
Efficient and Reliable Identification of Probabilistic Cloning Attacks in Large-Scale RFID Systems


Abstract
1. Introduction
- We consider a more comprehensive and realistic scenario, where some genuine tags are subjected to probabilistic cloning attacks and there exist missing genuine tags, and develop an efficient and reliable solution to address the compounded detection challenges.
- We propose a block-based tag sorting mechanism that organizes tags into distinct blocks for targeted sequential interrogation, thereby reducing the overhead of repeated parameter and vector broadcasts by the reader.
- We develop a multi-response verification method that uses differentiated interrogation lengths for blocks containing present or missing tags to reduce execution time, and introduces a superposition mechanism for concurrent verification of cloned tags across both block types to improve time efficiency.
- We theoretically analyze and optimize critical parameters to enhance both the identification accuracy and time efficiency of our protocol, validating its performance through extensive numerical experiments.
2. Related Works
2.1. Missing Tag Identification
2.2. Cloning Attack Identification
3. System Model and Problem Formulation
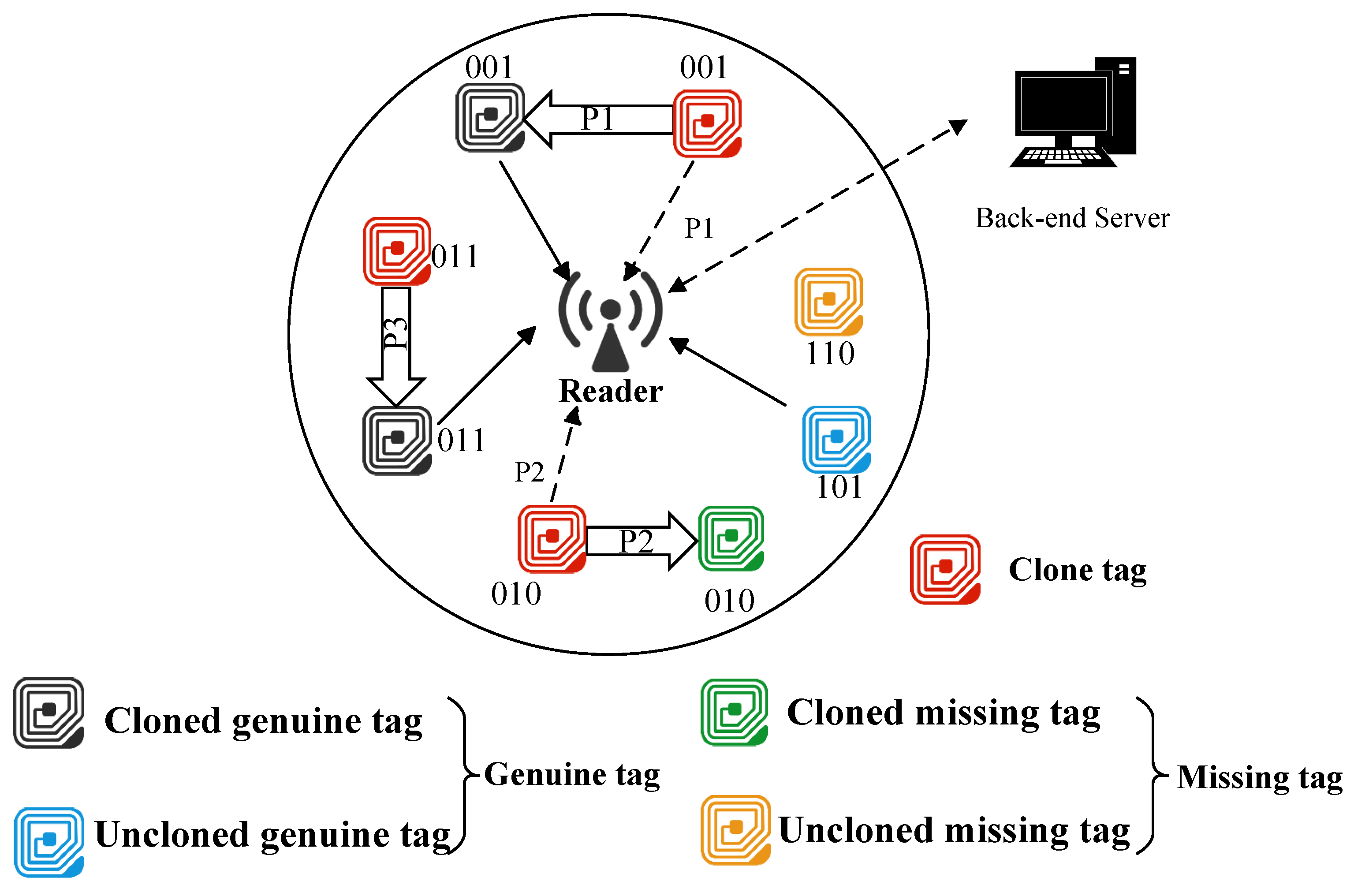
3.1. System Model
- Uncloned genuine tag: The original tag that is legally registered within the system and has not been cloned or removed from the system.
- Cloned genuine tag: The original tag that has been cloned due to the illegal acquisition of key information.
- Uncloned missing tag: The uncloned genuine tag that has been removed from the system’s identification range due to theft or management errors.
- Cloned missing tag: The genuine tag that has been cloned and removed from the system’s identification range.
- Clone tag: An unauthorized entity that copies genuine tag data, posing a security threat via cloning attacks.
3.2. Communication Model
3.3. Attack Model
- 1.
- Probabilistic Attacks: Each cloned genuine tag may be subject to probabilistic attacks from its corresponding clone version, with the attack probability .
- 2.
- Attack Impact: When a genuine tag is queried, its clone version may respond in the same time slot with probability , causing signal collisions that prevent the reader from receiving valid information.
- 3.
- Missing Impact: For a missing tag, the reader receives no response when no cloning attack occurs, but if an attack occurs on a cloned missing tag, the reader will receive data from the clone version with probability .
- 4.
- Attack Uncertainty: The reader lacks prior knowledge of which tags are cloned and the individual attack probabilities of each clone tag. This information gap introduces substantial unpredictability into attack dynamics, complicating the efficient identification of cloned tags.
3.4. Problem Formulation
4. BCTI Protocol Design
4.1. Description of BCTI
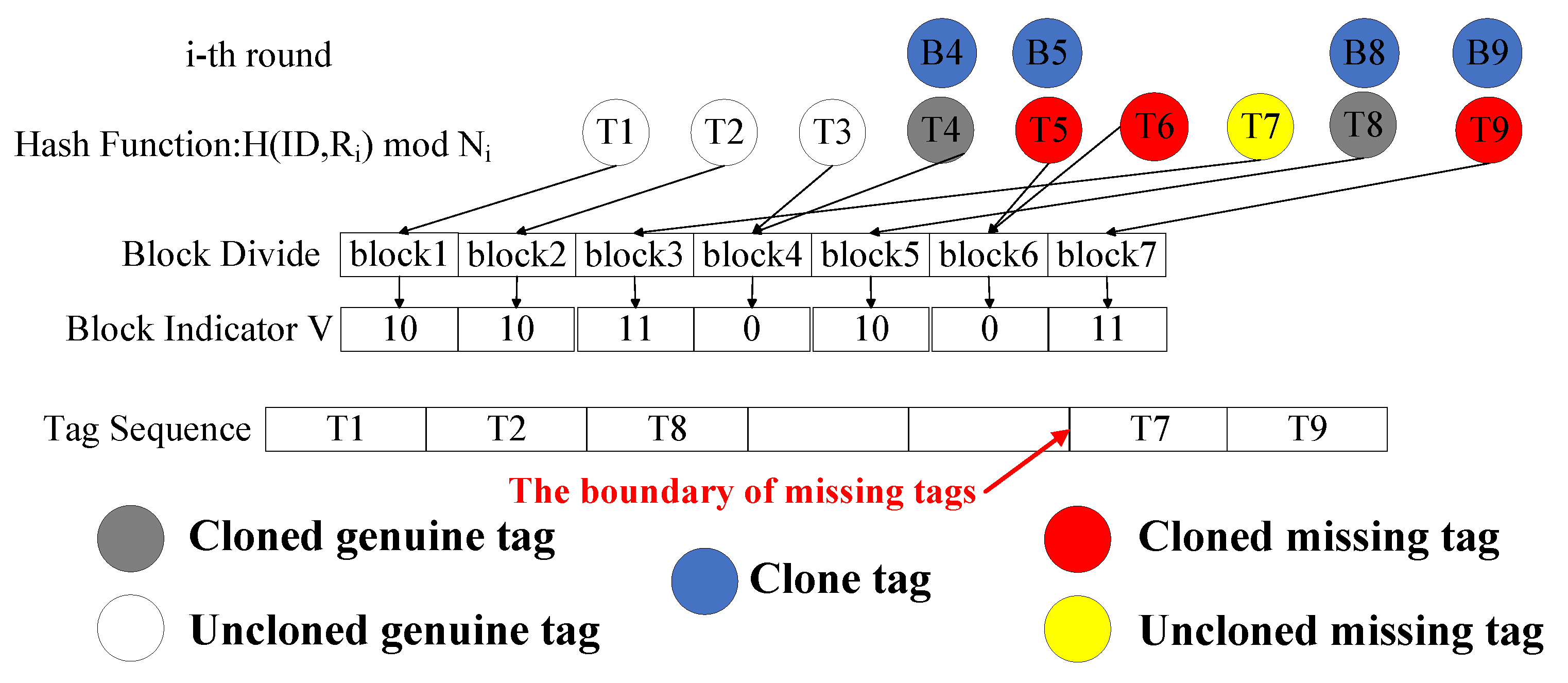
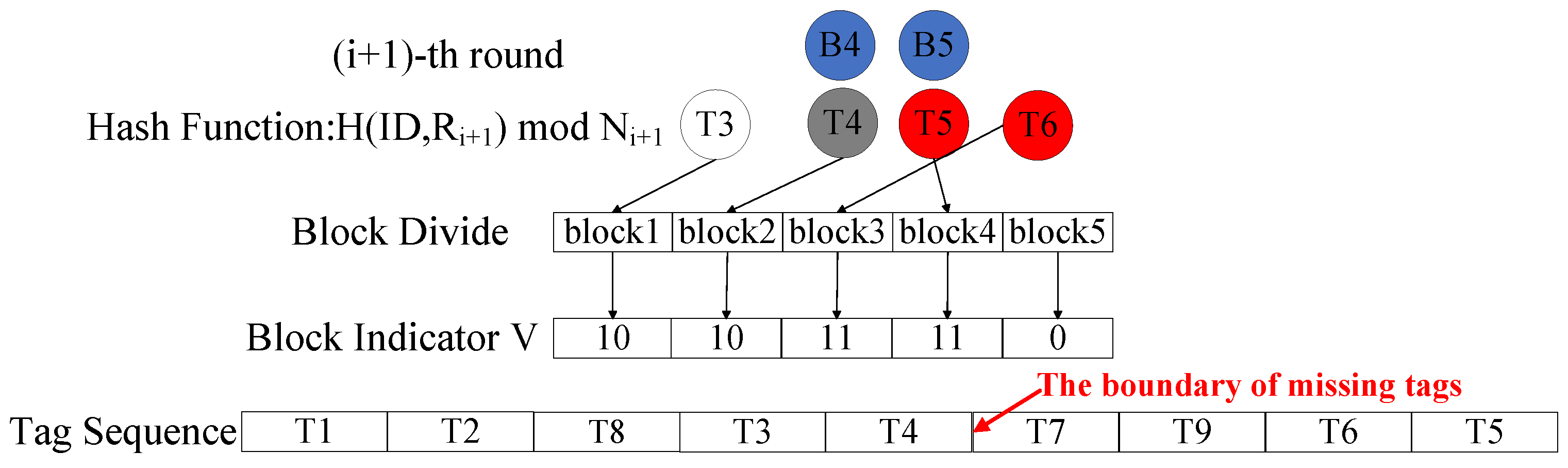
4.1.1. Vector Construction Phase
4.1.2. Tag Sorting Phase
4.1.3. Tag Verification Phase
4.2. Parameter Optimization
4.2.1. Optimal K-Value Analysis
4.2.2. Optimal N-Value Analysis
4.2.3. Superposition Strategy Analysis
5. Performance Evaluation
5.1. Performance Settings
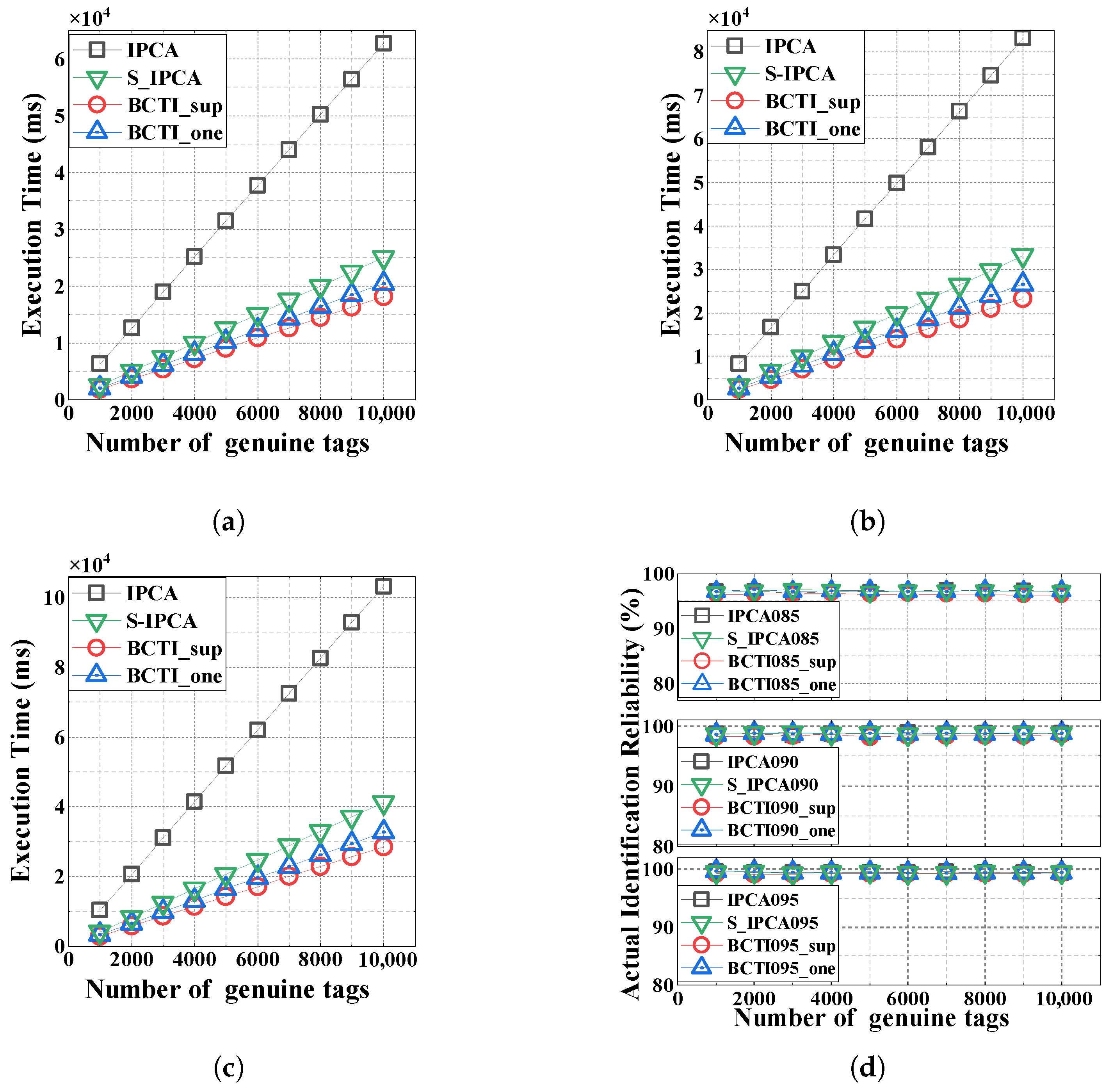
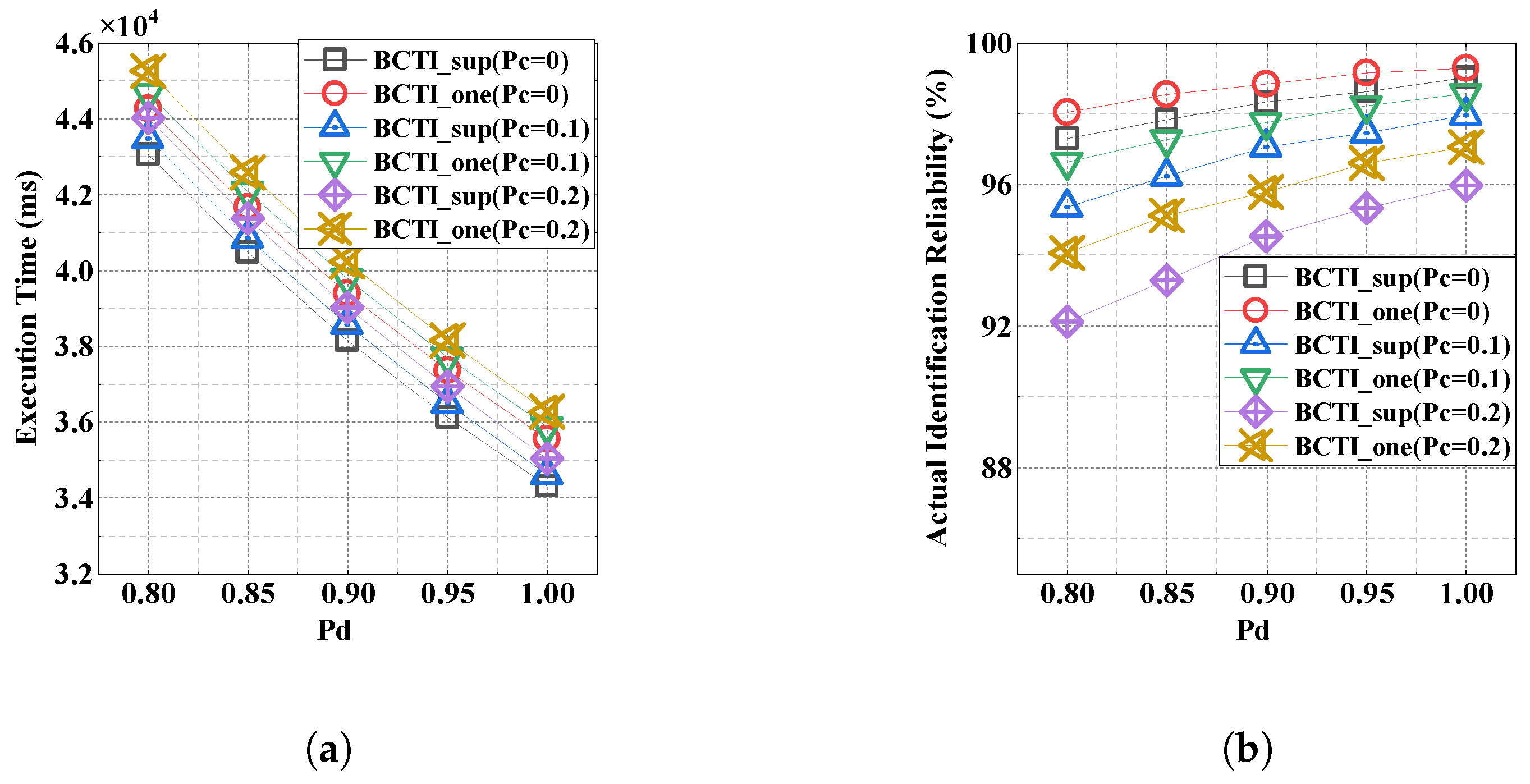
5.2. Impact of Genuine Tags
5.3. Impact of Cloned Tags
5.4. Impact of Missing Tags
5.5. Impact of the Cloning Attack Probability Threshold
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, C.; Tanghe, E.; Suanet, P.; Plets, D.; Hoebeke, J.; De Poorter, E.; Joseph, W. ReLoc 2.0: UHF-RFID Relative Localization for Drone-Based Inventory Management. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Luo, C.; Gil, I.; Fernández-García, R. Electro-Textile UHF-RFID Compression Sensor for Health-Caring Applications. IEEE Sens. J. 2022, 22, 12332–12338. [Google Scholar] [CrossRef]
- Song, Y.; Yu, F.R.; Zhou, L.; Yang, X.; He, Z. Applications of the Internet of Things (IoT) in Smart Logistics: A Comprehensive Survey. IEEE Internet Things J. 2021, 8, 4250–4274. [Google Scholar] [CrossRef]
- Khadka, G.; Ray, B.; Karmakar, N.C.; Choi, J. Physical-Layer Detection and Security of Printed Chipless RFID Tag for Internet of Things Applications. IEEE Internet Things J. 2022, 9, 15714–15724. [Google Scholar] [CrossRef]
- Shen, G.; Zhang, J.; Marshall, A.; Valkama, M.; Cavallaro, J.R. Toward Length-Versatile and Noise-Robust Radio Frequency Fingerprint Identification. IEEE Trans. Inf. Forensics Secur. 2023, 18, 2355–2367. [Google Scholar] [CrossRef]
- Wang, T.; Dai, S.; Liu, Y.; Ye, T.T. Battery-Less Sensing of Body Movements Through Differential Backscattered RFID Signals. IEEE Sens. J. 2022, 22, 8490–8498. [Google Scholar] [CrossRef]
- He, Y.; Zheng, Y.; Jin, M.; Yang, S.; Zheng, X.; Liu, Y. RED: RFID-Based Eccentricity Detection for High-Speed Rotating Machinery. IEEE Trans. Mob. Comput. 2021, 20, 1590–1601. [Google Scholar] [CrossRef]
- Wang, P.; Luo, W.; Shao, Y.; Jin, H. An UHF RFID Circularly Polarized Tag Antenna With Long Read Distance for Metal Objects. IEEE Antennas Wirel. Propag. Lett. 2022, 21, 217–221. [Google Scholar] [CrossRef]
- Yu, H.Y.; Chen, J.J.; Hsiang, T.R. Design and Implementation of a Real-Time Object Location System Based on Passive RFID Tags. IEEE Sens. J. 2015, 15, 5015–5023. [Google Scholar] [CrossRef]
- Bu, K.; Weng, M.; Zheng, Y.; Xiao, B.; Liu, X. You Can Clone But You Cannot Hide: A Survey of Clone Prevention and Detection for RFID. IEEE Commun. Surv. Tutor. 2017, 19, 1682–1700. [Google Scholar] [CrossRef]
- Zhang, B. Securing RFID With GNN: A Real-Time Tag Cloning Attack Detection System. IEEE Open J. Commun. Soc. 2024, 6, 3251–3264. [Google Scholar] [CrossRef]
- Bu, K.; Liu, X.; Luo, J.; Xiao, B.; Wei, G. Unreconciled Collisions Uncover Cloning Attacks in Anonymous RFID Systems. IEEE Trans. Inf. Forensics Secur. 2013, 8, 429–439. [Google Scholar] [CrossRef]
- Liu, X.; Xie, X.; Zhao, X.; Wang, K.; Li, K.; Liu, A.X.; Guo, S.; Wu, J. Fast Identification of Blocked RFID Tags. IEEE Trans. Mob. Comput. 2018, 17, 2041–2054. [Google Scholar] [CrossRef]
- Bu, K.; Liu, X.; Xiao, B. Approaching the time lower bound on cloned-tag identification for large RFID systems. Ad Hoc Netw. 2014, 13, 271–281. [Google Scholar] [CrossRef]
- Bu, K.; Xu, M.; Liu, X.; Luo, J.; Zhang, S.; Weng, M. Deterministic Detection of Cloning Attacks for Anonymous RFID Systems. IEEE Trans. Ind. Inform. 2015, 11, 1255–1266. [Google Scholar] [CrossRef]
- Huang, J.; Li, X.; Xing, C.-C.; Wang, W.; Hua, K.; Guo, S. DTD: A Novel Double-Track Approach to Clone Detection for RFID-Enabled Supply Chains. IEEE Trans. Emerg. Top. Comput. 2017, 5, 134–140. [Google Scholar] [CrossRef]
- Chen, H.; Ai, X.; Lin, K.; Yan, N.; Wang, Z.; Jiang, N.; Yu, J. DAP: Efficient Detection Against Probabilistic Cloning Attacks in Anonymous RFID Systems. IEEE Trans. Ind. Inform. 2022, 18, 345–355. [Google Scholar] [CrossRef]
- Wang, X.; Liu, J.; Wang, Y.; Chen, X.; Chen, L. Efficient missing tag identification in blocker-enabled RFID systems. Comput. Netw. 2019, 164, 106894. [Google Scholar] [CrossRef]
- Ţiplea, F.L.; Hristea, C. PUF Protected Variables: A Solution to RFID Security and Privacy Under Corruption With Temporary State Disclosure. IEEE Trans. Inf. Forensics Secur. 2021, 16, 999–1013. [Google Scholar] [CrossRef]
- Shi, J.; Kywe, S.M.; Li, Y. Batch Clone Detection in RFID-enabled supply chain. In Proceedings of the 2014 IEEE International Conference on RFID (IEEE RFID), Orlando, FL, USA, 8–10 April 2014; pp. 118–125. [Google Scholar] [CrossRef]
- Liu, X.; Li, K.; Min, G.; Shen, Y.; Liu, A.X.; Qu, W. Completely Pinpointing the Missing RFID Tags in a Time-Efficient Way. IEEE Trans. Comput. 2015, 64, 87–96. [Google Scholar] [CrossRef]
- Lin, K.; Chen, H.; Yan, N.; Li, Z.; Li, J.; Jiangz, N. Fast and Reliable Missing Tag Detection for Multiple-Group RFID Systems. IEEE Trans. Ind. Inform. 2022, 18, 2656–2664. [Google Scholar] [CrossRef]
- Zhong, D.; Zhou, J.; Liu, G.; Kaur, M.; Li, R.; Singh, D. Missing Unknown Tag Identification Protocol Based on Priority Strategy in Battery-Less RFID System. IEEE Sens. J. 2023, 23, 20845–20855. [Google Scholar] [CrossRef]
- Yin, J.; Xie, X.; Mao, H.; Guo, S. Efficient Missing Key Tag Identification in Large-Scale RFID Systems: An Iterative Verification and Selection Method. IEEE Trans. Mob. Comput. 2025, 24, 2253–2269. [Google Scholar] [CrossRef]
- Wang, F.; Xiao, B.; Bu, K.; Su, J. Detect and identify blocker tags in tree-based RFID systems. In Proceedings of the 2013 IEEE International Conference on Communications (ICC), Budapest, Hungary, 9–13 June 2013; pp. 2133–2137. [Google Scholar] [CrossRef]
- Ai, X.; Chen, H.; Lin, K.; Wang, Z.; Yu, J. Nowhere to Hide: Efficiently Identifying Probabilistic Cloning Attacks in Large-Scale RFID Systems. IEEE Trans. Inf. Forensics Secur. 2021, 16, 714–727. [Google Scholar] [CrossRef]
- EPCglobal. EPC Radio-Frequency Identity Protocols Class-1 Generation-2 UHF RFID Protocol for Communications at 860 MHz–960 MHz; EPCglobal Inc.: Washington, DC, USA, 2008; Version 1.2.0. [Google Scholar]
- Li, T.; Chen, S.; Ling, Y. Efficient Protocols for Identifying the Missing Tags in a Large RFID System. IEEE/ACM Trans. Netw. 2013, 21, 1974–1987. [Google Scholar] [CrossRef]
- Luo, W.; Chen, S.; Qiao, Y.; Li, T. Missing-Tag Detection and Energy–Time Tradeoff in Large-Scale RFID Systems With Unreliable Channels. IEEE/Acm Trans. Netw. 2014, 22, 1079–1091. [Google Scholar] [CrossRef]
- Zhang, R.; Liu, Y.; Zhang, Y.; Sun, J. Fast identification of the missing tags in a large RFID system. In Proceedings of the 2011 8th Annual IEEE Communications Society Conference on Sensor, Mesh and Ad Hoc Communications and Networks, Salt Lake City, UT, USA, 27–30 June 2011; pp. 278–286. [Google Scholar] [CrossRef]
- Zhang, L.; Xiang, W.; Tang, X.; Li, Q.; Yan, Q. A Time- and Energy-Aware Collision Tree Protocol for Efficient Large-Scale RFID Tag Identification. IEEE Trans. Ind. Inform. 2018, 14, 2406–2417. [Google Scholar] [CrossRef]
- Griffin, J.D.; Durgin, G.D. Gains For RF Tags Using Multiple Antennas. IEEE Trans. Antennas Propag. 2008, 56, 563–570. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| The set of genuine tags/cloned genuine tags/missing tags | |
| The number of blocks in the i-th round | |
| The number of unassigned genuine tags in the i-th round | |
| Required identification reliability | |
| The attack probability of each clone tag | |
| The attack probability threshold | |
| V | The block indicator |
| The maximum number of verifications for tags in each block | |
| The broadcast time of the reader in the i-th round |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chu, C.; Wang, R.; Deng, N.; Li, G. Efficient and Reliable Identification of Probabilistic Cloning Attacks in Large-Scale RFID Systems. Micromachines 2025, 16, 894. https://doi.org/10.3390/mi16080894
Chu C, Wang R, Deng N, Li G. Efficient and Reliable Identification of Probabilistic Cloning Attacks in Large-Scale RFID Systems. Micromachines. 2025; 16(8):894. https://doi.org/10.3390/mi16080894
Chicago/Turabian StyleChu, Chu, Rui Wang, Nanbing Deng, and Gang Li. 2025. "Efficient and Reliable Identification of Probabilistic Cloning Attacks in Large-Scale RFID Systems" Micromachines 16, no. 8: 894. https://doi.org/10.3390/mi16080894
APA StyleChu, C., Wang, R., Deng, N., & Li, G. (2025). Efficient and Reliable Identification of Probabilistic Cloning Attacks in Large-Scale RFID Systems. Micromachines, 16(8), 894. https://doi.org/10.3390/mi16080894