
Machine Learning for Anomaly Detection in Blockchain: A Critical Analysis, Empirical Validation, and Future Outlook


Abstract
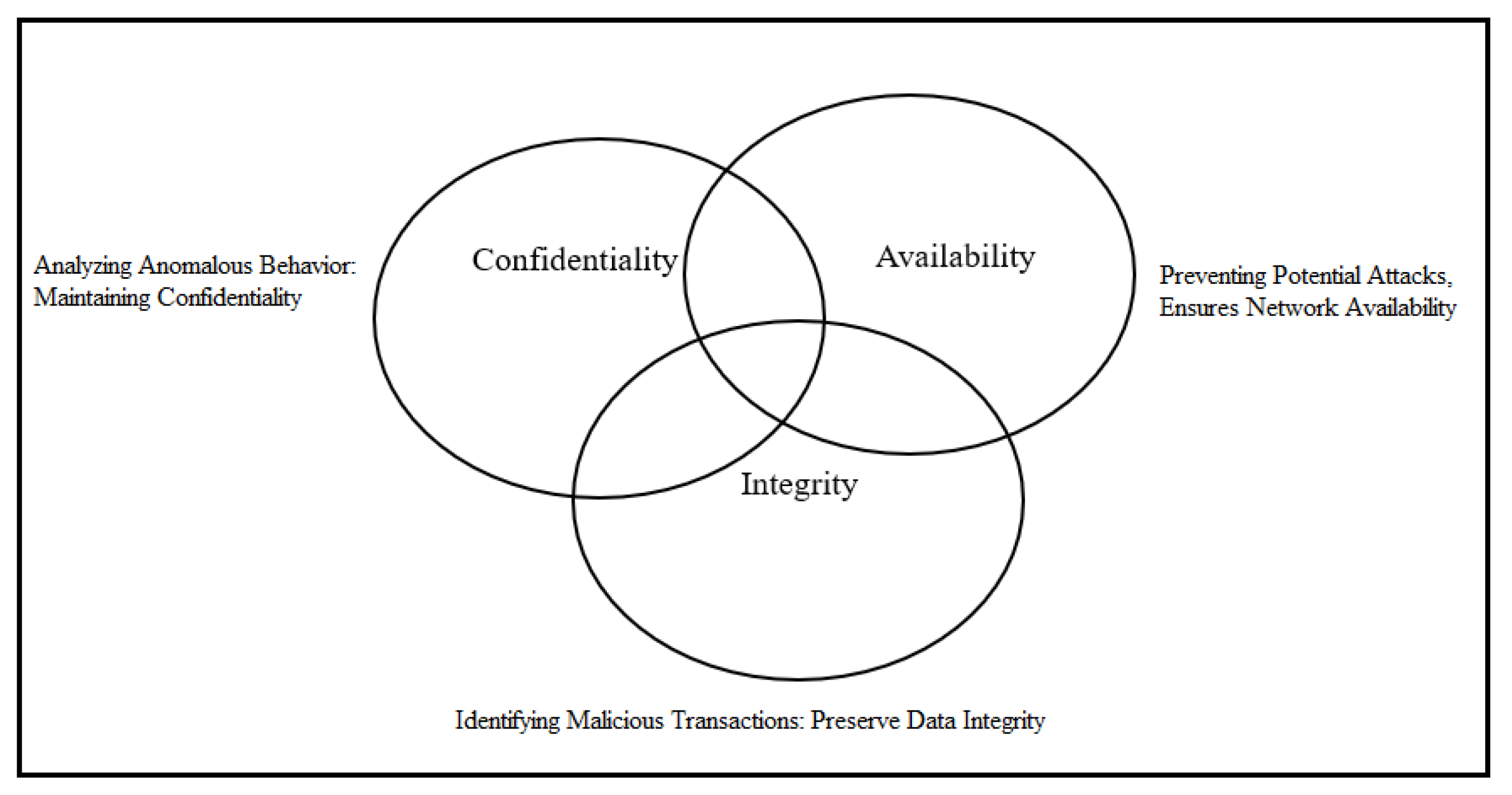
1. Introduction
- Evaluate the performance of ML models in anomaly detection, including supervised and unsupervised anomaly detection.
- Consequently, compare the performance of each of the given techniques.
- Classify according to algorithm type, learning type, data requirements, objective, optimization problem, decision boundary type, performance evaluation, regularization parameter, and merits/demerits of techniques.
- It spans the years 2019–2025, which is a relatively current period.
2. Background on Blockchain Technology
2.1. Hashing and Digital Signatures
2.2. Blockchain Mining
2.3. Proof of Work (PoW)
2.4. 51% Attack on Blockchain Network
2.5. Use Case of a 51% Attack
2.6. Probability of 51% Attack Calculation
3. Literature Review
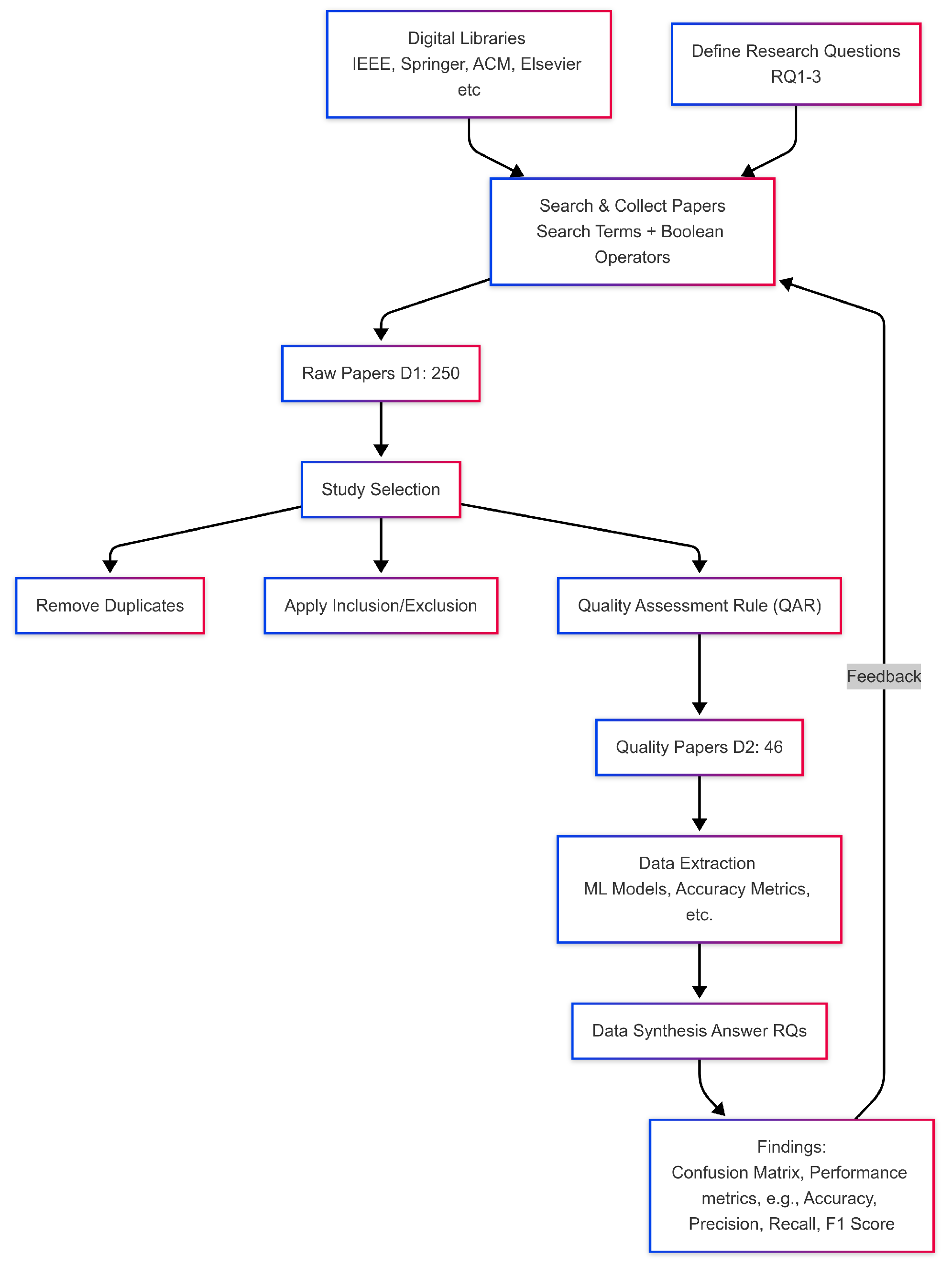
4. Research Methodology
4.1. Research Questions
4.2. Search Strategy
- The search terms relevant to anomaly detection and machine learning are utilized in this SLR;
- The research questions are analyzed to identify the key search terms for this SLR;
- We replaced the main terms with new key terms, such as malicious, outliers, and anomalous;
- Boolean operators like ORS and ANDS are also utilized to restrict the search results.
4.3. Study Selection
- Eliminate duplicate articles from various digital libraries.
- We set the inclusion and exclusion criteria based on the research questions to exclude irrelevant papers.
- Exclude books and lecture notes from the collected list.
- Quality assessment criteria were applied to comprise only those studies that best addressed our research goals.
4.4. Quality Assessment Rules (QARs)
- QAR1: Are the objectives of the study clearly defined?
- QAR2: Are the techniques for anomaly detection well-defined and discussed?
- QAR3: Is the proposed specific application of anomaly detection well-defined?
- QAR4: Are the implementation details of the proposed work included in the paper?
- QAR5: To what extent are the experiments valid and justified?
- QAR6: Is a sufficient dataset used to conduct experiments?
- QAR7: Are the criteria in the estimation accuracy report accurate?
- QAR8: Is the proposed approach compared with similar approaches?
- QAR9: Is the analysis of the outcomes based on the proper techniques?
- QAR10: Does the study have any implications for the academic fraternity or the industry?
4.5. Data Extraction Strategy
4.6. Synthesis of Extracted Data
5. Machine Learning Algorithms in Blockchain
5.1. Support Vector Machine (SVM)
5.2. K-Means
- In manifolds with irregular shapes and elongated clusters, inertia responds very poorly because it is assumed that clusters are isotropic and convex, which is not always the case.
- Inertia is a non-normalized metric; lower values are more effective, and zero is optimal. However, Euclidean distances tend to expand in very high-dimensional spaces.
5.3. Random Forest
5.4. XGBoost
5.5. Adaboost
6. Implementation Details
6.1. Dataset Description
6.2. Experimental Setup
6.3. Feature Engineering
- Hash: It represents the hash value of a transaction.
- Number of Transactions: It represents the number of transactions.
- Timestamp: It represents the mining time of a transaction.
- Height: It represents the block number.
- Difficulty changes over time: A block’s difficulty is determined by comparing it to its easiest possible state.
- Confirmations: It represents the number of times a transaction has been verified by subsequent blocks. More confirmations mean higher security and irreversibility.
6.4. Insert Anomalies
6.5. Train the ML Models
6.6. Anomaly Detection
6.7. Model Evaluation and Comparison
7. Findings
7.1. Confusion Matrix
7.2. Performance Matrix
7.3. Open Challenges
7.4. Discussion
7.5. Limitations
7.6. Future Directions
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Prasad, V.S.R.; Harshitha, G.; Sujitha, A.; Asmitha, M.; Aishwarya, A.; Priya, D.J. Strengthening Blockchain Security: Countering 51% Attacks Using Dynamic Miner Reputation and Weighted Block Acceptance (DRW-BA). Synth. Multidiscip. Res. J. 2025, 3, 1–13. [Google Scholar]
- Chen, S.; Liu, Y.; Zhang, Q.; Shao, Z.; Wang, Z. Multi-Distance Spatial-Temporal Graph Neural Network for Anomaly Detection in Blockchain Transactions. Adv. Intell. Syst. 2025, 2400898. [Google Scholar] [CrossRef]
- Hasan, M.; Rahman, M.S.; Janicke, H.; Sarker, I.H. Detecting anomalies in blockchain transactions using machine learning classifiers and explainability analysis. Blockchain Res. Appl. 2024, 5, 100207. [Google Scholar] [CrossRef]
- Cholevas, C.; Angeli, E.; Sereti, Z.; Mavrikos, E.; Tsekouras, G.E. Anomaly Detection in Blockchain Networks Using Unsupervised Learning: A Survey. Algorithms 2024, 17, 201. [Google Scholar] [CrossRef]
- Tukur, Y.M.; Thakker, D.; Awan, I.U. Edge-based blockchain enabled anomaly detection for insider attack prevention in Internet of Things. Trans. Emerg. Telecommun. Technol. 2021, 32, e4158. [Google Scholar] [CrossRef]
- Mishra, D.; Phansalkar, S. Blockchain Security in Focus: A Comprehensive Investigation into Threats, Smart Contract Security, Cross-Chain Bridges, Vulnerabilities Detection Tools & Techniques. IEEE Access 2025, 13, 60643–60671. [Google Scholar]
- Jain, A.K.; Gupta, N.; Gupta, B.B. A survey on scalable consensus algorithms for blockchain technology. Cyber Secur. Appl. 2025, 3, 100065. [Google Scholar] [CrossRef]
- Yusuf, F.; Widayanti, R.; Putri, S.R.; Wellington, A. A Comprehensive Framework for Enhancing Blockchain Security and Privacy. Blockchain Front. Technol. 2025, 4, 171–182. [Google Scholar]
- Liu, Z.; Gao, H.; Lei, H.; Liu, Z.; Liu, C. Blockchain Anomaly Transaction Detection: An Overview, Challenges, and Open Issues. In Proceedings of the International Conference on Information Science, Communication and Computing, Chongqing, China, 2–5 June 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 126–140. [Google Scholar]
- Sayeed, S.; Marco-Gisbert, H. Assessing blockchain consensus and security mechanisms against the 51% attack. Appl. Sci. 2019, 9, 1788. [Google Scholar] [CrossRef]
- Walker, H. How Digital Signatures and Blockchains Can Work Together. 2018. Available online: www.cryptomathic.com/news-events/blog/how-digital-signatures-and-blockchains-can-work-together (accessed on 1 August 2018).
- Acheson, N. How Bitcoin Mining Works. CoinDesk. 2018. Available online: https://www.coindesk.com/learn/how-bitcoin-mining-works-2 (accessed on 8 September 2023).
- Dey, S. Securing majority-attack in blockchain using machine learning and algorithmic game theory: A proof of work. In Proceedings of the 2018 10th Computer Science and Electronic Engineering (CEEC), Colchester, UK, 19–21 September 2018; pp. 7–10. [Google Scholar]
- Aponte-Novoa, F.A.; Orozco, A.L.S.; Villanueva-Polanco, R.; Wightman, P. The 51% attack on blockchains: A mining behavior study. IEEE Access 2021, 9, 140549–140564. [Google Scholar] [CrossRef]
- Liu, Q.; Xu, Y.; Cao, B.; Zhang, L.; Peng, M. Unintentional forking analysis in wireless blockchain networks. Digit. Commun. Netw. 2021, 7, 335–341. [Google Scholar] [CrossRef]
- Chaudhary, K.C.; Chand, V.; Fehnker, A. Double-spending analysis of bitcoin. In Proceedings of the Pacific Asia Conference on Information Systems, Dubai, United Arab Emirates, 22–24 June 2020. [Google Scholar]
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. 2008. Available online: https://assets.pubpub.org/d8wct41f/31611263538139.pdf (accessed on 1 August 2023).
- Sodhi, G.K.; Sharma, M.; Miglani, R. A Comprehensive Analysis of Blockchain Network Security: Attacks and Their Countermeasures. In Proceedings of the International Conference on Recent Trends in Image Processing and Pattern Recognition, Derby, UK, 7–8 December 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 276–291. [Google Scholar]
- Mohammed, M.A.; Boujelben, M.; Abid, M. A novel approach for fraud detection in blockchain-based healthcare networks using machine learning. Future Internet 2023, 15, 250. [Google Scholar] [CrossRef]
- Duong, T.; Fan, L.; Katz, J.; Thai, P.; Zhou, H.S. 2-hop blockchain: Combining proof-of-work and proof-of-stake securely. In Proceedings of the European Symposium on Research in Computer Security, Guildford, UK, 14–18 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 697–712. [Google Scholar]
- Yun, J.; Goh, Y.; Chung, J.M. Trust-based shard distribution scheme for fault-tolerant shard blockchain networks. IEEE Access 2019, 7, 135164–135175. [Google Scholar] [CrossRef]
- Sayadi, S.; Rejeb, S.B.; Choukair, Z. Anomaly detection model over blockchain electronic transactions. In Proceedings of the 2019 15th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 895–900. [Google Scholar]
- Chen, X.; Ji, J.; Luo, C.; Liao, W.; Li, P. When machine learning meets blockchain: A decentralized, privacy-preserving and secure design. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 1178–1187. [Google Scholar]
- Budgen, D.; Brereton, P. Performing systematic literature reviews in software engineering. In Proceedings of the 28th International Conference on Software Engineering, Shanghai, China, 20–28 May 2006; Volume 49, pp. 1051–1052. [Google Scholar]
- Buchdadi, A.D.; Al-Rawahna, A.S.M. Anomaly Detection in Open Metaverse Blockchain Transactions Using Isolation Forest and Autoencoder Neural Networks. Int. J. Res. Metaverse 2025, 2, 24–51. [Google Scholar] [CrossRef]
- Rwibasira, M.; Suchithra, R. ADOBSVM: Anomaly detection on block chain using support vector machine. Meas. Sens. 2022, 24, 100503. [Google Scholar] [CrossRef]
- Jatoth, C.; Jain, R.; Fiore, U.; Chatharasupalli, S. Improved classification of blockchain transactions using feature engineering and ensemble learning. Future Internet 2021, 14, 16. [Google Scholar] [CrossRef]
- Kim, J.; Nakashima, M.; Fan, W.; Wuthier, S.; Zhou, X.; Kim, I.; Chang, S.Y. Anomaly detection based on traffic monitoring for secure blockchain networking. In Proceedings of the 2021 IEEE International Conference on Blockchain and Cryptocurrency (ICBC), Sydney, Australia, 3–6 May 2021; pp. 1–9. [Google Scholar]
- Agarwal, R.; Barve, S.; Shukla, S.K. Detecting malicious accounts in permissionless blockchains using temporal graph properties. Appl. Netw. Sci. 2021, 6, 1–30. [Google Scholar] [CrossRef]
- Signorini, M.; Pontecorvi, M.; Kanoun, W.; Di Pietro, R. BAD: A blockchain anomaly detection solution. IEEE Access 2020, 8, 173481–173490. [Google Scholar] [CrossRef]
- Liao, Q.; Gu, Y.; Liao, J.; Li, W. Abnormal transaction detection of Bitcoin network based on feature fusion. In Proceedings of the 2020 IEEE 9th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 11–13 December 2020; Volume 9, pp. 542–549. [Google Scholar]
- Huang, D.; Chen, B.; Li, L.; Ding, Y. Anomaly detection for consortium blockchains based on machine learning classification algorithm. In Proceedings of the International Conference on Computational Data and Social Networks, Bangkok, Thailand, 16–18 December 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 307–318. [Google Scholar]
- Kumar, N.; Singh, A.; Handa, A.; Shukla, S.K. Detecting malicious accounts on the Ethereum blockchain with supervised learning. In Proceedings of the Cyber Security Cryptography and Machine Learning: Fourth International Symposium, CSCML 2020, Be’er Sheva, Israel, 2–3 July 2020; Proceedings 4. Springer: Berlin/Heidelberg, Germany, 2020; pp. 94–109. [Google Scholar]
- Poursafaei, F.; Hamad, G.B.; Zilic, Z. Detecting malicious Ethereum entities via application of machine learning classification. In Proceedings of the 2020 2nd Conference on Blockchain Research & Applications for Innovative Networks and Services (BRAINS), Paris, France, 28–30 September 2020; pp. 120–127. [Google Scholar]
- Song, J.; He, H.; Lv, Z.; Su, C.; Xu, G.; Wang, W. An efficient vulnerability detection model for ethereum smart contracts. In Proceedings of the Network and System Security: 13th International Conference, NSS 2019, Sapporo, Japan, 15–18 December 2019; Proceedings 13. Springer: Berlin/Heidelberg, Germany, 2019; pp. 433–442. [Google Scholar]
- Ostapowicz, M.; Żbikowski, K. Detecting fraudulent accounts on blockchain: A supervised approach. In Proceedings of the Web Information Systems Engineering–WISE 2019: 20th International Conference, Hong Kong, China, 19–22 January 2020; Proceedings 20. Springer: Berlin/Heidelberg, Germany, 2019; pp. 18–31. [Google Scholar]
- Baek, H.; Oh, J.; Kim, C.Y.; Lee, K. A model for detecting cryptocurrency transactions with discernible purpose. In Proceedings of the 2019 Eleventh International Conference on Ubiquitous and Future Networks (ICUFN), Zagreb, Croatia, 2–5 July 2019; pp. 713–717. [Google Scholar]
- Siddamsetti, S.; Tejaswi, C.; Maddula, P. Anomaly detection in blockchain using machine learning. J. Electr. Syst. 2024, 20, 619–634. [Google Scholar] [CrossRef]
- Li, Y.G. A clustering method based on K-means algorithm. Appl. Mech. Mater. 2013, 380, 1697–1700. [Google Scholar] [CrossRef]
- Hisham, S.; Makhtar, M.; Aziz, A.A. Combining multiple classifiers using ensemble method for anomaly detection in blockchain networks: A comprehensive review. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 404–422. [Google Scholar] [CrossRef]
- Primartha, R.; Tama, B.A. Anomaly detection using random forest: A performance revisited. In Proceedings of the 2017 International Conference on Data and Software Engineering (ICoDSE), Palembang, Indonesia, 1–2 November 2017; pp. 1–6. [Google Scholar]
- Awan, K.A.; Din, I.U.; Almogren, A.; Kim, B.S.; Guizani, M. Enhancing IoT Security with Trust Management Using Ensemble XGBoost and AdaBoost Techniques. IEEE Access 2024, 12, 116609–116621. [Google Scholar] [CrossRef]
- Wang, W.; Sun, D. The improved AdaBoost algorithms for imbalanced data classification. Inf. Sci. 2021, 563, 358–374. [Google Scholar] [CrossRef]
- Hafid, A.; Hafid, A.S.; Samih, M. Scaling blockchains: A comprehensive survey. IEEE Access 2020, 8, 125244–125262. [Google Scholar] [CrossRef]
- Zamyatin, A.; Al-Bassam, M.; Zindros, D.; Kokoris-Kogias, E.; Moreno-Sanchez, P.; Kiayias, A.; Knottenbelt, W.J. Sok: Communication across distributed ledgers. In Proceedings of the Financial Cryptography and Data Security: 25th International Conference, FC 2021, Virtual Event, 1–5 March 2021; Revised Selected Papers, Part II 25. Springer: Berlin/Heidelberg, Germany, 2021; pp. 3–36. [Google Scholar]
- Pang, G.; Shen, C.; Cao, L.; Hengel, A.V.D. Deep learning for anomaly detection: A review. ACM Comput. Surv. CSUR 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Conti, M.; Kumar, E.S.; Lal, C.; Ruj, S. A survey on security and privacy issues of bitcoin. IEEE Commun. Surv. Tutor. 2018, 20, 3416–3452. [Google Scholar] [CrossRef]
- Jia, X.; Xu, J.; Han, M.; Zhang, Q.; Zhang, L.; Chen, X. International Standardization of Blockchain and Distributed Ledger Technology: Overlaps, Gaps and Challenges. CMES Comput. Model. Eng. Sci. 2023, 137, 1491–1523. [Google Scholar] [CrossRef]
- Sanjay Rai, G.; Goyal, S.; Chatterjee, P. Anomaly detection in blockchain using machine learning. In Computational Intelligence for Engineering and Management Applications: Select Proceedings of CIEMA 2022; Springer: Berlin/Heidelberg, Germany, 2023; pp. 487–499. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Digital Libraries | Keywords | Total Records |
|---|---|---|
| Google Scholar | “Anomaly detection in blockchain”, “anomaly detection in blockchain AND machine learning” | 19,018 |
| Springer | “51% attack in blockchain”, “51 percent attack detection in blockchain” | 3784 |
| ACM Digital Library | “anomalous behavior of blockchain nodes detection” | 4779 |
| IEEE Explorer | “anomalous transactions detection in Blockchain AND machine learning”, “anomalous fork detection in blockchain” | 911 |
| Elsevier | 7954 |
| Inclusion Criteria | Exclusion Criteria |
|---|---|
| Publication of articles in peer-reviewed journals | Eliminate duplicate articles |
| Accessible research articles. | Exclude books, reports, lecture notes, and miscellany. |
| Relevant content to anomaly detection in the blockchain network | Grey literature, such as blogs and government documents |
| Ref. | Type | ML-Model | Blockchain | Application | Evaluation Criteria | Findings |
|---|---|---|---|---|---|---|
| [1] | Journal | TCN | Ethereum | 51% attack detection | F1-score, AUC-ROC | Reduces 51% attack success to 7.3%, better than PoW (78.4%) and CBL-PoW (26.7%) but has complexity issues. |
| [2] | Journal | GNN | Bitcoin | Anomaly detection | AUC-ROC, AUC-PR | Achieves 1.5% AUC-ROC and 2.9% AUC-PR, but limited by dataset and scalability issues. |
| [25] | Journal | Isolation Forest, Autoencoder | Open Metaverse | Anomaly detection | Precision, Recall, F1-score, AUC-ROC | Isolation Forest: 0.85 precision; Autoencoder: 0.87. Depends on threshold. |
| [3] | Journal | Tree-Based Ensemble | Bitcoin | Anomaly detection | Accuracy, TPR, FPR, ROC-AUC | SHAP values help identify normal/fraudulent transactions effectively. |
| [26] | Journal | Ensemble Boosting | Crypto-currency | anomaly detection | Accuracy, precision, F-measure, and Recall | It is evaluated that the ensemble boosting technique performs better than the other models. |
| [27] | Journal | ADOBSVM | Bitcoin | Anomaly detection | Accuracy, energy value matrices | SVM focuses on good security with less execution time. Its efficacy is measured with the help of attack detection rate, error rate, execution time, and power consumption. |
| [28] | Conference | Auto-Encoder | Bitcoin | Detection of malicious events | The standard metrics of accuracy and F1 score | Detect malicious events in blockchain networks with reduced time complexity. |
| [29] | Journal | Ensemble (DT) | Ethereum | malicious accounts | Balanced accuracy, Precision, and Recall, and F1 | Security analysis performed with the ensemble technique (ExtraTreesClassifier) classified the accounts as suspicious. It yielded an overall accuracy of 87.2% and 88.7%. |
| [14] | Journal | K-Means, DBScan, Birch | Bitcoin, Ethereum | detection of anomalous behaviors and preventing 51% attacks | means, one standard deviation, hash rate calculation | Any miners with a hash rate exceeding one per cent within previously established time intervals will develop profiles that could be used to identify anomalous behaviors. |
| [30] | Journal | BAD | Bitcoin | Anomalous Fork Detection | complexity and overhead calculation | BAD can identify blocks that are different but hold the same transactions (or a subset). |
| [31] | Journal | KNN | Bitcoin | Abnormal transaction | Kendall correlation coefficient matrix, correlation heat map | The analysis outcomes indicate that KNN effectively identifies suspicious transactions in the nodes. |
| [32] | Journal | SVN + KNN | Blockchain | Malicious Users | Precision, F1-score, recall, accuracy | While comparing KNN with the CNN algorithm, KNN and SVM are more appropriate, consuming one-third of the resources of the CNN algorithm, while having an accuracy value of more than 0.9, which is 0.9 per cent less than the CNN algorithm. |
| [33] | Conference | XGBoost | Ethereum | Malicious Account | Precision, F1-score, recall, accuracy | That assessment is 96.21% accurate with a false positive rate of 3 per cent. The ensemble approach provides considerable results (an F1 score of 0.996). |
| [34] | Journal | Ensemble | Ethereum | Malicious Transaction | Precision, F1-score, recall, accuracy | The accuracy of that assessment is 96.21%, with a false positive rate of 3%. The ensemble approach yields high results in the benchmark (F1 score of 0.996). |
| [35] | Conference | Random Forest | Ethereum | Vulnerability detection | Precision, F1-score, recall, accuracy | The model is capable of identifying these vulnerabilities effectively as well as expeditiously. |
| [36] | Journal | XGBoost | Ethereum | Vulnerability Detection | Accuracy, precision, F-measure, Recall | The Ethereum Micro-F1 and Macro-F1 yield a more accurate Turing-complete Ethereum Virtual Contract of over 96%. |
| [37] | Conference | OCSVM | Bitcoin | Anomaly Detection | Rand index (RI), Confusion matrix, | In the first stage, among 27 data instances, the OCSVM algorithm with an accuracy of 0.9 gave 15 anomalies by using K-means in the second stage, to cluster the anomalies detected in the first stage into 3 clusters, with 0.951 as a better result of clustering. |
| Category | SVM | K-Means | Random Forest | XGBoost | AdaBoost |
|---|---|---|---|---|---|
| Algorithm type | Supervised learning | Unsupervised learning | Supervised learning | Supervised learning | Supervised learning |
| Learning type | Batch learning | Prototype-based learning | Ensemble-based learning | Gradient boosting | Boosting |
| Data requirement | Labeled data | Unlabeled data | Labeled data | Labeled data | Labeled data |
| Objective | Classification | Clustering | Classification or regression | Classification or regression | Classification or regression |
| Optimization problem | Margin maximization | Minimize within-cluster sum of squares | Minimize loss function | Gradient boosting optimization | Minimize classification error |
| Decision boundary type | Linear or non-linear | Not Applicable | Linear or non-linear | Non-linear | Non-linear |
| Performance evaluation | Accuracy, F1-score | Inertia (within-cluster sum of squares) | Accuracy, Out-of-bag error | Accuracy, Log loss | Accuracy, Log loss |
| Regularization parameter | Term C | Number of clusters (k) | Number of estimators, Max depth | Learning rate, Max depth | Learning rate, Number of estimators |
| Advantages | Effective in high-dimensional spaces; Versatile | Simple; Computationally efficient; Scalable | High efficiency on large datasets; Fast convergence | Robust to overfitting; Handles missing values well | Reduces bias and variance; Resistant to overfitting |
| Disadvantages | Sensitive to noise and outliers; Memory-intensive | Sensitive to initial centers; Need to predefine number of clusters | Sensitive to feature scaling; Complex tuning | Computationally expensive; Sensitive to hyperparameters | Sensitive to noisy data; Affected by outliers |
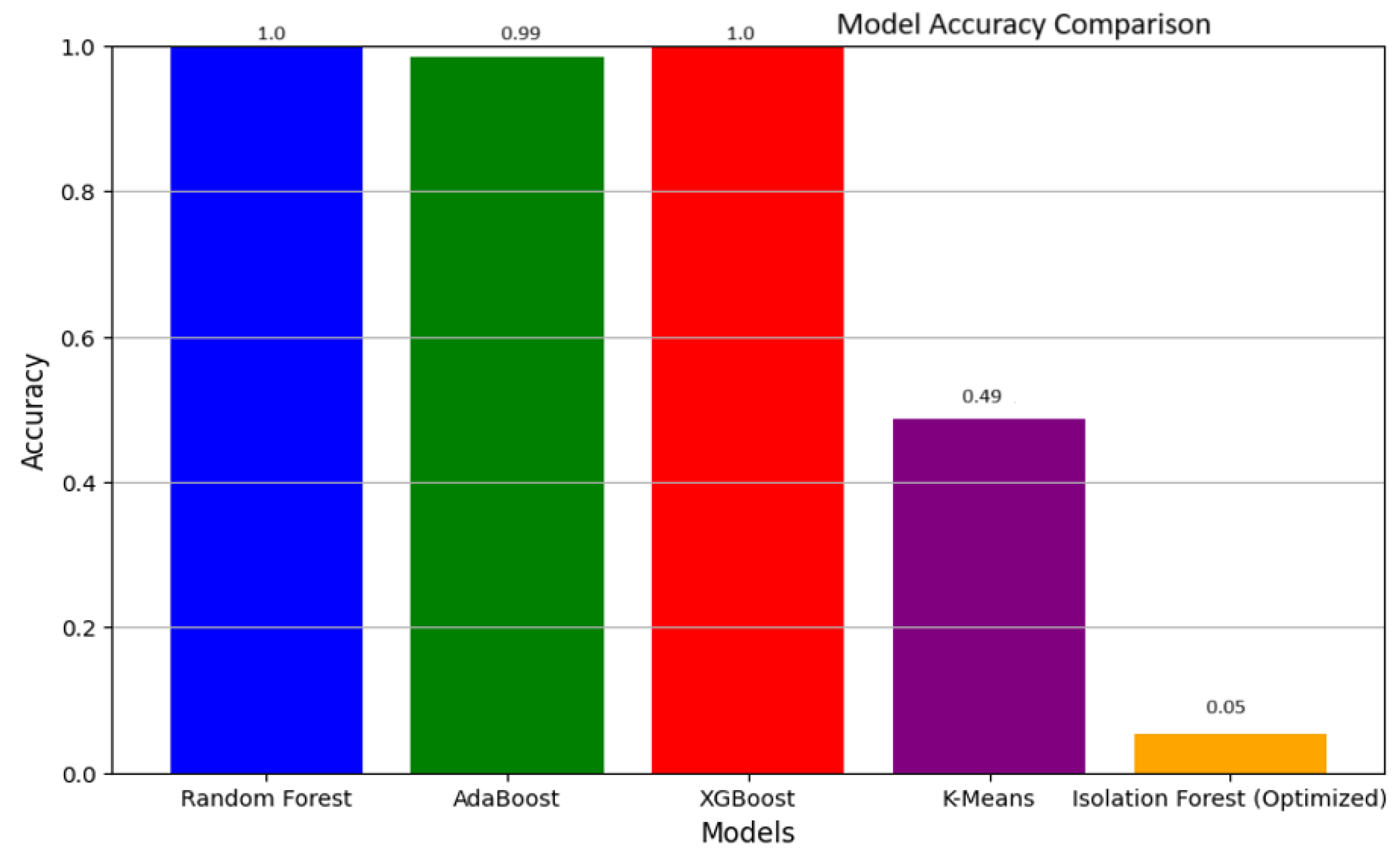
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Random Forest | 0.998345 | 0.997803 | 0.969250 | 0.983319 |
| AdaBoost | 0.984507 | 0.983993 | 0.703657 | 0.820542 |
| XGBoost | 0.997998 | 0.998289 | 0.961878 | 0.979745 |
| K-Means | 0.485452 | 0.950279 | 0.483475 | 0.640886 |
| Isolation Forest (Optimized) | 0.053114 | 0.644343 | 0.006530 | 0.012929 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jumani, F.; Raza, M. Machine Learning for Anomaly Detection in Blockchain: A Critical Analysis, Empirical Validation, and Future Outlook. Computers 2025, 14, 247. https://doi.org/10.3390/computers14070247
Jumani F, Raza M. Machine Learning for Anomaly Detection in Blockchain: A Critical Analysis, Empirical Validation, and Future Outlook. Computers. 2025; 14(7):247. https://doi.org/10.3390/computers14070247
Chicago/Turabian StyleJumani, Fouzia, and Muhammad Raza. 2025. "Machine Learning for Anomaly Detection in Blockchain: A Critical Analysis, Empirical Validation, and Future Outlook" Computers 14, no. 7: 247. https://doi.org/10.3390/computers14070247
APA StyleJumani, F., & Raza, M. (2025). Machine Learning for Anomaly Detection in Blockchain: A Critical Analysis, Empirical Validation, and Future Outlook. Computers, 14(7), 247. https://doi.org/10.3390/computers14070247