Simple Summary
Cancer arises through the accumulation of somatic mutations in key biological pathways. This paper aims to develop a probabilistic approach to delineate the temporal order of mutations during cancer development based on mutation profile data from a cohort of patients. A unique feature of our method is that it incorporates intra-tumor heterogeneity (ITH) information, which refers to the heterogeneous cell populations within a tumor and characterizes the evolutionary history of the tumor. We showed that by integrating ITH, pathways, and functional annotation information, our method yielded high accuracy in inferring the temporal order of pathway mutations during carcinogenesis.
Abstract
The development of cancer involves the accumulation of somatic mutations in several essential biological pathways. Delineating the temporal order of pathway mutations during tumorigenesis is crucial for comprehending the biological mechanisms underlying cancer development and identifying potential targets for therapeutic intervention. Several computational and statistical methods have been introduced for estimating the order of somatic mutations based on mutation profile data from a cohort of patients. However, one major issue of current methods is that they do not take into account intra-tumor heterogeneity (ITH), which limits their ability to accurately discern the order of pathway mutations. To address this problem, we propose PATOPAI, a probabilistic approach to estimate the temporal order of mutations at the pathway level by incorporating ITH information as well as pathway and functional annotation information of mutations. PATOPAI uses a maximum likelihood approach to estimate the probability of pathway mutational events occurring in a specific sequence, wherein it focuses on the orders that are consistent with the phylogenetic structure of the tumors. Applications to whole exome sequencing data from The Cancer Genome Atlas (TCGA) illustrate our method’s ability to recover the temporal order of pathway mutations in several cancer types.
1. Introduction
It is well understood that a human tumor is developed through the accumulation of somatic mutations in a number of essential biological pathways [1]. Studying the temporal order of somatic mutation occurrences is critically important to demystifying the biological mechanisms of tumor development, creating new therapeutic strategies, and predicting cancer prognosis. The most well-studied example of the order of mutations is from colorectal cancer, where the progression from normal epithelium to colorectal cancer often begins with mutations impacting the Wnt signaling pathway and subsequently progress with additional mutations in genes associated with MAPK, PI3K, TGF-beta, and p53 signaling pathways [1]. However, the temporal orders of mutations remain predominantly unknown in biological literature for many other types of cancer.
High-throughput DNA sequencing-based profiling of somatic mutations has presented an unparalleled opportunity to utilize statistical and computational methods in the study of cancer progression. Several methods have been devised to infer the order of somatic mutations based on mutation profile data from a cohort of patients. Fearon et al. modeled the relationship between mutations as a linear path [2]. Desper et al. [3] developed an oncogenetic tree model that illustrated the accumulation of mutations under ordering constraints by a tree. Szabo et al. [4] extended the pure oncogenetic tree model by introducing false positive and false negative observations, thereby increasing the model’s adaptability to accounting for potential sources of error. Beerenwinkel et al. [5] suggested using mixtures of oncogenetic trees, which offers a more adaptable option than fitting a single tree. Further, a more flexible conjunctive Bayesian network method was proposed [6,7,8], which did not presume a tree-like dependency structure and instead used a partially ordered set of mutations to describe the tumor’s evolutionary process. The aforementioned methods are topology-based, aiming to estimate the dependency structures among mutational events. Alternatively, Youn et al. [9] introduced a probabilistic approach to directly estimate the order of mutations without explicitly modeling the dependency structure. Instead, at each temporally ordered mutational step, they directly estimated the probability of each mutation occurring at that step. Wang et al. [10] extended this idea by incorporating functional annotation information of mutations and pathway annotations to improve the inference. These methods are free of complex modeling assumptions and, thus, are more robust and powerful in identifying early versus late mutations [11].
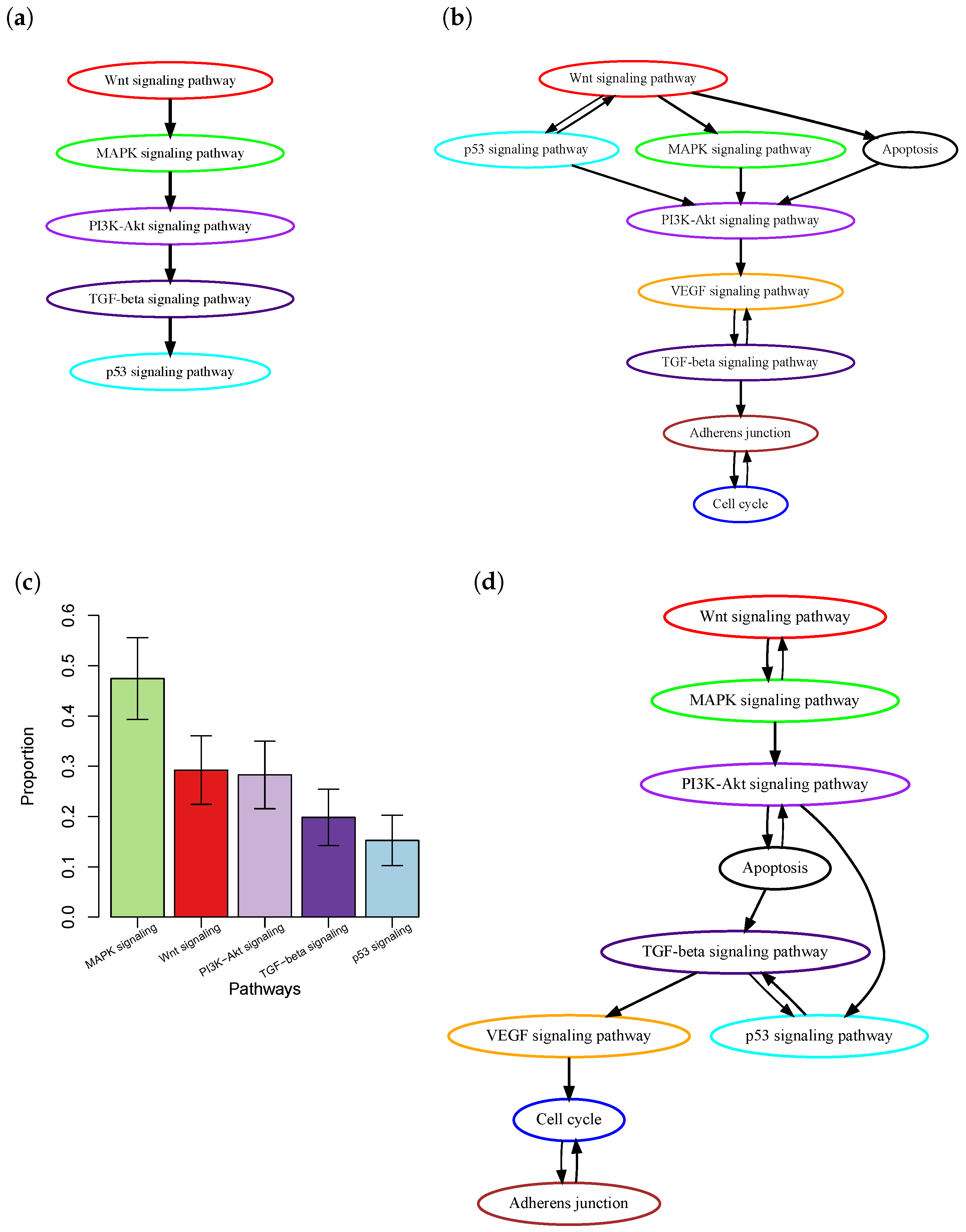
One major limitation of current methods is that most of them only consider the presence or absence of mutations in a patient’s tumor, but do not take into account intra-tumor heterogeneity (ITH) [12,13]. ITH refers to the presence of a heterogeneous collection of cells, i.e., subclones, with distinct mutation profiles within a patient’s tumor. During cancer progression, new somatic mutations are continuously acquired by cancer cells. Some advantageous mutations, which provide cells with new functional characteristics, lead to the expansion of the cells to form intra-tumor subclones. The lack of accounting for ITH may lead to inaccurate inference of the order of pathway mutations. Consider the case of colon cancer, where the order of pathway mutations has been well-documented in the biological literature based on ample evidence from biological, pathological, and epidemiological studies [1] (Figure 1a). Using this known order of pathway mutations as a benchmark, we evaluated the order of pathway mutations inferred by Wang et al. [10] (Figure 1c) based on The Cancer Genome Atlas (TCGA) colon cancer whole-exome sequencing data. The p53 signaling pathway was reported to be mutated in a later stage of cancer development [1]. However, it was estimated to occur at an early stage; see the work by Wang et al. [10]. Further investigation into this discrepancy found that although many mutations occurred in the p53 signaling pathway, most of them were subclonal mutations (Figure 1b) that were expected to occur in the later stage of cancer development. Therefore, simple counting of the presence or absence of mutations will ignore such information and lead to inaccurate inference.
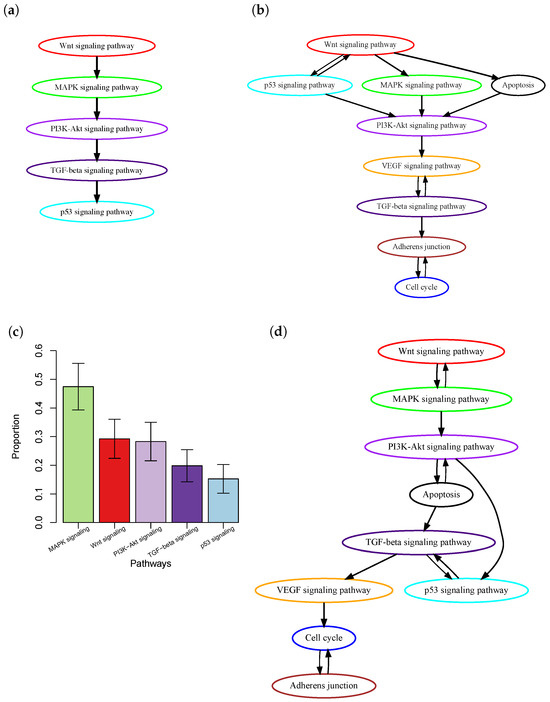
Figure 1.
Order of pathway mutations in colon cancer. (a) The well-documented order of five key colon cancer pathways in biological literature [1]. (b) Order estimated based on the TCGA colon cancer dataset using the method by Wang et al. [10]. The figure was adapted from Figure 5 in [10] with modifications. (c) Clonality of mutations in those pathways. The y-axis is the proportion of at least one mutation of a pathway that is clonal, i.e., in the trunk of a phylogenetic tree. Results were obtained based on the TCGA colon cancer dataset using PhyloWGS [14]. Mean ± SEM are presented. (d) Order estimated based on the TCGA colon cancer dataset using PATOPAI.
Several bioinformatic tools, such as PhyloWGS (v1.0) [14], Canopy (v1.3.0) [15], ClonEvol (v0.99.11) [16], SPRUCE (v0.99.0) [17] and PACTION (https://github.com/elkebir-group/paction) (accessed on 9 June 2024) [18], have been developed to infer the ITH information from either single-/multi-region bulk sequencing or single-cell sequencing. These tools usually characterize ITH by a phylogenetic tree or a set of trees with associated posterior probabilities, with nodes in the trees indicating different subclones and edges indicating the evolutionary relationships of subclones. As the phylogenetic trees describe the temporal order of mutations within an individual patient’s tumor, incorporating such in-depth intra-patient information into the tumor progression analysis across a cohort of patients is likely to substantially increase the power and accuracy of the analysis.
In this paper, we propose PATOPAI, a probabilistic model-based approach to characterize the temporal order of pathway mutations. PATOPAI incorporates the ITH information of each tumor sample by focusing the model on mutational sequences that are consistent with the phylogenetic structures of the sample. The pathway and functional annotation information of mutations is also integrated to enhance the inference. We applied PATOPAI to whole exome sequencing datasets of several cancer types from TCGA to demonstrate the performance of PATOPAI for delineating the order of pathway mutations.
2. Materials and Methods
2.1. Overview of the Method
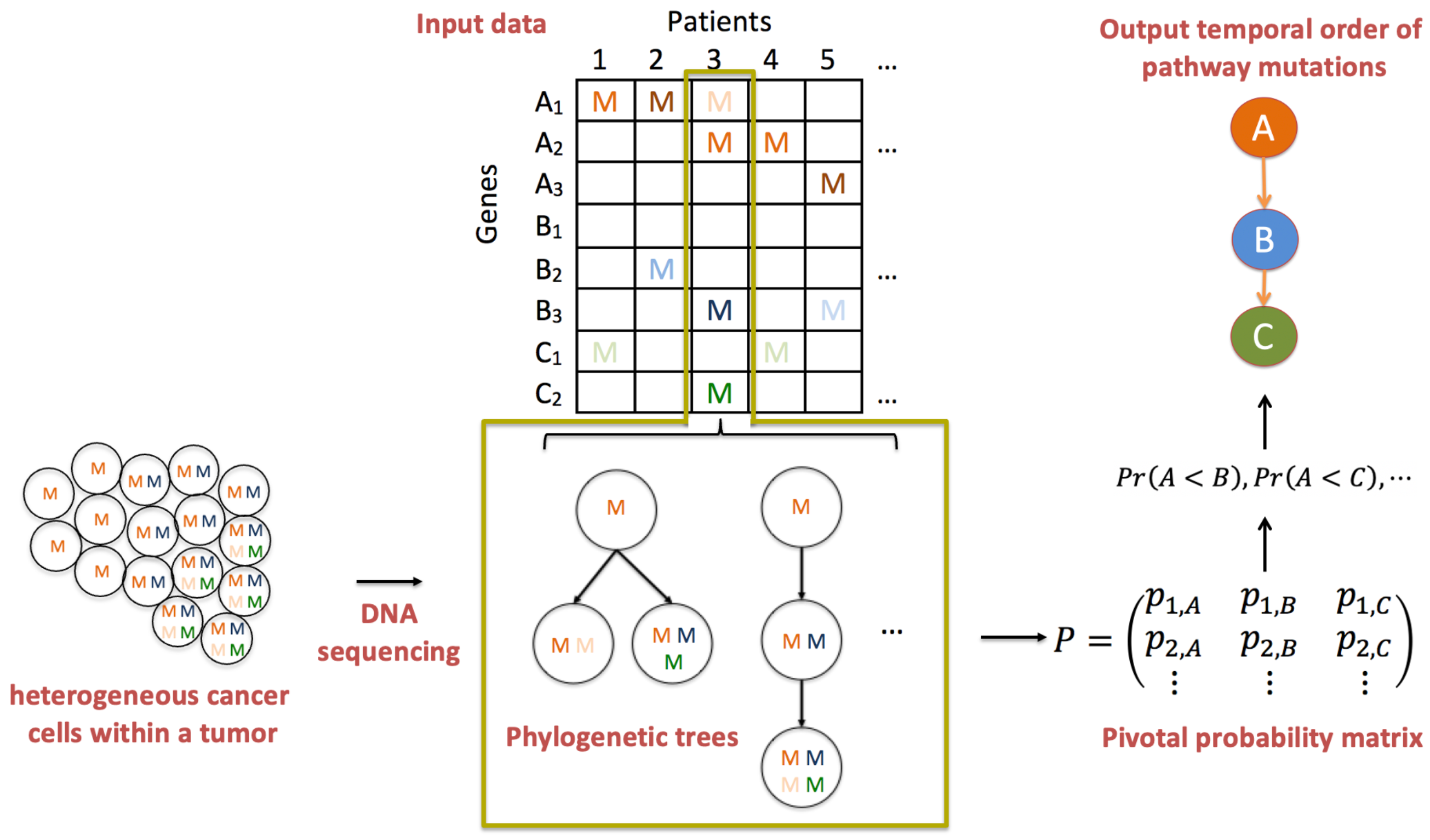
An overview of PATOPAI is depicted in Figure 2. Our algorithm starts with three pieces of information from a cohort of patients at different stages of a specific cancer type. The first piece of information is a phylogenetic tree or a set of trees with associated posterior probabilities, which characterizes the ITH of each tumor sample. The second piece of information is the functional annotation information for each non-synonymous somatic mutation in a phylogenetic tree, which represents the likelihood of the mutation being functional. The third piece of information is the gene-to-pathway mapping for each mutation. We will take such data as the inputs for PATOPAI to delineate the common temporal order of pathway mutations across the cohort of patients based on a probabilistic method. The primary part of PATOPAI is to estimate a pivotal probability matrix P, where the element of P indicates the probability of the k-th functional mutation occurring in the i-th pathway. Utilizing P, we calculate the probability of one pathway acquiring alterations before or after another for each pair of pathways. Lastly, a simplified partial-order graph is employed to summarize the results and visualize the temporal order of all pathways.
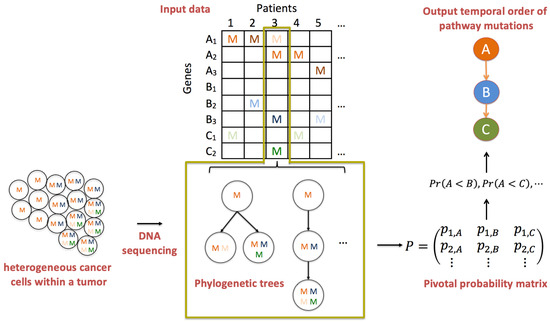
Figure 2.
Overview of PATOPAI algorithm. Consider three pathways: A (having genes , , and ), B (having genes , , and ) and C (having genes and ). Letter “M” indicates observed mutation with a darker color indicating the mutation is more likely to be functional. For each patient’s tumor, which is a collection of heterogeneous cancer cells, the mutation profile is obtained based on DNA sequencing. Phylogenetic trees are then constructed to characterize the ITH of the tumor. Next, the ITH structure is integrated with pathway information and functional annotations to estimate a pivotal probability matrix P, where the element of P is the probability that the k-th functional mutation occurs in the i-th pathway. Next, for each pair of pathways, we calculate the probability of one pathway being altered before the other, e.g., is the probability that A is mutated before B. Finally, a partial-order plot is generated to present the temporal order of pathway alterations.
The fundamental concept of PATOPAI can be elucidated through the example of delineating the temporal order of pathways A, B, and C as depicted in Figure 2. First, observe that every patient with mutations in pathway B also exhibits mutations in pathway A. Conversely, some patients (patients 2 and 5) only have mutations in pathway A without mutations in pathway B. This implies that pathway A is likely to acquire mutations before pathway B in the process of tumorigenesis. This concept originated from the work of Youn and Simon [9], and was extended by Wang et al. [10] to incorporate functional annotation information and perform analysis at the pathway level instead of individual genes to improve the inference. Figure 2 highlights the importance of further incorporating ITH information in such analysis. For example, patient 3 has mutations in all three pathways. Without studying ITH, data from this patient lacks the informativeness required to determine the order of the three pathways. However, phylogenetic trees of patient 3 suggest that the mutation in pathway A occurs first in the patient, followed by mutations in pathways B and C. Including this additional ITH information renders the data from this patient useful in substantiating the idea that pathway A is altered before pathways B and C. Figure 2 also illustrates the use of pathway analysis and functional annotation information. For example, it is difficult to infer the order of and since each gene only has one mutation that resides in different patients. In contrast, the mutation frequency at the pathway level is much higher, so estimating the temporal order between pathways A and B is more feasible. As another example, mutations are present in both pathways A and C in patient 5. Using functional annotation information, the mutation in pathway A is more likely to be functional, while the one in pathway C is more likely to be non-functional, which provides useful information supporting that A is altered before C. Thus, the integration of ITH, pathway, and functional annotation information will substantially increase the accuracy of cancer progression inference.
2.2. Probability Model
Let represent the count of non-synonymous mutations in pathway i, and represent the total count of non-synonymous mutations in patient j. Define to indicate whether the k-th mutation is functional ( = 1) or not ( = 0) for , and let be the total count of functional mutations in patient j. To consider ITH, let represent the phylogenetic tree of patient j, which takes a number of candidate tree structures with their associated posterior probabilities obtained from software such as PhyloWGS [14]. According to the law of total probability, the likelihood of observing can be formulated as follows:
where the first summation is over all phylogenetic trees for patient j and the second summation encompasses all possible sequences of . Next, we explain the computation of each of the four terms in the summation. Starting with the first term, let represent the (unknown) identity of the pathway that was mutated as the k-th functional event, and represent the (unknown) identity of the pathway that was mutated as the l-th non-functional event in patient j. For any specific phylogenetic tree , there may be multiple orders of occurrence of and that are consistent with tree t. An order of pathway identities of mutations, , is considered consistent with t if there exists a sequence of mutations, , from t, such that belongs to pathway for , and is not downstream of in tree t for any . Let and be the sets of all potential sequences of pathway identities for functional and non-functional mutations, respectively. We have the following:
where the last equation is derived under the assumption of independence of occurrences between functional mutations and non-functional mutations. By further assuming that the occurrences of mutations are independent and they are independent of , the probability for each possible sequence can be expressed as the product of the probabilities that and . Denote as the probability that . These values are parameters of interest, where we define the pivotal probability matrix as . For non-functional mutations, we assume that all orders of non-functional mutations have the same probability as their occurrences are most likely random. Define as the probability that a non-functional mutation occurs in pathway i, we estimate it by calculating the expected fractions of non-functional mutations that are from pathway i across patients. Specifically, following Wang et al. [10], let be the functional impact score of the kth mutation. The expected number of non-functional mutations in pathway l for patient j is . We can then estimate by , an average of across patients. Assuming that all mutations are independent, the above probability can be calculated as follows:
For the second and fourth terms in Equation (1), the assumptions and calculations are identical to what was performed in our prior paper [10]. For the third term, is obtained from software such as PhyloWGS [14] or Canopy [15]. These software are designed to reconstruct the evolutionary history of a tumor based on bulk DNA sequencing data. They characterize subclones and delineate the phylogeny within a tumor using phylogenetic trees. The outputs are possible phylogenetic tree structures of a tumor and their associated posterior probabilities, which are used to specify in our method. Therefore, the likelihood function can be written as follows:
Finally, in accordance with Wang et al. [10], we calculate , the probability that pathway A is altered before pathway B is altered, as
where and is the collection of pathway mutation sequences satisfying the first functional mutation in pathway A precedes the first functional mutation in B.
It is important to note that the method assumes non-overlapping pathways. In cases where pathways have overlapping genes, we re-organize the genes into sets that are mutually exclusive to perform the analysis and compute three probabilities, , , and , as described in [10]. The results obtained were visualized with a simplified version of a partial-order plot [19]. Specifically, each node in the plot represents a pathway. The thickness of a directed edge from one pathway to another indicates the estimated temporal-order probability between the two pathways. The nodes are arranged based on the layered graph drawing method in Graphviz [20] according to the estimated temporal order of pathways. For clarity, an edge with probability below a certain threshold is eliminated from the plot. An edge between two pathways that are indirectly connected by other edges is also removed, e.g., the edge from A to C is removed if there is an edge from A to B and an edge from B to C.
2.3. Entropy Constraint
A key step in our method is to estimate the pivotal probability matrix P. Due to its high dimensionality, the maximum likelihood estimate can be unstable. We address this issue by introducing the following entropy constraint to regularize the estimation. It is natural to expect that the certainty for delineating the mutational order of pathways is the highest at the first functional mutational event, and decreases as more mutational events occur. Based on information theory, the level of uncertainty for the k-th row of P matrix is quantified by entropy [21], . Therefore, we consider the following entropy constraint:
An estimate of is obtained by maximizing the likelihood under the entropy constraint. In addition to the entropy constraint, we also implement several approaches to improve the computational efficiency of the estimation, which are described in the following subsection.
2.4. Computational Efficiency Optimization
The estimation of the pivotal probability matrix P is computationally intensive. The number of parameters in P increases with both the number of pathways and the number of mutations. In addition, recent phylogenetic analysis tools like PhyloWGS [14] output a large number (several thousand) of candidate trees from the posterior distribution over phylogenies for each patient. The large number of trees causes a heavy computational burden. Further, the computational complexity for finding all the possible orders that are consistent with each phylogenetic tree increases sharply as the number of mutations used to construct the tree increases.
To improve the computational efficiency of our method, we consider the following three approaches. First, we conduct our analysis independently for each pair of pathways rather than analyzing all pathways together. This approach decreases the number of parameters we need to estimate at one time. It also reduces the complexity of finding the orders that are consistent with a phylogenetic tree since we only need to focus on the limited number of mutations belonging to the two pathways under consideration. This pairwise approach has been shown to yield similar results as the approach of analyzing all pathways together [10]. Second, as another advantage of the pairwise approach, we find that many candidate trees of a patient reduce to be the same when we confine the trees to only include mutations in a pair of pathways. Thus, for each pair of pathways, we combine trees with the same structure for mutations in the two pathways into one reduced tree with a posterior probability equal to the summation of posterior probabilities of the original trees. We then sort the reduced trees in descending order of their posterior probabilities, only considering the top ones whose cumulative probability reaches 95%. Based on this approach, the number of trees to be computed for each patient is largely reduced. Third, we reduce the number of parameters by setting for , which represents an averaged distribution for mutations occurring after the -th step. Wang et al. [10] showed that the estimated probabilities stabilize for . Thus, we set in our analyses.
3. Results
To assess the performance of PATOPAI, we utilized it to analyze whole exome sequencing data from TCGA for colon cancer (n = 461), hepatocellular carcinoma (n = 377), glioblastoma multiforme (n = 617), and pancreatic adenocarcinoma (n = 185). For each cancer type, we selected the key cancer pathways according to the KEGG database [22]. The genes within each pathway, as listed in Supplementary Table S1, were identified using the KEGG database with manual curation. In our analyses, phylogenetic trees of each tumor sample were obtained using PhyloWGS [14]. Data analysis was performed on the Morgan Compute Cluster of the University of Kentucky. Each compute node consists of an AMD 7702P CPU, with cores and 512 GB RAM. For each pair of pathways, the analysis was performed with 10 CPU cores and 64 GB of RAM. In this setup, the running time for these tasks varies between 220 s and 506 min, depending on the number of mutations and complexities of tree structures.
3.1. Analysis of TCGA Colon Adenocarcinoma Data
The TCGA-COAD project dataset contains whole exome sequencing data of tumor samples from 461 colon cancer patients. We excluded the top 16% of hyper-mutated samples, as the process of tumorigenesis in these samples involves specific sequences of genetic events [23], and the remaining 391 samples were used in our analysis. The temporal-order probabilities for each pair of pathways were estimated by PATOPAI, and the results were summarized in a simplified partial-order plot. (Figure 1d). Without considering the ITH information, Wang et al. [10] previously found that p53 pathway mutation occurred earlier than that of PI3K signaling mutations in colon cancer (Figure 1c). After incorporating the ITH information into the analysis, PATOPAI now shows that the pathway mutations in colon cancer follow a temporal order of WNT–MAPK–apoptosis–PI3K–p53–TGF-beta signaling pathways (Figure 1d), which agrees better with the ‘classic’ colorectal cancer formation model [1] since it puts p53 after the PI3K signaling pathway. The p53 pathway functions as a critical tumor suppressor mechanism and induces cell cycle arrest and apoptosis. Our analysis reveals that p53 pathway mutations occur after cancer cells accumulate pro-growth mutations in the WNT–MAPK–apoptosis–PI3K pathways. In late tumorigenesis processes, tumor cells initiate EMT and metastasize into other tissues, where TGF-beta–VEGF–adherens junction pathways play important roles [24]. Our analysis shows these pathways mutate late in the tumor formation process, which demonstrates improved predicting performance of our method.
3.2. Analysis of TCGA Hepatocellular Carcinoma Data
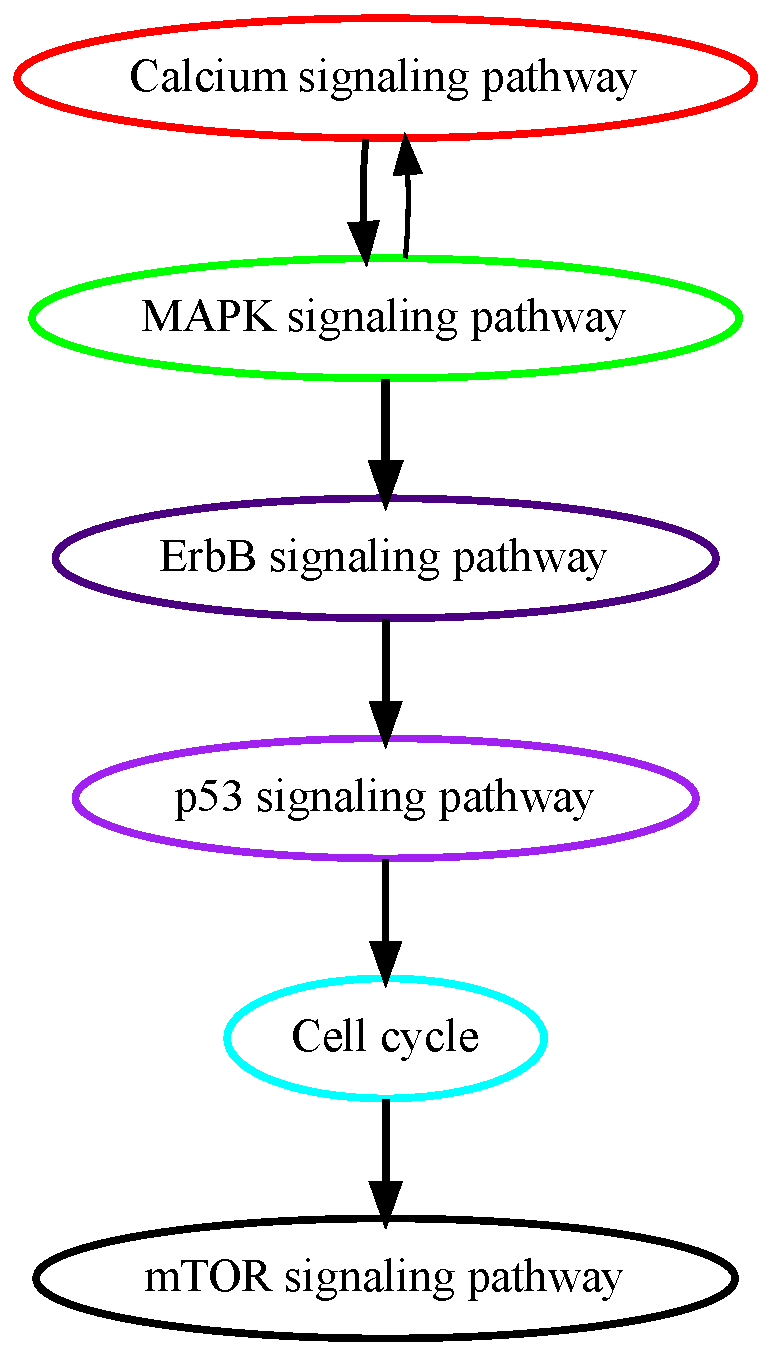
The pathogenesis of hepatocellular carcinoma (HCC) is primarily driven by genetic accumulation of molecular mutations governing oncogenic signaling pathways. Numerous alterations in genes in calcium signaling pathways have been identified in the early stages of HCC tumorigenesis [25]. Mutations in genes encoding proteins controlling calcium signaling processes including Ca2+ entry, release, and binding have been found and have profound implications in promoting the liver cancer cell cycle, metabolism, proliferation, and tumorigenesis in tumor initiations [25]. These previous findings confirm the results of our pathway mutation analysis that calcium signaling pathway mutations are on an earlier temporal order in HCC development (Figure 3). Around 50% of HCC cases harbor activating mutations in the MAPK signaling pathway, which, among other mutated signaling pathways in HCC, is deemed to be the most important in the HCC tumorigenesis process [26]. Aberrant activation of beta-catenin, which activates the WNT signaling pathway is observed in about 30% of HCC patients. The second most mutated gene in the WNT signaling pathway is AXIN1 which occurs in about 10% of HCC cases [27]. TP53 pathway mutations happen in around 30% of HCC patients and regulate gene expression in cancer cell apoptosis and senescence. Our results in pathway mutation analysis showed that these growth, proliferation, and apoptosis-related signaling pathways mutated in early to midterm stages in HCC.
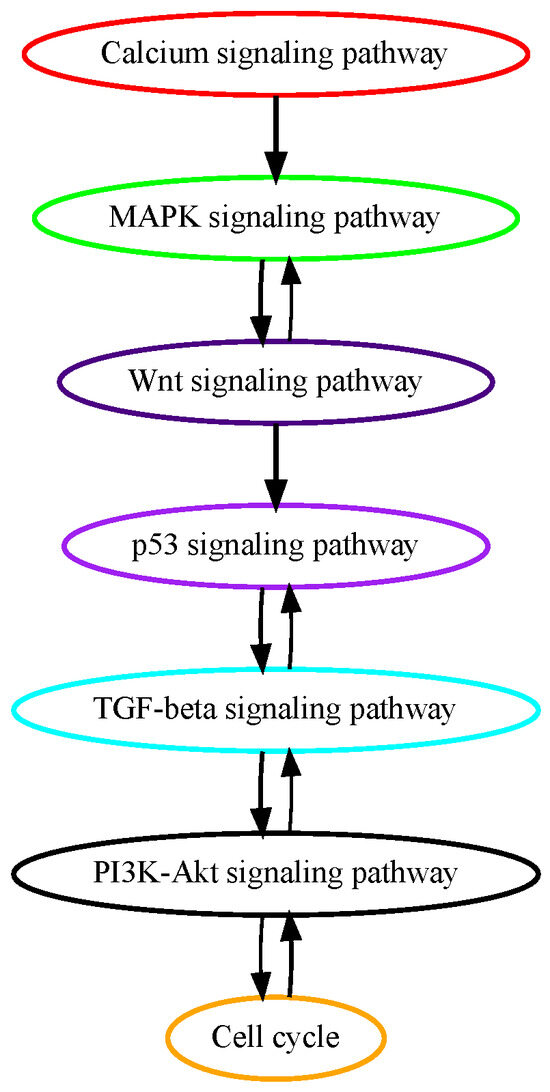
Figure 3.
Estimated order of pathway mutations based on TCGA HCC dataset. Each node represents a pathway, with nodes/pathways arranged according to estimated temporal-order probabilities. The width of a directed edge is proportional to the probability of the head node pathway being mutated before the tail node pathway. To enhance visualization, edges with probabilities < 0.4 have been excluded. In addition, the direct edge between two pathways that are indirectly connected by other edges is also removed for clarity, e.g., for three pathways with the order of , the edge will be removed from this figure.
3.3. Analysis of TCGA Glioblastoma Multiforme Data
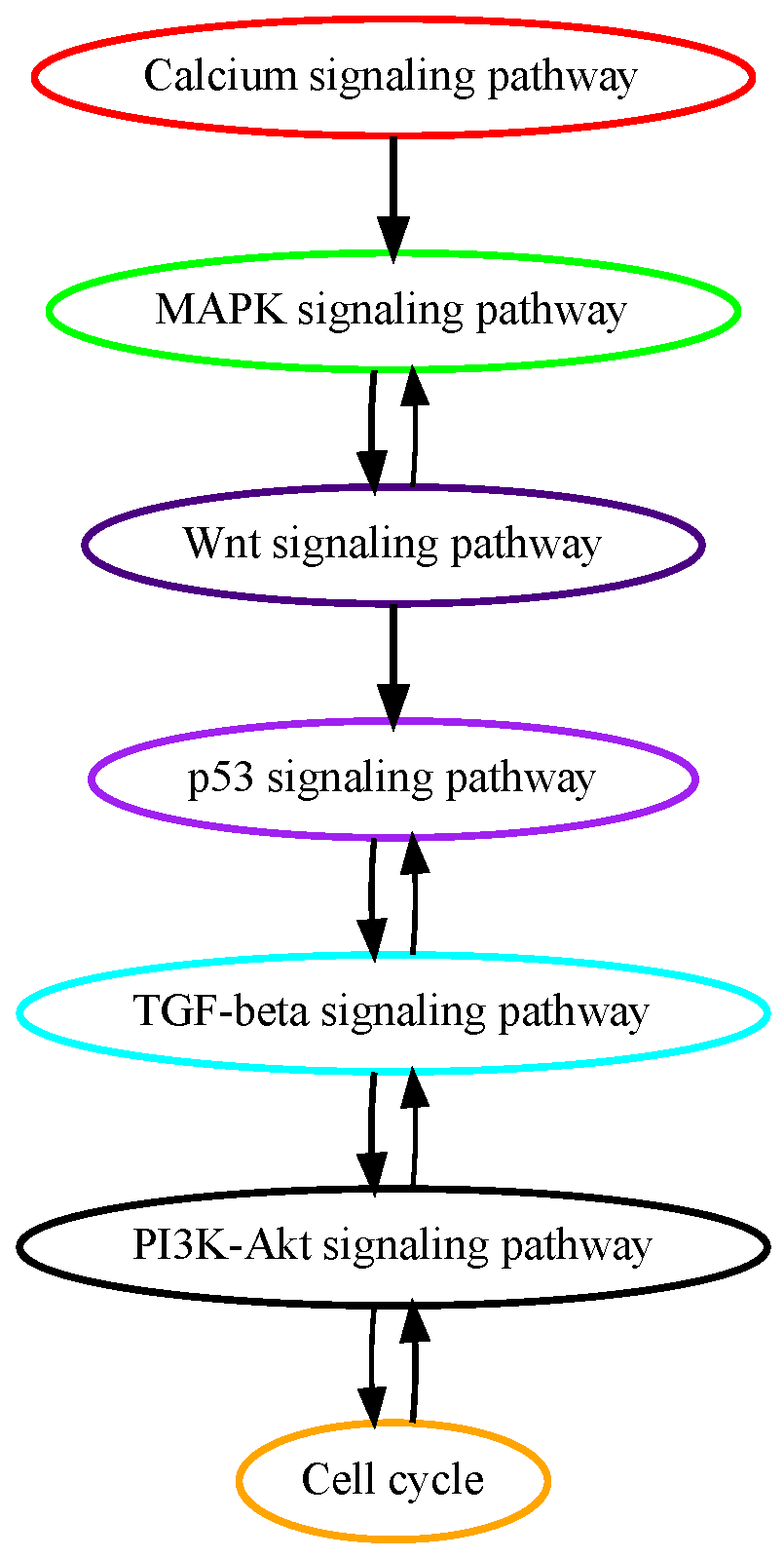
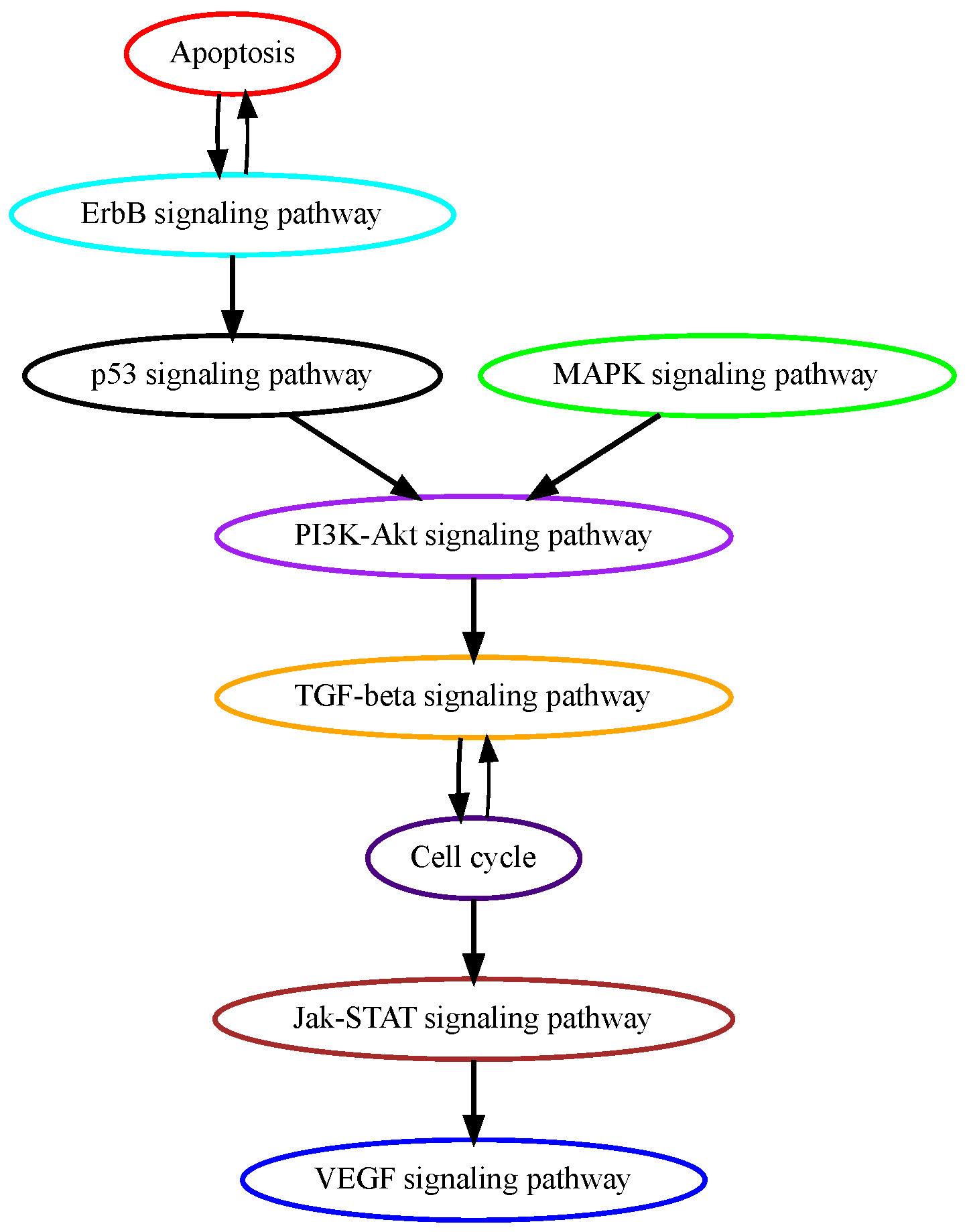
Glioblastoma multiforme (GBM) is grade IV glioma, the most aggressive malignant tumor in the central nervous system with patients’ mean survival time of less than 16 months [28]. The low-grade benign gliomas (Grade I) and lower-grade astrocytomas (Grade II/III) eventually develop into GBM through complicated processes in which a number of genetic alterations have been reported. While the mechanisms of how normal glial progenitor cells transform into low-grade gliomas are still under investigation, genetic alterations in calcium transportation and binding proteins in the calcium signaling pathway were found both in normal glial development and low-grade gliomas [29]. Ca2+, a second messenger that is involved in neuronal signaling, and other cellular processes, such as cell proliferation, apoptosis, and autophagy, may contribute to cancer development when dysregulated. TRPM7 (transient receptor potential cation channel subfamily M member 7) facilitates the transport of calcium ions, and its pharmacological inhibition decreases the proliferation, migration, and invasion of glioma cells [30]. These data suggest that alterations in calcium signaling occur at higher temporal orders in GBM progression, and our pathway analysis successfully captured calcium signaling as an early event (Figure 4). ErbB signaling pathway and its downstream mitogen-activated protein kinase (Ras/MAPK) signaling pathway regulate cellular processes such as growth, survival, differentiation, and migration and are frequently mutated in GBM [31]. A recent study analyzed genomic sequencing data from the temporally separated tumor pairs of 304 adult patients and found acquired CDKN2A deletions were associated with increased cell proliferation at tumor recurrence, suggesting mutations in cell cycle signaling might be late in temporal order in GBM development [32].
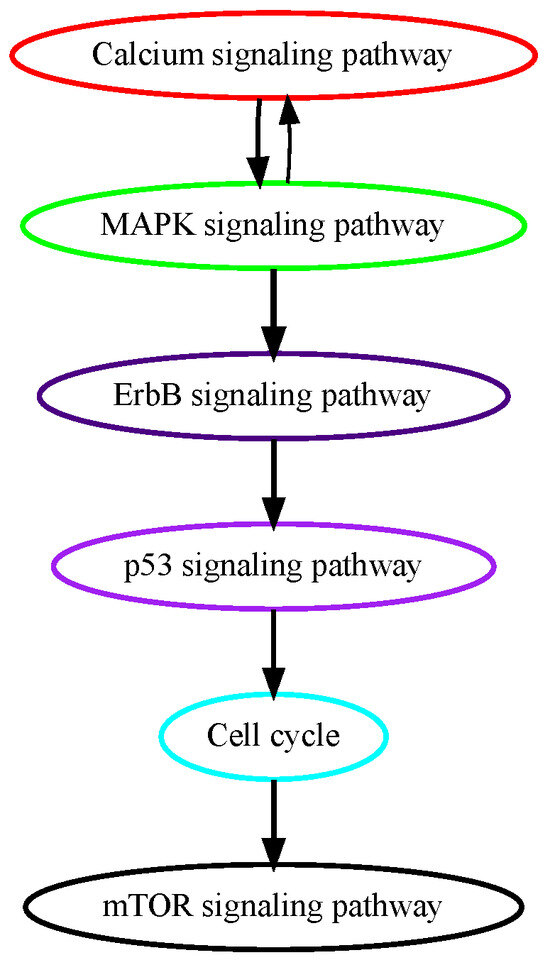
Figure 4.
Estimated order of pathway mutations based on TCGA GBM dataset. Each node represents a pathway, with nodes/pathways arranged according to estimated temporal-order probabilities. The width of a directed edge is proportional to the probability of the head node pathway being mutated before the tail node pathway. To enhance visualization, edges with probabilities < 0.4 are excluded, and edges between pathways that are indirectly connected by other edges are also removed from this figure.
3.4. Analysis of TCGA Pancreatic Adenocarcinoma Data
Pancreatic adenocarcinoma (PAAD) remains one of the most fatal cancers with a 5-year survival rate of around 8% [33]. The genetic progression model of pancreatic carcinogenesis has largely been established. Generally, pancreatic duct epithelium transforms into three progressing stages of pancreatic intraepithelial neoplasia (PanIN): PanIN-1, PanIN-2, and PanIN-3, eventually developing into pancreatic cancer [34]. More than 90% of KRAS mutations are found in PanIN-1 lesions, suggesting that MAPK signaling mutations are on an early temporal order in the PAAD tumorigenesis process [35]. The tumor suppressor gene CDKN2A is commonly inactivated in pancreatic cancer and can be detected as early as PanIN-2 lesions [36]. In PanIN-3 lesions, inactivating mutations of TP53 and SMAD4 in TGF-beta signaling were found [37]. While our model correctly recognizes MAPK signaling as an early mutational event and TGF-beta signaling as a late event, it contradicts the ligature by placing cell cycle signaling at a lower temporal position (Figure 5). Other mutations in the cycle cell signaling pathway may be late events but CDKN2A mutations happen as early as in PanIN-2 lesions.
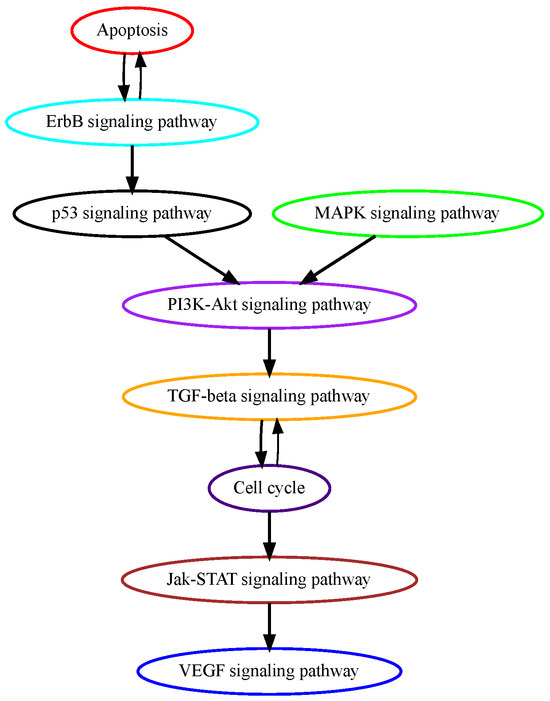
Figure 5.
Estimated order of pathway mutations based on TCGA PAAD dataset. Each node represents a pathway, with nodes/pathways arranged according to estimated temporal-order probabilities. The width of a directed edge is proportional to the probability of the head node pathway being mutated before the tail node pathway. To enhance visualization, edges with probabilities < 0.4 are excluded, and edges between pathways that are indirectly connected by other edges are also removed from this figure.
3.5. Comparison to Other Methods
We compared PATOPAI with two existing methods, OncoTree (2002) [4] and the method of Youn and Simon (2012) [9]. We focused our comparison on colon cancer, as for this cancer type, the temporal order of pathway alterations is well-documented in biological literature [1]; see Figure 1a. The estimated oncogenetic tree obtained from the R package OncoTree is provided in Figure S1. OncoTree was able to infer that the MAPK signaling pathway was altered before PI3K, p53, and TGF-beta signaling pathways, but failed to determine the Wnt signaling pathway as an upstream altered event. Also, it was unable to determine the order between the p53 and PI3K/TGF-beta signaling pathways. The result obtained from the method of Youn and Simon is provided in Figure S2. This method estimated that the first event most likely occurred in the MAPK signaling pathway and the fourth event occurred in the Wnt signaling pathway, which was inconsistent with the biological literature that the Wnt signaling pathway was altered before the MAPK signaling pathway. Likewise, it was also unable to determine the correct order between the PI3K and TGF-beta signaling pathways, as it inferred that the second event most likely occurred in the TGF-beta signaling pathway and the fourth event had a high probability of occurring in the PI3K signaling pathway. Therefore, the results from both methods did not align as closely with previous biological evidence compared to our method.
Comparison of Computational Efficiency
We evaluated the performance of our proposed computational efficiency optimization approaches. Our evaluation was based on estimating the temporal order of mutations in the MAPK and TGF-beta signaling pathways, using the TCGA pancreatic adenocarcinoma data. The running time with our computational efficiency optimization was 371 s. Without setting for , the running time of the same task increased to 430 s. By further excluding the approach of combining trees with the same structures in our method, the running time increased to 732 s. Therefore, our computational efficiency optimization shortened the computational time by half in this case.
4. Discussion
Our analysis focuses on delineating the common temporal order of pathway mutations across a cohort of patients by leveraging ITH, which provides the cancer progression information within each individual patient’s tumor, along with pathway and mutational functional annotation information. In our application studies, we used phylogenetic trees obtained from PhyloWGS [14] to characterize the ITH information. Other methods, such as Canopy [15], ClonEvol [16], and SPRUCE [17], can also be used as alternatives. Note that in our analysis, the ITH information is obtained from bulk sequencing as such data are widely available. But our method can also take ITH information from single-cell DNA sequencing, which quantifies ITH at a much higher resolution. One may replace PhyloWGS with phylogenetic analysis methods for single-cell data such as SCITE [38], SciFit [39], and SiCloneFit [40] to characterize the ITH of individual tumors, and then use the ITH for each individual patient’s tumor as an input for our method to infer the common temporal order of mutations across a cohort of patients. Note that for a phylogenetic tree inferred by SciFit or SiCloneFit, the temporal order of mutations can be obtained by inferring the mutation status of internal nodes based on a maximum likelihood approach as described in SciFit and SiCloneFit papers [39,40]. Ultimately, we anticipate our method could also be applied in the future using single-cell DNA sequencing data of a cohort of patients once such data becomes more accessible.
One limitation of our analysis is that we did not account for cancer subtypes [41,42]. As cancer is a complex disease, tumors of similar morphology often have dramatically different outcomes and responses to treatment [43,44]. Cancer sub-typing plays an important role in cancer prognosis and more personalized treatment planning. Analyzing each cancer subtype and comparing the results across subtypes would be intriguing. Such an approach may facilitate the identification of both common and subtype-specific mutational orders and provide new insights into the biological mechanisms of cancer development and drug resistance. This will be one of the crucial focuses in our future work.
5. Conclusions
In this paper, we introduced a novel model to estimate the temporal order of pathway mutations by integrating ITH, pathways, and mutational functional annotation information. We applied our method to studying the progression of colon, liver, glioblastoma, and pancreatic cancers at the level of biological pathways. The results show that our method yielded high accuracy for the cancer progression inference. Our analysis demonstrates that the ITH information is critical to recovering the temporal order of pathway mutations from cross-sectional datasets.
Supplementary Materials
The following supporting information can be downloaded at https://www.mdpi.com/article/10.3390/cancers16132488/s1. Table S1: “Core” Pathway genes; Figures S1 and S2: Estimated orders of pathway mutations based on the TCGA colon cancer dataset using OncoTree and Youn’s method, respectively.
Author Contributions
Conceptualization, C.W., C.L., S.M.A. and A.S.; methodology, M.W. and C.W.; software, M.W.; validation, M.W.; formal analysis, M.W., J.L. and A.L.; investigation, C.W.; resources, J.L.; data curation, J.L., M.W., Y.X., L.C. and S.M.A.; writing—original draft preparation, M.W., Y.X., L.C. and S.M.A.; writing—review and editing, C.W. and M.W.; visualization, M.W.; supervision, C.W.; project administration, C.W.; funding acquisition, C.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Institutes of Health [R03CA259670, UL1TR001998], and the Biostatistics and Bioinformatics Shared Resource Facility of the University of Kentucky’s Markey Cancer Center [P30CA177558].
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Our method is freely available for academic use at https://github.com/MarkeyBBSRF/PATOPAI, accessed on 9 June 2024.
Acknowledgments
Our data analysis results are based upon data generated by The Cancer Genome Atlas (dbGaP accession phs000178.v11.p8), managed by the NCI and NHGRI. Information about TCGA can be found at http://cancergenome.nih.gov (accessed on 9 June 2024). We also would like to thank Donna Gilbreath for the scientific editing.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ITH | intra-tumor heterogeneity |
| PATOPAI | a probabilistic approach for estimating the temporal order of pathway mutations by incorporating ITH information |
| TCGA | The Cancer Genome Atlas |
| HCC | hepatocellular carcinoma |
| GBM | glioblastoma multiforme |
| PAAD | pancreatic adenocarcinoma |
References
- Kuipers, E.; M Grady, W.; Lieberman, D.; Seufferlein, T.; J Sung, J.; Boelens, P.; H Cornelis, J.; De Velde, V.; Watanabe, T. Colorectal cancer. Nat. Rev. Dis. Prim. 2015, 1, 15065. [Google Scholar] [CrossRef] [PubMed]
- Fearon, E.R.; Vogelstein, B. A genetic model for colorectal tumorigenesis. Cell 1990, 61, 759–767. [Google Scholar] [CrossRef]
- Desper, R.; Jiang, F.; Kallioniemi, O.P.; Moch, H.; Papadimitriou, C.H.; Schäffer, A.A. Inferring tree models for oncogenesis from comparative genome hybridization data. J. Comput. Biol. 1999, 6, 37–51. [Google Scholar] [CrossRef] [PubMed]
- Szabo, A.; Boucher, K. Estimating an oncogenetic tree when false negatives and positives are present. Math. Biosci. 2002, 176, 219–236. [Google Scholar] [CrossRef] [PubMed]
- Beerenwinkel, N.; Rahnenführer, J.; Däumer, M.; Hoffmann, D.; Kaiser, R.; Selbig, J.; Lengauer, T. Learning multiple evolutionary pathways from cross-sectional data. J. Comput. Biol. 2005, 12, 584–598. [Google Scholar] [CrossRef] [PubMed]
- Beerenwinkel, N.; Eriksson, N.; Sturmfels, B. Conjunctive bayesian networks. Bernoulli 2007, 13, 893–909. [Google Scholar] [CrossRef]
- Beerenwinkel, N.; Sullivant, S. Markov models for accumulating mutations. Biometrika 2009, 96, 645–661. [Google Scholar] [CrossRef]
- Gerstung, M.; Baudis, M.; Moch, H.; Beerenwinkel, N. Quantifying cancer progression with conjunctive Bayesian networks. Bioinformatics 2009, 25, 2809–2815. [Google Scholar] [CrossRef]
- Youn, A.; Simon, R. Estimating the order of mutations during tumorigenesis from tumor genome sequencing data. Bioinformatics 2012, 28, 1555–1561. [Google Scholar] [CrossRef]
- Wang, M.; Yu, T.; Liu, J.; Chen, L.; Stromberg, A.J.; Villano, J.L.; Arnold, S.M.; Liu, C.; Wang, C. A probabilistic method for leveraging functional annotations to enhance estimation of the temporal order of pathway mutations during carcinogenesis. BMC Bioinform. 2019, 20, 620. [Google Scholar] [CrossRef]
- Beerenwinkel, N.; Schwarz, R.F.; Gerstung, M.; Markowetz, F. Cancer evolution: Mathematical models and computational inference. Syst. Biol. 2015, 64, e1–e25. [Google Scholar] [CrossRef]
- Schwartz, R.; Schäffer, A.A. The evolution of tumour phylogenetics: Principles and practice. Nat. Rev. Genet. 2017, 18, 213. [Google Scholar] [CrossRef] [PubMed]
- Goyette, M.A.; Lipsyc-Sharf, M.; Polyak, K. Clinical and translational relevance of intratumor heterogeneity. Trends Cancer 2023, 9, 726–737. [Google Scholar] [CrossRef]
- Deshwar, A.G.; Vembu, S.; Yung, C.K.; Jang, G.H.; Stein, L.; Morris, Q. PhyloWGS: Reconstructing subclonal composition and evolution from whole-genome sequencing of tumors. Genome Biol. 2015, 16, 35. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Y.; Qiu, Y.; Minn, A.J.; Zhang, N.R. Assessing intratumor heterogeneity and tracking longitudinal and spatial clonal evolutionary history by next-generation sequencing. Proc. Natl. Acad. Sci. USA 2016, 113, E5528–E5537. [Google Scholar] [CrossRef] [PubMed]
- Dang, H.; White, B.; Foltz, S.; Miller, C.; Luo, J.; Fields, R.; Maher, C. ClonEvol: Clonal ordering and visualization in cancer sequencing. Ann. Oncol. 2017, 28, 3076–3082. [Google Scholar] [CrossRef] [PubMed]
- Adam, G.; Rampášek, L.; Safikhani, Z.; Smirnov, P.; Haibe-Kains, B.; Goldenberg, A. Machine learning approaches to drug response prediction: Challenges and recent progress. NPJ Precis. Oncol. 2020, 4, 19. [Google Scholar] [CrossRef] [PubMed]
- Sashittal, P.; Zaccaria, S.; El-Kebir, M. Parsimonious clone tree integration in cancer. Algorithms Mol. Biol. 2022, 17, 3. [Google Scholar] [CrossRef] [PubMed]
- Jiao, W.; Vembu, S.; Deshwar, A.G.; Stein, L.; Morris, Q. Inferring clonal evolution of tumors from single nucleotide somatic mutations. BMC Bioinform. 2014, 15, 35. [Google Scholar] [CrossRef]
- Ellson, J. Graphviz-Graph Visualization Software. 2008. Available online: http://www.graphviz.org/ (accessed on 1 July 2018).
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Kanehisa, M.; Goto, S. KEGG: Kyoto encyclopedia of genes and genomes. Nucleic Acids Res. 2000, 28, 27–30. [Google Scholar] [CrossRef] [PubMed]
- The Cancer Genome Atlas Network. Comprehensive molecular characterization of human colon and rectal cancer. Nature 2012, 487, 330. [Google Scholar] [CrossRef] [PubMed]
- Hao, Y.; Baker, D.; Ten Dijke, P. TGF-β-mediated epithelial-mesenchymal transition and cancer metastasis. Int. J. Mol. Sci. 2019, 20, 2767. [Google Scholar] [CrossRef] [PubMed]
- Ali, E.S.; Rychkov, G.Y.; Barritt, G.J. Targeting Ca2+ signaling in the initiation, promotion and progression of hepatocellular carcinoma. Cancers 2020, 12, 2755. [Google Scholar] [CrossRef] [PubMed]
- Moon, H.; Ro, S.W. MAPK/ERK signaling pathway in hepatocellular carcinoma. Cancers 2021, 13, 3026. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.S. The mutational landscape of hepatocellular carcinoma. Clin. Mol. Hepatol. 2015, 21, 220. [Google Scholar] [CrossRef] [PubMed]
- Gittleman, H.; Lim, D.; Kattan, M.W.; Chakravarti, A.; Gilbert, M.R.; Lassman, A.B.; Lo, S.S.; Machtay, M.; Sloan, A.E.; Sulman, E.P.; et al. An independently validated nomogram for individualized estimation of survival among patients with newly diagnosed glioblastoma: NRG Oncology RTOG 0525 and 0825. Neuro-Oncology 2017, 19, 669–677. [Google Scholar] [PubMed]
- Pei, Z.; Lee, K.C.; Khan, A.; Erisnor, G.; Wang, H.Y. Pathway analysis of glutamate-mediated, calcium-related signaling in glioma progression. Biochem. Pharmacol. 2020, 176, 113814. [Google Scholar] [CrossRef]
- Chen, W.L.; Barszczyk, A.; Turlova, E.; Deurloo, M.; Liu, B.; Yang, B.B.; Rutka, J.T.; Feng, Z.P.; Sun, H.S. Inhibition of TRPM7 by carvacrol suppresses glioblastoma cell proliferation, migration and invasion. Oncotarget 2015, 6, 16321. [Google Scholar] [CrossRef]
- Tilak, M.; Holborn, J.; New, L.A.; Lalonde, J.; Jones, N. Receptor tyrosine kinase signaling and targeting in glioblastoma multiforme. Int. J. Mol. Sci. 2021, 22, 1831. [Google Scholar] [CrossRef]
- Varn, F.S.; Johnson, K.C.; Martinek, J.; Huse, J.T.; Nasrallah, M.P.; Wesseling, P.; Cooper, L.A.; Malta, T.M.; Wade, T.E.; Sabedot, T.S.; et al. Glioma progression is shaped by genetic evolution and microenvironment interactions. Cell 2022, 185, 2184–2199.e16. [Google Scholar] [CrossRef] [PubMed]
- Torre, L.A.; Bray, F.; Siegel, R.L.; Ferlay, J.; Lortet-Tieulent, J.; Jemal, A. Cancer statistics, 2012. CA Cancer J. Clin. 2014, 64, 9–29. [Google Scholar]
- Waters, A.M.; Der, C.J. KRAS: The critical driver and therapeutic target for pancreatic cancer. Cold Spring Harb. Perspect. Med. 2018, 8, a031435. [Google Scholar] [CrossRef] [PubMed]
- Kanda, M.; Matthaei, H.; Wu, J.; Hong, S.M.; Yu, J.; Borges, M.; Hruban, R.H.; Maitra, A.; Kinzler, K.; Vogelstein, B.; et al. Presence of somatic mutations in most early-stage pancreatic intraepithelial neoplasia. Gastroenterology 2012, 142, 730–733. [Google Scholar] [CrossRef]
- Moskaluk, C.A.; Hruban, R.H.; Kern, S.E. p16 and K-ras gene mutations in the intraductal precursors of human pancreatic adenocarcinoma. Cancer Res. 1997, 57, 2140–2143. [Google Scholar] [PubMed]
- Iacobuzio-Donahue, C.A. Genetic evolution of pancreatic cancer: Lessons learnt from the pancreatic cancer genome sequencing project. Gut 2012, 61, 1085–1094. [Google Scholar] [CrossRef] [PubMed]
- Jahn, K.; Kuipers, J.; Beerenwinkel, N. Tree inference for single-cell data. Genome Biol. 2016, 17, 86. [Google Scholar] [CrossRef] [PubMed]
- Zafar, H.; Tzen, A.; Navin, N.; Chen, K.; Nakhleh, L. SiFit: Inferring tumor trees from single-cell sequencing data under finite-sites models. Genome Biol. 2017, 18, 178. [Google Scholar] [CrossRef] [PubMed]
- Zafar, H.; Navin, N.; Chen, K.; Nakhleh, L. SiCloneFit: Bayesian inference of population structure, genotype, and phylogeny of tumor clones from single-cell genome sequencing data. Genome Res. 2019, 29, 1847–1859. [Google Scholar] [CrossRef]
- Perez-Moreno, P.; Brambilla, E.; Thomas, R.; Soria, J.C. Squamous cell carcinoma of the lung: Molecular subtypes and therapeutic opportunities. Clin. Cancer Res. 2012, 18, 2443–2451. [Google Scholar] [CrossRef] [PubMed]
- Brennan, C.W.; Verhaak, R.G.; McKenna, A.; Campos, B.; Noushmehr, H.; Salama, S.R.; Zheng, S.; Chakravarty, D.; Sanborn, J.Z.; Berman, S.H.; et al. The somatic genomic landscape of glioblastoma. Cell 2014, 157, 753. [Google Scholar] [CrossRef]
- Collisson, E.A.; Bailey, P.; Chang, D.K.; Biankin, A.V. Molecular subtypes of pancreatic cancer. Nat. Rev. Gastroenterol. Hepatol. 2019, 16, 207–220. [Google Scholar] [CrossRef]
- Johnson, K.S.; Conant, E.F.; Soo, M.S. Molecular subtypes of breast cancer: A review for breast radiologists. J. Breast Imaging 2021, 3, 12–24. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).