Prospects for Genetic Improvement in Internal Nitrogen Use Efficiency in Rice

 ,
,
Abstract
:1. Introduction
2. Results
2.1. Study 1: Effect of Genotype and Season on N Efficiency Parameters in Field-Grown Rice
2.1.1. Mean Yield and N Efficiency Data across the Dry and Wet Seasons
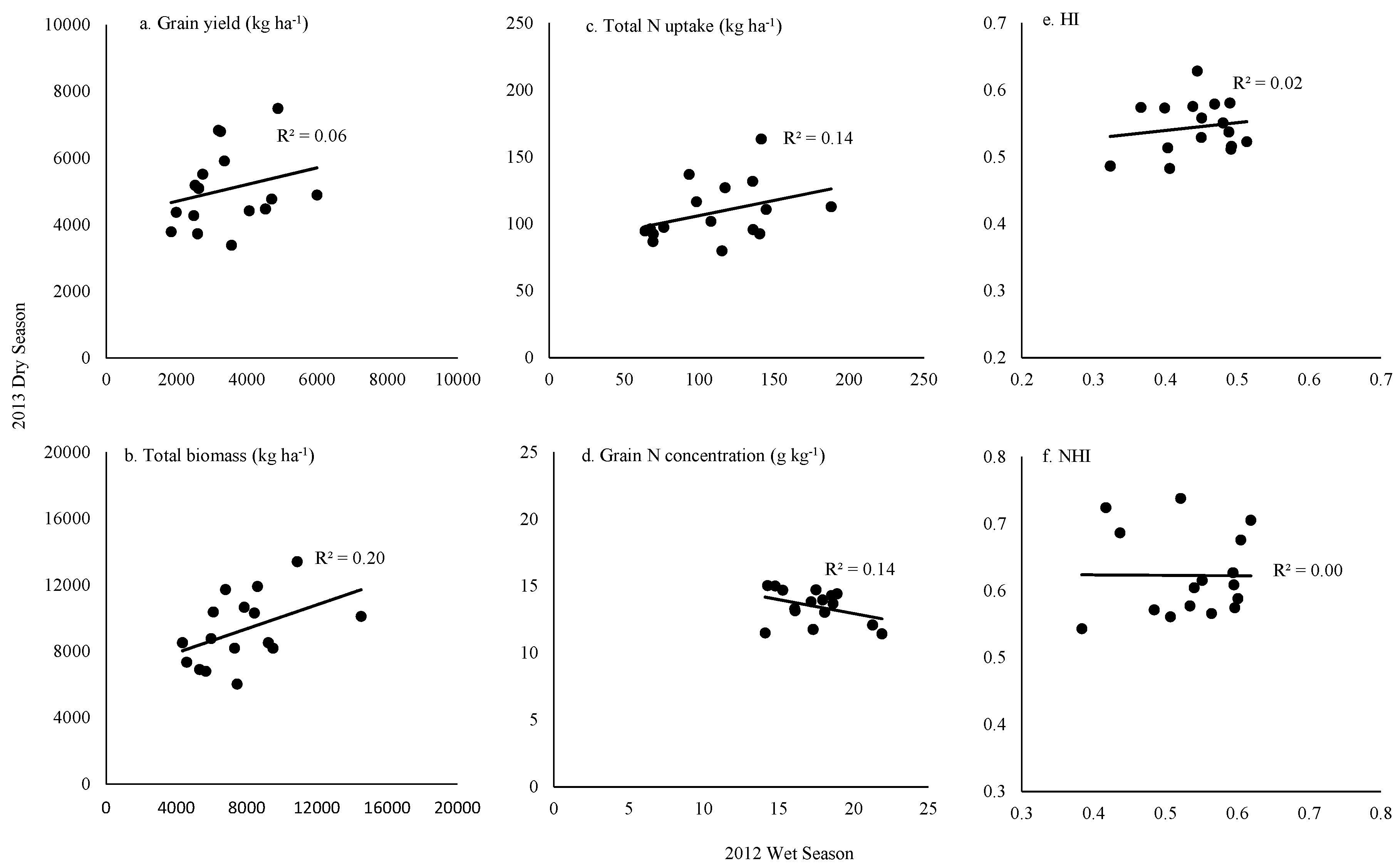
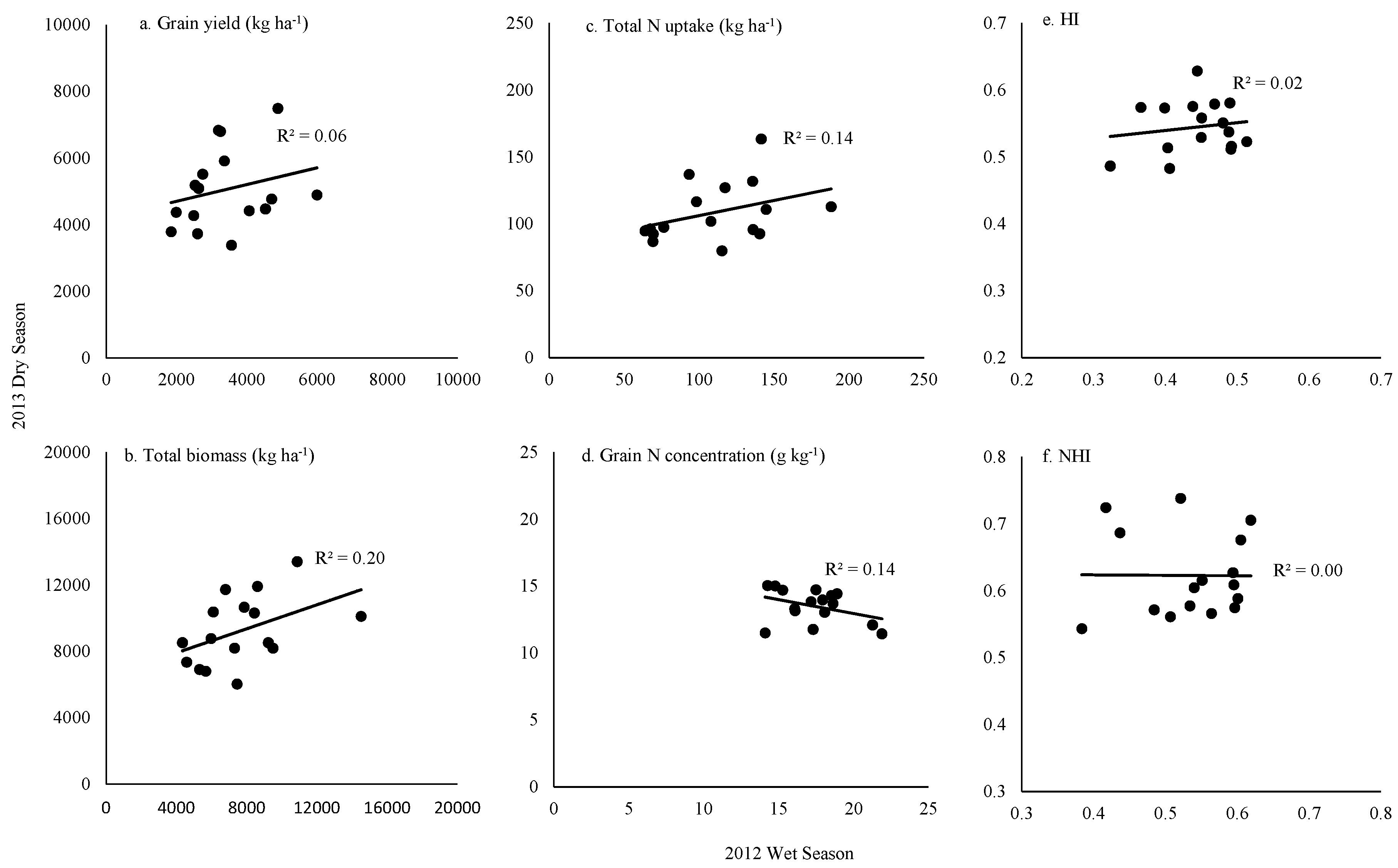
2.1.2. Genotype Variation for Yield and N Efficiency Parameters and Correlation across Seasons
2.1.3. Correlations between Yield and N Efficiency Parameters in the 2012 Wet Season (2012WS) and 2013 Dry Season (2013DS)
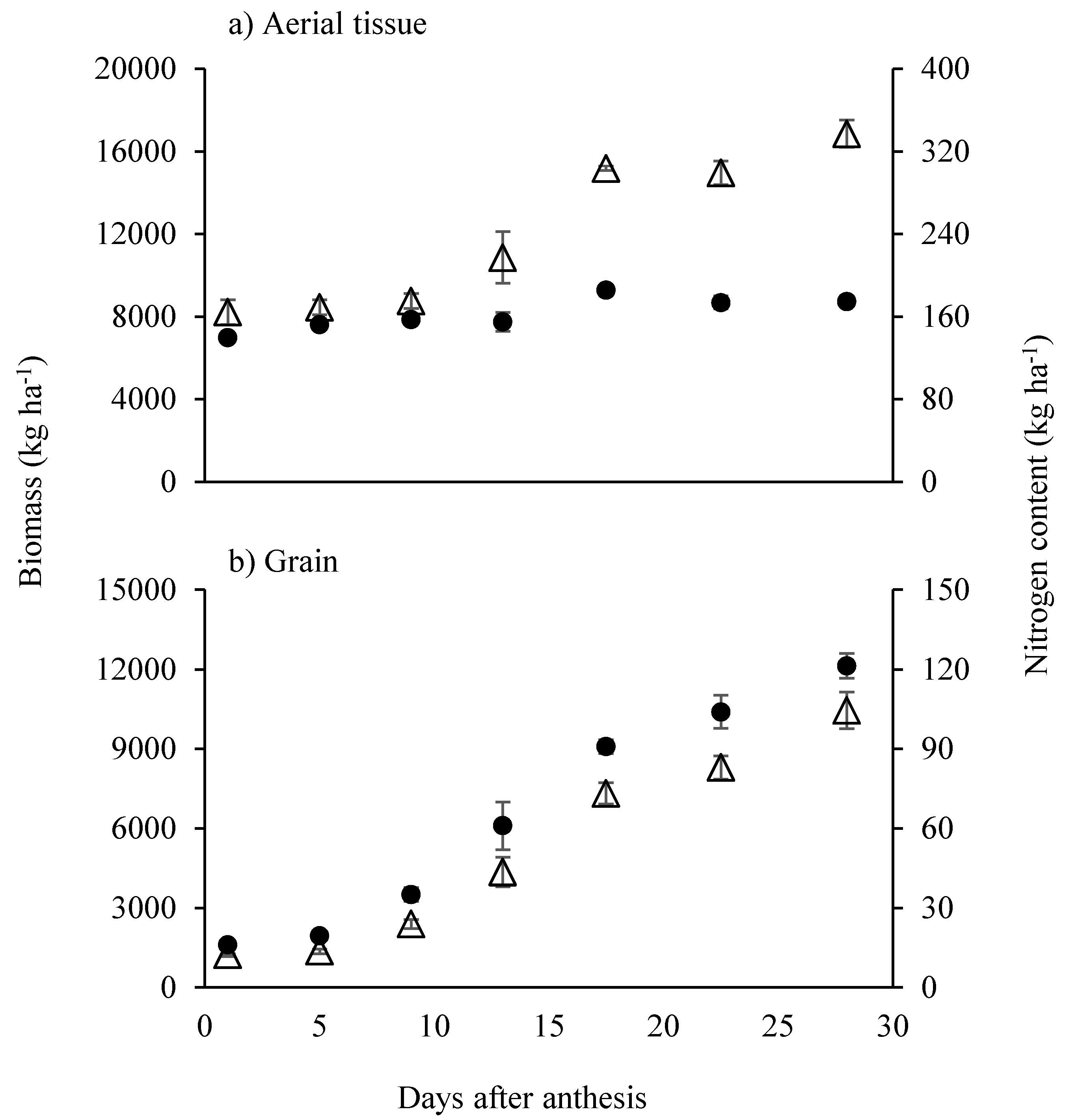
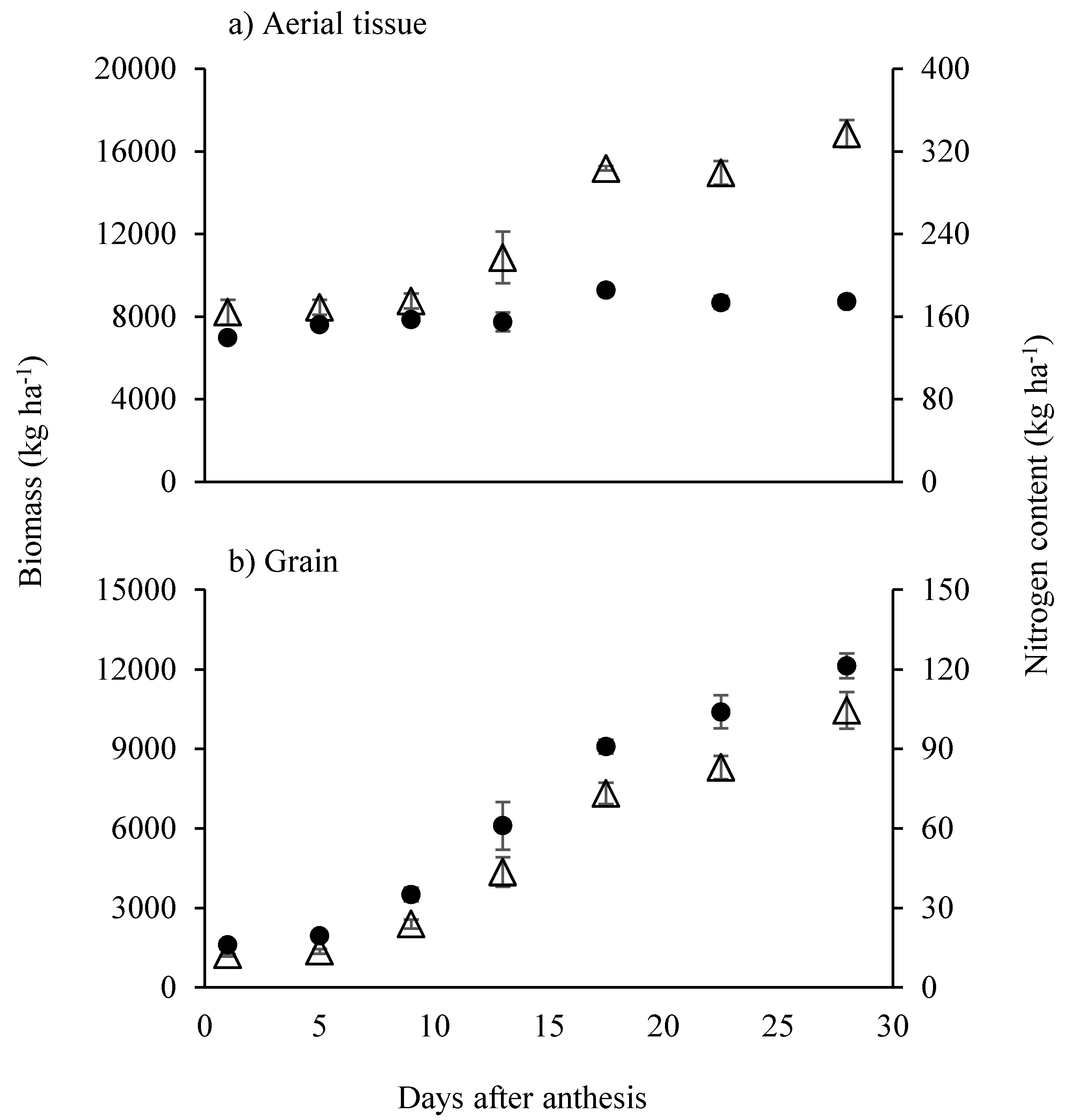
2.2. Study 2: Accumulation and Partitioning of N during Grain Filling in the High Yielding Rice Mega-Variety IR64 under Optimum Conditions during the Dry Season at the International Rice Research Institute (IRRI)
2.3. Study 3: Simulated Impact of Changes in Grain Protein and NHI on NUEveg
2.3.1. Low Yielding Germplasm/Environments
2.3.2. High Yielding Germplasm/Environments
3. Discussion
4. Materials and Methods
4.1. Study 1: Effect of Genotype and Season on N Efficiency Parameters in Field-Grown Rice
4.1.1. Plant Material
4.1.2. Measurements
4.2. Study 2: Accumulation and Partitioning of N during Grain Filling in the High Yielding Rice Mega-Variety IR64 under Optimum Conditions
4.2.1. Field Site
4.2.2. Cultivation of Rice Plants
4.2.3. Measurements
4.3. Study 3: Simulated Impact of Changes in Grain Protein and NHI on NUEveg
5. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Vinod, K.K.; Heuer, S. Approaches towards nitrogen- and phosphorus-efficient rice. AoB Plants 2012. [Google Scholar] [CrossRef] [PubMed]
- Cassman, K.G.; Gines, G.C.; Dizon, M.A.; Samson, M.I.; Alcantara, J.M. Nitrogen-use efficiency in tropical lowland rice systems: Contributions from indigenous and applied nitrogen. Field Crops Res. 1996, 47, 1–12. [Google Scholar] [CrossRef]
- Linquist, B.A.; Liu, L.; van Kessel, C.; van Groenigen, K.J. Enhanced efficiency nitrogen fertilizers for rice systems: Meta-analysis of yield and nitrogen uptake. Field Crops Res. 2013, 154, 246–254. [Google Scholar] [CrossRef]
- Cassman, K.G.; Peng, S.; Olk, D.C.; Ladha, J.K.; Reichardt, W.; Dobermann, A.; Singh, U. Opportunities for increased nitrogen-use efficiency from improved resource management in irrigated rice systems. Field Crops Res. 1998, 56, 7–39. [Google Scholar] [CrossRef]
- Dunn, B.W.; Dunn, T.S.; Beecher, H.G. Nitrogen timing and rate effects on growth and grain yield of delayed permanent water rice in south-east Australia. Crop Pasture Sci. 2014, 65, 878–887. [Google Scholar] [CrossRef]
- Dunn, B.W.; Dunn, T.S.; Orchard, B.A. Nitrogen rate and timing effects on growth and yield of drill-sown rice. Crop Pasture Sci. 2016, 67, 1149–1157. [Google Scholar] [CrossRef]
- Russell, C.A.; Dunn, B.W.; Batten, G.D.; Williams, R.L.; Angus, J.F. Soil tests to predict optimum fertilizer nitrogen rate for rice. Field Crops Res. 2006, 97, 286–301. [Google Scholar] [CrossRef]
- Ladha, J.K.; Kirk, G.J.D.; Bennet, J.; Peng, S.; Reddy, C.K.; Singh, U. Opportunities for increased nitrogen-use efficiency from improved lowland rice germplasm. Field Crops Res. 1998, 56, 41–71. [Google Scholar] [CrossRef]
- Tirol-Padre, A.; Ladha, J.K.; Singh, U.; Laureles, E.; Punzalan, G.; Akita, S. Grain yield performance of rice genotypes at suboptimal levels of soil N as affected by N uptake and utilization efficiency. Field Crops Res. 1996, 46, 127–143. [Google Scholar] [CrossRef]
- Singh, U.; Ladha, J.K.; Castilloa, E.G.; Punzalan, G.; Tirol-Padre, A.; Duqueza, M. Genotypic variation in nitrogen use efficiency in medium- and long-duration rice. Field Crop Res. 1998, 58, 35–53. [Google Scholar] [CrossRef]
- Barraclough, P.B.; Howarth, J.R.; Jones, J.; Lopez-Bellido, R.; Parmar, S.; Shepherd, C.E.; Hawkesford, M.J. Nitrogen efficiency of wheat: Genotypic and environmental variation and prospects for improvement. Eur. J. Agron. 2010, 33, 1–11. [Google Scholar] [CrossRef]
- Brancourt-Humel, M.; Doussinault, G.; Lecomte, C.; Bernard, P.; Le Buance, B.; Trottet, M. Genetic improvement of agronomic traits of winter wheat cultivars released in France from 1946–1992. Crop Sci. 2003, 43, 37–45. [Google Scholar] [CrossRef]
- Crafts-Brandner, S.J. Phosphorus nutrition influence on leaf senescence in soybean. Plant Physiol. 1992, 92, 1128–1132. [Google Scholar] [CrossRef]
- Teyker, R.H.; Moll, N.A.; Jackson, N.A. Divergent selection among maize seedlings for nitrate uptake. Crop Sci. 1989, 29, 879–884. [Google Scholar] [CrossRef]
- Fageria, N.K.; Barbosa Filho, M.P. Nitrogen use efficiency in lowland rice genotypes. Commun. Soil Sci. Plant Anal. 2001, 32, 2079–2089. [Google Scholar] [CrossRef]
- Rose, T.J.; Mori, A.; Julia, C.; Wissuwa, M. Screening for internal phosphorus utilisation efficiency: Comparison of genotypes at equal shoot content is critical. Plant Soil 2016, 401, 77–91. [Google Scholar] [CrossRef]
- Wong, H.W.; Liu, Q.; Sun, S.S.M. Biofortification of rice with lysine using endogenous histones. Plant Mol. Biol. 2015, 87, 235–248. [Google Scholar] [CrossRef] [PubMed]
- Shewry, P.R.; Halford, N.G. Cereal seed storage proteins: Structures, properties and role in grain utilization. J. Exp. Bot. 2002, 53, 947–958. [Google Scholar] [CrossRef] [PubMed]
- Iida, S.; Amano, E.; Nishio, T. A rice (Oryza sativa L.) mutant having a low content of glutelin and a high content of prolamine. Theor. Appl. Genet. 1993, 87, 374–378. [Google Scholar] [CrossRef] [PubMed]
- Ogawa, M.; Kumamaru, T.; Satoh, H.; Iwata, N.; Omura, T.; Kasai, Z.; Tanaka, K. Purification of protein body-1 of rice seed and its polypeptide composition. Plant Cell Physiol. 1987, 28, 1517–1528. [Google Scholar]
- Martin, M.; Fitzgerald, M.A. Proteins in Rice Grains Influence Cooking Properties. J. Cereal Sci. 2002, 36, 285–294. [Google Scholar] [CrossRef]
- Brennan, J.P.; Malabayabas, A. Impacts of IRRI Germplasm on the Philippines since 1985. International Rice Research Institute’s Contribution to Rice Varietal Yield Improvement in South-East Asia; ACIAR Impact Assessment Series Report No. 74; Australian Centre for International Agricultural Research: Canberra, Australia, 2001.
- Yoshida, S.; Parao, F.T. Climate and Rice; International Rice Research Institute: Manila, Philippines, 1976. [Google Scholar]
- Resurreccion, A.P.; Juliano, B.O. Properties of poorly digestible fraction of protein bodies of cooked milled rice. Plant Foods Hum. Nutr. 1981, 31, 119–128. [Google Scholar] [CrossRef]
- Rose, T.J.; Rose, M.T.; Pariasca-Tanaka, J.; Heuer, S.; Wissuwa, M. The frustration with utilisation: Why have improvements in internal phosphorus utilisation efficiency in crops remained so elusive? Front. Plant Sci. 2011, 2, 1–5. [Google Scholar] [CrossRef] [PubMed]
- Rose, T.J.; Erler, D.V.; Farzana, T.; Van Zwieten, L. Delayed permanent water rice production systems do not improve the recovery of 15N-urea compared to continuously flooded systems. Eur. J Agron. 2016, 81, 46–51. [Google Scholar] [CrossRef]
- Wissuwa, M.; Kondo, K.; Fukuda, T.; Mori, A.; Rose, M.T.; Pariasca-Tanaka, J.; Kretzschmar, T.; Haefele, S.M.; Rose, T.J. Unmasking novel loci for internal phosphorus utilization efficiency in rice germplasm through Genome-Wide Association Analysis. PLoS ONE 2015, 10, e0124215. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
| Biomass Yield | N Concentration | N Content | N Efficiency | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| GY | StY | TB | HI | GNc | StNc | GrN | StN | TotN | NUEagron | NHI | |
| Means | |||||||||||
| 2012 WS | 3402 | 4265 | 7666 | 0.43 | 17 | 12 | 61 | 59 | 110 | 31 | 0.53 |
| 2013 DS | 5056 | 4179 | 9235 | 0.54 | 14 | 10 | 68 | 41 | 109 | 47 | 0.62 |
| ANOVA | |||||||||||
| season | *** | ns | *** | *** | *** | *** | ** | *** | ns | *** | *** |
| genotype | *** | *** | *** | *** | *** | *** | *** | *** | *** | * | *** |
| interaction | ** | *** | *** | ns | *** | *** | *** | *** | *** | ** | *** |
| 2010WS | Biomass Yield | N Concentration | N Content | N Efficiency | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2013DS | GY | StY | TotY | HI | GNc | StNc | GrN | StN | TotN | NUEagron | NHI | |
| GY | 0.78 | 0.93 | 0.37 | −0.07 | −0.26 | 0.93 | 0.46 | 0.82 | 0.30 | 0.42 | ||
| StY | 0.73 | 0.95 | −0.27 | 0.21 | −0.09 | 0.83 | 0.77 | 0.92 | −0.19 | −0.03 | ||
| TotY | 0.95 | 0.91 | 0.02 | 0.09 | −0.18 | 0.93 | 0.67 | 0.92 | 0.04 | 0.18 | ||
| HI | 0.48 | −0.23 | 0.19 | −0.39 | −0.29 | 0.22 | −0.44 | −0.09 | 0.8 | 0.74 | ||
| GNc | −0.15 | −0.27 | −0.22 | 0.13 | 0.27 | 0.27 | 0.33 | 0.34 | −0.67 | −0.03 | ||
| StNc | −0.14 | −0.23 | −0.19 | 0.09 | 0.04 | −0.19 | 0.52 | 0.15 | −0.69 | −0.73 | ||
| GrN | 0.92 | 0.62 | 0.85 | 0.51 | 0.23 | −0.15 | 0.53 | 0.90 | 0.08 | 0.41 | ||
| StN | 0.54 | 0.70 | 0.65 | −0.13 | −0.24 | 0.51 | 0.42 | 0.85 | −0.57 | −0.50 | ||
| TotN | 0.91 | 0.76 | 0.91 | 0.32 | 0.06 | 0.12 | 0.92 | 0.75 | −0.25 | 0 | ||
| NUEagron | 0.47 | 0.16 | 0.36 | 0.49 | −0.52 | −0.59 | 0.28 | −0.27 | 0.08 | 0.74 | ||
| NHI | 0.38 | −0.08 | 0.20 | 0.68 | 0.39 | −0.59 | 0.54 | −0.51 | 0.17 | 0.58 | ||
| Grain Yield (kg ha−1) | Grain Protein (%) | Grain N (kg N ha−1) | NHI | Total N Uptake (kg N ha−1) | Shoot N Concentration at Flowering (mg g−1) | NUEveg at Flowering (g Biomass g N−1) |
|---|---|---|---|---|---|---|
| 5 t ha−1 grain yield | ||||||
| Pangil data | 8.1 | 65 | 0.60 | 108 | 17.3 | 57.8 |
| Simulation 1 | 8.1 | 65 | 0.80 | 81 | 13.0 | 77.2 |
| Simulation 2 | 12 | 96 | 0.80 | 120 | 19.2 | 52.1 |
| Simulation 3 | 12 | 96 | 0.60 | 160 | 25.6 | 39.1 |
| Simulation 4 | 5 | 40 | 0.60 | 66.7 | 10.7 | 93.5 |
| 10.4 t ha−1 grain yield | ||||||
| IRRI data | 7.3 | 121 | 0.69 | 176 | 16.9 | 59.1 |
| Simulation 5 | 7.3 | 121 | 0.8 | 151 | 14.6 | 68.5 |
| Simulation 6 | 12 | 201 | 0.80 | 250 | 24.0 | 41.7 |
| Simulation 7 | 12 | 201 | 0.69 | 291 | 27.8 | 39.9 |
| Simulation 8 | 5 | 83.6 | 0.69 | 121 | 11.6 | 86.3 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rose, T.J.; Kretzschmar, T.; Waters, D.L.E.; Balindong, J.L.; Wissuwa, M. Prospects for Genetic Improvement in Internal Nitrogen Use Efficiency in Rice. Agronomy 2017, 7, 70. https://doi.org/10.3390/agronomy7040070
Rose TJ, Kretzschmar T, Waters DLE, Balindong JL, Wissuwa M. Prospects for Genetic Improvement in Internal Nitrogen Use Efficiency in Rice. Agronomy. 2017; 7(4):70. https://doi.org/10.3390/agronomy7040070
Chicago/Turabian StyleRose, Terry J., Tobias Kretzschmar, Daniel L. E. Waters, Jeanette L. Balindong, and Matthias Wissuwa. 2017. "Prospects for Genetic Improvement in Internal Nitrogen Use Efficiency in Rice" Agronomy 7, no. 4: 70. https://doi.org/10.3390/agronomy7040070
APA StyleRose, T. J., Kretzschmar, T., Waters, D. L. E., Balindong, J. L., & Wissuwa, M. (2017). Prospects for Genetic Improvement in Internal Nitrogen Use Efficiency in Rice. Agronomy, 7(4), 70. https://doi.org/10.3390/agronomy7040070