
Latency Estimation Tool and Investigation of Neural Networks Inference on Mobile GPU


Abstract
:1. Introduction
- LETI Tool, which allows:
- -
- To generate TF.Keras models from parametrization, with parametrization same as in NAS-Benchmark-101.
- -
- To evaluate TF.Keras model on CUDA devices.
- -
- To convert to TFLite using TF converter and evaluate on Android device.
- -
- To encapsulate latency evaluation on device as black-box for direct optimization (e.g., with Nevergrad [22]).
- Evaluation of lookup table for several popular neural networks on a mobile CPU and providing an tool for such estimation.
2. Materials and Methods
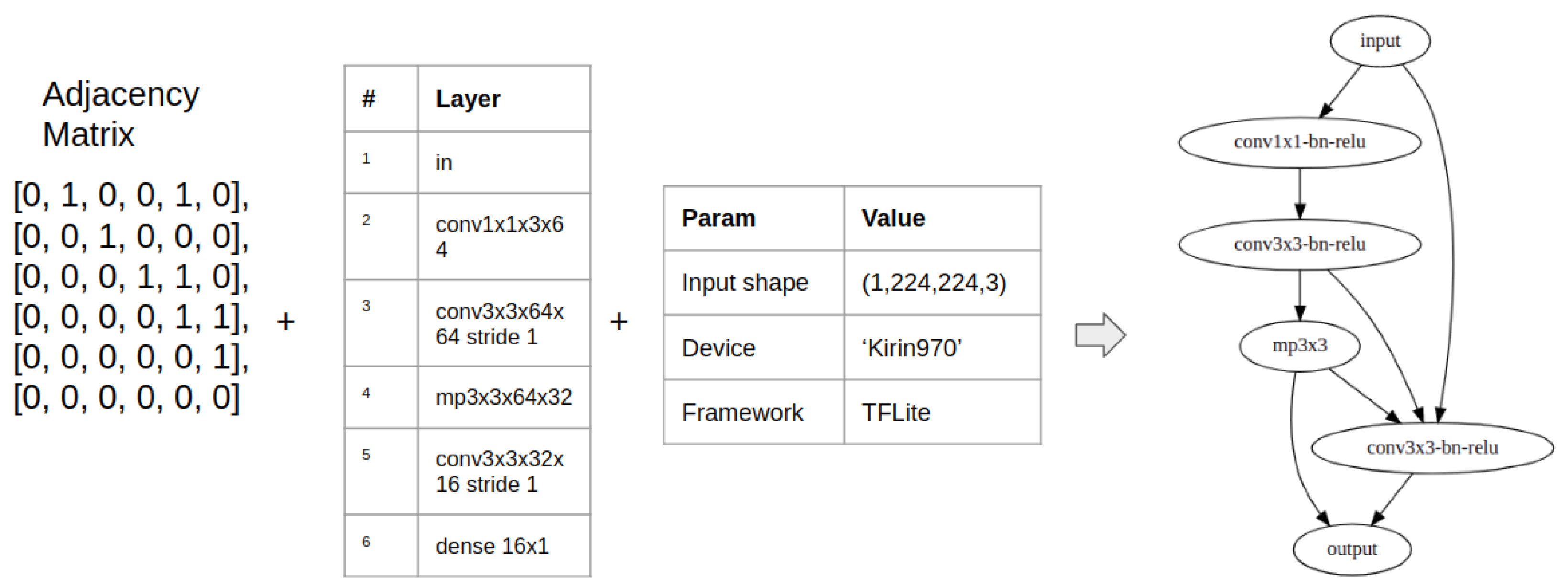
2.1. Neural Network Parametrization
2.2. Latency Dataset Generation Pipeline
- Firstly, we generate the set of parametrized architectures as in NAS-Benchmark. We verify uniqueness by the same hashing procedure as in Reference [10]. Thus, it is additional proof of the same parametrization and set of models. For NAS-Benchmark configuration at this step, we obtain 423,624 parametrized models/graphs with: max 7 vertices, max 9 edges with 3 possible layer values (except input and output): [‘conv3x3-bn-relu’, ‘conv1x1-bn-relu’, ‘maxpool3x3’].
- Next, we generate TF.Keras models. The tool is able to generate both only the basic block that is represented by the parametrization or the stacked models built from such blocks as in the NAS-Bench-101.
- Then, we build models for the specified input shape and convert it into TensorFlow Lite representation.
- After, we optionally evaluate the latency of TF.keras models on desktop/server GPU nodes. In our work, we run the model for times with guaranteed condition on standard deviation: .
- Finally, we evaluate the latency of TFLite models on the CPU, GPU, or NPU of the Android devices. In work, we evaluate only models which are fully delegated to GPU for TFLite Some operations are not supported for delegation by the framework, such as SLICE. See operations descriptions at: https://www.tensorflow.org/lite/guide/ops_compatibility (accessed on 19 August 2021). Part of the models use the addition of more than two intermediate layers, that ADD_N operation in TFLite, that is also unsupported by GPU. We substitute that operation with multiply ADD operation (addition of two tensors can be delegated for mobile GPU).

3. Results
3.1. Discussion about Choosing Implementation and Deploying on Mobile Devices
3.2. TensorFlow Lite Dataset
4. Latency Modeling
4.1. Lookup Table on Mobile CPU and GPU
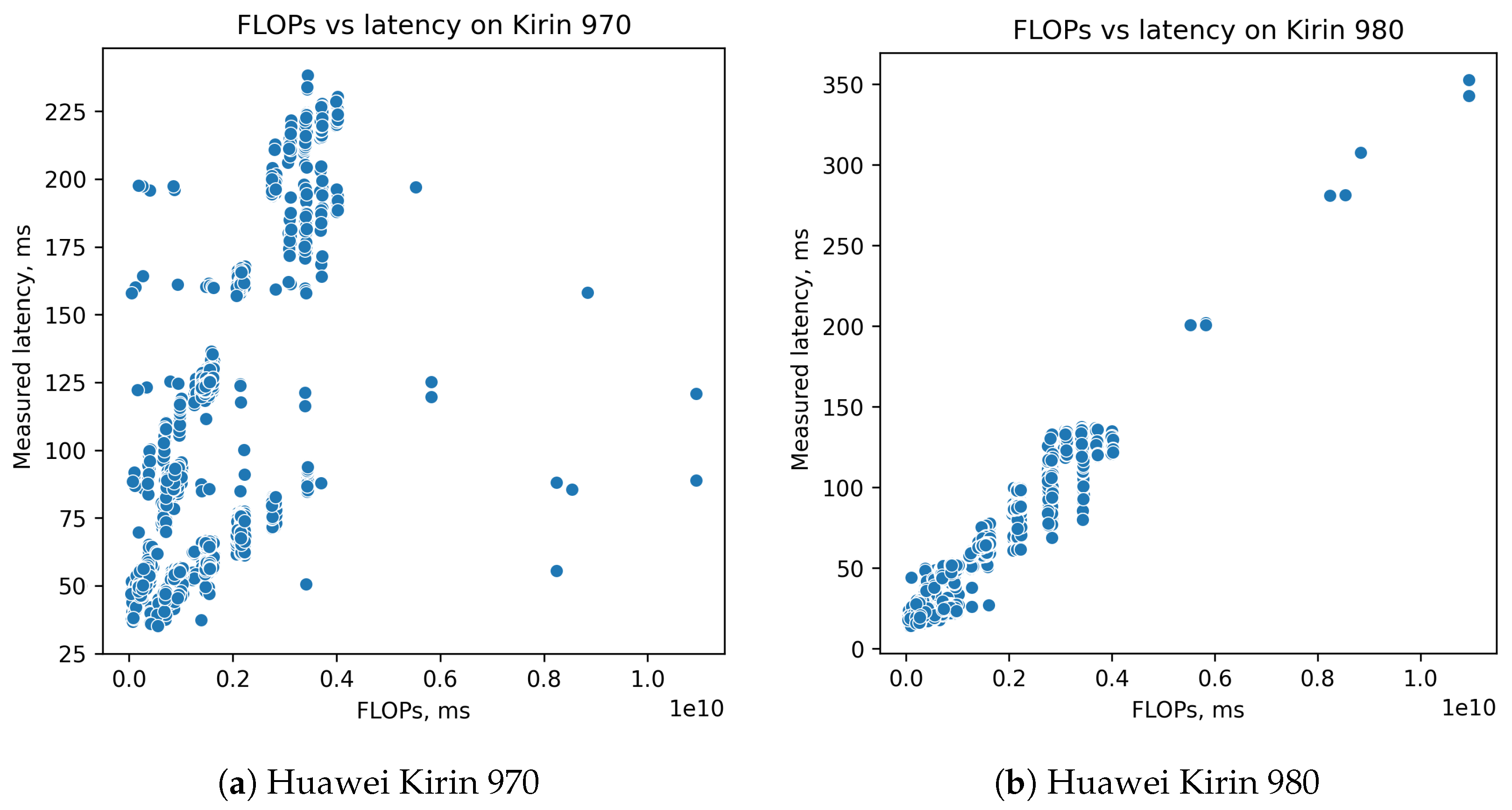
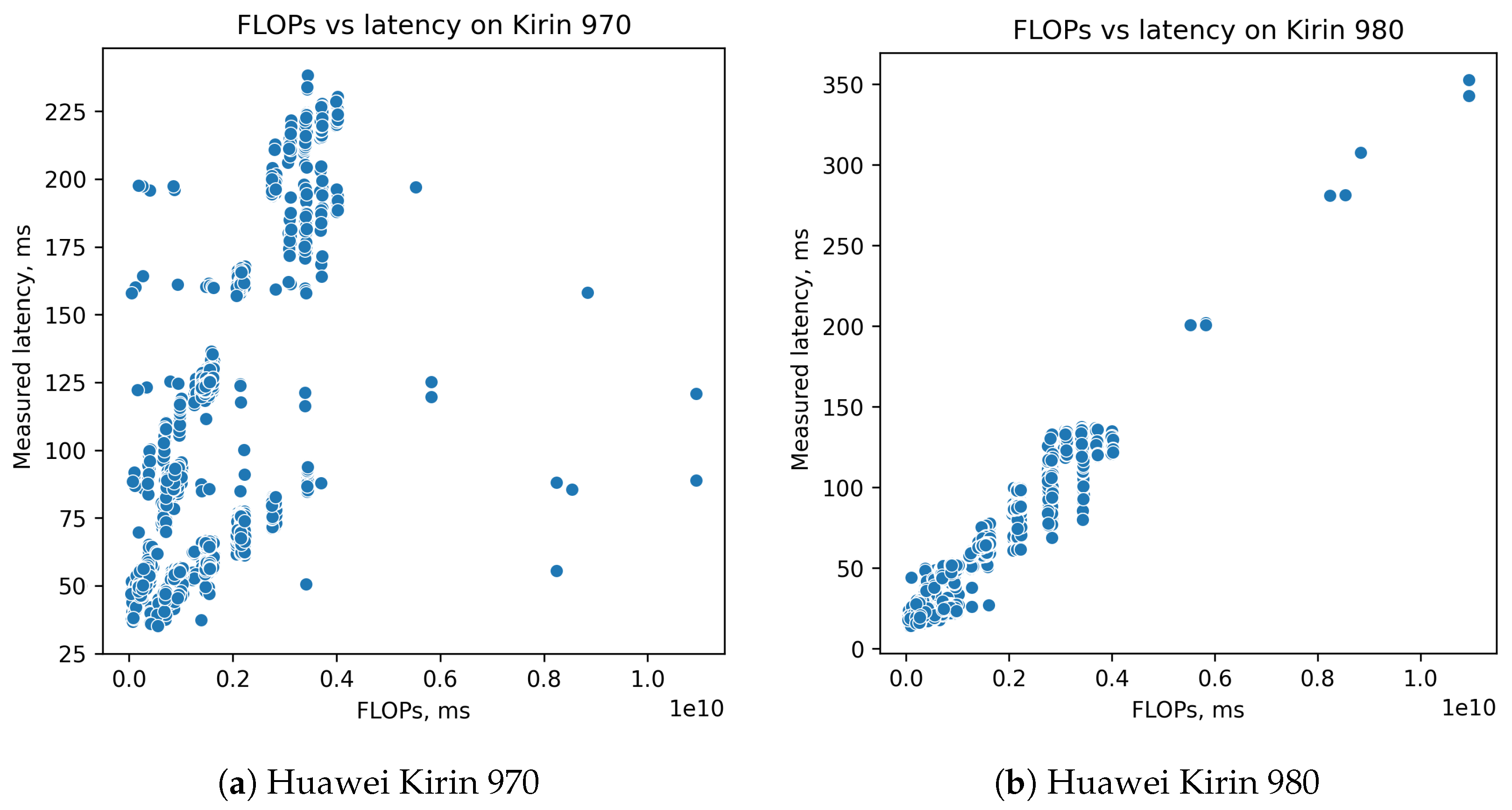
4.2. Linear Models Based on FLOPs
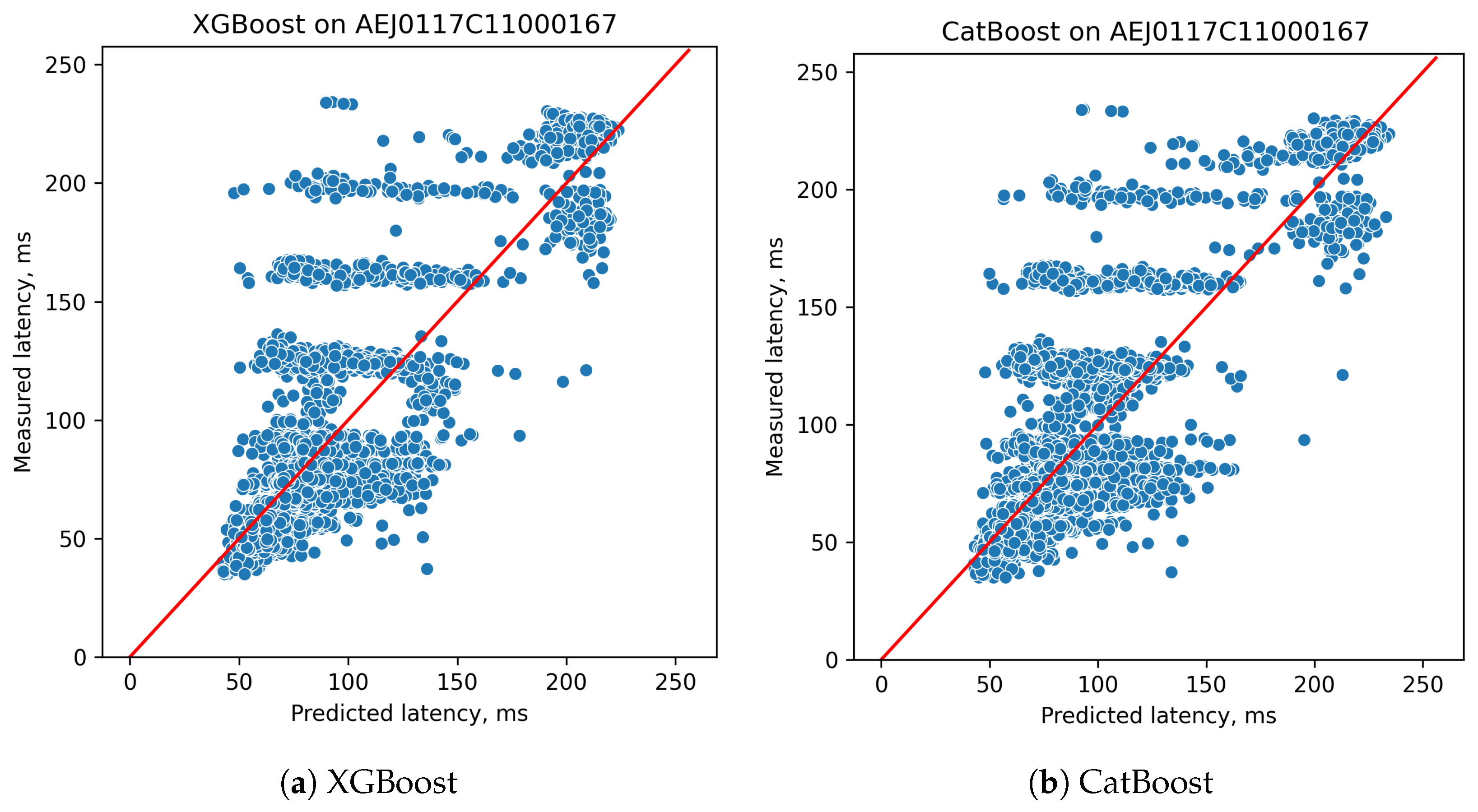
4.3. Gradient Boosting Methods
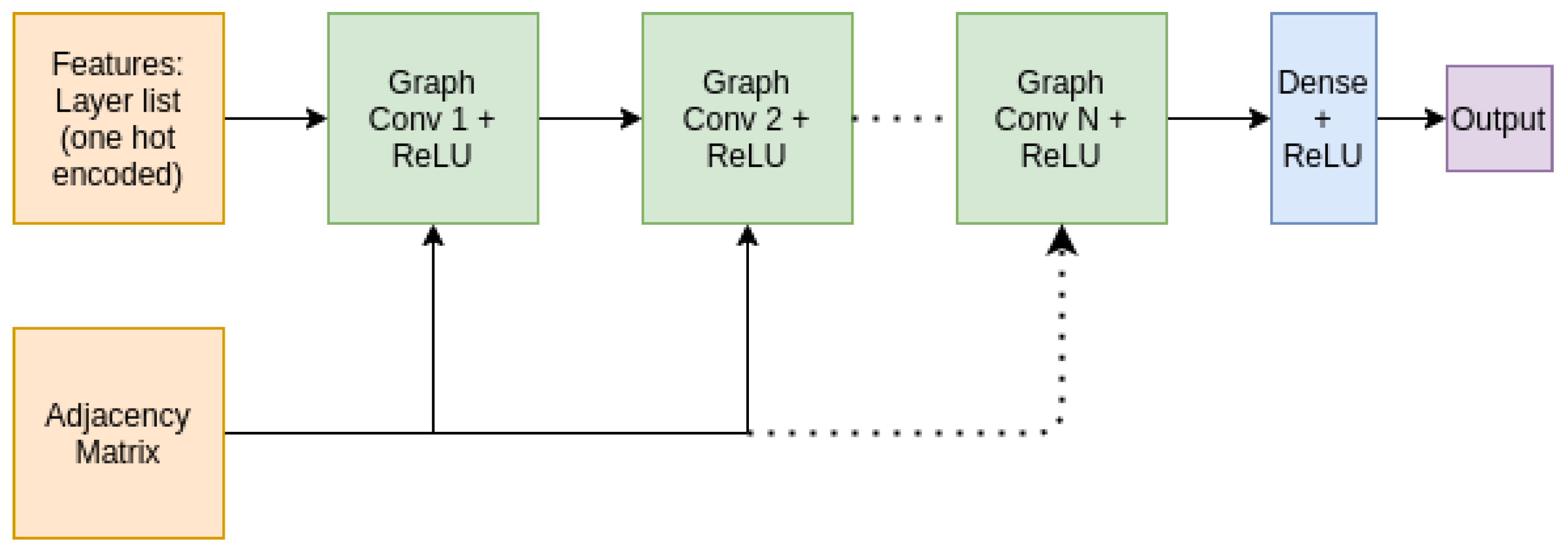
4.4. Graph Convolutional Network (GCN) for Latency Prediction
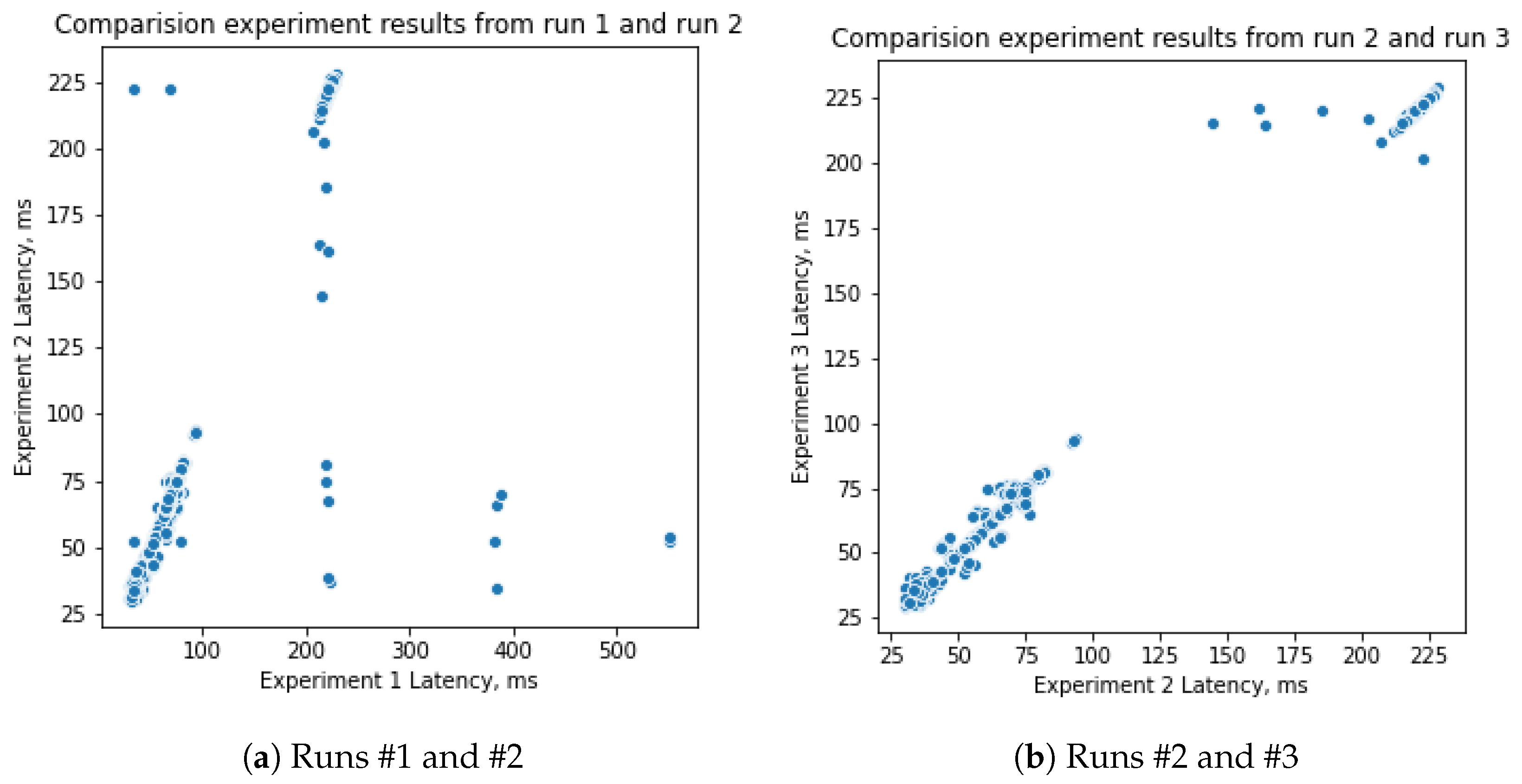
4.5. Numerical Results for Proposed Methods
5. Discussion
- FLOPsAdvantages: Easy to calculate. Gives information about number of computational operations, and it is obviously connected with latency.Disadvantages: Different operations can require different times to perform. In addition, that is both implementation and hardware-specific. Several devices, such as GPU, have very nonlinear dependency of inference time from number of operations. Data movement operations is not taken into account at all because, formally, it is not a computational operation, but it takes some time, and, sometimes, it may be significant.
- Lookup TableAdvantages: Requires only small number of experiments as large as number of all possible blocks.Disadvantages: It does not count data movement between blocks, model loading on device, which can take a lot of inference.
- Build Simulator of target deviceAdvantages: Allows getting precise estimation of inference time without real experiments. More robust, than experiments on a mobile device. Can be run in parallel on clusters.Disadvantages: Requires complex engineering work to construct simulator of each target hardware. Seems to be hard to use for not-CPU devices.
- Direct measurements on device for each modelAdvantages: Allows getting real estimation of inference time, the direct method. It has the best match to real user experience.Disadvantages: Inference time can highly vary from run to run and needs a series of experiments to get robust estimation. A huge number of experiments is required and leads to either long experiments or requires a huge cluster of same devices to conduct parallel experiments.
- Direct measurements for small subset of models and construction of prediction modelAdvantages: Requires tracktable in time number of real-world experiments for even one test device. Gets real experimental values for latency corresponding to user experience.Disadvantages: Model can be not as precise as direct measurements. Training subset of neural network search space can be not representative enough to cover the whole search space.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| LETI | Latency estimation tool and investigation of neural networks inference |
| FLOP | Floating point operations |
| GPU | Graphics processing unit |
| CPU | Central processing unit |
| NPU | Neural processing unit |
| RFBR | Russian Foundation for Basic Research |
| NAS | Neural architecture search |
| LUT | Lookup table |
| TFLite | TensorFlow Lite |
| TF.Keras | TensorFlow Keras |
References
- Krizhevsky, A. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- He, K. Identity mappings in deep residual networks. Lect. Notes Comput. Sci. 2016, 9908, 630–645. [Google Scholar]
- Lin, T. Microsoft COCO: Common objects in context. Lect. Notes Comput. Sci. 2014, 8693, 740–755. [Google Scholar]
- Wani, M. Advances in Deep Learning; Springer: Singapore, 2020. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 18–23 June 2018. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation, OSDI, Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
- Lee, J.; Chirkov, N.; Ignasheva, E.; Pisarchyk, Y.; Shieh, M.; Riccardi, F.; Sarokin, R.; Kulik, A.; Grundmann, M. On-device neural net inference with mobile gpus. arXiv 2019, arXiv:1907.01989. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 18–23 June 2018. [Google Scholar]
- Ying, C.; Klein, A.; Christiansen, E.; Real, E.; Murphy, K.; Hutter, F. NAS-bench-101: Towards reproducible neural architecture search. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 7105–7114. [Google Scholar]
- Dong, X.; Yang, Y. Nas-bench-201: Extending the scope of reproducible neural architecture search. In Proceedings of the International Conference on Learning Representations, Online, 26 April–1 May 2020. [Google Scholar]
- Krizhevsky, A.; Nair, V.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. Available online: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf (accessed on 19 August 2021).
- Liu, H.; Simonyan, K.; Yang, Y. DARTS: Differentiable architecture search. In Proceedings of the International Conference on Learning Representations, New Orleans, LO, USA, 6–9 May 2019. [Google Scholar]
- He, X.; Zhao, K.; Chu, X. AutoML: A Survey of the State-of-the-Art. In Knowledge-Based Systems; Elsevier: Amsterdam, The Netherlands, 2021. [Google Scholar]
- Google AI Blog: EfficientNet-EdgeTPU: Creating Accelerator-Optimized Neural Networks with AutoML. Available online: https://ai.googleblog.com/2019/08/efficientnet-edgetpu-creating.html (accessed on 19 August 2021).
- Cai, H.; Zhu, L.; Han, S. ProxylessNAS: Direct neural architecture search on target task and hardware. In Proceedings of the International Conference on Learning Representations, New Orleans, LO, USA, 6–9 May 2019. [Google Scholar]
- Dai, X.; Zhang, P.; Wu, B.; Yin, H.; Sun, F.; Wang, Y.; Dukhan, M.; Hu, Y.; Wu, Y.; Jia, Y.; et al. Chamnet: Towards efficient network design through platform-aware model adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11398–11407. [Google Scholar]
- Wu, B.; Dai, X.; Zhang, P.; Wang, Y.; Sun, F.; Wu, Y.; Tian, Y.; Vajda, P.; Jia, Y.; Keutzer, K. FBnet: Hardware-aware efficient convnet design via differentiable neural architecture search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10734–10742. [Google Scholar]
- Chu, X.; Zhang, B.; Xu, R. MOGA: Searching beyond mobilenet v3. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Dudziak, Ł.; Chau, T.; Abdelfattah, M.S.; Lee, R.; Kim, H.; Lane, N.D. BRP-NAS: Prediction-based NAS using GCNs. In Proceedings of the Conference on Neural Information Processing Systems, Online, 6–12 December 2020. [Google Scholar]
- Ignatov, A.; Timofte, R.; Chou, W.; Wang, K.; Wu, M.; Hartley, T.; Van Gool, L. AI Benchmark: Running deep neural networks on android smartphones. Lect. Notes Comput. Sci. 2019. [Google Scholar] [CrossRef] [Green Version]
- Rapin, J.; Teytaud, O. Nevergrad—A Gradient-Free Optimization Platform. 2018. Available online: https://github.com/facebookresearch/nevergrad (accessed on 19 August 2021).
- Martin, A. Fischler and Robert C. Bolles. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. arXiv 2017, arXiv:1706.09516. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. Technical Report. 2017. Available online: https://dl.acm.org/doi/pdf/10.5555/3294996.3295074 (accessed on 19 August 2021).
- Caffe2. Available online: https://caffe2.ai/ (accessed on 19 August 2021).
- Pytorch Mobile. Available online: https://pytorch.org/mobile/home/ (accessed on 19 August 2021).
- Luo, C.; He, X.; Zhan, J.; Wang, L.; Gao, W.; Dai, J. Comparison and Benchmarking of AI Models and Frameworks on Mobile Devices. arXiv 2020, arXiv:2005.05085v1. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device Name | Kirin 970 | Kirin 980 | Exynos 9810 |
|---|---|---|---|
| Serial num | AEJ0117C11000167 | 015NTV187K000112 | R39K708F15 |
| Lithography | 10 nm | 7 nm | 10 nm |
| Release date | 02/09/2017 | 31/08/2017 | 01/03/2018 |
| Architecture | ARM big.LITTLE | ARM big.LITTLE | ARM big.LITTLE |
| Series | Cortex-A73/-A53 | Cortex-A76/-A55 | Exynos M3/Cortex-A55 |
| 4x Cortex-A73 (2.4 GHz) + | 2x Cortex-A76 (2.6 GHz) + | 4x Exynos M3 (2.9 GHz) + | |
| CPU | 4x Cortex-A53 (1.8 GHz) | 2x Cortex-A76 (1.9 GHz) + | 4x Cortex-A55 (1.9 GHz) |
| 4x Cortex-A53 (1.8 GHz) | |||
| Memory | LPDDR4X | LPDDR4X | LPDDR4X |
| GPU | ARM Mali-G72 MP12 | ARM Mali-G76 MP10 | ARM Mali-G72 MP18 |
| GPU Lith. | 16 nm | 7 nm | 16 nm |
| GPU clock | 746 MHz | 720 MHz | 572 MHz |
| GPU Execut. | 12 units | 10 units | 18 units |
| GPU Shading | 192 units | 160 units | 288 units |
| GPU Cache | 1 MB | 2 MB | 1 MB |
| GPU Perf | 286 GFLOPS (FP32) | 230 GFLOPS (FP32) | 370 GFLOPS (FP32) |
| Model | Resnet50 | Resnet50 | NASNet |
|---|---|---|---|
| Device | Kirin 980 | Exynos 9810 | Exynos 9810 |
| Direct, ms | 552 ± 7.1 | 1806 ± 20.2 | 432 ± 3.1 |
| LUT, ms | 620 ± 3.6 | 1714 ± 53.0 | 388 ± 7.3 |
| Error, ms | 68.1 | 92.2 | 43.8 |
| Rel. err. | 12.32% | 5.38% | 11.29% |
| Acc@10% | ||||
|---|---|---|---|---|
| Method/Device | 970 | 980 | 970 | 980 |
| RANSAC | 68.29 | 80.14 | 0.04 | 0.93 |
| RANSAC + cluster | 71.31 | 84.11 | 0.51 | 0.93 |
| LightGBM | 49.17 | 84.79 | 0.74 | 0.90 |
| XGBoost | 57.51 | 85.58 | 0.77 | 0.92 |
| CatBoost | 55.55 | 86.10 | 0.765 | 0.93 |
| GCN | 44.61 | 67.16 | 0.69 | 0.81 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ponomarev, E.; Matveev, S.; Oseledets, I.; Glukhov, V. Latency Estimation Tool and Investigation of Neural Networks Inference on Mobile GPU. Computers 2021, 10, 104. https://doi.org/10.3390/computers10080104
Ponomarev E, Matveev S, Oseledets I, Glukhov V. Latency Estimation Tool and Investigation of Neural Networks Inference on Mobile GPU. Computers. 2021; 10(8):104. https://doi.org/10.3390/computers10080104
Chicago/Turabian StylePonomarev, Evgeny, Sergey Matveev, Ivan Oseledets, and Valery Glukhov. 2021. "Latency Estimation Tool and Investigation of Neural Networks Inference on Mobile GPU" Computers 10, no. 8: 104. https://doi.org/10.3390/computers10080104
APA StylePonomarev, E., Matveev, S., Oseledets, I., & Glukhov, V. (2021). Latency Estimation Tool and Investigation of Neural Networks Inference on Mobile GPU. Computers, 10(8), 104. https://doi.org/10.3390/computers10080104