In our experiments, we used the Adam optimizer for training all deep learning models with a learning rate of 0.001, batch size of 32, and up to 100 epochs. Additionally, the training data is shuffled at the beginning of each epoch to prevent the model from overfitting to the input sequence and to encourage better generalization. These hyperparameters were selected based on preliminary tuning to balance convergence speed and model generalization.
4.1. Data Preparation and Pre-Processing
While the original datasets are available as CSV files with multiple features and records, we prepared data as per the requirements of the experiments. First of all, we removed the columns (features) with missing values. Afterwards, we removed the records with missing values. Although other options such as duplication, interpolation, and average value replacement are possible, we aimed to maintain the originality of the data; therefore, we chose to remove the records with missing values over other options. Then, the text features such as upd packet, source ip, destination ip were converted into numeric values using the one-hot-encoding technique. Then, we prepared two separate sets of data for each dataset: the balanced dataset and imbalanced dataset.
4.1.1. Balanced Dataset
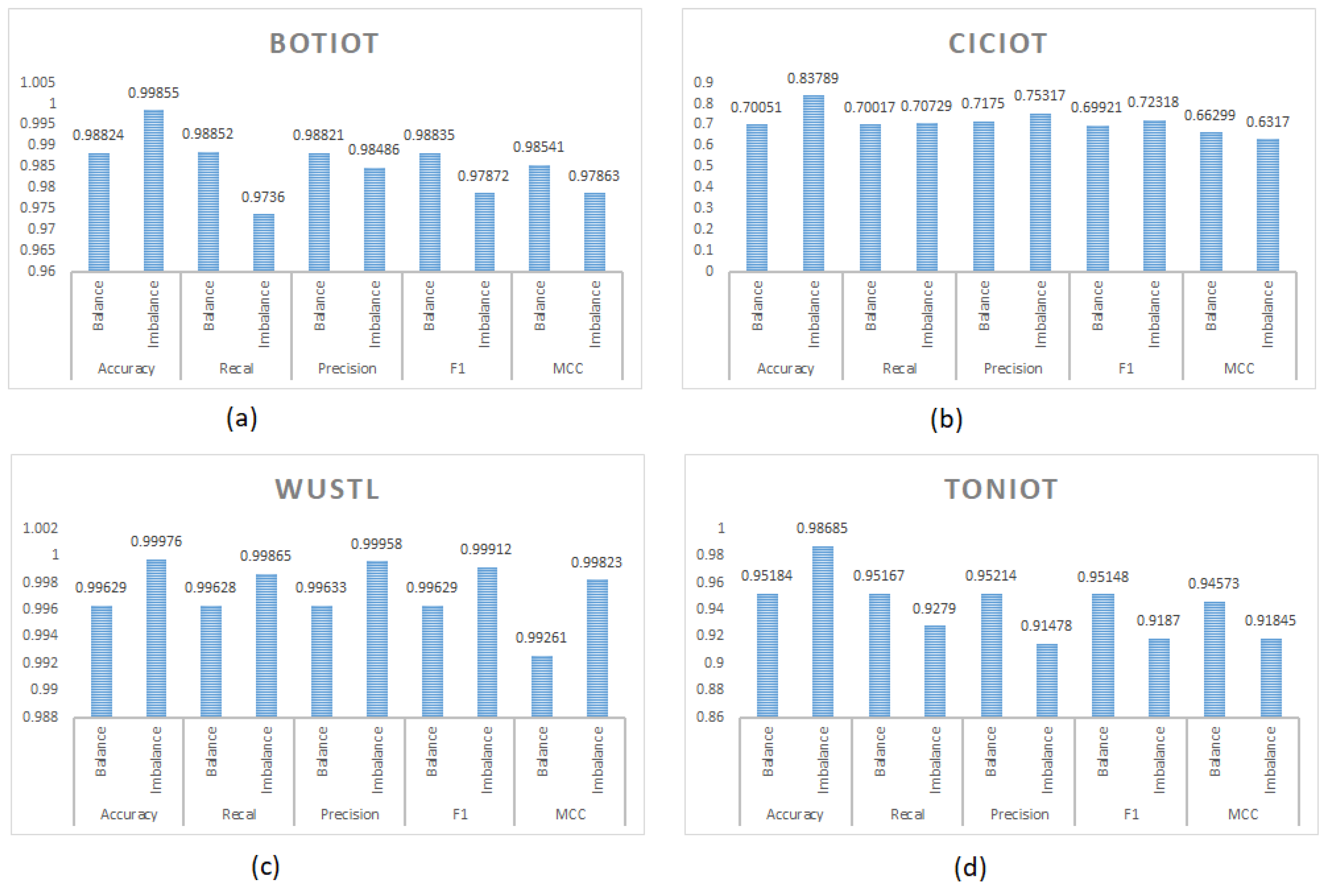
Data imbalance is a common challenge in many machine learning tasks, particularly in domains like intrusion detection where certain classes of data are significantly underrepresented compared to others. To address this issue and ensure fair model training, we employed a data balancing technique known as undersampling in our study. The undersampling reduces the number of samples in the majority class to achieve the balanced class distribution. In our experiments, the undersampling approach is chosen instead of oversampling (which balances the data by synthetic generation of samples) or duplication of existing samples to preserve the originality of the dataset. As a result, a balanced dataset is achieved while ensuring that the remaining samples in the class are still authentic and representative of the actual data distribution. The undersampling process involves careful selection of samples from categories with a higher number of instances and removing them until each category has a similar number of samples. This step is crucial to prevent bias and to maintain the integrity of the dataset. While undersampling helps to address the challenges of class imbalance, it also comes with considerations. One such consideration is the potential loss of information due to the removal of samples, which could impact the model’s ability to capture complex patterns in the data. In the context of deep learning techniques, data balancing through undersampling plays a vital role in improving model performance by reducing overfitting and ensuring a fair representation of all classes during training. By including this data balancing approach in our methodology, we aimed to enhance the robustness and accuracy of our deep learning-based intrusion detection system. The balanced datasets were subsequently split into 80% for training and 20% for testing. The resulting sample distribution is shown in
Table 1.
4.1.2. Imbalanced Dataset
To ease the handling of the dataset, we extracted a portion of records of the original datasets, from which 80% is used for training and 20% is used for testing. This split was applied consistently across all datasets to ensure comparability in model evaluation. The number of records of minority class were not reduced. This decision was made to preserve the natural class imbalance present in real-world IoT traffic, where certain attack types are significantly underrepresented compared to others. While processing with imbalanced datasets, we used the 5% samples of each category of original datasets. This sampling strategy was adopted to reduce computational load while retaining representative distributions across classes. The sampling was applied uniformly, ensuring the overall class proportions remain unchanged. By maintaining the original imbalance in class distributions, this setup allowed us to evaluate how well each model performs under realistic data conditions. In such scenarios, performance metrics like recall and MCC become critical, particularly for identifying rare but high-impact attack types. For WUSTL-IIoT-2021, only binary classification is considered in the imbalanced setup as well, with ‘Normal’ and ‘Attacked’ categories. This dataset is included to examine performance under simpler class distributions and industrial IoT settings. The number of observations while performing the experiments on the imbalanced dataset are shown in
Table 2.
4.2. Dataset Details and Comparison
The experiments conducted in this study utilize four key datasets: BoTIoT [
23], ToNIoT [
25,
26], CiCIoT [
24], and WUSTL-IIoT-2021 [
27]. Each dataset provides distinct insights into IoT and IIoT security challenges.
The BoTIoT dataset is built upon a realistic IoT network testbed designed at the University of New South Wales (UNSW), Australia, to simulate a smart home and smart city IoT environment. The testbed integrates multiple IoT devices and services with normal and malicious traffic streams to capture comprehensive network activity for intrusion detection research. The network consists of normal IoT devices, such as smart fridges, smart thermostats, smart garage doors, and surveillance cameras, all connected through a software-defined networking (SDN) environment to reflect modern IoT deployment models. These devices interact with remote cloud services via edge and gateway nodes, simulating real-world network behavior under normal operations. To generate malicious traffic, the environment includes simulated attack tools like Hping3, Slowloris, and Nmap, which are used to perform a variety of cyberattacks. These attacks are launched from compromised virtual machines within the network to mimic attacker behavior targeting the IoT infrastructure. The publicly available dataset is composed of multiple features and includes both training and testing subsets with detailed distributions of data items for different attack types.
The IoT network scenario in ToNIoT simulates a smart industrial environment composed of multiple interconnected devices, services, and operating systems. These include IoT/IIoT sensors and actuators (temperature, motion, humidity sensors), edge devices and gateways, operating systems (Windows 7, Windows 10, Ubuntu, and Android), and network infrastructure components. These entities are connected through a network topology that mirrors a smart manufacturing environment. The devices generate telemetry and communication data during normal operations and under various cyberattack scenarios. The attack traffic in the dataset is generated using tools such as Metasploit, Hping3, Nmap, GoldenEye, and Loic. The ToNIoT dataset incorporates diverse data sources from telemetry datasets of IoT and IIoT sensors, operating systems datasets, and network traffic datasets. It was collected from a network at the Australian Defence Force Academy, encompassing various virtual machines and hosts running different operating systems. This dataset includes many attack methods such as DoS, DDoS, and ransomware, against web apps, IoT gateways, and computer systems, thus providing a rich resource for developing intrusion detection systems.
The CiCIoT dataset was created by the Canadian Institute for Cybersecurity and is designed for deep learning-based intrusion detection in IoT contexts. The dataset is based on a smart home testbed environment that includes 105 IoT devices such as smart thermostats, lights, and cameras. These devices communicate through a Wi-Fi router to simulate real-world consumer IoT setups. The dataset captures both benign and malicious traffic to enable comprehensive evaluation of intrusion detection models in home IoT networks.
The WUSTL-IIoT-2021 dataset is developed by Washington University in St. Louis. The dataset includes telemetry data, network traffic data, and system logs. The testbed was developed by connecting industrial sensors and Programmable Logic Controllers (PLCs) using industrial protocols (e.g., Modbus/TCP) and edge computing gateways. The dataset collected from the testbed emulates the industrial IoT environment. This dataset supports binary classification by capturing normal and attack traffic flows, including unauthorized access and protocol misuse. Hence, it provides a comprehensive resource for analyzing device behavior in industrial settings.
The comparison of various features of datasets is crucial for evaluating the performance of the deep learning models in IoT-based intrusion detection systems.
Table 3 compares these four datasets presented in this work, considering a variety of parameters.
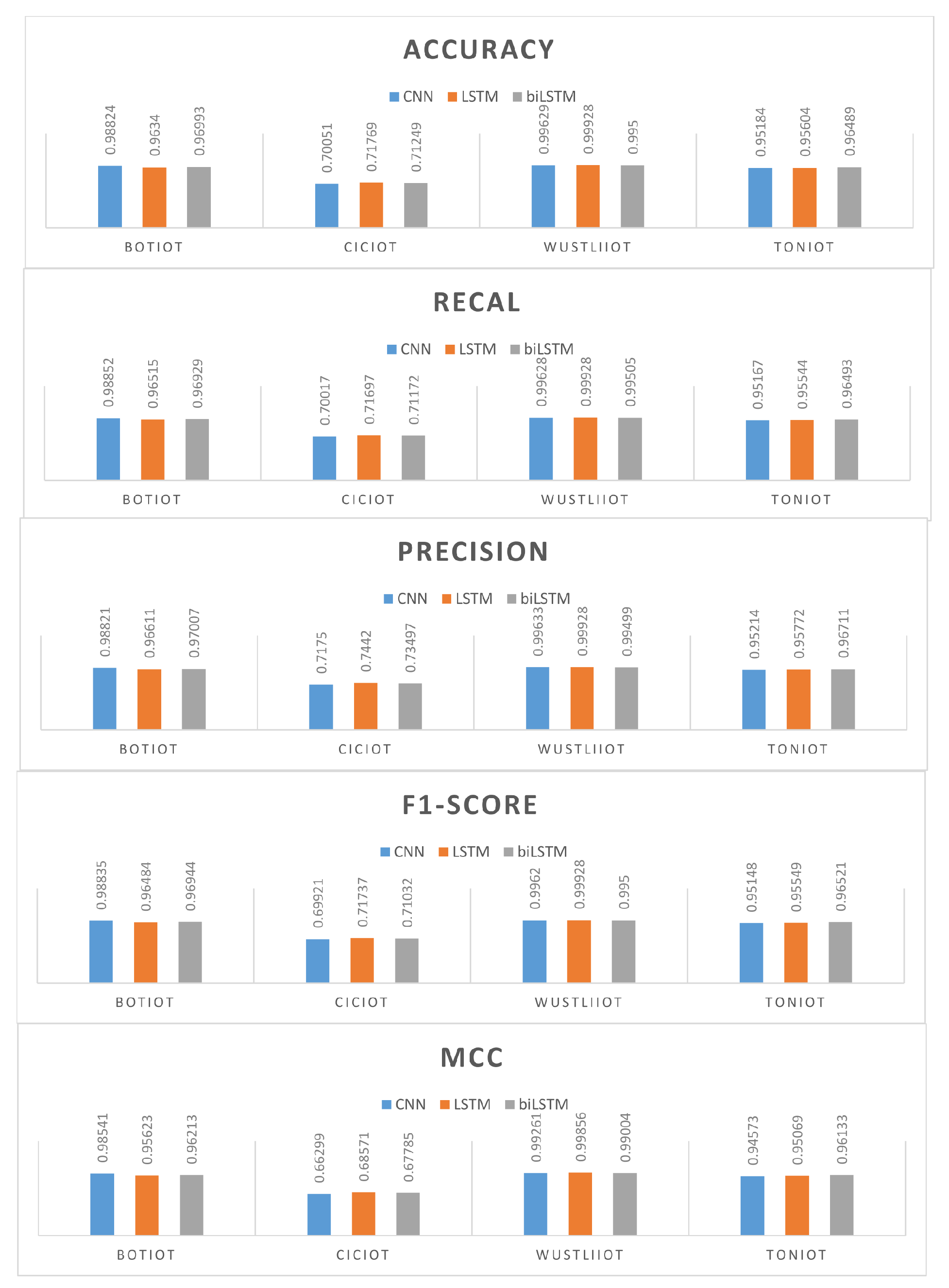
4.4. Precision
Precision is another metric used to evaluate the performance of a machine learning model. It refers to the quality of the positive predictions. Precision is the number of true positives divided by the overall number of positive predictions (i.e., the sum of true positives and false positives). In an IDS, the high precision indicates that if the system flags an event as an attack, it is more likely to be a genuine attack and less likely to be a harmless event (false alarm).
4.4.1. F1 Score
The F1 score is a balanced metric that takes into account both precision and recall. It provides a single figure that shows the trade-off between false positives and false negatives. It is computed as the harmonic mean of precision and recall. Recall and precision are better balanced when the F1 score is higher.
4.4.2. MCC (Matthews Correlation Coefficient)
False positives, false negatives, true positives, and true negatives are all taken into consideration by the Matthews correlation coefficient (MCC). It offers a fair assessment of the model’s effectiveness. The MCC metric is important specifically for the cases when there is an imbalance between the classes. The MCC metric is a number between −1 and 1, where 1 denotes ideal forecasts, 0 represents random predictions, and −1 denotes total discrepancy between predictions and actual results.







{kind=link}
{kind=link}