
Topographic Position Index Predicts Within-Field Yield Variation in a Dryland Cereal Production System

 , , ,
, , ,  , and
, and
Abstract
1. Introduction
- What landscape characteristics (i.e., soil characteristics and topographic influences) are most important in driving spatial variability of crop yield at the within-field scale over multiple years with variable precipitation?
- Given the considerable resolution of our dataset, what inferences can be made about data needs in future studies and applications to improve our ability to model and understand past crop yields, apply models in an operational forecasting capacity, and direct future data collection efforts?
2. Materials and Methods
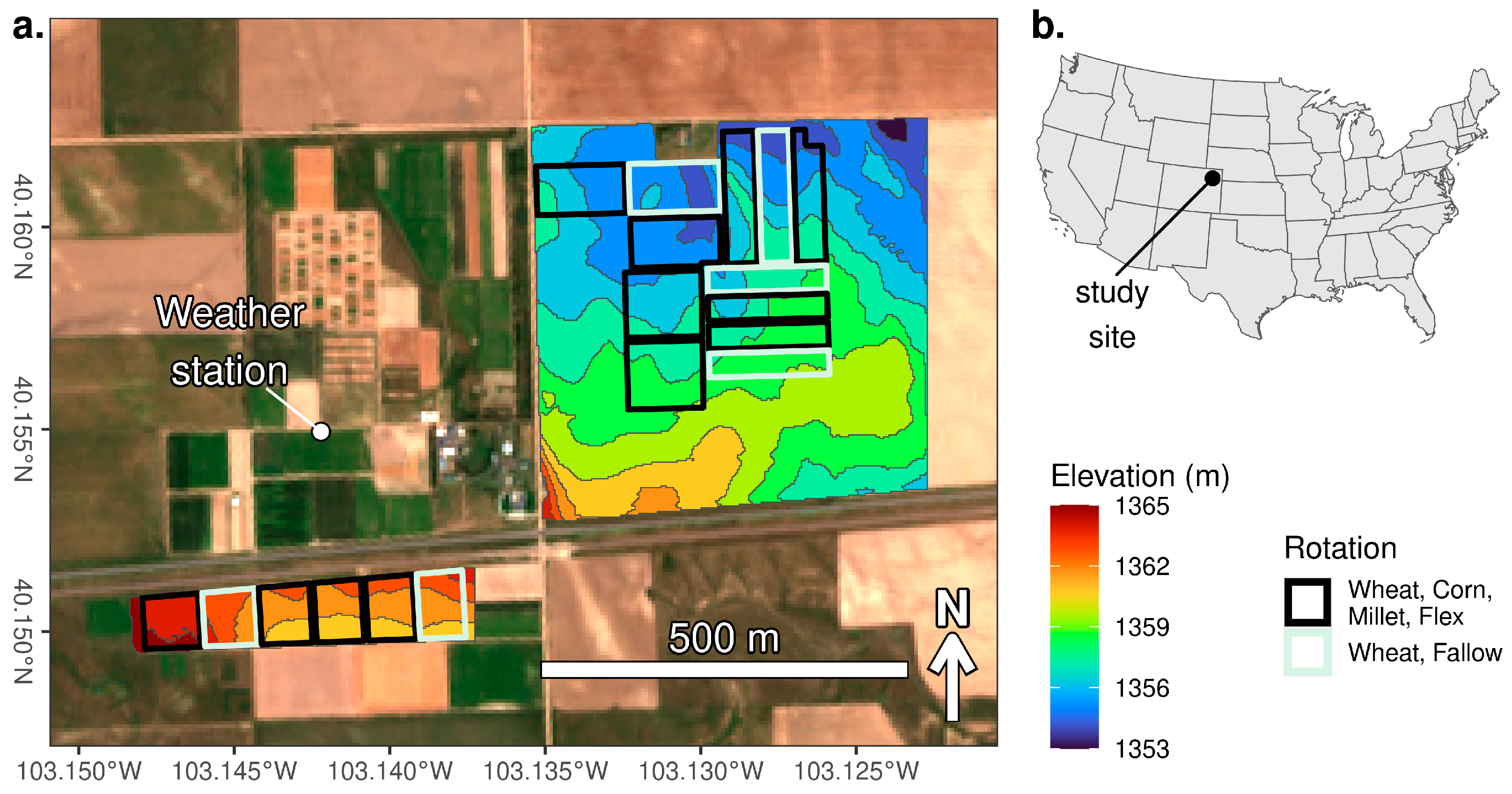
2.1. Study Site
2.2. Cropping Practices
2.3. Yield Data
2.4. Nitrogen Application Rate Data
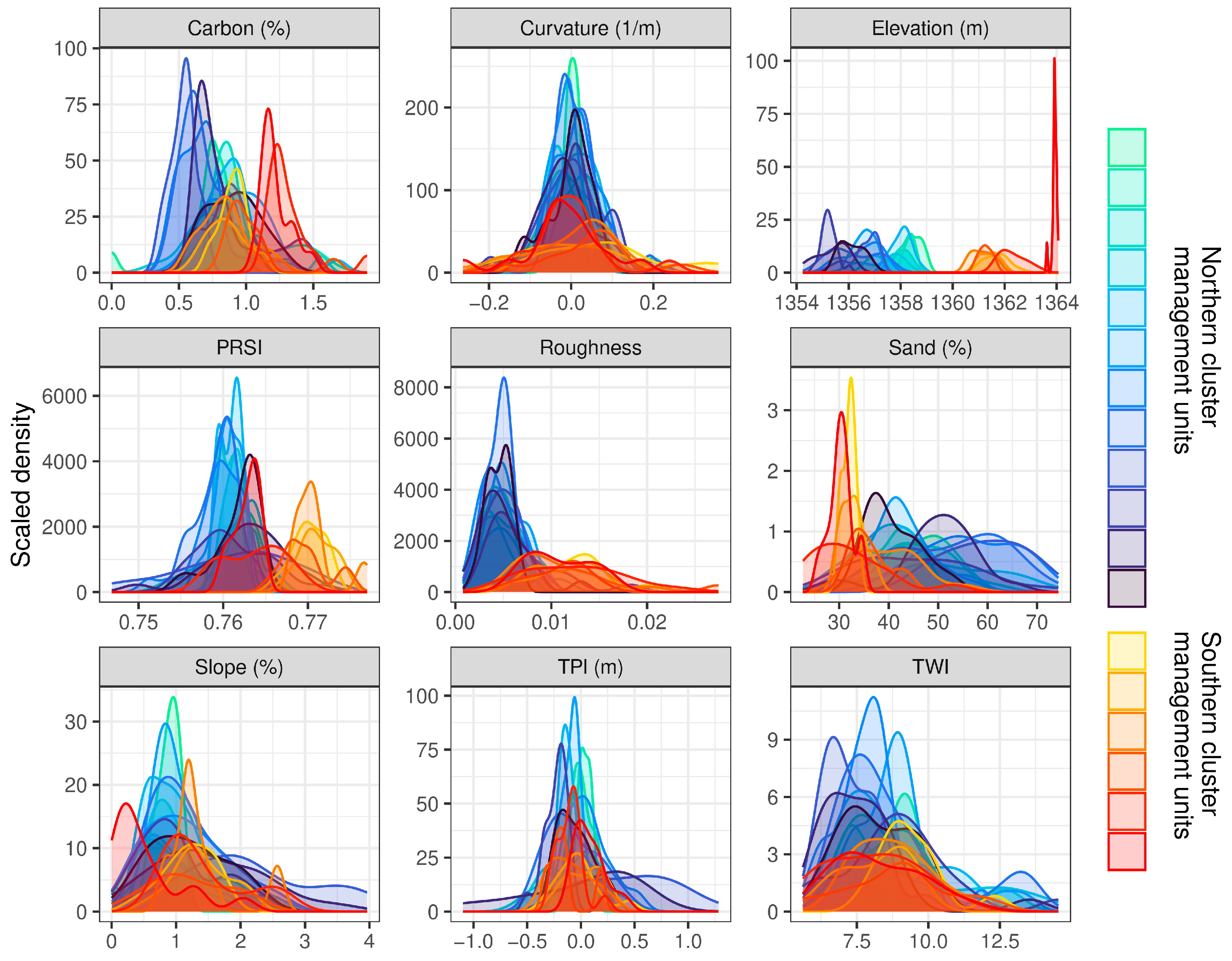
2.5. Soil Data
2.6. Elevation Data
2.7. Predictor Variables

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Abbreviation | Units | Description and Derivation |
|---|---|---|---|
| Slope | Slope | % | Percent slope in direction of maximum slope. Calculated by arcMap extension, TauDEM v.5.3.7 [52]. |
| Potential solar radiation index | PSRI | Unitless | where slope is degrees from horizontal. |
| Profile curvature | Curvature | m−1 | Curvature in direction of maximum slope. Positive value indicates concave upward. Calculated by ArcGIS Spatial Analyst. |
| Topographic wetness index | TWI | Unitless | where FlowAcc is flow accumulation, calculated by TauDEM, using D-infinity flow routing with sinks filled. |
| Topographic position index | TPI | m | Elevation of focal cell minus mean elevation of a 100 m radius circular neighborhood centered on focal cell. Calculated using the TPI function of the R package MultiscaleDTM version 0.8.3 [53]. |
| Roughness index-elevation | Roughness | m | Standard deviation of residual topography in a 3 by 3 cell focal window, where residual topography is calculated as the focal pixel elevation minus the focal window mean [54]. Calculated using MultiscaleDTM. |
2.8. Random Forest Modeling
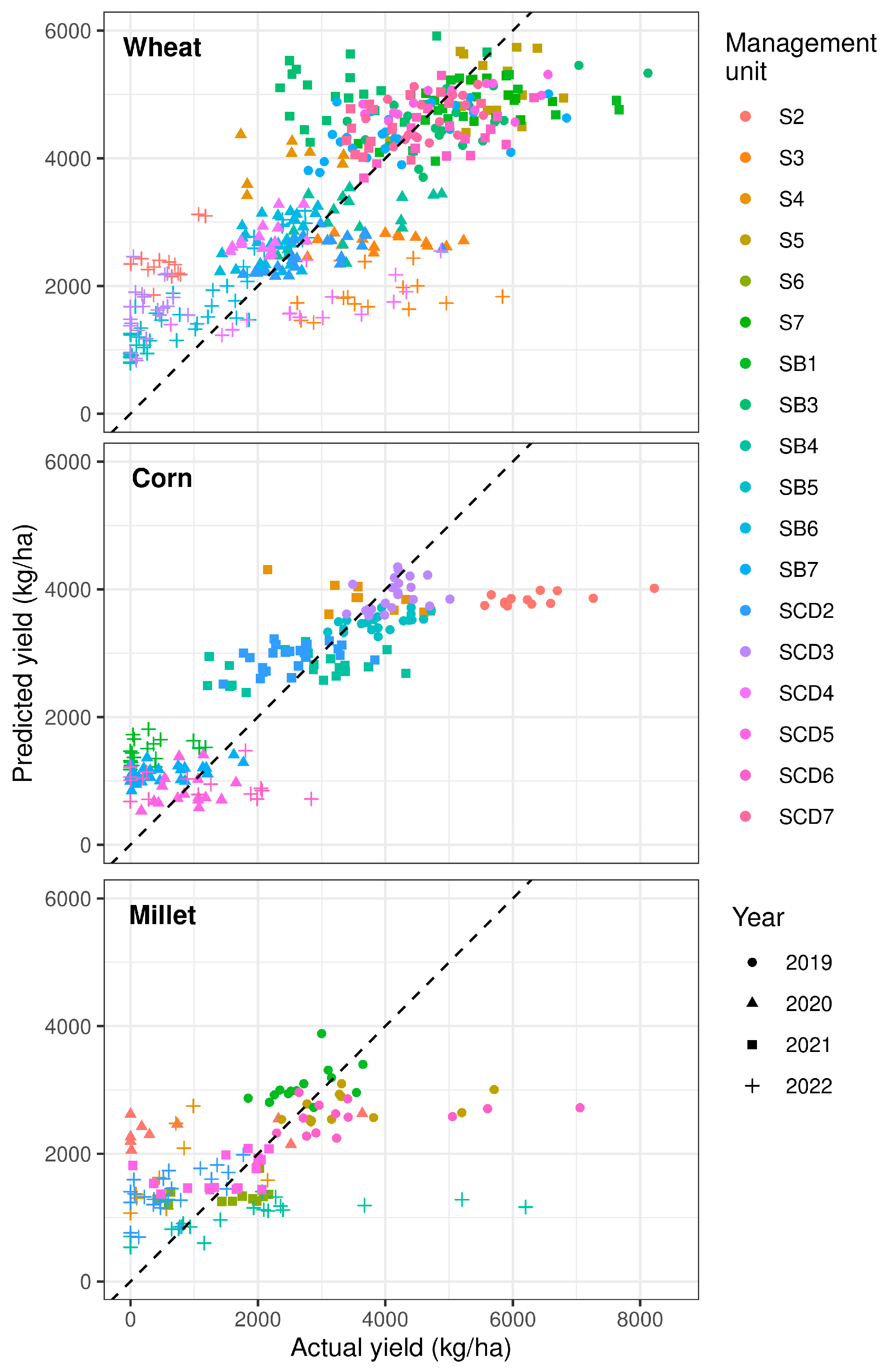
2.9. Evaluating Model Performance
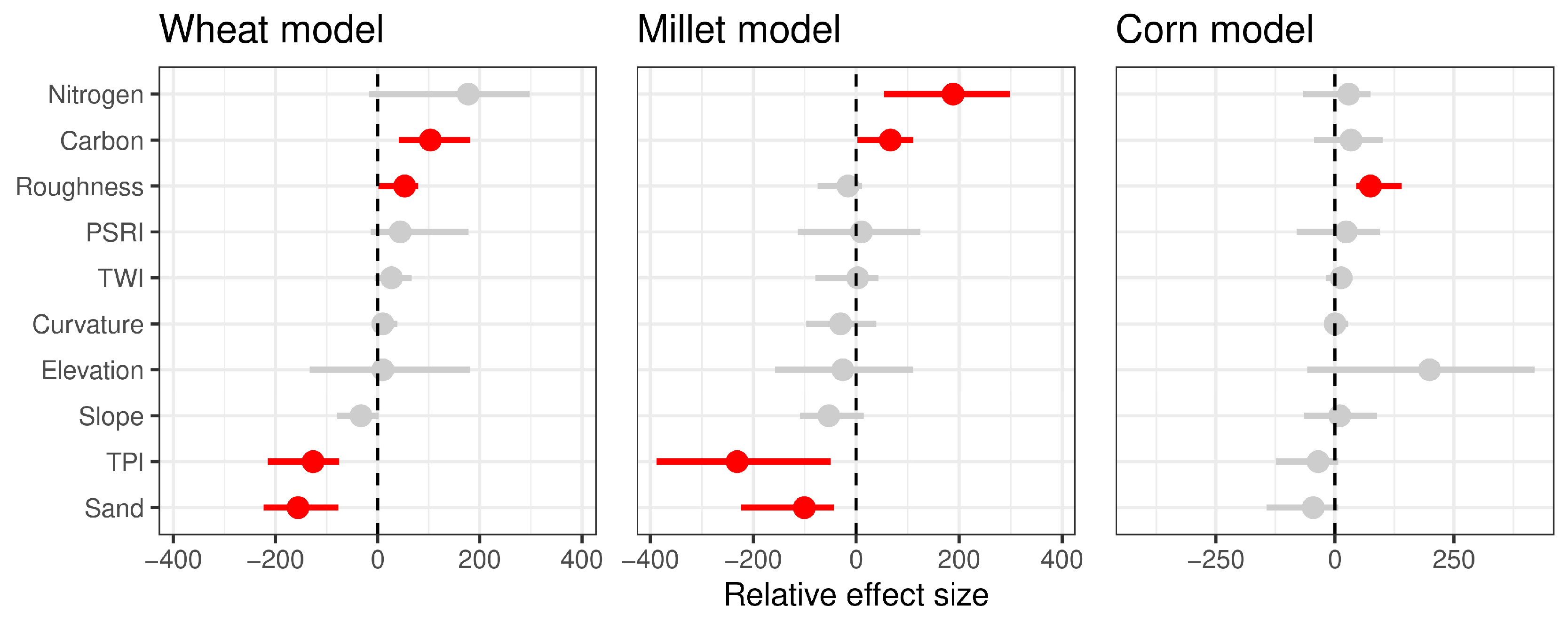
2.10. Calculating Effect Sizes and Significance
3. Results
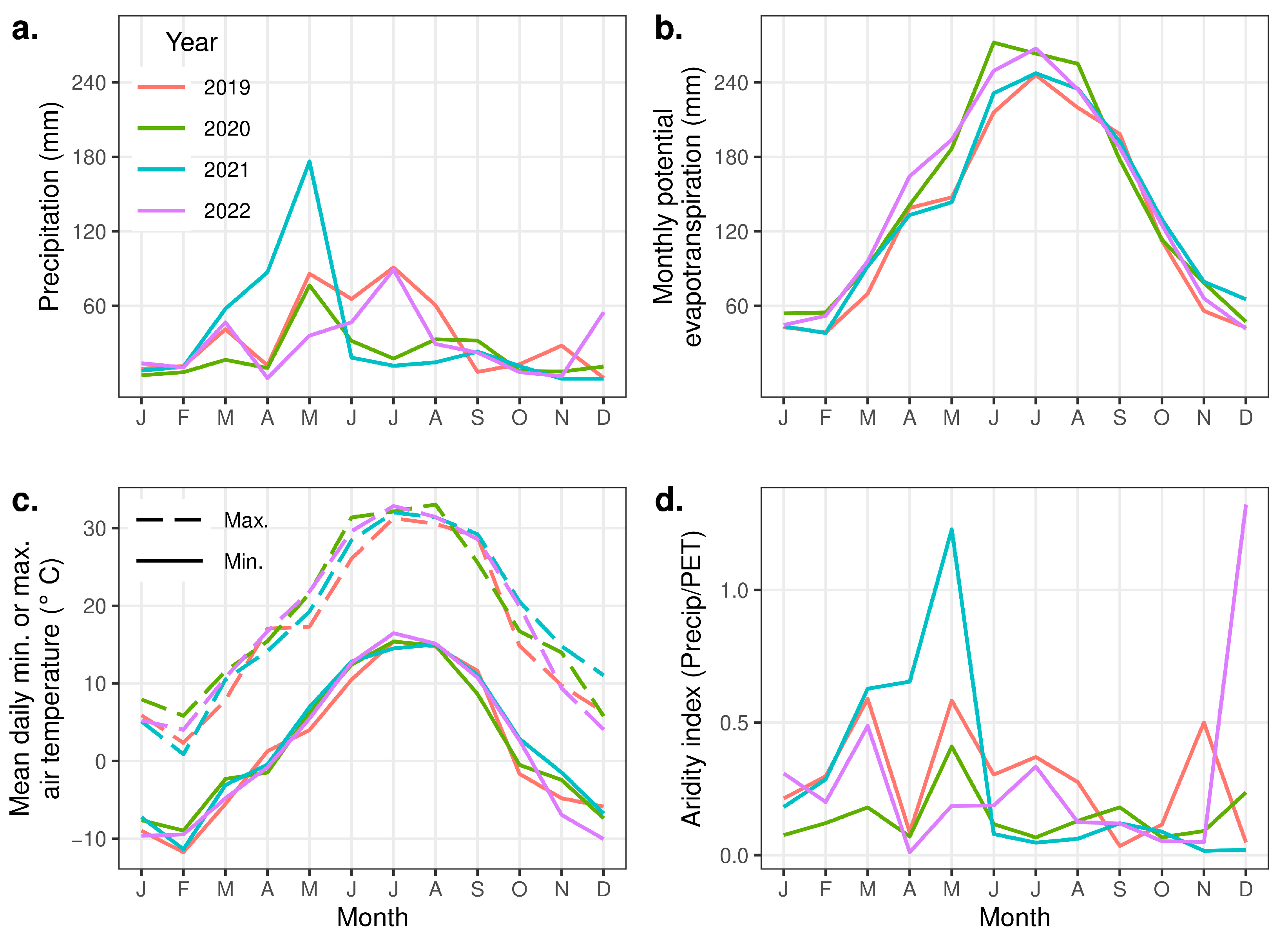
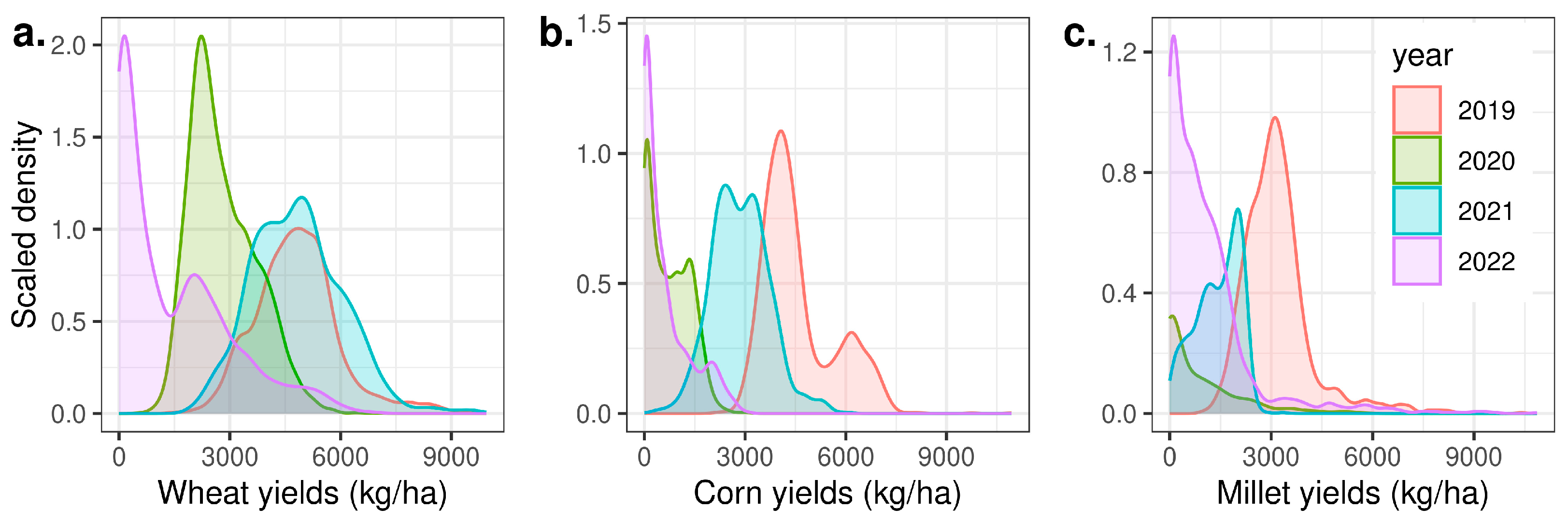
3.1. Data Summaries
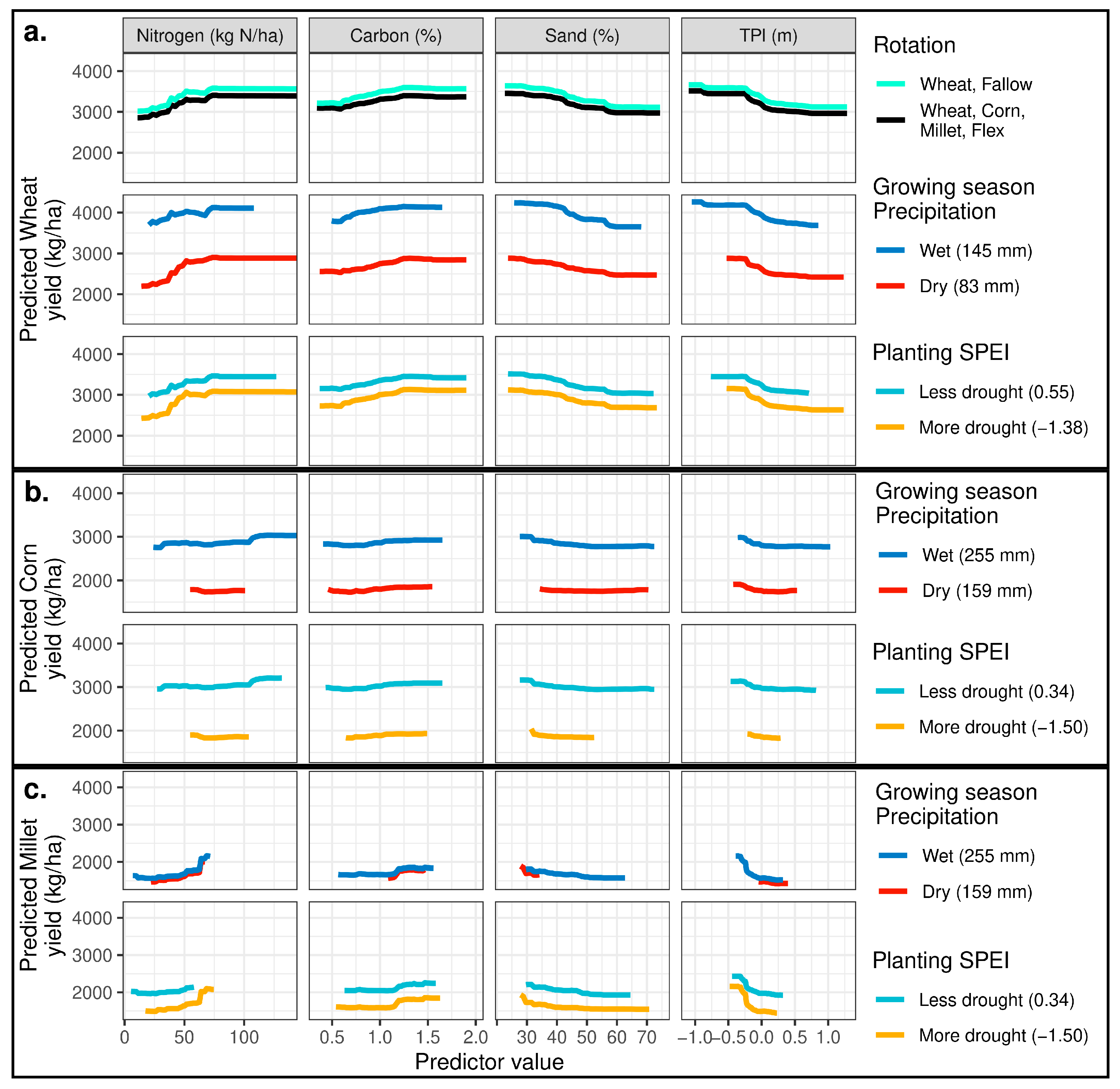
3.2. Modeling Results
4. Discussion
4.1. Effects of Topography
4.2. Effects of Nitrogen
4.3. Effects of Soil Characteristics
4.4. Model Performance
4.5. Sources of Unexplained Variance and Directions for Future Work
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DEM | Digital elevation model |
| N | Nitrogen |
| P | Phosphorus |
| PSRI | Potential solar radiation index |
| SPEI | Standardized Precipitation Evapotranspiration Index |
| TPI | Topographic position index |
| TWI | Topographic wetness index |
| WF | Wheat–fallow rotation |
| WCMFx | Wheat–corn–millet–flexible planting decision rotation |
References
- Fiorentini, M.; Schillaci, C.; Denora, M.; Zenobi, S.; Deligios, P.; Orsini, R.; Santilocchi, R.; Perniola, M.; Montanarella, L.; Ledda, L. A Machine Learning Modeling Framework for Triticum turgidum Subsp. Durum Desf. Yield Forecasting in Italy. Agron. J. 2024, 116, 1050–1070. [Google Scholar] [CrossRef]
- Iqbal, J.; Read, J.J.; Thomasson, A.J.; Jenkins, J.N. Relationships between Soil–Landscape and Dryland Cotton Lint Yield. Soil Sci. Soc. Am. J. 2005, 69, 872–882. [Google Scholar] [CrossRef]
- Martinez-Feria, R.A.; Basso, B. Unstable Crop Yields Reveal Opportunities for Site-Specific Adaptations to Climate Variability. Sci. Rep. 2020, 10, 2885. [Google Scholar] [CrossRef] [PubMed]
- Ramírez, P.B.; Calderón, F.J.; Vigil, M.F.; Mankin, K.R.; Poss, D.; Fonte, S.J. Dryland Winter Wheat Production and Its Relationship to Fine-Scale Soil Carbon Heterogeneity—A Case Study in the US Central High Plains. Agronomy 2023, 13, 2600. [Google Scholar] [CrossRef]
- Nielsen, D.C.; Vigil, M.F.; Hansen, N.C. Evaluating Potential Dryland Cropping Systems Adapted to Climate Change in the Central Great Plains. Agron. J. 2016, 108, 2391–2405. [Google Scholar] [CrossRef]
- Bongiovanni, R.; Lowenberg-Deboer, J. Precision Agriculture and Sustainability. Precis. Agric. 2004, 5, 359–387. [Google Scholar] [CrossRef]
- Pierce, F.J.; Nowak, P. Aspects of Precision Agriculture. In Advances in Agronomy; Elsevier: Amsterdam, The Netherlands, 1999; pp. 1–85. ISBN 0065-2113. [Google Scholar]
- Kharel, T.P.; Maresma, A.; Czymmek, K.J.; Oware, E.K.; Ketterings, Q.M. Combining Spatial and Temporal Corn Silage Yield Variability for Management Zone Development. Agron. J. 2019, 111, 2703–2711. [Google Scholar] [CrossRef]
- Karunathilake, E.M.B.M.; Le, A.T.; Heo, S.; Chung, Y.S.; Mansoor, S. The Path to Smart Farming: Innovations and Opportunities in Precision Agriculture. Agriculture 2023, 13, 1593. [Google Scholar] [CrossRef]
- Adhikari, K.; Smith, D.R.; Hajda, C.; Kharel, T.P. Within-Field Yield Stability and Gross Margin Variations across Corn Fields and Implications for Precision Conservation. Precis. Agric 2023, 24, 1401–1416. [Google Scholar] [CrossRef]
- Kravchenko, A.N.; Robertson, G.P.; Thelen, K.D.; Harwood, R.R. Management, Topographical, and Weather Effects on Spatial Variability of Crop Grain Yields. Agron. J. 2005, 97, 514–523. [Google Scholar] [CrossRef]
- Cox, M.S.; Gerard, P.D. Soil Management Zone Determination by Yield Stability Analysis and Classification. Agron. J. 2007, 99, 1357–1365. [Google Scholar] [CrossRef]
- Nawar, S.; Corstanje, R.; Halcro, G.; Mulla, D.; Mouazen, A.M. Delineation of Soil Management Zones for Variable-Rate Fertilization. In Advances in Agronomy; Elsevier: Amsterdam, The Netherlands, 2017; Volume 143, pp. 175–245. ISBN 978-0-12-812421-5. [Google Scholar]
- Rampant, P.; Abuzar, M. Geophysical Tools and Digital Elevation Models: Tools for Understanding Crop Yield and Soil Variability. In Proceedings of the SuperSoil 2004: 3rd Australian New Zealand Soils Conference, Sydney, Australia, 5–9 December 2004. [Google Scholar]
- Liebig, M.A.; Franzluebbers, A.J.; Alvarez, C.; Chiesa, T.D.; Lewczuk, N.; Piñeiro, G.; Posse, G.; Yahdjian, L.; Grace, P.; Cabral, O.M.R.; et al. MAGGnet: An International Network to Foster Mitigation of Agricultural Greenhouse Gases. Carbon Manag. 2016, 7, 243–248. [Google Scholar] [CrossRef]
- Ferrara, R.M.; Trevisiol, P.; Acutis, M.; Rana, G.; Richter, G.M.; Baggaley, N. Topographic Impacts on Wheat Yields under Climate Change: Two Contrasted Case Studies in Europe. Theor. Appl. Clim. 2010, 99, 53–65. [Google Scholar] [CrossRef]
- Erskine, R.H.; Green, T.R.; Ramirez, J.A.; MacDonald, L.H. Digital Elevation Accuracy and Grid Cell Size: Effects on Estimated Terrain Attributes. Soil Sci. Soc. Am. J. 2007, 71, 1371–1380. [Google Scholar] [CrossRef]
- Kumhálová, J.; Kumhála, F.; Kroulík, M.; Matějková, Š. The Impact of Topography on Soil Properties and Yield and the Effects of Weather Conditions. Precis. Agric. 2011, 12, 813–830. [Google Scholar] [CrossRef]
- Marques Da Silva, J.R.; Silva, L.L. Evaluation of the Relationship between Maize Yield Spatial and Temporal Variability and Different Topographic Attributes. Biosyst. Eng. 2008, 101, 183–190. [Google Scholar] [CrossRef]
- Rodriguez Miranda, D.A.; De Oliveira Alari, F.; Oldoni, H.; Bazzi, C.L.; Do Amaral, L.R.; Graziano Magalhães, P.S. Delineation of Management Zones in Integrated Crop–Livestock Systems. Agron. J. 2021, 113, 5271–5286. [Google Scholar] [CrossRef]
- Li, Y.; Lindstrom, M.J. Evaluating Soil Quality–Soil Redistribution Relationship on Terraces and Steep Hillslope. Soil Sci. Soc. Am. J. 2001, 65, 1500–1508. [Google Scholar] [CrossRef]
- Cox, M.S.; Gerard, P.D.; Abshire, M.J. Selected soil properties’ variability and their relationships with yield in three Mississippi fields. Soil Sci. 2006, 171, 541–551. [Google Scholar] [CrossRef]
- Rabia, A.H.; Neupane, J.; Lin, Z.; Lewis, K.; Cao, G.; Guo, W. Principles and Applications of Topography in Precision Agriculture. In Advances in Agronomy; Elsevier: Amsterdam, The Netherlands, 2022; pp. 143–189. ISBN 0065-2113. [Google Scholar]
- McCord, J.T.; Stephens, D.B. Lateral Moisture Flow beneath a Sandy Hillslope without an Apparent Impeding Layer. Hydrol. Process. 1987, 1, 225–238. [Google Scholar] [CrossRef]
- Nielsen, D.C.; Unger, P.W.; Miller, P.R. Efficient Water Use in Dryland Cropping Systems in the Great Plains. Agron. J. 2005, 97, 364–372. [Google Scholar] [CrossRef]
- Couëdel, A.; Edreira, J.; Lollato, R.; Archontoulis, S.; Sadras, V.; Grassini, P. Assessing Environment Types for Maize, Soybean, and Wheat in the United States as Determined by Spatio-Temporal Variation in Drought and Heat Stress. Agric. For. Meteorol. 2021, 307, 108513. [Google Scholar] [CrossRef]
- Miner, G.L.; Stewart, C.E.; Vigil, M.F.; Poss, D.J.; Haley, S.D.; Jones-Diamond, S.M.; Mason, R.E. Does Agroecosystem Management Mitigate Historic Climate Impacts on Dryland Winter Wheat Yields? Agron. J. 2022, 114, 3515–3530. [Google Scholar] [CrossRef]
- Wan, C.; Dang, P.; Gao, L.; Wang, J.; Tao, J.; Qin, X.; Feng, B.; Gao, J. How Does the Environment Affect Wheat Yield and Protein Content Response to Drought? A Meta-Analysis. Front. Plant Sci. 2022, 13, 896985. [Google Scholar] [CrossRef]
- Mikha, M.M.; Mankin, K.R.; Khan, S.B.; Barnard, D.M. Precision Management Influences Productivity and Nutrients Availability in Dryland Cropping System. Agron. J. 2024, 116, 3325–3343. [Google Scholar] [CrossRef]
- Kravchenko, A.N.; Bullock, D.G.; Boast, C.W. Joint Multifractal Analysis of Crop Yield and Terrain Slope. Agron. J. 2000, 92, 1279–1290. [Google Scholar] [CrossRef]
- Chi, B.-L.; Bing, C.-S.; Walley, F.; Yates, T. Topographic Indices and Yield Variability in a Rolling Landscape of Western Canada. Pedosphere 2009, 19, 362–370. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ziegler, A.; König, I.R. Mining Data with Random Forests: Current Options for Real-world Applications. WIREs Data Min. Knowl. Discov. 2014, 4, 55–63. [Google Scholar] [CrossRef]
- Leo, S.; De Antoni Migliorati, M.; Grace, P.R. Predicting Within-field Cotton Yields Using Publicly Available Datasets and Machine Learning. Agron. J. 2021, 113, 1150–1163. [Google Scholar] [CrossRef]
- Roberts, D.R.; Bahn, V.; Ciuti, S.; Boyce, M.S.; Elith, J.; Guillera-Arroita, G.; Hauenstein, S.; Lahoz-Monfort, J.J.; Schröder, B.; Thuiller, W.; et al. Cross-validation Strategies for Data with Temporal, Spatial, Hierarchical, or Phylogenetic Structure. Ecography 2017, 40, 913–929. [Google Scholar] [CrossRef]
- Koutsos, T.M.; Menexes, G.C.; Mamolos, A.P. The Use of Crop Yield Autocorrelation Data as a Sustainable Approach to Adjust Agronomic Inputs. Sustainability 2021, 13, 2362. [Google Scholar] [CrossRef]
- Miao, Y.; Mulla, D.J.; Robert, P.C. Identifying Important Factors Influencing Corn Yield and Grain Quality Variability Using Artificial Neural Networks. Precis. Agric 2006, 7, 117–135. [Google Scholar] [CrossRef]
- Oliveira, M.F.D.; Ortiz, B.V.; Morata, G.T.; Jiménez, A.-F.; Rolim, G.D.S.; Silva, R.P.D. Training Machine Learning Algorithms Using Remote Sensing and Topographic Indices for Corn Yield Prediction. Remote Sens. 2022, 14, 6171. [Google Scholar] [CrossRef]
- Soil Survey Staff. Soil Taxonomy: A Basic System of Soil Classification for Making and Interpreting Soil Surveys, Natural Resources Conservation Service. In Agricultural Handbook 436; Natural Resources Conservation Service: Washington, DC, USA; USDA: Washington, DC, USA, 1999; Volume 17, p. 869. [Google Scholar]
- Soil Survey Staff. Web Soil Survey, National Resources Conservation Service; United States Department of Agriculture: Washington, DC, USA, 2024.
- Nielsen, D.C.; Vigil, M.F.; Benjamin, J.G. Evaluating Decision Rules for Dryland Rotation Crop Selection. Field Crops Res. 2011, 120, 254–261. [Google Scholar] [CrossRef]
- Hergert, G.W.; Shaver, T.M. Fertilizing Winter Wheat (EC143); University of Nebraska-Lincoln Extension: Lincoln, NE, USA, 2009. [Google Scholar]
- Shapiro, C.A.; Ferguson, R.B.; Wortmann, C.S.; Maharjan, B.; Krienke, B. Nutrient Management Suggestions for Corn (EC117); University of Nebraska-Lincoln Extension: Lincoln, NE, USA, 2019. [Google Scholar]
- Blumenthal, J.M.; Baltensperger, D.D. Fertilizing Proso Millet (G89-924); University of Nebraska-Lincoln Extension: Lincoln, NE, USA, 2002. [Google Scholar]
- Barnard, D.M.; Germino, M.J.; Pilliod, D.S.; Arkle, R.S.; Applestein, C.; Davidson, B.E.; Fisk, M.R. Cannot See the Random Forest for the Decision Trees: Selecting Predictive Models for Restoration Ecology. Restor. Ecol. 2019, 27, 1053–1063. [Google Scholar] [CrossRef]
- Connor, D.J.; Loomis, R.S.; Cassman, K.G. Crop Ecology: Productivity and Management in Agricultural Systems, 2nd ed.; Cambridge University Press: Cambridge, UK, 2011; ISBN 978-0-521-76127-7. [Google Scholar]
- Beven, K.J.; Kirkby, M.J. A Physically Based, Variable Contributing Area Model of Basin Hydrology/Un Modèle à Base Physique de Zone d’appel Variable de l’hydrologie Du Bassin Versant. Hydrol. Sci. Bull. 1979, 24, 43–69. [Google Scholar] [CrossRef]
- Green, T.R.; Dunn, G.H.; Erskine, R.H.; Salas, J.D.; Ahuja, L.R. Fractal Analyses of Steady Infiltration and Terrain on an Undulating Agricultural Field. Vadose Zone J. 2009, 8, 310–320. [Google Scholar] [CrossRef]
- Keating, K.A.; Gogan, P.J.P.; Vore, J.M.; Irby, L.R. A Simple Solar Radiation Index for Wildlife Habitat Studies. J. Wildl. Manag. 2007, 71, 1344–1348. [Google Scholar] [CrossRef]
- Beguería, S.; Vicente-Serrano, S.M. SPEI: Calculation of the Standardized Precipitation-Evapotranspiration Index, version 1.8-1, Spanish National Research Council (CSIC): Zaragoza, Spain, 2023.
- Barnard, D.M.; Germino, M.J.; Bradford, J.B.; O’Connor, R.C.; Andrews, C.M.; Shriver, R.K. Are Drought Indices and Climate Data Good Indicators of Ecologically Relevant Soil Moisture Dynamics in Drylands? Ecol. Indic. 2021, 133, 108379. [Google Scholar] [CrossRef]
- Tarboton, D. TauDEM v5.3.7. Available online: https://hydrology.usu.edu/taudem/taudem5/ (accessed on 23 March 2023).
- Ilich, A.R.; Misiuk, B.; Lecours, V.; Murawski, S.A. MultiscaleDTM: An Open-source R Package for Multiscale Geomorphometric Analysis. Trans. GIS 2023, 27, 1164–1204. [Google Scholar] [CrossRef]
- Cavalli, M.; Tarolli, P.; Marchi, L.; Dalla Fontana, G. The Effectiveness of Airborne LiDAR Data in the Recognition of Channel-Bed Morphology. Catena 2008, 73, 249–260. [Google Scholar] [CrossRef]
- Wright, M.N.; Ziegler, A. Ranger: A Fast Implementation of Random Forests for High Dimensional Data in C++ and R. J. Stat. Softw. 2017, 77, 1–17. [Google Scholar] [CrossRef]
- Cafri, G.; Bailey, B.A. Understanding Variable Effects from Black Box Prediction: Quantifying Effects in Tree Ensembles Using Partial Dependence. J. Data Sci. 2021, 14, 67–96. [Google Scholar] [CrossRef]
- Green, T.R.; Erskine, R.H. Measurement and Inference of Profile Soil-water Dynamics at Different Hillslope Positions in a Semiarid Agricultural Watershed. Water Resour. Res. 2011, 47, 2010WR010074. [Google Scholar] [CrossRef]
- Sherrod, L.A.; Erskine, R.H.; Green, T.R. Spatial Patterns and Cross-Correlations of Temporal Changes in Soil Carbonates and Surface Elevation in a Winter Wheat-Fallow Cropping System. Soil Sci. Soc. Am. J. 2015, 79, 417–427. [Google Scholar] [CrossRef]
- Mieza, M.S.; Cravero, W.R.; Kovac, F.D.; Bargiano, P.G. Delineation of Site-Specific Management Units for Operational Applications Using the Topographic Position Index in La Pampa, Argentina. Comput. Electron. Agric. 2016, 127, 158–167. [Google Scholar] [CrossRef]
- Bouchard, A.; Vanasse, A.; Seguin, P.; Bélanger, G. Yield and Composition of Sweet Pearl Millet as Affected by Row Spacing and Seeding Rate. Agron. J. 2011, 103, 995–1001. [Google Scholar] [CrossRef]
- Tokatlidis, I.S. Addressing the Yield by Density Interaction Is a Prerequisite to Bridge the Yield Gap of Rain-fed Wheat. Ann. Appl. Biol. 2014, 165, 27–42. [Google Scholar] [CrossRef]
- Olorunfemi, I.; Fasinmirin, J.; Ojo, A. Modeling Cation Exchange Capacity and Soil Water Holding Capacity from Basic Soil Properties. EJSS 2016, 5, 266. [Google Scholar] [CrossRef]
- Augusto, L.; Achat, D.L.; Jonard, M.; Vidal, D.; Ringeval, B. Soil Parent Material—A Major Driver of Plant Nutrient Limitations in Terrestrial Ecosystems. Glob. Change Biol. 2017, 23, 3808–3824. [Google Scholar] [CrossRef] [PubMed]
- Lal, R. Soil Organic Matter Content and Crop Yield. J. Soil Water Conserv. 2020, 75, 27A–32A. [Google Scholar] [CrossRef]
- Zhu, M.; Feng, Q.; Qin, Y.; Cao, J.; Zhang, M.; Liu, W.; Deo, R.C.; Zhang, C.; Li, R.; Li, B. The Role of Topography in Shaping the Spatial Patterns of Soil Organic Carbon. Catena 2019, 176, 296–305. [Google Scholar] [CrossRef]
- Ehrenfeld, J.G.; Ravit, B.; Elgersma, K. Feedback in the plant-soil system. Annu. Rev. Environ. Resour. 2005, 30, 75–115. [Google Scholar] [CrossRef]
- De Sanctis, G.; Roggero, P.P.; Seddaiu, G.; Orsini, R.; Porter, C.H.; Jones, J.W. Long-Term No Tillage Increased Soil Organic Carbon Content of Rain-Fed Cereal Systems in a Mediterranean Area. Eur. J. Agron. 2012, 40, 18–27. [Google Scholar] [CrossRef]
- Liu, J.; Goering, C.E.; Tian, L. A neural network for setting target corn yields. Trans. ASAE 2001, 44, 705–713. [Google Scholar] [CrossRef]
- Raun, W.R.; Solie, J.B.; Stone, M.L.; Martin, K.L.; Freeman, K.W.; Mullen, R.W.; Zhang, H.; Schepers, J.S.; Johnson, G.V. Optical Sensor-Based Algorithm for Crop Nitrogen Fertilization. Commun. Soil Sci. Plant Anal. 2005, 36, 2759–2781. [Google Scholar] [CrossRef]
- Maestrini, B.; Basso, B. Predicting Spatial Patterns of Within-Field Crop Yield Variability. Field Crops Res. 2018, 219, 106–112. [Google Scholar] [CrossRef]
- Maresma, A.; Chamberlain, L.; Tagarakis, A.; Kharel, T.; Godwin, G.; Czymmek, K.J.; Shields, E.; Ketterings, Q.M. Accuracy of NDVI-Derived Corn Yield Predictions Is Impacted by Time of Sensing. Comput. Electron. Agric. 2020, 169, 105236. [Google Scholar] [CrossRef]
- Augustine, D.J. Spatial versus Temporal Variation in Precipitation in a Semiarid Ecosystem. Landsc. Ecol. 2010, 25, 913–925. [Google Scholar] [CrossRef]
- Nielsen, D.C.; Halvorson, A.D.; Vigil, M.F. Critical Precipitation Period for Dryland Maize Production. Field Crops Res. 2010, 118, 259–263. [Google Scholar] [CrossRef]
- Nielsen, D.C.; Lyon, D.J.; Higgins, R.K.; Hergert, G.W.; Holman, J.D.; Vigil, M.F. Cover Crop Effect on Subsequent Wheat Yield in the Central Great Plains. Agron. J. 2016, 108, 243–256. [Google Scholar] [CrossRef]
- Gauci, A.; Fulton, J.; Shearer, S.; Barker, D.J.; Hawkins, E.; Lindsey, A.J. Understanding the Limitations of Grain Yield Monitor Technology to Inform On-farm Research. Agron. J. 2024, 116, 3181–3190. [Google Scholar] [CrossRef]

| Crop | Year | WF | WCMFx | ||
|---|---|---|---|---|---|
| H | M | L | |||
| Wheat | 2019 | 34 | 16.1 | 12.8 | 19.9 |
| 2020 | — | — | — | — | |
| 2021 | — | 43.4 | 38.1 | 38.3 | |
| 2022 | 90 | 40.6 | 42 | 41.7 | |
| Corn | 2019 | — | 15.5 | 17.6 | 17.7 |
| 2020 | — | 11.2 | 11.2 | 11.2 | |
| 2021 | — | 85.6 | 71.7 | 71.4 | |
| 2022 | — | 27.6 | 27.2 | 26.1 | |
| Millet | 2019 | — | 48.6 | 44.1 | 51.2 |
| 2020 | — | — | — | — | |
| 2021 | — | 87.6 | 83.6 | 79.2 | |
| 2022 | — | 43.4 | 38.1 | 38.3 | |
| N | P | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Crop | Year | WF | WCMFx | WF | WCMFx | ||||
| H | M | L | H | M | L | ||||
| Wheat | 2019 | 39.2 | 39.2 | 39.2 | 39.2 | 7.3 | 7.3 | 7.3 | 7.3 |
| 2020 | 50.4 | 78.5 | 50.4 | 22.4 | 14.66 | 14.7 | 14.7 | 14.7 | |
| 2021 | 67.3 | 78.5 | 50.4 | 22.4 | 9.77 | 9.8 | 9.8 | 9.8 | |
| 2022 | 50.4 | 56.0 | 28.0 | 11.2 | 9.77 | 9.8 | 9.8 | 9.8 | |
| Corn | 2019 | — | 134.4 | 75.4 | 25.8 | — | 0.00 | 0.00 | 0.00 |
| 2020 | — | 105.4 | 74.0 | 53.8 | — | 0.00 | 0.00 | 0.00 | |
| 2021 | — | 60.2 | 43.7 | 26.9 | — | 0.00 | 0.00 | 0.00 | |
| 2022 | — | 104.2 | 104.2 | 104.2 | — | 0.00 | 0.00 | 0.00 | |
| Millet | 2019 | — | 67.3 | 28.0 | 0.00 | — | 7.3 | 7.3 | 7.3 |
| 2020 | — | 67.3 | 28.0 | 0.00 | — | 14.7 | 14.7 | 14.7 | |
| 2021 | — | 39.6 | 20.2 | 11.2 | — | 9.8 | 9.8 | 9.8 | |
| 2022 | — | 67.3 | 43.3 | 22.8 | — | 4.9 | 4.9 | 4.9 | |
| Foxtail | 2021 | — | 78.5 | 39.2 | 0.00 | — | 9.8 | 9.8 | 9.8 |
| Wheat Model Importance | Corn Model Importance | Millet Model Importance | |
|---|---|---|---|
| Precipitation | 24.4 | 19.2 | 16.2 |
| Rotation | 22 | — | — |
| Nitrogen | 20.9 | 10.7 | 8.9 |
| TPI | 20.1 | 8.8 | 12.1 |
| Sand | 19 | 8.8 | 5.2 |
| Planting SPEI | 18.6 | 19.1 | 12.1 |
| Soil Carbon | 18.2 | 8.2 | 0.4 |
| Year | 17.4 | 14.9 | 18.7 |
| Management unit | 16.9 | 15.1 | 7.4 |
| Elevation | 16.6 | 13.5 | 5.7 |
| PRSI | 13.6 | 10.6 | 4.8 |
| Roughness | 11.7 | 7.3 | 3.3 |
| Slope | 9.4 | 10 | 3.7 |
| TWI | 9.3 | 3.1 | 2.7 |
| Curvature | 3.4 | 1.2 | 1.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Macdonald, J.A.; Barnard, D.M.; Mankin, K.R.; Miner, G.L.; Erskine, R.H.; Poss, D.J.; Mehan, S.; Mahood, A.L.; Mikha, M.M. Topographic Position Index Predicts Within-Field Yield Variation in a Dryland Cereal Production System. Agronomy 2025, 15, 1304. https://doi.org/10.3390/agronomy15061304
Macdonald JA, Barnard DM, Mankin KR, Miner GL, Erskine RH, Poss DJ, Mehan S, Mahood AL, Mikha MM. Topographic Position Index Predicts Within-Field Yield Variation in a Dryland Cereal Production System. Agronomy. 2025; 15(6):1304. https://doi.org/10.3390/agronomy15061304
Chicago/Turabian StyleMacdonald, Jacob A., David M. Barnard, Kyle R. Mankin, Grace L. Miner, Robert H. Erskine, David J. Poss, Sushant Mehan, Adam L. Mahood, and Maysoon M. Mikha. 2025. "Topographic Position Index Predicts Within-Field Yield Variation in a Dryland Cereal Production System" Agronomy 15, no. 6: 1304. https://doi.org/10.3390/agronomy15061304
APA StyleMacdonald, J. A., Barnard, D. M., Mankin, K. R., Miner, G. L., Erskine, R. H., Poss, D. J., Mehan, S., Mahood, A. L., & Mikha, M. M. (2025). Topographic Position Index Predicts Within-Field Yield Variation in a Dryland Cereal Production System. Agronomy, 15(6), 1304. https://doi.org/10.3390/agronomy15061304