Abstract
Meteorological disasters are significant factors that impact agricultural production. Given the vast volume of online agrometeorological disaster information, accurately and automatically extracting essential details—such as the time, location, and extent of damage—is crucial for understanding disaster mechanisms and evolution, as well as for enhancing disaster prevention capabilities. This paper constructs a comprehensive dataset of agrometeorological disasters in China, providing a robust data foundation and strong support for event extraction tasks. Additionally, we propose a novel model named character and word embedding fusion-based GCN network (CWEF-GCN). This integration of character- and word-level information enhances the model’s ability to better understand and represent text, effectively addressing the challenges of multi-events and argument overlaps in the event extraction process. The experimental results on the agrometeorological disaster dataset indicate that the F1 score of the proposed model is 81.66% for trigger classification and 63.31% for argument classification. Following the extraction of batch agricultural meteorological disaster events, this study analyzes the triggering mechanisms, damage patterns, and disaster response strategies across various disaster types using the extracted event. The findings offer actionable decision-making support for research on agricultural disaster prevention and mitigation.
1. Introduction
An event refers to a specific occurrence involving participants, characterized by changes in state, and represents an action or process that takes place within a defined context [1]. Event extraction aims to identify event types and their corresponding arguments in the text, encompassing two primary subtasks: event detection and event argument extraction [2]. Event detection aims to identify triggers and classify them as event types. Event triggers are specific words or phrases—typically verbs or nouns—that clearly indicate the occurrence of an event and intuitively reflect the associated state changes. Event arguments are the participants or attributes involved in the event [3,4].
Agrometeorological disaster event extraction enables the timely acquisition of critical information during disasters, enhances the development of response strategies, improves the efficiency of information retrieval, and supports precise and informed decision-making for agricultural disaster prevention and mitigation [5]. The rapid evolution of internet technologies has made online resources a major source of information. Consequently, a large amount of agrometeorological disaster information is now presented in unstructured text form, containing valuable insights with significant potential for application.
As illustrated in Figure 1, the event triggers “hit,” “affected,” and “collapsed” are extracted. Based on these triggers and the surrounding context, it is determined that “hit” signals a “Torrential Flood/Disaster-causing event,” while “affected” and “collapsed” indicate a “Torrential Flood/Disaster-impact event.” For the “Torrential Flood/Disaster-causing event,” the argument extraction module identifies the arguments “From May 29 to 30” (duration), “Guizhou Province” (location), and “torrential or heavy rain” (severity). This process transforms unstructured text into a structured format, which facilitates rapid retrieval and deeper analysis, ultimately maximizing resource utilization and enhancing scientific management of agrometeorological disasters. This approach also plays a critical role in downstream tasks such as information retrieval and knowledge graph construction.
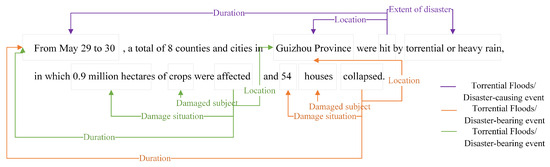
Figure 1.
Example of agrometeorological disaster event extraction; different colors represent different events.
However, there are two challenges in extracting agrometeorological disaster events. First, as shown in Figure 1, a single sentence can contain multiple events (e.g., “Torrential Flood/Disaster-causing event” and “Torrential Flood/Disaster-impact event”) that may share common arguments such as “duration” and “location.” Second, argument overlap is evident: as illustrated in Figure 2, the argument “public” serves as the “Recovery target” in the “Torrential Floods/Production recovery” event and as the “Responsible Party” in another event. Additionally, the “Responsible party” argument, “Agricultural technicians from the Luo Ding Municipal Bureau of Agriculture and Rural Affairs”, contains a nested “Location” argument, “Luo Ding”. These complexities increase the difficulty of event extraction, which requires advanced techniques to accurately identify interconnected triggers and arguments within the text.
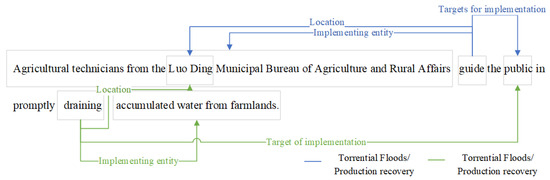
Figure 2.
Example of overlapping argument: different colors represent different events.
To address these issues, this study proposes a Chinese event extraction model named character and word embedding fusion-based GCN network (CWEF-GCN). Methods based on Graph Neural Networks (GNNs) have achieved remarkable results in event extraction tasks by modeling structural relationships between words. These approaches primarily rely on dependency parsing to construct sentence graph structures, which reveal dependency relations between words and help capture long-range contextual dependencies. However, current GNN-based event extraction methods suffer from high complexity in graph construction. To capture more diverse relations, complex heterogeneous graphs incorporating multiple types of relational edges are often constructed, which inevitably introduce substantial noise. Moreover, the characteristics of the Chinese language pose specific challenges: using only character-level features leads to word segmentation ambiguity and high complexity, whereas relying solely on word-level features risks error propagation due to segmentation mistakes. To address these issues, this paper proposes a fusion of character- and word-level features, leveraging character features to mitigate segmentation errors and word features to disambiguate character-level meanings. To efficiently align with the aforementioned graph structure and accurately identify triggers and arguments, this paper employs a pointer network for decoding. Traditional sequence labeling-based decoding methods often underperform when handling long sequences and nested arguments. In contrast, pointer decoding effectively addresses issues such as argument overlap and nesting by identifying the start and end positions of triggers and arguments. Furthermore, in the absence of a dataset for agricultural meteorological disaster event extraction, we constructed and annotated a dataset from two sources: the China Meteorological Disaster Yearbook and China News Network. This dataset defines 16 event-type labels and 18 argument roles, providing a valuable resource for evaluating the effectiveness of our algorithm for agricultural meteorological disaster event extraction tasks. The main contributions of this study are as follows:
- (1)
- We propose a novel graph construction method. Compared to the complex graph structures commonly used in existing studies, this strategy simplifies the graph construction process and reduces model complexity. Furthermore, by leveraging the fusion of character-level and word-level information, the graph convolutional network can learn semantic associations between triggers and arguments more efficiently and accurately.
- (2)
- A comprehensive agrometeorological disaster dataset is constructed to validate the proposed model. The experimental results show that our model outperforms competitive models.
- (3)
- We analyze the characteristics of disasters by examining the extracted event triggers and arguments, thereby offering decision-making support for the prevention and mitigation of agricultural disasters.
2. Related Work
Event extraction research has evolved through the eras of pattern matching, machine learning, and deep learning. While early pattern-based and statistical machine learning methods (e.g., Conditional Random Fields, CRFs) laid the groundwork, they relied heavily on manual feature engineering and demonstrated limited generalization. Since then, the field has been dominated by deep learning approaches, which can be categorized into several paradigms. Early deep learning models, such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), initially approached event extraction through pipeline models or joint learning frameworks. CNN-based models and RNN-based models—including Long Short-Term Memory networks (LSTMs) and Gated Recurrent Units (GRUs) [6,7]—demonstrated the ability to automatically learn features from raw text, overcoming previous limitations. However, a fundamental weakness of these sequence-based architectures is their inability to effectively capture long-range dependencies between event triggers and arguments, which are crucial for accurate event extraction.
Graph-based methods were subsequently introduced to explicitly model the syntactic structure of sentences, effectively addressing the long-distance dependency problem. By constructing graphs over dependency trees, Graph Convolutional Networks (GCNs) [8,9] can propagate information along syntactic paths, leading to significant performance gains. More recent studies have formulated event extraction entirely as a graph parsing problem [10,11]. While powerful, a key drawback of these methods is their tendency to construct overly complex and noisy heterogeneous graphs—incorporating multiple relation types—which can increase computational costs and obscure the most critical connections.
Transformer-based pre-trained language models (PLMs) have revolutionized the field by providing deeply contextualized token representations. Models such as BERT have become the standard encoder, substantially boosting performance [3]. A recent paradigm shift reformulates the task using generative PLMs (e.g., T5, GPT) through prompt-based learning [12,13], demonstrating great promise in low-resource scenarios and in handling complex cases such as argument overlap. Despite their strengths, purely sequence-based PLMs often lack explicit inductive biases for syntactic structure, which can be vital for accurate relational reasoning in event extraction. This limitation has spurred interest in hybrid approaches that integrate PLMs with graph neural networks to synergize contextualized representations with structured reasoning.
Task-specific reformulations include framing event extraction as a question-answering task [14] to address argument overlap. However, these methods often require designing numerous question–answer templates, which can be cumbersome and suboptimal.
Finally, Chinese event extraction presents unique challenges due to the absence of clear word delimiters, which makes trigger identification and word segmentation error-prone. Research in this area often focuses on effectively integrating character-level and word-level information [15,16,17,18] or incorporating external lexical knowledge [19,20] to mitigate these issues. A common challenge remains designing a model architecture that is both effective in capturing the nuances of Chinese and computationally efficient, avoiding the complexity introduced by many graph-based methods.
Our work is positioned at the intersection of these recent advancements. We propose a novel graph construction method that simplifies the complex graphs commonly used in GCN approaches, thereby reducing noise and computational overhead. Additionally, our model integrates a pre-trained Transformer (BERT) as a backbone encoder to generate powerful contextualized features. We specifically design a character–word fusion mechanism to address the unique challenges of Chinese text. This approach enables us to leverage the strengths of PLMs while incorporating a more efficient and focused structural inductive bias through our simplified graph.
3. Materials and Methods
In this section, we propose a novel event extraction model named character and word embedding fusion-based GCN network. As shown in Figure 3, the proposed CWEF-GCN model comprises four components: a sentence encoding layer, dependency feature extraction layer, feature fusion layer, and event decoding layer. First, the sentence encoding layer utilizes the robust encoding capabilities of BERT to capture contextual nuances and generate character-level embeddings from the input text. Subsequently, the dependency feature extraction layer implements a novel graph construction approach based on character and word embedding fusion, which is then processed using a graph convolutional network. This method effectively captures long-range dependencies between event triggers and arguments, uncovers complex semantic relationships, and addresses the challenge of disambiguating argument roles. The feature fusion layer employs a Bidirectional Long Short-Term Memory (BiLSTM) network to capture sequential dependencies within a sentence, facilitating the integration of trigger information with other contextual features. Finally, the event decoding layer utilizes a pointer mechanism to decode event triggers, arguments, event types, and their corresponding roles, thereby ensuring accurate event extraction and role classification.
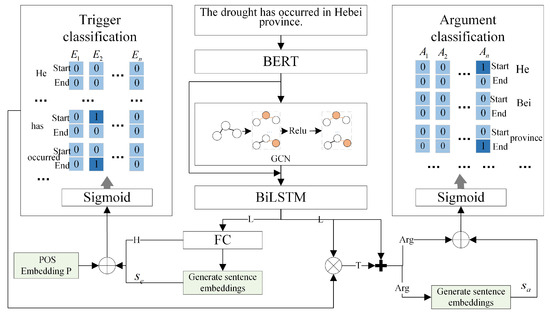
Figure 3.
Model architecture.
3.1. Sentence Encoding Layer
In this study, we employ BERT for sentence encoding owing to its ability to capture rich and complex semantic relationships using a bidirectional training approach. BERT encodes each character by simultaneously considering both the preceding and following contextual information, resulting in dynamic word representation. This approach allows BERT to generate distinct vector representations for the same word in different contexts, thereby enhancing the model’s ability to accurately interpret polysemous words and contextually related terms. Given a sentence , where denotes the ith character, we obtain the corresponding character encoding: token embedding, segment embedding, and position embedding. Token embedding encodes each word’s vocabulary index, segment embedding distinguishes between sentences, and position embedding indicates the relative position of each word in the sentence, guiding the model’s focus during processing. These character encodings are fed into the pre-trained BERT model, which produces semantically enriched vector representations , as illustrated in Figure 4.
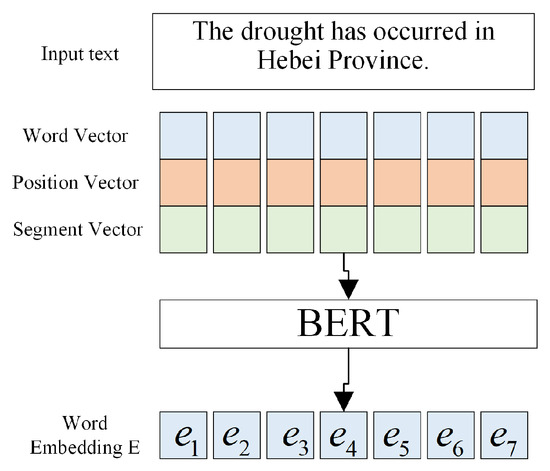
Figure 4.
Sentence encoding layer.
3.2. Dependency Feature Extraction Layer
To comprehensively explore both the semantic and syntactic features of a sentence, we employ GCNs to extract deeper semantic insights. Our approach utilizes dependency trees to propagate information across graphs, thereby enhancing the node representations. Previous approaches to event extraction using graph structures include research by Wu et al. [9], who proposed a word–character graph method. That model involved two sets of nodes derived from dependency parsing: character nodes, , and word nodes, , derived from dependency parsing. If a dependency existed between nodes and , edges were constructed between the corresponding character nodes and and word nodes . In addition, to integrate sequential features, the characters between nodes and were connected. Similarly, Xu et al. [21] employed word-level modeling for Chinese event extraction by constructing word-level graphs using dependency parsing. Liu et al. [22] further developed a character-level dependency tree that linked the internal characters of word nodes via dependency relationships to form edges. While word-based graphs provide a clear structure, they are vulnerable to errors arising from Chinese word segmentation. Conversely, character-based graphs reduce segmentation errors but often introduce substantial noise and create complex graph structures, which increase computational complexity.
In contrast to existing methods, we propose a novel graph construction approach that preserves essential syntactic structures while significantly reducing complexity and avoiding word segmentation errors. Specifically, this approach defines a dependency graph G = (V, E), where represents n nodes corresponding to the words in the sentence, and E represents the set of edges between the nodes. We capture the relationships between characters using the embedding vector generated from the sentence encoding layer. We also employ the spaCy tool to segment the sentence and derive the word set . SpaCy is a widely validated, high-performance industrial-strength natural language processing library. Its tokenization and dependency parsing pipelines demonstrate robust and consistent performance across multiple standard benchmark datasets. A word-length mask matrix M, represented as an matrix, is constructed, where indicates that character belongs to word , and otherwise. The BERT character vector is then multiplied by the mask matrix to obtain the word vector W as follows:
The word vectors are then averaged, resulting in averaged word vectors , which are used as graph nodes.
where denotes the length of each word. In spaCy, the dependency parser analyzes the syntactic structure of a sentence, which is used to generate a dependency graph for sentences by extracting pairs of words based on specific syntactic dependency paths. If a dependency relationship exists between nodes and , a forward syntactic edge is created. To allow bidirectional information flow, reverse syntactic edges are added and self-loop edges are included for each node to capture their own information. For example, in the sentence “Drought occurred in Hebei Province,” dependency parsing reveals that “occurred” is the core word, with a subject–predicate (SBV) relationship to “Hebei Province” and a verb–object (VOB) relationship to “drought.” Consequently, the dependency graph includes forward edges (occurred, Hebei Province) and (occurring, drought) along with the corresponding reverse edges and self-loops. This syntactic information is then encoded into an adjacency matrix A, where n is the number of nodes in the dependency syntax tree. Finally, the nodes and edges are input into the GCN to obtain word vector , which incorporates the dependency features. The calculation formula is as follows:
Here, represents the adjacency matrix of the graph, which includes self-loops for the nodes. denotes the identity matrix, the degree matrix, the weight matrix for layer l, and the activation function. represents the node feature matrix for layer l + 1, and denotes the node feature matrix for layer l. This graph construction method simplifies the process, while allowing word vectors to capture more semantic information. Because some character-level information contains too much detail, which can distract the model with irrelevant data, this approach minimizes the noise introduced by character-level dependencies. It preserves the relationships between words and maintains the structural integrity of the text, thereby improving the effectiveness of the event extraction. The dependency feature extraction layer is shown in Figure 5.
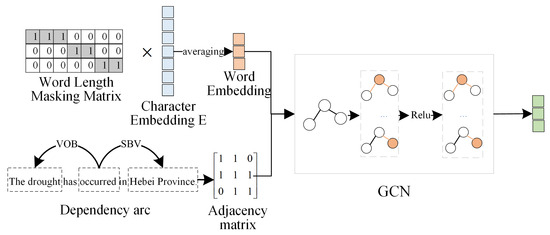
Figure 5.
Dependent feature extraction layer.
3.3. Feature Fusion Layer
The GCN model first generates word embeddings , which are then transformed into character embeddings using a word-length mask matrix. The transformed character embeddings are then concatenated with the BERT output E along the last dimension, thereby enriching the feature representation. This process produces a concatenated feature vector denoted by . The formula for this concatenation is as follows:
Subsequently, the fused sequence output is fed into the BiLSTM network. This network consists of two LSTMs: a forward LSTM, which processes the sequence from beginning to end, and a backward LSTM, which processes the sequence from end to beginning. Together, these LSTMs capture bidirectional contextual dependencies within the sentences. The encoding of character by the BiLSTM network is given by:
After BiLSTM processing, character is represented as a concatenated vector . This means the forward and backward encodings, , are combined to form a new encoded vector for the sequence, denoted as . This process is illustrated in Figure 6.
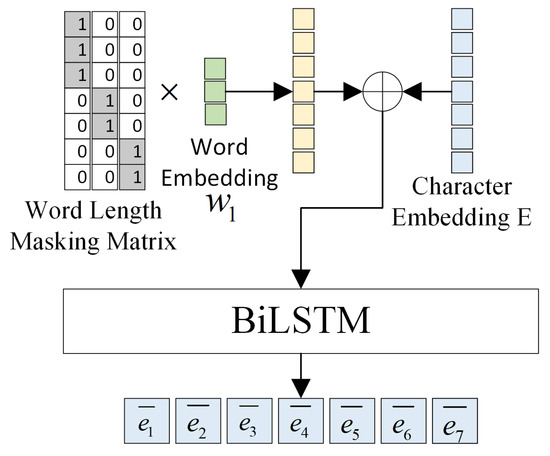
Figure 6.
Feature fusion layer.
3.4. Dependency Feature Extraction Layer
3.4.1. Trigger Classification Layer
The BiLSTM model processes a sequence to produce a hidden state sequence, denoted by H. That sequence is then fed into a fully connected layer, which maps it onto the event feature space, generating the event feature. The event features are then averaged along the second dimension to derive sentence-level embedding . To enrich the feature representation, we concatenate the generated sentence embedding , original event features H, and part-of-speech (POS) embedding along the last dimension to form a comprehensive feature vector. This method enables the model to capture finer sequential information and improve performance. This process is described by the following equations:
where FC denotes a fully connected layer. The concatenated feature vector C is then passed through a linear layer to map the input features into the output label space, followed by a sigmoid activation layer to perform the trigger classification. In this study, we adopted pointer decoding rather than the commonly used Conditional Random Field structure to identify the trigger labels. Traditional CRF methods have limitations in handling nested or overlapping arguments, often necessitating complex label designs while still yielding suboptimal performance. In contrast, the pointer network effectively addresses argument overlap by directly and independently predicting the start and end positions of each argument. Additionally, the node representations produced by the GCN module, enriched with structural information, offer high-quality feature inputs for the pointer network. Specifically, the goal of trigger classification is to predict whether a token marks the start or end position of a trigger for a given event type i. By inputting the concatenated feature vector C into a fully connected layer, followed by a sigmoid activation function, the model predicts the start and end positions of the event trigger with probabilities calculated as follows:
Here, the subscripts s and e represent the start and end of the trigger, denotes the ith event type; and are the trainable weights of the binary classifiers for detecting the start and end of the trigger, respectively; and and represent the corresponding biases. Thresholds and are established for the start and end positions of the trigger, respectively. If , the token is identified as the start of a candidate event-type label. Similarly, if , the token is identified as the end of the candidate event-type label.
3.4.2. Argument Classification Layer
Once the trigger is identified, a trigger mask matrix Tm is generated, based on the positional information of the trigger. This mask is then applied to the BiLSTM output sequence L to generate the trigger embedding T. The embedding T encapsulates the contextual information of the trigger as follows:
Trigger embedding T is added to the corresponding elements of the BiLSTM output L to construct the event argument embedding, integrating the trigger information into each token’s embedding:
Sentence-level embedding Sa is obtained by averaging the argument embeddings across the first dimension. The sentence-level embedding Sa is then concatenated with the original argument embedding along the last dimension to form a richer representation. Finally, the argument embeddings are passed through linear layers and classifiers to generate an argument classification result for each token.
Like trigger classification, argument extraction seeks to predict whether a token represents the start or end of argument role. The model predicts the start and end positions of the argument by passing the concatenated vector Ca through a fully connected layer, followed by a sigmoid activation function, resulting in the following probabilities:
In this case, the subscripts s and e represent the argument’s start and end positions, respectively, Ri refers to the ith argument role, and and are the trainable weights for detecting the start and end of the argument, respectively. The bias terms, and , are also included. Thresholds and are set for the argument’s start and end positions, respectively. If , then the token is identified as the start of the candidate argument role. Similarly, if , then the token is identified as the end of the candidate argument role.
4. Results
4.1. Datasets
To validate the effectiveness of the proposed model, experiments were conducted on two datasets: the publicly available ACE2005 Chinese dataset, and an agrometeorological disaster dataset developed as part of this study. The ACE2005 dataset is a widely used benchmark for information extraction tasks and contains eight major categories and 33 subcategories of event types.
We developed a new agrometeorological disaster dataset by classifying events into three main types—disaster causing, disaster impact, and disaster relief—based on the evolution of agrometeorological disasters, referencing the framework proposed by Ning et al. [23]. The disaster-causing event type primarily captured agrometeorological disasters. This study focused on the most common agrometeorological disasters, identifying four major categories: typhoons, droughts, torrential floods, and low-temperature, frost, and snow disasters. The disaster-impact event type recorded the direct impact and damage caused by disasters on agricultural production. These events integrated agricultural disaster indicators from the national standard, “Natural Disaster Loss Statistics—Part 2: Extended Indicators,” [24] and primarily covered three categories: crop damage, infrastructure damage, and economic loss. The disaster-relief event type pertained to the measures taken to mitigate and respond to agricultural meteorological disasters, drawing from the Ministry of Agriculture’s emergency response plan for major agricultural natural disasters. These events were divided into two main categories: production recovery and post-disaster claims. The production recovery category included material allocation and farmland management, whereas the post-disaster claim category focused on providing financial support and protection to affected farmers. Each event type was associated with specific event argument roles for extraction, covering 4 event types and 16 subtypes, as shown in Appendix A.
The agrometeorological disaster dataset in this study was compiled from two main sources: the China Meteorological Disaster Yearbook, which offers comprehensive records of meteorological disaster events in China, and the China News Network, which added data on disaster relief. The event annotation task involved, for a given sentence, first determining whether it was an event sentence. For event sentences, the process included annotating event triggers and arguments and assigning each argument to its corresponding trigger. Generally, an event sentence must contain a trigger—typically a noun or verb—which can be identified based on the sentence’s core word. Non-event sentences can be categorized by core word types such as declarative, predictive, directive, and descriptive. Declarative words represent facts expressed by others and require further evaluation. Predictive words refer to events that have not yet occurred; sentences containing such words were not annotated. Directive words indicate instructions, guidance, or suggestions and were excluded from the annotation process. Descriptive words objectively state certain situations; although they may express facts, further analysis is needed to determine whether subordinate clauses contain event sentences.
Reports from the China Meteorological Disaster Yearbook and China News Network often encompass all impacts of disasters, including effects on transportation, society, communications, agriculture, economic losses, and more. Since this study focused specifically on agrometeorological disasters—that is, the impact of meteorological disasters on agricultural production—the annotation process prioritized the event arguments defined in this paper. Furthermore, it was stipulated that an event must have a trigger but does not need to include all types of arguments, allowing for overlapping and nested argument structures.
We used the Doccano tool to annotate the data in this study. Doccano is an open-source text-annotation tool. Based on the defined categories of agrometeorological disaster events, we designed sequence annotation tasks using Doccano. Sixteen labels were created for event types and eighteen labels for argument roles. Event types were identified by labeling the triggers in the format “trigger-event type.” Argument role labels were used to identify specific elements associated with each event type. Because sentences often contain multiple events, relational labeling was applied to distinguish between them during the annotation process. The annotated data were exported in the JSON format.
This study successfully annotated 6919 sentences, comprising 4022 events and 9095 argument roles. Among the disaster types, rainstorm accounted for the largest proportion at 61.5%, followed by typhoon (14.1%), low-temperature, frost, and snow disasters (13.7%), and drought (10.7%). Regarding the distribution of argument roles, it was notably uneven due to the fact that not every event contained all argument types and the frequent omission of elements in Chinese expression. Among them, the categories of “affected entity” and “damage” constituted the majority.
4.2. Evaluation Metrics
The performance of the event extraction model was evaluated using the standard metrics precision (P), recall (R), and F1 score, defined as follows:
where true positive (TP) denotes the number of instances in which the model correctly identifies positive cases. False positive (FP) refers to number of instances where negative cases are incorrectly classified as positive, whereas false negative (FN) indicates the number of instances where the model fails to recognize actual positive cases. The F1 score represents the harmonic mean of the precision and recall and provides a comprehensive measure of the model’s performance. In the context of event extraction, the evaluation comprised two distinct subtasks, trigger classification and argument classification, each with specific criteria for successful identification. For trigger classification, a trigger was classified correctly if it was correctly identified and assigned to the correct type. In argument classification, an argument was considered correctly classified if it was correctly identified and the predicted role and event subtype matched the ground-truth labels.
4.3. Experimental Parameter Settings
The experiments in this study were conducted using the PyTorch 2.1.1 deep learning framework within the PyCharm Python 3.11 development environment. For encoding, the model utilized BERT, which comprises 12 layers of transformer encoders. The architecture also included a two-layer GCN with an output dimension of 768, followed by a single-layer BiLSTM network with an output dimension of 768. An AdamW optimizer was employed, incorporating weight decay as a regularization technique to reduce overfitting. The detailed parameter settings are listed in Table 1.

Table 1.
Parameter Settings.
4.4. Experimental Results and Analysis
To evaluate the effectiveness of the proposed model, we compared it to several established baseline models.
CAEE: Wu et al. utilized a graph attention network-based framework for Chinese event extraction, enhancing word representations by integrating character-level embeddings into the vocabulary [9].
ATCEE: Liu et al. employed graph attention and table pointer networks to construct character-level syntactic dependency trees for Chinese event extraction [22].
JMCEE: Xu et al. introduced a joint event extraction framework that addressed the issue of argument overlap by defining event relation triples to capture the interdependencies among event triggers, arguments, and argument roles [25].
CasEE: Sheng et al. utilized a cascade decoding joint-learning framework for overlapping event extraction, leveraging dependencies between subtasks through joint learning [26].
PLMEE: Yang. addressed the overlapping argument issue by extracting role-specific arguments based on event triggers [27].
Table 2 and Table 3 display the performance comparison of the different methods on the ACE2005 and agrometeorological disaster datasets. Although our proposed model achieved good F1 scores in trigger classification tasks, it fell short in argument classification compared to ATCEE and JMCEE on the ACE2005 dataset. However, on the agrometeorological disaster dataset, our model outperformed the other methods across most metrics, except for recall, which trailed behind JMCEE. Notably, both CasEE and JMCEE exhibited significantly higher recall than precision. The main reasons for these discrepancies are as follows: CAEE leverages lexical embeddings, providing richer semantic information compared to the tokenization performed by SpaCy in our model. JMCEE employs multiple classifiers to accurately predict trigger start and end positions, leading to fewer false positives (FPs) and higher precision. CWEF-GCN has relatively high recall but low precision on argument classification, probably due to the data imbalance on the ACE2005 dataset. ATCEE introduces a table-filling strategy that enhances information interactions both within and between events, improving the model’s extraction performance for event categories with fewer samples. This approach ultimately leads to higher precision.
Table 2.
Comparison of the overall performance of the models on the ACE2005 dataset.
Table 3.
Comparison of the overall performance of the models on agrometeorological disaster dataset.
In agrometeorological disaster datasets, which often contain multiple events per sentence, CasEE and JMCEE generate samples for each event, thereby expanding the dataset and enhancing semantic feature learning. This approach results in more true positives (TPs) and higher recall but may also lead to increased false positives and lower precision. Compared to CasEE and JMCEE, our model’s precision and recall remained more stable, indicating that GNN-based multi-event extraction effectively facilitates event information interaction and enhances extraction performance.
4.5. Ablation Experiments
To assess the contributions of key model components, we conducted ablation experiments. The results are detailed in Table 4 and Table 5, with bold figures indicating the optimal outcomes. The experiments evaluated the impact of excluding character-level information fusion (“w/o character level fusion”) and the different BiLSTM layers.
Table 4.
Results of ablation experiments with different modules.
Table 5.
Results of ablation experiments with different layers.
- Impact of character-level fusion: We explored the impact of combining word vectors from a GCN with BERT character embeddings on performance improvement. Disabling the BERT splicing module and using only GCN-encoded embeddings resulted in a 2.03% decrease in the F1 score for trigger classification and a 3.08% decrease in argument classification. This drop is attributed to BERT’s focus on local semantic and syntactic information, whereas GCN emphasizes global semantic and structural information. The concatenation of these embeddings integrates the features from multiple perspectives, thereby underscoring the importance of character-embedding integration.
- Effect of the different BiLSTM layers: To evaluate the effect of the different BiLSTM layers, we increased the number of layers in the BiLSTM from one to three. The experiments demonstrated that the one-layer BiLSTM network achieved the highest F1 score for argument classification. However, its performance in trigger classification was slightly inferior to that of the two-layer BiLSTM network, although the difference remained within an acceptable range. Additionally, the lower complexity of the one-layer model enhances training efficiency, reduces the risk of overfitting, and enables faster inference speeds in practical applications.
4.6. Analysis of Event Extraction Effect
We applied the proposed model to large-scale event extraction, processing 5653 sentences with an average length of 76.59 characters. The total processing time was 425.48 s, resulting in an average speed of 13.3 sentences per second.
- (1)
- Analysis of event trigger extraction performance: The model successfully extracted 75% of events. Errors in event trigger recognition were categorized into two main types: recognition errors and boundary errors, with their distribution illustrated in Figure 7.
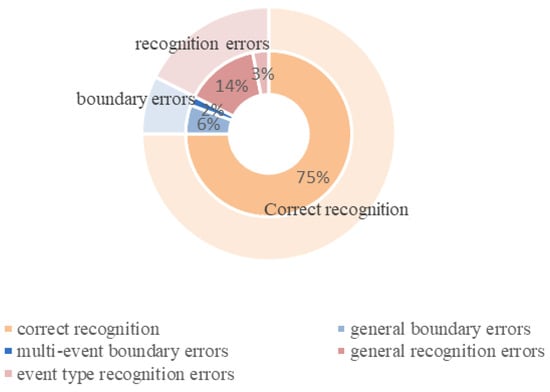 Figure 7. Distribution of the recognition of event triggers.
Figure 7. Distribution of the recognition of event triggers.
Recognition errors can be categorized into general recognition errors and event-type recognition errors. General recognition errors occur when the model identifies triggers in sentences that do not contain any events. Event-type recognition errors arise when the model misclassifies the event type, leading to incorrect trigger identification. This issue is particularly challenging in the field of agricultural meteorological disasters, where different event types often share overlapping contexts. The model, which relied on local context windows, struggled to capture global document-level cues, resulting in misclassification of event types. Furthermore, the long-tail distribution of disaster event types contributed to poorer prediction performance for low-frequency events. Boundary errors can be categorized into two types: general boundary errors and multi-event boundary errors. General boundary errors occur when the model identifies only a portion of a trigger word or mistakenly classifies a phrase as a trigger. Multi-event boundary errors arise when the model incorrectly identifies a phrase as a trigger, as illustrated in Table 6, where the correct trigger (“collapse”) was misidentified due to overlapping event boundaries. The pointer decoding mechanism independently predicts the start and end positions, selecting characters with logit values above a specified threshold for the current event type, without considering the joint constraints between the start and end positions. In agricultural meteorological disaster texts, the presence of multiple events increases the probability of boundary overlaps, and shared contexts between adjacent event triggers contribute to feature confusion, resulting in boundary errors. Examples of event recognition errors are presented in Table 6.
Table 6.
Examples of event trigger recognition errors.
To address these issues, this study removed incorrectly recognized events, reprocessed triggers with boundary errors, completed partially recognized triggers, and truncated overly long triggers. A trigger word dictionary and a set of regular expression rules were constructed to facilitate matching, completion, and truncation, ultimately yielding 4685 events.
- (2)
- Analysis of event argument extraction: The model successfully identified 70% of arguments, with errors categorized into recognition errors, classification errors, and boundary errors. Boundary errors accounted for only 2% of the total errors. This analysis focused on the three argument roles with the highest classification accuracy and the three with the lowest. The model achieved precision rates of 92.23%, 89.38%, and 86.67% for time, location, and disaster severity arguments, respectively. Despite the varied expressions of time, such as “early May to mid-July,” “late July to early August,” “summer,” and “autumn,” the model effectively captured core temporal elements (e.g., year, month, day, hour, minute, second, early/mid/late month, season) and inferred logical relationships to maintain high precision. Location arguments, being clear and semantically explicit, were recognized with even higher accuracy. Disaster severity expressions, which are relatively fixed, facilitated feature extraction by the model. However, the precision rates for damaged subjects, damage conditions, and typhoon names were only 64.96%, 44.11%, and 31.39%, respectively. The recognition precision—defined as the accurate identification of boundaries and classification of argument roles—for damaged subjects and damage conditions reached 97.94% and 95.87%, respectively. The lower classification precision for these roles was primarily due to misclassification, where the model correctly identified the arguments but assigned them to incorrect roles. In sentences containing multiple events, the model may inappropriately assign all arguments to all triggers, particularly in complex sentences with multiple clauses, leading to inaccurate classifications. The low precision for typhoon names was attributed to recognition errors, as the model lacked comprehensive training on diverse expressions of typhoon names and had limited data for this category. To address these issues, misclassified data were removed, and boundary errors were corrected through completion and truncation, ultimately yielding 10,768 event arguments that provided valuable data support for downstream event knowledge graph construction and data analysis.
5. Analysis of Characteristics of Agricultural Meteorological Disaster Events
Based on the previously mentioned event extraction results, this study analyzed the characteristics of agricultural meteorological disasters. Event triggers were utilized to identify the occurrence or changes in the state of events. By examining the high-frequency triggers associated with various types of agricultural meteorological disaster events, the core characteristics of these events could be revealed. This analysis can reflect the damage patterns experienced by affected entities, providing a foundation for developing targeted disaster mitigation measures. Furthermore, it can aid in uncovering semantic patterns related to disasters, offering data support for optimizing models. To achieve this, the study investigated the high-frequency triggers for each event type, with the specific distribution detailed in Table 7.
Table 7.
High-frequency triggers for each event type.
In the disaster phase, high-frequency words for rainstorms and floods focus on precipitation descriptions (fall/widespread fall) and disaster occurrence (occur/happen), reflecting the direct triggering mechanism of heavy rainfall. For droughts, the high-frequency word “develop” indicates the progressive nature of droughts, highlighting the need to monitor long-term meteorological cumulative effects. The high-frequency word “landfall” for typhoons marks the transition of disaster impact from the ocean to land. For low-temperature, frost, and snow disasters, the high-frequency word “continuous fall” emphasizes the persistent low-temperature process, while “suffer” reflects insufficient preparation for cold weather. In the affected phase, the damage patterns of rainstorms and floods are reflected in infrastructure damage (collapse/damage) and short-term agricultural losses (inundated). Drought damage patterns primarily involve the failure of water infrastructure (dry up/run dry) and direct yield reduction (drought-affected). Typhoon damage patterns mainly include infrastructure damage (collapse/damage), while low-temperature, frost, and snow disasters primarily cause livestock deaths (death/freeze to death) and frost damage to cash crops (frost-damaged). In the recovery phase, post-disaster recovery strategies vary. For engineering recovery, such as “repair” and “rush to repair” for rainstorms and floods, the focus is on infrastructure. For typhoons, “guide” and “participate” emphasize social mobilization capabilities. In terms of resource allocation, “issue” for rainstorms, droughts, and typhoons reflects government directive-driven emergency responses, while “arrange” and “dispatch” for low-temperature disasters indicate localized management. In terms of compensation response speed, “pay” and “compensate” for rainstorms and typhoons reflect rapid economic compensation.
The arguments of agricultural meteorological disaster events can elucidate the entities affected by such disasters. For instance, by examining the primary entities impacted by various disasters, we can gain insights into the key elements of agricultural production that are influenced. This study explored the main affected entities under the categories of rainstorm and flood, drought, typhoon, and low-temperature, frost, and snow events. The entities affected by rainstorms, floods, and typhoons were relatively concentrated. Specifically, the consequences of rainstorms and floods primarily included house collapses, crop damage, direct economic losses, and farmland inundations. Similarly, the damage caused by typhoons predominantly involved house collapses, crop damage, and direct economic losses. In contrast, the entities affected by droughts and low-temperature, frost, and snow events were more dispersed. The entities affected by droughts primarily included crop damage, farmland desiccation, reservoir depletion, direct economic losses, reduced grain yields, and the drying up of rivers. The damage caused by low-temperature, frost, and snow-related disasters typically resulted in crop loss, livestock fatalities due to freezing, direct economic losses, structural collapses, and frost damage to wheat. The distribution of affected entities highlights the varying impacts of different disasters on various sectors during the affected phase, providing clear evidence for targeted rescue and recovery strategies. For instance, in the case of rainstorms, floods, and typhoons, rescue efforts should prioritize repairing damaged homes, reinforcing structures, and salvaging crops. In contrast, drought responses must focus on addressing water shortages and ensuring adequate agricultural irrigation. During low-temperature, frost, and snow events, special attention should be given to protecting livestock from the cold and implementing frost protection measures for crops.
In the future, a knowledge graph can be constructed based on event extraction to visually represent the evolution of disasters, analyze the mechanisms behind their occurrence, and contribute to research on the prevention and mitigation of agricultural meteorological disasters.
6. Discussion
Although the proposed character–word fusion-based GCN event extraction model achieved baseline performance on the agrometeorological disaster task, it still faces challenges such as limited generalization due to data sparsity and insufficient modeling of complex event semantic relationships. Future improvements to the model’s performance may proceed in the following directions: First, to address the data sparsity issue in low-frequency event categories, data augmentation strategies can be employed. Beyond traditional methods such as synonym replacement and syntactic transformation, generative techniques using large language models can be leveraged to design domain-specific prompt templates for generating high-quality training samples that align with the characteristics of agrometeorological disasters. Second, we can integrate prompt engineering with the proposed model. Specifically, the strong semantic understanding capabilities of large language models can be utilized to perform deep semantic encoding of the text, generating representation vectors rich in global semantic information as input to the GCN model, thereby effectively enhancing the ability to model complex events such as nested multi-events and cross-sentence event associations. Third, introducing an external knowledge enhancement mechanism that incorporates entity relations from agricultural and meteorological knowledge graphs can be combined with attention mechanisms to strengthen the model’s comprehension of domain-specific semantics and improve the accuracy and generalization of event extraction.
The current agrometeorological disaster dataset is relatively limited in scope. First, the data sources are fairly homogeneous, relying exclusively on news networks and the China Statistical Yearbook, without supplementation from diverse, multi-source heterogeneous data. This limitation may restrict the model’s generalization ability and robustness. Second, there is a noticeable imbalance in the distribution of event types, which is likely to degrade recognition performance for minority classes. Additionally, the dataset covers a limited range of disaster types and does not encompass all categories of agrometeorological disasters. The dataset boundaries require further clarification, and future work should focus on incorporating additional disaster types to develop a more comprehensive agrometeorological disaster dataset.
7. Conclusions
This paper explored the extraction of agrometeorological disaster events, a technology that efficiently and accurately identifies key disaster information from textual data. It offered valuable data support for real-time disaster response, assessment, and subsequent relief efforts. Additionally, it advanced research on agrometeorological disasters, opening new avenues for investigating disaster impact mechanisms and enhancing capabilities for disaster prevention and mitigation. We addressed the challenges of multi-events and argument overlap in agrometeorological disaster events by proposing a novel joint extraction method based on character and word embedding fusion. We introduced a new graph construction approach that utilized a word-length mask matrix to transform the character embeddings generated by the BERT language model into word embeddings. These embeddings were processed through a graph convolutional network, which facilitated efficient character-to-word transitions and reduced the graph construction complexity. The graph convolutional network effectively modeled complex relationships and semantic information. Our experiments demonstrated the significant performance of CWEF-GCN on both the public ACE2005 dataset and a constructed agricultural meteorological disaster dataset. In the future, the powerful language understanding and generation capabilities of large models will be leveraged for data annotation through prompt learning. By designing prompt templates that integrate extensive knowledge and comprehension abilities acquired during pre-training, these models can generate annotation results. This approach can reduce the manual annotation workload while enhancing both efficiency and quality. Furthermore, future work will concentrate on constructing an event knowledge graph utilizing structured event information obtained from the extraction step. This effort aims to uncover the mechanisms underlying hazard causation, such as spatiotemporal patterns and cascading effects, thereby advancing research on the prevention and mitigation of agricultural meteorological disasters.
Author Contributions
Conceptualization, L.J. and N.X.; methodology, M.Q.; data curation, Y.C. and Y.L.; writing—original draft preparation, M.Q.; writing—review and editing, Y.C.; supervision, H.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key R&D Program of China (grant number 2022ZD0119500).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The datasets generated or analyzed during this study are available from the corresponding author on reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
Table A1.
Definitions of agricultural meteorological disaster events.
Table A1.
Definitions of agricultural meteorological disaster events.
| Number | Category | Event Type | Argument Role |
|---|---|---|---|
| 1 | Disasters/Droughts | Disaster-causing event | Start time, duration, end time, location, severity |
| 2 | Disasters/Droughts | Disaster-impact event | Start time, duration, end time, location, affected entity, damage |
| 3 | Disasters/Droughts | Production recovery | Start time, duration, end time, location, responsible party, recovery target, relief resources |
| 4 | Disasters/Droughts | Post-disaster claims | Start time, duration, end time, location, agency, recipient, amount |
| 5 | Disasters/Typhoons | Disaster-causing event | Formation time, landfall time, weakening time, location, wind intensity |
| 6 | Disasters/Typhoons | Disaster-impact event | Start time, duration, end time, location, affected entity, damage |
| 7 | Disasters/Typhoons | Production recovery | Start time, duration, end time, location, responsible party, recovery target, relief resources |
| 8 | Disasters/Typhoons | Post-disaster claims | Start time, duration, end time, location, agency, recipient, amount |
| 9 | Disasters/Torrential Floods | Disaster-causing event | Start time, duration, end time, location, severity |
| 10 | Disasters/Torrential Floods | Disaster-impact event | Start time, duration, end time, location, affected entity, damage |
| 11 | Disasters/Torrential Floods | Production recovery | Start time, duration, end time, location, responsible party, recovery target, relief resources |
| 12 | Disasters/Torrential Floods | Post-disaster claims | Start time, duration, end time, location, agency, recipient, amount |
| 13 | Disasters/Low-Temperature, Frost, Snow Disasters | Disaster-causing event | Start time, duration, end time, location, severity |
| 14 | Disasters/Low-Temperature, Frost, Snow Disasters | Disaster-impact event | Start time, duration, end time, location, affected entity, damage |
| 15 | Disasters/Low-Temperature, Frost, Snow Disasters | Production recovery | Start time, duration, end time, location, responsible party, recovery target, relief resources |
| 16 | Disasters/Low-Temperature, Frost, Snow Disasters | Post-disaster claims | Start time, duration, end time, location, agency, recipient, amount |
References
- Linguistic Data Consortium. ACE (Automatic Content Extraction) English Annotation Guidelines for Events. University of Pennsylvania, Philadelphia, 2005. Available online: https://www.ldc.upenn.edu/sites/www.ldc.upenn.edu/files/english-relations-guidelines-v5.8.3.pdf (accessed on 28 December 2024).
- Yang, J.; Gao, H.; Dang, D. Graph Convolutional Networks with Syntactic and Semantic Structures for Event Detection. IEEE Access 2024, 12, 64949–64957. [Google Scholar] [CrossRef]
- Ding, L.; Chen, X.J.; Wei, J.; Xiang, Y. MABERT: Mask-Attention-Based BERT for Chinese Event Extraction. Acm Trans. Asian Low-Resour. Lang. Inf. Process. 2023, 22, 192. [Google Scholar] [CrossRef]
- Grishman, R.; Westbrook, D.; Meyers, A. NYU’s English ACE 2005 System Description. Ace 2005, 5. [Google Scholar]
- Zhao, C.J. Agricultural Knowledge Intelligent Service Technology: A Review. Smart Agric. 2023, 5, 26–148. [Google Scholar]
- Chen, Y.B.; Xu, L.H.; Liu, K.; Zhao, D.J. Event Extraction via Dynamic Multi-Pooling Convolutional Neural Networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 167–176. [Google Scholar]
- Nguyen, T.H.; Cho, K.; Grishman, R. Joint Event Extraction via Recurrent Neural Networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 300–309. [Google Scholar]
- Balali, A.; Asadpour, M.; Campos, R.; Jatowt, A. Joint event extraction along shortest dependency paths using graph convolutional networks. Knowl.-Based Syst. 2020, 210, 106492. [Google Scholar] [CrossRef]
- Wu, X.H.; Wang, T.R.; Fan, Y.P.; Yu, F.J. Chinese Event Extraction via Graph Attention Network. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2022, 21, 71. [Google Scholar] [CrossRef]
- Sun, H.T.; Zhou, J.S.; Kong, L.; Gu, Y.H.; Qu, W.G. Seq2EG: A novel and effective event graph parsing approach for event extraction. Knowl.-Based Syst. 2023, 65, 4273–4294. [Google Scholar] [CrossRef]
- Huang, H.; Chen, Y.P.; Lin, C.; Huang, R.Z.; Zheng, Q.H.; Qin, Y.B. A multi-graph representation for event extraction. Artif. Intell. 2024, 332, 104144. [Google Scholar] [CrossRef]
- Peng, J.R.; Yang, W.Z.; Wei, F.Y.; He, L. Prompt for extraction: Multiple templates choice model for event extraction. Knowl.-Based Syst. 2024, 289, 111544. [Google Scholar] [CrossRef]
- Chen, J.X.; Chen, P.; Wu, X.X. Generating Chinese Event Extraction Method Based on ChatGPT and Prompt Learning. Appl. Sci. 2024, 13, 9500. [Google Scholar] [CrossRef]
- Zhang, Y.Y.; Xu, G.L.; Wang, Y.; Lin, D.Y.; Li, F.; Wu, C.L.; Zhang, J.Y.; Huang, T.L. A Question Answering-Based Framework for One-Step Event Argument Extraction. IEEE Access 2020, 8, 65420–65431. [Google Scholar] [CrossRef]
- Wan, X.; Mao, Y.C.; Qi, R.Z. Chinese Event Detection without Triggers Based on Dual Attention. Appl. Sci. 2023, 13, 4523. [Google Scholar] [CrossRef]
- Wu, F.; Zhu, P.P.; Wang, Z.Q.; Li, P.F.; Zhu, Q.M. Chinese Event Detection with Joint Representation of Characters and Words. Comput. Sci. 2021, 48, 249–253. [Google Scholar]
- Yan, J.T.; Li, Y.; Wang, S.G.; Pan, B.Z. Overlap Event Extraction Method with Language Granularity Fusion Based on Joint Learning. Comput. Sci. 2021, 51, 287–295. [Google Scholar]
- Ji, Z.X.; Wu, Y. Event extraction of Chinese text based on composite neural network. J. Shanghai Univ. (Nat. Sci. Ed.) 2021, 27, 535–543. [Google Scholar]
- Dai, L.; Wang, B.; Xiang, W.; Mo, Y.J. Modeling Character-Word Interaction via a Novel Mesh Transformer for Chinese Event Detection. Neural Process. Lett. 2023, 55, 11429–11448. [Google Scholar] [CrossRef]
- Gong, J.; Cao, Y.; Miao, Z.J.; Chen, Q.S. MFEE: A multi-word lexical feature enhancement framework for Chinese geological hazard event extraction. PeerJ Comput. Sci 2023, 9, e1275. [Google Scholar] [CrossRef] [PubMed]
- Xu, Z.L.; Zhu, R.S.; Yu, D.H.; Xing, S.N. Joint Extraction of Sudden Hot Events Based on Graph Attention Network. J. Chin. Comput. Syst. 2021, 44, 902–909. [Google Scholar]
- Liu, W.; Ma, Y.W.; Peng, Y.; Li, W.M. Chinese Event Extraction Method Based on Graph Attention and Table Pointer Network. Pattern Recognit. Artif. Intell. 2023, 36, 459–470. [Google Scholar]
- Ning, H.H.; Sui, H.G.; Wang, J.D.; Hu, L.Y.; Liu, J.S.; Liu, J.Y. Construction of Disaster Event Evolutionary Graph Based on Spatiotemporal Relationship. Geomat. Inf. Sci. Wuhan Univ. 2024, 49, 831–843. [Google Scholar]
- GB/T 24438.2-2012; Natural Disaster Information Statistics, Part 2: Extended Indicators. Ministry of Emergency Management of the People’s Republic of China: Beijing, China, 2012.
- Xu, N.; Xie, H.H.; Zhao, D.Y. A Novel Joint Framework for Multiple Chinese Events Extraction. In Proceedings of the 19th Chinese National Conference on Computational Linguistics, Haikou, China, 30 October–1 November 2020; pp. 950–961. [Google Scholar]
- Sheng, J.W.; Guo, S.; Yu, B.W.; Li, Q.; Hei, Y.M.; Wang, L.H.; Liu, T.W.; Xu, H.B. CasEE: A Joint Learning Framework with Cascade Decoding for Overlapping Event Extraction. arXiv 2021, arXiv:2107.01583. [Google Scholar] [CrossRef]
- Yang, S.; Feng, D.W.; Qiao, L.B.; Kan, Z.G.; Li, D.S. Exploring Pre-trained Language Models for Event Extraction and Generation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5284–5294. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).