
ASE-YOLOv8n: A Method for Cherry Tomato Ripening Detection

 ,
,  , ,
, , 
Abstract
1. Introduction
2. Materials and Methods
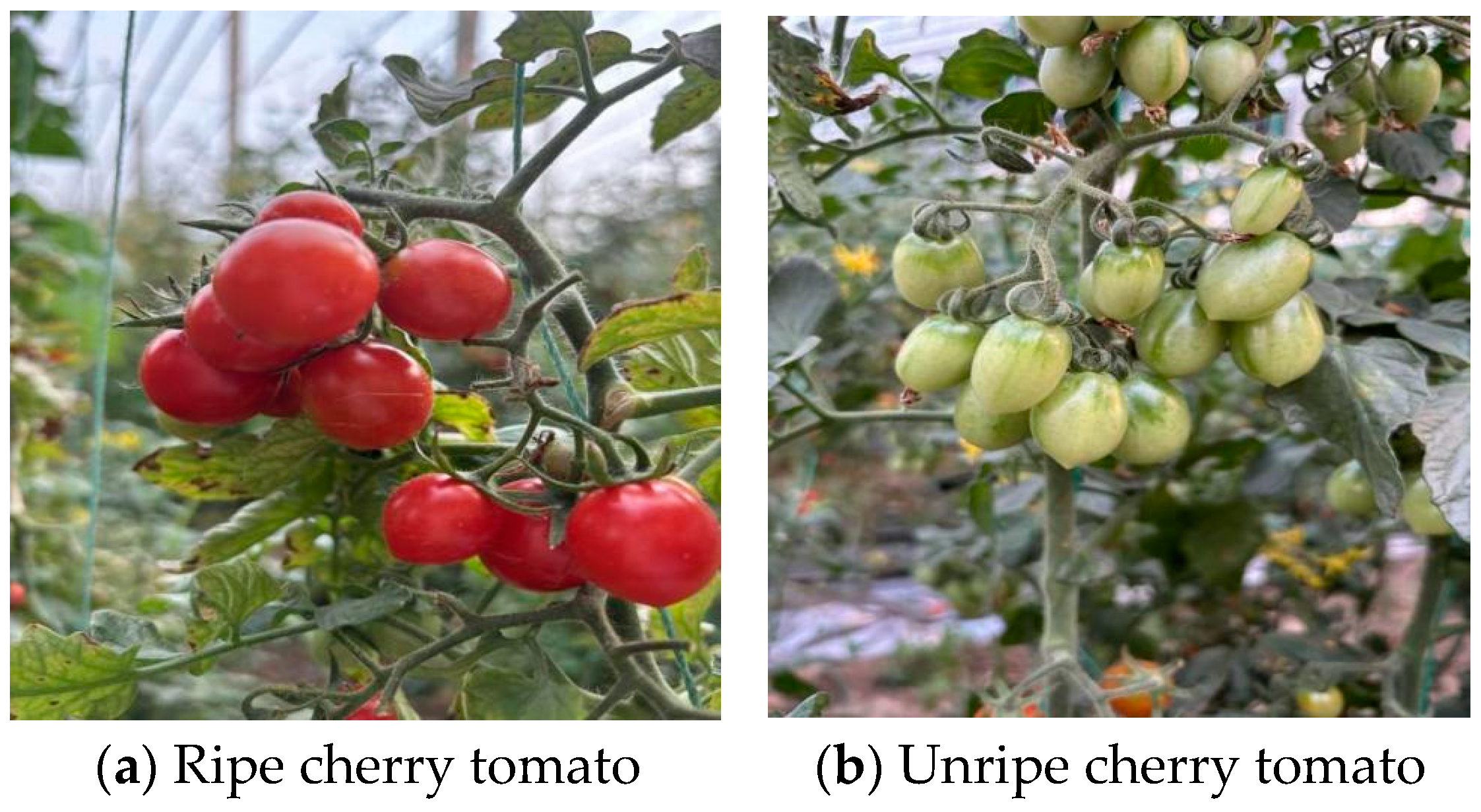
2.1. Materials
2.1.1. Image Collection
2.1.2. Data Enhancement
2.1.3. Data Labeling
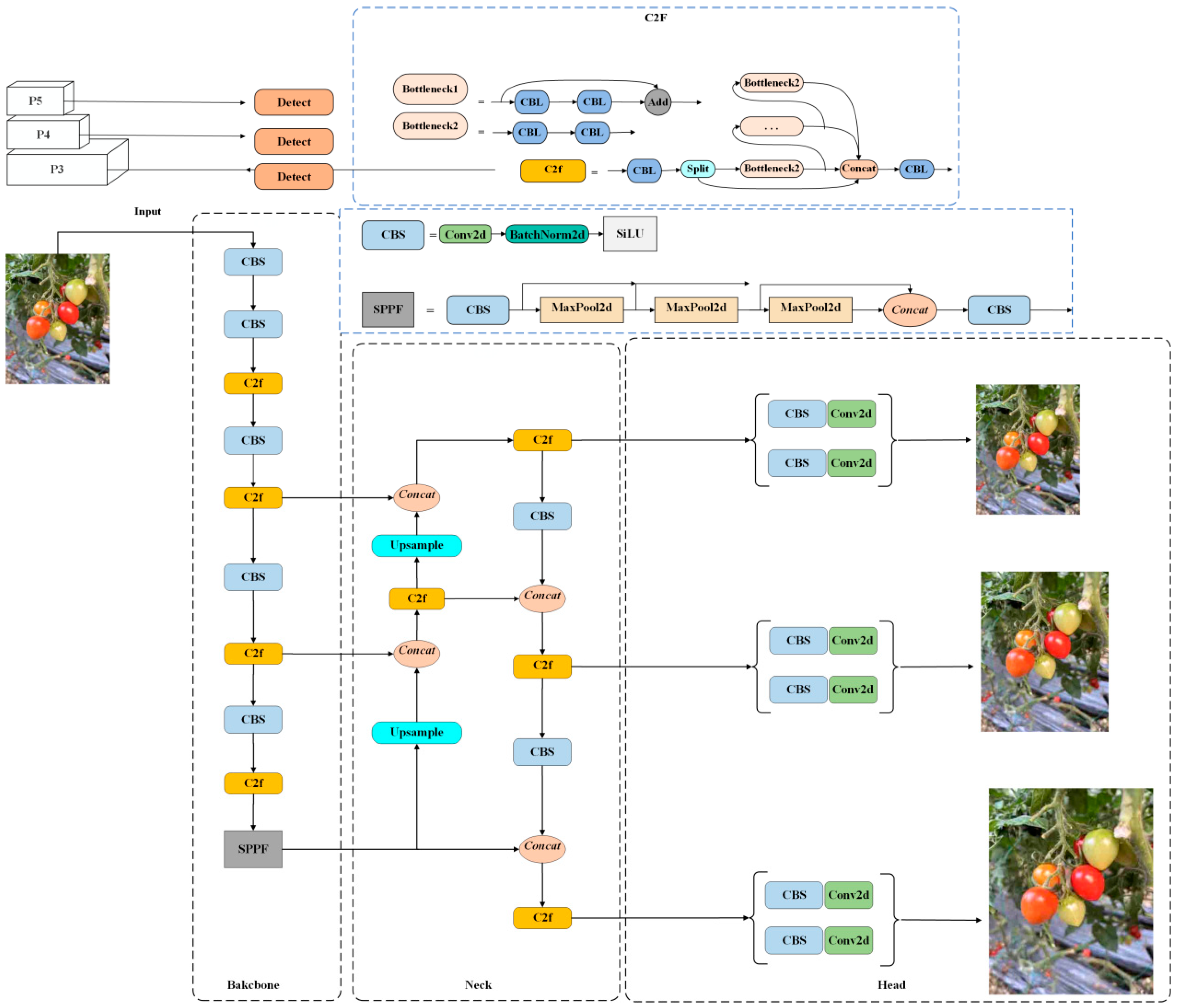
2.2. Standard YOLOv8 Model
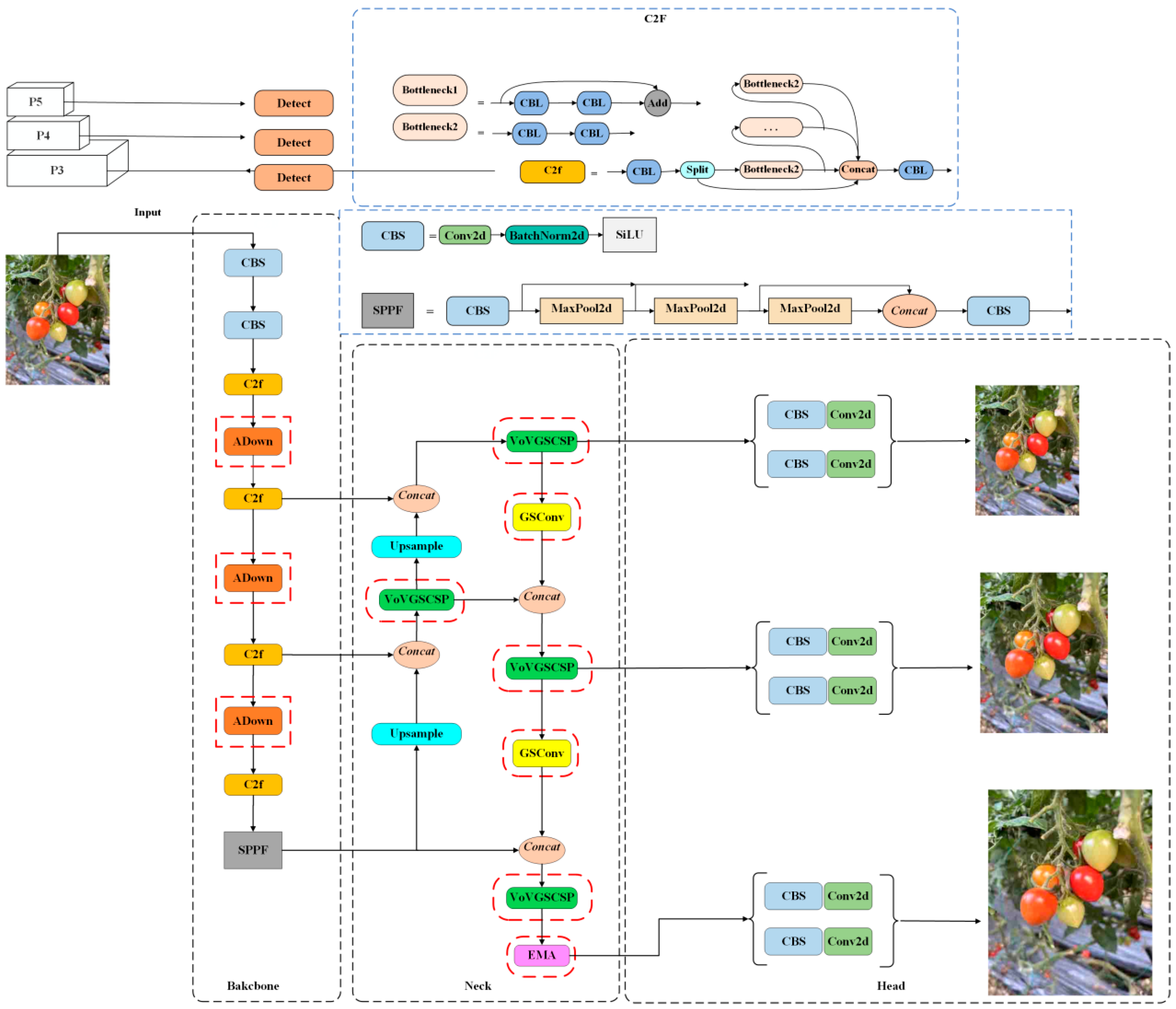
2.3. Improved YOLOv8 Model
2.3.1. YOLOv8-ADown Down-Sampling Module
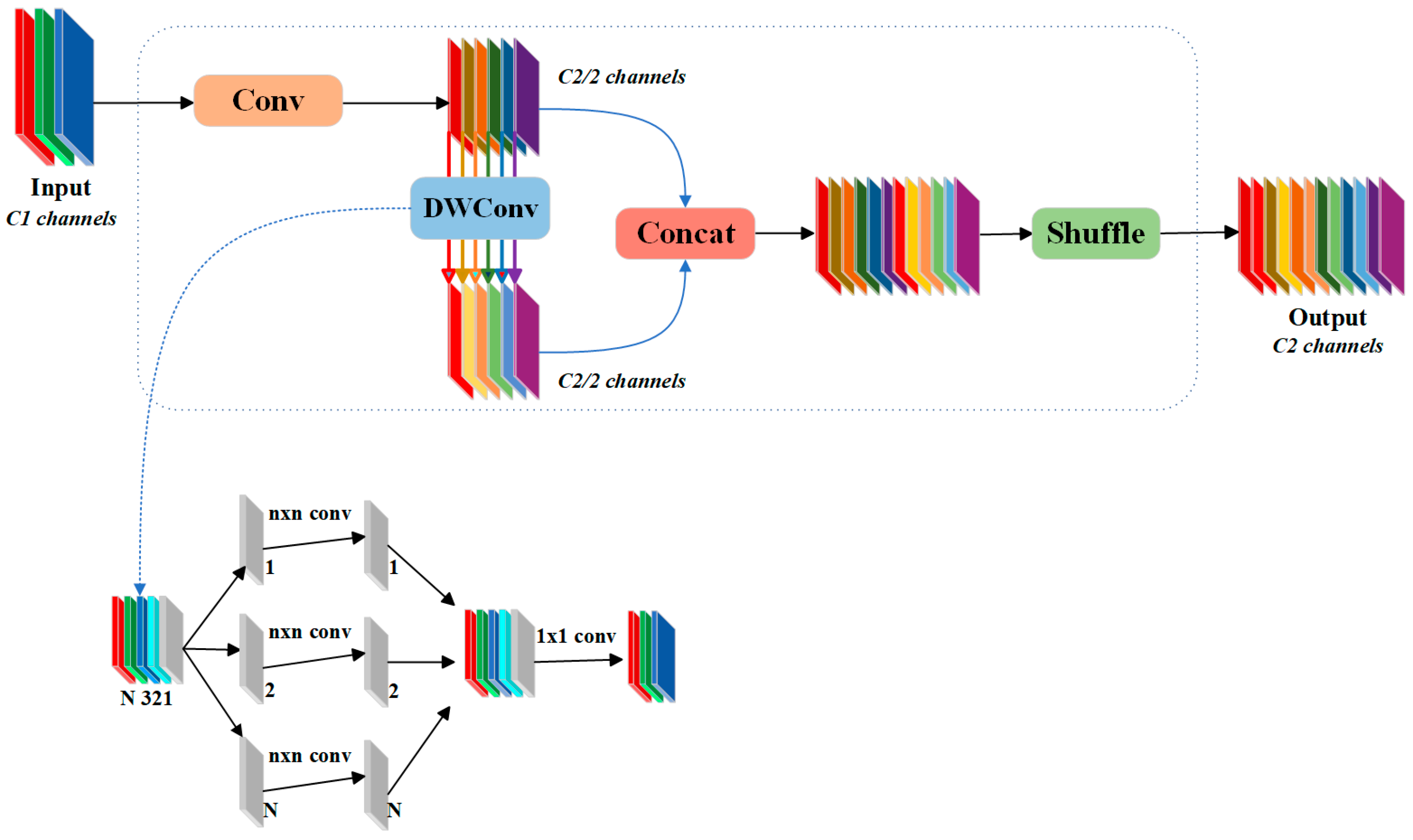
- 1.
- Channel splitting:
- 2.
- Different ways of down-sampling:
- Convolutional down-sampling (X1 part):
- 3.
- Feature integration:
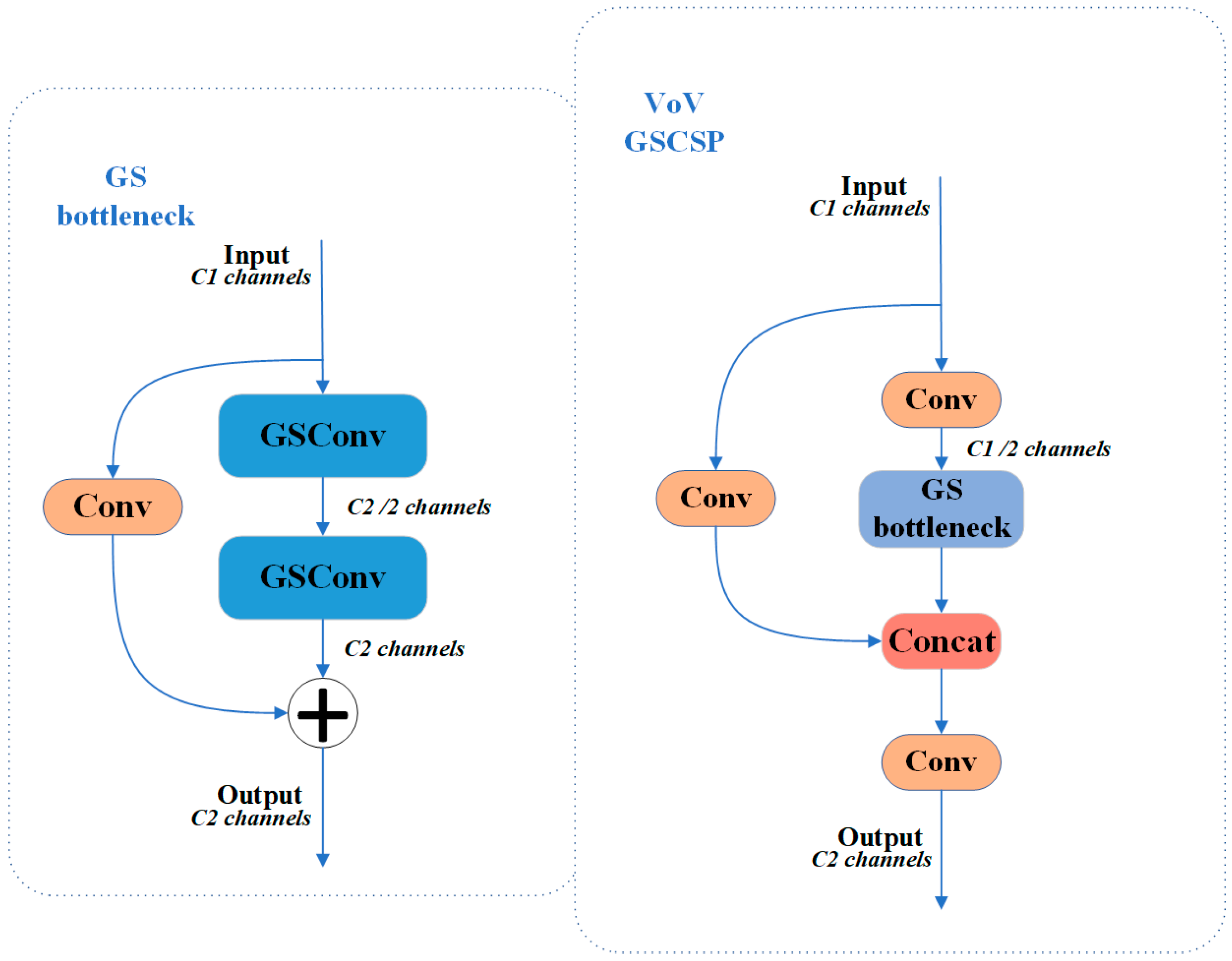
2.3.2. YOLOv8-Slim-Neck
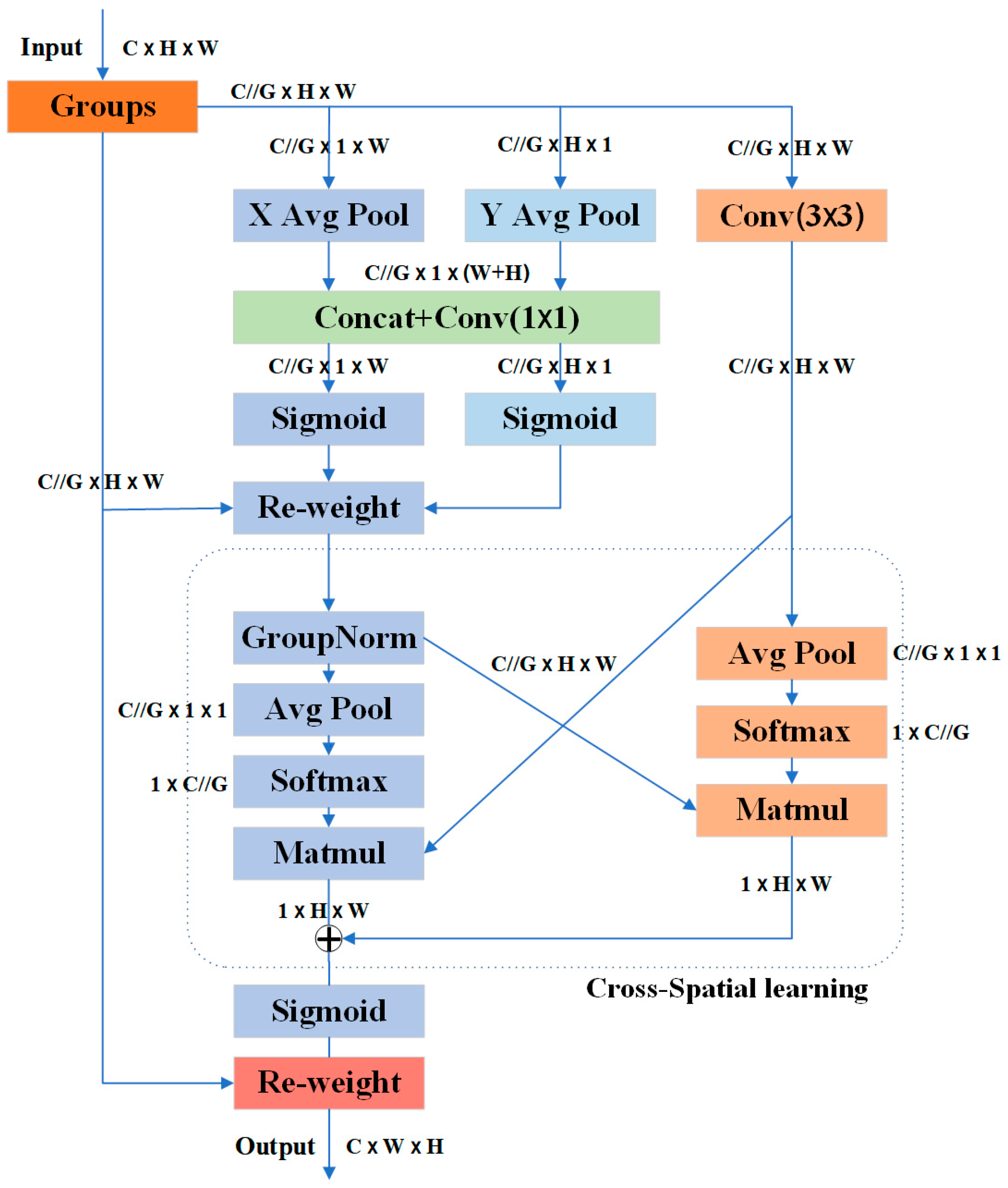
2.3.3. YOLOv8-EMA (Efficient Multi-Scale Attention)
2.4. Training Equipment and Parameter Setting
2.4.1. Experimental Environment and Parameter Adjustment
2.4.2. Model Evaluation Indicators
3. Experiment and Result Analysis
3.1. Experimental Comparison Before and After Model Improvement
3.2. Comparison of Ablation Experiments
3.3. Comparison of Results for Different Attention Mechanisms
3.4. The k-Fold Across-Validation Experiment of Improved YOLOv8 Model
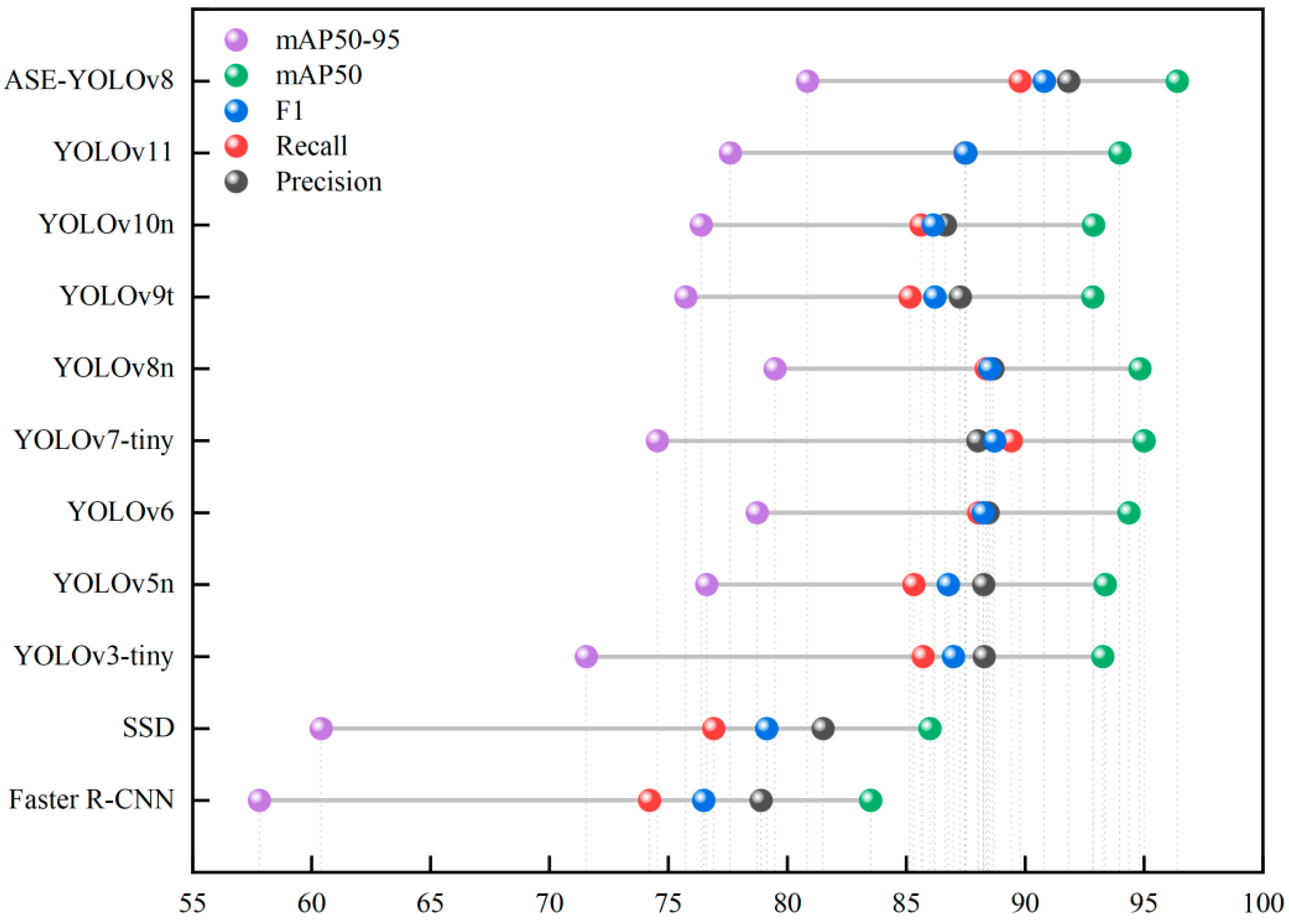
3.5. Comparative Experiments
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Soare, R.; Dinu, M.; Apahidean, A.-I.; Soare, M. The evolution of some nutritional parameters of the tomato fruit during the harvesting stages. Hortic. Sci. 2019, 46, 132–137. [Google Scholar] [CrossRef]
- Lowenberg-DeBoer, J.; Huang, I.Y.; Grigoriadis, V.; Blackmore, S. Economics of robots and automation in field crop production. Precis. Agric. 2020, 21, 278–299. [Google Scholar] [CrossRef]
- Chen, Z.; Lei, X.; Yuan, Q.; Qi, Y.; Ma, Z.; Qian, S.; Lyu, X. Key Technologies for Autonomous Fruit-and Vegetable-Picking Robots: A Review. Agronomy 2024, 14, 2233. [Google Scholar] [CrossRef]
- Rong, J.; Wang, P.; Wang, T.; Hu, L.; Yuan, T. Fruit pose recognition and directional orderly grasping strategies for tomato harvesting robots. Comput. Electron. Agric. 2022, 202, 107430. [Google Scholar] [CrossRef]
- Gill, H.S.; Murugesan, G.; Mehbodniya, A.; Sajja, G.S.; Gupta, G.; Bhatt, A. Fruit type classification using deep learning and feature fusion. Comput. Electron. Agric. 2023, 211, 107990. [Google Scholar] [CrossRef]
- Tsouvaltzis, P.; Gkountina, S.; Siomos, A.S. Quality traits and nutritional components of cherry tomato in relation to the harvesting period, storage duration and fruit position in the truss. Plants 2023, 12, 315. [Google Scholar] [CrossRef] [PubMed]
- Hou, G.; Chen, H.; Jiang, M.; Niu, R. An Overview of the Application of Machine Vision in Recognition and Localization of Fruit and Vegetable Harvesting Robots. Agriculture 2023, 13, 1814. [Google Scholar] [CrossRef]
- Bai, Y.; Mao, S.; Zhou, J.; Zhang, B. Clustered tomato detection and picking point location using machine learning-aided image analysis for automatic robotic harvesting. Precis. Agric. 2023, 24, 727–743. [Google Scholar] [CrossRef]
- Mao, S.; Li, Y.; Ma, Y.; Zhang, B.; Zhou, J.; Wang, K. Automatic cucumber recognition algorithm for harvesting robots in the natural environment using deep learning and multi-feature fusion. Comput. Electron. Agric. 2020, 170, 105254. [Google Scholar] [CrossRef]
- Guzmán, E.; Baeten, V.; Pierna, J.A.F.; García-Mesa, J.A. Determination of the olive maturity index of intact fruits using image analysis. J. Food Sci. Technol. 2015, 52, 1462–1470. [Google Scholar] [CrossRef]
- Li, H.; Lee, W.S.; Wang, K. Identifying blueberry fruit of different growth stages using natural outdoor color images. Comput. Electron. Agric. 2014, 106, 91–101. [Google Scholar] [CrossRef]
- Zhou, R.; Damerow, L.; Sun, Y.; Blanke, M.M. Using colour features of cv.‘Gala’apple fruits in an orchard in image processing to predict yield. Precis. Agric. 2012, 13, 568–580. [Google Scholar] [CrossRef]
- Song, Y.; Glasbey, C.; Horgan, G.; Polder, G.; Dieleman, J.; Van der Heijden, G. Automatic fruit recognition and counting from multiple images. Biosyst. Eng. 2014, 118, 203–215. [Google Scholar] [CrossRef]
- Bulanon, D.; Burks, T.; Alchanatis, V. Image fusion of visible and thermal images for fruit detection. Biosyst. Eng. 2009, 103, 12–22. [Google Scholar] [CrossRef]
- Maldonado, W., Jr.; Barbosa, J.C. Automatic green fruit counting in orange trees using digital images. Comput. Electron. Agric. 2016, 127, 572–581. [Google Scholar] [CrossRef]
- Lin, G.; Tang, Y.; Zou, X.; Xiong, J.; Fang, Y. Color-, depth-, and shape-based 3D fruit detection. Precis. Agric. 2020, 21, 1–17. [Google Scholar] [CrossRef]
- Lin, G.; Tang, Y.; Zou, X.; Cheng, J.; Xiong, J. Fruit detection in natural environment using partial shape matching and probabilistic Hough transform. Precis. Agric. 2020, 21, 160–177. [Google Scholar] [CrossRef]
- Saleem, M.H.; Potgieter, J.; Arif, K.M. Automation in agriculture by machine and deep learning techniques: A review of recent developments. Precis. Agric. 2021, 22, 2053–2091. [Google Scholar]
- Lawal, O.M. YOLOMuskmelon: Quest for fruit detection speed and accuracy using deep learning. IEEE Access 2021, 9, 15221–15227. [Google Scholar] [CrossRef]
- Pal, A.; Leite, A.C.; From, P.J. A novel end-to-end vision-based architecture for agricultural human–robot collaboration in fruit picking operations. Robot. Auton. Syst. 2024, 172, 104567. [Google Scholar] [CrossRef]
- Ismail, N.; Malik, O.A. Real-time visual inspection system for grading fruits using computer vision and deep learning techniques. Inf. Process. Agric. 2022, 9, 24–37. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Maleva, T.; Soloviev, V. Using YOLOv3 algorithm with pre-and post-processing for apple detection in fruit-harvesting robot. Agronomy 2020, 10, 1016. [Google Scholar] [CrossRef]
- Gai, R.; Chen, N.; Yuan, H. A detection algorithm for cherry fruits based on the improved YOLO-v4 model. Neural Comput. Appl. 2023, 35, 13895–13906. [Google Scholar] [CrossRef]
- Zhang, F.; Chen, Z.; Ali, S.; Yang, N.; Fu, S.; Zhang, Y. Multi-class detection of cherry tomatoes using improved Yolov4-tiny model. Int. J. Agric. Biol. Eng. 2023, 16, 225–231. [Google Scholar]
- Wang, C.; Wang, C.; Wang, L.; Wang, J.; Liao, J.; Li, Y.; Lan, Y. A lightweight cherry tomato maturity real-time detection algorithm based on improved YOLOV5n. Agronomy 2023, 13, 2106. [Google Scholar] [CrossRef]
- Zhang, C.; Ding, H.; Shi, Q.; Wang, Y. Grape cluster real-time detection in complex natural scenes based on YOLOv5s deep learning network. Agriculture 2022, 12, 1242. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, H.; Liu, Y.; Luo, Y.; Li, H.; Chen, H.; Liao, K.; Li, L. A trunk detection method for camellia oleifera fruit harvesting robot based on improved YOLOv7. Forests 2023, 14, 1453. [Google Scholar] [CrossRef]
- Gu, B.; Wen, C.; Liu, X.; Hou, Y.; Hu, Y.; Su, H. Improved YOLOv7-tiny complex environment citrus detection based on lightweighting. Agronomy 2023, 13, 2667. [Google Scholar] [CrossRef]
- Zhao, Y.; Gong, L.; Zhou, B.; Huang, Y.; Liu, C. Detecting tomatoes in greenhouse scenes by combining AdaBoost classifier and colour analysis. Biosyst. Eng. 2016, 148, 127–137. [Google Scholar] [CrossRef]
- Wang, J.; Zhou, Y. Electronic-nose technique: Potential for monitoring maturity and shelf life of tomatoes. New Zealand J. Agric. Res. 2007, 50, 1219–1228. [Google Scholar] [CrossRef]
- Dai, C.; Sun, J.; Huang, X.; Zhang, X.; Tian, X.; Wang, W.; Sun, J.; Luan, Y. Application of hyperspectral imaging as a nondestructive technology for identifying tomato maturity and quantitatively predicting lycopene content. Foods 2023, 12, 2957. [Google Scholar] [CrossRef] [PubMed]
- Lawal, M.O. Tomato detection based on modified YOLOv3 framework. Sci. Rep. 2021, 11, 1447. [Google Scholar] [CrossRef]
- Li, R.; Ji, Z.; Hu, S.; Huang, X.; Yang, J.; Li, W. Tomato maturity recognition model based on improved YOLOv5 in greenhouse. Agronomy 2023, 13, 603. [Google Scholar] [CrossRef]
- Salim, N.O.; Mohammed, A.K. Comparative Analysis of Classical Machine Learning and Deep Learning Methods for Fruit Image Recognition and Classification. Trait. Du Signal 2024, 41, 1331–1343. [Google Scholar] [CrossRef]
- Goyal, K.; Kumar, P.; Verma, K. Tomato ripeness and shelf-life prediction system using machine learning. J. Food Meas. Charact. 2024, 18, 2715–2730. [Google Scholar] [CrossRef]
- GH T1193-2021; Standards for Supply and Distribution Cooperation in the People’s Republic of China. All China Federation of Supply and Marketing Cooperatives (ACFSMC): Beijing, China, 2021.
- Wang, Y.; Rong, Q.; Hu, C. Ripe Tomato Detection Algorithm Based on Improved YOLOv9. Plants 2024, 13, 3253. [Google Scholar] [CrossRef]
- Hasan, M.M.; Nishi, J.S.; Habib, M.T.; Islam, M.M.; Ahmed, F. A Deep Learning Approach to Recognize Bangladeshi Shrimp Species. In Proceedings of the 2023 14th International Conference on Computing Communication and Networking Technologies (ICCCNT), Delhi, India, 6–8 July 2023; pp. 1–5. [Google Scholar]
- Boutin, V.; Franciosini, A.; Chavane, F.; Perrinet, L.U. Pooling strategies in V1 can account for the functional and structural diversity across species. PLOS Comput. Biol. 2022, 18, e1010270. [Google Scholar] [CrossRef]
- Persello, C.; Stein, A. Deep fully convolutional networks for the detection of informal settlements in VHR images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2325–2329. [Google Scholar] [CrossRef]
- Bjorck, N.; Gomes, C.P.; Selman, B.; Weinberger, K.Q. Understanding batch normalization. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 2–8 December 2018; Volume 31. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles. arXiv 2022, arXiv:2206.02424. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21 July 2017; pp. 1251–1258. [Google Scholar]
- Doğan, Y. Which pooling method is better: Max, avg, or concat (Max, Avg). Commun. Fac. Sci. Univ. Ank. Ser. A2-A3 Phys. Sci. Eng. 2023, 66, 95–117. [Google Scholar] [CrossRef]
- Stofa, M.M.; Zulkifley, M.A.; Mohamed, N.A. Exploration of Group and Shuffle Module for Semantic Segmentation of Sea Ice Concentration. In Proceedings of the 2024 IEEE 8th International Conference on Signal and Image Processing Applications (ICSIPA), Kuala Lumpur, Malaysia, 3–5 September 2024; pp. 1–5. [Google Scholar]
- Li, X.; Zhong, Z.; Wu, J.; Yang, Y.; Lin, Z.; Liu, H. Expectation-maximization attention networks for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9167–9176. [Google Scholar]
- Menon, A.; Mehrotra, K.; Mohan, C.K.; Ranka, S. Characterization of a class of sigmoid functions with applications to neural networks. Neural Netw. 1996, 9, 819–835. [Google Scholar] [CrossRef] [PubMed]
- Yi, F.; Yu, Z.; Chen, H.; Du, H.; Guo, B. Cyber-physical-social collaborative sensing: From single space to cross-space. Front. Comput. Sci. 2018, 12, 609–622. [Google Scholar] [CrossRef]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greek, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Zhu, L.; Wang, X.; Ke, Z.; Zhang, W.; Lau, R.W. Biformer: Vision transformer with bi-level routing attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10323–10333. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global attention mechanism: Retain information to enhance channel-spatial interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]
- Liu, Y.; Shao, Z.; Teng, Y.; Hoffmann, N. NAM: Normalization-based attention module. arXiv 2021, arXiv:2111.12419. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Yang, L.; Zhang, R.-Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Qiu, H.; Zhang, Q.; Li, J.; Rong, J.; Yang, Z. Lightweight Mulberry Fruit Detection Method Based on Improved YOLOv8n for Automated Harvesting. Agronomy 2024, 14, 2861. [Google Scholar] [CrossRef]
- Zhang, L.; You, H.; Wei, Z.; Li, Z.; Jia, H.; Yu, S.; Zhao, C.; Lv, Y.; Li, D. DGS-YOLOv8: A Method for Ginseng Appearance Quality Detection. Agriculture 2024, 14, 1353. [Google Scholar] [CrossRef]
- Gao, X.; Ding, J.; Zhang, R.; Xi, X. YOLOv8n-CA: Improved YOLOv8n Model for Tomato Fruit Recognition at Different Stages of Ripeness. Agronomy 2025, 15, 188. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Original | Data Enhancement |
|---|---|---|
| Ripe_tomato | 5063 | 55,342 |
| Unripe_tomato | 4745 | 51,974 |
| Category | Configuration |
|---|---|
| CPU | 12th Gen Intel Core i7-12700KF@3.60 GHz |
| GPU | NVIDIA GeForce RTX 4060ti 16 G |
| System environment | Windows 11 |
| Framework | Pytorch 2.1.0 |
| Programming voice | Python 3.8 |
| Level | Model | Precision (%) | Recall (%) | F1 (%) | mAP50 (%) | mAP50-95 (%) |
|---|---|---|---|---|---|---|
| Ripe | YOLOv8 | 88.75 | 89.12 | 88.93 | 94.83 | 79.48 |
| ASE-YOLOv8 | 91.15 | 91.05 | 91.10 | 96.94 | 83.11 | |
| Unripe | YOLOv8 | 88.54 | 87.59 | 88.06 | 93.92 | 77.07 |
| ASE-YOLOv8 | 92.52 | 88.52 | 90.48 | 95.86 | 78.59 | |
| ALL | YOLOv8 | 88.65 | 88.36 | 88.50 | 94.83 | 79.48 |
| ASE-YOLOv8 | 91.83 | 89.79 | 90.80 | 96.40 | 80.85 |
| YOLOv8n | ADown | Slim-Neck | EMA | Precision (%) | Recall (%) | F1 (%) | mAP50 (%) | mAP50-95 (%) | Parameters (M) | Weight (MB) |
|---|---|---|---|---|---|---|---|---|---|---|
| √ | 88.65 | 88.36 | 88.50 | 94.83 | 79.48 | 3.01 | 5.97 | |||
| √ | √ | 90.92 | 89.48 | 90.20 | 96.03 | 80.91 | 2.73 | 5.42 | ||
| √ | √ | 90.21 | 88.27 | 89.23 | 95.42 | 80.20 | 2.80 | 5.60 | ||
| √ | √ | 90.23 | 88.71 | 89.46 | 95.69 | 80.21 | 3.01 | 5.95 | ||
| √ | √ | √ | 90.84 | 90.12 | 90.48 | 96.19 | 80.83 | 2.52 | 5.08 | |
| √ | √ | √ | 91.51 | 89.75 | 90.62 | 96.19 | 80.76 | 2.73 | 5.43 | |
| √ | √ | √ | 89.68 | 89.01 | 89.34 | 95.54 | 79.84 | 2.80 | 5.61 | |
| √ | √ | √ | √ | 91.83 | 89.79 | 90.80 | 96.40 | 80.85 | 2.52 | 5.08 |
| Attention Mechanisms | Precision (%) | Recall (%) | F1 (%) | mAP50 (%) | mAP50-95 (%) |
|---|---|---|---|---|---|
| No | 90.84 | 90.12 | 90.48 | 96.19 | 80.83 |
| BRA | 90.52 | 90.14 | 90.33 | 95.90 | 80.73 |
| CBAM | 90.79 | 89.64 | 90.21 | 96.08 | 80.75 |
| CA | 91.40 | 89.92 | 90.65 | 96.28 | 80.84 |
| ECA | 90.97 | 89.95 | 90.46 | 96.08 | 80.78 |
| GAM | 90.90 | 89.95 | 90.42 | 96.12 | 80.79 |
| NAM | 91.40 | 89.53 | 90.46 | 96.13 | 80.62 |
| SE | 91.79 | 89.30 | 90.53 | 96.23 | 80.96 |
| SimAM | 91.61 | 89.58 | 90.58 | 96.21 | 80.80 |
| EMA | 91.83 | 89.79 | 90.80 | 96.40 | 80.85 |
| Group | Train Set | Val Set | Test Set | Category | Precision (%) | Recall (%) | F1 (%) | mAP50 (%) | mAP50-95 (%) |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Ripe | 92.05 | 90.47 | 91.25 | 96.54 | 83.62 | |||
| 1, 2, 3, 4, 5, 6, 7, 8 | 9 | 10 | Unripe All | 93.22 92.31 | 87.91 90.35 | 90.49 91.32 | 95.18 96.44 | 78.54 80.02 | |
| 2 | Ripe | 91.06 | 91.22 | 91.14 | 96.71 | 82.63 | |||
| 2, 3,4, 5, 6, 7, 8, 10 | 9 | 1 | Unripe All | 93.32 92.68 | 89.11 90.03 | 91.17 91.34 | 96.55 97.27 | 78.58 80.64 | |
| 3 | Ripe | 91.41 | 91.21 | 91.31 | 96.05 | 82.19 | |||
| 1, 3, 4, 5, 6, 7, 8, 10 | 9 | 2 | Unripe All | 92.72 92.18 | 88.73 88.88 | 90.68 90.50 | 95.27 95.69 | 78.57 81.37 | |
| 4 | Ripe | 91.17 | 90.91 | 91.04 | 97.02 | 82.93 | |||
| 1, 2, 4, 5, 6, 7, 8, 10 | 9 | 3 | Unripe All | 92.37 92.33 | 88.60 90.11 | 90.45 91.21 | 96.01 96.94 | 78.79 80.76 | |
| 5 | Ripe | 92.45 | 92.10 | 92.27 | 96.74 | 82.82 | |||
| 1, 2, 3, 5, 6, 7, 8, 10 | 9 | 4 | Unripe All | 92.05 91.10 | 88.57 89.94 | 90.28 90.52 | 96.03 96.85 | 77.76 80.42 | |
| 6 | 1, 2, 3, 4, 6, 7, 8, 10 | 9 | 5 | Ripe Unripe All | 90.85 92.32 92.15 | 91.38 88.87 89.25 | 91.11 90.56 90.68 | 97.29 95.94 96.61 | 83.58 78.41 80.65 |
| 7 | 1, 2, 3, 4, 5, 7, 8, 10 | 9 | 6 | Ripe Unripe All | 91.39 92.53 91.56 | 92.06 88.86 89.55 | 91.72 90.66 90.54 | 96.81 96.19 95.50 | 83.09 78.62 81.02 |
| 8 | 1, 2, 3, 4, 5, 6, 8, 10 | 9 | 7 | Ripe Unripe All | 92.11 92.59 91.52 | 90.67 89.12 89.60 | 91.38 90.82 90.55 | 97.14 95.38 96.44 | 83.03 78.59 81.78 |
| 9 | 1, 2, 3, 4, 5, 6, 7, 10 | 9 | 8 | Ripe Unripe All | 90.98 92.39 91.55 | 91.09 89.36 90.71 | 91.03 90.85 91.13 | 96.86 96.28 95.89 | 83.43 78.82 79.71 |
| 10 | 1, 2, 3, 4, 5, 6, 7, 8 | 10 | 9 | Ripe Unripe All | 91.27 92.35 91.77 | 90.54 89.14 89.50 | 90.90 90.72 90.62 | 97.03 94.88 95.86 | 83.21 78.46 81.20 |
| Ave. | Ripe Unripe All | 91.47 92.59 91.92 | 91.17 88.83 89.79 | 91.32 90.67 90.84 | 96.82 95.77 96.35 | 83.05 78.51 80.76 |
| Model | Precision (%) | Recall (%) | F1 (%) | mAP50 (%) | mAP50-95 (%) | Parameters (M) | Weight (MB) |
|---|---|---|---|---|---|---|---|
| Faster R-CNN | 78.90 | 74.20 | 76.48 | 83.50 | 57.80 | 28.48 | 113.92 |
| SSD | 81.50 | 76.90 | 79.13 | 86.00 | 60.40 | 14.34 | 57.36 |
| YOLOv3-tiny | 88.28 | 85.71 | 86.98 | 93.27 | 71.55 | 12.13 | 23.20 |
| YOLOv5n | 88.26 | 85.32 | 86.77 | 93.37 | 76.61 | 2.50 | 5.04 |
| YOLOv6 | 88.44 | 88.04 | 88.24 | 94.36 | 78.73 | 4.23 | 8.30 |
| YOLOv7-tiny | 88.01 | 89.42 | 88.71 | 95.00 | 74.53 | 6.02 | 11.70 |
| YOLOv8n | 88.65 | 88.36 | 88.50 | 94.83 | 79.48 | 3.01 | 5.97 |
| YOLOv9t | 87.27 | 85.16 | 86.20 | 92.85 | 75.73 | 1.97 | 4.44 |
| YOLOv10 | 86.65 | 85.62 | 86.13 | 92.88 | 76.38 | 2.70 | 5.50 |
| YOLOv11 | 87.51 | 87.47 | 87.49 | 93.99 | 77.60 | 2.58 | 5.23 |
| ASE-YOLOv8 | 91.83 | 89.79 | 90.80 | 96.40 | 80.85 | 2.52 | 5.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, X.; Jia, H.; Wang, H.; Zhang, L.; Li, D.; Wei, Z.; You, H.; Wan, X.; Li, R.; Li, W.; et al. ASE-YOLOv8n: A Method for Cherry Tomato Ripening Detection. Agronomy 2025, 15, 1088. https://doi.org/10.3390/agronomy15051088
Liang X, Jia H, Wang H, Zhang L, Li D, Wei Z, You H, Wan X, Li R, Li W, et al. ASE-YOLOv8n: A Method for Cherry Tomato Ripening Detection. Agronomy. 2025; 15(5):1088. https://doi.org/10.3390/agronomy15051088
Chicago/Turabian StyleLiang, Xuemei, Haojie Jia, Hao Wang, Lijuan Zhang, Dongming Li, Zhanchen Wei, Haohai You, Xiaoru Wan, Ruixin Li, Wei Li, and et al. 2025. "ASE-YOLOv8n: A Method for Cherry Tomato Ripening Detection" Agronomy 15, no. 5: 1088. https://doi.org/10.3390/agronomy15051088
APA StyleLiang, X., Jia, H., Wang, H., Zhang, L., Li, D., Wei, Z., You, H., Wan, X., Li, R., Li, W., & Yang, M. (2025). ASE-YOLOv8n: A Method for Cherry Tomato Ripening Detection. Agronomy, 15(5), 1088. https://doi.org/10.3390/agronomy15051088