

A Context-Aware Doorway Alignment and Depth Estimation Algorithm for Assistive Wheelchairs

 ,
,  , and
, and 
Abstract
1. Introduction
- Enhanced spatial and channel-wise focus on structural features of doorways by integrating an attention module within the YOLOv8 backbone.
- Improved accuracy in detecting semantically similar regions by utilizing multi-scale contextual refinement.
- Development of a lightweight dual head structure for simultaneous door detection and depth estimation.
- Construction of a module to detect and correct door misalignment and provide real-time guidance to the wheelchair control system.
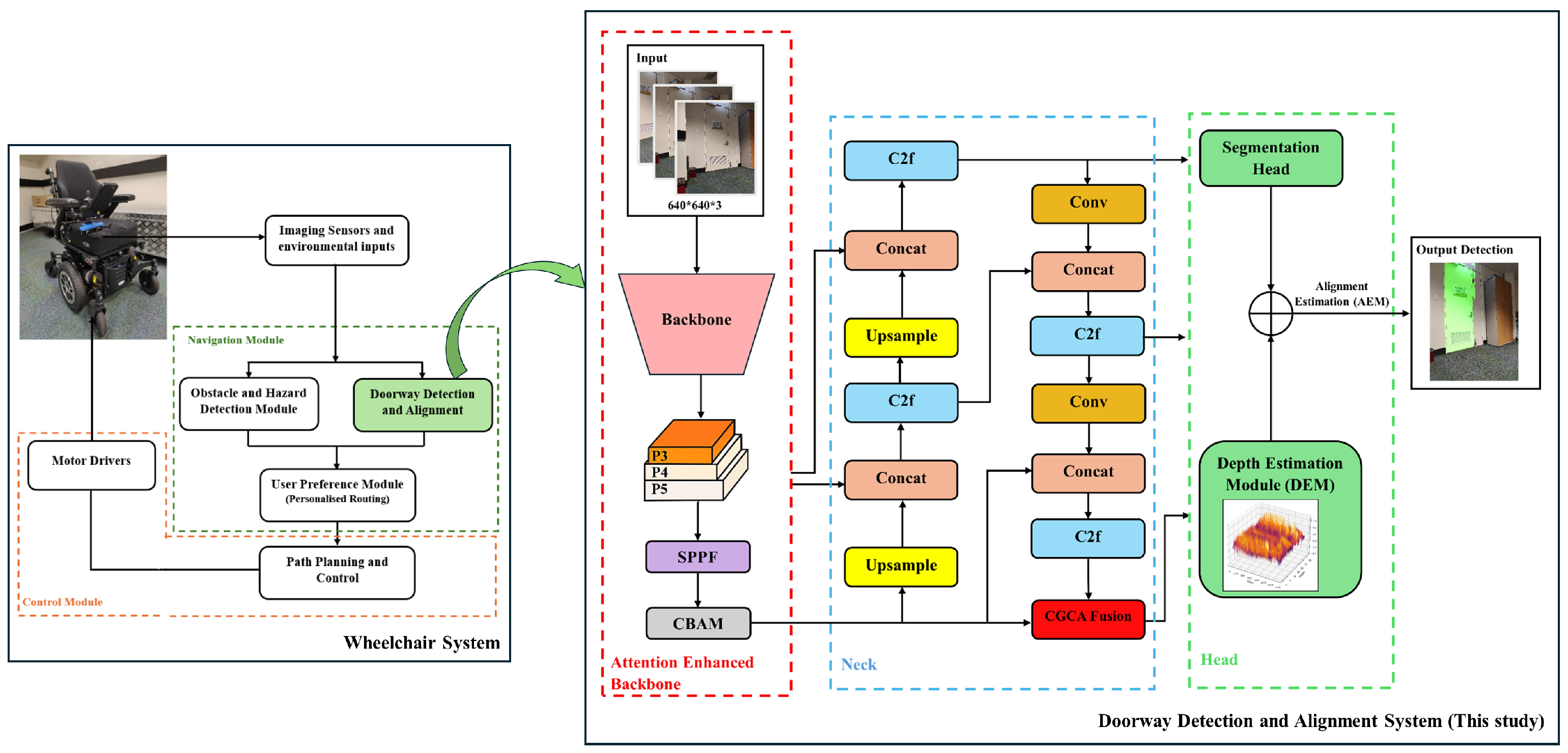
2. Materials and Methods
- (1)
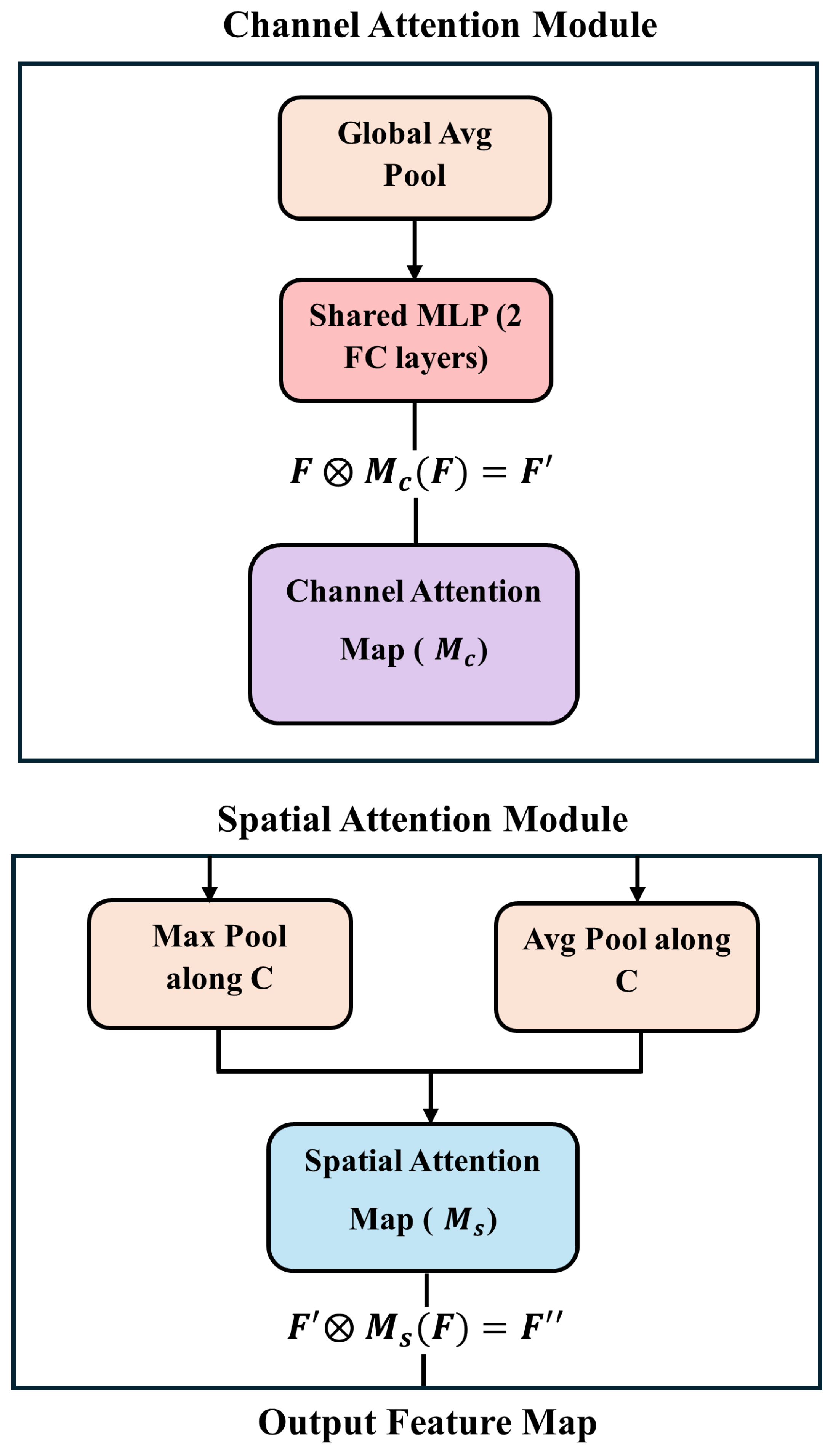
- CBAM: This sub-module enhances feature representation within the YOLOv8 backbone by enabling the model to more effectively focus on salient regions associated with doorways, thereby improving detection accuracy and robustness (Section 2.2).
- (2)
- CGCAFusion: This sub-module is responsible for dynamically modeling contextual relationships based on the input feature content, thereby enhancing structural segmentation performance, particularly in cluttered and visually complex environments (Section 2.3).
- (3)
- Depth Estimation Module (DEM): The objective of this sub-module is to predict relative depth information directly from RGB inputs, while incorporating spatial context to support accurate alignment estimation (Section 2.4).
- (4)
- Alignment Estimation Module (AEM): This sub-module computes the offset of the detected doorway relative to the image center, enabling the generation of precise directional guidance for the controller (Section 2.5).
2.1. Dataset Description
2.2. CBAM
2.3. CGCAFusion
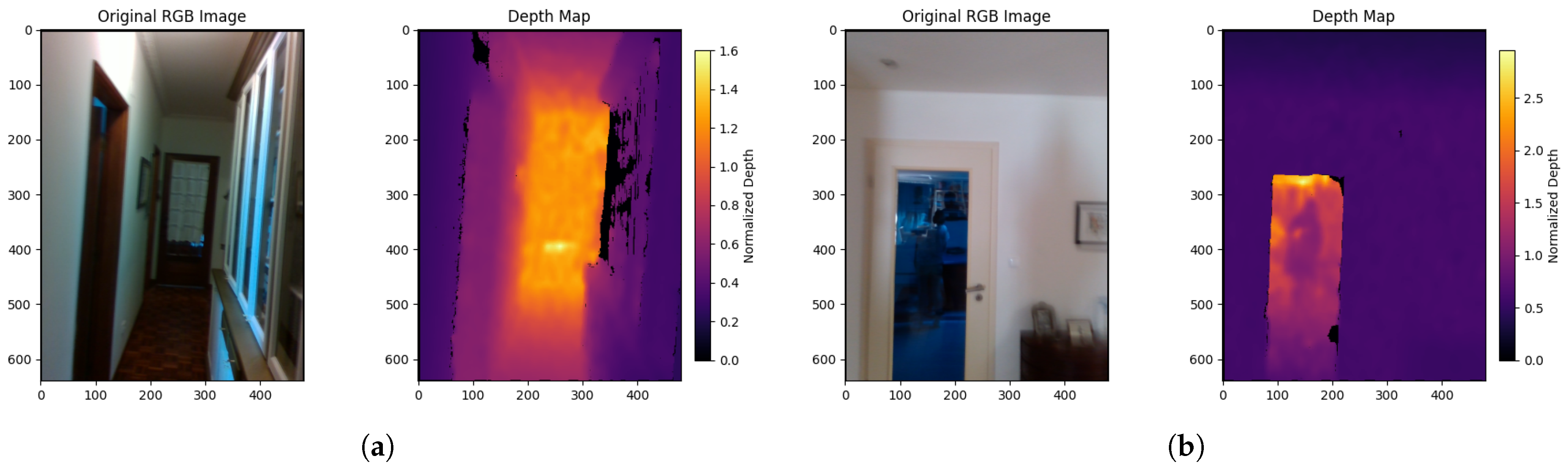
2.4. DEM
2.5. AEM
3. Results and Discussion
3.1. Structural Attention Enhancement Through CBAM
3.2. Improved Precision and Semantic Fusion Using CGCAFusion
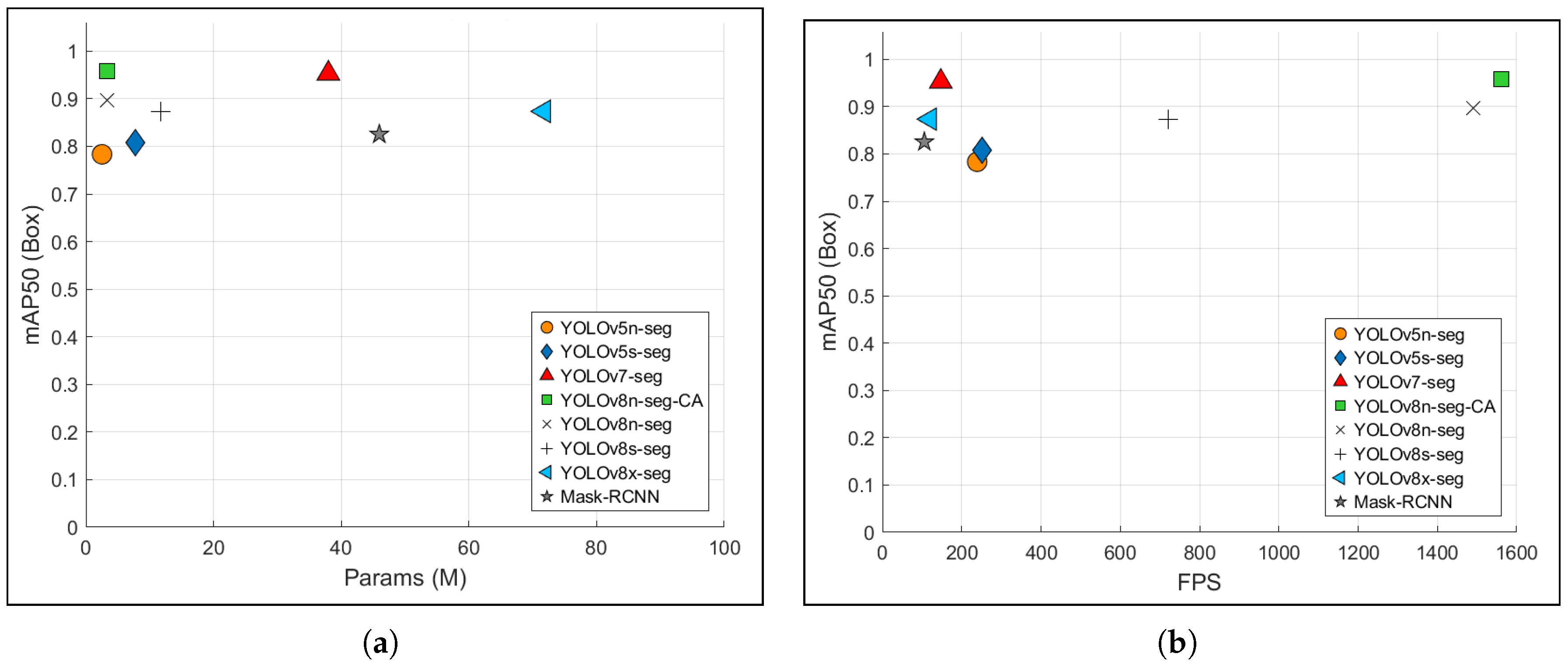
- Mean Average Precision (mAP50) quantifies detection accuracy by averaging precision of all detections. A higher mAP50 indicates more accurate localization and classification of objects.
- Params (M) refers to the total count of learnable weights (in Millions) within the model, reflecting its computational complexity. Models with fewer parameters are more suitable for resource-constrained environments.
- Frames Per Second (FPS) measures the real-time processing capability of the model. The model exhibits higher FPS, signifying that it can process video frames more rapidly, which is critical for responsive assistive navigation.
- Model Size (MB) represents the storage footprint of the trained model. Smaller models are more efficient for deployment on embedded hardware.
- Inference Time (ms) denotes the time required to process a single frame. Lower inference times are essential for real-time operation in time-sensitive applications.
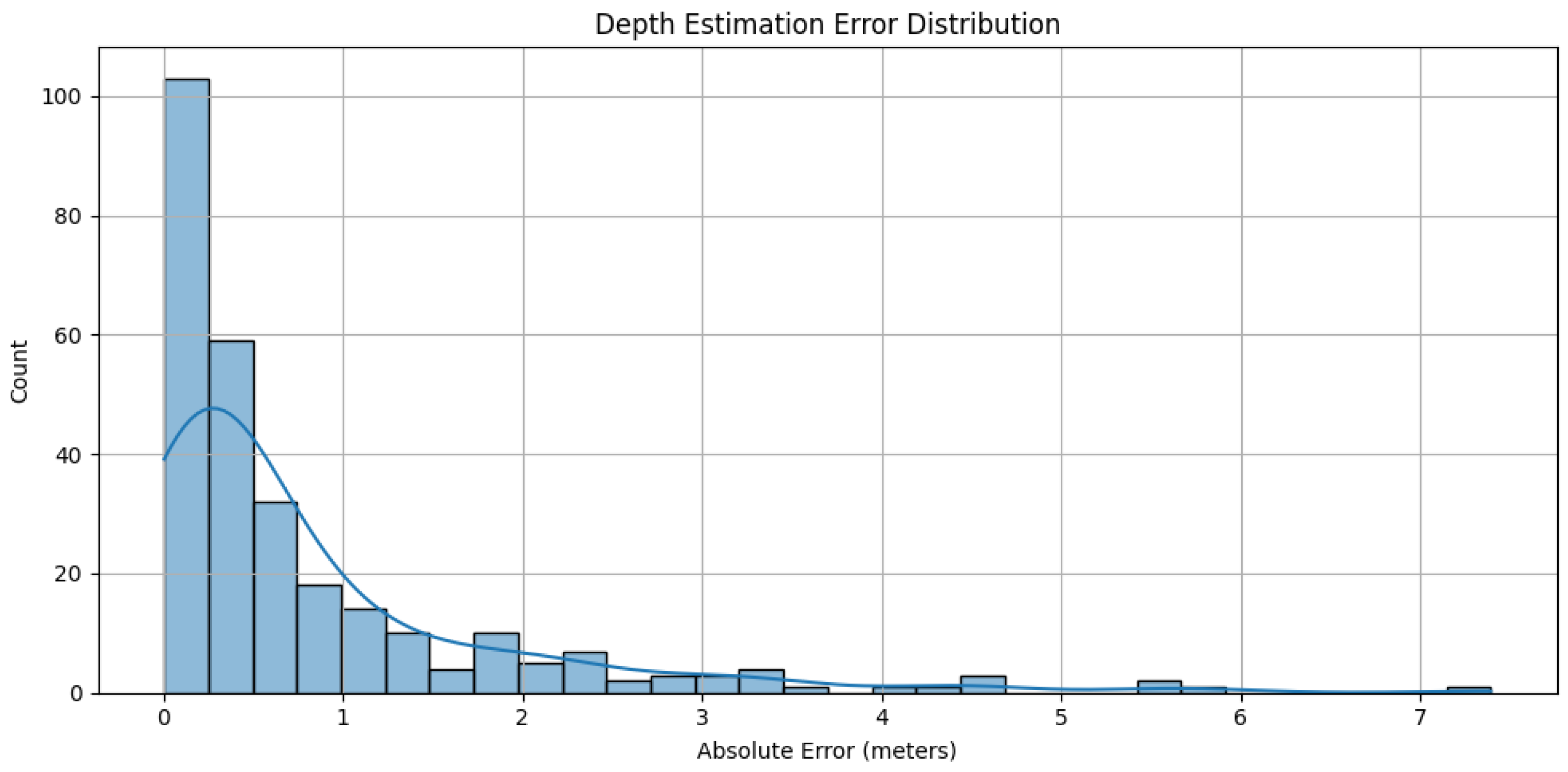
3.3. Performance of Unsupervised DEM
3.4. Accurate Alignment Estimation for Intelligent Guidance
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| YOLO | You Only Look Once |
| DSPP | DenseNet Spatial Pyramid Pooling |
| SPPF | Spatial Pyramid Pooling-Fast |
| CBAM | Convolutional Block Attention Module |
| CGCAFusion | Content-Guided Convolutional Attention Fusion Module |
| DEM | Depth Estimation Module |
| AEM | Alignment Estimation Module |
| CAM | Channel Attention Module |
| GAP | Global Average Pooling |
| GMP | Global Max Pooling |
| MLP | Multi-Layer Perceptron |
| SAM | Spatial Attention Module |
| CGA | Content-Guided Attention |
| CAFM | Convolutional Attention Fusion Module |
| mAP | Mean Average Precision |
| MAE | Mean Absolute Error |
| MiDaS | Mixed Datasets for Monocular Depth Estimation |
| DPT | Dense Prediction Transformer |
References
- Dickinson, L. Autonomy and motivation a literature review. System 1995, 23, 165–174. [Google Scholar] [CrossRef]
- Atkinson, J. Autonomy and mental health. In Ethical Issues in Mental Health; Springer: Berlin/Heidelberg, Germany, 1991; pp. 103–126. [Google Scholar]
- Mayo, N.E.; Mate, K.K.V. Quantifying Mobility in Quality of Life. In Quantifying Quality of Life: Incorporating Daily Life into Medicine; Wac, K., Wulfovich, S., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 119–136. [Google Scholar] [CrossRef]
- Meijering, L. Towards meaningful mobility: A research agenda for movement within and between places in later life. Ageing Soc. 2021, 41, 711–723. [Google Scholar] [CrossRef]
- World Health Organization (WHO); United Nations Children’s Fund (UNICEF). Global Report on Assistive Technology. Licence: CC BY-NC-SA 3.0 IGO. 2022. Available online: https://www.who.int/publications/i/item/9789240074521 (accessed on 10 July 2025).
- Marsden, J.F. Spasticity. Rheumatol. Rehabil. 2016, 2, 197–206. [Google Scholar]
- Elias, W.J.; Shah, B.B. Tremor. JAMA 2014, 311, 948–954. [Google Scholar] [CrossRef] [PubMed]
- MacDonald, A.E. General paresis. Am. J. Psychiatry 1877, 33, 451–482. [Google Scholar] [CrossRef]
- Cooper, R.A.; Cooper, R.; Boninger, M.L. Trends and issues in wheelchair technologies. Assist. Technol. 2008, 20, 61–72. [Google Scholar] [CrossRef] [PubMed]
- Tsao, C.C.; Mirbagheri, M.R. Upper limb impairments associated with spasticity in neurological disorders. J. NeuroEng. Rehabil. 2007, 4, 45. [Google Scholar] [CrossRef] [PubMed]
- Rizzo, J.R.; Beheshti, M.; Hudson, T.E.; Mongkolwat, P.; Riewpaiboon, W.; Seiple, W.; Ogedegbe, O.G.; Vedanthan, R. The global crisis of visual impairment: An emerging global health priority requiring urgent action. Disabil. Rehabil. Assist. Technol. 2023, 18, 240–245. [Google Scholar] [CrossRef] [PubMed]
- Pascolini, D.; Mariotti, S.P. Global estimates of visual impairment: 2010. Br. J. Ophthalmol. 2012, 96, 614–618. [Google Scholar] [CrossRef] [PubMed]
- Chang, K.y.J.; Rogers, K.; Lung, T.; Shih, S.; Huang-Lung, J.; Keay, L. Population-based projection of vision-related disability in australia 2020–2060: Prevalence, causes, associated factors and demand for orientation and mobility services. Ophthalmic Epidemiol. 2021, 28, 516–525. [Google Scholar] [CrossRef] [PubMed]
- Stevens, G.A.; White, R.A.; Flaxman, S.R.; Price, H.; Jonas, J.B.; Keeffe, J.; Leasher, J.; Naidoo, K.; Pesudovs, K.; Resnikoff, S.; et al. Global prevalence of vision impairment and blindness: Magnitude and temporal trends, 1990–2010. Ophthalmology 2013, 120, 2377–2384. [Google Scholar] [CrossRef] [PubMed]
- Kim, E.Y. Wheelchair navigation system for disabled and elderly people. Sensors 2016, 16, 1806. [Google Scholar] [CrossRef] [PubMed]
- Sanders, D.; Tewkesbury, G.; Stott, I.J.; Robinson, D. Simple expert systems to improve an ultrasonic sensor-system for a tele-operated mobile-robot. Sens. Rev. 2011, 31, 246–260. [Google Scholar] [CrossRef]
- Zheng, T.; Duan, Z.; Wang, J.; Lu, G.; Li, S.; Yu, Z. Research on distance transform and neural network lidar information sampling classification-based semantic segmentation of 2d indoor room maps. Sensors 2021, 21, 1365. [Google Scholar] [CrossRef] [PubMed]
- Gallo, V.; Shallari, I.; Carratù, M.; Laino, V.; Liguori, C. Design and Characterization of a Powered Wheelchair Autonomous Guidance System. Sensors 2024, 24, 1581. [Google Scholar] [CrossRef] [PubMed]
- Perra, C.; Kumar, A.; Losito, M.; Pirino, P.; Moradpour, M.; Gatto, G. Monitoring Indoor People Presence in Buildings Using Low-Cost Infrared Sensor Array in Doorways. Sensors 2021, 21, 4062. [Google Scholar] [CrossRef] [PubMed]
- Grewal, H.; Matthews, A.; Tea, R.; George, K. LIDAR-based autonomous wheelchair. In Proceedings of the 2017 IEEE Sensors Applications Symposium (SAS), Glassboro, NJ, USA, 13–15 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Durrant-Whyte, H.; Bailey, T. Simultaneous localization and mapping: Part I. IEEE Robot. Autom. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef]
- Sahoo, S.; Choudhury, B. Voice-activated wheelchair: An affordable solution for individuals with physical disabilities. Manag. Sci. Lett. 2023, 13, 175–192. [Google Scholar] [CrossRef]
- Sahoo, S.K.; Choudhury, B.B. Autonomous navigation and obstacle avoidance in smart robotic wheelchairs. J. Decis. Anal. Intell. Comput. 2024, 4, 47–66. [Google Scholar] [CrossRef]
- Ess, A.; Schindler, K.; Leibe, B.; Van Gool, L. Object detection and tracking for autonomous navigation in dynamic environments. Int. J. Robot. Res. 2010, 29, 1707–1725. [Google Scholar] [CrossRef]
- Qiu, Z.; Lu, Y.; Qiu, Z. Review of ultrasonic ranging methods and their current challenges. Micromachines 2022, 13, 520. [Google Scholar] [CrossRef] [PubMed]
- Derry, M.; Argall, B. Automated doorway detection for assistive shared-control wheelchairs. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1254–1259. [Google Scholar]
- Rusu, R.B.; Marton, Z.C.; Blodow, N.; Holzbach, A.; Beetz, M. Model-based and learned semantic object labeling in 3D point cloud maps of kitchen environments. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 3601–3608. [Google Scholar]
- Anguelov, D.; Koller, D.; Parker, E.; Thrun, S. Detecting and modeling doors with mobile robots. In Proceedings of the IEEE International Conference on Robotics and Automation, 2004. Proceedings. ICRA’04, New Orleans, LA, USA, 26 April–1 May 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 4, pp. 3777–3784. [Google Scholar]
- Lecrosnier, L.; Khemmar, R.; Ragot, N.; Decoux, B.; Rossi, R.; Kefi, N.; Ertaud, J.Y. Deep learning-based object detection, localisation and tracking for smart wheelchair healthcare mobility. Int. J. Environ. Res. Public Health 2021, 18, 91. [Google Scholar] [CrossRef] [PubMed]
- Ju, M.; Luo, H.; Wang, Z.; Hui, B.; Chang, Z. The application of improved YOLO V3 in multi-scale target detection. Appl. Sci. 2019, 9, 3775. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3464–3468. [Google Scholar]
- Zhang, T.; Li, J.; Jiang, Y.; Zeng, M.; Pang, M. Position detection of doors and windows based on dspp-yolo. Appl. Sci. 2022, 12, 10770. [Google Scholar] [CrossRef]
- Iandola, F.; Moskewicz, M.; Karayev, S.; Girshick, R.; Darrell, T.; Keutzer, K. Densenet: Implementing efficient convnet descriptor pyramids. arXiv 2014, arXiv:1404.1869. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Mochurad, L.; Hladun, Y. Neural network-based algorithm for door handle recognition using RGBD cameras. Sci. Rep. 2024, 14, 15759. [Google Scholar] [CrossRef] [PubMed]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Hussain, M. YOLOv5, YOLOv8 and YOLOv10: The Go-To Detectors for Real-time Vision. arXiv 2024, arXiv:2407.02988. [Google Scholar]
- Wei, L.; Tong, Y. Enhanced-YOLOv8: A new small target detection model. Digit. Signal Process. 2024, 153, 104611. [Google Scholar] [CrossRef]
- Sharma, P.; Tyagi, R.; Dubey, P. Bridging the Perception Gap A YOLO V8 Powered Object Detection System for Enhanced Mobility of Visually Impaired Individuals. In Proceedings of the 2024 First International Conference on Technological Innovations and Advance Computing (TIACOMP), Bali, Indonesia, 29–30 June 2024; pp. 107–117. [Google Scholar] [CrossRef]
- Choi, E.; Dinh, T.A.; Choi, M. Enhancing Driving Safety of Personal Mobility Vehicles Using On-Board Technologies. Appl. Sci. 2025, 15, 1534. [Google Scholar] [CrossRef]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Tennekoon, S.; Wedasingha, N.; Welhenge, A.; Abhayasinghe, N.; Murray Am, I. Advancing Object Detection: A Narrative Review of Evolving Techniques and Their Navigation Applications. IEEE Access 2025, 13, 50534–50555. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference On Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, Z.; Zou, Y.; Tan, Y.; Zhou, C. YOLOv8-seg-CP: A lightweight instance segmentation algorithm for chip pad based on improved YOLOv8-seg model. Sci. Rep. 2024, 14, 27716. [Google Scholar] [CrossRef] [PubMed]
- Ramôa, J.; Lopes, V.; Alexandre, L.; Mogo, S. Real-time 2D–3D door detection and state classification on a low-power device. SN Appl. Sci. 2021, 3, 590. [Google Scholar] [CrossRef] [PubMed]
- Kruse, R.; Mostaghim, S.; Borgelt, C.; Braune, C.; Steinbrecher, M. Multi-layer perceptrons. In Computational Intelligence: A Methodological Introduction; Springer: Cham, Switzerland, 2022; pp. 53–124. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Zhu, L.; Wang, X.; Ke, Z.; Zhang, W.; Lau, R.W. Biformer: Vision transformer with bi-level routing attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10323–10333. [Google Scholar]
- Xu, W.; Wan, Y. ELA: Efficient local attention for deep convolutional neural networks. arXiv 2024, arXiv:2403.01123. [Google Scholar] [CrossRef]
- Hu, S.; Gao, F.; Zhou, X.; Dong, J.; Du, Q. Hybrid convolutional and attention network for hyperspectral image denoising. IEEE Geosci. Remote Sens. Lett. 2024, 21, 5504005. [Google Scholar] [CrossRef]
- Jocher, G. YOLOv5 by Ultralytics; Zenodo: Geneva, Switzerland, 2020. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Jocher, G.; Qiu, J.; Chaurasia, A. Ultralytics YOLO. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 28 December 2024).
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Ranftl, R.; Lasinger, K.; Hafner, D.; Schindler, K.; Koltun, V. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1623–1637. [Google Scholar] [CrossRef] [PubMed]
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision transformers for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 12179–12188. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Description |
|---|---|
| Dataset source | DeepDoorsv2 [45] + Custom RGB images |
| Total images | 3100 |
| Resolution | 480 × 640 pixels |
| Door states | Closed, Semi-open, Open |
| Door types | Single, Double, Sliding, Glass |
| Conditions | Diverse lighting, occlusions, angles, and layouts |
| Segmentation pixels | Door/Frame: (192, 224, 192); Background: (0, 0, 0) |
| Data split | 7:1.5:1.5 (train:val:test) |
| Parameters | Value |
|---|---|
| Epochs | 150 |
| Ir0 | 0.002 |
| Irf | 0.002 |
| Momentum | 0.9 |
| Batchsize | 16 |
| Cache | False |
| Input image size | 640 × 640 |
| Optimizer | AdamW |
| Model | mAP50 (Bounding Box) | Params (M) | FPS | Model Size (MB) | Inference Time (ms) |
|---|---|---|---|---|---|
| Mask R-CNN | 0.825 | 45.96 | 105.7 | 346.52 | 9.33 |
| YOLOv5n-seg | 0.783 | 2.53 | 239 | 5.14 | 4.62 |
| YOLOv5s-seg | 0.808 | 7.74 | 252.1 | 15.6 | 4.26 |
| YOLOv7-seg | 0.953 | 37.98 | 147.23 | 78.1 | 6.9 |
| YOLOv8n-seg | 0.896 | 3.26 | 1490 | 6.45 | 0.64 |
| YOLOv8s-seg | 0.872 | 11.79 | 720 | 22.73 | 1.39 |
| YOLOv8x-seg | 0.873 | 71.75 | 120 | 137.26 | 8.62 |
| Proposed Model | 0.958 | 2.96 | 1560 | 3.6 | 0.42 |
| Model | Size (MB) | Inference Time (ms) | Memory Usage (MB per FPS) | MAE |
|---|---|---|---|---|
| MiDaS | 100 | 0.017 | 1.7 | 3.19 |
| DPT | 350 | 0.046 | 16 | 0.08 |
| Proposed DEM | <3.6 | 0.026 | 0.1 | 0.69 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tennekoon, S.; Wedasingha, N.; Welhenge, A.; Abhayasinghe, N.; Murray, I. A Context-Aware Doorway Alignment and Depth Estimation Algorithm for Assistive Wheelchairs. Computers 2025, 14, 284. https://doi.org/10.3390/computers14070284
Tennekoon S, Wedasingha N, Welhenge A, Abhayasinghe N, Murray I. A Context-Aware Doorway Alignment and Depth Estimation Algorithm for Assistive Wheelchairs. Computers. 2025; 14(7):284. https://doi.org/10.3390/computers14070284
Chicago/Turabian StyleTennekoon, Shanelle, Nushara Wedasingha, Anuradhi Welhenge, Nimsiri Abhayasinghe, and Iain Murray. 2025. "A Context-Aware Doorway Alignment and Depth Estimation Algorithm for Assistive Wheelchairs" Computers 14, no. 7: 284. https://doi.org/10.3390/computers14070284
APA StyleTennekoon, S., Wedasingha, N., Welhenge, A., Abhayasinghe, N., & Murray, I. (2025). A Context-Aware Doorway Alignment and Depth Estimation Algorithm for Assistive Wheelchairs. Computers, 14(7), 284. https://doi.org/10.3390/computers14070284