1. Introduction
Turbulence in the atmosphere and in the oceans prevails over a very wide range of scales, from planetary motions down to the millimeter scale where dissipation begins to set in Reference [
1,
2]. The nonlinearities characteristic of turbulence also lead to the development in the flow of intermittency, in the form of strong localized events and multi-fractal scaling [
3,
4]. In turn, these extreme events impact the dynamics of atmospheric and oceanic flows, such as, e.g., in the observed persistence of strong aerosol contents in the atmosphere [
5]. The multiscale nature of geophysical flows, and the localized development of structures in space and time, thus require high order methods for their proper numerical modeling. Moreover, flows in the atmosphere and in the oceans often display dynamics at disparate time scales, with slow wave motions as those observed to be persistent over Antarctica at large scales [
6], fast waves, such as as gravity waves, which are often modeled in current global circulation models [
7], and slow three-dimensional eddies in the ocean which lead to a redistribution of mixing and salinity [
8]. Understanding the interplay between such waves and turbulent eddies is a key question in the study of geophysical flows, which is in many cases answered using highly accurate numerical simulations.
As a result, turbulent flows and multi-scale interactions are often studied computationally using the pseudospectral numerical method [
9,
10]. This is because of its inherent high order truncation, its consequent lack of diffusivity and dispersion and, importantly, because of its local (per node) computational complexity, which, using fast spectral transforms at a linear grid resolution of
N, goes as
instead of
. However, the grid resolutions required to study geophysically relevant turbulent flows–without resorting to modeling–vary as a high power of the Reynolds number that characterizes the flow. For geophysical fluids with Reynolds numbers often larger than
, this can translate into grids requiring more than
gridpoints in three dimensions, yielding a truly exascale computation. Moreover, pseudospectral methods when parallelized require all-to-all communication patterns (i.e., all computing tasks must eventually communicate with each other), and to different extents, this problem is also common to other high order numerical methods. For these reasons, even when lower Reynolds numbers are considered, computational fluid dynamics (CFD) approaches to geophysical turbulence require efficient parallelization methods with good scalability up to a very large number of processors.
In Mininni et al. [
11] (hereafter,
M11), we presented a hybrid MPI-OpenMP pseudospectral method to study geophysical turbulence, and showed its scalability and parallel efficiency up to reasonably high core counts. We also provided guidance on optimization on NUMA systems which touched on issues of MPI task and thread affinity to avoid resource contention. The present paper builds upon this previous study. It was recognized early that we could achieve significant performance gains if we could essentially eliminate the cost of local Fast Fourier Transforms (FFTs) and perhaps other computations by offloading this work to an accelerator. The CUDA FFT library [
12] together with the CUDA runtime library [
13] allow us to do this. The idea is straightforward: copy the data to the device, compute the local transform and perhaps other local calculations, and copy back so that communication and additional computation may be carried out.
Because of the shear number of applications in geophysical fluid dynamics (GFD) and in space physics, and because of the desire to reach higher Reynolds numbers and larger and more complex computational domains, fluid and gas dynamics applications have often been at the forefront of development for new computational technology. The most successful of these efforts for accelerators have generally been particle-based or particle-like methods that are known to scale well and have been ported to GPU-based systems [
14,
15], and even to cell processor-based systems [
16]. It is not uncommon, however, to find even with ostensibly highly scalable methods that reported performance measurements are restricted to single nodes or even to single kernels on a single accelerator rather than to holistic performance. On the other hand, global modeling efforts have shown superb aggregate performance on GPU-based systems [
17], but such codes often used for numerical weather or climate are typically low-order, and not suited for studies of detailed scale interactions.
While there are some efforts in the literature to port pseudospectral methods to GPUs (see, e.g., Reference [
18]), most appear to be tailored to smaller accelerated desktop solutions that avoid the issue of network communication that necessarily arises in massively distributed applications of the method (see
Section 2). This communication is usually considered such a severe limitation [
15] that it has repeatedly sounded the death knell for pseudospectral methods for some time, reputedly preventing scaling to large node counts and yielding poor parallel efficiency in multi-node CPU- and GPU-based systems. This may eventually be borne out; however, as demonstrated in
M11 and in subsequent work [
19], our basic hybrid scheme continues to scale on CPU-based multicore systems with good parallel efficiency, likely due in part to the one-dimensional (1D) domain decomposition scheme that is used (see
Section 2).
While ours appears to be the first in the published literature on extreme scaling, other state-of-the art pseudospectral codes have also recently adopted a 1D decomposition to accommodate current-generation large-scale GPU systems that utilize comparatively few well-provisioned nodes [
20]. Alternative two-dimensional (2D) or “pencil” decompositions [
21,
22,
23,
24,
25], however, have also demonstrated good scaling on many multicore (non-GPU) systems. As we will see below, good scaling is expected to continue on emerging GPU-based systems with our new CUDA implementation.
In this paper, we present a new method based on the hybrid algorithm originally discussed in
M11 that allows the efficient computation of geophysical turbulent flows with a parallel pseudospectral method using GPUs. The problem is formulated and given context in
Section 2, where we also update the formulation in
M11 to accommodate anisotropic grids, of importance to the modeling of atmospheric and oceanic flows. In
Section 3, the implementation of the method is discussed, showing how the interfaces to the CUDA runtime and cuFFT libraries are handled, as well as how portability is maintained; these details form a chief contribution of this work. Results showing the efficacy of the CUDA implementation on
total runtimes are provided in
Section 4 for our reference equations, and aggregate speed-ups for other solvers are also presented. Heuristics tailored for our application are used to indicate the way in which transfer to and from the device can affect the gains otherwise achieved by reducing computational cost on the GPUs, and we show how CUDA streams may be used to diminish the impact of data transfer on different systems. Finally, in
Section 5, we offer our conclusions, as well as some observations about the code and future work. Overall, the method we present gives significant speed-ups on GPUs, ideal or better than ideal parallel scaling when multiple nodes and GPUs are used, and can be used to generate fast parallel implementations of FFTs, or three-level (MPI-OpenMP-CUDA) parallelizations of pseudospectral CFD codes, or of other CFD methods requiring all-to-all communication.
2. Problem Description
Our motivation is to solve systems of partial differential equations (PDEs) that describe fluids in periodic Cartesian domains for purposes of investigating turbulent interactions at all resolvable scales. In GFD, a prototypical system of PDEs that describes the conservation of momentum of an incompressible fluid in a stably stratified domain is given by the Boussinesq equations:
in which
is the velocity,
p the pressure (effectively a Lagrange multiplier used to satisfy the incompressibility constraint given by Equation (3)),
the temperature (or density) fluctuations, and
is the Brunt-Väisälä frequency which establishes the magnitude of the background stratification. The dissipation terms are governed by the viscosity
and the scalar diffusivity
. These equations, essentially the incompressible Navier–Stokes equations together with an active scalar (the temperature) and additional source terms, are relevant for many studies of geophysical turbulence, and in the following will be considered as our reference equations for most tests.
We will also consider three other systems of PDEs often used for turbulence investigations in different physical contexts, of similar form except for the last case relevant for condensed matter physics. These cases are considered for the sole purpose of illustrating the adaptability of our parallelization method to other PDEs. When in the equations above the temperature is set to zero (
), we are only left with the incompressible Navier–Stokes equations, given by Equations (1) and (3). This set of equations is used to study hydrodynamic (HD) turbulent flows. In space physics, magnetohydrodynamic (MHD) flows are often considered, which describe the evolution of the velocity field
and of a magnetic field
:
where
is the magnetic diffusivity. Finally, to study quantum turbulence the Gross–Pitaevskii equation (GPE) describes the evolution of a complex wavefunction
:
where
g is a scattering length and
m a mass. The four sets of equations (Boussinesq, HD, MHD, and GPE) allow us to explore the performance of the method for different equations often used in CFD applications.
Our work relies on the Geophysical High Order Suite for Turbulence (GHOST) code (
M11), which provides a framework for solving these types of PDEs using a pseudospectral method [
10,
26,
27]. To discretize the PDEs, in general, each component of the fields is expanded in terms of a discrete Fourier transform of the form
where
represent the (complex) expansion coefficients in spectral space. We focus here on 3D transforms and neglect any normalization. The expansion above represents the
forward Fourier transform; a similar equation holds for the
backward transform but with a sign change in the exponential (again, neglecting any normalization). The indices
represent the physical space grid point, and
represent the wave number grid location. Note that both the physical box size,
, and the number of physical space points,
, may be specified independently in each direction in our implementation, enabling non-isotropic expansions in the
domain. This is a major difference between the current algorithm and the version discussed in
M11 [
28].
Taking the continuous Fourier transform and utilizing the discrete expansion given by Equation (8) in the system of PDEs, yields a system of time-dependent ordinary differential equations (ODEs) in terms of the complex Fourier coefficients, , for each field component. These represent the solution at a point (or mode) in the associated 3D spectral space. In GHOST, the system of ODEs is solved using an explicit Runge-Kutta scheme (of 2nd-4th order); explicit time stepping is used to resolve all wave modes. In the pseudospectral method, the nonlinear terms appearing in Equations (1)–(3) (or in any other of the PDEs considered) are computed in physical space, and then transformed into spectral space using the multidimensional Fourier transform, in order to obviate the need to compute the convolution integrals explicitly, which is expensive. Since the pressure is a Lagrange multiplier, its action is taken by projecting the nonlinear term in spectral space onto a divergence-free space, so that the velocity update will satisfy Equation (3). If not for the physical space computation of nonlinear terms, the method, as is done in pure spectral codes, would solve the PDEs entirely in spectral space.
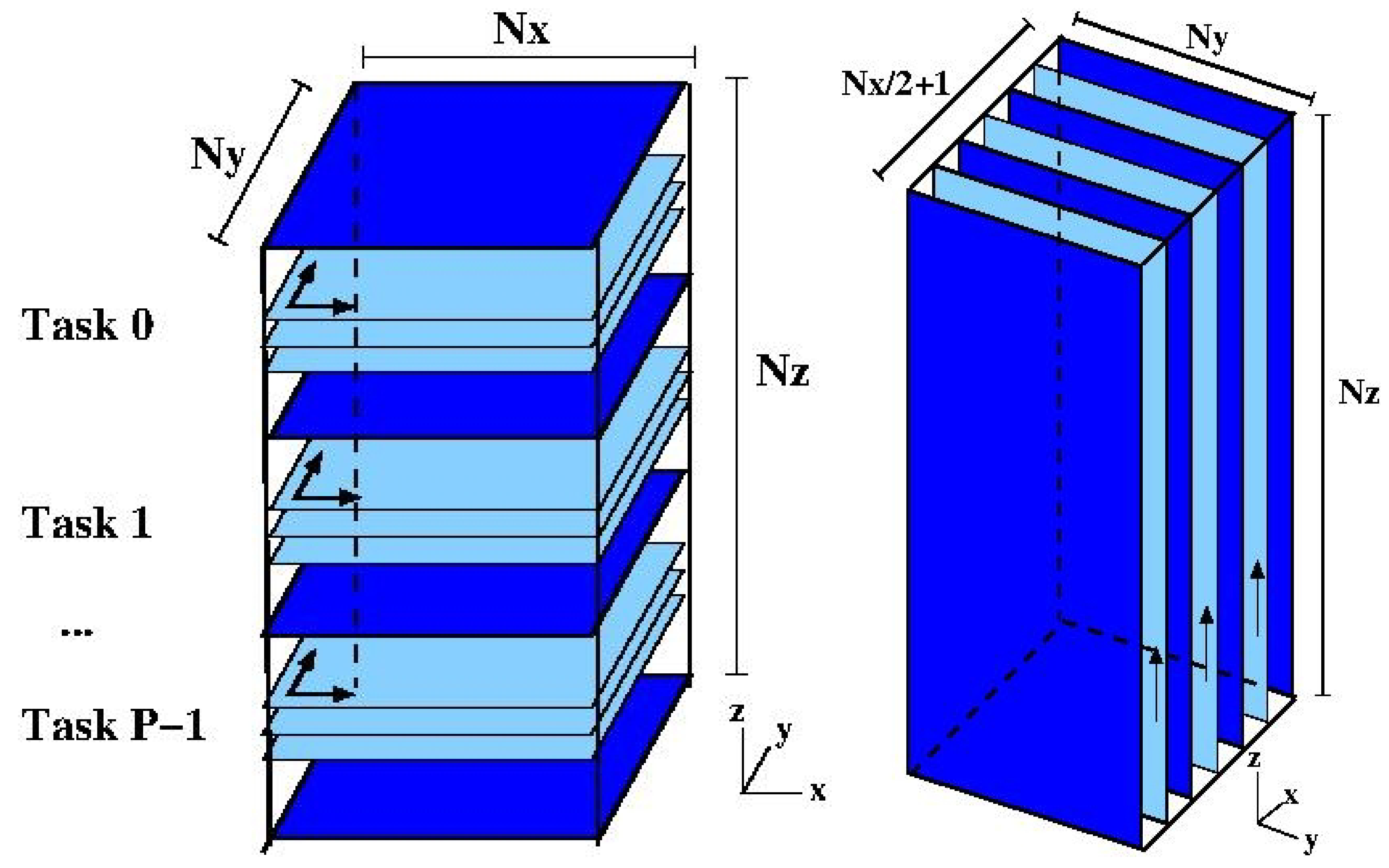
The global physical domain may be represented schematically as shown in
Figure 1 left. The domain is decomposed in the vertical direction (a so-called 1D or
slab decomposition) in such a way that the the vertical planes are evenly distributed to all MPI tasks (the slabs will be further decomposed into smaller domains using OpenMP, as described below). A relatively common alternative to this approach is to use the 2D “pencil” decomposition [
23,
25], whose performance implications were considered in
M11. If
P is the number of MPI tasks, there are
planes of the global domain assigned as work to each task, and from the figure, it is clear that each task “owns” a slab of size
points. The forward transform (for the moment, only considering MPI parallelization) consists of three main steps:
A local 2D transform is carried out on the real physical data in each plane (lightly shaded in the figure) of the local slab, over the coordinates indicated by the arrows in
Figure 1 left, which produces a partial (complex) transform that is
z-incomplete because of the domain decomposition.
Next, a global transpose (
Figure 1, right) of the partially transformed data block is made so that the data becomes
z- and
y-complete (and, hence,
x-incomplete).
Finally, a local 1D transform is performed in the now complete
z-direction for each plane of the data in the partially transformed slab (indicated by an arrow on the lightly shaded planes in
Figure 1b ), producing a fully transformed data block.
Note that the total number of data points in
Figure 1 left is now
, and reflects the fact that the data is now complex, and that the transform satisfies the relation
(assuming the data in physical space is real). However, the
total amount of complex (real and imaginary) data is still the same as in the original data block. The reverse transform essentially reverses these steps to produce a real physical space field. On the CPU, the local transforms are computed using the Fast Fourier Transform (FFT) in the open source FFTW package [
29,
30].
The global transpose in the second step requires that all MPI tasks communicate a portion of their data to all other tasks, in an MPI all-to-all. This is handled using a non-blocking scheme detailed in [
11,
31], so we do not describe it further here, except to state this MPI communication is the only communication involved in the solution of the PDEs, and that it usually represents a large fraction of the global transform time, as seen below. In addition to the communication, the data local to each task must also be transposed, which can be identified as a separate computational cost. Thus, the three steps involved in computing the global FFT transform yield in turn three distinct operations whose costs (times) will be considered further below: (1) the local FFT (i.e., computation of the 2D and 1D FFTs), (2) communication (to do the global transpose), and (3) the local transpose of data.
Our previous work in M11 demonstrated how OpenMP directives enable loop-level thread parallelization of the algorithm described above to compute parallel forward transforms, its implementation in the MPI-parallelized GHOST code, and provided a detailed examination of single NUMA node performance, as well as a discussion of scaling to large core counts. This thread parallelization, on top of the MPI parallelization, results in operations performed by each thread over a smaller portion of the slab that belongs to each MPI task, and thus can be equivalent (depending on the number of MPI tasks and threads) to a pencil decomposition, in which the MPI tasks operate over slabs, and the threads over pencils in each slab. While the motivation in M11 was mainly to show the overall efficacy of this hybrid MPI-OpenMP parallelization scheme, we also described the specific directives for thread parallelization and the cache-blocking procedure used for the local transpose step. Because of the centrality of the transform, we investigate here the effect of placing as much as possible of the multidimensional Fourier transform on GPUs using CUDA, while leaving other operations done by the CFD code on the CPUs. Thus, the method we present has three layers of parallelization: MPI and OpenMP for operations done on the CPUs, and CUDA for the operations that will be moved to the GPUs.
In order to estimate the benefit of a potential GPU port of the transform, we consider timings of the basic transform operations in typical simulations at various resolutions. In
Table 1 are presented fractional timing results of runs solving Equations (1)–(3) on uniform isotropic 3D grids of size
for
, 256, 512, and 1024. These runs were made on the NCAR-Wyoming Cheyenne cluster described in
Table 2, using 4 MPI tasks per node without threading. No attempts were made to optimize MPI communication via task placement or changes to the default MPI environment. As with all subsequent timing results, the code runs in “benchmark” mode in which all computations are performed in solving the PDEs—thus, both forward and backward transforms are done—but with no intermediate I/O for
time steps, and the overall time, as well as the operation (component) times, are averaged over this number of time steps.
Table 1 provides the fraction of total average runtime spent on each of the transform operations identified above.
The sum of the fractional times shows that the cumulative time fraction of the distributed transform (counting FFTs, communication, and transpose) is high, and reasonably constant at about 90%, which justifies our focus on the distributed transform in isolation from the remaining computations. Indeed, the last column in
Table 1 shows the maximum speed-up that could be achieved if the time to do FFTs and transposition is reduced to zero (leaving communication time the same). In terms of the component times (where
represents costs not included in the transform), we can estimate this maximum possible speed-up
assuming no additional costs by offloading to an accelerator as:
where the denominator approximates the aggregate runtime by using acceleration on the distributed transform, assuming
and
both go to 0, and that
does not change by simply adding the accelerators. Here,
indicates the time to compute the operation
when using CPUs only, where
can be communication (Comm), local FFTs (FFT), or local transpose (Transp). Since the aggregate time fraction of the transform component is so high, we can neglect
. The final column in
Table 1 gives this potential speed-up for each resolution.
This estimate indicates that speed-up is strongly connected to performance of the local FFT and transform relative to the communication time. While the potential speed-ups in the table may look impressive, any optimization that serves to reduce the time for the FFT and transpose on the CPU relative to the communication time will also reduce the speed-up. An obvious such optimization is threading (which is already implemented in the code, as discussed above), but we will see in
Section 4 that the realized speed-ups when using GPUs are still superior to the purely CPU-based code even when multithreading is enabled.
4. Results: Scaling and Performance
A series of tests have been performed to evaluate the implementation discussed in
Section 3. Most of these tests have been conducted on Oak Ridge Leadership Computing Facility’s SummitDev described in
Table 2, using CUDA 9. For all tests on this system, we restrict ourselves to 16 of the 20 CPU cores on each node. Using runtime directives, the MPI tasks are placed symmetrically across the sockets, and threads from each socket are bound to their respective tasks; the GPUs are selected to optimize data transfer. When stated, for comparison purposes, we have also run on the NCAR-Wyoming Caldera analysis and visualization cluster, also described in
Table 2, for which only CUDA 8 is available.
The test procedure is the same as described in
Section 2, and the resulting timing output contains the total average runtime per time step (
), and the component operation times for the local FFTs (
), for the the MPI communication (
), and for the transpose time (
). The additional data transfer time (
, to and from the GPUs) now also appears. These times are measured by the main thread using primarily the MPI_WTIME function, and, on the GPU, the timers wrap the entire kernel launch and execution. We compared the results of these times with Fortran, OpenMP, and CUDA timers, to verify consistency. In addition to the solver for Equations (1)–(3), we now also examine briefly the other solvers in
Section 2, since we want to evaluate the performance when different sets of PDEs are used (requiring different numbers of distributed transforms). As with timings of Equations (1)–(3) presented in
Section 2, we examine aggregate timings that reflect complete solutions to the equations being considered, not just of the transform kernels. Thus, component times are accumulated over both the forward and backward transforms that occur in a timestep before averaging over the number of timesteps integrated.
Table 3 provides the “fiducial” runs we consider. Others, unless otherwise stated, derive from these, most often by changing task or GPU counts.
4.1. Variation with Nstreams
We examine first the performance of the CUDA streams for overlapping communication and computation. The pure HD equations are used here (so the temperature evolution equation Equation (2) is omitted, as is the temperature term in Equation (1)), corresponding to run 1 in
Table 3. Therefore, there are two fewer (forward plus backward) distributed transforms required when compared to the full system of Equations (1)–(3) (as the HD system has one fewer nonlinear term when compared with the Boussinesq system). The grid is taken to be isotropic with
points. Sixteen cores and 2 GPUs of one SummitDev (
Table 2) node are used; since each GPU is bound to a single MPI task, this implies that 2 MPI tasks each with 8 threads are used (configuration 1 in
Table 3).
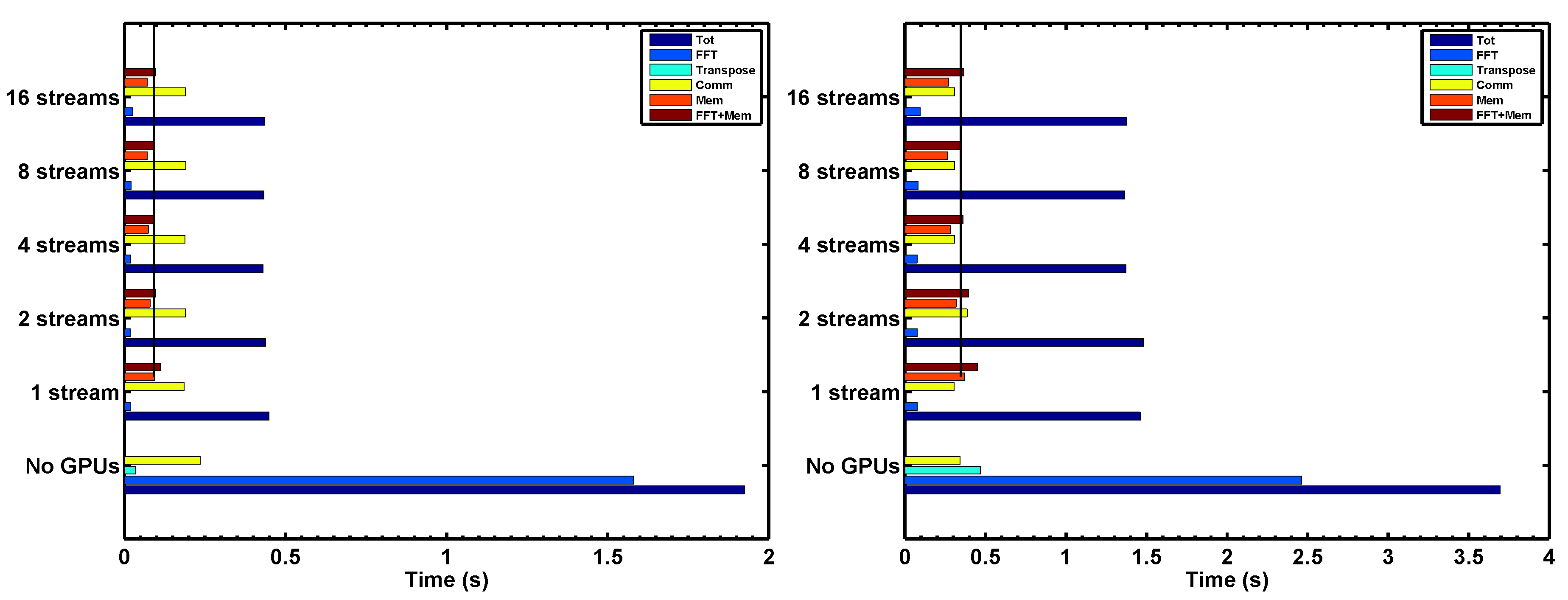
Figure 3 left shows the timings as the number of CUDA streams is varied in this system, at the bottom the times are compared to a CPU-only run. The first thing seen in the figure is that there is a good speed-up over the CPU-only case, about a factor of 4.4, achieved with the best GPU time. As expected, the FFT and local transpose times have been reduced significantly, by factors of 85 and 1300, respectively, making them nearly negligible on the GPU runs. Unexpectedly, the communication time for the identical run without GPUs is somewhat longer than for the GPU runs, and this behavior is persistent for this problem. It had been observed on the Titan development system (predecessor to SummitDev) that power supply performance on a node could explain such communication timings, at least episodically. Here, we emphasize that the slight differences in the communication timings between the GPU and CPU-only runs affect neither our subsequent results nor our conclusions.
Since both the local FFTs and the device transfers add up to the total time to compute FFTs on the GPUs, we must add the two measured times in order to determine the optimal number of streams. The
and 8 runs yield nearly the same aggregated time
, but
gives a slightly better result, so we adopt this as the optimal number of streams for subsequent tests. The speed-up,
, over the time to move data to and from the GPU and to compute the FFTs, for
over that for
, is
. Testing on the PCIe-based Caldera system (in
Table 2) for comparison (see
Figure 3, right), we also find that
gives the best times, but that
, a larger effect due to importance of using stream optimization in the slower PCIe port. As expected, the PCIe transfer times are uniformly slower than for NVLink (see
Figure 3). Because of this, the improvement when using multiple streams on the total runtime of the CFD code (when compared with the case using GPUs with 1 stream) is about
on the NVLink system, versus
on the PCIe system with the optimized streamed transforms. Similar results were obtained when varying
for anisotropic grids with
, as well as for other PDEs.
Heuristically, the aggregate speed-up,
, afforded by the (streamed) GPU transforms over the CPU-only version on this system may be computed by setting the GPU times
and
to zero (see
Figure 3), yielding
where
is the remainder of the time spent on the CPU that is unrelated to distributed transform operations. For these tests,
. Plugging in the values
,
, and
for this stream test yields
, which is very close to the observed speed-up. As expected, the speed-up results from the gains in the FFT computed on the GPUs, minus the cost of moving the data to the device (which is reduced by overlapping memory copies and computation using multiple streams). From this value, we also see that the speed-ups obtained are close to the maximum we can achieve (given the fraction of computations that were moved to the GPUs, see also
Table 1); thus, we now consider the scaling of the method with increasing number of MPI tasks and GPUs.
4.2. Speedups on an Anisotropic Grid
Since we are motivated strongly by the need to solve the equations for atmospheric dynamics, we consider speedup on solutions of Equations (1)–(3) on an anisotropic grid [
28] (configuration 3 in
Table 3). On the left in
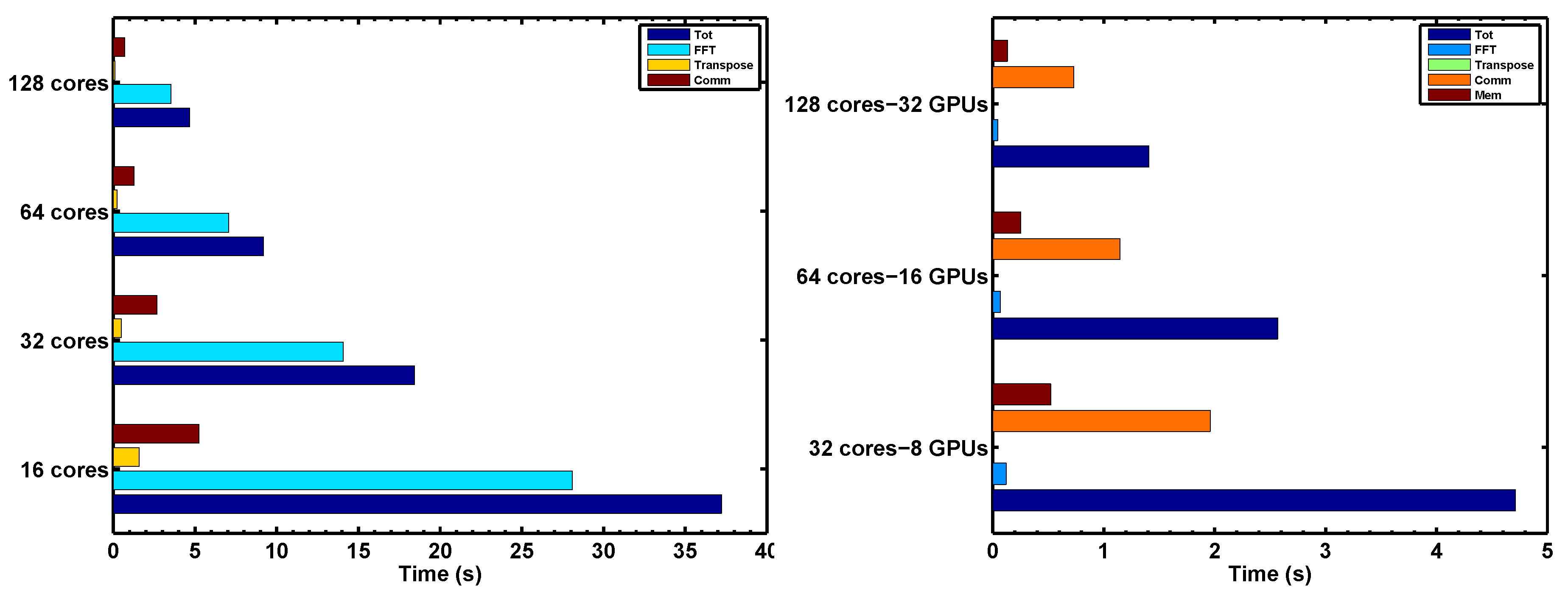
Figure 4 is a plot of CPU-only process timers, increasing the number of nodes in order to increase the number of MPI tasks. The timers indicate that each operation scales well on this system. Indeed, the average parallel efficiency
, with respect to the reference aggregate time
at the smallest core count
, is about 98% for this problem.
In
Figure 4 (right), is shown the process timers when all parallelization is turned on in configuration 3, for the SummitDev NVLink system. Comparing the aggregate speedup of the GPU runs to the CPU in
Figure 4 left, we find an average speedup of
over all task/node-counts. Like in
Section 4.1, we observe that the FFT and local transpose times have been reduced significantly at each task/node count as well.
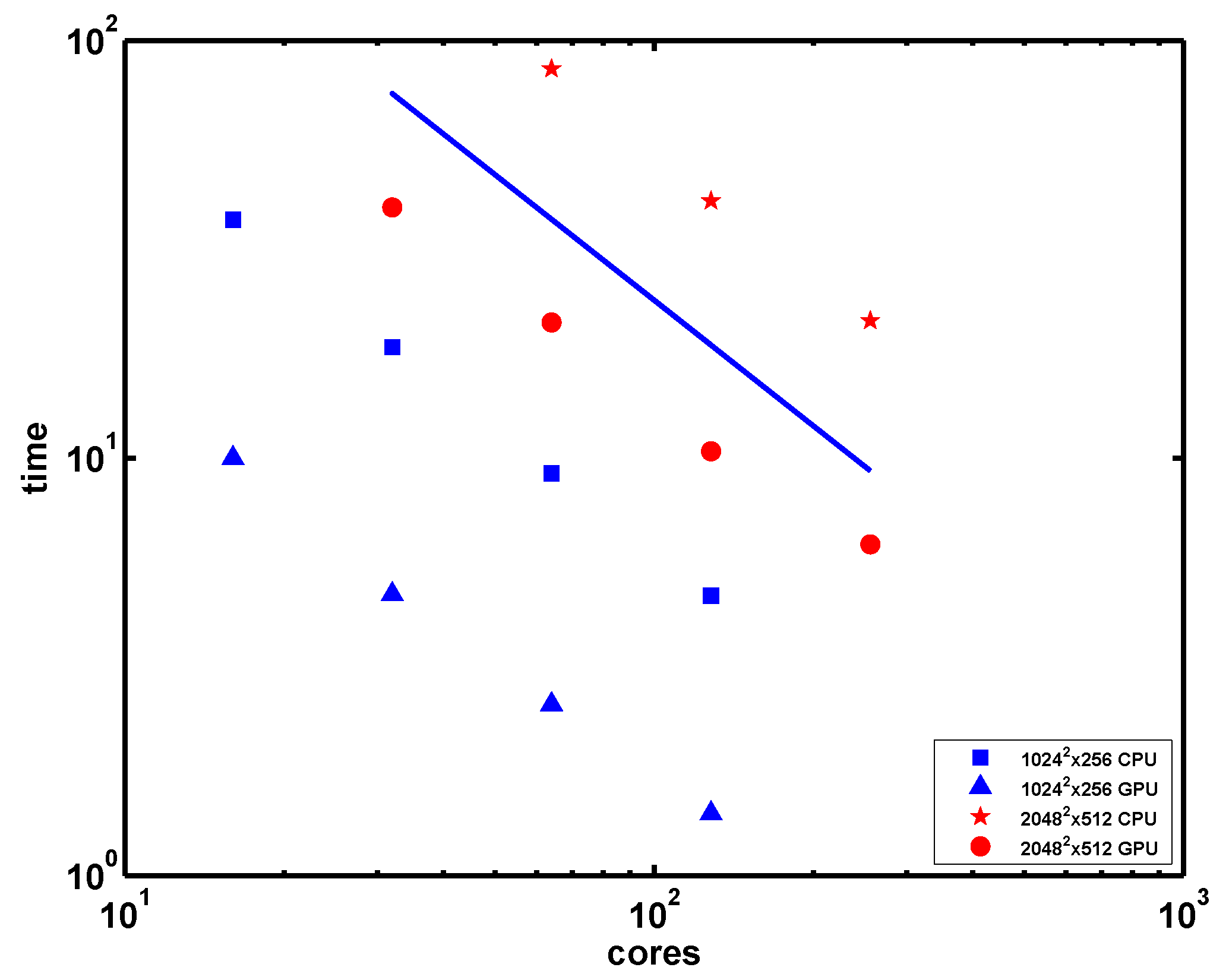
Strong scaling is perhaps seen better in the more traditional scaling plot of
Figure 5, in which CPU-only and GPU total times are provided for Boussinesq runs at two different spatial resolutions (
, and
grid points). The simulations for the largest resolution in
Figure 5 are performed using configuration 4 in
Table 3. It is clear from this figure that the scaling is nearly ideal on this system for all cases considered. The average parallel efficiency of the lower resolution GPU runs based on the aggregate time is around 1, and for the higher resolution runs is
.
4.3. Profiling Results
Here, we consider the GPU performance in more detail. Since the CUDA modifications apply currently only to the 3D transforms, we apply NVIDIA NVProf [
34] to these CUDA kernels to examine total FlOp counts, and number of read and write transactions from/to memory. To do this, NVProf is used to examine the
flop_count_sp, dram_read_transactions, and
dram_write_transactions metrics. Our goal is to compute FlOp-rate and arithmetic computational intensity (CI), which is the ratio of FlOp count to the total number of memory posts and retrievals. For each metric, NVProf provides the number of invocations over all time steps and the minimum, maximum, and average of the metrics over this number for each kernel. Using run configuration 2 in
Table 3, we select the average FlOp count and the average number of memory transactions for a single time step; the data is provided in
Table 4. All kernels represented are from the cuFFT library, except the final transpose kernel. Note that the transpose does no computation, and only operates on memory, so it contributes nothing to the FlOp count.
The aggregate number of FlOps is given by the number of invocations times the number of total FlOp counts per invocation in
Table 4, and this is
GFlOps. We determine the total
lcompute time for the transform as the sum of the relevant component times
and we can obtain the FlOp rate for the transform computation by dividing the FlOp count by
to get 737 GFlOps/s. The
nominal single-precision performance metric is 9300 GFlOps/s [
35], which means we are seeing about 8% of the
lnominal peak for the transform computations.
Roofline Modeling
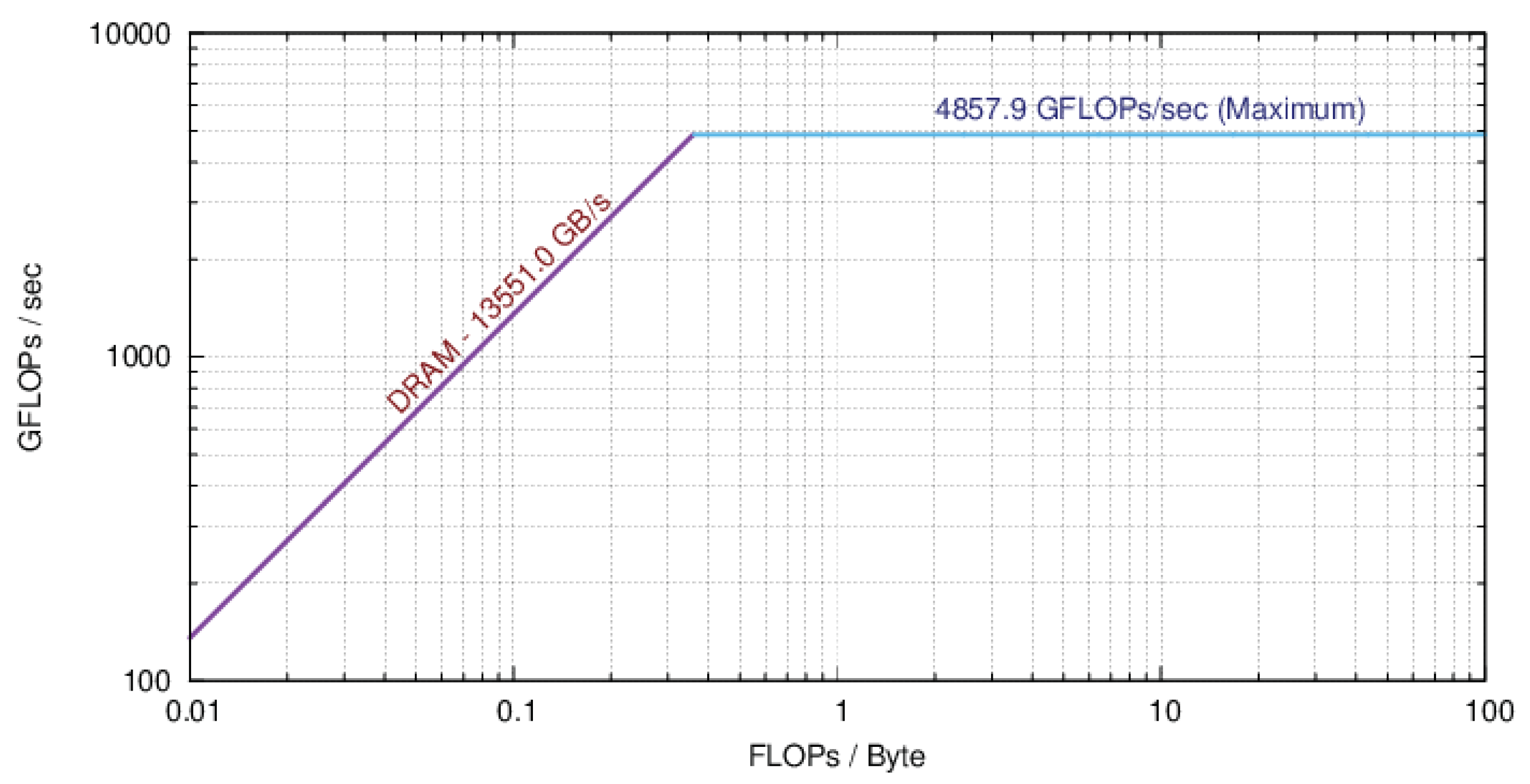
While the nominal performance on the SummitDev P100 GPUs is 9300 GFlOps/s, this is never achievable by a real application. To determine what is achievable, we turn to a roofline model [
36], namely, the Empirical Roofline Toolkit (ERT) [
37] on SummitDev. This is presented in
Figure 6 in a plot of attainable FlOp-rate versus computational intensity. The curve shows that below a threshold (or “machine balance”), in computational intensity, the FlOp-rate is governed by memory bandwidth, and that above machine balance, it is compute-bound, reflecting a competition between memory bandwidth, memory locality (reuse), and computation (peak FlOp-rate). ERT sweeps over a variety of micro-kernel configurations to collect its data using
actual kernels while operating within
lactual power environments.
Given these results, we can compute the percent-of-actual-peak performance of the GPU implementation. In
Table 4, we find that the computational intensity for the transform is 12 FlOps/byte on SummitDev. From the ERT plot,
Figure 6, we see that this value places us in the compute-bound region, and in the range of the realizable peak in FlOp-rate, about 4860 GFlOp/s, which is slightly greater than half of the nominal, theoretical peak. Compared with this maximum attainable value, the transform then achieves about 15% of the attainable peak performance.
4.4. Behavior of Different Solvers
In the previous subsections, we have shown that the the total runtime (and component times) for the GPU implementation follow largely the CPU-only results in their strong scaling, when solving the Boussinesq and HD equations. We expect that, as the number of nonlinear terms in the PDEs (or the number of primitive variables) is changed by a change of PDEs, the overall scaling will remain good for each PDE solver for both the CPU-only and GPU results, and we have verified this (not shown). We also expect that the speed-up in the runs with the CUDA transform over the hybrid runs for different PDEs will be similar to those in
Section 4.2, another behavior that was verified by our tests. For the sake of brevity, here we summarize those studies by providing some actual measurements on the SummitDev NVLink test system.
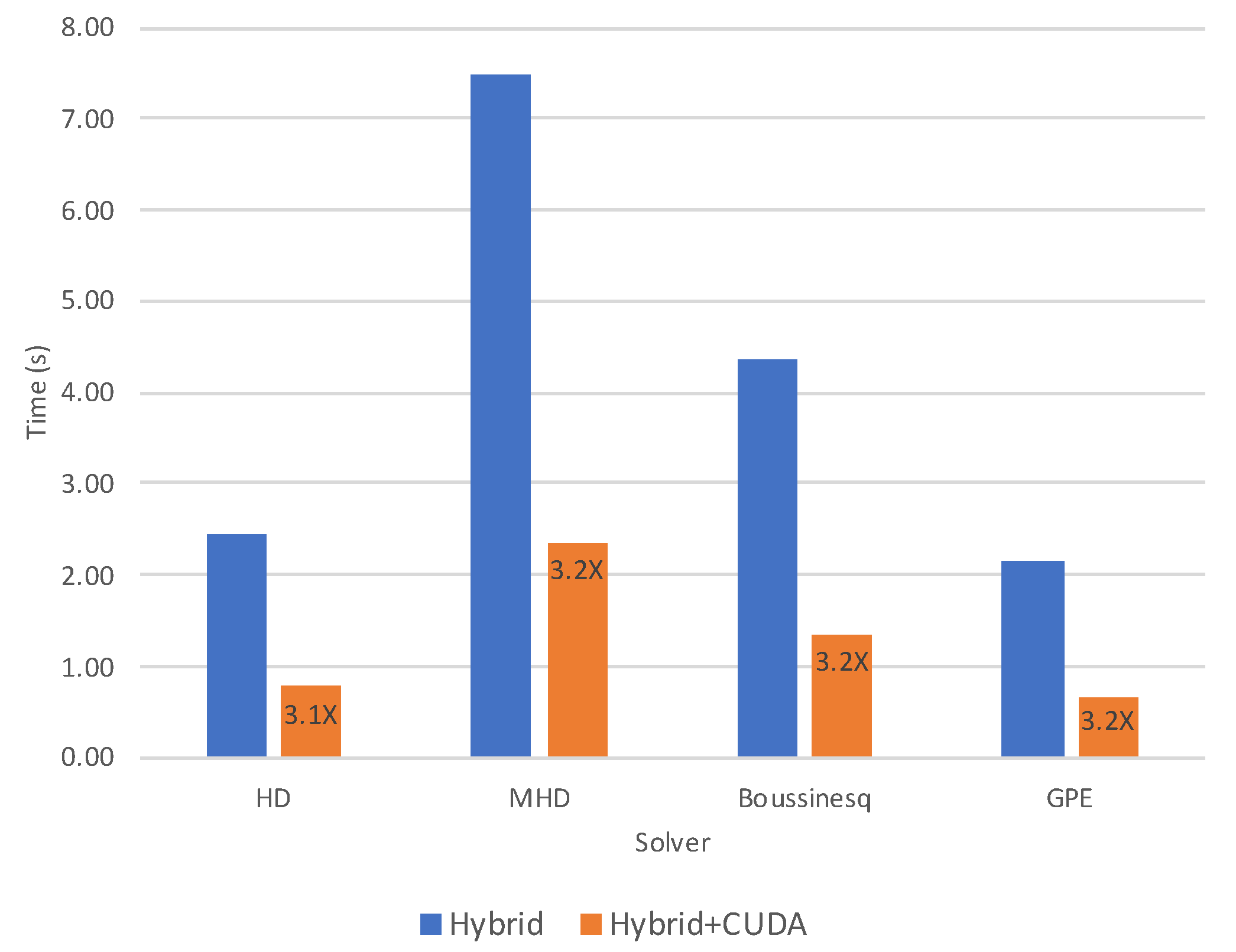
Figure 7 shows the aggregate runtimes for four different solvers. Total times are provided for a CPU-only run and a GPU run in order to compare observed speed-ups. The solvers, HD [
38], MHD [
39], GPE [
40], and Boussinesq [
19], have 3, 6, 1 complex (or 2 real), and 4 primitive fields, respectively, each solver requiring a number of distributed forward and backward transforms per time step proportional to the number of nonlinear terms in the equations (and proportional to the number of fields). The node layout is the same as that in
Section 4.2, and four nodes are used for each solver, each on a grid of
points. The measured speed-up of the GPU implementation of each solver over its CPU-only counterpart is indicated. All solvers see approximately the same speed-up of
, similar to the anisotropic Boussinesq runs above. It is clear that neither the number of distributed transforms nor the type of grid affects the aggregate speed-up on this system. This finding, together with the scaling (admittedly to small node counts) gives us strong confidence that we will see a convincing advantage in using the CUDA implementation in our production turbulence runs on forthcoming GPU-based systems.
5. Discussion and Conclusions
We have built upon the hybrid MPI-OpenMP parallelization scheme presented in M11 to add a third level of parallelization by developing a CUDA implementation of the Geophysical High Order Suite for Turbulence (GHOST) code’s distributed multi-dimensional Fourier transform. GHOST is an accurate and highly scalable pseudospectral code that solves a variety of PDEs often encountered in studies of turbulent flows, with a special focus on the modeling of atmospheric, oceanic, and space physics turbulent flows. Whereas in M11 an isotropic grid alone was considered, in this paper, the tests admit grids with non-unit aspect ratio, a useful device for atmospheric and ocean turbulence studies. The method leverages the 1D coarse domain decomposition of the basic hybrid (CPU-only) scheme, and each MPI task now binds one GPU for additional fine grain parallelization. Our implementation hinges on the NVIDIA cuFFT advanced data layout library for device-capable local FFT routines, and depends considerably on the CUDA runtime to help manage data motion between the host and device. Implementation details have been provided that show how we integrated the access to the CUDA run time and cuFFT libraries into the code in a portable manner by using ISO bindings. We also explain how the additional parallelism leverages the existing hybrid (“CPU-only”) scheme and may be useful for multicore systems that may have fewer GPUs than cores. The resulting method is portable and provides three levels of parallelization, allowing the usage by a high-order CFD code of all CPU cores and GPUs in a system, while providing typical realizable speed-ups between 3 and 4 in tests with multiple GPUs.
Results have been presented that test the new hybrid/CUDA, GPU-based approach using, importantly, timings measuring the aggregate benefit of the implementation. As mentioned, we have demonstrated that the method can provide significant speed-up over the CPU-only computations with the addition of GPU-based computations of the distributed transform. We showed that the speed-ups are reasonably consistent with heuristics when factoring in the performance enhancement afforded by threads for the primary costs in the transform. Aside from communication, which remains a major issue in a distributed transform like ours, device data transfer times can be a significant bottleneck with this method, but we saw that NVIDIA’s NVLink effectively remedies this situation. Lastly, we examined the efficiency of the GPU implementation by examining NVProf metrics and demonstrating that we achieved about 15% of the lattainable peak of the system, based on a roofline model.
While we saw that 80–90% of total runtime is spent on the distributed transform alone, the rest of the computations could in principle be placed on the device, as well. One possibility is to use OpenACC [
41], which is a directive-based programming model that allows access to the offloading device with a rich set of features particularly for GPUs. Indeed, this is the route many developers take to port legacy Fortran codes. There are several reasons why we chose not to initially adopt the OpenACC approach. First, despite early testimonials and some demonstrations of initial promise about the ease of use, we had difficulty finding clear successes in terms of aggregate performance for legacy fluid codes. Second, by the end of our development effort most compiler vendors had stopped supporting the OpenACC standard, leaving essentially a single commercial compiler vendor that does (NVIDIA via its procurement of Portland Group). Relying on a single compiler is a rather severe risk, especially in view of our requirements highlighted in
Section 3.1. The implementation described herein enables the code to run with any compiler that implements OpenMP producing code that can be linked with NVCC-compiled code. That said, beginning with OpenMP 4 and and with additional features to be added to OpenMP 5 [
42], it is clear that OpenMP will also provide significant support for offloading to specified “target” devices. Given the broad support by compiler vendors for OpenMP, it seems that the directive-based approach for offloading espoused by OpenACC will again be supported widely in the near future and should be considered again.
While in our implementation we transfer data from the GPU back to the host in order to handle our all-to-all communication, GPUDirect
TM (see
Section 3.1) may even help incentivize migrating all computations to the GPU. GPUDirect
TM enables the GPU to share (page-locked) memory with network devices without having to go through the CPU using an extra copy to host memory. This should, at a minimum, reduce communication latency and may prove to be an important future path to explore.
We concentrated on the CUDA stream implementation in this version as a way to overlap data transfer with computation of the cuFFTs. In general, we see a benefit on runtimes of about 30% when using PCIe, but that this benefit is reduced when using NVLink. We have not explored whether zero-copy access of the data by the CUDA kernels can provide a larger gain when using PCIe. Since we are already using the page-locked host memory, it may be possible to see still more improved transfer speeds using zero-copy access with the CUDA Unified Memory model [
43], but with the sizable improvement offered by NVLink, it seems a questionable investment. On the other hand, Unified Memory also offers the potential to considerably clean up the data management code presented in this work. We have begun such an implementation and will report on it in the future.
As parallel pseudospectral methods (as well as other high order numerical methods which require substantial communication when parallelized in distributed memory environments) are heavily used in the study of geophysical turbulence, we believe the method described here, with three levels of parallelization and with GPUs used for acceleration, can be useful for other GFD codes and for general PDEs solvers that require fast dispersion–less and dissipation–less estimations of spatial derivatives at high spatial resolutions.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}