
DBSCAN-PCA-INFORMER-Based Droplet Motion Time Prediction Model for Digital Microfluidic Systems


Abstract
1. Introduction
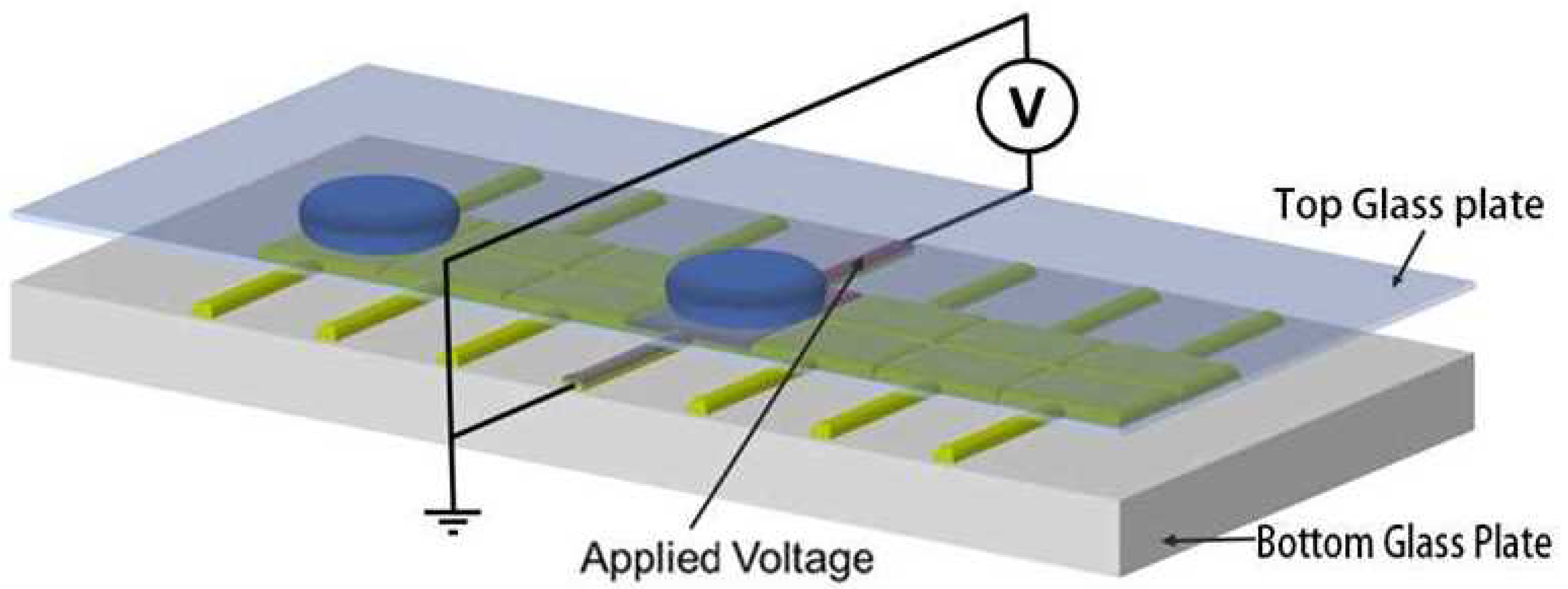
2. Mechanism of Digital Microfluidic Systems Based on Dielectrophoresis
3. DBSCAN Dimensionality Reduction Algorithm
- (1)
- Given a k value, typically taken as , where dim is the dimension of the input data.
- (2)
- For every data point, calculate the distance to its k-nearest neighbors and sort them in descending order.
- (3)
- Find the abrupt points (inflection points) in the sequence from step (2), which will determine the value of Eps.
- (1)
- Neighborhood: The region around a given object with a radius of Eps.
- (2)
- Core Point: A point within the neighborhood radius Eps that has a number of data points greater than or equal to MinPts.
- (3)
- Border Point: A point within the neighborhood radius Eps that contains fewer than MinPts data points but lies within the neighborhood of a core point.
- (4)
- Noise Point: A point that is not a core point or a border point.
- (5)
- Density Reachable: Other points Q located in the vicinity of core point P are described as density reachable from P.
- (6)
- Density Reachability: Given a sample set H, where n sample points are , and and . if is density reachable to , then p is said to be density reachable to q.
- (7)
- Density Connected: In the same dataset H, if is density reachable from and , then and are density connected.
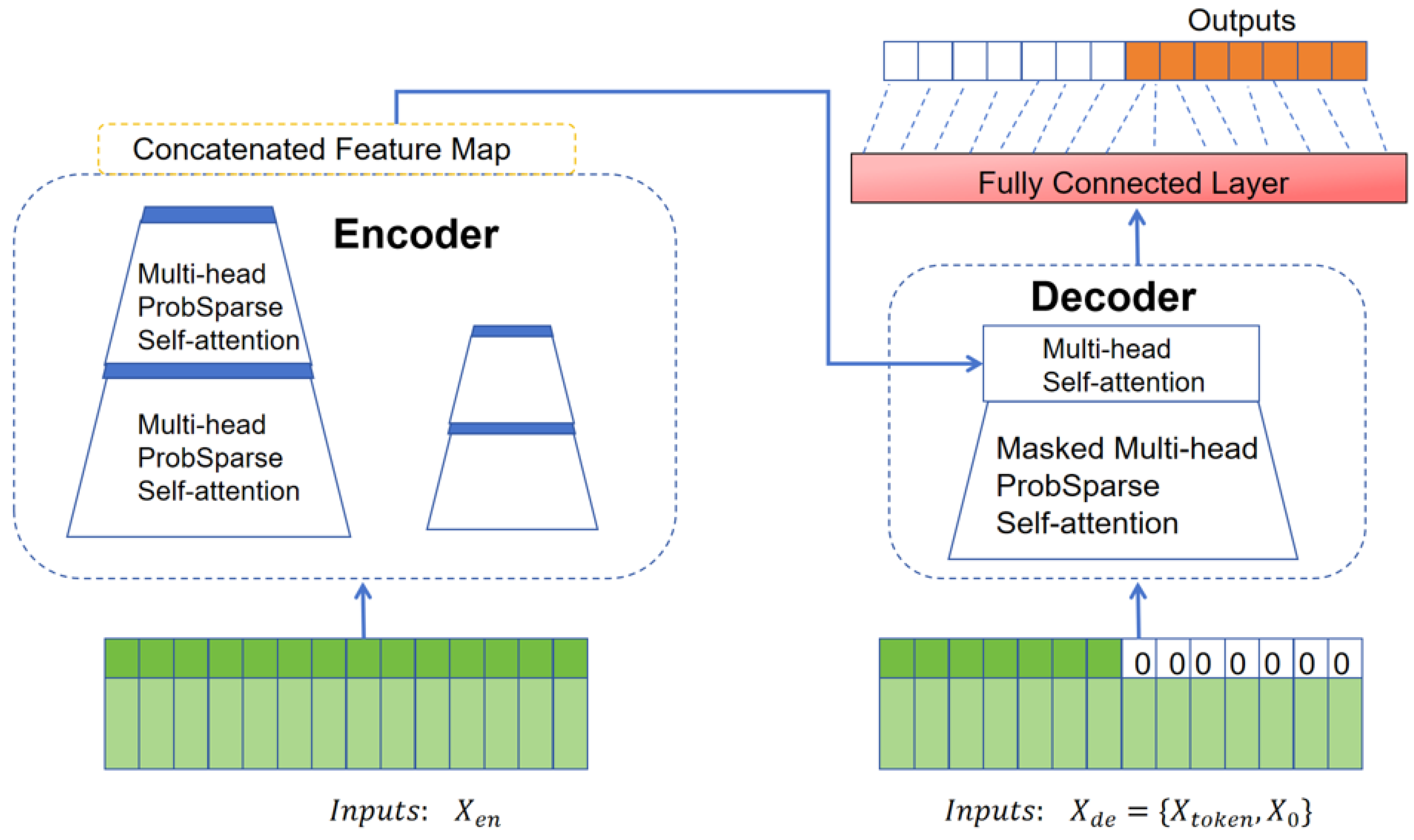
4. The Basic Principles of the INFORMER Neural Model
4.1. Probabilistic Sparse Self-Attention Mechanism
4.2. Encoder
4.3. Decoder
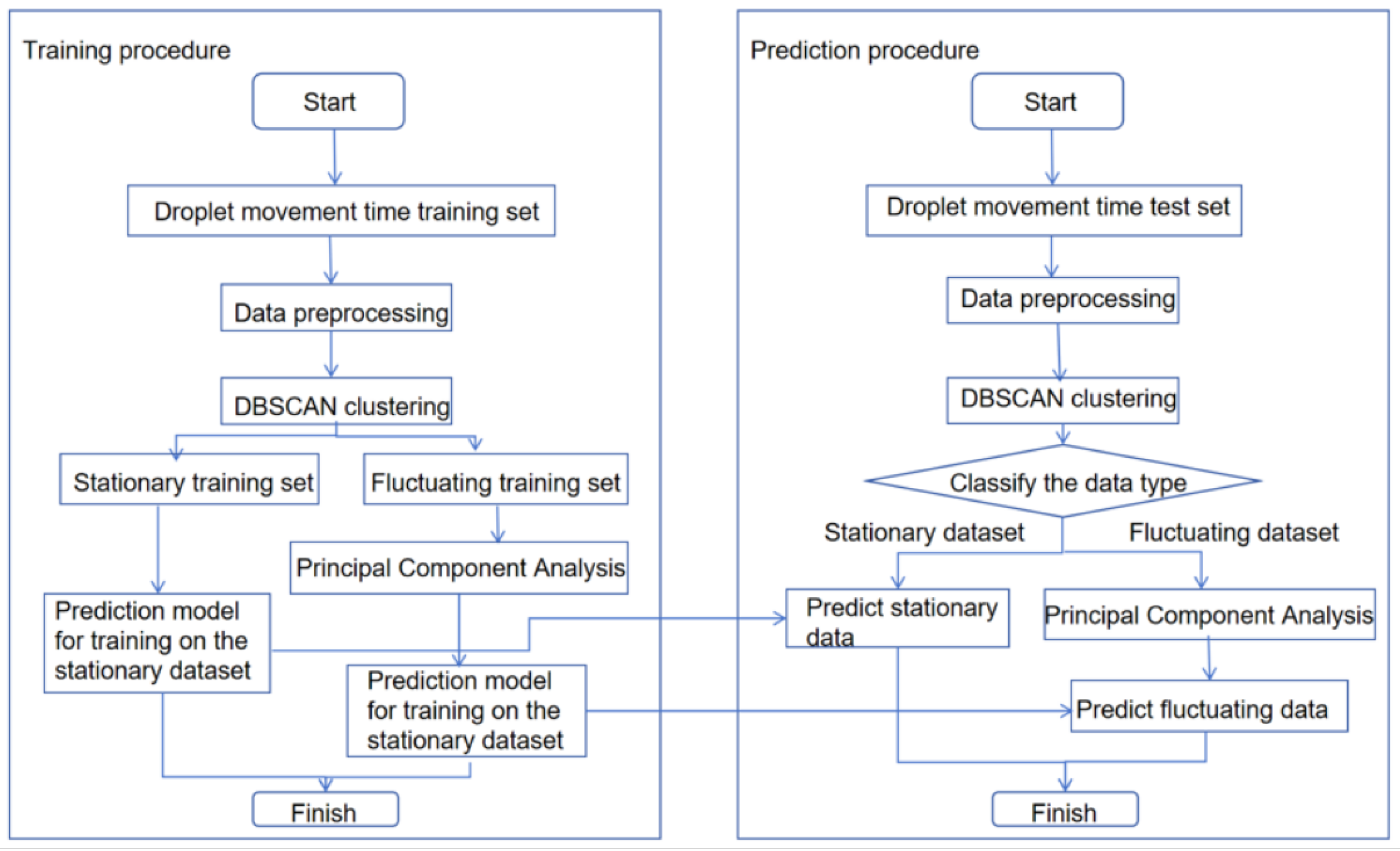
5. DBSCAN-PCA-INFORMER-Based Digital Microfluidic System Droplet Motion Time Prediction Model
5.1. Model Structure Design
5.2. Evaluation Metrics
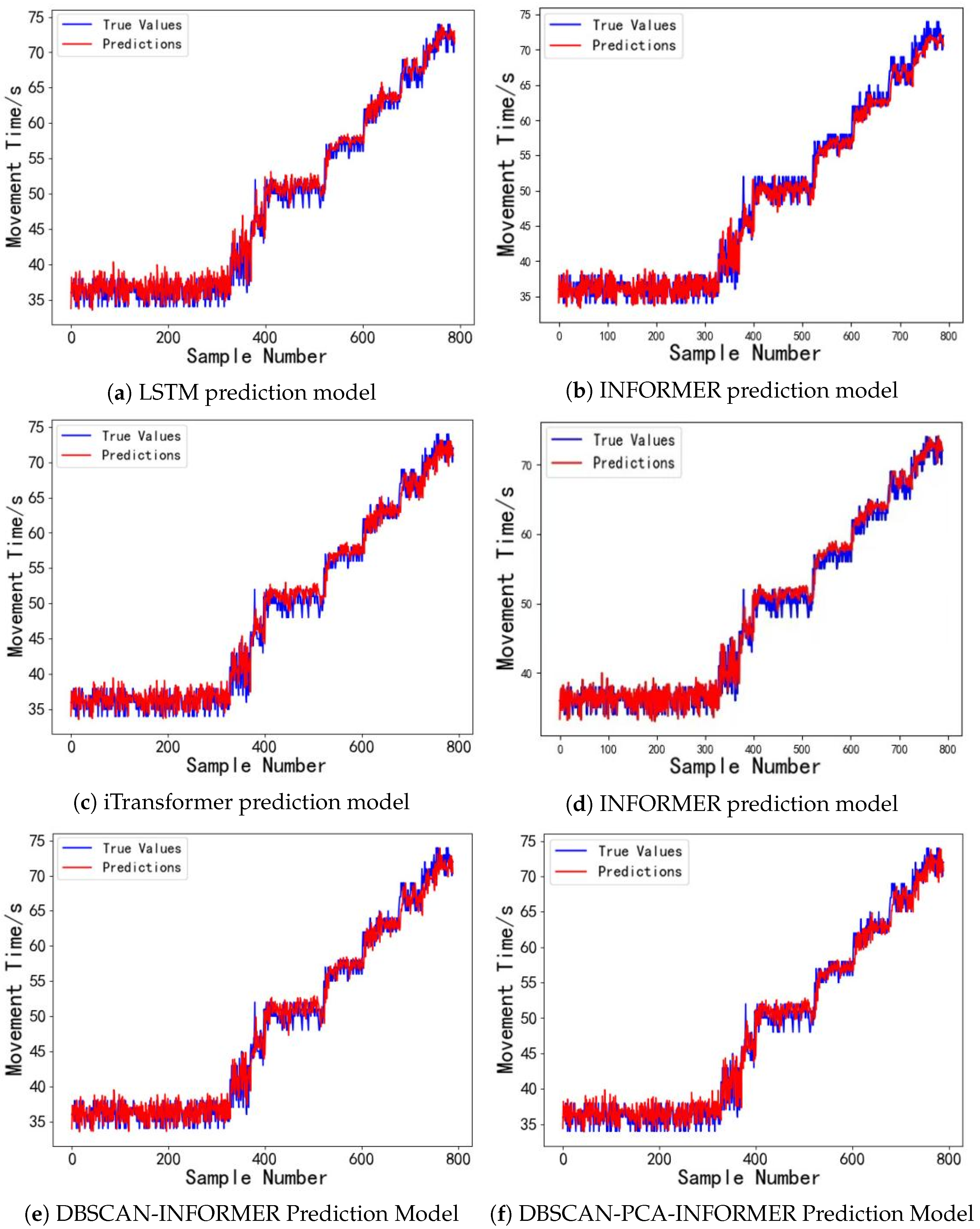
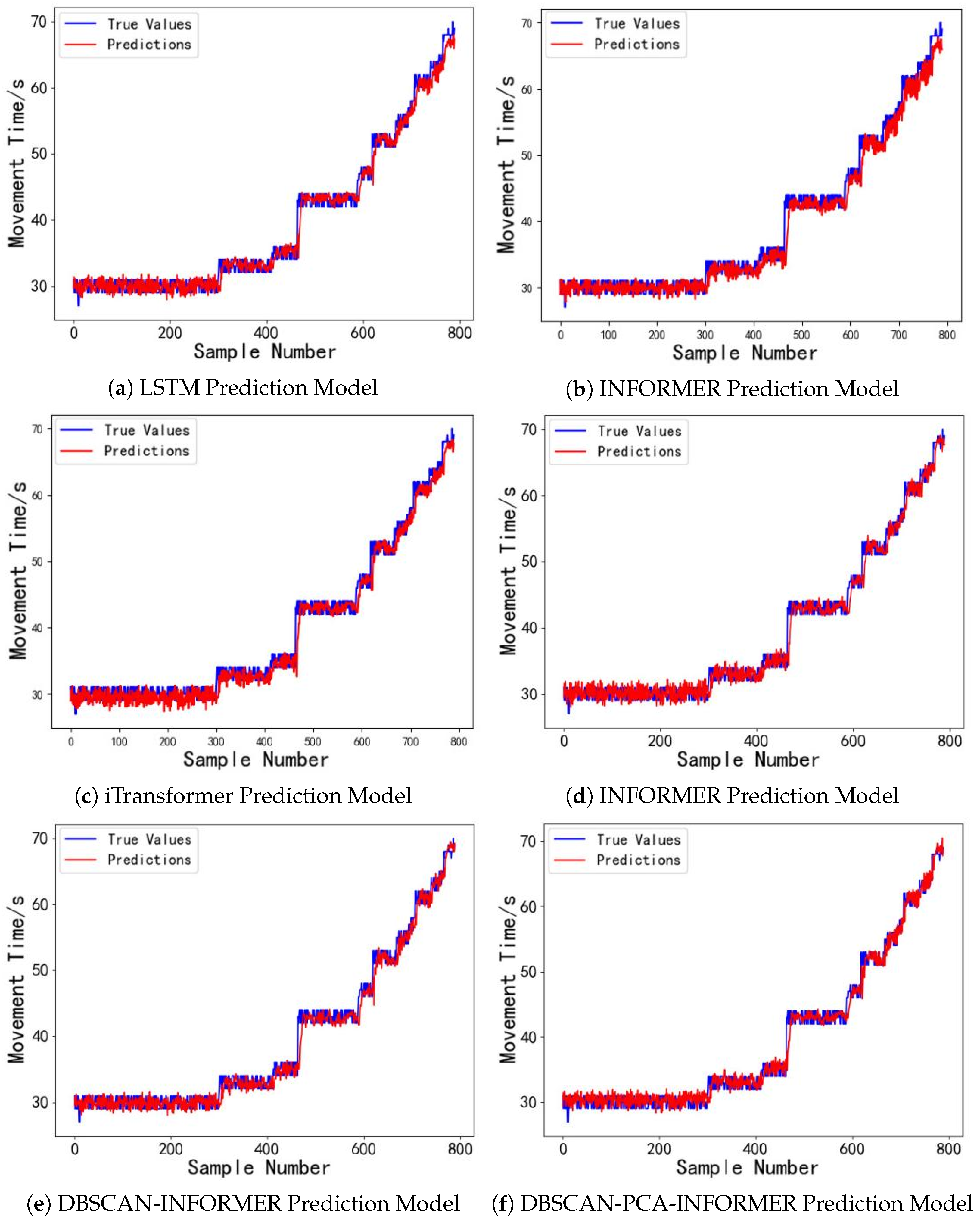
6. Experiments and Discussion
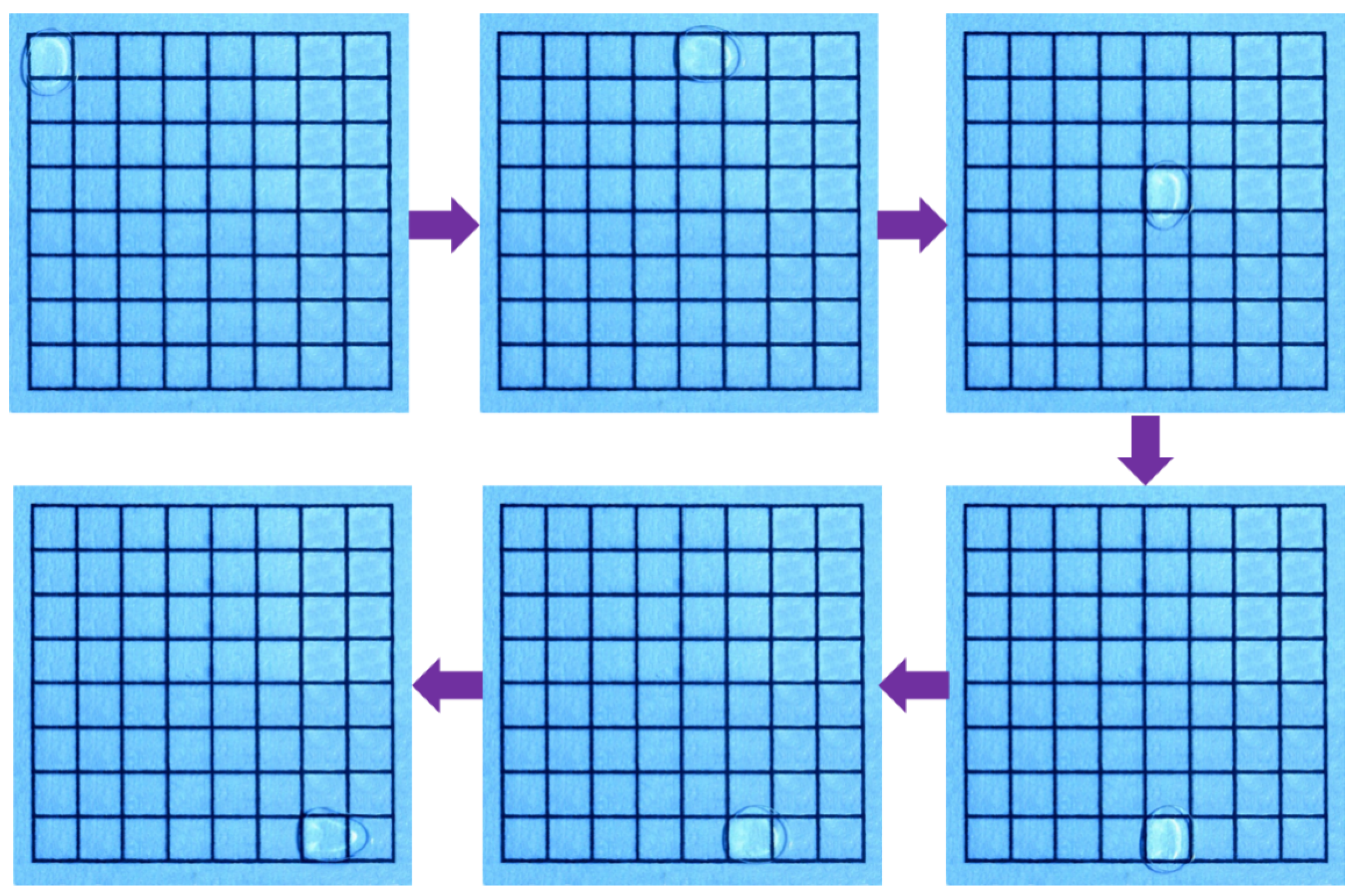
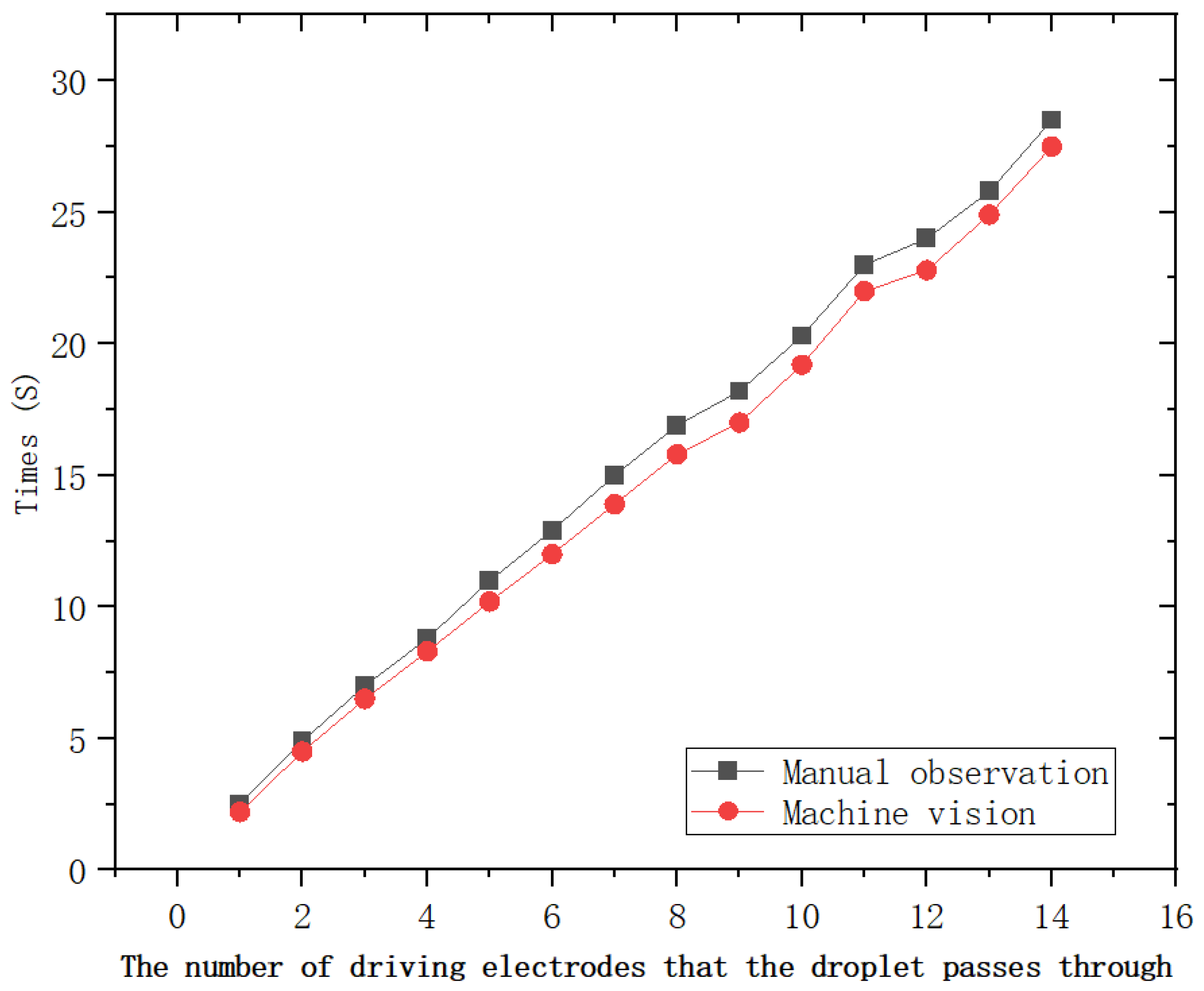
6.1. Device Fabrication and Dataset Collection
6.2. Data Preprocessing
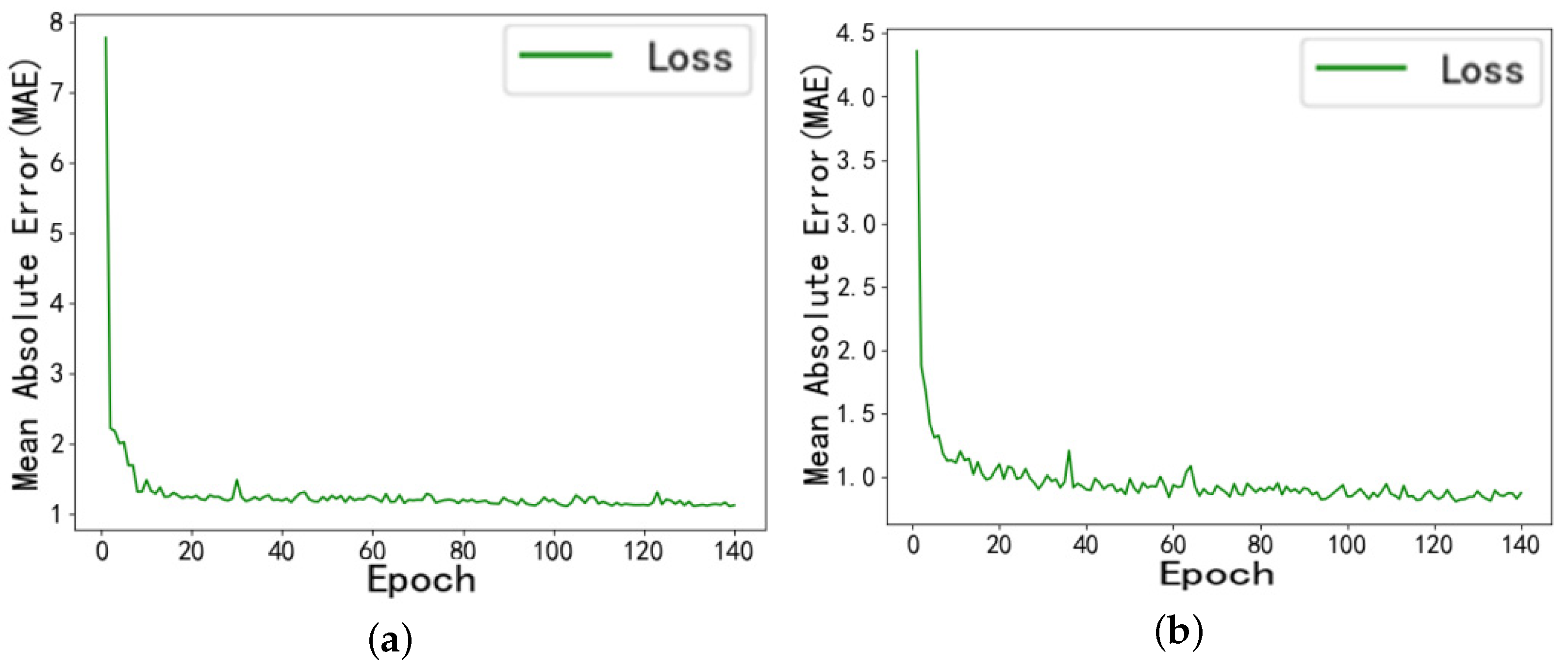
6.3. Model Training
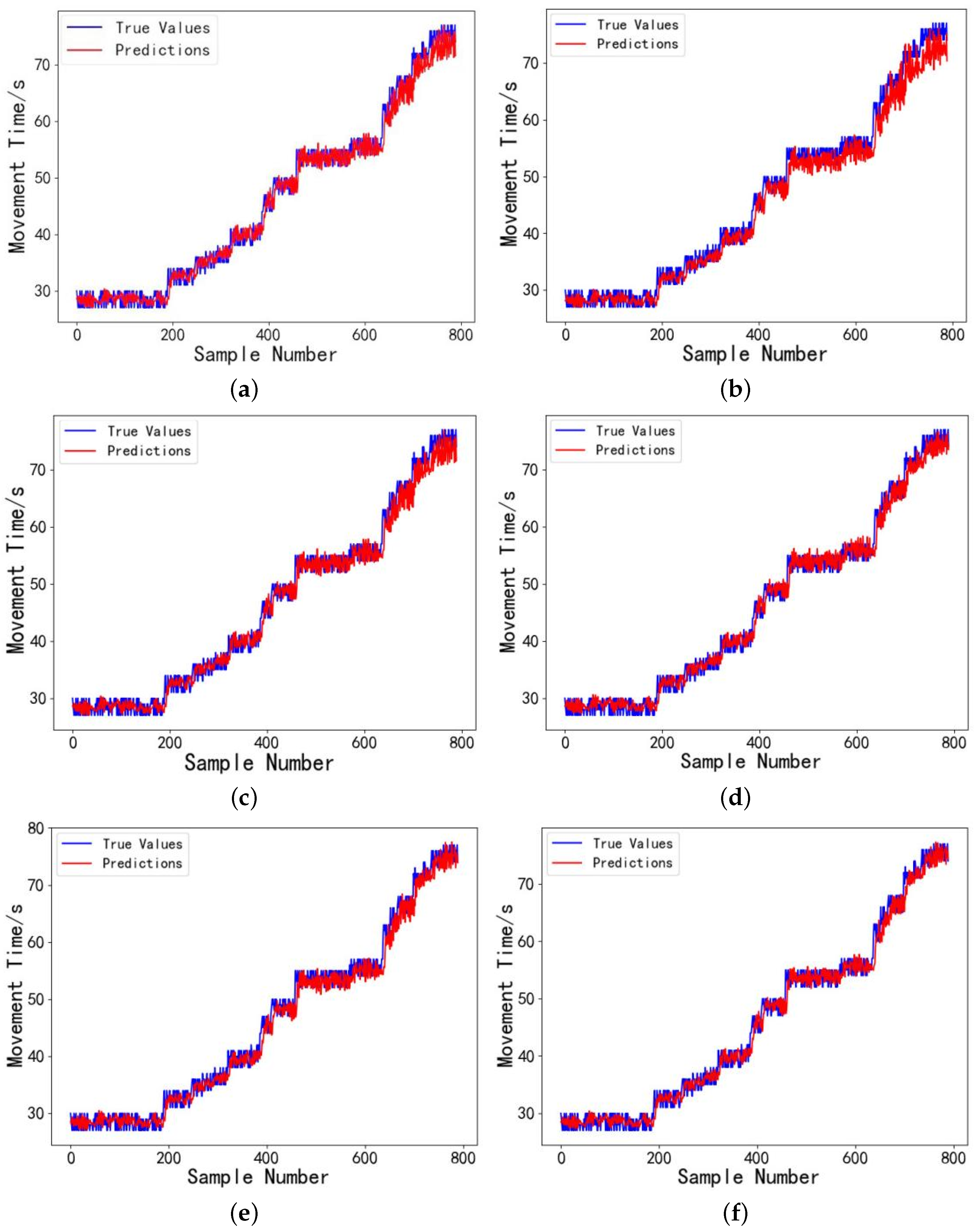
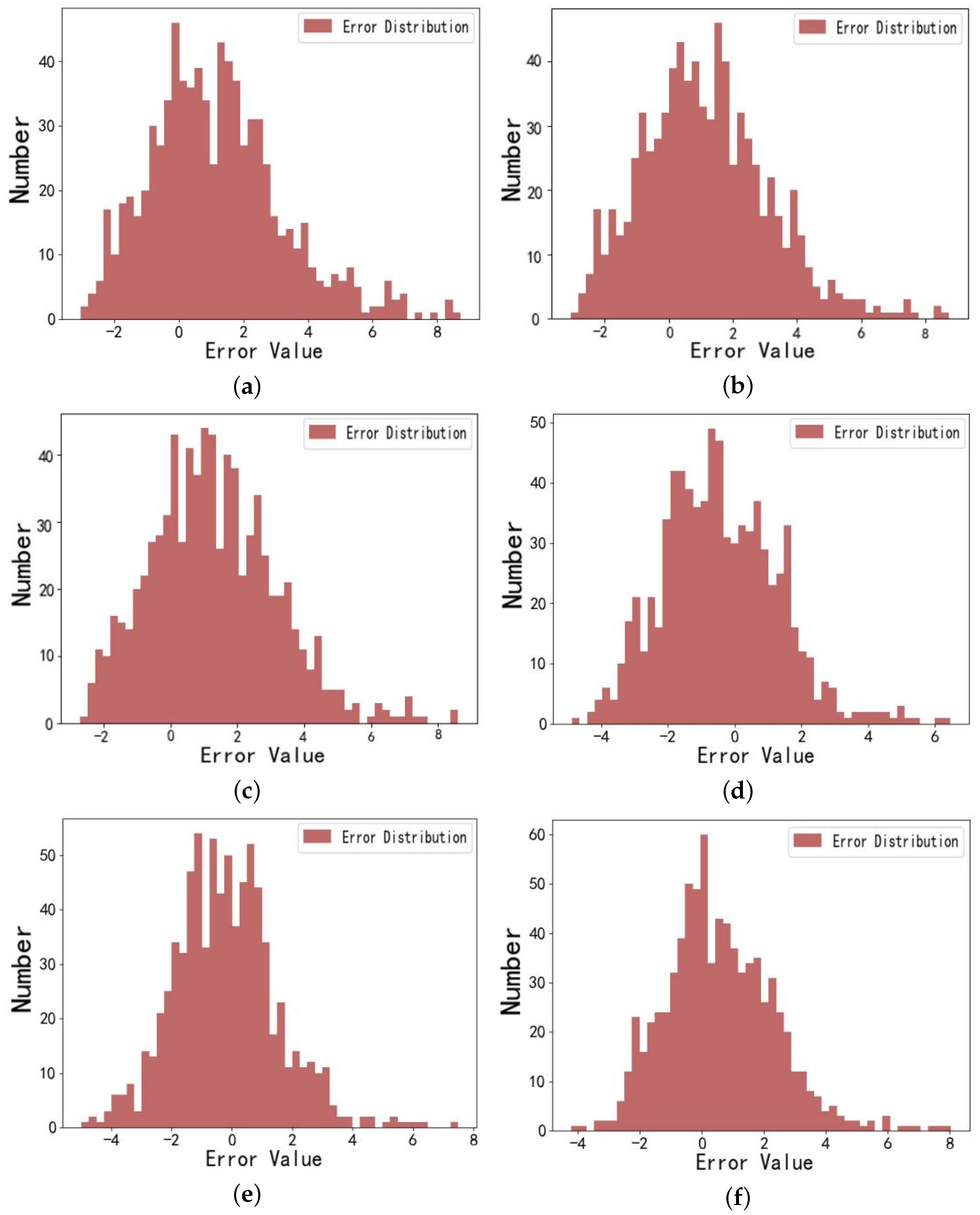
6.4. Performance Evaluation of the Model Under Different Driving Voltages
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fan, S.K.; Hsieh, T.H.; Lin, D.Y. General digital microfluidic platform manipulating dielectric and conductive droplets by dielectrophoresis and electrowetting. Lab Chip 2009, 9, 1236–1242. [Google Scholar] [CrossRef] [PubMed]
- Rajeev, R.; Samath, J.A.; Karthikeyan, N.K. An Intelligent Recurrent Neural Network with Long Short-Term Memory (LSTM) Based Batch Normalization for Medical Image Denoising. J. Med. Syst. 2019, 43, 234. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Li, C.; Zhang, J.; Wang, J.; Ma, Y.; Lian, Y. A new LSTM-based gene expression prediction model: L-GEPM. J. Bioinform. Comput. Biol. 2019, 17, 1950022. [Google Scholar] [CrossRef] [PubMed]
- Islam, Z.M.; Islam, M.M.; Asraf, A. A combined deep CNN-LSTM network for the detection of novel coronavirus (COVID-19) using X-ray images. Inform. Med. Unlocked 2020, 20, 100412. [Google Scholar] [CrossRef] [PubMed]
- Grant, N.; Geiss, B.; Field, S.; Demann, A.; Chen, T.W. Design of a Hand-Held and Battery-Operated Digital Microfluidic Device Using EWOD for Lab-on-a-Chip Applications. Micromachines 2021, 12, 1065. [Google Scholar] [CrossRef] [PubMed]
- Tong, Z.; Shen, C.; Li, Q.; Yin, H.; Mao, H. Combining sensors and actuators with electrowetting-on-dielectric (EWOD): Advanced digital microfluidic systems for biomedical applications. Analyst 2023, 148, 1399–1421. [Google Scholar] [CrossRef] [PubMed]
- Mehmood, A.; Iqbal, M.; Mehmood, Z.; Irtaza, A.; Nawaz, M.; Nazir, T.; Masood, M. Prediction of Heart Disease Using Deep Convolutional Neural Networks. Arab. J. Sci. Eng. 2021, 46, 3409–3422. [Google Scholar] [CrossRef]
- Alfian, G.; Syafrudin, M.; Fitriyani, N.L.; Anshari, M.; Stasa, P.; Svub, J.; Rhee, J. Deep Neural Network for Predicting Diabetic Retinopathy from Risk Factors. Mathematics 2020, 8, 1620. [Google Scholar] [CrossRef]
- Cao, B.; Zhao, J.; Lv, Z.; Gu, Y.; Yang, P.; Halgamuge, S.K. Multiobjective Evolution of Fuzzy Rough Neural Network via Distributed Parallelism for Stock Prediction. IEEE Trans. Fuzzy Syst. 2020, 28, 939–952. [Google Scholar] [CrossRef]
- Wu, J.; Ma, J.; Liang, F.; Dong, W.; Shi, G.; Lin, W. End-to-End Blind Image Quality Prediction with Cascaded Deep Neural Network. IEEE Trans. Image Process. 2020, 29, 741–7426. [Google Scholar] [CrossRef]
- Wang, Q.J.; Du, Y.; Wang, J. LSTM based long-term energy consumption prediction with periodicity. Energy 2020, 197, 117197. [Google Scholar] [CrossRef]
- Huang, R.; Wei, C.; Wang, B.; Yang, J.; Xu, X.; Wu, S.; Huang, S. Well performance prediction based on Long Short-Term Memory (LSTM) neural network. J. Pet. Sci. Eng. 2022, 208, 109686. [Google Scholar] [CrossRef]
- Chuyao, L.; Xutao, L.; Yunming, Y. PFST-LSTM: A SpatioTemporal LSTM Model With Pseudoflow Prediction for Precipitation Nowcasting. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 14843–14857. [Google Scholar]
- Wan, A.; Chang, Q.; Khalil, A.B.; He, J. Short-term power load forecasting for combined heat and power using CNN-LSTM enhanced by attention mechanism. Energy 2023, 282, 128274. [Google Scholar] [CrossRef]
- Anjuman, Z.S.; Saiful, M.I. A hybrid CNN–KNN approach for identification of COVID-19 with 5-fold cross validation. Sens. Int. 2023, 4, 100229. [Google Scholar]
- El-Assy, A.M.; Amer, H.M.; Ibrahim, H.M.; Mohamed, M.A. A novel CNN architecture for accurate early detection and classification of Alzheimer’s disease using MRI data. Sci. Rep. 2024, 14, 3463. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Ji, L.; Wu, C.W.D.; Tso, K.F.G. Using SARIMA–CNN–LSTM approach to forecast daily tourism demand. J. Hosp. Tour. Manag. 2021, 49, 25–33. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN revisited, revisited: Why and how you should (still) use DBSCAN. ACM Trans. Database Syst. (TODS) 2017, 42, 1–21. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, virtually, 2–9 February 2021; Volume 35. [Google Scholar]
- Luo, Z.; Huang, B.; Xu, J.; Wang, L.; Huang, Z.; Cao, L.; Liu, S. Machine vision-based driving and feedback scheme for digital microfluidics system. Open Chem. 2021, 19, 665–677. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Name | Parameter |
|---|---|---|
| DBSCAN | Eps | 0.4 |
| Min_samples | 5 | |
| INFORMER | BatchSize | 64 |
| Learning Rate | 0.0005 | |
| Encode Input Size | 7 | |
| Decode Input Size | 7 | |
| Encoder Layer | 2 | |
| Decoder Layer | 1 | |
| Epoch | 140 | |
| Loss | MeanSquareError | |
| Optimizer | Adam Optimizer |
| Model | MSE | MAE | MAPE | R2 |
|---|---|---|---|---|
| LSTM | 3.8535 | 1.5153 | 3.3847 | 0.9836 |
| FEDFORMER | 3.8234 | 1.4945 | 3.3702 | 0.9838 |
| ITRANSFORMER | 3.7578 | 1.4721 | 3.3407 | 0.9841 |
| INFORMER | 3.7003 | 1.4585 | 3.3534 | 0.9843 |
| DBSCAN-INFORMER | 3.4103 | 1.4609 | 3.3283 | 0.9855 |
| DBSCAN-PCA-INFORMER | 3.1925 | 1.3661 | 3.1813 | 0.9864 |
| Model | Inference Time per 100 Samples (ms) |
|---|---|
| LSTM | 92.4 |
| FEDFORMER | 101.7 |
| ITRANSFORMER | 89.3 |
| INFORMER | 68.9 |
| DBSCAN-INFORMER | 66.5 |
| DBSCAN-PCA-INFORMER | 59.1 |
| Driving Voltage/V | Model | MSE | MAE | MAPE | R2 |
|---|---|---|---|---|---|
| 30 | LSTM | 3.7343 | 1.4826 | 3.3351 | 0.9763 |
| FEDFORMER | 3.5035 | 1.4550 | 3.2890 | 0.9778 | |
| ITRANSFORMER | 3.4070 | 1.4210 | 3.1520 | 0.9784 | |
| INFORMER | 3.4873 | 1.4402 | 3.1565 | 0.9779 | |
| DBSCAN-INFORMER | 3.1888 | 1.3737 | 3.1472 | 0.9798 | |
| DBSCAN-PCA-INFORMER | 3.0649 | 1.3312 | 2.9962 | 0.9806 | |
| 50 | LSTM | 2.8270 | 1.2903 | 3.4057 | 0.9786 |
| FEDFORMER | 2.8105 | 1.2872 | 3.3921 | 0.9787 | |
| ITRANSFORMER | 2.7708 | 1.2834 | 3.3407 | 0.9790 | |
| INFORMER | 2.7511 | 1.2802 | 3.3248 | 0.9792 | |
| DBSCAN-INFORMER | 2.5846 | 1.2438 | 3.3219 | 0.9805 | |
| DBSCAN-PCA-INFORMER | 2.1541 | 1.1072 | 2.9393 | 0.9837 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, Z.; Zhao, B.; Liu, W.; Zheng, J.; Chen, W. DBSCAN-PCA-INFORMER-Based Droplet Motion Time Prediction Model for Digital Microfluidic Systems. Micromachines 2025, 16, 594. https://doi.org/10.3390/mi16050594
Luo Z, Zhao B, Liu W, Zheng J, Chen W. DBSCAN-PCA-INFORMER-Based Droplet Motion Time Prediction Model for Digital Microfluidic Systems. Micromachines. 2025; 16(5):594. https://doi.org/10.3390/mi16050594
Chicago/Turabian StyleLuo, Zhijie, Bin Zhao, Wenjin Liu, Jianhua Zheng, and Wenwen Chen. 2025. "DBSCAN-PCA-INFORMER-Based Droplet Motion Time Prediction Model for Digital Microfluidic Systems" Micromachines 16, no. 5: 594. https://doi.org/10.3390/mi16050594
APA StyleLuo, Z., Zhao, B., Liu, W., Zheng, J., & Chen, W. (2025). DBSCAN-PCA-INFORMER-Based Droplet Motion Time Prediction Model for Digital Microfluidic Systems. Micromachines, 16(5), 594. https://doi.org/10.3390/mi16050594