
Malaysia PM10 Air Quality Time Series Clustering Based on Dynamic Time Warping

 ,
,  , , and
, , and
Abstract
1. Introduction
2. Methods
2.1. Dynamic Time Warping
- (i)
- and
- (ii)
- and
- (iii)
- and .
2.2. Clustering Algorithms
2.2.1. K-Means Clustering
- (i)
- randomly initialize a k-cluster, then compute the cluster centroids or means,
- (ii)
- by employing an appropriate distance measure, allocate each data set to the nearest cluster,
- (iii)
- recompute the cluster centroids based on the current cluster members,
- (iv)
- repeat steps ii and iii until no further changes.
2.2.2. Partitioning around Medoid (PAM) Clustering
- (i)
- randomly select k elements from the data set that are centrally located as the initial medoids to represent each cluster.
- (ii)
- change the selected data points or medoids to other unselected data points and if they can reduce the objective function, then the swap is carried out,
- (iii)
- assign each of the remaining data to the cluster with the nearest medoid,
- (iv)
- this step continues until the objective function can no longer be reduced.
2.2.3. Hierarchical Clustering
2.2.4. Fuzzy K-Means (FKM) Clustering
3. Results and Analysis
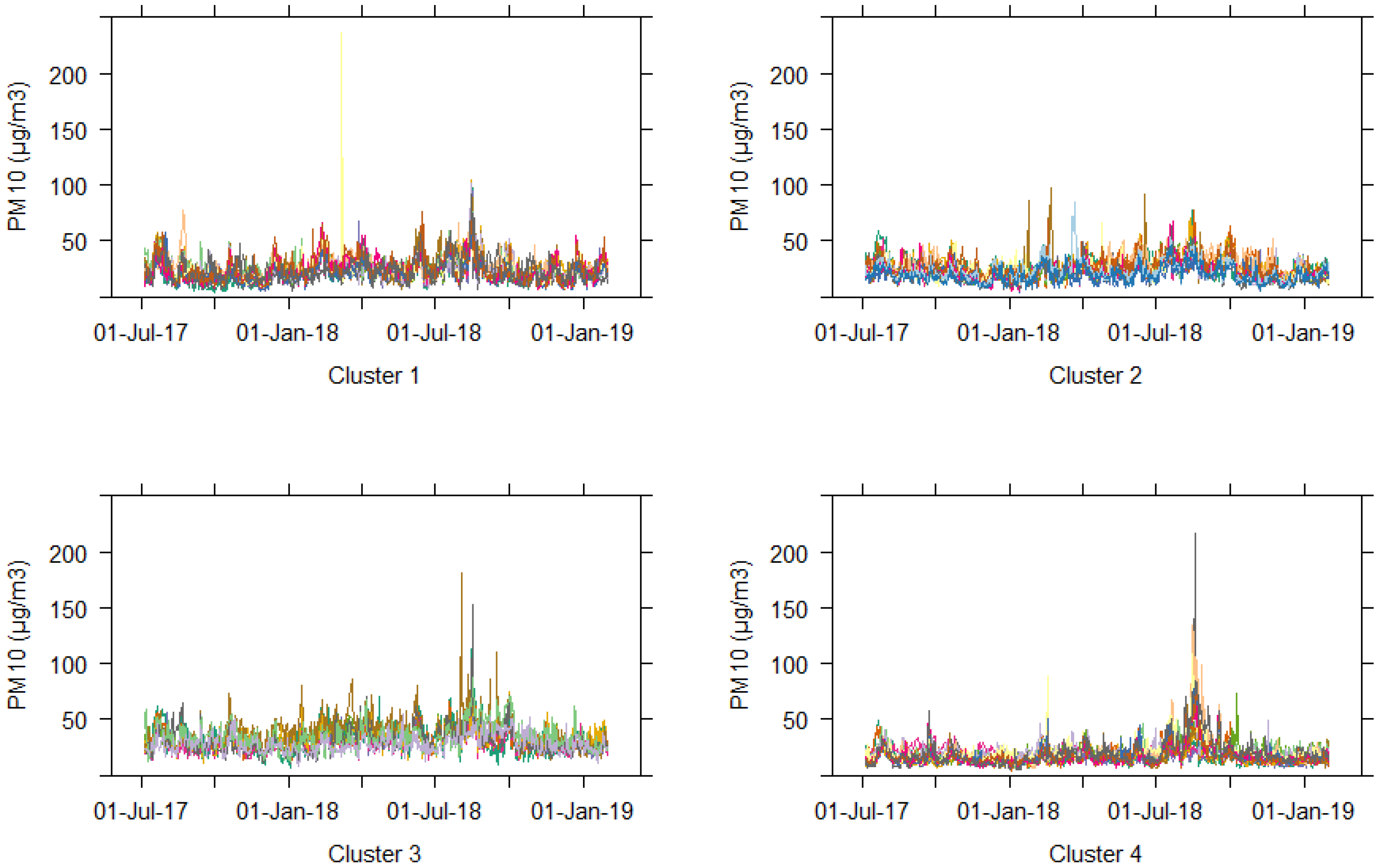
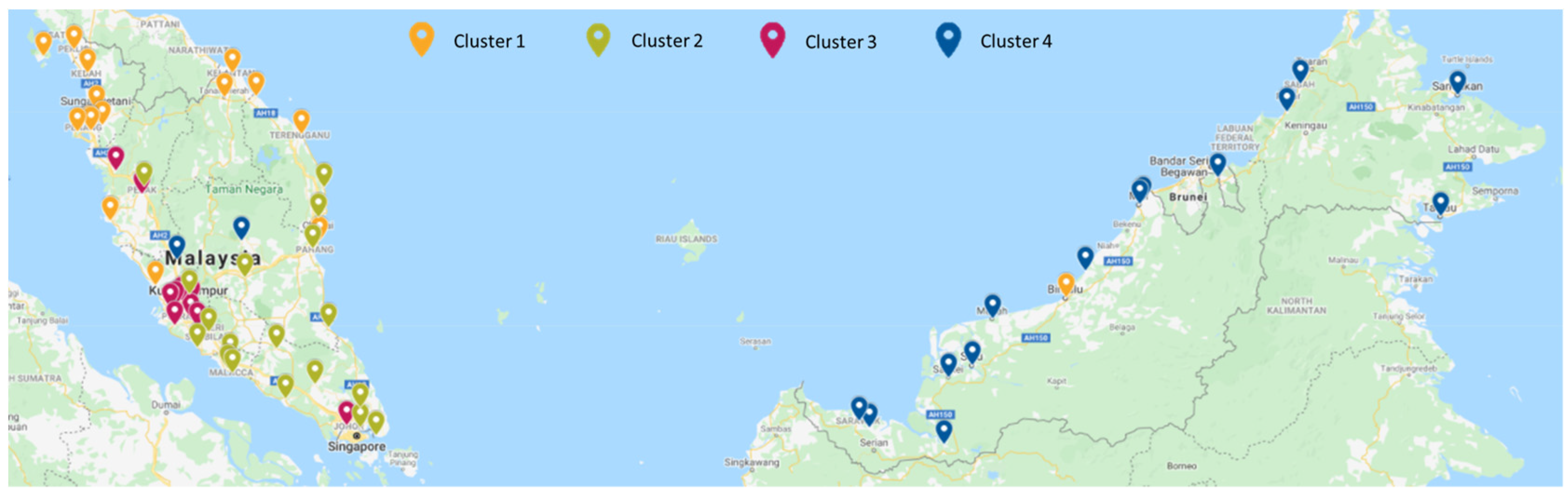
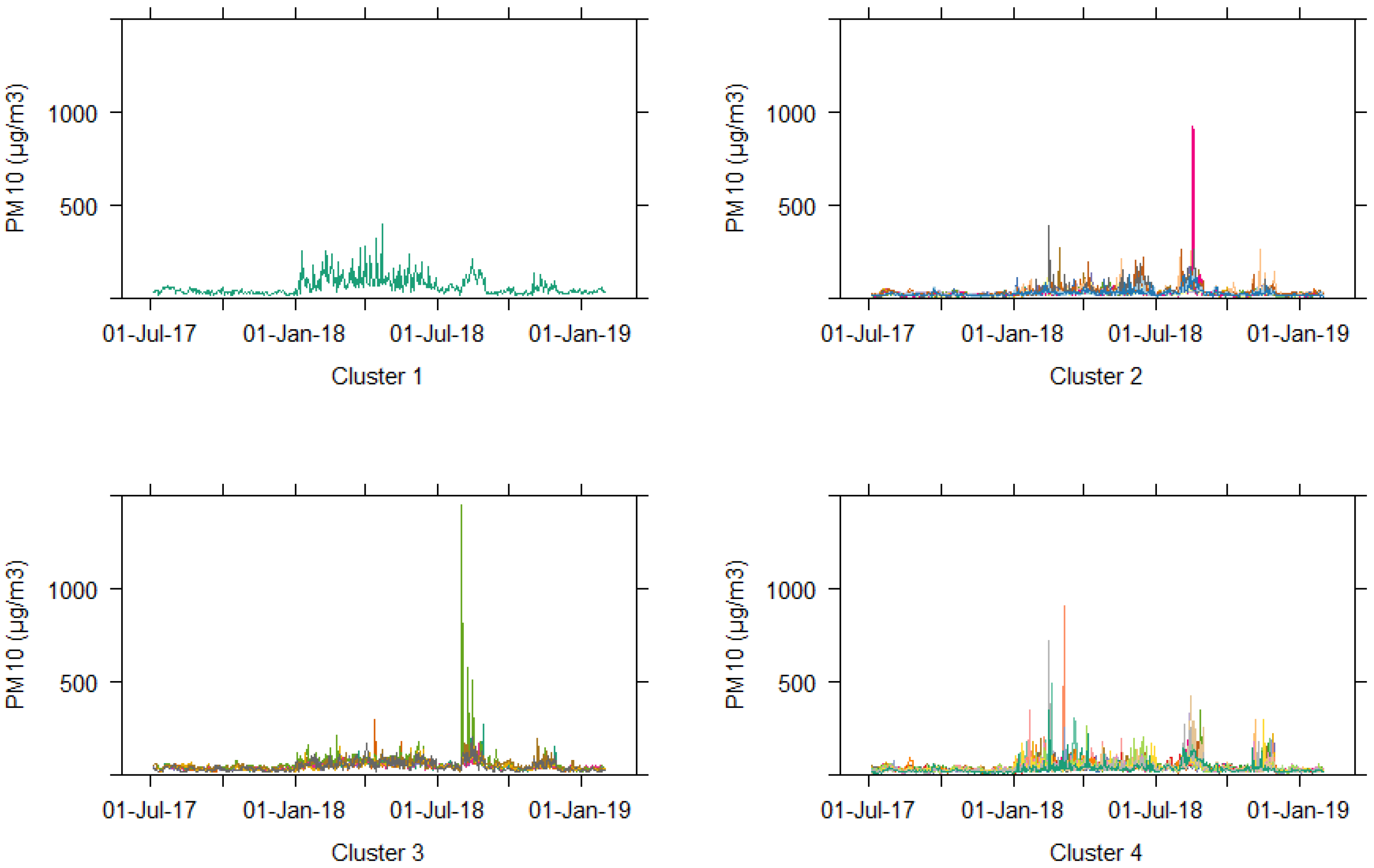
3.1. Clustering of Daily Average Data
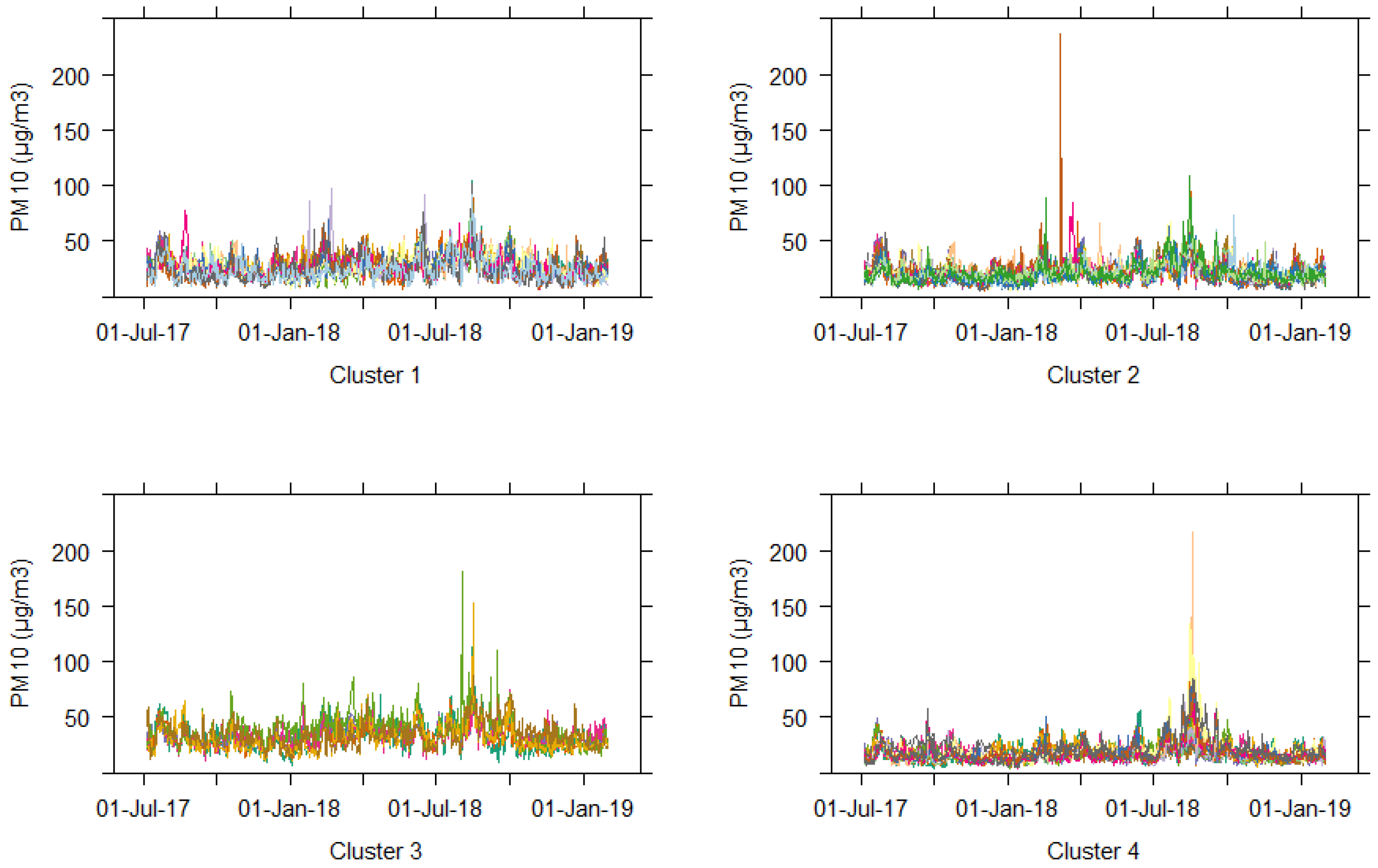
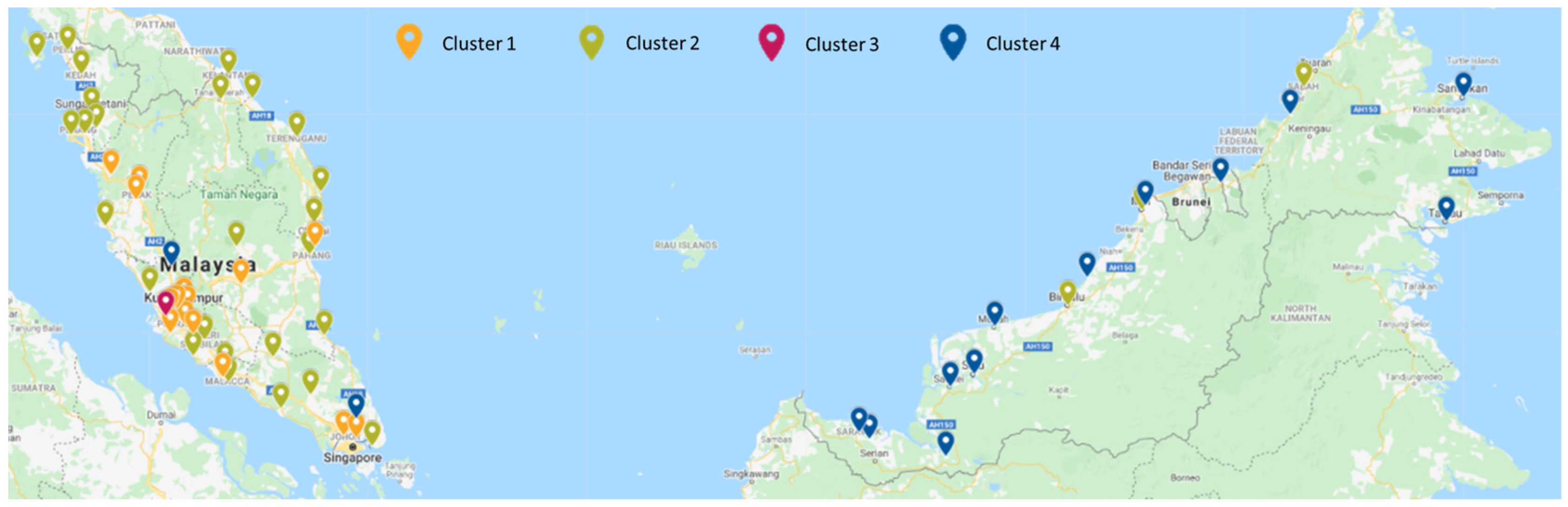
3.2. Clustering of Daily Maximum Data
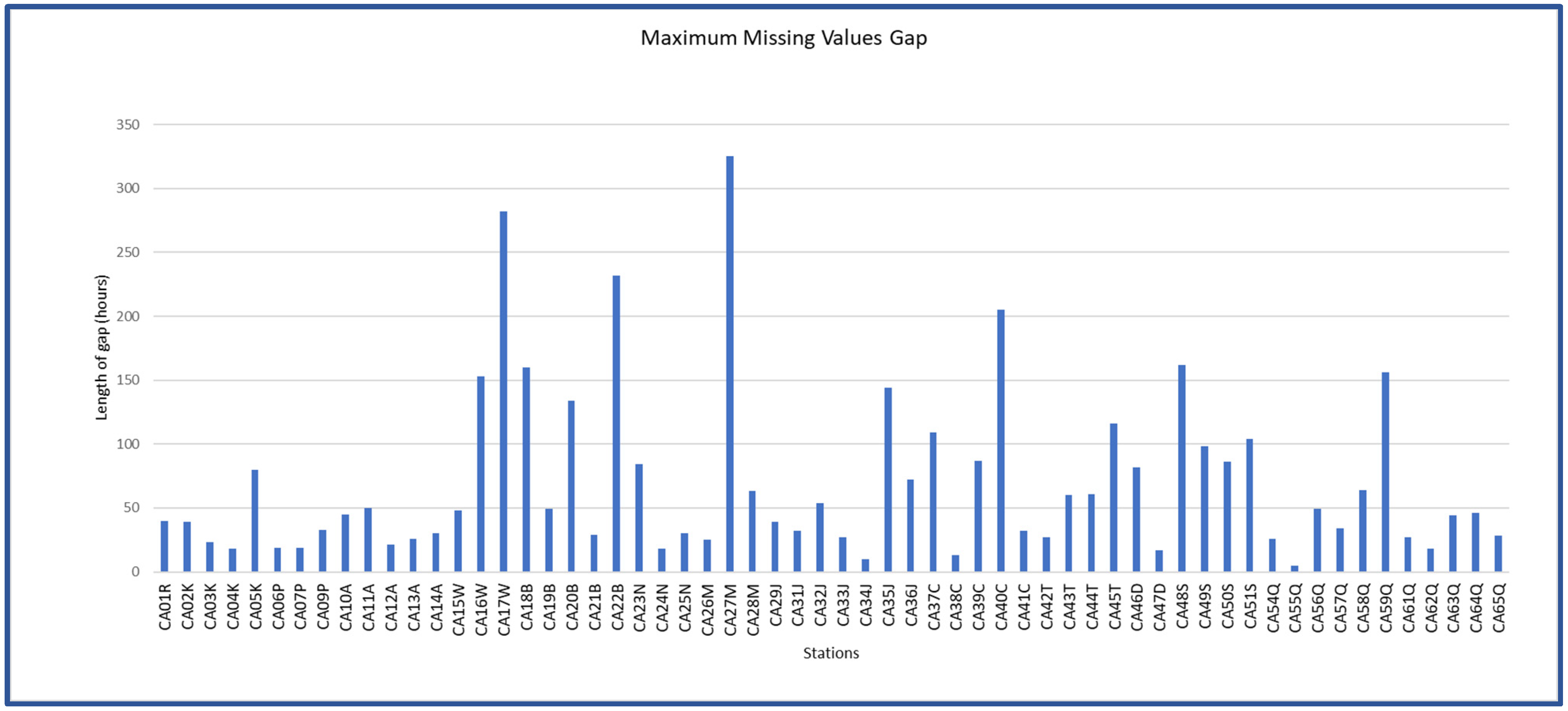
3.3. Evaluation of Clustering
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Afroz, R.; Hassan, M.N.; Ibrahim, N.A. Review of air pollution and health impacts in Malaysia. Environ. Res. 2003, 92, 71–77. [Google Scholar] [CrossRef]
- Usmani, R.S.A.; Saeed, A.; Abdullahi, A.M.; Pillai, T.R.; Jhanjhi, N.; Hashem, I.A.T. Air pollution and its health impacts in Malaysia: A review. Air Qual. Atmos. Health 2020, 13, 1093–1118. [Google Scholar] [CrossRef]
- Azmi, S.Z.; Latif, M.T.; Ismail, A.S.; Juneng, L.; Jemain, A.A. Trend and status of air quality at three different monitoring stations in the Klang Valley, Malaysia. Air Qual. Atmos. Health 2010, 3, 53–64. [Google Scholar] [CrossRef] [PubMed]
- Aghabozorgi, S.; Shirkhorshidi, A.S.; Wah, T.Y. Time-series clustering–A decade review. Inf. Syst. 2015, 53, 16–38. [Google Scholar] [CrossRef]
- D’Urso, P.; Cappelli, C.; Di Lallo, D.; Massari, R. Clustering of financial time series. Phys. A Stat. Mech. Appl. 2013, 392, 2114–2129. [Google Scholar] [CrossRef]
- Lavin, A.; Klabjan, D. Clustering time-series energy data from smart meters. Energy Effic. 2015, 8, 681–689. [Google Scholar] [CrossRef]
- Ariff, N.M.; Abu Bakar, M.A.; Mahbar, S.F.S.; Nadzir, M.S.M. Clustering of Rainfall Distribution Patterns in Peninsular Malaysia Using Time Series Clustering Method. Malays. J. Sci. 2019, 38, 84–99. [Google Scholar] [CrossRef]
- Chandra, B.; Gupta, M.; Gupta, M.P. A multivariate time series clustering approach for crime trends prediction. In Proceedings of the 2008 IEEE International Conference on Systems, Man and Cybernetics, Singapore, 12–15 October 2008; pp. 892–896. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, L.; Li, F.; Du, B.; Choo, K.-K.R.; Hassan, H.; Qin, W. Air quality data clustering using EPLS method. Inf. Fusion 2017, 36, 225–232. [Google Scholar] [CrossRef]
- Dogruparmak, S.C.; Keskin, G.A.; Yaman, S.; Alkan, A. Using principal component analysis and fuzzy c–means clustering for the assessment of air quality monitoring. Atmos. Pollut. Res. 2014, 5, 656–663. [Google Scholar] [CrossRef][Green Version]
- Stolz, T.; Huertas, M.E.; Mendoza, A. Assessment of air quality monitoring networks using an ensemble clustering method in the three major metropolitan areas of Mexico. Atmos. Pollut. Res. 2020, 11, 1271–1280. [Google Scholar] [CrossRef]
- Dominick, D.; Juahir, H.; Latif, M.T.; Zain, S.M.; Aris, A.Z. Spatial assessment of air quality patterns in Malaysia using multivariate analysis. Atmos. Environ. 2012, 60, 172–181. [Google Scholar] [CrossRef]
- Mutalib, S.N.S.A.; Juahir, H.; Azid, A.; Sharif, S.M.; Latif, M.T.; Aris, A.Z.; Zain, S.M.; Dominick, D. Spatial and temporal air quality pattern recognition using environmetric techniques: A case study in Malaysia. Environ. Sci. Process. Impacts 2013, 15, 1717–1728. [Google Scholar] [CrossRef]
- Yan, R.; Liao, J.; Yang, J.; Sun, W.; Nong, M.; Li, F. Multi-hour and multi-site air quality index forecasting in Beijing using CNN, LSTM, CNN-LSTM, and spatiotemporal clustering. Expert Syst. Appl. 2021, 169, 114513. [Google Scholar] [CrossRef]
- Alahamade, W.; Lake, I.; Reeves, C.E.; De La Iglesia, B. A multi-variate time series clustering approach based on intermediate fusion: A case study in air pollution data imputation. Neurocomputing 2021, in press. [CrossRef]
- Anuradha, J.; Vandhana, S.; Reddi, S.I. Forecasting Air Quality in India through an Ensemble Clustering Technique. In Applied Intelligent Decision Making in Machine Learning; CRC Press: Boca Raton, FL, USA, 2020; pp. 113–136. [Google Scholar] [CrossRef]
- Zhan, D.; Kwan, M.-P.; Zhang, W.; Yu, X.; Meng, B.; Liu, Q. The driving factors of air quality index in China. J. Clean. Prod. 2018, 197, 1342–1351. [Google Scholar] [CrossRef]
- Qiao, Z.; Wu, F.; Xu, X.; Yang, J.; Liu, L. Mechanism of Spatiotemporal Air Quality Response to Meteorological Parameters: A National-Scale Analysis in China. Sustainability 2019, 11, 3957. [Google Scholar] [CrossRef]
- Tüysüzoğlu, G.; Birant, D.; Pala, A. Majority Voting Based Multi-Task Clustering of Air Quality Monitoring Network in Turkey. Appl. Sci. 2019, 9, 1610. [Google Scholar] [CrossRef]
- Cotta, H.H.A.; Reisen, V.A.; Bondon, P.; Filho, P.R.P. Identification of Redundant Air Quality Monitoring Stations using Robust Principal Component Analysis. Environ. Model. Assess. 2020, 25, 521–530. [Google Scholar] [CrossRef]
- Alahamade, W.; Lake, I.; Reeves, C.E.; Iglesia, B.D.L. Clustering imputation for air pollution data. In Proceedings of the 15th International Conference, HAIS 2020, Gijón, Spain, 11–13 November 2020. [Google Scholar]
- Govender, P.; Sivakumar, V. Application of k-means and hierarchical clustering techniques for analysis of air pollution: A review (1980–2019). Atmos. Pollut. Res. 2020, 11, 40–56. [Google Scholar] [CrossRef]
- Van der Laan, M.; Pollard, K.; Bryan, J. A new partitioning around medoids algorithm. J. Stat. Comput. Simul. 2003, 73, 575–584. [Google Scholar] [CrossRef]
- Łuczak, A.; Kalinowski, S. Fuzzy Clustering Methods to Identify the Epidemiological Situation and Its Changes in European Countries during COVID-19. Entropy 2022, 24, 14. [Google Scholar] [CrossRef] [PubMed]
- Abu Bakar, M.A.; Ariff, N.M.; Jemain, A.A.; Nadzir, M.S.M. Cluster Analysis of Hourly Rainfalls Using Storm Indices in Peninsular Malaysia. J. Hydrol. Eng. 2020, 25, 05020011. [Google Scholar] [CrossRef]
- Basu, B.; Srinivas, V.V. Regional flood frequency analysis using kernel-based fuzzy clustering approach. Water Resour. Res. 2014, 50, 3295–3316. [Google Scholar] [CrossRef]
- Rai, P.; Singh, S. A survey of clustering techniques. Int. J. Comput. Appl. 2010, 7, 1–5. [Google Scholar] [CrossRef]
- Sardá-Espinosa, A. Comparing time-series clustering algorithms in r using the dtwclust package. R Package Vignette 2017, 12, 41. [Google Scholar]
- Niennattrakul, V.; Ratanamahatana, C.A. On clustering multimedia time series data using k-means and dynamic time warping. In Proceedings of the 2007 International Conference on Multimedia and Ubiquitous Engineering (MUE’07), Seoul, Korea, 26–28 April 2007. [Google Scholar]
- Izakian, H.; Pedrycz, W.; Jamal, I. Fuzzy clustering of time series data using dynamic time warping distance. Eng. Appl. Artif. Intell. 2015, 39, 235–244. [Google Scholar] [CrossRef]
- Huy, V.T.; Anh, D.T. An efficient implementation of anytime k-medoids clustering for time series under dynamic time warping. In Proceedings of the Seventh Symposium on Information and Communication Technology, Ho Chi Minh City, Vietnam, 8–9 December 2016; pp. 22–29. [Google Scholar] [CrossRef]
- Łuczak, M. Hierarchical clustering of time series data with parametric derivative dynamic time warping. Expert Syst. Appl. 2016, 62, 116–130. [Google Scholar] [CrossRef]
- Ariff, N.M.; Abu Bakar, M.A.; Zamzuri, Z.H. Academic preference based on students’ personality analysis through k-means clustering. Malays. J. Fundam. Appl. Sci. 2020, 16, 328–333. [Google Scholar] [CrossRef]
- Maharaj, E.A.; D’Urso, P.; Caiado, J. Time Series Clustering and Classification; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Partitioning around medoids (program pam). In Finding Groups in Data: An Introduction to Cluster Analysis; Wiley: Hoboken, NJ, USA, 1990; Volume 344, pp. 68–125. [Google Scholar]
- Zhao, Y.; Karypis, G. Evaluation of hierarchical clustering algorithms for document datasets. In Proceedings of the Eleventh International Conference on Information and Knowledge Management, McLean, VA, USA, 4–9 November 2002. [Google Scholar]
- Sonagara, D.; Badheka, S. Comparison of basic clustering algorithms. Int. J. Comput. Sci. Mob. Comput. 2014, 3, 58–61. [Google Scholar]
- Rani, Y.; Rohil, H. A study of hierarchical clustering algorithm. Int. J. Inf. Comput. Technol. 2013, 3, 1225–1232. [Google Scholar]
- Xu, D.; Tian, Y. A Comprehensive Survey of Clustering Algorithms. Ann. Data Sci. 2015, 2, 165–193. [Google Scholar] [CrossRef]
- D’Urso, P.; Massari, R.; Cappelli, C.; De Giovanni, L. Autoregressive metric-based trimmed fuzzy clustering with an application to PM10 time series. Chemom. Intell. Lab. Syst. 2017, 161, 15–26. [Google Scholar] [CrossRef]
- Ottosen, T.-B.; Kumar, P. Outlier detection and gap filling methodologies for low-cost air quality measurements. Environ. Sci. Processes Impacts 2019, 21, 701–713. [Google Scholar] [CrossRef]
- Yen, N.Y.; Chang, J.-W.; Liao, J.-Y.; Yong, Y.-M. Analysis of interpolation algorithms for the missing values in IoT time series: A case of air quality in Taiwan. J. Supercomput. 2020, 76, 6475–6500. [Google Scholar] [CrossRef]
- Junninen, H.; Niska, H.; Tuppurainen, K.; Ruuskanen, J.; Kolehmainen, M. Methods for imputation of missing values in air quality data sets. Atmos. Environ. 2004, 38, 2895–2907. [Google Scholar] [CrossRef]
- Meesrikamolkul, W.; Niennattrakul, V.; Ratanamahatana, C.A. Shape-based clustering for time series data. In Proceedings of the 16th Pacific-Asia Conference, PAKDD 2012, Kuala Lumpur, Malaysia, 29 May–1 June 2012. [Google Scholar] [CrossRef]
- Syakur, M.A.; Khotimah, B.K.; Rochman, E.M.S.; Satoto, B.D. Integration K-Means Clustering Method and Elbow Method for Identification of The Best Customer Profile Cluster. IOP Conf. Ser. Mater. Sci. Eng. 2018, 336, 012017. [Google Scholar] [CrossRef]
- Ghosh, S.; Dubey, S.K. Comparative analysis of k-means and fuzzy c-means algorithms. Int. J. Adv. Comput. Sci. Appl. 2013, 4, 35–39. [Google Scholar] [CrossRef]
- Wang, Y.; Qin, K.; Chen, Y.; Zhao, P. Detecting Anomalous Trajectories and Behavior Patterns Using Hierarchical Clustering from Taxi GPS Data. ISPRS Int. J. Geo-Inf. 2018, 7, 25. [Google Scholar] [CrossRef]
- Mazarbhuiya, F.A.; AlZahrani, M.Y.; Georgieva, L. Anomaly detection using agglomerative hierarchical clustering algorithm. In Proceedings of the 9th iCatse Conference on Information Science and Applications, Hong Kong, China, 25–27 June 2018. [Google Scholar]
- Reynolds, A.P.; Richards, G.; de la Iglesia, B.; Rayward-Smith, V.J. Clustering Rules: A Comparison of Partitioning and Hierarchical Clustering Algorithms. J. Math. Model. Algorithms 2006, 5, 475–504. [Google Scholar] [CrossRef]
- D’Urso, P.; Maharaj, E.A. Autocorrelation-based fuzzy clustering of time series. Fuzzy Sets Syst. 2009, 160, 3565–3589. [Google Scholar] [CrossRef]
- Mingoti, S.A.; Lima, J.O. Comparing SOM neural network with Fuzzy c-means, K-means and traditional hierarchical clustering algorithms. Eur. J. Oper. Res. 2006, 174, 1742–1759. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | Cluster | Minimum Observation | Lower Quartile | Median | Upper Quartile | Maximum Observation (Below Upper Fence) |
|---|---|---|---|---|---|---|
| DTW + k-Means | Cluster 1 | 6.52 | 20.37 | 25.78 | 32.92 | 51.71 |
| Cluster 2 | 4.46 | 16.01 | 20.55 | 26.67 | 42.67 | |
| Cluster 3 | 6.57 | 25.46 | 31.75 | 39.67 | 60.86 | |
| Cluster 4 | 4.37 | 12.96 | 15.92 | 20.23 | 31.13 | |
| DTW + PAM | Cluster 1 | 4.46 | 16.71 | 22.00 | 28.86 | 47.06 |
| Cluster 2 | 4.37 | 17.47 | 22.54 | 29.13 | 46.58 | |
| Cluster 3 | 6.57 | 24.46 | 30.51 | 38.05 | 58.21 | |
| Cluster 4 | 4.55 | 13.42 | 16.67 | 21.58 | 33.80 | |
| DTW + Hierarchical | Cluster 1 | 6.57 | 22.81 | 28.57 | 35.69 | 54.97 |
| Cluster 2 | 4.46 | 16.37 | 21.23 | 27.71 | 44.69 | |
| Cluster 3 | 14.11 | 28.02 | 36.01 | 46.22 | 73.38 | |
| Cluster 4 | 4.37 | 13.31 | 16.40 | 21.13 | 32.84 | |
| DTW + FKM | Cluster 1 | 6.52 | 19.96 | 25.38 | 32.54 | 51.42 |
| Cluster 2 | 5.00 | 16.33 | 20.90 | 26.87 | 42.67 | |
| Cluster 3 | 6.57 | 25.46 | 31.75 | 39.67 | 60.86 | |
| Cluster 4 | 4.37 | 13.05 | 16.32 | 21.10 | 33.13 |
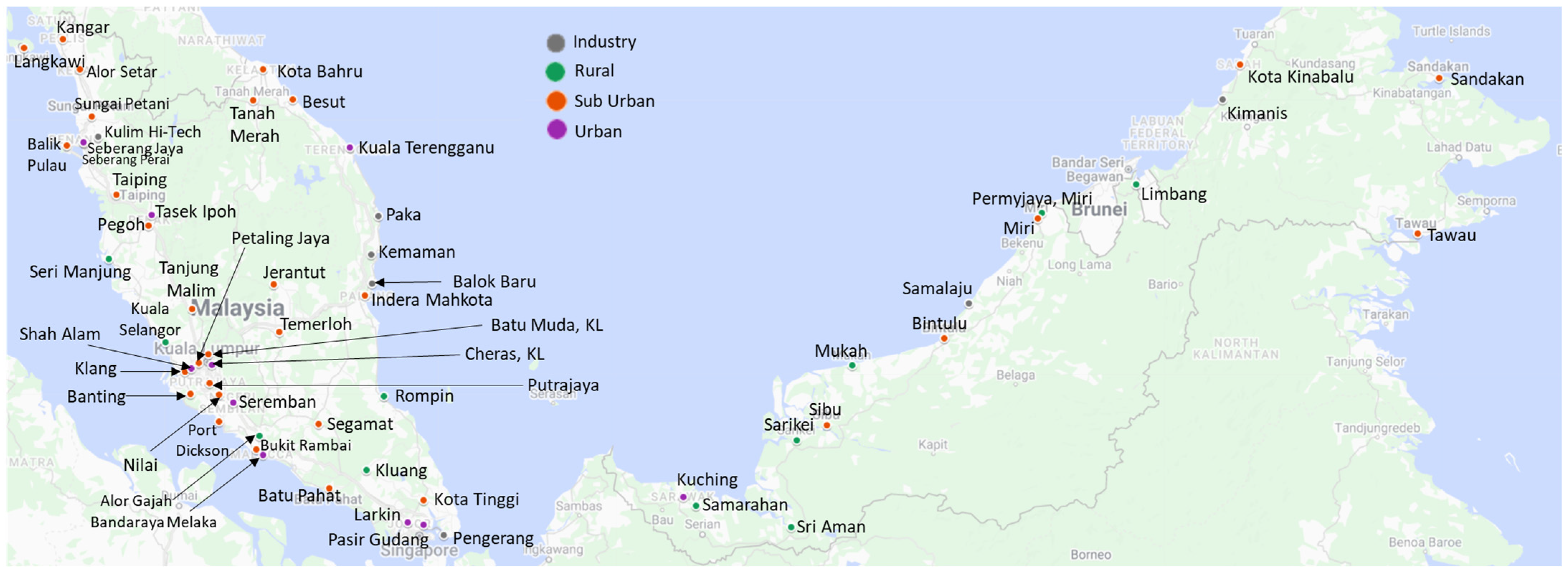
| Station ID | Station Location | Station Category | DTW + k-Means | DTW + PAM | DTW + Hierarchical | DTW + FKM |
|---|---|---|---|---|---|---|
| CA01R | Kangar, PERLIS | Sub Urban | 2 | 1 | 2 | 4 |
| CA02K | Langkawi, KEDAH | Sub Urban | 2 | 1 | 2 | 2 |
| CA03K | Alor Setar, KEDAH | Sub Urban | 2 | 1 | 2 | 2 |
| CA04K | Sungai Petani, KEDAH | Sub Urban | 2 | 1 | 2 | 2 |
| CA05K | Kulim Hi-Tech, KEDAH | Industry | 2 | 1 | 2 | 2 |
| CA06P | Seberang Jaya, PULAU PINANG | Urban | 1 | 1 | 2 | 1 |
| CA07P | Seberang Perai, PULAU PINANG | Sub Urban | 1 | 1 | 2 | 1 |
| CA09P | Balik Pulau, PULAU PINANG | Sub Urban | 2 | 1 | 2 | 4 |
| CA10A | Taiping, PERAK | Sub Urban | 3 | 3 | 1 | 3 |
| CA11A | Tasek Ipoh, PERAK | Urban | 1 | 2 | 1 | 1 |
| CA12A | Pegoh Ipoh, PERAK | Sub Urban | 3 | 3 | 1 | 3 |
| CA13A | Seri Manjung, PERAK | Rural | 1 | 1 | 2 | 1 |
| CA14A | Tanjung Malim, PERAK | Sub Urban | 4 | 4 | 4 | 4 |
| CA15W | Batu Muda, KL WILAYAH PERSEKUTUAN | Sub Urban | 1 | 2 | 1 | 1 |
| CA16W | Cheras, KL WILAYAH PERSEKUTUAN | Urban | 1 | 3 | 1 | 1 |
| CA17W | Putrajaya, WILAYAH PERSEKUTUAN | Sub Urban | 1 | 3 | 1 | 1 |
| CA18B | Kuala Selangor, SELANGOR | Rural | 2 | 1 | 2 | 1 |
| CA19B | Petaling Jaya, SELANGOR | Sub Urban | 3 | 3 | 1 | 3 |
| CA20B | Shah Alam, SELANGOR | Urban | 3 | 3 | 1 | 3 |
| CA21B | Klang, SELANGOR | Sub Urban | 3 | 3 | 3 | 3 |
| CA22B | Banting, SELANGOR | Sub Urban | 3 | 3 | 1 | 3 |
| CA23N | Nilai, NEGERI SEMBILAN | Sub Urban | 3 | 3 | 1 | 3 |
| CA24N | Seremban, NEGERI SEMBILAN | Urban | 2 | 2 | 2 | 2 |
| CA25N | Port Dickson, NEGERI SEMBILAN | Sub Urban | 2 | 2 | 2 | 2 |
| CA26M | Alor Gajah, MELAKA | Rural | 2 | 2 | 2 | 2 |
| CA27M | Bukit Rambai, MELAKA | Sub Urban | 1 | 2 | 1 | 1 |
| CA28M | Bandaraya Melaka, MELAKA | Urban | 2 | 2 | 2 | 1 |
| CA29J | Segamat, JOHOR | Sub Urban | 2 | 2 | 2 | 2 |
| CA31J | Batu Pahat, JOHOR | Sub Urban | 2 | 2 | 2 | 2 |
| CA32J | Kluang, JOHOR | Rural | 2 | 2 | 2 | 2 |
| CA33J | Larkin, JOHOR | Urban | 1 | 3 | 1 | 1 |
| CA34J | Pasir Gudang, JOHOR | Urban | 1 | 2 | 1 | 1 |
| CA35J | Pengerang, JOHOR | Industry | 2 | 2 | 2 | 2 |
| CA36J | Kota Tinggi, JOHOR | Sub Urban | 4 | 2 | 4 | 4 |
| CA37C | Rompin, PAHANG | Rural | 2 | 2 | 2 | 2 |
| CA38C | Temerloh, PAHANG | Sub Urban | 1 | 2 | 1 | 1 |
| CA39C | Jerantut, PAHANG | Sub Urban | 2 | 4 | 2 | 4 |
| CA40C | Indera Mahkota, Kuantan, PAHANG | Sub Urban | 2 | 2 | 2 | 2 |
| CA41C | Balok Baru, Kuantan, PAHANG | Industry | 1 | 1 | 1 | 1 |
| CA42T | Kemaman, TERENGGANU | Industry | 2 | 2 | 2 | 2 |
| CA43T | Paka, TERENGGANU | Industry | 2 | 2 | 2 | 4 |
| CA44T | Kuala Terengganu, TERENGGANU | Urban | 2 | 1 | 2 | 2 |
| CA45T | Besut, TERENGGANU | Sub Urban | 2 | 1 | 2 | 2 |
| CA46D | Tanah Merah, KELANTAN | Sub Urban | 1 | 1 | 2 | 1 |
| CA47D | Kota Bahru, KELANTAN | Sub Urban | 1 | 1 | 2 | 1 |
| CA48S | Tawau, SABAH | Sub Urban | 4 | 4 | 4 | 4 |
| CA49S | Sandakan, SABAH | Sub Urban | 4 | 4 | 4 | 4 |
| CA50S | Kota Kinabalu, SABAH | Sub Urban | 2 | 4 | 2 | 2 |
| CA51S | Kimanis, SABAH | Industry | 4 | 4 | 4 | 4 |
| CA54Q | Limbang, SARAWAK | Rural | 4 | 4 | 4 | 4 |
| CA55Q | Permyjaya, Miri, SARAWAK | Rural | 4 | 4 | 4 | 4 |
| CA56Q | Miri, SARAWAK | Sub Urban | 2 | 4 | 2 | 2 |
| CA57Q | Samalaju, SARAWAK | Industry | 2 | 4 | 4 | 2 |
| CA58Q | Bintulu, SARAWAK | Sub Urban | 1 | 1 | 2 | 1 |
| CA59Q | Mukah, SARAWAK | Rural | 4 | 4 | 4 | 4 |
| CA61Q | Sibu, SARAWAK | Sub Urban | 2 | 4 | 4 | 2 |
| CA62Q | Sarikei, SARAWAK | Rural | 4 | 4 | 4 | 4 |
| CA63Q | Sri Aman, SARAWAK | Rural | 4 | 4 | 4 | 4 |
| CA64Q | Samarahan, SARAWAK | Rural | 4 | 4 | 4 | 4 |
| CA65Q | Kuching, SARAWAK | Urban | 4 | 4 | 4 | 4 |
| Stations’ Location Categories | Clusters | DTW + k-Means | DTW + PAM | DTW + Hierarchical | DTW + FKM |
|---|---|---|---|---|---|
| Industry | 1 | 1 | 2 | 1 | 1 |
| 2 | 5 | 3 | 4 | 4 | |
| 3 | 0 | 0 | 0 | 0 | |
| 4 | 1 | 2 | 2 | 2 | |
| Rural | 1 | 1 | 2 | 0 | 2 |
| 2 | 4 | 3 | 5 | 3 | |
| 3 | 0 | 0 | 0 | 0 | |
| 4 | 6 | 6 | 6 | 6 | |
| Urban | 1 | 5 | 2 | 5 | 6 |
| 2 | 3 | 4 | 4 | 2 | |
| 3 | 1 | 3 | 0 | 1 | |
| 4 | 1 | 1 | 1 | 1 | |
| Sub-Urban | 1 | 8 | 10 | 9 | 8 |
| 2 | 14 | 8 | 17 | 11 | |
| 3 | 6 | 7 | 1 | 6 | |
| 4 | 4 | 7 | 5 | 7 |
| Algorithms | Cluster | Minimum Observation | Lower Quartile | Median | Upper Quartile | Maximum Observation (Below Upper Fence) |
|---|---|---|---|---|---|---|
| DTW + k-Means | Cluster 1 | 11.67 | 32.00 | 46.91 | 72.52 | 133.12 |
| Cluster 2 | 6.00 | 18.02 | 25.15 | 34.66 | 59.58 | |
| Cluster 3 | 9.10 | 29.30 | 40.03 | 55.16 | 93.65 | |
| Cluster 4 | 7.00 | 22.22 | 31.00 | 43.11 | 74.42 | |
| DTW + PAM | Cluster 1 | 11.67 | 29.24 | 43.00 | 74.69 | 142.18 |
| Cluster 2 | 6.00 | 17.00 | 23.00 | 31.76 | 53.88 | |
| Cluster 3 | 11.95 | 31.00 | 41.98 | 57.66 | 97.57 | |
| Cluster 4 | 7.00 | 23.00 | 31.00 | 42.67 | 72.17 | |
| DTW + Hierarchical | Cluster 1 | 11.67 | 29.24 | 43.00 | 74.69 | 142.18 |
| Cluster 2 | 6.00 | 19.00 | 26.33 | 37.00 | 64.00 | |
| Cluster 3 | 17.00 | 36.00 | 49.00 | 69.87 | 120.01 | |
| Cluster 4 | 10.00 | 28.00 | 37.00 | 50.24 | 83.37 | |
| DTW + FKM | Cluster 1 | 11.67 | 32.00 | 46.91 | 72.52 | 133.12 |
| Cluster 2 | 6.00 | 18.02 | 25.15 | 34.66 | 59.58 | |
| Cluster 3 | 7.00 | 23.88 | 32.70 | 45.75 | 78.51 | |
| Cluster 4 | 7.00 | 23.75 | 33.16 | 47.18 | 82.31 |
| Station ID | Station Location | Station Category | DTW + k-Means | DTW + PAM | DTW + Hierarchical | DTW + FKM |
|---|---|---|---|---|---|---|
| CA01R | Kangar, PERLIS | Sub Urban | 2 | 2 | 2 | 2 |
| CA02K | Langkawi, KEDAH | Sub Urban | 2 | 4 | 2 | 2 |
| CA03K | Alor Setar, KEDAH | Sub Urban | 2 | 2 | 2 | 2 |
| CA04K | Sungai Petani, KEDAH | Sub Urban | 2 | 4 | 2 | 2 |
| CA05K | Kulim Hi-Tech, KEDAH | Industry | 4 | 4 | 2 | 4 |
| CA06P | Seberang Jaya, PULAU PINANG | Urban | 4 | 4 | 4 | 3 |
| CA07P | Seberang Perai, PULAU PINANG | Sub Urban | 4 | 4 | 4 | 4 |
| CA09P | Balik Pulau, PULAU PINANG | Sub Urban | 2 | 2 | 2 | 2 |
| CA10A | Taiping, PERAK | Sub Urban | 1 | 1 | 1 | 1 |
| CA11A | Tasek Ipoh, PERAK | Urban | 4 | 4 | 4 | 3 |
| CA12A | Pegoh Ipoh, PERAK | Sub Urban | 3 | 3 | 4 | 3 |
| CA13A | Seri Manjung, PERAK | Rural | 4 | 4 | 2 | 3 |
| CA14A | Tanjung Malim, PERAK | Sub Urban | 2 | 2 | 2 | 2 |
| CA15W | Batu Muda, KL WILAYAH PERSEKUTUAN | Sub Urban | 4 | 4 | 4 | 3 |
| CA16W | Cheras, KL WILAYAH PERSEKUTUAN | Urban | 3 | 3 | 4 | 3 |
| CA17W | Putrajaya, WILAYAH PERSEKUTUAN | Sub Urban | 4 | 4 | 4 | 3 |
| CA18B | Kuala Selangor, SELANGOR | Rural | 4 | 4 | 4 | 3 |
| CA19B | Petaling Jaya, SELANGOR | Sub Urban | 3 | 3 | 4 | 4 |
| CA20B | Shah Alam, SELANGOR | Urban | 3 | 3 | 4 | 3 |
| CA21B | Klang, SELANGOR | Sub Urban | 1 | 3 | 3 | 1 |
| CA22B | Banting, SELANGOR | Sub Urban | 3 | 3 | 4 | 3 |
| CA23N | Nilai, NEGERI SEMBILAN | Sub Urban | 3 | 3 | 4 | 4 |
| CA24N | Seremban, NEGERI SEMBILAN | Urban | 2 | 4 | 2 | 2 |
| CA25N | Port Dickson, NEGERI SEMBILAN | Sub Urban | 2 | 4 | 2 | 2 |
| CA26M | Alor Gajah, MELAKA | Rural | 2 | 4 | 2 | 2 |
| CA27M | Bukit Rambai, MELAKA | Sub Urban | 4 | 4 | 4 | 4 |
| CA28M | Bandaraya Melaka, MELAKA | Urban | 4 | 4 | 2 | 3 |
| CA29J | Segamat, JOHOR | Sub Urban | 2 | 4 | 2 | 2 |
| CA31J | Batu Pahat, JOHOR | Sub Urban | 2 | 4 | 2 | 2 |
| CA32J | Kluang, JOHOR | Rural | 2 | 4 | 2 | 2 |
| CA33J | Larkin, JOHOR | Urban | 4 | 4 | 4 | 3 |
| CA34J | Pasir Gudang, JOHOR | Urban | 4 | 4 | 4 | 4 |
| CA35J | Pengerang, JOHOR | Industry | 4 | 4 | 2 | 3 |
| CA36J | Kota Tinggi, JOHOR | Sub Urban | 2 | 2 | 2 | 2 |
| CA37C | Rompin, PAHANG | Rural | 2 | 4 | 2 | 2 |
| CA38C | Temerloh, PAHANG | Sub Urban | 4 | 4 | 2 | 3 |
| CA39C | Jerantut, PAHANG | Sub Urban | 2 | 2 | 2 | 2 |
| CA40C | Indera Mahkota, Kuantan, PAHANG | Sub Urban | 2 | 2 | 2 | 2 |
| CA41C | Balok Baru, Kuantan, PAHANG | Industry | 4 | 4 | 4 | 4 |
| CA42T | Kemaman, TERENGGANU | Industry | 4 | 4 | 2 | 4 |
| CA43T | Paka, TERENGGANU | Industry | 2 | 2 | 2 | 2 |
| CA44T | Kuala Terengganu, TERENGGANU | Urban | 4 | 4 | 2 | 3 |
| CA45T | Besut, TERENGGANU | Sub Urban | 2 | 4 | 2 | 2 |
| CA46D | Tanah Merah, KELANTAN | Sub Urban | 4 | 4 | 2 | 4 |
| CA47D | Kota Bahru, KELANTAN | Sub Urban | 3 | 4 | 2 | 3 |
| CA48S | Tawau, SABAH | Sub Urban | 2 | 2 | 2 | 2 |
| CA49S | Sandakan, SABAH | Sub Urban | 2 | 2 | 2 | 2 |
| CA50S | Kota Kinabalu, SABAH | Sub Urban | 4 | 2 | 2 | 3 |
| CA51S | Kimanis, SABAH | Industry | 2 | 2 | 2 | 2 |
| CA54Q | Limbang, SARAWAK | Rural | 2 | 2 | 2 | 2 |
| CA55Q | Permyjaya, Miri, SARAWAK | Rural | 4 | 2 | 2 | 3 |
| CA56Q | Miri, SARAWAK | Sub Urban | 4 | 2 | 2 | 4 |
| CA57Q | Samalaju, SARAWAK | Industry | 4 | 4 | 2 | 3 |
| CA58Q | Bintulu, SARAWAK | Sub Urban | 3 | 3 | 4 | 4 |
| CA59Q | Mukah, SARAWAK | Rural | 4 | 4 | 2 | 3 |
| CA61Q | Sibu, SARAWAK | Sub Urban | 4 | 4 | 2 | 4 |
| CA62Q | Sarikei, SARAWAK | Rural | 4 | 2 | 2 | 3 |
| CA63Q | Sri Aman, SARAWAK | Rural | 2 | 2 | 2 | 2 |
| CA64Q | Samarahan, SARAWAK | Rural | 2 | 2 | 2 | 2 |
| CA65Q | Kuching, SARAWAK | Urban | 4 | 4 | 2 | 4 |
| Stations’ Location Categories | Clusters | DTW + k-Means | DTW + PAM | DTW + Hierarchical | DTW + FKM |
|---|---|---|---|---|---|
| Industry | 1 | 0 | 0 | 0 | 0 |
| 2 | 2 | 2 | 6 | 2 | |
| 3 | 0 | 0 | 0 | 2 | |
| 4 | 5 | 5 | 1 | 3 | |
| Rural | 1 | 0 | 0 | 0 | 0 |
| 2 | 5 | 5 | 10 | 6 | |
| 3 | 0 | 0 | 0 | 5 | |
| 4 | 6 | 6 | 1 | 0 | |
| Urban | 1 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 4 | 1 | |
| 3 | 2 | 2 | 0 | 7 | |
| 4 | 8 | 8 | 6 | 2 | |
| Sub-Urban | 1 | 1 | 1 | 1 | 2 |
| 2 | 11 | 11 | 21 | 15 | |
| 3 | 6 | 6 | 1 | 7 | |
| 4 | 14 | 14 | 9 | 8 |
| Algorithm | Rand Index | |
|---|---|---|
| Daily Average | Daily Maximum | |
| k-Means | 0.6559322 | 0.5694915 |
| PAM | 0.7548023 | 0.5903955 |
| Hierarchical | 0.6423729 | 0.499435 |
| FKM | 0.6570621 | 0.580226 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suris, F.N.A.; Bakar, M.A.A.; Ariff, N.M.; Mohd Nadzir, M.S.; Ibrahim, K. Malaysia PM10 Air Quality Time Series Clustering Based on Dynamic Time Warping. Atmosphere 2022, 13, 503. https://doi.org/10.3390/atmos13040503
Suris FNA, Bakar MAA, Ariff NM, Mohd Nadzir MS, Ibrahim K. Malaysia PM10 Air Quality Time Series Clustering Based on Dynamic Time Warping. Atmosphere. 2022; 13(4):503. https://doi.org/10.3390/atmos13040503
Chicago/Turabian StyleSuris, Fatin Nur Afiqah, Mohd Aftar Abu Bakar, Noratiqah Mohd Ariff, Mohd Shahrul Mohd Nadzir, and Kamarulzaman Ibrahim. 2022. "Malaysia PM10 Air Quality Time Series Clustering Based on Dynamic Time Warping" Atmosphere 13, no. 4: 503. https://doi.org/10.3390/atmos13040503
APA StyleSuris, F. N. A., Bakar, M. A. A., Ariff, N. M., Mohd Nadzir, M. S., & Ibrahim, K. (2022). Malaysia PM10 Air Quality Time Series Clustering Based on Dynamic Time Warping. Atmosphere, 13(4), 503. https://doi.org/10.3390/atmos13040503