains site coordinates and a set of site-specific stationary and non-stationary feature values. Boundary latitude values , . Boundary longitude values , Initialize 40 × 40 array grid A. Initialize weighted directed graph fordo = , vector of site-specific stationary values Set as vertex of G end for fordo for do Let be the starting coordinates of a weighted directed edge in G Recover from site-specific non-stationary value . Create weighted directed edge in G starting from vertex located at and ending at vertex located at with weight of . end for end for Output: Geographically bound graph feature matrix grid A, Weighted Directed Graph G |
For each of the data sources, we construct a set of 3D input “images” with dimensions of (rows, columns, filters). To construct a 5D tensor for the Keras ConvLSTM layer, we bundle all input frames over time into multiple samples. We bundle 24 consecutive frames into a single sample, where each frame represents information at a timestep with an hourly temporal frequency. Each bundle of 24 frames then represents a single day’s worth of data.
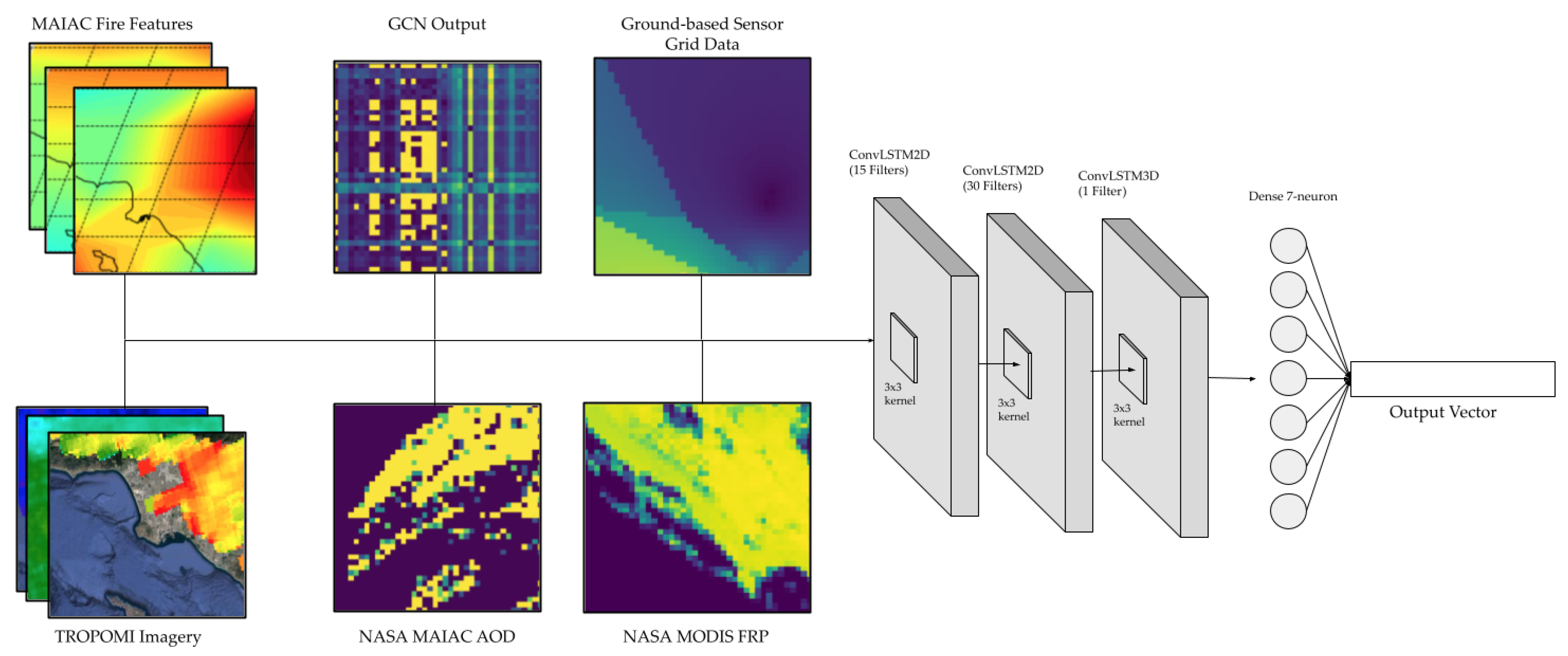
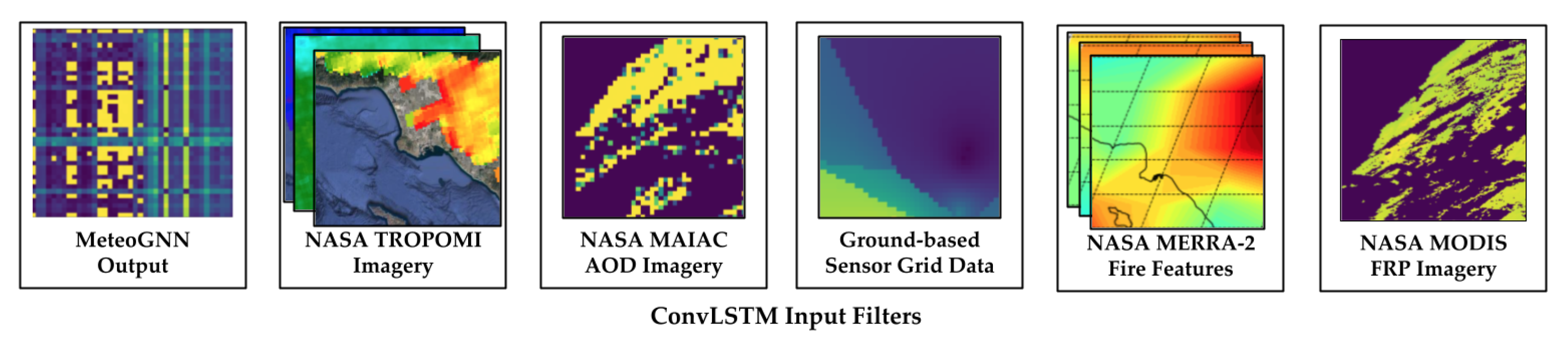
The input data bundles are staggered such that the first sample consists of data from frames 1–24, the second sample consists of data from frames 2–25, and so on. In this way, we continue to preserve a continuous flow of temporal correlations among samples. By constructing this 5D tensor, we can transform the 26,304 3D input “images” (24 samples of 1096 days) into a 5D tensor of shape (26,304, 24, 40, 40, 10). The 10 filters in the 5D tensor consist of three filters for the MERRA-2 fire features (PBL height, surface temperature, and surface exchange coefficient for heat), 1 filter for the MODIS FRP imagery, one filter for the MAIAC MODIS AOD imagery, three filters for the TROPOMI data of air pollutants (nitrogen dioxide, carbon monoxide, and methane), one filter for the output of the GCN on meteorological data, and one filter for the ground-based PM2.5 sensor data from AQMIS2.
Figure 11 provides a visualization of these input filters.
To evaluate and test our model, we add a final Dense Keras layer with seven neurons to give a prediction for solely the seven PM2.5 sensor locations instead of a spatially continuous prediction of a 40-by-40-pixel grid over Los Angeles county [
37]. We have the capability to produce spatially continuous predictions of PM2.5 with our current model, but to evaluate against existing ground truth values with little to no measurement error or uncertainty, we restrict the prediction to monitoring sites available in the California ARB AQMIS2 portal.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}