
Dynamic Privacy-Preserving Recommendations on Academic Graph Data


Abstract
:1. Introduction
2. Related Work
2.1. Privacy-Preserving Recommender Systems
2.2. Pseudonymisation Strategies for Personal Data
2.3. Dynamic Recommender Systems
3. Preliminaries
3.1. Definitions
- Personal data Any information relating to an identified or identifiable natural person (namely a data subject).
- Personally identifiable information (PII) Any information about an individual maintained by an agency, including any information that can be used to distinguish or trace an individual’s identity, such as name, social security number, date and place of birth, mother’s maiden name or biometrics records; and any other information that is linked or linkable to an individual, such as medical, educational, financial and employment information.
- Direct identifiers called directly identifying variables or direct identifying data are defined as data that directly identifies a single individual. Some direct identifiers are unique (e.g., social security number, credit card number, healthcare identification or employee number); others are considered as highly identifying (e.g., name and address in a dataset could not be unique, but they are very likely to be referable to a specific individual). In a privacy preservation process, it is mandatory to remove or obscure any direct identifier.
- Indirect identifiers Known as quasi-identifiers or sometimes as indirectly identifying variables are identifiers that by themselves do not identify a specific individual but can be combined and linked with other information in order to identify a data subject. Examples of indirect or quasi-identifiers are the zip code or the date of birth: there will be many people who share the same zip code or the exact date of birth, but undoubtedly not many have both equally.
- De-identification General term for any process of removing the association between a set of identifying data and the data subject. De-identification is designed to protect individual identity, making it hard or even impossible to learn if the data in a dataset is related to a specific individual while preserving some dataset’s utility for other purposes.
- Re-identification Process of attempting to discern the identities that have been removed from de-identified data. Since an important goal of de-identification is to prevent unauthorised re-identification, such attempts are often called re-identification attacks.
- Redaction is based on a core principle of privacy: “if you don’t need data, don’t use it”. It is nothing more than removing data by completely dropping a column in a database or replacing it with a constant value for every individual.
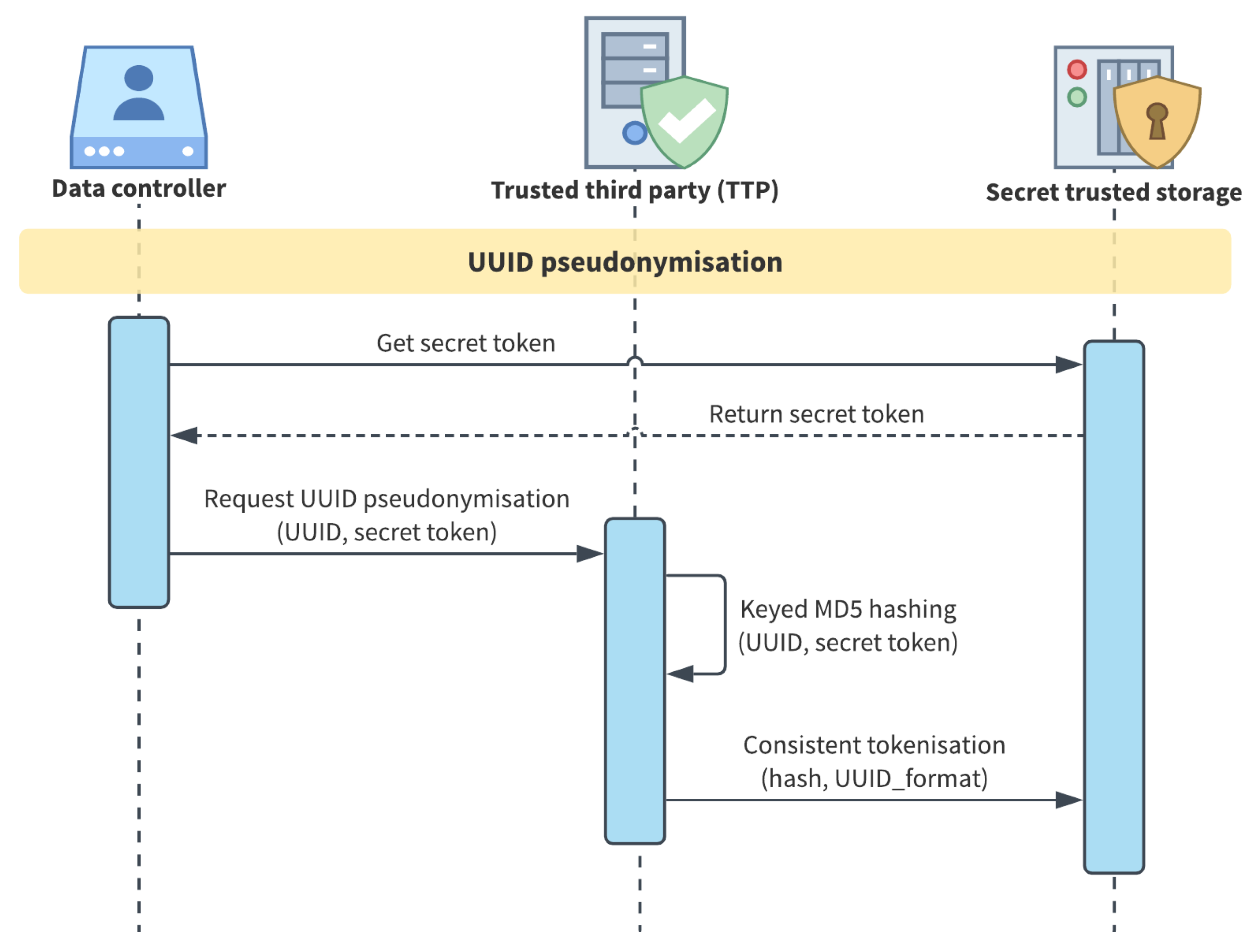
- Tokenisation is the practice to replace the original value with a new generated random value, namely a token. Using this approach, the original data format can be preserved, enabling a scenario where pseudonyms can be used in a meaningful manner (e.g., a real email address erasmo@gei.de could be replaced by the token abcde@xyz.de). When the new token is consistently generated, meaning that the same pseudonym always replaces an original value, we call that consistent tokenisation, and it is beneficial when the de-identification process needs to be reversible.
- Perturbation is masking the original data by the addition of random noise to it. For example, all ages may be randomly adjusted with a fixed amount of years, or dates may be shifted by the same number of days.
- Substitution makes use of a mapping table to assign specific replacements to original values. Replacements are not randomly chosen, but based on the mentioned table that defines the substitution for each individual’s identifier; they could be one-to-one or many-to-one that is aggregating several values into a single substitute (e.g., different mapping cities to a unique name identifying the region).
- Field-level encryption works on a particular field or set of data. It aims to replace the value of an identifier with an encrypted version of that through a specific encryption key (that is secret in most privacy preservation scenarios), used for reversibility and reproducibility purposes. The length of the resulting pseudonym will vary depending on which encryption algorithm one uses.
- Hashing is a well-known technique that creates new values using standard algorithms (e.g., SHA256, SHA1 or MD5) built on mathematical functions. Due to the intrinsic reproducibility property of hashing, very often, a random value (called “salt”) is added to the original data before generating the hash value. However, as stated by Privitar, “because hashing is vulnerable to attacks which can lead to uncovering original sensitive values, hashing is not a recommended approach to de-identification” ( Check “Why hashing will not give you complete protection” at: https://www.privitar.com/blog/hashing-is-not-enough/; last seen on 18 August 2021).
- Generalisation is the technique of transforming identifiers’ values into more general ones, such as replacing a number with a range (e.g., for age, one can generalise 29 by the interval 25–30). This method is commonly used to de-identify quasi-identifiers, and its primary goal is to reduce the risk of re-identification by creating several individuals sharing the same identifiers’ value. The k-anonymity model is used to measure whether there are at least k records for any given combination of generalised quasi-identifiers (e.g., age in the range 40–45 and zip code 115xx).
- Generalisation Hierarchy is a tree structure with increasing concept abstraction level towards the root. Such a hierarchy can be obtained from existing taxonomies or hand-crafted for a specific domain. The application for generalisation hierarchies in pseudonymisation is to replace rare concepts with their broader term, increasing the occurrence of the surrogate term and decreasing the chances of re-identification. The rare original concepts are removed after substitution.
- Hypernymy is a relation between two words—the hypernym and the hyponym—where the hypernym is a more general term, encompassing several other hyponyms (e.g., animal is a hypernym for both cat and dog).
- Word Embeddings are dense, distributed, and fixed-length word vectors, following the notion of distributional semantics [48]. Popularised in their static form by Mikolov et al. [49], they assign a fixed vector to each word in the vocabulary. The more recent contextual word embedding variant obtained from language models such as BERT [50] conditions the embedding vector values on the surrounding words, enabling the distinction of homonyms given their everyday contextual use. Word embeddings are a state-of-the-art text representation method, and using the vectors of pre-trained models from extensive collections has been shown to perform well on semantic tasks.
3.2. Notations
- is the set of persons (or users) in which each entity is described by;
- is the set of research works (i.e., publications) in which each entity is described by ;
- is the set of research interests (also useful as fields of study) in which each entity is described by ;
- represents the set of projects in which each entity is described by;
- is the set of organisational units (i.e., university, research institutions along with their internal departments) in which each entity is described by.
- is the connection between a person and a research output he/she authored;
- is the connection between a person and a research interest he/she cares about;
- represents the connection between a person and an organisational unit he/she belongs to;
- is the connection between a project and a person who is taking part in;
- represents the connection between a project and the organisational unit managing it.
3.3. GEI Knowledge Graph
4. Proposed Approach
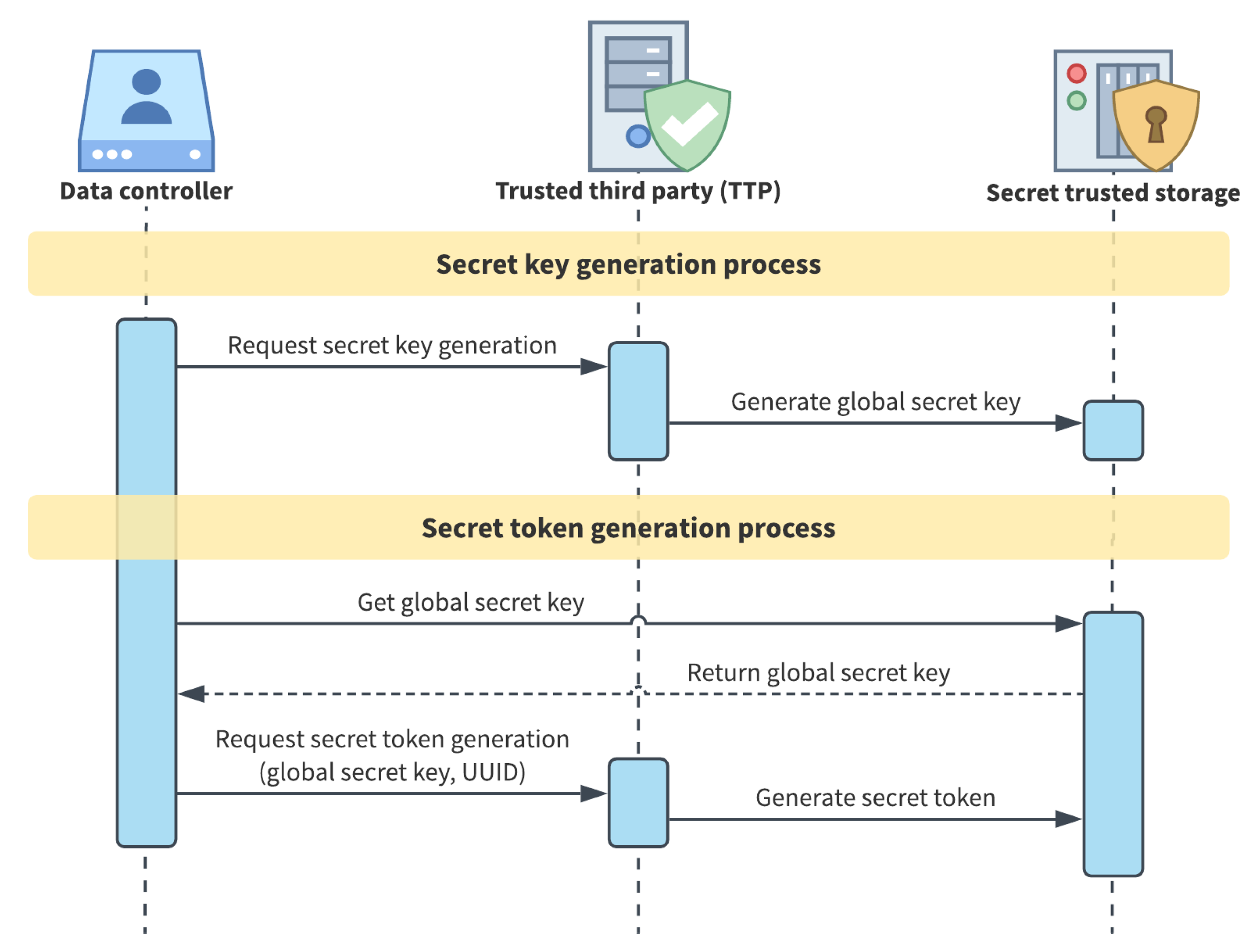
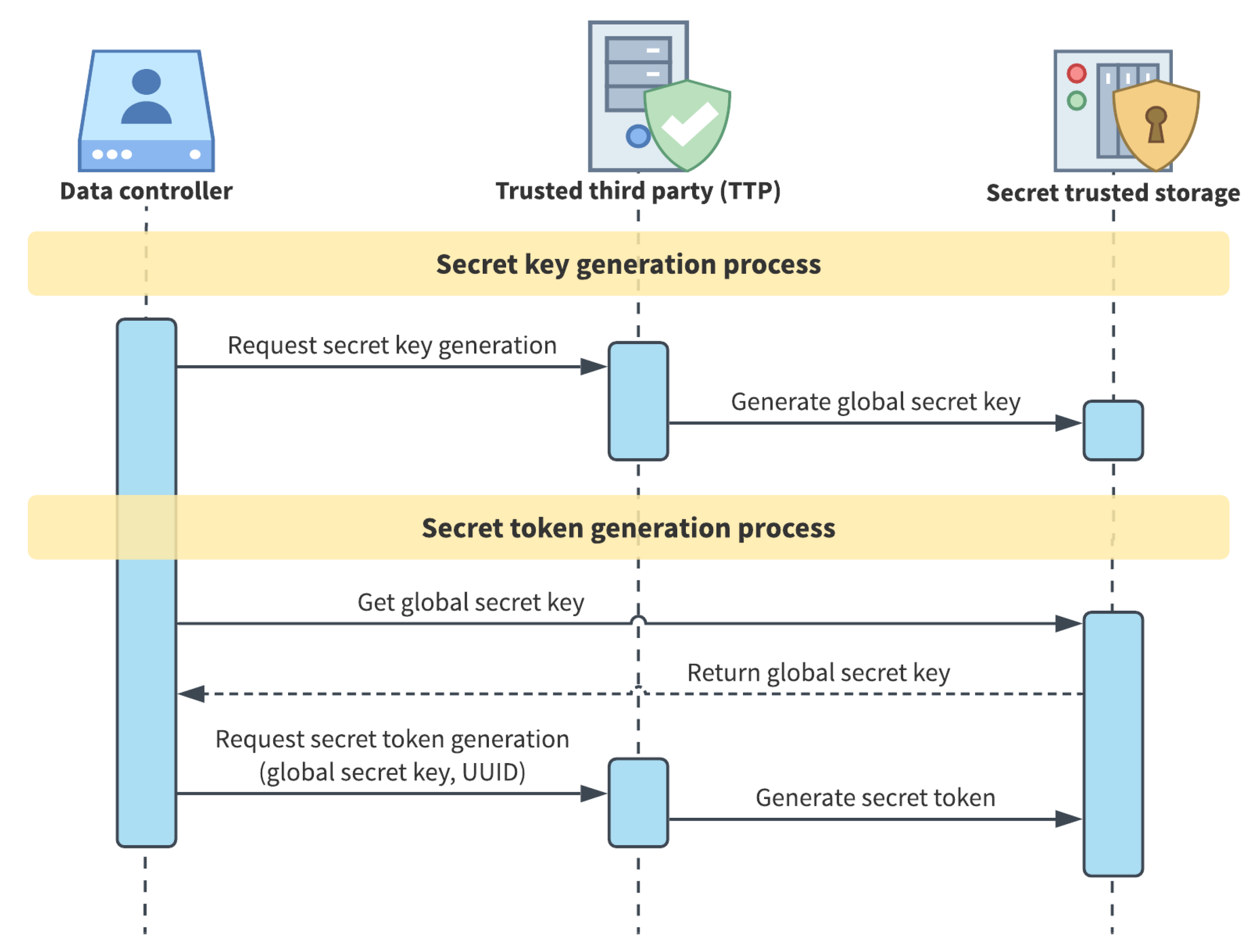
4.1. Pseudonymisation Secrets
| Algorithm 1 Pseudonymisation process |
|
4.2. Person Pseudonymisation
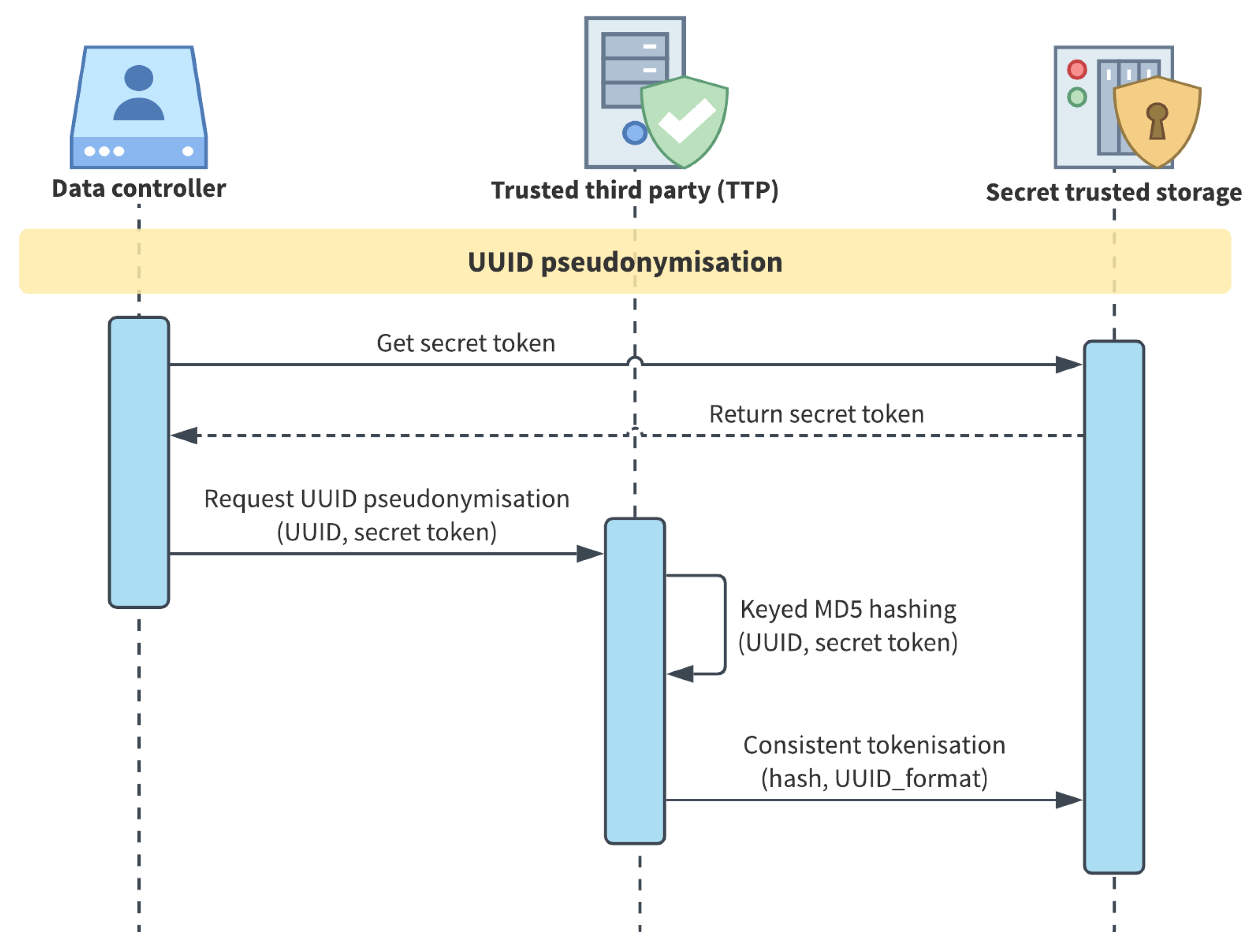
- UUID is pseudonymised with a two-step procedure, represented in Figure 4: (1) a keyed hash function is applied using the entity secret token as the key and (2) consistent tokenisation produces the pseudo UUID from hashing result. The developed method provides a choice between MD5, SHA1 and SHA256 as hash algorithms. While MD5 and SHA1 are almost comparable, recent research demonstrates that they are less secure than SHA256, but 20–30% faster in being computed [51]. For this reason, and since in the described process it is just the last step of a more complex process than a simple hashing, we employ the MD5 Algorithm by default;
- Pure ID, email and employee ID are pseudonymised via consistent tokenisation using the secret token as the “salt” of the tokenisation function;
- Person’s name is transformed by substitution. The mapping table is composed of real male and female names and real surnames. According to the actual gender of the user being pseudonymised, a couple (name, surname) is picked from the table leveraging the secret token as the seed for the consistent choice;
- Finally, generalisation is exploited to de-identify nationality and employee start date. For the former, countries are generalised with the corresponding continents, whereas, for the latter, the full date is replaced only by the year.
4.3. Research Outputs Pseudonymisation
- UUID is pseudonymised following the same procedure explained for persons in Section 4.2;
- Pure ID is transformed by consistent tokenisation using the secret token as the “salt” of the tokenisation function;
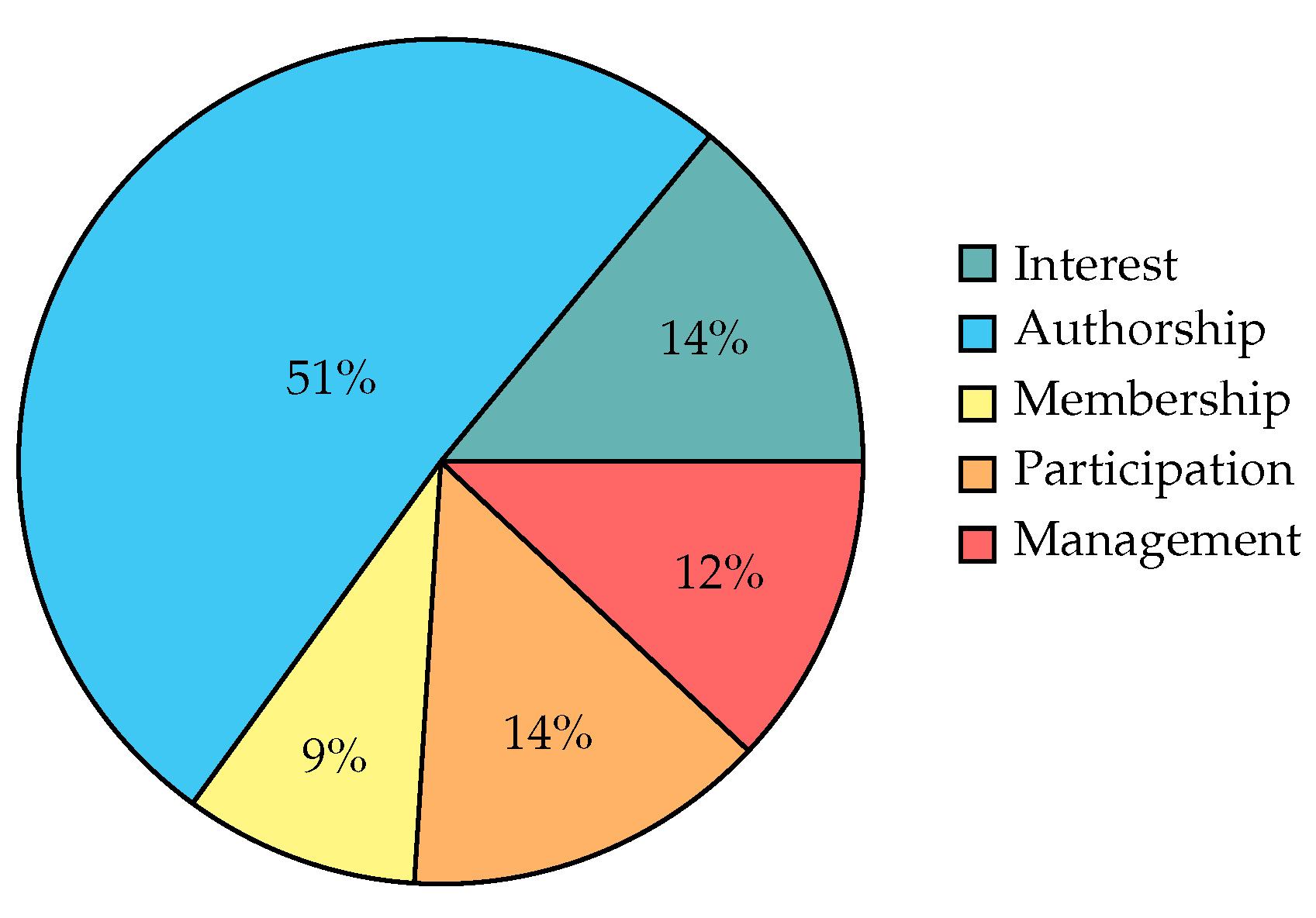
- Title is an attribute with large variability so that we may not rely on hand-crafted hierarchies in this case. Instead, an unsupervised and scalable method is required to reliably transform the title using higher abstraction levels without losing all of its meaning. Therefore, the title is first reduced to keywords, which are then automatically replaced by their closest hypernym from a set of candidates drawn from the WordNet [52]. To select the keywords, we use a model for dependency parsing provided by the Python spaCy library [53] (https://spacy.io/models/en#en_core_web_lg; last seen on 18 August 2021) and thereby extract nouns, proper nouns and adjectives, which have proven to be useful in preliminary experiments. The best candidate is selected using semantic similarity metrics between a hypernym’s word embedding representation and the original keyword or title. We test two methods: first, we compute the Word Mover’s Distance [54] using static word embeddings from Google’s pre-trained word2vec model (https://code.google.com/archive/p/word2vec/; last seen on 18 August 2021) to compare keyword and hypernym. This method is opposed to the second one of employing the contextual word embedding distance between the hypernym (with optional expansion to synonyms and domains) and the whole text of the title, computed by the BERTScore [55] using the pre-trained SciBERT model [56]. As a baseline, we also compare the results of both methods with the originally extracted keywords instead of choosing their hypernyms. To measure the extent of pseudonymisation gained by each method, we compute the entropy of the resulting keyword distribution across all nodes and select the approach providing the lowest entropy to perform recommendation experiments:
- For the abstract, we employ the redaction technique in order to meet the principle as mentioned earlier of privacy “if you do not need data, do not use it”. The choice is also supported by the fact that this attribute is not present for all research outputs.
- As for a person’s nationality, generalisation is used to pseudonymise place of publication, replacing city names with the corresponding continent;
- The remaining attributes, i.e., number of authors, number of pages and ISBN, are pseudonymised via consistent tokenisation.
4.4. Research Interests Pseudonymisation
- Processing each person to be pseudonymised sequentially, the first phase of the procedure generalises the research interests that are not connected to other individuals:
- (a)
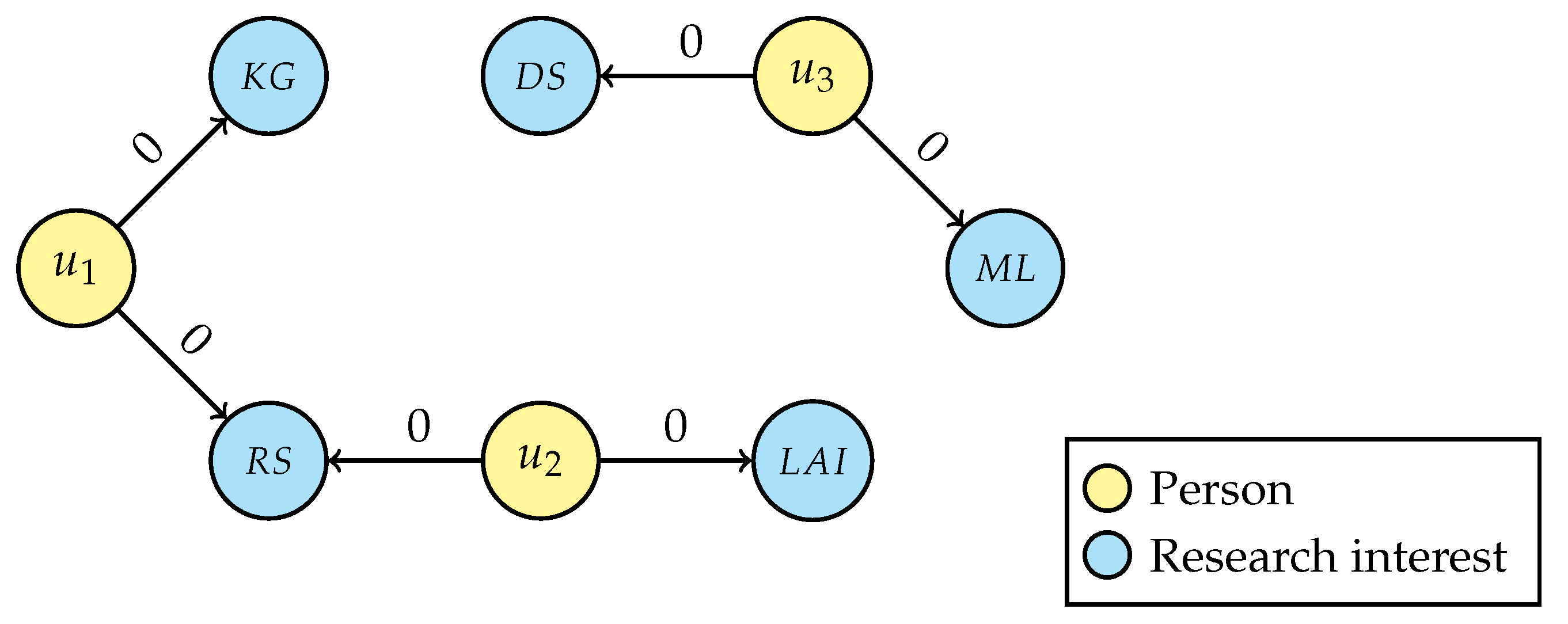
- Get the list of unique research interests, namely for , for , and for . Note that, depending on the starting person node, some research interests may no longer be unique and therefore are no longer considered for subsequent steps;
- (b)
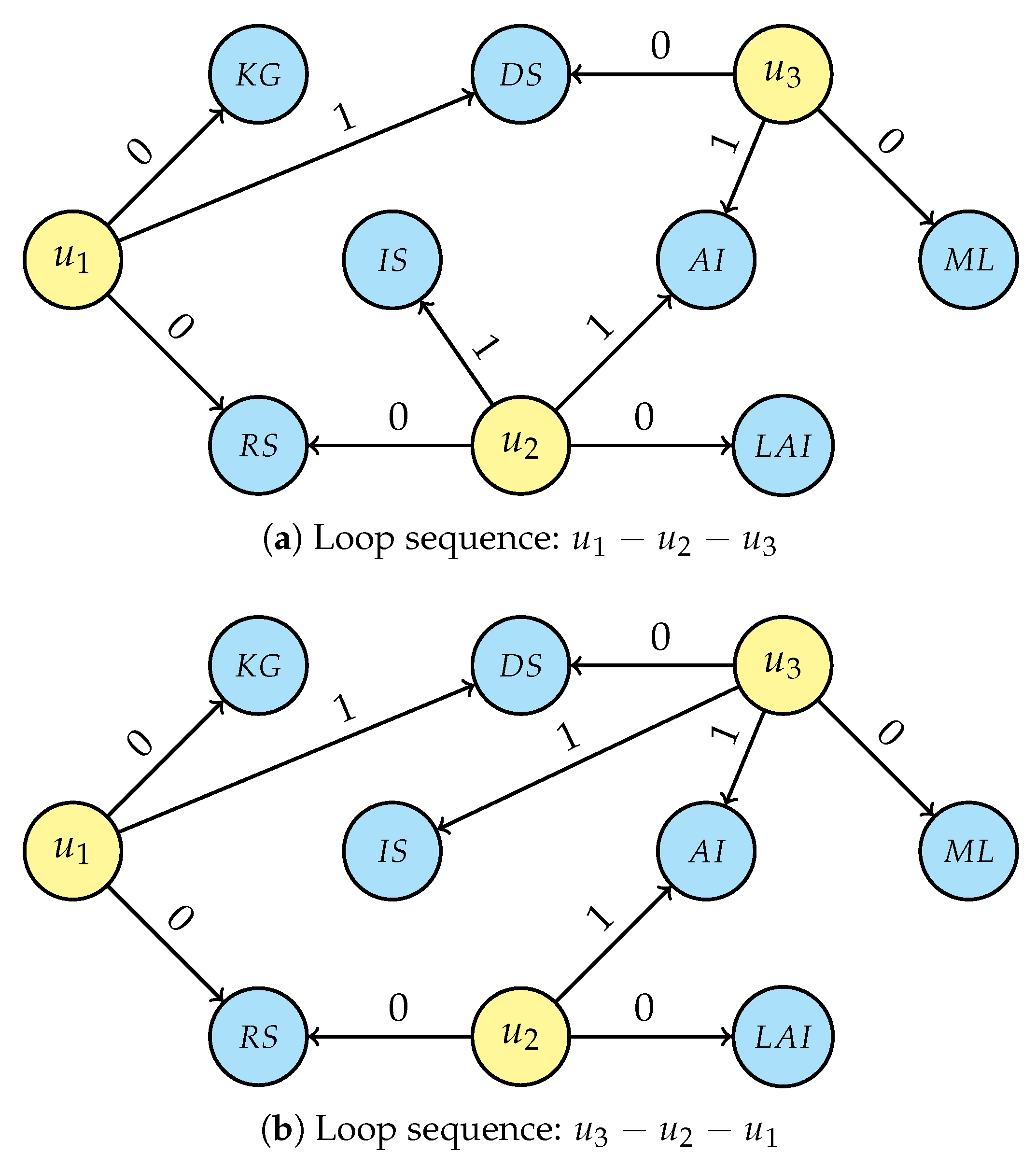
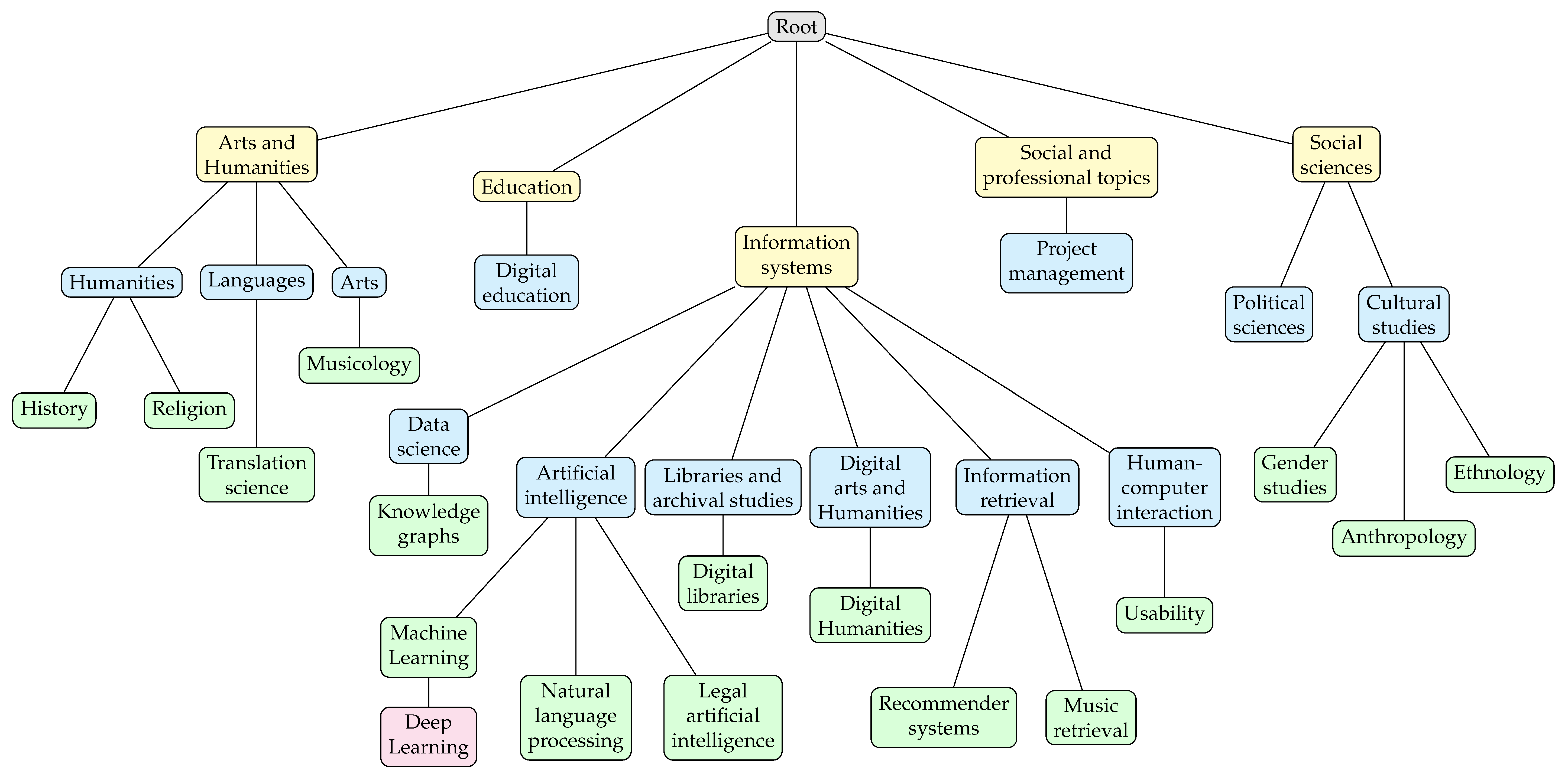
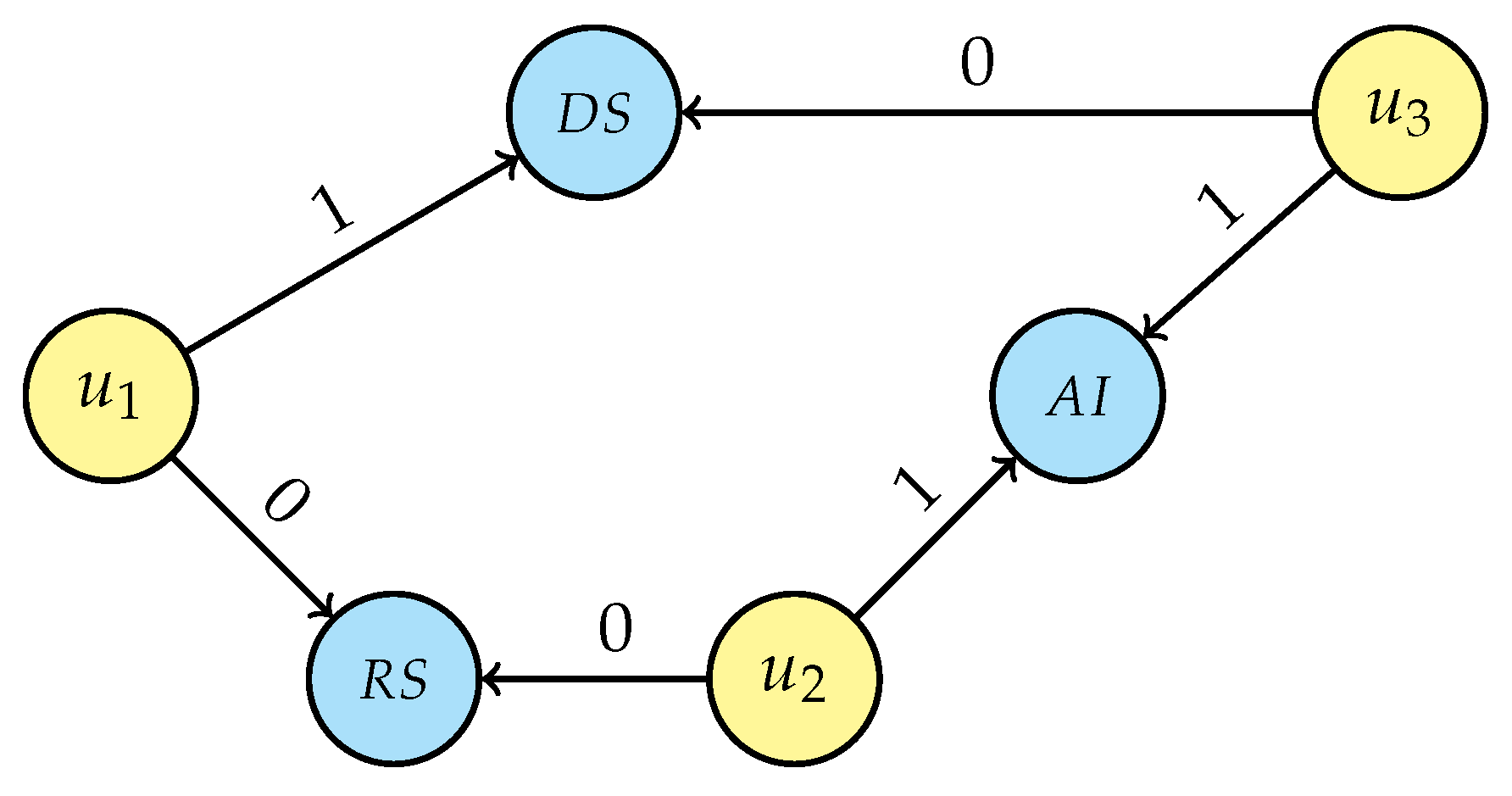
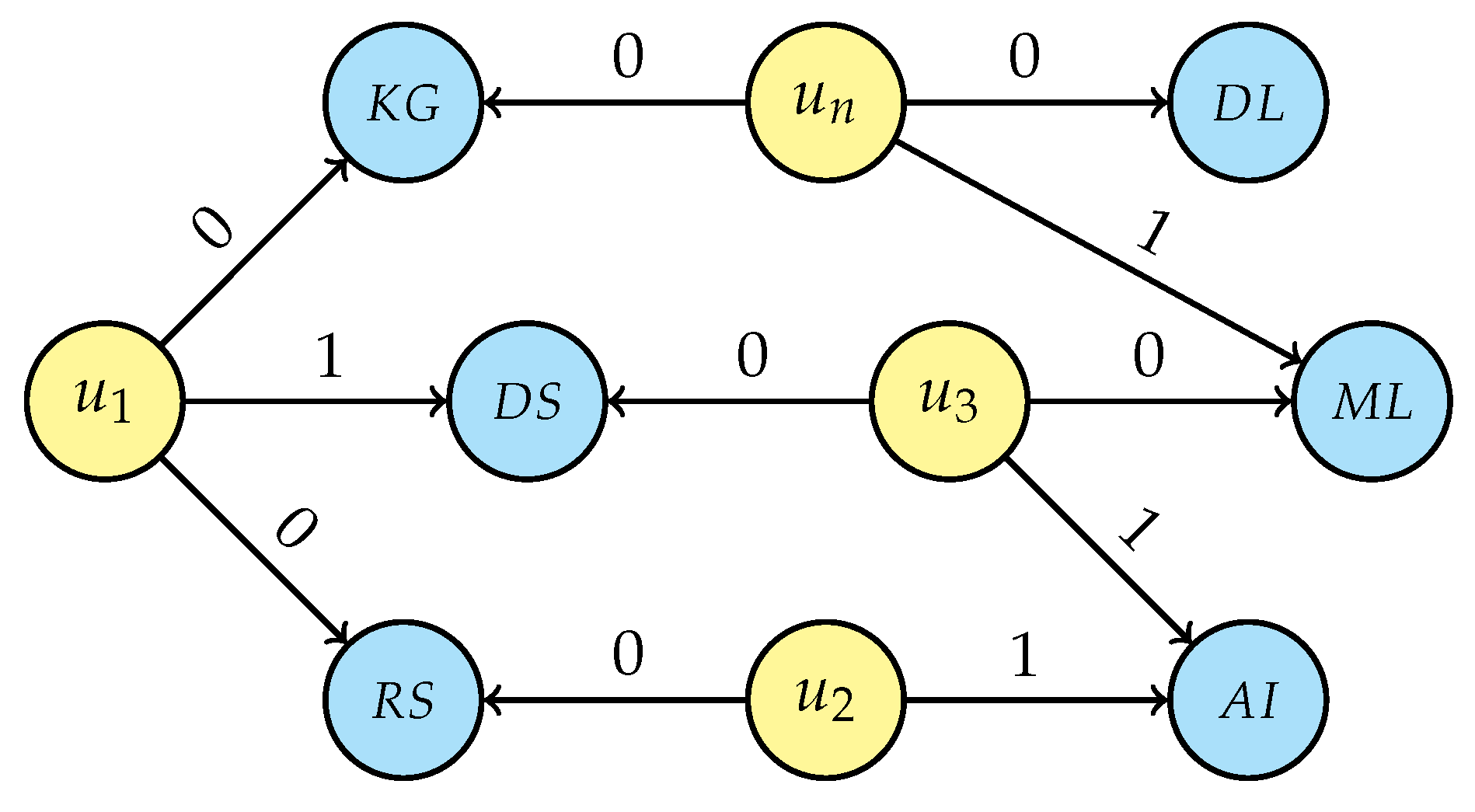
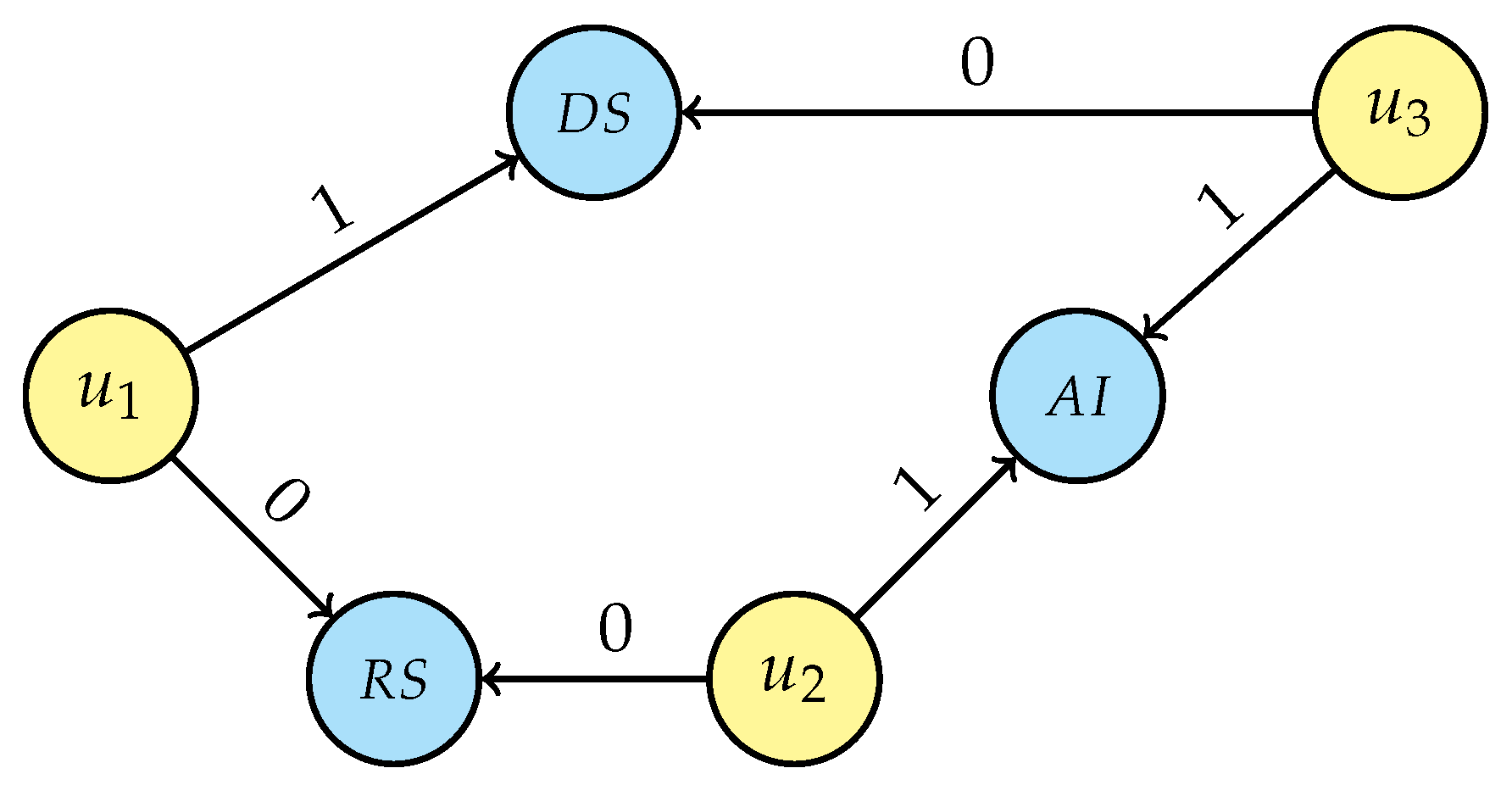
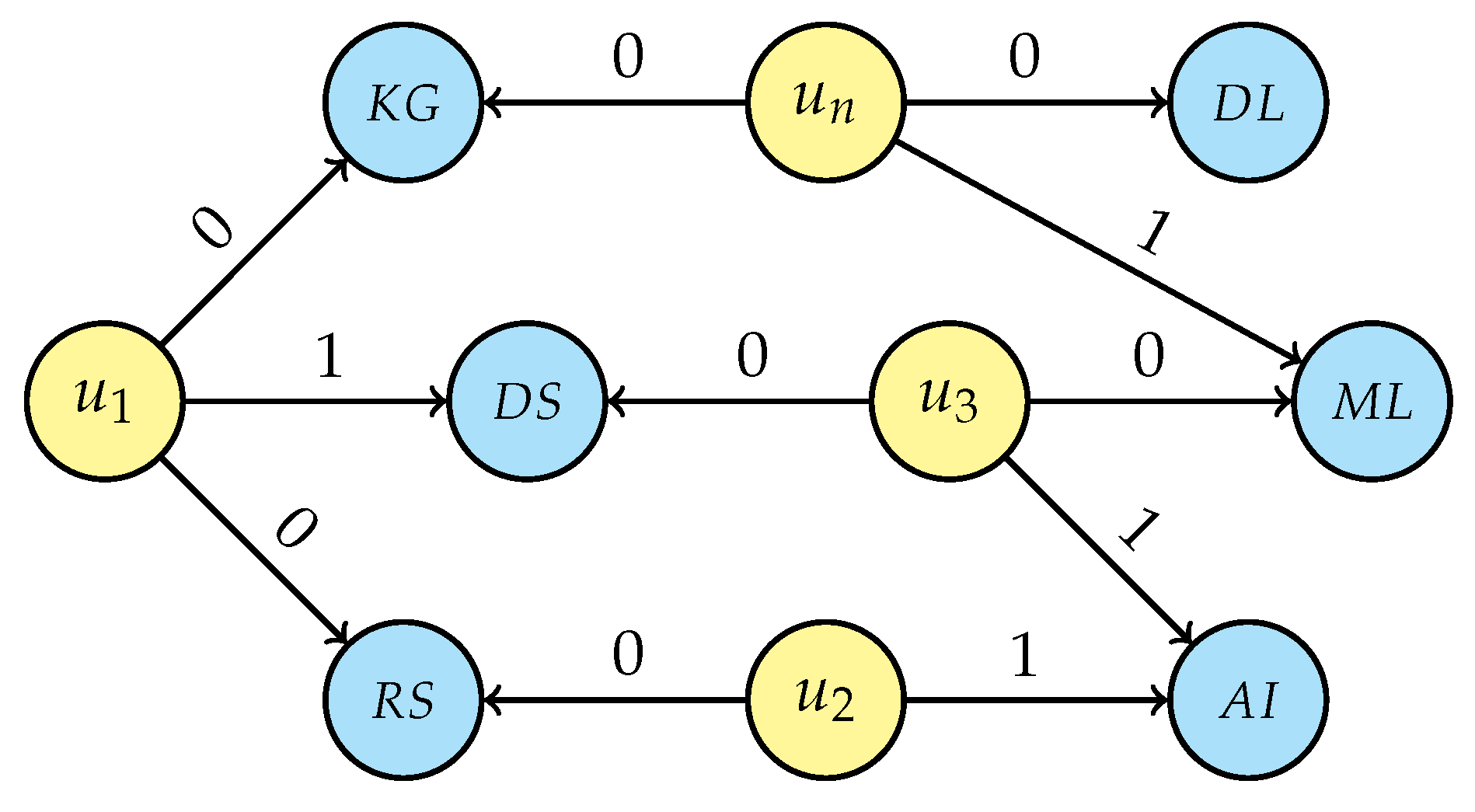
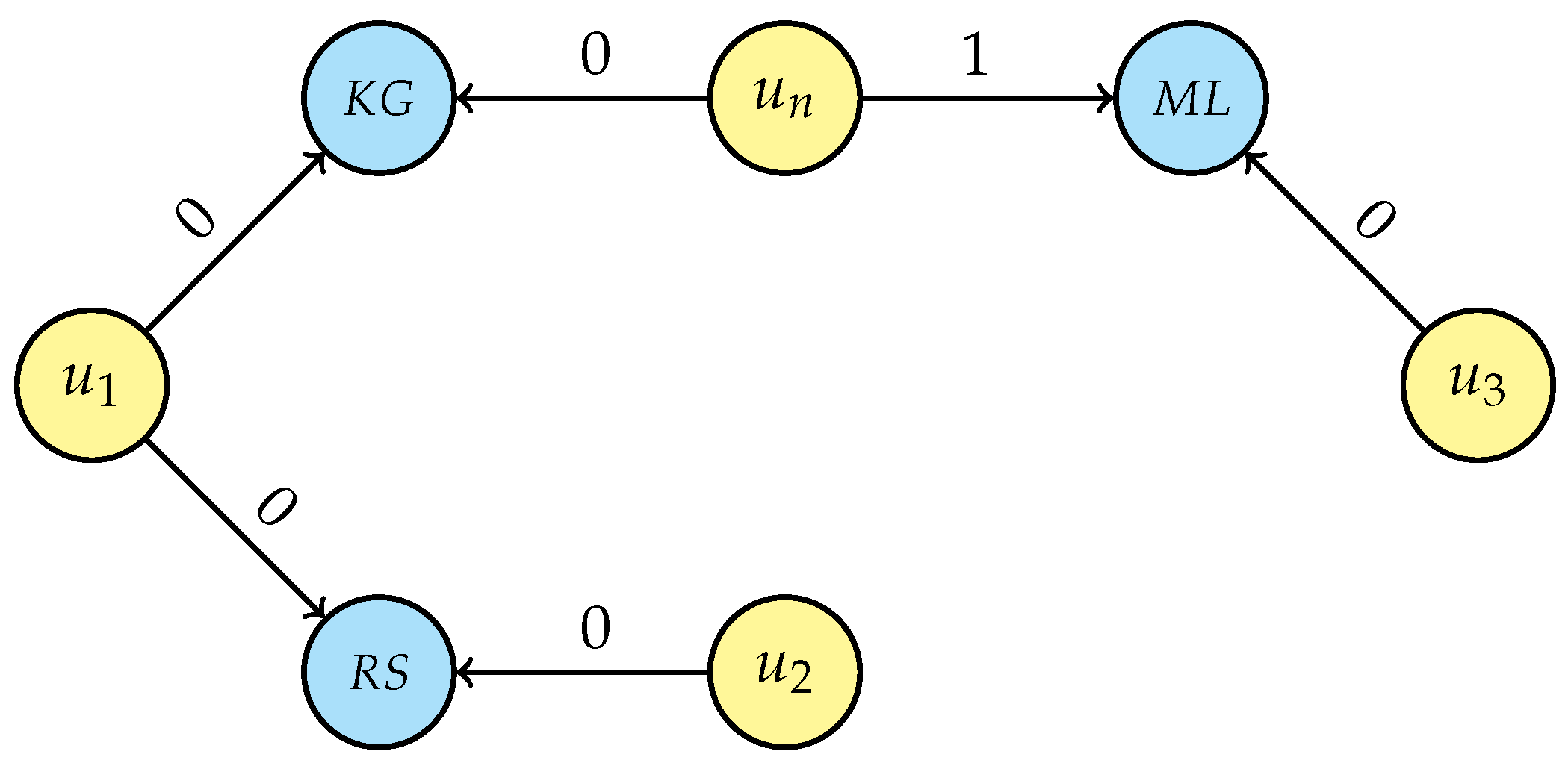
- For each person’s unique interest, generalise the selected entity by traversing the research area tree structure (Figure 5) from that node up to the root and connecting the user with all nodes in the research area’s hierarchy, setting the attribute value to “1” and then breaking the traversal if a link with a non-unique interest is generated. If a research interest is not in the graph, creation of that new node is required before linking, e.g., “Artificial intelligence” (AI) and “Information systems” (IS) while generalising LAI. Even for this step, the intermediate result depends on the starting person node and two possible scenarios are displayed in Figure 7a (considering the loop sequence −−) and in Figure 7b (for sequence −−); it is, however, easy to prove that the final result of the de-identification operation is the same for every loop sequence.
- To complete the pseudonymisation process, the second phase aims to check the minimum-non-unique connection for each of the original unique research interests of pseudonymised persons . It means selecting, among the original and generated “interest” relations, those relations which are no longer unique and thus make the user entity not re-identifiable. Processing one pseudonymised person at a time:
- (a)
- Dealing with person nodes one by one, the starting step is to mark the selected entity as “processed”. The reason behind this operation will be clear with the next steps;
- (b)
- For each person’s original unique interest (i.e., with attribute value “0”), check whether it is still only connected with the user being processed. If so, the connection will be removed, and the relation is stored in a secret table only accessible to data controllers; the correspondent person’s and interest’s UUID will be saved following the pseudonymisation technique explained in Section 4.2, but using a different tokenisation method for pseudo UUIDs generation in order to meet the principle of “unlinkability across domains” [57]. Unlinkability ensures that personal data cannot be linked across domains that are constituted by a common purpose and context. It is related to the principles of necessity and data minimisation as well as purpose binding. One of the mechanisms to achieve or support unlinkability is the usage of different identifiers. Saving original interest relations provides the possibility of future restores, in case a new person with the same research interest will be inserted into the knowledge graph, making that relation valid again;
- (c)
- Starting from the interest processed in the previous step and browsing the related research hierarchy, find the lowest node of the hierarchy not uniquely connected to the pseudonymised person and gradually delete the connections with the traversed nodes (which are necessarily unique);
- (d)
- Once the minimum-non-unique connection has been reached, all connections to any higher nodes in the hierarchy generated earlier must also be deleted. In doing so, it must be borne in mind that the relations may not be unique from this point onwards. If this is the case, in addition to removing the link with the person being processed, it is necessary to check whether this node is connected to only one other user and whether that user has already been processed, since, in that case, the relation must be deleted so that no re-identification is possible.
4.5. Adding a New Person
5. Evaluation
5.1. Experimental Scenarios
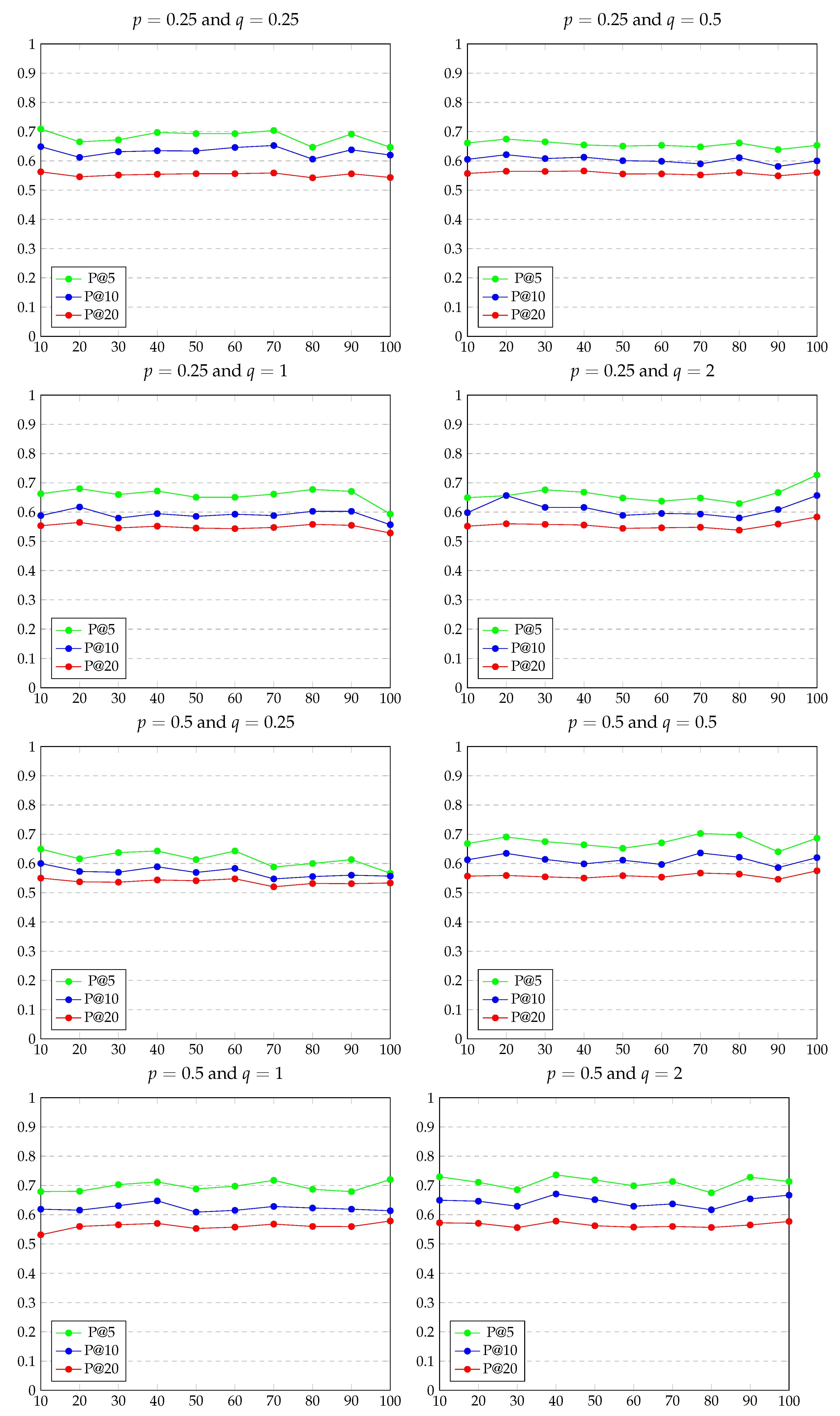
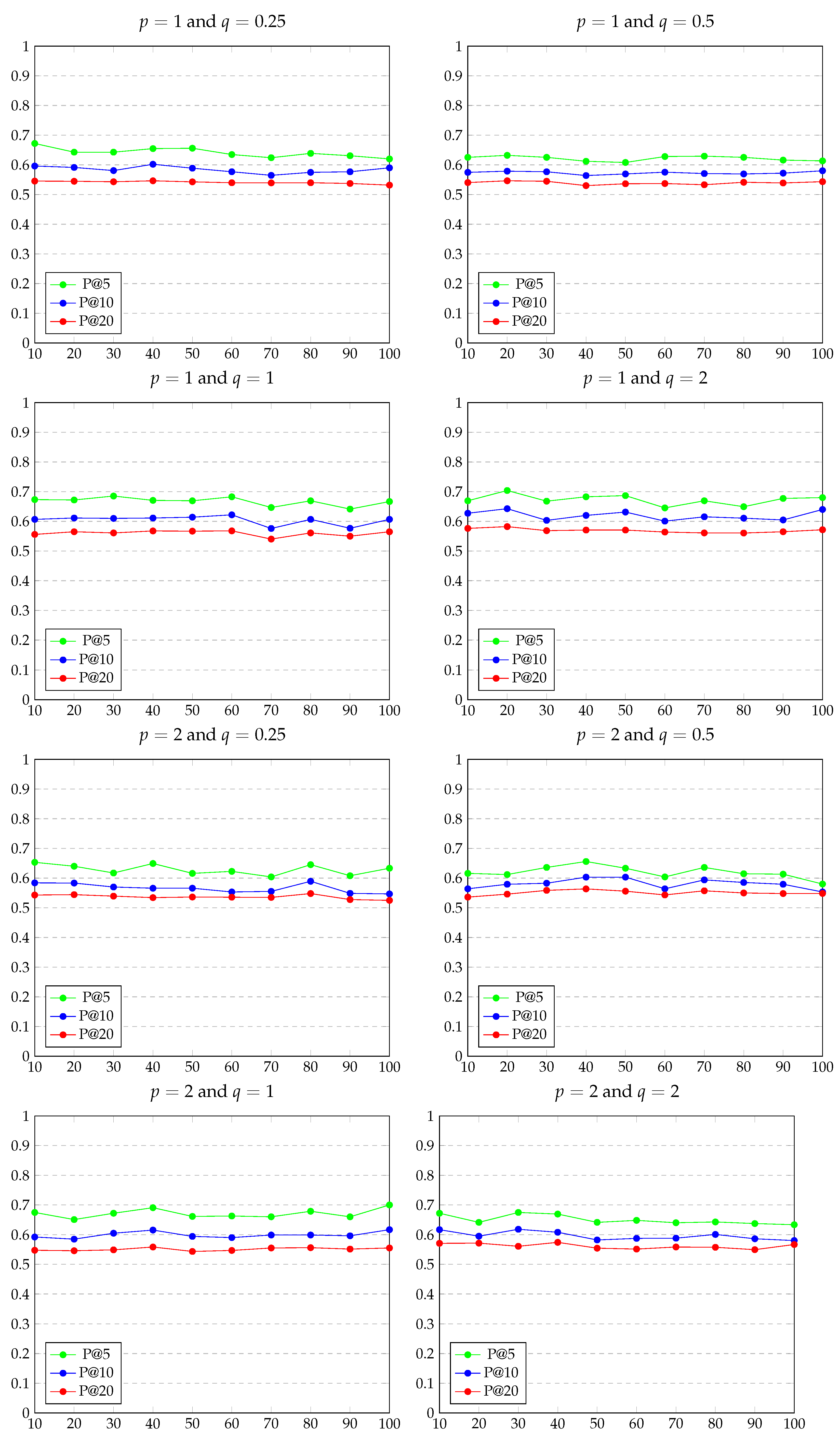
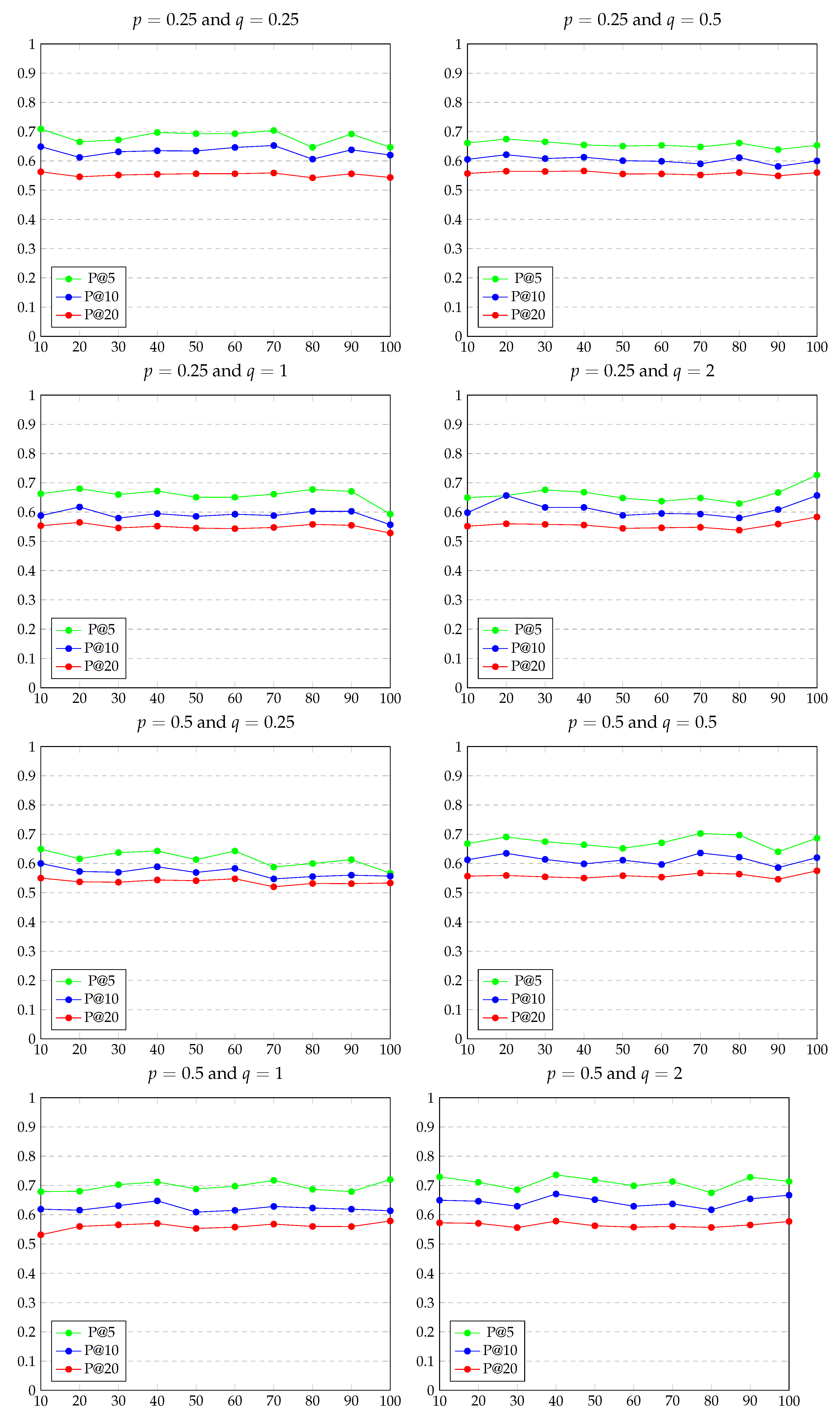
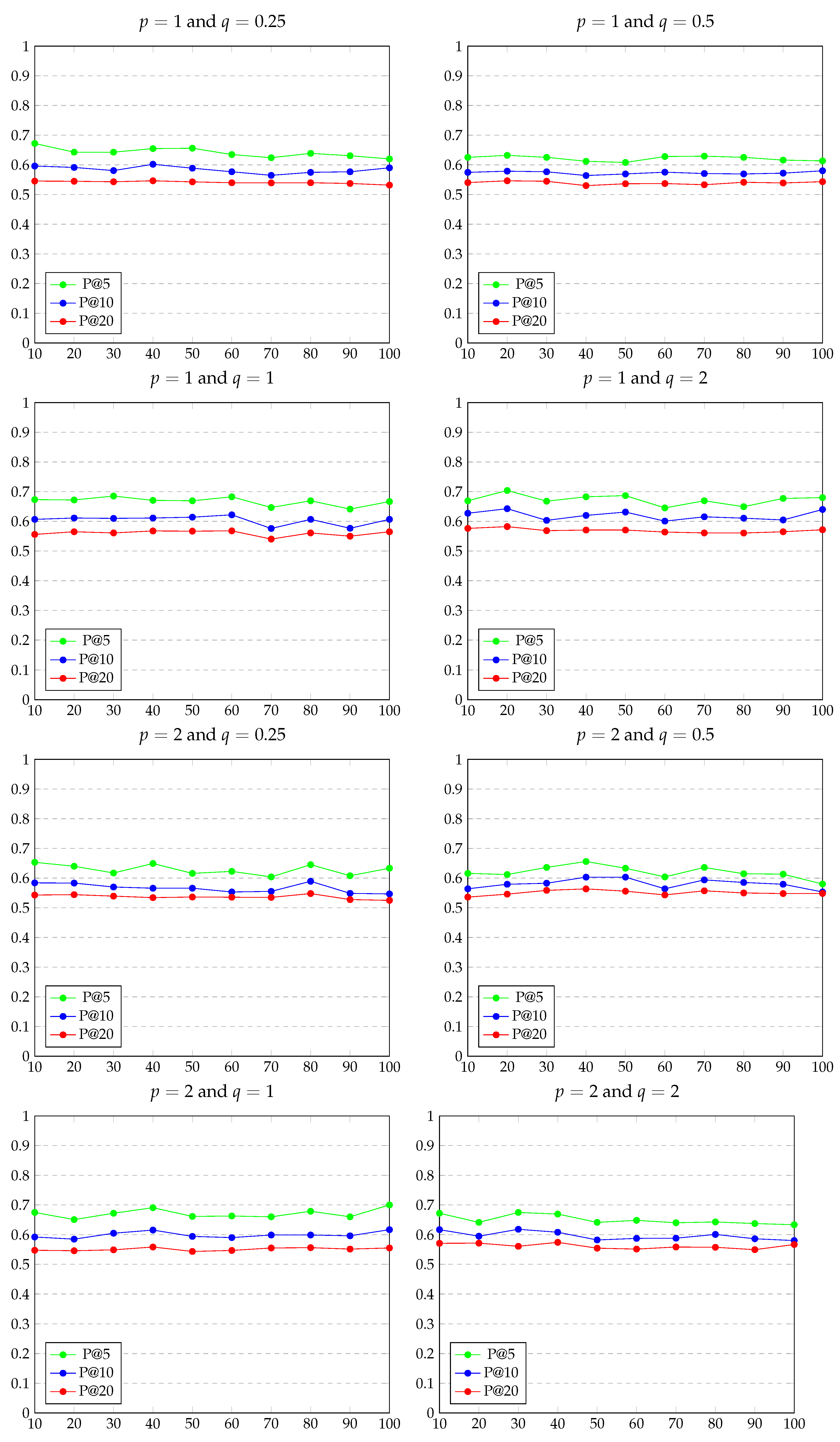
5.2. Experimental Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CPA | Chosen-plaintext attack |
| ENISA | European Union Agency for Cybersecurity (previously European Network and Information Security Agency) |
| GDPR | General Data Protection Regulation |
| GEI | Georg Eckert Institute for International Textbook Research |
| KG | Knowledge graph |
| NIST | (U.S.) National Institute of Standards and Technology |
| PII | Personally identifiable information |
| TTP | Trusted third party |
| UUID | Universally unique identifier |
Appendix A. Evaluation Results
References
- Pavan, M.; Lee, T.; De Luca, E.W. Semantic enrichment for adaptive expert search. In Proceedings of the 15th International Conference on Knowledge Technologies and Data-driven Business, Graz, Austria, 21–22 October 2015; Number Article 36 in i-KNOW’15. pp. 1–4. [Google Scholar]
- Mangaravite, V.; Santos, R.L.; Ribeiro, I.S.; Gonçalves, M.A.; Laender, A.H. The LExR collection for expertise retrieval in academia. In Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 721–724. [Google Scholar]
- Bai, X.; Wang, M.; Lee, I.; Yang, Z.; Xia, F.; Kong, X. Scientific Paper Recommendation: A Survey. IEEE Access 2019, 7, 9324–9339. [Google Scholar] [CrossRef]
- Hassan, H.A.M. Personalized research paper recommendation using deep learning. In Proceedings of the 25th Conference on User Modeling, Adaptation and Personalization, Bratislava, Slovakia, 9–10 July 2017; pp. 327–330. [Google Scholar]
- Yu, S.; Liu, J.; Yang, Z.; Chen, Z.; Jiang, H.; Tolba, A.; Xia, F. PAVE: Personalized Academic Venue recommendation Exploiting co-publication networks. J. Netw. Comput. Appl. 2018, 104, 38–47. [Google Scholar] [CrossRef]
- Ramakrishnan, N.; Keller, B.J.; Mirza, B.J.; Grama, A.Y.; Karypis, G. Privacy Risks in Recommender Systems. IEEE Internet Comput. 2001, 5, 54–62. [Google Scholar] [CrossRef] [Green Version]
- Lam, S.K.; Frankowski, D.; Riedl, J. Do You Trust Your Recommendations? An Exploration of Security and Privacy Issues in Recommender Systems. In Internation Conference on Emerging Trends in Information and Communication Security; Springer: Berlin/Heidelberg, Germany, 2006; pp. 14–29. [Google Scholar]
- Aghasian, E.; Garg, S.; Montgomery, J. User’s Privacy in Recommendation Systems Applying Online Social Network Data, A Survey and Taxonomy. In Big Data Recommender Systems: Recent Trends and Advances; The Institution of Engineering and Technology: London, UK, 2018; pp. 1–26. [Google Scholar]
- Jeckmans, A.J.P.; Beye, M.; Erkin, Z.; Hartel, P.; Lagendijk, R.L.; Tang, Q. Privacy in Recommender Systems. In Social Media Retrieval; Ramzan, N., van Zwol, R., Lee, J.S., Clüver, K., Hua, X.S., Eds.; Springer: London, UK, 2013; pp. 263–281. [Google Scholar]
- Wang, C.; Zheng, Y.; Jiang, J.; Ren, K. Toward Privacy-Preserving Personalized Recommendation Services. Engineering 2018, 4, 21–28. [Google Scholar] [CrossRef]
- Catherine, R.; Cohen, W. Personalized Recommendations using Knowledge Graphs: A Probabilistic Logic Programming Approach. In Proceedings of the 10th ACM Conference on Recommender Systems, RecSys ’16, Boston, MA, USA, 15–19 September 2016; pp. 325–332. [Google Scholar]
- Palumbo, E.; Rizzo, G.; Troncy, R. entity2rec: Learning User-Item Relatedness from Knowledge Graphs for Top-N Item Recommendation. In Proceedings of the Eleventh ACM Conference on Recommender Systems, RecSys ’17, Como, Italy, 27–31 August 2017; pp. 32–36. [Google Scholar]
- European Union Agency for Cybersecurity (ENISA). Pseudonymisation Techniques and Best Practices—Recommendations on Shaping Technology According to Data Protection and Privacy Provisions; Technical Report; ENISA: Attiki, Greece, 2019. [Google Scholar]
- Data Protection Focus Group. Requirements for the Use of Pseudonymisation Solutions in Compliance with Data Protection Regulations; Technical Report; German Society for Data Protection and Data Security: Bonn, Germany, 2018. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable Feature Learning for Networks. KDD 2016, 2016, 855–864. [Google Scholar] [PubMed] [Green Version]
- Wang, J.; Arriaga, A.; Tang, Q.; Ryan, P.Y.A. CryptoRec: Privacy-preserving Recommendation as a Service. arXiv 2018, arXiv:1802.02432. [Google Scholar]
- Kim, J.; Koo, D.; Kim, Y.; Yoon, H.; Shin, J.; Kim, S. Efficient Privacy-Preserving Matrix Factorization for Recommendation via Fully Homomorphic Encryption. Acm Trans. Priv. Secur. (TOPS) 2018, 21, 1–30. [Google Scholar] [CrossRef] [Green Version]
- Gentry, C. Fully homomorphic encryption using ideal lattices. In Proceedings of the Forty-First Annual ACM Symposium on Theory of Computing, STOC ’09, Bethesda, MD, USA, 31 May–2 June 2009; pp. 169–178. [Google Scholar]
- Aïmeur, E.; Brassard, G.; Fernandez, J.M.; Mani Onana, F.S. Alambic: A privacy-preserving recommender system for electronic commerce. Int. J. Inf. Secur. 2008, 7, 307–334. [Google Scholar] [CrossRef]
- Nikolaenko, V.; Ioannidis, S.; Weinsberg, U.; Joye, M.; Taft, N.; Boneh, D. Privacy-preserving matrix factorization. In Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, CCS ’13, Berlin, Germany, 4–8 November 2013; pp. 801–812. [Google Scholar]
- Badsha, S.; Yi, X.; Khalil, I. A Practical Privacy-Preserving Recommender System. Data Sci. Eng. 2016, 1, 161–177. [Google Scholar] [CrossRef] [Green Version]
- Desmedt, Y. ElGamal Public Key Encryption. In Encyclopedia of Cryptography and Security; van Tilborg, H.C.A., Jajodia, S., Eds.; Springer: Boston, MA, USA, 2011; p. 396. [Google Scholar]
- Liu, Z.; Wang, Y.X.; Smola, A. Fast Differentially Private Matrix Factorization. In Proceedings of the 9th ACM Conference on Recommender Systems, RecSys ’15, Vienna, Austria, 16–20 September 2015; pp. 171–178. [Google Scholar]
- McSherry, F.; Mironov, I. Differentially private recommender systems: Building privacy into the Netflix Prize contenders. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’09, Paris, France, 28 June–1 July 2009; pp. 627–636. [Google Scholar]
- Berlioz, A.; Friedman, A.; Kaafar, M.A.; Boreli, R.; Berkovsky, S. Applying Differential Privacy to Matrix Factorization. In Proceedings of the 9th ACM Conference on Recommender Systems, RecSys ’15, Vienna, Austria, 16–20 September 2015; pp. 107–114. [Google Scholar]
- Zhu, J.; He, P.; Zheng, Z.; Lyu, M.R. A Privacy-Preserving QoS Prediction Framework for Web Service Recommendation. In Proceedings of the 2015 IEEE International Conference on Web Services, New York, NY, USA, 27 June–2 July 2015; pp. 241–248. [Google Scholar]
- European Union Agency for Cybersecurity (ENISA). Recommendations on Shaping Technology According to GDPR Provisions—An Overview on Data Pseudonymisation; Technical Report; ENISA: Attiki, Greece, 2018. [Google Scholar]
- Pfitzmann, A.; Hansen, M. A Terminology for Talking about Privacy by Data Minimization: Anonymity, Unlinkability, Undetectability, Unobservability, Pseudonymity, and Identity Management. Technical Report; Dresden, Germany. 2010. Available online: https://dud.inf.tu-dresden.de/literatur/Anon_Terminology_v0.34.pdf (accessed on 18 August 2021).
- Stalla-Bourdillon, S.; Knight, A. Anonymous Data v. Personal Data—A False Debate: An EU Perspective on Anonymization, Pseudonymization and Personal Data. Wis. Int. Law J. 2017, 34, 284. [Google Scholar]
- Lehmann, A. ScrambleDB: Oblivious (Chameleon) Pseudonymization-as-a-Service. Proc. Priv. Enhancing Technol. 2019, 2019, 289–309. [Google Scholar] [CrossRef] [Green Version]
- Friedrich, M.; Köhn, A.; Wiedemann, G.; Biemann, C. Adversarial Learning of Privacy-Preserving Text Representations for De-Identification of Medical Records. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July 2019; pp. 5829–5839. [Google Scholar]
- Richter-Pechanski, P.; Amr, A.; Katus, H.A.; Dieterich, C. Deep Learning Approaches Outperform Conventional Strategies in De-Identification of German Medical Reports. Stud. Health Technol. Inform. 2019, 267, 101–109. [Google Scholar]
- Eder, E.; Krieg-Holz, U.; Hahn, U. CodE Alltag 2.0—A Pseudonymized German-Language Email Corpus. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 4466–4477. [Google Scholar]
- Štarchoň, P.; Pikulík, T. GDPR principles in Data protection encourage pseudonymization through most popular and full-personalized devices - mobile phones. Procedia Comput. Sci. 2019, 151, 303–312. [Google Scholar] [CrossRef]
- Yao, Y.; Liu, J. On privacy-preserving context-aware recommender system. Int. J. Hybrid Inf. Technol. 2015, 8, 27–40. [Google Scholar] [CrossRef]
- Rana, C.; Jain, S.K. A study of the dynamic features of recommender systems. Artif. Intell. Rev. 2015, 43, 141–153. [Google Scholar] [CrossRef]
- Rana, C.; Shokeen, J. A review on the dynamics of social recommender systems. Int. J. Web Eng. Technol. 2018, 13, 255. [Google Scholar] [CrossRef]
- Koren, Y. Collaborative filtering with temporal dynamics. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’09, Paris, France, 28 June–1 July 2009; pp. 447–456. [Google Scholar]
- Jannach, D.; Ludewig, M. When Recurrent Neural Networks meet the Neighborhood for Session-Based Recommendation. In Proceedings of the 11th ACM Conference on Recommender Systems, RecSys ’17, Como, Italy, 27–31 August 2017; pp. 306–310. [Google Scholar]
- Quadrana, M.; Karatzoglou, A.; Hidasi, B.; Cremonesi, P. Personalizing Session-based Recommendations with Hierarchical Recurrent Neural Networks. In Proceedings of the Eleventh ACM Conference on Recommender Systems, RecSys ’17, New York, NY, USA, 27–31 August 2017; pp. 130–137. [Google Scholar]
- You, J.; Wang, Y.; Pal, A.; Eksombatchai, P.; Rosenberg, C.; Leskovec, J. Hierarchical Temporal Convolutional Networks for Dynamic Recommender Systems. In Proceedings of the The World Wide Web Conference 2019, San Francisco, CA, USA, 13–17 May 2019; pp. 2236–2246. [Google Scholar]
- Adomavicius, G.; Tuzhilin, A. Context-Aware Recommender Systems. In Recommender Systems Handbook; Ricci, F., Rokach, L., Shapira, B., Kantor, P.B., Eds.; Springer: Boston, MA, USA, 2011; pp. 217–253. [Google Scholar]
- Varatharajah, Y.; Chen, H.; Trotter, A.; Iyer, R. A dynamic human-in-the-loop recommender system for evidence-based clinical staging of COVID-19. In Proceedings of the 5th International Workshop on Health Recommender Systems, Rio de Janeiro, Brazil, 26 September 2020; Volume 2684, pp. 21–22. [Google Scholar]
- Erkin, Z.; Veugen, T.; Lagendijk, R.L. Privacy-preserving recommender systems in dynamic environments. In Proceedings of the 2013 IEEE International Workshop on Information Forensics and Security (WIFS), Guangzhou, China, 18–21 November 2013; pp. 61–66. [Google Scholar]
- Zhu, T.; Li, J.; Hu, X.; Xiong, P.; Zhou, W. The Dynamic Privacy-preserving Mechanisms for Online Dynamic Social Networks. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef]
- United States Government Accountability Office (GAO). Privacy: Alternatives Exist for Enhancing Protection of Personally Identifiable Information (GAO-08-536); Technical Report; United States Government Accountability Office (GAO): Washington, DC, USA, 2008. [Google Scholar]
- Garfinkel, S.L. De-Identification of Personal Information; Technical Report; National Institute of Standards and Technology Internal Report 8053: Gaithersburg, MD, USA, 2015. [Google Scholar]
- Almeida, F.; Xexéo, G. Word embeddings: A survey. arXiv 2019, arXiv:1901.09069. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Rachmawati, D.; Tarigan, J.T.; Ginting, A.B.C. A comparative study of Message Digest 5(MD5) and SHA256 algorithm. J. Phys. Conf. Ser. 2018, 978, 012116. [Google Scholar] [CrossRef]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Honnibal, M.; Montani, I.; Van Landeghem, S.; Boyd, A. spaCy: Industrial-strength Natural Language Processing in Python. Web documentation. 2020. Available online: https://spacy.io/ (accessed on 18 August 2021).
- Kusner, M.; Sun, Y.; Kolkin, N.; Weinberger, K. From word embeddings to document distances. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6–11 July 2015; pp. 957–966. [Google Scholar]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. Bertscore: Evaluating text generation with bert. arXiv 2019, arXiv:1904.09675. [Google Scholar]
- Beltagy, I.; Lo, K.; Cohan, A. SciBERT: A pretrained language model for scientific text. arXiv 2019, arXiv:1903.10676. [Google Scholar]
- European Union Agency for Cybersecurity (ENISA). Privacy and Data Protection by Design—From Policy to Engineering; Technical Report; ENISA: Attiki, Greece, 2014. [Google Scholar]
- Palumbo, E.; Rizzo, G.; Troncy, R.; Baralis, E.; Osella, M.; Ferro, E. Knowledge graph embeddings with node2vec for item recommendation. In Proceedings of the 15th European Semantic Web Conference, Heraklion, Greece, 3–7 June 2018; pp. 117–120. [Google Scholar]
- Pavan, M.; De Luca, E.W. Semantic-based expert search in textbook research archives. In Proceedings of the 5th International Workshop on Semantic Digital Archives, Poznan, Poland, 18 September 2015. [Google Scholar]

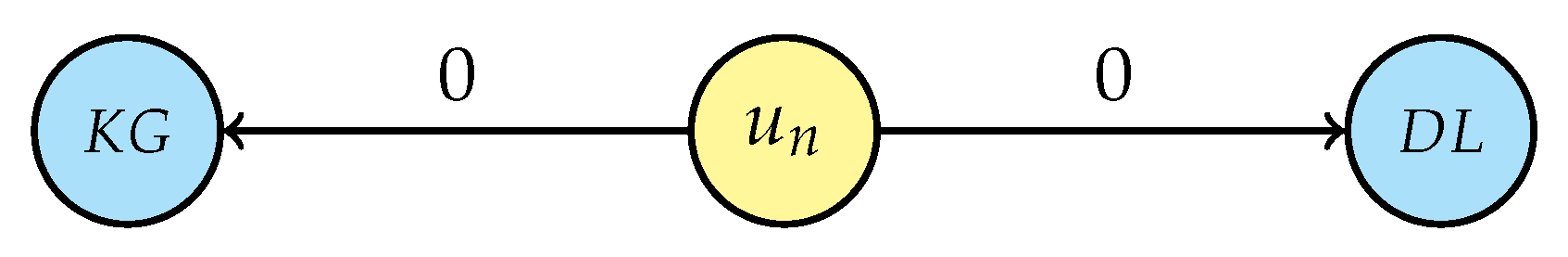


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Replacement Strategy | Entropy |
|---|---|
| None (Baseline) | 5.934 |
| Word2Vec (Static; Nouns) | 5.560 |
| SciBERT (Context; H; Nouns) | 5.549 |
| SciBERT (Context: H; Nouns/Adjectives) | 5.591 |
| SciBERT (Context; H + Synonyms + Domains; Nouns/Adjectives) | 5.874 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Purificato, E.; Wehnert, S.; De Luca, E.W. Dynamic Privacy-Preserving Recommendations on Academic Graph Data. Computers 2021, 10, 107. https://doi.org/10.3390/computers10090107
Purificato E, Wehnert S, De Luca EW. Dynamic Privacy-Preserving Recommendations on Academic Graph Data. Computers. 2021; 10(9):107. https://doi.org/10.3390/computers10090107
Chicago/Turabian StylePurificato, Erasmo, Sabine Wehnert, and Ernesto William De Luca. 2021. "Dynamic Privacy-Preserving Recommendations on Academic Graph Data" Computers 10, no. 9: 107. https://doi.org/10.3390/computers10090107
APA StylePurificato, E., Wehnert, S., & De Luca, E. W. (2021). Dynamic Privacy-Preserving Recommendations on Academic Graph Data. Computers, 10(9), 107. https://doi.org/10.3390/computers10090107