
Analyzing Public Reactions, Perceptions, and Attitudes during the MPox Outbreak: Findings from Topic Modeling of Tweets


Abstract
:1. Introduction
2. Literature Review
2.1. A Brief Review of Recent Works Related to the Mining and Analysis of Tweets for Interdisciplinary Research
2.2. A Brief Review of Recent Works Related to the Mining and Analysis of Tweets for Healthcare Research
2.3. Review of Recent Works Related to the Mining and Analysis of Tweets about MPox
3. Methodology
3.1. Technical Overview of RapidMiner
- It supplies pre-built “operators” encompassing distinct functions that can be directly employed or customized for the creation and execution of algorithms and applications.
- RapidMiner is developed using Java, which ensures that RapidMiner “workflows” retain the write once run anywhere (WORA) attribute of Java.
- The platform permits the installation of various extensions to facilitate seamless connectivity and integration of RapidMiner “workflows” with other software and hardware environments.
- Scripts developed in programming languages, such as Python and R, can also be imported into a RapidMiner “workflow” to supplement its functionalities.
- The software enables the creation of new “operators” and effortless dissemination of the same within the RapidMiner community.
- RapidMiner consists of “operators” that enable it to establish connections with social media platforms, such as Twitter and Facebook. Such connections facilitate the extraction of tweets, comments, posts, reactions, and other relevant social media interactions.
3.2. Description of the Topic Modeling Architecture for System Design
- Select a multinomial distribution for each topic z from a Dirichlet distribution with parameter .
- For every document d, select a multinomial distribution from a Dirichlet distribution with parameter .
- In document d, for each word w, select a topic z, such that z {1….K} from the multinomial distribution .
- Select w from the multinomial distribution .
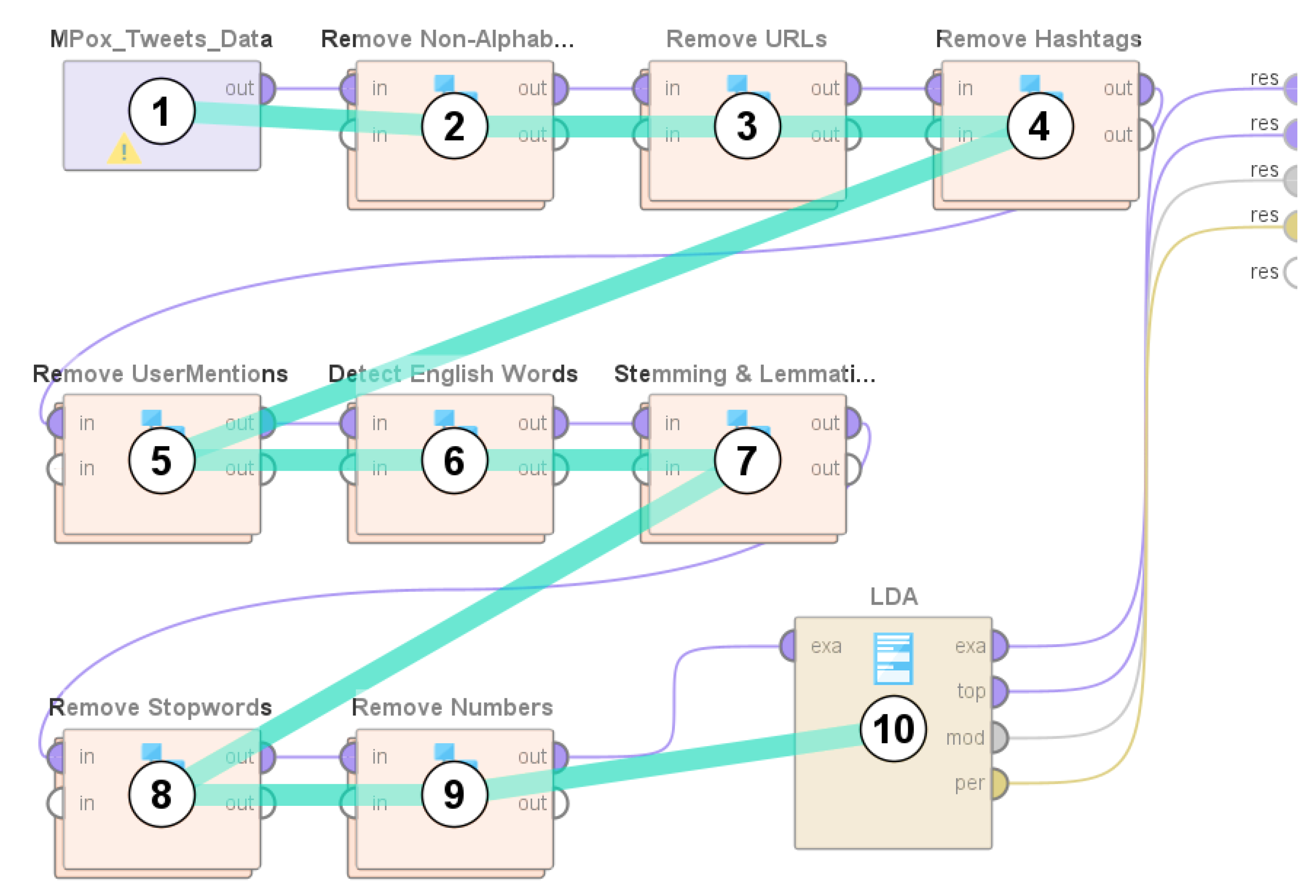
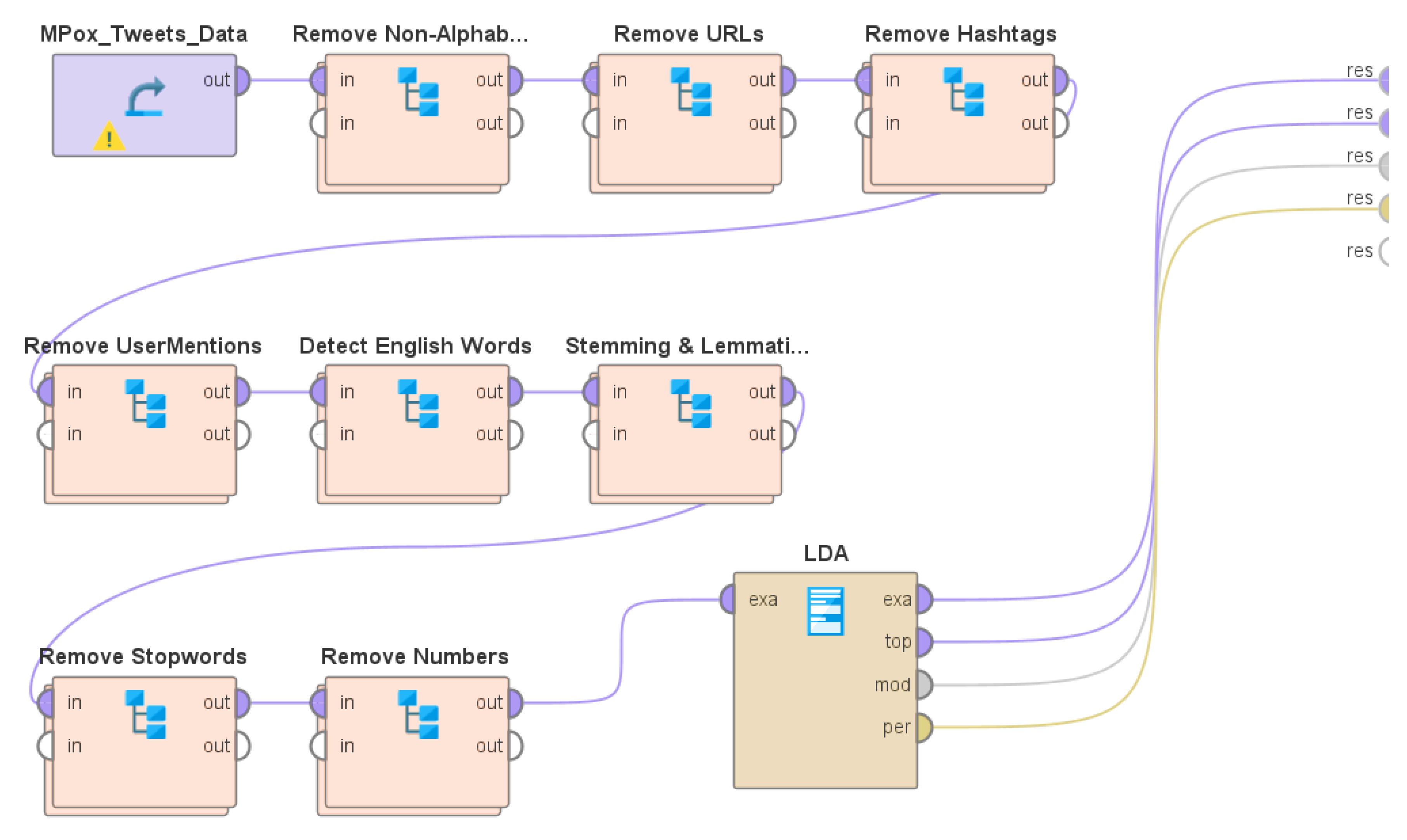
3.3. Description of the System Design and Implementation
- (a)
- Removal of characters that are not alphabets (RegEx used: ^a-zA-Z).
- (b)
- Removal of URLs (RegEx used: http\S+).
- (c)
- Removal of hashtags (RegEx used: #[A-Za-z0-9]).
- (d)
- Removal of user mentions (RegEx used: @[A-Za-z0-9]).
- (e)
- Detection of English words using tokenization.
- (f)
- Stemming and Lemmatization.
- (g)
- Removal of stop words.
- (h)
- Removal of numbers.
4. Results and Discussions
- Limited time range of the analyzed Tweets: The time range of the Tweets that were analyzed in these works represents Tweets that were posted only during certain months of the 2022 MPox outbreak. One of the works [109] included Tweets that were posted on the day the first case of the 2022 MPox outbreak was recorded (7 May 2022) but the other work [113] did not. Furthermore, none of these works analyzed Tweets posted after 23 July 2022.
- Limited number of Tweets used for topic modeling: The number of Tweets that were used for topic modeling in these works is 352,182 and 128,037 Tweets, respectively. It is relevant to mention here that the work presented in [113] involved a two-step process. In the first step, the authors analyzed a dataset of 556,402 Tweets about MPox and performed sentiment analysis of those Tweets. The results showed that 128,037 Tweets (23.01%) had a negative sentiment. Thereafter, only these 128,037 Tweets that had a negative sentiment were used for topic modeling in the second step of that study. The number of Tweets used for topic modeling in the previous works represents a fraction of the total number of Tweets that have been posted since the first recorded case of the 2022 Mpox outbreak on 7 May 2022.
- Elimination of a topic from the study: The work of Ng et al. [109] reports that after performing topic modeling, one topic was categorized as “Miscellaneous”, which accounted for 31.1% of the total number of Tweets. The work also reports that this topic was omitted from the results or, in other words, the specific themes or focus areas of conversation reported in that study [109] are based on the analysis of 68.9% of the Tweets only.
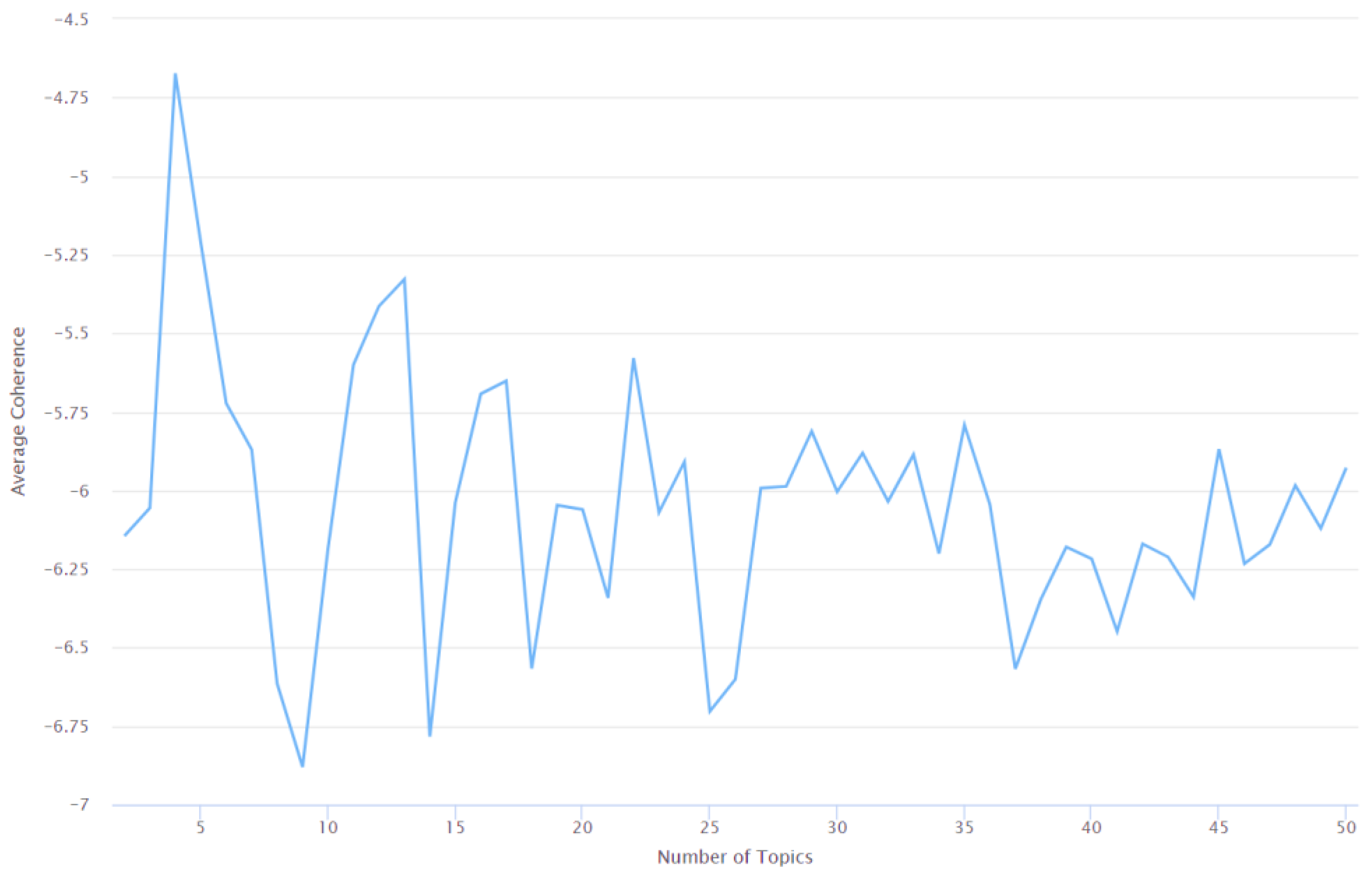
- Lack of reporting of metrics to discuss the working or the accuracy of the topic modeling approaches: The average coherence value of an LDA model serves as a key indicator for the determination of the optimal number of topics. At the same time, metrics such as exclusivity, document entropy, number of tokens, and average word length of each topic help to provide a better understanding of the working of the underlying topic modeling approach. The two prior works that exist in this field [109,113] do not report any of these metrics to discuss either the working or the accuracy of the topic modeling approaches that were used.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- McCollum, A.M.; Damon, I.K. Human Monkeypox. Clin. Infect. Dis. 2014, 58, 260–267. [Google Scholar] [CrossRef] [PubMed]
- Beer, E.M.; Rao, V.B. A Systematic Review of the Epidemiology of Human Monkeypox Outbreaks and Implications for Outbreak Strategy. PLoS Negl. Trop. Dis. 2019, 13, e0007791. [Google Scholar] [CrossRef] [PubMed]
- Likos, A.M.; Sammons, S.A.; Olson, V.A.; Frace, A.M.; Li, Y.; Olsen-Rasmussen, M.; Davidson, W.; Galloway, R.; Khristova, M.L.; Reynolds, M.G.; et al. A Tale of Two Clades: Monkeypox Viruses. J. Gen. Virol. 2005, 86, 2661–2672. [Google Scholar] [CrossRef] [PubMed]
- Heymann, D.L.; Szczeniowski, M.; Esteves, K. Re-Emergence of Monkeypox in Africa: A Review of the Past Six Years. Br. Med. Bull. 1998, 54, 693–702. [Google Scholar] [CrossRef] [PubMed]
- Mandja, B.-A.M.; Brembilla, A.; Handschumacher, P.; Bompangue, D.; Gonzalez, J.-P.; Muyembe, J.-J.; Mauny, F. Temporal and Spatial Dynamics of Monkeypox in Democratic Republic of Congo, 2000–2015. Ecohealth 2019, 16, 476–487. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, P.-Y.; Ajisegiri, W.S.; Costantino, V.; Chughtai, A.A.; MacIntyre, C.R. Reemergence of Human Monkeypox and Declining Population Immunity in the Context of Urbanization, Nigeria, 2017–2020. Emerg. Infect. Dis. 2021, 27, 1007. [Google Scholar] [CrossRef] [PubMed]
- Yong, S.E.F.; Ng, O.T.; Ho, Z.J.M.; Mak, T.M.; Marimuthu, K.; Vasoo, S.; Yeo, T.W.; Ng, Y.K.; Cui, L.; Ferdous, Z.; et al. Imported Monkeypox, Singapore. Emerg. Infect. Dis. 2020, 26, 1826–1830. [Google Scholar] [CrossRef] [PubMed]
- Saxena, S.K.; Ansari, S.; Maurya, V.K.; Kumar, S.; Jain, A.; Paweska, J.T.; Tripathi, A.K.; Abdel-Moneim, A.S. Re-emerging Human Monkeypox: A Major Public-health Debacle. J. Med. Virol. 2023, 95. [Google Scholar] [CrossRef]
- Kozlov, M. Monkeypox Declared a Global Emergency: Will It Help Contain the Outbreaks? Nature 2022. [CrossRef]
- Multi-Country Outbreak of Mpox, External Situation Report #22-11 May 2023. Available online: https://www.who.int/publications/m/item/multi-country-outbreak-of-mpox--external-situation-report--22---11-may-2023 (accessed on 31 August 2023).
- Liu, L.; Xu, Z.; Fuhlbrigge, R.C.; Peña-Cruz, V.; Lieberman, J.; Kupper, T.S. Vaccinia Virus Induces Strong Immunoregulatory Cytokine Production in Healthy Human Epidermal Keratinocytes: A Novel Strategy for Immune Evasion. J. Virol. 2005, 79, 7363–7370. [Google Scholar] [CrossRef]
- MacLeod, D.T.; Nakatsuji, T.; Wang, Z.; di Nardo, A.; Gallo, R.L. Vaccinia Virus Binds to the Scavenger Receptor MARCO on the Surface of Keratinocytes. J. Investig. Dermatol. 2015, 135, 142–150. [Google Scholar] [CrossRef] [PubMed]
- Vaccines. Available online: https://www.cdc.gov/smallpox/clinicians/vaccines.html (accessed on 31 August 2023).
- Berhanu, A.; Prigge, J.T.; Silvera, P.M.; Honeychurch, K.M.; Hruby, D.E.; Grosenbach, D.W. Treatment with the Smallpox Antiviral Tecovirimat (ST-246) Alone or in Combination with ACAM2000 Vaccination Is Effective as a Postsymptomatic Therapy for Monkeypox Virus Infection. Antimicrob. Agents Chemother. 2015, 59, 4296–4300. [Google Scholar] [CrossRef] [PubMed]
- O’Shea, J.; Filardo, T.D.; Morris, S.B.; Weiser, J.; Petersen, B.; Brooks, J.T. Interim Guidance for Prevention and Treatment of Monkeypox in Persons with HIV Infection—United States, August 2022. MMWR Morb. Mortal. Wkly. Rep. 2022, 71, 1023–1028. [Google Scholar] [CrossRef] [PubMed]
- Piccolo, A.J.L.; Chan, J.; Cohen, G.M.; Mgbako, O.; Pitts, R.A.; Postelnicu, R.; Wallach, A.; Mukherjee, V. Critical Elements of an Mpox Vaccination Model at the Largest Public Health Hospital System in the United States. Vaccines 2023, 11, 1138. [Google Scholar] [CrossRef] [PubMed]
- CDC Detection & Transmission of Mpox Virus during the 2022 Clade IIb Out. Available online: https://www.cdc.gov/poxvirus/mpox/about/science-behind-transmission.html (accessed on 31 August 2023).
- Mohanto, S.; Faiyazuddin, M.; Dilip Gholap, A.; Jogi, D.; Bhunia, A.; Subbaram, K.; Gulzar Ahmed, M.; Nag, S.; Shabib Akhtar, M.; Bonilla-Aldana, D.K.; et al. Addressing the Resurgence of Global Monkeypox (Mpox) through Advanced Drug Delivery Platforms. Travel Med. Infect. Dis. 2023, 56, 102636. [Google Scholar] [CrossRef] [PubMed]
- Fifth Meeting of the International Health Regulations (2005) (IHR) Emergency Committee on the Multi-Country Outbreak of Mpox (Monkeypox). Available online: https://www.who.int/news/item/11-05-2023-fifth-meeting-of-the-international-health-regulations-(2005)-(ihr)-emergency-committee-on-the-multi-country-outbreak-of-monkeypox-(mpox) (accessed on 31 August 2023).
- Miraz, M.H.; Ali, M.; Excell, P.S.; Picking, R. A Review on Internet of Things (IoT), Internet of Everything (IoE) and Internet of Nano Things (IoNT). In Proceedings of the 2015 Internet Technologies and Applications (ITA), IEEE, Wrexham, UK, 8–11 September 2015; pp. 219–224. [Google Scholar]
- Twitter: Number of Users Worldwide 2024. Available online: https://www.statista.com/statistics/303681/twitter-users-worldwide/ (accessed on 31 August 2023).
- Hutchinson, A. New Study Shows Twitter Is the Most Used Social Media Platform among Journalists. Available online: https://www.socialmediatoday.com/news/new-study-shows-twitter-is-the-most-used-social-media-platform-among-journa/626245/ (accessed on 31 August 2023).
- Biggest Social Media Platforms 2023. Available online: https://www.statista.com/statistics/272014/global-social-networks-ranked-by-number-of-users/ (accessed on 31 August 2023).
- Lin, Y. 10 Twitter Statistics Every Marketer Should Know in 2023 [Infographic]. Available online: https://www.oberlo.com/blog/twitter-statistics (accessed on 13 September 2023).
- Martin, M. 29 Twitter Stats That Matter to Marketers in 2023. Available online: https://blog.hootsuite.com/twitter-statistics/ (accessed on 13 September 2023).
- Twitter ‘Lurkers’ Follow—and Are Followed by—Fewer Accounts. Available online: https://www.pewresearch.org/short-reads/2022/03/16/5-facts-about-twitter-lurkers/ft_2022-03-16_twitterlurkers_03/ (accessed on 13 September 2023).
- Thakur, N. Sentiment Analysis and Text Analysis of the Public Discourse on Twitter about COVID-19 and MPox. Big Data Cogn. Comput. 2023, 7, 116. [Google Scholar] [CrossRef]
- Blei, D.M. Probabilistic Topic Models. Commun. ACM 2012, 55, 77–84. [Google Scholar] [CrossRef]
- Gretarsson, B.; O’Donovan, J.; Bostandjiev, S.; Höllerer, T.; Asuncion, A.; Newman, D.; Smyth, P. TopicNets: Visual Analysis of Large Text Corpora with Topic Modeling. ACM Trans. Intell. Syst. Technol. 2012, 3, 1–26. [Google Scholar] [CrossRef]
- Sievert, C.; Shirley, K.E. LDAvis: A Method for Visualizing and Interpreting Topics. Available online: https://aclanthology.org/W14-3110.pdf (accessed on 13 September 2023).
- Panichella, A.; Dit, B.; Oliveto, R.; Di Penta, M.; Poshynanyk, D.; De Lucia, A. How to Effectively Use Topic Models for Software Engineering Tasks? An Approach Based on Genetic Algorithms. In Proceedings of the 2013 35th International Conference on Software Engineering (ICSE), IEEE, San Francisco, CA, USA, 18–26 May 2013; pp. 522–531. [Google Scholar]
- Silva, C.C.; Galster, M.; Gilson, F. Topic Modeling in Software Engineering Research. Empir. Softw. Eng. 2021, 26, 120. [Google Scholar] [CrossRef]
- Linton, M.; Teo, E.G.S.; Bommes, E.; Chen, C.Y.; Härdle, W.K. Dynamic Topic Modelling for Cryptocurrency Community Forums. In Applied Quantitative Finance; Springer: Berlin/Heidelberg, Germany, 2017; pp. 355–372. ISBN 9783662544853. [Google Scholar]
- Schnoering, H. Short Text Topic Modeling: Application to Tweets about Bitcoin. arXiv 2022.
- Kang, H.-J.; Han, J.; Kwon, G.H. Determining the Intellectual Structure and Academic Trends of Smart Home Health Care Research: Coword and Topic Analyses. J. Med. Internet Res. 2021, 23, e19625. [Google Scholar] [CrossRef] [PubMed]
- Thakur, N.; Han, C.Y. A Simplistic and Cost-Effective Design for Real-World Development of an Ambient Assisted Living System for Fall Detection and Indoor Localization: Proof-of-Concept. Information 2022, 13, 363. [Google Scholar] [CrossRef]
- Huynh, T.; Fritz, M.; Schiele, B. Discovery of Activity Patterns Using Topic Models. In Proceedings of the 10th International Conference on Ubiquitous Computing, Seoul, Republic of Korea, 21–24 September 2008; ACM: New York, NY, USA, 2008. [Google Scholar]
- Thakur, N.Y.; Han, C. Pervasive Activity Logging for Indoor Localization in Smart Homes. In Proceedings of the 2021 4th International Conference on Data Science and Information Technology, Shanghai, China, 23–25 July 2021; ACM: New York, NY, USA, 2021. [Google Scholar]
- Goudarzvand, S.; St. Sauver, J.; Mielke, M.M.; Takahashi, P.Y.; Lee, Y.; Sohn, S. Early Temporal Characteristics of Elderly Patient Cognitive Impairment in Electronic Health Records. BMC Med. Inform. Decis. Mak. 2019, 19, 149. [Google Scholar] [CrossRef] [PubMed]
- Thakur, N.; Han, C.Y. A Multimodal Approach for Early Detection of Cognitive Impairment from Tweets. In Human Interaction, Emerging Technologies and Future Systems V; Springer: Cham, Switzerland, 2022; pp. 11–19. ISBN 9783030855390. [Google Scholar]
- Yun, E. Review of Trends in Physics Education Research Using Topic Modeling. J. Balt. Sci. Educ. 2020, 19, 388–400. [Google Scholar] [CrossRef]
- Chen, Y.; Yu, B.; Zhang, X.; Yu, Y. Topic Modeling for Evaluating Students’ Reflective Writing: A Case Study of Pre-Service Teachers’ Journals. In Proceedings of the Sixth International Conference on Learning Analytics & Knowledge—LAK ’16, Edinburgh, UK, 25–29 April 2016; ACM Press: New York, NY, USA, 2016. [Google Scholar]
- Zhao, W.; Zou, W.; Chen, J.J. Topic Modeling for Cluster Analysis of Large Biological and Medical Datasets. BMC Bioinform. 2014, 15, S11. [Google Scholar] [CrossRef] [PubMed]
- Zheng, B.; McLean, D.C., Jr.; Lu, X. Identifying Biological Concepts from a Protein-Related Corpus with a Probabilistic Topic Model. BMC Bioinform. 2006, 7, 58. [Google Scholar] [CrossRef] [PubMed]
- Porturas, T.; Taylor, R.A. Forty Years of Emergency Medicine Research: Uncovering Research Themes and Trends through Topic Modeling. Am. J. Emerg. Med. 2021, 45, 213–220. [Google Scholar] [CrossRef]
- Yao, L.; Zhang, Y.; Wei, B.; Zhang, W.; Jin, Z. A Topic Modeling Approach for Traditional Chinese Medicine Prescriptions. IEEE Trans. Knowl. Data Eng. 2018, 30, 1007–1021. [Google Scholar] [CrossRef]
- Firdaniza, F.; Ruchjana, B.; Chaerani, D.; Radianti, J. Information Diffusion Model in Twitter: A Systematic Literature Review. Information 2021, 13, 13. [Google Scholar] [CrossRef]
- Bokaee Nezhad, Z.; Deihimi, M.A. Twitter Sentiment Analysis from Iran about COVID 19 Vaccine. Diabetes Metab. Syndr. 2022, 16, 102367. [Google Scholar] [CrossRef]
- Wang, Y.; Guo, J.; Yuan, C.; Li, B. Sentiment Analysis of Twitter Data. Appl. Sci. 2022, 12, 11775. [Google Scholar] [CrossRef]
- Manias, G.; Mavrogiorgou, A.; Kiourtis, A.; Symvoulidis, C.; Kyriazis, D. Multilingual Text Categorization and Sentiment Analysis: A Comparative Analysis of the Utilization of Multilingual Approaches for Classifying Twitter Data. Neural Comput. Appl. 2023, 35, 21415–21431. [Google Scholar] [CrossRef] [PubMed]
- Rodrigues, A.P.; Fernandes, R.; Aakash; Abhishek; Shetty, A.; Atul; Lakshmanna, K.; Shafi, R.M. Real-Time Twitter Spam Detection and Sentiment Analysis Using Machine Learning and Deep Learning Techniques. Comput. Intell. Neurosci. 2022, 2022, 5211949. [Google Scholar] [CrossRef] [PubMed]
- Mao, H.; Shuai, X.; Kapadia, A. Loose Tweets: An Analysis of Privacy Leaks on Twitter. In Proceedings of the 10th annual ACM workshop on Privacy in the electronic society, Chicago, IL, USA, 17 October 2011; ACM: New York, NY, USA, 2011. [Google Scholar]
- Mendoza, M.; Poblete, B.; Castillo, C. Twitter under Crisis: Can We Trust What We RT? In Proceedings of the First Workshop on Social Media Analytics, Washington, DC, USA, 25 July 2010; ACM: New York, NY, USA, 2010. [Google Scholar]
- Zagheni, E.; Garimella, V.R.K.; Weber, I. Bogdan State Inferring International and Internal Migration Patterns from Twitter Data. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Republic of Korea, 7–11 April 2014; ACM: New York, NY, USA, 2014. [Google Scholar]
- Ibrahim, R.; Elbagoury, A.; Kamel, M.S.; Karray, F. Tools and Approaches for Topic Detection from Twitter Streams: Survey. Knowl. Inf. Syst. 2018, 54, 511–539. [Google Scholar] [CrossRef]
- Thakur, N. Social Media Mining and Analysis: A Brief Review of Recent Challenges. Information 2023, 14, 484. [Google Scholar] [CrossRef]
- Abu Samah, K.A.F.; Amirah Misdan, N.F.; Hasrol Jono, M.N.H.; Riza, L.S. The Best Malaysian Airline Companies Visualization through Bilingual Twitter Sentiment Analysis: A Machine Learning Classification. JOIV Int. J. Inform. Vis. 2022, 6, 130. [Google Scholar] [CrossRef]
- Bodaghi, A.; Oliveira, J. The Theater of Fake News Spreading, Who Plays Which Role? A Study on Real Graphs of Spreading on Twitter. Expert Syst. Appl. 2022, 189, 116110. [Google Scholar] [CrossRef]
- Collins, S.; DeWitt, J. Words Matter: Presidents Obama and Trump, Twitter, and U.s. Soft Power. World Aff. 2023, 186, 530–571. [Google Scholar] [CrossRef]
- Berrocal-Gonzalo, S.; Zamora-Martínez, P.; González-Neira, A. Politainment on Twitter: Engagement in the Spanish Legislative Elections of April 2019. Media Commun. 2023, 11, 163–175. [Google Scholar] [CrossRef]
- Chang, R.-C.; Rao, A.; Zhong, Q.; Wojcieszak, M.; Lerman, K. #RoeOverturned: Twitter Dataset on the Abortion Rights Controversy. Proc. Int. AAAI Conf. Web Soc. Media 2023, 17, 997–1005. [Google Scholar] [CrossRef]
- Peña-Fernández, S.; Larrondo-Ureta, A.; Morales-i-Gras, J. Feminism, gender identity and polarization in TikTok and Twitter. Comunicar 2023, 31, 49–60. [Google Scholar] [CrossRef]
- Goetz, S.J.; Heaton, C.; Imran, M.; Pan, Y.; Tian, Z.; Schmidt, C.; Qazi, U.; Ofli, F.; Mitra, P. Food Insufficiency and Twitter Emotions during a Pandemic. Appl. Econ. Perspect. Policy 2023, 45, 1189–1210. [Google Scholar] [CrossRef] [PubMed]
- Tao, W.; Peng, Y. Differentiation and Unity: A Cross-Platform Comparison Analysis of Online Posts’ Semantics of the Russian–Ukrainian War Based on Weibo and Twitter. Commun. Public 2023, 8, 105–124. [Google Scholar] [CrossRef]
- Yavuz, G.R.; Kocak, M.E.; Ergun, G.; Alemdar, H.; Yalcin, H.; Incel, O.D.; Akarun, L.; Ersoy, C. A Smartphone Based Fall Detector with Online Location Support. Available online: http://sensorlab.cs.dartmouth.edu/phonesense/papers/Yavuz-fall.pdf (accessed on 13 September 2023).
- Thakur, N.; Han, C.Y. An Approach for Detection of Walking Related Falls during Activities of Daily Living. In Proceedings of the 2020 International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Fuzhou, China, 12–14 June 2020; pp. 280–283. [Google Scholar]
- Albín-Rodríguez, A.-P.; De-La-Fuente-Robles, Y.-M.; López-Ruiz, J.-L.; Verdejo-Espinosa, Á.; Espinilla Estévez, M. UJAmI Location: A Fuzzy Indoor Location System for the Elderly. Int. J. Environ. Res. Public Health 2021, 18, 8326. [Google Scholar] [CrossRef] [PubMed]
- Thakur, N.; Han, C.Y. A Context Driven Indoor Localization Framework for Assisted Living in Smart Homes. In HCI International 2020—Late Breaking Papers: Universal Access and Inclusive Design; Springer: Cham, Switzerland, 2020; pp. 387–400. ISBN 9783030601485. [Google Scholar]
- Tamplain, P.M.; Fears, N.E.; Robinson, P.; Chatterjee, R.; Lichtenberg, G.; Miller, H.L. #DCD/Dyspraxia in Real Life: Twitter Users’ Unprompted Expression of Experiences with Motor Differences. J. Mot. Learn. Dev. 2023, 1, 1–14. [Google Scholar] [CrossRef]
- Thakur, N.; Han, C.Y. An Ambient Intelligence-Based Human Behavior Monitoring Framework for Ubiquitous Environments. Information 2021, 12, 81. [Google Scholar] [CrossRef]
- Song, B.-K.; Yang, B.-I. A Study on Cognitive Activity Programs for Elderly Person with Mild Cognitive Impairment. JRTDD 2023, 6, 13–17. [Google Scholar]
- Thakur, N.; Han, C.Y. An Intelligent Ubiquitous Activity Aware Framework for Smart Home. In Human Interaction, Emerging Technologies and Future Applications III.; Springer: Cham, Switzerland, 2021; pp. 296–302. ISBN 9783030553067. [Google Scholar]
- Lu, X.; Brelsford, C. Network Structure and Community Evolution on Twitter: Human Behavior Change in Response to the 2011 Japanese Earthquake and Tsunami. Sci. Rep. 2014, 4, 6773. [Google Scholar] [CrossRef]
- Thakur, N.; Han, C.Y. A Framework for Prediction of Cramps during Activities of Daily Living in Elderly. In Proceedings of the 2020 International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Fuzhou, China, 12–14 June 2020; pp. 284–287. [Google Scholar]
- Contreras-Somoza, L.M.; Irazoki, E.; Toribio-Guzmán, J.M.; de la Torre-Díez, I.; Diaz-Baquero, A.A.; Parra-Vidales, E.; Perea-Bartolomé, M.V.; Franco-Martín, M.Á. Usability and User Experience of Cognitive Intervention Technologies for Elderly People with MCI or Dementia: A Systematic Review. Front. Psychol. 2021, 12, 636116. [Google Scholar] [CrossRef]
- Thakur, N.; Han, C.Y. Methodology for Forecasting User Experience for Smart and Assisted Living in Affect Aware Systems. In Proceedings of the 8th International Conference on the Internet of Things, Santa Barbara, CA, USA, 15–18 October 2018; ACM: New York, NY, USA, 2018. [Google Scholar]
- Carpenter, J.P.; Krutka, D.G. How and Why Educators Use Twitter: A Survey of the Field. J. Res. Technol. Educ. 2014, 46, 414–434. [Google Scholar] [CrossRef]
- Thakur, N. A Large-Scale Dataset of Twitter Chatter about Online Learning during the Current COVID-19 Omicron Wave. Data 2022, 7, 109. [Google Scholar] [CrossRef]
- Sama, T.B.; Konttinen, I.; Hiilamo, H. Alcohol Industry Arguments for Liberalizing Alcohol Policy in Finland: Analysis of Twitter Data. J. Stud. Alcohol Drugs 2021, 82, 279–287. [Google Scholar] [CrossRef] [PubMed]
- Curtis, B.; Giorgi, S.; Buffone, A.E.K.; Ungar, L.H.; Ashford, R.D.; Hemmons, J.; Summers, D.; Hamilton, C.; Schwartz, H.A. Can Twitter Be Used to Predict County Excessive Alcohol Consumption Rates? PLoS ONE 2018, 13, e0194290. [Google Scholar] [CrossRef] [PubMed]
- Kamiński, M.; Muth, A.; Bogdański, P. Smoking, Vaping, and Tobacco Industry during COVID-19 Pandemic: Twitter Data Analysis. Cyberpsychol. Behav. Soc. Netw. 2020, 23, 811–817. [Google Scholar] [CrossRef] [PubMed]
- Myslín, M.; Zhu, S.-H.; Chapman, W.; Conway, M. Using Twitter to Examine Smoking Behavior and Perceptions of Emerging Tobacco Products. J. Med. Internet Res. 2013, 15, e174. [Google Scholar] [CrossRef] [PubMed]
- Williams, J.; Chinn, S.J.; Suleiman, J. The Value of Twitter for Sports Fans. J. Direct Data Digit. Mark. Pract. 2014, 16, 36–50. [Google Scholar] [CrossRef]
- Hutchins, B. Twitter: Follow the Money and Look beyond Sports. Commun. Sport 2014, 2, 122–126. [Google Scholar] [CrossRef]
- López-de-Ipiña, D.; Díaz-de-Sarralde, I.; García-Zubia, J. An Ambient Assisted Living Platform Integrating RFID Data-on-Tag Care Annotations and Twitter. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=3484a2c17c27695659a925cb4892dc9d7ac318ec (accessed on 13 September 2023).
- Thakur, N.; Han, C.Y. A Study of Fall Detection in Assisted Living: Identifying and Improving the Optimal Machine Learning Method. J. Sens. Actuator Netw. 2021, 10, 39. [Google Scholar] [CrossRef]
- Aresta, M.; Pedro, L.; Santos, C.; Moreira, A. Portraying the Self in Online Contexts: Context-Driven and User-Driven Online Identity Profiles. Contemp. Soc. Sci. 2015, 10, 70–85. [Google Scholar] [CrossRef]
- Thakur, N.; Han, C.Y. A Multilayered Contextually Intelligent Activity Recognition Framework for Smart Home. In Human Interaction, Emerging Technologies and Future Applications III.; Springer: Cham, Switzerland, 2021; pp. 278–283. ISBN 9783030553067. [Google Scholar]
- Weeks, R.; White, S.; Hartner, A.-M.; Littlepage, S.; Wolf, J.; Masten, K.; Tingey, L. COVID-19 Messaging on Social Media for American Indian and Alaska Native Communities: Thematic Analysis of Audience Reach and Web Behavior. JMIR Infodemiol. 2022, 2, e38441. [Google Scholar] [CrossRef]
- Thakur, N.; Han, C.Y. Country-Specific Interests towards Fall Detection from 2004–2021: An Open Access Dataset and Research Questions. Data 2021, 6, 92. [Google Scholar] [CrossRef]
- Eriksson, H.; Salzmann-Erikson, M. Twitter Discussions about the Predicaments of Robots in Geriatric Nursing: Forecast of Nursing Robotics in Aged Care. Contemp. Nurse 2018, 54, 97–107. [Google Scholar] [CrossRef] [PubMed]
- Thakur, N.; Han, C.Y. An Approach to Analyze the Social Acceptance of Virtual Assistants by Elderly People. In Proceedings of the 8th International Conference on the Internet of Things, Santa Barbara, CA, USA, 15–18 October 2018; ACM: New York, NY, USA, 2018. [Google Scholar]
- Cevik, F.; Kilimci, Z.H. Analysis of Parkinson’s Disease Using Deep Learning and Word Embedding Models. Acad. Perspect. Procedia 2019, 2, 786–797. [Google Scholar] [CrossRef]
- Kesler, S.R.; Henneghan, A.M.; Thurman, W.; Rao, V. Identifying Themes for Assessing Cancer-Related Cognitive Impairment: Topic Modeling and Qualitative Content Analysis of Public Online Comments. JMIR Cancer 2022, 8, e34828. [Google Scholar] [CrossRef] [PubMed]
- Klein, A.Z.; Kunatharaju, S.; O’Connor, K.; Gonzalez-Hernandez, G. Pregex: Rule-Based Detection and Extraction of Twitter Data in Pregnancy. J. Med. Internet Res. 2023, 25, e40569. [Google Scholar] [CrossRef] [PubMed]
- Thakur, N.; Han, C.Y. A Human-Human Interaction-Driven Framework to Address Societal Issues. In Human Interaction, Emerging Technologies and Future Systems V; Springer International Publishing: Cham, Switzerland, 2022; pp. 563–571. ISBN 9783030855390. [Google Scholar]
- Thakur, N.; Han, C.Y. A Framework for Facilitating Human-Human Interactions to Mitigate Loneliness in Elderly. In Human Interaction, Emerging Technologies and Future Applications III; Springer: Cham, Switzerland, 2021; pp. 322–327. ISBN 9783030553067. [Google Scholar]
- Klein, A.Z.; O’Connor, K.; Levine, L.D.; Gonzalez-Hernandez, G. Using Twitter Data for Cohort Studies of Drug Safety in Pregnancy: Proof-of-Concept with β-Blockers. JMIR Form. Res. 2022, 6, e36771. [Google Scholar] [CrossRef] [PubMed]
- Gomide, J.; Veloso, A.; Meira, W., Jr.; Almeida, V.; Benevenuto, F.; Ferraz, F.; Teixeira, M. Dengue Surveillance Based on a Computational Model of Spatio-Temporal Locality of Twitter. In Proceedings of the 3rd International Web Science Conference, Koblenz, Germany, 15–17 June 2011; ACM: New York, NY, USA, 2011. [Google Scholar]
- Radzikowski, J.; Stefanidis, A.; Jacobsen, K.H.; Croitoru, A.; Crooks, A.; Delamater, P.L. The Measles Vaccination Narrative in Twitter: A Quantitative Analysis. JMIR Public Health Surveill. 2016, 2, e1. [Google Scholar] [CrossRef]
- Signorini, A.; Segre, A.M.; Polgreen, P.M. The Use of Twitter to Track Levels of Disease Activity and Public Concern in the U.S. during the Influenza A H1N1 Pandemic. PLoS ONE 2011, 6, e19467. [Google Scholar] [CrossRef]
- Sugumaran, R.; Voss, J. Real-Time Spatio-Temporal Analysis of West Nile Virus Using Twitter Data. In Proceedings of the 3rd International Conference on Computing for Geospatial Research and Applications, Washington, DC, USA, 1–3 July 2012; ACM: New York, NY, USA, 2012. [Google Scholar]
- Porat, T.; Garaizar, P.; Ferrero, M.; Jones, H.; Ashworth, M.; Vadillo, M.A. Content and Source Analysis of Popular Tweets Following a Recent Case of Diphtheria in Spain. Eur. J. Public Health 2019, 29, 117–122. [Google Scholar] [CrossRef]
- Knudsen, B.; Høeg, T.B.; Prasad, V. Analysis of Tweets Discussing the Risk of Mpox among Children and Young People in School (May–October 2022): Public Health Experts on Twitter Consistently Exaggerated Risks and Infrequently Reported Accurate Information. bioRxiv 2023.
- Zuhanda, M.K. Analysis of Twitter User Sentiment on the Monkeypox Virus Issue Using the Nrc Lexicon. Available online: https://www.iocscience.org/ejournal/index.php/mantik/article/view/3502 (accessed on 31 August 2023).
- Ortiz-Martínez, Y.; Sarmiento, J.; Bonilla-Aldana, D.K.; Rodríguez-Morales, A.J. Monkeypox Goes Viral: Measuring the Misinformation Outbreak on Twitter. J. Infect. Dev. Ctries. 2022, 16, 1218–1220. [Google Scholar] [CrossRef] [PubMed]
- Rahmanian, V.; Jahanbin, K.; Jokar, M. Using Twitter and Web News Mining to Predict the Monkeypox Outbreak. Asian Pac. J. Trop. Med. 2022, 15, 236. [Google Scholar] [CrossRef]
- Cooper, L.N.; Radunsky, A.P.; Hanna, J.J.; Most, Z.M.; Perl, T.M.; Lehmann, C.U.; Medford, R.J. Analyzing an Emerging Pandemic on Twitter: Monkeypox. Open Forum Infect. Dis. 2023, 10. [Google Scholar] [CrossRef] [PubMed]
- Ng, Q.X.; Yau, C.E.; Lim, Y.L.; Wong, L.K.T.; Liew, T.M. Public Sentiment on the Global Outbreak of Monkeypox: An Unsupervised Machine Learning Analysis of 352,182 Twitter Posts. Public Health 2022, 213, 1–4. [Google Scholar] [CrossRef] [PubMed]
- Bengesi, S.; Oladunni, T.; Olusegun, R.; Audu, H. A Machine Learning-Sentiment Analysis on Monkeypox Outbreak: An Extensive Dataset to Show the Polarity of Public Opinion from Twitter Tweets. IEEE Access 2023, 11, 11811–11826. [Google Scholar] [CrossRef]
- Olusegun, R.; Oladunni, T.; Audu, H.; Houkpati, Y.A.O.; Bengesi, S. Text Mining and Emotion Classification on Monkeypox Twitter Dataset: A Deep Learning-Natural Language Processing (NLP) Approach. IEEE Access 2023, 11, 49882–49894. [Google Scholar] [CrossRef]
- Farahat, R.A.; Yassin, M.A.; Al-Tawfiq, J.A.; Bejan, C.A.; Abdelazeem, B. Public Perspectives of Monkeypox in Twitter: A Social Media Analysis Using Machine Learning. New Microbes New Infect. 2022, 49–50, 101053. [Google Scholar] [CrossRef] [PubMed]
- Sv, P.; Ittamalla, R. What Concerns the General Public the Most about Monkeypox Virus?—A Text Analytics Study Based on Natural Language Processing (NLP). Travel Med. Infect. Dis. 2022, 49, 102404. [Google Scholar] [CrossRef]
- Mohbey, K.K.; Meena, G.; Kumar, S.; Lokesh, K. A CNN-LSTM-Based Hybrid Deep Learning Approach to Detect Sentiment Polarities on Monkeypox Tweets. arXiv 2022.
- Nia, Z.M.; Bragazzi, N.L.; Wu, J.; Kong, J.D. A Twitter Dataset for Monkeypox, May 2022. Data Brief 2023, 48, 109118. [Google Scholar] [CrossRef]
- Iparraguirre-Villanueva, O.; Alvarez-Risco, A.; Herrera Salazar, J.L.; Beltozar-Clemente, S.; Zapata-Paulini, J.; Yáñez, J.A.; Cabanillas-Carbonell, M. The Public Health Contribution of Sentiment Analysis of Monkeypox Tweets to Detect Polarities Using the CNN-LSTM Model. Vaccines 2023, 11, 312. [Google Scholar] [CrossRef] [PubMed]
- AL-Ahdal, T.; Coker, D.; Awad, H.; Reda, A.; Żuratyński, P.; Khailaie, S. Improving Public Health Policy by Comparing the Public Response during the Start of COVID-19 and Monkeypox on Twitter in Germany: A Mixed Methods Study. Vaccines 2022, 10, 1985. [Google Scholar] [CrossRef] [PubMed]
- Mierswa, I.; Wurst, M.; Klinkenberg, R.; Scholz, M.; Euler, T. YALE: Rapid Prototyping for Complex Data Mining Tasks. In Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining, Philadelphia, PA, USA, 20–23 August 2006; ACM: New York, NY, USA, 2006. [Google Scholar]
- Thakur, N.; Han, C.Y. Multimodal Approaches for Indoor Localization for Ambient Assisted Living in Smart Homes. Information 2021, 12, 114. [Google Scholar] [CrossRef]
- Garner, S.R. WEKA: The Waikato Environment for Knowledge Analysis. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=b732d47f60ff8b3e0dbe09dd098578fb00a971f4 (accessed on 13 September 2023).
- Kohavi, R.; Sommerfield, D. D2.1.2 MLC ++. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=7fd85a0b6ab6b37dd7a940e6b2813917493cb7fe (accessed on 13 September 2023).
- Jelodar, H.; Wang, Y.; Yuan, C.; Feng, X.; Jiang, X.; Li, Y.; Zhao, L. Latent Dirichlet Allocation (LDA) and Topic Modeling: Models, Applications, a Survey. Multimed. Tools Appl. 2019, 78, 15169–15211. [Google Scholar] [CrossRef]
- Wei, X.; Croft, W.B. LDA-Based Document Models for Ad-Hoc Retrieval. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Seattle, DC, USA, 6–11 August 2006; ACM: New York, NY, USA, 2006. [Google Scholar]
- Yao, L.; Mimno, D.; McCallum, A. Efficient Methods for Topic Model Inference on Streaming Document Collections. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June 2009–1 July 2009; ACM: New York, NY, USA, 2009. [Google Scholar]
- Thakur, N. MonkeyPox2022Tweets: A Large-Scale Twitter Dataset on the 2022 Monkeypox Outbreak, Findings from Analysis of Tweets, and Open Research Questions. Infect. Dis. Rep. 2022, 14, 855–883. [Google Scholar] [CrossRef] [PubMed]
- Anupriya, P.; Karpagavalli, S. LDA Based Topic Modeling of Journal Abstracts. In Proceedings of the 2015 International Conference on Advanced Computing and Communication Systems, Washington, DC, USA, 26–27 February 2015; pp. 1–5. [Google Scholar]
- Guo, H.; Liang, Q.; Li, Z. An Improved AD-LDA Topic Model Based on Weighted Gibbs Sampling. In Proceedings of the 2016 IEEE Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Xi’an, China, 3–5 October 2016; pp. 1978–1982. [Google Scholar]
- Syed, S.; Spruit, M. Full-Text or Abstract? Examining Topic Coherence Scores Using Latent Dirichlet Allocation. In Proceedings of the 2017 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Tokyo, Japan, 19–21 October 2017; pp. 165–174. [Google Scholar]
- Omar, M.; On, B.-W.; Lee, I.; Choi, G.S. LDA Topics: Representation and Evaluation. J. Inf. Sci. 2015, 41, 662–675. [Google Scholar] [CrossRef]
- Stevens, K.; Kegelmeyer, P.; Andrzejewski, D.; Buttler, D. Exploring Topic Coherence over Many Models and Many Topics. Available online: https://aclanthology.org/D12-1087.pdf (accessed on 14 September 2023).
- Xue, J.; Chen, J.; Chen, C.; Zheng, C.; Li, S.; Zhu, T. Public Discourse and Sentiment during the COVID 19 Pandemic: Using Latent Dirichlet Allocation for Topic Modeling on Twitter. PLoS ONE 2020, 15, e0239441. [Google Scholar] [CrossRef] [PubMed]
- Orellana-Rodriguez, C.; Keane, M.T. Attention to News and Its Dissemination on Twitter: A Survey. Comput. Sci. Rev. 2018, 29, 74–94. [Google Scholar] [CrossRef]
- Twitter’s Inactive Account Policy. Available online: https://help.twitter.com/en/rules-and-policies/inactive-twitter-accounts (accessed on 13 September 2023).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Topics | Average Coherence Value |
|---|---|
| 2 | −6.1450 |
| 3 | −6.0560 |
| 4 | −4.6730 |
| 5 | −5.2120 |
| 6 | −5.7230 |
| 7 | −5.8700 |
| 8 | −6.6150 |
| 9 | −6.8800 |
| 10 | −6.1840 |
| 11 | −5.6000 |
| 12 | −5.4140 |
| 13 | −5.3280 |
| 14 | −6.7830 |
| 15 | −6.0380 |
| 16 | −5.6930 |
| 17 | −5.6520 |
| 18 | −6.5670 |
| 19 | −6.0470 |
| 20 | −6.0610 |
| 21 | −6.3420 |
| 22 | −5.5790 |
| 23 | −6.0700 |
| 24 | −5.9090 |
| 25 | −6.7030 |
| 26 | −6.6010 |
| 27 | −5.9930 |
| 28 | −5.9870 |
| 29 | −5.8120 |
| 30 | −6.0040 |
| 31 | −5.8810 |
| 32 | −6.0350 |
| 33 | −5.8860 |
| 34 | −6.2010 |
| 35 | −5.7920 |
| 36 | −6.0450 |
| 37 | −6.5680 |
| 38 | −6.3470 |
| 39 | −6.1800 |
| 40 | −6.2180 |
| 41 | −6.4490 |
| 42 | −6.1700 |
| 43 | −6.2120 |
| 44 | −6.3390 |
| 45 | −5.8690 |
| 46 | −6.2330 |
| 47 | −6.1720 |
| 48 | −5.9840 |
| 49 | −6.1210 |
| 50 | −5.9280 |
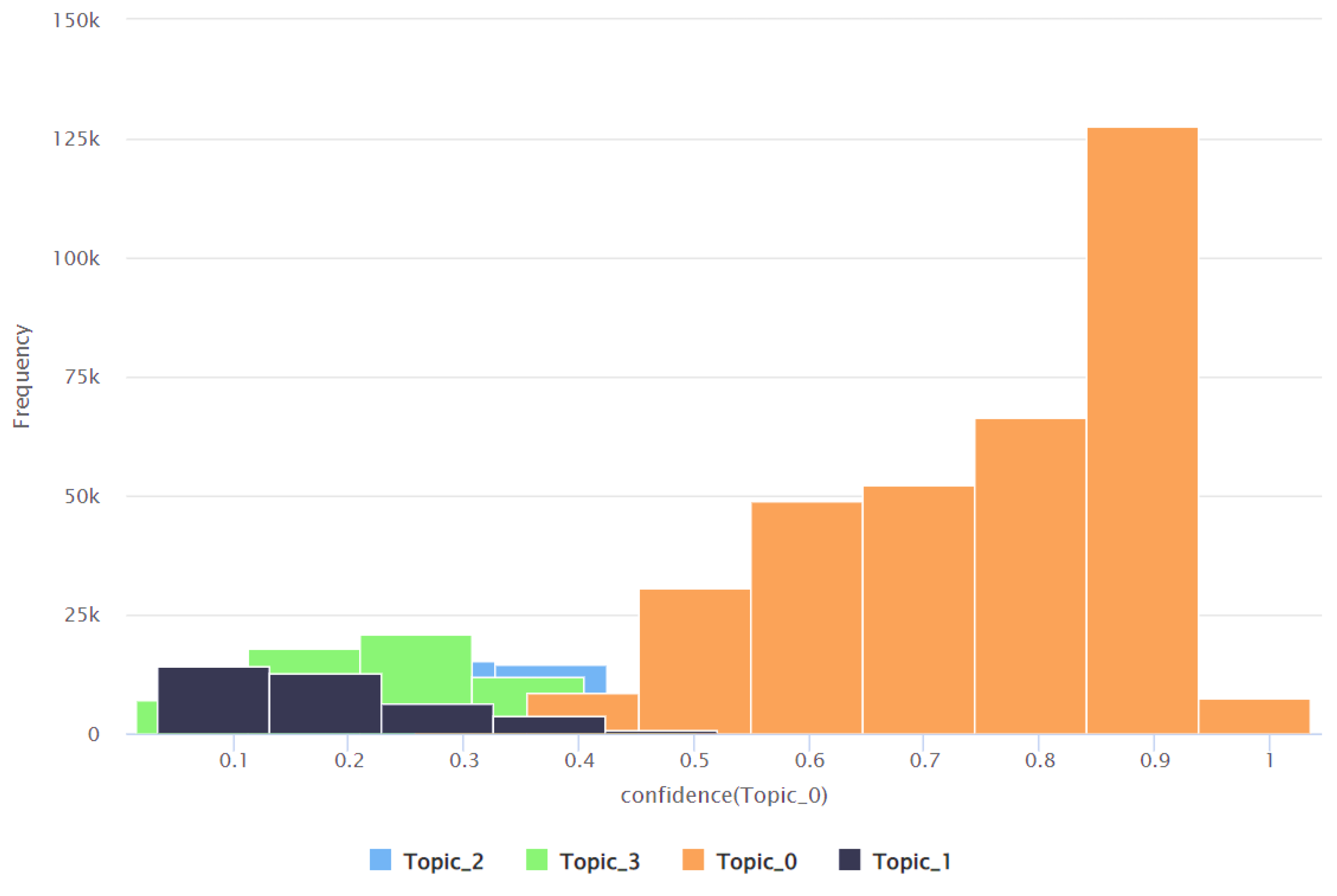
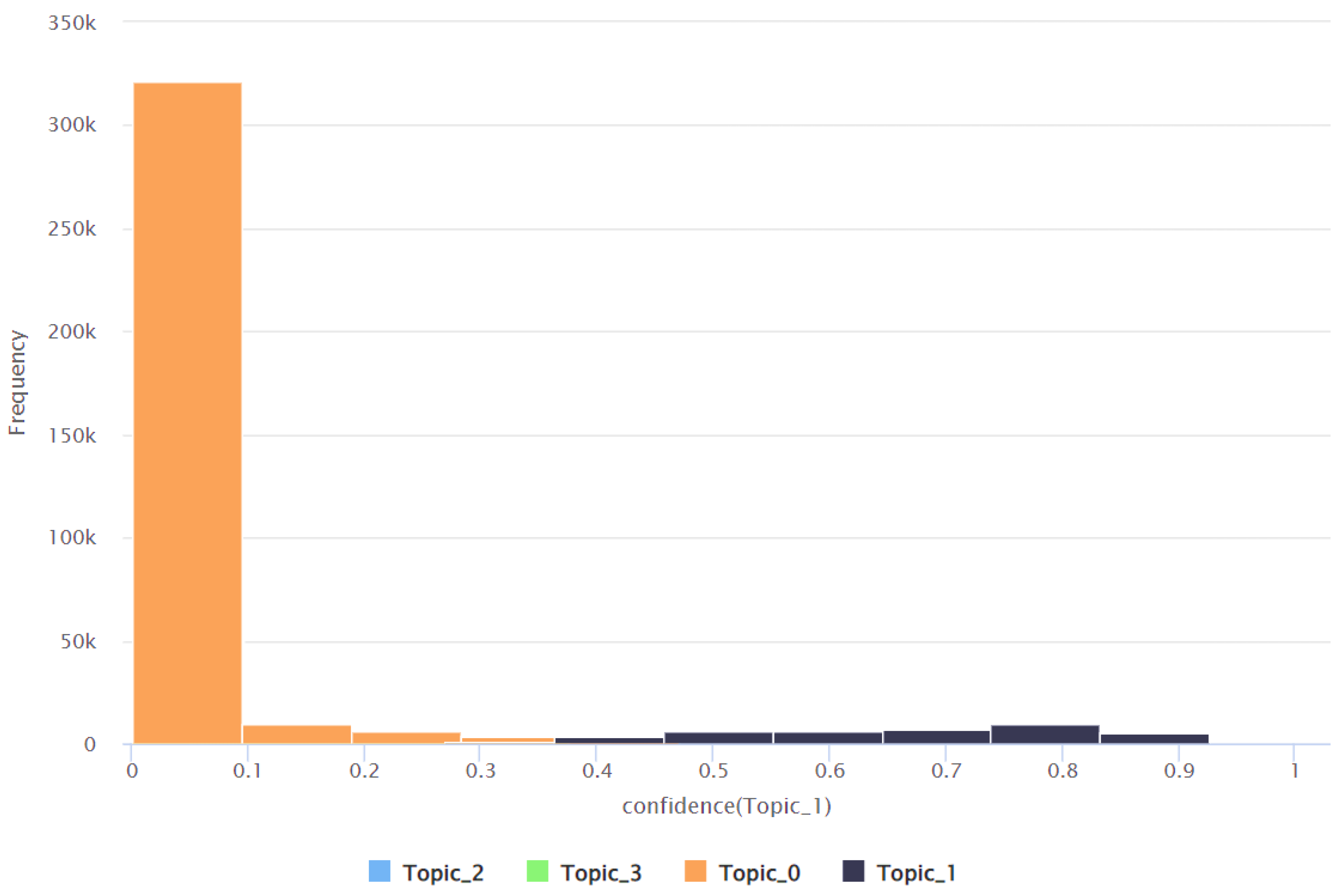
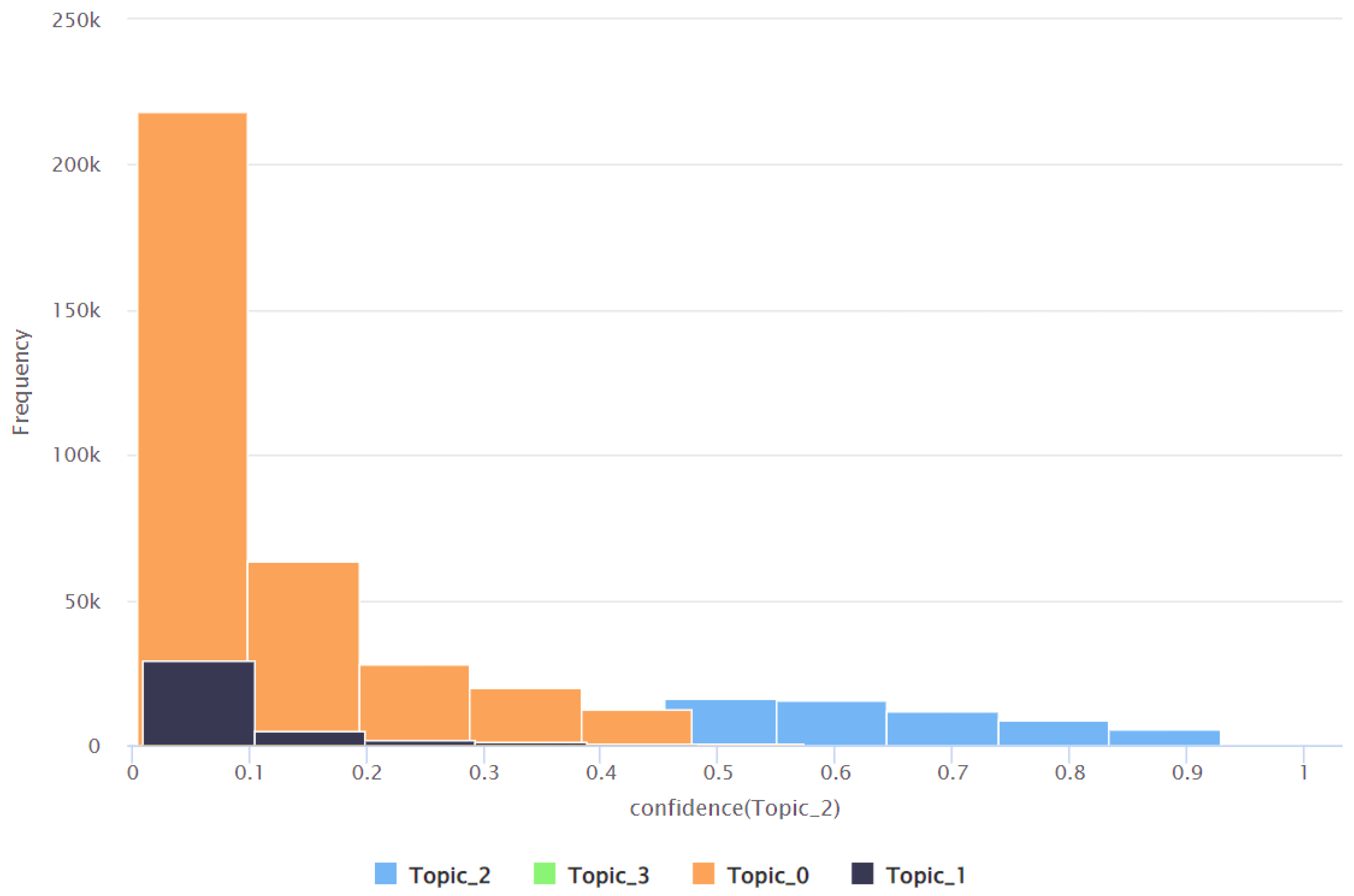
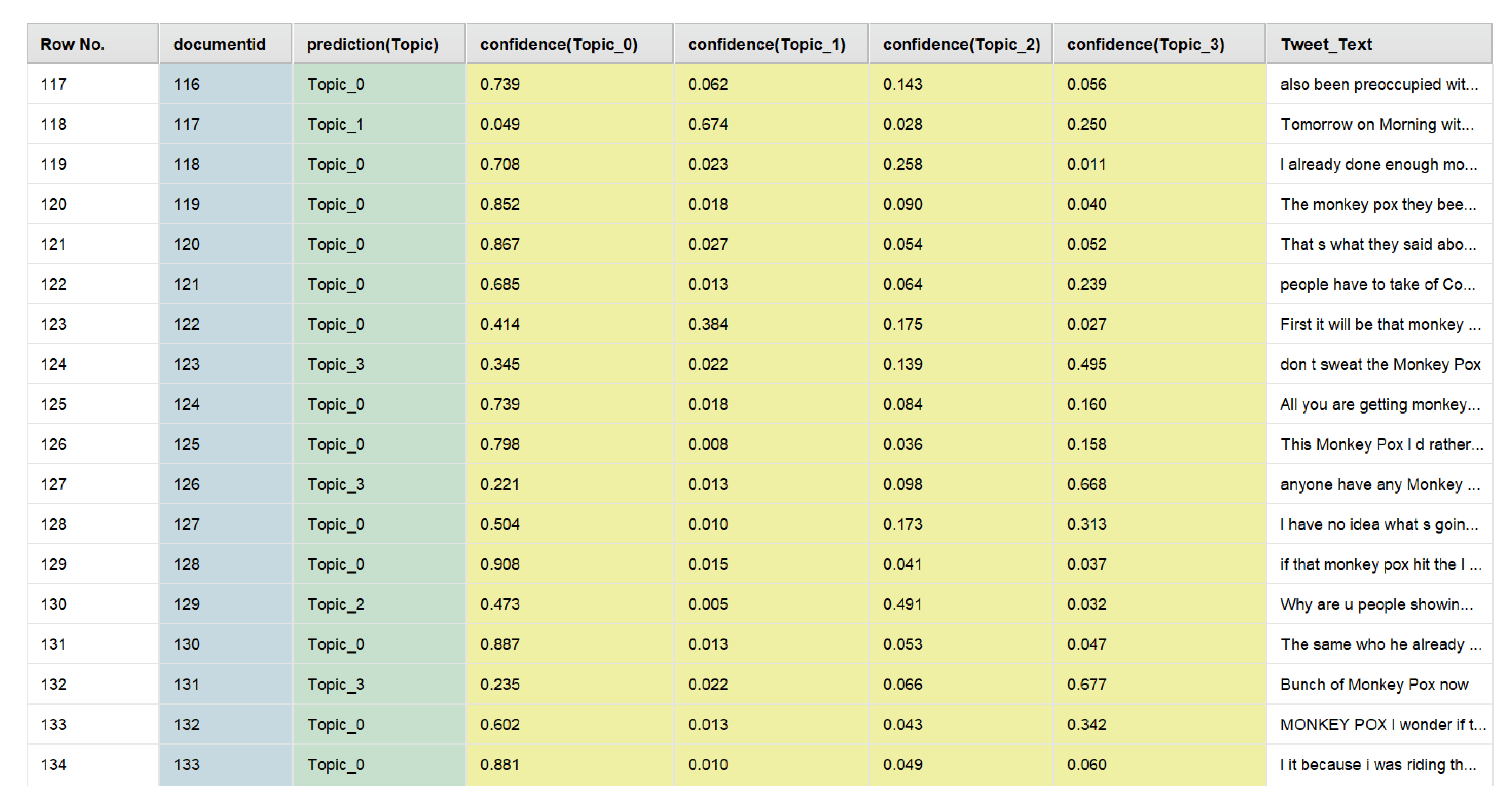
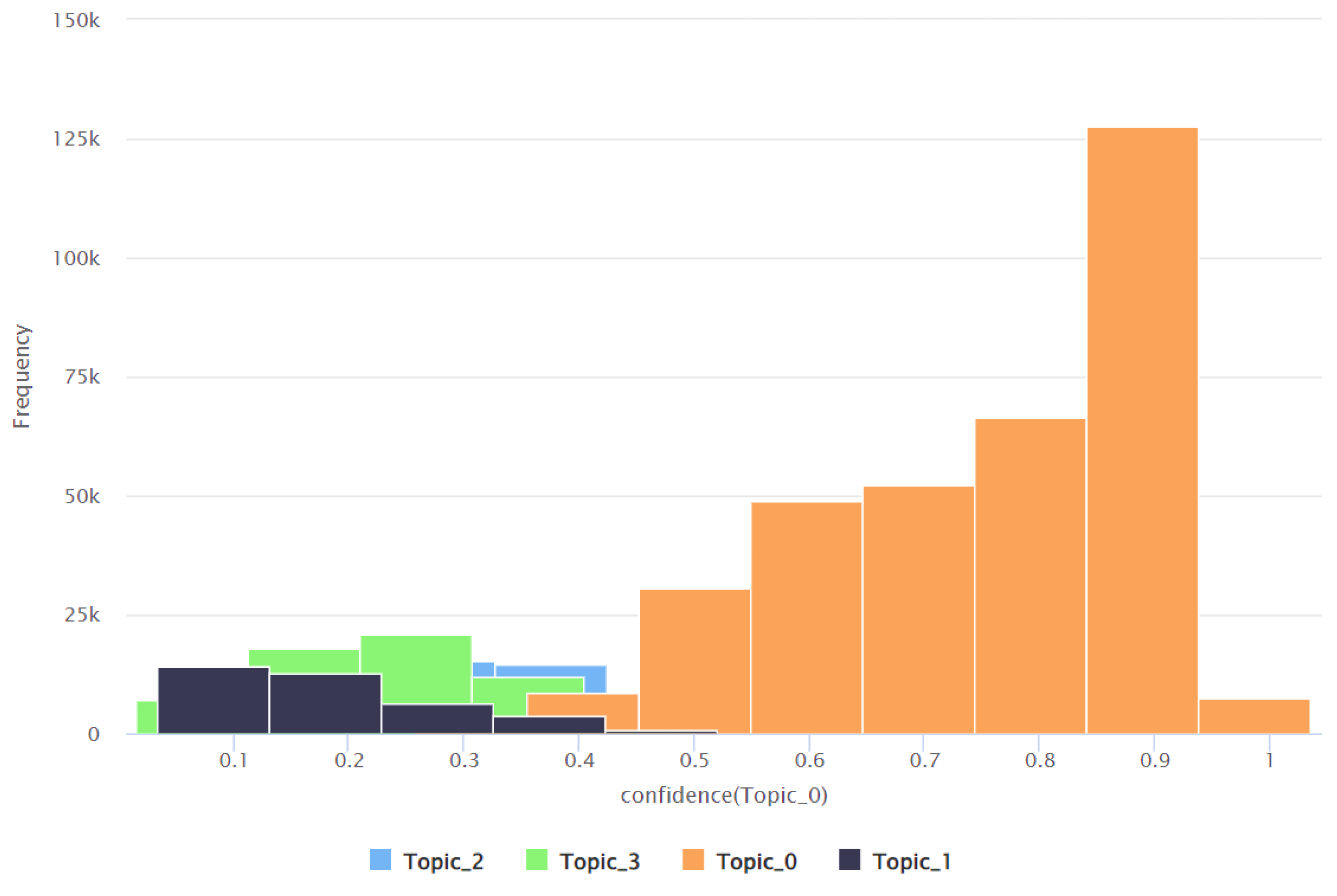
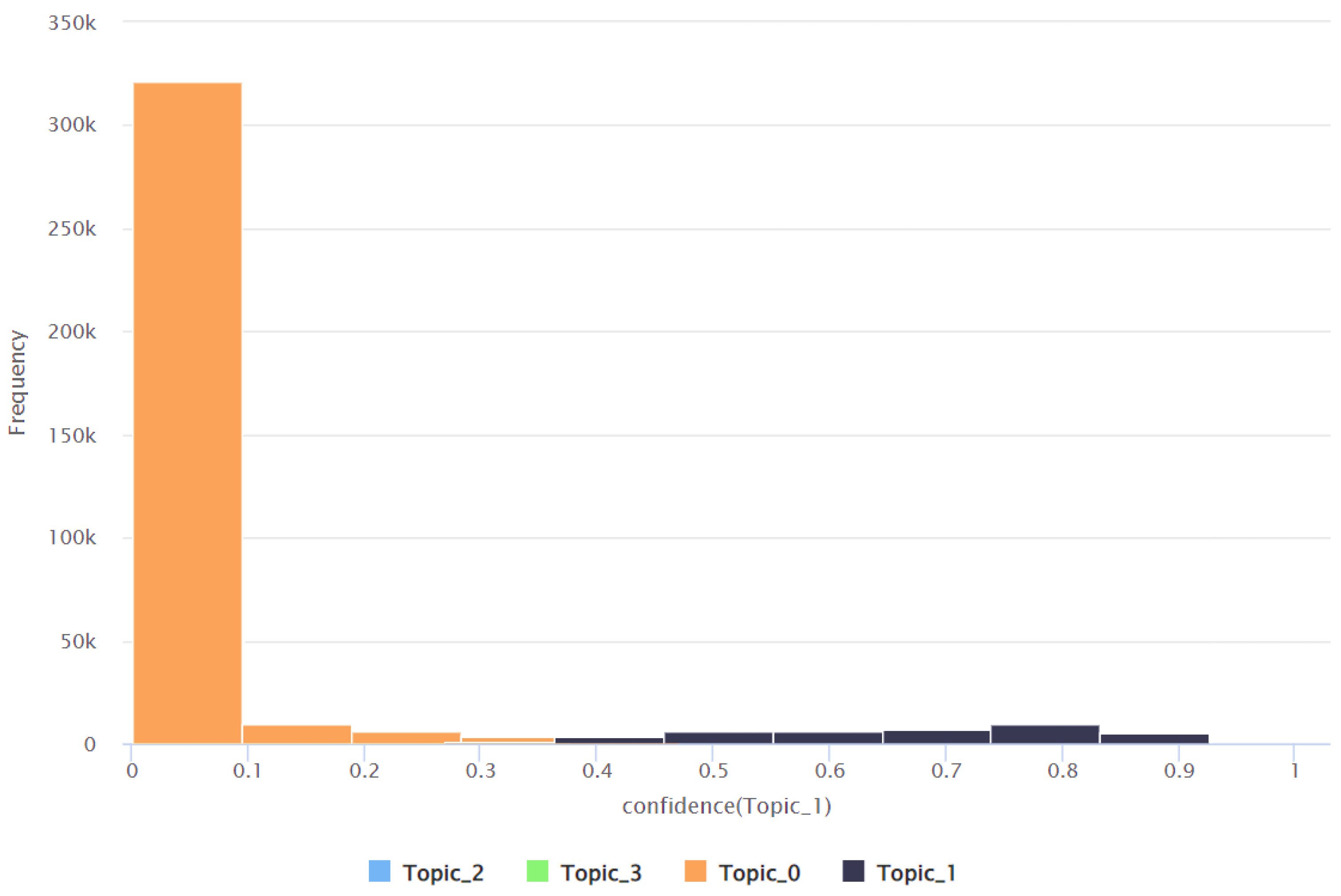
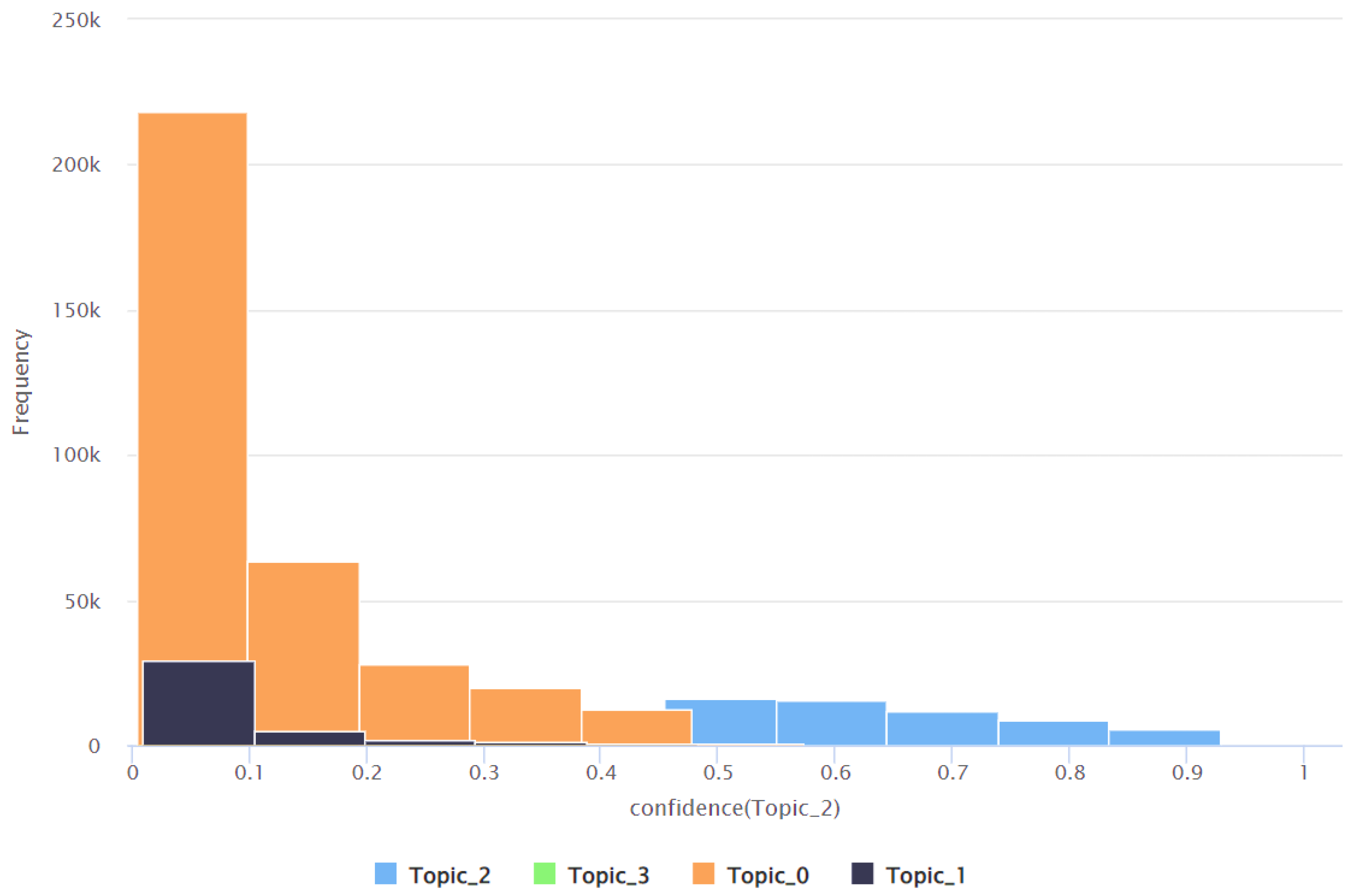
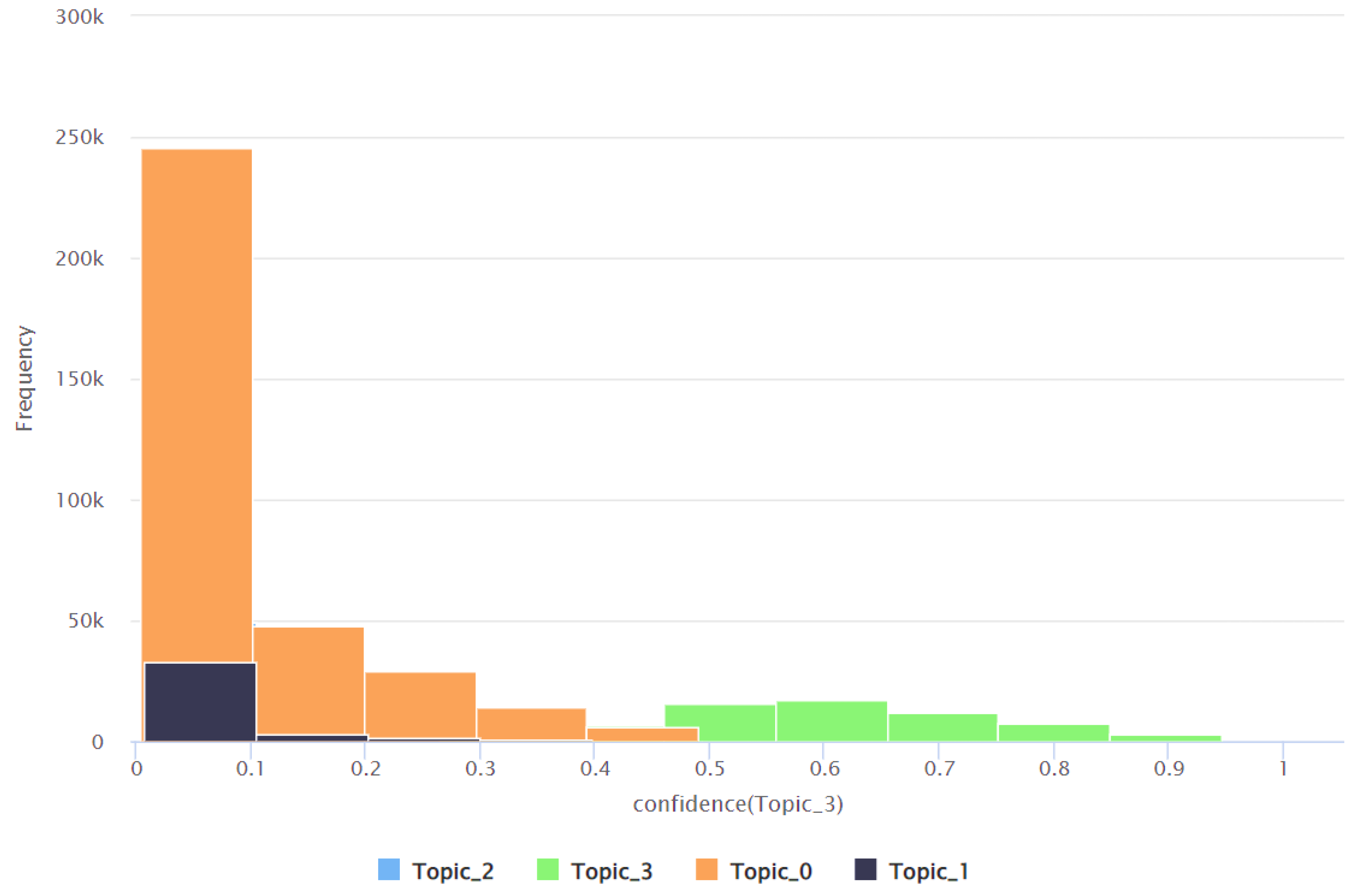
| Topic | Minimum Confidence Value | Maximum Confidence Value | Average Confidence Value | Standard Deviation of the Confidence Value |
|---|---|---|---|---|
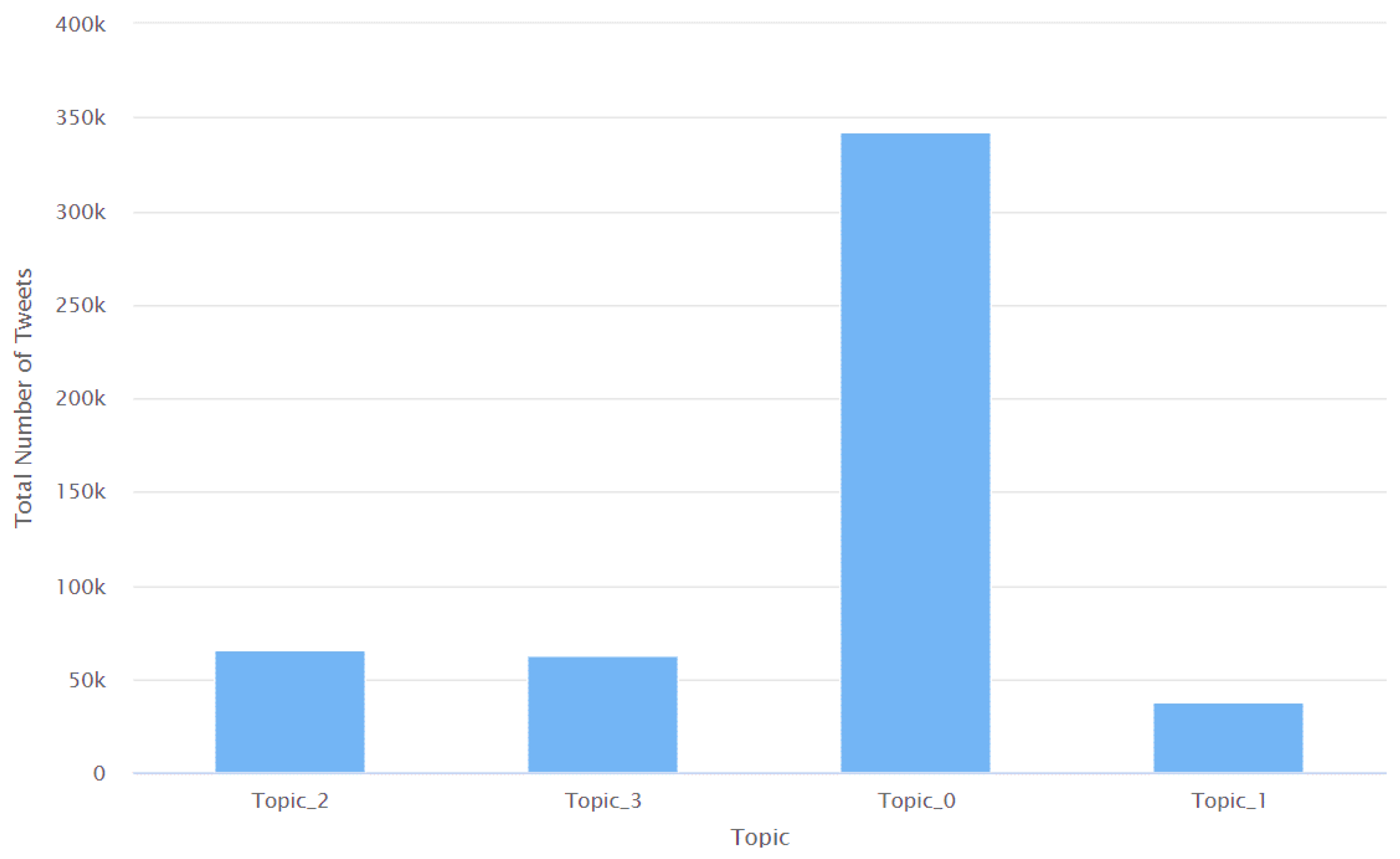
| Topic 0 | 0.016 | 0.989 | 0.584 | 0.280 |
| Topic 1 | 0.002 | 0.940 | 0.083 | 0.180 |
| Topic 2 | 0.005 | 0.951 | 0.179 | 0.200 |
| Topic 3 | 0.005 | 0.978 | 0.154 | 0.200 |
| Tweet # | Original Text of the Tweet |
|---|---|
| Topic 0, Theme: Views and Perspectives about MPox | |
| Tweet #1 | @vancemurphy @pfizer @moderna_tx @US_FDA Well, you know the new thing is monkey pox, right? Vaccines are so yesterday. |
| Tweet #2 | Its annoys me how they use pictures of black peoples hands when they discuss monkey pox |
| Tweet #3 | The pics of monkey pox looks exactly like shingles |
| Tweet #4 | @masthahh1 Are there any stats on the people who have gotten monkey pox? Were they all vaccinated? |
| Tweet #5 | Looking at the state of the UK. I’d be more worried about Monkey Pox catching a dose of Englishman! |
| Topic 1, Theme: Updates on Cases and Investigations about MPox | |
| Tweet #1 | BREAKING: Health department investigating possible monkey pox case in NYC |
| Tweet #2 | New York health officials are investigating a potential case of monkeypox after a patient tested positive for the family of viruses associated with the rare illness. |
| Tweet #3 | U.S. government officials are placing orders for millions of doses of monkeypox vaccines amid a worldwide outbreak and a possible case in New York City, the Independent reports. |
| Tweet #4 | WHO is convening an Emergency Committee meeting out of concern for international spread of monkeypox, a high consequence infection. They will likely discuss whether to declare monkeypox a Public Health Emergency of International Concern (PHEIC) |
| Tweet #5 | The UK Health Security Agency said the new cases of the rare monkeypox infection do not have known connections with the previous confirmed cases announced on 14 May and a case on 7 May |
| Topic 2, Theme: MPox and the LGBTQIA+ Community | |
| Tweet #1 | @CraigbryCraig @BreezerGalway Moneypox has been known about since 1958. Majority of case are in gay males. No need to freak out |
| Tweet #2 | . Gay? Had “close” contact with someone whose in the hospital now in Montreal. Apparently majority in Montreal who contracted the Monkey Pox were gay 35–50 year old men. AIDS started in the gay community too. Something about monkeying around… |
| Tweet #3 | @jmcrookston Just to be SUPER CLEAR, what I mean by this, is that no, monkeypox isn’t a “gay disease”. I’m queer and super not okay with the way the media is framing this the same way HIV/AIDS was framed in the 70s/80s. |
| Tweet #4 | @jeffreyatucker @ezralevant Some knowledge about Monkey pox, it’s mostly for gay. Not a threat. |
| Tweet #5 | @EnemyInAState @TimothyVollmer Absolutely agree only other events won’t have the stigma attached which is happening with monkey pox so many people are convinced it’s a gay disease because there’s no context |
| Topic 3, Theme: MPox and COVID-19 | |
| Tweet #1 | @COVIDnewsfast Transmission of Monkey Pox is not the same as Covid! |
| Tweet #2 | MUST WATCH: Amazing Polly exposes 2021 DAVOS pandemic event for a 15 May 2022 release of Monkey-Pox! BOOM! This Monkey Pox, like COVID, is being exploited to push a global government. Amazing Polly catches them. |
| Tweet #3 | @ANCParliament What are your plans on preventing Monkey Pox that has “accidentally” been released in the United States of America from coming into South Africa before it becomes a big Issue like COVID-19? |
| Tweet #4 | WW3 is on the horizon, COVID-19, and Monkey Pox about to be released into the world we’ll be lucky if any humans survive? Nice work Joe. #LetsGoBrandon |
| Tweet #5 | Monkey Pox is coming! Covid did not do the trick. |
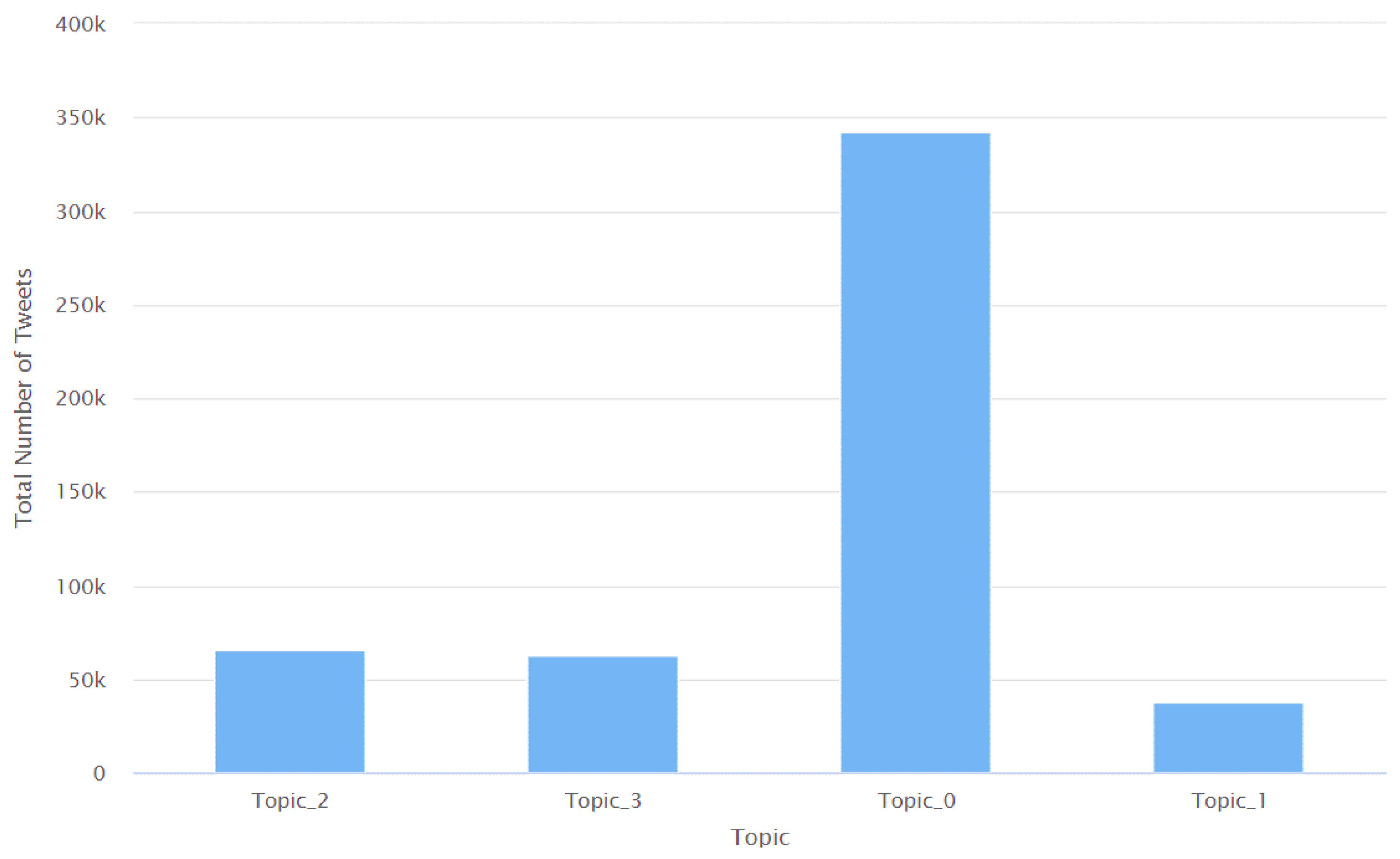
| Topic | Average Coherence | Average Word Length | Exclusivity | Document Entropy | Tokens |
|---|---|---|---|---|---|
| Topic 0 | −5.017 | 4 | 0.925 | 12.707 | 2,146,002 |
| Topic 1 | −2.000 | 7 | 0.972 | 11.084 | 310,322 |
| Topic 2 | −5.730 | 4 | 0.899 | 11.828 | 902,967 |
| Topic 3 | −5.946 | 4.667 | 0.855 | 11.758 | 572,057 |
| Work | Sentiment Analysis | Content Analysis | Topic Modeling | Dataset Development |
|---|---|---|---|---|
| Knudsen et al. [104] | ✓ | |||
| Zuhanda et al. [105] | ✓ | |||
| Ortiz-Martínez et al. [106] | ✓ | |||
| Rahmanian et al. [107] | ✓ | |||
| Cooper et al. [108] | ✓ | ✓ | ||
| Ng et al. [109] | ✓ | |||
| Bengesi et al. [110] | ✓ | |||
| Olusegun et al. [11] | ✓ | |||
| Farahat et al. [112] | ✓ | ✓ | ||
| Sv et al. [113] | ✓ | ✓ | ||
| Mohney et al. [114] | ✓ | |||
| Nia et al. [115] | ✓ | |||
| Iparraguirre-Villanueva [116] | ✓ | |||
| AL-Ahdal [117] | ✓ |
| Work | Number of Tweets Used for Topic Modeling | Time Range of the Tweets |
|---|---|---|
| Ng et al. [109] | 352,182 Tweets | 6 May 2022 to 23 July 2022 |
| Sv et al. [113] | 128,037 Tweets | 1 June 2022 to 25 June 2022 |
| Thakur et al. [this work] | 601,432 Tweets | 7 May 2022 to 3 March 2023 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thakur, N.; Duggal, Y.N.; Liu, Z. Analyzing Public Reactions, Perceptions, and Attitudes during the MPox Outbreak: Findings from Topic Modeling of Tweets. Computers 2023, 12, 191. https://doi.org/10.3390/computers12100191
Thakur N, Duggal YN, Liu Z. Analyzing Public Reactions, Perceptions, and Attitudes during the MPox Outbreak: Findings from Topic Modeling of Tweets. Computers. 2023; 12(10):191. https://doi.org/10.3390/computers12100191
Chicago/Turabian StyleThakur, Nirmalya, Yuvraj Nihal Duggal, and Zihui Liu. 2023. "Analyzing Public Reactions, Perceptions, and Attitudes during the MPox Outbreak: Findings from Topic Modeling of Tweets" Computers 12, no. 10: 191. https://doi.org/10.3390/computers12100191
APA StyleThakur, N., Duggal, Y. N., & Liu, Z. (2023). Analyzing Public Reactions, Perceptions, and Attitudes during the MPox Outbreak: Findings from Topic Modeling of Tweets. Computers, 12(10), 191. https://doi.org/10.3390/computers12100191