Detection of Microaneurysms in Fundus Images Based on an Attention Mechanism


Abstract
1. Introduction
- This paper proposes a fundus image quality equalization method for preprocessing and slicing fundus images; then, based on the proposed method, we construct the fundus dataset IDRiD_VOC.
- This paper proposes a feature fusion algorithm based on a multilayer attention mechanism that includes both feature layer and channel fusion. Using this algorithm, the feature layer with obvious small target features can be selected more accurately, and the preliminary detection of small target can be realized.
- This paper proposes a confidence discrimination method based on spatial positional relationships, including target and blood vessel distance calculations, target confidence scores, and a voting mechanism. We use this method to perform a secondary screening of the small target results of the preliminary detection process. Our confidence discrimination method improves the detection sensitivity while ensuring sufficient detection accuracy.
2. Materials and Methods
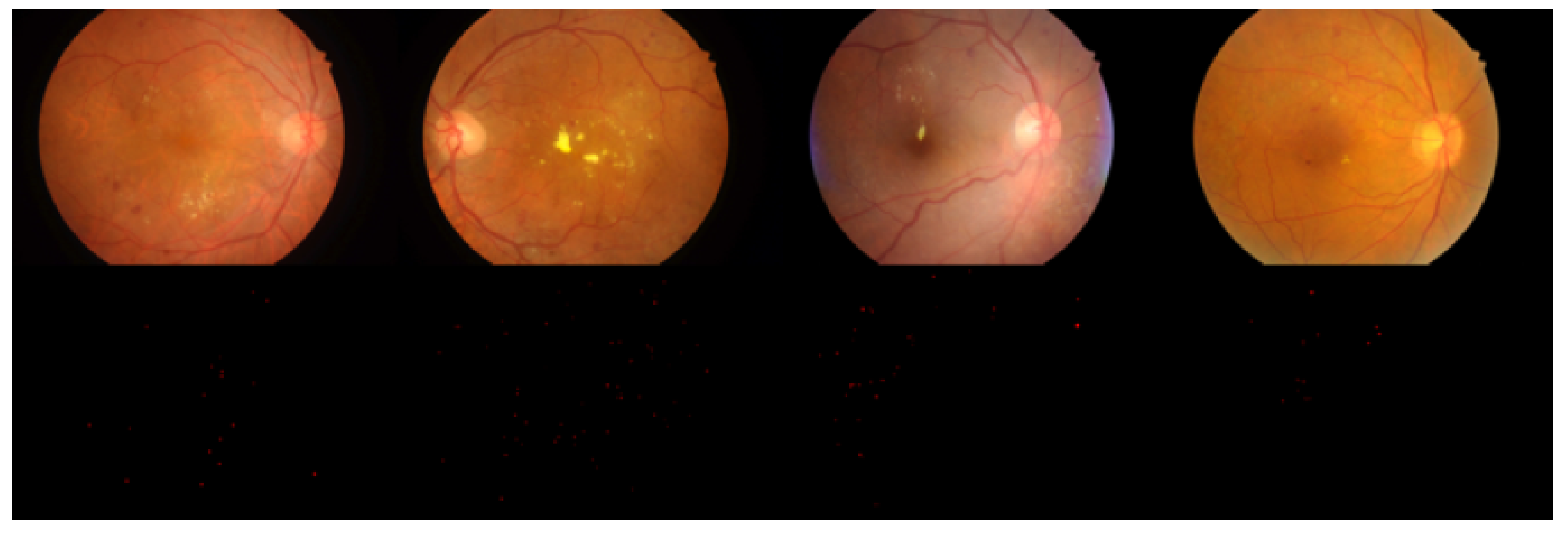
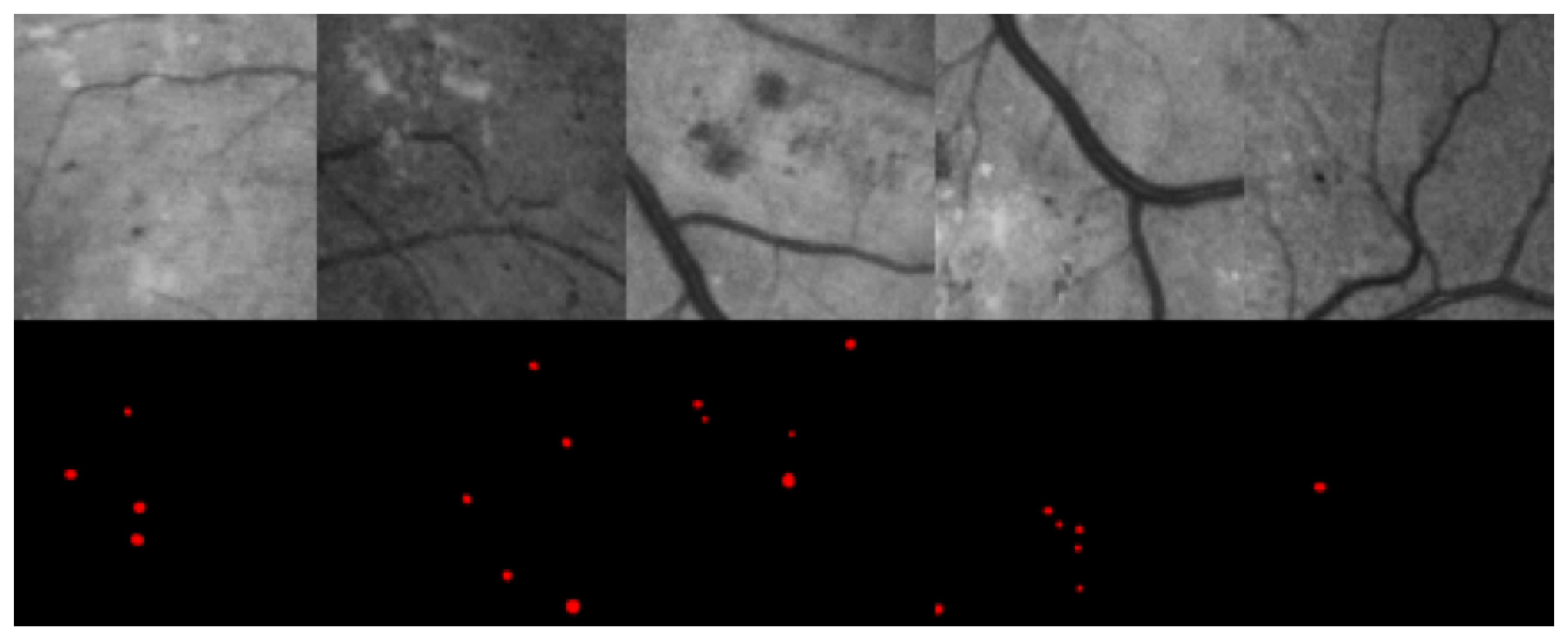
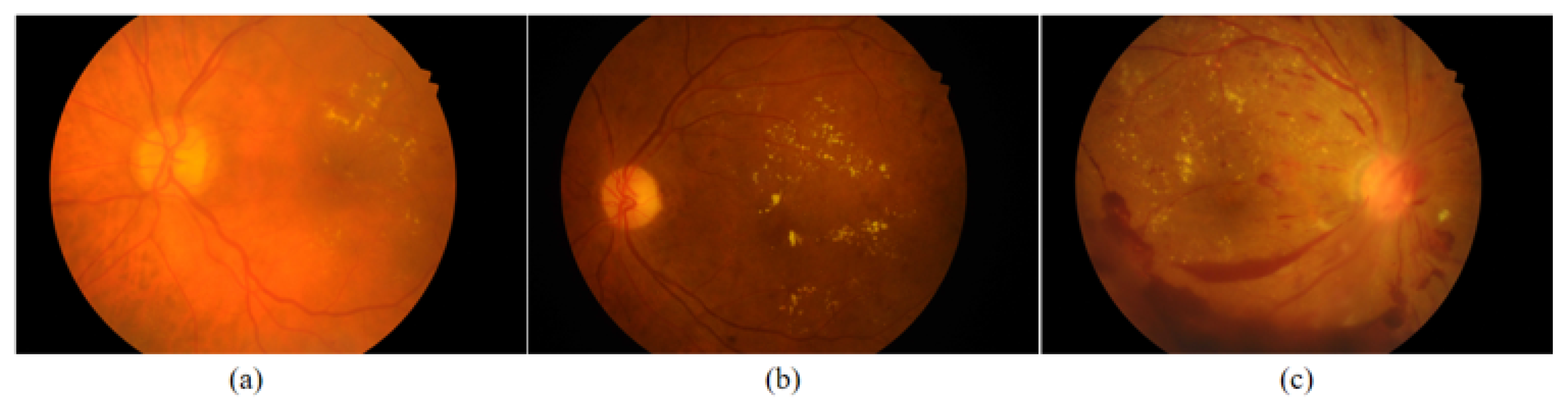
2.1. Dataset
2.2. Related Work
2.2.1. Current Object Detection Methods
2.2.2. Attention Mechanism
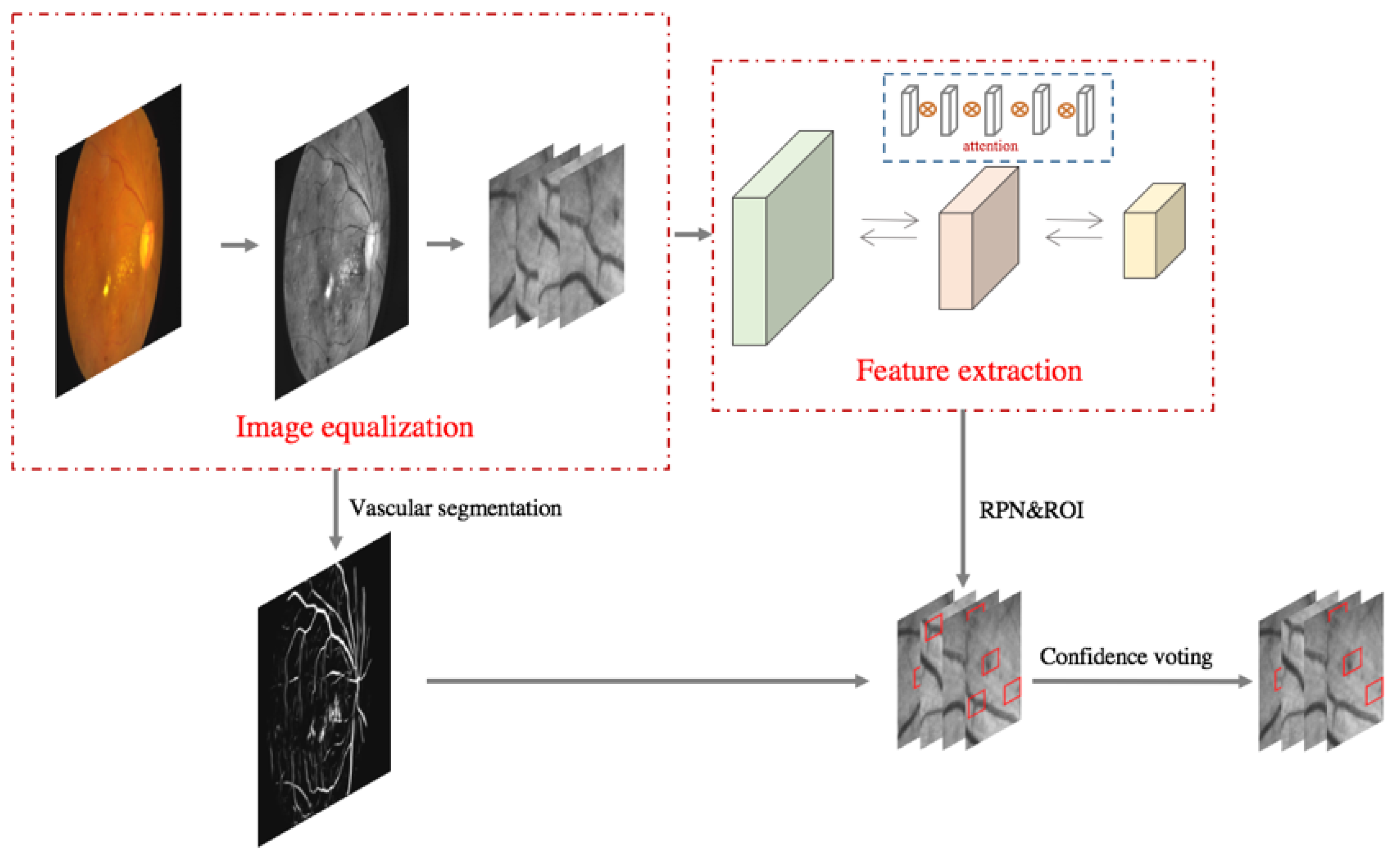
2.3. Methods
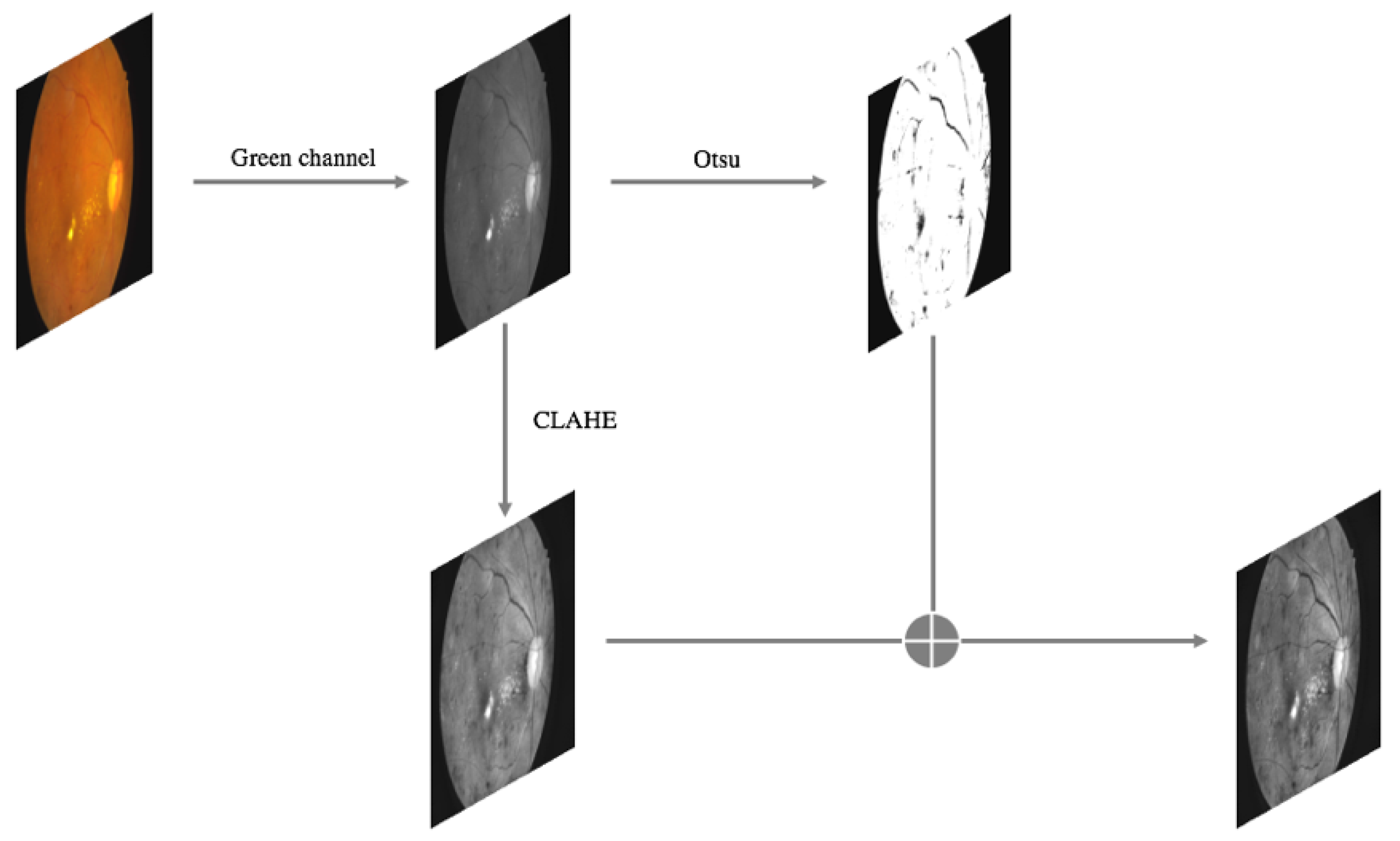
2.3.1. Fundus Image Quality Equalization
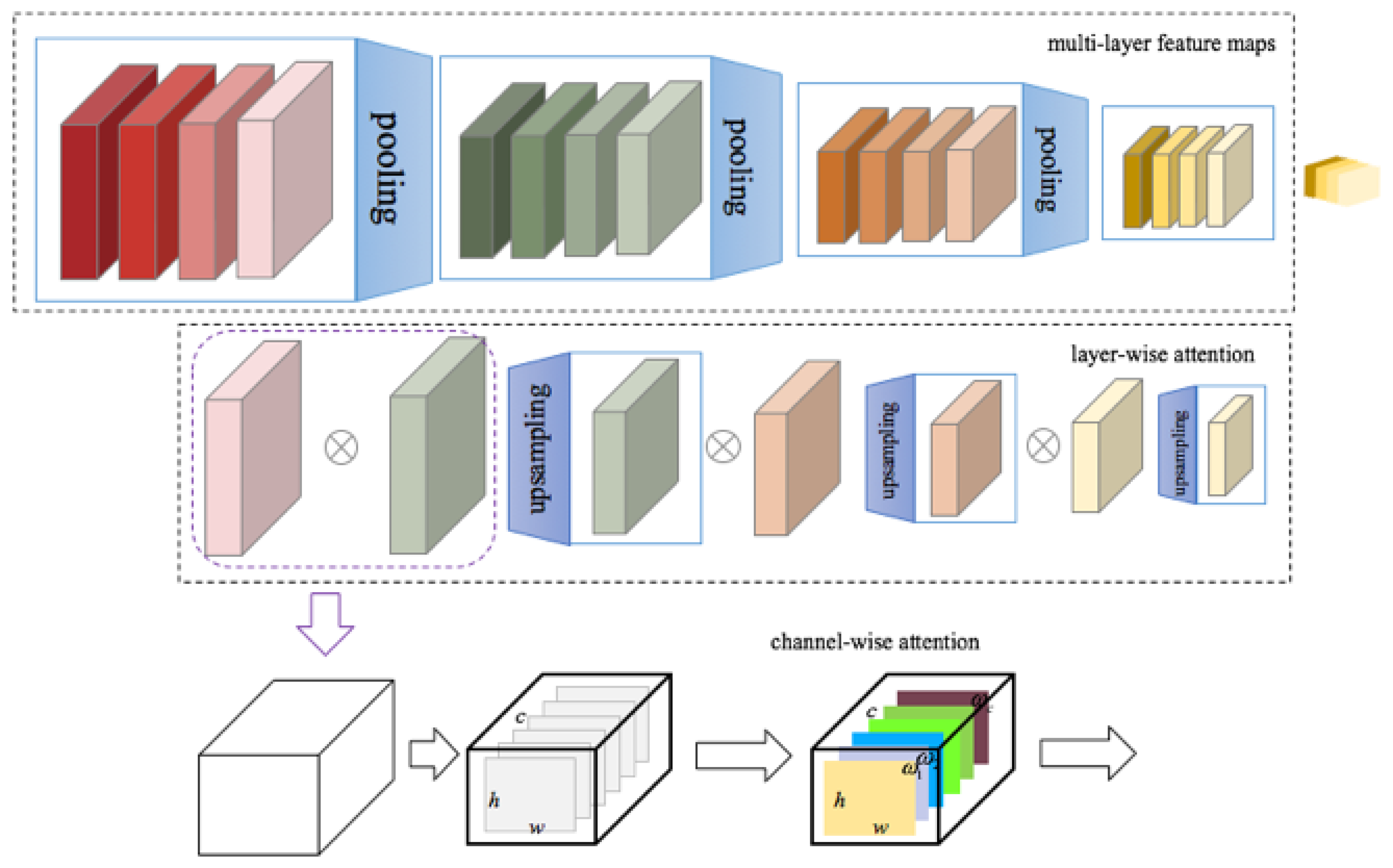
2.3.2. Feature Fusion Based on Attention
2.3.3. Feature Layer Selection
2.3.4. Layer-Wise Feature Fusion
2.3.5. Channel-Wise Feature Fusion
2.3.6. Loss Function
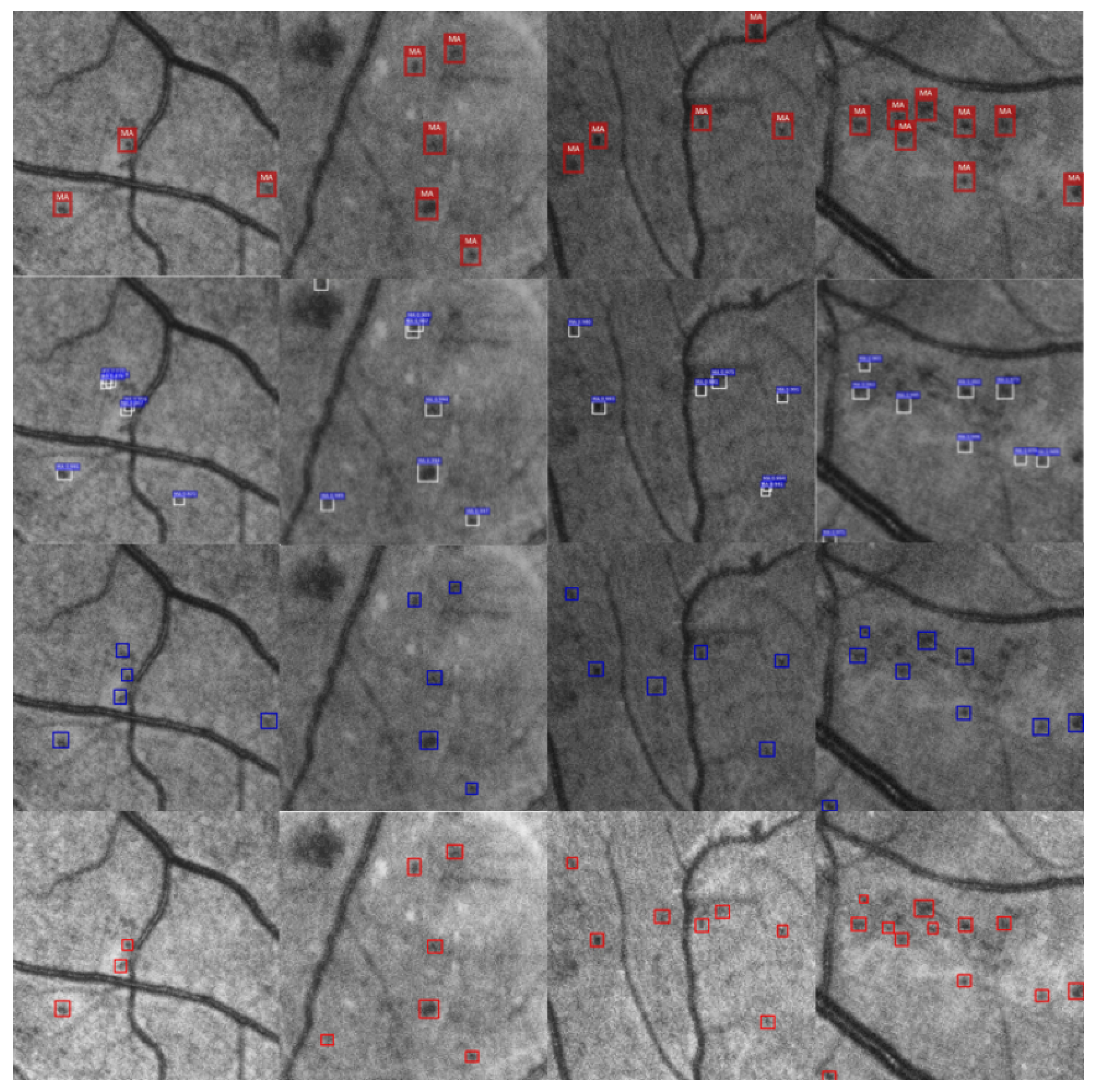
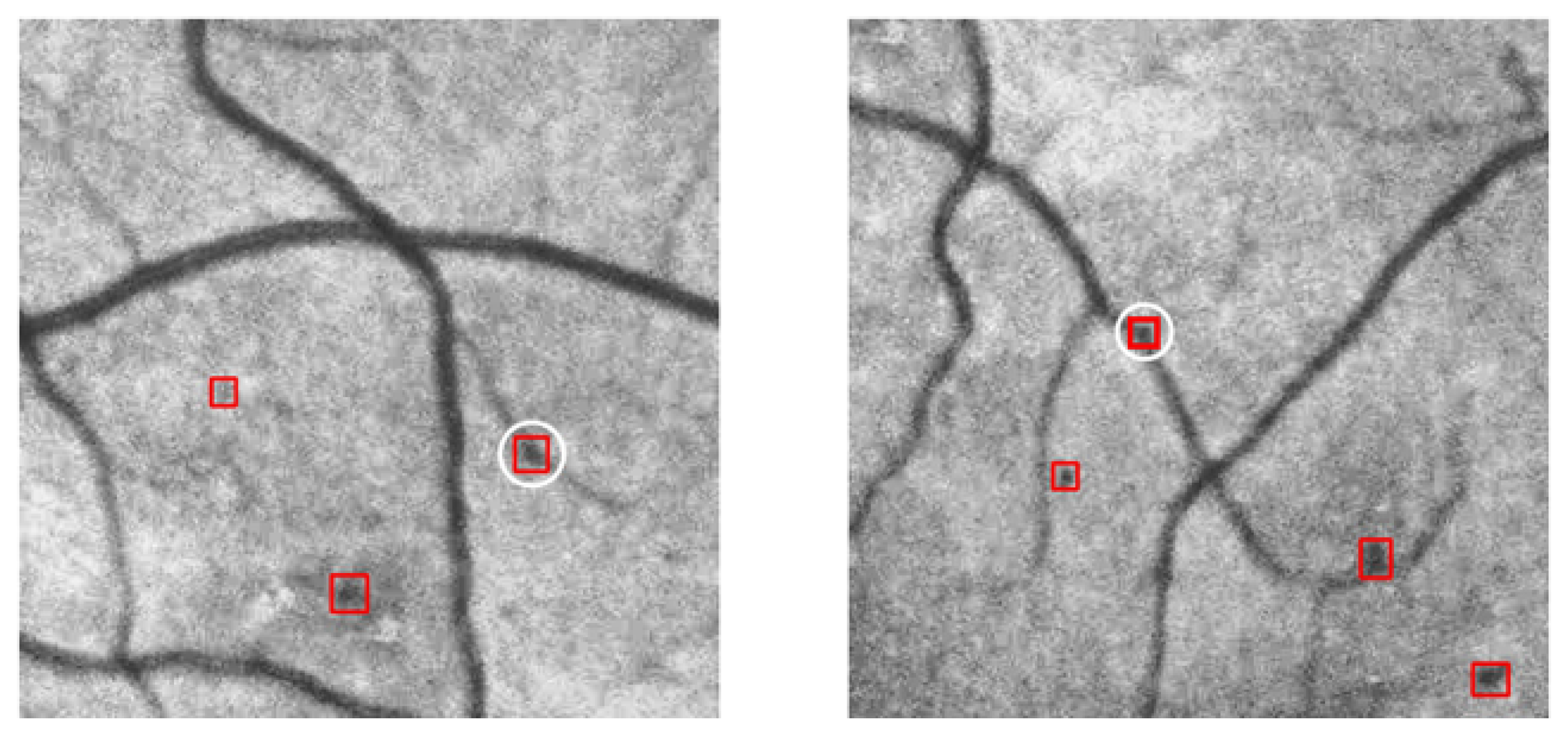
2.3.7. Secondary Screening Based on Spatial Confidence
| Algorithm 1: Distance Calculation Algorithm. |
| Input: Vascular segmentation map I; Candidate object set ;
Output: Candidate object and vascular distance set D;
|
3. Results and Discussion
3.1. Configuration
3.2. Experimental Results
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Leontidis, G.; Al-Diri, B.; Hunter, A. A new unified framework for the early detection of the progression to diabetic retinopathy from fundus images. Comput. Biol. Med. 2017, 90, 98–115. [Google Scholar] [CrossRef] [PubMed]
- Mookiah, M.R.K.; Acharya, U.R.; Chua, C.K.; Lim, C.M.; Ng, E.; Laude, A. Computer-aided diagnosis of diabetic retinopathy: A review. Comput. Biol. Med. 2013, 43, 2136–2155. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.; Zhang, T.; Wang, X. A Computational Framework for Influenza Antigenic Cartography. PLoS Comput. Biol. 2010, 6, e1000949. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.; Ducatez, M.F.; Yang, J.; Zhang, T.; Long, L.; Boon, A.C.; Webby, R.J.; Wan, X. Residues Determining Antigenic Drift among the Clades of H5N1 Highly Pathogenic Avian In uenza Viruses. J. Mol. Biol. 2012, 422, 145–155. [Google Scholar] [CrossRef]
- Hansen, M.B.; Abràmoff, M.D.; Folk, J.C.; Mathenge, W.; Bastawrous, A.; Peto, T. Results of automated retinal image analysis for detection of diabetic retinopathy from the Nakuru Study, Kenya. PLoS ONE 2015, 10, e0139148. [Google Scholar] [CrossRef]
- Porwal, P.; Pachade, S.; Kamble, R. Indian diabetic retinopathy image dataset (IDRiD): A database for diabetic retinopathy screening research. Data 2018, 3, 25. [Google Scholar] [CrossRef]
- Cho, J.; Mirzaei, S.; Oberg, J.; Kastner, R. FPGA-based face detection system using Haar classifiers. In Proceedings of the ACM/SIGDA International Symposium on Field Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2009; ACM: New York, NY, USA, 2009; pp. 103–112. [Google Scholar]
- Lienhart, R.; Maydt, J. An extended set of Haar-like features for rapid object detection. In Proceedings of the International Conference on Image Processing, Rochester, NY, USA, 22–25 September 2002; Volume 1, p. I. [Google Scholar]
- Wilson, P.I.; Fernandez, J. Facial feature detection using Haar classifiers. J. Comput. Sci. Coll. 2006, 21, 127–133. [Google Scholar]
- Xiong, Z.; Li, W.; Han, Q.; Cai, Z. Privacy-Preserving Auto-Driving: A GAN-based Approach to Protect Vehicular Camera Data. In Proceedings of the 19th IEEE International Conference on Data Mining, Beijing, China, 8–11 November 2019. [Google Scholar]
- Shumin, D.; Zhoufeng, L.; Chunlei, L. Adaboost learning for fabric defect detection based on HOG and SVM. In Proceedings of the 2011 International Conference on Multimedia Technology, Hangzhou, China, 26–28 July 2011; pp. 2903–2906. [Google Scholar]
- Pang, Y.; Yuan, Y.; Li, X.; Pan, J. Efficient HOG human detection. Signal Process. 2011, 91, 773–781. [Google Scholar] [CrossRef]
- Suard, F.; Rakotomamonjy, A.; Bensrhair, A.; Broggi, A. Pedestrian detection using infrared images and histograms of oriented gradients. In Proceedings of the 2006 IEEE Intelligent Vehicles Symposium, Tokyo, Japan, 13–15 June 2006; pp. 206–212. [Google Scholar]
- Felzenszwalb, P.F.; McAllester, D.A.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; Volume 2, p. 7. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D. Cascade object detection with deformable part models. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2241–2248. [Google Scholar]
- Ranjan, R.; Patel, V.M.; Chellappa, R. A deep pyramid deformable part model for face detection. In Proceedings of the 2015 IEEE 7th International Conference on Biometrics Theory, Applications and Systems (BTAS), Arlington, VA, USA, 8–11 September 2015; pp. 1–8. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrelland, T.; Malik, J. Rich feature hierarchies for object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; Volume 28, pp. 91–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Xia, J.; Feng, Y.; Liu, L. An information fusion model of innovation alliances based on the bayesian network. Tsinghua Sci. Technol. 2018, 23, 347–356. [Google Scholar] [CrossRef]
- Zhang, R.; Meng, F.; Zhou, Y. Relation classification via recurrent neural network with attention and tensor layers. Big Data Min. Anal. 2018, 1, 234–244. [Google Scholar]
- Hu, P.; Ramanan, D. Finding tiny faces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 951–959. [Google Scholar]
- Cao, G.; Xie, X.; Yang, W.; Liao, Q.; Shi, G.; Wu, J. Feature-fused SSD: Fast detection for small objects. In Proceedings of the Ninth International Conference on Graphic and Image Processing (ICGIP 2017), Qingdao, China, 14–16 October 2017; International Society for Optics and Photonics: Bellingham, WA, USA, 2018; Volume 10615, p. 106151E. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Tan, J.H.; Fujita, H.; Sivaprasad, S.; Bhandary, S.V.; Rao, A.K.; Chua, K.C.; Acharya, U.R. Automated segmentation of exudates, haemorrhages, microaneurysms using single convolutional neural network. Inf. Sci. 2017, 420, 66–76. [Google Scholar] [CrossRef]
- Dai, B.; Wu, X.; Bu, W. Retinal microaneurysms detection using gradient vector analysis and class imbalance classification. PLoS ONE 2016, 11, e0161556. [Google Scholar] [CrossRef] [PubMed]
- Khojasteh, P.; Aliahmad, B.; Kumar, D.K. Fundus images analysis using deep features for detection of exudates, hemorrhages and microaneurysms. BMC Ophthalmol. 2018, 18, 288. [Google Scholar] [CrossRef] [PubMed]
- Adal, K.M.; Sidibé, D.; Ali, S.; Chaum, E.; Karnowski, T.P.; Mériaudeau, F. Automated detection of microaneurysms using scale-adapted blob analysis and semi-supervised learning. Comput. Methods Progr. Biomed. 2014, 114, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Hu, D. An introductory survey on attention mechanisms in NLP problems. arXiv 2018, arXiv:1811.05544. [Google Scholar]
- Wang, W.; Pan, S.J.; Dahlmeier, D.; Xiao, X. Coupled multi-layer attention for co-extraction of aspect and opinion terms. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 483–499. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Yoo, D.; Park, S.; Lee, J.Y.; Paek, A.S.; So Kweon, I. Attentionnet: Aggregating weak directions for accurate object detection. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 Decmber 2015; pp. 2659–2667. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2016; pp. 379–387. [Google Scholar]
- Liu, J.; Gao, C.; Meng, D.; Hauptmann, A.G. Decidenet: Counting varying density crowds through attention guided detection and density estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5197–5206. [Google Scholar]
- Zhang, Z.; Xie, Y.; Xing, F.; McGough, M.; Yang, L. MDNet: A semantically and visually interpretable medical image diagnosis network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6428–6436. [Google Scholar]
- Li, L.; Xu, M.; Wang, X.; Jiang, L.; Liu, H. Attention based glaucoma detection: A large-scale database and CNN Model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10571–10580. [Google Scholar]
- Tang, M.; Zhang, Z.; Cobzas, D.; Jagersand, M.; Jaremko, J.L. Segmentation-by-detection: A cascade network for volumetric medical image segmentation. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 1356–1359. [Google Scholar]
- Srivastava, R.; Wong, D.W.; Duan, L.; Liu, J.; Wong, T.Y. Red lesion detection in retinal fundus images using Frangi-based filters. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 5663–5666. [Google Scholar]
- Roychowdhury, S.; Koozekanani, D.D.; Parhi, K.K. Blood vessel segmentation of fundus images by major vessel extraction and subimage classification. IEEE J. Biomed. Health Inform. 2014, 19, 1118–1128. [Google Scholar]
- Raja, N.; Rajinikanth, V.; Latha, K. Otsu based optimal multilevel image thresholding using firefly algorithm. Model. Simul. Eng. 2014, 2014, 37. [Google Scholar]
- Zhou, C.; Tian, L.; Zhao, H.; Zhao, K. A method of two-dimensional Otsu image threshold segmentation based on improved firefly algorithm. In Proceedings of the 2015 IEEE International Conference on Cyber Technology in Automation, Control, and Intelligent Systems (CYBER), Shenyang, China, 8–10 June 2015; pp. 1420–1424. [Google Scholar]
- Talab, A.M.A.; Huang, Z.; Xi, F.; HaiMing, L. Detection crack in image using Otsu method and multiple filtering in image processing techniques. Opt. Int. J. Light Electron Opt. 2016, 127, 1030–1033. [Google Scholar] [CrossRef]
- Qi, C.; Wang, D.; Muñoz-Avila, H.; Zhao, P.; Wang, H. Hierarchical task network planning with resources and temporal constraints. Knowl.-Based Syst. 2017, 133, 17–32. [Google Scholar] [CrossRef]
- Qi, C.; Wang, D. Dynamic aircraft carrier flight deck task planning based on HTN. IFAC-PapersOnLine 2016, 49, 1608–1613. [Google Scholar] [CrossRef]
- Ye, X.; Zhou, W.; Dong, L. Body Part-Based Person Re-identification Integrating Semantic Attributes. Neural Process. Lett. 2019, 49, 1111–1124. [Google Scholar] [CrossRef]
- Cai, Z.; Goebel, R.; Salavatipour, M.; Lin, G. Selecting dissimilar genes for multi-class classification, an application in cancer subtyping. BMC Bioinform. 2007, 8, 206. [Google Scholar] [CrossRef]
- Wu, X.; Cai, Z.; Wang, X.; Hoang, T.; Goebel, R.; Lin, G. Nucleotide Composition String Selection in HIV-1 Subtyping Using Whole Genomes. Bioinformatics 2007, 23, 1744–1752. [Google Scholar] [CrossRef]
- Liu, B.; Feng, S.; Guo, X. Bayesian analysis of complex mutations in HBV, HCV, and HIV studies. Big Data Min. Anal. 2019, 2, 145–158. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Wu, Y.; Ma, W.; Su, Q.; Liu, S.; Ge, Y. Remote sensing image registration based on local structural information and global constraint. J. Appl. Remote Sens. 2019, 13, 016518. [Google Scholar] [CrossRef]
- Mughees, A.; Tao, L. Multiple deep-belief-network-based spectral-spatial classification of hyperspectral images. Tsinghua Sci. Technol. 2018, 24, 183–194. [Google Scholar] [CrossRef]
- Niemeijer, M.; Van Ginneken, B.; Cree, M.J.; Mizutani, A.; Quellec, G.; Sánchez, C.I.; Zhang, B.; Hornero, R.; Lamard, M.; Muramatsu, C.; et al. Retinopathy online challenge: Automatic detection of microaneurysms in digital color fundus photographs. IEEE Trans. Med. Imaging 2009, 29, 185–195. [Google Scholar] [CrossRef] [PubMed]
- Kauppi, T.; Kämäräinen, J.K.; Lensu, L.; Kalesnykiene, V.; Sorri, I.; Uusitalo, H.; Kälviäinen, H. Constructing benchmark databases and protocols for medical image analysis: Diabetic retinopathy. Comput. Math. Methods Med. 2013, 2013, 368514. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Diameter (Pixels) | <5 | 5–10 | 10–20 | 20–30 | 30–40 | 40–50 | >50 |
| Percentage | 0.02% | 1.58% | 47.40% | 39.70% | 9.80% | 1.2% | 0.30% |
| Distance (Pixels) | 0–10 | 10–20 | 20–30 | 30–40 | 40–50 | 50–100 | 100∼200 |
| Percentage | 80.70% | 7.60% | 4.20% | 1.30% | 2.20% | 2.20% | 1.80% |
| Parameter | Value |
|---|---|
| Learning rate | 0.001 |
| Momentum | 0.9 |
| Gamma | 0.1 |
| Weight_decay | 0.0001 |
| Batch_size | 64 |
| Num_seed_boxex | 10000 |
| Num_output_boxes | 2000 |
| Method | Proposals | Features | Fusion | Attention | |||
|---|---|---|---|---|---|---|---|
| SSD | – | ,, | ✓ | – | 0.582 | 0.473 | 0.231 |
| Faster R-CNN | 300 | – | – | 0.684 | 0.515 | 0.269 | |
| AttractioNet | 2000 | – | – | 0.721 | 0.517 | 0.264 | |
| Ours-1 | 2000 | ,,, | ✓ | ✓ | 0.757 | 0.523 | 0.321 |
| Ours-1 | Attention | Precision | Recall | F1 |
|---|---|---|---|---|
| + | – | 0.793 | 0.420 | 0.549 |
| ✓ | 0.833 | 0.447 | 0.582 | |
| ++ | – | 0.823 | 0.591 | 0.688 |
| ✓ | 0.876 | 0.639 | 0.739 | |
| +++ | – | 0.801 | 0.763 | 0.782 |
| ✓ | 0.872 | 0.810 | 0.840 |
| 0.4 | 0.6 | 0.8 | ||||
|---|---|---|---|---|---|---|
| Precision | Sensitivity | Precision | Sensitivity | Precision | Sensitivity | |
| Ours-1 | 0.831 | 0.868 | 0.851 | 0.849 | 0.870 | 0.823 |
| Ours-2 | 0.874 | – | 0.885 | – | 0.895 | – |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Feng, S.; Duan, G.; Li, Y.; Liu, G. Detection of Microaneurysms in Fundus Images Based on an Attention Mechanism. Genes 2019, 10, 817. https://doi.org/10.3390/genes10100817
Zhang L, Feng S, Duan G, Li Y, Liu G. Detection of Microaneurysms in Fundus Images Based on an Attention Mechanism. Genes. 2019; 10(10):817. https://doi.org/10.3390/genes10100817
Chicago/Turabian StyleZhang, Lizong, Shuxin Feng, Guiduo Duan, Ying Li, and Guisong Liu. 2019. "Detection of Microaneurysms in Fundus Images Based on an Attention Mechanism" Genes 10, no. 10: 817. https://doi.org/10.3390/genes10100817
APA StyleZhang, L., Feng, S., Duan, G., Li, Y., & Liu, G. (2019). Detection of Microaneurysms in Fundus Images Based on an Attention Mechanism. Genes, 10(10), 817. https://doi.org/10.3390/genes10100817