
Fine-Grained Cross-Modal Retrieval for Cultural Items with Focal Attention and Hierarchical Encodings


Abstract
:1. Introduction
- Our approach focuses on the fine-grained cross-modal alignment and retrieval of visual and textual fragments, while previous approaches on artwork item retrieval focus on a coarse level of full images and text.
- We propose a novel indicator function on top of the current text-to-image attention function to remove irrelevant image features when computing image–text similarities. This approach significantly improves the retrieval performance for image annotation.
- We encode the inputs of our alignment model with hierarchical encodings to provide both local information and global context to the model during training. This approach enhances the retrieval ability in both the image search and annotation.
- We investigate multiple visual and textual augmentation techniques and determine the one that is most helpful for our task.
- The proposed alignment and retrieval models are compared with three baseline models. Two of them are state-of-art methods adapted to the fine-grained cross-modal retrieval of cultural items. An extensive analysis of our proposed models and the baseline models is given to guide future research.
2. Related Work
3. Datasets
4. Methodology
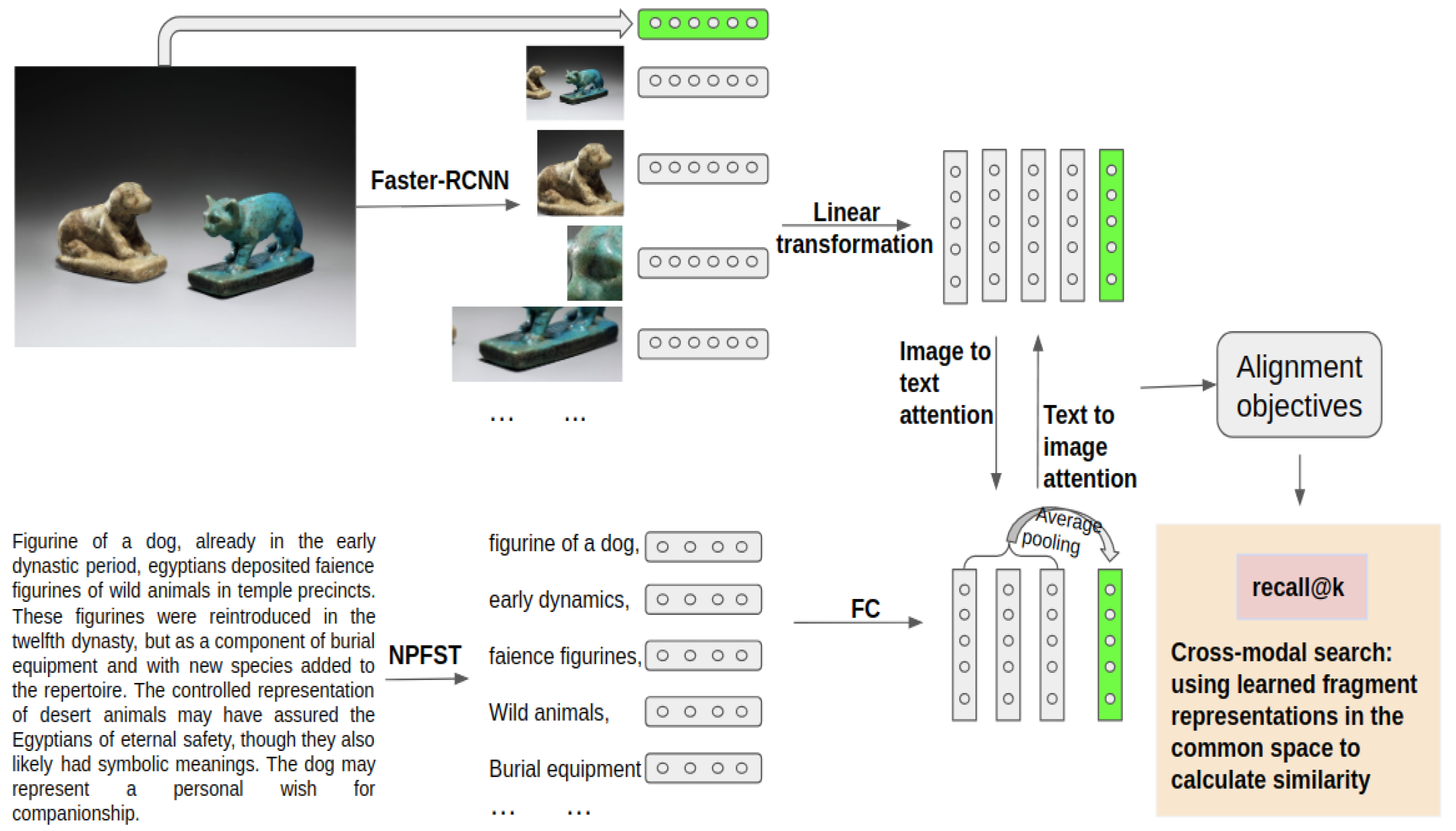
4.1. Image Region Extraction and Representation
4.2. Textual Fragment Extraction and Representation
4.3. Alignment Objectives
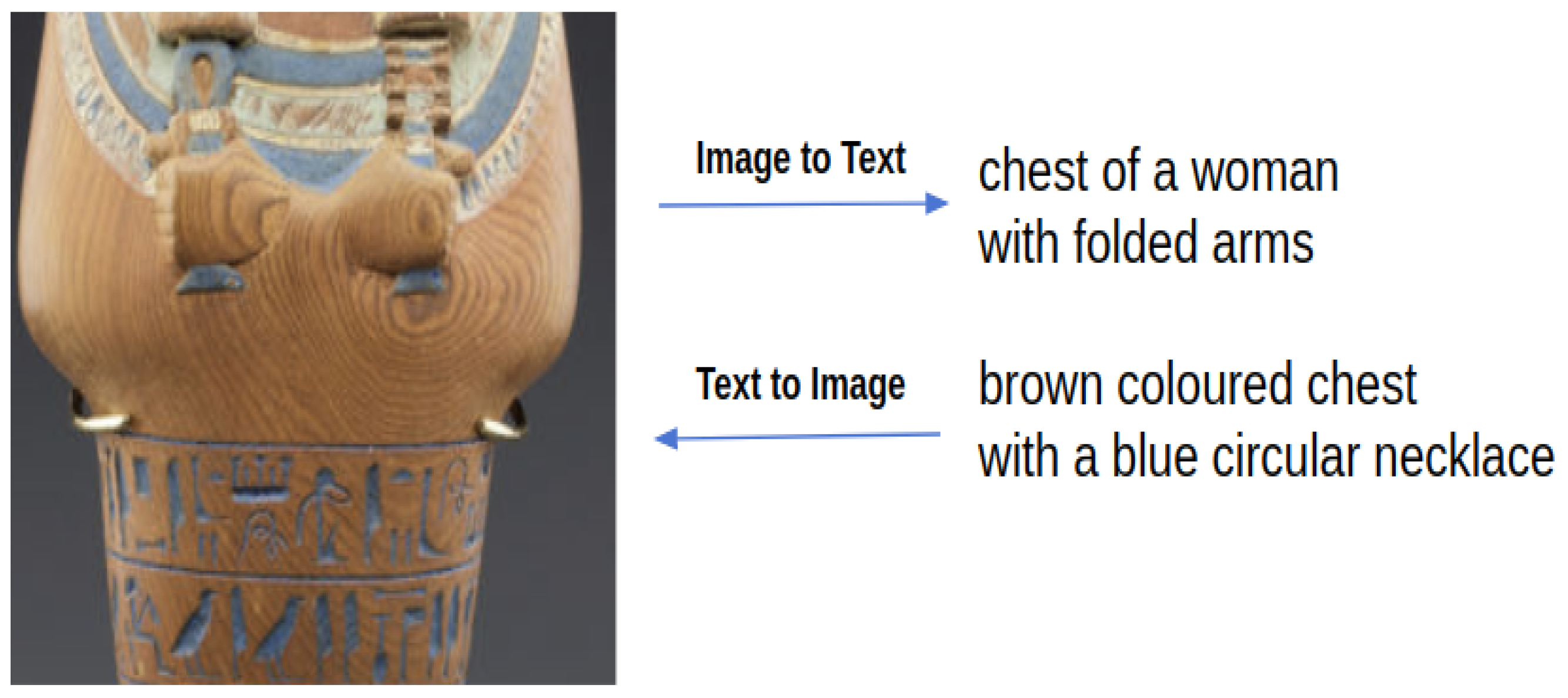
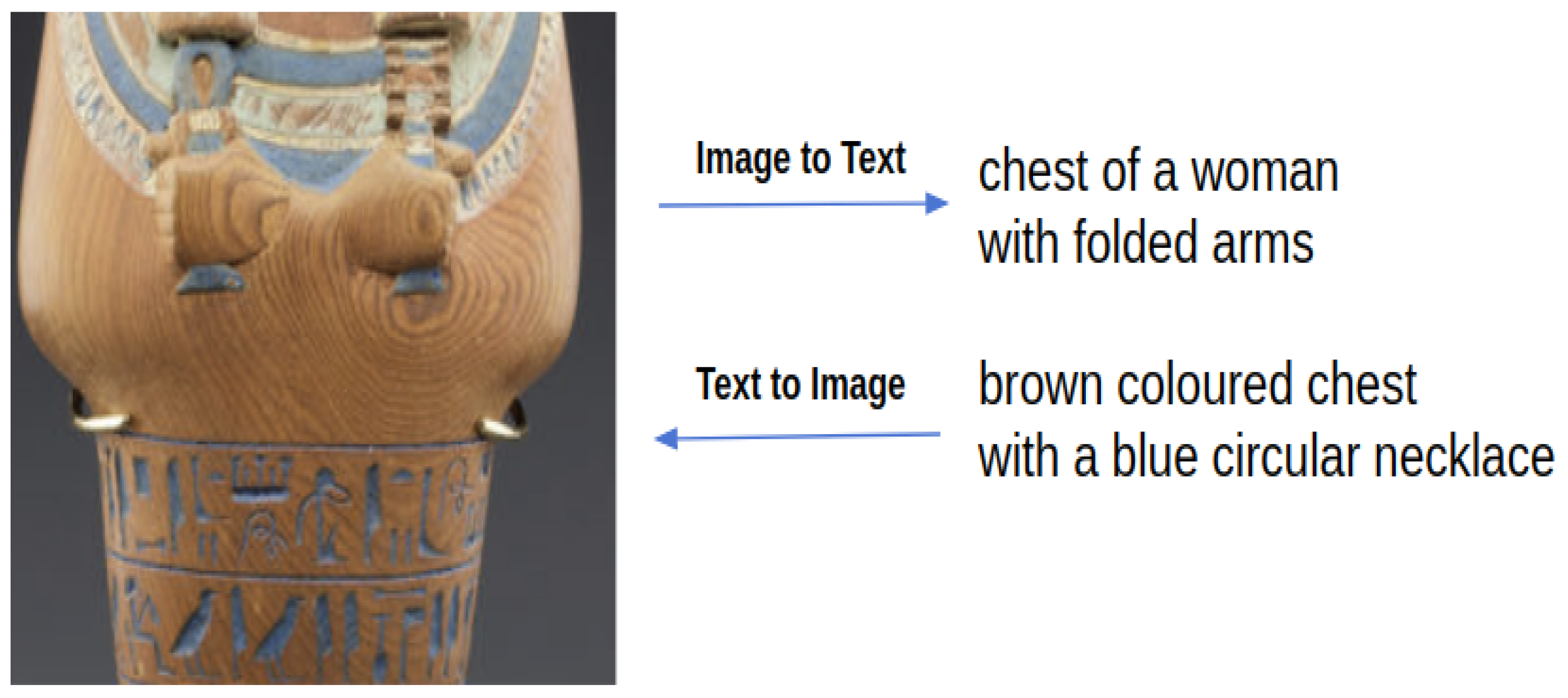
4.3.1. Text-to-Image Attention
- Step one We follow the SCAN model [9] to assign the weights by the approaches expressed in Equations (9) and (10). Equation (9) introduces an adapted softmax function that compares the relevance of text fragment to image fragment with its correlation to all image fragments in the image. This equation is also called the partition function or energy function in some works. Here, is the inversed temperature of the softmax function, and the correlation between and is computed by the approach given in Equation (10), in which is their cosine similarity. It is beneficial to threshold the similarity function score to zero and normalize it with , as described in [9].
- Step two The weights computed in step one consider all image fragments in an image. This is problematic because irrelevant image fragments carrying no information are also incorporated into the computation; these image fragments can mislead the training process and thus decrease the model’s learning performance. Figure 3 gives some examples of image fragments unrelated to any noun phrases. These images either have a uniform color, are very blurred or contain object fragments that are too fine-grained to be expressed. We propose a novel indicator function to remove irrelevant image fragments from the SIFT-based weight computation. Specifically, rather than use SIFT to represent an image fragment as is tradition, we instead use SIFT to build our indicator function according to the number of key points extracted from an image fragment. An image fragment is considered relevant when the number of key points is greater than a threshold z. We define the indicator function for image fragment as in Equation (11). The weight factor obtained from step one is then reassigned by an elementwise product with the indicator function as defined in Equation (12). With this equation, irrelevant regions will not contribute to the representation computation, as their attention score is zero. We call this approach the SIFT filter in the remainder of this paper.
- Step three If application of the SIFT filter is sufficient to remove unrelated image fragments, we simply renormalize the weight obtained from Equation (12) as the final weight for , i.e., . However, if the SIFT filter only removes obviously defective image fragments, we also follow the BFAN model [10] to further clean the image representation computation according to the intramodal similarities between the fragments of an artwork. The intuition behind this idea is that irrelevant fragments always obtain lower importance to the shared semantic meanings than other relevant fragments. The scoring function that evaluates this fragment importance is:where comprises a pairwise function that computes the importance of the target image fragment relative to that of another image fragment for an artwork. is the confidence score for the image fragment being compared. The summation operation compares with all other image fragments for an artwork. We define the pairwise function as and the confidence score as .
4.3.2. Image-to-Text Attention
4.4. Training Parameters and Model Fine-Tuning
4.5. Baseline Alignment Approaches
- (1)
- The DeepFrag [13] model consists of a fragment alignment objective and a global ranking objective. The fragment objective adopts a multiple-instance learning method and encourages that the inner product of and is greater than 1 if they are semantically correlated and below −1 otherwise. The global ranking objective is similar to the loss function introduced in Section 4.3, but it sums over the loss between the image/text and all its negative examples instead of only the most difficult negative one. In addition, it considers the image–text similarity as a normalized sum of its fragment similarities calculated by the inner product, and no attention is involved in the objectives. Please refer to [6] for more details.
- (2)
- The SCAN model [9] is different from our approach in two ways, as mentioned in Section 4.3: (1) It utilizes a single-level representation for both the image and the text in an image–text pair and therefore has one corresponding loss function. (2) For the attention schemes introduced in Section 4.3.1, it employs only step one to calculate text-to-image attention and does not filter out irrelevant image fragments.
- (3)
- The BFAN model [10] does not have global-level representations or a SIFT filter to remove irrelevant image fragments.
4.6. Cross-Modal Search
5. Experimental Set-Up
6. Results and Discussion
6.1. Quantitative Results
6.1.1. Image Annotation
- (1)
- Comparison of the use of different variants as textual fragment data. Table 6 shows the results achieved by the BFAN_SF (ens) model when different textual formats are used as training data. The performances obtained for the ‘tokens’ and ‘nouns’ variants are very poor. We assume this is the result of the large syntactic gap between the training and test data.
- (2)
- Efficiency of using attention. The results obtained by the model DeepFrag using no attention are lower than all other models with attention to both datasets, as shown in Table 4. This proves the power of the attention schemes in calculating fragment importance. The improvements in recall@1 for the Chinese and Egyptian alignment datasets are 4.1% and 2.1%, respectively.
- (3)
- Effect of the SIFT filter. We check the effect of the SIFT filter by comparing the results obtained by model SCAN_SF (t2i) and the baseline models conducted with the same settings except for the SIFT filter in Table 7. These results show that the SCAN_SF (t2i) model yields better performance on most evaluation metrics for the image annotation task on both datasets. Compared with the best SCAN baseline model (t2i), the SIFT-enhanced model gains 1.2% improvement for the Chinese art alignment dataset and competitive results for the Egyptian art alignment dataset in terms of recall@1. This improvement is more distinct for recall@10, with the largest achievement gain of 2.9% for the Egyptian art alignment dataset. The baseline BFAN (t2i) model also removes irrelevant image fragments in the text-to-image attention mechanism but in a different way, i.e., based on intramodal similarity. It does not have improved performance over SCAN (t2i) but does decrease the recall scores in all rank cut-offs. This implies the difficulty in pursuing a performance increase by filtering out irrelevant image fragments and verifies the excellence of our SIFT filter approach. However, when we combine model SCAN_SF (t2i) and model SCAN (i2t) into the ensemble model SCAN_SF (ens), the advantage of using the SIFT filter approach over the SCAN (ens) approach disappears, as we can see from Table 4. This phenomenon suggests that using a weighted sum for multiple loss functions as expressed in Equation (7) is not optimal when using a fixed weight value for a certain loss. It is very rigid because the weight is the same for all the batches/training samples. However, finding appropriate custom weights for a certain loss with respect to different batches/training samples is very challenging. The SIFT filter also helps when we combine it with the BFAN model, as shown by a comparison of the results obtained by models BFAN_SF (ens) and BFAN (ens) in Table 4.
- (4)
- Effect of the global representation approach. We can compare the models with and without GB in their model names in Table 4 to see the effect of utilizing global image and text representations: model SCAN_GB (ens) versus model SCAN (ens), model SCAN_SF_GB (ens) versus model SCAN_SF (ens), and model BFAN_SF_GB (ens) versus model BFAN_SF (ens). The conclusion for this comparison is that the global representation approach yields performance improvements either on recall@1 or on all evaluation metrics for the Chinese art alignment dataset. However, this is not true for the Egyptian art alignment dataset, probably because the annotation data for Egyptian artwork images are not as good as those of the Chinese artwork images and therefore adding context information using the global representation method could introduce noise into the alignment.
- (5)
- Effect of augmenting the data. Among all the data augmentation approaches we attempted, the image annotation performance was improved only by adding synthetic relevant textual data, i.e., using the textual data extracted from NPFST. This conclusion is derived from the fact that the model using textual fragments obtained from NPFST performs better than that using the longest phrase that represents a cluster of similar phrases obtained with NPFST (see Table 8). Visual augmentation did not improve performance, likely because the augmented fragments did not align with the text any more and thus mislead the training of our model.
6.1.2. Image Search
6.2. Qualitative Results
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Baraldi, L.; Cornia, M.; Grana, C.; Cucchiara, R. Aligning text and document illustrations: Towards visually explainable digital humanities. In Proceedings of the 24th International Conference on Pattern Recognition, Beijing, China, 20–24 August 2018; pp. 1097–1102. [Google Scholar]
- Carraggi, A.; Cornia, M.; Baraldi, L.; Cucchiara, R. Visual-Semantic Alignment Across Domains Using a Semi-Supervised Approach. In Proceedings of the European Conference on Computer Vision Workshops, Munich, Germany, 8–14 September 2018; pp. 625–640. [Google Scholar]
- Cornia, M.; Stefanini, M.; Baraldi, L.; Corsini, M.; Cucchiara, R. Explaining digital humanities by aligning images and textual descriptions. Pattern Recognit. Lett. 2020, 129, 166–172. [Google Scholar] [CrossRef]
- Garcia, N.; Vogiatzis, G. How to read paintings: Semantic art understanding with multi-modal retrieval. In Proceedings of the European Conference in Computer Vision Workshops, Munich, Germany, 8–14 September 2018; pp. 676–691. [Google Scholar]
- Stefanini, M.; Cornia, M.; Baraldi, L.; Corsini, M.; Cucchiara, R. Artpedia: A new visual-semantic dataset with visual and contextual sentences in the artistic domain. In Proceedings of the International Conference on Image Analysis and Processing, Trento, Italy, 9–13 September 2019; pp. 729–740. [Google Scholar]
- Karpathy, A.; Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Zhen, L.; Hu, P.; Wang, X.; Peng, D. Deep supervised cross-modal retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10394–10403. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual Genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef] [Green Version]
- Lee, K.H.; Chen, X.; Hua, G.; Hu, H.; He, X. Stacked cross attention for image–text matching. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 201–216. [Google Scholar]
- Liu, C.; Mao, Z.; Liu, A.A.; Zhang, T.; Wang, B.; Zhang, Y. Focus Your Attention: A Bidirectional Focal Attention Network for image–text Matching. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 3–11. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Young, P.; Lai, A.; Hodosh, M.; Hockenmaier, J. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Trans. Assoc. Comput. Linguist. 2014, 2, 67–78. [Google Scholar] [CrossRef]
- Karpathy, A.; Joulin, A.; Fei-Fei, L.F. Deep fragment embeddings for bidirectional image sentence mapping. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 8–13 December 2014; pp. 1889–1897. [Google Scholar]
- Lu, J.; Yang, J.; Batra, D.; Parikh, D. Hierarchical Question-Image Co-Attention for Visual Question Answering. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 289–297. [Google Scholar]
- Sheng, S.; Moens, M.F. Generating captions for images of ancient artworks. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 7–12 December 2015; pp. 91–99. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar]
- Handler, A.; Denny, M.; Wallach, H.; O’Connor, B. Bag of what? simple noun phrase extraction for text analysis. In Proceedings of the First Workshop on NLP and Computational Social Science, Austin, TX, USA, 1–5 November 2016; pp. 114–124. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Lodhi, H.; Saunders, C.; Shawe-Taylor, J.; Cristianini, N.; Watkins, C. Text classification using string kernels. J. Mach. Learn. Res. 2002, 2, 419–444. [Google Scholar]
- Ketkar, N. Introduction to pytorch. In Deep Learning with Python; Apress: New York, NY, USA, 2017; pp. 195–208. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Cuevas, A.; Febrero, M.; Fraiman, R. An anova test for functional data. Comput. Stat. Data Anal. 2004, 47, 111–122. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Ruder, S. An overview of multi-task learning in deep neural networks. arXiv 2017, arXiv:1706.05098. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Split | Num.atks | Num.frags | Num.phrs | Num.tks | Num.nns |
|---|---|---|---|---|---|
| Chinese art alignment dataset | |||||
| Train | 6086 | 6086 × 10 | 43,212 | 8592 | 4765 |
| Val | 761 | 761 × 10 | 7095 | 2855 | 1555 |
| Golden | 500 | 1134 | 2234 | - | - |
| Egyptian art alignment dataset | |||||
| Train | 14,352 | 14,352 × 10 | 60,805 | 13,420 | 7598 |
| Val | 1795 | 1795 × 10 | 11,105 | 5246 | 2890 |
| Golden | 536 | 1225 | 2724 | - | - |
| Variants | Aver.frq | Aver.snt.len | Std.snt.len | Frq ≥ 10 | Frq ≥ 5 |
|---|---|---|---|---|---|
| Chinese art alignment dataset | |||||
| Phrases | 1.9 | 13.2 | 13.7 | 1.6% | 3.9% |
| Tokens | 13.1 | 18.5 | 17.0 | 15.8% | 26.2% |
| Nouns | 11.2 | 8.7 | 7.0 | 14.6% | 25.1% |
| Egyptian art alignment dataset | |||||
| Phrases | 2.1 | 8.7 | 15.1 | 2.2% | 6.6% |
| Tokens | 14.2 | 13.3 | 23.8 | 21.5% | 33.8% |
| Nouns | 12.1 | 6.4 | 9.8 | 19.5% | 31.9% |
| Dimension of the visual input space | |
| h | Dimension of the common space |
| Dimension of the textual input space | |
| Vector representation of a textual fragment | |
| A matrix of n textual fragment vector representations | |
| Vector representation of a textual fragment in the common space | |
| Attended vector representation of a textual fragment | |
| Vector representation of a textual fragment unit in the common space | |
| A matrix of n textual embeddings in the common space | |
| Vector representation of an artwork image fragment | |
| A matrix of m image fragment vector representations | |
| Vector representation of a full artwork image | |
| Vector representation of an artwork image fragment in the common space | |
| Attended vector representation of an artwork image fragment | |
| Vector representation of a full artwork image in the common space | |
| A matrix of m image embeddings in the common space | |
| A weight matrix that projects a visual input vector to the common space | |
| A weight matrix that projects a textual input vector to the common space |
| Model | Image Annotation | Image Search | ||||
|---|---|---|---|---|---|---|
| r@1 | r@5 | r@10 | r@1 | r@5 | r@10 | |
| Chinese art alignment dataset | ||||||
| DeepFrag [13] | 5.0 | 23.1 | 36.2 | 6.0 | 20.3 | 34.0 |
| SCAN [9] (ens) | 6.8 | 28.0 | 41.4 | 8.6 | 29.2 | 43.5 |
| BFAN [10] (ens) | 7.5 | 26.6 | 43.3 | 7.2 | 23.9 | 38.5 |
| SCAN_SF (ens) | 7.0 | 24.1 | 38.2 | 8.1 | 28.2 | 43.6 |
| SCAN_GB (ens) | 7.4 | 26.7 | 41.7 | 8.9 | 29.6 | 44.2 |
| SCAN_SF_GB (ens) | 8.3 | 28.4 | 45.1 | 8.1 | 26.7 | 41.4 |
| BFAN_SF (ens) | 9.1 | 31.0 | 47.8 | 7.6 | 27.8 | 43.0 |
| BFAN_SF_GB (ens) | 9.0 | 31.7 | 49.0 | 8.6 | 27.3 | 42.7 |
| Egyptian art alignment dataset | ||||||
| DeepFrag [13] | 5.2 | 16.6 | 29.0 | 3.6 | 13.2 | 22.0 |
| SCAN [9] (ens) | 5.0 | 18.2 | 30.5 | 6.1 | 21.2 | 33.7 |
| BFAN [10] (ens) | 5.4 | 20.5 | 33.7 | 5.4 | 19.2 | 30.7 |
| SCAN_SF (ens) | 5.2 | 18.2 | 30.5 | 6.3 | 21.5 | 32.9 |
| SCAN_GB (ens) | 5.2 | 17.9 | 30.2 | 6.4 | 21.8 | 33.7 |
| SCAN_SF_GB (ens) | 4.8 | 18.3 | 31.1 | 6.0 | 20.6 | 33.1 |
| BFAN_SF (ens) | 7.3 | 25.1 | 39.6 | 6.2 | 21.3 | 33.2 |
| BFAN_SF_GB (ens) | 5.4 | 20.6 | 34.6 | 5.2 | 19.3 | 30.9 |
| Model Comparison | Image Annotation | Image Search | ||||
|---|---|---|---|---|---|---|
| Chinese art dataset | BFAN vs. BFAN_SF_GB | SCAN vs. SCAN_GB | ||||
| 0.70 | 0.06 | 0.07 | 0.74 | 0.19 | 0.03 | |
| Egyptian art dataset | BFAN vs. BFAN_SF | SCAN vs. SCAN_GB | ||||
| 0.89 | 0.63 | 0.35 | 0.39 | 0.37 | 0.85 | |
| Variants | Image Annotation | Image Search | ||||
|---|---|---|---|---|---|---|
| r@1 | r@5 | r@10 | r@1 | r@5 | r@10 | |
| Tokens | 0.3 | 1.7 | 2.7 | 0.3 | 1.8 | 3.5 |
| Nouns | 0.5 | 2.4 | 3.5 | 0.4 | 1.7 | 3.4 |
| Phrases | 9.1 | 31.0 | 47.8 | 7.6 | 27.8 | 43.0 |
| Model | Image Annotation | Image Search | ||||
|---|---|---|---|---|---|---|
| r@1 | r@5 | r@10 | r@1 | r@5 | r@10 | |
| Chinese art alignment dataset | ||||||
| SCAN [9] (t2i) | 6.0 | 24.6 | 41.2 | 6.9 | 25.0 | 38.4 |
| BFAN [10] (t2i) | 4.6 | 17.6 | 28.4 | 4.5 | 17.0 | 27.4 |
| SCAN_SF (t2i) | 7.2 | 25.2 | 40.1 | 8.1 | 28.5 | 43.2 |
| Egyptian art alignment dataset | ||||||
| SCAN [9] (t2i) | 5.0 | 19.2 | 30.4 | 5.6 | 20.1 | 32.1 |
| BFAN [10] (t2i) | 3.1 | 13.4 | 20.8 | 3.0 | 11.3 | 18.9 |
| SCAN_SF (t2i) | 5.0 | 20.1 | 33.3 | 6.0 | 19.6 | 32.3 |
| Text Data | Image Annotation | Image Search | ||||
|---|---|---|---|---|---|---|
| r@1 | r@5 | r@10 | r@1 | r@5 | r@10 | |
| Longest | 8.6 | 27.5 | 44.1 | 7.6 | 24.7 | 38.7 |
| NPFST | 9.1 | 31.0 | 47.8 | 7.6 | 27.8 | 43.0 |
| Model | Image Annotation | Image Search | ||||
|---|---|---|---|---|---|---|
| r@1 | r@5 | r@10 | r@1 | r@5 | r@10 | |
| Chinese Art Alignment Dataset | ||||||
| SCAN [9] (i2t) | 6.9 | 23.4 | 37.2 | 8.5 | 26.2 | 40.6 |
| BFAN [10] (i2t) | 7.1 | 25.4 | 39.5 | 6.8 | 23.6 | 37.0 |
| Egyptian art alignment dataset | ||||||
| SCAN [9] (i2t) | 6.1 | 20.9 | 33.6 | 5.7 | 18.7 | 27.1 |
| BFAN [10] (i2t) | 5.1 | 18.8 | 31.2 | 4.5 | 17.1 | 27.2 |
| BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 |
|---|---|---|---|
| Chinese art alignment dataset | |||
| 40.1 | 21.1 | 12.9 | 10.4 |
| Egyptian art alignment dataset | |||
| 37.1 | 18.9 | 11.1 | 8.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sheng, S.; Laenen, K.; Van Gool, L.; Moens, M.-F. Fine-Grained Cross-Modal Retrieval for Cultural Items with Focal Attention and Hierarchical Encodings. Computers 2021, 10, 105. https://doi.org/10.3390/computers10090105
Sheng S, Laenen K, Van Gool L, Moens M-F. Fine-Grained Cross-Modal Retrieval for Cultural Items with Focal Attention and Hierarchical Encodings. Computers. 2021; 10(9):105. https://doi.org/10.3390/computers10090105
Chicago/Turabian StyleSheng, Shurong, Katrien Laenen, Luc Van Gool, and Marie-Francine Moens. 2021. "Fine-Grained Cross-Modal Retrieval for Cultural Items with Focal Attention and Hierarchical Encodings" Computers 10, no. 9: 105. https://doi.org/10.3390/computers10090105
APA StyleSheng, S., Laenen, K., Van Gool, L., & Moens, M.-F. (2021). Fine-Grained Cross-Modal Retrieval for Cultural Items with Focal Attention and Hierarchical Encodings. Computers, 10(9), 105. https://doi.org/10.3390/computers10090105