1. Introduction
Hyperspectral images (HSIs) enjoy the rich information underlying hundreds of spectral bands, having demonstrated a strong discrimination ability to divide land covers, particularly for those that show extremely similar signatures in color space [
1]. As a result, HSIs have been widely used for some high-level Earth observation tasks like mineral analysis, mineral exploration, precision agriculture, military monitoring, etc. However, in practical applications, annotating a large number of pixels is cumbersome and intractable [
2], which forces us to consider classifying land covers in an unsupervised way, i.e., clustering. Clustering is a classic topic in data mining; it partitions pixels into different groups by specific distance (or similarity) criteria such that similar pixels are assigned to the same group. HSI clustering is a pixel-level clustering task that can be roughly divided into the centroid-based method, density-based method, subspace-based method, deep-based method, and graph-based method. The centroid-based method forces pixels close to the nearest centroid during iterations. Classic methods include K-means [
3], fuzzy C-means [
4], and kernel K-means [
5]. It is well known that the centroid-based method is extremely sensitive to the initialization of the centroid, resulting in unstable performance [
6]. The density-based method achieves clustering via the density differences of pixels in a particular space. A basic assumption is that highly dense pixels belong to the same cluster, and sparse pixels are outliers or boundary points. For this branch, the representative method DBSCAN [
7] has demonstrated a strong clustering ability for arbitrary shapes of data, but it may fail to address relatively balanced data distribution. The subspace-based method assumes that all the data can be presented in a self-expressed way. Classic algorithms include diffusion-subspace-based clustering [
8], sparse-subspace-based clustering [
9], and dictionary-learning-based subspace clustering [
10]. These methods often suffer from a heavy computational burden, limiting their scalability to large-scale data. Inspired by cluster hierarchical building, HESSC [
11] proposed a sparse subspace clustering method that has a lower calculation burden. Moreover, thanks to the rapid development of deep learning, many deep-learning-based methods have been proposed for HSI clustering. Recent deep-learning-based works have studied graph neural networks (GNNs) [
12] and the Transformer architecture [
13] for HSI clustering. More recently, a lightweight contrast learning deep model [
14] was proposed, which requires fewer model parameters than most backbones. However, current deep-learning-based methods still have poor theoretical explainability.
The graph-based method, as an important branch of HSI clustering, has been widely studied in recent years. The graph-based method learns a graph representation to model the paired relations between any two pixels and then partitions the clusters based on the learned graph [
15]. Some classic methods [
16,
17] involve learning a symmetrical pixel–pixel graph, which needs
memory complexity and, in general,
computational complexity, where
n denotes the number of pixels. Therefore, the high storage and calculation burden means that these methods can only handle small-scale HSI datasets, and they become much slower as the number
n of pixels increases. To solve the problem, large-scale HSI clustering has become the key study direction, which can be roughly divided into superpixel-based methods and anchor-based methods. Superpixel-based methods use classic superpixel segmentation models like entropy rate superpixel (ERS) [
18] or simple linear iterative clustering (SLIC) [
19] to group similar pixels located in local neighborhoods. Pixels in the same group are generally linearly weighted as a representative pixel termed a superpixel. These superpixels are built as a symmetrical superpixel–superpixel graph to achieve clustering. Therefore, the superpixel-based method drops memory complexity to
and computational complexity to
, where
M is the number of superpixels. As
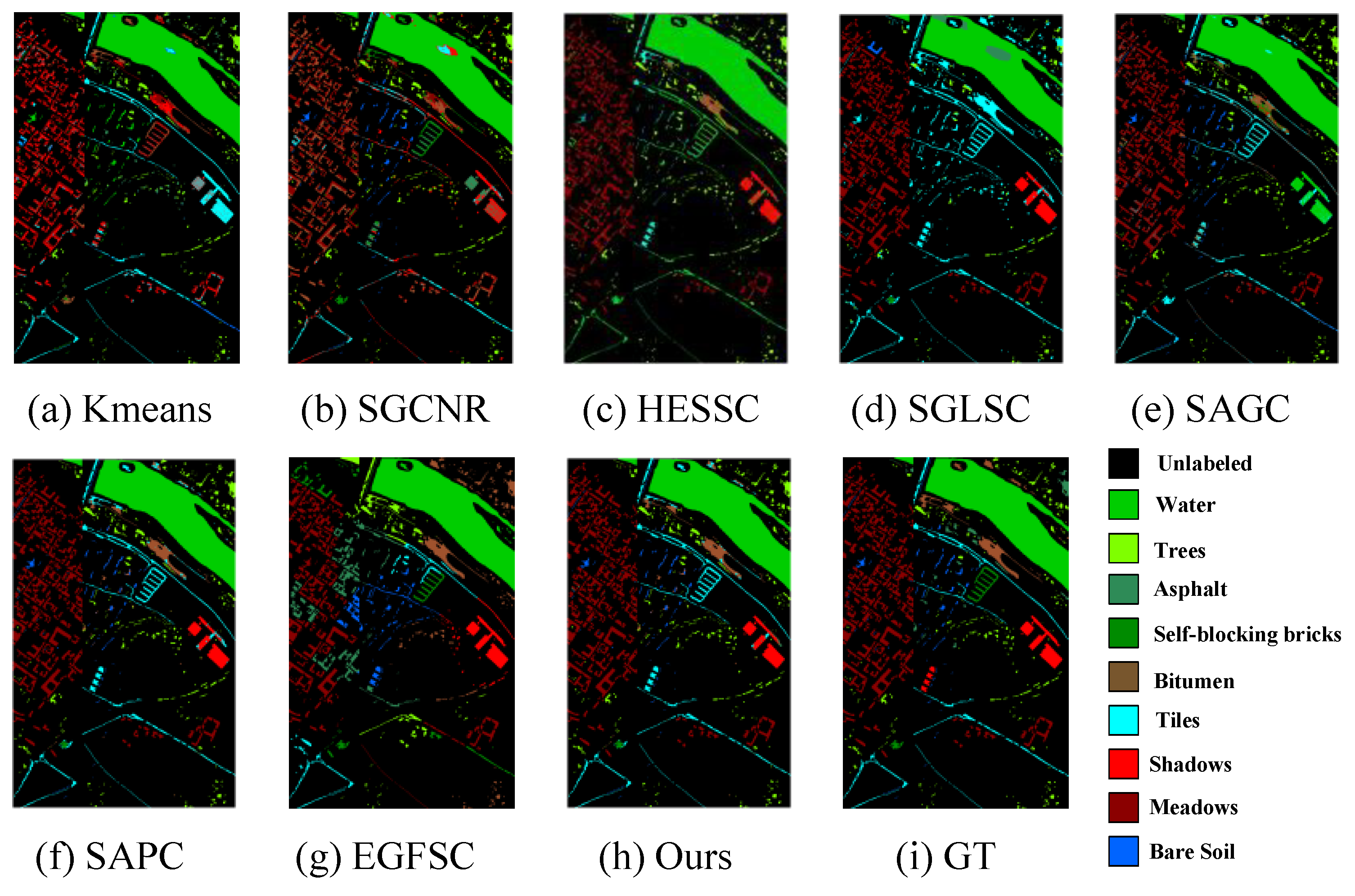
, it can be extended to large-scale HSI datasets. For this line, some representative works have been proposed. SGLSC [
20] proposed a superpixel-level graph-learning method from both global and local aspects. The global graph is built in a self-expressed way, while the local graph is built by using the Manhattan distance to retain the nearest four superpixels. After fusing global and local graphs, spectral clustering is used to obtain the final results. More recently, EGFSC [
21] simultaneously learned a superpixel-level graph and spectral-level graph for fusion. As EGFSC is a multistage model free of iterations, it is much faster than SGLSC. However, superpixel-based models have an internal limitation, i.e., they regard all the pixels in one superpixel as the same cluster. Therefore, these models cannot obtain high-quality pixel-level clustering results, and their performance is highly sensitive to the number of superpixels.
The anchor-based method is more popular for large-scale HSI clustering, which selects
m representative anchors (
) to learn a pixel–anchor graph for clustering, and, thus, both memory and computational complexity are dropped as a linear relation to
n. Some works [
22,
23] have used random sampling or K-means to generate anchors for pixel–anchor graph learning and then partition the clusters by conducting singular value decomposition (SVD) and extra discretization operations. To generate more reasonable anchors, a recent model, SAGC [
24], used ERS to obtain superpixels and regarded the center of each superpixel as an anchor. By this way, the selected anchors reflect the spatial context, unveiling exact pixel–anchor relations. However, the multistage process and the instability of postprocessing still limit the clustering performance. More efforts have been spent to design a one-step paradigm. For example, SGCNR [
25] proposed a non-negative and orthogonal relaxation method to directly obtain the cluster indicator from low-dimensional embeddings. GNMF [
26] proposed a unified framework that conducts non-negative matrix factorization to yield the soft cluster indicator. SSAFC [
27] proposed a joint learning framework of self-supervised spectral clustering and fuzzy clustering to directly generate the soft cluster indicator. By learning an anchor–anchor graph to provide cluster results, SAPC [
28] achieves large-scale HSI clustering via label propagation. Moreover, a structured bipartite-graph-based HSI clustering model termed BGPC [
29] is proposed, which conducts low-rank constraint to bipartite graphs, directly providing cluster results via connectivity. Although many efforts have been made, current works confront two problems: First, performing SVD on an
pixel–anchor graph leads to
complexity, which is still a little high. Second, many current works are based on the graph learning mode of CAN [
30]. However, CAN ignored the symmetry condition of graph during the process of affinity estimation, which always generates a suboptimal graph with poor clustering results. Moreover, although some doubly stochastic graph learning methods (like DSN [
31]) have been proposed to solve the problem, they rely on predefined graph inputs due to the difficulty of optimization design.
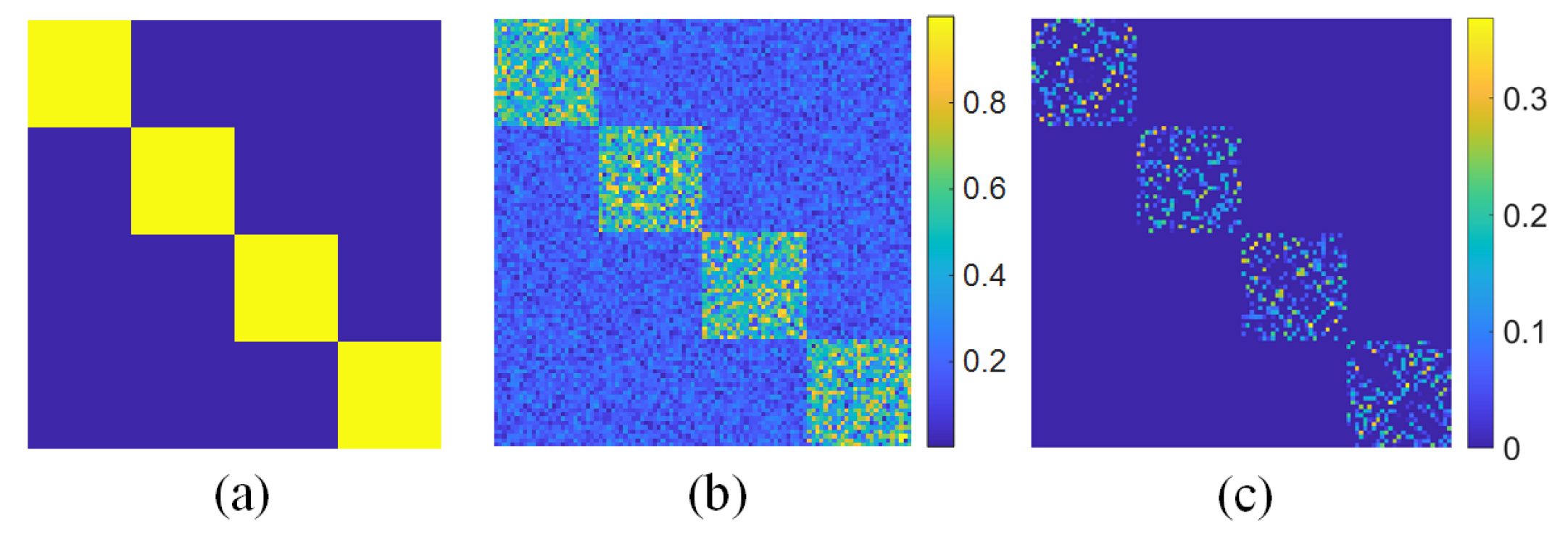
To address the issues, this paper introduces a large-scale hyperspectral image projected clustering model (abbreviated as HPCDL) via doubly stochastic graph learning. The main contributions of this paper are as follows:
We introduce HPCDL (Code has been published at
https://github.com/NianWang-HJJGCDX/HPCDL.git) (accessed on 18 February 2025), a unified framework that learns a projected feature space to simultaneously build a pixel–anchor graph and an anchor–anchor graph. The doubly stochastic constraints (symmetric, non-negative, row sum being 1) are applied to the anchor–anchor graph, combining affinity estimation and graph symmetry into one step, which ultimately produces a better graph with strict probabilistic affinity. The learned anchor–anchor graph directly derives anchor cluster indicators via its connectivity and propagates labels to pixel-level clusters through nearest-neighbor relationships in the pixel–anchor graph.
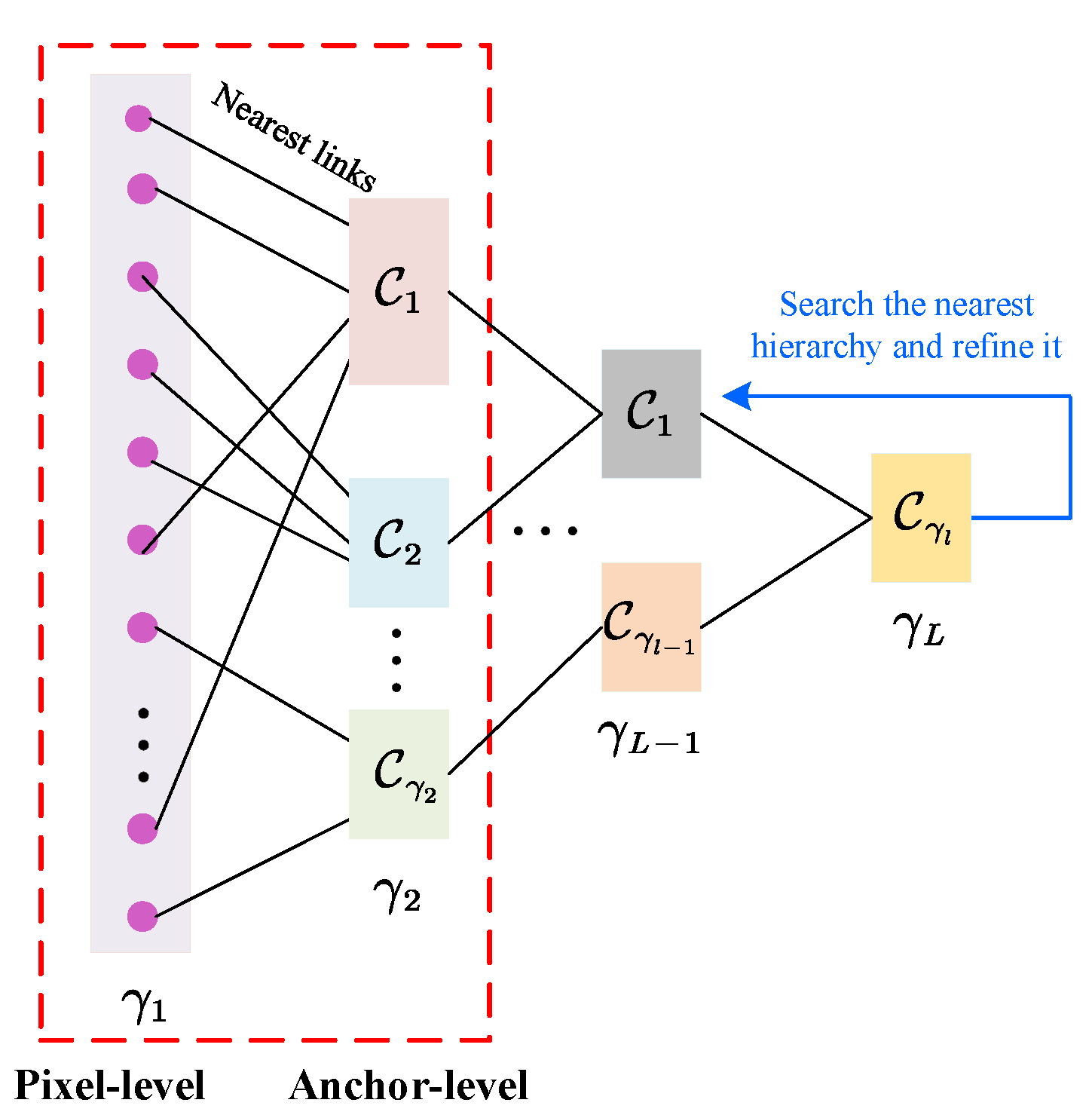
We analyze the relationship between the proposed HPCDL and existing hierarchical clustering models from a theoretical perspective while also providing in-depth insights.
We design an effective optimization scheme. Specifically, we first deduce a key equivalence relation and propose a novel method for optimizing the subproblem with doubly stochastic constraints. Unlike the widely used von Neumann successive projection (VNSP) lemma, our method does not require decomposition of the doubly stochastic constraints for alternating projections. Instead, it optimizes all constraints simultaneously, thereby guaranteeing convergence to a globally optimal solution.
The experiments on three widely used HSI datasets demonstrate that our method achieves state-of-the-art (SOTA) clustering performance while maintaining low computational costs, making it easily extensible to large-scale datasets.
Organization:
Section 2 introduces related works.
Section 3 illustrates the proposed HPCDL and then designs an effective optimization scheme.
Section 4 conducts experiments to verify the merits of our proposed model.
Section 5 discusses the motivation, parameters, and limitations.
Section 6 concludes the paper with future research directions.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}