
Novel Transfer Learning Approach for Medical Imaging with Limited Labeled Data

 ,
,  , ,
, , 
 ,
,  ,
, 
 and
and 
Abstract
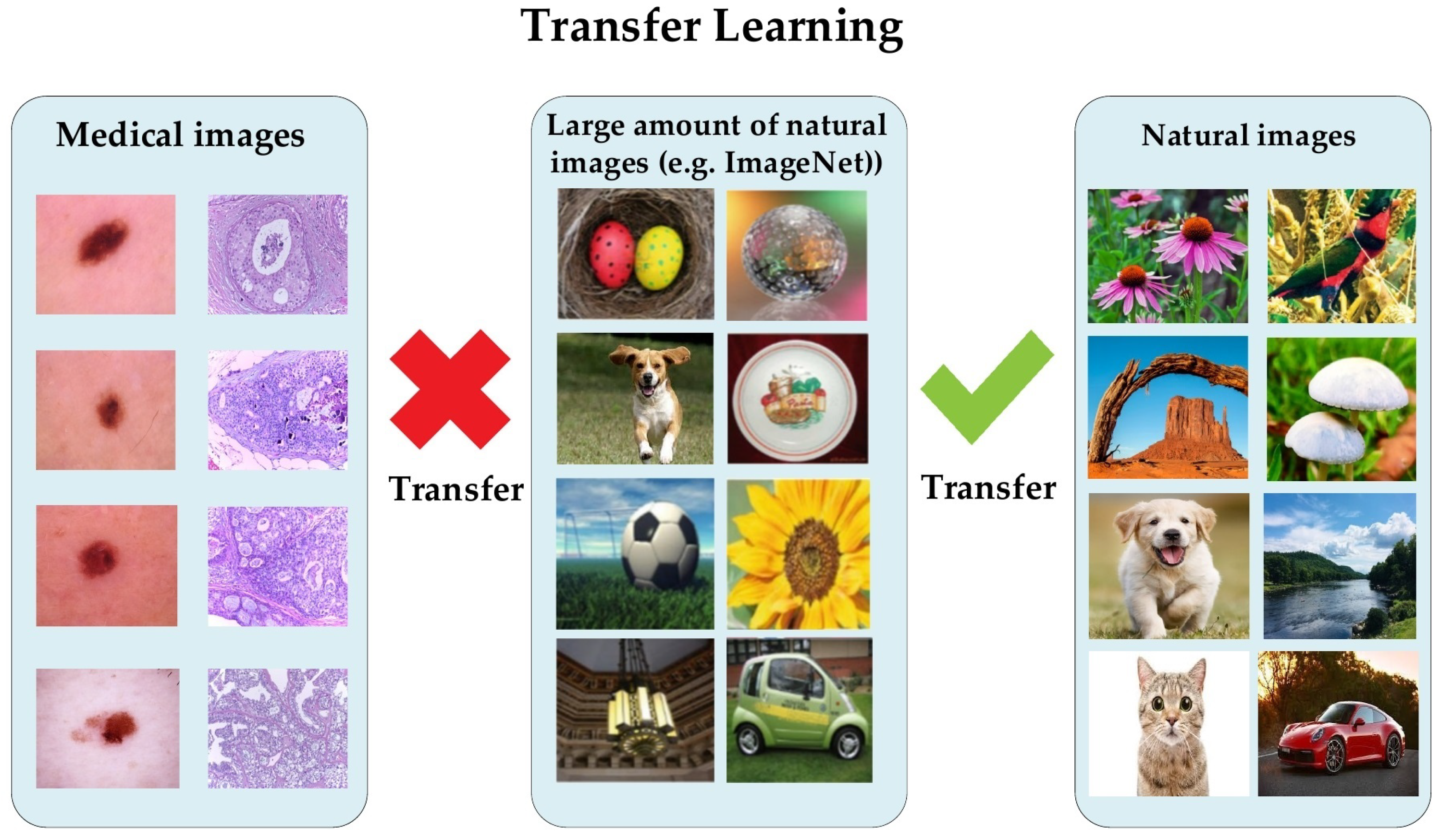
1. Introduction
- We demonstrate that the proposed approach of transfer learning from large unlabeled images can lead to excellent performance in medical imaging tasks.
- We introduce a hybrid DCNN model that integrates parallel convolutional layers and residual connections along with global average pooling.
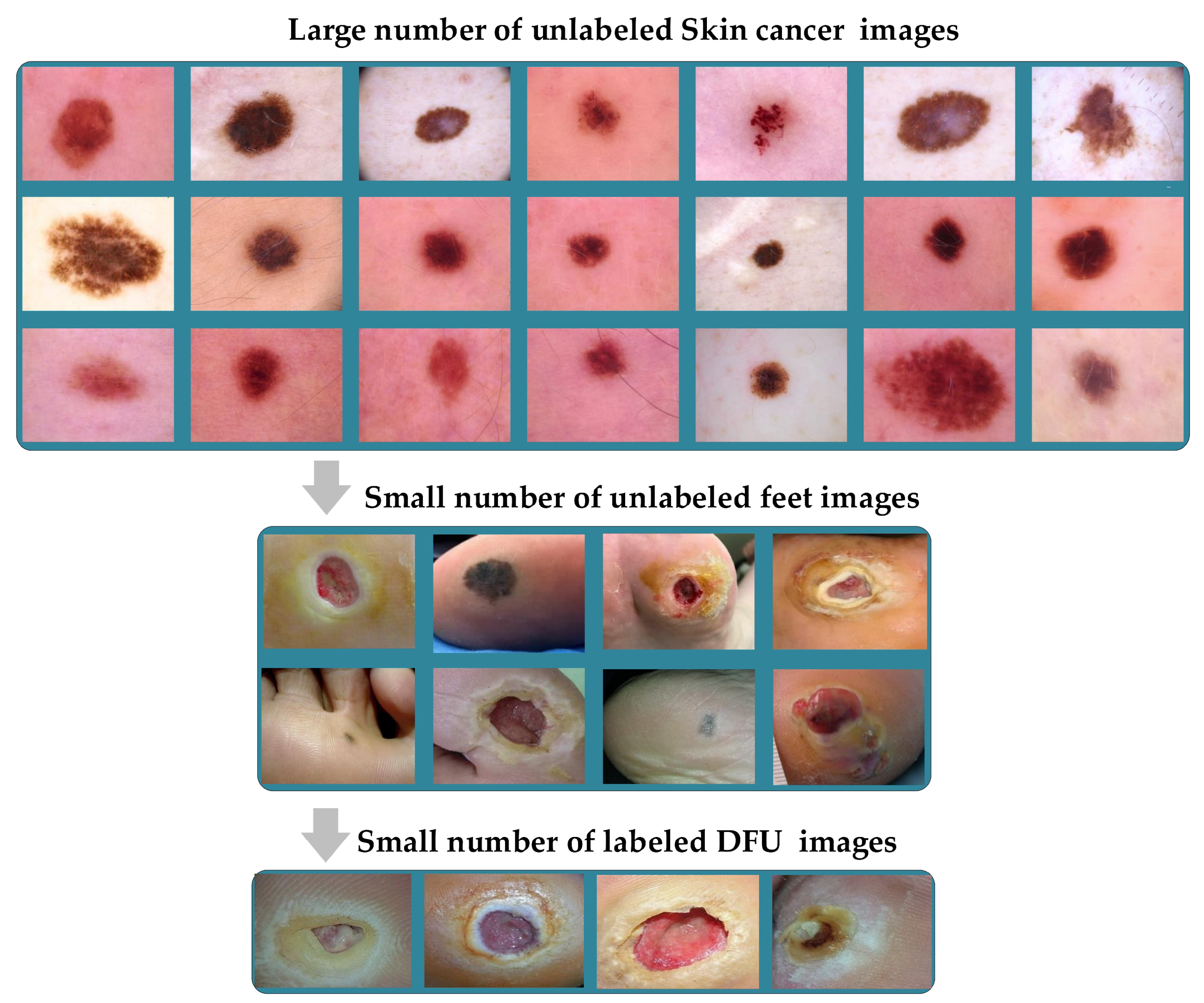
- We train the proposed model with more than 200,000 unlabeled images of skin cancer and then fine-tune the model for a small dataset of labeled skin cancer to classify them into two classes, namely benign and malignant. We also train the proposed model with more than 200,000 unlabeled hematoxylin–eosin-stained breast biopsy images. We then fine-tune the model for a small dataset of labeled hematoxylin–eosin-stained breast biopsy images to classify them into four classes: invasive carcinoma, in situ carcinoma, benign tumor, and normal tissue.
- We apply several data augmentation techniques to overcome the issue of unbalanced data.
- We combine all contributions to improve the performance of two challenging tasks: skin and breast cancer classification tasks. In the skin cancer classification, the proposed model achieved an F1-score value of 89.09% when trained from scratch and 98.53% with the proposed approach on SIIM-ISIC Melanoma Classification 2020. The proposed model achieved an F1-score value of 85.29% when trained from scratch and 97.51% with the proposed approach ICIAR-2018 dataset for the breast cancer classification task. The results proved that the first and second contributions are effective in the medical imaging tasks.
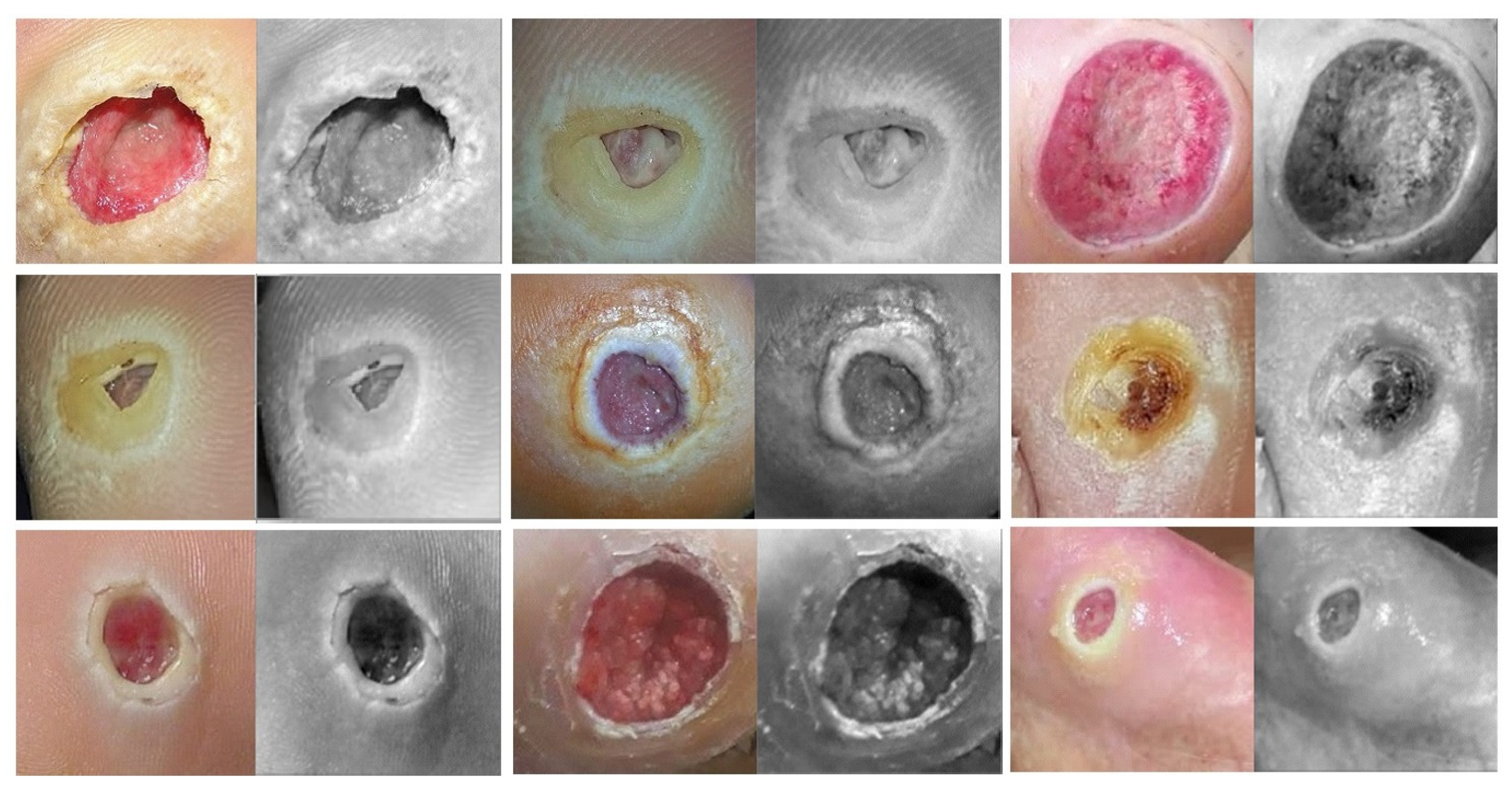
- We utilize the pretrained skin cancer model to improve the performance DFU classification task by fine-tuning it to train on feet skin images to classify them into two classes, either normal or abnormal. It attained an F1-score value of 86.0% when trained from scratch and 96.25% with transfer learning.
- We introduce another type of transfer learning besides the proposed approach, which is double-transfer learning. We achieved an F1-score value of 99.25% with the DFU classification task using this technique.
- We test our model trained with the double-transfer learning technique on unseen DFU test set images. Our model achieved an accuracy of 97.7%, which proves that our model is robust against overfitting.
2. Literature Review
2.1. Transfer Learning for Medical Imaging
2.2. Convolutional Neural Networks
3. Materials and Methods
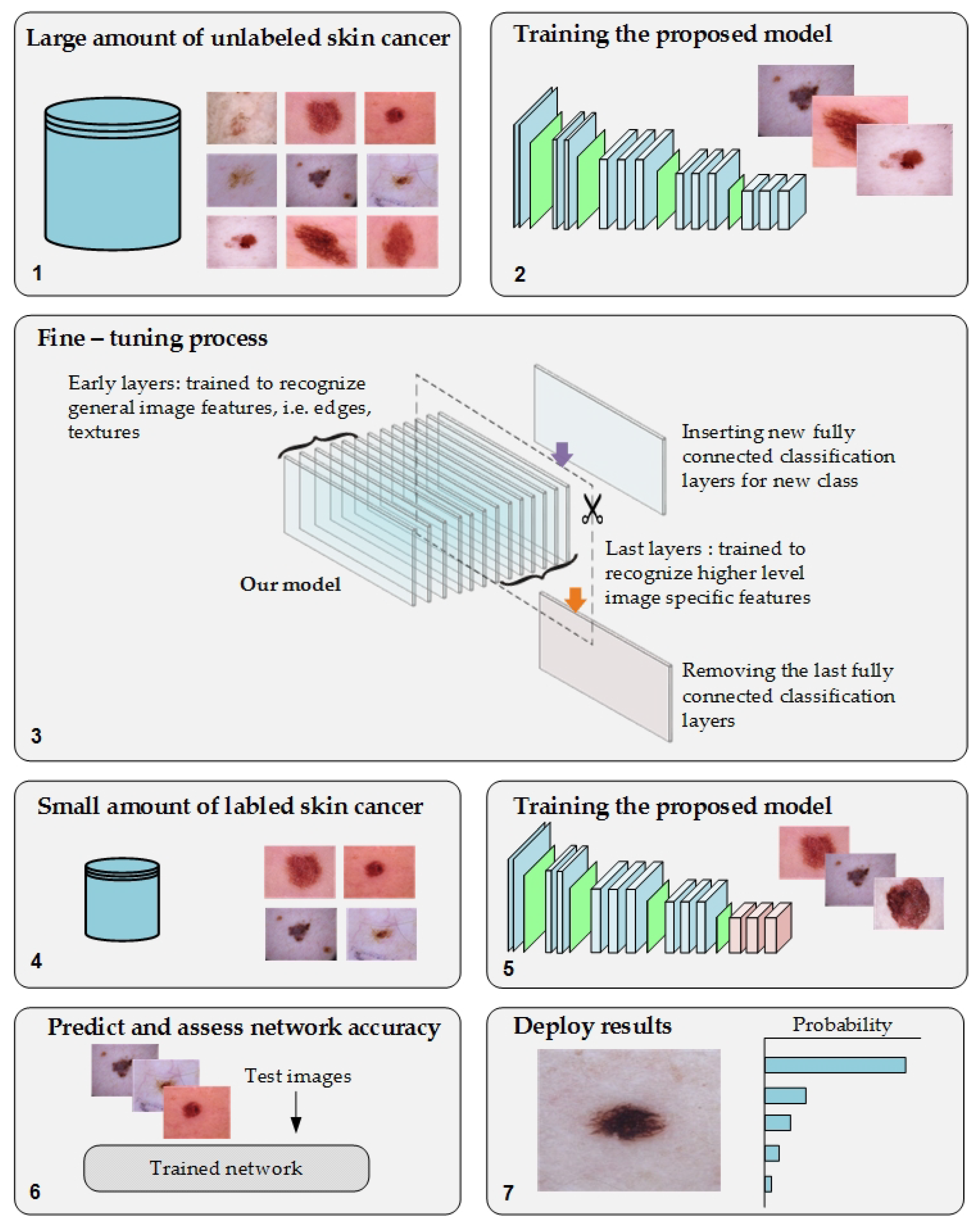
3.1. The Proposed Approach
3.2. Dataset
3.2.1. Source Dataset
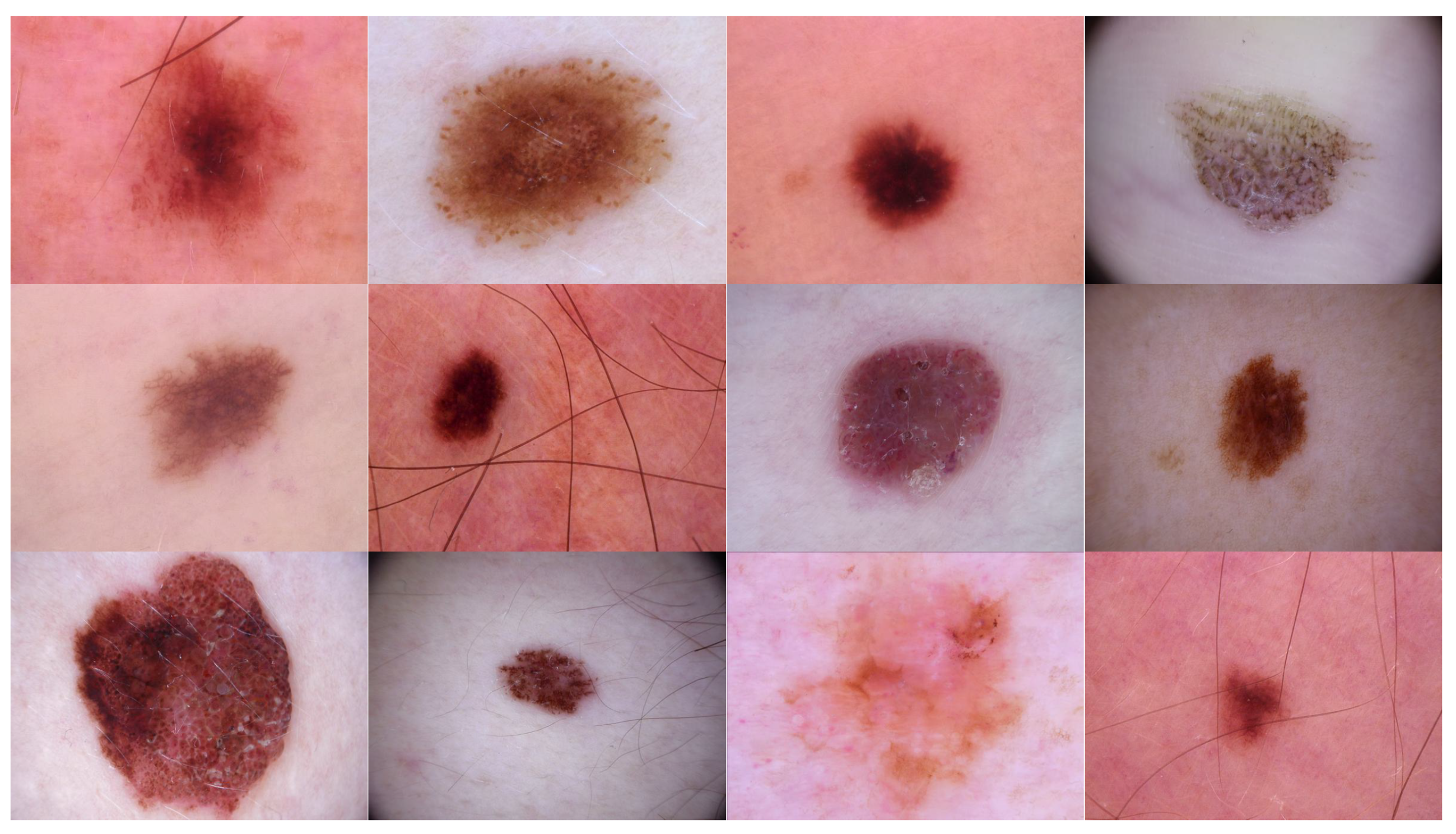
- Source domain dataset of skin cancer: The main source of this dataset is the ISIC Challenges datasets (2016, 2017, 2018, 2019, and 2020) of skin lesion classification tasks [20,45,46,47,48,49]. The total number of images is 81,475. We added 100 melanoma and 70 naevus images of the MED-NODE dataset [50]. The last source is the Dermofit dataset, which consists of 1300 skin lesion images of malignant and benign [51]. All collected images were duplicated to more than 200,000 images by using data augmentation techniques. Figure 3 shows some samples of the dataset.
- Source domain dataset of breast cancer: we collected the histopathology images of breasts from various sources. The first source is the BreakHis dataset [52]. This dataset is composed of 9109 microscopic images of breast tumor tissue with a size of 700 × 460 pixels. Each image was divided into two images of 350 × 230 and then resized to 512 × 512. The second source is the histopathological microscopy image dataset of IDC [53]. It consists of 922 images with sizes of 2100 × 1574 and 1276 × 956 pixels. The third source is the breast cancer dataset, which is composed of 537 H&E-stained histopathological images with a size of 2200 × 2200 pixels [54]. The fourth source is the BreCaHAD dataset [55]. This dataset consists of 162 breast cancer histopathology images with a size of 1360 × 1024 pixels. The fifth source is the SPIE-AAPM-NCI BreastPathQ dataset [56], which is composed of 2579 patches of histopathology images of the breast. These patches were extracted from 96 images with a size of 512 × 512. The sixth source is the image dataset from the bioimaging 2015 breast histology classification challenge [57]. There are 249 images with a size of 2040 × 1536 pixels. All the images of sources two to six were divided into 12 nonoverlapping patches of 512 × 512 sizes. The total was 50,314 breast histology patches. All collected patches were duplicated to more than 200,000 images by using data augmentation techniques. It is worth mentioning that we cropped the images to 512 × 512 to fit the input size of the model. This guarantees that the proposed model detects the features that define the nucleus-localized organization and the overall tissue architecture required to distinguish between the classes. Conversely, taking a small size could result in a loss of information associated with the same assigned class of the entire image. Figure 4 shows some samples of the dataset.
3.2.2. Target Dataset
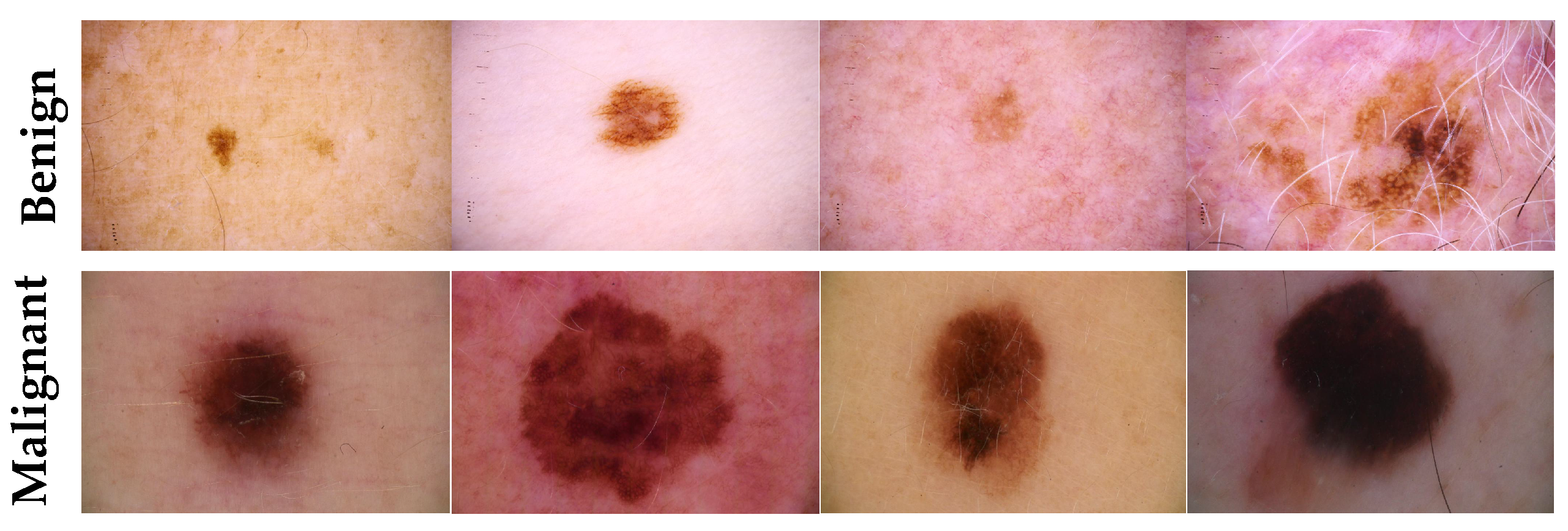
- Target dataset of skin cancer: The proposed model has been trained and tested after TL from the source skin cancer dataset on the SIIM-ISIC 2020 dataset [49]. The latter consists of 33,000 skin lesion samples classified into two categories: benign and malignant. We took part of the dataset, which was 9000 images, for the benign class, and the rest was added to the source dataset, with only 584 samples of the malignant class. To tackle the issue of imbalanced classes, we performed several data augmentation techniques on malignant class samples. The reason behind taking part of the dataset is to check how the proposed model with the proposed approach can perform when it trains on a small dataset. The part taken from the dataset was divided into 80% for training and 20% for testing. We resized all images to 500 × 375 to minimize the computational cost and to speed up the training process. Figure 5 shows some samples of the dataset.
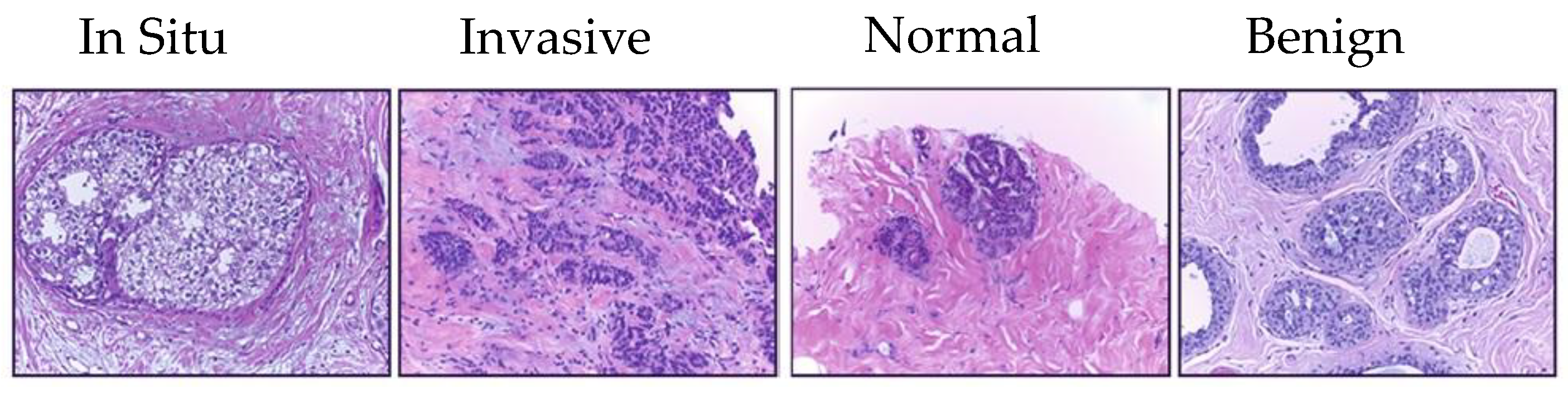
- Target dataset of breast cancer: the ICIAR-2018 (BACH 2018) Grand Challenge provided this dataset [58]. The images were uncompressed and in high-resolution mode (2040 × 1536 pixels). They consisted of H&E-stained breast histology microscopy images and were labeled as normal tissue, benign lesion, in situ carcinoma, or invasive carcinoma (see Figure 6). The labeling stage was achieved by two medical steps, utilizing identical acquisition cases, with an enlargement of 200. A total of 400 images were used (100 samples in each class). These images were chosen so that the pathology recognition could be independently distinguished from the visible organization and the tissue structure. The dataset was divided into 300 images for the training set and 100 for the testing set. The original image was divided into 12 nonoverlapping patches of 512 × 512 pixels in size.
3.3. Augmentation Techniques
- Random rotation between 45 and 315 degrees
- Crop the region of interest (in the task of the skin and DFU)
- Random brightness, random contrast
- Zoom
- Perform an erosion effect. The erosion is a morphological effect applied on the image that shrinks the object in the image and can be mathematically defined as in Equation (1):where A is the image to be eroded and B is the structuring element.
- A dilation is an inverse of erosion that is performed on an image and can increase the area of the object. Here, we perform a double dilation effect. The dilation process can be described mathematically as in Equation (2):
- Add Gaussian Noise.
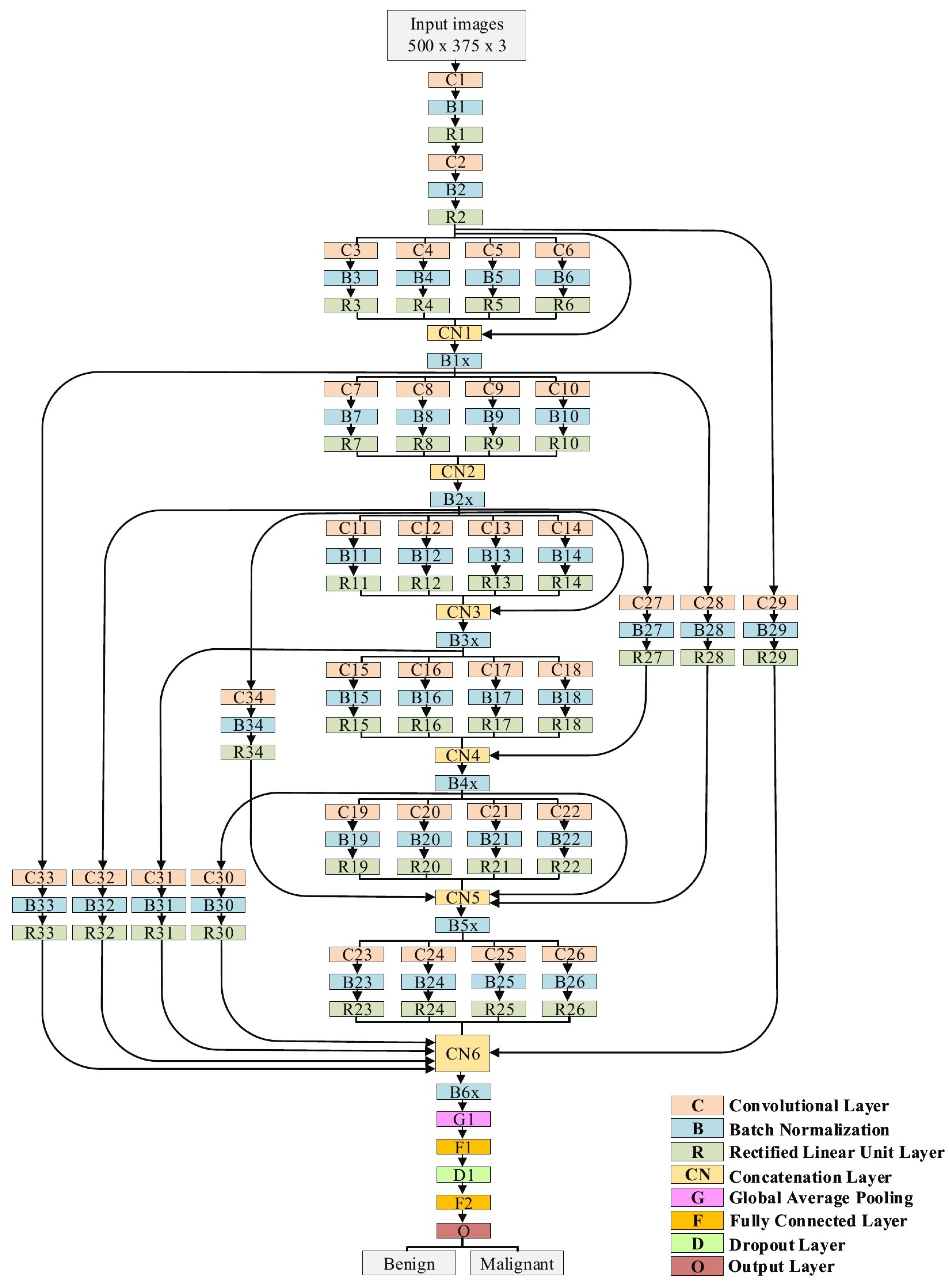
3.4. The Proposed Model
- Traditional convolutional layers at the beginning of the model to reduce the size of input images
- Parallel convolutional layers with different filter sizes to extract different levels of features to guarantee that the model learns the small and large features
- Residual connections and deep connections for better feature representation. These connections also handle the issue of gradient vanishing.
- Batch normalization to expedite the training process
- A rectified linear unit (ReLU) does not squeeze the input value, which helps minimize the effect of the vanishing gradient problem.
- Dropout to avoid the issue of overfitting
- Global average pooling makes an extreme dimensionality reduction by transforming the entire size to one dimension. This layer helps to reduce the effect of overfitting.
3.5. Training Scenario
- Phase #1: Training the proposed model from scratch using the target dataset of the skin cancer classification task.
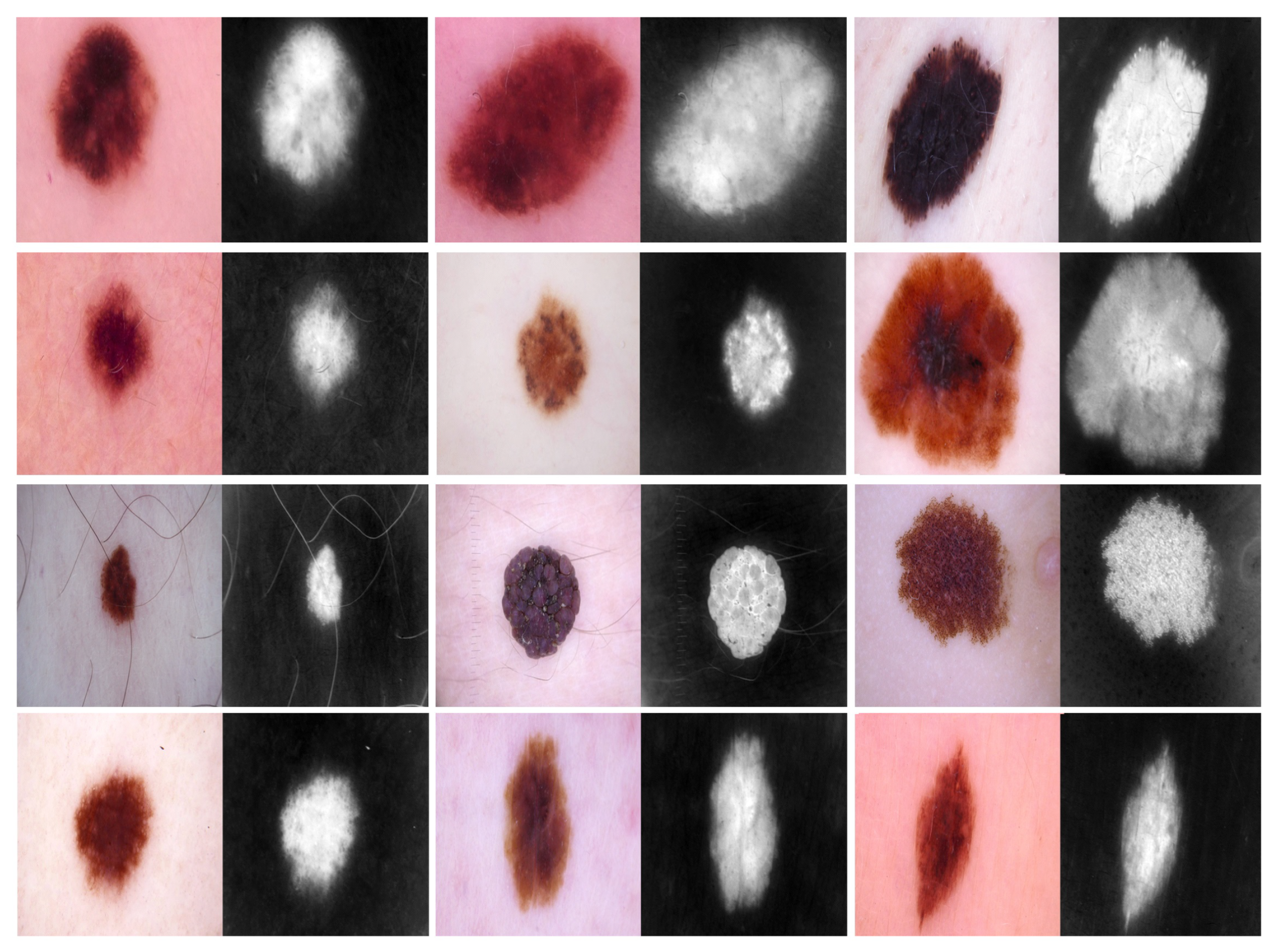
- Phase #2: Training our model on source domain dataset of skin cancer. We then fine-tune the model for the target dataset of the skin cancer classification task (see Figure 2). Figure 8 shows the learned filters from the first convolutional layer. The learned filters from the first convolutional layer indicate that our model learned excellent features from the beginning.
- Stochastic gradient descent with a momentum set to 0.9
- The mini-batch size was 64 and MaxEpochs was 100.
- The learning rate was initially set to 0.001.
3.6. Double-Transfer Learning Technique
- Phase #1: Training our model from scratch using the DFU dataset [59] that contained two classes, normal and abnormal
- Phase #3: First, fine-tuning the pretrained model of skin cancer task to train it on a small number of unlabeled feet skin images. We collected 2000 images of feet skin diseases including DFU from an internet search and part of the DermNet dataset [60]. We increased this number to more than 10,000 using data augmentation techniques. Second, fine-tuning the pretrained model that results from the first step to train it on a small number of labeled DFU images [59]: by doing that, we achieve a double-transfer learning technique. Figure 12 shows the steps of the double-transfer learning technique.
4. Results
4.1. Evaluation Metrics
- Accuracy calculates the ratio of correct predicted classes to the total number of samples evaluated (Equation (3)).
- Sensitivity or recall is utilized to calculate the fraction of positive patterns that are correctly classified (Equation (4)).
- Precision is utilized to calculate the positive patterns that are correctly predicted by all predicted patterns in a positive class (Equation (5)).
4.2. Results of the Skin Cancer Classification Scenario
4.3. Results of DFU Classification Scenario
4.4. Results of Breast Cancer Classification Scenario
4.5. Performance Evaluation on Unseen DFU Test Set
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Valieris, R.; Amaro, L.; Osório, C.A.B.T.; Bueno, A.P.; Rosales Mitrowsky, R.A.; Carraro, D.M.; Nunes, D.N.; Dias-Neto, E.; da Silva, I.T. Deep Learning Predicts Underlying Features on Pathology Images with Therapeutic Relevance for Breast and Gastric Cancer. Cancers 2020, 12, 3687. [Google Scholar] [CrossRef]
- Liu, Y.; Jain, A.; Eng, C.; Way, D.H.; Lee, K.; Bui, P.; Kanada, K.; de Oliveira Marinho, G.; Gallegos, J.; Gabriele, S.; et al. A deep learning system for differential diagnosis of skin diseases. Nat. Med. 2020, 26, 900–908. [Google Scholar] [CrossRef]
- Hamamoto, R.; Suvarna, K.; Yamada, M.; Kobayashi, K.; Shinkai, N.; Miyake, M.; Takahashi, M.; Jinnai, S.; Shimoyama, R.; Sakai, A.; et al. Application of artificial intelligence technology in oncology: Towards the establishment of precision medicine. Cancers 2020, 12, 3532. [Google Scholar] [CrossRef] [PubMed]
- Rajpurkar, P.; Irvin, J.; Zhu, K.; Yang, B.; Mehta, H.; Duan, T.; Ding, D.; Bagul, A.; Langlotz, C.; Shpanskaya, K.; et al. Chexnet: Radiologist-level pneumonia detection on chest x-rays with deep learning. arXiv 2017, arXiv:1711.05225. [Google Scholar]
- Nazir, T.; Irtaza, A.; Javed, A.; Malik, H.; Hussain, D.; Naqvi, R.A. Retinal Image Analysis for Diabetes-Based Eye Disease Detection Using Deep Learning. Appl. Sci. 2020, 10, 6185. [Google Scholar] [CrossRef]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. Jama 2016, 316, 2402–2410. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Iqbal Hussain, M.A.; Khan, B.; Wang, Z.; Ding, S. Woven Fabric Pattern Recognition and Classification Based on Deep Convolutional Neural Networks. Electronics 2020, 9, 1048. [Google Scholar] [CrossRef]
- Jeon, H.K.; Kim, S.; Edwin, J.; Yang, C.S. Sea Fog Identification From GOCI Images Using CNN Transfer Learning Models. Electronics 2020, 9, 311. [Google Scholar] [CrossRef]
- Raghu, M.; Zhang, C.; Kleinberg, J.; Bengio, S. Transfusion: Understanding transfer learning for medical imaging. arXiv 2019, arXiv:1902.07208. [Google Scholar]
- Alzubaidi, L.; Fadhel, M.A.; Al-Shamma, O.; Zhang, J.; Santamaría, J.; Duan, Y.; Oleiwi, S.R. Towards a better understanding of transfer learning for medical imaging: A case study. Appl. Sci. 2020, 10, 4523. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Fadhel, M.A.; Al-Shamma, O.; Zhang, J.; Duan, Y. Deep learning models for classification of red blood cells in microscopy images to aid in sickle cell anemia diagnosis. Electronics 2020, 9, 427. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Al-Shamma, O.; Fadhel, M.A.; Farhan, L.; Zhang, J.; Duan, Y. Optimizing the performance of breast cancer classification by employing the same domain transfer learning from hybrid deep convolutional neural network model. Electronics 2020, 9, 445. [Google Scholar] [CrossRef]
- Monisha, M.; Suresh, A.; Bapu, B.T.; Rashmi, M. Classification of malignant melanoma and benign skin lesion by using back propagation neural network and ABCD rule. Clust. Comput. 2019, 22, 12897–12907. [Google Scholar] [CrossRef]
- Yuan, Y.; Chao, M.; Lo, Y.C. Automatic skin lesion segmentation using deep fully convolutional networks with jaccard distance. IEEE Trans. Med. Imaging 2017, 36, 1876–1886. [Google Scholar] [CrossRef]
- Xie, F.; Fan, H.; Li, Y.; Jiang, Z.; Meng, R.; Bovik, A. Melanoma classification on dermoscopy images using a neural network ensemble model. IEEE Trans. Med. Imaging 2016, 36, 849–858. [Google Scholar] [CrossRef] [PubMed]
- Celebi, M.E.; Kingravi, H.A.; Uddin, B.; Iyatomi, H.; Aslandogan, Y.A.; Stoecker, W.V.; Moss, R.H. A methodological approach to the classification of dermoscopy images. Comput. Med. Imaging Graph. 2007, 31, 362–373. [Google Scholar] [CrossRef]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef] [PubMed]
- Codella, N.C.; Gutman, D.; Celebi, M.E.; Helba, B.; Marchetti, M.A.; Dusza, S.W.; Kalloo, A.; Liopyris, K.; Mishra, N.; Kittler, H.; et al. Skin lesion analysis toward melanoma detection: A challenge at the 2017 international symposium on biomedical imaging (isbi), hosted by the international skin imaging collaboration (isic). In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 168–172. [Google Scholar]
- Khan, S.; Islam, N.; Jan, Z.; Din, I.U.; Rodrigues, J.J.C. A novel deep learning based framework for the detection and classification of breast cancer using transfer learning. Pattern Recognit. Lett. 2019, 125, 1–6. [Google Scholar] [CrossRef]
- Munir, K.; Elahi, H.; Ayub, A.; Frezza, F.; Rizzi, A. Cancer diagnosis using deep learning: A bibliographic review. Cancers 2019, 11, 1235. [Google Scholar] [CrossRef] [PubMed]
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA A Cancer J. Clin. 2021, 68, 394–424. [Google Scholar]
- Xie, H.; Shan, H.; Cong, W.; Zhang, X.; Liu, S.; Ning, R.; Wang, G. Dual network architecture for few-view CT-trained on ImageNet data and transferred for medical imaging. In Developments in X-ray Tomography XII; International Society for Optics and Photonics: San Diego, CA, USA, 2019; Volume 11113, p. 111130V. [Google Scholar]
- Irvin, J.; Rajpurkar, P.; Ko, M.; Yu, Y.; Ciurea-Ilcus, S.; Chute, C.; Marklund, H.; Haghgoo, B.; Ball, R.; Shpanskaya, K.; et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. Proc. AAAI Conf. Artif. Intell. 2019, 33, 590–597. [Google Scholar] [CrossRef]
- Neyshabur, B.; Sedghi, H.; Zhang, C. What is being transferred in transfer learning? arXiv 2020, arXiv:2008.11687. [Google Scholar]
- Chen, S.; Ma, K.; Zheng, Y. Med3d: Transfer learning for 3d medical image analysis. arXiv 2019, arXiv:1904.00625. [Google Scholar]
- Heker, M.; Greenspan, H. Joint liver lesion segmentation and classification via transfer learning. arXiv 2020, arXiv:2004.12352. [Google Scholar]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep learning applications and challenges in big data analytics. J. Big Data 2015, 2, 1–21. [Google Scholar] [CrossRef]
- Goebel, R.; Chander, A.; Holzinger, K.; Lecue, F.; Akata, Z.; Stumpf, S.; Kieseberg, P.; Holzinger, A. Explainable ai: The new 42? In International Cross-Domain Conference for Machine Learning and Knowledge Extraction; Springer: Berlin/Heidelberg, Germany, 2018; pp. 295–303. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M.; Furht, B. Deep Learning applications for COVID-19. J. Big Data 2021, 8, 1–54. [Google Scholar] [CrossRef] [PubMed]
- Mallio, C.A.; Napolitano, A.; Castiello, G.; Giordano, F.M.; D’Alessio, P.; Iozzino, M.; Sun, Y.; Angeletti, S.; Russano, M.; Santini, D.; et al. Deep Learning Algorithm Trained with COVID-19 Pneumonia Also Identifies Immune Checkpoint Inhibitor Therapy-Related Pneumonitis. Cancers 2021, 13, 652. [Google Scholar] [CrossRef]
- Dayal, A.; Paluru, N.; Cenkeramaddi, L.R.; Yalavarthy, P.K. Design and Implementation of Deep Learning Based Contactless Authentication System Using Hand Gestures. Electronics 2021, 10, 182. [Google Scholar] [CrossRef]
- Jang, H.J.; Song, I.H.; Lee, S.H. Generalizability of Deep Learning System for the Pathologic Diagnosis of Various Cancers. Appl. Sci. 2021, 11, 808. [Google Scholar] [CrossRef]
- Goh, G.B.; Hodas, N.O.; Vishnu, A. Deep learning for computational chemistry. J. Comput. Chem. 2017, 38, 1291–1307. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, T.; Sun, S.; Gao, X. Accelerating flash calculation through deep learning methods. J. Comput. Phys. 2019, 394, 153–165. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Shrestha, A.; Mahmood, A. Review of deep learning algorithms and architectures. IEEE Access 2019, 7, 53040–53065. [Google Scholar] [CrossRef]
- Wang, J.; Liu, Q.; Xie, H.; Yang, Z.; Zhou, H. Boosted EfficientNet: Detection of Lymph Node Metastases in Breast Cancer Using Convolutional Neural Networks. Cancers 2021, 13, 661. [Google Scholar] [CrossRef]
- Lin, C.H.; Lin, C.J.; Li, Y.C.; Wang, S.H. Using Generative Adversarial Networks and Parameter Optimization of Convolutional Neural Networks for Lung Tumor Classification. Appl. Sci. 2021, 11, 480. [Google Scholar] [CrossRef]
- Bi, L.; Feng, D.D.; Fulham, M.; Kim, J. Multi-label classification of multi-modality skin lesion via hyper-connected convolutional neural network. Pattern Recognit. 2020, 107, 107502. [Google Scholar] [CrossRef]
- Taylor, G.W.; Fergus, R.; LeCun, Y.; Bregler, C. Convolutional learning of spatio-temporal features. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 140–153. [Google Scholar]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Hasan, M.; Van Essen, B.C.; Awwal, A.A.; Asari, V.K. A state-of-the-art survey on deep learning theory and architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef]
- Gutman, D.; Codella, N.C.; Celebi, E.; Helba, B.; Marchetti, M.; Mishra, N.; Halpern, A. Skin lesion analysis toward melanoma detection: A challenge at the international symposium on biomedical imaging (ISBI) 2016, hosted by the international skin imaging collaboration (ISIC). arXiv 2016, arXiv:1605.01397. [Google Scholar]
- Tschandl, P.; Rosendahl, C.; Kittler, H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci. Data 2018, 5, 1–9. [Google Scholar] [CrossRef]
- Combalia, M.; Codella, N.C.; Rotemberg, V.; Helba, B.; Vilaplana, V.; Reiter, O.; Carrera, C.; Barreiro, A.; Halpern, A.C.; Puig, S.; et al. BCN20000: Dermoscopic lesions in the wild. arXiv 2019, arXiv:1908.02288. [Google Scholar]
- International Skin Imaging Collaboration, | ISIC 2019. Available online: https://challenge2019.isic-archive.com/ (accessed on 17 December 2020).
- SIIM-ISIC Melanoma Classification. Available online: https://www.kaggle.com/c/siim-isic-melanoma-classification (accessed on 15 December 2020).
- Giotis, I.; Molders, N.; Land, S.; Biehl, M.; Jonkman, M.F.; Petkov, N. MED-NODE: A computer-assisted melanoma diagnosis system using non-dermoscopic images. Expert Syst. Appl. 2015, 42, 6578–6585. [Google Scholar] [CrossRef]
- Ballerini, L.; Fisher, R.B.; Aldridge, B.; Rees, J. A color and texture based hierarchical K-NN approach to the classification of non-melanoma skin lesions. In Color Medical Image Analysis; Springer: Berlin/Heidelberg, Germany, 2013; pp. 63–86. [Google Scholar]
- Spanhol, F.A.; Oliveira, L.S.; Petitjean, C.; Heutte, L. A dataset for breast cancer histopathological image classification. IEEE Trans. Biomed. Eng. 2015, 63, 1455–1462. [Google Scholar] [CrossRef]
- Bolhasani, H.; Amjadi, E.; Tabatabaeian, M.; Jassbi, S.J. A histopathological image dataset for grading breast invasive ductal carcinomas. Inform. Med. Unlocked 2020, 19, 100341. [Google Scholar] [CrossRef]
- Xu, J.; Xiang, L.; Liu, Q.; Gilmore, H.; Wu, J.; Tang, J.; Madabhushi, A. Stacked sparse autoencoder (SSAE) for nuclei detection on breast cancer histopathology images. IEEE Trans. Med. Imaging 2015, 35, 119–130. [Google Scholar] [CrossRef] [PubMed]
- Aksac, A.; Demetrick, D.J.; Ozyer, T.; Alhajj, R. BreCaHAD: A dataset for breast cancer histopathological annotation and diagnosis. BMC Res. Notes 2019, 12, 1–3. [Google Scholar] [CrossRef]
- SPIE-AAPM-NCI BreastPathQ. Available online: https://breastpathq.grand-challenge.org/Overview/ (accessed on 19 December 2020).
- Araújo, T.; Aresta, G.; Castro, E.; Rouco, J.; Aguiar, P.; Eloy, C.; Polónia, A.; Campilho, A. Classification of breast cancer histology images using convolutional neural networks. PLoS ONE 2017, 12, e0177544. [Google Scholar] [CrossRef]
- Aresta, G.; Araújo, T.; Kwok, S.; Chennamsetty, S.S.; Safwan, M.; Alex, V.; Marami, B.; Prastawa, M.; Chan, M.; Donovan, M.; et al. Bach: Grand challenge on breast cancer histology images. Med. Image Anal. 2019, 56, 122–139. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Fadhel, M.A.; Oleiwi, S.R.; Al-Shamma, O.; Zhang, J. DFU_QUTNet: Diabetic foot ulcer classification using novel deep convolutional neural network. Multimed. Tools Appl. 2020, 79, 15655–15677. [Google Scholar] [CrossRef]
- Dermnetnz Online Medical Resources | Home. Available online: https://www.dermnetnz.org/ (accessed on 13 January 2021).
- Goyal, M.; Reeves, N.D.; Davison, A.K.; Rajbhandari, S.; Spragg, J.; Yap, M.H. Dfunet: Convolutional neural networks for diabetic foot ulcer classification. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 4, 728–739. [Google Scholar] [CrossRef]
- Karki, S.; Kulkarni, P.; Stranieri, A. Melanoma classification using EfficientNets and Ensemble of models with different input resolution. In Proceedings of the 2021 Australasian Computer Science Week Multiconference, Dunedin, New Zealand, 1 February 2021; pp. 1–5. [Google Scholar]
- Shapovalova, S.; Moskalenko, Y. Methods for increasing the classification accuracy based on modifications of the basic architecture of convolutional neural networks. ScienceRise 2020, 10–16. [Google Scholar] [CrossRef]
- Guo, Y.; Dong, H.; Song, F.; Zhu, C.; Liu, J. Breast cancer histology image classification based on deep neural networks. In International Conference Image Analysis and Recognition; Springer: Berlin/Heidelberg, Germany, 2018; pp. 827–836. [Google Scholar]
- Vang, Y.S.; Chen, Z.; Xie, X. Deep learning framework for multi-class breast cancer histology image classification. In International Conference Image Analysis and Recognition; Springer: Berlin/Heidelberg, Germany, 2018; pp. 914–922. [Google Scholar]
- Sarker, M.I.; Kim, H.; Tarasov, D.; Akhmetzanov, D. Inception Architecture and Residual Connections in Classification of Breast Cancer Histology Images. arXiv 2019, arXiv:1912.04619. [Google Scholar]
- Alzubaidi, L.; Hasan, R.I.; Awad, F.H.; Fadhel, M.A.; Alshamma, O.; Zhang, J. Multi-class Breast Cancer Classification by a Novel Two-Branch Deep Convolutional Neural Network Architecture. In Proceedings of the 2019 12th International Conference on Developments in eSystems Engineering (DeSE), Kazan, Russia, 7–10 October 2019; pp. 268–273. [Google Scholar]
- Ferreira, C.A.; Melo, T.; Sousa, P.; Meyer, M.I.; Shakibapour, E.; Costa, P.; Campilho, A. Classification of breast cancer histology images through transfer learning using a pre-trained inception resnet v2. In International Conference Image Analysis and Recognition; Springer: Berlin/Heidelberg, Germany, 2018; pp. 763–770. [Google Scholar]
- Kassani, S.H.; Kassani, P.H.; Wesolowski, M.J.; Schneider, K.A.; Deters, R. Breast cancer diagnosis with transfer learning and global pooling. In Proceedings of the 2019 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Korea, 16–18 October 2019; pp. 519–524. [Google Scholar]
- Wang, Z.; Dong, N.; Dai, W.; Rosario, S.D.; Xing, E.P. Classification of breast cancer histopathological images using convolutional neural networks with hierarchical loss and global pooling. In International Conference Image Analysis and Recognition; Springer: Berlin/Heidelberg, Germany, 2018; pp. 745–753. [Google Scholar]
- Louisiana State University Health Sciences Center. Available online: https://www.lsuhsc.edu/ (accessed on 15 March 2021).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name of Layer | Filter Size (FS) and Stride (S) | Activations |
|---|---|---|
| Input layer | - | 500 × 375 × 3 |
| C1, B1, R1 | FS = 3 × 3, S = 1 | 500 × 375 × 32 |
| C2, B2, R2 | FS = 5 × 3, S = 2 | 250 × 188 × 32 |
| C3, B3, R3 | FS = 1 × 1, S = 1 | 250 × 188 × 32 |
| C4, B4, R4 | FS = 3 × 3, S = 1 | 250 × 188 × 32 |
| C5, B5, R5 | FS = 5 × 5, S = 1 | 250 × 188 × 32 |
| C6, B6, R6 | FS = 7 × 7, S = 1 | 250 × 188 × 32 |
| CN1 | Five inputs | 250 × 188 × 160 |
| B1x | Batch normalization layer | 250 × 188 × 160 |
| C7, B7, R7 | FS = 1 × 1, S = 2 | 125 × 94 × 64 |
| C8, B8, R8 | FS = 3 × 3, S = 2 | 125 × 94 × 64 |
| C9, B9, R9 | FS = 5 × 5, S = 2 | 125 × 94 × 64 |
| C10, B10, R10 | FS = 7 × 7, S = 2 | 125 × 94 × 64 |
| CN2 | Four inputs | 125 × 94 × 256 |
| B2x | Batch normalization layer | 125 × 94 × 256 |
| C11, B11, R11 | FS = 1 × 1, S = 1 | 125 × 94 × 64 |
| C12, B12, R12 | FS = 3 × 3, S = 1 | 125 × 94 × 64 |
| C13, B13, R13 | FS = 5 × 5, S = 1 | 125 × 94 × 64 |
| C14, B14, R14 | FS = 7 × 7, S = 1 | 125 × 94 × 64 |
| CN3 | Five inputs | 125 × 94 × 512 |
| B3x | Batch normalization layer | 125 × 94 × 512 |
| C15, B15, R15 | FS = 1 × 1, S = 2 | 63 × 47 × 128 |
| C16, B16, R16 | FS = 3 × 3, S = 2 | 63 × 47 × 128 |
| C17, B17, R17 | FS = 5 × 5, S = 2 | 63 × 47 × 128 |
| C18, B18, R18 | FS = 7 × 7, S = 2 | 63 × 47 × 128 |
| C27, B27, R27 | FS = 3 × 3, S = 2 | 63 × 47 × 32 |
| CN4 | Five inputs | 63 × 47 × 544 |
| B4x | Batch normalization layer | 63 × 47 × 544 |
| C19, B19, R19 | FS = 1 × 1, S = 1 | 63 × 47 × 256 |
| C20, B20, R20 | FS = 3 × 3, S = 1 | 63 × 47 × 256 |
| C21, B21, R20 | FS = 5 × 5, S = 1 | 63 × 47 × 256 |
| C22, B22, R22 | FS = 7 × 7, S = 1 | 63 × 47 × 256 |
| C28, B28, R28 | FS = 3 × 3, S = 4 | 63 × 47 × 32 |
| C34, B34, R34 | FS = 3 × 3, S = 2 | 63 × 47 × 32 |
| CN5 | Seven inputs | 63 × 47 × 1632 |
| B5x | Batch normalization layer | 63 × 47 × 1632 |
| C23, B23, R23 | FS = 1 × 1, S = 2 | 32 × 24 × 384 |
| C24, B24, R24 | FS = 3 × 3, S = 2 | 32 × 24 × 384 |
| C25, B25, R25 | FS = 5 × 5, S = 2 | 32 × 24 × 384 |
| C26, B26, R26 | FS = 7 × 7, S = 2 | 32 × 24 × 384 |
| C29, B29, R29 | FS = 3 × 3, S = 8 | 32 × 24 × 32 |
| C30, B30, R30 | FS = 3 × 3, S = 2 | 32 × 24 × 32 |
| C31, B31, R31 | FS = 3 × 3, S = 4 | 32 × 24 × 32 |
| C32, B32, R32 | FS = 3 × 3, S = 4 | 32 × 24 × 32 |
| C33, B33, R33 | FS = 3 × 3, S = 8 | 32 × 24 × 32 |
| CN6 | Nine inputs | 32 × 24 × 1696 |
| B6x | Batch normalization layer | 32 × 24 × 1696 |
| G1 | - | 1 × 1 × 1696 |
| F1 | 1200 FC (Fully Connected) | 1 × 1 × 1200 |
| D1 | Dropout layer with learning rate: 0.5 | 1 × 1 × 1200 |
| G2 | 2 | 1 × 1 × 2 |
| O (softmax function) | benign, malignant | 1 × 1 × 2 |
| Phases | Accuracy (%) | Recall (%) | Precision (%) | F-Score (%) |
|---|---|---|---|---|
| Phase #1 | 89.69 | 85.60 | 92.86 | 89.09 |
| Phase #2 | 98.57 | 97.90 | 99.18 | 98.53 |
| Phases | Accuracy (%) | Recall (%) | Precision (%) | F-Score (%) |
|---|---|---|---|---|
| Phase #1 | 83.18 | 83.03 | 89.21 | 86.0 |
| Phase #2 | 96.10 | 97.06 | 95.45 | 96.25 |
| Phase #3 | 99.03 | 99.81 | 98.7 | 99.25 |
| Method | Recall (%) | Precision (%) | F-Score (%) |
|---|---|---|---|
| DFUNet [61] | 92.5 | 93.8 | 93.1 |
| DFU_QUTNet [59] | 92.6 | 94.2 | 93.4 |
| DFU_QUTNet + KNN [59] | 92.7 | 93.8 | 93.2 |
| DFU_QUTNet + SVM [59] | 93.6 | 95.4 | 94.5 |
| Ours (Phase #3) | 99.81 | 98.7 | 99.25 |
| Phases | Image-Wise Accuracy (%) |
|---|---|
| Phase #1 | 85.29 |
| Phase #2 | 97.51 |
| Phases | Image-Wise Accuracy (%) |
|---|---|
| Guo, Y., et al. [64] | 87.5 |
| Vang, Y.S., et al. [65] | 87.5 |
| Sarker, M.I., et al. [66] | 89 |
| Alzubaidi, L., et al. [67] | 89.4 |
| Ferreira, C.A., et al. [68] | 90 |
| Kassani, S.H., et al. [69] | 92.5 |
| Wang, Z., et al. [70] | 93 |
| Alzubaidi, L., et al. [14] | 96.1 |
| Ours (Phase #2) | 97.51 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alzubaidi, L.; Al-Amidie, M.; Al-Asadi, A.; Humaidi, A.J.; Al-Shamma, O.; Fadhel, M.A.; Zhang, J.; Santamaría, J.; Duan, Y. Novel Transfer Learning Approach for Medical Imaging with Limited Labeled Data. Cancers 2021, 13, 1590. https://doi.org/10.3390/cancers13071590
Alzubaidi L, Al-Amidie M, Al-Asadi A, Humaidi AJ, Al-Shamma O, Fadhel MA, Zhang J, Santamaría J, Duan Y. Novel Transfer Learning Approach for Medical Imaging with Limited Labeled Data. Cancers. 2021; 13(7):1590. https://doi.org/10.3390/cancers13071590
Chicago/Turabian StyleAlzubaidi, Laith, Muthana Al-Amidie, Ahmed Al-Asadi, Amjad J. Humaidi, Omran Al-Shamma, Mohammed A. Fadhel, Jinglan Zhang, J. Santamaría, and Ye Duan. 2021. "Novel Transfer Learning Approach for Medical Imaging with Limited Labeled Data" Cancers 13, no. 7: 1590. https://doi.org/10.3390/cancers13071590
APA StyleAlzubaidi, L., Al-Amidie, M., Al-Asadi, A., Humaidi, A. J., Al-Shamma, O., Fadhel, M. A., Zhang, J., Santamaría, J., & Duan, Y. (2021). Novel Transfer Learning Approach for Medical Imaging with Limited Labeled Data. Cancers, 13(7), 1590. https://doi.org/10.3390/cancers13071590