1. Introduction
Power electronic systems are fundamental components in energy conversion and control, where the reliability of power devices is critical to the overall system performance. Among them, the Insulated Gate Bipolar Transistor (IGBT) has become one of the most widely used power semiconductor devices due to its high input impedance and low on-state voltage drop [
1]. In smart grids, IGBTs act as core switching elements in inverter topologies, motor drive systems, and high-voltage direct current (HVDC) transmission systems for energy regulation [
2,
3]. In new energy vehicle powertrains, IGBTs are integrated into the motor control unit to realize power conversion functionalities [
4]. In renewable energy applications, IGBTs significantly enhance the energy conversion efficiency of wind power converters and photovoltaic inverters by optimizing switching loss characteristics [
5].
However, due to continuous operation under extreme conditions such as high temperature, high voltage, and high current, the IGBTs’ reliability issues have become increasingly prominent, posing a critical challenge to extending the system lifespan and improving the overall performance. According to relevant statistical data, IGBT failures are among the leading causes of power electronic system malfunctions [
6,
7]. Therefore, conducting reliability assessments and lifetime predictions of IGBTs is of significant engineering importance and application value.
Prognostics and Health Management (PHM) technology is a systematic engineering methodology that combines signal processing and data analysis techniques [
8]. Applying PHM techniques to power electronic devices allows for a systematic and efficient assessment of the device reliability. In recent years, PHM-based reliability research on power electronic devices has emerged as a significant research focus. Based on the PHM framework, this paper conducts a failure prediction of IGBTs, explicitly focusing on estimating their remaining useful life (RUL).
Existing studies on IGBT failure prediction can broadly be classified into physics-based and data-driven modeling. The former investigates the theoretical basis of the degradation process through specific mathematical formulations, typically requiring the assumption that dynamic systems can be precisely modeled and requiring extensive expertise in degradation mechanisms [
9]. However, the highly nonlinear nature of complex systems and the diversity of failure modes significantly constrain the practical application of physics-based methods. Consequently, driven by advancements in data acquisition and processing technologies, data-driven methods have emerged as the mainstream approach in fault prediction research [
10].
Common data-driven fault prediction models include statistical models, including Particle Filtering [
11,
12], Markov Process [
13], Gaussian Process Regression [
14], and Kalman Filter [
15,
16]; machine learning models, such as Support Vector Machine (SVM) [
17], Convolutional Neural Network (CNN) [
18], Decision Tree, and K-Nearest Neighbors (KNN) [
19,
20]; deep learning models, including Recurrent Neural Network (RNN) [
21], Long Short-Term Memory (LSTM) [
22,
23,
24], and Transformer-based models [
9]. Although these methods have achieved notable progress, they still exhibit several limitations. Statistical models typically rely on strong prior assumptions, restricting their performance when dealing with high-dimensional, nonlinear degradation data. Machine learning models heavily depend on manual feature extraction and selection and often struggle to capture complex temporal dependencies.
Recent research on IGBT fault prediction has mainly focused on improving classical deep learning models through structure fusion, optimization algorithms, and uncertainty modeling to enhance the prediction accuracy and robustness. One common approach is model fusion to strengthen the feature representation. For example, refs. [
25,
26] combined CNN with LSTM or Transformer to leverage CNN’s local feature extraction. However, such combinations often increase the model complexity and risk overfitting due to the growing number of parameters. In [
27], a stacked denoising autoencoder (SDAE) was integrated with LSTM to enhance the data quality via denoising, thereby improving the prediction performance. Nevertheless, this method is sensitive to noise-handling parameters and less stable during training. Some works adopted intelligent optimization algorithms—such as dung beetle optimization (DBO) [
28], particle swarm optimization (PSO) [
29], improved sparrow search algorithm (ISSA) [
30], and sailfish optimization (SFO) [
31]—to tune hyperparameters and model structures. Although these methods offer performance gains, they tend to rely on prior experience and are prone to local optima, which may affect the stability and generalization. For uncertainty modeling, refs. [
9,
32] applied Monte Carlo Dropout to LSTM and Transformer, enabling the quantification of output uncertainty. This improves the robustness and interpretability but increases the training and inference costs. Bidirectional temporal models like Bi-GRU [
33] and BiLSTM [
34] capture both forward and backward dependencies, slightly improving the prediction accuracy. However, their enhancements over unidirectional models are often limited and may not justify the increased structural complexity.
While deep learning models have demonstrated remarkable capabilities in prediction, they still face the following challenges:
(a) Feature extraction and data processing: The raw accelerated aging experimental data often contain substantial redundant information. Directly feeding such data into prediction models can hinder effective fault feature extraction, leading to reduced prediction accuracy and increased computational burden. Therefore, the appropriate data preprocessing and feature extraction methods are required to provide high-quality inputs for subsequent fault prediction tasks.
(b) Model robustness and generalization: Deep learning models are susceptible to data distribution shifts under complex operating conditions, resulting in potential overfitting or underfitting in fault prediction. Conventional neural networks typically employ fixed activation functions (e.g., ReLU, SiLu), which lack the adaptability to varying data distributions, particularly during the early stages of device aging or under rapidly changing operating conditions, leading to a decline in the prediction accuracy.
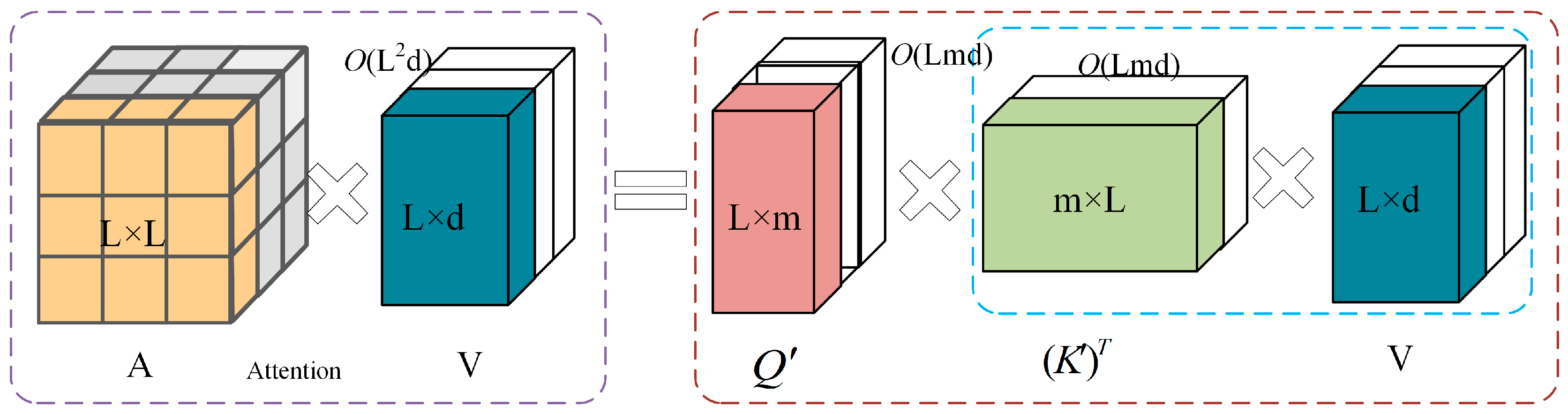
(c) Balancing prediction accuracy and computational efficiency: Transformer models exhibit superior performance in capturing global dependencies over long time series through self-attention mechanisms. However, their computational complexity scales quadratically with the sequence length (O(n2)). Furthermore, achieving an optimal performance often requires stacking multiple layers with hundreds of millions of parameters, imposing significant demands on the computational resources and training data. These challenges limit the direct application of standard Transformer models to large-scale IGBT fault prediction tasks. Thus, reducing the computational complexity while maintaining prediction accuracy remains an open problem.
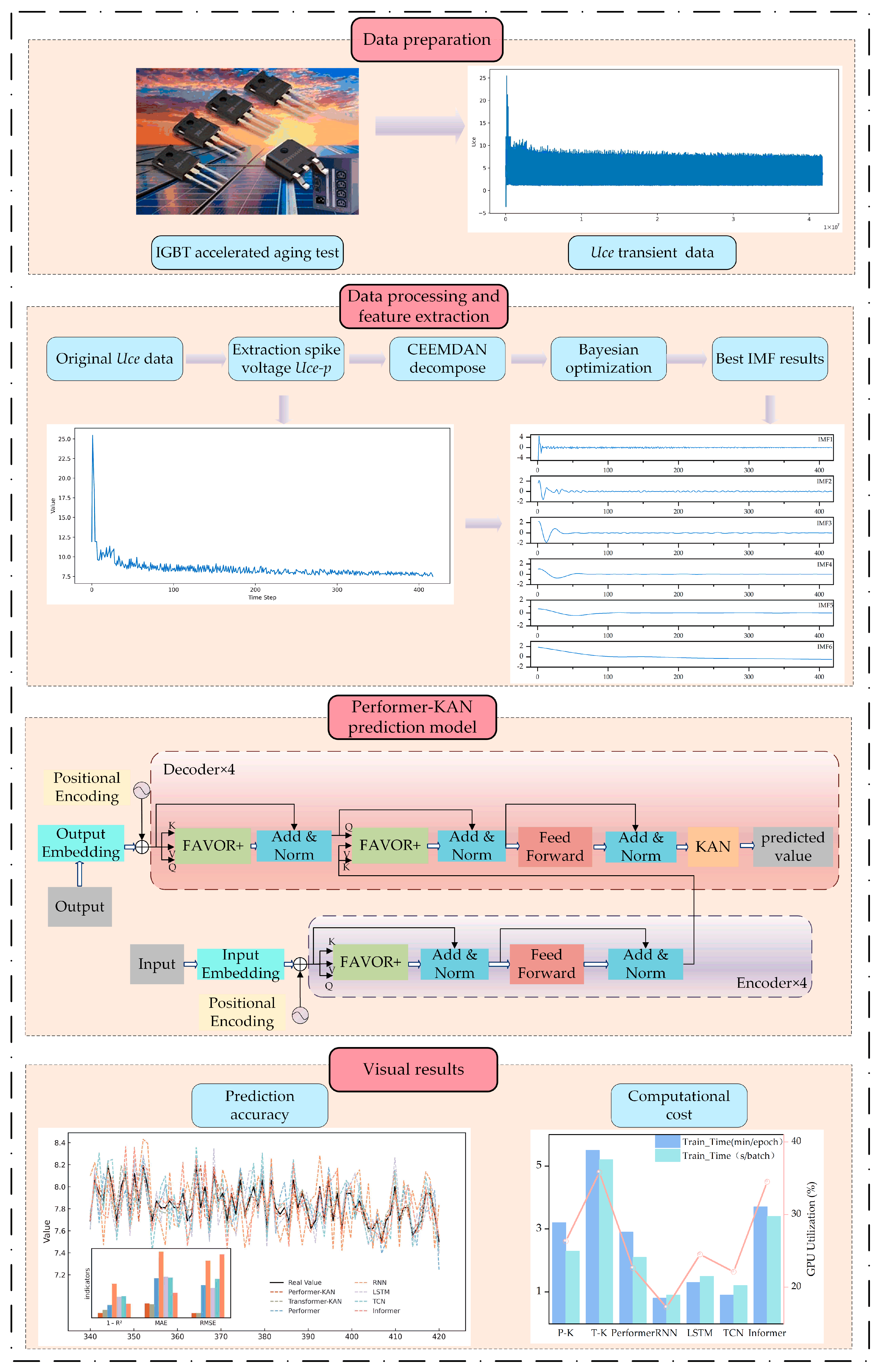
Inspired by the challenges above, this paper proposes a Performer-based IGBT fault prediction method that, for the first time, combines the Performer architecture with the Kolmogorov–Arnold Network (KAN) and applies it to IGBT fault prediction tasks. The overall technical procedure is illustrated in
Figure 1.
To solve the limitation (a), the adaptive noise complete ensemble empirical mode decomposition (CEEMDAN) technique is introduced to decompose the original accelerated aging experimental data into multiple Intrinsic Mode Functions (IMFs) across different frequency bands, thereby enabling the efficient extraction of key fault features and providing high-quality data support for subsequent model construction. To solve the limitation (b), the KAN is incorporated as the fundamental network module, employing Spline Activation Functions to replace the fixed activation functions commonly used in traditional neural networks. This design improves the nonlinear approximation capacity while reducing the model complexity, reducing the risk of overfitting, improving the generalization ability, and enhancing the adaptability to complex degradation patterns. To solve the limitation (c), the proposed method adopts the FAVOR+ (Fast Attention Via positive Orthogonal Random features) mechanism within the Performer framework, which utilizes orthogonal random feature mapping to approximate Softmax attention. This approach reduces the computational complexity of the attention mechanism from O(n2) to O(n), significantly improving the computational efficiency and reducing the memory consumption, making it more suitable for large-scale IGBT fault prediction applications.
The main highlights of the proposed method are summarized as follows:
(1) The original signal is decomposed using the CEEMDAN technique, and Bayesian optimization is employed to adjust the key parameters, thereby automatically minimizing the signal reconstruction error. The best IMF sequences obtained will provide higher-quality input features for subsequent modeling.
(2) First attempt to design a Performer-based prognostic framework with the KAN to enhance the model’s generalization capability through trainable spline-based activation functions, enabling effective adaptation to varying data distributions under different operating conditions.
(3) The FAVOR+ mechanism is introduced to reduce the attention module’s computational complexity from O(n2) to O(n) while maintaining high prediction accuracy, thereby improving computational performance and scalability for large-scale IGBT fault prediction tasks.
2. Selection of IGBT Failure Precursor Parameters and Feature Extraction
2.1. IGBT Failure Parameter Selection
Common IGBT fault parameters include collector current (
IC), gate-emitter threshold voltage (
Uge,th), collector-emitter voltage (
Uce), and turn-on/turn-off time (
ton/toff) [
35]. This paper systematically analyzes and identifies the most suitable precursor parameters for failure prediction, based on failure mechanisms and accelerated aging experimental data.
Abnormal IC increases may result from load short circuits, drive signal faults, or parasitic conduction. Latch-up conduction of internal parasitic thyristors can also trigger sudden IC surges. The IC responds rapidly to transient faults such as short circuits and overcurrents but is susceptible to disturbances from load fluctuations; under normal conditions, the IC typically varies with load changes.
The gate-emitter threshold voltage (Uge,th) reflects degradation phenomena such as gate oxide deterioration and gate drive circuit failures and may exhibit drift, reduction, or abnormal fluctuations. Nevertheless, the Uge,th is sensitive to temperature and voltage stresses, and environmental variations can destabilize measurements, affecting the fault detection reliability. Variations in drive resistance or capacitance parameters can also prolong ton/toff. During normal aging processes, the Uce gradually increases, due to rising internal parasitic resistance, a shortened carrier lifetime, and increased package thermal resistance. In cases of packaging failure, an increase in the Equivalent Series Resistance (ESR) directly elevates the steady-state value of the Uce. In contrast, chip failures (e.g., gate oxide breakdown) induce transient Uce aberrations through carrier concentration fluctuations. In summary, the Uce can comprehensively reflect multiple types of IGBT failure modes.
During the early stage of this study, the parameters mentioned above were considered for failure prediction. However, further analysis and preliminary experiments showed that the IC showed poor stability and was highly sensitive to load fluctuations, which introduced noise and reduced its reliability. The measurement of ton/toff was relatively complex and difficult to standardize, making the accuracy of timing-based features difficult to ensure across different experimental conditions. The Uge,th displayed a limited sensitivity to degradation and was not effective in signaling early fault trends. In contrast, the Uce provided a good balance between sensitivity and measurement feasibility. It was easy to acquire using standard probes, demonstrated stable performance under varying conditions, and involved a low measurement cost. Therefore, this paper selects the Uce as the core parameter for IGBT failure prediction.
The natural aging IGBT experiment is usually not a feasible solution because collecting all source materials from such a long failing time is nearly impossible. Accelerated aging tests shorten the experimental duration by artificially increasing the operational stress or workload without altering the failure mechanisms. NASA provides an open-access database containing datasets from accelerated aging experiments, recording several IGBT characteristic parameters, including transient and steady-state data. Transient data captures rapid dynamic changes during system state transitions, characterized by high-frequency oscillations, focusing on switching processes, dynamic responses, and transient behaviors. In contrast, steady-state data are measured after the system stabilization and reflect long-term operational characteristics, thermal stability, and aging effects.
In the accelerated aging experiment, the tested IGBT was an IRF-G4BC30KD device(Infineon Technologies AG, Neubiberg, Germany) with a TO-220 package, a rated voltage of 600 V, and a rated current of 15 A. To enhance the thermal stress and accelerate the degradation process, no heat sink was applied during the experiment. A PWM gate drive signal with a frequency of 10 kHz and a duty cycle of 40% was continuously applied to the IGBT. Accelerated aging was achieved through thermal cycling, where the gate signal was disabled when the device temperature exceeded 330 °C and re-enabled when the temperature dropped below 329 °C, forming an automatic feedback loop. The protection temperature was set to 345 °C. The IGBT failed after 418 complete switching cycles, with 100,000 high-resolution transient data points collected per cycle for subsequent degradation analysis and feature extraction.
However, IGBTs undergo frequent turn-on and turn-off operations as power devices, where transient voltages, current spikes, and rapid junction temperature variations often trigger failures. Therefore, this study selects transient data as the research focus and employs it as failure parameters for IGBT lifetime prediction. The transient dataset records 418 switching process parameter groups, each containing 100,000 sampling points.
These 418 groups of switching process data were all obtained from the same IGBT device, which was subjected to continuous thermal-electrical stress during the accelerated aging test. Each group corresponds to a complete PWM-controlled switching cycle, capturing voltage and current behaviors within a single period. As the aging progressed, the sequential cycles reflected the gradual degradation of the same device, providing a continuous dataset that enables the model to learn the entire failure evolution process.
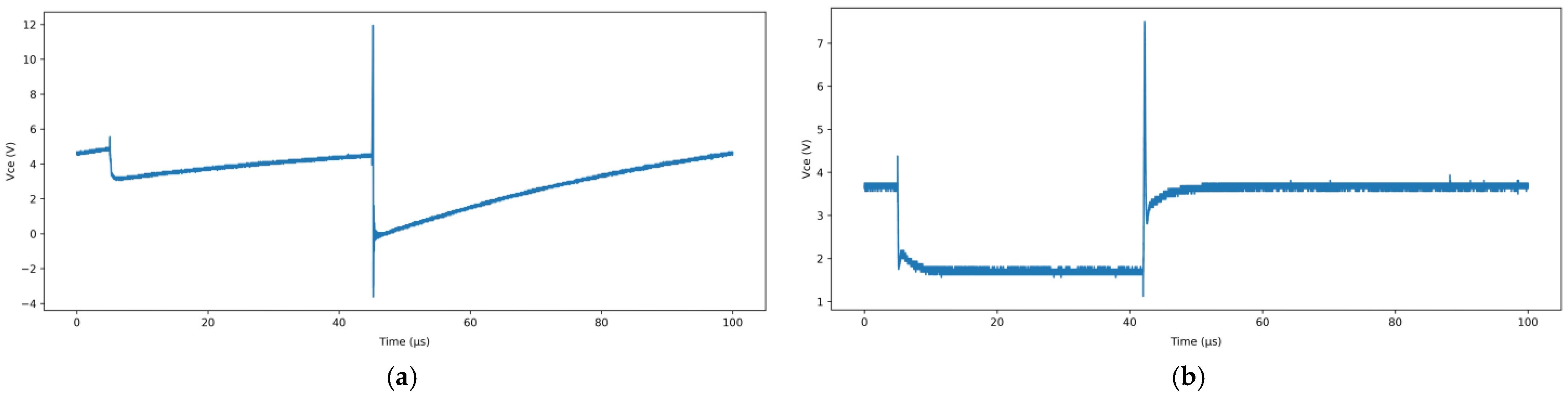
Figure 2a presents the variation of the
Uce during the first switching cycle, while
Figure 2b presents the variation during the final switching cycle before the device failure. It can be observed that in the early stages of the accelerated aging progression, the
Uce exhibits relatively stable behavior. In contrast, during the later stages, the fluctuation amplitude of
Uce increases significantly, revealing clear signs of degradation, which indicates a substantial decline in the IGBT performance.
A large volume of Uce data was collected in the accelerated aging experiments, reaching specific sampling points. Direct processing of such high-dimensional data faces two significant challenges: a high proportion of redundant information leads to exponential growth in computation, and signal noise coupled with parameter interactions mask potential fault features, hindering the efficient extraction of sensitive degradation indicators by traditional time- and frequency-domain methods. Therefore, further screening of the raw data is necessary to optimize the fault prediction model’s training efficiency and generalization ability.
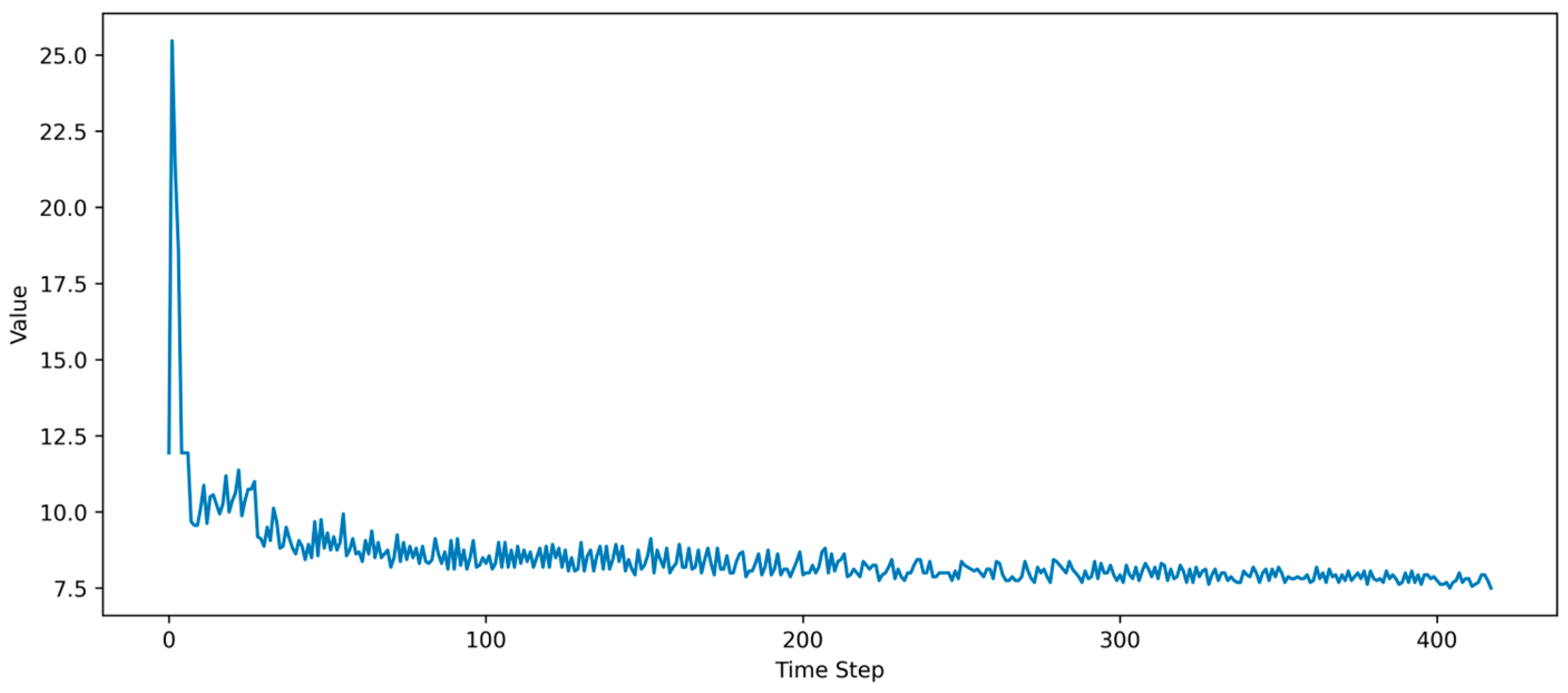
During the continuous turn-on and turn-off cycles under the combined influence of the PWM signals and temperature thresholds, parasitic transistors inhibit the growth of the anode current during the turn-off phase, generating a transient voltage between the collector and emitter, aligned with the supply voltage. This transient is superimposed on the supply voltage, forming a spike voltage higher than the supply voltage, referred to as the collector-emitter transient spike voltage (
Uce-p). The decay waveform of the collector-emitter turn-off transient spike voltage is shown in
Figure 3. As the IGBT ages, the
Uce-p amplitude gradually decays and stabilizes before the complete device failure.
2.2. Bo-CEEMDAN-Based Failure Feature Extraction
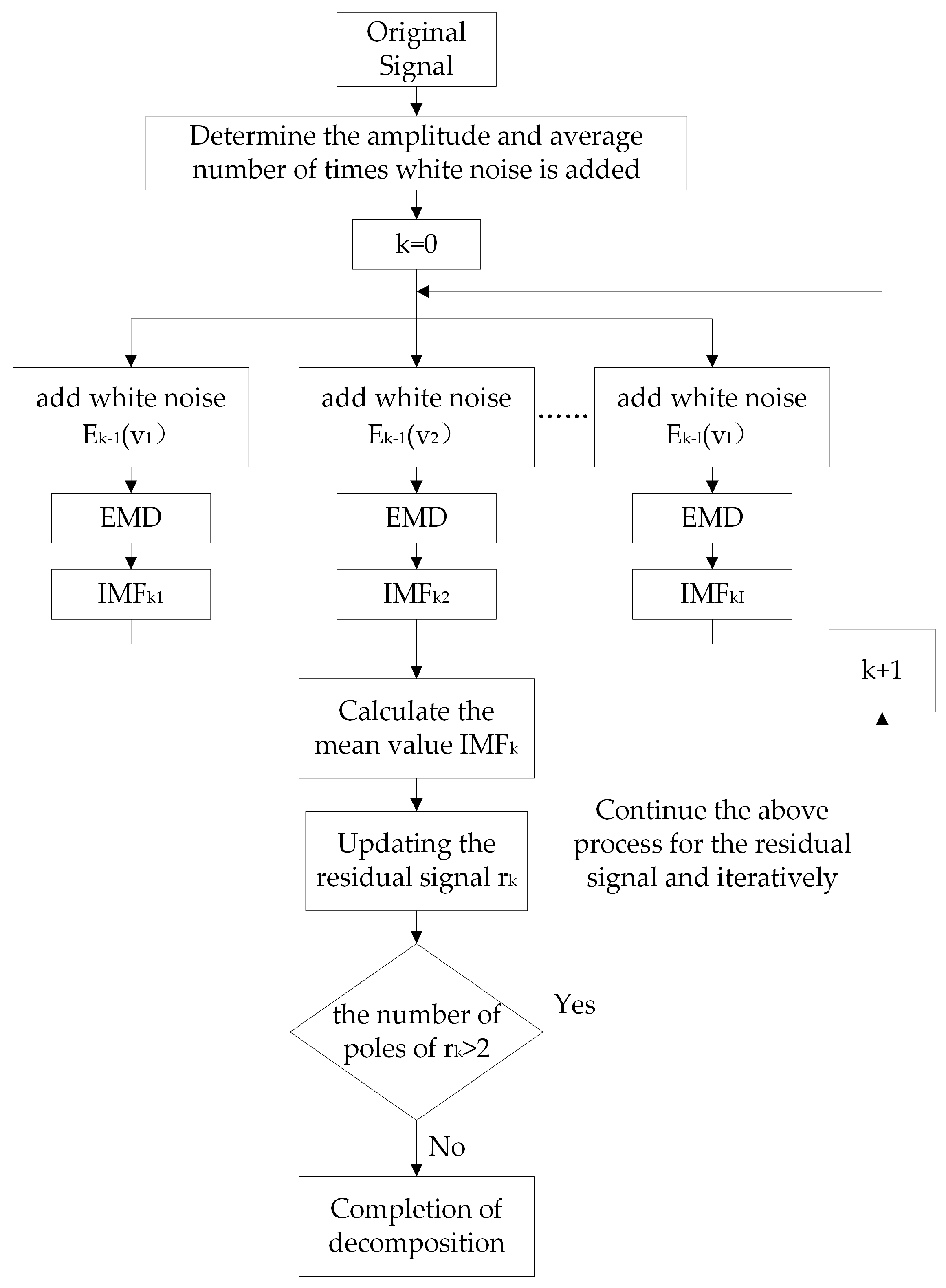
CEEMDAN decomposes an original time series into subsequences of different frequencies, known as IMFs [
36]. The underlying Empirical Mode Decomposition (EMD) method utilizes the data’s intrinsic time-scale characteristics for modal decomposition, making it suitable for non-stationary and nonlinear time series analysis. Building on this, CEEMDAN gradually adds adaptive white noise at each iteration to mitigate noise interference in the decomposition process. CEEMDAN achieves a near-zero reconstruction error with fewer ensemble runs, significantly alleviates modal aliasing, and improves the decomposition and reconstruction accuracy. It also avoids the computational inefficiency of EEMD, which requires many integrations to reduce the reconstruction error.
The algorithm flowchart of CEEMDAN is illustrated in
Figure 4. For a given sequence of original signals
x(
t), construct
i signals after adding noise, where
vi(
t) is a sequence of white noise with standard normal distribution added in the ith experiment (mean zero, variance 1), is a tuning parameter of the noise amplitude, and
I denotes the number of experiments. The obtained noise signal is expressed as:
EMD decomposition is employed, and the resulting IMFs are averaged to extract the kth-order IMF component. The extracted IMF is then removed , and the decomposition process is repeated on the remaining residual signals until the residuals become monotonic functions or approach zero, at which point further decomposition is not possible. The process concludes with the extraction of the complete set of IMF components.
The formula for the IMF and residual signals is given in Equations (2) and (3).
The CEEMDAN decomposition involves two key parameters: the noise amplitude and the number of integrations. The former determines the intensity of the added perturbation signal, while the latter controls the number of averaged samples. Since both parameters significantly influence the decomposition quality, this study adopts Bayesian Optimization (BO) based on Gaussian Process Regression (GPR) to identify their optimal combination by minimizing the signal reconstruction error [
37]. The objective function is defined as the mean squared error (MSE) between the reconstructed and original signals:
where
denotes the original signal,
denotes the signal obtained from IMF reconstruction, and
N is the data length. To perform parameter optimization, this paper further defines the parameters to be tuned and their search space, where
denotes the noise amplitude and
K denotes the number of integrations.
GPR is used to approximate this function, employing a Radial Basis Function (RBF) kernel to construct the covariance matrix and predict the mean and variance for any parameter combination. To balance exploration and exploitation, the acquisition function guides the selection of the following evaluation point. In this work, the Expected Improvement (EI) criterion is adopted, with the current best MSE denoted as
.
The model is iteratively trained and evaluated based on selected parameter sets. After each update, the objective function values are recalculated and the GPR model is refined. This process continues until a predefined number of iterations is reached; at this point, the optimal parameters are used for the final CEEMDAN decomposition.
In this study, the previously extracted
Uce-p is decomposed using CEEMDAN with the optimized parameters. The decomposition performance is evaluated by the MSE between the reconstructed and original signals, and the results are presented in
Table 1.
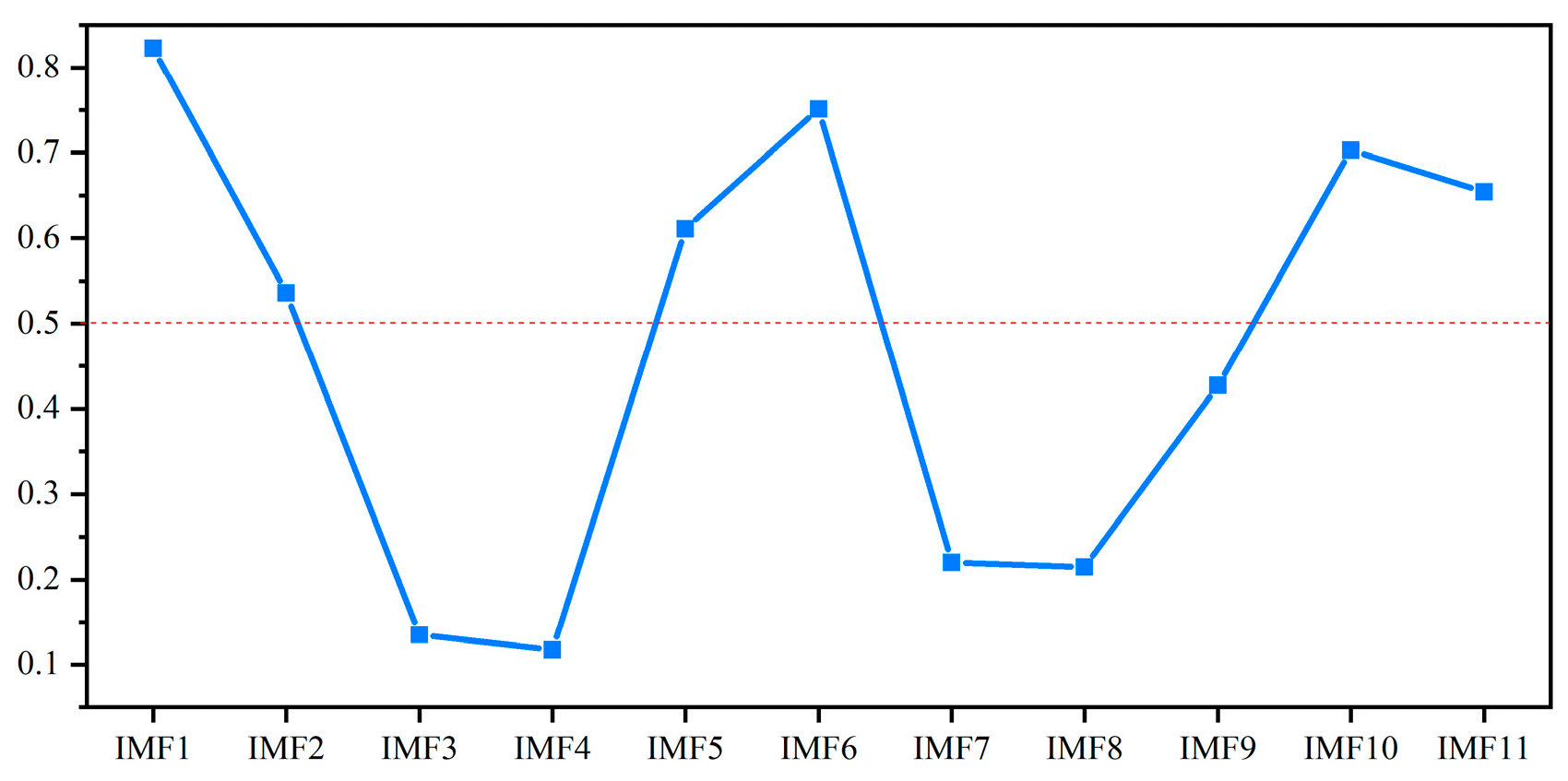
To identify the informative components and eliminate the noise, the Pearson Correlation Coefficient (PCC) is introduced to assess the linear correlation between each IMF and the original signal [
38]. The PCC values range from −1 to 1, where values above 0.5 indicate a meaningful correlation, and it can be expressed as:
Accordingly, 0.5 is the threshold for selecting the relevant IMFs from the 11 extracted components [
39]. As shown in
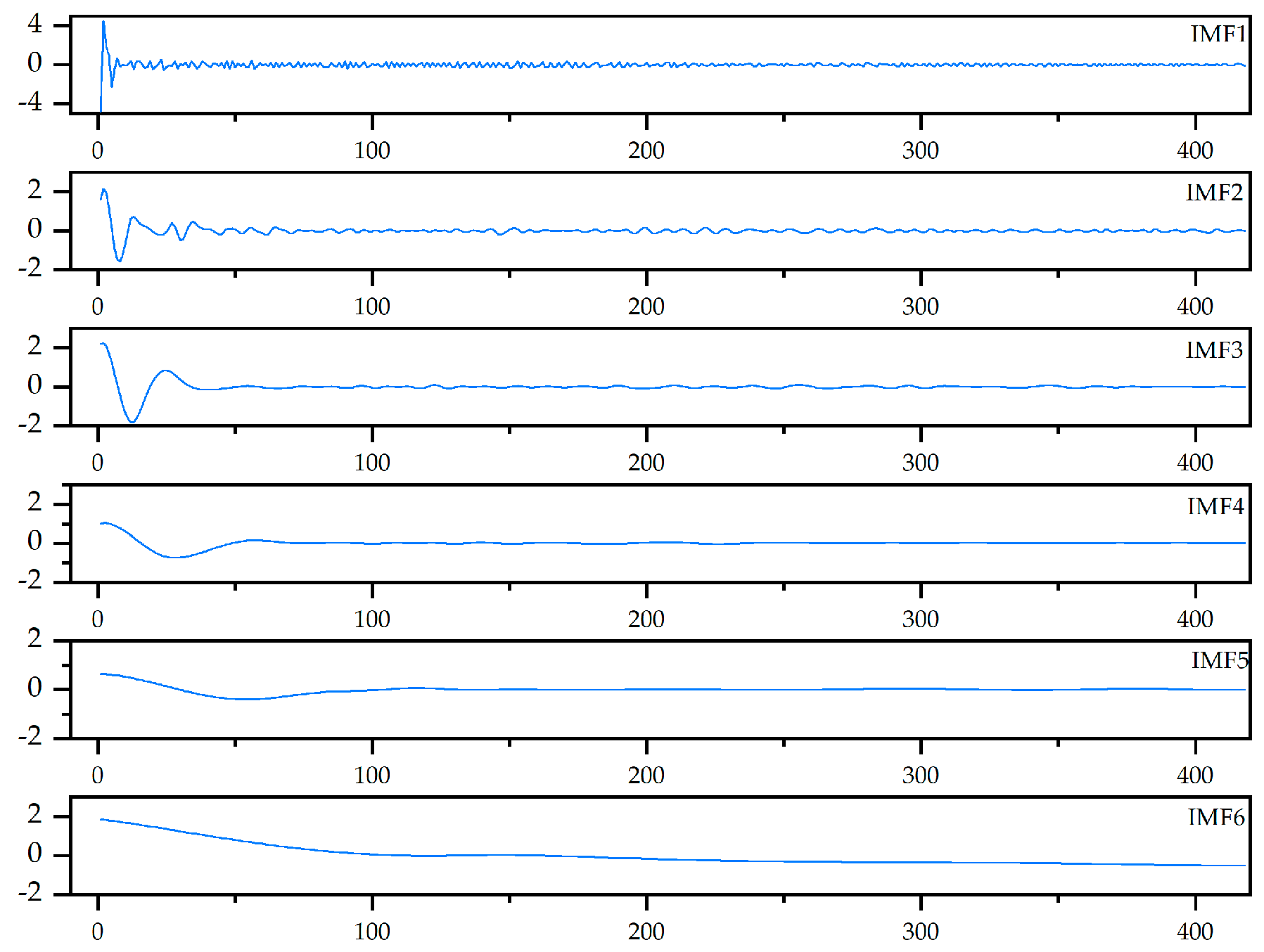
Figure 5, the six IMFs exhibit strong correlation, suggesting that they capture dominant signal features. The remaining IMFs likely contain noise or low-frequency drift. These six IMF components are selected to construct the fault feature vector for subsequent model training and prediction, as illustrated in
Figure 6.
4. Experimental Results and Analysis
Experiments were conducted on the extracted fault parameter sequences to validate the applicability and effectiveness of the proposed model. The dataset was divided into a training set (80%) and a testing set (20%). In addition, several classical time-series prediction models and Transformer-based variants were introduced for comparison. This allows for a comprehensive evaluation of the Performer-KAN model in terms of both the prediction accuracy and computational efficiency.
4.1. Analysis of IGBT Fault Prediction Results Based on Performer-KAN Modeling
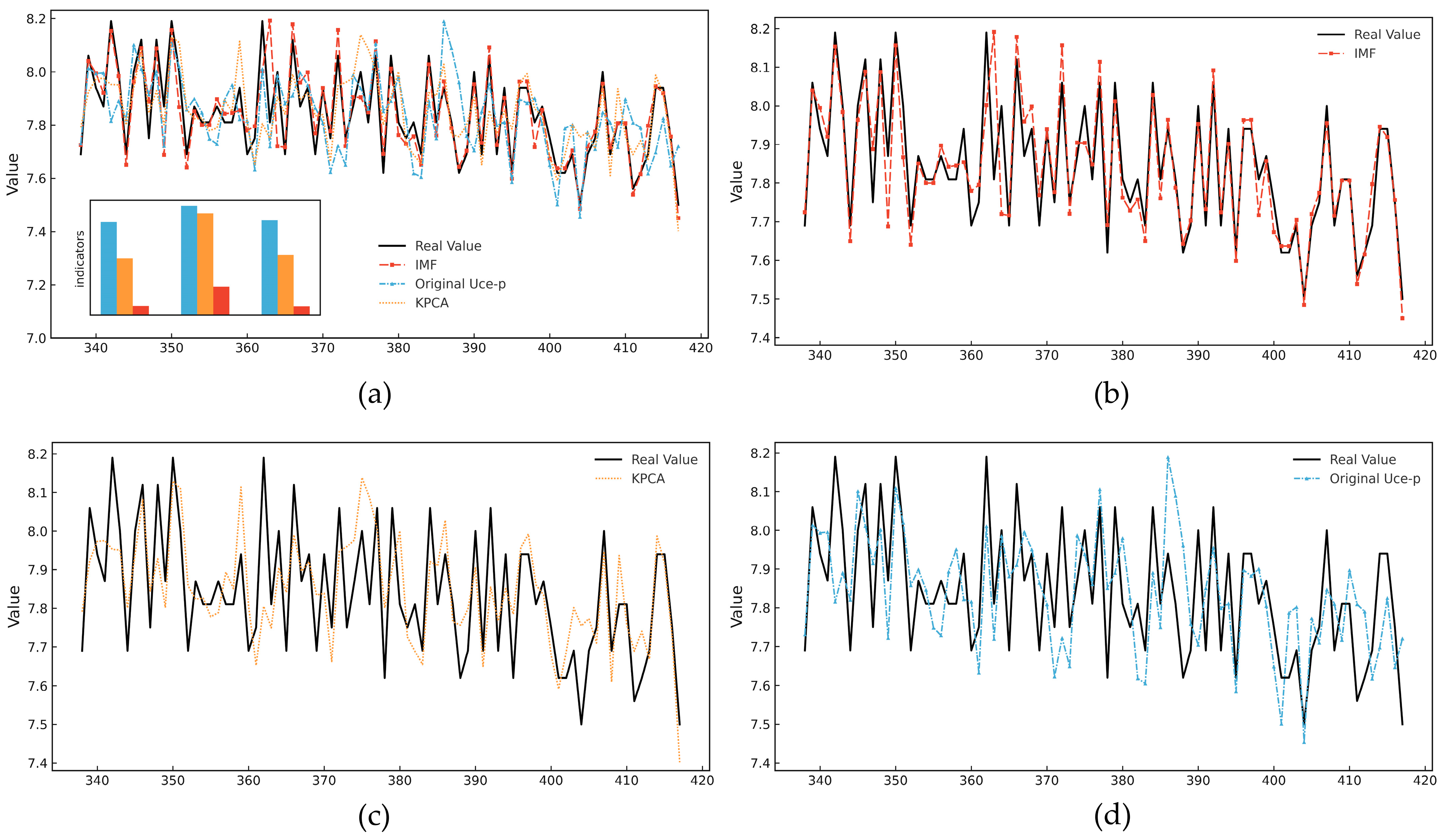
To validate the applicability and effectiveness of the CEEMDAN method, this study employs three types of input sequences: the original
Uce-p, the features processed by Kernel Principal Component Analysis (KPCA), and the IMFs obtained through CEEMDAN decomposition, to train and test the Performer-KAN model. The corresponding results are presented in
Table 3.
Experimental results show that the model performs best across all evaluation metrics when using IMF sequences as input. Compared with the original
Uce-p data and KPCA, the IMF-based model achieves an R
2 exceeding 0.98 and significantly reduced MAE and RMSE, demonstrating its superior prediction accuracy. These results indicate that the CEEMDAN method effectively separates key signal features from noise, significantly improving both the robustness and accuracy of the fault prediction model.
Figure 10 compares the predicted values and the ground truth for the three types of input sequences. It is observed that when using the IMF sequences, the predicted curves closely match the actual values in both the trend and amplitude. In contrast, when using the original
Uce-p data, the model captures only the general trend due to redundant information, rleading to prediction amplitude deviation. Although KPCA enhances feature extraction to some extent, it still struggles to accurately capture local high-frequency variations, leading to noticeable fitting errors.
Therefore, in subsequent comparative experiments, the IMF sequences are consistently selected as the fault feature input to further evaluate the proposed method’s comprehensive performance.
4.2. Comparative Experimental Results Analysis
This study compares the Performer-KAN model against six representative deep learning models, including RNN, LSTM, and Temporal Convolutional Network (TCN), to validate its effectiveness. These reflect three major technical paradigms in time series modeling: recurrent iteration, gated mechanisms, and convolutional expansion. All three have shown solid performance in time-series forecasting tasks. In addition, two Transformer variants are introduced for comparison: the Transformer-KAN model, which replaces the original MLP with KAN, and the Informer model, another improved Transformer architecture. These models are selected to comprehensively evaluate the proposed method’s advantages over classical and Transformer-based alternatives. All baseline models were equivalent.
The experimental results in
Table 4 demonstrate that the Performer-KAN model performs best across all evaluation metrics, with an R
2 of 0.9841, MAE of 0.049, and RMSE of 0.0153. These results highlight its superior fitting capability and robustness in time-series modeling. Compared to the original Performer model, Performer-KAN significantly improves prediction accuracy, suggesting that incorporating KAN enhances the model’s ability to capture complex fault characteristics and improves generalization.
Relative to conventional time-series models such as LSTM, RNN, and TCN, Performer-KAN exhibits a stronger performance in modeling long-term dependencies and capturing degradation trends, thereby reducing the prediction lag and amplitude deviation. Although the Transformer-KAN model achieves a slightly lower MAE, it performs slightly worse in other metrics, indicating that the Performer-KAN model offers a better overall performance. Informer, while moderately effective in specific tasks, suffers from amplitude amplification during long sequence modeling, compromising its stability and prediction accuracy.
To further illustrate the model performance,
Figure 11 visualizes the predicted and real sequences across models using IMF inputs. The Performer-KAN model matches the ground truth in trend and magnitude, reinforcing its superiority and reliability in IGBT fault prediction tasks.
To evaluate the computational efficiency, three metrics were recorded for each model using IMF sequences: training time per epoch (min/epoch), training time per batch (s/batch), and GPU utilization, as shown in
Figure 12. Among all the models, the Transformer-KAN incurs the highest computational overhead, reflecting an increased resource consumption despite an improved modeling capacity.
In contrast, the Performer-KAN achieves notable efficiency improvements, requiring only 3.2 min per epoch, 2.3 s per batch, and utilizing 26.3% of the GPU on average. This is primarily attributed to the FAVOR+ mechanism, which significantly reduces the time and memory complexity, enabling a high-accuracy prediction with lower latency and hardware demands.
The TCN benefits from parallel convolutional operations among traditional models, leading to the fastest training speed. The RNN and LSTM are slower due to sequential dependencies, with RNN being slightly quicker than LSTM due to its simpler architecture.
For Transformer-based variants, Informer’s training efficiency lies between the Transformer-KAN and the Performer-KAN. Although it adopts a sparse attention mechanism, its acceleration is less effective than FAVOR+ in this experimental setting.
The Performer-KAN demonstrates the best balance between prediction accuracy, training efficiency, and computational resource utilization. Its scalable performance and low complexity make it well-suited for practical engineering applications. While Transformer-KAN shows marginal improvements in MAE, its high computational cost may limit the deployment in real-time environments. Though fast and resource-efficient, traditional models like the RNN, LSTM, and TCN fall short in delivering high-precision degradation predictions.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}