
CAT-CAD: A Computer-Aided Diagnosis Tool for Cataplexy



Abstract
1. Introduction
- Automatic detection of cataplexy symptoms (ptosis, head-drop, mouth opening).
- Real-time video analysis, to provide instantaneous alerts to the patient treating doctor or parents.
- Video playback functionalities, to allow the neurologist to carefully investigate patient videos, possibly focusing only on sequences where symptoms were detected by automatic analysis. This has also to be complemented with the simultaneous analysis of automatically extracted symptom detections, so that results of video analysis must be displayed during the video playback.
- Similarity-based video retrieval, to allow comparing the video of the patient currently under analysis with videos of patients with similar behavioral patterns.
- We introduce the CAT-CAD tool for the automatic recognition of cataplexy symptoms from patients’ video recordings.
- We present the CAT-CAD GUI, showing its advanced functionalities for video playback and browsing/retrieval.
- We detail the pattern-based technique used to automatically analyze videos, able to recognize facial patterns.
- We introduce a novel approach for the detection of motor phenomena, based on convolutional neural networks.
- We provide results obtained from an extensive experimental evaluation to compare the performance of the two video analysis approaches, using a benchmark containing recordings from real patients.
2. Related Work
2.1. Detection of Motor Phenomena
2.2. Deep Learning for Analysis of Medical Images/Videos
3. The CAT-CAD Tool
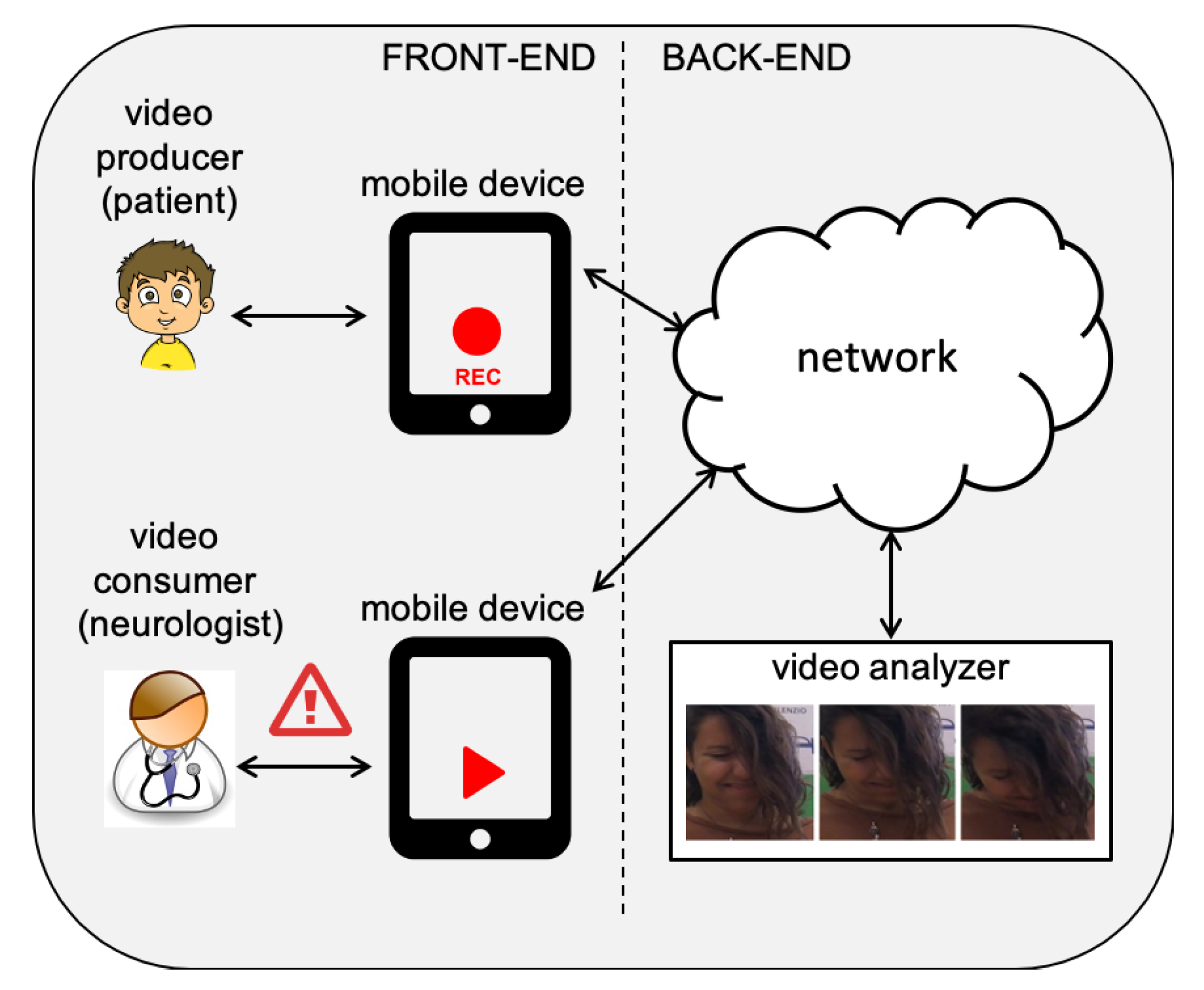
- Patients play the role of “video producers”, when videos are recorded (by exploiting a mobile device, such as an iPad/iPhone) showing their face during the vision of funny movies designed to evoke the laughter, thus providing emotional stimulation.
- Neurologists are “video consumers”, receiving the output of visual analysis performed on their patients, such as the automatic “alert” generation in case of positive classification of the disease symptoms.
- automatic recognition of motor behaviors patterns to detect cataplexy symptoms, and
- video recordings searching and browsing facilities.
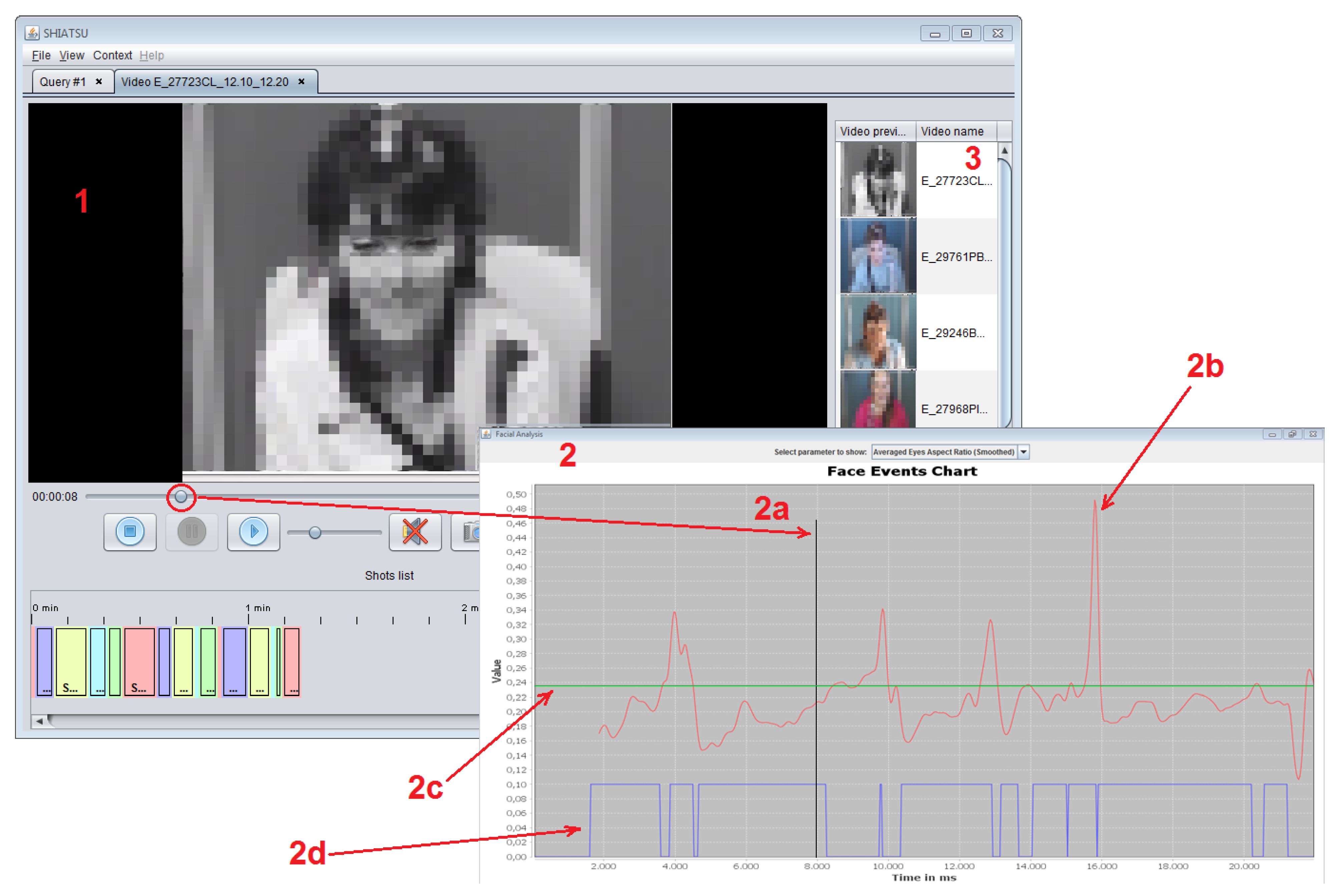
- The central part represents the area where videos are played and contains playback control buttons; at the bottom of this area, the automatically segmented video shots are reported.
- The external panel displays the face events chart, where the selected feature for the current patient is shown; graphs contained in this view include:
- (a)
- The vertical timeline, highlighting the current time value which is synchronized with the video playback.
- (b)
- The time series of the currently selected feature (in the figure, the Eye Aspect Ratio (EAR), see Section 4.1.1).
- (c)
- The reference value for the displayed feature.
- (d)
- The binary time series that indicates whether the selected motor phenomenon is detected or not for the current patient.
- The right vertical panel contains videos which are similar to the currently displayed one; similarity between two videos is asserted by comparing the percentage of frames where the selected motor phenomenon is detected, and videos are sorted for decreasing values of similarity.
4. Methods
- The Pattern-Based approach is presented in Section 4.1.
- The Deep-Learning approach is detailed in Section 4.2.
- Section 4.3 describes the setup used in the experiments.
4.1. Video Analyzer Back-End: Pattern-Based Approach
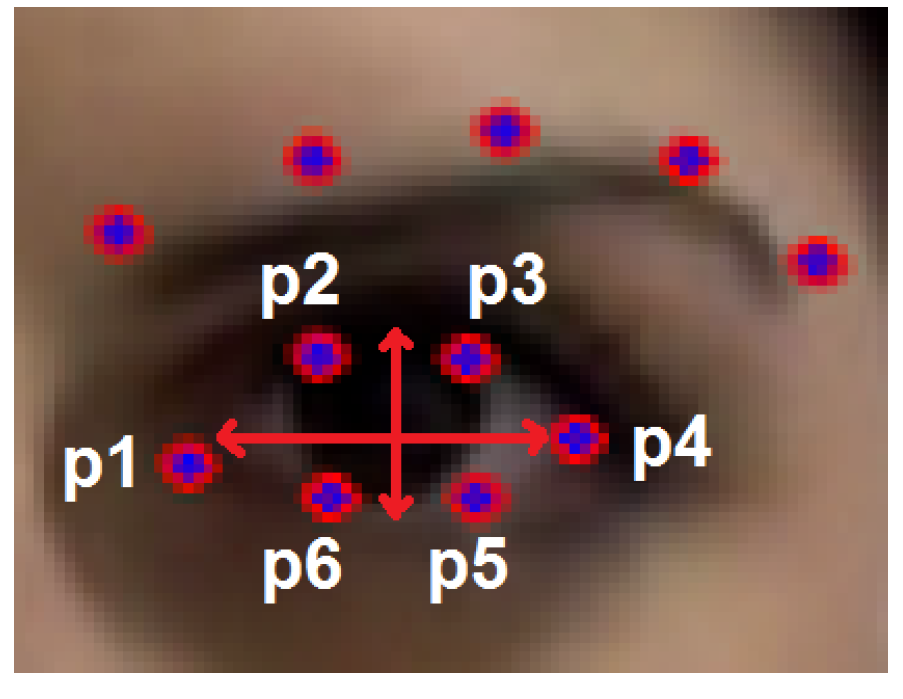
4.1.1. Ptosis
| Algorithm 1 Ptosis Detection |
|
4.1.2. Head-Drop
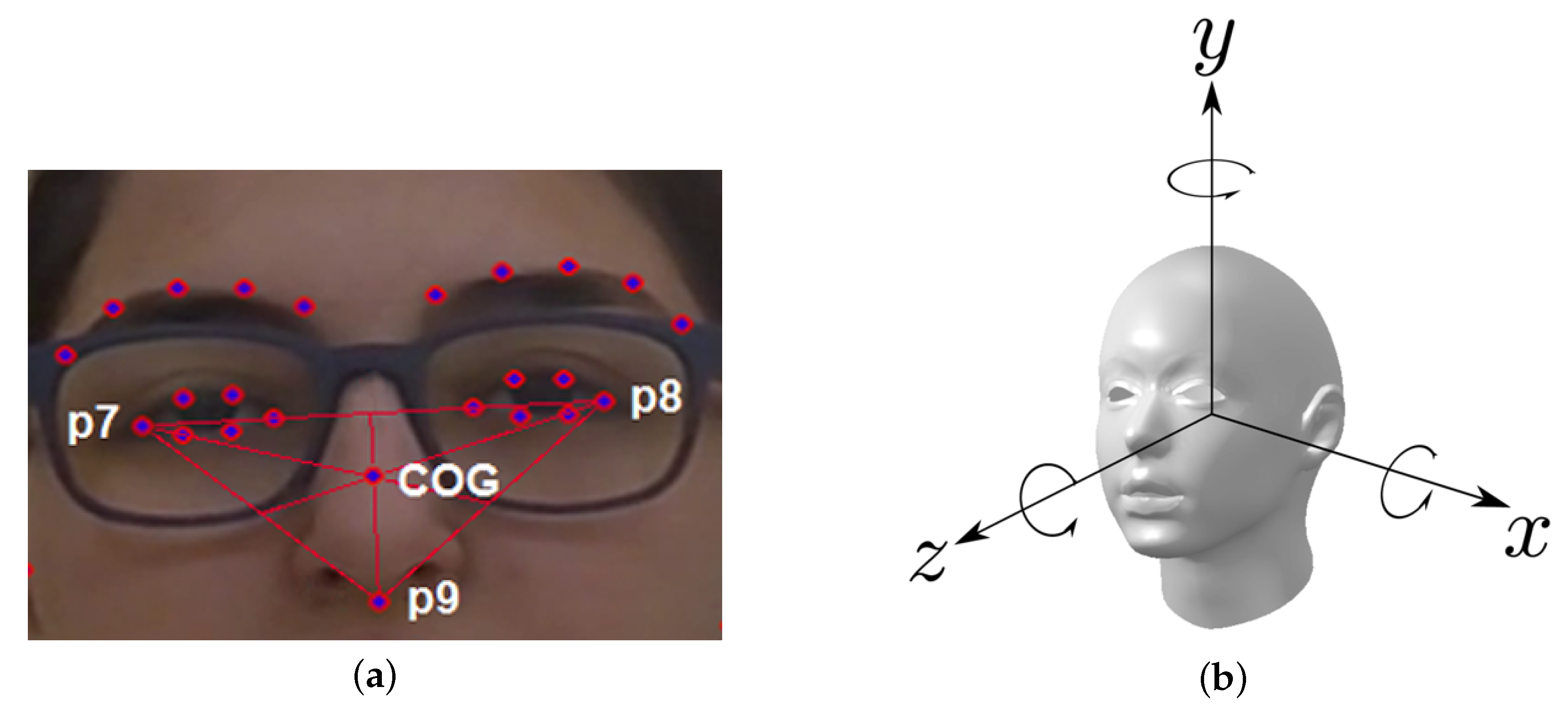
- The head moves down, i.e., the (relative) value of the CoG y coordinate increases too much (as we measure y coordinates from the top of the frame downward).
- The head moves up or backward, i.e., the (relative) value of the CoG y coordinate decreases too much.
- Excessive head rotation around the X axis.
- Excessive head rotation around the Z axis.
| Algorithm 2 Head-Drop Detection |
|
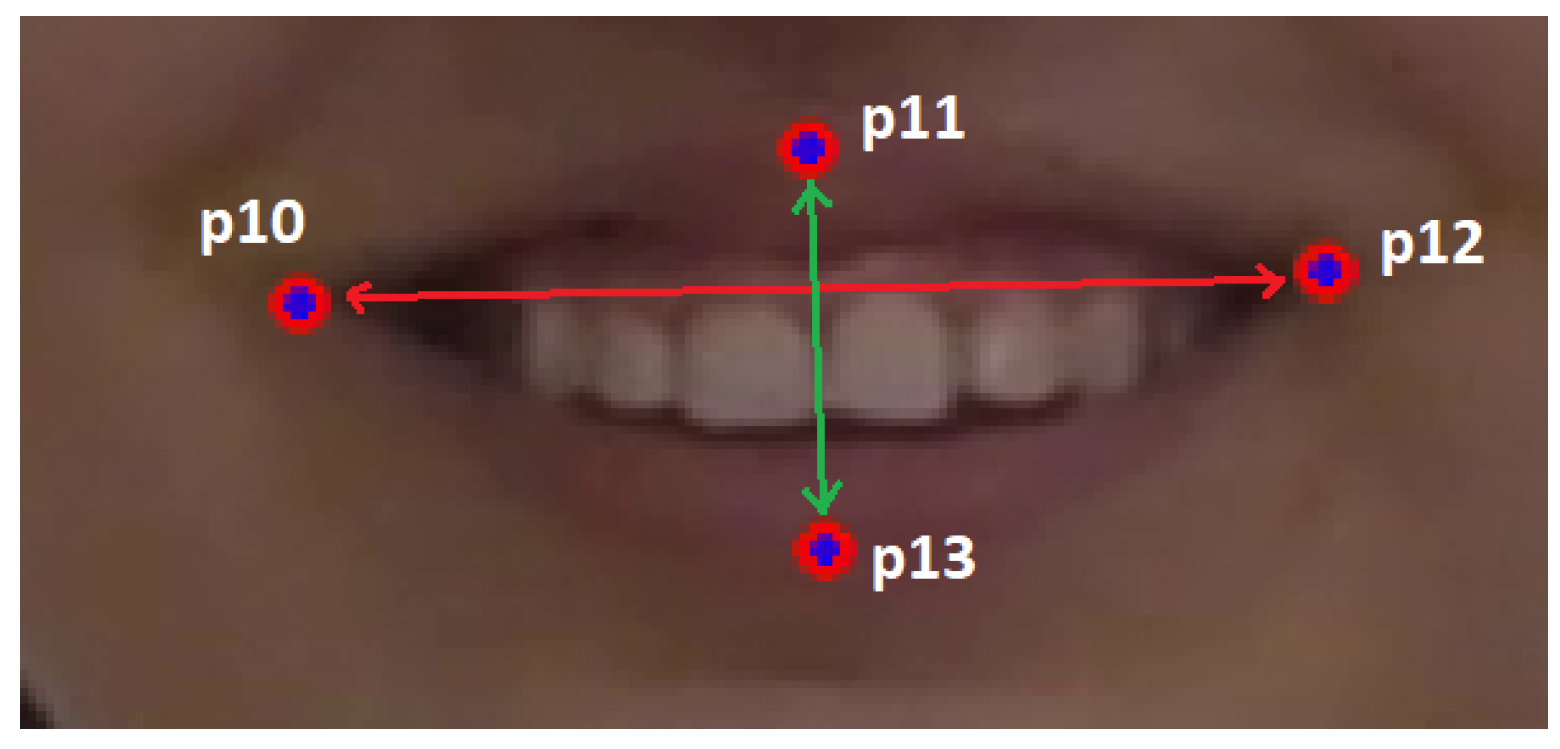
4.1.3. Smile/Mouth Opening
| Algorithm 3 Mouth Opening Detection |
4.2. Video Analyzer Back-End: Deep-Learning Approach
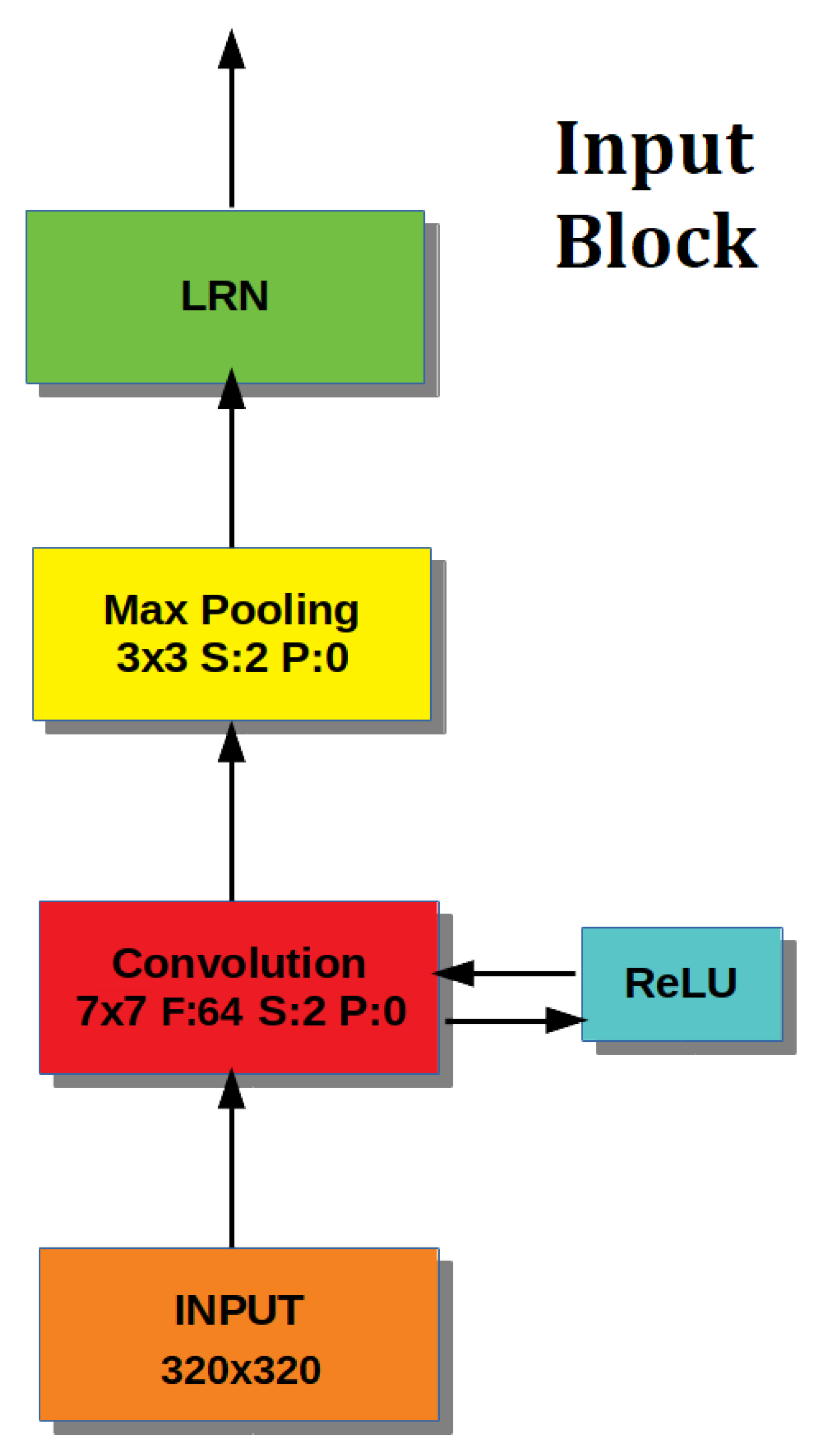
- an Input Block, which performs image pre-processing,
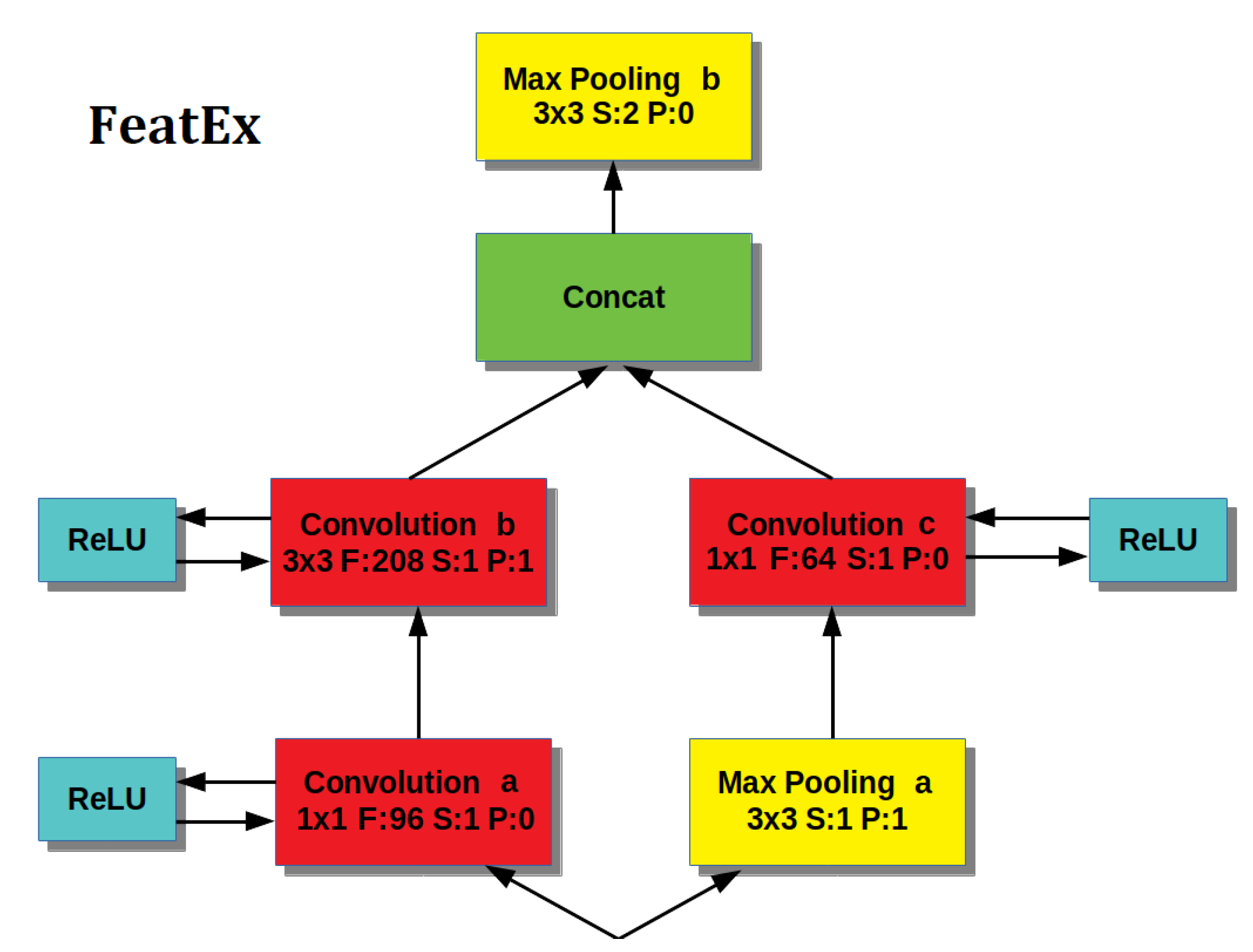
- a Feature Extraction Block, inspired by the architectural principles introduced by GoogleNet, which is repeated four times, and
- an Output Block, which is used to produce the result class from the features extracted by previous layers.
4.2.1. Input Block
4.2.2. Feature Extraction Block
- The left path provides a first Convolutional layer that uses a filter to perform a bitwise analysis of the image, enhanced by a ReLU layer to create the desired sparseness [33], then the output is processed by a Convolutional layer with a filter of size , enhanced by a ReLU layer.
- The right path provides a Max Pooling layer (with filter size) to reduce information followed by a (ReLU enhanced) Convolutional layer with filter size.
- The output of the two paths represents face features at different scales and are concatenated together for a richer representation of the input image.
- Finally, the feature concatenation is input to a layer of Max Pooling (with filter size or in the last FeatEx block), which reduces the output size.
4.2.3. Output Block
4.3. Experimental Setup
- We first describe the population of subjects included in the study (Section 4.3.1).
- Then, we provide details on the video recordings used in the experiments (Section 4.3.2).
- Finally, we describe the performance measures used to assess the accuracy of the proposed approaches (Section 4.3.3).
4.3.1. Population
4.3.2. Video Recording and Labeling
4.3.3. Performance Measures
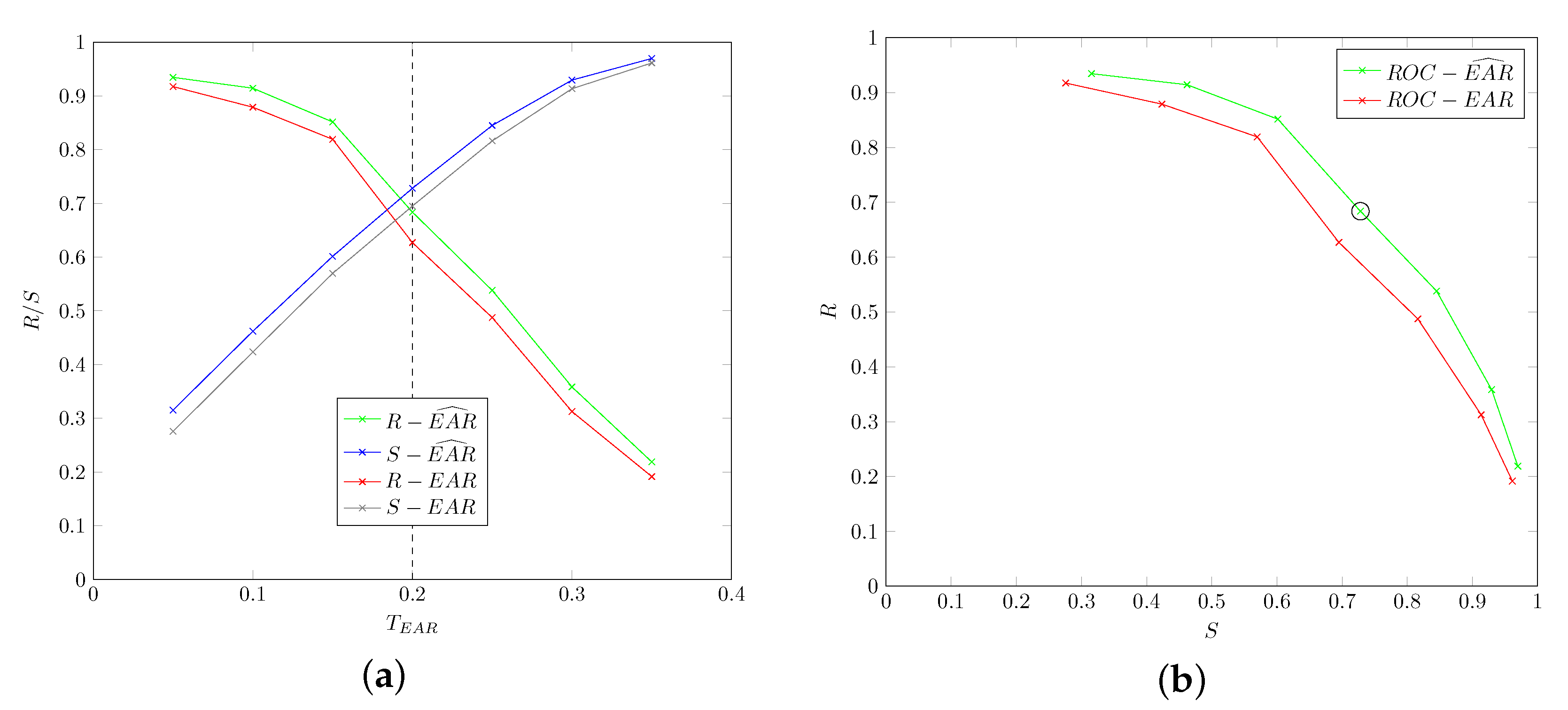
- Recall/Sensitivity (R): is defined as the fraction of the frames showing signs of the disease (positives) that are correctly identified. R is therefore used to measure the accuracy of a technique in recognizing the presence of the disease:
- Specificity (S): is computed as the ratio of frames not showing the disease (negatives) that are correctly classified. S thus expresses the ability of a technique to avoid false alarms (which can lead to expensive/invasive exams):
- Precision (P): is another popular metric, besides R and S, which are the fundamental prevalence-independent statistics. P is defined as the fraction of correct positively classified frames and assesses the predictive power of the classifier:
- Accuracy (A): measures the fraction of correct decisions, to assess the overall effectiveness of the algorithm:
- Balanced Score (): is a commonly used measure, combining P and R in a single metric computed as their harmonic mean:
- A in the detection of any symptom will always correspond to a in the overall detection.
- Either a or a in the detection of a motor phenomenon can be transformed in a in the disease detection, because another symptom has been detected. A can be corrected by the detection of another motor phenomenon, while a can be corrected by the fact that a cataplectic attack is nevertheless present, due to the actual presence of another motor phenomenon.
- A in the detection of a symptom can correspond to a , a , or a , according to a correct/incorrect detection of another symptom.
5. Results
- We first detail the procedure used to derive the optimal values for thresholds used by the pattern-based approach (Section 5.1).
- Then, we describe the data augmentation procedure necessary to train the CNNs for the deep-learning approach (Section 5.2).
- The overall performance of the two approaches is finally presented in Section 5.3.
5.1. Parameter Tuning
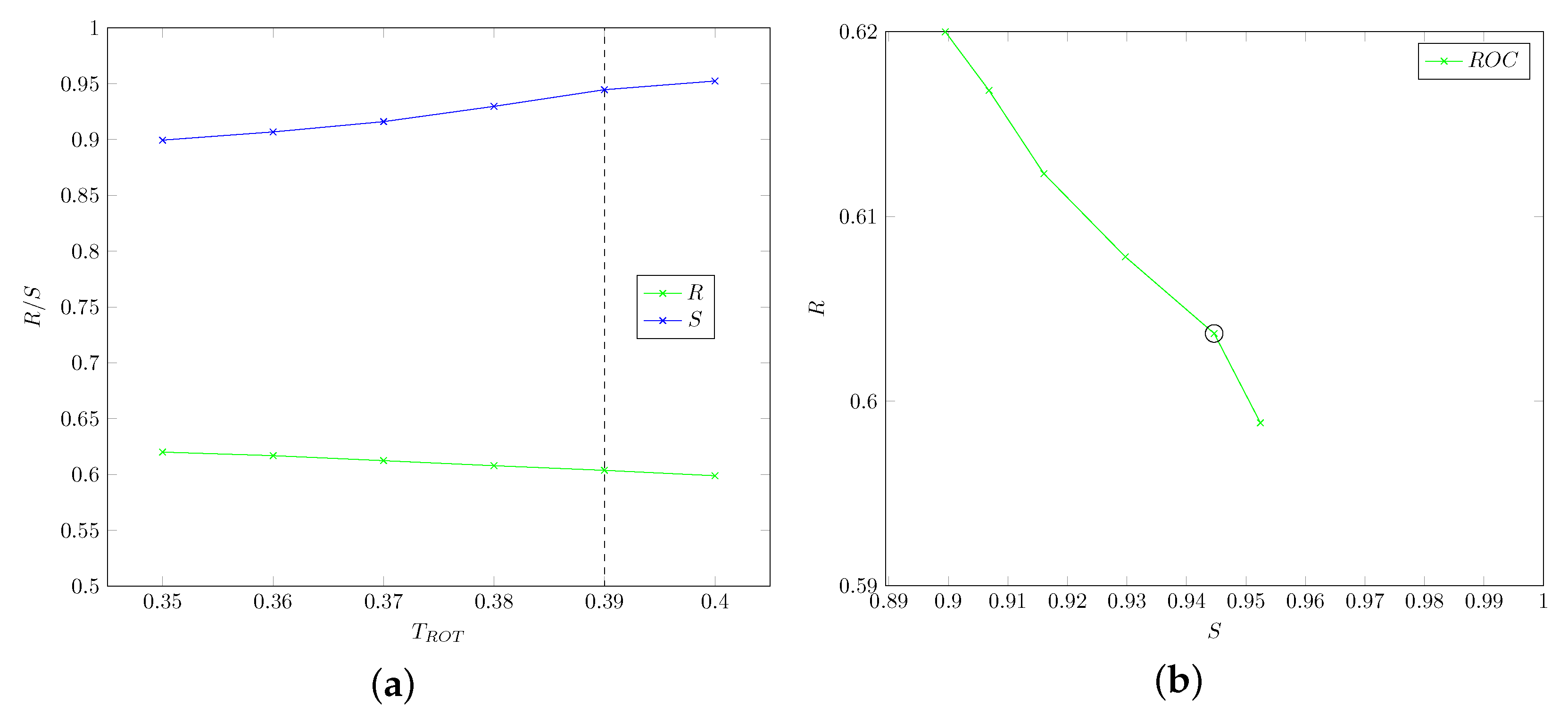
5.1.1. Ptosis: Threshold
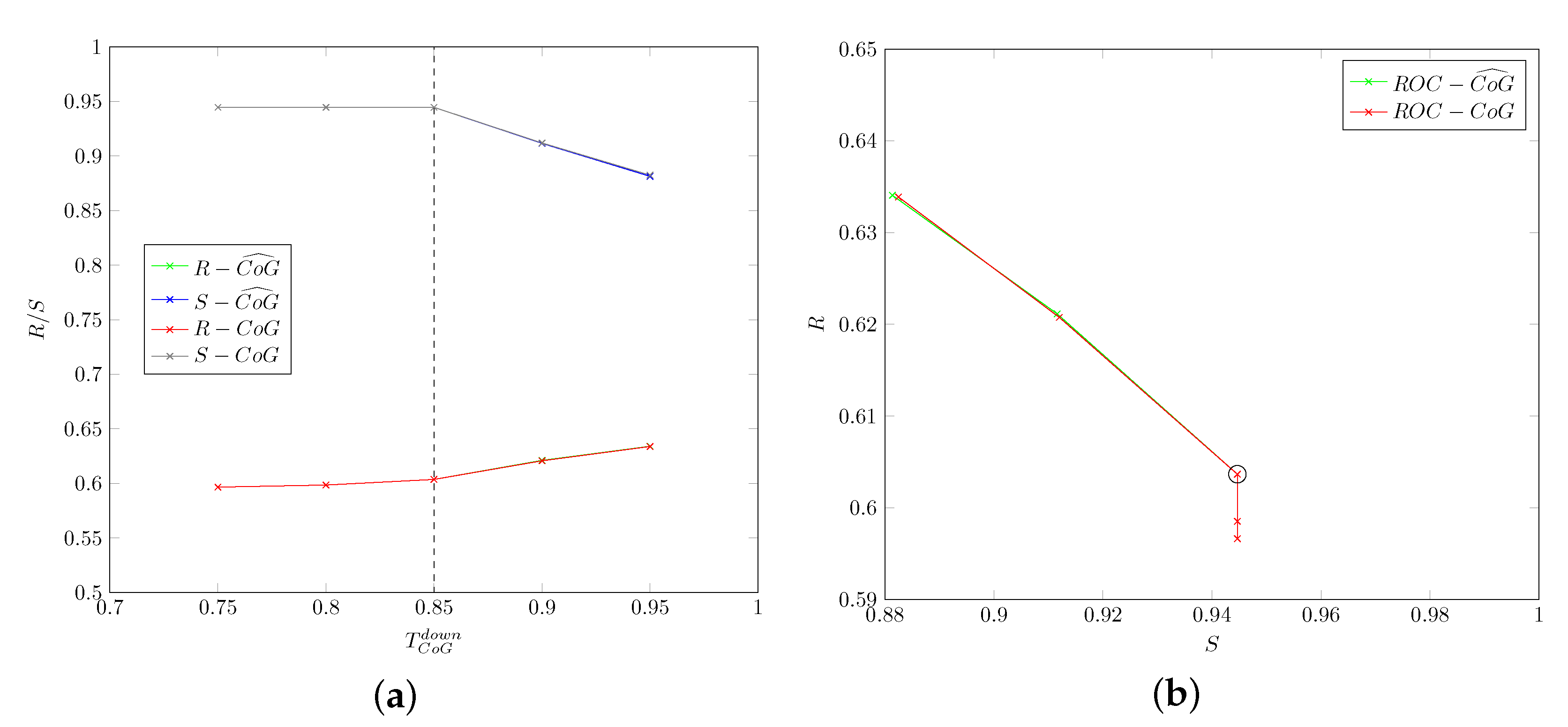
5.1.2. Head-Drop: Thresholds , ,
- that the use of smoothed values does not improve accuracy for the considered data.
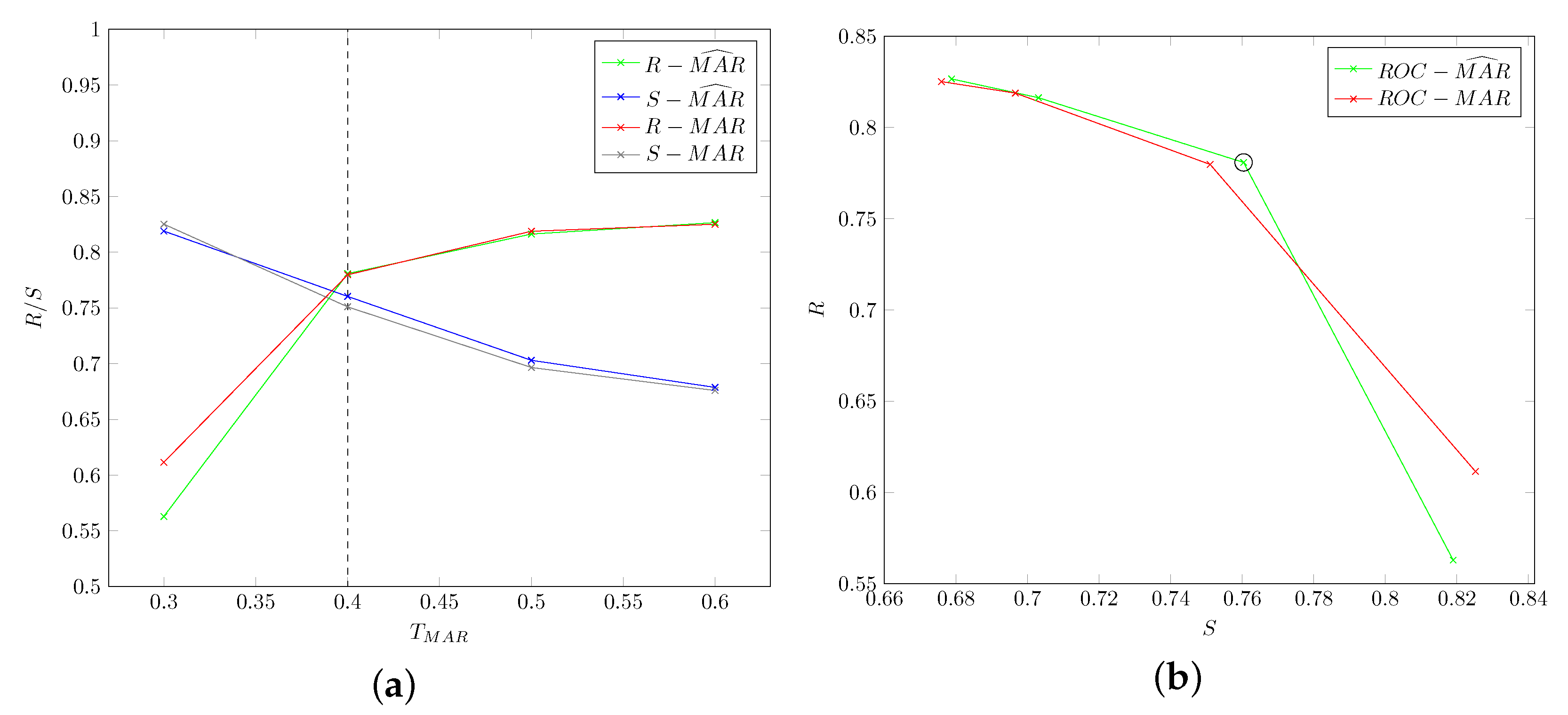
5.1.3. Mouth Open: Threshold
5.2. Data Augmentation Procedure
- 3 rotations with a random angle between −45 and +45,
- 3 translations with a random shift between −50 and 50 pixels, and
- 1 horizontal flipping.
- Ptosis: 191140 labeled images.
- Head-Drop: 61216 labeled images.
- Mouth Opening: 108196 labeled images.
5.3. Overall Performance
5.3.1. Pattern-Based Approach
5.3.2. Deep-Learning Approach
6. Discussion
- The pattern-based approach led to significantly superior results with respect to its deep-learning counterpart. In particular, for cataplectic subjects the former attains the best performance in 85% of the metrics (17 out of performance measures).
- When considering specific motor phenomena, the pattern-based approach consistently outperforms the deep-learning approach in detecting ptosis, while the latter sports superior measures only for specificity and precision in detecting mouth opening and for recall in head-drop detection.
- The superior specificity of the pattern-based technique is confirmed in non-cataplectic subjects.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Background
- the SHIATSU framework for video retrieval and analysis,
- the OpenFace library for detection of face landmarks,
- Convolutional Neural Networks (CNNs), which are the basic technology for the deep-learning approach, and
- the Tensorflow library, which was used to implement CNNs.
Appendix A.1. The SHIATSU Framework
- The visual features extractor is used to automatically extract visual features from video frames, exploiting functionalities of the Windsurf library [41].
- The annotation processor implements algorithms for the automatic tagging of videos by exploiting video features.
- The query processor contains the logic for retrieval of videos based on semantics (tags) and/or similarity (features).
- Splitting of videos into individual frames.
- Video playback.
- Persistence of video and metadata (labels manually entered by the neurologist or automatically extracted by the video analyzers) exploiting the MySQL RDBMS.
- Video retrieval based on tags: in particular, the multi-dimensional tagging approach already present in SHIATSU allows the coherent and seamless management of the 3-D tagging in CAT-CAD. This is because a single frame could be tagged to reflect the presence of any of the three independent motor phenomena.
- Feature-based video retrieval: since the feature used to assess similarity in CAT-CAD (percentage of presence of a specific motor phenomenon, see Section 3) is simpler than the visual features commonly exploited in SHIATSU, the query processor has been properly extended to exploit indexing functionalities of the underlying DBMS.
Appendix A.2. OpenFace
- Sample a region from the image around the current estimate.
- For each keypoint, generate a response image giving a cost for having the point at each pixel.
- Search for a combination of points optimizing the total cost, by manipulating the shape model parameters.
- a Point Distribution Model (PDM),
- local detectors that evaluate the probability of a landmark being aligned at a particular pixel location, and
- the fitting strategy to be used.
- a PDM which captures landmark shape variations, and
- local detectors which capture local appearance variations of each landmark.
Appendix A.3. Convolutional Neural Networks
Appendix A.3.1. Convolutional
Appendix A.3.2. Max Pooling
Appendix A.3.3. Rectified Linear Unit
Appendix A.3.4. Local Response Normalization
Appendix A.3.5. Fully Connected
Appendix A.3.6. Output
Appendix A.4. Tensorflow
References
- Plazzi, G.; Pizza, F.; Palaia, V.; Franceschini, C.; Poli, F.; Moghadam, K.K.; Cortelli, P.; Nobili, L.; Bruni, O.; Dauvilliers, Y.; et al. Complex Movement Disorders at Disease Onset in Childhood Narcolepsy with Cataplexy. Brain J. Neurol. 2011, 134, 3480–3492. [Google Scholar] [CrossRef] [PubMed]
- American Academy of Sleep Medicine. The International Classification of Sleep Disorders, 3rd ed.; (ICSD-3); Elsevier: San Diego, CA, USA, 2014. [Google Scholar]
- Anic-Labat, S.; Guilleminault, C.; Kraemer, H.C.; Meehan, J.; Arrigoni, J.; Mignot, E. Validation of a Cataplexy Questionnaire in 983 Sleep-Disorders Patients. Sleep 1999, 22, 77–87. [Google Scholar]
- Pizza, F.; Antelmi, E.; Vandi, S.; Meletti, S.; Erro, R.; Baumann, C.R.; Bhatia, K.P.; Dauvilliers, Y.; Edwards, M.J.; Iranzo, A.; et al. The Distinguishing Motor Features of Cataplexy: A Study from Video-Recorded Attacks. Sleep 2018, 41, zsy026. [Google Scholar] [CrossRef] [PubMed]
- Lazli, L.; Boukadoum, M.; Mohamed, O.A. A Survey on Computer-Aided Diagnosis of Brain Disorders through MRI Based on Machine Learning and Data Mining Methodologies with an Emphasis on Alzheimer Disease Diagnosis and the Contribution of the Multimodal Fusion. Appl. Sci. 2020, 10, 1894. [Google Scholar] [CrossRef]
- Bartolini, I.; Di Luzio, A. Towards Automatic Recognition of Narcolepsy with Cataplexy. In Proceedings of the 15th ACM International Conference on Advances in Mobile Computing & Multimedia (MoMM2017), Salzburg, Austria, 4–6 December 2017. [Google Scholar]
- Mandal, B.; Li, L.; Wang, G.S.; Lin, J. Towards Detection of Bus Driver Fatigue Based on Robust Visual Analysis of Eye State. IEEE Trans. Intell. Transp. Syst. 2017, 18, 545–557. [Google Scholar] [CrossRef]
- Bakheet, S.; Al-Hamadi, A. A Framework for Instantaneous Driver Drowsiness Detection Based on Improved HOG Features and Naïve Bayesian Classification. Brain Sci. 2021, 11, 240. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Jo, J.; Jung, H.G.; Ryoung, K.; Kim, J. Vision-Based Method for Detecting Driver Drowsiness and Distraction in Driver Monitoring System. Opt. Eng. 2011, 50, 127202. [Google Scholar] [CrossRef]
- Yao, K.; Lin, W.; Fang, C.; Wang, J.; Chang, S.; Chen, S. Real-Time Vision-Based Driver Drowsiness/Fatigue Detection System. In Proceedings of the 71st IEEE Vehicular Technology Conference Proceedings (VTC 2010), Taipei, Taiwan, 16–19 May 2010. [Google Scholar]
- Bergasa, L.M.; Buenaposada, J.M.; Nuevo, J.; Jimenez, P.; Baumela, L. Analysing Driver’s Attention Level Using Computer Vision. In Proceedings of the 11th International IEEE Conference on Intelligent Transportation Systems (ITSC 2008), Beijing, China, 12–15 October 2008. [Google Scholar]
- Wang, P.; Shen, L. A Method Detecting Driver Drowsiness State Based on Multi-Features of Face. In Proceedings of the 5th International Congress on Image and Signal Processing (CISP 2012), Chongqing, China, 16–18 October 2012. [Google Scholar]
- Vandi, S.; Pizza, F.; Antelmi, E.; Neccia, G.; Iloti, M.; Mazzoni, A.; Avoni, P.; Plazzi, G. A Standardized Test to Document Cataplexy. Sleep Med. 2019, 53, 197–204. [Google Scholar] [CrossRef] [PubMed]
- Greenspan, H.; Van Ginneken, B.; Summers, R.M. Guest Editorial Deep Learning in Medical Imaging: Overview and Future Promise of an Exciting New Technique. IEEE Trans. Med. Imaging 2016, 35, 1153–1159. [Google Scholar] [CrossRef]
- Ker, J.; Wang, L.; Rao, J.; Lim, T. Deep Learning Applications in Medical Image Analysis. IEEE Access 2018, 6, 9375–9389. [Google Scholar] [CrossRef]
- Sriporn, K.; Tsai, C.-F.; Tsai, C.-E.; Wang, P. Analyzing Malaria Disease Using Effective Deep Learning Approach. Diagnostics 2020, 10, 744. [Google Scholar] [CrossRef]
- Chen, J.-W.; Lin, W.-J.; Lin, C.-Y.; Hung, C.-L.; Hou, C.-P.; Cho, C.-C.; Young, H.-T.; Tang, C.-Y. Automated Classification of Blood Loss from Transurethral Resection of the Prostate Surgery Videos Using Deep Learning Technique. Appl. Sci. 2020, 10, 4908. [Google Scholar] [CrossRef]
- Gil-Martín, M.; Montero, J.M.; San-Segundo, R. Parkinson’s Disease Detection from Drawing Movements Using Convolutional Neural Networks. Electronics 2019, 8, 907. [Google Scholar] [CrossRef]
- Oudah, M.; Al-Naji, A.; Chahl, J. Elderly Care Based on Hand Gestures Using Kinect Sensor. Computers 2021, 10, 5. [Google Scholar] [CrossRef]
- Mazurowski, M.A.; Habas, P.A.; Zurada, J.M.; Lo, J.Y.; Baker, J.A.; Tourassi, G.D. Training Neural Network Classifiers for Medical Decision Making: The Effects of Imbalanced Datasets on Classification Performance. Neural Netw. 2008, 21, 427–436. [Google Scholar] [CrossRef] [PubMed]
- Ajay, J.; Song, C.; Wang, A.; Langan, J.; Li, Z.; Xu, W. A Pervasive and Sensor-Free Deep Learning System for Parkinsonian Gait Analysis. In Proceedings of the 2018 IEEE-EMBS International Conference on Biomedical and Health Informatics (BHI 2019), Las Vegas, NV, USA, 4–7 March 2018. [Google Scholar]
- Dentamaro, V.; Impedovo, D.; Pirlo, G. Real-Time Neurodegenerative Disease Video Classification with Severity Prediction. In Proceedings of the 20th International Conference on Image Analysis and Processing (ICIAP 2019), Trento, Italy, 9–13 September 2019. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef]
- Zheng, Y.; Liu, D.; Georgescu, B.; Nguyen, H.; Comaniciu, D. 3D Deep Learning for Efficient and Robust Landmark Detection in Volumetric Data. In Proceedings of the 2015 IEEE Medical Image Computing and Computer-Assisted Intervention (MICCAI 2015), Munich, Germany, 5–9 October 2015. [Google Scholar]
- Palazzo, S.; Spampinato, C.; D’Oro, P.; Giordano, D.; Shah, M. Generating Synthetic Video Sequences by Explicitly Modeling Object Motion. In Proceedings of the 9th International Workshop on Human Behavior Understanding (HBUGEN2018), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Bartolini, I.; Patella, M.; Romani, C. SHIATSU: Tagging and retrieving videos without worries. Multimed. Tools Appl. 2013, 63, 357–385. [Google Scholar] [CrossRef][Green Version]
- Soukupová, T.; Čech, J. Real-Time Eye Blink Detection Using Facial Landmarks. In Proceedings of the 21st Computer Vision Winter Workshop (CVWW ’16), Rimske Toplice, Slovenia, 3–5 February 2016. [Google Scholar]
- Sukno, F.M.; Pavani, S.-K.; Butakoff, C.; Frangi, A.F. Automatic Assessment of Eye Blinking Patterns through Statistical Shape Models. In Proceedings of the 7th International Conference on Computer Vision Systems (ICVS 2009), Liège, Belgium, 13–15 October 2009. [Google Scholar]
- Schiffman, H.R. Sensation and Perception: An Integrated Approach; John Wiley and Sons: Hoboken, NJ, USA, 2001. [Google Scholar]
- Bartolini, I.; Pizza, F.; Di Luzio, A.; Neccia, G.; Antelmi, E.; Vandi, S.; Plazzi, G. Automatic Detection of Cataplexy. Sleep Med. 2018, 52, 7–13. [Google Scholar] [CrossRef]
- Burkert, P.; Trier, F.; Afzal, M.Z.; Dengel, A.; Liwicki, M. DeXpression: Deep Convolutional Neural Network for Expression Recognition. arXiv 2015, arXiv:1509.05371. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Sokolova, M.; Japkowicz, N.; Szpakowicz, S. Beyond Accuracy, F-score and ROC: A Family of Discriminant Measures for Performance Evaluation. In Proceedings of the 19th Australian Joint Conference on Artificial Intelligence: Advances in Artificial Intelligence (AI 2006), Hobart, Australia, 4–8 December 2006. [Google Scholar]
- Fawcett, T. An Introduction to ROC Analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Provost, F. Machine Learning from Imbalanced Data Sets 101. In Proceedings of the AAAI’2000 Workshop on Imbalanced Data Sets, 68(2000), Austin, TX, USA, 31 July 2000. [Google Scholar]
- Viola, P.; Jones, M.J. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Antelmi, E.; Plazzi, G.; Erro, R.; Tinuper, P.; Balint, B.; Liguori, R.; Bhatia, K.P. Intermittent Head Drops: The Differential Spectrum. J. Neurol. Neurosurg. Psychiatry 2016, 87, 414–419. [Google Scholar] [CrossRef] [PubMed]
- Bartolini, I.; Patella, M.; Romani, C. SHIATSU: Semantic-Based Hierarchical Automatic Tagging of Videos by Segmentation using Cuts. In Proceedings of the 3rd International Workshop on Automated Information Extraction in Media Production (AIEMPro 10), Firenze, Italy, 10–13 October 2010. [Google Scholar]
- Bartolini, I.; Patella, M.; Stromei, G. The Windsurf Library for the Efficient Retrieval of Multimedia Hierarchical Data. In Proceedings of the International Conference on Signal Processing and Multimedia Applications (SIGMAP 2011), Seville, Spain, 18–21 July 2011. [Google Scholar]
- Baltrušaitis, T.; Zadeh, A.; Yao Chong, L.; Morency, L.-P. OpenFace 2.0: Facial Behavior Analysis Toolkit. In Proceedings of the 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018. [Google Scholar]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. Decaf: A Deep Convolutional Activation Feature for Generic Visual Recognition. In Proceedings of the 31st International Conference on International Conference on Machine Learning (ICML’14), Beijing, China, 21–26 June 2014. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’16), Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
Short Biography of Authors
 | Ilaria Bartolini received the Ph.D. degree in electronic and computer engineering from the University of Bologna, Italy, in 2002. She is an Associate Professor in Multimedia Data Management andWeb Applications Design at the Department of Computer Science and Engineering (DISI) at the University of Bologna since 2014. She was a Visiting Researcher at CWI, Amsterdam, The Netherlands and NJIT, Newark, NJ, USA, and she has been a Visiting Professor at HKUST, Hong Kong, China. Her research span from the effective and efficient management of multimedia big data to similarity and preference-based query processing, and collaborative filtering/advertising. She has developed and spread worldwide query models for searching and browsing multimedia collections based on both the automatic characterizations of the content and its semantics, together with efficient and scalable query processing algorithms for highly differentiated users. She is the EU ICT Coordinator of the H2020 project DETECt: Detecting Transcultural Identity in European Popular Crime Narratives. She is an Associate Editor for the journals Multimedia Systems and Distributed and Parallel Databases and a member of IEEE and ACM SIGMOD. |
 | Andrea Di Luzio received the Master’s degree in computer science engineering from the University of Bologna, Bologna, Italy. He is research fellow at Department of Computer Science and Engineering (DISI) at University of Bologna for the H2020 project DETECt (Detecting Transcultural Identity in European Popular Crime Narratives), with research topic: “Design and Implementation of the DETECt Digital Framework and Web Portal”. He has in-depth knowledge of both front-end and back-end Web Technologies, Data Mining and Artificial Intelligence techniques. |














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
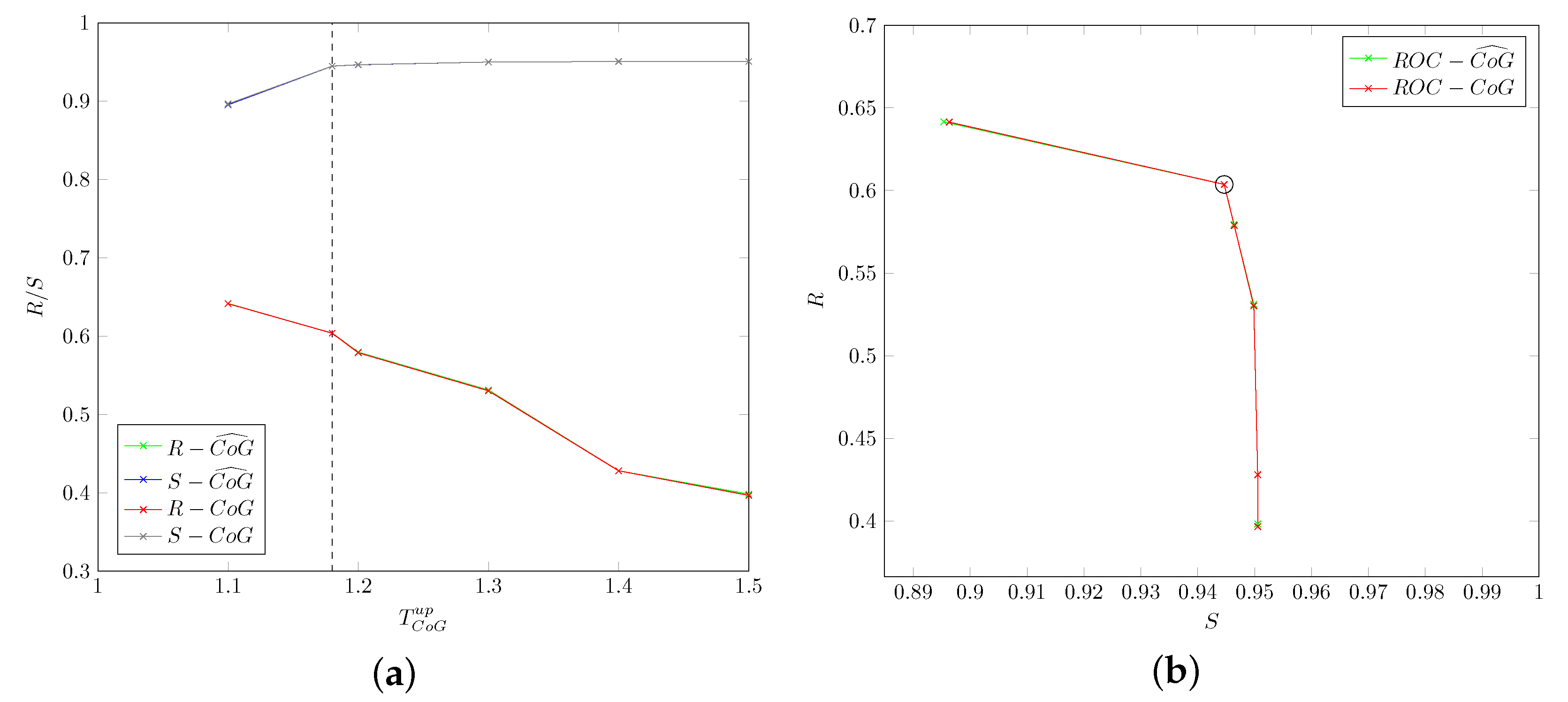{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Block | Layer | Output Size |
|---|---|---|
| Input Block | Data | |
| Convolution 1 | ||
| Pooling 1 | ||
| LRN 1 | 80 | |
| FeatEx Block 1 | Convolution 2a | |
| Convolution 2b | ||
| Pooling 2a | ||
| Convolution 2c | ||
| Concat 2 | ||
| Pooling 2b | ||
| FeatEx Block 2 | Convolution 3a | |
| Convolution 3b | ||
| Pooling 3a | ||
| Convolution 3c | ||
| Concat 3 | ||
| Pooling 3b | ||
| FeatEx Block 3 | Convolution 4a | |
| Convolution 4b | ||
| Pooling 4a | ||
| Convolution 4c | ||
| Concat 4 | ||
| Pooling 4b | ||
| FeatEx Block 4 | Convolution 5a | |
| Convolution 5b | ||
| Pooling 5a | ||
| Convolution 5c | ||
| Concat 5 | ||
| Pooling 5b | ||
| ine Output Block | Classifier | 1 |
| Patient | Sex | Age | Avg. Duration (s) | No. of Attacks |
|---|---|---|---|---|
| 1 | F | 14 | 14.1 | 9 |
| 2 | F | 16 | 5.76 | 5 |
| 3 | F | 22 | 1.12 | 10 |
| 4 | M | 11 | 0.71 | 13 |
| 5 | M | 14 | 1.44 | 10 |
| 6 | M | 11 | 2.16 | 16 |
| 7 | M | 6 | 65.8 | 3 |
| 8 | M | 13 | 2.41 | 9 |
| 9 | M | 9 | 1.28 | 10 |
| 10 | M | 45 | 14.3 | 14 |
| 11 | F | 11 | 1.80 | 6 |
| 12 | F | 42 | 7.76 | 11 |
| 13 | F | 7 | 9.10 | 13 |
| 14 | M | 11 | 0.95 | 8 |
| Class/Recognized | As Present | As Absent |
|---|---|---|
| present | ||
| absent |
| Motor Phenomenon | R | S | P | A | |
|---|---|---|---|---|---|
| ptosis | 0.72 | 0.84 | 0.82 | 0.78 | 0.77 |
| mouth opening | 0.78 | 0.76 | 0.75 | 0.76 | 0.77 |
| head-drop | 0.60 | 0.94 | 0.89 | 0.77 | 0.72 |
| overall | 0.75 | 0.79 | 0.79 | 0.77 | 0.77 |
| Motor Phenomenon | S |
|---|---|
| ptosis | 0.99 |
| mouth opening | 0.98 |
| head-drop | 0.99 |
| overall | 0.98 |
| Motor Phenomenon | R | S | P | A | |
|---|---|---|---|---|---|
| ptosis | 0.71 | 0.67 | 0.68 | 0.69 | 0.70 |
| mouth opening | 0.72 | 0.81 | 0.79 | 0.76 | 0.75 |
| head-drop | 0.67 | 0.81 | 0.78 | 0.74 | 0.72 |
| overall | 0.70 | 0.74 | 0.73 | 0.72 | 0.71 |
| Motor Phenomenon | S |
|---|---|
| ptosis | 0.83 |
| mouth opening | 0.83 |
| head-drop | 0.81 |
| overall | 0.66 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bartolini, I.; Di Luzio, A. CAT-CAD: A Computer-Aided Diagnosis Tool for Cataplexy. Computers 2021, 10, 51. https://doi.org/10.3390/computers10040051
Bartolini I, Di Luzio A. CAT-CAD: A Computer-Aided Diagnosis Tool for Cataplexy. Computers. 2021; 10(4):51. https://doi.org/10.3390/computers10040051
Chicago/Turabian StyleBartolini, Ilaria, and Andrea Di Luzio. 2021. "CAT-CAD: A Computer-Aided Diagnosis Tool for Cataplexy" Computers 10, no. 4: 51. https://doi.org/10.3390/computers10040051
APA StyleBartolini, I., & Di Luzio, A. (2021). CAT-CAD: A Computer-Aided Diagnosis Tool for Cataplexy. Computers, 10(4), 51. https://doi.org/10.3390/computers10040051