Fine-Grained Power Gating Using an MRAM-CMOS Non-Volatile Flip-Flop


Abstract
:1. Introduction
2. MRAM-CMOS Non-Volatile Flip-Flops
2.1. State-of-the-Art MRAM-CMOS NVFFs
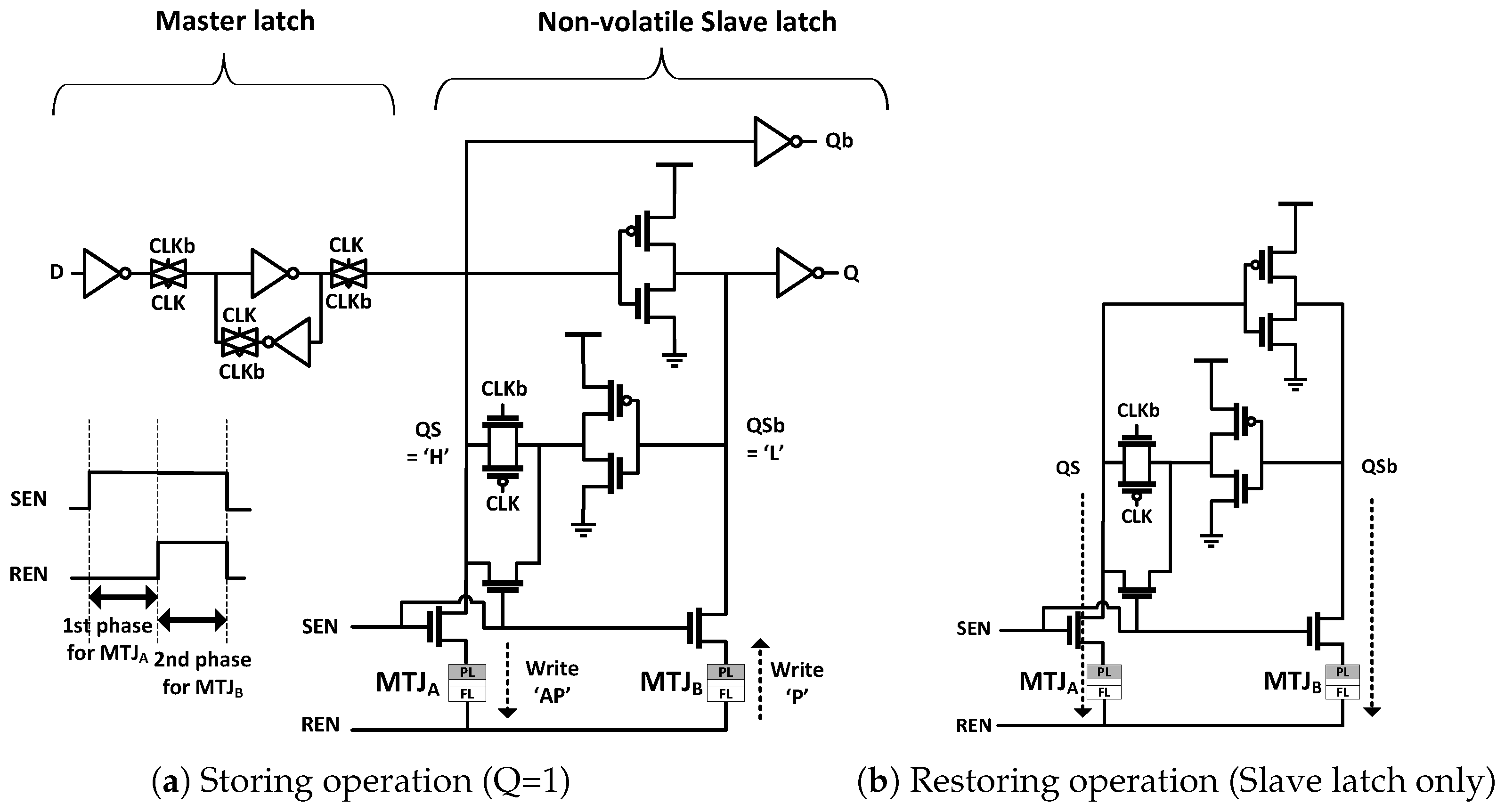
2.2. Current Reutilization NVFF
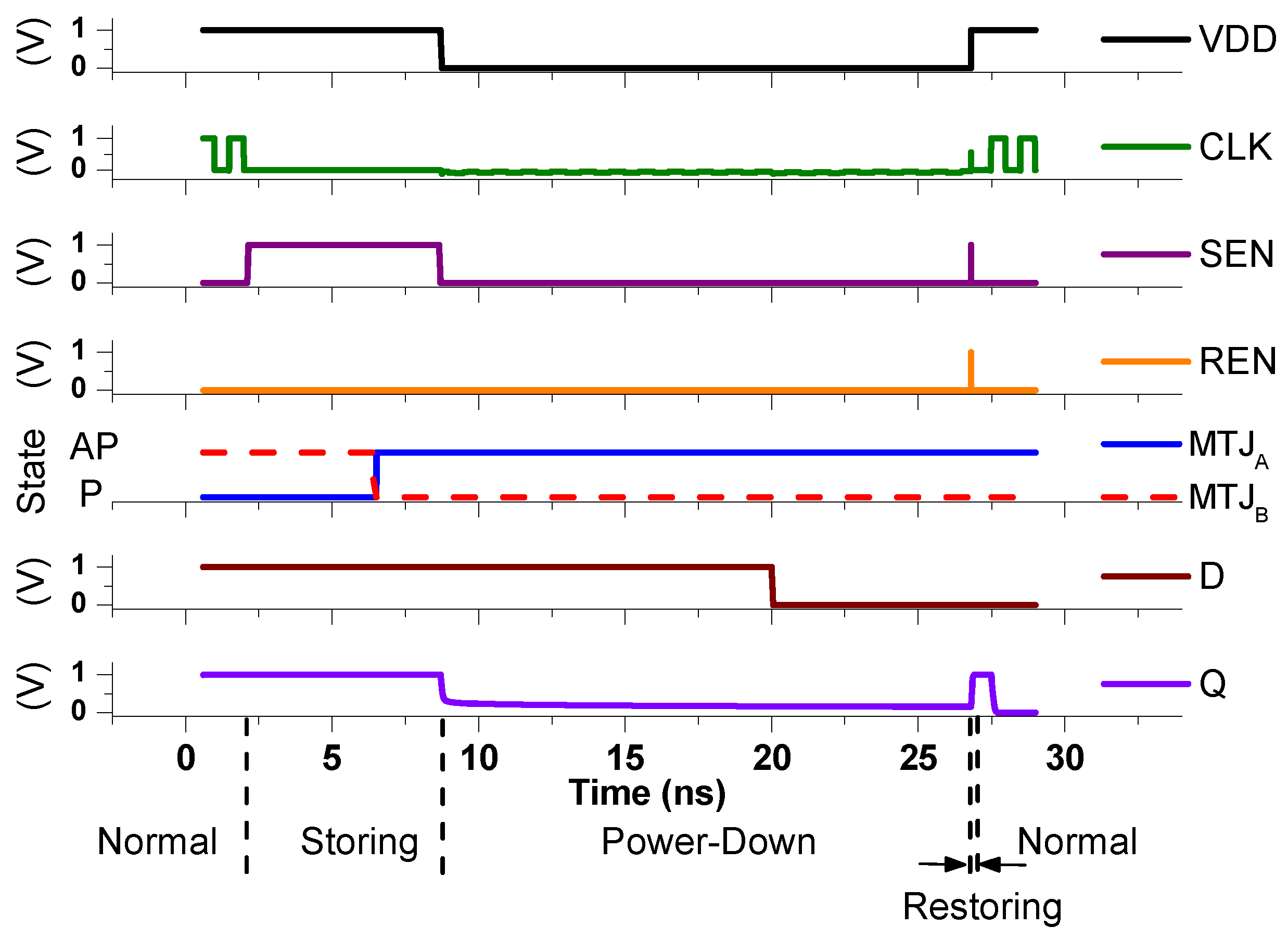
2.3. Evaluation of the Proposed NVFF
3. Optimization Strategies for the Proposed NVFF
3.1. Pre-Fabrication Optimization: A Module-Based Placement
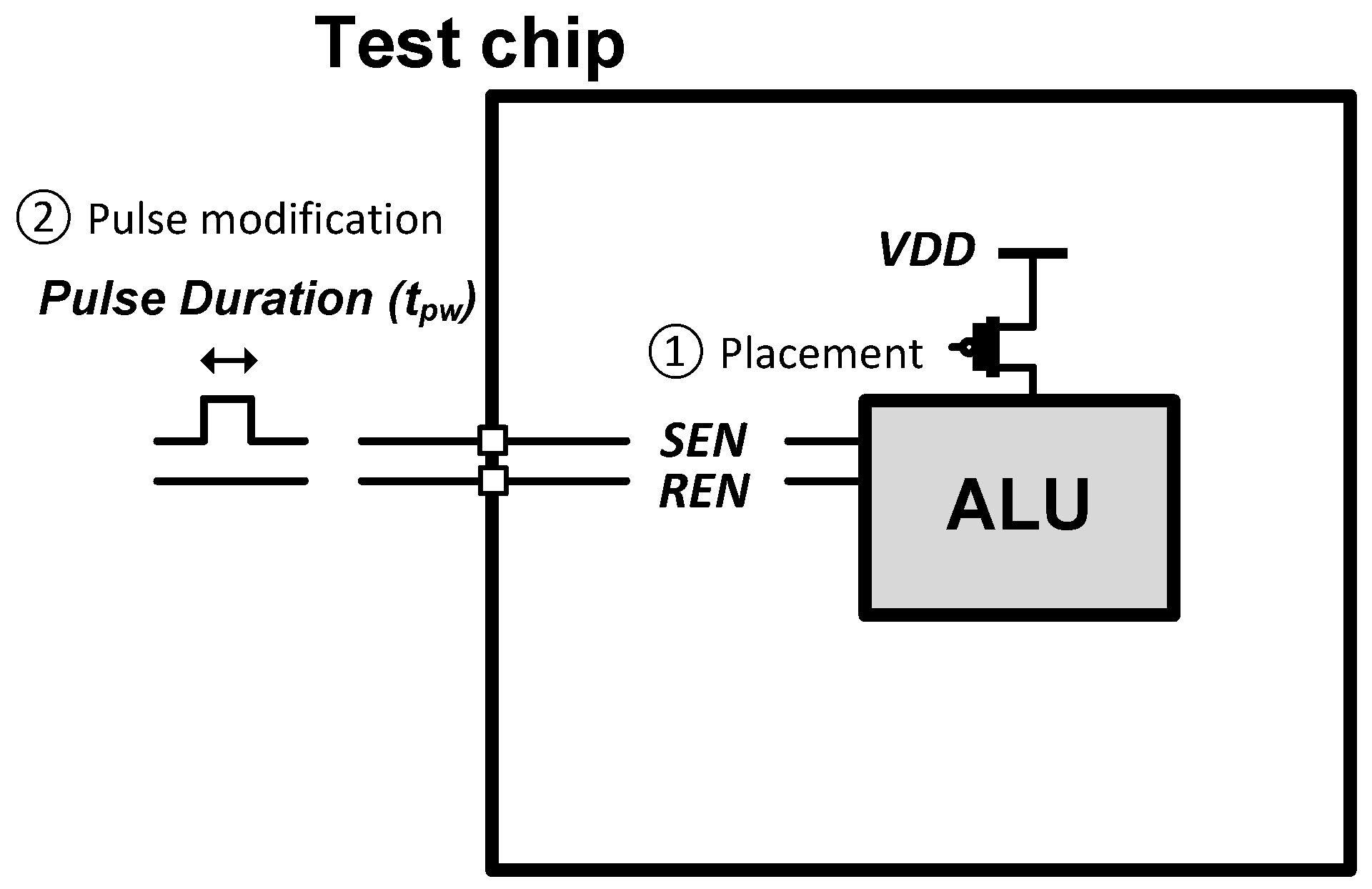
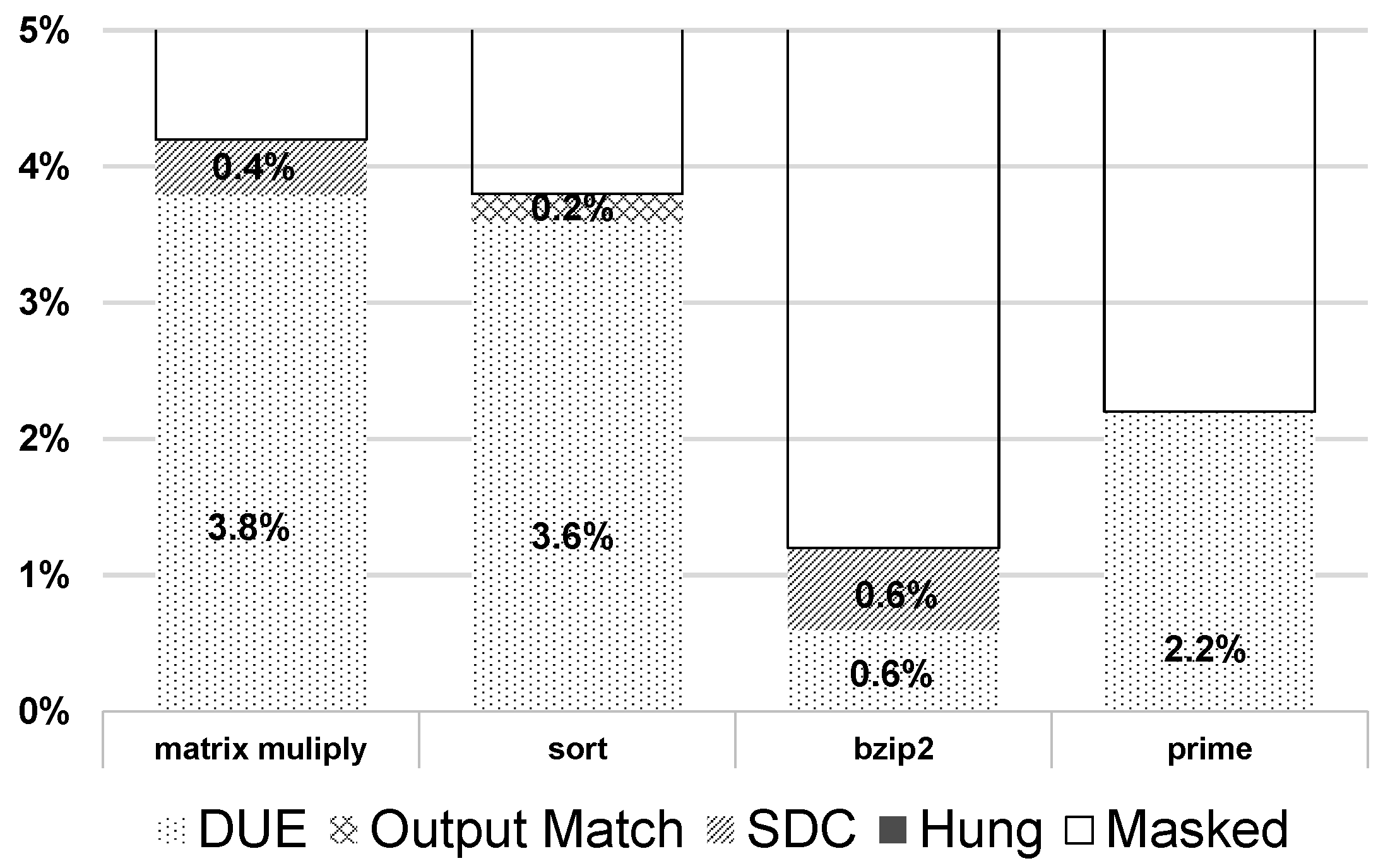
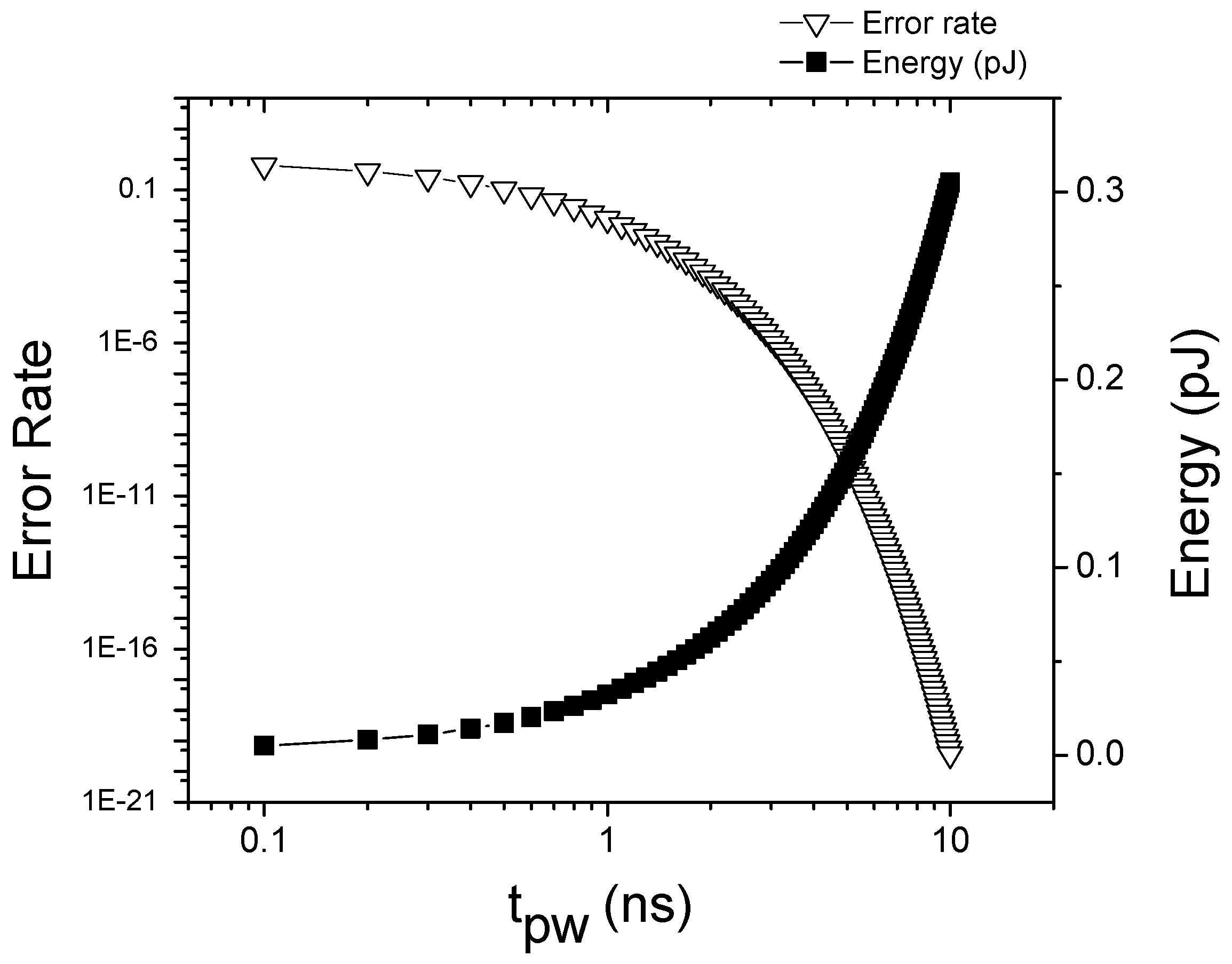
3.2. Post-Fabrication Optimization: A Pulse Width Modulation
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| STT-MRAM | spin torque transfer magnetic RAM |
| MTJ | magnetic tunnel junction |
| FF | flip flop |
| NVFF | non-volatile flip flop |
| PTM | predictive technology model |
| MUX | multiplexer |
| EDK | educational design kit |
| VCS | verilog compiler and simulator |
| ALU | arithmetic logic unit |
| DUE | detected unrecoverable error |
| SDC | silent data corruption |
References
- Shin, Y.; Seomun, J.; Choi, K.M.; Sakurai, T. Power gating: Circuits, design methodologies, and best practice for standard-cell VLSI designs. ACM Trans. Design Autom. Electron. Syst. 2010, 15, 28. [Google Scholar] [CrossRef]
- Jeong, K.; Kahng, A.B.; Kang, S.; Rosing, T.S.; Strong, R. MAPG: Memory access power gating. In Proceedings of the Conference on Design, Automation and Test in Europe, Dresden, Germany, 12–16 March 2012; pp. 1054–1059. [Google Scholar]
- Chiou, D.S.; Chen, S.H.; Chang, S.C.; Yeh, C. Timing driven power gating. In Proceedings of the 43rd Annual Design Automation Conference, San Francisco, CA, USA, 24–28 July 2006; pp. 121–124. [Google Scholar]
- Sorin, D.J.; Martin, M.M.; Hill, M.D.; Wood, D.A. SafetyNet: Improving the availability of shared memory multiprocessors with global checkpoint/recovery. In Proceedings of the 29th Annual International Symposium on Computer Architecture, Anchorage, AK, USA, 25–29 May 2002; pp. 123–134. [Google Scholar]
- Prvulovic, M.; Zhang, Z.; Torrellas, J. ReVive: Cost-effective architectural support for rollback recovery in shared-memory multiprocessors. In Proceedings of the 29th Annual International Symposium on Computer Architecture, Anchorage, AK, USA, 25–29 May 2002; pp. 111–122. [Google Scholar]
- Sato, H.; Yamamoto, T.; Yamanouchi, M.; Ikeda, S.; Fukami, S.; Kinoshita, K.; Matsukura, F.; Kasai, N.; Ohno, H. Comprehensive study of CoFeB-MgO magnetic tunnel junction characteristics with single-and double-interface scaling down to 1X nm. In Proceedings of the 2013 IEEE International Electron Devices Meeting, Washington, DC, USA, 9–11 December 2013; Volume 3, pp. 1–3. [Google Scholar]
- Zhang, Y.; Zhao, W.; Lakys, Y.; Klein, J.; Kim, J.V.; Ravelosona, D.; Chappert, C. Compact Modeling of Perpendicular-Anisotropy CoFeB/MgO Magnetic Tunnel Junctions. IEEE Trans. Electron Devices 2012, 59, 819–826. [Google Scholar] [CrossRef]
- Zhao, W.; Cao, Y. Predictive technology model for nano-CMOS design exploration. ACM J. Emerg. Technol. Comput. Syst. 2007, 3, 1. [Google Scholar] [CrossRef]
- Worledge, D.; Hu, G.; Trouilloud, P.; Abraham, D.; Brown, S.; Gaidis, M.; Nowak, J.; O’Sullivan, E.; Robertazzi, R.; Sun, J.; et al. Switching distributions and write reliability of perpendicular spin torque MRAM. In Proceedings of the 2010 International Electron Devices Meeting, San Francisco, CA, USA, 6–8 December 2010. [Google Scholar]
- Raychowdhury, A.; Somasekhar, D.; Karnik, T.; De, V. Design space and scalability exploration of 1t-1stt mtj memory arrays in the presence of variability and disturbances. In Proceedings of the 2009 IEEE International Electron Devices Meeting (IEDM), Baltimore, MD, USA, 7–9 December 2009. [Google Scholar]
- Diao, Z.; Li, Z.; Wang, S.; Ding, Y.; Panchula, A.; Chen, E.; Wang, L.C.; Huai, Y. Spin-transfer torque switching in magnetic tunnel junctions and spin-transfer torque random access memory. J. Phys. Condens. Matter 2007, 19, 165209. [Google Scholar] [CrossRef]
- Microsystem, S. OpenSPARCTM T1 Microarchitecture Specification. 2009. Available online: https://www.oracle.com/technetwork/systems/opensparc/t1-01-opensparct1-micro-arch-1538959.html.
- Dujmovic, J.J.; Dujmovic, I. Evolution and evaluation of SPEC benchmarks. ACM Sigmetrics Perform. Eval. Rev. 1998, 26, 2–9. [Google Scholar] [CrossRef]
- Yamamoto, S.; Shuto, Y.; Sugahara, S. Nonvolatile delay flip-flop using spin-transistor architecture with spin transfer torque MTJs for power-gating systems. Electron. Lett. 2011, 47, 1027–1029. [Google Scholar] [CrossRef]
- Jung, Y.; Kim, J.; Ryu, K.; Kim, J.P.; Kang, S.H.; Jung, S.O. An MTJ-based non-volatile flip-flop for high-performance SoC. Int. J. Circuit Theory Appl. 2014, 42, 394–406. [Google Scholar] [CrossRef]
- Ryu, K.; Kim, J.; Jung, J.; Kim, J.P.; Kang, S.H.; Jung, S.O. A magnetic tunnel junction based zero standby leakage current retention flip-flop. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2012, 20, 2044–2053. [Google Scholar] [CrossRef]
- Zhao, W.; Belhaire, E.; Chappert, C. Spin-mtj based non-volatile flip-flop. In Proceedings of the 2007 7th IEEE Conference on Nanotechnology (IEEE NANO), Hong Kong, China, 2–5 August 2007; pp. 399–402. [Google Scholar]
- Suzuki, D.; Hanyu, T. Magnetic-tunnel-junction based low-energy nonvolatile flip-flop using an area-efficient self-terminated write driver. J. Appl. Phys. 2015, 117, 17B504. [Google Scholar] [CrossRef]
- Kwon, K.W.; Choday, S.H.; Kim, Y.; Fong, X.; Park, S.P.; Roy, K. SHE-NVFF: Spin Hall effect-based nonvolatile flip-flop for power gating architecture. IEEE Electron Device Lett. 2014, 35, 488–490. [Google Scholar] [CrossRef]
- Kimura, H.; Fuchikami, T.; Maramoto, K.; Fujimori, Y.; Izumi, S.; Kawaguchi, H.; Yoshimoto, M. A 2.4 pJ ferroelectric-based non-volatile flip-flop with 10-year data retention capability. In Proceedings of the 2014 IEEE Asian Solid-State Circuits Conference (A-SSCC), KaoHsiung, Taiwan, 10–12 November 2014; pp. 21–24. [Google Scholar]
- Lo, C.P.; Chen, W.H.; Wang, Z.; Lee, A.; Hsu, K.H.; Su, F.; King, Y.C.; Lin, C.J.; Liu, Y.; Yang, H.; et al. A ReRAM-based single-NVM nonvolatile flip-flop with reduced stress-time and write-power against wide distribution in write-time by using self-write-termination scheme for nonvolatile processors in IoT era. In Proceedings of the 2016 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 3–7 December 2016. [Google Scholar]
- Na, T.; Ryu, K.; Kim, J.; Kang, S.H.; Jung, S.O. A comparative study of STT-MTJ based non-volatile flip-flops. In Proceedings of the 2013 IEEE International Symposium on Circuits and Systems (ISCAS), Beijing, China, 19–23 May 2013; pp. 109–112. [Google Scholar]
- Goldman, R.; Bartleson, K.; Wood, T.; Kranen, K.; Melikyan, V.; Babayan, E. 32/28nm Educational Design Kit: Capabilities, deployment and future. In Proceedings of the 2013 IEEE Asia Pacific Conference on Postgraduate Research in Microelectronics and Electronics (PrimeAsia), Visakhapatnam, India, 19–21 December 2013; pp. 284–288. [Google Scholar]
- Design Compiler; User Guide, Synopsys, 2000. Available online: https://www.synopsys.com/implementation-and-signoff/rtl-synthesis-test/design-compiler-graphical.html.
- IC Compiler, User Guide, Synopsys, 2013. Available online: https://www.synopsys.com/implementation-and-signoff/physical-implementation/ic-compiler.html.
- PrimeTime, User Guide version c-2009.06. Synopsys, June 2009. Available online: https://www.synopsys.com/content/dam/synopsys/implementation&signoff/datasheets/primetime-ds.pdf.
- Borkar, S. Design challenges of technology scaling. IEEE Micro 1999, 19, 23–29. [Google Scholar] [CrossRef]
- Verilog Compiler Simulator Synopsys, 2004. Available online: https://www.synopsys.com/verification/simulation/vcs.html.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Unit |
|---|---|---|
| Intrinsic critical current | 24 | A |
| Thermal stability factor | 58 | |
| Tunnel Magnetoresistance ratio (TMR) | ∼100 | % |
| Diameter of MTJ | 20 | nm |
| Out-of-plane magnetic field | 0.4 | T |
| MRAM-Based | FeRAM- | ReRAM- | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| This Work | [17] | [16] | [15] | [18] | [14] | [19] a | [20] | [21] | ||
| Technology node (nm) | 10 | 90 | 45 | 45 | 90 | 65 | 65 | 130 | 65 | |
| Area overhead b (%) | 6.9 | 131.0 | 160.0 | 120.0 | 103.4 | 109.0 | 28.0 | 64.0 | 32.0 | |
| Energy () | Storing | 0.2 | 175.5 | 1.9 | 1.6 | 0.3 | 5.0 | 0.5 | 2.4 | - |
| Restoring | 0.002 | - | 0.171 | 0.007 | - | 0.349 | 0.197 | - | - | |
| Delay () | Storing | 6.6 | - | - | - | 10.0 | 29.5 | 6.4 | 1640.0 | - |
| Restoring | 0.01 | 0.169 c | 2.0 | 0.184 | 1.0 | 2.0 | 2.0 | 1230.0 | 16.0 | |
| C-Q delay () | 43.8 | 318.1 c | 68.8 | 186.2 | 67.2 | 73.8 | - | - | <1 ns | |
| Power-Delay Product () | 0.3 | 2.8 c | 1.1 | 2.3 | 0.7 | 1.4 | - | - | - | |
| FF Area (m) | Total Area (m) | FF/Total (%) | NVFF Area (M) | Increased Area (%) | (mW) | + (pJ) | (ns) | |
|---|---|---|---|---|---|---|---|---|
| exu_alu | 429.5 | 15,022.5 | 2.9 | 459.1 | 0.2 | 1.8 | 72.6 | 40.8 |
| exu_div | 3714.6 | 12,218.2 | 30.4 | 3970.9 | 2.1 | 0.2 | 628.0 | 3924.0 |
| exu_ecl | 2319.3 | 6869.5 | 33.8 | 2479.4 | 2.3 | 0.1 | 392.1 | 4292.9 |
| exu_rml | 1729.2 | 4340.0 | 39.8 | 1848.5 | 2.7 | 0.4 | 733.1 | 1929.6 |
| ifu_dec | 277.5 | 4049.1 | 6.8 | 296.7 | 0.5 | 0.4 | 46.9 | 119.7 |
| ifu_fcl | 1785.6 | 5991.8 | 29.8 | 1908.8 | 2.1 | 0.5 | 301.9 | 616.6 |
| ffu_dp | 5466.6 | 13,722.1 | 39.8 | 5843.8 | 2.7 | 1.3 | 924.2 | 716.1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.; Yim, Y.U. Fine-Grained Power Gating Using an MRAM-CMOS Non-Volatile Flip-Flop. Micromachines 2019, 10, 411. https://doi.org/10.3390/mi10060411
Park J, Yim YU. Fine-Grained Power Gating Using an MRAM-CMOS Non-Volatile Flip-Flop. Micromachines. 2019; 10(6):411. https://doi.org/10.3390/mi10060411
Chicago/Turabian StylePark, Jaeyoung, and Young Uk Yim. 2019. "Fine-Grained Power Gating Using an MRAM-CMOS Non-Volatile Flip-Flop" Micromachines 10, no. 6: 411. https://doi.org/10.3390/mi10060411
APA StylePark, J., & Yim, Y. U. (2019). Fine-Grained Power Gating Using an MRAM-CMOS Non-Volatile Flip-Flop. Micromachines, 10(6), 411. https://doi.org/10.3390/mi10060411