1. Introduction
Citrus is one of the most critical global cash crops and one of the most productive fruit categories in the world. In South China, citrus is the fruit tree with the most extensive cultivation area and the most critical economic status [
1]. In 2022, the national citrus production amounted to 6.0389 million tons [
2]. However, due to the complex environment of citrus picking, picking still mainly relies on manual operation, which is the most significant labor input in the fruit production process, accounting for 50% to 70% of the overall workload [
3]. To solve this problem, in recent years, the development of intelligent agriculture has promoted the research of fruit-picking robots [
4]. The vision system is one of the critical components of picking robots [
5], and how to accurately identify and detect citrus fruits in complex environments will directly affect the accuracy and efficiency of the determining robots [
6].
Traditional image techniques for fruit detection usually require manual feature extraction, mainly through features such as color [
7], shape [
8], and texture [
9], and feature extraction is highly dependent on the researcher’s experience. In addition, the detection accuracy is low, and the real-time generalization ability is poor in the case of changing lighting conditions, the presence of occlusion of the fruit [
10], the similarity of the fruit and the background color [
11,
12], and even weather and environmental changes. In addition, the detection and classification of citrus fruits can also be performed using infrared imaging and multispectral imaging techniques [
13,
14,
15,
16,
17], but the equipment cost is high and requires expertise.
With the development of deep learning in recent years, deep convolutional neural network (CNN) has become a mainstream algorithm for fruit target detection due to its strong robustness and generalization ability [
18]. It has been studied by many scholars [
19,
20,
21,
22]. CNN-based target detection algorithms can be divided into two stages and one stage. The two-stage detection algorithm first generates candidate regions that may contain the target through several strategies, and these candidate regions are then passed through a convolutional neural network to classify samples to determine if they contain the target object [
23]. The representative algorithms are Fast R-CNN [
24] and Faster R-CNN [
25]. Using Faster R-CNN, Xiong et al. [
26] conducted experiments on green mandarin oranges in the natural environment, which were divided into different light, size, and numbers to carry out, and the average detection accuracies were 77.45%, 73.53%, and 82.58%, respectively. Juntao et al. [
27] used the Faster R-CNN model to detect green mandarin oranges on the tree, and the average of the test set accuracy (mAP) was 85.49%. The average computation time for seeing a single image was 0.4 s. However, the two-stage detection algorithm suffers from higher complexity and slower detection speed.
The one-stage detection algorithm directly predicts the category probability and location of the output target, which reduces the complexity while increasing the detection speed and thus receives more attention [
28]. The representative algorithms are SSD [
29] and the YOLO series [
30,
31,
32,
33,
34,
35,
36]. Li et al. [
37] proposed a citrus detection algorithm based on improved SSD, with an average accuracy of 87.89%. However, the dataset of the paper was derived from the laboratory and differed from the natural environment. Lv et al. [
38] proposed a citrus recognition method based on improved YOLOv3-LITE with an average precision (AP) value of 92.75%. However, the model occupies a large amount of memory, which could not be more conducive to practical deployment. Mirhaji [
39] et al. used YOLOv4 for detecting and counting oranges in an orchard, with an accuracy, recall, F1, and mAP of 91.23%, 92.8%, 92%, and 90.8%, respectively. However, the method needs to improve its average precision. Chen et al. [
40] used the improved YOLOv4 citrus detection algorithm and pruned the trained model with an average accuracy of 96.04%. Zheng et al. [
41] pruned the backbone of YOLOv4 and removed the redundant portion of the neck network to propose the YOLO BP green citrus detection algorithm with an average precision of 91.55%. Huo et al. [
42] used “Shantanju” citrus collected from Conghua, Guangzhou, and improved the YOLOv5s algorithm to detect and locate mature citrus. The recall rates under uneven, weak, and good lighting were 99.55%, 98.47%, and 98.48, respectively. The average detection time per frame was 78.96 ms. However, the detection speed of this method needs to be improved. Xinyang et al. [
43] improved YOLOv5s by introducing ShuffleNetV2, SimAM attention, and Alpha-IoU using images taken from Foshan citrus orchards in Guangdong Province, as well as pictures acquired from the web, and proposed the YOLO-DoC citrus detection method, with a
p value and a mAP value of 98.8% and 99.1%, respectively, and an FPS of 187. However, the model’s training samples need to be increased. In a study by Liu et al. [
44], by using CA attention, replacing PAFPN with BiFPN, and using the zoom loss function, YOLOv5 was improved to detect four varieties of citrus collected from Lingui City, Guilin, Guangxi, namely, “Kumquat”, “Nanfeng tangerine”, “Fertile tangerine”, and “Shatang tangerine”. “Fertile tangerine” and “Shatang tangerine” were collected from Lingui City, Guilin, Guangxi Province, and the mAP was 98.4% and 98.4%, and the detection time for a single image was 19 ms. However, the number of parameters for this model is large. The above research method supports the application of CNN on citrus detection and provides a reference for designing subsequent algorithms. However, the current citrus detection algorithms need more research on citrus detection work in complex environments.
Table 1 provides the citrus variety, dataset sizes, models used, and experimental results for some references.
Firstly, citrus-picking robots face different fruit sizes, random distribution, fruit overlapping, and branch and leaf shading when picking citrus grown in natural environments. Secondly, the light intensity and angle of light in the natural environment vary randomly, which significantly impacts the image quality. Thirdly, the picking robot will cause blurring of the image due to the varying movement speed when the material is outdoors. Finally, when using models trained by deep convolutional neural networks, they tend to require more significant memory, which could be more conducive to deploying edge devices.
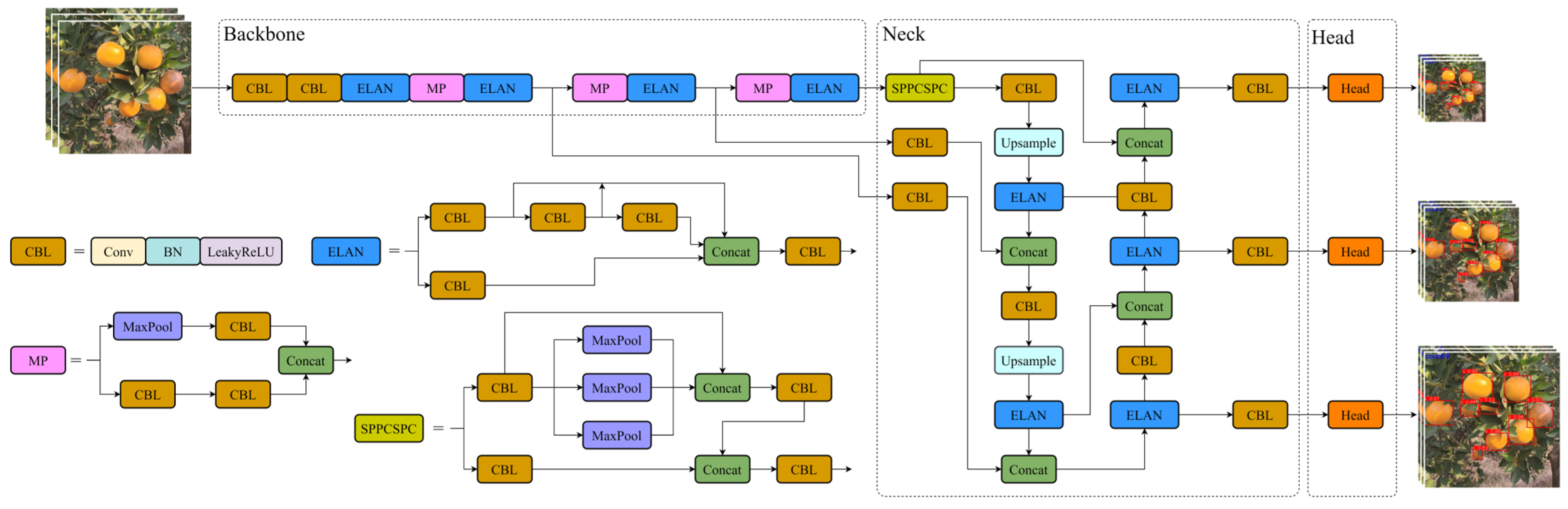
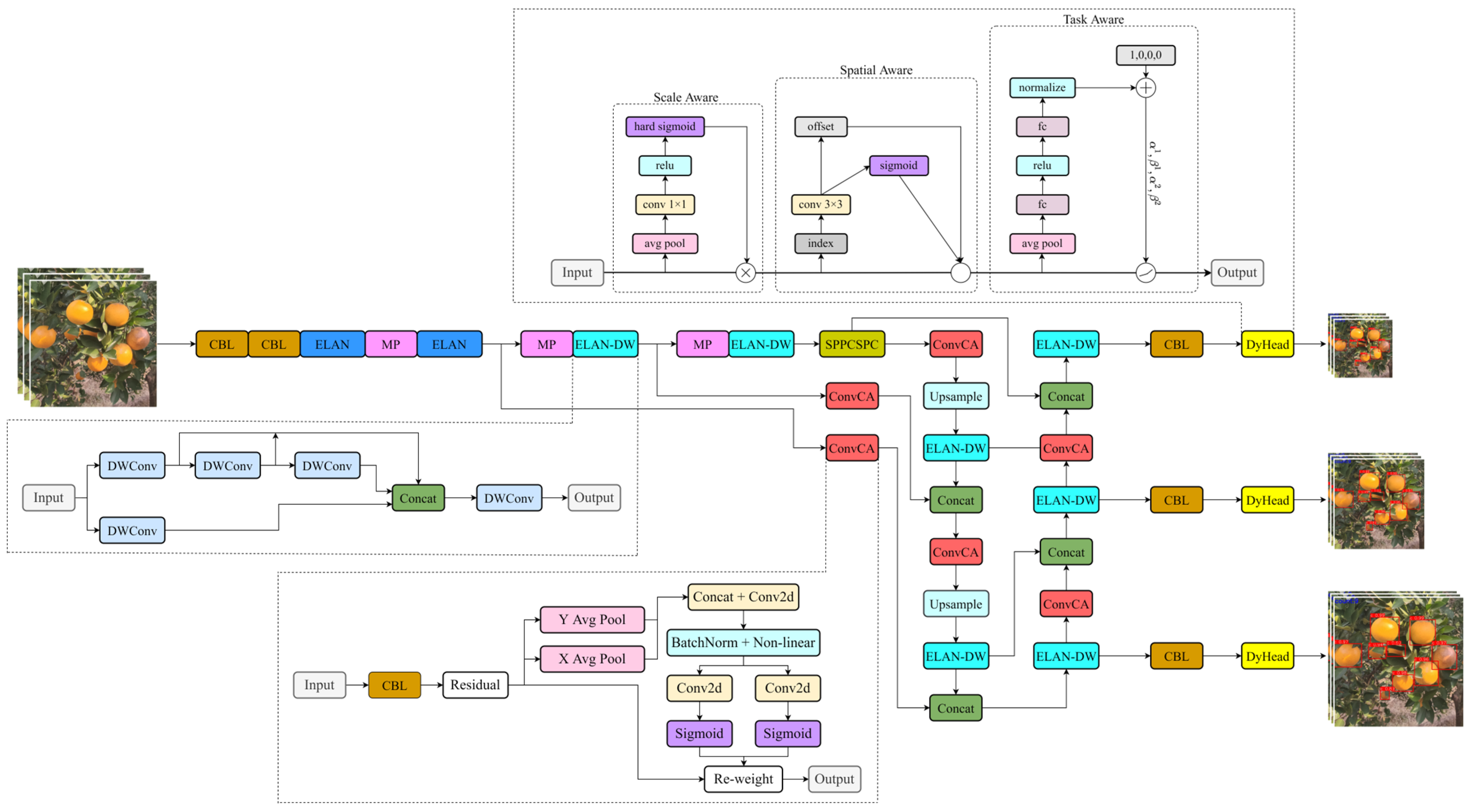
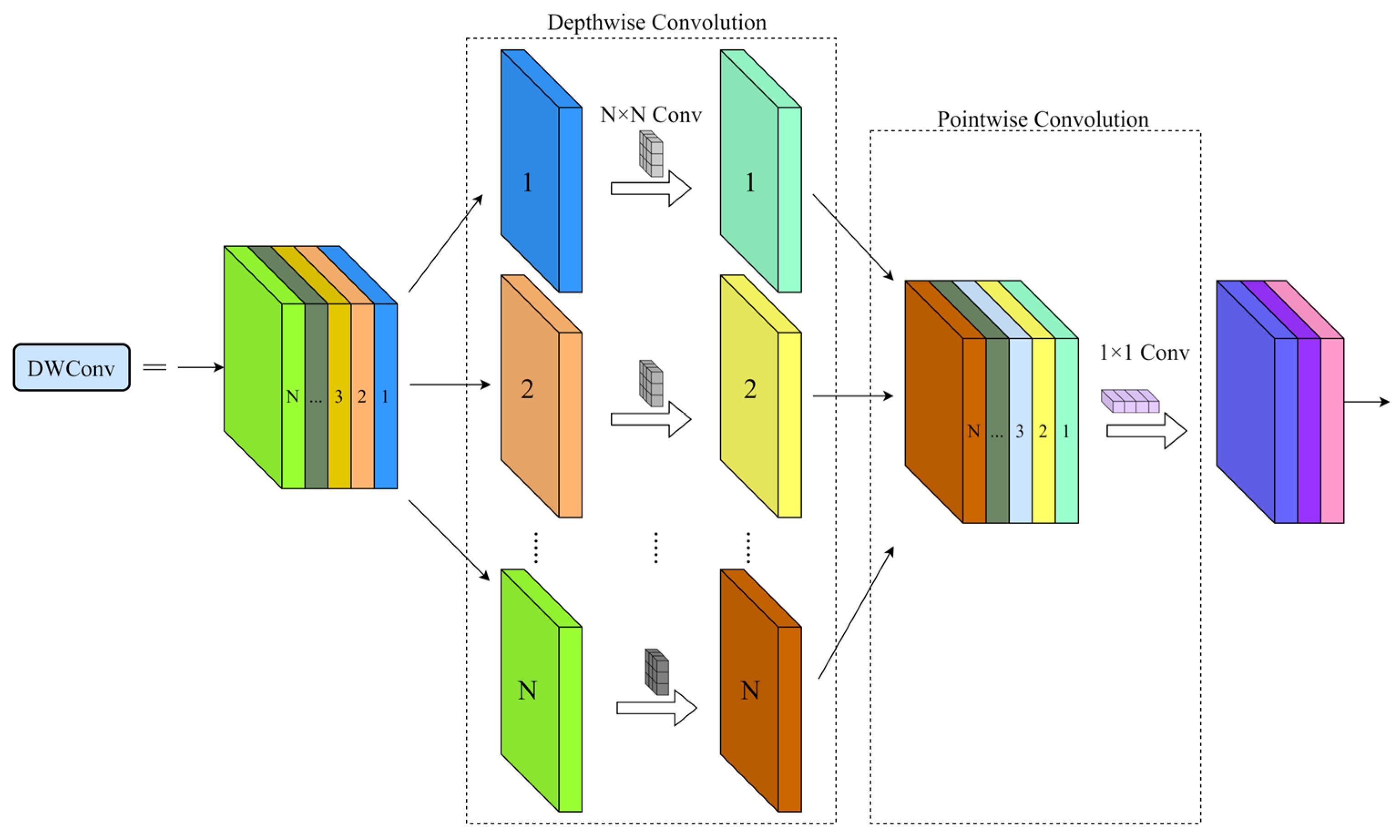
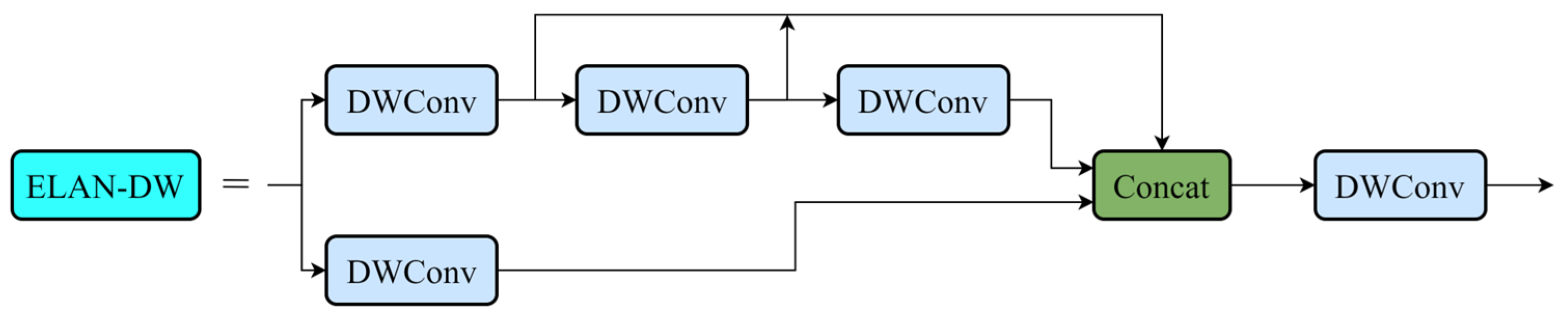
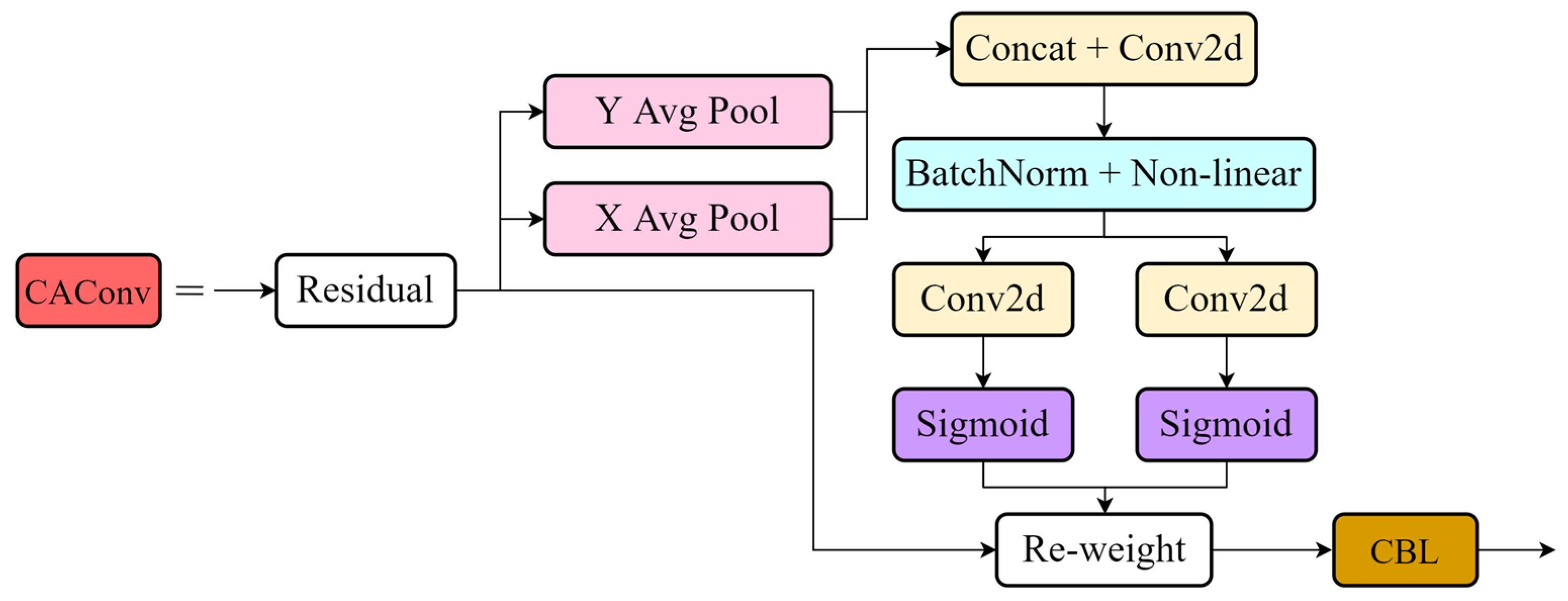
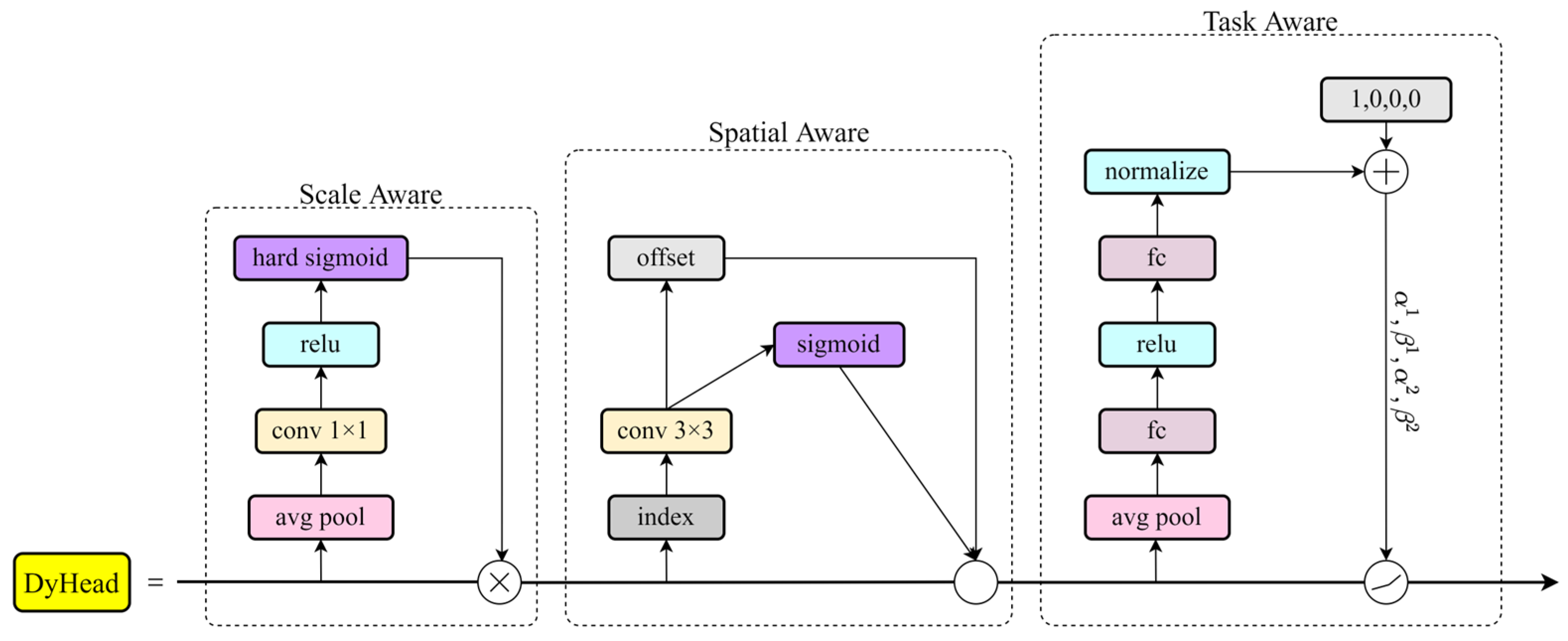
This paper proposes a lightweight citrus detection model based on YOLOv7-tiny for recognizing ripe fruits in a complex citrus orchard environment. By comparing different light backbone networks, the use of depth separable convolution (DWConv) to replace the regular convolution in an efficient layer aggregation network (ELAN) to reduce the number of parameters in the model is finally determined. In the neck network, the coordinate attention mechanism (CA) is combined with ordinary convolution to form CAConv, which is experimentally shown to improve the feature extraction ability of the model. In the detection part, the Dynamic Head is used instead of the ordinary detection head to improve the model’s ability to detect citrus fruits at different scales based on fusing multi-layer features.
The lightweight citrus detection model proposed in this paper can provide vision algorithm support for the picking robot and improve the robot’s environmental adaptability. Meanwhile, this model’s small memory and low computation make it easy to deploy on the robot. In addition, the method proposed in this paper achieves fast real-time detection of citrus.
3. Results and Analysis
3.1. Ablation Experiments
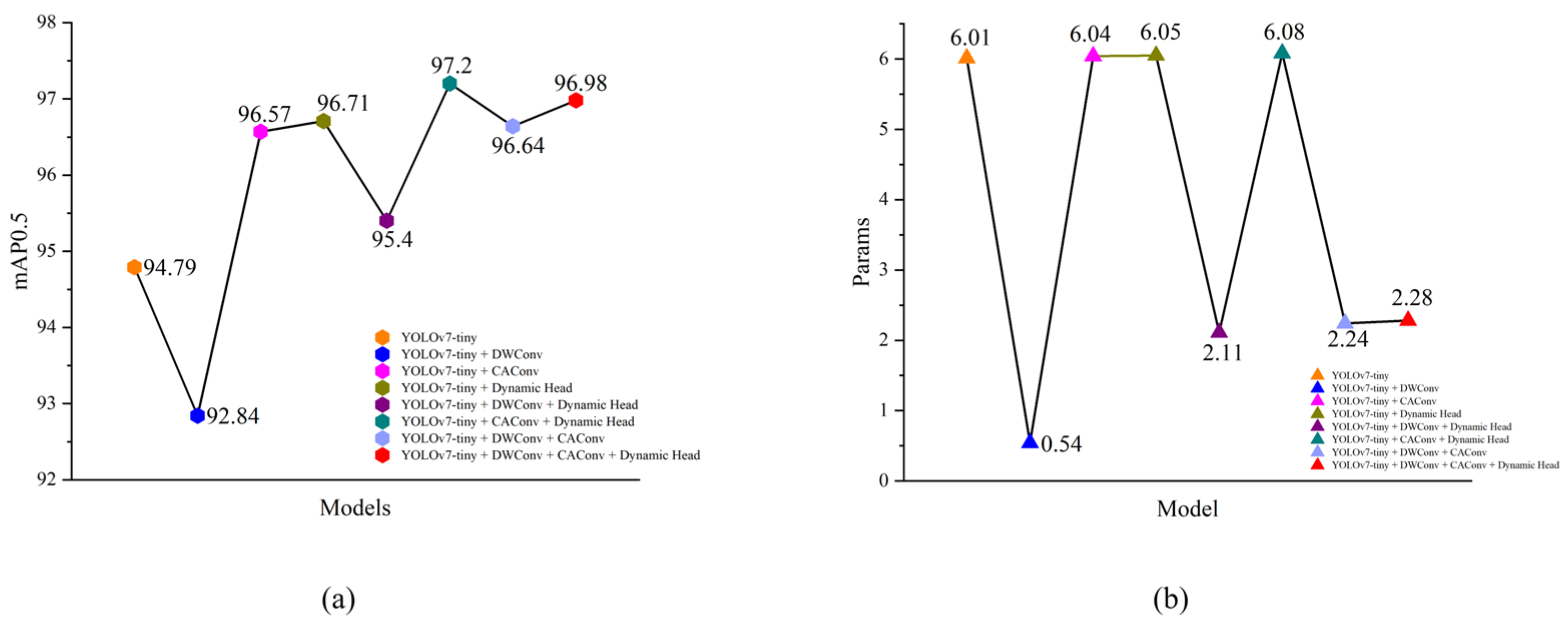
In order to verify the improvement of the model by each module, we conducted experiments on the YOLOv7-tiny network. We replaced the convolution of the backbone network with DWConv, inserted CA in the neck network, and replaced the original detection head with Dynamic Head. Subsequently, we analyzed and evaluated the experimental results presented in
Table 2. Part of the ablation experimental metrics curves are shown in
Figure 12.
According to the experimental results, by replacing the ordinary convolution with DWConv, the number of model parameters is reduced by 91.01%, and mAP is reduced by 1.95% compared to the original model. When adding CA to YOLOv7-tiny, the parameters increased by 0.03 M and mAP improved by 1.78%. Similarly, when adding the Dynamic Head in YOLOv7-tiny instead of the original detection head, the parameters increased by 0.04 M and mAP increased by 1.92%. When adding CA to DWConv, mAP increased by 1.85%, and the parameter count decreased by 3.77 M. After using CA and Dynamic Head, mAP increased by 2.41%, and the number of parameters increased by 0.07 M. When using Dynamic Head after DWConv, mAP increased by 0.61%. The parameter count decreased by 3.90 M. When using all three structures simultaneously, mAP improved by 2.09%, and the parameter count decreased by 3.73 M, providing an even more significant overall performance improvement over the original YOLOv7-tiny.
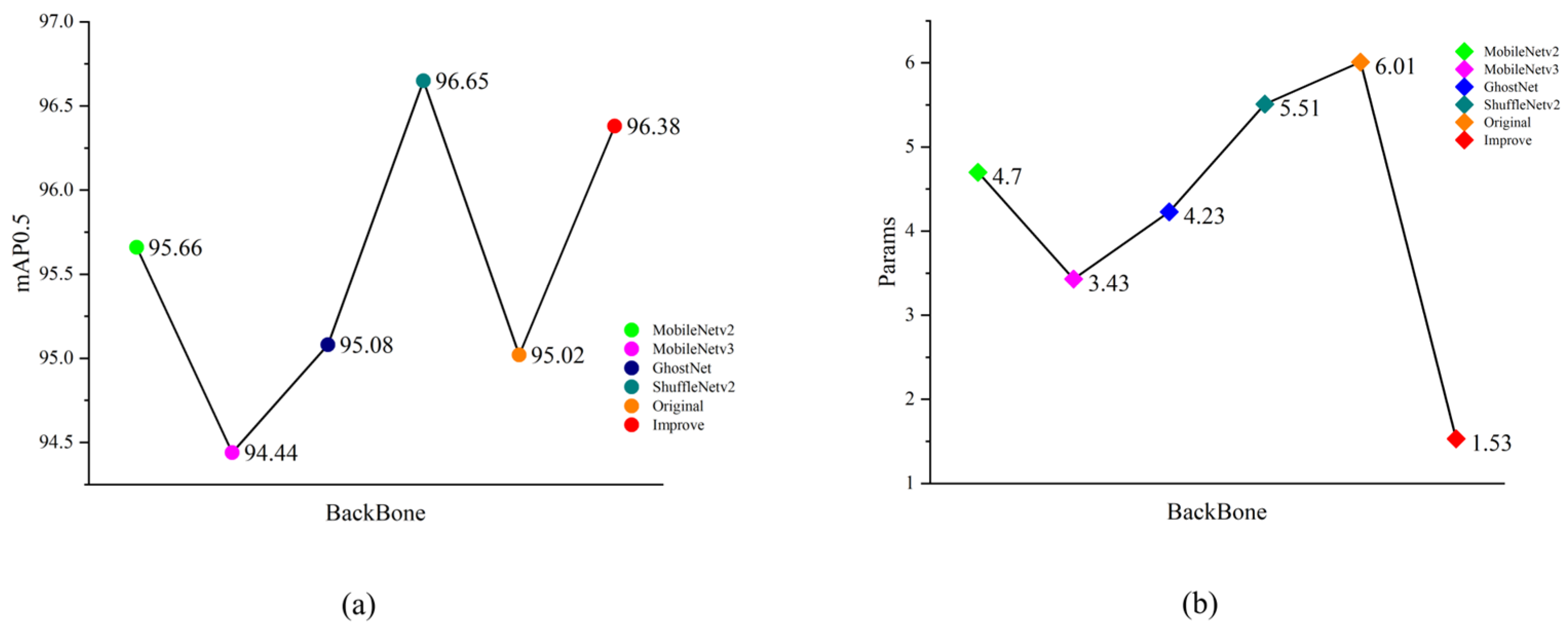
3.2. Comparison of Lightweight BackBone Networks
In order to compare the effectiveness of the lightweight of this model, a commonly used lightweight network is selected as the backbone network of YOLOv7-tiny, and comparative experiments are conducted in this paper. The experimental results are shown in
Table 3. Part of the lightweight backbone experimental metrics curve is shown in
Figure 13.
According to the experimental results, when using MobileNetv2, MobileNetv3, GhostNet, ShuffleNetv2, and the improved backbone network in this paper as the backbone network of YOLOv7-tiny, the number of parameters and the number of floating-point operations (GFLOPs) are reduced to different degrees compared with the original YOLOv7-tiny. Among them, the backbone network that was improved with the DW-CA structure has the most significant reduction, with a 74.5% reduction in parameter quantity and a 69.7% reduction in GFLOPs compared to the original model. The proposed network outperforms the other compared models regarding precision and recall and is only 0.27% lower than the best ShuffleNetv2 on mAP0.5. It can be attributed to the CA module’s ability to fuse features across locations and channels. However, when other parametric metrics are considered together, this slight decrease in average accuracy has an almost negligible effect on YOLOv7-DCA.
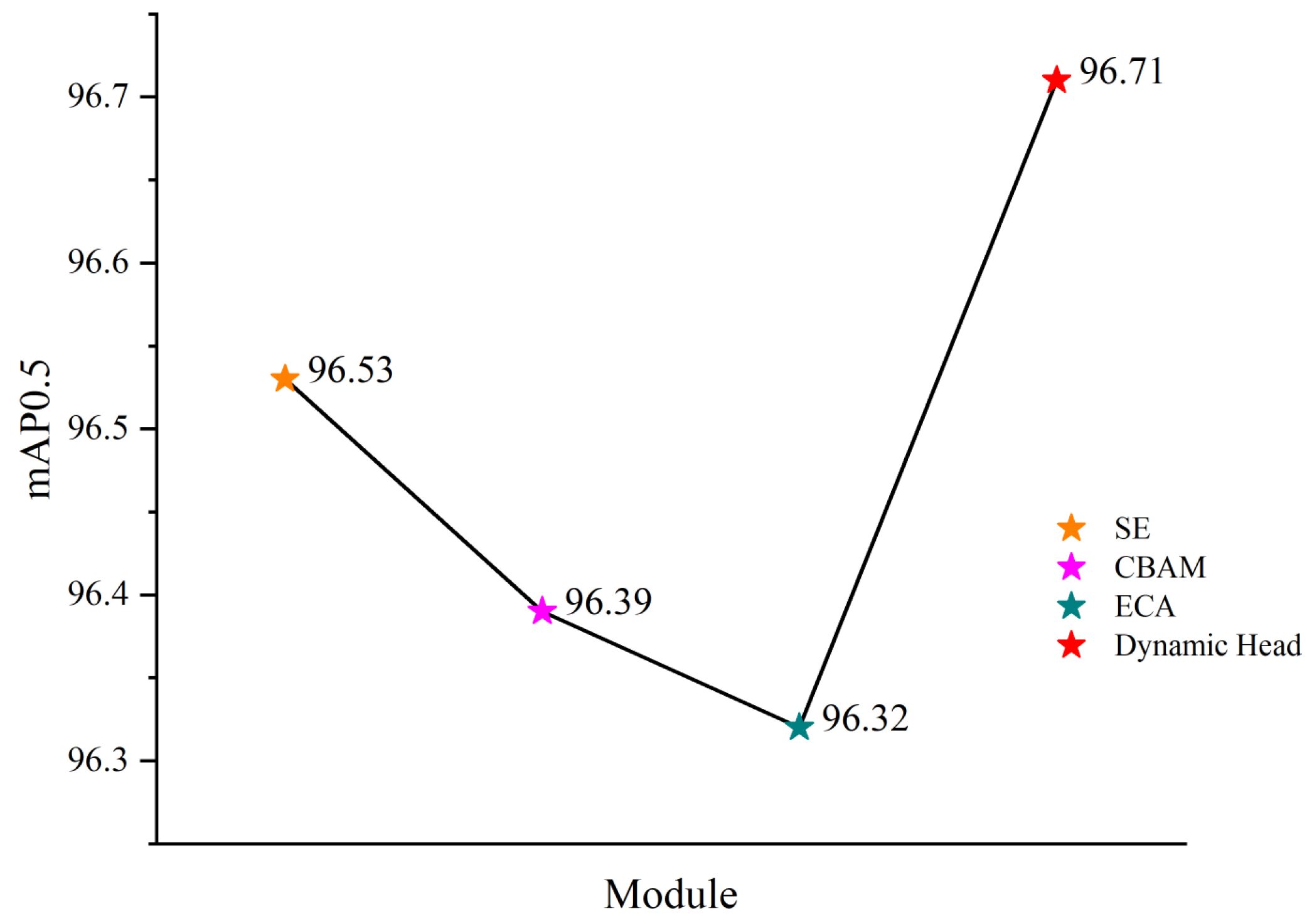
3.3. Attention Detection Head Comparison
Embedding an attention mechanism into the detection head part of a target detection model is a commonly used technique that can help the model’s detection effectiveness. In this paper, we select the commonly used attention mechanisms, SE, CBAM, and ECA, and insert them into the detection head to verify the effectiveness of Dynamic Head (Dynamic Head) in this model; the experimental results are shown in
Table 4. The attention module mAP0.5 metric curve is shown in
Figure 14.
Table 4 shows that the Dynamic Head performs better than other attention detection heads, indicating a more vital generalization ability, robustness, and detection effect. At the same time, the number of parameters added by Dynamic Head is relatively tiny compared to other attention mechanisms, which has little impact on the complexity of the model.
3.4. Comparison of Occluded Object Recognition
In citrus orchards in natural environments, it is often the case that fruits overlap each other, and leaves, branches, and weeds obscure fruits. Losing the contour information of the fruit parts increases the difficulty of fruit detection. When the occlusion becomes severe, the fruit contour information is more lost, and the size information of the occluded part after the feature pyramid transfer becomes less and less, making it difficult to detect. Therefore, the model’s accuracy in detecting citrus with different levels of occlusion must be analyzed. We selected slightly occluded test set A and severely occluded test set B as the test experimental datasets, and the detection results of the Faster R-CNN, YOLOv3, YOLOv4, YOLOv5s, YOLOX-s, YOLOv6s, and YOLOv7 models are shown in
Table 5.
The experimental results show that YOLO-DCA performs the best among all the compared models in the slight occlusion scenario. Under a severe occlusion scenario, YOLOv7 has the highest p value; it is 2.5% higher than YOLO-DCA. However, under the R and mAP metrics, YOLO-DCA performs best at 88.7% and 89.2%, which is 1.5% and 1.7% higher than YOLOv7, respectively. In summary, compared to other models, YOLO-DCA performs better in the comprehensive metrics.
Table 5 displays the detection results of the three models on the test sets under different occlusion degrees. As shown in
Figure 15, slight occlusion does not significantly affect citrus contour and color features, and all models successfully detected the fruit with no leaks. However, Faster R-CNN experienced issues with repeated detection. As shown in
Figure 16, with the occlusion increased, all models except YOLO-DCA struggled with recognition difficulties, resulting in leakage, false detection, and repeated detection. Therefore, YOLO-DCA exhibited superior recognition performance for detecting citrus fruit in severe occlusion. The statistical results of some detection with different occlusion degrees are shown in
Table 6.
3.5. Comparison of Detection under Different Light Conditions
To test the robustness of models in different illumination angles, we selected 30 front-light, 30 side-light, and 30 dark-light images from the mildly occluded dataset A, severely blocked dataset B, and the validation set. We then used them as experimental materials.
Table 7 and
Figure 17 show the corresponding test results. YOLO-DCA’s comprehensive performance in front-light and side-light scenarios is slightly lower than that of YOLOv7. Still, both of them are better than YOLOv7 in dark–light environments. However, the combined performance of all three models decreases in dark–light situations, affecting the model’s detection accuracy due to the loss of fruit color and texture features caused by the lack of light.
Nevertheless, the combined performance of YOLO-DCA is the highest among all models. It indicates that YOLO-DCA is more adaptable to scenes with complex lighting and robust to changes in illumination angles.
Figure 17 shows that YOLOv7-tiny has a leakage problem in the front-light background, while citrus presents a clear texture in the Side-light scene, and there is no leakage of signatures in all models. YOLOv7 has a leakage problem in the Dark-light background. However, YOLO-DCA had no leakage problems in the above three scenarios.
3.6. Comparison of Different Blur Detection
To verify the fault tolerance of YOLO-DCA for blurred images, we randomly selected 30 shots from the unenhanced mildly occluded dataset A and the severely occluded dataset B, totaling 60 images. These images simulate problems in outdoor working environments, such as dirty lenses, mechanical shake, and ambient light variations. In this paper, we investigate the lens shake at different motion movement speeds of the picking robot by applying motion blur operation and setting the blur radius to 11, 31, and 51.
Table 8 displays the statistical results;
Figure 18 displays the test results.
The analysis of the experimental data shows that YOLOv7-tiny, YOLOv7, and YOLO-DCA can accurately detect the target at a blur radius of 11, and YOLOv7 and YOLO-DCA can also accurately identify some targets at a blur radius of 31. However, in the case of a blur radius of 51, YOLOv7-tiny and YOLOv7 cannot remember the main target correctly, while YOLO-DCA can still identify the target accurately. These results show that YOLO-DCA exhibits strong fault tolerance in the face of blurred images.
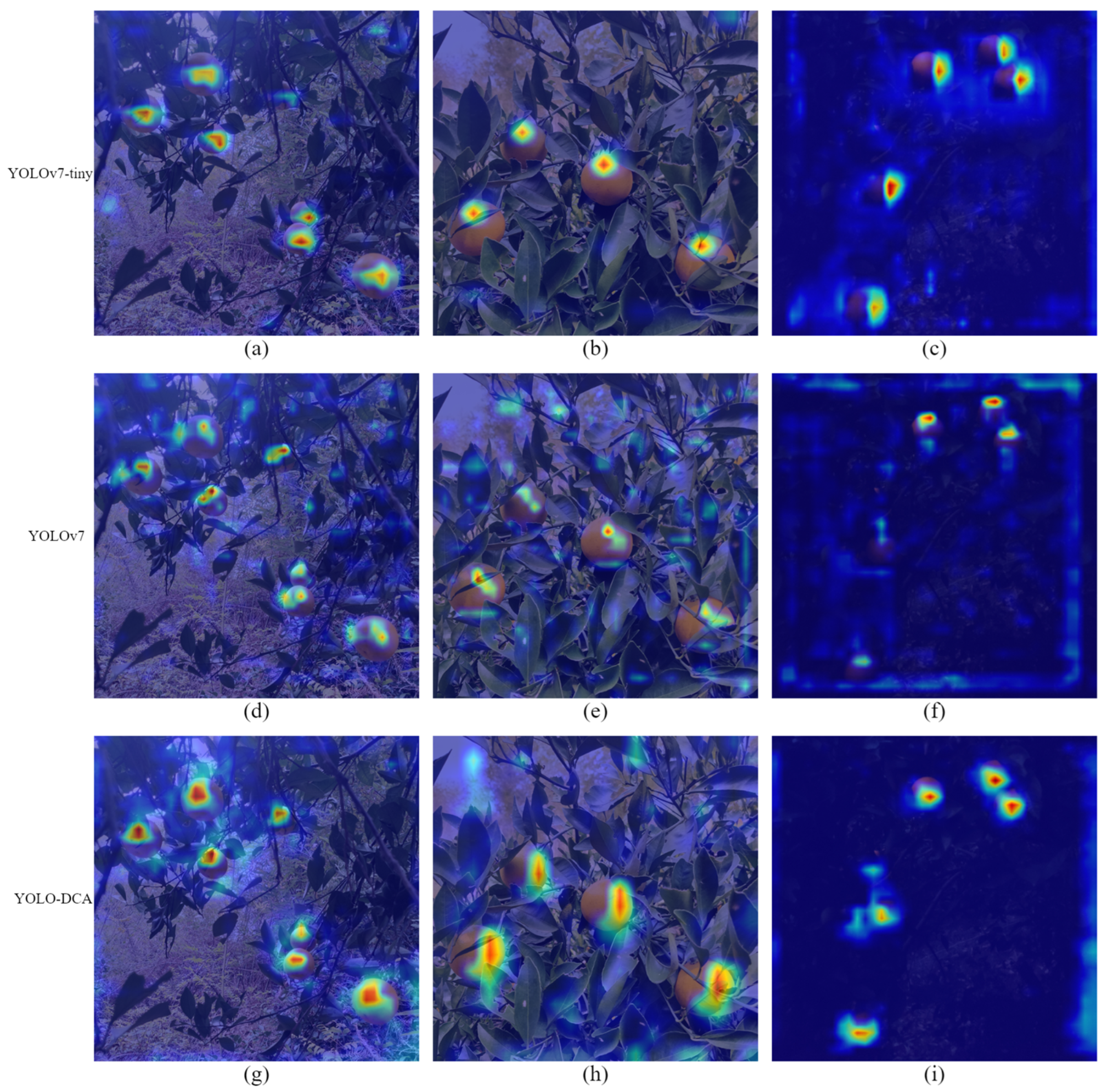
3.7. Visual Analysis of Model
Convolutional neural networks can only obtain detection results when dealing with target detection problems but could not be more interpretable in network processing. Therefore, this study uses visual activation heatmaps to compare the visualization of YOLOv7-tiny, YOLOv7, and the improved YOLO-DCA model to visualize the features extracted after the last convolution for citrus detection. The darker the red region in the heatmap, the more significant the impact of the location on detection and differentiation. As shown in
Figure 19, the feature extraction ability of YOLO-DCA is generally more robust than that of the unimproved YOLOv7-tiny as well as YOLOv7 under different lighting conditions and different disturbing factors. The proposed lightweight citrus target detection model YOLO-DCA is more suitable to be deployed to the citrus picking robotic terminal for citrus recognition.
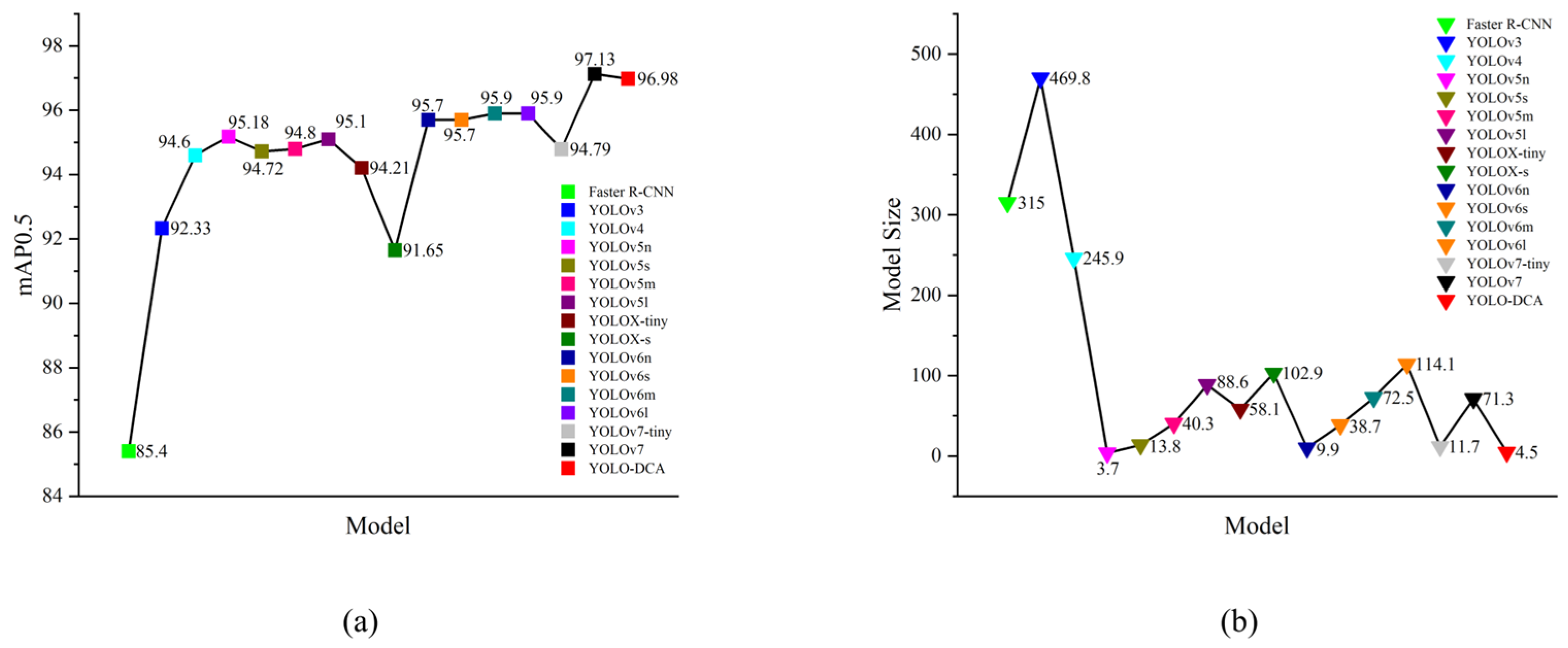
3.8. Comparison of Different Models
To verify the performance of YOLO-DCA, 16 models of Faster R-CNN, YOLOv3, YOLOv4, YOLOv5 series, YOLOv6 series, YOLOX-tiny, YOLOX-S, YOLOv7-tiny, YOLOv7, and YOLO-DCA were selected for comparison.
Table 9 shows the results. Part of the metric curve of the comparison models is shown in
Figure 20.
According to the experimental results, YOLO-DCA is second only to YOLOv5n in terms of GFLOPs, number of parameters, and model size, with an increase of 2.7 GFLOPs, 0.33 M, and 0.8 MB, respectively. Still, it has a better overall performance with a rise of 1.8% and 75.4 FPS in mAP and detection rate, respectively, than YOLOv5n. In addition, YOLO-DCA is second only to YOLOv7 in terms of mAP, which is only 0.15% lower than YOLOv7, but the GFLOPS and Params of YOLO-DCA are 93.5% and 94.24% lower than YOLOv7. Meanwhile, in terms of detection rate, YOLO-DCA has the fastest detection rate among all compared models, with a detection rate of 169.8 FPS.
This paper also compares recent fruit detection methods using YOLOv7 or YOLOv7-tiny despite the existence of different factors such as datasets, experimental environments, hardware equipment, and hyperparameters, which make it impossible to make a fair comparison between related studies, since this paper uses a similar methodology with other researchers, and the subjects of the study are more similar. The evaluation metrics used are similar. We present a discussion of their research results.
Table 10 compares the relevant performance indicators.
The table is incomplete as some data are not in the related literature.
Ma et al. [
57] used an improved YOLOv7-tiny to detect small apple targets using the public dataset MinneApple, and compared to their model, YOLO-DCA has advantages in mAP, detection speed, number of parameters, and model size. Zhang et al. [
58] used a DJI Phantom 4 RTK quadrotor UAV to collect citrus images from Sihui City, Guangdong Province, at an altitude of 50 m above the ground, and improved YOLOv7-tiny for the study. Compared with their model, YOLO-DCA is 6.64% and 40.97 higher in mAP and detection speed, respectively, while Params and Model size only increased by 1.08 M and 0.52 MB. Liu et al. [
59] used yellow peach images collected from the yellow peach plantation in Daping Village, Jinggangshan City, Jiangxi Province, and improved YOLOv7-tiny to conduct the study. Compared with their model, YOLO-DCA has advantages regarding mAP, detection speed, and model size. Compared with the above models, YOLO-DCA balances the detection speed, model parameters, and model size while improving the accuracy.
Combining the above results, YOLO-DCA has better overall performance among all the compared models, ensures the accuracy of the model while significantly reducing the number of model parameters and computation, and has a relatively high detection speed, which makes it more suitable for edge devices, resource-constrained platforms, and the deployment of mobile applications.


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}