


An Improved MobileNetV3 Mushroom Quality Classification Model Using Images with Complex Backgrounds


Abstract
:1. Introduction
- A new method for constructing data sets to enhance the model’s focus on subjects in complex background images is proposed.
- A mushroom quality classification strategy based on the MobilenetV3_large network model is introduced to classify mushrooms of different quality levels.
- An improved MobilenetV3_large network model for mushroom quality classification is proposed based on different training strategies to improve the recognition accuracy of the model while reducing the time cost and arithmetic power spent on training the model, such as data enhancement techniques, migration learning techniques, and replacing the loss function with a better one.
- The recognition performance of the model after replacing the SE attention mechanism in the MobilenetV3_large network model is compared with CBAM, CA, scSE, and improved SE.
- The recognition performances for mushroom quality classification of eight other popular deep learning models are compared with that of the improved MobilenetV3_large network model.
2. Data Collection and Processing
2.1. Data Source and Division
2.2. Data Processing
2.2.1. Background Segmentation
2.2.2. Building a Hybrid Data Set
2.2.3. Data Enhancement
3. Construction of a Quality Classification Model for Shiitake Mushrooms
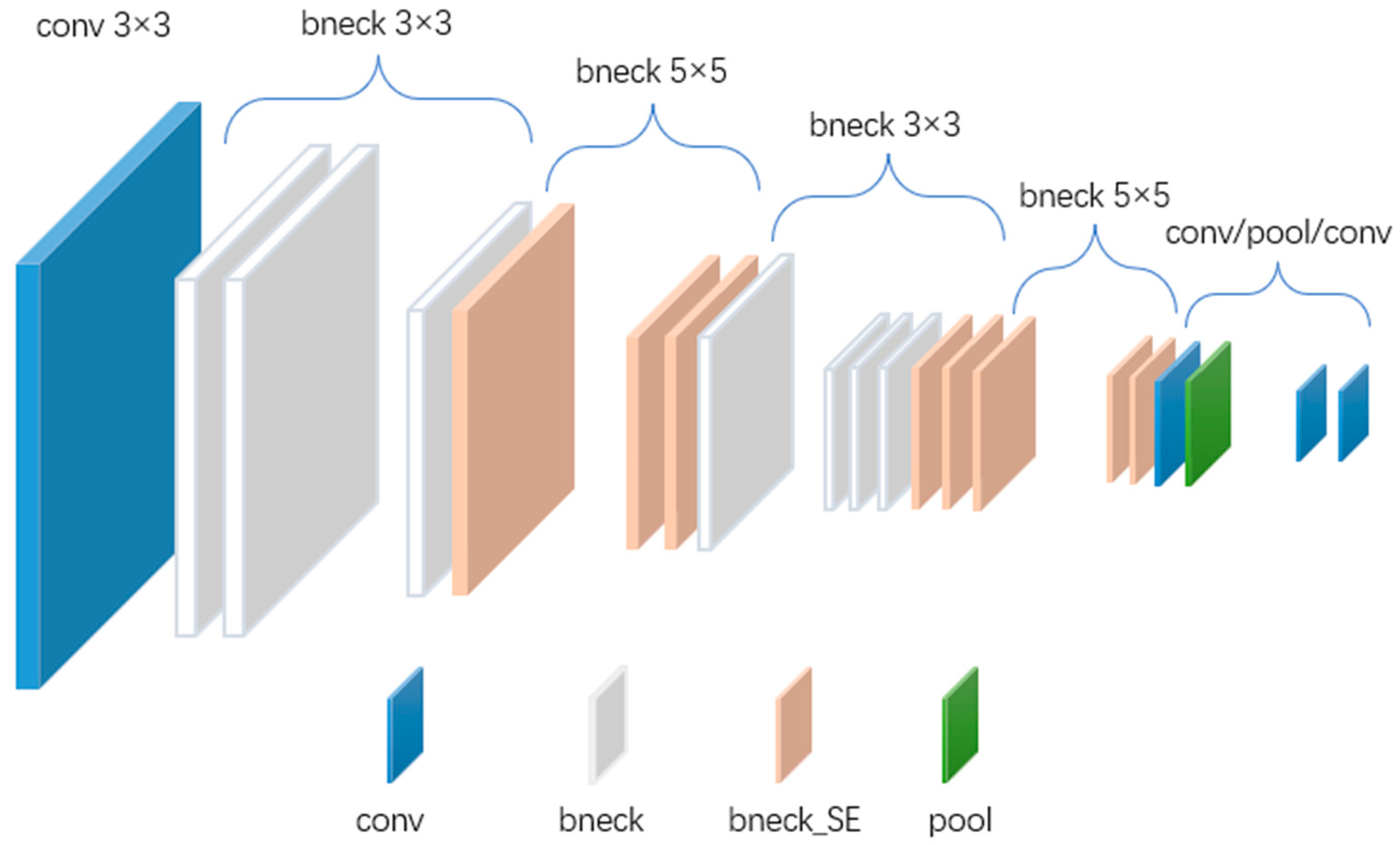
3.1. MobileNetV3-Large Network Model
3.2. Improving the MobileNetV3-Large Network Model
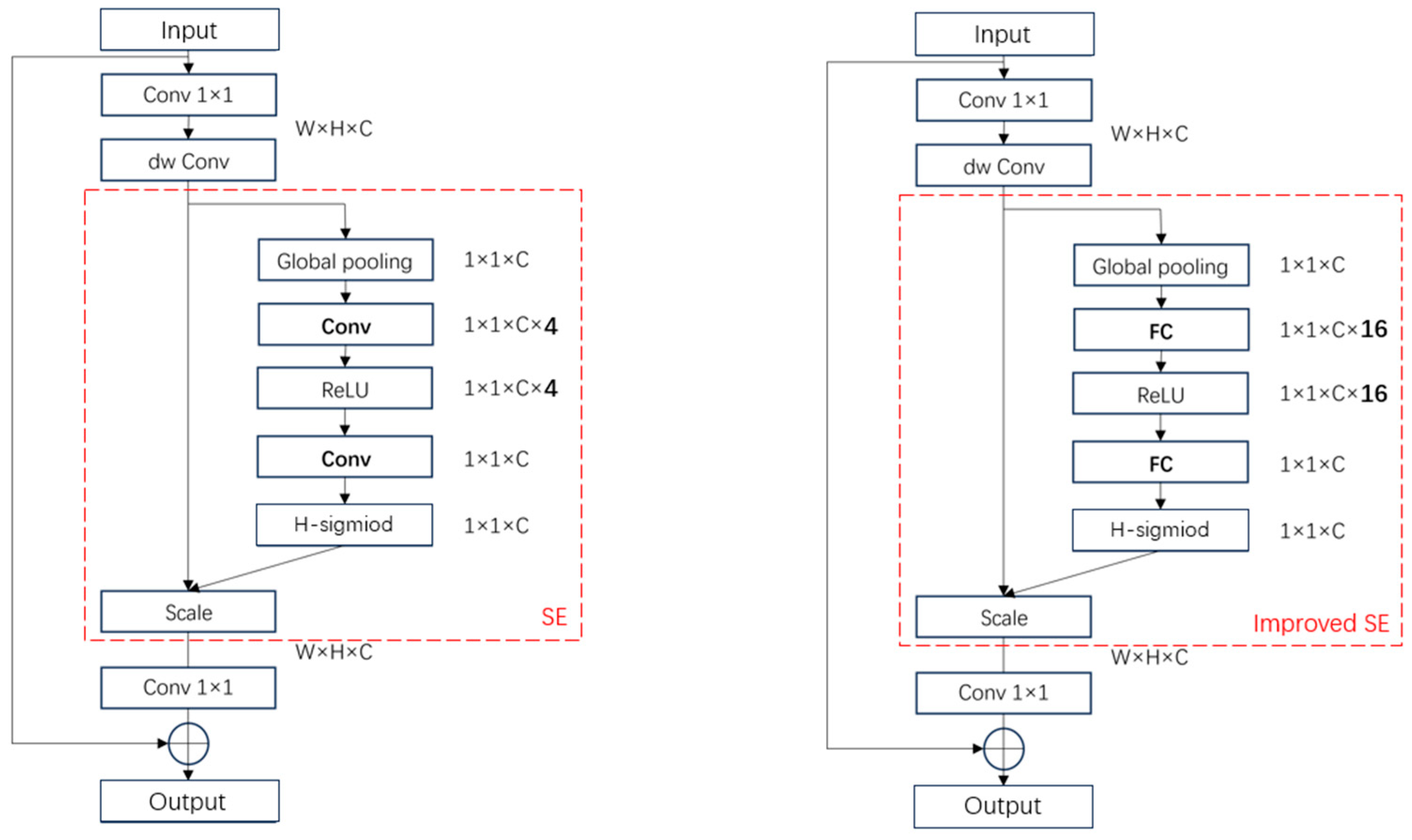
3.2.1. Improved SE Module
3.2.2. PolyLoss
3.3. Migration Learning
4. Test Results and Evaluation
4.1. Test Environment
4.2. Evaluation Indicators
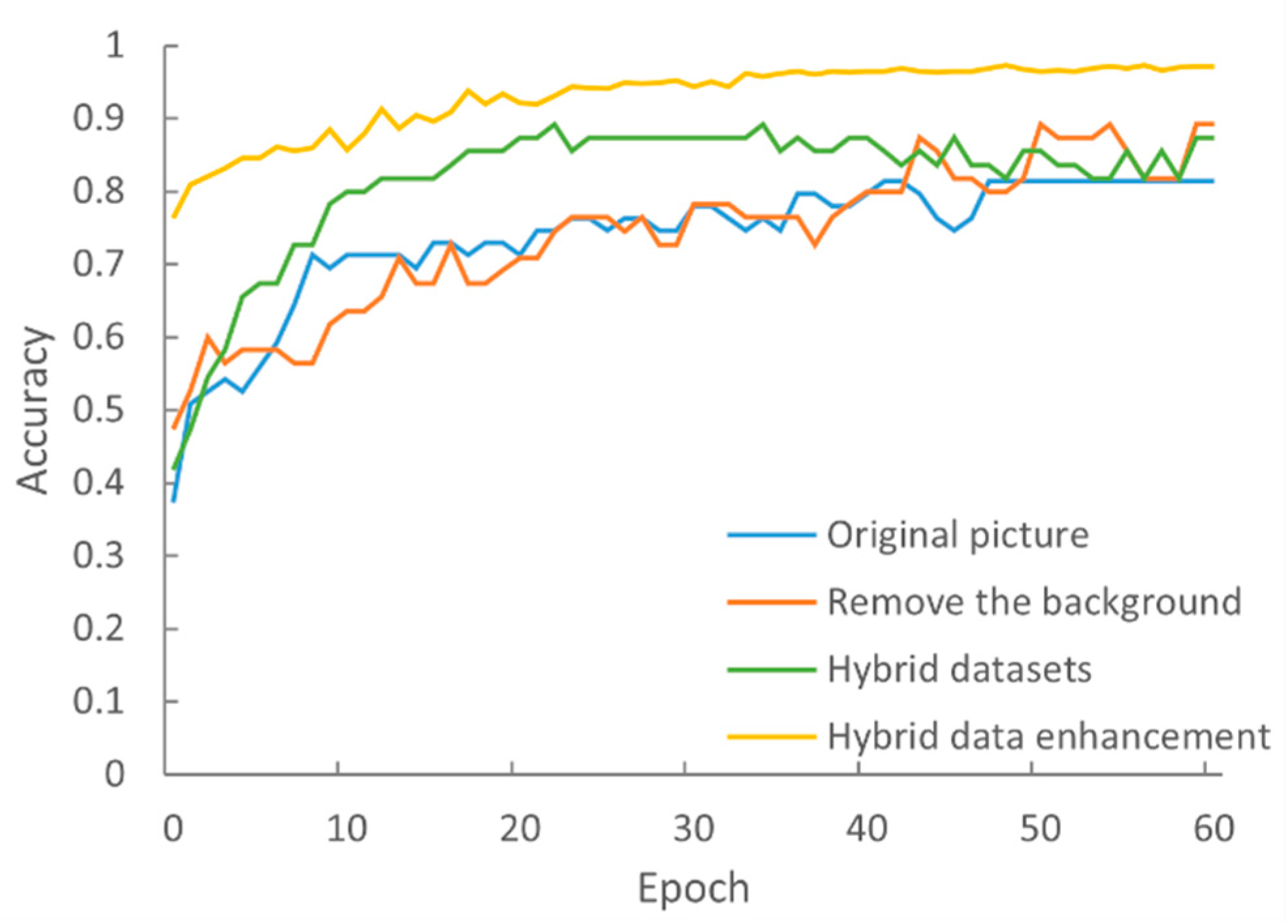
4.3. The Impact of Data Processing on the Accuracy of the Model
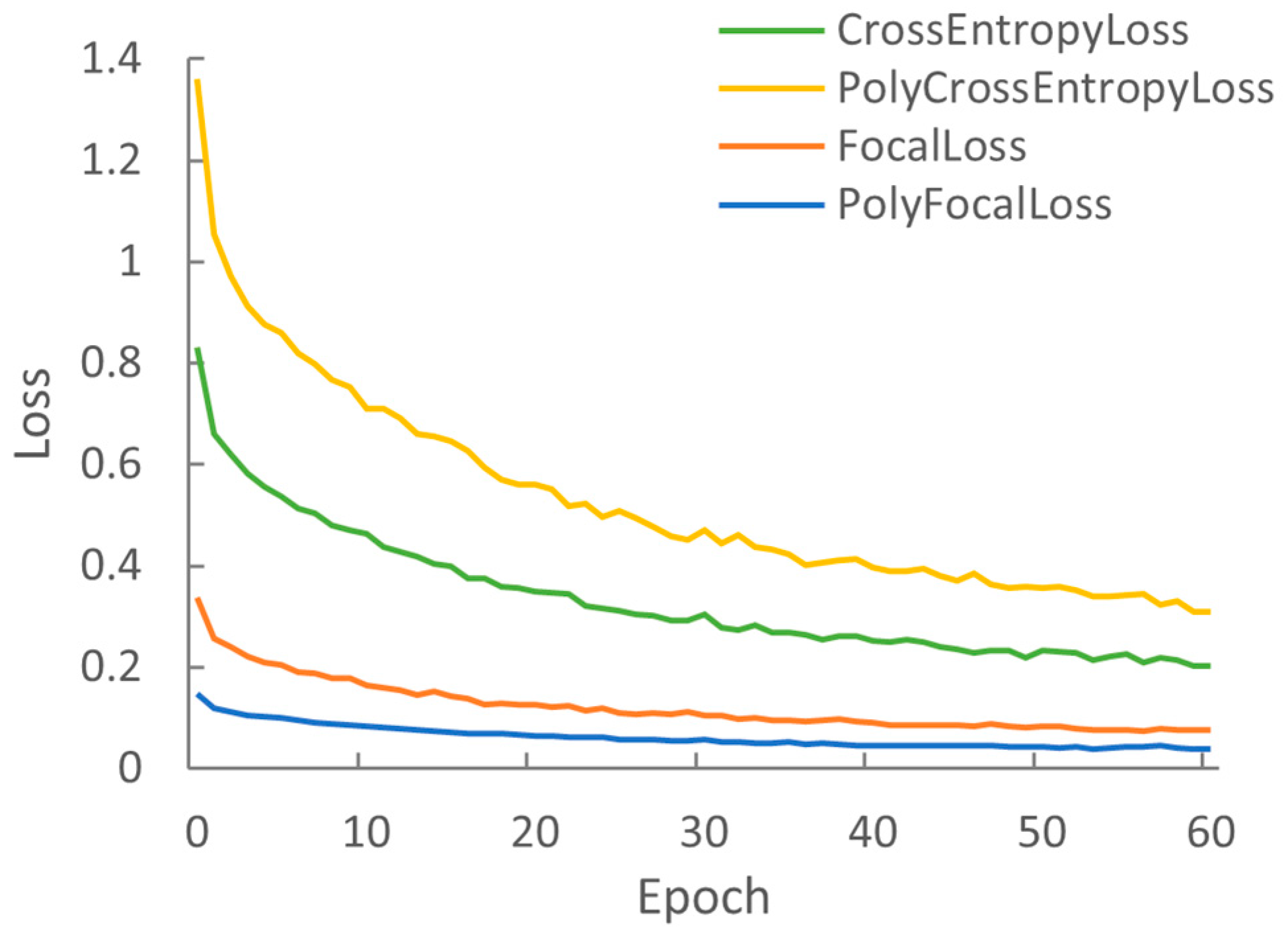
4.4. Comparative Test of Loss Function
4.5. Comparative Test of the Attention Mechanism
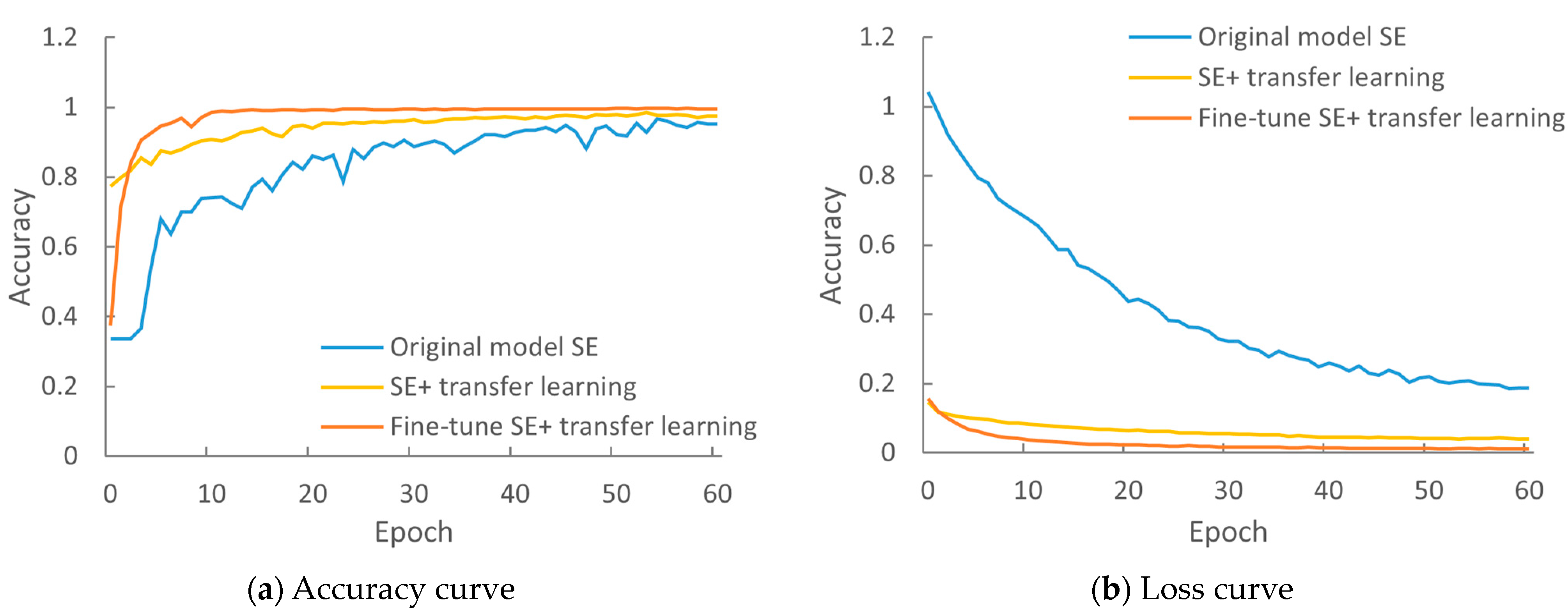
4.6. Improved Model Evaluation
4.7. Comparison of Recognition Performance of Different Models
4.8. Visual Result Verification
4.9. Improvement of Mobilenet_V3 Compared to State-of-the-Art Methods
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jorge, C.G.; Pardo, J.E.; Manuel, A.O.; Eulogio, L.M.; Zied, D.C.; Arturo, P.G. An intelligent mushroom strain selection model based on their quality characteristics. Food Biosci. 2023, 56, 103232. [Google Scholar]
- China Edible Mushroom Association (CEMA). Analysis of the survey results of the national edible fungus statistics in 2021. Chin. Edible Fungi 2023, 42, 118–127. (In Chinese) [Google Scholar]
- Reed, J.N.; Miles, S.J.; Butler, J.; Baldwin, M.; Noble, R. AE—Automation and Emerging Technologies: Automatic Mushroom Harvester Development. J. Agric. Eng. Res. 2001, 78, 15–23. [Google Scholar] [CrossRef]
- Gulzar, Y.; Ünal, Z.; Aktaş, H.; Mir, M.S. Harnessing the Power of Transfer Learning in Sunflower Disease Detection: A Comparative Study. Agriculture 2023, 13, 1479. [Google Scholar] [CrossRef]
- Gulzar, Y. Fruit Image Classification Model Based on MobileNetV2 with Deep Transfer Learning Technique. Sustainability 2023, 15, 1906. [Google Scholar] [CrossRef]
- Dhiman, P.; Kaur, A.; Balasaraswathi, V.R.; Gulzar, Y.; Alwan, A.A.; Hamid, Y. Image Acquisition, Preprocessing and Classification of Citrus Fruit Diseases: A Systematic Literature Review. Sustainability 2023, 15, 9643. [Google Scholar] [CrossRef]
- Mamat, N.; Othman, M.F.; Abdulghafor, R.; Alwan, A.A.; Gulzar, Y. Enhancing Image Annotation Technique of Fruit Classification Using a Deep Learning Approach. Sustainability 2023, 15, 901. [Google Scholar] [CrossRef]
- Liu, Q.; Fang, M.; Li, Y.S.; Gao, M.W. Deep learning based research on quality classification of shiitake mushrooms. LWT 2022, 168, 113902. [Google Scholar] [CrossRef]
- Liu, Y.S.; Zhou, S.B.; Han, W.; Liu, W.X.; Qiu, Z.F.; Li, C. Convolutional neural network for hyperspectral data analysis and effective wavelengths selection. Anal. Chim. Acta 2019, 1086, 46–54. [Google Scholar] [CrossRef]
- Wang, X.Y.; Li, Y.X.; Yang, Z.Y.; Zhang, M.; Wang, R.M.; Cui, L.X. Detection Method of Clods and Stones from Impurified Potatoes Based on Improved YOLO v4 Algorithm. Trans. Chin. Soc. Agric. Mach. 2021, 52, 241–247. [Google Scholar]
- Medeiros, A.D.; Bernardes, R.C.; Silva, L.J.; Freitas, B.A.L.; Santos Dias, D.C.F.; Silva, C.B. Deep learning-based approach using x-ray images for classifying crambe abyssinica seed quality. Ind. Crops Prod. 2021, 164, 113378. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, G.H. Stud pose detection based on photometric stereo and lightweight YOLOv4. CAAI Trans. Intell. Technol. 2022, 2, 32–37. [Google Scholar] [CrossRef]
- Zou, Q.J.; Xiong, K.; Fang, Q.; Jiang, B.H. Deep imitation reinforcement learning for self-driving by vision. CAAI Trans. Intell. Technol. 2021, 6, 493–503. [Google Scholar] [CrossRef]
- Liu, Y.M.; Wang, Z.L.; Wang, R.J.; Chen, J.S.; Gao, H.J.; Jia, S.J.; Wang, P.; Jia, P.V. Flooding-based MobileNet to identify cucumber diseases from leaf images in natural scenes. Comput. Electron. Agric. 2023, 213, 108166. [Google Scholar] [CrossRef]
- Jia, S.J.; Wang, P.; Jia, P.Y.; Hu, S.P. Research on data augmentation for image classification based on convolution neural networks. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017. [Google Scholar]
- Shi, C.; Xia, R.; Wang, L. A novel multi-branch channel expansion network for garbage image classification. IEEE Access 2020, 8, 154436–154452. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Leng, Z.Q.; Tan, X.M.; Liu, X.C.; Cubuk, E.D.; Shi, X.J.; Cheng, S.Y.; Anguelov, D. Polyloss: A polynomial expansion perspective of classification loss functions. arXiv 2022, arXiv:2204.12511. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Fei, Z.G.; Wu, Z.Y.; Xiao, Y.Q.; Ma, J.; He, W.B. A new short-arc fitting method with high precision using Adam optimization algorithm. Optik 2020, 212, 164788. [Google Scholar] [CrossRef]
- Sun, J.; Zhu, W.D.; Luo, Y.Q. Recognizing the diseases of crop leaves in fields using improved Mobilenet-V2. Trans. CSAE 2021, 37, 161–169. (In Chinese) [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conferenceon Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Roy, A.G.; Navab, N.; Wachinger, C. Concurrent spatial and channel‘squeeze & excitation’in fully convolutional networks. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 421–429. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Christian, S.; Liu, W.; Jia, Y.Q.; Pierre, S.; Scott, R.; Dragomir, A.; Dumitru, E.; Vicent, V.; Andrew, R. Going deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.J.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical guidelines for efficient cnn architecture design. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 122–138. [Google Scholar]
- Tan, M.; Le, Q. Efficientnetv2: Smaller Models and Faster Training. International conference on machine learning. PMLR 2021, 139, 10096–10106. [Google Scholar]
- Selvaraju, R.R.; Cogewell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Ban, Z.; Fang, C.; Liu, L.; Wu, Z.; Chen, C.; Zhu, Y. Detection of Fundamental Quality Traits of Winter Jujube Based on Computer Vision and Deep Learning. Agronomy 2023, 13, 2095. [Google Scholar] [CrossRef]
- Jiang, H.W.; Zhang, S.L.; Yang, Z.; Zhao, L.K.; Zhou, Y.; Zhou, D.X. Quality classification of stored wheat based on evidence reasoning rule and stacking ensemble learning. Comput. Electron. Agric. 2023, 214, 108339. [Google Scholar] [CrossRef]
- Wang, L.; Dong, P.H.; Wang, Q.; Jia, K.M.; Niu, Q.F. Dried shiitake mushroom grade recognition using D-VGG network and machine vision. Front. Nutr. 2023, 10, 1247075. [Google Scholar] [CrossRef]
- Du, J.; Zhang, M.; Teng, X.X.; Wang, Y.C.; Law, C.L.; Fang, D.C.; Liu, K. Evaluation of vegetable sauerkraut quality during storage based on convolution neural network. Food Res. Int. 2023, 164, 112420. [Google Scholar] [CrossRef]
- Yang, Z.; Li, Z.; Hu, N.; Zhang, M.; Zhang, W.; Gao, L.; Ding, X.; Qi, Z.; Duan, S. Multi-Index Grading Method for Pear Appearance Quality Based on Machine Vision. Agriculture 2023, 13, 290. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicator Level | First Class | Second Class | Third Class |
|---|---|---|---|
| The degree of opening of shiitake mushrooms | Half open | Fully open | - |
| Mushroom cap contour curvature | Full | Flat | - |
| Appearance defect | No | No | Yes |
| Data Division | Original Image/Removed Background Image | Mixed Data Set | Enhanced Data Set | ||||||
|---|---|---|---|---|---|---|---|---|---|
| First Class | Second Class | Third Class | First Class | Second Class | Third Class | First Class | Second Class | Third Class | |
| Training data set | 76 | 74 | 72 | 152 | 148 | 144 | 3007 | 2943 | 2844 |
| Verification data set | 9 | 9 | 9 | 18 | 18 | 18 | 376 | 368 | 355 |
| Test data set | 9 | 9 | 8 | 18 | 18 | 16 | 375 | 367 | 356 |
| Input | Operator | Exp Size | #out | SE | NL | s |
|---|---|---|---|---|---|---|
| 2242 × 3 | conv2d | - | 16 | - | HS | 2 |
| 1122 × 16 | bneck, 3 × 3 | 16 | 16 | - | RE | 1 |
| 1122 × 16 | bneck, 3 × 3 | 64 | 24 | - | RE | 2 |
| 562 × 24 | bneck, 3 × 3 | 72 | 24 | - | RE | 1 |
| 562 × 24 | bneck, 5 × 5 | 72 | 40 | √ | RE | 2 |
| 282 × 40 | bneck, 5 × 5 | 120 | 40 | √ | RE | 1 |
| 282 × 40 | bneck, 5 × 5 | 120 | 40 | √ | RE | 1 |
| 282 × 40 | bneck, 3 × 3 | 240 | 80 | - | HS | 2 |
| 142 × 80 | bneck, 3 × 3 | 200 | 80 | - | HS | 1 |
| 142 × 80 | bneck, 3 × 3 | 184 | 80 | - | HS | 1 |
| 142 × 80 | bneck, 3 × 3 | 184 | 80 | - | HS | 1 |
| 142 × 80 | bneck, 3 × 3 | 480 | 112 | √ | HS | 1 |
| 142 × 112 | bneck, 3 × 3 | 672 | 112 | √ | HS | 1 |
| 142 × 112 | bneck, 5 × 5 | 672 | 160 | √ | HS | 2 |
| 72 × 160 | bneck, 5 × 5 | 960 | 160 | √ | HS | 1 |
| 72 × 160 | bneck, 5 × 5 | 960 | 160 | √ | HS | 1 |
| 72 × 160 | conv2d, 1 × 1 | - | 960 | - | HS | 1 |
| 72 × 960 | pool, 7 × 7 | - | - | - | - | 1 |
| 12 × 960 | conv2d 1 × 1, NBN | - | 1280 | - | HS | 1 |
| 12 × 1280 | conv2d 1 × 1, NBN | - | k | - | - | 1 |
| Data Set | Accuracy on the Training Data Set (%) | Accuracy on the Test Set (%) |
|---|---|---|
| Original image | 81.4 | 81.1 |
| Removed background | 89.1 | 86.8 |
| Mixed data | 89.1 | 90.7 |
| Mixed data enhanced | 97.3 | 97.2 |
| Loss Function | Accuracy (%) | Precision (%) | Recall (%) | F1 |
|---|---|---|---|---|
| CrossEntropyLoss | 97.18 | 97.17 | 97.20 | 97.18 |
| PolyCrossEntropyLoss | 97.81 | 97.83 | 97.83 | 97.83 |
| FocalLoss | 98.18 | 98.20 | 98.18 | 98.19 |
| PolyFocalLoss | 98.45 | 98.48 | 98.45 | 98.46 |
| Test Number | Attention Module | Whether to Migrate to Learn | Accuracy (%) | Precision (%) | Recall (%) | F1 | Model Size (M) |
|---|---|---|---|---|---|---|---|
| 1 | SE | no | 97.18 | 97.19 | 97.20 | 97.19 | 16.2 |
| 2 | SE | yes | 98.45 | 98.48 | 98.45 | 98.46 | 16.2 |
| 3 | CBAM | yes | 99.64 | 99.64 | 99.64 | 99.64 | 11.9 |
| 4 | CA | yes | 99.09 | 99.10 | 99.09 | 99.09 | 11.2 |
| 5 | scSE | yes | 99.73 | 99.73 | 99.73 | 99.73 | 22.3 |
| 6 | Improved SE | yes | 99.91 | 99.91 | 99.91 | 99.91 | 11.9 |
| Grade Category | Accuracy (%) | Precision (%) | Recall (%) | F1 |
|---|---|---|---|---|
| First class | 100.00 | 100.00 | 100.00 | 100.00 |
| Second class | 100.00 | 99.72 | 100.00 | 99.86 |
| Third class | 99.72 | 100.00 | 99.72 | 99.86 |
| Avg | 99.91 | 99.91 | 99.91 | 99.91 |
| Model | Migrate to Learn | Accuracy (%) | Precision (%) | Recall (%) | F1 | Model Size (M) |
|---|---|---|---|---|---|---|
| VGG16 | yes | 69.76 | 73.84 | 69.92 | 71.83 | 512 |
| GoogLeNet | no | 74.04 | 82.04 | 74.35 | 78.01 | 38 |
| ResNet50 | yes | 82.24 | 72.90 | 82.24 | 77.29 | 90 |
| MobileNetV1 | no | 90.80 | 91.09 | 90.82 | 90.95 | 12.3 |
| MobileNetV2 | yes | 81.88 | 82.08 | 81.89 | 81.98 | 8.73 |
| MobileNetV3-Large | no | 97.18 | 97.19 | 97.20 | 97.19 | 16.2 |
| ShuffleNetV2×1 | yes | 71.58 | 71.83 | 71.58 | 71.70 | 4.95 |
| EfficientNetV2-s | yes | 97.45 | 97.48 | 97.45 | 97.46 | 77.8 |
| Improved MobileNetV3-Large | yes | 99.91 | 99.91 | 99.91 | 99.91 | 11.9 |
| Paper | Data Set | Classes | Images | Method/Model | Accuracy (%) | Precision (%) | Recall (%) |
|---|---|---|---|---|---|---|---|
| [32] | Winter Jujube | 5 | 20,000 | iResnet-50 | 98.35 | 98.40 | 98.35 |
| [33] | Wheat | 4 | 108 | ER-Stacking | 88.10 | 88.05 | 89.31 |
| [34] | Mushrooom | 6 | 6775 | D-VGG | 96.21 | 96.18 | 96.33 |
| [35] | Sauerkraut | 3 | 2190 | CNN | 95.3 | 93.2 | 92.9 |
| [36] | Pear | 3 | 398 | BP | 91.0 | 91.0 | 91.1 |
| Improved MobilnetV3 | Mushrooom | 3 | 10,991 | MobilnetV3 | 99.91 | 99.91 | 99.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, F.; Sun, Y.; Zhang, Y.; Zhang, W.; Qi, J. An Improved MobileNetV3 Mushroom Quality Classification Model Using Images with Complex Backgrounds. Agronomy 2023, 13, 2924. https://doi.org/10.3390/agronomy13122924
Zhu F, Sun Y, Zhang Y, Zhang W, Qi J. An Improved MobileNetV3 Mushroom Quality Classification Model Using Images with Complex Backgrounds. Agronomy. 2023; 13(12):2924. https://doi.org/10.3390/agronomy13122924
Chicago/Turabian StyleZhu, Fengwu, Yan Sun, Yuqing Zhang, Weijian Zhang, and Ji Qi. 2023. "An Improved MobileNetV3 Mushroom Quality Classification Model Using Images with Complex Backgrounds" Agronomy 13, no. 12: 2924. https://doi.org/10.3390/agronomy13122924
APA StyleZhu, F., Sun, Y., Zhang, Y., Zhang, W., & Qi, J. (2023). An Improved MobileNetV3 Mushroom Quality Classification Model Using Images with Complex Backgrounds. Agronomy, 13(12), 2924. https://doi.org/10.3390/agronomy13122924