Abstract
Recent advancements in planning prompting techniques for Large Language Models have improved their reasoning, planning, and action abilities. This paper develops a planning framework for Large Language Models using model predictive control that enables them to iteratively solve complex problems with long horizons. We show that in the model predictive control formulation, LLM planners act as approximate cost function optimizers and solve complex problems by breaking them down into smaller iterative steps. With our proposed planning framework, we demonstrate improved performance over few-shot prompting and improved efficiency over Monte Carlo Tree Search on several planning benchmarks.
1. Introduction
Recent work has demonstrated remarkable success in enhancing Large Language Model (LLM) capabilities through integration with planning and control algorithms. From early prompting techniques like chain-of-thought [1] and self-consistency [2], to more sophisticated approaches combining LLMs with tree search [3,4] and reinforcement learning [5], researchers have found that guiding LLM outputs with structured planning significantly improves performance on complex reasoning tasks.
In robotics and embodied AI, frameworks like SayCan [6] and Voyager [7] successfully use LLMs to generate action plans for physical systems. LLM-Assist demonstrated improved autonomous vehicle planning by combining LLMs with traditional planners [8]. Knowledge-guided approaches like KnowAgent [9] further enhance LLM planning by incorporating domain expertise and constraints. Enabling LLMs to solve planning problems involving safety constraints was explored with the SageAgent benchmark [10].
Several approaches have explored using LLMs for hierarchical and multi-agent planning. Two-step goal decomposition [11] showed that LLMs could break down complex multi-agent tasks more effectively than traditional PDDL planners. ISR-LLM [12] and hierarchical constraint planning [13] demonstrated improved performance on problems requiring coordination between multiple constraints and objectives.
Search-based methods have proven particularly effective when combined with LLMs. Tree search algorithms [3,4,14,15] use LLMs to guide exploration while value functions evaluate candidate solutions. Scattered forest search [16] showed improved solution diversity in code generation tasks. Natural language planning [17] demonstrated that describing search spaces in natural language improved code generation performance. In the context of web agents, some work has explored the use of LLMs as world models [18,19].
Recent work has also explored enhancing LLM planning through learning. Supervised fine-tuning approaches like TravelPlanner [20] showed improved planning performance through targeted training. World models have been used to enable more structured planning [21], while continual learning approaches [22] demonstrated better exploration in reinforcement learning settings.
A key underpinning of the previous approaches is the ability of LLMs to act as general-purpose problem solvers after they have undergone instruction fine-tuning [23,24]. However, progress has been hampered by a number of limitations of instruction fine-tuned LLMs. While the LLM will produce a proposed solution to a given input task, there are no guarantees on the optimality of the solution. Indeed, the distribution of solutions produced by LLMs is still not well understood, but empirical evidence indicates there are limits to the complexity of tasks that can be solved by LLMs. Additionally, limits on the input sequence length prevent the use of LLMs on problems that require large amounts of input context, such as, e.g., developing a large codebase.
While planning prompts and search algorithms have been successful in extending the problem domains that can be solved using LLMs, a number of open questions remain. The first is that more explanation is needed as to why planning algorithms and formulations can improve the performance of LLMs on complex tasks. Second, the key factors and tradeoffs that influence the quality of LLM planning algorithms could be better understood. Finally, it necessary to explore how LLM planning algorithms can overcome the limitations of problems that require large input and output token sequences. We show that integration of LLMs as planners in an MPC framework explains how planning algorithms help to boost LLM performance, illustrates what the key design considerations are, and provides a natural way to handle large input and output spaces.
Our work makes the following key contributions:
- We formulate a novel framework, LLMPC, that integrates Large Language Models with wodel predictive control principles to enable iterative solving of complex planning problems.
- We highlight that planning methods improve LLM performance by breaking large complex problems down into simpler sub-tasks that can be solved by the LLM due to instruction fine-tuning.
- We show that sampling multiple plans from LLMs and selecting the best according to a cost function significantly improves planning performance as problem complexity increases.
- We empirically validate LLMPC on three diverse planning benchmarks, showing improved performance over few-shot prompting and better computational efficiency than Monte Carlo Tree Search approaches.
In this paper, we first discuss the model predictive control framework and how it is used to make control problems with long horizons tractable in Section 2. Thereafter, in Section 3 we show our proposed method of integrating LLMs with MPC to create an improved LLM planning procedure. In Section 4, we evaluate our method on several problems, including a dynamical spring–mass system, a trip-planning problem, and a meeting scheduling problem. In particular, we compare LLMPC against a few-shot prompting approach and against MCTS [4]. Finally, we discuss the results in Section 5.
The code for our experiments is available at https://github.com/gmaher/llmpc (accessed on 14 March 2025).
2. Model Predictive Control
Model predictive control is a control framework that was developed to enable autonomous agents to solve control problems with long or even infinite horizons [25,26,27]. In the model predictive control setting, an agent must navigate a state space by selecting actions from an action space, . The agent’s state is then updated based on the current state and the selected action according to a state transition model . In stochastic formulations of MPC, the state is instead sampled from a distribution conditioned on the the current state and selected action .
Typically, the control problem will have constraints on feasible states and actions as well as a goal state and notion of cost to indicate preferred states and actions. Given a maximum horizon length T and initial state , these conditions can be modeled through the use of a cost function and a set of equality and inequality constraint functions. The exact solution of the planning problem is obtained by solving the following constrained optimization problem:
However, for most problems of interest solving (1) is intractable, as the horizon may be infinite or large and typically one or more of the cost function, state update function, and constraint functions are nonlinear.
MPC relaxes the exact planning problem by introducing a shorter finite horizon H and the concept of replanning. In the MPC framework, the relaxed version of (1) is solved from the current state to obtain the next H actions. A number of actions are executed to obtain the next states, and then the relaxed problem is again solved from the new state to obtain the next actions, and so forth. As such, MPC approximately solves (1) through iterated replanning over a shorter horizon. Furthermore, MPC enables linearized approximations of any nonlinear functions in (1) to be used, as replanning around the current state with a short horizon reduces the magnitude of state and action changes. This increases the likelihood the linearizations will remain accurate.
Given the horizon H and current state , the MPC relaxation is formulated as
where the tilde indicates potential linearized forms of any of the relevant functions. In contrast to (1), (2) can often be solved exactly or to numerical precision limits through the use of constrained optimization algorithms.
3. LLM as MPC Plan Sampler
As previously discussed, instruction fine-tuned LLMs produce sample solutions to a given input text description of a task . However, they suffer from limitations when the task is sufficiently complex or the input and output sequences are long. We note the striking similarity to the exact form of the MPC problem, where the exact form of MPC is intractable due to the long horizon. We propose that, similar to MPC relaxation, complex problems can be tractably solved by LLMs by iteratively solving finite horizon relaxed versions of the problem instead of trying to solve the full problem in one step. Furthermore, this highlights why planning algorithms can enhance LLM performance: the iterative relaxation bounds the complexity at each step, increasing the likelihood that the LLM can solve the problem at that step. Here, we describe a precise framework for integrating LLMs with MPC to allow them to iteratively solve complex long-horizon problems.
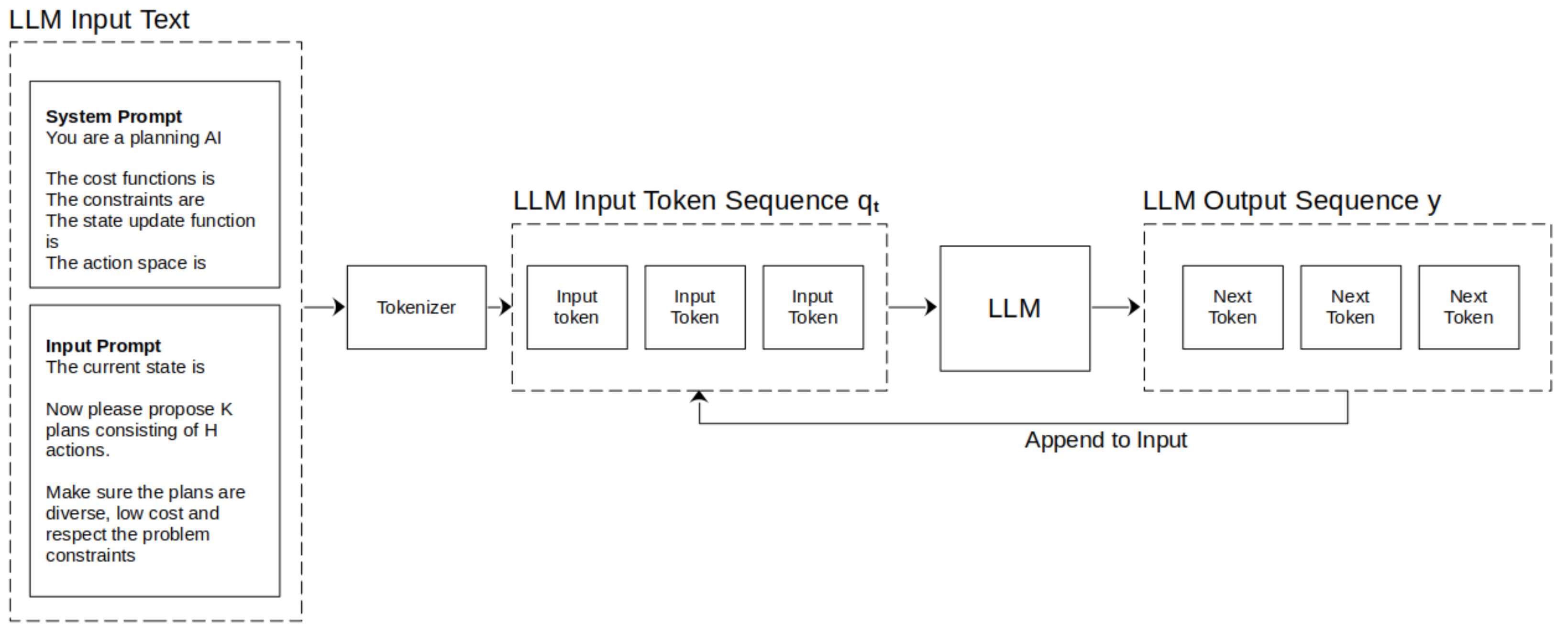
Due to instruction fine-tuning, to integrate LLMs with MPC we can formulate an input task to the LLM that incorporates the state , the cost function , and the constraints and tasks the LLM with producing the sequence of H next actions . Since the LLM operates on a length L sequence of input tokens , we can use a prompting function to use the sequence of tokens generated up to step t and the current state to produce the next LLM input (Figure 1 and Figure 2). The cost function and constraints can be incorporated through the prompting function as well.
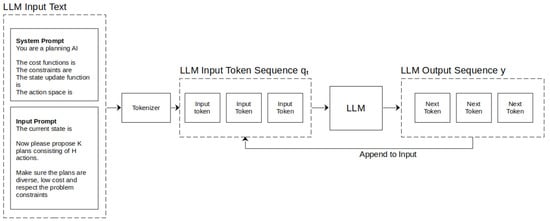
Figure 1.
Diagram illustrating sampling the output token sequence y from the input token sequence using the LLM. The input prompt describes the task for the LLM in text form. A tokenizer converts the input text to the sequence of input tokens . The LLM function then produces an output probability distribution from which the next token is sampled. The generated tokens are repeatedly added to the input sequence to obtain the subsequent tokens.
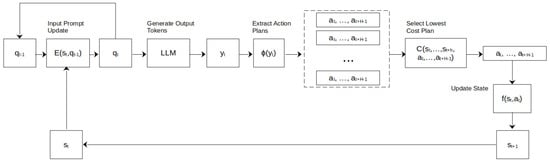
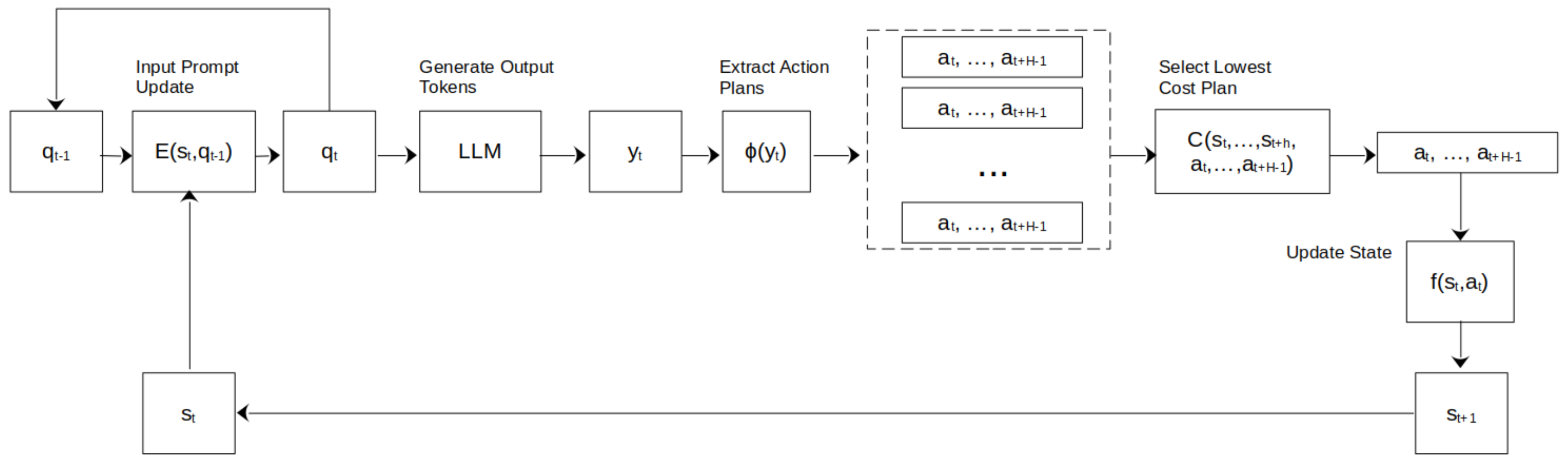
Figure 2.
LLMPC controller diagram. The new LLM input is obtained from the current state and previous prompt through . Evaluating the LLM on produces the output token sequence y, containing the plans proposed by the LLM. The plans are extract from the output sequence using the extraction function . Using the cost function, the lowest cost plan is selected. The next state is then obtained through the state update function . The process then repeats for the next state.
The LLM will then produce a probability vector over the possible M tokens for the next token in the sequence (Figure 1). Various methods are used for sampling the actual next token value [28]. For example, Beam Search is a common approach, where several likely token sequences are sampled by selecting the top most likely tokens at each step and using these to sample subsequent tokens, with repeated pruning to remove unlikely sequences. Repeatedly evaluating the LLM with the new output tokens produces a sequence of output tokens , where is the length of the output sequence (Figure 1). We can represent the process of sampling the output token sequence as a function .
To close the MPC control loop, we then need a way to extract the action sequence from the LLM output token sequence. This can be carried out using a mapping function , similar to the Tool-Use scenario [29]. We now see that the LLM plan approximately solves the relaxed MPC problem through
In the MPC framework, we thus see that generating a plan using the LLM is equivalent to approximately solving the constrained minimization of the MPC cost function. Indeed, due to instruction fine-tuning LLMs can be used as approximate cost function minimizers, but there is no guarantee on the optimality of their proposed solutions [30,31]. Since the LLM output y is a sequence of random variables, the LLM-generated plan will also be random. We propose that the generated LLM plan can be improved by using the LLM to sample a number of control sequences and then using the cost function to evaluate and rank each plan. The best sample is selected as the control sequence to apply.
That is, we sample a number of plans from the LLM. For each plan, we simulate the system to obtain the states . We then pick the plan that minimizes the cost function among the sampled plans
We then execute up to H steps from the plan and then replan with the new state information. A diagram for the full LLMPC controller algorithm is shown in Figure 2.
We note that sampling multiple plans can be carried out in a performant and computationally efficient manner by asking the LLM to produce multiple diverse plans in the input prompt rather than naively evaluating the same prompt K times. Asking for diverse plans enables the space of plans to be sampled more effectively, thus increasing the likelihood that low-cost plans will be found. Additionally, using modern LLM inference methods such as Key-Value caching [32], the input prompt only needs to be evaluated once to sample multiple plans rather than once for each plan, substantially reducing the computational cost.
Finally, we note that in the constrained MPC case, a plan generated by the LLM may not necessarily respect the constraints of the problem and may potentially lead to unsafe or invalid control trajectories [10,33,34,35]. Here too, sampling multiple plans can be used to improve constraint satisfaction; each sampled plan can be evaluated using the constraint functions and invalid plans discarded, leaving only feasible plans to select from.
4. Experiments
4.1. Control of Spring-and-Mass System
Here, we compare LLMPC against MPC on the problem of applying force to a spring-and-mass system to arrive at a particular goal state. The equations of motion for the system are
Here, u is a force applied by the controller to control the spring. The objective is to bring the spring to the goal state with zero velocity. The cost function is
For both MPC and LLMPC, we set and execute two of every three steps from the returned action sequence. For MPC, we use CVXPY to solve the planning problem. For LLMPC, we use GPT-4o-mini, a temperature of , and a of . The LLM is asked to suggest five plans at every step using a templated prompt (Listing A1 in Appendix A). Each of the suggested action sequences is evaluated using (5), and the plan with the lowest cost value is selected.
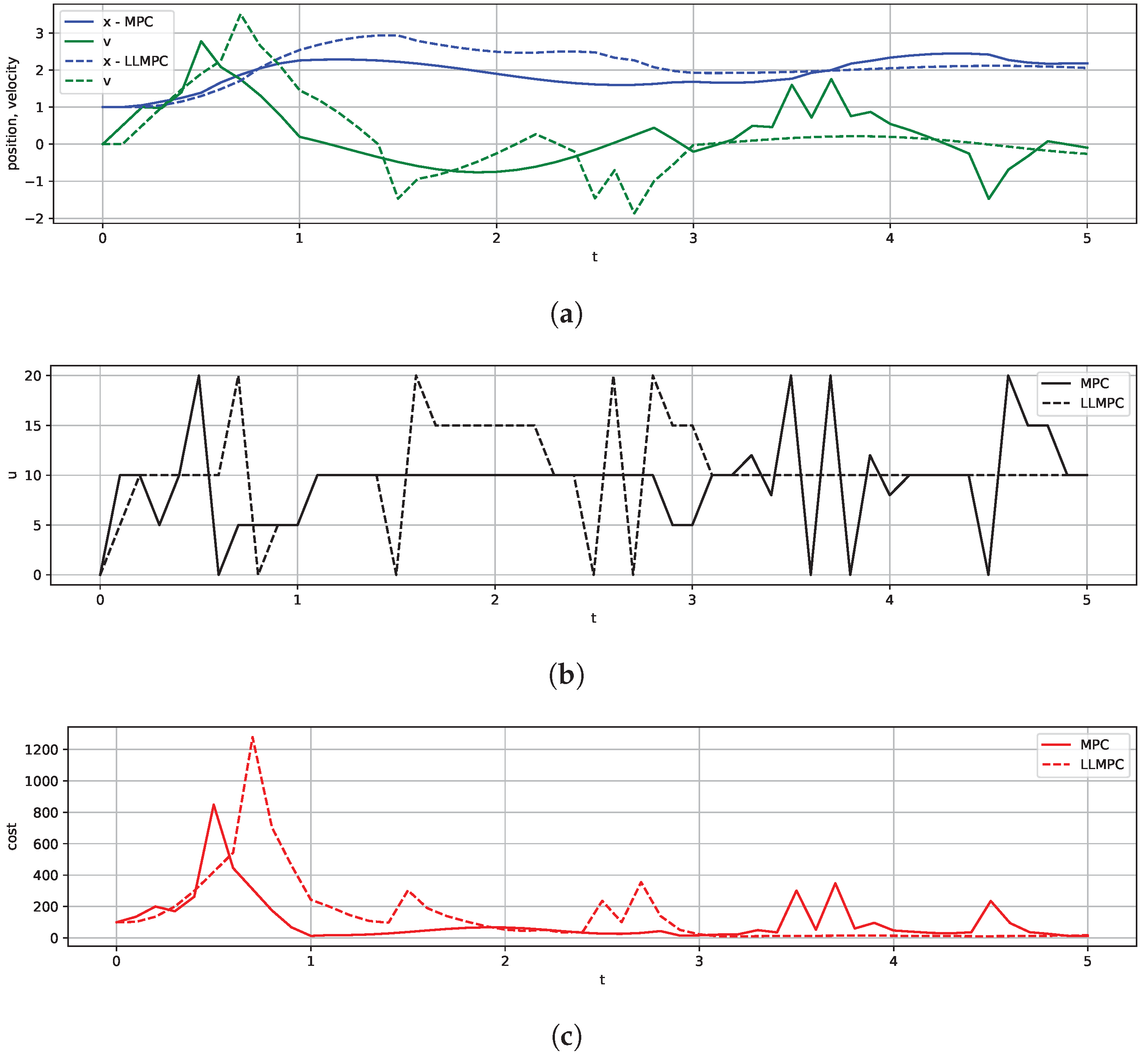
We solved the control problem with both MPC and LLMPC with , , , , , and (Figure 3). Both MPC and LLMPC produce control sequences that control the spring to the goal state. As expected, the cost values from the plans produced by LLMPC are higher than when solving the problem exactly with MPC, highlighting that LLMs are approximate planners.
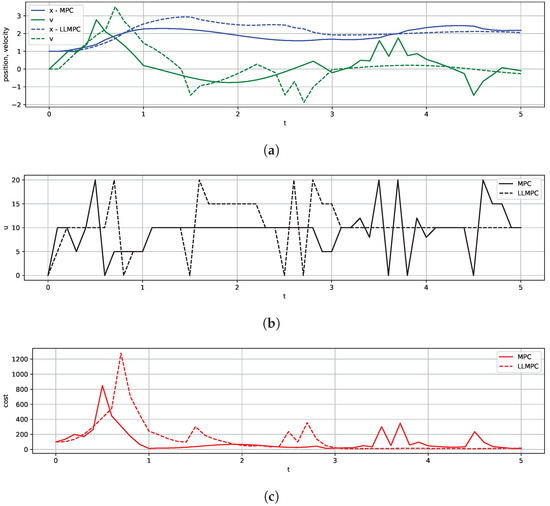
Figure 3.
State, control, and cost trajectories for MPC and LLMPC algorithms on spring–mass problem: (a) position and velocity trajectory; (b) control trajectory; and (c) cost trajectory.
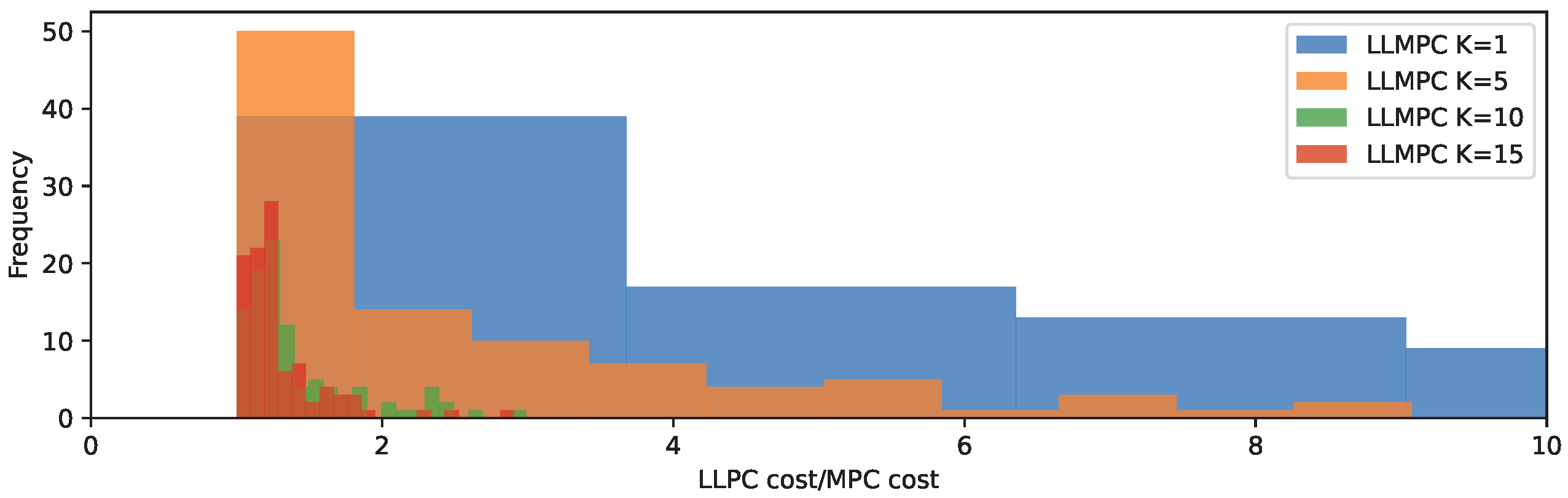
To further illustrate the approximate planning capacities of LLMs, we sample a range of state vectors for the mass–spring system and solve the planning problem using both LLMPC and MPC at each sampled state. We then calculate the ratio of the optimized cost value returned by LLMPC against that of MPC (Table 1, Figure 4). We see that sampling only a single plan from an LLM produces poor cost values when compared to MPC (cost ratio of 8.21). However, as we increase the number of plans the performance of LLMPC significantly increases, with the ratio decreasing to 1.3 when 15 plans are sampled per iteration.

Table 1.
Mean cost ratio for LLMPC vs MPC across range of states and number of plans sampled.
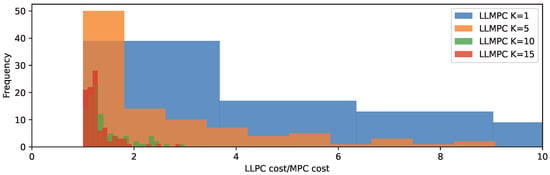
Figure 4.
Ratio of LLMPC optimized planning cost value to MPC optimized planning cost value for mass–spring system over a range of states.
4.2. Trip Planning
We evaluate LLMPC on the trip-planning test case from the Natural Plan benchmark [36]. The trip-planning problem involves proposing a travel itinerary to visit multiple cities, with given constraints on the number of days for visiting each city and the available flights between cities (see Listing A2 in Appendix B for an example). We compare LLMPC with increasing iteration budgets against a single-round few-shot prompt solution and MCTS. For both LLMPC and the few-shot prompting approach, we used GPT-4o, a temperature of , and a of . For MCTS, we used a temperature of to enhance its ability to explore the solution space and simulation budgets of and .
We construct a sequential planning system prompt and instruction prompt (Listings A3 and A4 in Appendix B) that provides the problem description to an LLM along with few-shot examples and feedback on the previously proposed plan. To provide feedback on the previous plan, we use an evaluation function that checks whether the constraints from the problem description are met and lists any unmet constraints. If no plan has been proposed yet, the feedback section is omitted. The LLM is asked to then propose a new plan to address any issue and solve the problem. With these prompts, the trip-planning problem can be solved using LLMPC by proposing an initial plan without feedback and then sequentially iterating and improving the proposed plan.
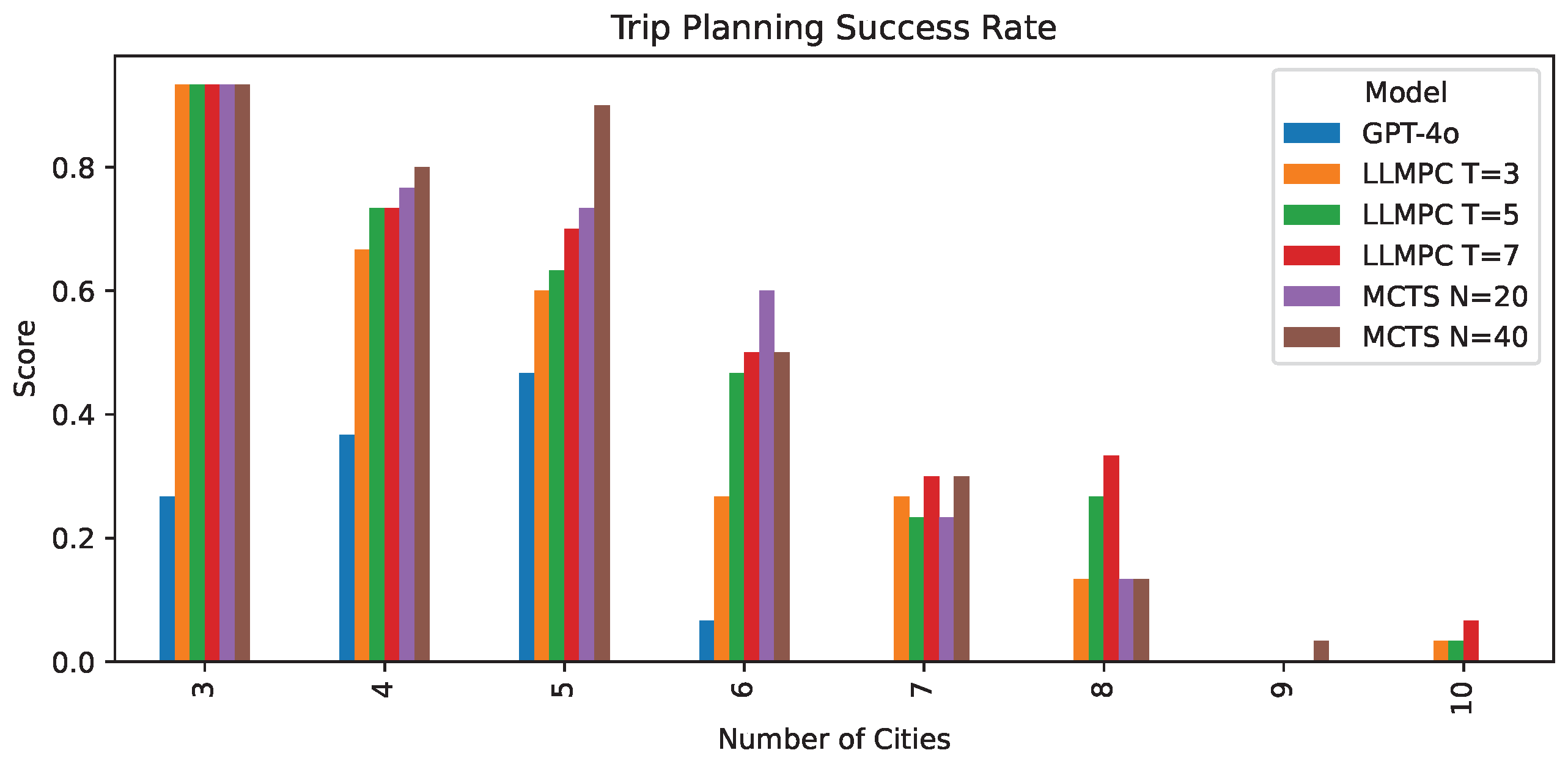
We measure the overall success rate and success rate segmented by the number of cities the problem description lists. Adding more cities to the problem increases its complexity and difficulty. The results show that LLMPC significantly outperforms single-round GPT-4o planning, with success rates improving from 14.5% to 44.6% as we increase the number of iterations (Table 2). The performance gains are particularly notable for problems with more cities to visit (Figure 5). Increasing the iteration budget for LLMPC improves the performance as problem complexity increases. However, as the number of cities increases beyond eight cities, LLMPC is also not able to solve the itinerary.
Table 2.
Trip planning success rate for single-round GPT-4o and LLMPC.
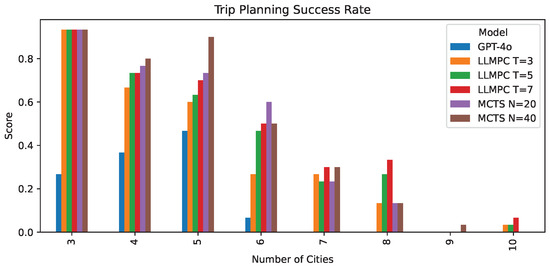
Figure 5.
Trip planning success rate grouped by number of cities.
We also compare LLMPC against Monte Carlo Tree Search (MCTS), a search algorithm that has shown strong performance on sequential decision problems. With a search budget of simulations, MCTS achieves a success rate of 45%, slightly outperforming our best LLMPC configuration (44.6%). However, LLMPC uses significantly fewer iterations, 7 for LLMPC vs 40 for the best MCTS configuration, showing that LLMPC is computationally more efficient for the trip-planning problem while still being competitive with MCTS. Furthermore, LLMPC performs better as problem complexity increases (Figure 5).
4.3. Meeting Planning
We evaluate LLMPC on the meeting planning test case from the Natural Plan benchmark [36]. In this problem, a user must plan meetings with multiple friends in different locations across a city while satisfying temporal and spatial constraints. Each friend is available at a specific location during a fixed time window and requires a minimum meeting duration. The planner must account for travel times between locations, meeting duration requirements, and friend availability windows to construct a valid schedule that maximizes the number of successful meetings.
The meeting planning problem presents several key challenges that make it an ideal test case for LLMPC. There are complex temporal dependencies between travel times, meeting durations, and availability windows. Additionally, the problem contains spatial constraints from the city travel network that limit possible meeting sequences. Finally, the problem involves multiple competing objectives around maximizing meetings while satisfying minimum durations.
For LLMPC, we again construct a system prompt and instruction prompt that provides the problem description, few-shot examples, and plan feedback as input (Listings A5 and A6 in Appendix C). We again use an evaluation function to assess any unmet constraints of the proposed plan and provide these as feedback.
We compare LLMPC against single-round few-shot prompting and evaluate different configurations:
- Varying the number of iterations T to refine plans;
- Sampling multiple plans per iteration (K > 1);
- Combinations of iteration and sampling to balance exploration and refinement.
We also compare it to MCTS. For both LLMPC and the few-shot approach, we used GPT-4o, a temperature of and a of . For MCTS, we used a temperature of to enhance its ability to explore the solution space and simulation budgets of and .
We measure the overall success rate and success rate segmented by number of friends that are listed in the problem description. More meetings increase the complexity and difficulty of the problem.
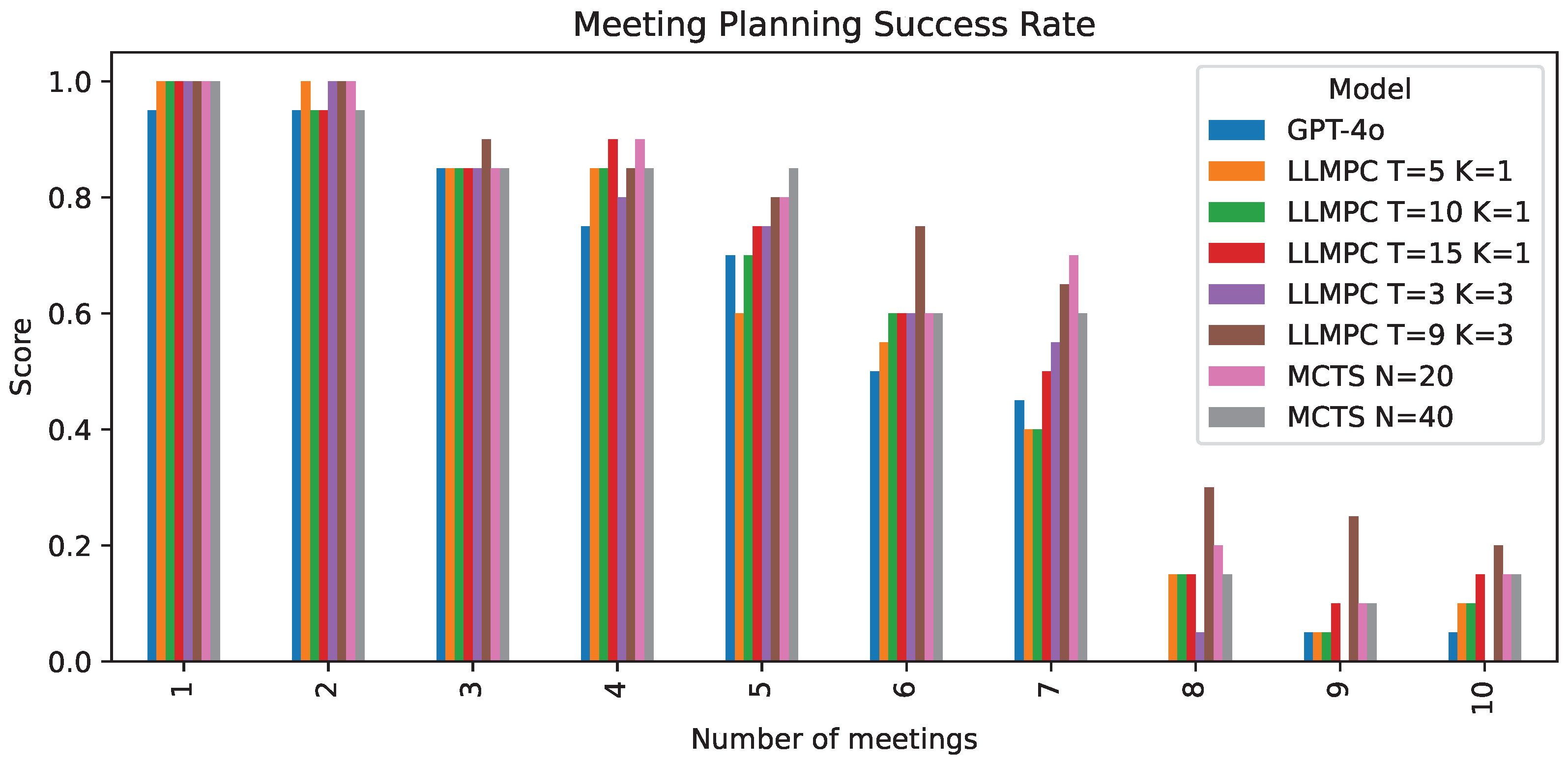
The results demonstrate that LLMPC provides consistent improvements over single-round planning (Table 3). Increasing both the number of iterations T and plans per iteration K leads to better performance, with the best results achieved using and (67% success rate vs 52.5% for single-round planning). These results highlight the fact that the largest improvements come from both sampling multiple plans and iterating on previous solutions. Figure 6 shows the performance breakdown, highlighting LLMPC’s ability to better handle the temporal and spatial constraints of the meeting planning problem. For the meeting planning problem, as complexity increases it becomes increasingly necessary to both iterate and sample multiple plans.
Table 3.
Meeting planning success rate for single-round GPT-4o and LLMPC.
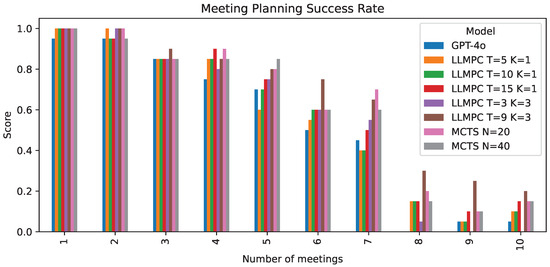
Figure 6.
Comparison of LLMPC against GPT-4o with few-shot prompt on meeting planning problem, success rate segmented by number of meetings.
When comparing LLMPC to Monte Carlo Tree Search (MCTS), we observe that our best LLMPC configuration (, ) outperforms MCTS with both and simulation budgets. MCTS achieves success rates of 60.3% and 60.5%, respectively, compared to LLMPC’s 67%. This again highlights the improved computational efficiency of LLMPC vs MCTS. Similar to the trip-planning problem, LLMPC outperforms MCTS, particularly as problem complexity increases (Figure 6).
5. Discussion
This paper introduced LLMPC—an MPC control framework for improving the ability of LLMs to solve complex problems. The framework relaxes complex problems into an iterative stepwise replanning formulation, allowing the LLM to solve a simpler problem at each planning step. We showed that with this formulation, LLMs act as implicit optimization algorithms when generating plans and that making this optimization explicit through MPC improves performance. Furthermore, sampling multiple plans from LLMs and selecting the best according to a cost function significantly improves planning performance.
We demonstrated these benefits empirically on three test cases—a mass–spring control problem, trip planning, and meeting scheduling. In all cases, LLMPC improved performance over single-round few-shot prompting, with the gains increasing as problem complexity grew. For the spring–mass system, increasing the number of sampled plans reduced the cost gap with exact MPC from 8.21× to 1.3×. On the Natural Plan benchmarks, LLMPC improved success rates by 30.1% on trip planning and 14.5% on meeting scheduling.
When comparing LLMPC to Monte Carlo Tree Search (MCTS), we observed several interesting differences. While both approaches iterate through potential solutions, LLMPC achieved comparable or better performance with fewer iterations—particularly on the meeting planning benchmark, where LLMPC with , outperformed MCTS with a budget of 40 simulations. This suggests that LLMPC’s explicit cost function evaluation and iterative refinement provide a more computationally efficient approach to planning than purely search-based methods in these domains. Furthermore, LLMPC demonstrated stronger performance as problem complexity increased. This advantage likely stems from LLMPC’s ability to directly incorporate feedback from constraint violations into subsequent planning iterations, whereas MCTS must discover these constraints through exploration. Future work could explore hybrid approaches that combine LLMPC’s efficient feedback mechanism with MCTS’s structured exploration.
Future work could explore several promising directions. Combining LLMPC with other planning techniques like beam search may yield further improvements. Additional work could explore the use of learned cost functions and state update functions when exact versions are not available. Further work is also needed to address problems of increasing complexity. Here, a promising direction is to develop alternative state and action representations that will work better with an MPC framing.
We note a limitation of LLMPC in the case of planning tasks requiring explicit safety guarantees. LLMPC handles constraints through sampling multiple plans from an LLM, which does not provide strict guarantees on generating a feasible plan. As such, future work should focus on improved methods to guarantee feasibility and constraint satisfaction when planning using LLMs.
The LLMPC framework provides both practical benefits for real-world planning problems and theoretical insights into how LLMs function as planners. We believe this perspective will be valuable for developing more capable AI planning systems that combine the flexibility of LLMs with the rigor of traditional control approaches.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The code and data for experiments are available at https://github.com/gmaher/llmpc (Accessed on 14 March 2025) The Natural Plan benchmark data are available at https://github.com/google-deepmind/natural-plan (Accessed on 6 March 2025).
Conflicts of Interest
The author declares no conflicts of interest.
Appendix A. Mass–Spring System
Listing A1. LLMPC prompt template for mass-spring problem (python v3.12)

Appendix B. Trip Planning
Listing A2. Example trip planning problem

Listing A3. Trip Planning LLMPC System Prompt Template

Listing A4. Trip Planning LLMPC Instruction Prompt Template
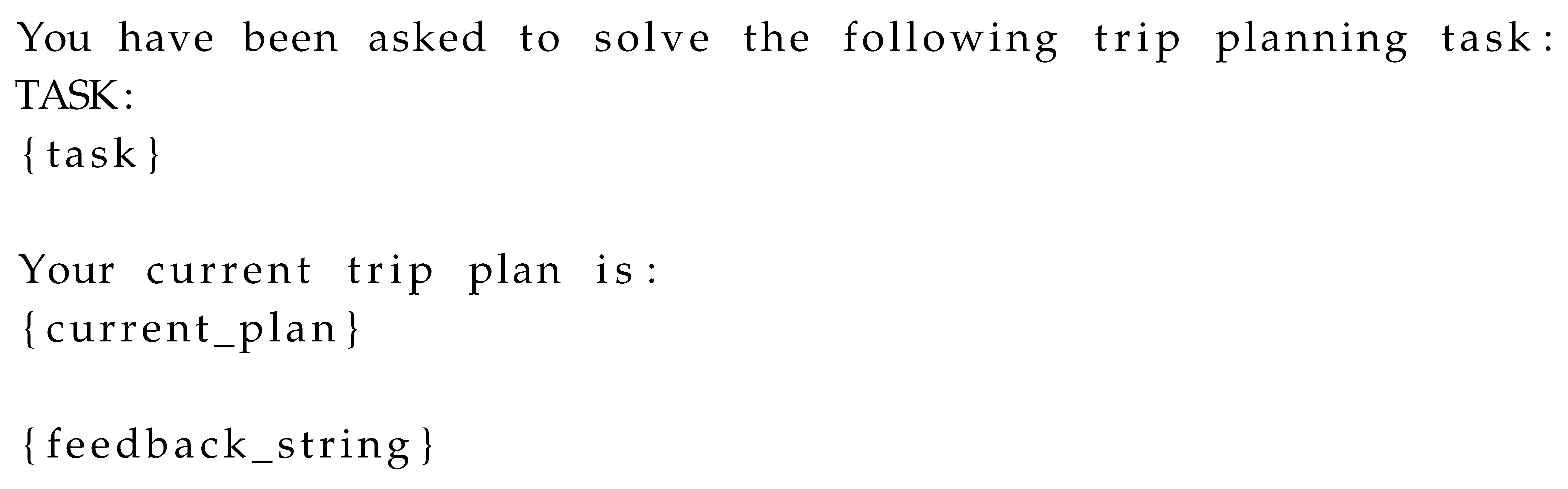
Appendix C. Meeting Planning
Listing A5. Example meeting planning problem

Listing A6. Meeting Planning LLMPC System Prompt Template


Listing A7. Meeting Planning LLMPC Instruction Prompt Template

References
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv 2022, arXiv:2201.11903. [Google Scholar]
- Wang, X.; Wei, J.; Schuurmans, D.; Le, Q.; Chi, E.; Narang, S.; Chowdhery, A.; Zhou, D. Self-Consistency Improves Chain of Thought Reasoning in Language Models. arXiv 2022, arXiv:2203.11171. [Google Scholar]
- Wang, A.; Song, L.; Tian, Y.; Peng, B.; Yu, D.; Mi, H.; Su, J.; Yu, D. LiteSearch: Efficacious Tree Search for LLM. arXiv 2024, arXiv:2407.00320. [Google Scholar]
- Jiang, J.; Chen, Z.; Min, Y.; Chen, J.; Cheng, X.; Wang, J.; Tang, Y.; Sun, H.; Deng, J.; Zhao, W.X.; et al. Enhancing LLM Reasoning with Reward-guided Tree Search. arXiv 2024, arXiv:2411.11694. [Google Scholar]
- DeepSeek-AI; Guo, D.; Yang, D.; Zhang, H.; Song, J.; Zhang, R.; Xu, R.; Zhu, Q.; Ma, S.; Wang, P.; et al. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv 2025, arXiv:2501.12948. [Google Scholar]
- Ahn, M.; Brohan, A.; Brown, N.; Chebotar, Y.; Cortes, O.; David, B.; Finn, C.; Fu, C.; Gopalakrishnan, K.; Hausman, K.; et al. Do As I Can, Not As I Say: Grounding Language in Robotic Affordances. arXiv 2022, arXiv:2204.01691. [Google Scholar]
- Wang, G.; Xie, Y.; Jiang, Y.; Mandlekar, A.; Xiao, C.; Zhu, Y.; Fan, L.; Anandkumar, A. Voyager: An Open-Ended Embodied Agent with Large Language Models. arXiv 2023, arXiv:2305.16291. [Google Scholar]
- Song, C.H.; Wu, J.; Washington, C.; Sadler, B.M.; Chao, W.L.; Su, Y. LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Language Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023; pp. 2998–3009. [Google Scholar]
- Zhu, Y.; Qiao, S.; Ou, Y.; Deng, S.; Zhang, N.; Lyu, S.; Shen, Y.; Liang, L.; Gu, J.; Chen, H. KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents. arXiv 2024, arXiv:2403.03101. [Google Scholar]
- Yin, S.; Pang, X.; Ding, Y.; Chen, M.; Bi, Y.; Xiong, Y.; Huang, W.; Xiang, Z.; Shao, J.; Chen, S. SafeAgentBench: A Benchmark for Safe Task Planning of Embodied LLM Agents. arXiv 2024, arXiv:cs.CR/2412.13178. [Google Scholar]
- Singh, I.; Traum, D.; Thomason, J. TwoStep: Multi-agent Task Planning using Classical Planners and Large Language Models. arXiv 2024, arXiv:cs.AI/2403.17246. [Google Scholar]
- Zhou, Z.; Song, J.; Yao, K.; Shu, Z.; Ma, L. ISR-LLM: Iterative Self-Refined Large Language Model for Long-Horizon Sequential Task Planning. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024. [Google Scholar] [CrossRef]
- Zhang, C.; Deik, D.G.X.; Li, D.; Zhang, H.; Liu, Y. Planning with Multi-Constraints via Collaborative Language Agents. arXiv 2024, arXiv:cs.AI/2405.16510. [Google Scholar]
- Hao, S.; Gu, Y.; Ma, H.; Hong, J.J.; Wang, Z.; Wang, D.Z.; Hu, Z. Reasoning with Language Model is Planning with World Model. arXiv 2023, arXiv:cs.CL/2305.14992. [Google Scholar]
- Putta, P.; Mills, E.; Garg, N.; Motwani, S.; Finn, C.; Garg, D.; Rafailov, R. Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents. arXiv 2024, arXiv:2408.07199. [Google Scholar]
- Light, J.; Wu, Y.; Sun, Y.; Yu, W.; Liu, Y.; Zhao, X.; Hu, Z.; Chen, H.; Cheng, W. Scattered Forest Search: Smarter Code Space Exploration with LLMs. arXiv 2024, arXiv:cs.SE/2411.05010. [Google Scholar]
- Wang, E.; Cassano, F.; Wu, C.; Bai, Y.; Song, W.; Nath, V.; Han, Z.; Hendryx, S.; Yue, S.; Zhang, H. Planning In Natural Language Improves LLM Search For Code Generation. arXiv 2024, arXiv:cs.LG/2409.03733. [Google Scholar]
- Gu, Y.; Zheng, B.; Gou, B.; Zhang, K.; Chang, C.; Srivastava, S.; Xie, Y.; Qi, P.; Sun, H.; Su, Y. Is Your LLM Secretly a World Model of the Internet? Model-Based Planning for Web Agents. arXiv 2024, arXiv:cs.AI/2411.06559. [Google Scholar]
- Chae, H.; Kim, N.; Iunn Ong, K.T.; Gwak, M.; Song, G.; Kim, J.; Kim, S.; Lee, D.; Yeo, J. Web Agents with World Models: Learning and Leveraging Environment Dynamics in Web Navigation. arXiv 2024, arXiv:cs.CL/2410.13232. [Google Scholar]
- Chen, Y.; Pesaranghader, A.; Sadhu, T.; Yi, D.H. Can We Rely on LLM Agents to Draft Long-Horizon Plans? Let’s Take TravelPlanner as an Example. arXiv 2024, arXiv:2408.06318. [Google Scholar]
- Xiong, S.; Payani, A.; Yang, Y.; Fekri, F. Deliberate Reasoning for LLMs as Structure-aware Planning with Accurate World Model. arXiv 2024, arXiv:cs.CL/2410.03136. [Google Scholar]
- Paul, S.K. Continually Learning Planning Agent for Large Environments guided by LLMs. In Proceedings of the 2024 IEEE Conference on Artificial Intelligence (CAI), Singapore, 25–27 June 2024; pp. 377–382. [Google Scholar] [CrossRef]
- Peng, B.; Li, C.; He, P.; Galley, M.; Gao, J. Instruction Tuning with GPT-4. arXiv 2023, arXiv:cs.CL/2304.03277. [Google Scholar]
- Ghosh, S.; Evuru, C.K.R.; Kumar, S.; S, R.; Aneja, D.; Jin, Z.; Duraiswami, R.; Manocha, D. A Closer Look at the Limitations of Instruction Tuning. arXiv 2024, arXiv:cs.CL/2402.05119. [Google Scholar]
- Mayne, D.Q.; Rawlings, J.B.; Rao, C.V.; Scokaert, P.O.M. Constrained model predictive control: Stability and optimality. Automatica 2000, 36, 789–814. [Google Scholar] [CrossRef]
- Schwenzer, M.; Ay, M.; Bergs, T.; Abel, D. Review on model predictive control: An engineering perspective. Int. J. Adv. Manuf. Technol. 2021, 117, 1327–1349. [Google Scholar] [CrossRef]
- Shi, H.; Zuo, L.; Wang, S.; Yuan, Y.; Su, C.; Li, P. Robust predictive fault-tolerant switching control for discrete linear systems with actuator random failures. Comput. Chem. Eng. 2024, 181, 108554. [Google Scholar] [CrossRef]
- Holtzman, A.; Buys, J.; Du, L.; Forbes, M.; Choi, Y. The Curious Case of Neural Text Degeneration. arXiv 2020, arXiv:cs.CL/1904.09751. [Google Scholar]
- Qin, Y.; Liang, S.; Ye, Y.; Zhu, K.; Yan, L.; Lu, Y.; Lin, Y.; Cong, X.; Tang, X.; Qian, B.; et al. ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. arXiv 2023, arXiv:2307.16789. [Google Scholar]
- Guo, P.F.; Chen, Y.H.; Tsai, Y.D.; Lin, S.D. Towards Optimizing with Large Language Models. arXiv 2024, arXiv:cs.LG/2310.05204. [Google Scholar]
- Jiang, C.; Shu, X.; Qian, H.; Lu, X.; Zhou, J.; Zhou, A.; Yu, Y. LLMOPT: Learning to Define and Solve General Optimization Problems from Scratch. arXiv 2025, arXiv:cs.AI/2410.13213. [Google Scholar]
- Li, H.; Li, Y.; Tian, A.; Tang, T.; Xu, Z.; Chen, X.; Hu, N.; Dong, W.; Li, Q.; Chen, L. A Survey on Large Language Model Acceleration based on KV Cache Management. arXiv 2025, arXiv:cs.AI/2412.19442. [Google Scholar]
- Hafez, A.; Akhormeh, A.N.; Hegazy, A.; Alanwar, A. Safe LLM-Controlled Robots with Formal Guarantees via Reachability Analysis. arXiv 2025, arXiv:cs.RO/2503.03911. [Google Scholar]
- Wu, Y.; Xiong, Z.; Hu, Y.; Iyengar, S.S.; Jiang, N.; Bera, A.; Tan, L.; Jagannathan, S. SELP: Generating Safe and Efficient Task Plans for Robot Agents with Large Language Models. arXiv 2025, arXiv:cs.RO/2409.19471. [Google Scholar]
- Hua, W.; Yang, X.; Jin, M.; Li, Z.; Cheng, W.; Tang, R.; Zhang, Y. TrustAgent: Towards Safe and Trustworthy LLM-based Agents. arXiv 2024, arXiv:cs.CL/2402.01586. [Google Scholar]
- Zheng, H.S.; Mishra, S.; Zhang, H.; Chen, X.; Chen, M.; Nova, A.; Hou, L.; Cheng, H.T.; Le, Q.V.; Zhou, D. Natural Plan: Benchmarking LLMs on Natural Language Planning. arXiv 2025, arXiv:2406.04520. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).