
Construction and Validation of Cardiovascular Disease Prediction Model for Dietary Macronutrients—Data from the China Health and Nutrition Survey

Abstract
1. Introduction
2. Methods
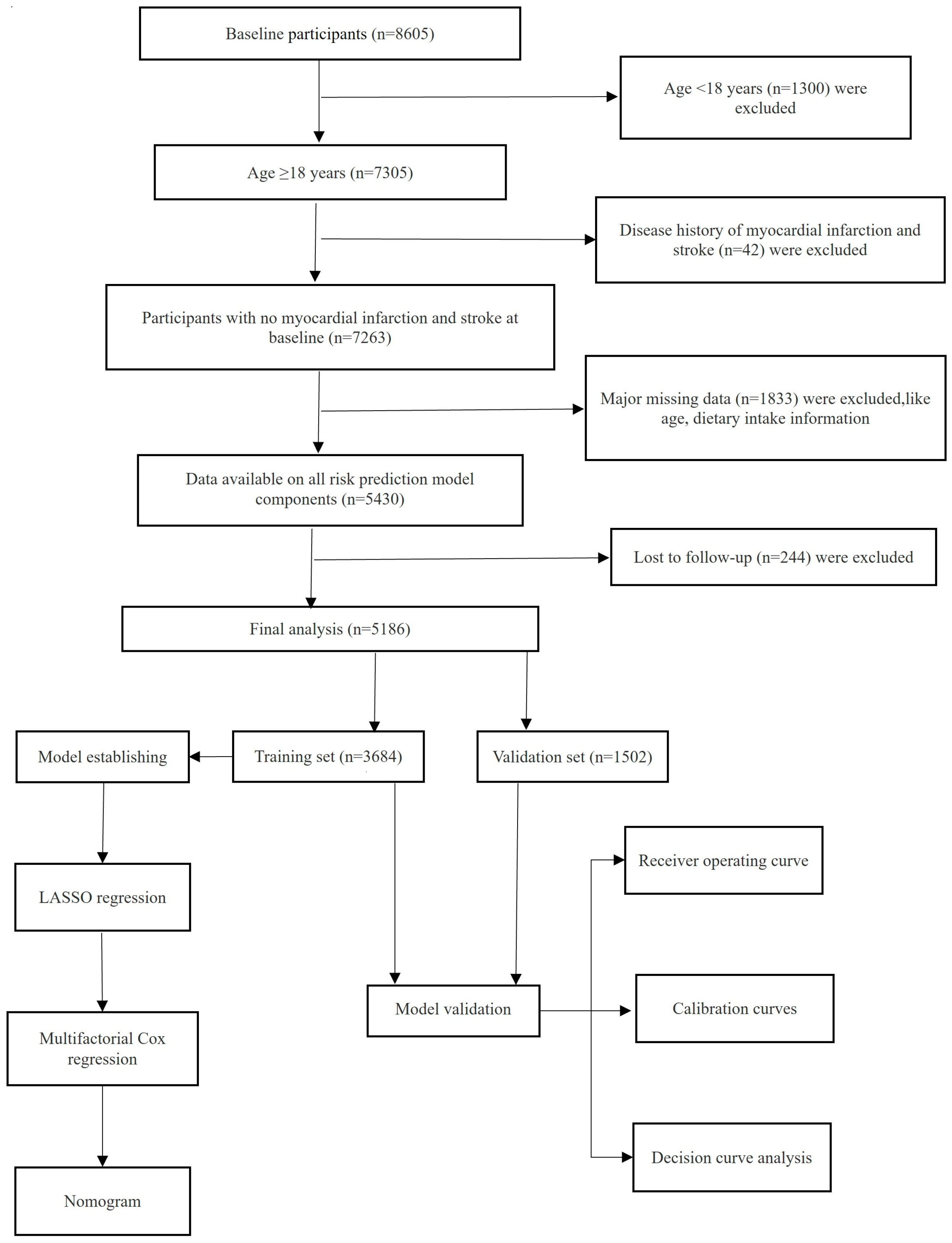
2.1. Study Design and Subject Selection
2.2. Data Collection
2.3. Diagnostic Criteria
2.4. Predictive Variable Selection
2.5. Statistical Analysis
3. Results
3.1. General Characteristics of Training and Validation Sets
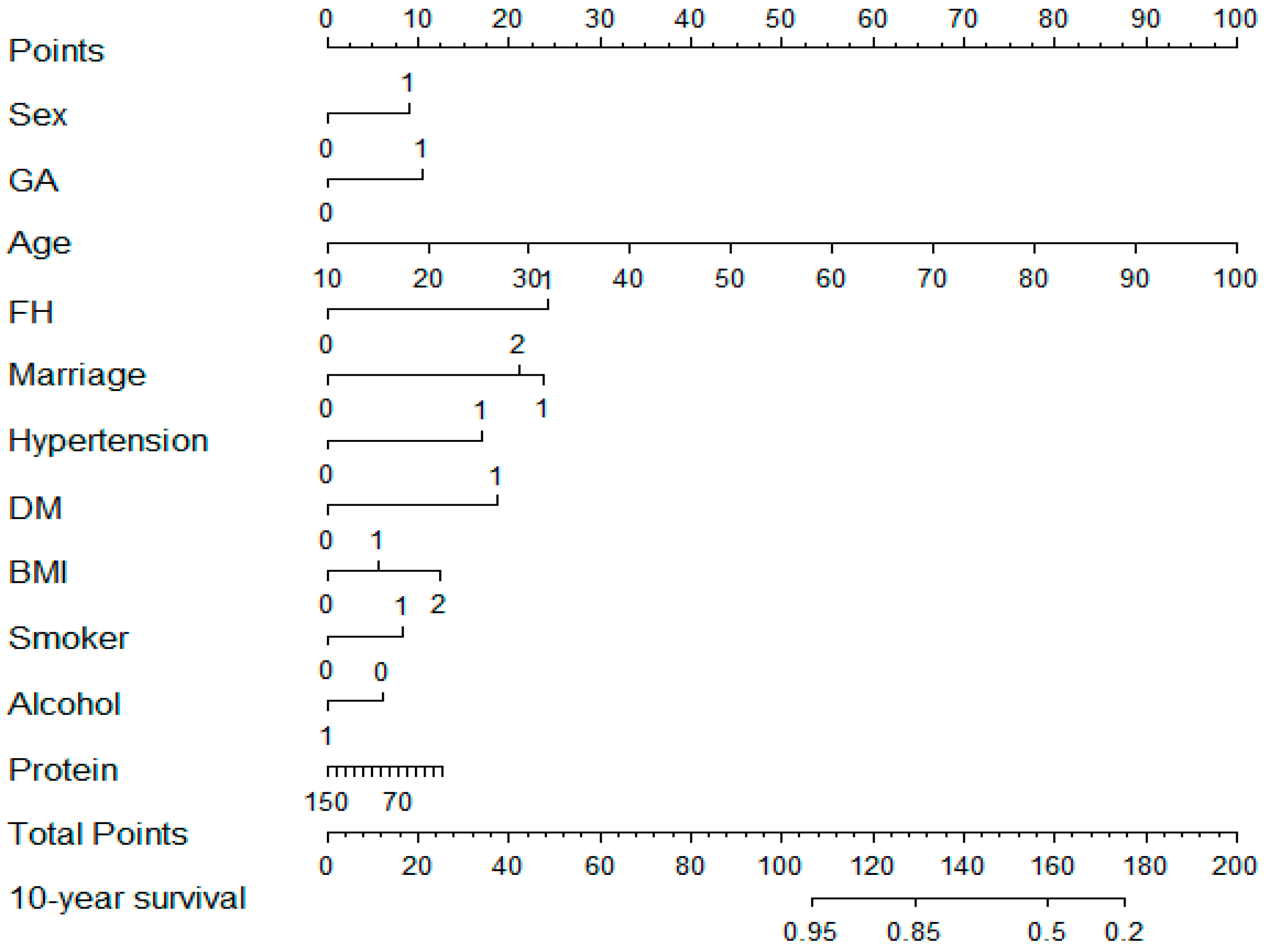
3.2. Construction of Prediction Models
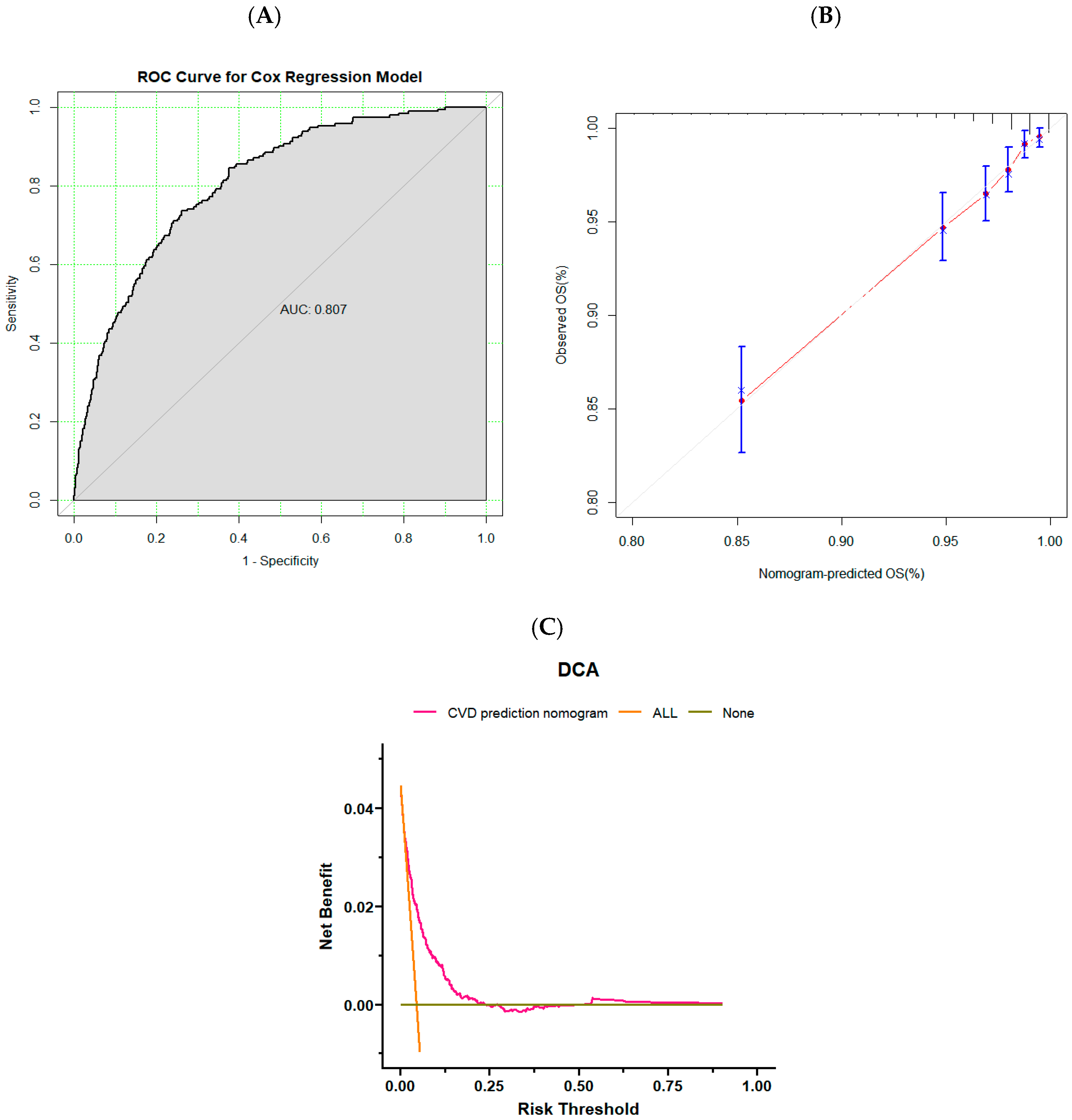
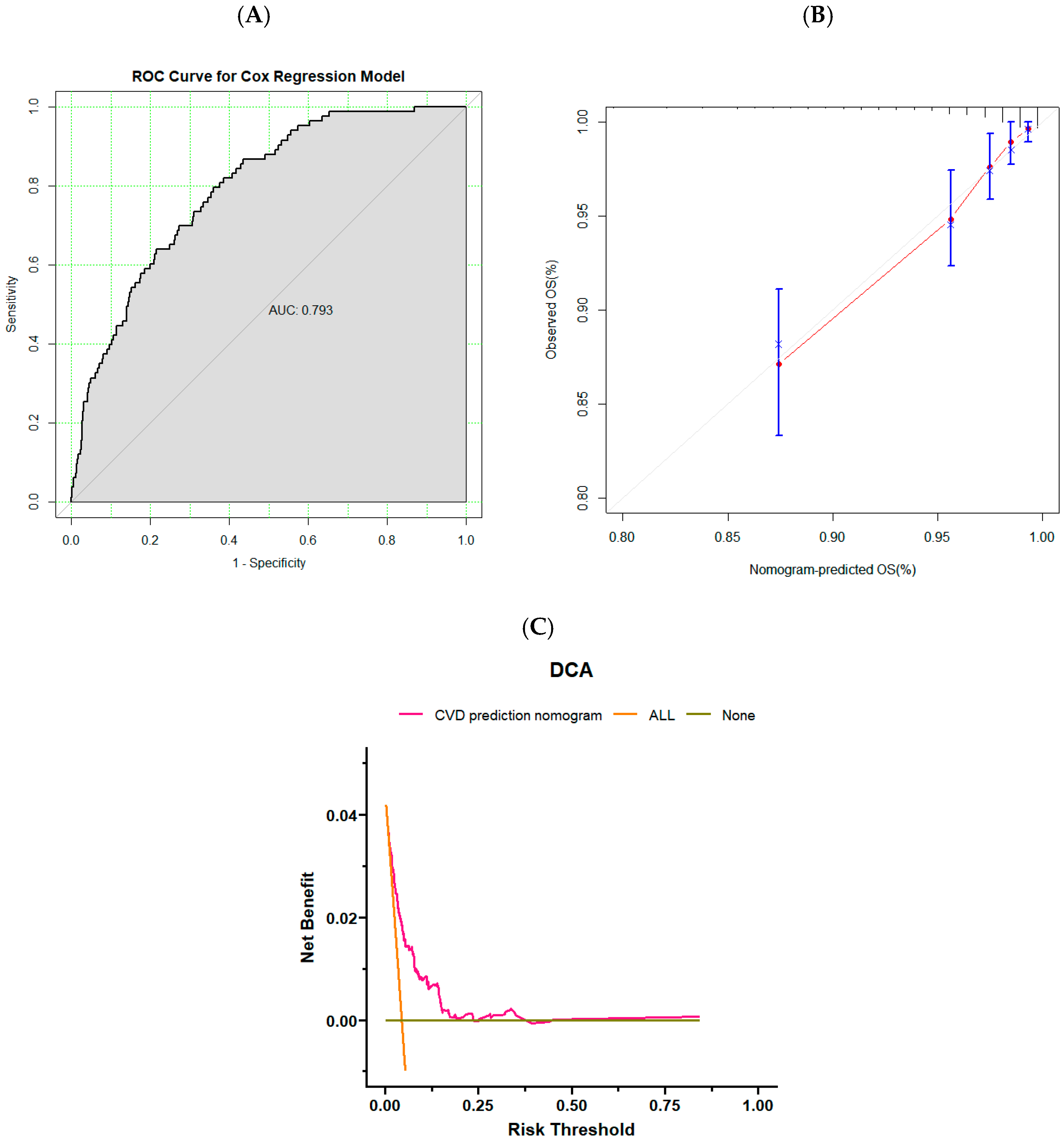
3.3. Validation of Risk Prediction Models
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vos, T.; Lim, S.S.; Abbafati, C.; Abbas, K.M.; Abbasi, M.; Abbasifard, M.; Abbasi-Kangevari, M.; Abbastabar, H.; Abd-Allah, F.; Abdelalim, A.; et al. Global Burden of 369 Diseases and Injuries in 204 Countries and Territories, 1990–2019: A Systematic Analysis for the Global Burden of Disease Study 2019. Lancet 2020, 396, 1204–1222. [Google Scholar] [CrossRef] [PubMed]
- Fahimfar, N.; Malekzadeh, R.; Fotouhi, A.; Mansournia, M.A.; Sarrafzadegan, N.; Azizi, F.; Sepanlou, S.G.; Mansourian, M.; Hadaegh, F.; Emamian, M.H.; et al. An Office-Based Cardiovascular Prediction Model Developed and Validated in Cohort Studies of a Middle-Income Country. J. Clin. Epidemiol. 2022, 146, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Tong, H.; Jiang, L.; Zhang, Y.; Hu, J. Trends and Disparities in China’s Cardiovascular Disease Burden from 1990 to 2019. Nutr. Metab. Cardiovasc. Dis. 2023, 33, 2344–2354. [Google Scholar] [CrossRef] [PubMed]
- The Writing Committee of the Report on Cardiovascular Health and Diseases in China. Report on Cardiovascular Health and Diseases in China 2022: An Updated Summary. Biomed. Environ. Sci. 2023, 36, 669–701. [Google Scholar]
- Zhang, Y.; Miao, H.; Chia, Y.C.; Buranakitjaroen, P.; Siddique, S.; Shin, J.; Turana, Y.; Park, S.; Tsoi, K.; Chen, C.H.; et al. Cardiovascular Risk Assessment Tools in Asia. J. Clin. Hypertens. 2022, 24, 369–377. [Google Scholar] [CrossRef]
- D’Agostino, R.B.; Vasan, R.S.; Pencina, M.J.; Wolf, P.A.; Cobain, M.; Massaro, J.M.; Kannel, W.B. General Cardiovascular Risk Profile for Use in Primary Care: The Framingham Heart Study. Circulation 2008, 117, 743–753. [Google Scholar] [CrossRef]
- Andrus, B.; Lacaille, D. 2013 ACC/AHA Guideline on the Assessment of Cardiovascular Risk. J. Am. Coll. Cardiol. 2014, 63, 2886. [Google Scholar] [CrossRef]
- Hippisley-Cox, J.; Coupland, C.; Brindle, P. Development and Validation of QRISK3 Risk Prediction Algorithms to Estimate Future Risk of Cardiovascular Disease: Prospective Cohort Study. BMJ 2017, 357, j2099. [Google Scholar] [CrossRef]
- Conroy, R.M.; Pyörälä, K.; Fitzgerald, A.E.; Sans, S.; Menotti, A.; De Backer, G.; De Bacquer, D.; Ducimetiere, P.; Jousilahti, P.; Keil, U.; et al. Estimation of Ten-Year Risk of Fatal Cardiovascular Disease in Europe: The SCORE Project. Eur. Heart J. 2003, 24, 987–1003. [Google Scholar] [CrossRef]
- Kaptoge, S.; Pennells, L.; De Bacquer, D.; Cooney, M.T.; Kavousi, M.; Stevens, G.; Riley, L.M.; Savin, S.; Khan, T.; Altay, S.; et al. World Health Organization Cardiovascular Disease Risk Charts: Revised Models to Estimate Risk in 21 Global Regions. Lancet Glob. Health 2019, 7, e1332–e1345. [Google Scholar] [CrossRef]
- Mahin, N.; Davood, K.; Mehdi, Y.; Ali, M.M.; Aryan, A.; Hossein, N.; Saharnaz, N. Validity of the Models Predicting 10-Year Risk of Cardiovascular Diseases in Asia: A Systematic Review and Prediction Model Meta-Analysis. PLoS ONE 2023, 18, e0292396. [Google Scholar]
- Yang, S.; Ding, Y.; Yu, C.; Guo, Y.; Pang, Y.; Sun, D.; Pei, P.; Yang, L.; Chen, Y.; Du, H.; et al. WHO Cardiovascular Disease Risk Prediction Model Performance in 10 Regions, China. Bull. World Health Organ. 2023, 101, 238–247. [Google Scholar] [CrossRef] [PubMed]
- Bendera, A.; Nakamura, K.; Seino, K.; Alemi, S. Performance of the Non-Laboratory Based 2019 WHO Cardiovascular Disease Risk Prediction Chart in Eastern Sub-Saharan Africa. Nutr. Metab. Cardiovasc. Dis. 2024, 34, 1448–1455. [Google Scholar] [CrossRef] [PubMed]
- Marsh, R.W. Predicting Cardiovascular Events Using Three Stage Discriminant Function Is Much More Accurate than Framingham or QRISK. Eur. J. Epidemiol. 2011, 26, 915–918. [Google Scholar] [CrossRef] [PubMed]
- Xueli, Y.; Jianxin, L.; Dongsheng, H.; Jichun, C.; Ying, L.; Jianfeng, H.; Xiaoqing, L.; Fangchao, L.; Jie, C.; Chong, S.; et al. Predicting the 10-Year Risks of Atherosclerotic Cardiovascular Disease in Chinese Population: The China-PAR Project (Prediction for ASCVD Risk in China). Circulation 2016, 134, 1430–1440. [Google Scholar]
- Niu, J.; Li, B.; Zhang, Q.; Chen, G.; Papadaki, A. Exploring the Traditional Chinese Diet and Its Association with Health Status—A Systematic Review. Nutr. Rev. 2024, nuae013. [Google Scholar] [CrossRef]
- Arnett, D.K.; Blumenthal, R.S.; Albert, M.A.; Buroker, A.B.; Goldberger, Z.D.; Hahn, E.J.; Dennison, H.C.; Amit, K.; Donald, L.-J.; William, M.J.; et al. 2019 ACC/AHA Guideline on the Primary Prevention of Cardiovascular Disease: A Report of the American College of Cardiology/American Heart Association Task Force on Clinical Practice Guidelines. Circulation 2019, 140, e596–e646. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, S.; Gu, X.; Qiu, H.; Zhang, Y. L-Shaped Association between Dietary Zinc Intake and the Risk of Developing Cardiovascular Disease in Chinese Adults: A Cohort Study. Front. Nutr. 2023, 10, 1032048. [Google Scholar] [CrossRef]
- Yu, E.; Malik, V.S.; Hu, F.B. Cardiovascular Disease Prevention by Diet Modification. J. Am. Coll. Cardiol. 2018, 72, 914–926. [Google Scholar] [CrossRef]
- Yang, S.; Han, Y.; Yu, C.; Guo, Y.; Pang, Y.; Sun, D.; Pei, P.; Yang, L.; Chen, Y.; Du, H.; et al. Development of a Model to Predict 10-Year Risk of Ischemic and Hemorrhagic Stroke and Ischemic Heart Disease Using the China Kadoorie Biobank. Neurology 2022, 98, e2307–e2317. [Google Scholar] [CrossRef]
- Joint Task Force for Guideline on the Assessment and Management of Cardiovascular Risk in China. Guideline on the Assessment and Management of Cardiovascular Risk in China. Chin. J. Prev. Med. 2019, 53, 13–35. [Google Scholar] [CrossRef]
- Development and Validation of Non-Invasive Prediction Models for Migraine in Chinese Adults. Available online: https://www.pmop.cn/pubmed/37926825 (accessed on 2 August 2024).
- Predicting Parkinson’s Disease and Its Pathology via Simple Clinical Variables. Available online: https://www.pmop.cn/pubmed/34602502 (accessed on 2 August 2024).
- Wilson, S.J.; Cole, S.W.; Shrout, M.R.; Malarkey, W.B.; Andridge, R.; Kiecolt-Glaser, J.K. Your Suffering Is My Stressor: Proinflammatory Gene Expression Rises with Spousal Distress in Middle-Aged and Older Couples. Psychoneuroendocrinology 2023, 153, 106116. [Google Scholar] [CrossRef] [PubMed]
- Choi, E.; Shimbo, D.; Chen, L.; Foti, K.; Ghazi, L.; Hardy, S.T.; Muntner, P. Trends in All-Cause, Cardiovascular, and Noncardiovascular Mortality Among US Adults with Hypertension. Hypertension 2024, 81, 1055–1064. [Google Scholar] [CrossRef] [PubMed]
- Surendran, P.; Drenos, F.; Young, R.; Warren, H.; Cook, J.P.; Manning, A.K.; Grarup, N.; Sim, X.; Barnes, D.R.; Witkowska, K.; et al. Trans-Ancestry Meta-Analyses Identify Rare and Common Variants Associated with Blood Pressure and Hypertension. Nat. Genet. 2016, 48, 1151–1161. [Google Scholar] [CrossRef] [PubMed]
- Estruch, R.; Sacanella, E.; Badia, E.; Antúnez, E.; Nicolás, J.M.; Fernández-Solá, J.; Rotilio, D.; De Gaetano, G.; Rubin, E.; Urbano-Márquez, A. Different Effects of Red Wine and Gin Consumption on Inflammatory Biomarkers of Atherosclerosis: A Prospective Randomized Crossover Trial. Atherosclerosis 2004, 175, 117–123. [Google Scholar] [CrossRef] [PubMed]
- Kang, D.O.; Lee, D.-I.; Roh, S.-Y.; Na, J.O.; Choi, C.U.; Kim, J.W.; Kim, E.J.; Rha, S.-W.; Park, C.G.; Kim, Y.-S.; et al. Reduced Alcohol Consumption and Major Adverse Cardiovascular Events Among Individuals with Previously High Alcohol Consumption. JAMA Netw. Open 2024, 7, e244013. [Google Scholar] [CrossRef] [PubMed]
- Ahmadi, S.-F.; Streja, E.; Zahmatkesh, G.; Streja, D.; Kashyap, M.; Moradi, H.; Molnar, M.Z.; Reddy, U.; Amin, A.N.; Kovesdy, C.P.; et al. Reverse Epidemiology of Traditional Cardiovascular Risk Factors in the Geriatric Population. J. Am. Med. Dir. Assoc. 2015, 16, 933–939. [Google Scholar] [CrossRef]
- Qiong, W.; Yang, Z.; Lihua, L.; Yuehui, L.; Jianchao, L. Trend, Regional Variation and Socioeconomic Inequality in Cardiovascular Disease among the Elderly Population in China: Evidence from a Nationwide Longitudinal Study during 2011–2018. BMJ Glob. Health 2023, 8, e013311. [Google Scholar]
- Manas, C.; Sankara, S.P.; Sivadasanpillai, H.; Geevar, Z.; Panniyammakal, J. Family History of Cardiovascular Disease and Risk of Premature Coronary Heart Disease: A Matched Case-Control Study. Wellcome Open Res. 2020, 5, 70. [Google Scholar]
- Jae, K.S.; Deog, K.O.; EungJoon, L.; Myeong, O.S.; KyungSoo, K. Impact of a Family History of Cardiovascular Disease on Prevalence, Awareness, Treatment, Control of Dyslipidemia, and Healthy Behaviors: Findings from the Korea National Health and Nutrition Examination Survey. PLoS ONE 2021, 16, e0254907. [Google Scholar]
- Chareonrungrueangchai, K.; Wongkawinwoot, K.; Anothaisintawee, T.; Reutrakul, S. Dietary Factors and Risks of Cardiovascular Diseases: An Umbrella Review. Nutrients 2020, 12, 1088. [Google Scholar] [CrossRef]
- Koemel, N.A.; Senior, A.M.; Celermajer, D.S.; Grech, A.; Gill, T.P.; Simpson, S.J.; Raubenheimer, D.; Skilton, M.R. Multi-Nutrient Analysis of Dietary Macronutrients with All-Cause, Cardiovascular, and Cancer Mortality: Data from NHANES 1999–2014. Nutrients 2023, 15, 345. [Google Scholar] [CrossRef] [PubMed]
- Ma, Y.; Zheng, Z.; Zhuang, L.; Wang, H.; Li, A.; Chen, L.; Liu, L. Dietary Macronutrient Intake and Cardiovascular Disease Risk and Mortality: A Systematic Review and Dose-Response Meta-Analysis of Prospective Cohort Studies. Nutrients 2024, 16, 152. [Google Scholar] [CrossRef] [PubMed]
- Hu, F.B. Protein, Body Weight, and Cardiovascular Health. Am. J. Clin. Nutr. 2005, 82, 242S–247S. [Google Scholar] [CrossRef] [PubMed]
- Layman, D.K. Dietary Guidelines Should Reflect New Understandings about Adult Protein Needs. Nutr. Metab. 2009, 6, 12. [Google Scholar] [CrossRef]
- Richter, C.K.; Skulas-Ray, A.C.; Champagne, C.M.; Kris-Etherton, P.M. Plant Protein and Animal Proteins: Do They Differentially Affect Cardiovascular Disease Risk? Adv. Nutr. 2015, 6, 712–728. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total (n = 5186) | Validation Set (n = 1502) | Training Set (n = 3684) | p-Value | |
|---|---|---|---|---|
| Follow-up time, y | 9.81 ± 2.23 | 9.84 ± 2.20 | 9.81 ± 2,24 | 0.648 |
| Age, y | 46.89 ± 13.51 | 46.65 ± 13.50 | 46.99 ± 13.52 | 0.412 |
| Sex, n (%) | 0.524 | |||
| Male | 2496 (48.1) | 712 (47.4) | 1784 (48.4) | |
| Female | 2690 (51.9) | 790 (52.6) | 790 (52.6) | |
| Geographic area, n (%) | 0.030 | |||
| North | 2122 (40.9) | 650 (43.3) | 1472 (40.0) | |
| South | 3064 (59.1) | 852 (56.7) | 2212 (60.0) | |
| Urbanization, n (%) | 0.198 | |||
| Urban | 1427 (27.5) | 394 (26.2) | 1033 (28.0) | |
| Rural | 3759 (72.5) | 1108 (73.8) | 2651 (72.0) | |
| Marriage, n (%) | 0.422 | |||
| Unmarried | 351 (6.8) | 91 (6.1) | 260 (7.1) | |
| Married | 4518 (87.1) | 1320 (87.9) | 3198 (86.8) | |
| Divorced or widowed | 317 (6.1) | 91 (6.1) | 226 (6.1) | |
| Education, n (%) | 0.119 | |||
| Less than high school | 2367 (45.6) | 678 (45.1) | 1689 (45.9) | |
| High school or above | 2819 (54.4) | 824 (54.9) | 1995 (54.1) | |
| Family history of CVD, n (%) | 0.301 | |||
| Yes | 319 (6.2) | 101 (6.7) | 218 (5.9) | |
| No | 4867 (93.8) | 1401 (93.3) | 3466 (94.1) | |
| Hypertension, n (%) | 0.262 | |||
| Yes | 362 (7.0) | 95 (6.3) | 267 (7.2) | |
| No | 4824 (93.0) | 1407 (93.7) | 3417 (92.8) | |
| Antihypertensive therapy, n (%) | 0.319 | |||
| Yes | 243 (4.7) | 63 (4.2) | 180 (4.9) | |
| No | 4943 (95.3) | 1439 (95.8) | 3504 (95.1) | |
| Diabetes mellitus, n (%) | 0.774 | |||
| Yes | 47 (0.9) | 15 (1.0) | 32 (0.9) | |
| No | 5139 (99.1) | 1487 (99.0) | 3652 (99.1) | |
| BMI, n (%) | 0.298 | |||
| <24.0 | 3362 (64.8) | 998 (66.4) | 2364 (64.2) | |
| 24.0 to <28.0 | 1414 (27.3) | 391 (26.0) | 1023 (27.8) | |
| ≥28 | 410 (7.9) | 113 (7.5) | 297 (8.1) | |
| Smoker, n (%) | 0.905 | |||
| Yes | 1739 (33.5) | 506 (33.7) | 1233 (33.5) | |
| No | 3447 (66.5) | 996 (66.3) | 2451 (66.5) | |
| Alcohol, n (%) | 0.743 | |||
| Yes | 1749 (33.5) | 501 (33.4) | 1248 (33.9) | |
| No | 3437 (66.5) | 1001 (66.6) | 2436 (66.1) | |
| Averagedaily kcal intake, kcal | 2238.69 ± 640.43 | 2214.31 ± 636.71 | 2248.63 ± 641.76 | 0.080 |
| Average daily carbohydrate intake, g | 332.27 ± 105.57 | 328.86 ± 103.79 | 333.66 ± 106.28 | 0.137 |
| Average daily fat intake, g | 67.94 ± 35.20 | 67.07 ± 35.94 | 68.30 ± 34.89 | 0.256 |
| Average daily protein intake, g | 66.95 ± 22.68 | 66.23 ± 22.51 | 67.24 ± 34.89 | 0.145 |
| Characteristics | LASSO Regression | Multifactorial Cox Regression Analysis | |||
|---|---|---|---|---|---|
| Coefficients | λ. 1 min | Hazard Ratio | 95% CI | p-Value | |
| Sex | 0.3482311288 | 0.0007369600 | 1.577 | 1.060, 2.344 | <0.05 |
| Age | 0.0559861979 | 1.057 | 1.044, 1.071 | <0.05 | |
| Geographic area | 0.4996928955 | 1.697 | 1.258, 2.290 | <0.05 | |
| Urbanization | −0.0359183200 | - | - | - | |
| Family history of CVD | 1.1926354994 | 3.369 | 2.322, 4.887 | <0.05 | |
| Marriage | 0.0610897230 | - | - | - | |
| Unmarried | - | - | - | - | |
| Married | - | 3.278 | 0.803, 13.388 | 0.098 | |
| Divorced or widowed | - | 2.883 | 0.649, 12.801 | 0.164 | |
| Hypertension | 0.8170091153 | 2.353 | 1.662, 3.333 | <0.05 | |
| Antihypertensive | 0.0660699743 | - | - | - | |
| Diabetes mellitus | 0.7864943617 | 2.552 | 1.221, 5.333 | <0.05 | |
| BMI | 0.2907036033 | - | - | - | |
| <24.0 | - | - | - | - | |
| 24.0 to <28.0 | - | 1.328 | 0.958, 1.839 | 0.088 | |
| ≥28 | - | 1.856 | 1.198, 2.875 | <0.05 | |
| Smoker | 0.3947906943 | 1.512 | 1.048, 2.181 | <0.05 | |
| Alcohol | −0.2245586523 | 0.732 | 0.515, 1.039 | <0.05 | |
| Average daily carbohydrate intake | 0.0007983668 | - | - | - | |
| Average daily protein intake | −0.0060387404 | 0.995 | 0.9884, 1.002 | 0.162 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, J.; Dai, Y.; Peng, Y.; Zhang, L.; Jia, H. Construction and Validation of Cardiovascular Disease Prediction Model for Dietary Macronutrients—Data from the China Health and Nutrition Survey. Nutrients 2024, 16, 4180. https://doi.org/10.3390/nu16234180
Guo J, Dai Y, Peng Y, Zhang L, Jia H. Construction and Validation of Cardiovascular Disease Prediction Model for Dietary Macronutrients—Data from the China Health and Nutrition Survey. Nutrients. 2024; 16(23):4180. https://doi.org/10.3390/nu16234180
Chicago/Turabian StyleGuo, Jia, Yanyan Dai, Yating Peng, Liangchuan Zhang, and Hong Jia. 2024. "Construction and Validation of Cardiovascular Disease Prediction Model for Dietary Macronutrients—Data from the China Health and Nutrition Survey" Nutrients 16, no. 23: 4180. https://doi.org/10.3390/nu16234180
APA StyleGuo, J., Dai, Y., Peng, Y., Zhang, L., & Jia, H. (2024). Construction and Validation of Cardiovascular Disease Prediction Model for Dietary Macronutrients—Data from the China Health and Nutrition Survey. Nutrients, 16(23), 4180. https://doi.org/10.3390/nu16234180