
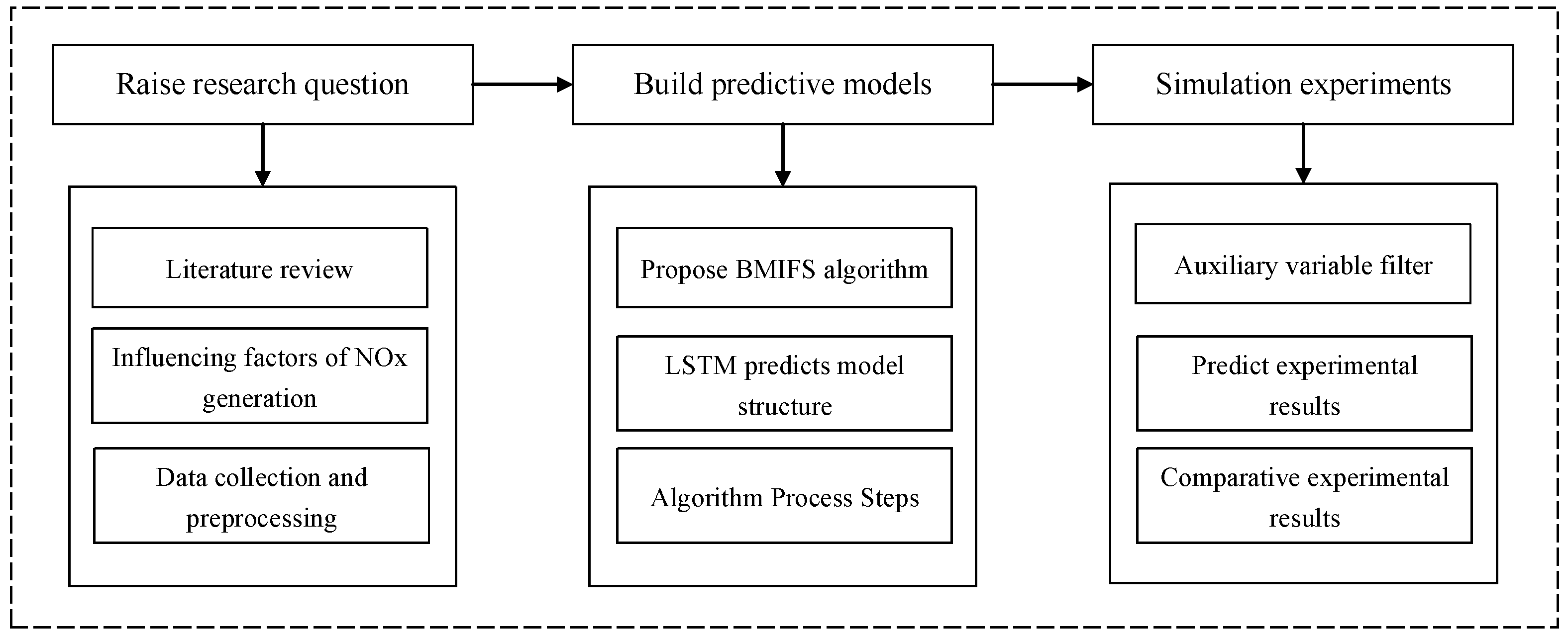
Prediction of NOx Concentration at SCR Inlet Based on BMIFS-LSTM

Abstract
:1. Introduction
2. Influencing Factors of NOx Production
3. Data Collection and Preprocessing
4. NOx Concentration Prediction Model Based on BMIFS-LSTM
4.1. Improved Mutual Information Feature Selection Algorithm (BMIFS)
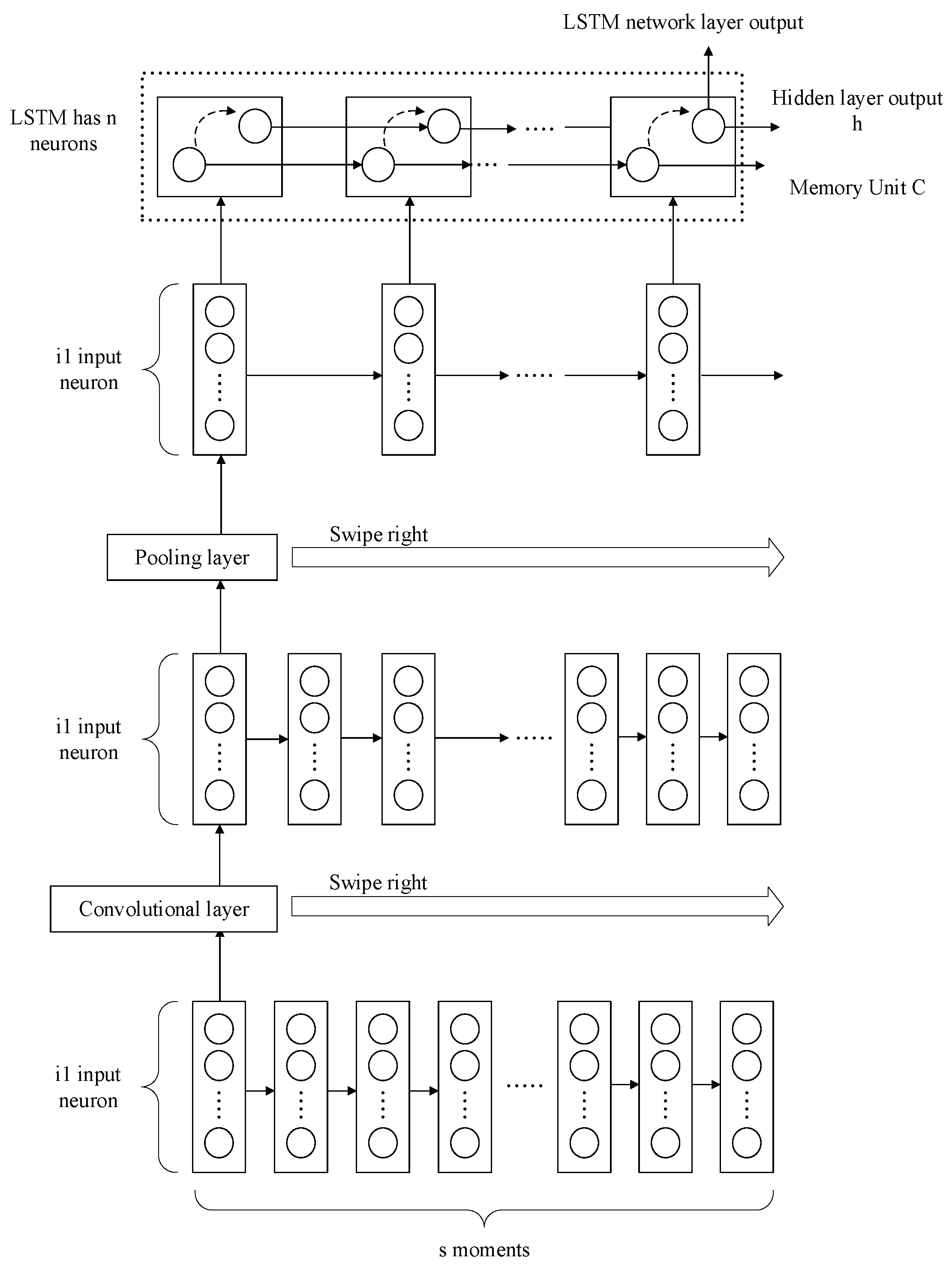
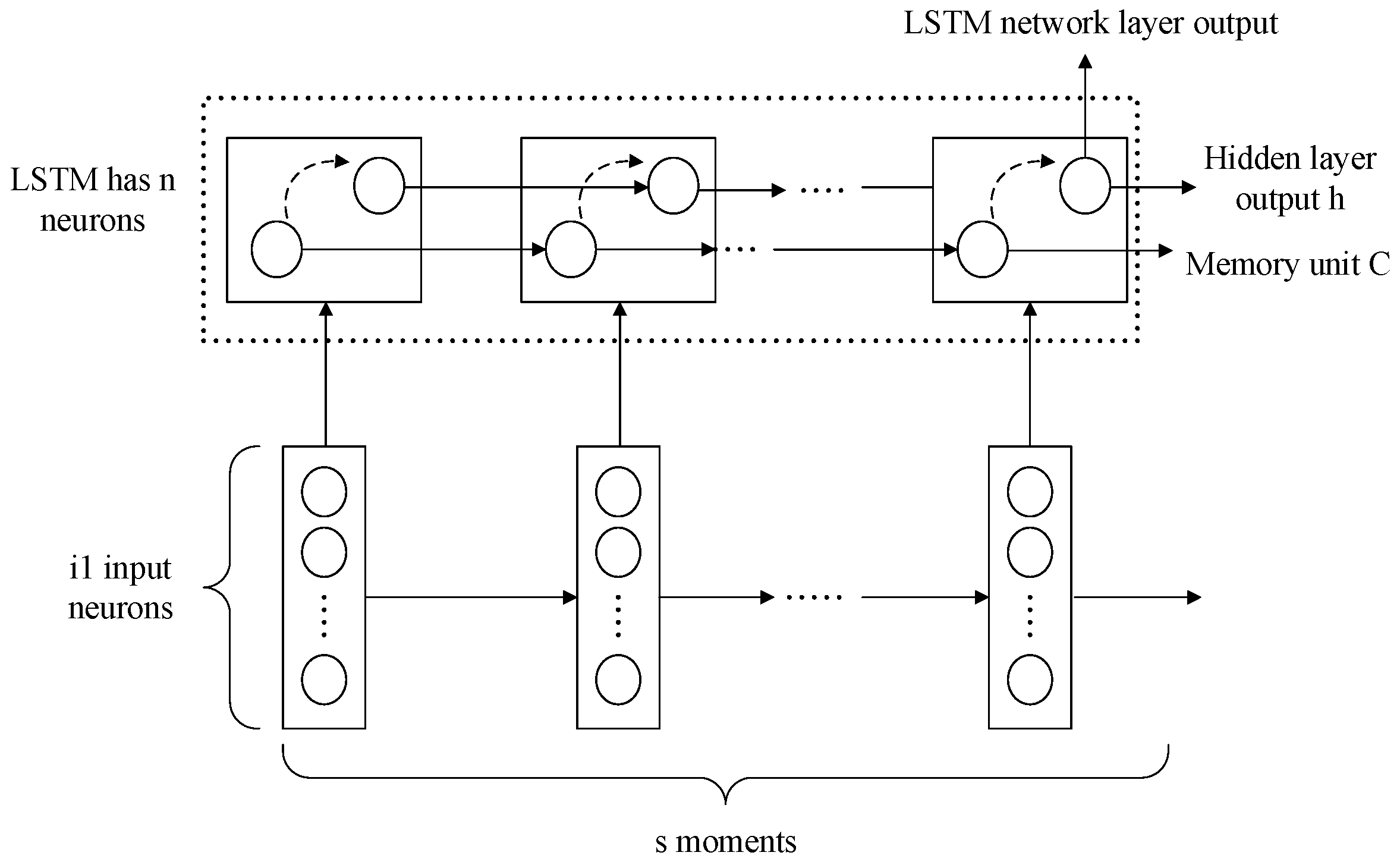
4.2. LSTM Prediction Model Structure
- (1)
- Input layer
- (2)
- LSTM network layer
- (3)
- Output layer
- (4)
- Loss function
5. Discussion
5.1. NOx Auxiliary Variable Screening Results
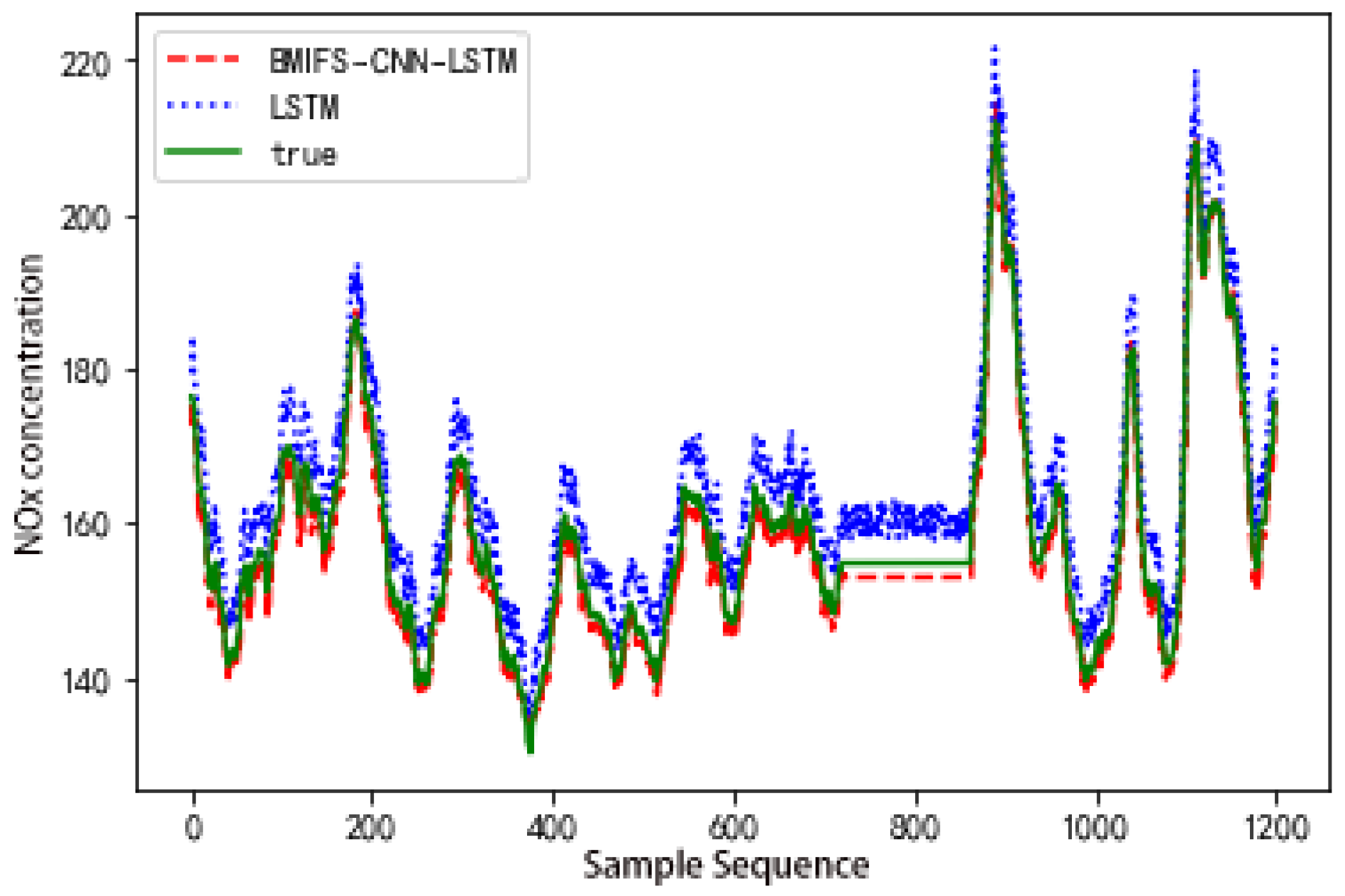
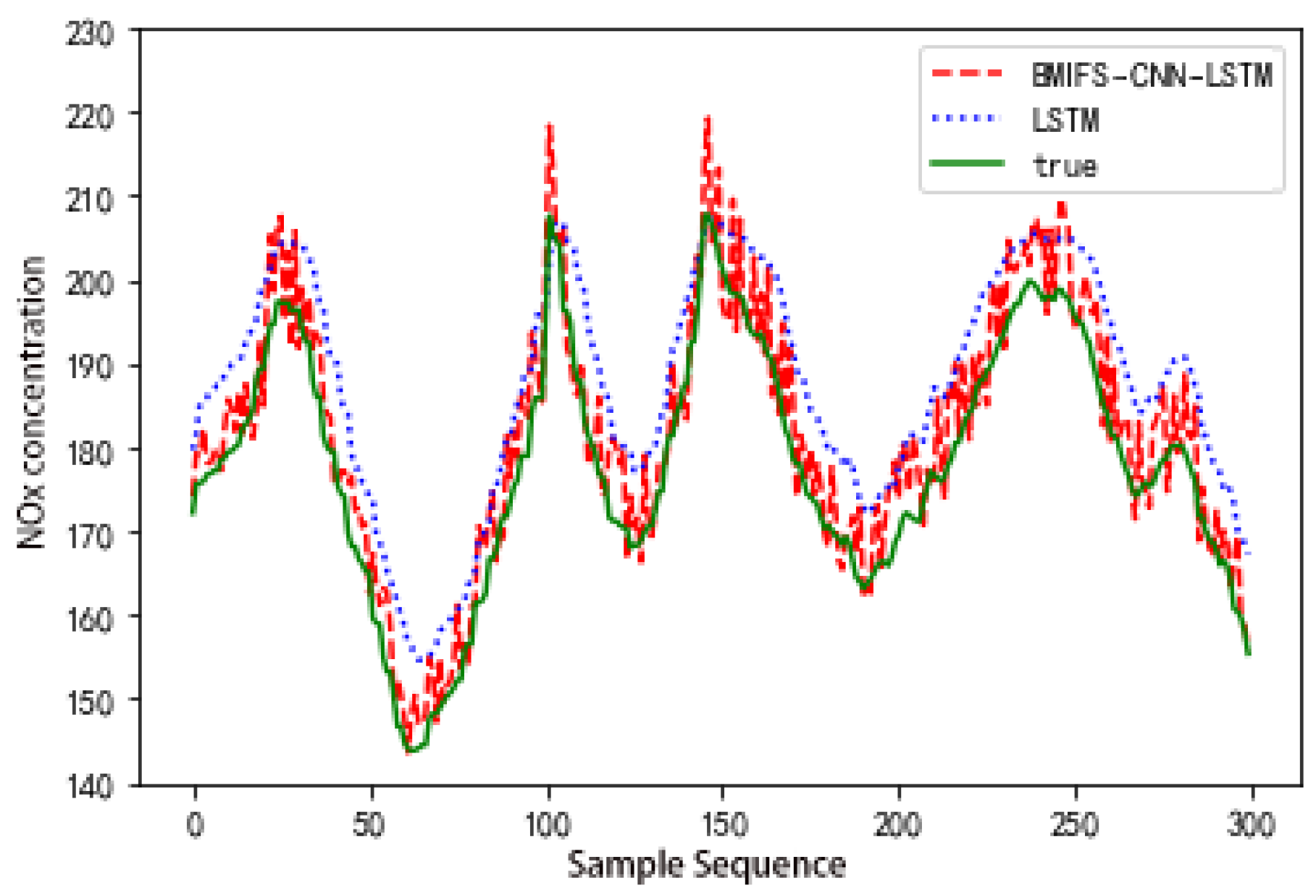
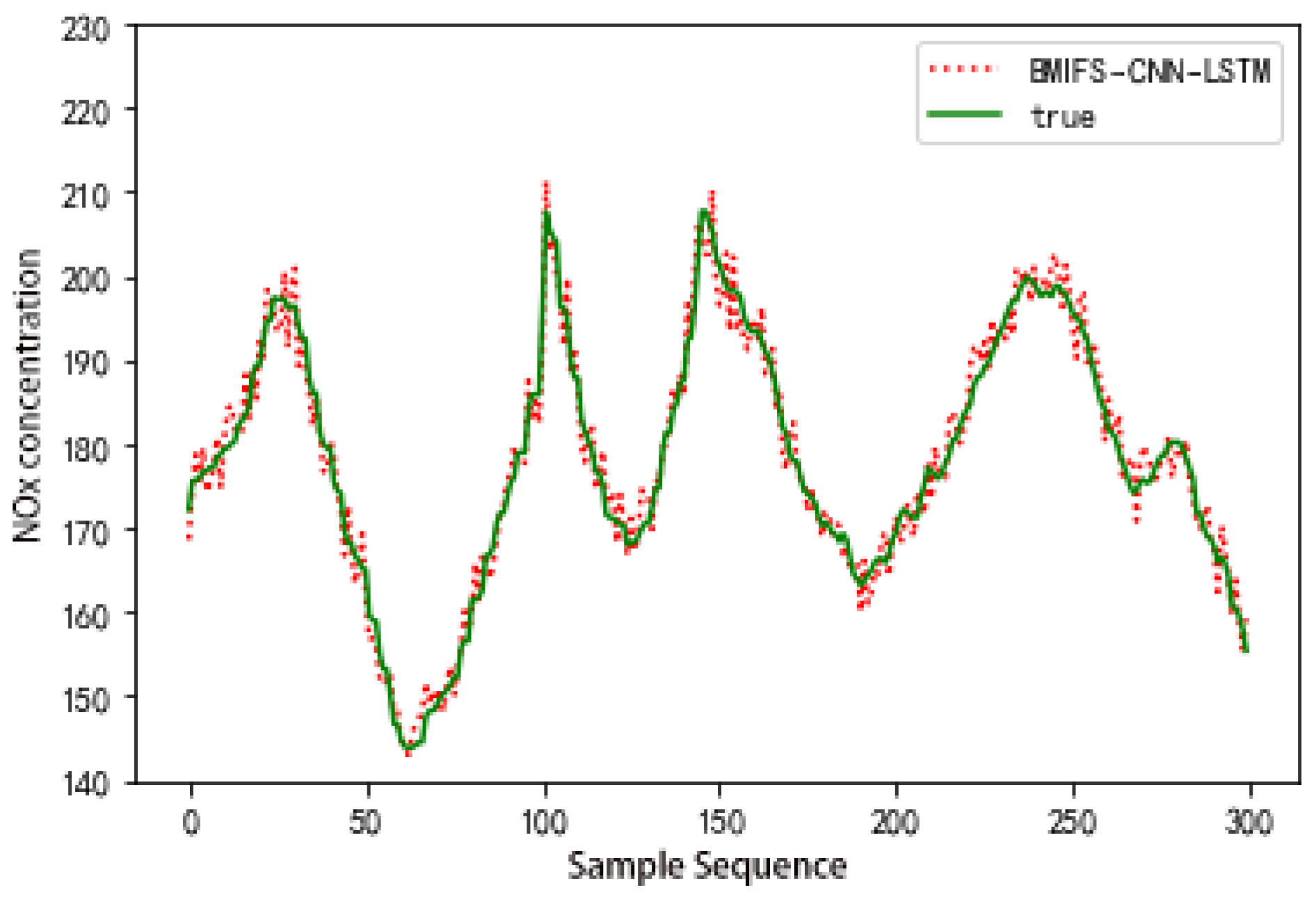
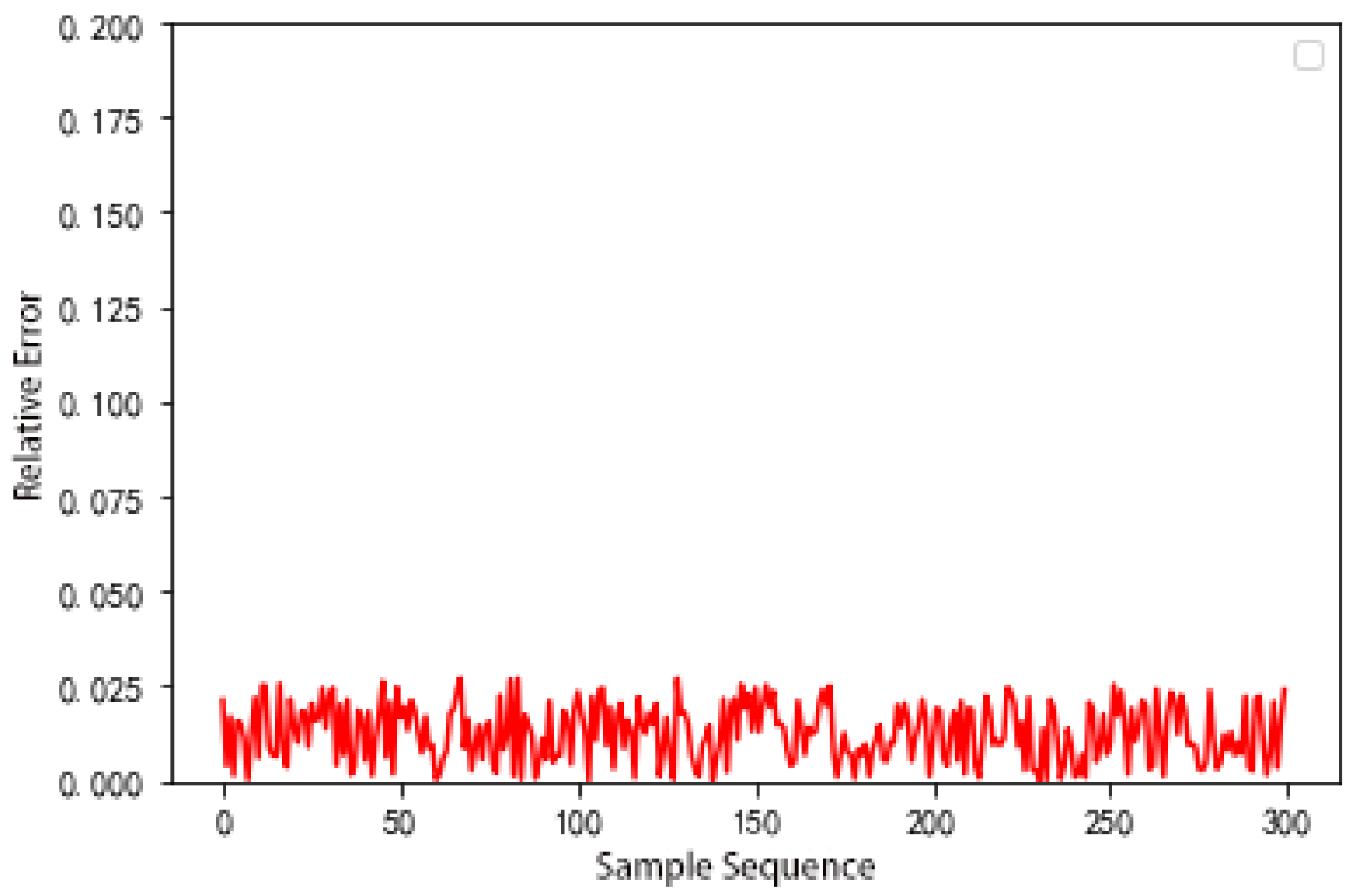
5.2. Forecast Result
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhong, J. The Economics of Low-NOx Technology and the Exploration of New Low-NOx Control Technology; Zhejiang University: Hangzhou, China, 2006. [Google Scholar]
- Li, Y.; Huang, W.; Xi, J. Power plant NO_x emission prediction based on Stacking algorithm integration model. Therm. Energy Power Eng. 2021, 36, 73–81. [Google Scholar] [CrossRef]
- Liu, K.; Wei, B.; Chen, L.; Wang, J.; Li, J.; Liu, J. Influence of low-load flue gas recirculation on combustion and NOx emissions of pulverized coal boilers. Chin. J. Power Eng. 2021, 41, 345–349, 379. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Verma, S.; Singh, S.; Majumdar, A. Multi-label LSTM autoencoder for non-intrusive appliance load monitoring. Electr. Power Syst. Res. 2021, 199, 107414. [Google Scholar] [CrossRef]
- Wu, P.; Luo, L. Prediction of ship motion trajectory based on RNN-LSTM. Shipbuild. Technol. 2021, 49, 11–16. [Google Scholar]
- Xiang, Z. Confidence Interval Prediction of Smart Grid Link Quality Based on LSTM. Electrical Measurement and Instrumentation. pp. 1–10. Available online: http://kns.cnki.net/kcms/detail/23.1202.TH.20210623.0948.004.html (accessed on 4 July 2021).
- Zhao, Y. Power data analysis method combining GA and LSTM network. Electron. Des. Eng. 2021, 29, 161–165. [Google Scholar]
- Song, S.; Li, B. Research on short-term prediction method of photovoltaic power generation based on LSTM network. Renew. Energy 2021, 39, 594–602. [Google Scholar]
- Chen, C.; Wang, X.; Liang, J.; Ma, W. LSTM photovoltaic power generation prediction method based on a new attention mechanism. Mod. Comput. 2021, 11, 28–32+38. [Google Scholar]
- Zhang, Z. Research on Spacecraft Time Series Prediction Method Based on LSTM; Beijing Jiaotong University: Beijing, China, 2020. [Google Scholar]
- Zheng, T. Near-Space Hypersonic Target Track Estimation and Prediction Based on Recurrent Neural Network; Harbin Institute of Technology: Harbin, China, 2020. [Google Scholar]
- Hu, D.; Meng, X.; Lu, S.; Xing, L. The application of a parallel LSTM-FCN model in ship trajectory prediction. Control Decis. 2021, 4, 1–7. [Google Scholar] [CrossRef]
- Yang, B. Research and Application of Ship Trajectory Analysis Based on AIS; University of Electronic Science and Technology of China: Chengdu, China, 2018. [Google Scholar]
- Lu, J.; Song, S.; Jing, Y.; Zhang, Y.; Gu, L.; Lu, F.; Hu, Z.; Li, S. Fundamental Frequency Detection of Underwater Moving Target Noise Based on DEMON Spectrum and LSTM Network. Applied Acoustics. pp. 1–11. Available online: http://kns.cnki.net/kcms/detail/11.2121.o4.20210621.1436.006.html (accessed on 4 July 2021).
- Ding, C. Planning of RMB Exchange Rate Prediction Scheme Based on Multi-Time Scale CNN-LSTM Neural Network; Shanghai Normal University: Shanghai, China, 2021. [Google Scholar]
- Tian, Y. Research on Stock Price Trend Prediction Based on Investor Sentiment and LSTM; Shanghai Normal University: Shanghai, China, 2021. [Google Scholar]
- Wei, Q.; Chen, S.; Tan, Z.; Huang, W.; Ma, G. Based on SA-LSTM, the dynamic lag relationship between hydropower stations. Hydropower Energy Sci. 2021, 39, 16–19. [Google Scholar]
- Zhang, D. Research on Optimization Technology of Large-Scale Reservoir Water Temperature Regulation Based on Artificial Intelligence Algorithm; China Institute of Water Resources and Hydropower Research: Beijing, China, 2020. [Google Scholar]
- Sun, B.M.; Wang, D.H.; Yang, B.; Zhang, S.H.; Kong, L.Y. Prediction Model for the Boiler NOx Emission with Material Properties Based on the Artificial Neural Network. Adv. Mater. Res. 2013, 676, 40–45. [Google Scholar] [CrossRef]
- Li, X.; Xu, G. Wind power generation power prediction method based on long short-term memory neural network. Power Gener. Technol. 2019, 40, 426–433. [Google Scholar]
- Zhai, Y.; Xu, L.; Ji, X.; Ji, H.; Wang, J.; Sha, Y. Short-term load forecasting based on long and short-term memory neural network. Inf. Technol. 2019, 10, 27–31. [Google Scholar]
- Mao, X.; Tan, J.; Yao, Y.; Li, B.; Wu, C. Saturated load forecasting method and application based on long and short-term memory neural network. Hydropower Energy Sci. 2019, 37, 192–195+168. [Google Scholar]
- Tang, Z.; Zhao, G.; Cao, S.; Zhao, B. Ultra-short-term wind direction prediction based on SWLSTM algorithm. Chin. J. Electr. Eng. 2019, 39, 4459–4468. [Google Scholar]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Minimum | Maximum |
|---|---|---|
| Load | 218.0 | 265.4 |
| Coal feed | 123.2 | 168.1 |
| Total air volume | 368.4 | 479.2 |
| Total secondary air volume | 589.8 | 824.1 |
| Oxygen content of flue gas | 1.46 | 3.09 |
| SOFA3 layer air door damper opening | 47.5 | 57.8 |
| OF2 layer damper opening | 27.3 | 46.1 |
| DE layer damper opening | 12.5 | 17.1 |
| SCR reactor inlet NOx concentration | 128.5 | 289.1 |
| Variable | |
|---|---|
| primary air volume | 0.015 |
| total coal | 0.4461 |
| load | 0.1834 |
| AB layer secondary air door baffle | 0.3455 |
| oxygen | 0.098 |
| flue gas temperature | 0.2056 |
| Model | MRE (%) | RMSE |
|---|---|---|
| BMIFS-LSTM training model | 0.0246 | 1.3715 |
| LSTM training model | 0.0458 | 2.2024 |
| BMIFS-LSTM test model | 0.0297 | 1.5237 |
| LSTM test model | 0.0643 | 3.0251 |
| Models | Average Relative Error (%) | Root Mean Square Error |
|---|---|---|
| BMIFS-LSTM Prediction Model | 0.0297 | 1.5237 |
| BMIFS-CNN-LSTM Prediction Model | 0.0126 | 1.0113 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, M.; Xue, J.; Gao, S.; Cheng, G.; Chen, J.; Lu, H.; Dong, Z. Prediction of NOx Concentration at SCR Inlet Based on BMIFS-LSTM. Atmosphere 2022, 13, 686. https://doi.org/10.3390/atmos13050686
Song M, Xue J, Gao S, Cheng G, Chen J, Lu H, Dong Z. Prediction of NOx Concentration at SCR Inlet Based on BMIFS-LSTM. Atmosphere. 2022; 13(5):686. https://doi.org/10.3390/atmos13050686
Chicago/Turabian StyleSong, Meiyan, Jianzhong Xue, Shaohua Gao, Guodong Cheng, Jun Chen, Haisong Lu, and Ze Dong. 2022. "Prediction of NOx Concentration at SCR Inlet Based on BMIFS-LSTM" Atmosphere 13, no. 5: 686. https://doi.org/10.3390/atmos13050686
APA StyleSong, M., Xue, J., Gao, S., Cheng, G., Chen, J., Lu, H., & Dong, Z. (2022). Prediction of NOx Concentration at SCR Inlet Based on BMIFS-LSTM. Atmosphere, 13(5), 686. https://doi.org/10.3390/atmos13050686