1. Introduction
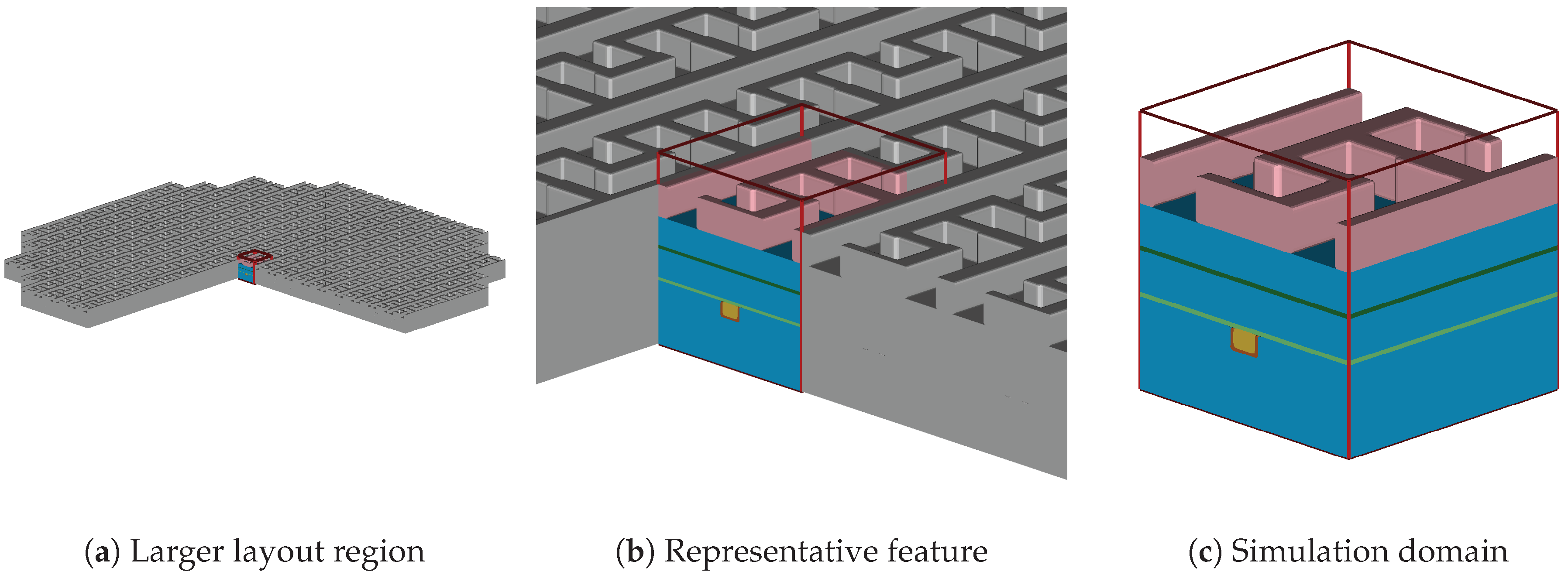
Semiconductor process simulations can be partitioned into two major types: reactor-scale and feature-scale simulations. The former simulates the full reactor chamber whereas the simulation domain of the latter is a small region of the wafer surface (see
Figure 1). Feature-scale simulations (which are the focus of this work) are used when the detailed topographical behavior and the prediction of the surface evolution is of major interest, instead of focusing on the global behavior of the wafer in a reactor-scale simulation [
1].
Particularly challenging is the simulation of etching processes, where the large number of possible process parameters and available materials renders conventional evaluation unreasonable considering costs and time [
2], since even the smallest change in an experimental setup can have a major impact on the properties of a device [
3]. Additionally, the more and more used three-dimensional (3D) designs (e.g., FinFET [
4] or 3D NAND flash memory [
5]) prohibits the problem reduction to two dimensions as a simple yet effective technique to minimize computational effort for larger 3D structures. Hence, the development of faster algorithms and methods is a substantial objective to solve the increasingly complex 3D problems and thereby sustaining the high pace of ultra-large scale integrated circuit developments [
2].
The common computational tasks in a single timestep of a feature-scale etching simulation are (a) the preparation of a suitable surface representation for the surface flux rate calculations, (b) the calculation of the surface flux rate distributions on the surface, (c) the evaluation of the surface velocity models using the surface flux rate distributions, and (d) the advection of the surface according to the computed surface velocity field. Typically, the majority of the computational time is spent on the calculation of the flux rates [
6,
7]. In turn, the models for the etch rates depend on the flux rates of the involved etchants where the flux rate calculations constitute the main computational bottleneck.
The common flux calculation methods (which assume ballistic particle transport) rely on a large number of ray-surface intersection tests. Most frameworks are based on an implicit representation of the surface, using the level-set method for advection [
8,
9,
10]. In [
11], the authors study the Bosch process for a micro-electromechanical system (MEMS) application with Silvaco’s Victory Process simulator, which uses an implicit representation of the surface during ray casting [
12]. However, during ray casting, different (temporary) representations for the surface are also used. Ertl et al. use the ViennaTS [
13] simulator to investigate the Bosch process [
14]. The process is simulated in three dimensions and the flux calculation is based on a Monte Carlo approach. A representation of the surface as a set of overlapping disks is used to approximate a closed surface. Heitzinger et al. showed a method to accelerate such Monte Carlo based flux calculations by coarsening the explicit surface mesh representing the surface [
15]. Recently, Yu et al. presented a 3D topography simulation of a deep reactive ion etching (DRIE) process [
16]. Therein, the surface is approximated using a set of spheres during the Monte Carlo ray tracing task.
A common way to increase the computational performance of ray casting is the use of hierarchical spatial acceleration structures, where a bounding volume hierarchy (BVH) is a common choice [
17,
18]. A similar approach is to apply a bi-level spatial subdivision for reducing the search space for an explicit surface representation in order to accelerate the Monte Carlo based ray tracing as shown by Yu et al. [
19]. This method relies on a proper subdivision tree and an optimal choice of the underlying parameters, which need to be determined beforehand. Naeimi et al. accelerate their ray-tracing based heat transfer model by merging empty voxels, explicitly representing their geometry, inside their static simulation domain [
20]. Hence, when a ray is traversing through the domain, it can quickly traverse the empty voxels, since they are much bigger than those on the respective surface. Although their algorithm provides a considerable speedup concerning the underlying ray-tracing, the voxel merging process can have a major impact on the performance in transient simulations, when it has to be applied in each timestep. Aguerre et al. proposed a method to reduce the computational effort if the flux calculation is radiosity based [
21]. The method relies on a hierarchical strategy and a sorting scheme for acceleration of the necessary calculations based on explicit meshes. Bailey showed that an adaptive sampling of the geometrical elements can improve the computational performance of ray tracing tasks [
7]. In [
22], it is shown that the overhead introduced by generating a temporary explicit mesh in each timestep is by far compensated using optimized computer graphics libraries for single-precision ray casting.
Another acceleration approach was presented in [
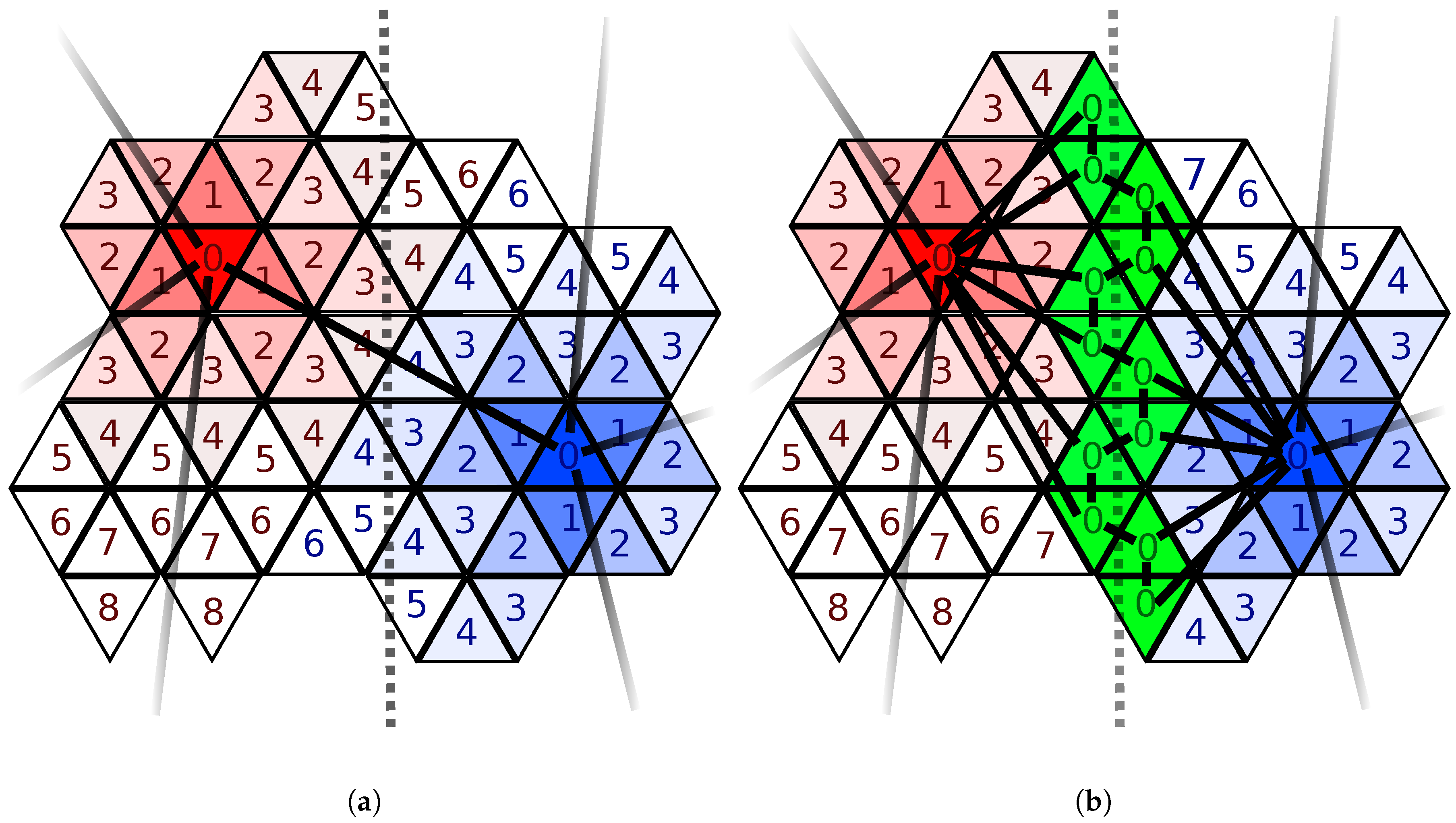
6], where the computational performance of the flux calculation is improved by evaluating the surface speed only on a sparse set of cells on an explicit surface mesh. This set is found using an iterative partitioning of the surface, without adapting the surface mesh itself. The approach is evaluated using a simple 3D single-material etching simulation of a cylindric hole. The computational performance of the flux calculation is increased by a factor of 2–8 (compared to the conventional evaluation on the mesh using all cells) while preserving the geometrical features of the surface.
In this paper, we extend the method presented in [
6] by including multi-material interfaces into the partitioning scheme and by evaluating practically relevant multi-material problems. We evaluate the new scheme by simulating the etching of a dielectric layer as part of a Dual-Damascene fabrication process sequence, which is an important technique in today’s semiconductor industry [
23,
24]. We show that the novel flux calculation based on the sparse set of surface cells significantly improves the computational performance for practically relevant multi-material simulations, achieving speedups of 1.9 to 8, which is in the range of the speedups reported in [
6]. Additionally, we show that the resulting surface deviations for the sparse set are below two grid cells after many timesteps (corresponding to 0.6 to 3% of the via size) for a wide range of surface resolutions. The study is completed with an in-depth analysis of the parallel performance of the sparse and dense flux calculation approaches.
2. Materials and Methods
2.1. Dual-Damascene Process
To reduce the required processing steps in the fabrication pipeline, the Dual-Damascene process was introduced in the 1990s and became an industry standard [
25]. In this process, only a single metal deposition step is required, where vias and trenches are filled simultaneously, typically using copper as filling metal [
26]. Additionally, the number of chemical-mechanical planarization steps as well as the number of deposition steps for the dielectric are reduced. This yields a shorter overall processing time together with less possibilities for failures.
In general, there are three different major Dual-Damascene process sequences: (1) trench-first, (2) via-first, and (3) self-aligned or buried-via. In the trench-first sequence, the etching of the trenches is conducted before the etching of the vias, whereas, in the via-first approach, the etching is done vice versa. Both methods apply a metal deposition step after each etching step, where the via and the trench are filled with copper. The self-aligned Dual-Damascene process etches both the via and the trench at the same time [
25,
27] and is the target application of this work.
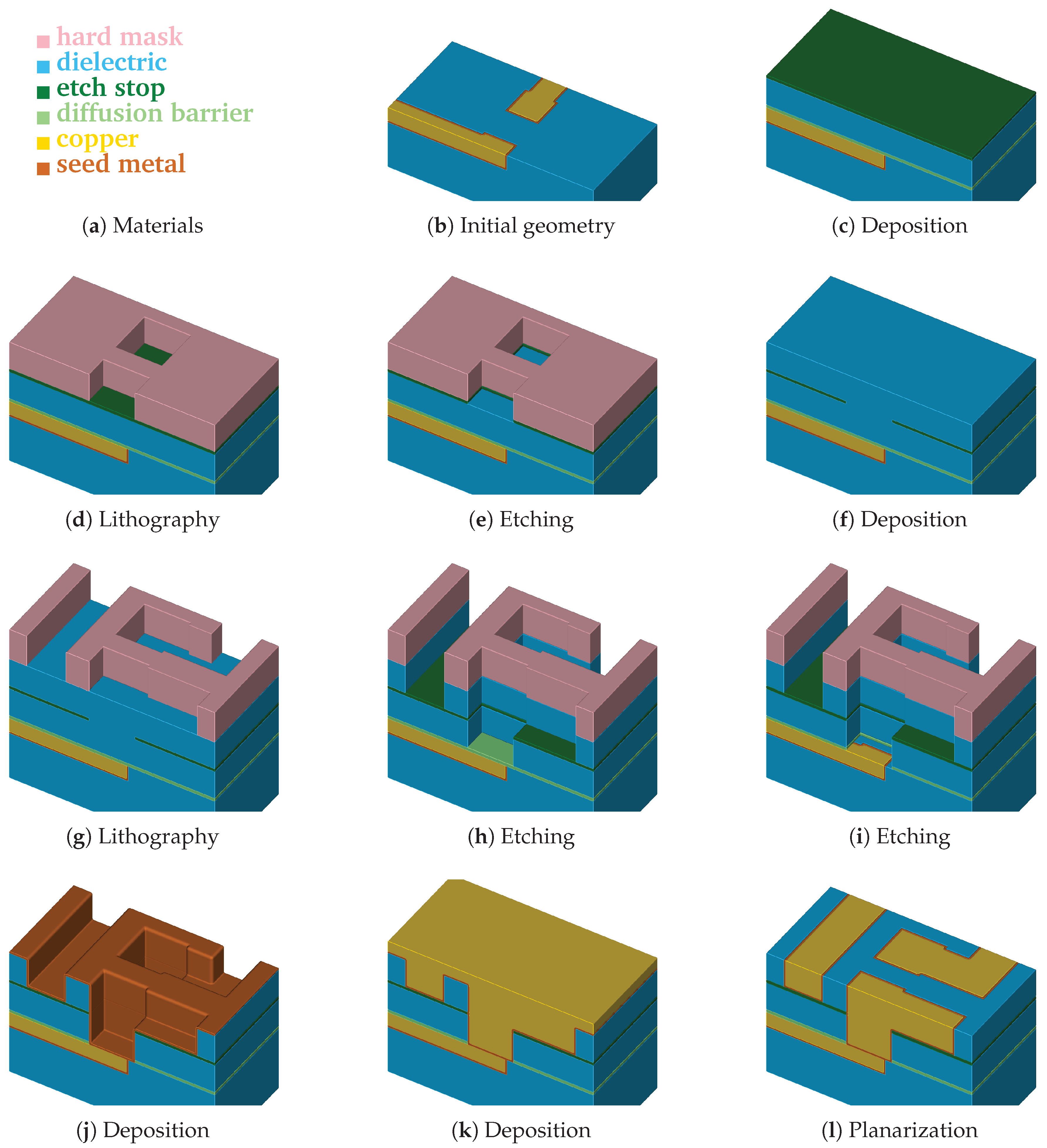
Figure 2 depicts a typical sequence of processing steps in the self-aligned Dual-Damascene process. The different steps show the initial surface of the wafer (
Figure 2b), which is followed by the deposition of the diffusion barrier, a dielectric, and the etch stop (
Figure 2c). Afterwards, a hard mask is deposited and subsequently the etch stop layer is patterned (
Figure 2d,e). After the removal of the hard mask, a second dielectric is deposited and a hard mask is patterned again (
Figure 2f,g). The next step is the combined etching of trenches and vias (
Figure 2h). Afterwards, the finalizing steps are the removal of the etch barrier (
Figure 2i), the deposition of the metal seed layer (
Figure 2j), the copper deposition (
Figure 2k), and the chemical-mechanical planarization (
Figure 2l).
After switching from Aluminum to Copper as interconnect material in the early 2000s to overcome the problems surfacing in the sub-micron regime [
25], today, new challenges arise on the continued path of miniaturization down to a few nanometers. For example, to reduce the interconnect capacitance, new dielectrics such as SiO
2 or porous SiCOH have to be used [
28]. As previously discussed, computer simulations provide a highly attractive option to assess the different etching behaviors of various materials to determine process designs and optimizations before proceeding with actual, conventional experimental investigations. Therefore, within this work, we show the applicability of the approach presented in [
6] using the etching process of a dielectric layer (
Figure 2g–h) as a practically relevant example of a multi-material simulation.
2.2. Multi-Material Simulation Framework
A single-material simulation framework [
6] was developed to investigate efficient flux calculation methods for 3D etching and deposition processes. It is based on the sparse volume data structure of OpenVDB [
29,
30] and uses the accompanying tools to handle surface advection and surface extraction. All advection steps described in the following are performed using the level-set representation of the surface. The explicit representation of the surface, which is only used during the flux calculation, is obtained using OpenVDB’s “volumeToMesh” routine producing quads. We subdivide each potentially non-planar quad into two triangles using the distance to the zero-level-set as guidance for the subdivision pattern. The ray-surface intersection tests are performed using Embree [
31]. In the following, we provide a short summary of the method to set the stage for the subsequent discussion on the improved multi-material iterative partitioning scheme and the detailed analysis of plasma etching steps for a Dual-Damascene process.
In each timestep of the simulation, the main computational tasks are (a) the calculation of the flux rates
R on the surface, (b) the evaluation of the normal surface velocity
(which depends on the flux rates), and (c) the advection of the surface. Typically, the normal surface velocity
during an etching process depends on the flux rates
R of the involved particle species
where
k denotes the number of different particle species. The flux rates depend on the incoming flux distribution
. In the simplest case, all incoming directions are equally weighted, which results in
with
being the incoming direction, and
denoting the upper hemisphere facing the source plane.
The surface of this hemisphere is discretized using a subdivided icosahedron. The directions from a surface point towards the centroids of the triangular discretization of the hemisphere are tested for visibility of the source. After obtaining the visibility information for all directions, a numerical integration is performed over the visible solid angles using a centroid rule [
22].
Typically, different material regions are present during an etching process simulation, e.g., a dielectric patterned with a hard mask (
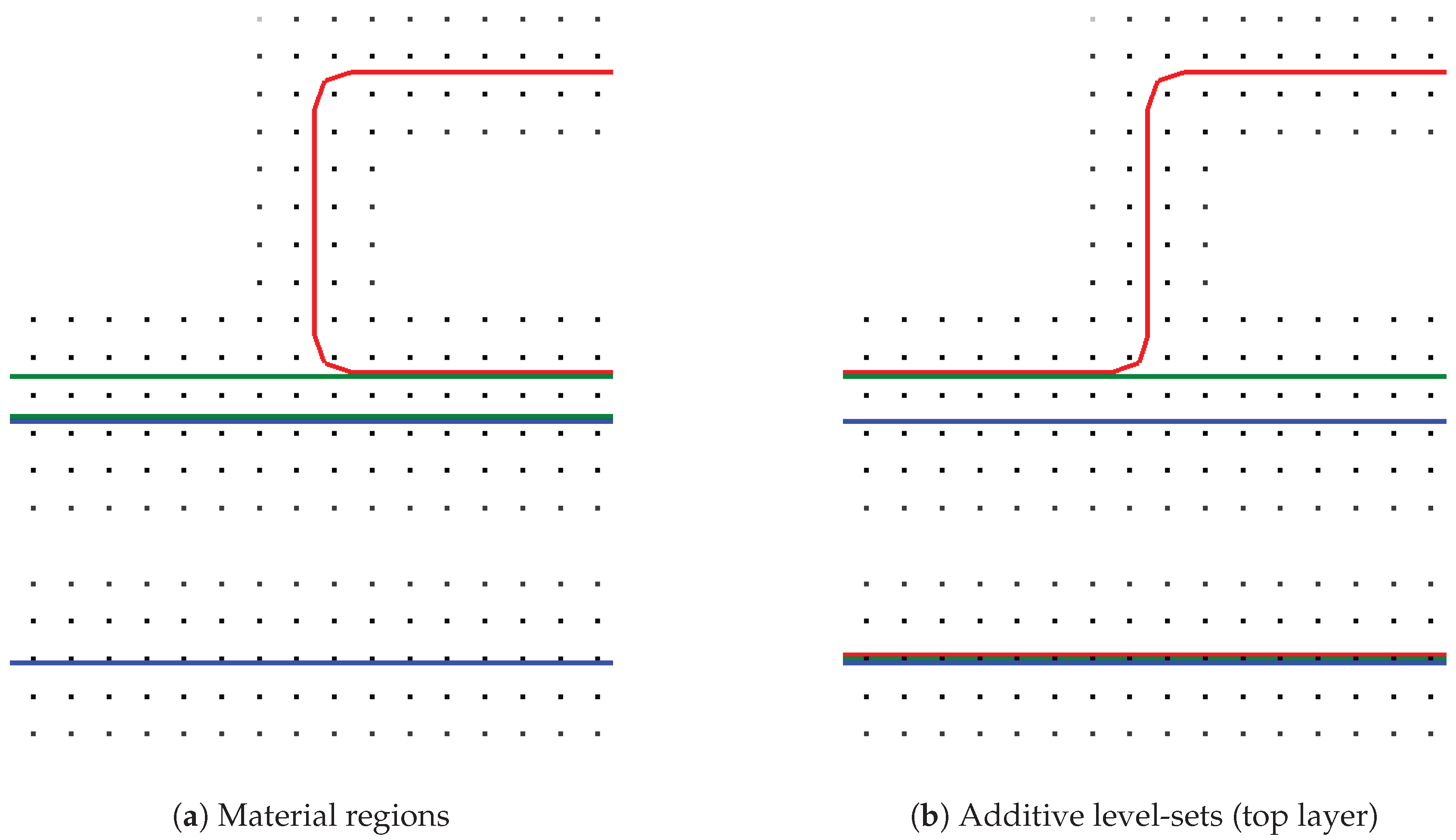
Figure 2g). A straightforward approach would be to represent each material region with a corresponding level-set function, as shown in
Figure 3a. To simultaneously advect all material regions, each region would then be advected separately, leading to potentially mutual penetration. In this case, the parts of a region which are penetrated by another region would be treated inactive, i.e., not subject to advection. One approach would be to perform Boolean operations between material regions to dissolve the penetrations. Hence, a strategy to decide which material fills the former penetrated volume is needed.
We extended the simulation framework presented in [
6] using an approach analogous to [
32,
33], which constructs a total union of all regions and advects the “top layer” (see
Figure 3b). To perform the advection with the correct surface speed of the underlying material region, it is necessary to detect the active material for each point in the top layer. This active material for a point
is obtained by querying the value of all level-sets at
. The material of the level-set with the smallest value is considered active. Additionally, the level-sets have a fixed order and the lower level-set is chosen as active material, if the values are numerically identical. The etching itself is conducted by advecting the top layer, and subsequently transferring the removal of the material to the underlying level-sets representing the material regions using a Boolean operation between the top layer and each material region. One significant advantage of this top layer approach is that material layers can be represented with sub-grid resolution. This is possible if the level-sets representing the materials are chosen to not map directly to the material regions, but are constructed additively.
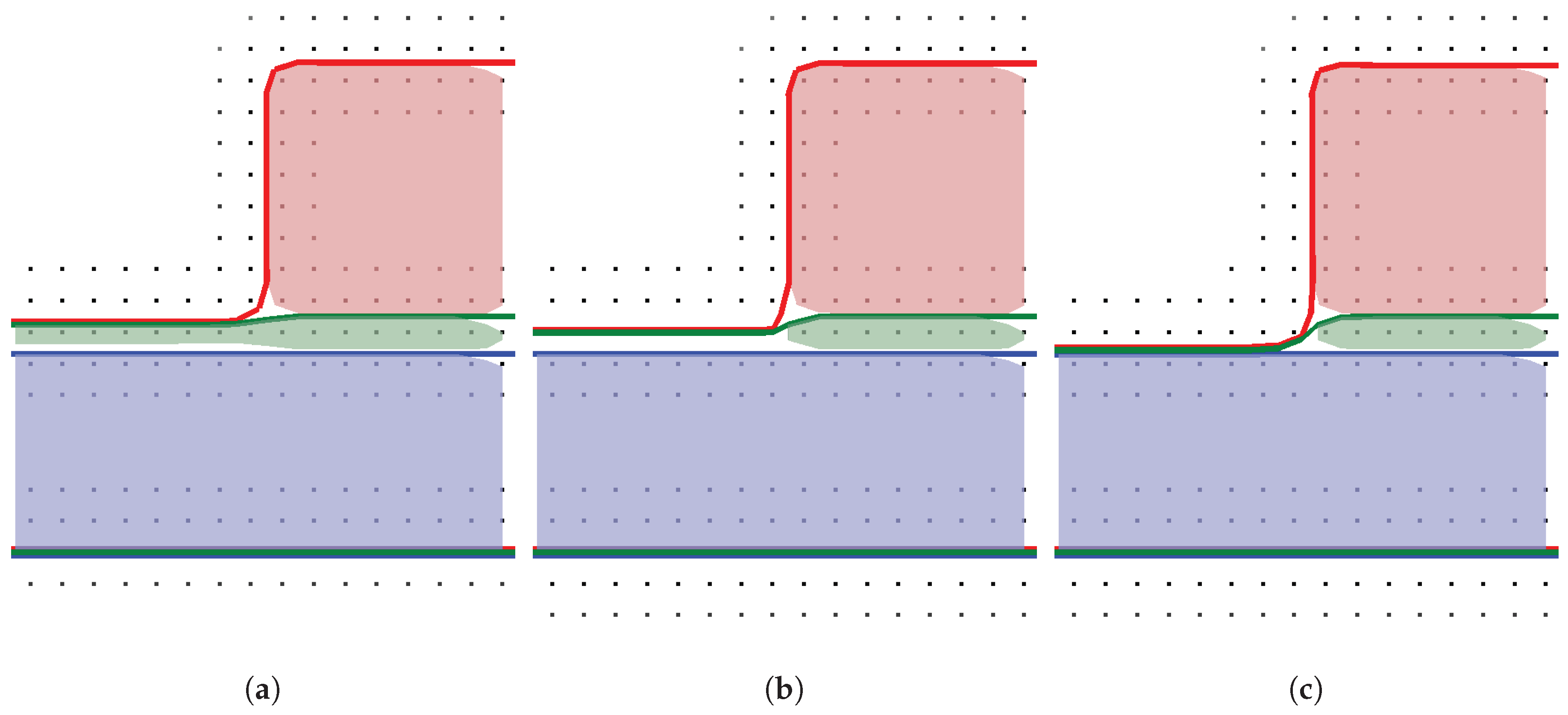
The chronological development of an exemplary material stack using the top layer advection is shown in
Figure 4. Starting from
Figure 4a, the green layer is represented with sub-grid resolution (see
Figure 4b), until it is fully etched away in
Figure 4c. In a time step where a region of a layer is fully etched and the underlying material becomes active, the surface velocities of the involved materials must be averaged. If only the surface velocity for the green layer is considered for the full time step, the surface advection speed is too slow or too fast, if the surface velocity for the blue material is faster or slower, respectively.
2.3. Material Interface-Aware Iterative Partitioning
The approach presented in [
6] is used to obtain the surface flux rates. The main idea herein is to select a subset (sparse set) of the triangles present in the surface mesh, to minimize the number of integration points used in the flux calculation process. The sparse set is created starting by selecting randomly surface cells with a fixed minimum edge distance of
, i.e., the minimum number of edges to be crossed to connect two cells on the surface mesh. The iterative partitioning scheme to refine this initial sparse set is guided by two refinement conditions: a threshold for the difference of the normal angles of two neighboring sparse points and a threshold based on the flux difference between two neighboring sparse points. If the normal angle of two neighboring points exceeds the threshold value, the region in between is marked for further refinement. The obtained solution for the sparse set is then extrapolated constantly into the surrounding patch of each sparse point and smoothed using a diffusion approach.
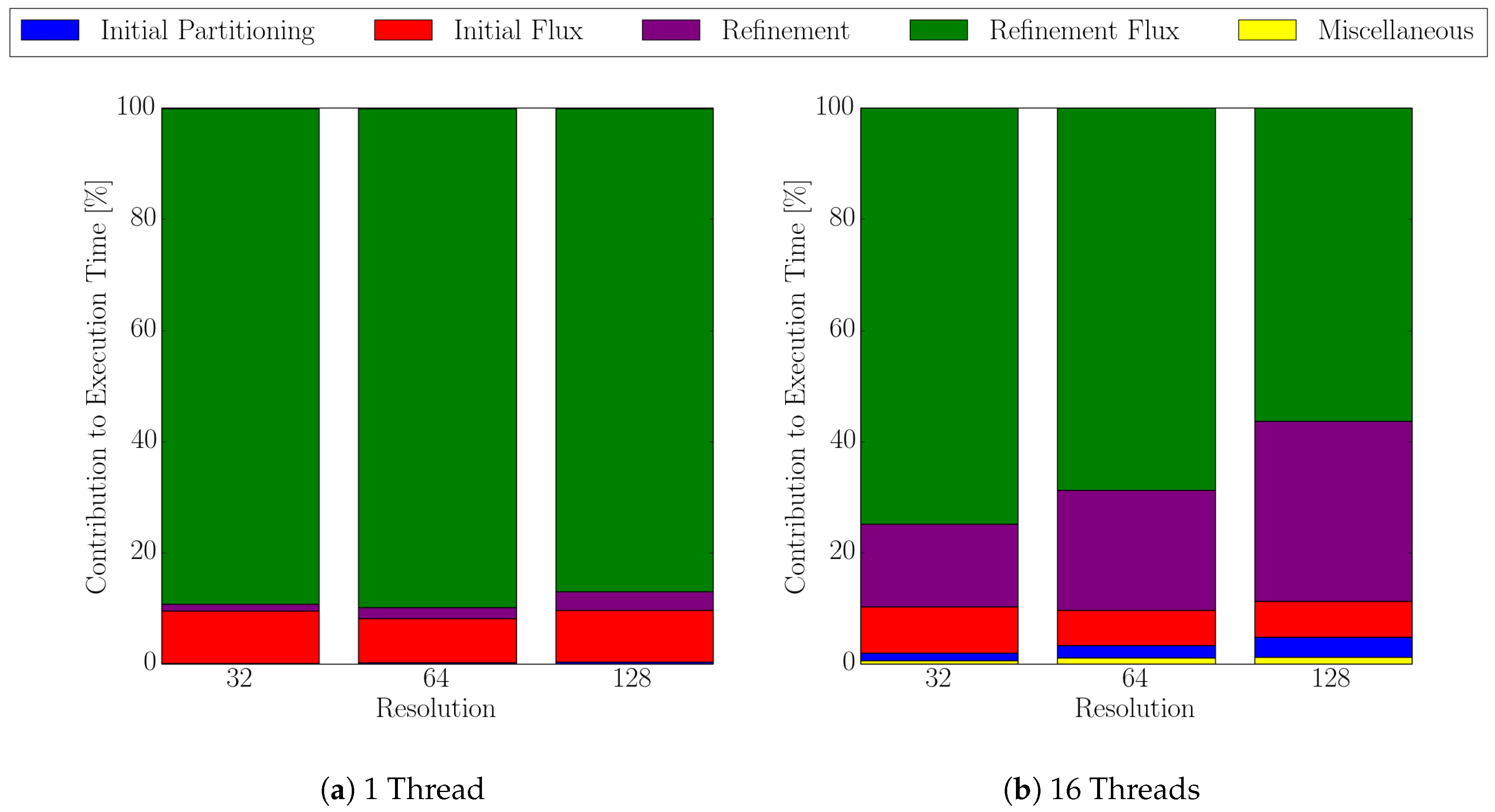
The flux calculation algorithm using the sparse set is comprised of four major parts: (a) the initial partitioning of the surface with a maximum distance between sparse points, (b) the calculation of the flux rates at the sparse points, (c) the refinement of the sparse set where new points are added according to the refinement conditions, and (d) the calculation of the flux rates for the recently added points. Steps (c) and (d) are executed iteratively until a minimum distance between sparse points is reached. The flux calculations steps (b) and (d) are parallelized with OpenMP, whereas the initial partitioning (a) and the refinement (c) are implemented serially.
The refinement condition presented in [
6] is used in the multi-material iterative partitioning scheme for the sparse surface evaluation using the maximal normal deviation
, the average flux difference
, and the maximum flux difference
. A combination of thresholds for the normal deviation (
) and the flux difference (
) is used in all of the following results to model the refinement condition
for a sparse surface location
i:
is used in all simulations, which gives a total of six iterations, whereas the number of Jacobi iterations (for smoothing of the constant extrapolation) is fixed to
.
The refinement condition aims at capturing geometric features as well as high gradients in flux distribution. However, different simulation scenarios might require a tailored refinement condition to ensure proper refinement of the sparse set in relevant regions.
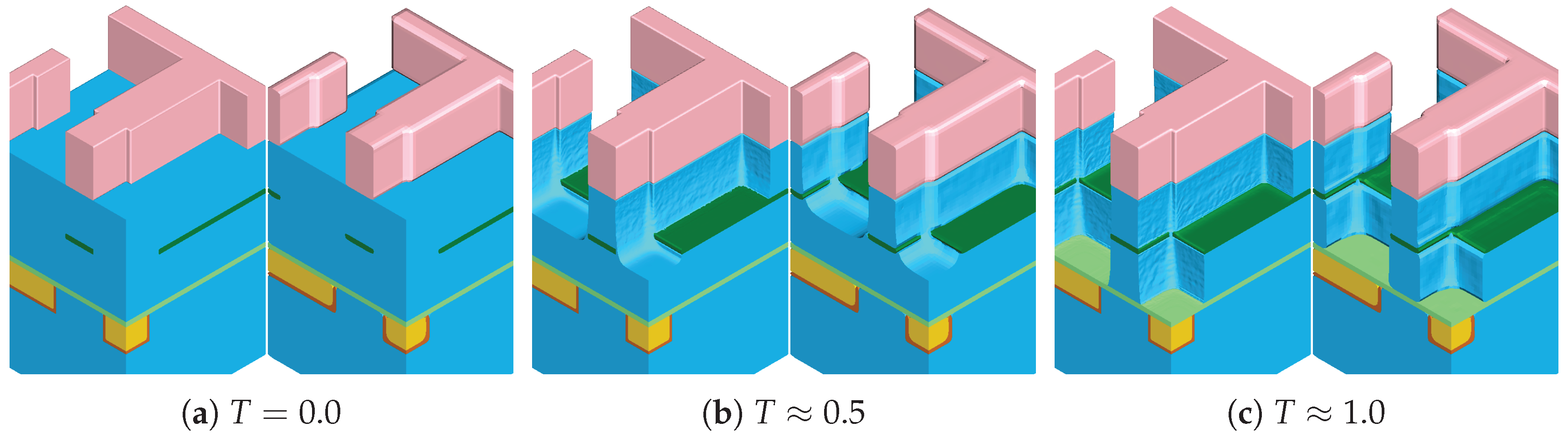
Since different materials experience potentially high differences in their surface velocities, it is important to ensure a material interface-aware partitioning. Therefore, we extend the scheme presented in [
6] by identifying all cells on the top layer embedding a material interface and subsequently set
for these surface cells. The effect of this material-interface-aware partitioning is shown in
Figure 5, where all cells on the interface are present in the sparse set. Thus, we ensure that the sparse set contains a high amount of cells in the material interface regions.
2.4. Simulation Setup
From the different process steps in the Dual-Damascene process (see
Figure 2), we focus solely on the simulation and evaluation of the etching step indicated in
Figure 2g,h. Thus, this section describes the details of the simulation setup of this etching process step.
The used normal surface velocity is defined as
where
is denoting a material dependent scalar weighting factor and
R is the direct flux from the ion source.
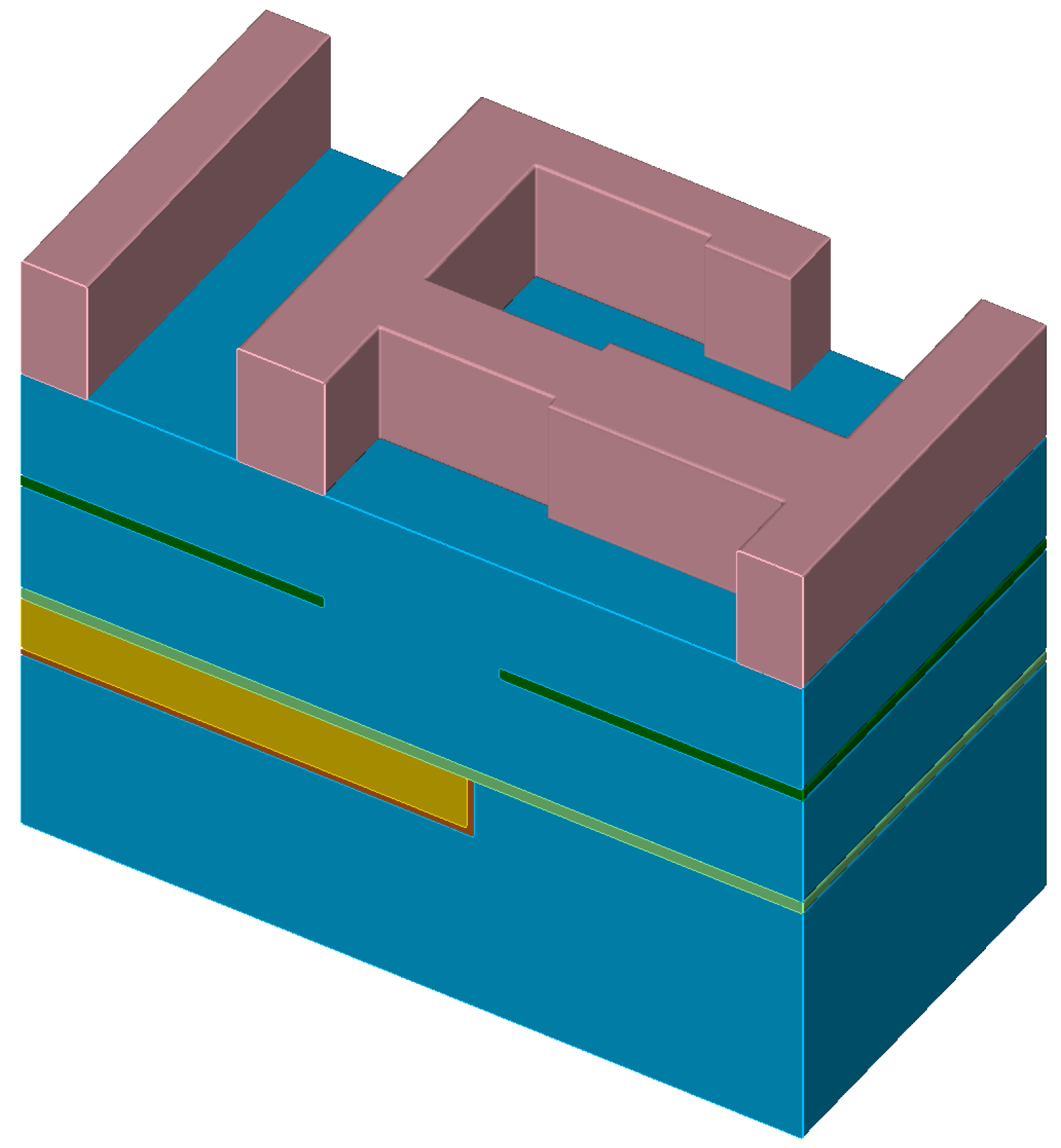
Figure 6 depicts the simulation geometry used in this study and
Table 1 lists the applied scalar weighting factors normalized to the weighting factors of the dielectric.
We set equal weighting factors for the etch stop and the diffusion barrier () as well as for copper and the metal seed layer (). The weighting factor of the hard mask is set to . These values were arbitrarily chosen to highlight the approach’s ability to handle highly different surface reactions in a multi-material simulation.
A power cosine source with exponent
[
22] is used to model a highly vertically focused ion source, where only the direct flux is considered. In order to compute the direct flux rates on the surface elements, we use the method based on an icosahedron presented in [
22], with the subdivision factor set to 5.
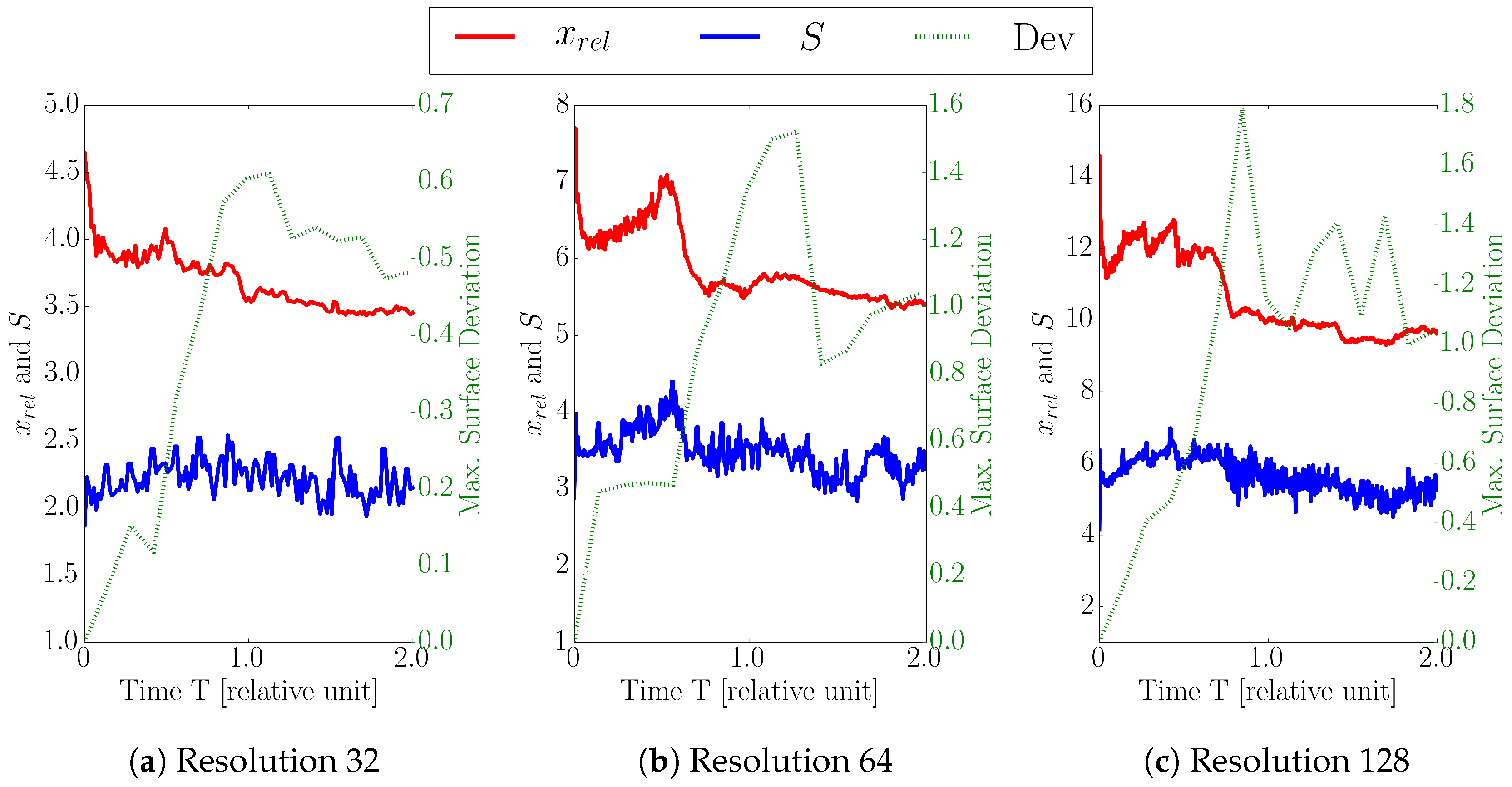
Each simulation is conducted until the simulation time
, where the edge stop layer and the diffusion barrier are reached at
and
, respectively. We investigate level-set resolutions ranging from 32 to 128 cells per unit length resulting in 140 to 560 timesteps (
Table 2).
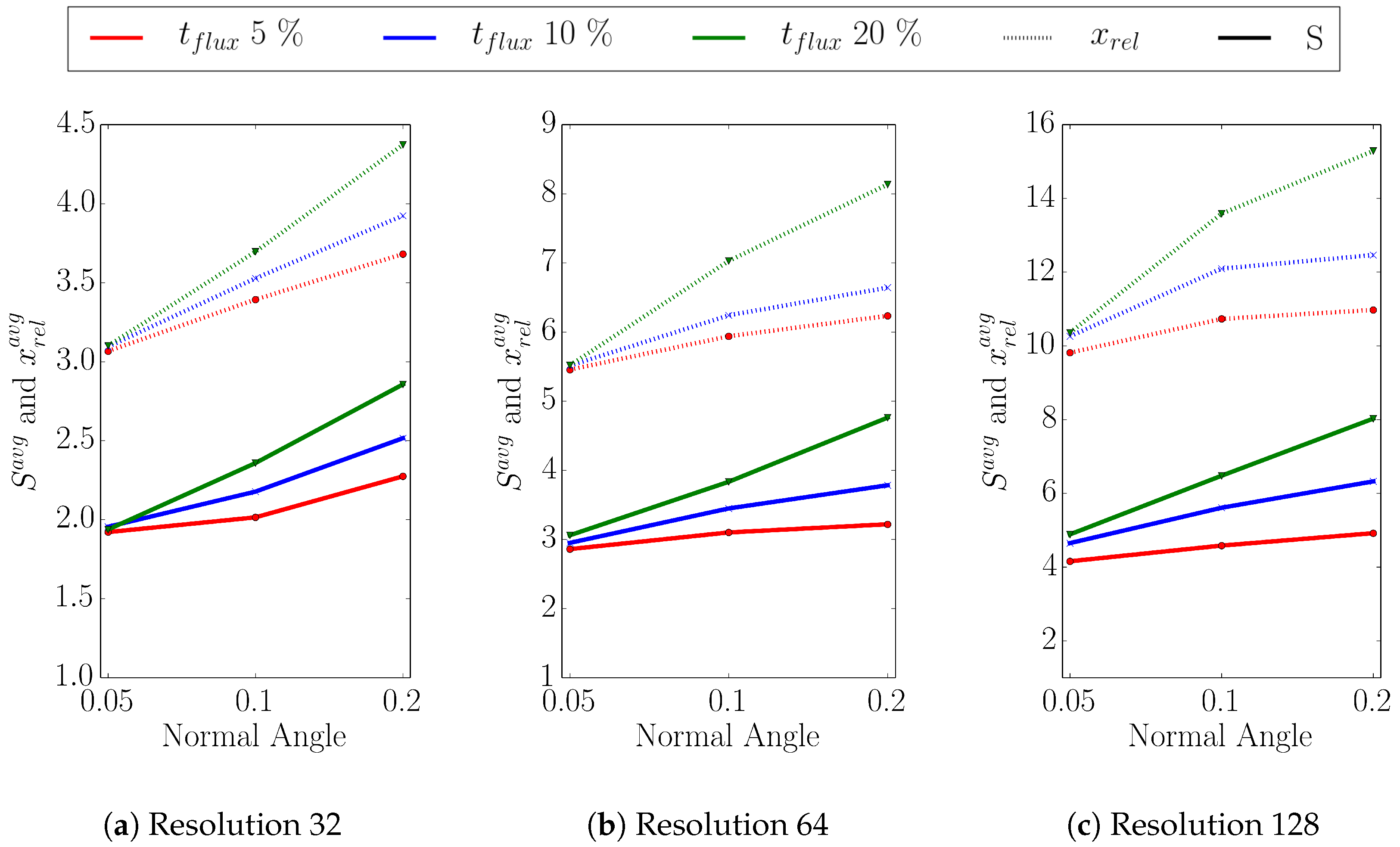
The choice of the threshold values must be chosen according to the simulated process and which information will be extracted from the simulation results. To investigate their influence on the accuracy and performance of the flux calculation, we varied the parameters of the refinement conditions around their default values [
6]. The threshold
for the difference of the normal angles between two sparse points was set to three different values: 0.05, 0.1, and 0.2. For the flux difference, we set the threshold
to 5, 10, and 20% of the global maximum flux calculated in each timestep.
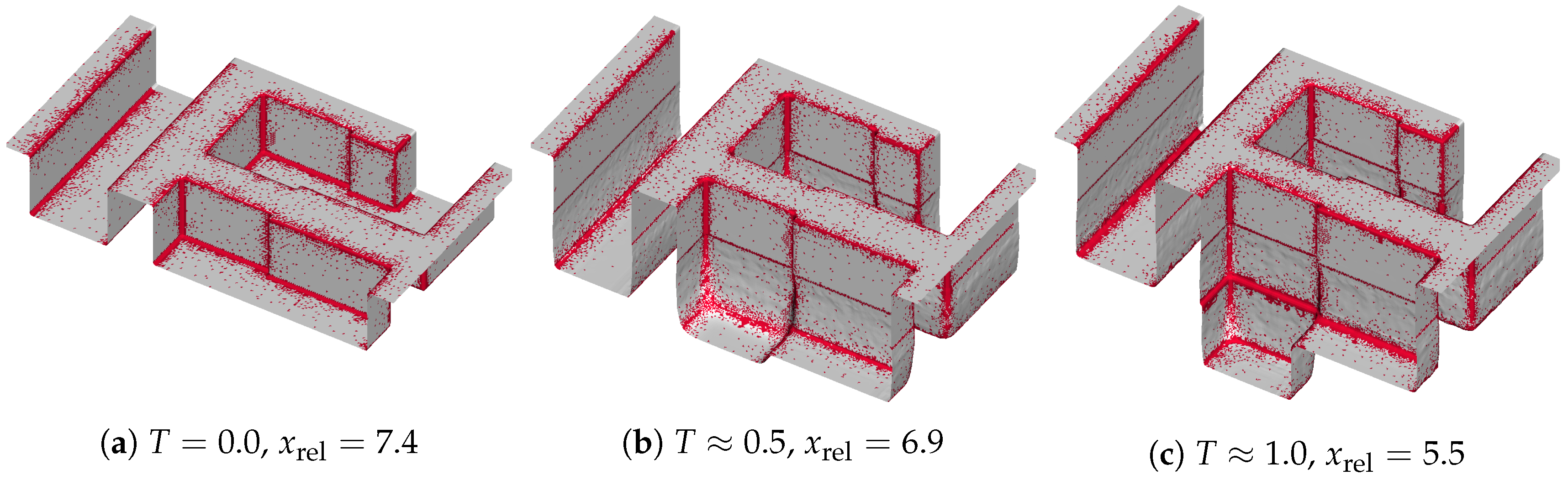
To assess the influence of the sparse surface evaluation, we perform each simulation twice: once using the sparse surface evaluation (sparse approach) and once using a full evaluation (dense approach)—the latter represents the conventional reference approach.
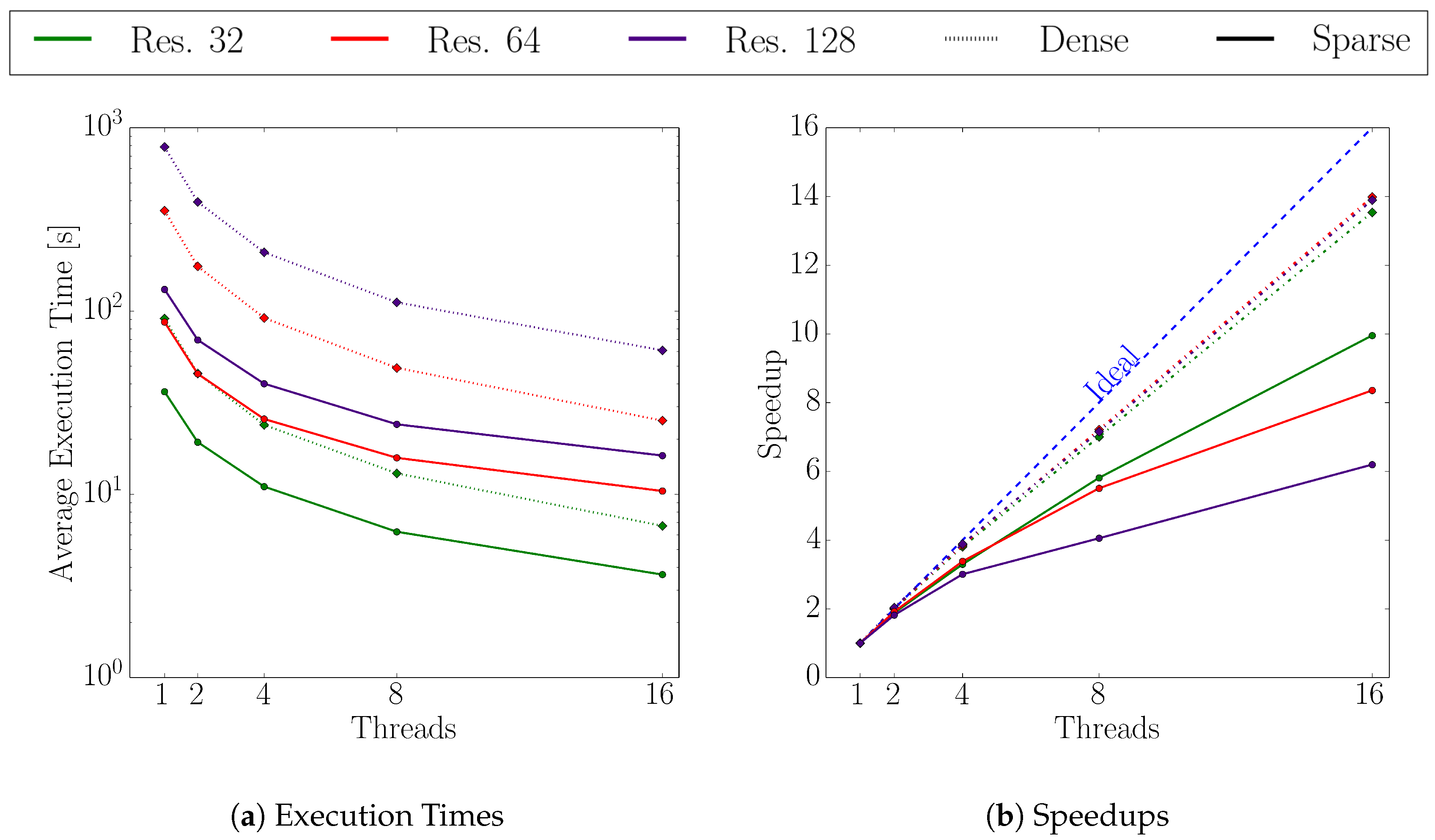
We investigate the scalability for a fixed problem size (i.e., strong scalability) for both the dense and the sparse approach, with 1, 2, 4, 8, and 16 threads. The execution times of the major parts of the sparse flux calculation (a)–(d) are tracked individually.
A single node of the Vienna Scientific Cluster 3 (VSC-3) [
34] is used for all simulations. This node has 64 GB main memory and is comprised of two Intel Xeon E5-2660v2 Sandy Bridge EP processors with 10 physical cores on each processor running at 2.20 GHz. Hence, a total of 20 physical and 40 logical cores are available.
4. Conclusions
We have shown that the flux calculation for a multi-material etching simulation of a dielectric layer in the Dual-Damascene process can be accelerated using our recently developed multi-material interface-aware surface evaluation approach. For different surface resolutions and threshold values for the flux difference and the normal angle deviation in our refinement condition for the sparse set, we obtain speedups from 1.9 to 8.0. Our approach introduces minor surface deviations in the surface positions, where the maxima occur inside the vias and are below two grid cells for the highest resolution, corresponding to about 0.6% of the via size. For the lowest resolution, we obtain deviations below 0.7 grid cells which corresponds to 3% of the via size. We evaluated the scalability for a fixed problem size for up to 16 threads, revealing a nearly linear scaling for up to four threads for both the dense and the sparse set approach. Currently, the serial implementation of the iterative partitioning limits the speedup to roughly 50% of the theoretical limit, i.e., the ratio of the size of the dense and sparse set. However, our sparse approach still massively outperforms the conventional approach in terms of execution time. We plan to overcome this limitation by adopting the partitioning scheme to allow for a parallel implementation.
To increase the general applicability of the presented approach, we also aim to support reemitted flux. Either the already existing sparse set is reused and further refined where necessary or a dedicated sparse set is created in each subsequent reemission step. Additionally, it could be an advantage to adapt the refinement condition for the calculation of the reemitted flux distributions.
References

 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
