
Deep-Learning-Based Automated Palm Tree Counting and Geolocation in Large Farms from Aerial Geotagged Images



Abstract
:1. Introduction
2. Theoretical Overview
2.1. YOLOv3
- Localization loss: we try to maximize the overlap between the ground-truth bounding box of the object and the predicted one.
- Classification loss: the difference between the predicted vector probabilities over the classes and the true one.
- Confidence loss: the disparity metric between the real box confidence score and the predicted one.
- : This is the weight of the localization loss.
- : This is the specific weight of the confidence loss for boxes that do not contain objects.
- : This is an indicator function. It is equal to 1 if the object exists in the cell , and 0 otherwise.
- : This is also a binary weight. It is equal to 1 if the th bounding box is responsible for the prediction, and 0 otherwise.
- is the ground truth of x while is its predicted value. Similarly for other variables: y, (width), and h.
- C: This is the confidence score estimated for the bounding box.
- : The ground truth probability that the th grid cell belongs to the class c, while denotes the predicted probability by YOLOv3.
2.2. YOLOv4
2.2.1. Bag of Freebies (BoF)
2.2.2. Bag of Specials (BoS)
2.3. Faster R-CNN
- is the probability that the ith anchor inside a mini-batch corresponds to an object; this probability is generated by the network.
- is a binary value that equals 1 if the anchor is positive, and 0 otherwise. The anchor is positive if it has one highest IoU overlap with one ground-truth box or the IoU overlap with the ground-truth box is superior to 0.7. The anchor is negative if, for all the ground-truth boxes, the IoU overlap is inferior to 0.3.
- corresponds to the coordinates of the bounding box predicted by the network.
- corresponds to the ground-truth bounding box’s coordinates for which the anchor is positive.
- corresponds to the classification loss.
- corresponds to the regression loss.
- and are the normalization factors.
- corresponds to the weight used to balance the two losses.
2.4. Efficient-Det
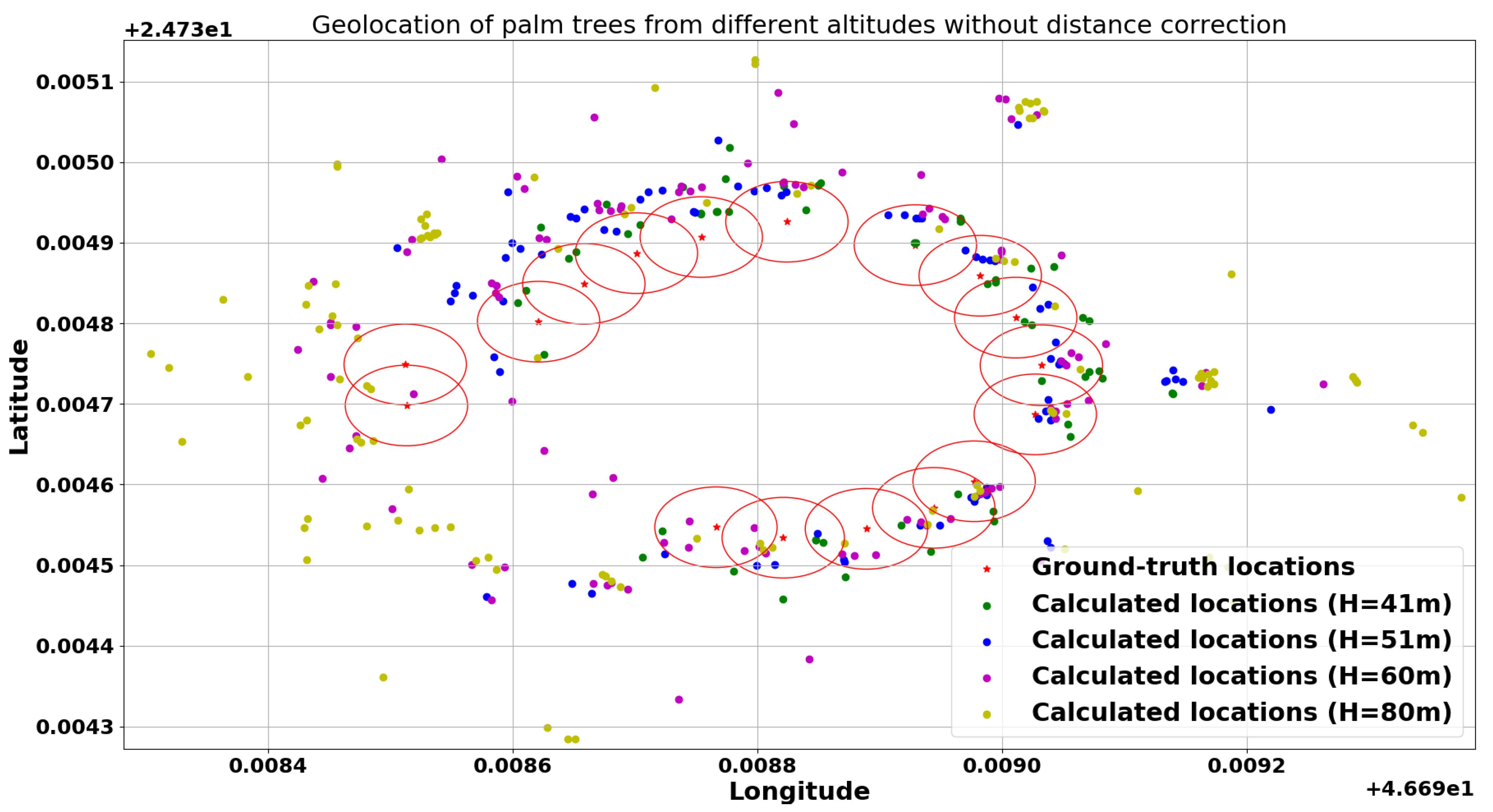
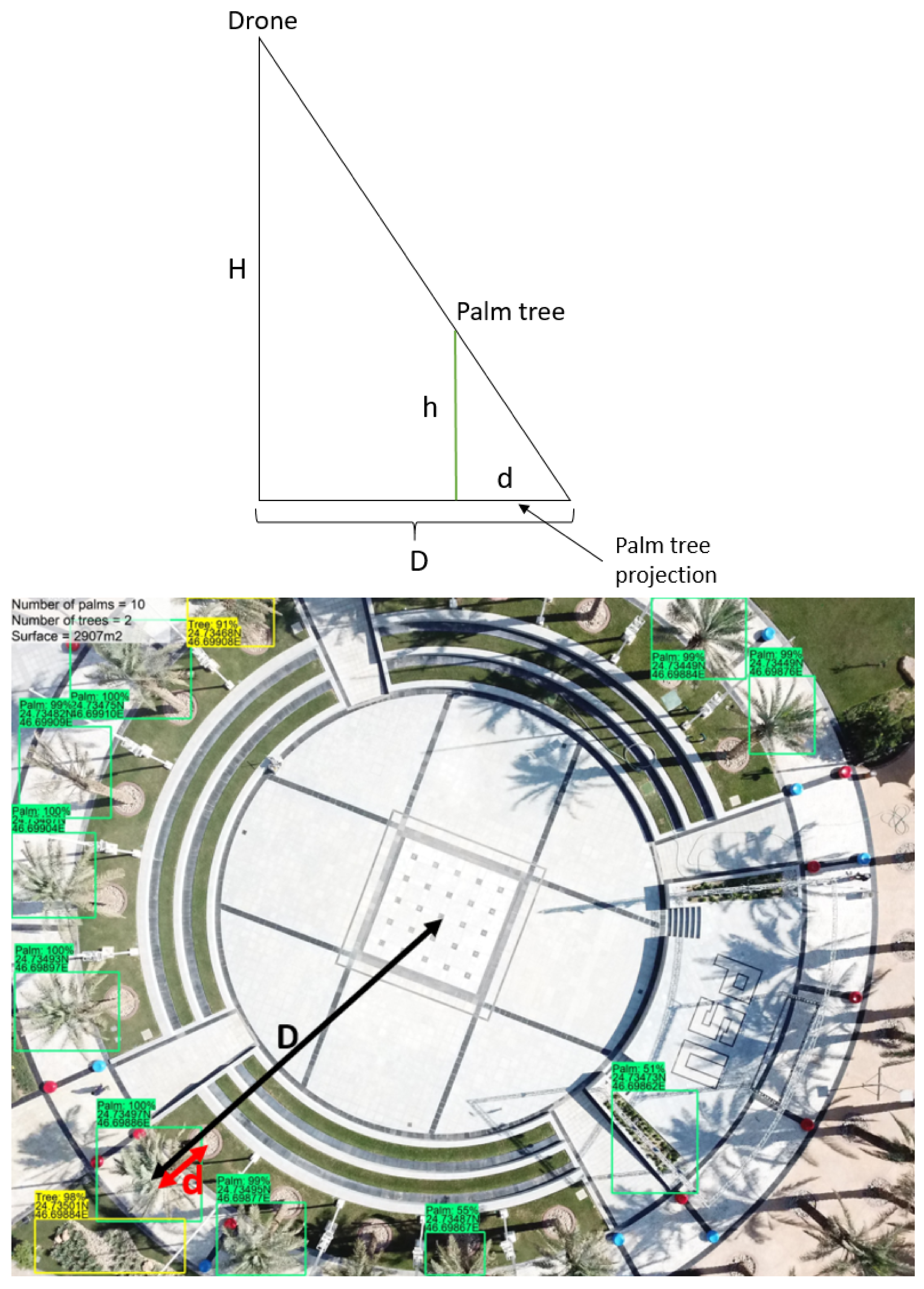
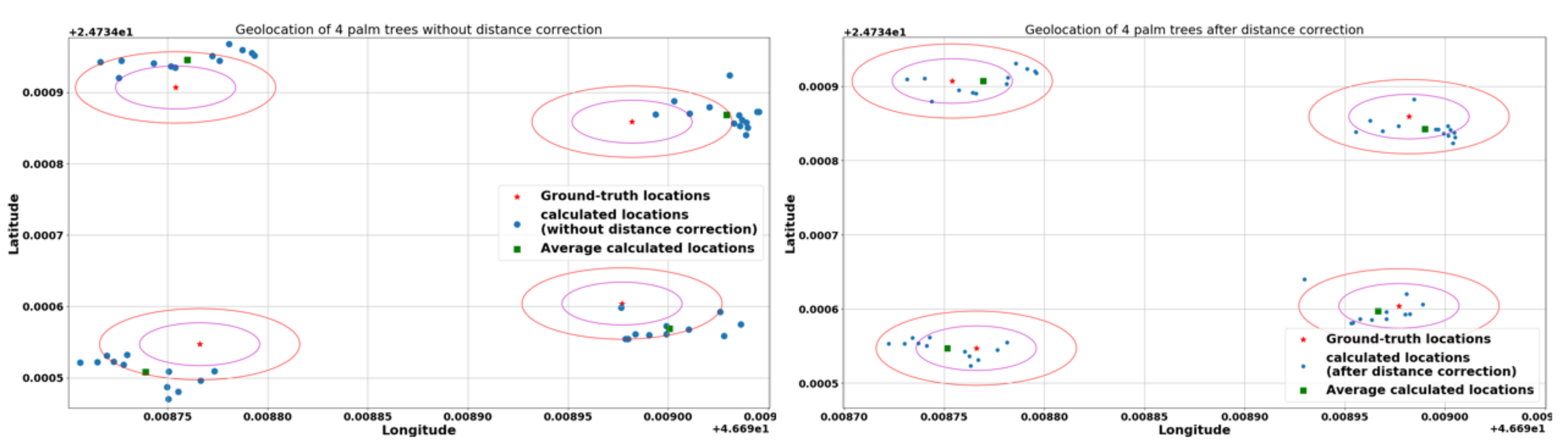
2.5. Geolocation
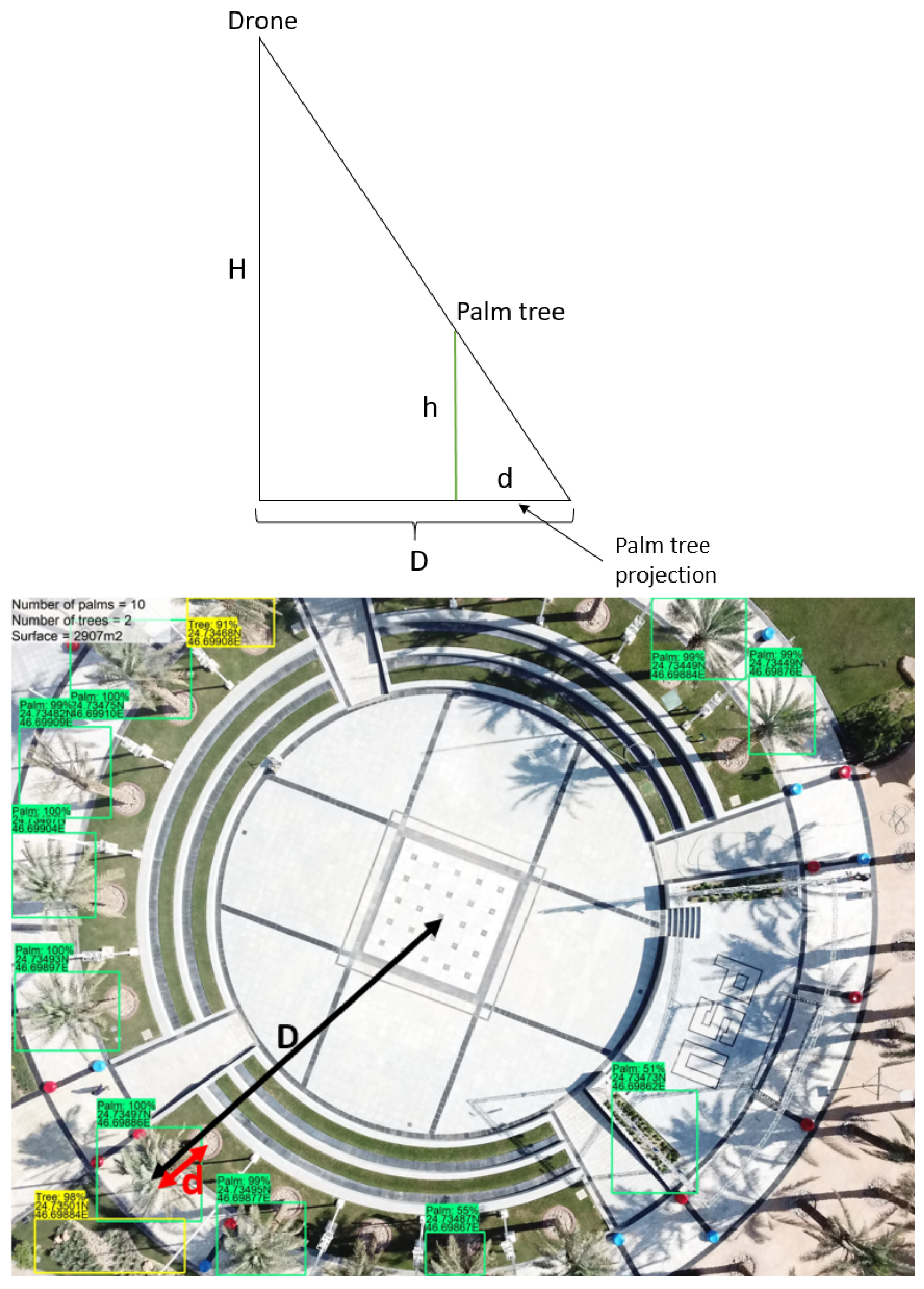
2.5.1. Calculation of the Distance to Image Center
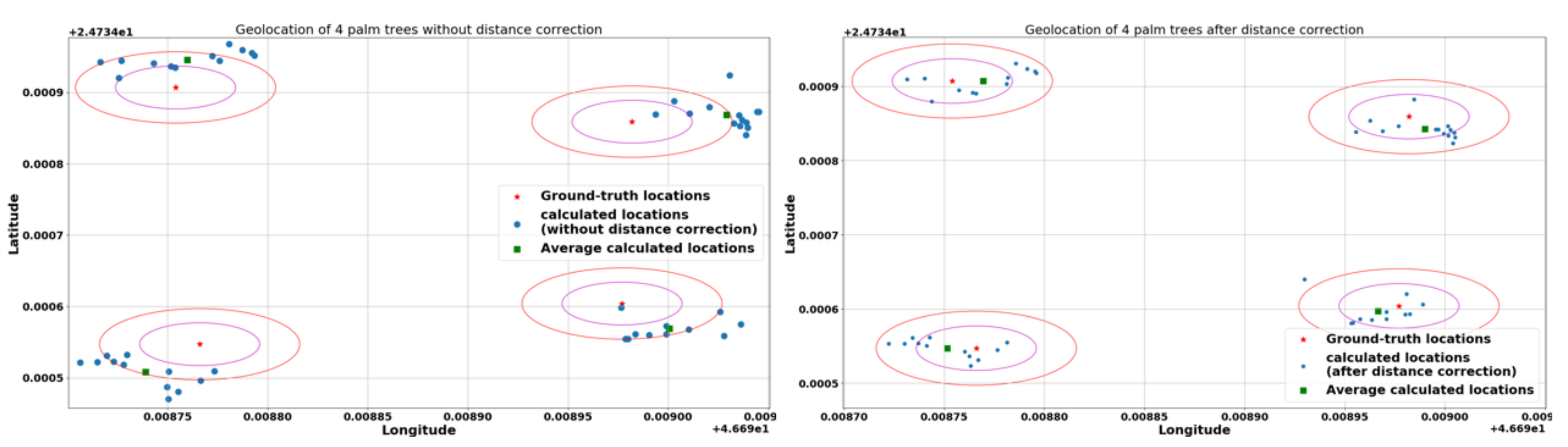
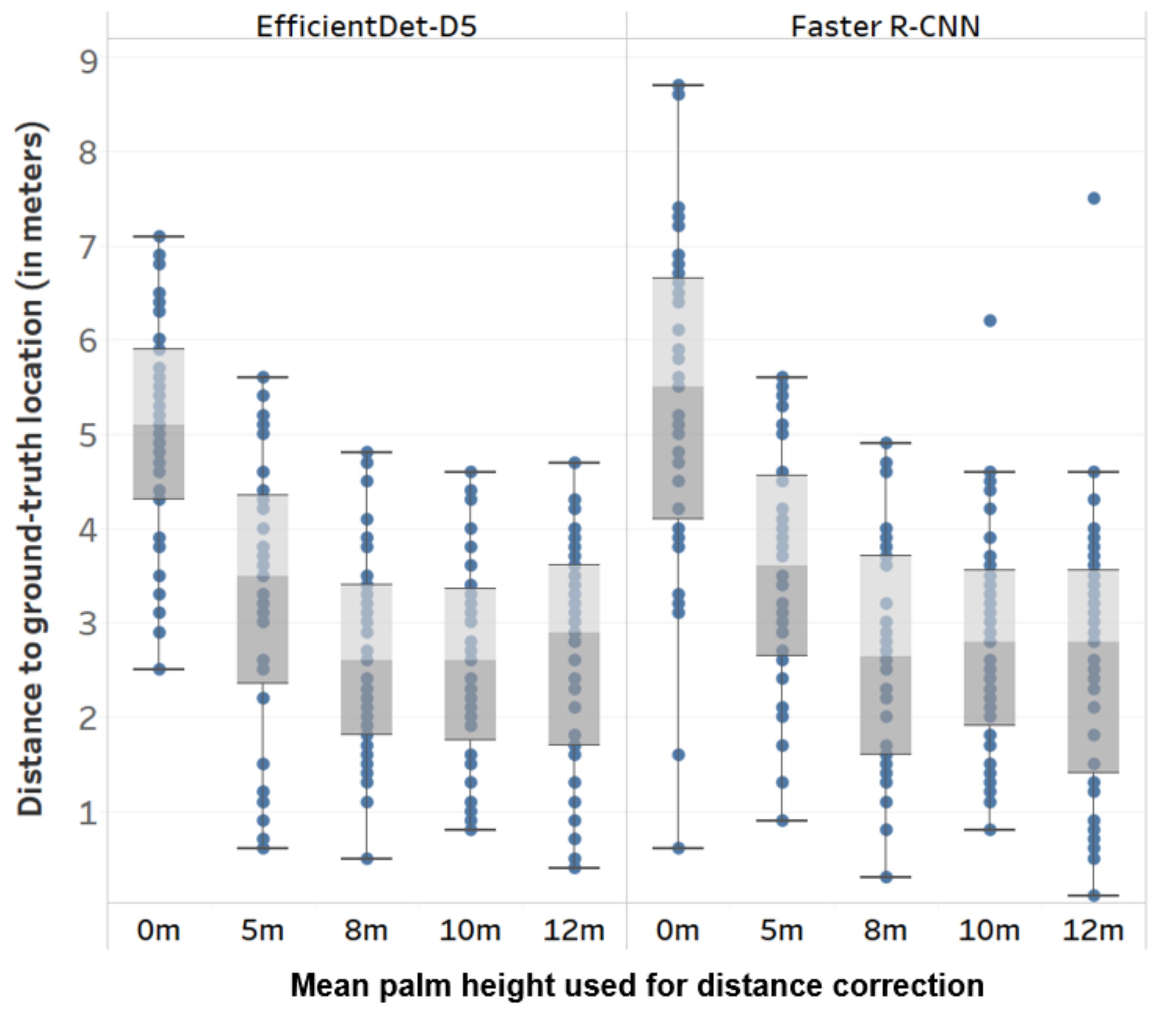
2.5.2. Distance Correction
2.5.3. Conversion to GPS Coordinates
| Algorithm 1 Palm detection and geolocation. |
 |
3. Experiments
3.1. Datasets
3.2. Object Detection
3.2.1. Experimental Setup
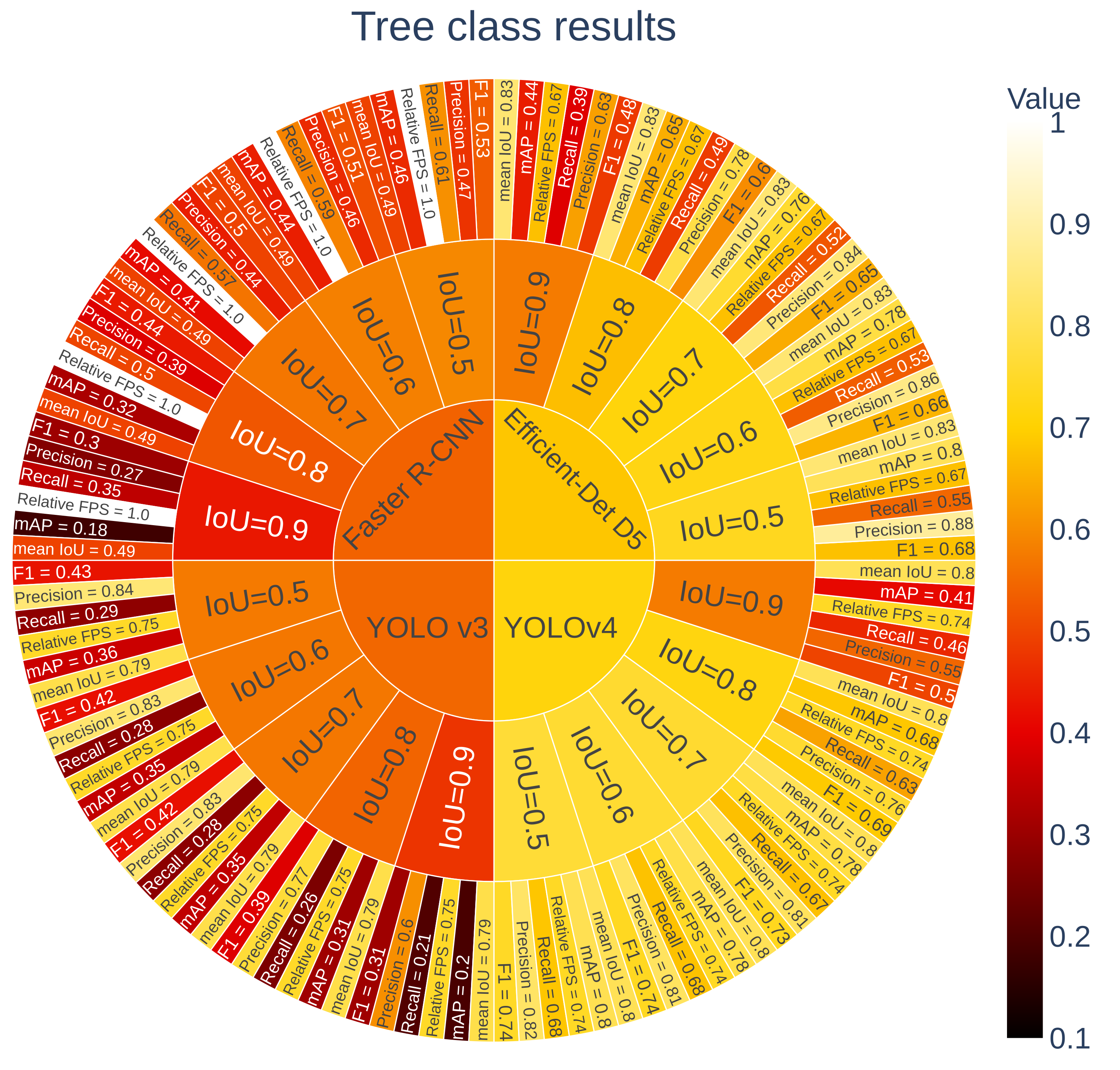
3.2.2. Metrics
- IoU: intersection over union. It measures the overlap between the predicted () and the ground-truth () bounding boxes by dividing the area of their intersection by the area of their union:
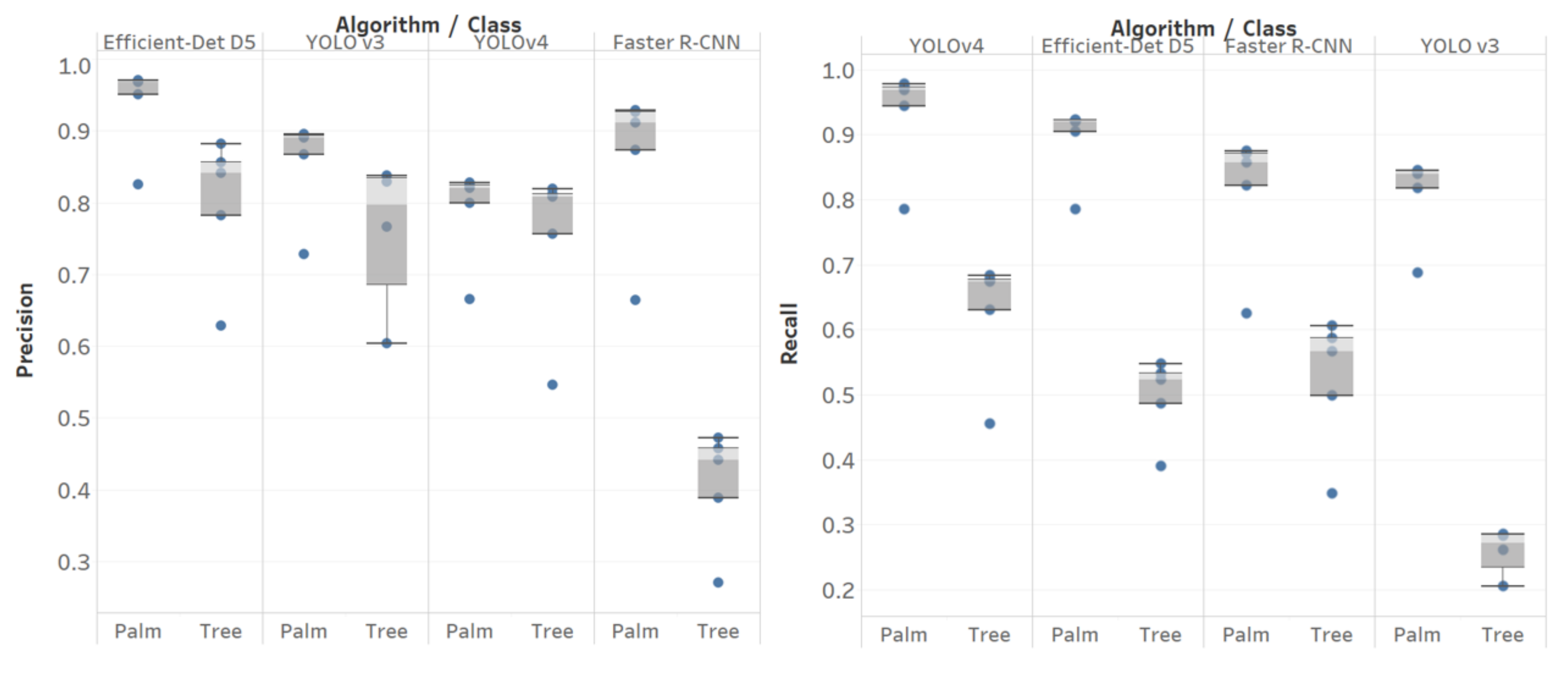
- Precision: ratio of true positives (TP) over all detections (true positives and false positives (FP)).
- Recall: ratio of true positives over the number of relevant objects (true positives and false negatives (FN)).
- F1 score: harmonic mean of precision and recall.
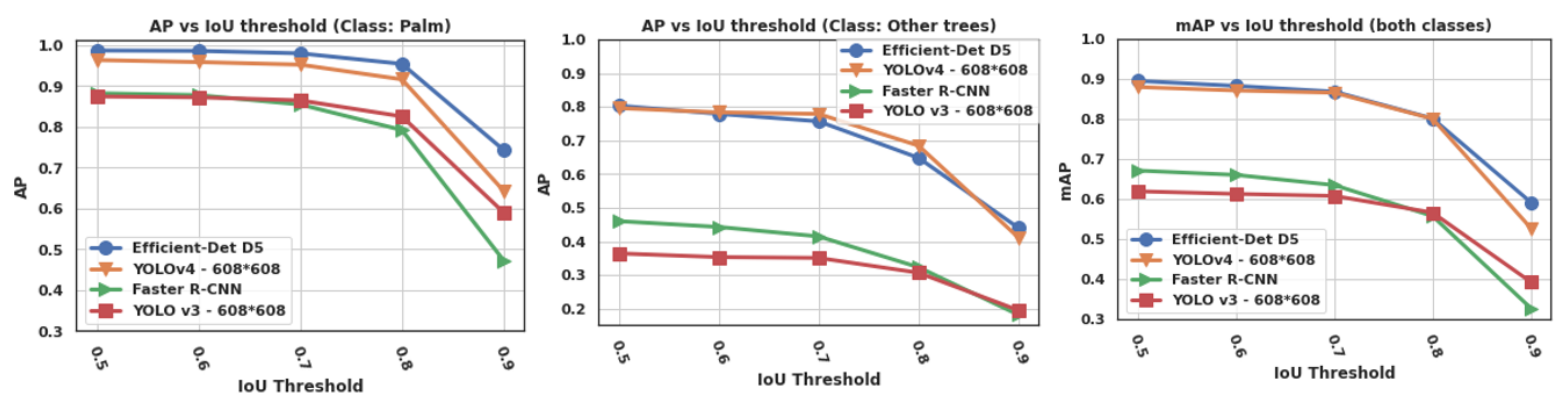
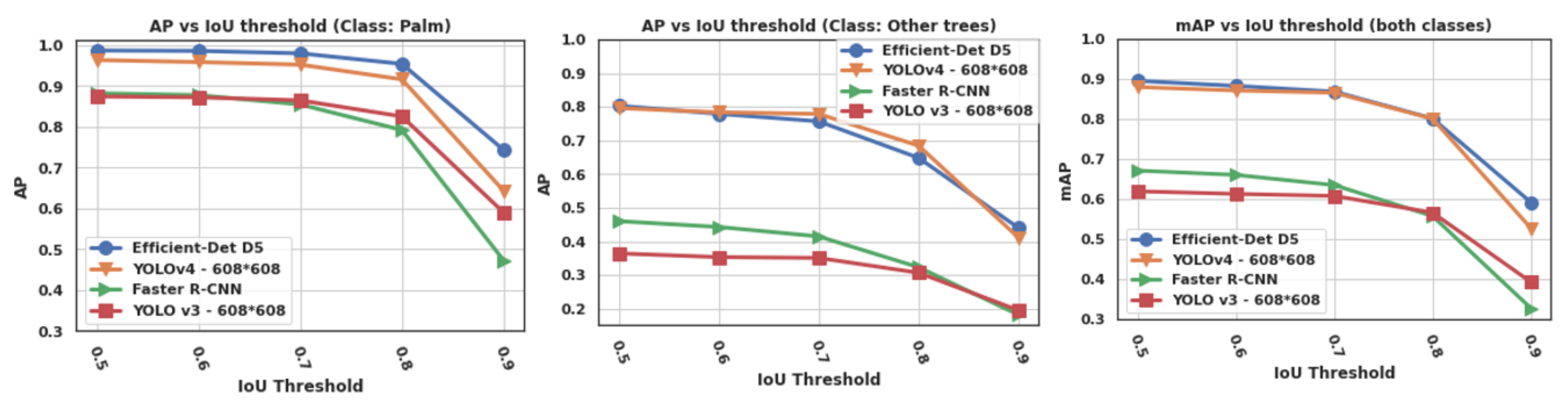
- AP: average precision for one class. It is an approximation of the area under the precision vs. recall curve (AUC). AP was measured for different values of IoU thresholds (0.5, 0.6, 0.7, 0.8, and 0.9).
- mAP: mean average precision over the two classes. The mAP is the main metric used for evaluating object detectors [48].
- Inference time (in millisecond per image): it measures the average inference processing time per image.
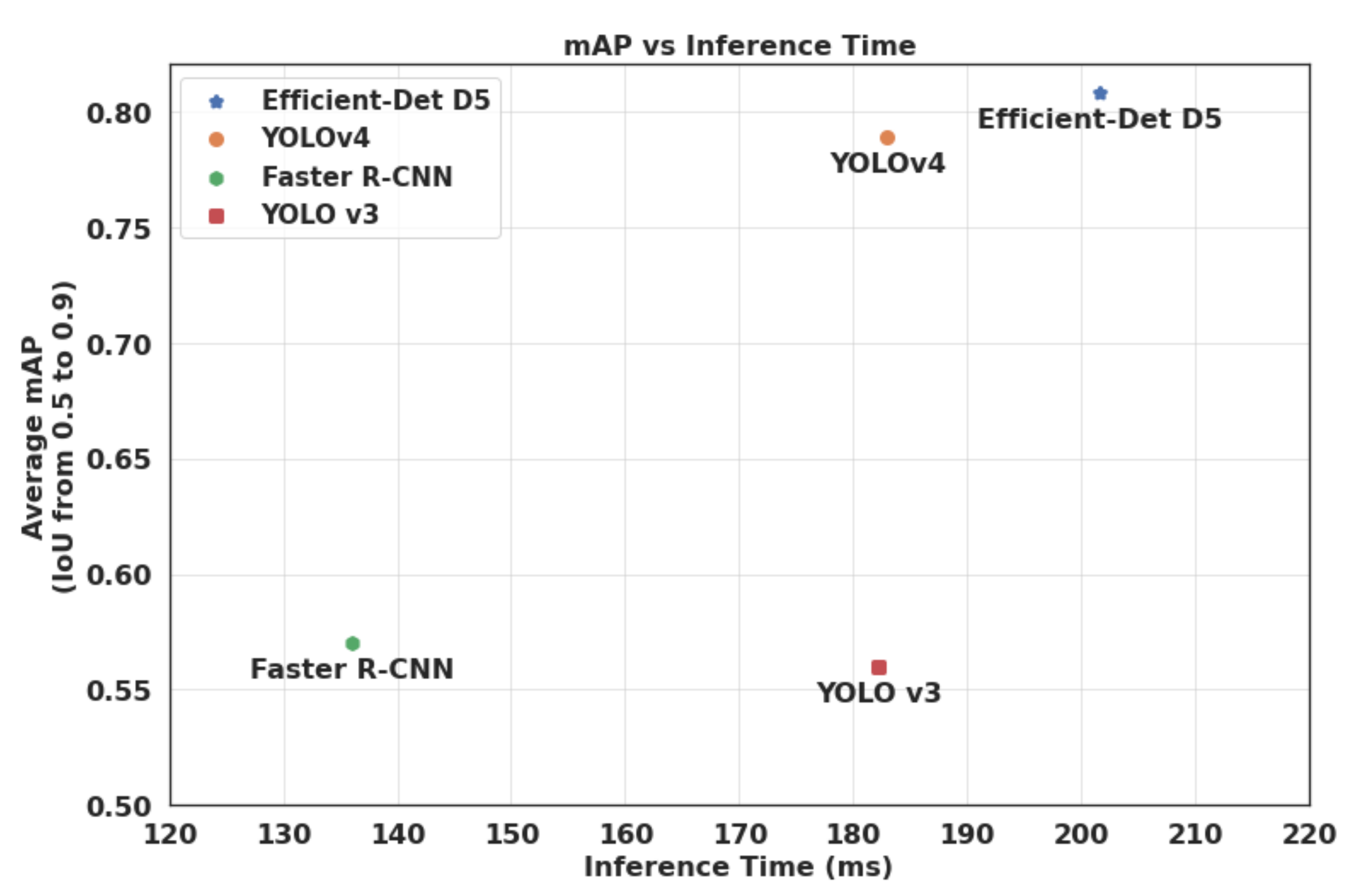
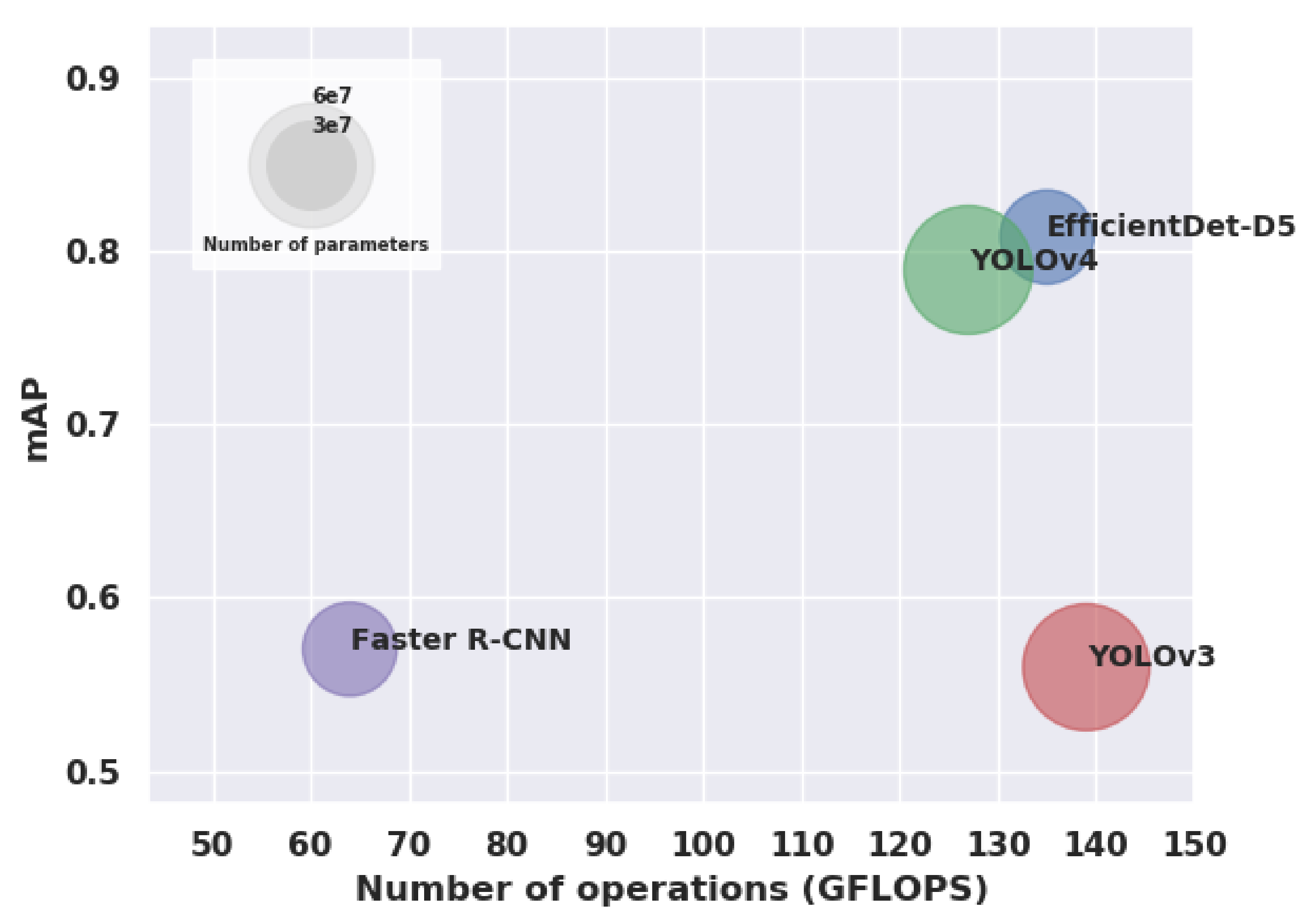
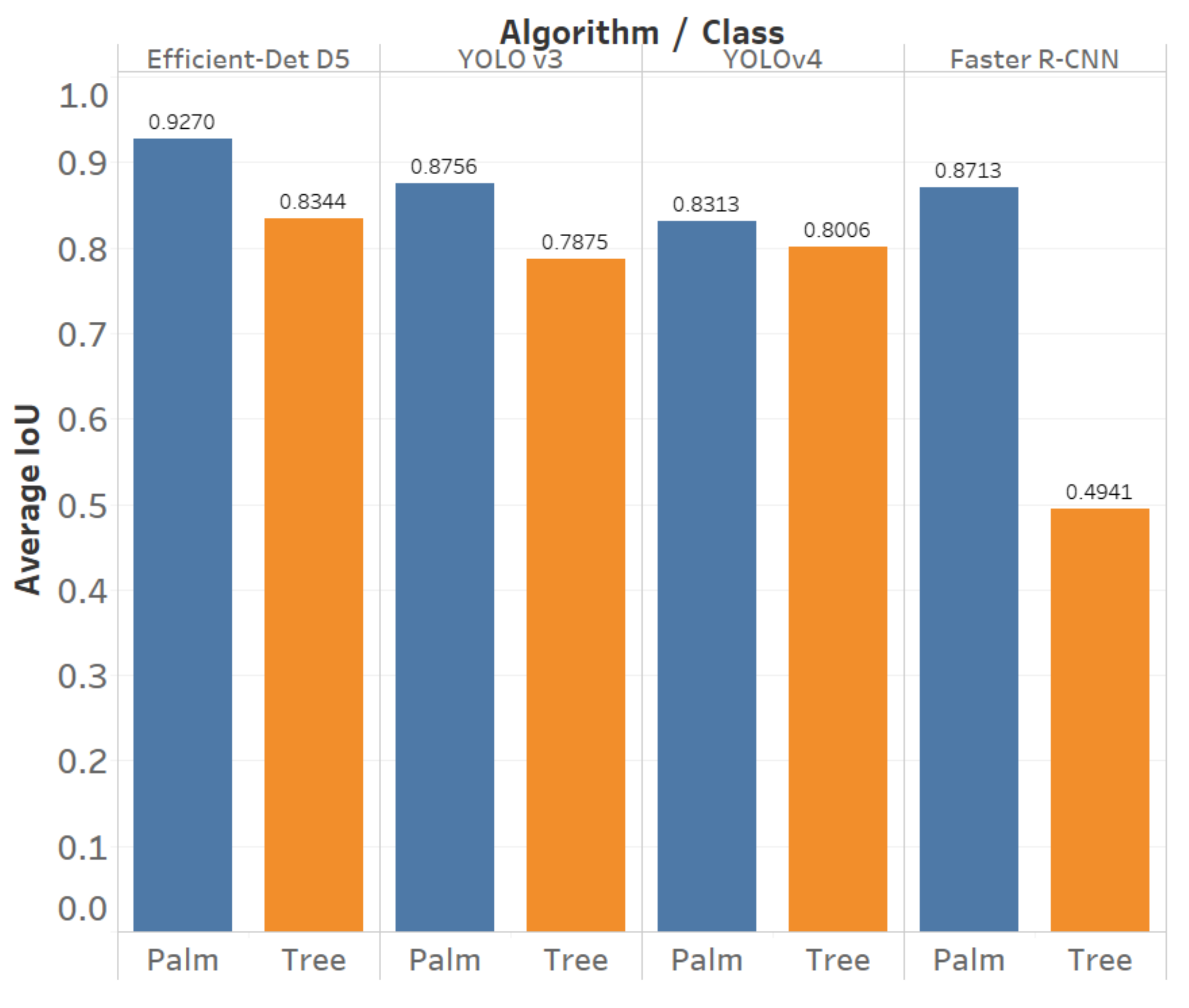
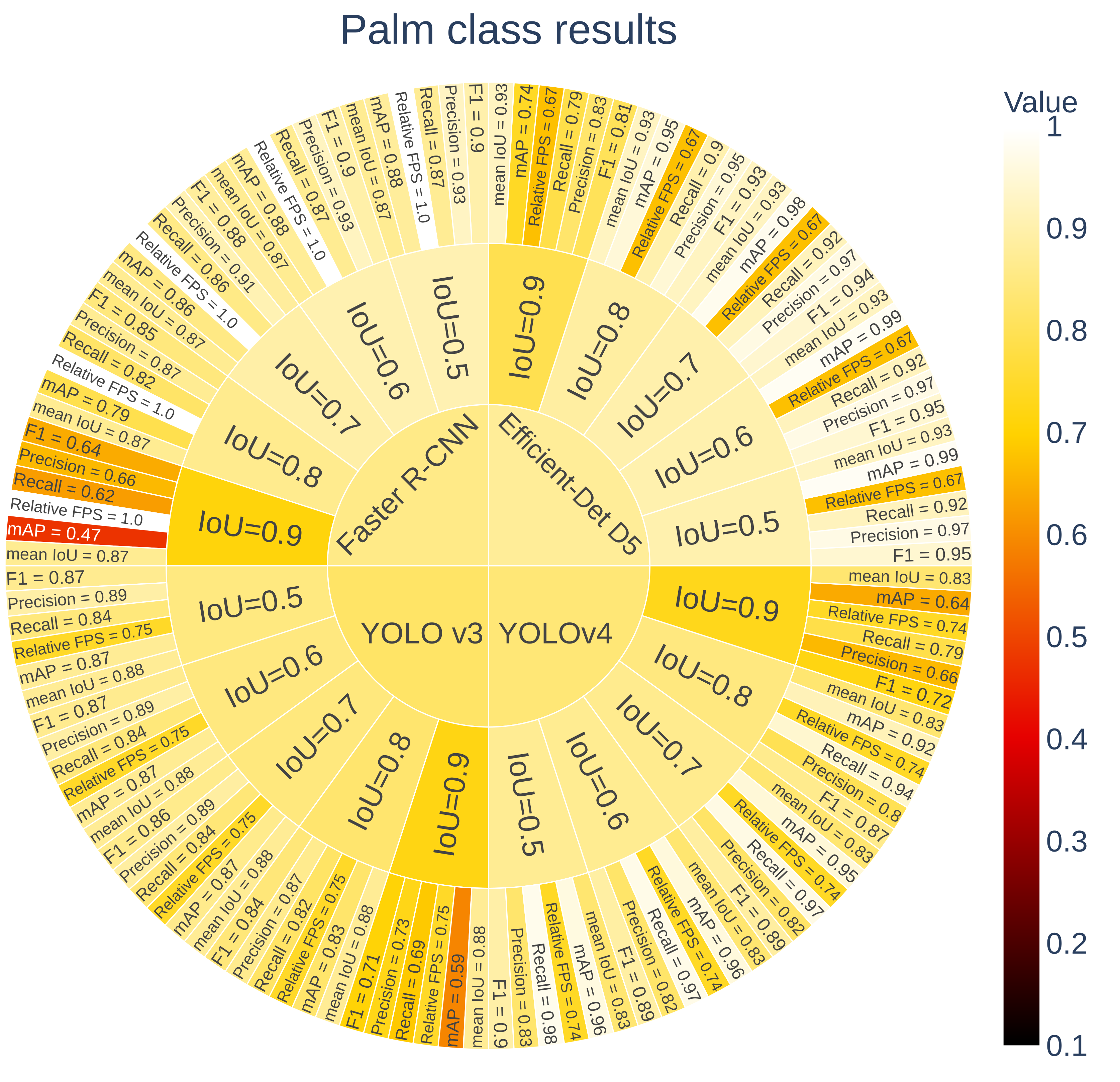
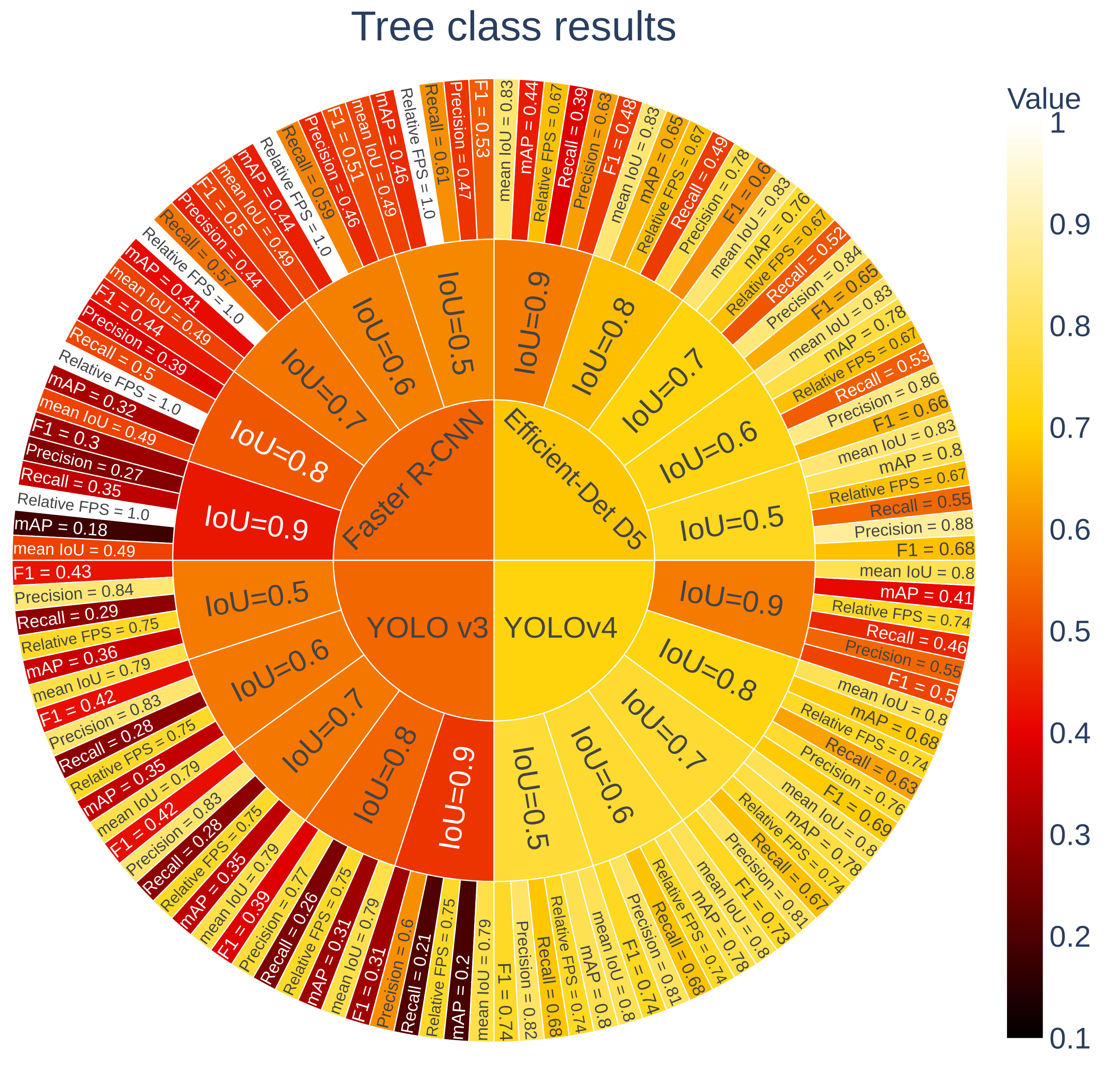
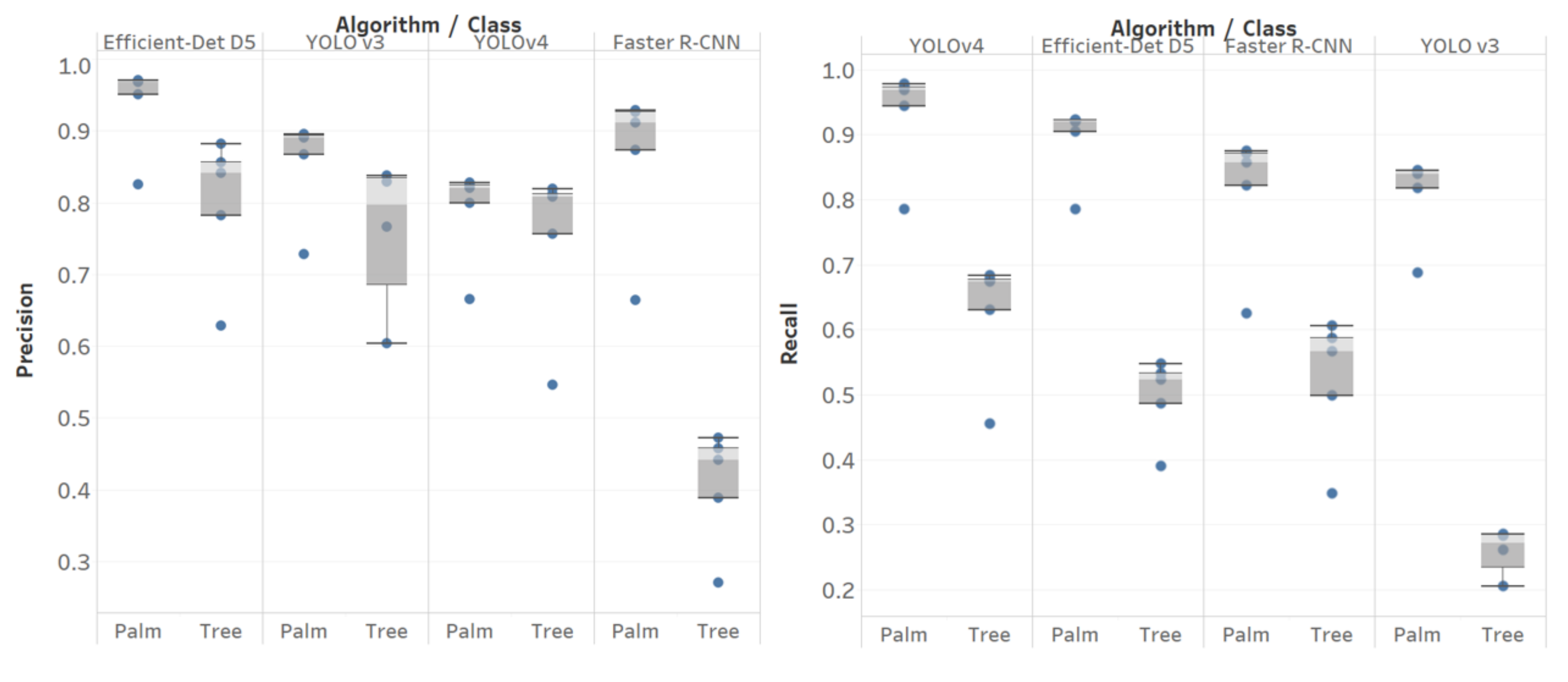
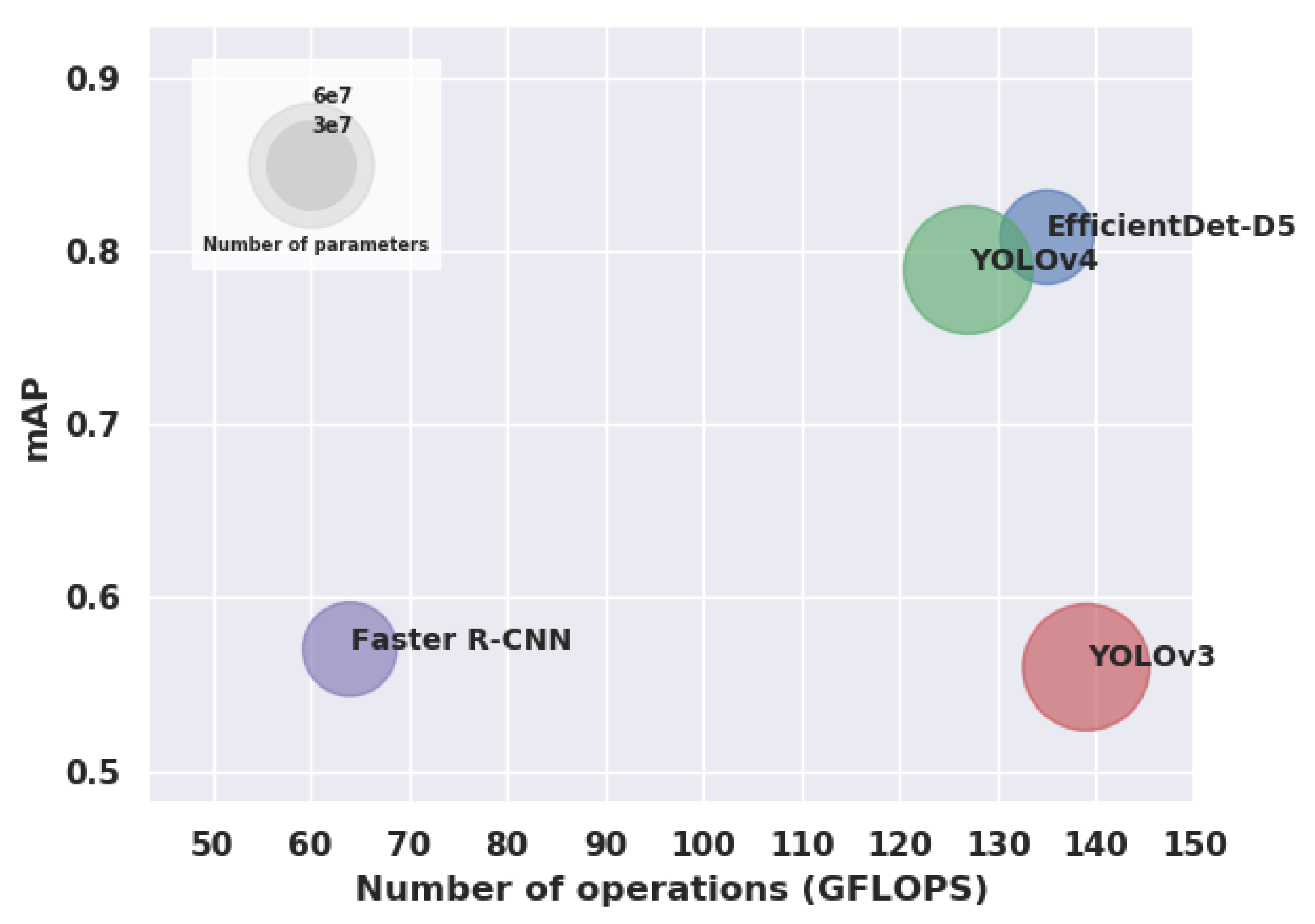
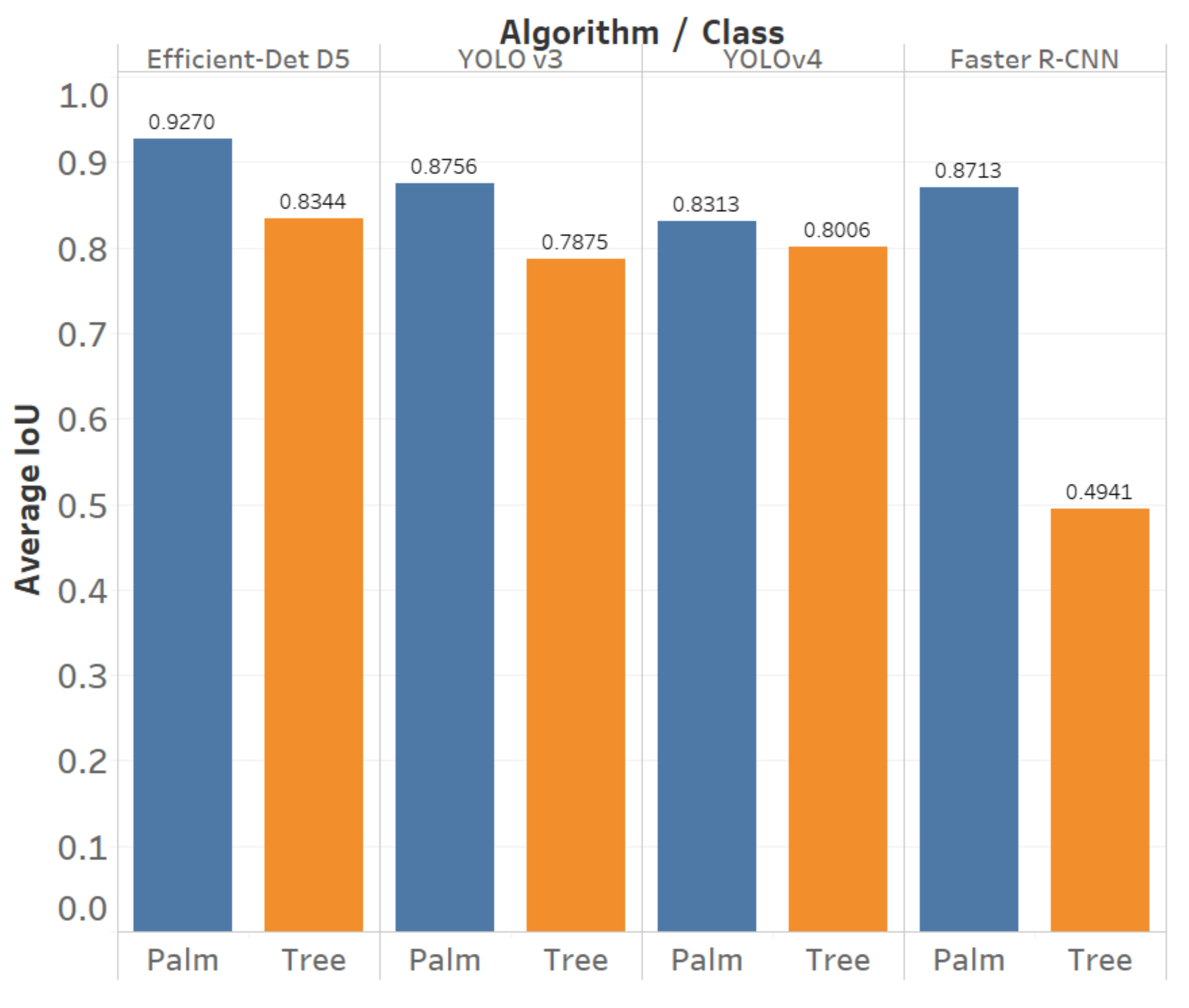
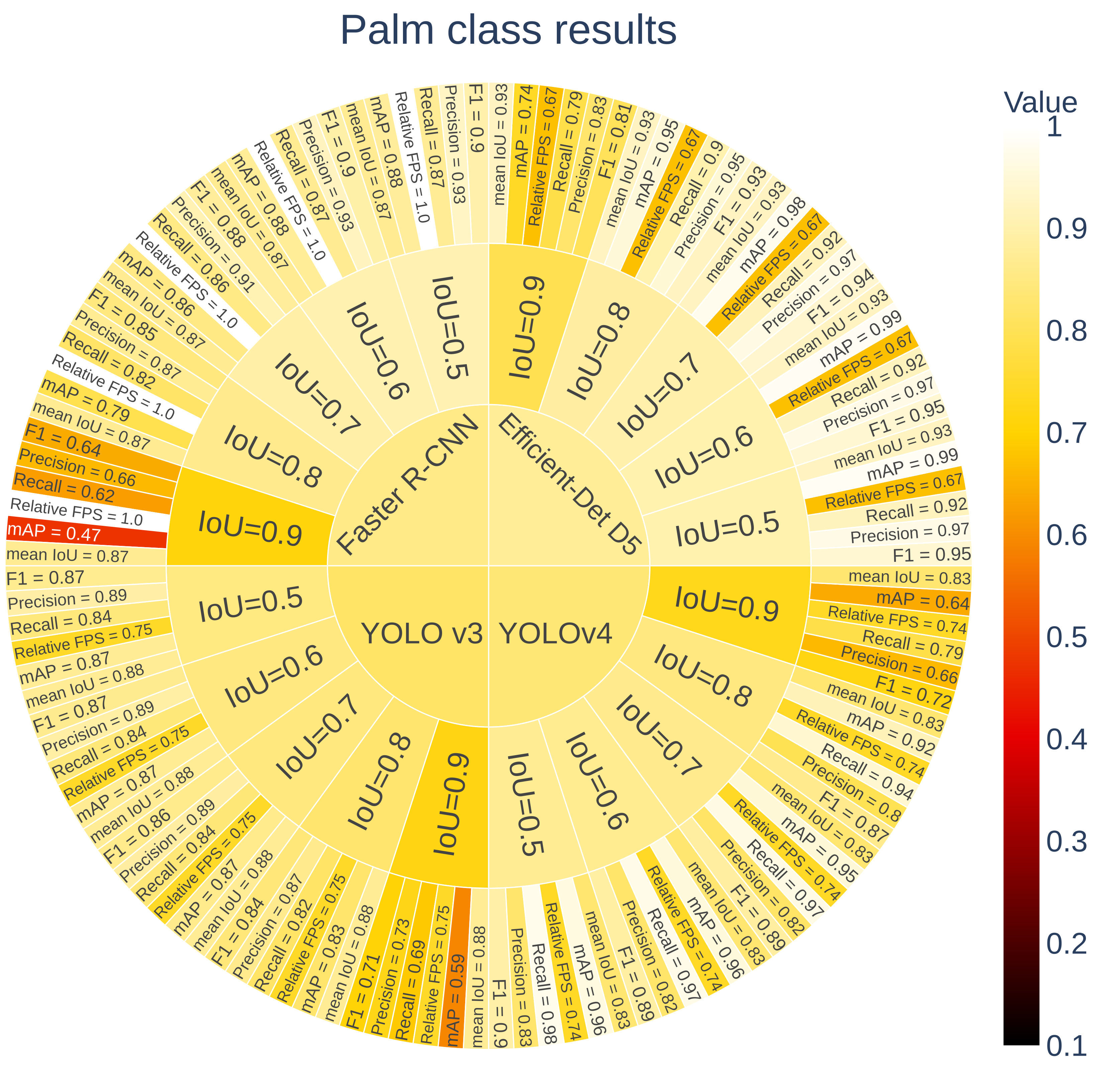
3.2.3. Results
3.2.4. Discussion
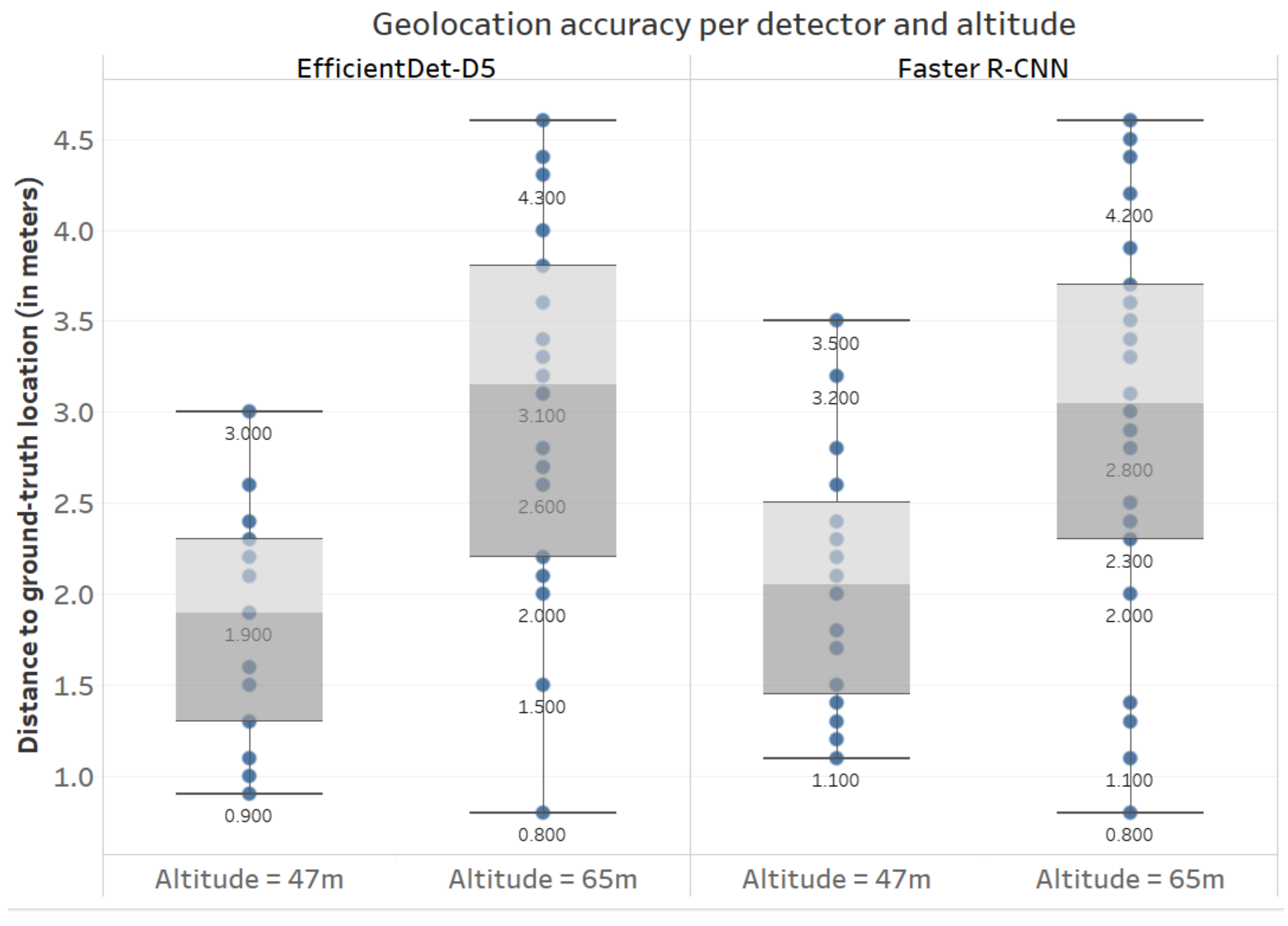
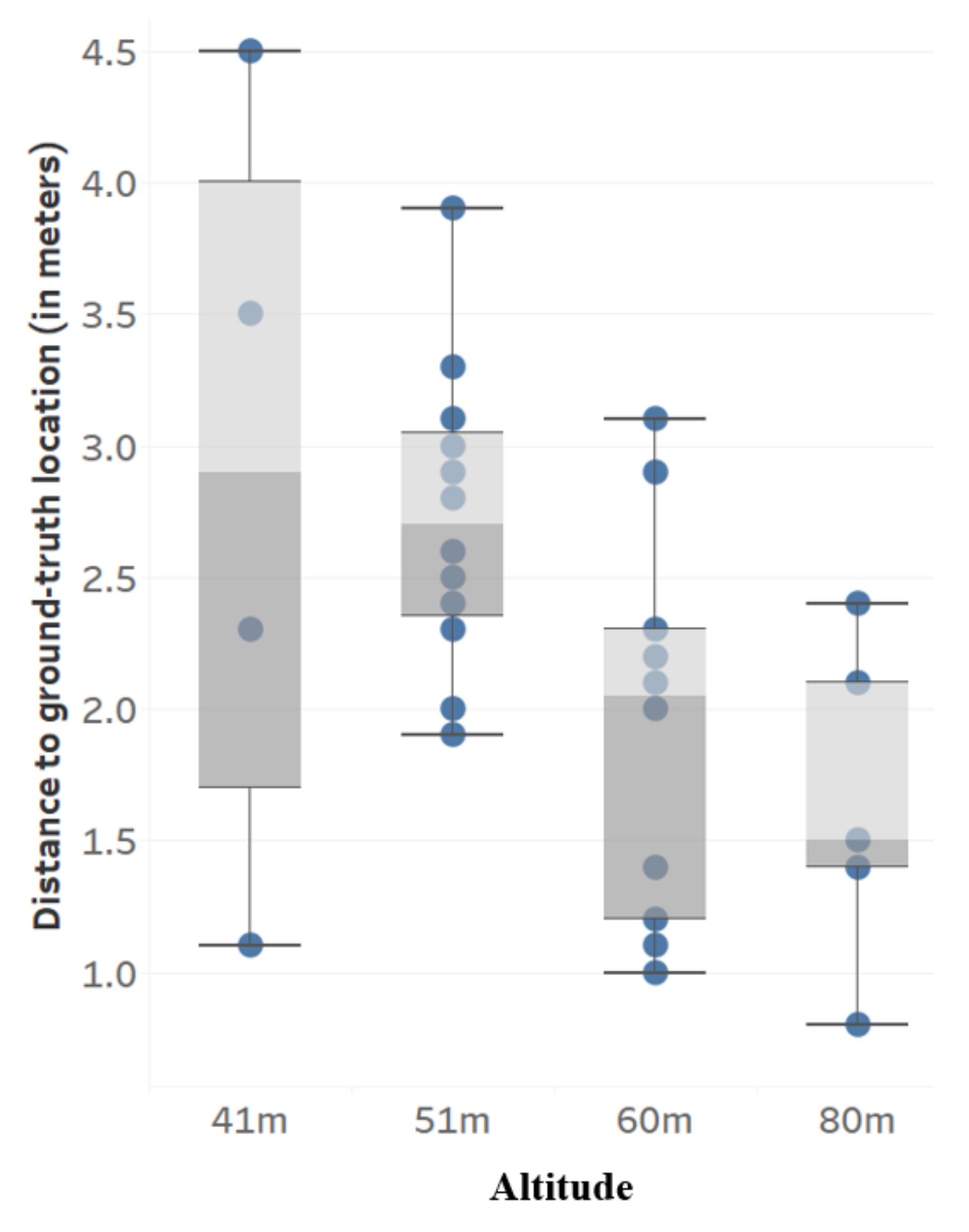
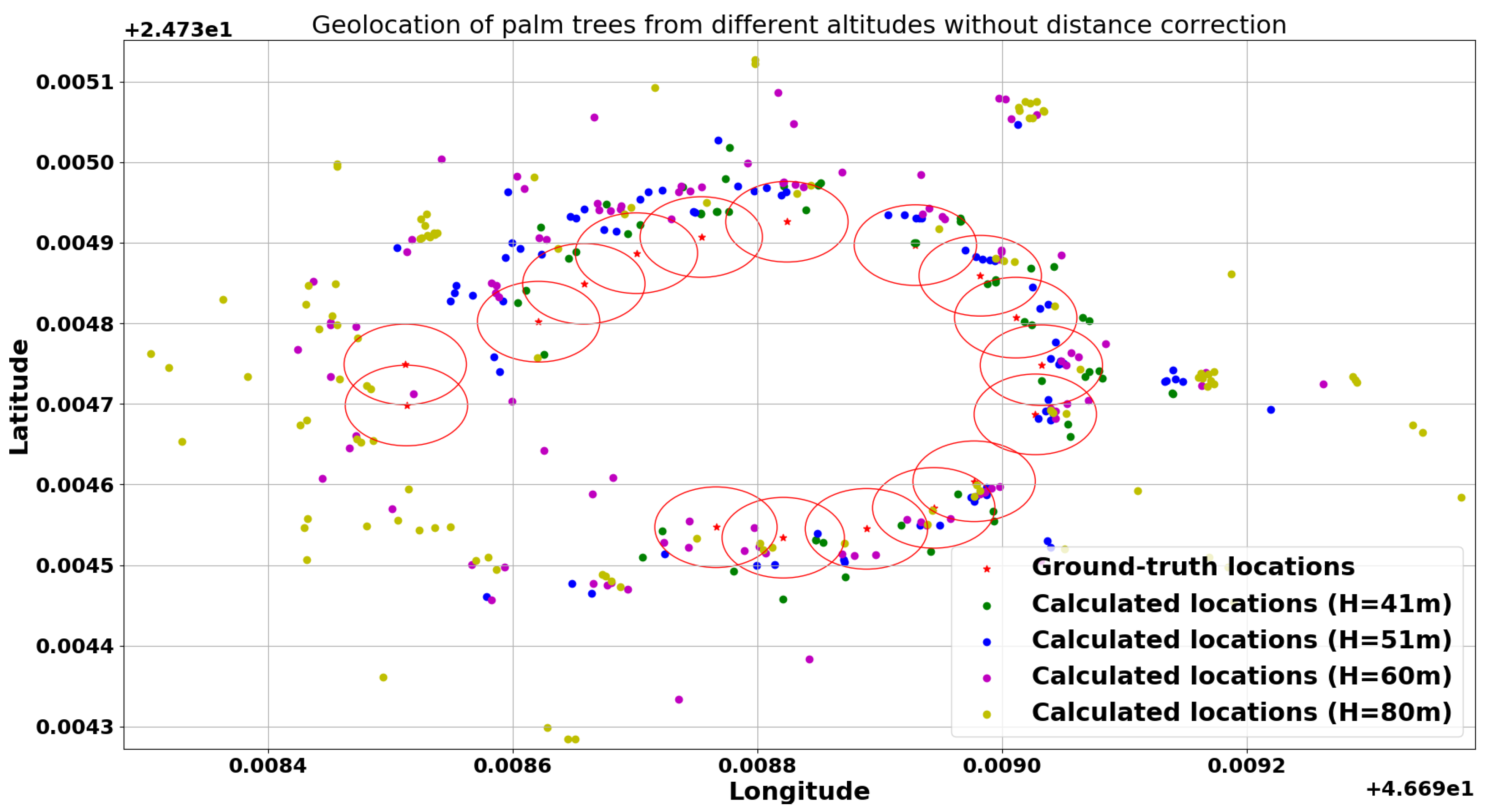
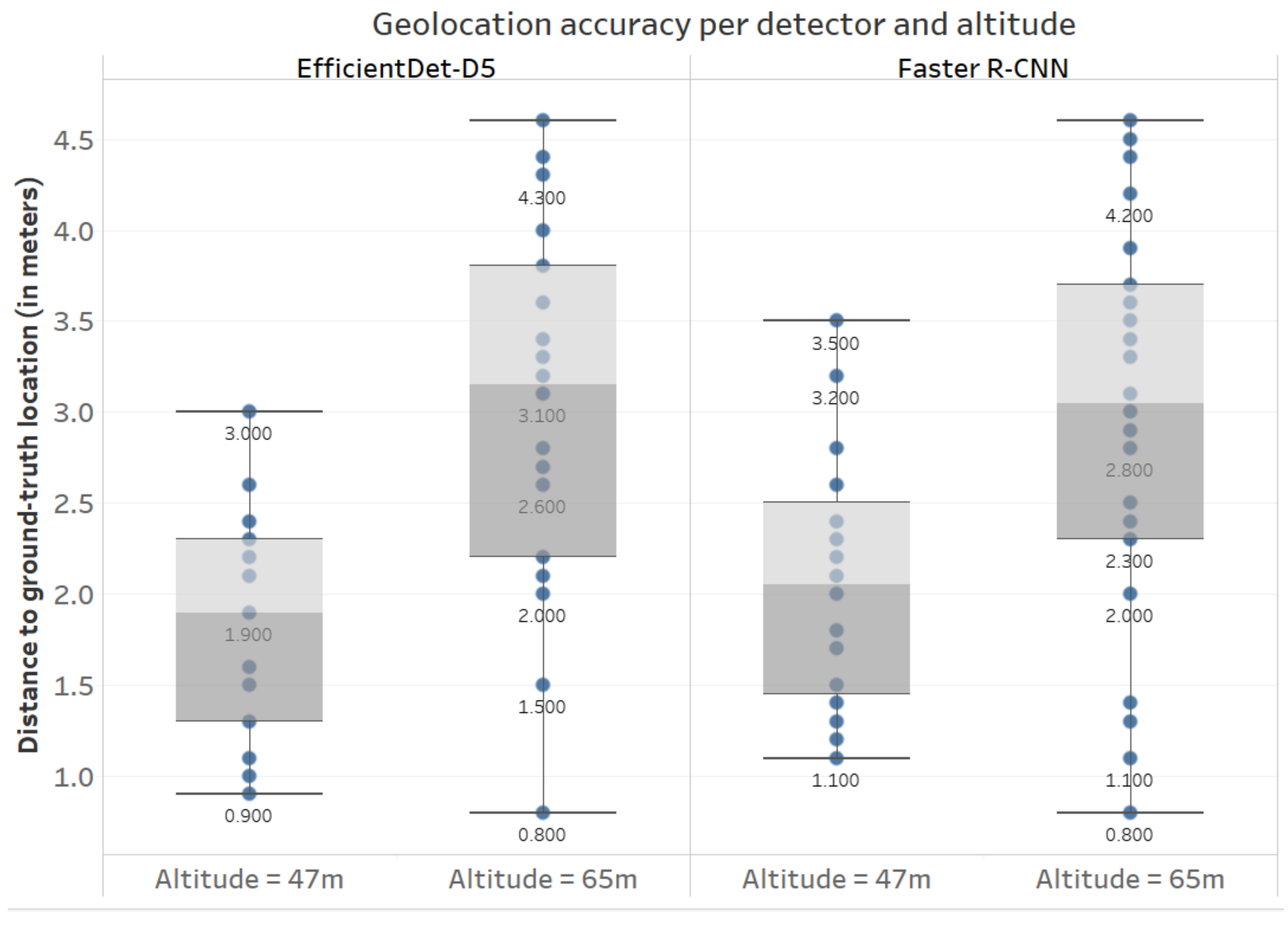
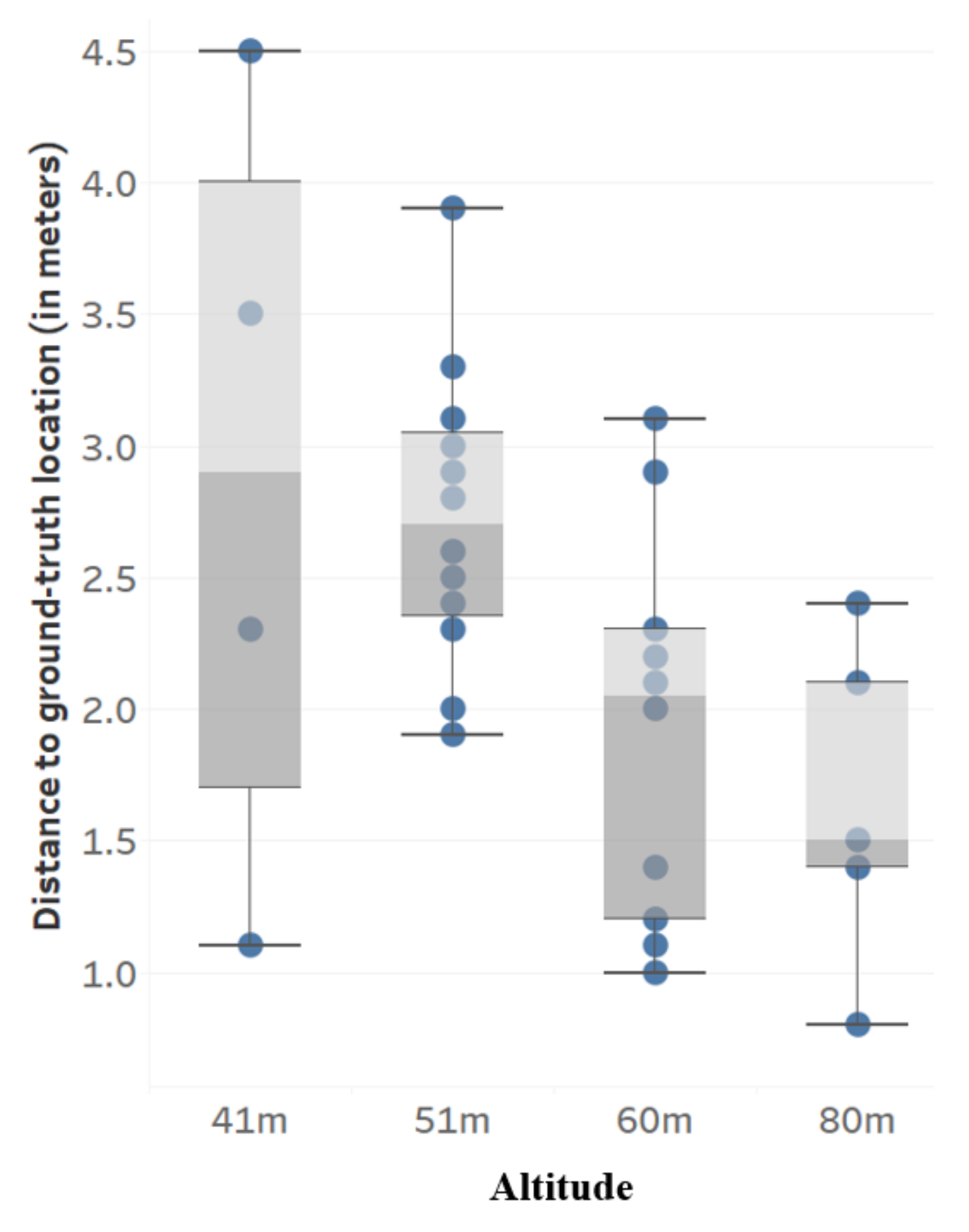
3.3. Geolocation Accuracy
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Otero, V.; Van De Kerchove, R.; Satyanarayana, B.; Martínez-Espinosa, C.; Fisol, M.A.B.; Ibrahim, M.R.B.; Sulong, I.; Mohd-Lokman, H.; Lucas, R.; Dahdouh-Guebas, F. Managing mangrove forests from the sky: Forest inventory using field data and Unmanned Aerial Vehicle (UAV) imagery in the Matang Mangrove Forest Reserve, peninsular Malaysia. For. Ecol. Manag. 2018, 411, 35–45. [Google Scholar] [CrossRef]
- Yue, J.; Yang, G.; Li, C.; Li, Z.; Wang, Y.; Feng, H.; Xu, B. Estimation of winter wheat above-ground biomass using unmanned aerial vehicle-based snapshot hyperspectral sensor and crop height improved models. Remote Sens. 2017, 9, 708. [Google Scholar] [CrossRef] [Green Version]
- Caruso, G.; Zarco-Tejada, P.J.; González-Dugo, V.; Moriondo, M.; Tozzini, L.; Palai, G.; Rallo, G.; Hornero, A.; Primicerio, J.; Gucci, R. High-resolution imagery acquired from an unmanned platform to estimate biophysical and geometrical parameters of olive trees under different irrigation regimes. PLoS ONE 2019, 14, e0210804. [Google Scholar] [CrossRef] [Green Version]
- Shahbazi, M.; Théau, J.; Ménard, P. Recent applications of unmanned aerial imagery in natural resource management. GIScience Remote Sens. 2014, 51, 339–365. [Google Scholar] [CrossRef]
- Kaartinen, H.; Hyyppä, J. EuroSDR/ISPRS Project Commission II, Tree Extraction; Final Report; EuroSDR: Dublin, Ireland, 2008; pp. 1–60. [Google Scholar]
- Kaartinen, H.; Hyyppä, J.; Yu, X.; Vastaranta, M.; Hyyppä, H.; Kukko, A.; Holopainen, M.; Heipke, C.; Hirschmugl, M.; Morsdorf, F.; et al. An International Comparison of Individual Tree Detection and Extraction Using Airborne Laser Scanning. Remote Sens. 2012, 4, 950–974. [Google Scholar] [CrossRef] [Green Version]
- FAOSTAT Crop Statistics. Available online: http://www.fao.org/faostat/en/ (accessed on 24 November 2020).
- Yao, S.; Al-Redhaiman, K. Date Palm Cultivation in Saudi Arabia: Current Status and Future Prospects for Development. In Proceedings of the ASHS Annual Conference, Orlando, FL, USA, 28–31 July 2014; Volume 49, pp. 139–140. [Google Scholar]
- Shafri, H.Z.M.; Hamdan, N.; Saripan, M.I. Semi-automatic detection and counting of oil palm trees from high spatial resolution airborne imagery. Int. J. Remote Sens. 2011, 32, 2095–2115. [Google Scholar] [CrossRef]
- Bazi, Y.; Malek, S.; Alajlan, N.; AlHichri, H. An automatic approach for palm tree counting in UAV images. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 537–540. [Google Scholar] [CrossRef]
- Li, W.; Fu, H.; Yu, L.; Cracknell, A. Deep Learning Based Oil Palm Tree Detection and Counting for High-Resolution Remote Sensing Images. Remote Sens. 2016, 9, 22. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Fu, H.; Yu, L. Deep convolutional neural network based large-scale oil palm tree detection for high-resolution remote sensing images. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 846–849. [Google Scholar] [CrossRef]
- Zheng, J.; Fu, H.; Li, W.; Wu, W.; Zhao, Y.; Dong, R.; Yu, L. Cross-regional oil palm tree counting and detection via a multi-level attention domain adaptation network. ISPRS J. Photogramm. Remote Sens. 2020, 167, 154–177. [Google Scholar] [CrossRef]
- Zheng, J.; Fu, H.; Li, W.; Wu, W.; Yu, L.; Yuan, S.; Tao, W.Y.W.; Pang, T.K.; Kanniah, K.D. Growing status observation for oil palm trees using Unmanned Aerial Vehicle (UAV) images. ISPRS J. Photogramm. Remote Sens. 2021, 173, 95–121. [Google Scholar] [CrossRef]
- Yarak, K.; Witayangkurn, A.; Kritiyutanont, K.; Arunplod, C.; Shibasaki, R. Oil Palm Tree Detection and Health Classification on High-Resolution Imagery Using Deep Learning. Agriculture 2021, 11, 183. [Google Scholar] [CrossRef]
- Zortea, M.; Nery, M.; Ruga, B.; Carvalho, L.B.; Bastos, A.C. Oil-Palm Tree Detection in Aerial Images Combining Deep Learning Classifiers. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 657–660. [Google Scholar] [CrossRef]
- Mansour, S.; Chockalingam, J. Diagnostically counting palm date trees in Al-Ahssa Governorate of Saudi Arabia: An integrated GIS and remote sensing processing of IKONOS imagery. Spat. Inf. Res. 2020, 28, 579–588. [Google Scholar] [CrossRef]
- Neupane, B.; Horanont, T.; Hung, N.D. Deep learning based banana plant detection and counting using high-resolution red-green-blue (RGB) images collected from unmanned aerial vehicle (UAV). PLoS ONE 2019, 14, e0223906. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Song, S.; Jing, J.; Huang, Y.; Shi, M. EfficientDet for fabric defect detection based on edge computing. J. Eng. Fibers Fabr. 2021, 16. [Google Scholar] [CrossRef]
- Liao, J.; Zou, J.; Shen, A.; Liu, J.; Du, X. Cigarette end detection based on EfficientDet. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2021; Volume 1748, p. 062015. [Google Scholar]
- Wu, D.; Lv, S.; Jiang, M.; Song, H. Using channel pruning-based YOLO v4 deep learning algorithm for the real-time and accurate detection of apple flowers in natural environments. Comput. Electron. Agric. 2020, 178, 105742. [Google Scholar] [CrossRef]
- Ammar, A.; Koubaa, A.; Ahmed, M.; Saad, A.; Benjdira, B. Vehicle detection from aerial images using deep learning: A comparative study. Electronics 2021, 10, 820. [Google Scholar] [CrossRef]
- Huang, Y.Q.; Zheng, J.C.; Sun, S.D.; Yang, C.F.; Liu, J. Optimized YOLOv3 algorithm and its application in traffic flow detections. Appl. Sci. 2020, 10, 3079. [Google Scholar] [CrossRef]
- Hung, J.; Carpenter, A. Applying faster R-CNN for object detection on malaria images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 56–61. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Yun, S.; Han, D.; Chun, S.; Oh, S.J.; Yoo, Y.; Choe, J. CutMix: Regularization Strategy to Train Strong Classifiers With Localizable Features. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–3 November 2019; pp. 6023–6032. [Google Scholar] [CrossRef] [Green Version]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. DropBlock: A regularization method for convolutional networks. arXiv 2018, arXiv:1810.12890. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. arXiv 2019, arXiv:1911.08287. [Google Scholar] [CrossRef]
- Yao, Z.; Cao, Y.; Zheng, S.; Huang, G.; Lin, S. Cross-Iteration Batch Normalization. arXiv 2020, arXiv:2002.05712. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Misra, D. Mish: A Self Regularized Non-Monotonic Neural Activation Function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Yeh, I.H.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. arXiv 2019, arXiv:1911.11929. [Google Scholar]
- Shen, F.; Gan, R.; Zeng, G. Weighted residuals for very deep networks. In Proceedings of the 2016 3rd International Conference on Systems and Informatics (ICSAI), Shanghai, China, 19–21 November 2016. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Wang, J.; Fu, X.; Yu, T.; Guo, Y.; Wang, R. DC-SPP-YOLO: Dense connection and spatial pyramid pooling based YOLO for object detection. Inf. Sci. 2020, 522, 241–258. [Google Scholar] [CrossRef] [Green Version]
- Ferrari, V.; Hebert, M.; Sminchisescu, C.; Weiss, Y. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018; Ferrari, V.; Hebert, M.; Sminchisescu, C.; Weiss, Y. Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11211, pp. 3–19. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. arXiv 2019, arXiv:1911.09070. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2020, arXiv:1905.11946. [Google Scholar]
- US National Imagery and Mapping Agency. World Geodetic System 1984, Its Definition and Relationships with Local Geodetic Systems; NIMA Technical Report 8350.2; US National Imagery and Mapping Agency: Fort Belvoir, VA, USA, 1997. [Google Scholar]
- Labelbox. Available online: https://labelbox.com (accessed on 10 February 2020).
- Padilla, R.; Netto, S.L.; da Silva, E.A. A survey on performance metrics for object-detection algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niteroi, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar]
- Jahromi, M.K.; Jafari, A.; Rafiee, S.; Mohtasebi, S. Survey on some physical properties of the Date Palm tree. J. Agric. Technol. 2007, 3, 317–322. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Dataset | Testing Dataset | |
|---|---|---|
| Number of images | 279 | 70 |
| Percentage | 80% | 20% |
| Instances of class “Palm tree” | 8805 | 2345 |
| Instances of class “Other tree” | 1596 | 325 |
| Object Detector | Feature Extractor | Input Size | Number of Parameters | FLOPS | Learning Rate | Batch Size | Number of Steps | Code Repository |
|---|---|---|---|---|---|---|---|---|
| Faster R-CNN | Resnet-50 | - Conserves the aspect ratio of the original image. - Either the smallest dimension is 600, or the largest dimension is 1024. | 3.4 × 10 | 64 G | 3 × 10 | 1 | 30,000 | github.com/tensorflow/models/tree/master/research/object_detection Accessed on 21/07/2021 |
| YOLO v3 | Darknet-53 | 608 × 608 | 6.2 × 10 | 139 G | 1 × 10 | 64 | 30,000 | github.com/AlexeyAB/darknet Accessed on 21/07/2021 |
| YOLO v4 | CSPDarknet-53 | 608 × 608 | 6.4 × 10 | 127 G | 1 × 10 | 64 | 1400 | github.com/AlexeyAB/darknet Accessed on 21/07/2021 |
| EfficientDet-D5 | EfficientNet-B5 | 1280 × 1280 | 3.4 × 10 | 135 G | 1 × 10 | 4 | 30,000 | github.com/xuannianz/EfficientDet Accessed on 21/07/2021 |
| Palm ID | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Height (in meters) | 15 | 14 | 14 | 13 | 13 | 11 | 8.3 | 8.3 | 9.1 | 8.9 | 10 | 10.1 | 11 | 10.5 | 9.8 | 8.4 | 8.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ammar, A.; Koubaa, A.; Benjdira, B. Deep-Learning-Based Automated Palm Tree Counting and Geolocation in Large Farms from Aerial Geotagged Images. Agronomy 2021, 11, 1458. https://doi.org/10.3390/agronomy11081458
Ammar A, Koubaa A, Benjdira B. Deep-Learning-Based Automated Palm Tree Counting and Geolocation in Large Farms from Aerial Geotagged Images. Agronomy. 2021; 11(8):1458. https://doi.org/10.3390/agronomy11081458
Chicago/Turabian StyleAmmar, Adel, Anis Koubaa, and Bilel Benjdira. 2021. "Deep-Learning-Based Automated Palm Tree Counting and Geolocation in Large Farms from Aerial Geotagged Images" Agronomy 11, no. 8: 1458. https://doi.org/10.3390/agronomy11081458
APA StyleAmmar, A., Koubaa, A., & Benjdira, B. (2021). Deep-Learning-Based Automated Palm Tree Counting and Geolocation in Large Farms from Aerial Geotagged Images. Agronomy, 11(8), 1458. https://doi.org/10.3390/agronomy11081458