
A Hybrid Algorithm of ML and XAI to Prevent Breast Cancer: A Strategy to Support Decision Making
 , , and
, , and
Abstract
Simple Summary
Abstract
1. Introduction
2. Related Literature
2.1. Impact of COVID-19 for Managing Cancer in the World
2.2. Strategies for the Prevention and Management of Breast Cancer
2.3. Justification of the Chosen Method
- Extensive international evidence demonstrates the importance of including dynamic and machine-learning methodologies for the prevention and management of patients with breast cancer. That is why it is urgent in the countries with the highest incidence to implement these tools that support medical management to help patients.
- One of the elements rarely addressed in the literature on breast cancer prevention is the inclusion of interpretable algorithms that facilitate understanding for decision makers.
- Finally, one of the relevant factors discussed in the literature is the importance of medical opinion when defining methods, criteria, and factors that allow the development of the oncological strategy since each clinical unit and its committee have its way of managing its patients.
3. Materials and Methods
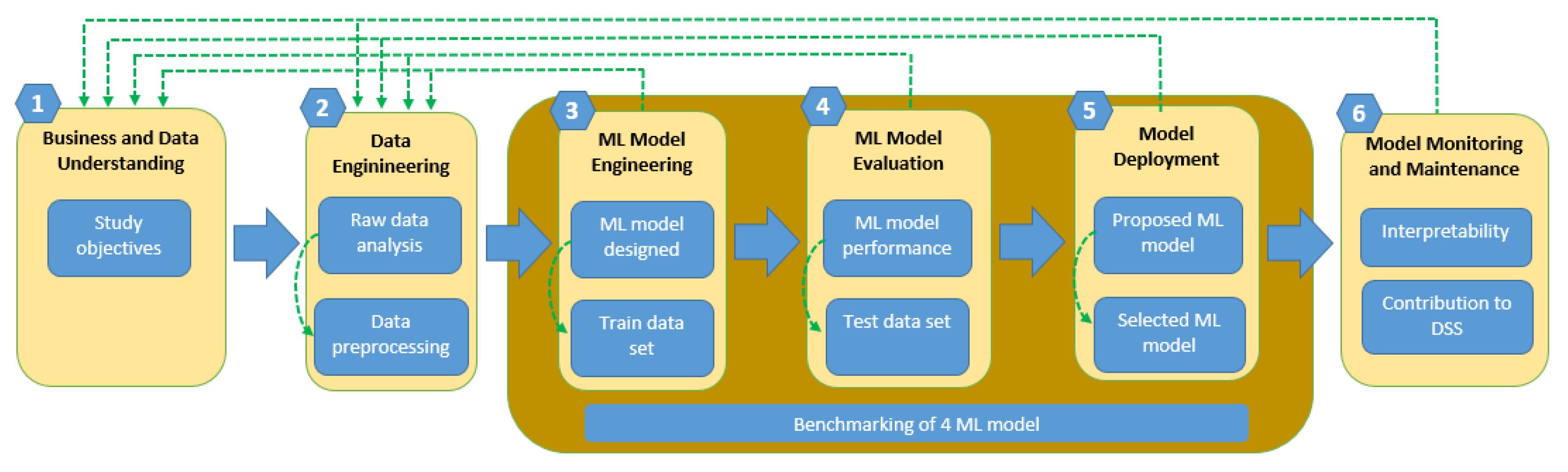
3.1. New Strategy to Classify Patients with Breast Cancer
3.2. Case Study: Breast Cancer Patients in Indonesia
3.3. Extreme Gradient Boosting: XGBoots Algorithm to Predict Breast Cancer
3.4. Selection Model
3.5. SHAP Mathematical Method: Strategy to Interpret the XGBoost Model of Breast Cancer
4. Results
4.1. Algorithm Selection
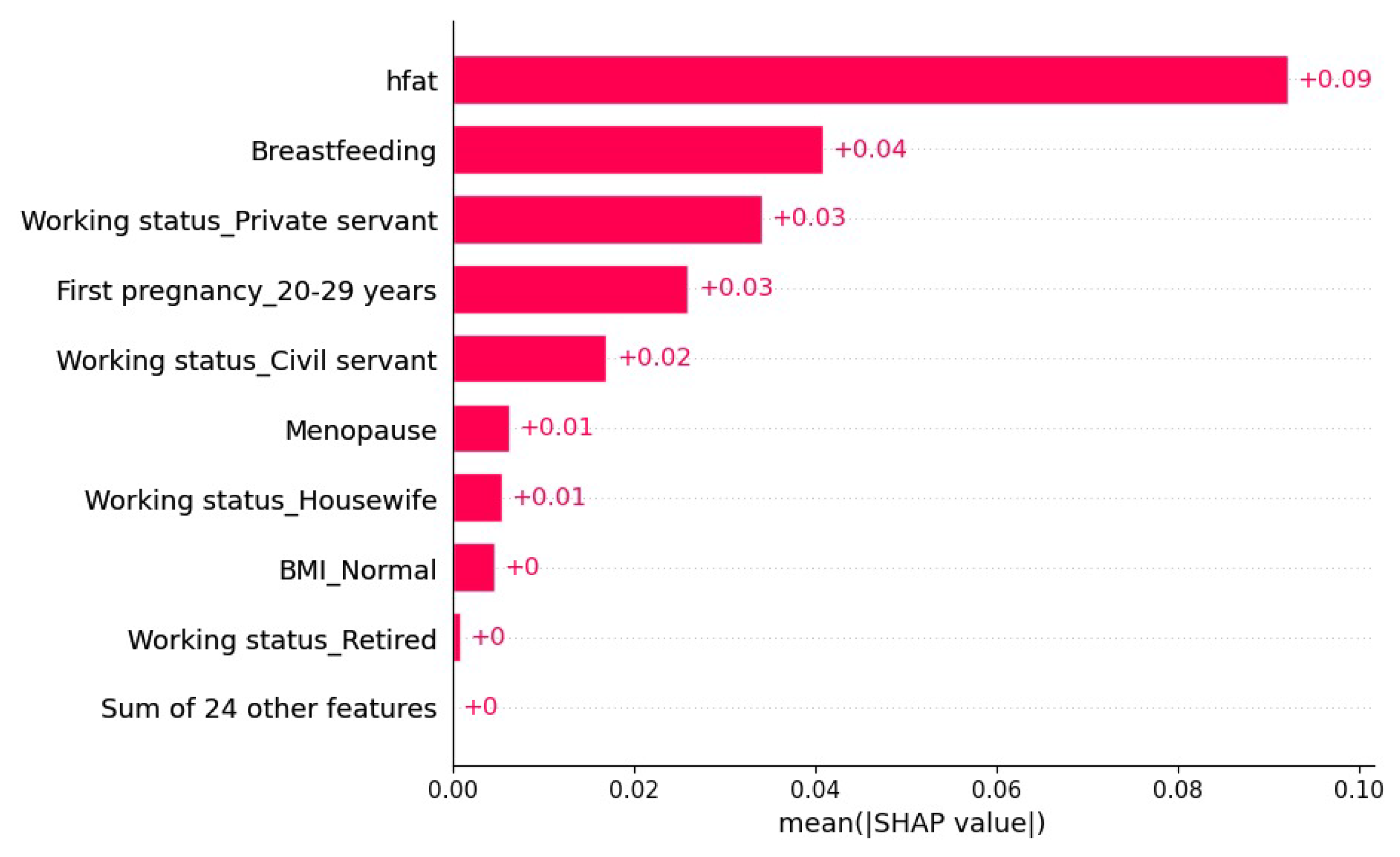
4.2. Model Explainability
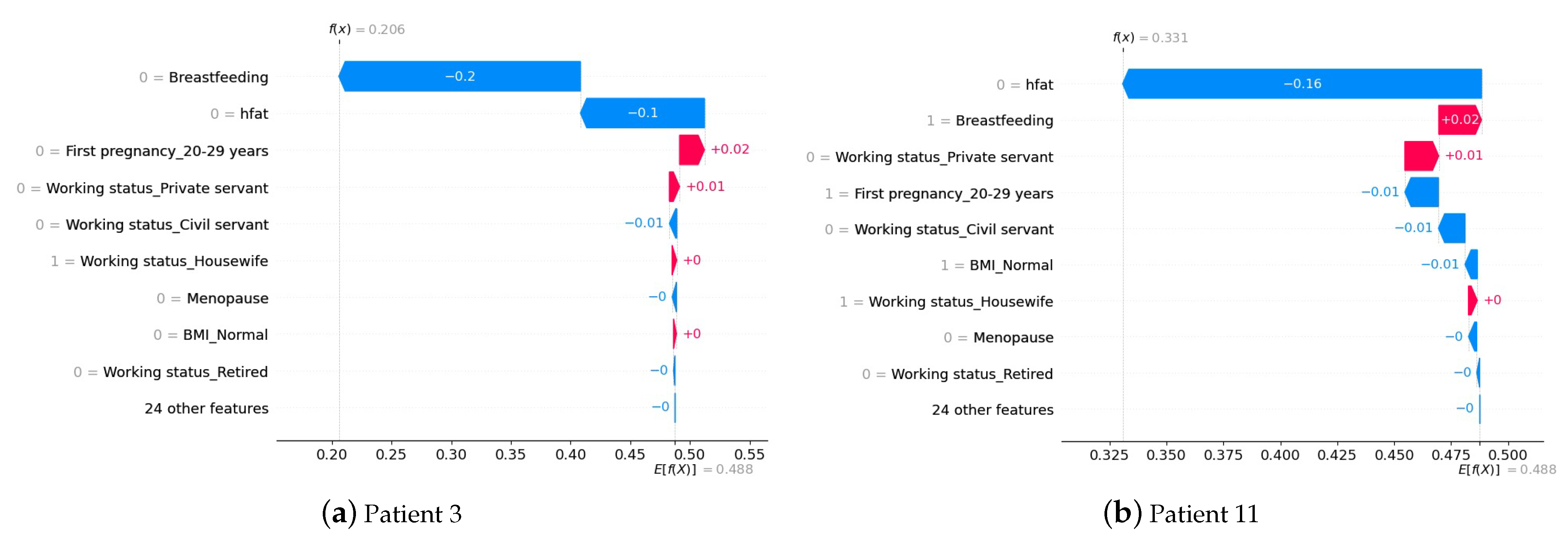
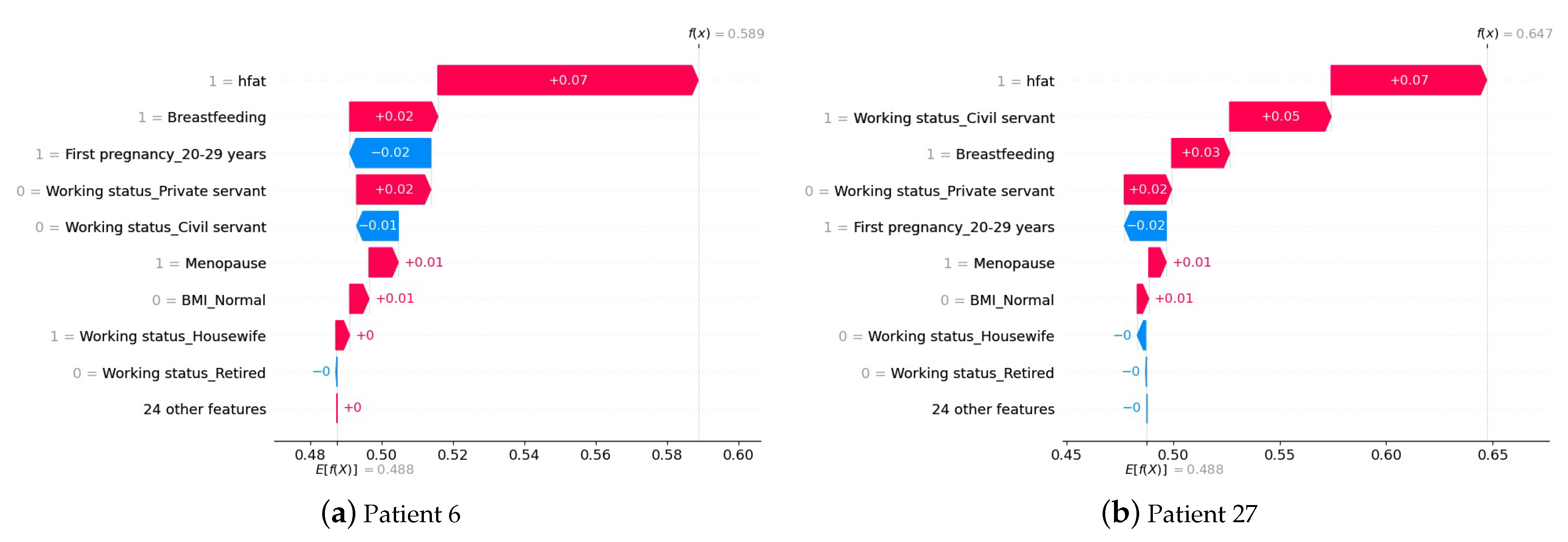
4.3. Interpretation of the Prediction at the Patient Level
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Hyperparameter Search Space for Each Algorithm
| Algorithm | Hyperparameter | Search Space |
| XGBoots | n_estimators | [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000] |
| learning_rate | [0.0001, 0.001, 0.01, 0.1, 1] | |
| max_depth | range(3, 21, 3) | |
| min_child_weight | range(1, 21, 3) | |
| gamma | [i/10.0 for i in range(0, 7)] | |
| colsample_bytree | [i/10.0 for i in range(3, 10)] | |
| reg_alpha | [, , 0.1, 1, 10, 40, 80, 100] | |
| reg_lambda | [, , 0.1, 1, 10, 40, 80, 100] | |
| Logistic Regression | penalty | [‘l1’, ‘l2’, ‘elasticnet’] |
| dual | [True, False] | |
| tol | [, , , , 1, 10, 100, 1000] | |
| C | [, , , , 1, 10, 100, 1000] | |
| intercept_scaling | [1, 2, 3, 4, 5] | |
| solver | [‘newton-cg’, ‘lbfgs’, ‘sag’, ‘saga’] | |
| Random Forest | n_estimators | [5, 20, 50, 100] |
| max_features | [‘auto’, ‘sqrt’] | |
| max_depth | [int(x) for x in np.linspace(10, 120, num = 12)] | |
| min_samples_split | [2, 6, 10] | |
| min_samples_leaf | [1, 3, 4] | |
| bootstrap | [True, False] | |
| SVM | C | [0.1, 1, 10, 100, 1000] |
| gamma | [“scale”, “auto”] | |
| kernel | [‘rbf’, ‘poly’, ‘sigmoid’] | |
| degree | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] | |
| coef0 | [0.1, 0.5, 1, 2, 5, 10] | |
| shrinking | [True, False] | |
| probability | [True, False] | |
| tol | [, , , , 1, 10, 100, 1000] | |
| cache_size | [200, 500, 1000] | |
| class_weight | [None, “balanced”] | |
| decision_function_shape | [‘ovo’, ‘ovr’] | |
| break_ties | [True, False] | |
| decision_function_shape | [‘ovo’, ‘ovr’] | |
| break_ties | [True, False] |
References
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global cancer statistics 2020: Globocan estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef] [PubMed]
- Gupta, A.; Arora, V.; Nair, D.; Agrawal, N.; Su, Y.x.; Holsinger, F.C.; Chan, J.Y. Status and strategies for the management of head and neck cancer during COVID-19 pandemic: Indian scenario. Head Neck 2020, 42, 1460–1465. [Google Scholar] [CrossRef]
- Ferrara, G.; De Vincentiis, L.; Ambrosini-Spaltro, A.; Barbareschi, M.; Bertolini, V.; Contato, E.; Crivelli, F.; Feyles, E.; Mariani, M.P.; Morelli, L.; et al. Cancer diagnostic delay in northern and central Italy during the 2020 lockdown due to the coronavirus disease 2019 pandemic: Assessment of the magnitude of the problem and proposals for corrective actions. Am. J. Clin. Pathol. 2021, 155, 64–68. [Google Scholar] [CrossRef] [PubMed]
- Maringe, C.; Spicer, J.; Morris, M.; Purushotham, A.; Nolte, E.; Sullivan, R.; Rachet, B.; Aggarwal, A. The impact of the COVID-19 pandemic on cancer deaths due to delays in diagnosis in England, UK: A national, population-based, modelling study. Lancet Oncol. 2020, 21, 1023–1034. [Google Scholar] [CrossRef] [PubMed]
- Spicer, J.; Chamberlain, C.; Papa, S. Provision of cancer care during the COVID-19 pandemic. Nat. Rev. Clin. Oncol. 2020, 17, 329–331. [Google Scholar] [CrossRef] [PubMed]
- González-Montero, J.; Valenzuela, G.; Ahumada, M.; Barajas, O.; Villanueva, L. Management of cancer patients during COVID-19 pandemic at developing countries. World J. Clin. Cases 2020, 8, 3390. [Google Scholar] [CrossRef]
- Saini, K.S.; de Las Heras, B.; de Castro, J.; Venkitaraman, R.; Poelman, M.; Srinivasan, G.; Saini, M.L.; Verma, S.; Leone, M.; Aftimos, P.; et al. Effect of the COVID-19 pandemic on cancer treatment and research. Lancet Haematol. 2020, 7, e432–e435. [Google Scholar] [CrossRef] [PubMed]
- Nolan, G.S.; Dunne, J.A.; Kiely, A.L.; Pritchard Jones, R.O.; Gardiner, M.; Jain, A. The effect of the COVID-19 pandemic on skin cancer surgery in the United Kingdom: A national, multi-centre, prospective cohort study and survey of plastic surgeons. J. Br. Surg. 2020, 107, e598–e600. [Google Scholar]
- Collaborative, I.S.R.; Italian Society of Colorectal Surgery; Association of Surgeons in Training; Transatlantic Australasian Retroperitoneal Sarcoma Working Group. Effect of COVID-19 pandemic lockdowns on planned cancer surgery for 15 tumour types in 61 countries: An international, prospective, cohort study. Lancet Oncol. 2021, 22, 1507–1517. [Google Scholar]
- Ricciardiello, L.; Ferrari, C.; Cameletti, M.; Gaianill, F.; Buttitta, F.; Bazzoli, F.; de’Angelis, G.L.; Malesci, A.; Laghi, L. Impact of SARS-CoV-2 pandemic on colorectal cancer screening delay: Effect on stage shift and increased mortality. Clin. Gastroenterol. Hepatol. 2021, 19, 1410–1417. [Google Scholar] [CrossRef]
- Picchio, C.A.; Valencia, J.; Doran, J.; Swan, T.; Pastor, M.; Martró, E.; Colom, J.; Lazarus, J.V. The impact of the COVID-19 pandemic on harm reduction services in Spain. Harm Reduct. J. 2020, 17, 87. [Google Scholar] [CrossRef] [PubMed]
- Radfar, S.R.; De Jong, C.A.; Farhoudian, A.; Ebrahimi, M.; Rafei, P.; Vahidi, M.; Yunesian, M.; Kouimtsidis, C.; Arunogiri, S.; Massah, O.; et al. Reorganization of substance use treatment and harm reduction services during the COVID-19 pandemic: A global survey. Front. Psychiatry 2021, 12, 349. [Google Scholar] [CrossRef] [PubMed]
- Garcia, M.; Jemal, A.; Ward, E.; Center, M.; Hao, Y.; Siegel, R.; Thun, M. Global cancer facts & figures 2007. Atlanta GA Am. Cancer Soc. 2007, 1, 52. [Google Scholar]
- Chavez, K.J.; Garimella, S.V.; Lipkowitz, S. Triple negative breast cancer cell lines: One tool in the search for better treatment of triple negative breast cancer. Breast Dis. 2010, 32, 35. [Google Scholar] [CrossRef]
- Hachesu, P.R.; Ahmadi, M.; Alizadeh, S.; Sadoughi, F. Use of data mining techniques to determine and predict length of stay of cardiac patients. Healthc. Inform. Res. 2013, 19, 121–129. [Google Scholar] [CrossRef]
- Saranya, G.; Pravin, A. An Efficient Feature Selection Approach using Sensitivity Analysis for Machine Learning based Heart Desease Classification. In Proceedings of the 2021 10th IEEE International Conference on Communication Systems and Network Technologies (CSNT), Bhopal, India, 18–19 June 2021; pp. 539–542. [Google Scholar]
- Silva-Aravena, F.; Delafuente, H.N.; Astudillo, C.A. A Novel Strategy to Classify Chronic Patients at Risk: A Hybrid Machine Learning Approach. Mathematics 2022, 10, 3053. [Google Scholar] [CrossRef]
- Madanu, R.; Abbod, M.F.; Hsiao, F.J.; Chen, W.T.; Shieh, J.S. Explainable ai (xai) applied in machine learning for pain modeling: A review. Technologies 2022, 10, 74. [Google Scholar] [CrossRef]
- Loh, H.W.; Ooi, C.P.; Seoni, S.; Barua, P.D.; Molinari, F.; Acharya, U.R. Application of explainable artificial intelligence for healthcare: A systematic review of the last decade (2011–2022). Comput. Methods Programs Biomed. 2022, 226, 107161. [Google Scholar] [CrossRef]
- Panigutti, C.; Perotti, A.; Pedreschi, D. Doctor XAI: An ontology-based approach to black-box sequential data classification explanations. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; pp. 629–639. [Google Scholar]
- Osareh, A.; Shadgar, B. Machine learning techniques to diagnose breast cancer. In Proceedings of the 2010 5th International Symposium on Health Informatics and Bioinformatics, Ankara, Turkey, 20–22 April 2010; pp. 114–120. [Google Scholar]
- Ahmad, L.G.; Eshlaghy, A.; Poorebrahimi, A.; Ebrahimi, M.; Razavi, A. Using three machine learning techniques for predicting breast cancer recurrence. J. Health Med. Inform. 2013, 4, 3. [Google Scholar]
- Yue, W.; Wang, Z.; Chen, H.; Payne, A.; Liu, X. Machine learning with applications in breast cancer diagnosis and prognosis. Designs 2018, 2, 13. [Google Scholar] [CrossRef]
- Ganggayah, M.D.; Taib, N.A.; Har, Y.C.; Lio, P.; Dhillon, S.K. Predicting factors for survival of breast cancer patients using machine learning techniques. BMC Med. Inform. Decis. Mak. 2019, 19, 48. [Google Scholar] [CrossRef]
- Rajendran, K.; Jayabalan, M.; Thiruchelvam, V.; Sivakumar, V. Feasibility study on data mining techniques in diagnosis of breast cancer. Int. J. Mach. Learn. Comput. 2019, 9, 328–333. [Google Scholar] [CrossRef]
- Ming, C.; Viassolo, V.; Probst-Hensch, N.; Chappuis, P.O.; Dinov, I.D.; Katapodi, M.C. Machine learning techniques for personalized breast cancer risk prediction: Comparison with the BCRAT and BOADICEA models. Breast Cancer Res. 2019, 21, 75. [Google Scholar] [CrossRef] [PubMed]
- Rajendran, K.; Jayabalan, M.; Thiruchelvam, V. Predicting breast cancer via supervised machine learning methods on class imbalanced data. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 54–63. [Google Scholar] [CrossRef]
- Chaurasia, V.; Pal, S. Applications of machine learning techniques to predict diagnostic breast cancer. SN Comput. Sci. 2020, 1, 270. [Google Scholar] [CrossRef]
- Naji, M.A.; El Filali, S.; Aarika, K.; Benlahmar, E.H.; Abdelouhahid, R.A.; Debauche, O. Machine learning algorithms for breast cancer prediction and diagnosis. Procedia Comput. Sci. 2021, 191, 487–492. [Google Scholar] [CrossRef]
- Rabiei, R.; Ayyoubzadeh, S.M.; Sohrabei, S.; Esmaeili, M.; Atashi, A. Prediction of breast cancer using machine learning approaches. J. Biomed. Phys. Eng. 2022, 12, 297. [Google Scholar] [CrossRef]
- Zeng, L.; Liu, L.; Chen, D.; Lu, H.; Xue, Y.; Bi, H.; Yang, W. The innovative model based on artificial intelligence algorithms to predict recurrence risk of patients with postoperative breast cancer. Front. Oncol. 2023, 13, 807. [Google Scholar] [CrossRef]
- Idrees, M.; Sohail, A. Explainable machine learning of the breast cancer staging for designing smart biomarker sensors. Sensors Int. 2022, 3, 100202. [Google Scholar] [CrossRef]
- Rodriguez-Sampaio, M.; Rincón, M.; Valladares-Rodríguez, S.; Bachiller-Mayoral, M. Explainable Artificial Intelligence to Detect Breast Cancer: A Qualitative Case-Based Visual Interpretability Approach. In Proceedings of the International Work-Conference on the Interplay Between Natural and Artificial Computation, Puerto de la Cruz, Spain, 31 May–3 June 2022; pp. 557–566. [Google Scholar]
- Nindrea, R.D.; Kusnanto, H.; Haryono, S.J.; Harahap, W.A.; Dwiprahasto, I.; Lazuardi, L.; Aryandono, T. Development of Breast Cancer Risk Prediction Model for Women in Indonesia: A Case-Control Study. 2020. Available online: https://assets.researchsquare.com/files/rs-24225/v1/79816af2-b565-4447-906b-315495b64a26.pdf?c=1631833888 (accessed on 17 April 2023).
- Magna, A.A.R.; Allende-Cid, H.; Taramasco, C.; Becerra, C.; Figueroa, R.L. Application of machine learning and word embeddings in the classification of cancer diagnosis using patient anamnesis. IEEE Access 2020, 8, 106198–106213. [Google Scholar] [CrossRef]
- Acevedo, F.; Bravo, L.; Sanchez, C.; Muñiz, S.; Petric, M.; Martinez, R.; Guerra, C.; Navarro, M.; Causa, L.; Bravo, S.; et al. Machine Learning Analysis of a Chilean Breast Cancer Registry. Biomed. J. Sci. Tech. Res. 2021, 37, 29654–29657. [Google Scholar]
- Yu, K.; Tan, L.; Lin, L.; Cheng, X.; Yi, Z.; Sato, T. Deep-learning-empowered breast cancer auxiliary diagnosis for 5 GB remote E-health. IEEE Wirel. Commun. 2021, 28, 54–61. [Google Scholar] [CrossRef]
- Iunes, R.F.; Uribe, M.V.; Torres, J.B.; Garcia, M.M.; Dias, C.Z.; Alvares-Teodoro, J.; de Assis Acurcio, F.; Guerra-Junior, A.A. Confidentiality agreements: A challenge in market regulation. Int. J. Equity Health 2019, 18, 11. [Google Scholar] [CrossRef] [PubMed]
- Durán, D.; Monsalves, M.J. Spatial autocorrelation of breast cancer mortality in the Metropolitan Region, Chile: An ecological study. Medwave 2020, 20, e7766. [Google Scholar] [CrossRef]
- Ramírez-Parada, K.; Courneya, K.S.; Muñiz, S.; Sánchez, C.; Fernández-Verdejo, R. Physical activity levels and preferences of patients with breast cancer receiving chemotherapy in Chile. Support. Care Cancer 2019, 27, 2941–2947. [Google Scholar] [CrossRef]
- Zavala, V.A.; Serrano-Gomez, S.J.; Dutil, J.; Fejerman, L. Genetic epidemiology of breast cancer in Latin America. Genes 2019, 10, 153. [Google Scholar] [CrossRef]
- Mella-Abarca, W.; Barraza-Sánchez, V.; Ramírez-Parada, K. Telerehabilitation for people with breast cancer through the COVID-19 pandemic in Chile. Ecancermedicalscience 2020, 14, 1085. [Google Scholar] [CrossRef]
- Valverde-Ampai, W.; Palma-Rozas, G.; Conei, D.; Marzuca-Nassr, G.N.; Medina-González, P.; Escobar-Cabello, M.; del Sol, M.; Muñoz-Cofre, R. Effects of concurrent chemotherapy and radiotherapy on lung volumes in women with breast cancer living in Talca, Chile. Rev. Fac. Med. 2020, 68, 222–228. [Google Scholar]
- Cheng, M.; Akalestos, A.; Scudder, S. Budget Impact Analysis of EGFR Mutation Liquid Biopsy for First-and Second-Line Treatment of Metastatic Non-Small Cell Lung Cancer in Greece. Diagnostics 2020, 10, 429. [Google Scholar] [CrossRef]
- Flores, S.; Kurian, N.; Yohannan, A.; Persaud, C.; Saif, M.W. Consequences of the COVID-19 pandemic on cancer clinical trials. Cancer Med. J. 2021, 4, 38. [Google Scholar]
- Obek, C.; Doganca, T.; Argun, O.B.; Kural, A.R. Management of prostate cancer patients during COVID-19 pandemic. Prostate Cancer Prostatic Dis. 2020, 23, 398–406. [Google Scholar] [CrossRef] [PubMed]
- Levit, L.A.; Byatt, L.; Lyss, A.P.; Paskett, E.D.; Levit, K.; Kirkwood, K.; Schenkel, C.; Schilsky, R.L. Closing the rural cancer care gap: Three institutional approaches. JCO Oncol. Pract. 2020, 16, 422–430. [Google Scholar] [CrossRef] [PubMed]
- Abu-Odah, H.; Molassiotis, A.; Liu, J. Challenges on the provision of palliative care for patients with cancer in low-and middle-income countries: A systematic review of reviews. BMC Palliat. Care 2020, 19, 55. [Google Scholar] [CrossRef]
- Hwang, E.S.; Balch, C.M.; Balch, G.C.; Feldman, S.M.; Golshan, M.; Grobmyer, S.R.; Libutti, S.K.; Margenthaler, J.A.; Sasidhar, M.; Turaga, K.K.; et al. Surgical oncologists and the COVID-19 pandemic: Guiding cancer patients effectively through turbulence and change. Ann. Surg. Oncol. 2020, 27, 2600–2613. [Google Scholar] [CrossRef] [PubMed]
- Okereke, M.; Ukor, N.A.; Adebisi, Y.A.; Ogunkola, I.O.; Favour Iyagbaye, E.; Adiela Owhor, G.; Lucero-Prisno III, D.E. Impact of COVID-19 on access to healthcare in low-and middle-income countries: Current evidence and future recommendations. Int. J. Health Plan. Manag. 2021, 36, 13–17. [Google Scholar] [CrossRef] [PubMed]
- Elkaddoum, R.; Haddad, F.G.; Eid, R.; Kourie, H.R. Telemedicine for Cancer Patients during COVID-19 Pandemic: Between Threats and Opportunities. 2020. Available online: https://www.futuremedicine.com/doi/full/10.2217/fon-2020-0324 (accessed on 17 April 2023).
- Al-Quteimat, O.M.; Amer, A.M. The impact of the COVID-19 pandemic on cancer patients. Am. J. Clin. Oncol. 2020. [Google Scholar] [CrossRef] [PubMed]
- Sorrentino, L.; Guaglio, M.; Cosimelli, M. Elective colorectal cancer surgery at the oncologic hub of Lombardy inside a pandemic COVID-19 area. J. Surg. Oncol. 2020, 122, 117–119. [Google Scholar] [CrossRef] [PubMed]
- de la Viña, J.I.; Mayol, J.; Ortega, A.L.; Navarrete, B.A. Lung cancer patients on the waiting list in the midst of the COVID-19 crisis: What do we do now? Arch. Bronconeumol. 2020, 56, 602. [Google Scholar] [CrossRef]
- Cadili, L.; DeGirolamo, K.; McKevitt, E.; Brown, C.J.; Prabhakar, C.; Pao, J.S.; Dingee, C.; Bazzarelli, A.; Warburton, R. COVID-19 and breast cancer at a Regional Breast Centre: Our flexible approach during the pandemic. Breast Cancer Res. Treat. 2021, 186, 519–525. [Google Scholar] [CrossRef]
- Lo, B.D.; Zhang, G.Q.; Stem, M.; Sahyoun, R.; Efron, J.E.; Safar, B.; Atallah, C. Do specific operative approaches and insurance status impact timely access to colorectal cancer care? Surg. Endosc. 2021, 35, 3774–3786. [Google Scholar] [CrossRef]
- Greenwood, E.; Swanton, C. Consequences of COVID-19 for cancer care—A CRUK perspective. Nat. Rev. Clin. Oncol. 2021, 18, 3–4. [Google Scholar] [CrossRef] [PubMed]
- Sud, A.; Torr, B.; Jones, M.E.; Broggio, J.; Scott, S.; Loveday, C.; Garrett, A.; Gronthoud, F.; Nicol, D.L.; Jhanji, S.; et al. Effect of delays in the 2-week-wait cancer referral pathway during the COVID-19 pandemic on cancer survival in the UK: A modelling study. Lancet Oncol. 2020, 21, 1035–1044. [Google Scholar] [CrossRef]
- Malagón, T.; Yong, J.H.; Tope, P.; Miller, W.H., Jr.; Franco, E.L.; McGill Task Force on the Impact of COVID-19 on Cancer Control and Care. Predicted long-term impact of COVID-19 pandemic-related care delays on cancer mortality in Canada. Int. J. Cancer 2022, 150, 1244–1254. [Google Scholar] [CrossRef]
- Vourganti, S.; Rastinehad, A.; Yerram, N.K.; Nix, J.; Volkin, D.; Hoang, A.; Turkbey, B.; Gupta, G.N.; Kruecker, J.; Linehan, W.M.; et al. Multiparametric magnetic resonance imaging and ultrasound fusion biopsy detect prostate cancer in patients with prior negative transrectal ultrasound biopsies. J. Urol. 2012, 188, 2152–2157. [Google Scholar] [CrossRef]
- Lu, Y.Y.; Chen, J.H.; Chien, C.R.; Chen, W.T.L.; Tsai, S.C.; Lin, W.Y.; Kao, C.H. Use of FDG-PET or PET/CT to detect recurrent colorectal cancer in patients with elevated CEA: A systematic review and meta-analysis. Int. J. Color. Dis. 2013, 28, 1039–1047. [Google Scholar] [CrossRef]
- Janas, Ł. Current clinical application of serum biomarkers to detect and monitor ovarian cancer-update. Prz. Menopauzalny Menopause Rev. 2021, 20, 211. [Google Scholar] [CrossRef]
- Keenan, J.I.; Frizelle, F.A. Biomarkers to Detect Early-Stage Colorectal Cancer. Biomedicines 2022, 10, 255. [Google Scholar] [CrossRef]
- Zhu, W.; Xie, L.; Han, J.; Guo, X. The application of deep learning in cancer prognosis prediction. Cancers 2020, 12, 603. [Google Scholar] [CrossRef] [PubMed]
- Leung, W.K.; Cheung, K.S.; Li, B.; Law, S.Y.; Lui, T.K. Applications of machine learning models in the prediction of gastric cancer risk in patients after Helicobacter pylori eradication. Aliment. Pharmacol. Ther. 2021, 53, 864–872. [Google Scholar] [PubMed]
- Adams, S.J.; Mondal, P.; Penz, E.; Tyan, C.C.; Lim, H.; Babyn, P. Development and Cost Analysis of a Lung Nodule Management Strategy Combining Artificial Intelligence and Lung-RADS for Baseline Lung Cancer Screening. J. Am. Coll. Radiol. 2021, 18, 741–751. [Google Scholar] [CrossRef]
- Santiago-Montero, R.; Sossa, H.; Gutiérrez-Hernández, D.A.; Zamudio, V.; Hernández-Bautista, I.; Valadez-Godínez, S. Novel mathematical model of breast cancer diagnostics using an associative pattern classification. Diagnostics 2020, 10, 136. [Google Scholar] [CrossRef] [PubMed]
- Yerukala Sathipati, S.; Ho, S.Y. Identifying a miRNA signature for predicting the stage of breast cancer. Sci. Rep. 2018, 8, 16138. [Google Scholar] [CrossRef] [PubMed]
- Padmanabhan, R.; Kheraldine, H.S.; Meskin, N.; Vranic, S.; Al Moustafa, A.E. Crosstalk between HER2 and PD-1/PD-L1 in breast cancer: From clinical applications to mathematical models. Cancers 2020, 12, 636. [Google Scholar] [CrossRef] [PubMed]
- Jarrett, A.M.; Hormuth II, D.A.; Wu, C.; Kazerouni, A.S.; Ekrut, D.A.; Virostko, J.; Sorace, A.G.; DiCarlo, J.C.; Kowalski, J.; Patt, D.; et al. Evaluating patient-specific neoadjuvant regimens for breast cancer via a mathematical model constrained by quantitative magnetic resonance imaging data. Neoplasia 2020, 22, 820–830. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Virostko, J.; Hormuth, D.A.; Liu, J.; Brock, A.; Kowalski, J.; Yankeelov, T.E. An experimental-mathematical approach to predict tumor cell growth as a function of glucose availability in breast cancer cell lines. PLoS ONE 2021, 16, e0240765. [Google Scholar] [CrossRef]
- Szczurek, E.; Krüger, T.; Klink, B.; Beerenwinkel, N. A mathematical model of the metastatic bottleneck predicts patient outcome and response to cancer treatment. PLoS Comput. Biol. 2020, 16, e1008056. [Google Scholar] [CrossRef]
- Avanzini, S.; Kurtz, D.M.; Chabon, J.J.; Moding, E.J.; Hori, S.S.; Gambhir, S.S.; Alizadeh, A.A.; Diehn, M.; Reiter, J.G. A mathematical model of ctDNA shedding predicts tumor detection size. Sci. Adv. 2020, 6, eabc4308. [Google Scholar] [CrossRef]
- Chamseddine, I.M.; Rejniak, K.A. Hybrid modeling frameworks of tumor development and treatment. Wiley Interdiscip. Rev. Syst. Biol. Med. 2020, 12, e1461. [Google Scholar] [CrossRef]
- Altaf, M.M. A hybrid deep learning model for breast cancer diagnosis based on transfer learning and pulse-coupled neural networks. Math. Biosci. Eng. 2021, 18, 5029–5046. [Google Scholar] [CrossRef]
- Hosseinpour, M.; Ghaemi, S.; Khanmohammadi, S.; Daneshvar, S. A hybrid high-order type-2 FCM improved random forest classification method for breast cancer risk assessment. Appl. Math. Comput. 2022, 424, 127038. [Google Scholar] [CrossRef]
- Oladele, T.O.; Olorunsola, B.J.; Aro, T.O.; Akande, H.B.; Olukiran, O.A. Nature-Inspired Meta-heuristic Optimization Algorithms for Breast Cancer Diagnostic Model: A Comparative Study. Fuoye J. Eng. Technol. 2021, 6. [Google Scholar] [CrossRef]
- Alsaeedi, A.H.; Aljanabi, A.H.; Manna, M.E.; Albukhnefis, A.L. A proactive meta heuristic model for optimizing weights of artificial neural network. Indones. J. Electr. Eng. Comput. Sci. 2020, 20, 976–984. [Google Scholar]
- Kang, C.; Yu, X.; Wang, S.H.; Guttery, D.S.; Pandey, H.M.; Tian, Y.; Zhang, Y.D. A heuristic neural network structure relying on fuzzy logic for images scoring. IEEE Trans. Fuzzy Syst. 2020, 29, 34–45. [Google Scholar] [CrossRef] [PubMed]
- Moncada-Torres, A.; van Maaren, M.C.; Hendriks, M.P.; Siesling, S.; Geleijnse, G. Explainable machine learning can outperform Cox regression predictions and provide insights in breast cancer survival. Sci. Rep. 2021, 11, 6968. [Google Scholar] [CrossRef] [PubMed]
- Kolyshkina, I.; Simoff, S. Interpretability of machine learning solutions in public healthcare: The CRISP-ML approach. Front. Big Data 2021, 4, 660206. [Google Scholar] [CrossRef]
- Silva-Aravena, F.; Morales, J. Dynamic Surgical Waiting List Methodology: A Networking Approach. Mathematics 2022, 10, 2307. [Google Scholar] [CrossRef]
- Silva-Aravena, F.; Gutiérrez-Bahamondes, J.H.; Núñez Delafuente, H.; Toledo-Molina, R.M. An intelligent system for patients’ well-being: A multi-criteria decision-making approach. Mathematics 2022, 10, 3956. [Google Scholar] [CrossRef]
- Nindrea, R.D.; Usman, E.; Katar, Y.; Darma, I.Y.; Hendriyani, H.; Sari, N.P. Dataset of Indonesian women’s reproductive, high-fat diet and body mass index risk factors for breast cancer. Data Brief 2021, 36, 107107. [Google Scholar] [CrossRef]
- Listyawardhani, Y.; Mudigdo, A.; Adriani, R.B. Risk Factors of Breast Cancer in Women: A New Evidence from Surakarta, Central Java, Indonesia. In Proceedings of the Mid-International Conference on Public Health, Solo, Indonesia, 18–19 April 2018; p. 75. [Google Scholar]
- Alsolami, F.J.; Azzeh, F.S.; Ghafouri, K.J.; Ghaith, M.M.; Almaimani, R.A.; Almasmoum, H.A.; Abdulal, R.H.; Abdulaal, W.H.; Jazar, A.S.; Tashtoush, S.H. Determinants of breast cancer in Saudi women from Makkah region: A case-control study (breast cancer risk factors among Saudi women). BMC Public Health 2019, 19, 1554. [Google Scholar] [CrossRef]
- Solikhah, S.; Perwitasari, D.; Permatasari, T.A.E.; Safitri, R.A. Diet, Obesity, and Sedentary Lifestyle as Risk Factor of Breast Cancer among Women at Yogyakarta Province in Indonesia. Open Access Maced. J. Med. Sci. 2022, 10, 398–405. [Google Scholar] [CrossRef]
- Ramraj, S.; Uzir, N.; Sunil, R.; Banerjee, S. Experimenting XGBoost algorithm for prediction and classification of different datasets. Int. J. Control. Theory Appl. 2016, 9, 651–662. [Google Scholar]
- Tian, H.; Jiang, X.; Tao, P. PASSer: Prediction of allosteric sites server. Mach. Learn. Sci. Technol. 2021, 2, 035015. [Google Scholar] [CrossRef] [PubMed]
- Liu, L. Research on logistic regression algorithm of breast cancer diagnose data by machine learning. In Proceedings of the 2018 International Conference on Robots & Intelligent System (ICRIS), Amsterdam, The Netherlands, 21–23 February 2018; pp. 157–160. [Google Scholar]
- Khandezamin, Z.; Naderan, M.; Rashti, M.J. Detection and classification of breast cancer using logistic regression feature selection and GMDH classifier. J. Biomed. Inform. 2020, 111, 103591. [Google Scholar] [CrossRef] [PubMed]
- Sultana, J.; Jilani, A.K. Predicting breast cancer using logistic regression and multi-class classifiers. Int. J. Eng. Technol. 2018, 7, 22–26. [Google Scholar] [CrossRef]
- Nguyen, C.; Wang, Y.; Nguyen, H.N. Random forest classifier combined with feature selection for breast cancer diagnosis and prognostic. J. Biomed. Sci. Eng. 2013, 6, 31887. [Google Scholar] [CrossRef]
- Begum, A.; Dhilip Kumar, V.; Asghar, J.; Hemalatha, D.; Arulkumaran, G. A Combined Deep CNN: LSTM with a Random Forest Approach for Breast Cancer Diagnosis. Complexity 2022, 9299621. [Google Scholar] [CrossRef]
- Kabiraj, S.; Raihan, M.; Alvi, N.; Afrin, M.; Akter, L.; Sohagi, S.A.; Podder, E. Breast cancer risk prediction using XGBoost and random forest algorithm. In Proceedings of the 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020; pp. 1–4. [Google Scholar]
- Mahesh, T.; Vinoth Kumar, V.; Muthukumaran, V.; Shashikala, H.; Swapna, B.; Guluwadi, S. Performance Analysis of XGBoost Ensemble Methods for Survivability with the Classification of Breast Cancer. J. Sens. 2022, 2022, 4649510. [Google Scholar] [CrossRef]
- Liew, X.Y.; Hameed, N.; Clos, J. An investigation of XGBoost-based algorithm for breast cancer classification. Mach. Learn. Appl. 2021, 6, 100154. [Google Scholar] [CrossRef]
- Kim, W.; Kim, K.S.; Lee, J.E.; Noh, D.Y.; Kim, S.W.; Jung, Y.S.; Park, M.Y.; Park, R.W. Development of novel breast cancer recurrence prediction model using support vector machine. J. Breast Cancer 2012, 15, 230–238. [Google Scholar] [CrossRef]
- Wang, H.; Zheng, B.; Yoon, S.W.; Ko, H.S. A support vector machine-based ensemble algorithm for breast cancer diagnosis. Eur. J. Oper. Res. 2018, 267, 687–699. [Google Scholar] [CrossRef]
- Chiu, H.J.; Li, T.H.S.; Kuo, P.H. Breast cancer—Detection system using PCA, multilayer perceptron, transfer learning, and support vector machine. IEEE Access 2020, 8, 204309–204324. [Google Scholar] [CrossRef]
- Alshutbi, M.; Li, Z.; Alrifaey, M.; Ahmadipour, M.; Othman, M.M. A hybrid classifier based on support vector machine and Jaya algorithm for breast cancer classification. Neural Comput. Appl. 2022, 34, 16669–16681. [Google Scholar] [CrossRef]
- Shekhar, S.; Bansode, A.; Salim, A. A Comparative study of Hyper-Parameter Optimization Tools. In Proceedings of the 2021 IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE), Brisbane, Australia, 8–10 December 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Keren Evangeline, I.; Angeline Kirubha, S.; Glory Precious, J. Prediction of Breast Cancer Recurrence in Five Years using Machine Learning Techniques and SHAP. In Intelligent Computing Techniques for Smart Energy Systems; Springer: Berlin/Heidelberg, Germany, 2022; pp. 441–453. [Google Scholar]
- Zhang, G.; Shi, Y.; Yin, P.; Liu, F.; Fang, Y.; Li, X.; Zhang, Q.; Zhang, Z. A machine learning model based on ultrasound image features to assess the risk of sentinel lymph node metastasis in breast cancer patients: Applications of scikit-learn and SHAP. Front. Oncol. 2022, 12, 944569. [Google Scholar] [CrossRef] [PubMed]
- Meshoul, S.; Batouche, A.; Shaiba, H.; AlBinali, S. Explainable Multi-Class Classification Based on Integrative Feature Selection for Breast Cancer Subtyping. Mathematics 2022, 10, 4271. [Google Scholar] [CrossRef]
- Larasati, R. Explainable AI for Breast Cancer Diagnosis: Application and User’s Understandability Perception. In Proceedings of the 2022 International Conference on Electrical, Computer and Energy Technologies (ICECET), Czechi, Prague, 20–22 July 2022; pp. 1–6. [Google Scholar]
- Kim, J.; Lee, J.; Park, M. Identification of Smartwatch-Collected Lifelog Variables Affecting Body Mass Index in Middle-Aged People Using Regression Machine Learning Algorithms and SHapley Additive Explanations. Appl. Sci. 2022, 12, 3819. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Silva-Aravena, F.; Álvarez-Miranda, E.; Astudillo, C.A.; González-Martínez, L.; Ledezma, J.G. Patients’ Prioritization on Surgical Waiting Lists: A Decision Support System. Mathematics 2021, 9, 1097. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Phase | Label | Precision | Recall | Accuracy |
|---|---|---|---|---|---|
| XGBoots | Train | 1 | 91.7% | 75.0% | 81.33% |
| 0 | 71.8% | 90.3% | |||
| Test | 1 | 85.7% | 81.4% | 81.00% | |
| 0 | 75.0% | 80.5% | |||
| Logistic Regression | Train | 1 | 88.2% | 76.5% | 81.33% |
| 0 | 75.0% | 87.3% | |||
| Test | 1 | 82.1% | 78.0% | 77.00% | |
| 0 | 70.5% | 75.6% | |||
| Random Forest | Train | 1 | 87.5% | 75.9% | 80.67% |
| 0 | 74.4% | 86.6% | |||
| Test | 1 | 83.9% | 79.7% | 79.00% | |
| 0 | 72.7% | 78.0% | |||
| SVM | Train | 1 | 89.6% | 76.8% | 82.00% |
| 0 | 75.0% | 88.6% | |||
| Test | 1 | 83.9% | 77.0% | 77.00% | |
| 0 | 68.2% | 76.9% |
| Algorithm | Label | Precision | Recall | Accuracy |
|---|---|---|---|---|
| XGBoots | 1 | 85.4% | 79.5% | 85.0% |
| 0 | 84.7% | 89.3% | ||
| Logistic Regression | 1 | 75.0% | 81.8% | 80.0% |
| 0 | 84.6% | 78.6% | ||
| Random Forest | 1 | 75.5% | 84.1% | 81.0% |
| 0 | 86.3% | 78.6% | ||
| SVM | 1 | 81.0% | 77.3% | 82.0% |
| 0 | 82.8% | 85.7% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Silva-Aravena, F.; Núñez Delafuente, H.; Gutiérrez-Bahamondes, J.H.; Morales, J. A Hybrid Algorithm of ML and XAI to Prevent Breast Cancer: A Strategy to Support Decision Making. Cancers 2023, 15, 2443. https://doi.org/10.3390/cancers15092443
Silva-Aravena F, Núñez Delafuente H, Gutiérrez-Bahamondes JH, Morales J. A Hybrid Algorithm of ML and XAI to Prevent Breast Cancer: A Strategy to Support Decision Making. Cancers. 2023; 15(9):2443. https://doi.org/10.3390/cancers15092443
Chicago/Turabian StyleSilva-Aravena, Fabián, Hugo Núñez Delafuente, Jimmy H. Gutiérrez-Bahamondes, and Jenny Morales. 2023. "A Hybrid Algorithm of ML and XAI to Prevent Breast Cancer: A Strategy to Support Decision Making" Cancers 15, no. 9: 2443. https://doi.org/10.3390/cancers15092443
APA StyleSilva-Aravena, F., Núñez Delafuente, H., Gutiérrez-Bahamondes, J. H., & Morales, J. (2023). A Hybrid Algorithm of ML and XAI to Prevent Breast Cancer: A Strategy to Support Decision Making. Cancers, 15(9), 2443. https://doi.org/10.3390/cancers15092443