1. Introduction
An accurate assessment of the
environmental risk of urban climate events is of great importance for populations, authorities, and decision makers (DMs) [
1,
2]. Spatial
risk assessment provides DMs with the necessary information to make informed decisions and allocate resources in a meaningful way that aims at improving the overall welfare of the population. The allocation of resources is central to the DMs’ operation and may have long-term implications, and should, therefore, be accurately modeled [
3,
4,
5].
While there are a myriad of aspects that DMs should take into account, one aspect which is widely accepted as important is the perception of thermal comfort experienced by the population [
6,
7]. The thermal comfort of the population affects multiple aspects of life and directly and indirectly contributes to the well-being of the population [
8]. In particular, outdoor thermal comfort (OTC) is a key indicator of people’s well-being, productivity, and happiness in general [
9,
10,
11]. Therefore, in this work, we concentrate on OTC as a key indicator of people’s well-being and acknowledge its contribution to key performance indicators of a city. To reflect this, a myriad of different indices have been developed; see [
12] for an overview. The OTC indices can be divided into two main categories:
rational or
empirical indices. The
rational indices are based on heat transfer and energy balance principles of a typical human body in relation to its physical environment [
13]. The second type of indices is based on empirical studies of the subjective experience of OTC in relation to meteorological phenomena [
9,
10]. While
rational indices are based on fundamentals of physics and bio-meteorology, thereby making them more favorable than their empirical counterparts, they may be more complicated and less intuitive to understand. They also lack mathematical tractability and can only be evaluated through numerical calculations; see, for example, the evaluation of physiological equivalent temperature (PET) in [
14].
1.1. Literature Review on OTC-Informed Urban Planning
We begin by stating that, currently, there are no works that address the problem of resource allocation and aims at improving OTC levels at different spatial locations jointly. In our previous works, we have developed a framework to score and rank different urban designs, but the important aspect of (spatial) resource allocation was not addressed and the analysis concentrated on small-scale developments [
15,
16,
17]. While our work is the first to address this problem, there have been some works on related topics that investigated the concept of improving OTC levels via different intervention strategies, and here we review some of them. The evaluation of the quality of urban spaces from an OTC perspective has been the focus of many previous works; see, for example [
18,
19,
20,
21,
22]. In [
23], the authors investigated the OTC perception of subjects and their physical wellbeing. In [
24], the authors reviewed the effects of green spaces and plants on the micro-climate, urban heat islands, and human outdoor thermal comfort. In [
20], the authors conducted detailed CFD simulations under a large range of wind conditions and evaluated the OTC under each scenario. In [
21], the authors examined the effect of plant types, arrangements, and their orientation on OTC. More recently, in [
25], the authors developed a method to optimize the OTC levels by setting the optimal parameters of building heights, street widths, and orientations. While those studies provide many important insights regarding the impact of different techniques and technologies on OTC improvements, an important gap still remains when considering the problem of improving OTC on a large geographical scale (i.e., a city or country). Those are still open questions which have been not been fully addressed. For example, in [
26], the authors provide an overview on how machine learning-based methods could be used in order to help DMs make “geographically differentiated” allocations of resources in a systematic way. In [
27], the authors developed a method to create climate zoning based on the relationship between spatial temperature distribution and the various associated factors using observed data and numerical simulations.
Those papers make progress in mapping geographical areas and their OTC quality. Still, an open question remains: How should DMs allocate their financial resources in order to improve OTC on a large geographical scale? It could be that some regions experience worse OTC levels than others. Should such regions receive more resources in order to improve their OTC levels? Or, perhaps, would the finite resources be better used if allocated to regions where the OTC levels are mediocre, aiming, thus, at improving those areas while neglecting the regions with low- and high-quality OTC levels?
Similar to [
26,
27], we are also interested in the concept of “geographically differentiated” allocations of resources. We, however, develop a novel systematic approach for addressing this problem using the notions of
risk modeling and
resource allocation methods.
1.2. The Proposed Framework—Spatial Resource Allocation for OTC Enhancement
Ultimately, the DM (say, a government agency) is required to allocate finite financial resources in order to improve OTC levels in a geographical area. A common approach for allocating the resources would be to partition the physical domain into a finite number of regions, and allocate the money to each region according to some decision mechanism. The problem of spatial resource allocation is common in many areas of engineering, including wireless communication [
28,
29], logistics and planning [
30], transportation networks [
31,
32], and many others. Much less attention has been given to spatial resource allocation in the context of urban-climate management. To address this open question, we develop a spatial risk model and link it to a spatial resource allocation method, which is based on similar concepts to the ones used in modern portfolio allocation (MPA), known as the Markowitz mean-variance model [
33,
34]. In order to be able to develop such a tractable mathematical framework for resource allocation, we need to be able to express the OTC equations in closed form. This can be obtained by using a machine learning technique known as
surrogate models. Surrogate models refers to a
model of a model; that is, instead of using the original model, we replace it with a simpler and mathematically tractable one. This way, we can gain the desired mathematical tractability at the expense of possible loss of accuracy. The loss of accuracy can be easily calculated (via model validation techniques) and then can be incorporated into the model, thus retaining all statistical information available. One more important aspect which is usually overlooked or ignored is the simple fact that no model is perfect [
35]. Even the most advanced state-of-the-art climate models are still simplifications of reality and incur estimation errors [
36]. Validating the model is paramount in order to quantify the magnitude and statistical properties of the estimation error of the various climate variables [
37]. Then, incorporating the errors from both sources (that is, the surrogate and climate models) is required, if one wishes to accurately quantify the OTC spatial risk. Other works which have taken climate and climate model uncertainty into consideration in urban design decision making include [
15,
16,
37]. However, these works did not consider the use of a surrogate model and only considered climate model uncertainty.
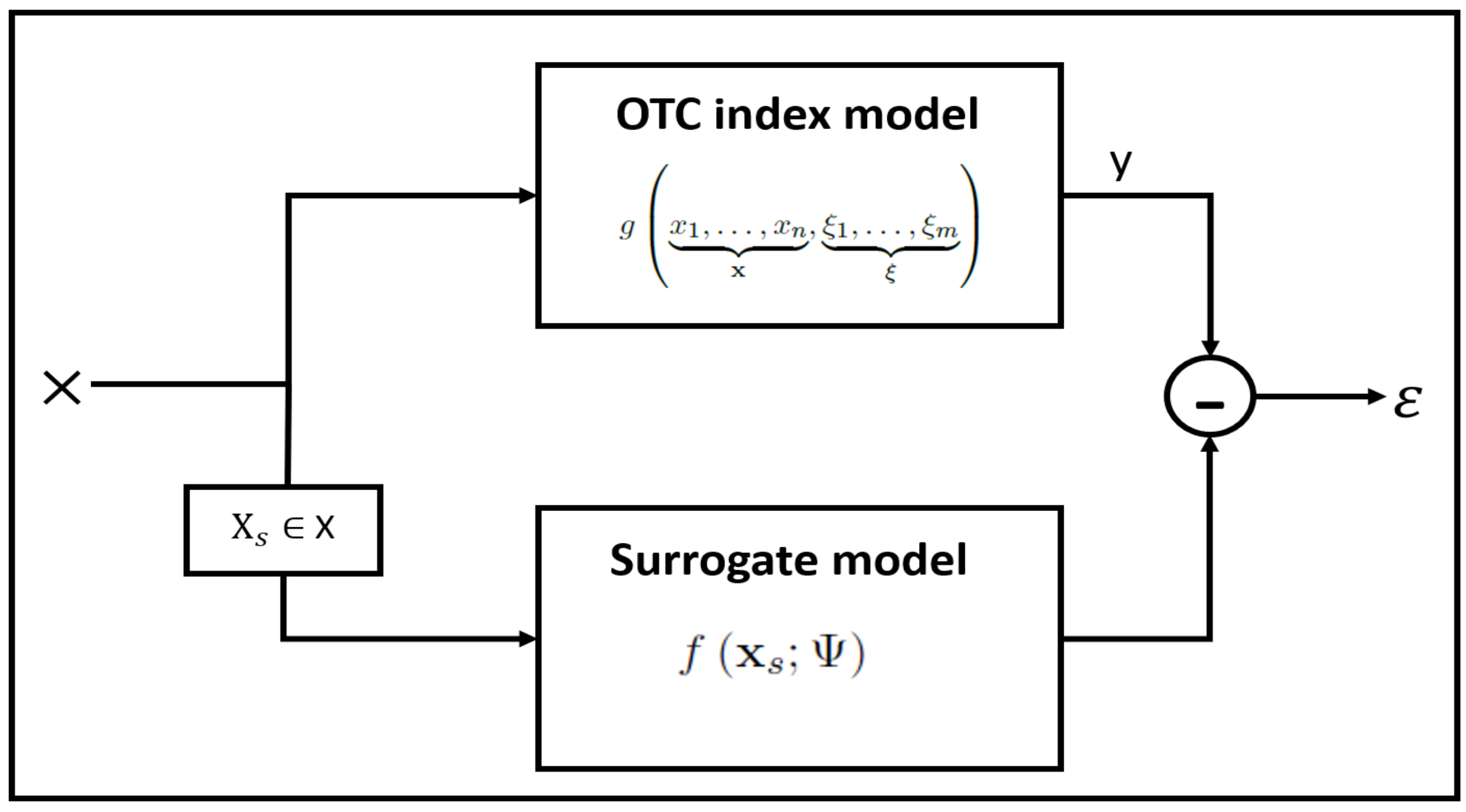
A graphical illustration of the framework that contains the aforementioned components is depicted in
Figure 1.
1.3. Goals of This Paper
The goals of this paper are threefold:
Develop a generic and accurate regression-based surrogate model that is suitable for a wide range of OTC index models;
Introduce and develop the notions of spatial risk measures in the context of urban climate and provide a unified framework for spatial risk profile estimation;
Develop a spatial (geographically differentiated) resource allocation scheme to improve the overall OTC levels in a region of interest.
We summarize the main contributions that we make in this paper:
- C1.
We develop a surrogate model for
any OTC index that is based on multiple non-linear regressions with interactions (
Section 2);
- C2.
We derive the statistical properties of the OTC index under
both climate and surrogate model uncertainty (
Section 3);
- C3.
We present two
risk measures and derive their properties for the OTC index (
Section 4);
- C4.
We show how to spatially aggregate the risk in order to obtain the risk of a spatial domain (
Section 4);
- C5.
We develop a new algorithm for spatial resource allocation that is based on the aggregate risk model (
Section 5).
1.4. Mathematical Notations
We now introduce much of the notations we will use in the rest of the paper and recall certain important notions. The symbols
and
denote the
real and
integer numbers, respectively. Random variables are denoted by upper case letters and their realizations by lower case letters. In addition, bold will be used to denote a vector or matrix quantity, and lower subscripts refer to the element of a vector or matrix. We denote the distribution of random variable
X by
. The operator
is the statistical mean of the random variable
X, and the operator
is the statistical variance of the random variable
X. The notation
denotes a normally distributed R.V. with the mean and variance given by
and
, respectively. The notation
denotes a multivariate normally distributed R.V., with the mean vector and covariance matrix given by
and
, respectively. The notation
denotes the non-central chi-squared distribution with degrees of freedom
k and non-centrality parameter
. The symbols used throughout the paper are presented in
Table 1.
2. Generic Representation of OTC Indices via a Surrogate Model
As mentioned before, there are hundreds of OTC indices and it would be impossible to analyze each one separately. Instead, we are interested in a single modeling approach which can encompass as many indices as possible, making our approach general. In order to achieve that we develop a generic representation of any OTC model via a statistical regression model, known as surrogate model. Having a single family of regression models will simplify the analysis, allow for interpretability, and provide mathematical tractability. Any OTC index can be expressed as a mapping from an input space (usually high-dimensional) to an output space (one-dimensional). More specifically, as it is commonly used in machine learning, we treat the OTC model as a black box which contains a set of n input climatic variables, , and other non-climatic variables (e.g., personal parameters), , and a single output variable, . The OTC index model can be understood as a mapping from the input space to the output space . We now provide a formal definition of the OTC index model.
Definition 1 (Generic OTC index model).
Let denote the climatic variables, and let denote non-climatic variables. Let be the OTC index value; then, a generic OTC index model can be expressed as:where is the mathematical representation of the OTC index model. We now provide two examples which illustrate how this definition applies for two widely used OTC indices, the PET and heat index.
Example 1 (PET index model [
14]).
The ubiquitous PET model requires a 10-dimensional input vector, where is the 4 climatic variables (mean radiant temperature (MRT), air temperature (AT), relative humidity (RH), and wind speed (WS)), and is the 6 personal variables (age, sex, weight, height, metabolic activity level, and clothing level) [14]. The PET model is complex and cannot be expressed in a simple analytic way, and can only be evaluated numerically; see [14] for details. Example 2 (Heat index model [
38]).
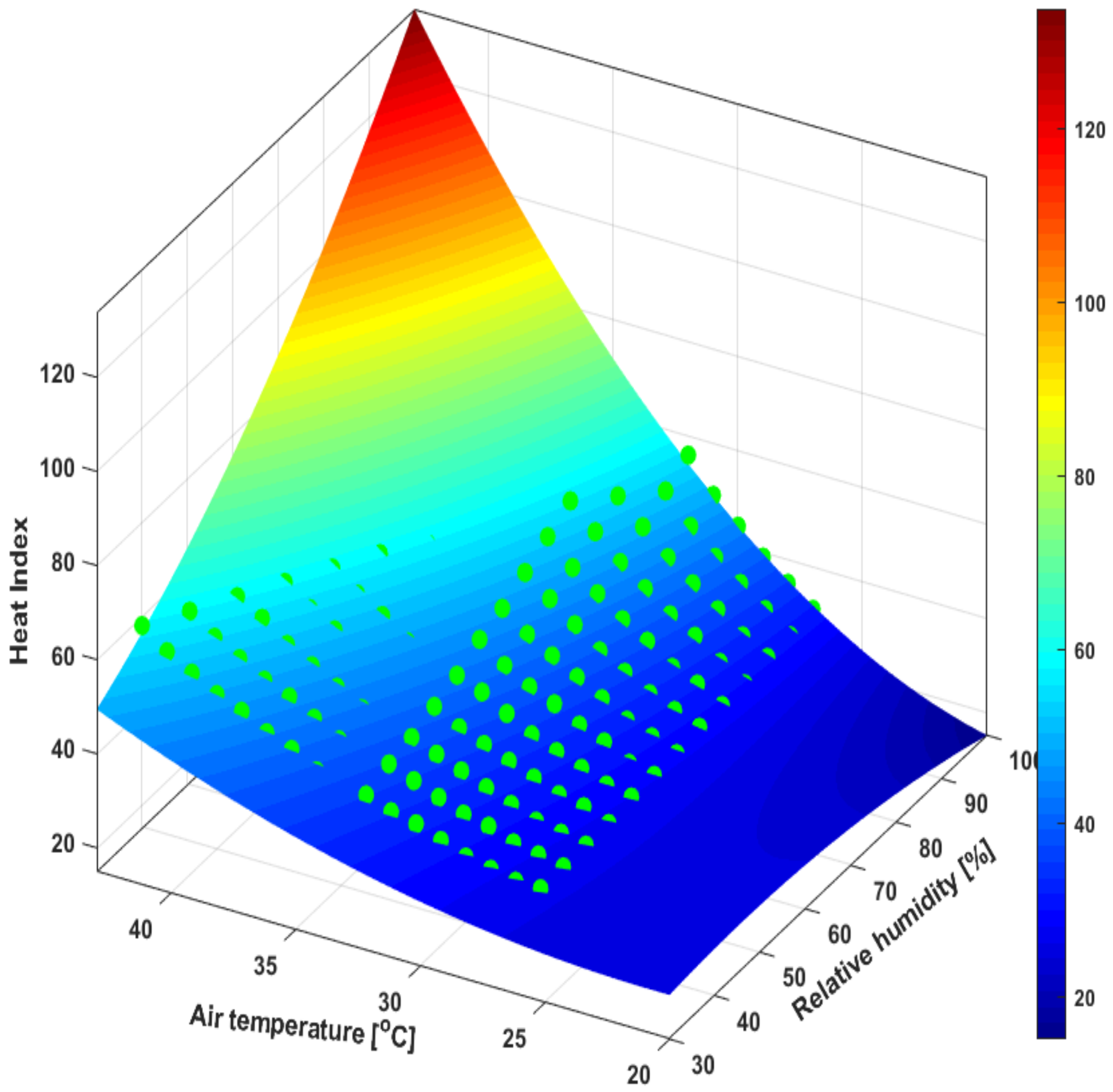
The heat index (HI) model requires a 2-dimensional input vector, where is the 2 climatic variables (air temperature and relative humidity) [38,39]. The heat index model is tabulated (look-up table), which means that for different combinations of air temperature and relative humidity values, the value of the HI can be expressed. 2.1. Surrogate Model for OTC Indices
Since there are a myriad of OTC indices, it would be a good idea to develop a single model which is able to represent all the models in the same way. While this model might be an approximation of the original OTC model, it will posses the following desirable properties:
To achieve this goal, we now present the concept of a surrogate model.
Definition 2 (Generic surrogate OTC index model).
The generic surrogate OTC index model, , of the generic OTC index model (See Definition 1), , is given by:where , , Ψ is a vector of model parameters, and is a normal random variable accounting for the mismatch between the OTC index model and the surrogate model . The model is depicted in Figure 2. Next, we define the specific family of regression models, , which will be used for the generic surrogate OTC index model and is based on a second-order polynomial regression with coefficient interactions.
Definition 3 (Surrogate OTC index model via 2-order (quadratic) polynomial).
The generic surrogate OTC index model is modeled as a 2-order (quadratic) polynomial regression, given by:where the second line is a compact vector notation defined as:The model coefficients are grouped into .
2.2. Estimation of Surrogate Model Coefficients
We now present the estimation procedure for the model coefficients . We use the maximum likelihood estimator (MLE), which calculates the values that maximize the likelihood function for a given dataset .
Lemma 1 (Estimation of surrogate model coefficients,
).
The model parameters estimators are given by: Proposition 1 (OTC index estimation).
Given the climatic variables , the estimated OTC index values are given by:where the estimated model parameters are presented in Lemma 1. Example 3 (Surrogate model of the PET index).
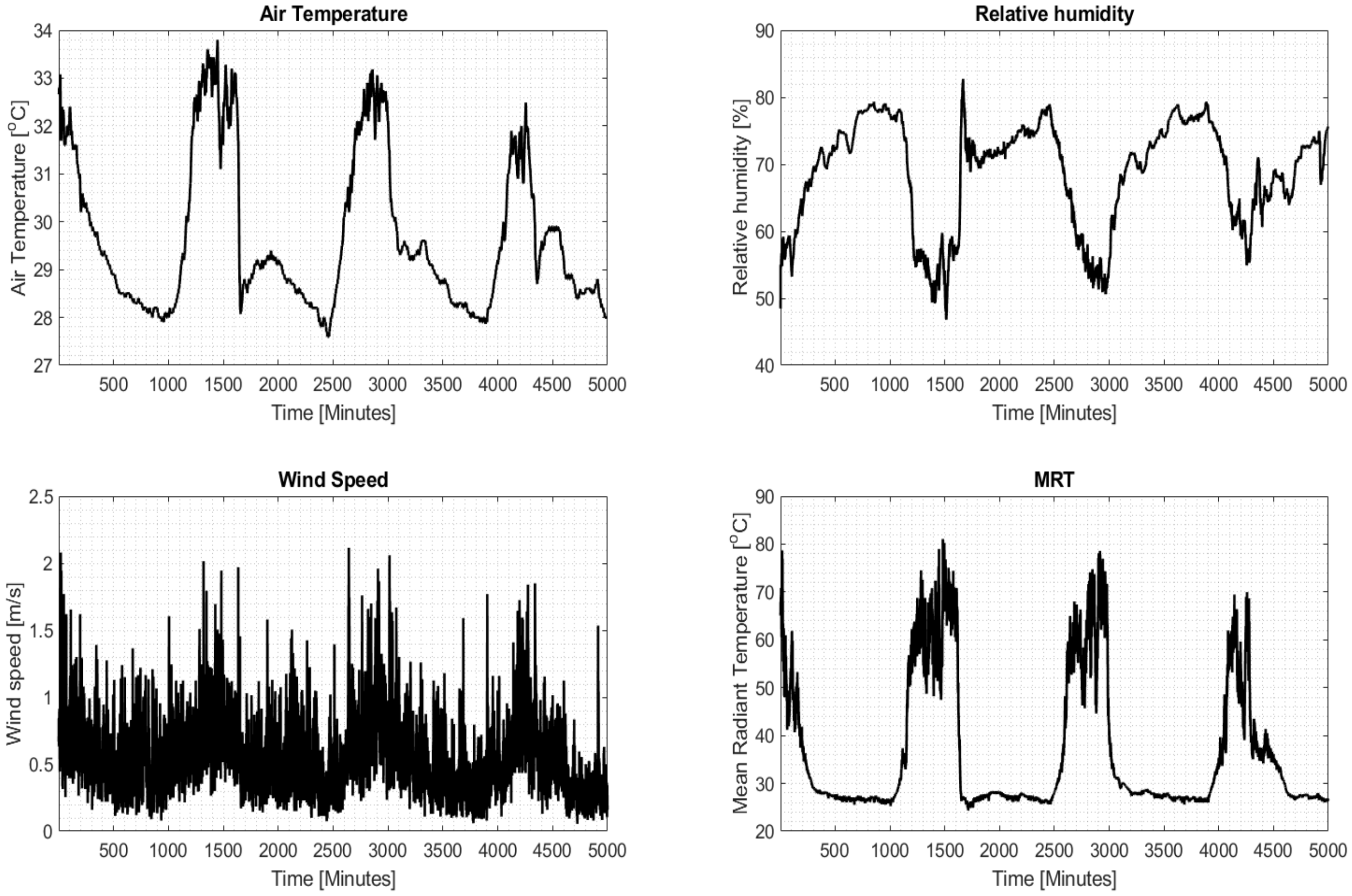
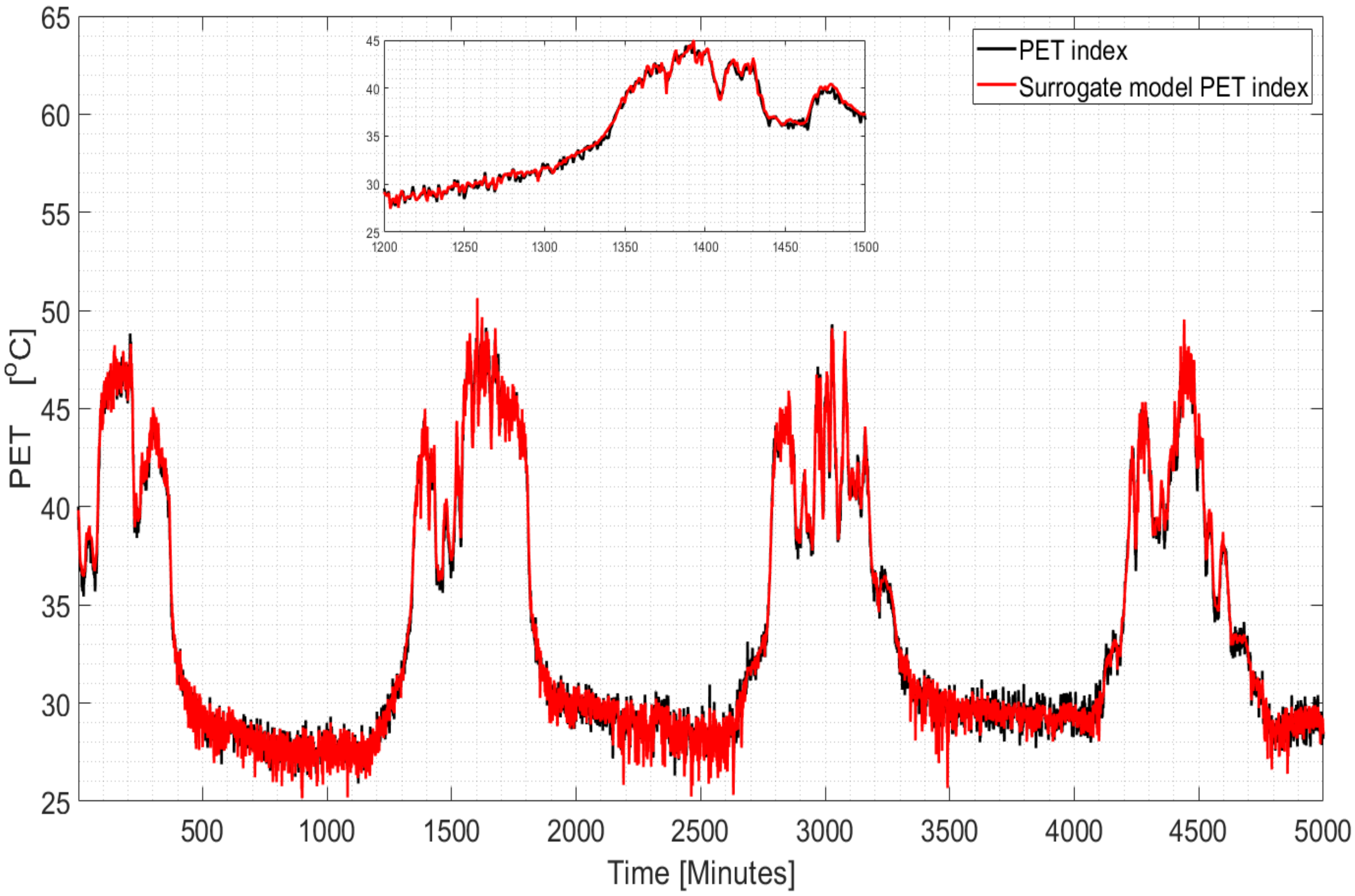
We present the performance of the OTC index surrogate model based on Proposition 1. We use a dataset which was collected in Singapore and contains the four climatic variables (the order of the vector is: MRT, AT, RH, and WS). The climatic variables are presented as time series in Figure 3. We then generated the six personal variables (age, sex, weight, height, metabolic activity level, and clothing level) using Monte Carlo draws. The PET index was calculated and used as a training set to estimate the parameters of the surrogate model as per Proposition 1. The time series of the true PET index values and the surrogate model-based one are presented in Figure 4. Clearly, the surrogate model provides very accurate estimates of the true PET values. 3. Statistical Properties of OTC Indices under Climate Model Uncertainty
In the previous section, we estimated the parameters of the surrogate model for the OTC index, where the data was provided by high-accuracy weather stations. In practice, we use a climate model to estimate the climatic variables in both space and time. Urban climate models, such as EnviMet, ANSYS Fluent for micro-scales or weather research forecast (WRF) for meso-scales, and other models, are physics-based models. Such models exhibit different levels of inaccuracy, which we generically define as
uncertainty. We do not aim at distinguishing the different types of uncertainties; instead, we are only interested in the output accuracy of the climate model. We do not restrict the use to any specific climate model, but allow the usage of any model as long as the uncertainty has been quantified by the user, as in, for example, [
40,
41]. To this end, we model the overall behavior of the climate model as a “truth plus error” model, which is widely used [
37]. As such, we assume that the true value of the physical phenomenon is
, while the output of the climate model is given by
. The discrepancy between the two is given by a RV
, as is presented in the following definition.
Definition 4 (Imperfect climate model).
The output variables of the climate model are modeled as an additive error model:where is the true climate variable value and is the climate variable estimate from the climate model. The term represents the inaccuracy (estimation error) of the climate model. We further assume that the error term is temporally, spatially, as well as modally independent: The value
depends on the accuracy of the climate model and can be calculated using multiple calibration procedures [
42].
We express the collection of climate variables in a compact vector form,
, and express the climate model uncertainty as:
where
and
is a diagonal matrix with elements
on its main diagonal.
3.1. Joint Surrogate OTC Index and Climate Model
We now utilize the results from the previous section, integrate them with the climate model uncertainty, and derive the statistical properties of the OTC index while taking the climate model uncertainty into consideration.
Definition 5 (Surrogate model for OTC indices under climate model uncertainty).
The surrogate model for OTC indices under climate model uncertainty is given by:where: 3.2. Distribution of OTC Index under Climate Model Uncertainty
We now present the distribution of the OTC index under climate model uncertainty, where we condition (that is, assume to be known) the following two components:
The estimated surrogate model parameters, ;
The climate model estimated values and the climate model estimation error .
The distribution is presented in the following.
Theorem 1 (Distribution of OTC index under climate model uncertainty).
The OTC index value, y, follows a generalized chi-squared distribution as follows:where are defined in Appendix B. Now that we have derived the distribution of the OTC index, we present its statistical properties, which will be useful in the following section, where we develop the risk model. For notation tractability, we drop the conditioning on model parameters , and it is understood that those parameters are known.
3.3. Statistical Properties of OTC Index under Climate Model Uncertainty
Here, we present some of the statistical properties of the OTC index which will be used in the following section, which include the mean and variance of the OTC index.
Proposition 2 (Statistical properties of OTC index under climate model uncertainty).
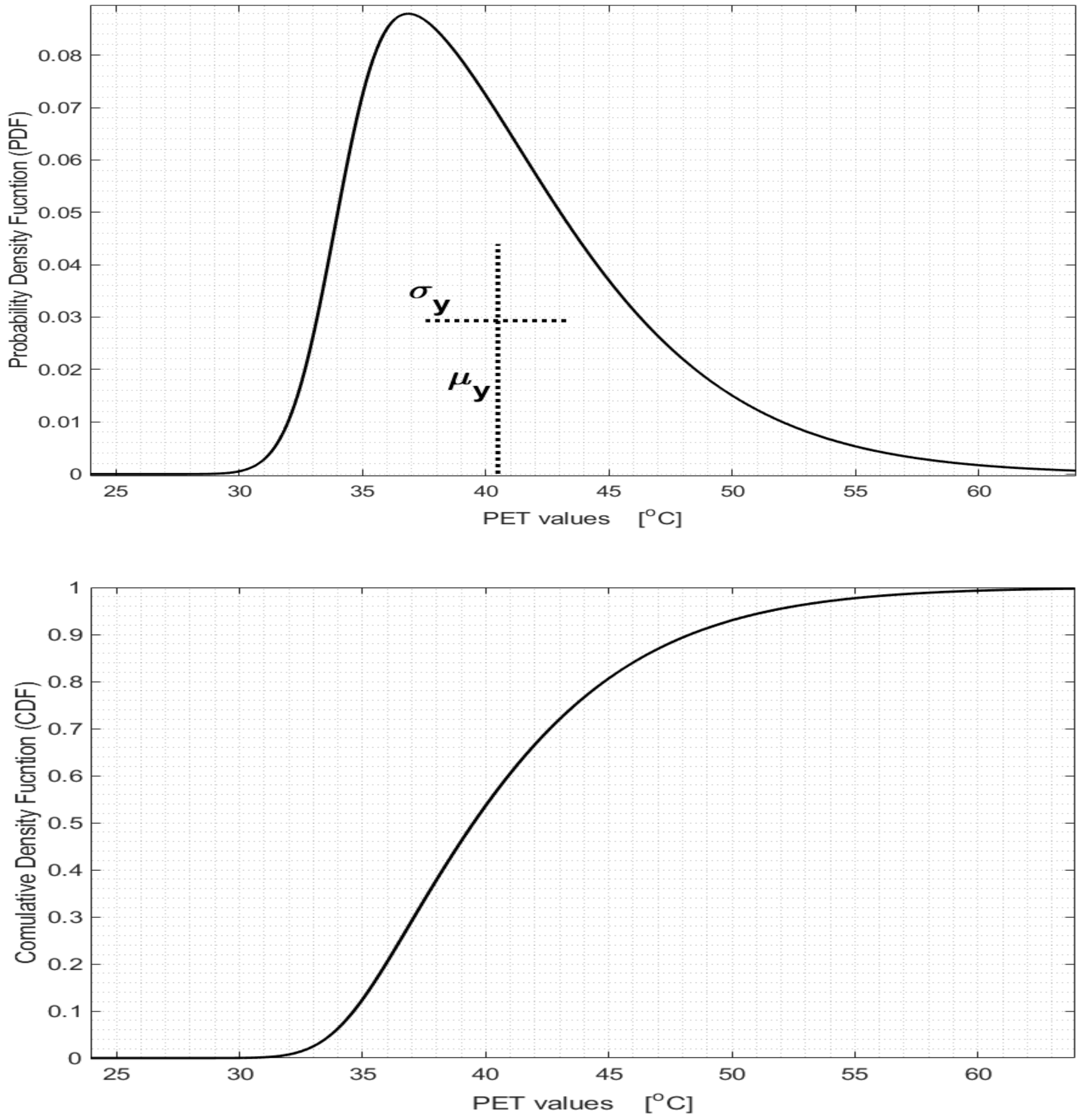
The mean and variance of the OTC index value, y, as presented in Theorem 1, are given by: Example 4. We now illustrate, in Figure 5, the result in Theorem 1 for the PET index. We set the estimated climatic variables to (the order of the vector is: MRT, AT, RH, and WS). We also present the mean and variance values as presented in Proposition 2. 3.4. Spatial-Temporal Representation of the OTC Index
Until now, we have considered the surrogate modeling of the OTC index based on the available climatic variables (perfect and imperfect). We now use those results and present the previous results, which are relevant to the domain of the climate model output, which is both spatial and temporal. The physical domain (site) is defined on some predefined spatial domain which is of interest to the designer, and a duration of time (usually a 24-h profile). To this end, we define the spatio-temporal space that the climate model is simulating:
The spatial area is denoted by . Examples include a whole city or a residential neighborhood;
The time duration of interest is denoted by . Examples include a whole year or a single day;
The estimated climate values at location
time
are denoted in a similar manner to Equation (
6), with the inclusion of spatial and temporal indicators
.
Based on these definitions, we can re-write the
generic surrogate OTC index model of Definition 5, in both space and time, as:
As this set of equations depicts, there is one set of model parameters for the whole spatio-temporal domain, making our regression-based surrogate model parsimonious. It is important to note that while this set of equations reflects the spatio-temporal model, the parameters of the model that belong to the surrogate model are common and need be estimated once, based on the training dataset, which is described in Lemma 1. In addition, we can express the mean and variance, as per Proposition 2, as a function of the spatio-temporal domain: and .
In the following section, we utilize the surrogate model in order to derive spatial risk models.
4. Spatial Risk Models for OTC
In the previous sections, we derived the distribution of the OTC index under the climate model uncertainty. We now use those results in order to calculate the spatio-temporal risk that stems from the climatic conditions. Before we do that, we first need to understand that is meant by “risk measures”.
4.1. Risk Measures
Mathematically, a risk measure is a mapping from a class of random variables to the real line (i.e.,
). The properties of
risk measures and the means for their application depend on the context of the problem and the requirements of the decision makers.
Risk measures are valuable, as they translate the high-dimensional spatio-temporal climate model data into easy-to-understand real-valued numbers. Many developments have been derived over the last few decades. One important concept is known as
coherent risk measures. The concept of the “coherence” of
risk measures was introduced in the seminal paper of Artzner, and initiated a rigorous and axiomatic analysis of risk assessments. Under
coherent risk measures theory, the mathematical properties of risk measures were derived from a set of four intuitive axioms:
monotonicity,
subadditivity,
positive homogeneity, and
translation invariance [
43]. We now present the most basic definition of
risk measures.
Definition 6 (Risk measure [
44]).
A risk measure is a function (mapping) of a random variable Y to the extended real line, . That is, given a random variable , a risk measure is the mapping This definition is quite broad, and it is clear that there are infinite number of
risk measures to choose from, since any combination of
risk measures is, in itself, a
risk measure, making the choice of a “good”
risk measure complicated. One simple and intuitive choice of a
risk measure is the
mean-variance risk measure, which combines the
expected value as well as its dispersion. This combinations is easy to follow and has been studied for many years since the seminal work of Markowitz on portfolio allocation [
34].
Definition 7 (Mean-variance risk measure [
44]).
The mean-variance risk measure of a random variable Y is defined as:where is the risk aversion parameter and is a known constant. The main idea of mean–variance models is to characterize the uncertain outcome by two scalar characteristics:
The mean , describing the expected outcome;
The dispersion measure , which measures the uncertainty of the outcome.
A different risk measure that is widely used is the value-at-risk (VaR), which calculates the probability that the risk is above a pre-defined allowed level.
Definition 8 (Value-at-risk (VaR) [
44]).
The value-at-risk (VaR) of a random variable Y and a probability level is defined as the α-percentile of the distribution of y:where is the CDF of y. The VaR is simply the
-quantile of the R.V.
y, and is the most widely used risk measure in insurance applications, where one is interested in modeling the losses due to extreme events [
45]. Before we analyze the risk measures of the OTC index, we present a simple illustration of the aforementioned risk measures.
Example 5 (Scalar risk measures).
Consider a R.V. Y, which follows a Gamma distribution, i.e., , where we set and . Then, and . This is depicted in Figure 6, in addition to the VaR measure for : . Now that we have defined the notion of risk measures, we are ready to extend this definition to the case where many OTC values are aggregated either spatially, temporally, or both.
4.2. Aggregate Spatial Risk Models for OTC
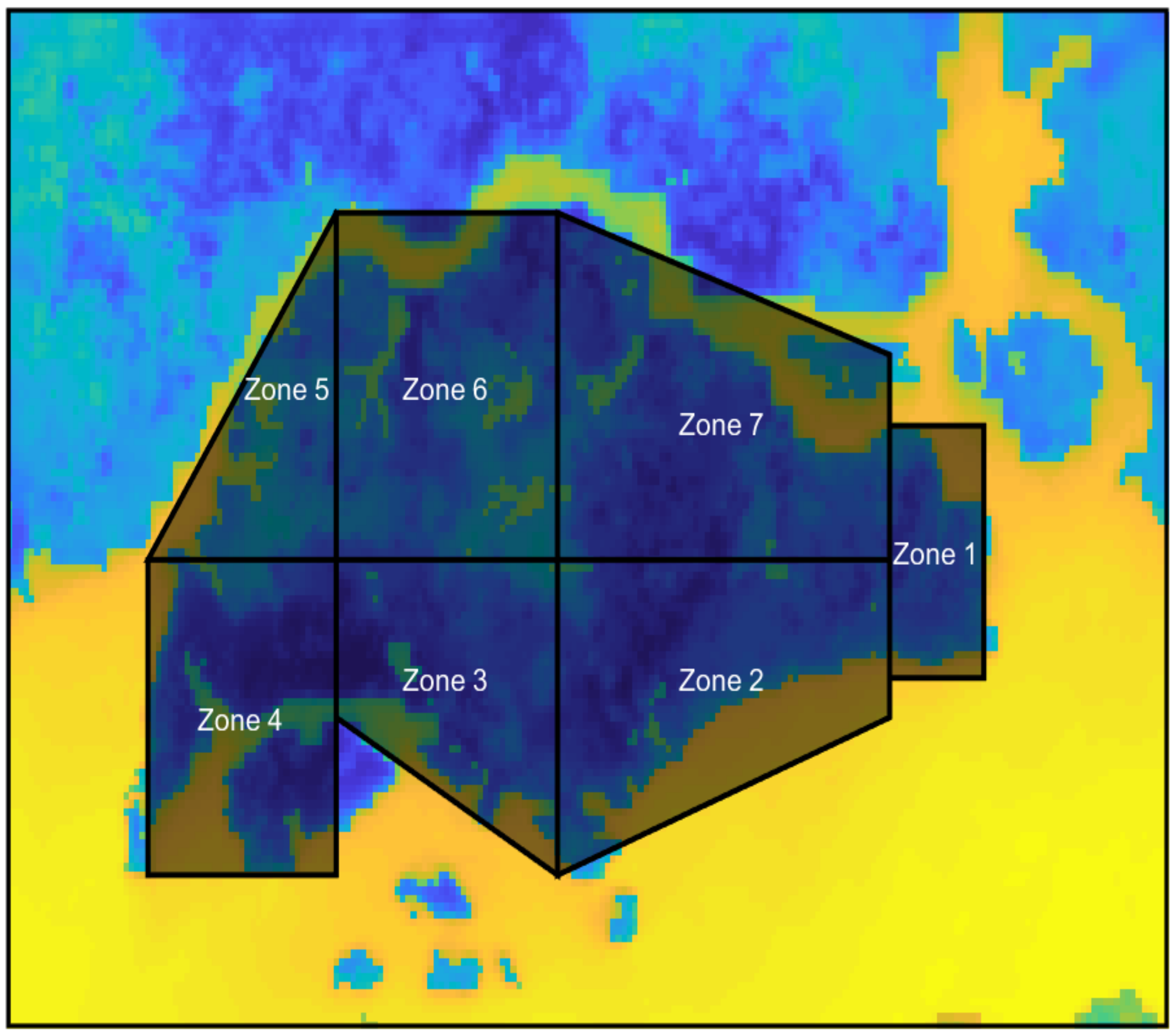
Spatial-temporal aggregation refers to the aggregation of all the OTC values of the elementary units (e.g., squares of 300 × 300 m
) in a specified region and over a specified period of time. This operator enables us to analyze a whole region of interest and compare it to another one. There are different aggregation functions which we could consider. Generically, an
aggregation function is a mapping from a high-dimensional space
to the real-line:
. We now define the generic representation of aggregated risk; see more details on the topic in [
46].
Definition 9 (Generic aggregate OTC risk).
The generic aggregate risk measure is defined as:where (see Definition 6), is an aggregation function, and and are the spatial and temporal subsets, respectively. There are many different choices of the aggregation function, including the summation, average, minimum, maximum, and more. The aggregation function acts as a statistical summary of the spatio-temporal data. In this work, we concentrate on the intuitive choice of a summation function, defined next.
Definition 10 (Spatio-temporal aggregate risk (STAR) measure for OTC).
The Spatio-temporal aggregate risk (STAR) measure is defined as:where and and . We now derive the distribution of , which is obtained by summing independent generalized chi-squared RVs and is presented in the following Theorem.
Theorem 2 (Statistical properties of STAR).
The STAR is a random variable , as defined in Proposition 4, and follows a generalized chi-squared distribution as follows:where are defined in Appendix C. The mean and variance can be calculated similarly to Proposition 2. This result is important since it tells us than when we aggregate the spatial-temporal values, the sum of the values follows a generalized chi-squared distribution, which we have already analyzed, and therefore, makes a very convenient mathematical structure.
We express two risk measures of STAR, as per Definitions 7 and 8.
Theorem 3 (Statistical properties of STAR).
The STAR is a random variable , which follows a generalized chi-squared distribution as follows:where are defined in Appendix C. Proposition 3 (STAR under mean-variance risk measure).
Under the mean-variance risk measure, we have that the STAR is given by:where and can be calculated according to Proposition 2. Proposition 4 (STAR under VaR risk measure).
Under the VaR risk measure, we have that the STAR is given by:where is the CDF of . 5. Spatial Resource Allocation for OTC Improvement
Now that we have shown how to derive the spatial risk measures, we turn our attention to developing a
spatial resource allocation framework which uses the previous results. In many practical problems, the DM (say, a government agency) is given a sum of money to invest in improving the OTC throughout a pre-specified region. This could be a city, a canton, or even a country; see [
15] for an example where the cost of implementation was integrated into the overall objective function. Here, we extend this concept to allocating the resources to multiple spatial sites. A practical and common approach for allocating the money is to partition the physical domain into a finite number of regions, and allocate the money to each region according to some decision mechanism. For example, in [
47], the authors presented a list of more than 80 heat-mitigation strategies which could be implemented. The strategies aiming at improving OTC levels are grouped into seven categories: vegetation, urban geometry, water bodies, materials, shading, transport, and energy. In [
48], the authors evaluated the costs and benefits of different mitigation strategies. They concentrated on the impact of two aspects: the electrification of vehicle fleets and district cooling. They used the PET as the OTC index and showed how to combine economic costs with thermal comfort jointly as the objective function. To decide which strategy to implement in each spatial sector, a decision mechanism needs to be formulated and solved. This decision mechanism, which we call the
spatial resource allocation, is presented next.
Let
K, be the number of spatial regions; we then partition the spatial domain
into
K disjoint regions, such that:
where
denotes the empty set.
Each region will be allocated a portion of the money, denoted by , such that , meaning that all the money will be used. Next, we define how much a region would benefit if an amount was invested in it. To do so, we need to introduce a function which quantifies this improvement (through some physical and technological intervention). In many practical cases, we are interested in reducing the OTC index levels. This is relevant to many hot countries and regions, and we, therefore, interpret the improvement as a reduction of OTC levels; in the following, we define the impact of the intervention in such a way. In cases where the DM is interested in increasing the OTC index levels (e.g., cold regions), the next definition can be trivially adapted to accommodate for such cases.
Definition 11 (Marginal OTC intervention impact).
The marginal OTC intervention impact is defined as the change (i.e., reduction) in OTC level which results from an intervention of level α when the non-intervention level (i.e., baseline) is . That is, if the current OTC level is , then the α-impact is defined as follows:where is the utility function, which provides a measure of improvement. Then, its risk measure is given by . A practical example of a utility function will be presented in more detail in Example 6, but we keep the notion of a utility function generic, and it is up to the DM to use the appropriate utility function. Now that we have defined the -impact on the STAR value , we move to defining the resource allocation problem, where we are interested in finding the set of weights such that the aggregate risk is minimized.
Definition 12 (Optimal resource allocation for spatial risk minimization).
The optimal spatial resource allocation is given by minimizing the aggregate STAR measure, after the intervention has been implemented, as follows: In the following, we concentrate on the
mean-variance risk measure, which complies with the celebrated Markowitz optimal portfolio allocation theory [
33,
34]. To this end, we need to calculate the first two moments of
This is difficult to obtain in cases where the
utility function is non-linear. Therefore, we present here a general method to approximate the first two moments in such cases by using the Taylor series expansion, presented next.
Proposition 5 (Calculation of moments via Taylor series expansion). The first and second moments of the marginal OTC intervention impact in Definition 11 can be approximated using Taylor series expansion, presented next.
Expectation ofwhere , so that the second term disappears and Variance ofwhere are the first and second derivatives of , with respect to . We are now ready to present the optimal spatial resource allocation optimization problem.
Lemma 2 (Optimal spatial resource allocation under the
mean-variance risk measure).
The optimal spatial resource allocation under the mean-variance risk measure is given by: Solving the optimization problem in Lemma 2 is not difficult, since we assume that the
utility function is concave. This means that the objective function is concave, and so is the constraint set, and the optimization problem can be easily solved via Lagrange multiplier [
49].
To illustrate this result, we now provide an example which shows how to implement the spatial resource allocation for the simplest case, that is, when the spatial domain contains two regions (). Since the optimization problem, in this case, is only two-dimensional, we are able to visualize this scenario.
Example 6 (Optimal spatial resource allocation for two regions).
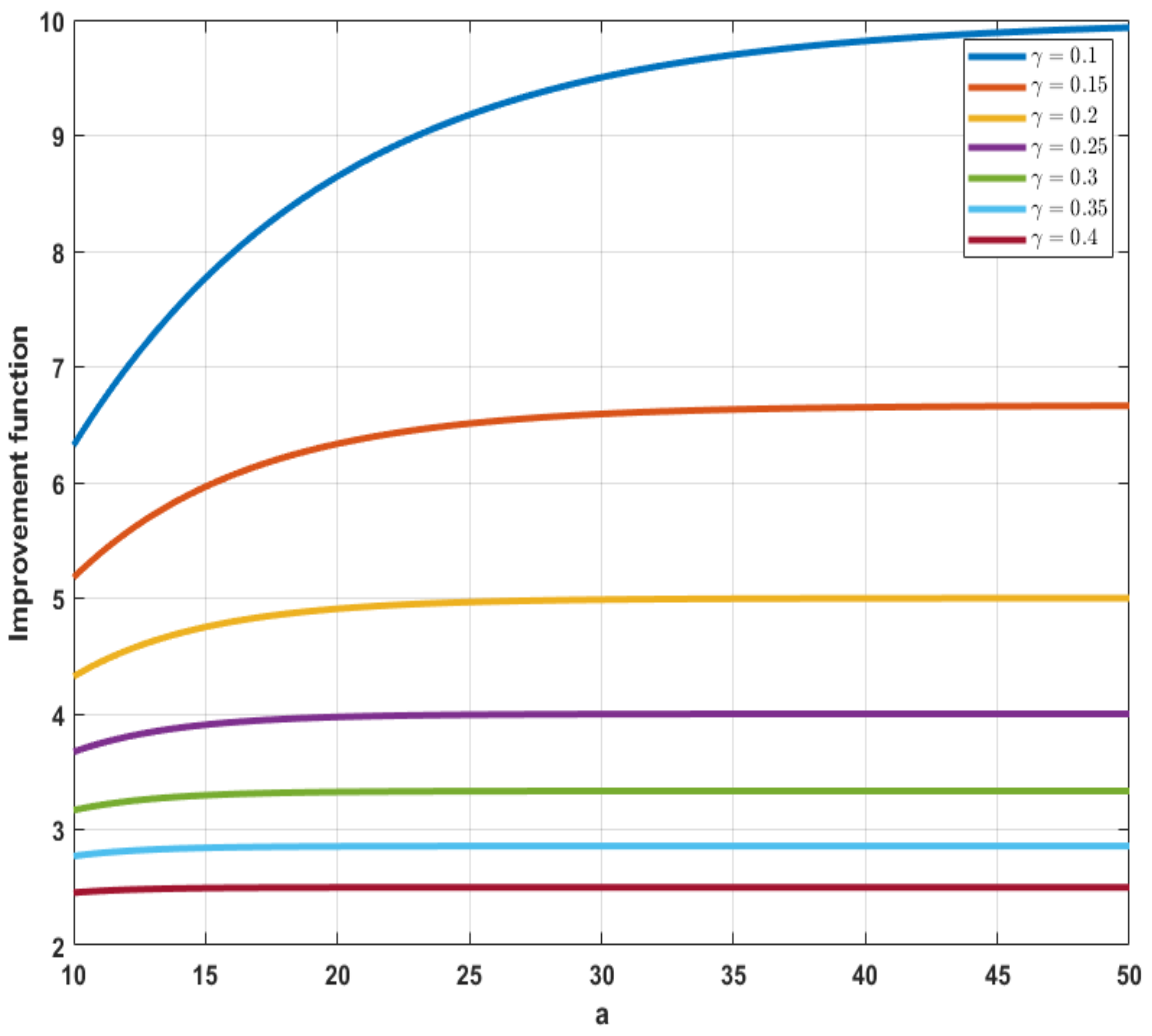
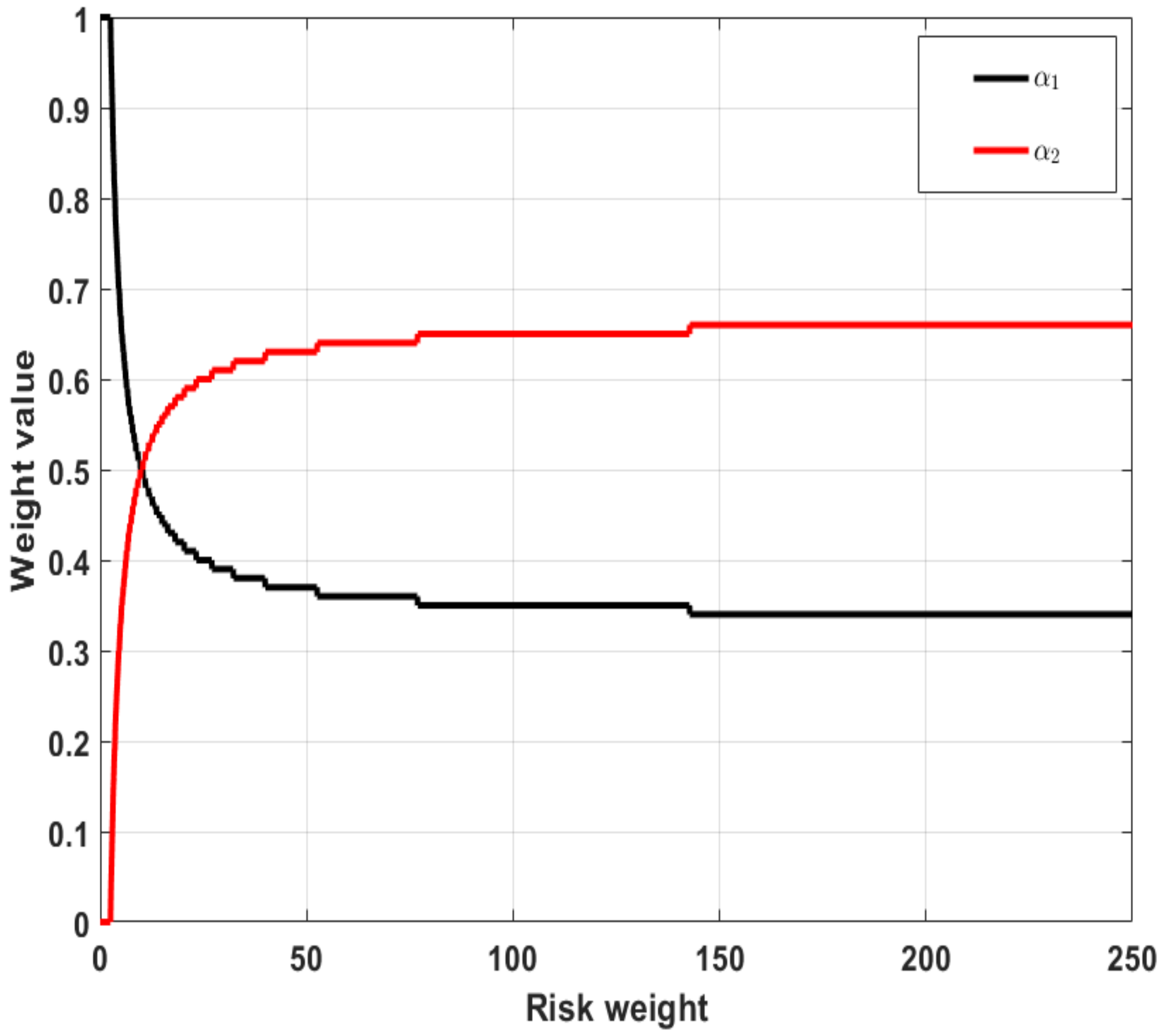
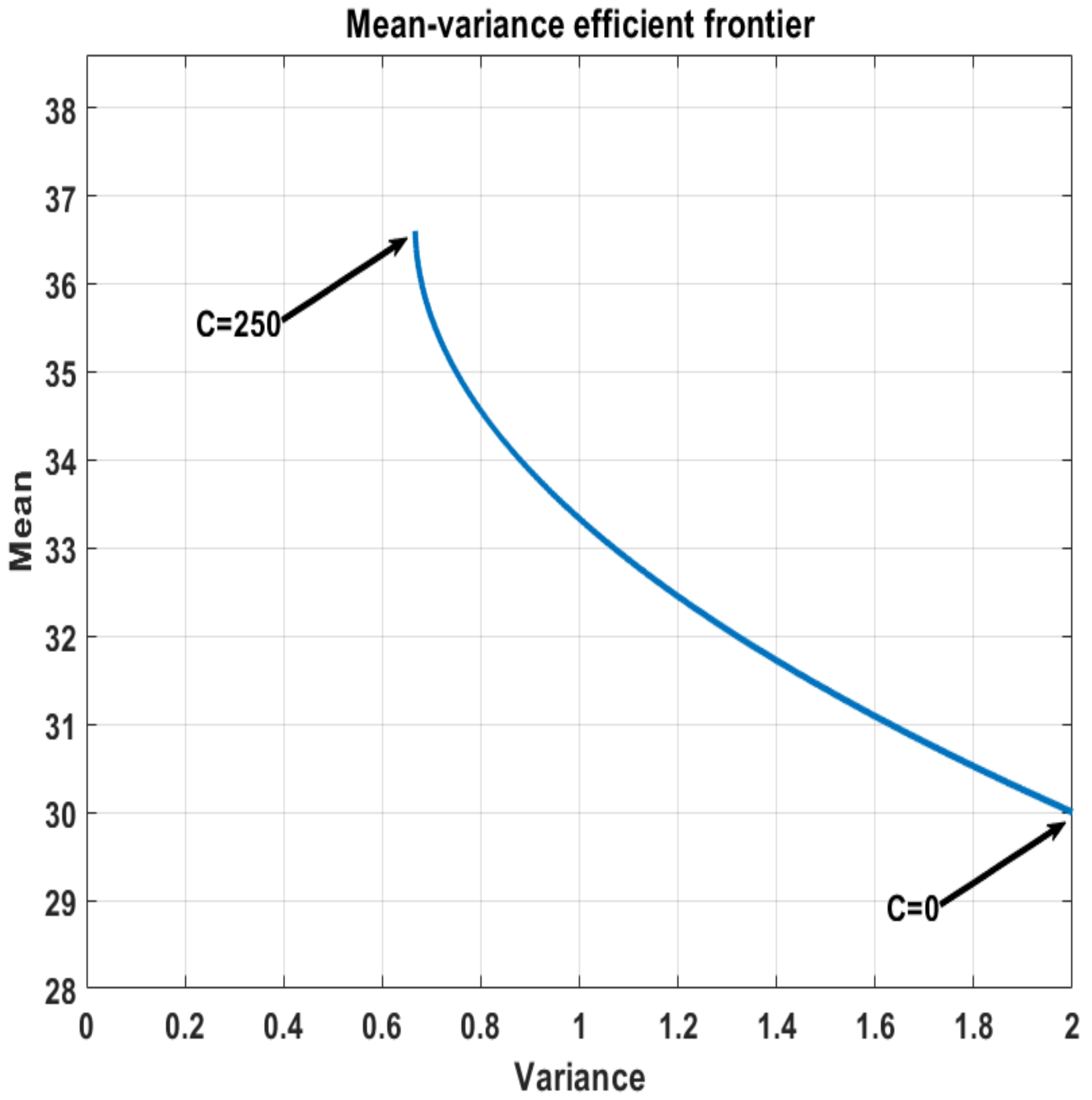
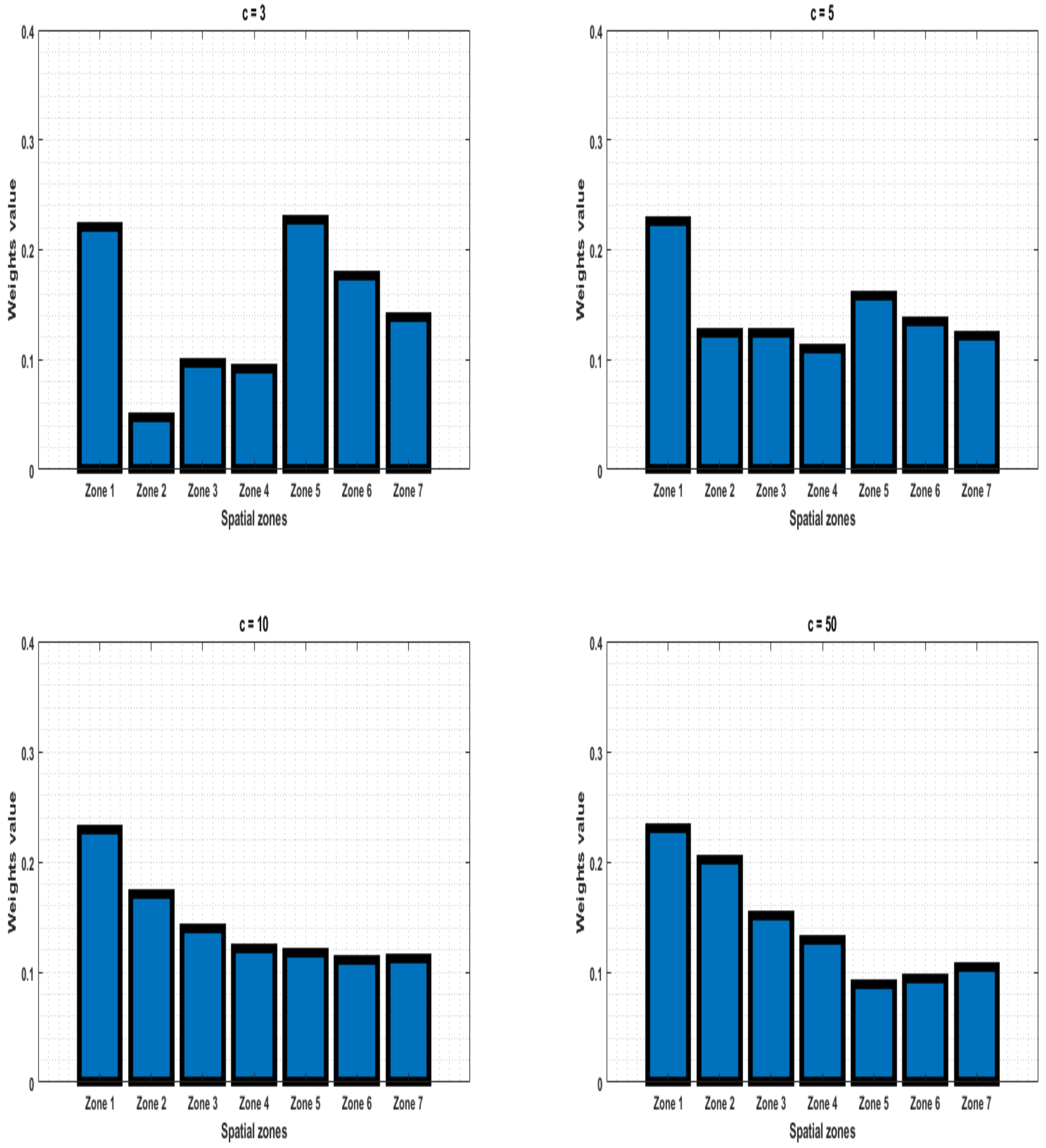
We assume that the utility function is given by the following exponential function:where is a known constant. This is depicted in Figure 7 and is widely used due to its flexibility by varying the values of γ.Its first and second derivatives, with respect to the input variable , are given by: Then, we have that the objective function in Lemma 2 is given by: Let us assume that ; then, their mean and variance values are and , respectively. The optimal allocation optimization problem reads: This optimization can be easily solved by setting , taking the derivative, setting it to 0, and solving for . In this example, we set The values of for different values of risk weight (c in Lemma 2) are presented in Figure 8. In Figure 9, we present the mean-variance plot under the optimal solution for different values of c; see Definition 12.
Figure 7.
The exponential utility function with .
Figure 7.
The exponential utility function with .
Figure 8.
Illustration of the optimal choice of the weights for different risk attitudes ().
Figure 8.
Illustration of the optimal choice of the weights for different risk attitudes ().
Figure 9.
Illustration of the mean and variance under the optimal choice of the weights for different risk attitudes ().
Figure 9.
Illustration of the mean and variance under the optimal choice of the weights for different risk attitudes ().








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}