
Multi-Feature Lightweight DeeplabV3+ Network for Polarimetric SAR Image Classification with Attention Mechanism

 , , ,
, , ,
Abstract
1. Introduction
- (1)
- A novel multi-feature deep attention network is proposed, which fully exploits diverse types of polarimetric features as the input, and automatically integrate the multi-feature learning, selection and classification into a unified framework. The multiple features include PolSAR original data, scattering features and image features, providing complementary information from different perspectives.
- (2)
- A lightweight DeeplabV3+ is developed as the backbone network of the MFDAnet. This architecture facilitates the learning of both multi-scale and multi-feature information, designing a lightweight scheme tailed for PolSAR images, ensuring a fast and effective network.
- (3)
- Attention mechanism-based feature selection module is embedded in the proposed MLDnet, adaptively learning weights of multi-dimensional features. This module enhances valuable features and suppresses redundant ones, thereby improving the classification performance.
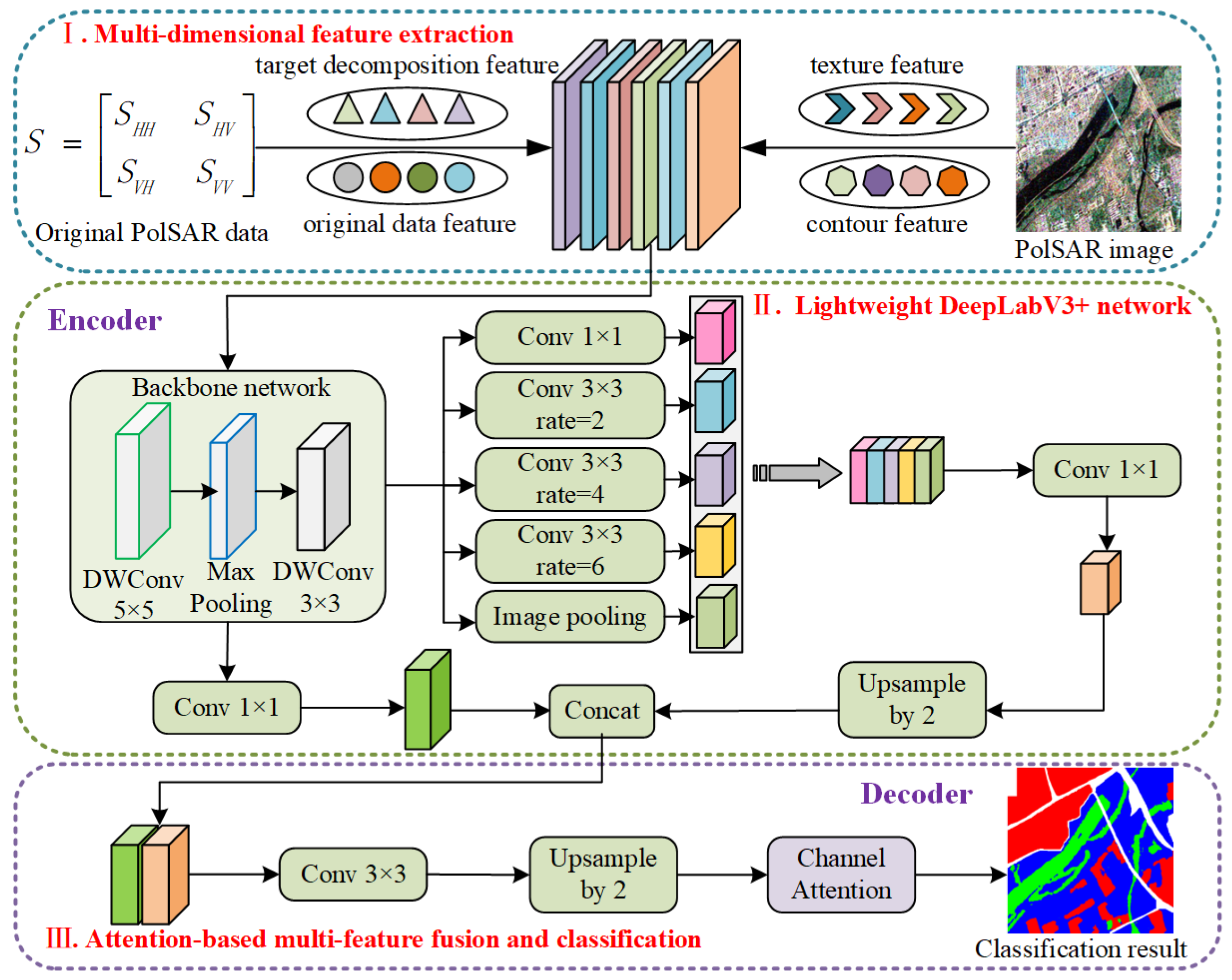
2. Proposed Method
2.1. Multi-Feature Extraction Module
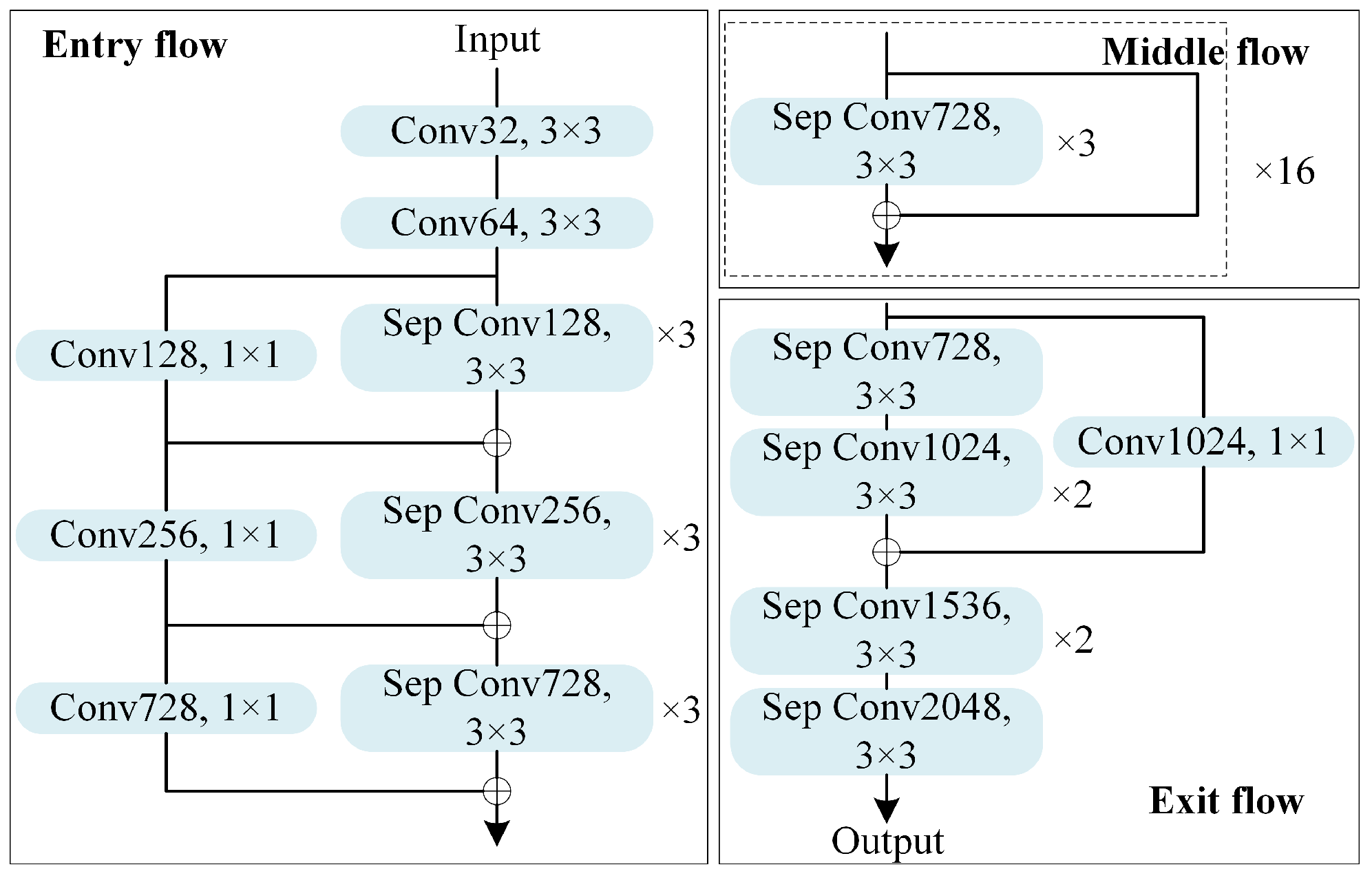
2.2. Lightweight DeepLabV3+ Network
2.3. Attention-Based Multi-Feature Fusion and Classification
| Algorithm 1 Procedure of the proposed MLDnet method. |
| Input: PolSAR original data , PolSAR original image , class label map and class number . Step 1: Apply a refined Lee filter to PolSAR original image to obtain the filtered PolSAR image . Step 2: Extract 57-dimensional features F from PolSAR image and PolSAR original data based on Table 1. Step 3: Using a fixed-size square window to sample the extracted 57-dimensional features F pixel by pixel, obtaining N data with a shape of , where N is the total number of image pixels. Step 4: According to a certain ratio, the N data obtained in step 3 and the label map L are divided into training set and test set . Step 5: Import the training set into the MLDnet network for training until reaching the iteration number, saving the training model, training loss, and model parameters. Step 6: Using the trained model to predict and classify the test set . Output: class label estimation map and various evaluation indicators. |
3. Experimental Results
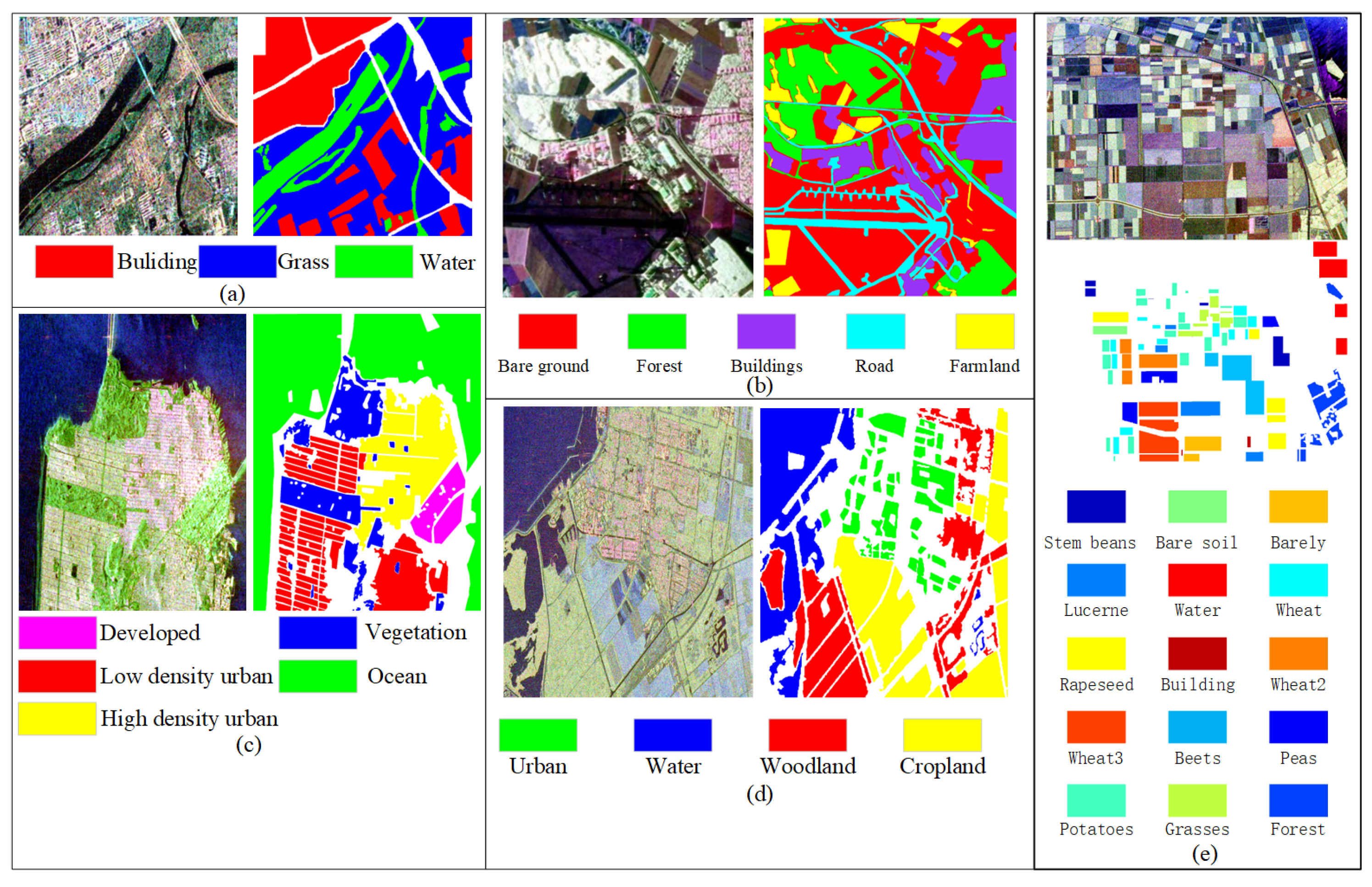
3.1. Experimental Data and Settings
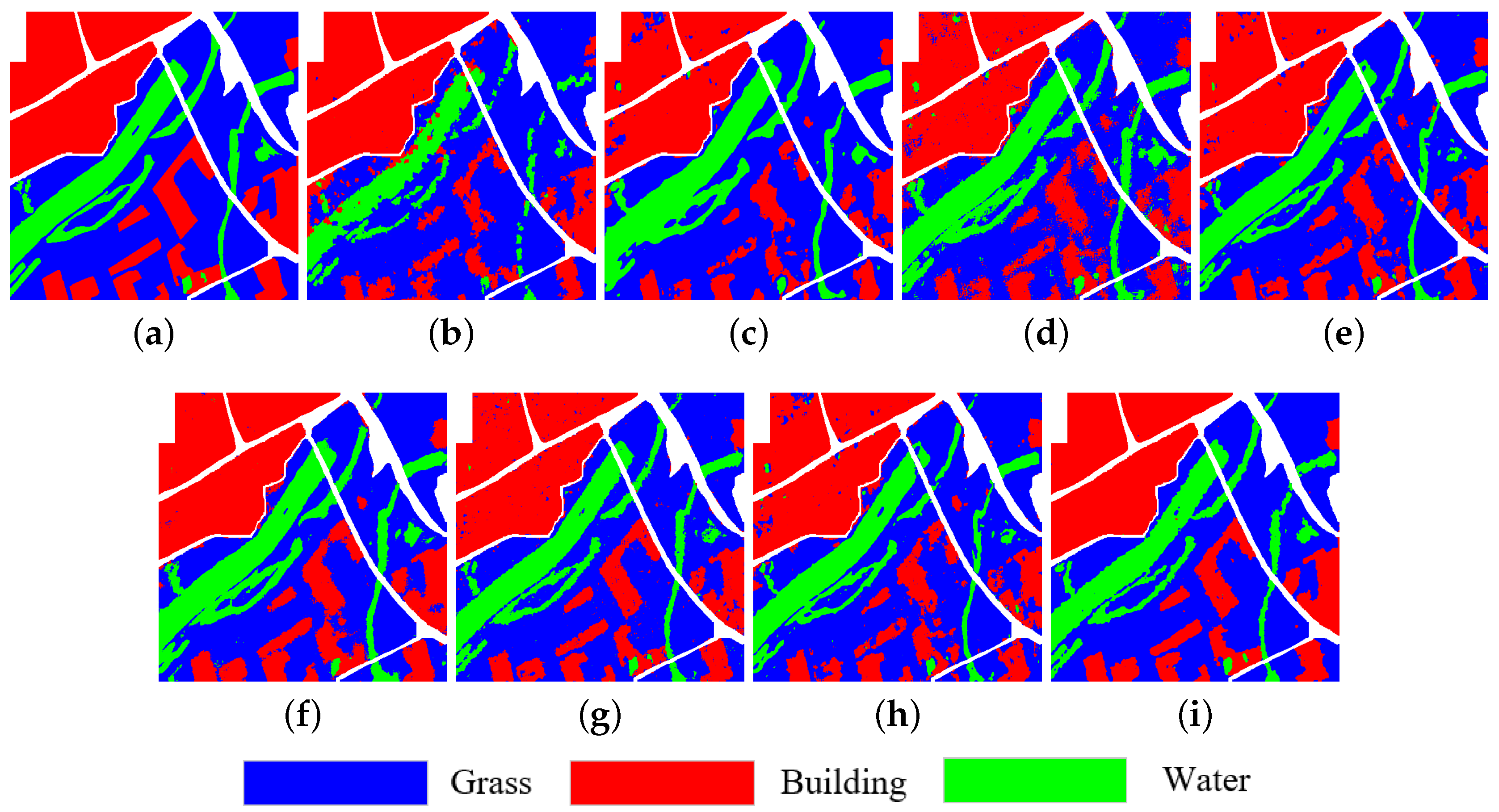
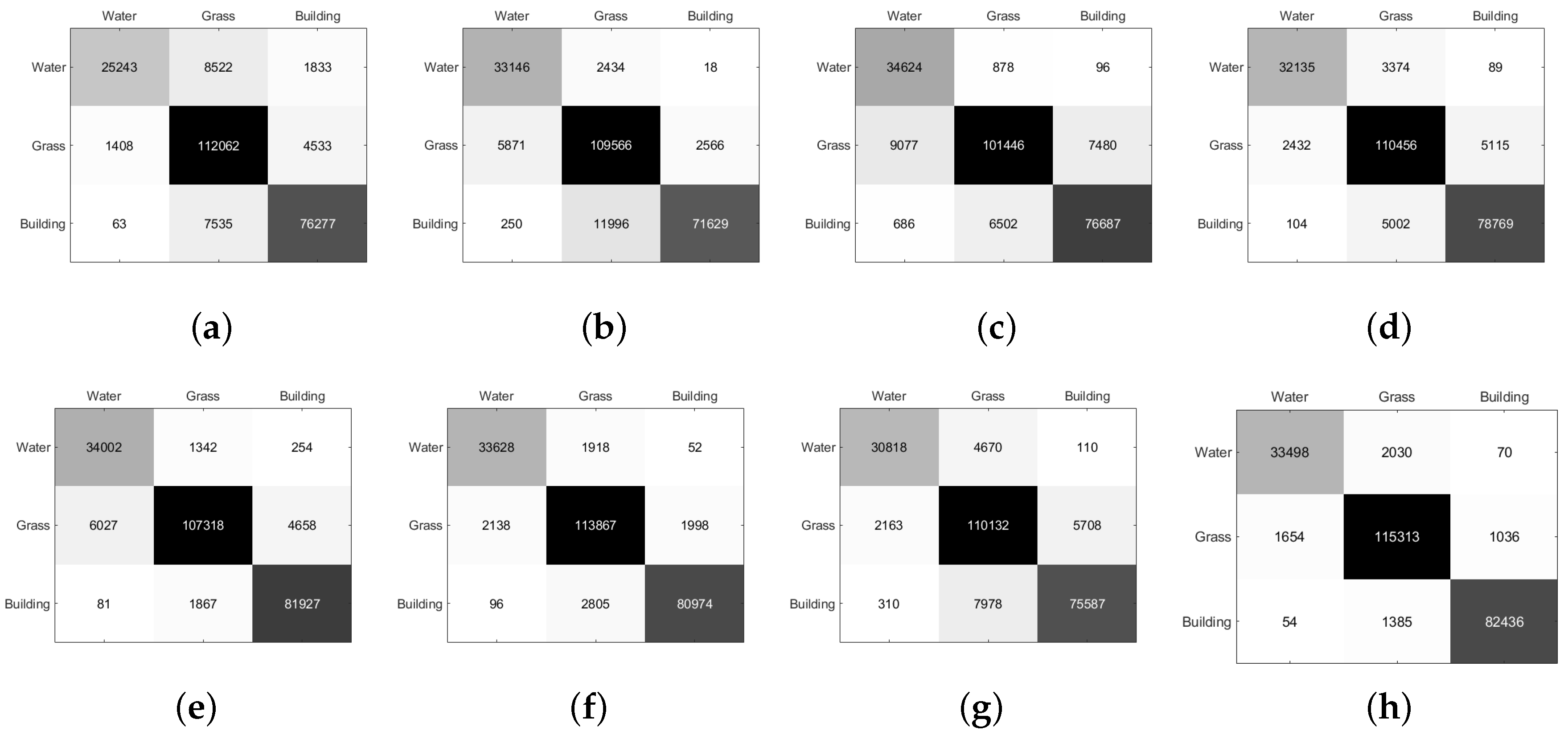
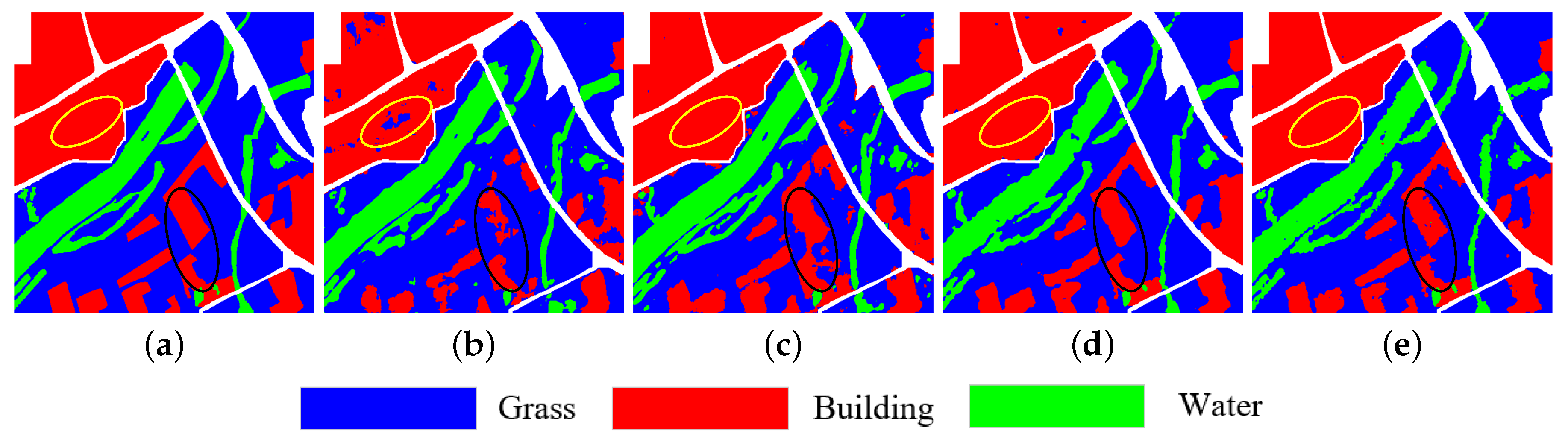
3.2. Experimental Results on Xi’an Data Set
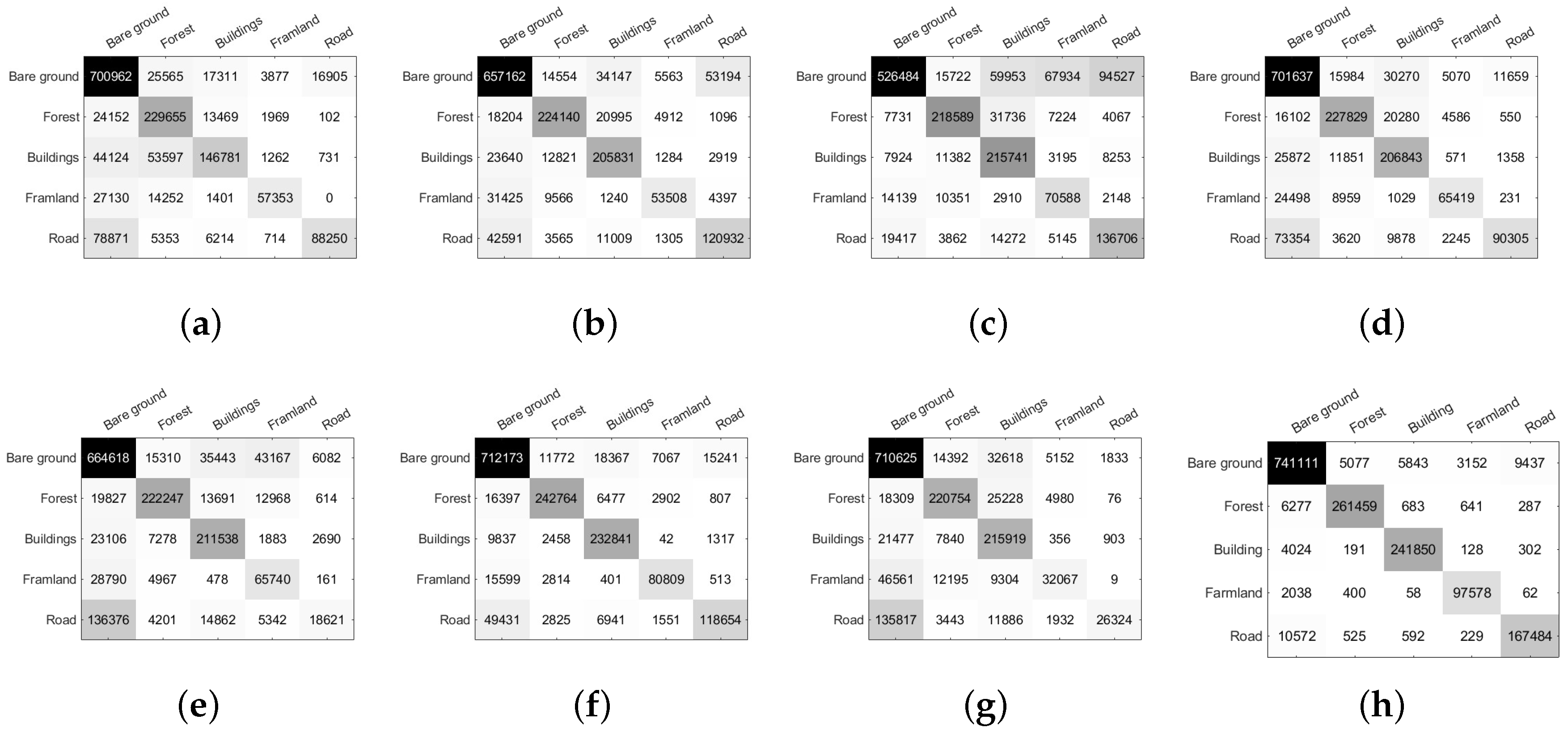
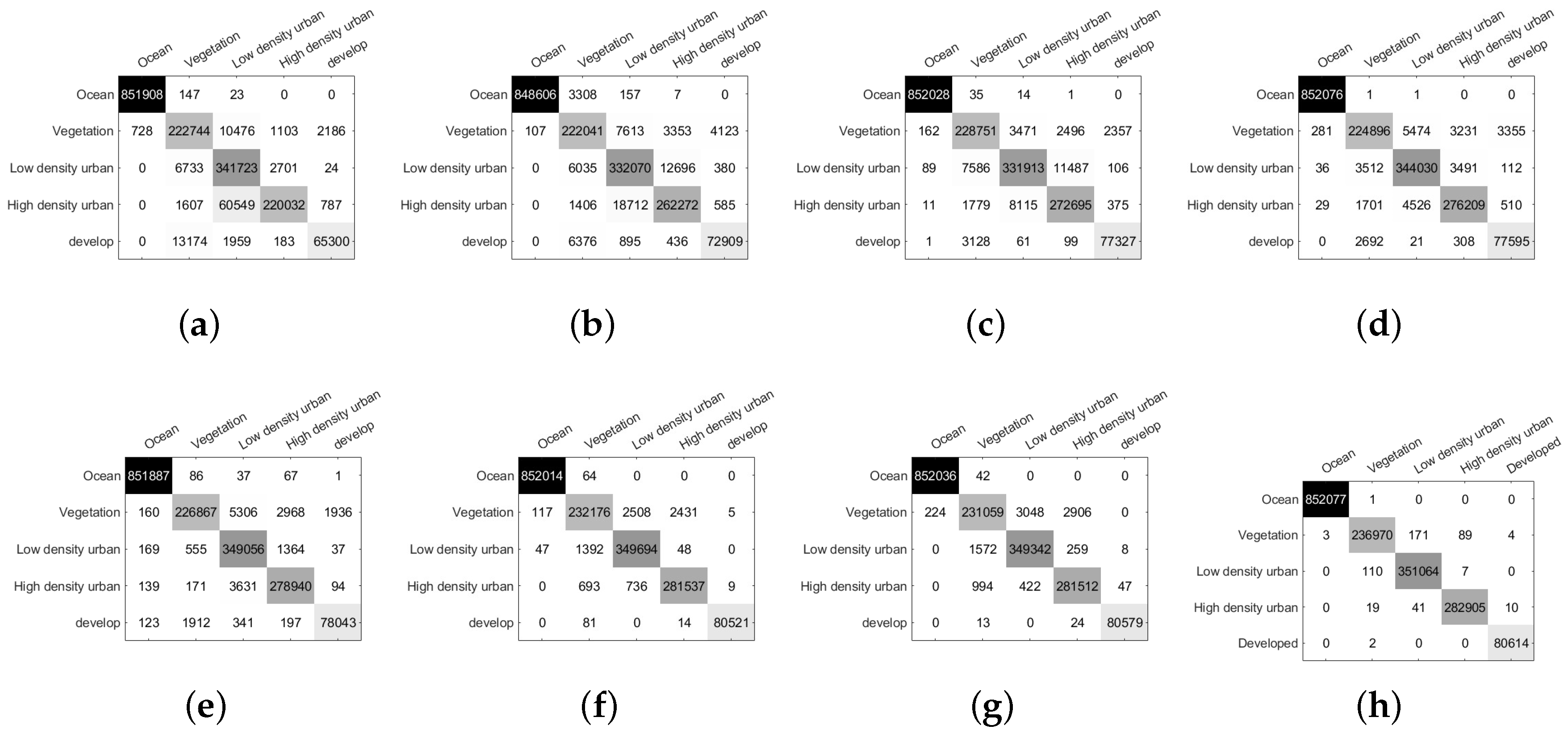
3.3. Experimental Results on Oberpfaffenhofen Data Set
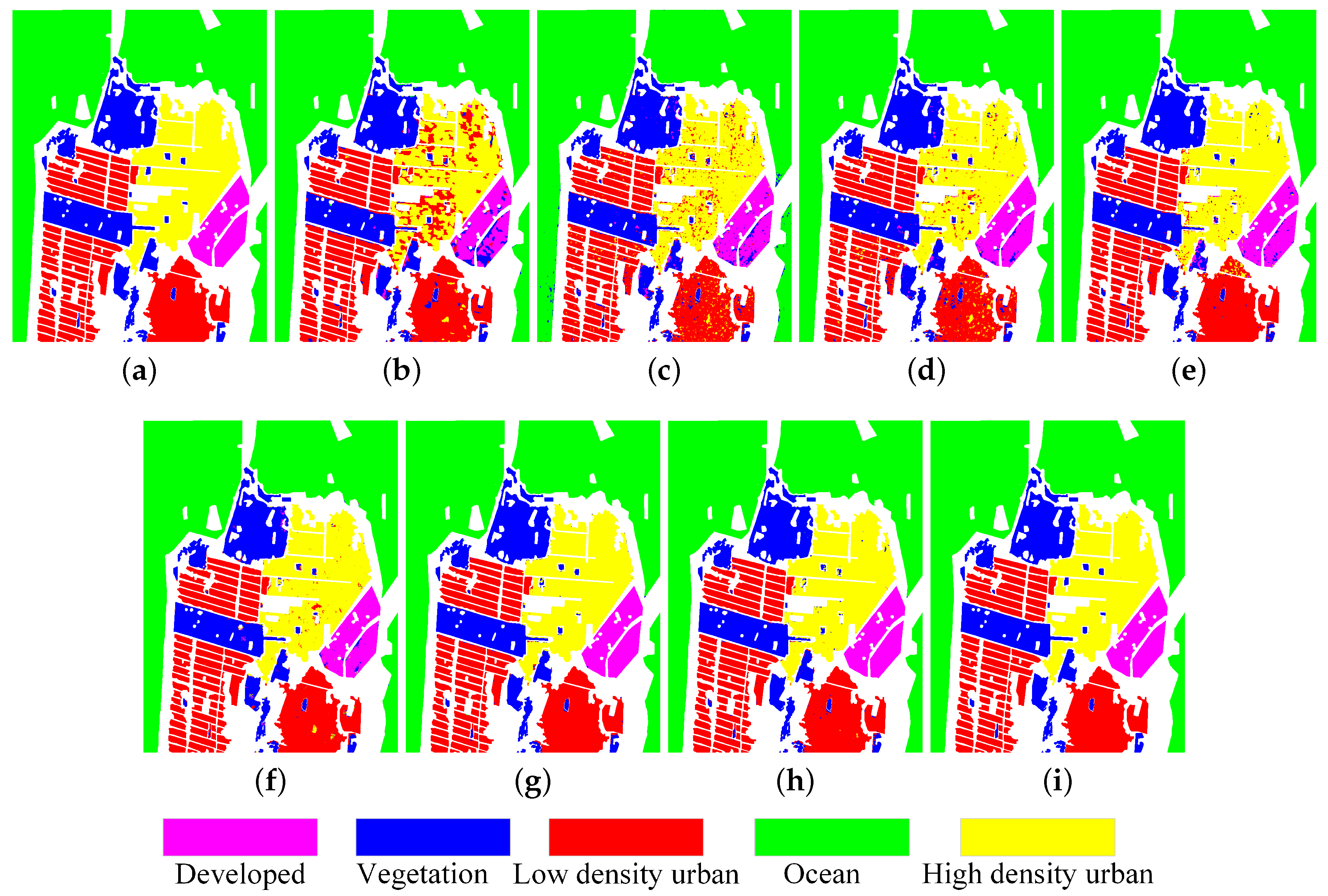
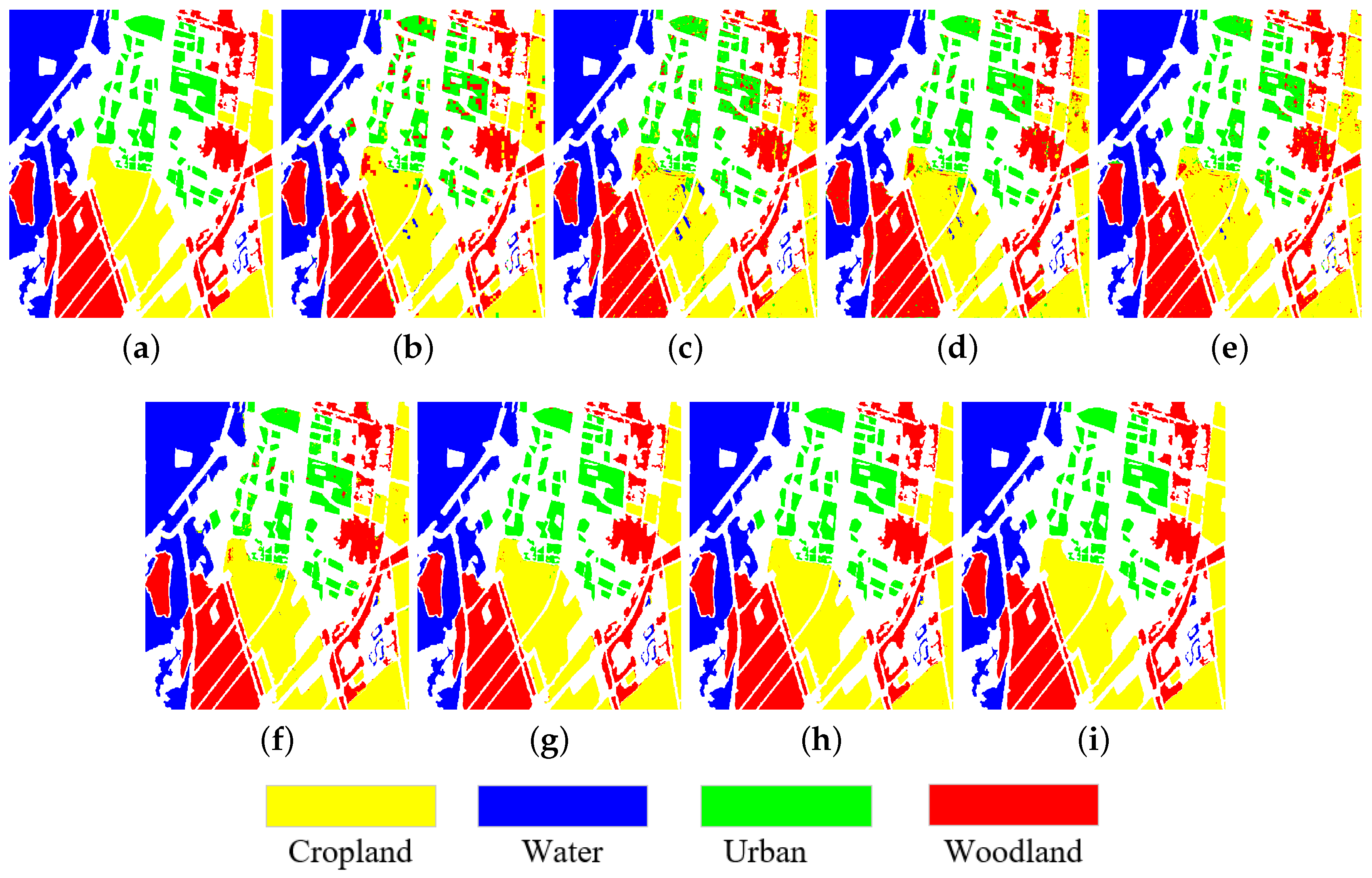
3.4. Experimental Results on San Francisco Data Set
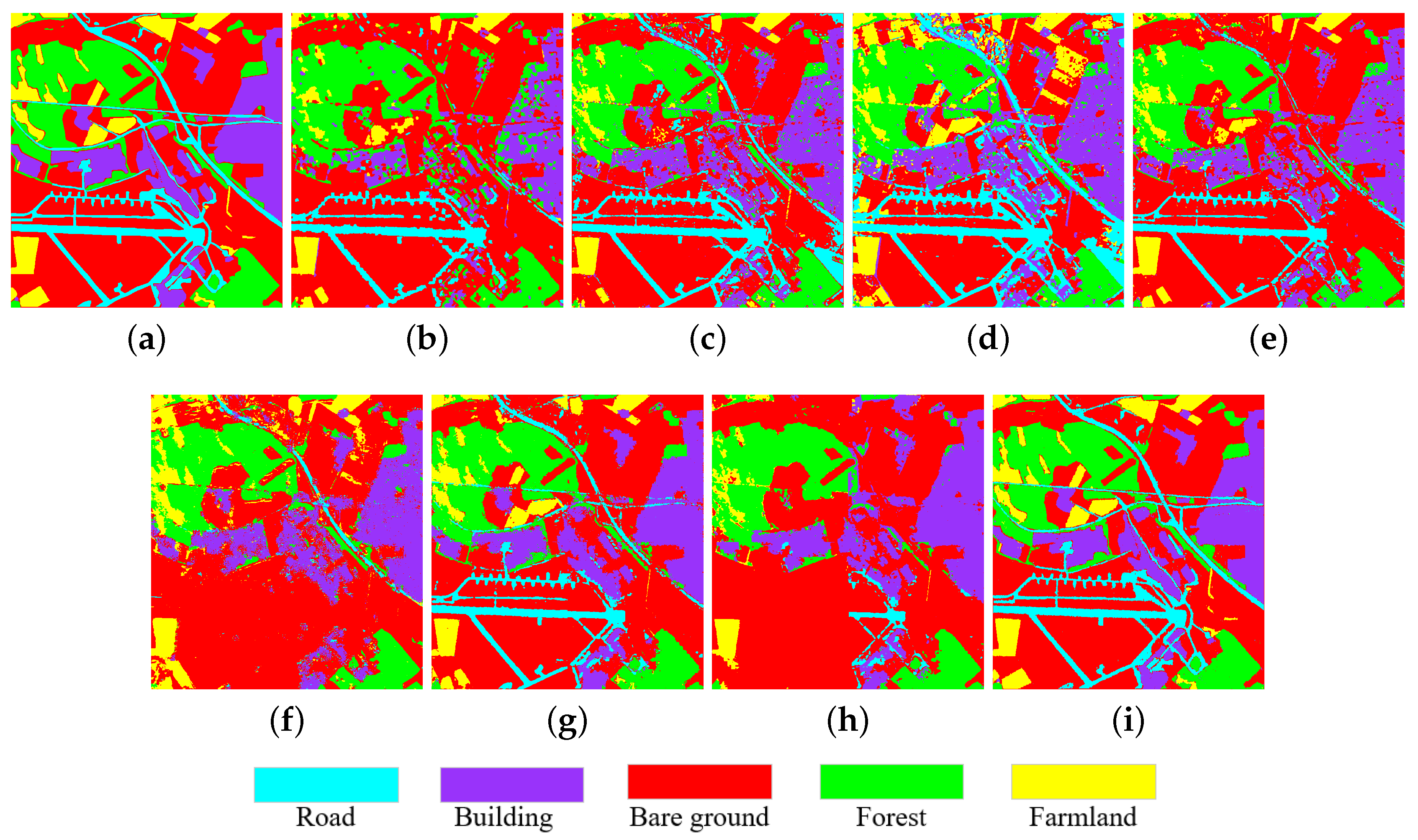
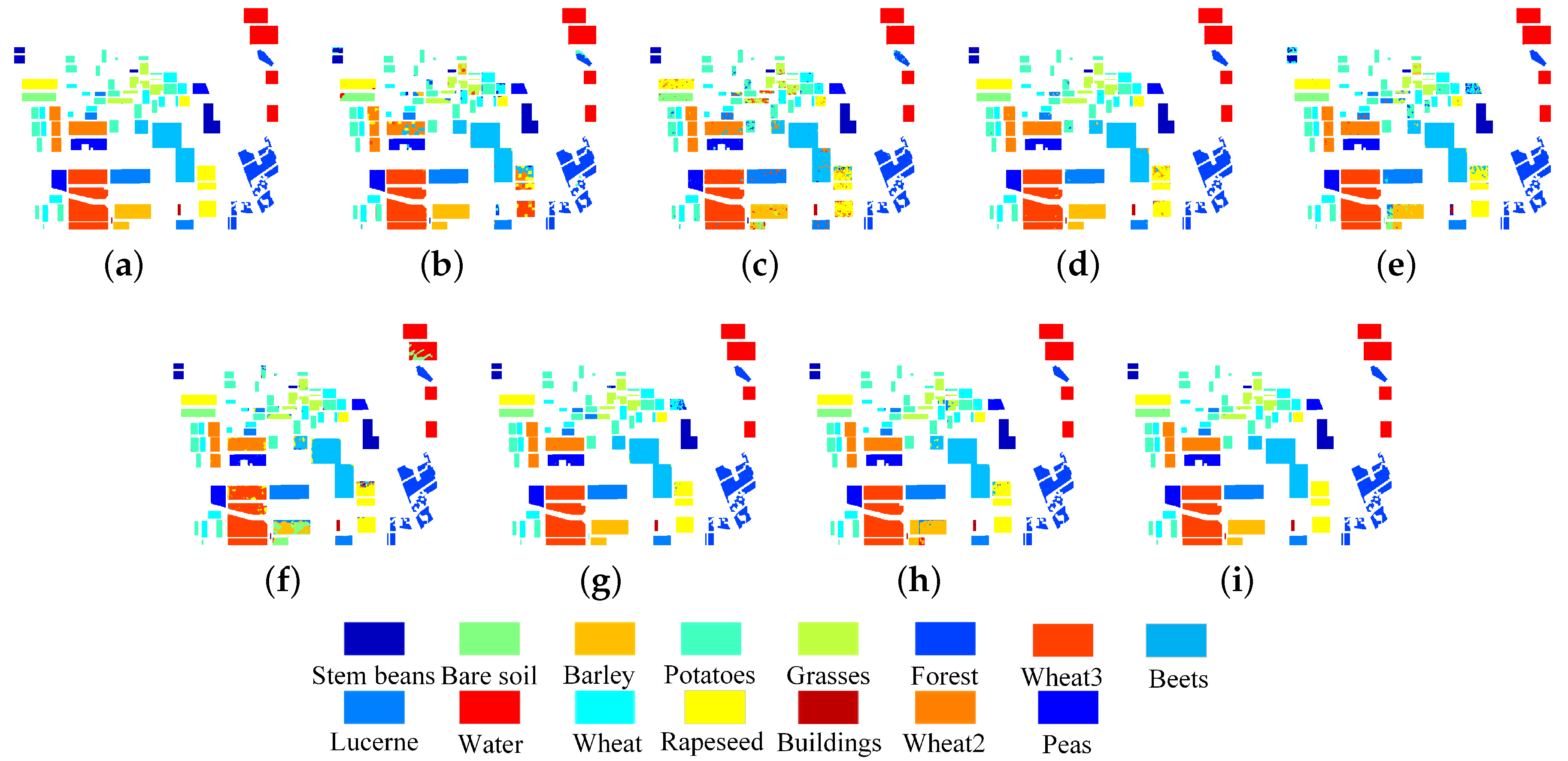
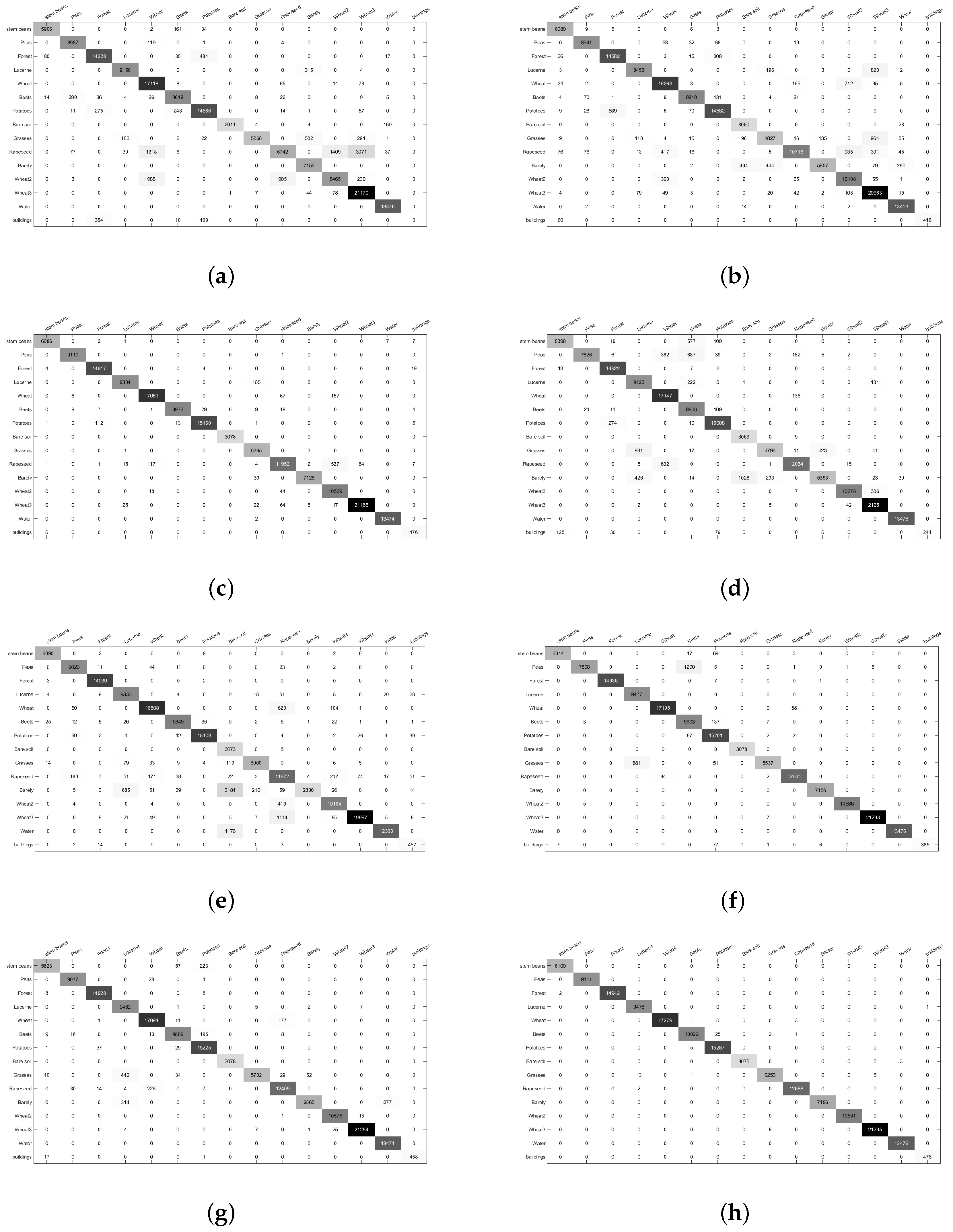
3.5. Experimental Results on Flevoland1 Data Set
3.6. Experimental Results on Flevoland2 Data Set
4. Discussion
4.1. Effect of Each Submodule
4.2. Validity Analysis of L-DeeplabV3+ Network
4.3. Validity Analysis of Multi-Features
4.4. Validity Analysis of Channel Attention Module
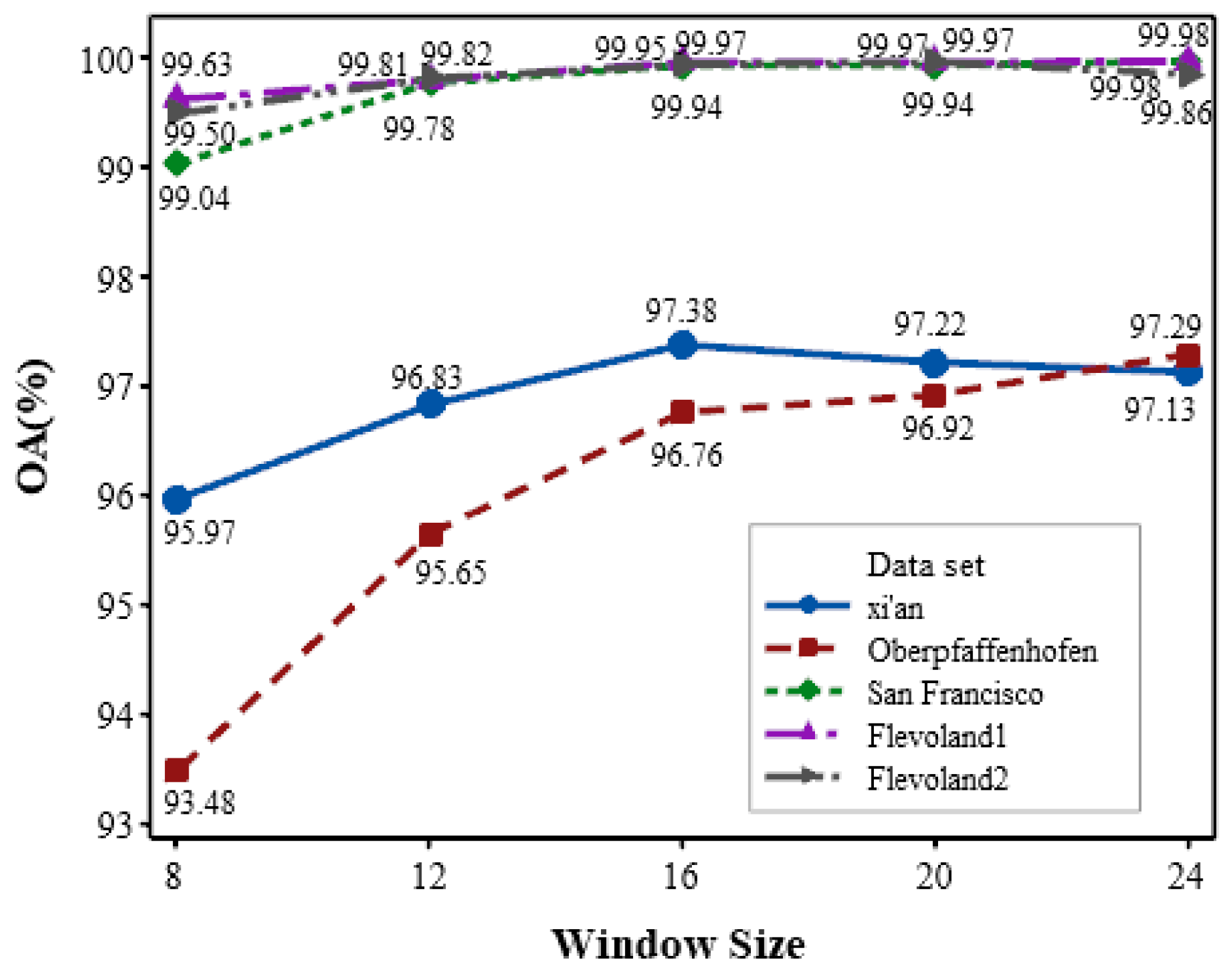
4.5. Effect of Sampling Window Size
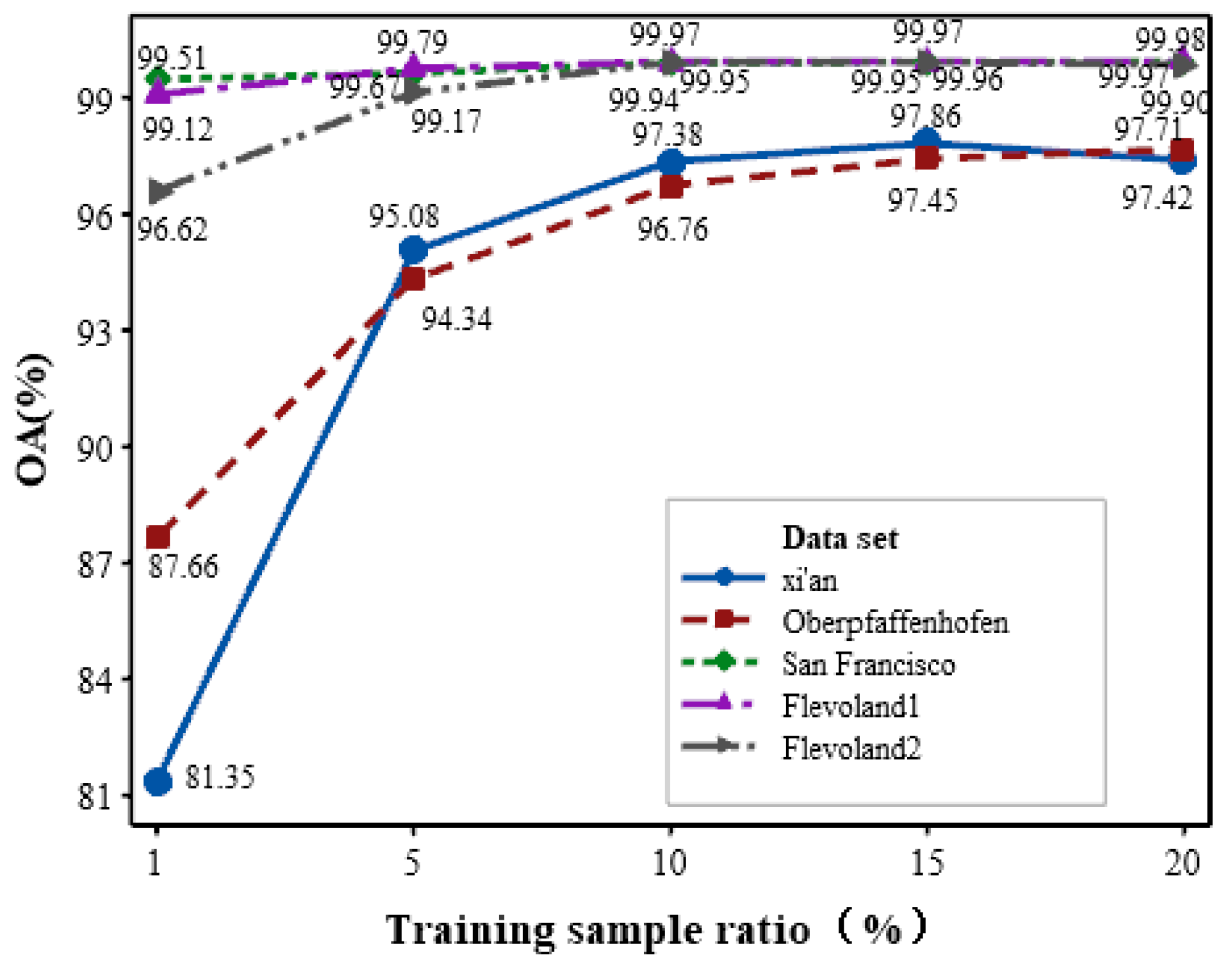
4.6. Effect of Training Sample Ratio
4.7. Analysis of Running Time
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dong, Y.; Li, F.; Hong, W.; Zhou, X.; Ren, H. Land cover semantic segmentation of Port Area with High Resolution SAR Images Based on SegNet. In Proceedings of the 2021 SAR in Big Data Era (BIGSARDATA), Nanjing, China, 22–24 September 2021; pp. 1–4. [Google Scholar]
- Liu, H.; Zhu, T.; Shang, F.; Liu, Y.; Lv, D.; Yang, S. Deep Fuzzy Graph Convolutional Networks for PolSAR Imagery Pixelwise Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 504–514. [Google Scholar] [CrossRef]
- Li, F.; Yi, M.; Zhang, C.; Yao, W.; Hu, X.; Liu, F. POLSAR Target Recognition Using a Feature Fusion Framework Based on Monogenic Signal and Complex-Valued Nonlocal Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 7859–7872. [Google Scholar] [CrossRef]
- Chen, S.; Cui, X.; Wang, X.; Xiao, S. Speckle-Free SAR Image Ship Detection. IEEE Trans. Image Process. 2021, 30, 5969–5983. [Google Scholar] [CrossRef]
- Sanchez, S.; Marpu, P.R.; Plaza, A.J.; Paz, A. Parallel Implementation of Polarimetric Synthetic Aperture Radar Data Processing for Unsupervised Classification Using the Complex Wishart Classifier. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 5376–5387. [Google Scholar] [CrossRef]
- Bombrun, L.; Vasile, G.; Gay, M.; Totir, F. Hierarchical Segmentation of Polarimetric SAR Images Using Heterogeneous Clutter Models. IEEE Trans. Geosci. Remote Sens. 2011, 49, 726–737. [Google Scholar] [CrossRef]
- Liu, M.; Deng, Y.; Han, C.; Hou, W.; Gao, Y.; Wang, C.; Liu, X. An Innovative Supervised Classification Algorithm for PolSAR Image Based on Mixture Model and MRF. Remote. Sens. 2022, 14, 5506. [Google Scholar] [CrossRef]
- Pallotta, L.; Tesauro, M. Screening Polarimetric SAR Data via Geometric Barycenters for Covariance Symmetry Classification. IEEE Geosci. Remote Sens. Lett. 2023, 20, 4002905. [Google Scholar] [CrossRef]
- Chen, S.W.; Wang, X.S.; Li, Y.Z.; Sato, M. Adaptive Model-Based Polarimetric Decomposition Using PolInSAR Coherence. IEEE Trans. Geosci. Remote Sens. 2014, 52, 1705–1718. [Google Scholar] [CrossRef]
- Pallotta, L.; Orlando, D. Polarimetric Covariance Eigenvalues Classification in SAR Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 746–750. [Google Scholar] [CrossRef]
- Hanis, D.; Hadj-Rabah, K.; Belhadj-Aissa, A.; Pallotta, L. Dominant Scattering Mechanism Identification from Quad-Pol-SAR Data Analysis. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 14408–14420. [Google Scholar] [CrossRef]
- Chen, S.W.; Li, M.D.; Cui, X.; Li, H.L. Polarimetric Roll-Invariant Features and Applications for Polarimetric Synthetic Aperture Radar Ship Detection: A comprehensive summary and investigation. IEEE Geosci. Remote Sens. Mag. 2024, 12, 36–66. [Google Scholar] [CrossRef]
- Luo, S.; Sarabandi, K.; Tong, L.; Pierce, L.E. A SAR Image Classification Algorithm Based on Multi-Feature Polarimetric Parameters Using FOA and LS-SVM. IEEE Access 2019, 7, 175259–175276. [Google Scholar] [CrossRef]
- Chen, Q.; Cao, W.; Shang, J.; Liu, J.; Liu, X. Superpixel-Based Cropland Classification of SAR Image with Statistical Texture and Polarization Features. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4503005. [Google Scholar] [CrossRef]
- Salakhutdinov, R.; Hinton, G.E. Deep Boltzmann Machines. In Proceedings of the Twelfth International Conference on Artificial Intelligence and Statistics, Clearwater Beach, FL, USA, 16–18 April 2009. [Google Scholar]
- Luo, J.; Lv, Y.; Guo, J. Multi-temporal PolSAR Image Classification Using F-SAE-CNN. In Proceedings of the 2022 3rd China International SAR Symposium (CISS), Shanghai, China, 2–4 November 2022; pp. 1–5. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Chen, S.; Tao, C. PolSAR Image Classification Using Polarimetric-Feature-Driven Deep Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2018, 15, 627–631. [Google Scholar] [CrossRef]
- Shi, J.; He, T.; Ji, S.; Nie, M.; Jin, H. CNN-Improved Superpixel-to-Pixel Fuzzy Graph Convolution Network for PolSAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4410118. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, H.; Xu, F.; Jin, Y. Complex-Valued Convolutional Neural Network and Its Application in Polarimetric SAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7177–7188. [Google Scholar] [CrossRef]
- Guo, Y.; Jiao, L.; Qu, R.; Sun, Z.; Wang, S.; Wang, S.; Liu, F. Adaptive Fuzzy Learning Superpixels Representation for PolSAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5217818. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, S.; Zou, B.; Dong, H. Unsupervised Deep Representation Learning and Few-Shot Classification of PolSAR Images. IEEE Trans. Geosci. Remote Sens. 2020, 60, 5100316. [Google Scholar] [CrossRef]
- Ai, J.; Wang, F.; Mao, Y.; Luo, Q.; Yao, B.; Yan, H.; Xing, M.d.; Wu, Y. A Fine PolSAR Terrain Classification Algorithm Using the Texture Feature Fusion Based Improved Convolutional Autoencoder. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5218714. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.P.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.P.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, Q.; Yang, Z.; Zhao, W.; Yu, X.; Yin, Z. Polarimetric SAR Landcover Classification Based on CNN with Dimension Reduction of Feature. In Proceedings of the 2021 IEEE 6th International Conference on Signal and Image Processing (ICSIP), Nanjing, China, 22–24 October 2021; pp. 331–335. [Google Scholar]
- Zhang, F.; Li, P.; Zhang, Y.; Liu, X.; Ma, X.; Yin, Z. A Enhanced DeepLabv3+ for PolSAR image classification. In Proceedings of the 2023 4th International Conference on Computer Engineering and Application (ICCEA), Hangzhou, China, 7–9 April 2023; pp. 743–746. [Google Scholar]
- Chen, S.W.; Wang, X.S.; Sato, M. Uniform Polarimetric Matrix Rotation Theory and Its Applications. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4756–4770. [Google Scholar] [CrossRef]
- Li, M.D.; Xiao, S.P.; Chen, S.W. Three-Dimension Polarimetric Correlation Pattern Interpretation Tool and its Application. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5238716. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, L.; Wang, N.; Zou, B. Joint Polarimetric-Adjacent Features Based on LCSR for PolSAR Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6230–6243. [Google Scholar] [CrossRef]
- Shi, J.; Jin, H.; Li, X. A Novel Multi-Feature Joint Learning Method for Fast Polarimetric SAR Terrain Classification. IEEE Access 2020, 8, 30491–30503. [Google Scholar] [CrossRef]
- Shang, R.; Wang, J.; Jiao, L.; Yang, X.H.; Li, Y. Spatial feature-based convolutional neural network for PolSAR image classification. Appl. Soft Comput. 2022, 123, 108922. [Google Scholar] [CrossRef]
- Xu, X.; Lu, Y.; Zou, B. Building Extraction From PolSAR Image Based on Deep CNN with Polarimetric Features. In Proceedings of the 2020 21st International Radar Symposium (IRS), Warsaw, Poland, 5–8 October 2020; pp. 117–120. [Google Scholar]
- Wu, Q.; Wen, Z.; Wang, Y.; Luo, Y.; Li, H.; Chen, Q.Y. A Statistical-Spatial Feature Learning Network for PolSAR Image Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4016305. [Google Scholar] [CrossRef]
- Singh, S.R.; Murthy, H.A.; Gonsalves, T.A. Feature Selection for Text Classification Based on Gini Coefficient of Inequality. In Proceedings of the Fourth International Workshop on Feature Selection in Data Mining, Hyderabad, India, 21 June 2010. [Google Scholar]
- Lv, Z.; Zhang, P.; SUN, W.; Benediktsson, J.A.; Li, J.; Wang, W. Novel Adaptive Region Spectral–Spatial Features for Land Cover Classification With High Spatial Resolution Remotely Sensed Imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5609412. [Google Scholar] [CrossRef]
- Yao, C.; Zheng, L.; Feng, L.; Yang, F.; Guo, Z.; Ma, M. A Collaborative Superpixelwise Autoencoder for Unsupervised Dimension Reduction in Hyperspectral Images. Remote Sens. 2023, 15, 4211. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Wang, W.; Xiao, C.; Dou, H.; Liang, R.; Yuan, H.; Zhao, G.; Chen, Z.; Huang, Y. CCRANet: A Two-Stage Local Attention Network for Single-Frame Low-Resolution Infrared Small Target Detection. Remote Sens. 2023, 15, 5539. [Google Scholar] [CrossRef]
- Sparse Mix-Attention Transformer for Multispectral Image and Hyperspectral Image Fusion. Remote Sens. 2023, 16, 144. [CrossRef]
- You, H.; Gu, J.; Jing, W. Multi-Label Remote Sensing Image Land Cover Classification Based on a Multi-Dimensional Attention Mechanism. Remote. Sens. 2023, 15, 4979. [Google Scholar] [CrossRef]
- Chen, S.; Li, Y.; Wang, X.; Xiao, S.; Sato, M. Modeling and Interpretation of Scattering Mechanisms in Polarimetric Synthetic Aperture Radar: Advances and perspectives. IEEE Signal Process. Mag. 2014, 31, 79–89. [Google Scholar] [CrossRef]
- Chen, S. Polarimetric Coherence Pattern: A Visualization and Characterization Tool for PolSAR Data Investigation. IEEE Trans. Geosci. Remote Sens. 2018, 56, 286–297. [Google Scholar] [CrossRef]
- Lee, J.S.; Grunes, M.; de Grandi, G. Polarimetric SAR speckle filtering and its implication for classification. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2363–2373. [Google Scholar]
- Chen, S.W. SAR Image Speckle Filtering with Context Covariance Matrix Formulation and Similarity Test. IEEE Trans. Image Process. 2020, 29, 6641–6654. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, W.; Guo, Z.; Li, N. Enhanced PGA for Dual-Polarized ISAR Imaging by Exploiting Cloude-Pottier Decomposition. IEEE Geosci. Remote Sens. Lett. 2024, 21, 4000505. [Google Scholar] [CrossRef]
- Zhao, L.; Zhou, X.; Jiang, Y.; Kuang, G. Iterative classification of polarimetric SAR image based on the freeman decomposition and scattering entropy. In Proceedings of the 2007 1st Asian and Pacific Conference on Synthetic Aperture Radar, Huangshan, China, 5–9 November 2007; pp. 473–476. [Google Scholar]
- Li, D.; Zhang, Y. Unified Huynen Phenomenological Decomposition of Radar Targets and Its Classification Applications. IEEE Trans. Geosci. Remote Sens. 2016, 54, 723–743. [Google Scholar] [CrossRef]
- Wang, S.; Pei, J.; Liu, K.; Zhang, S.; Chen, B. Unsupervised classification of POLSAR data based on the polarimetric decomposition and the co-polarization ratio. In Proceedings of the 2011 IEEE International Geoscience and Remote Sensing Symposium, Vancouver, BC, Canada, 24–29 July 2011; pp. 424–427. [Google Scholar]
- Hong, S.H.; Wdowinski, S. Double-Bounce Component in Cross-Polarimetric SAR From a New Scattering Target Decomposition. IEEE Trans. Geosci. Remote Sens. 2013, 52, 3039–3051. [Google Scholar] [CrossRef]
- Benco, M.; Kamencay, P.; Radilova, M.; Hudec, R.; Šinko, M. The Comparison of Color Texture Features Extraction based on 1D GLCM with Deep Learning Methods. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niteroi, Brazil, 1–3 July 2020; pp. 285–289. [Google Scholar]
- Shi, J.; Jin, H.; Xiao, Z. A Novel Hybrid Edge Detection Method for Polarimetric SAR Images. IEEE Access 2020, 8, 8974–8991. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, H.; Shen, Q. Spectral-Spatial Classification of Hyperspectral Imagery with 3D Convolutional Neural Network. Remote. Sens. 2017, 9, 67. [Google Scholar] [CrossRef]
- Cui, Y.; Liu, F.; Jiao, L.; Guo, Y.; Liang, X.; Li, L.; Yang, S.; Qian, X. Polarimetric Multipath Convolutional Neural Network for PolSAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5207118. [Google Scholar] [CrossRef]
- Liu, Q.; Xiao, L.; Yang, J.; Wei, Z. CNN-Enhanced Graph Convolutional Network With Pixel- and Superpixel-Level Feature Fusion for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 8657–8671. [Google Scholar] [CrossRef]
- Jin, H.; He, T.; Shi, J.; Ji, S. Combine Superpixel-Wise GCN and Pixel-Wise CNN for PolSAR Image Classification. In Proceedings of the IGARSS 2023—2023 IEEE International Geoscience and Remote Sensing Symposium, Pasadena, CA, USA, 16–21 July 2023; pp. 8014–8017. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Feature Name | Feature Parameter | Number |
|---|---|---|---|
| Original data features | Scattering matrix elements | , | 6 |
| Coherency matrix elements | , | 9 | |
| SPAN | 1 | ||
| Target decomposition features | Cloud and Pottier decomposition | H, A, | 3 |
| Freeman decomposition | the surface, double-bounce and volume scattering power | 3 | |
| Huynen decomposition | , , | 9 | |
| Co-polarization ratio | 1 | ||
| Cross-polarization ratio | 1 | ||
| Textural and contour features | GLCM features | 4 | |
| 4 | |||
| 4 | |||
| 4 | |||
| Edge-line energy features | 4 | ||
| , | 4 | ||
| Total | 57 | ||
| Network | DeeplabV3+ | L-DeeplabV3+ |
|---|---|---|
| Input feature map | ||
| Backbone network | Xception network | DWConv + Maxpooling + DWConv |
| ASPP | Conv , r = 6, 12, 18 | Conv , r = 2, 4, 6 |
| Class | Super-RF [14] | CNN [18] | CV-CNN [20] | 3D-CNN [57] | PolMPCNN [58] | CEGCN [59] | SGCN-CNN [60] | MLDnet |
|---|---|---|---|---|---|---|---|---|
| Water | 70.91 | 93.12 | 97.26 | 90.27 | 95.52 | 94.47 | 86.57 | 94.10 |
| Grass | 94.97 | 92.82 | 85.97 | 93.60 | 90.95 | 96.50 | 93.33 | 97.72 |
| Building | 90.94 | 85.31 | 91.43 | 93.91 | 97.68 | 96.54 | 90.12 | 98.28 |
| OA | 89.94 | 90.21 | 89.59 | 93.21 | 94.01 | 96.21 | 91.18 | 97.38 |
| AA | 85.61 | 90.42 | 91.55 | 92.60 | 94.71 | 95.83 | 90.01 | 96.70 |
| Kappa | 83.02 | 83.83 | 83.18 | 88.77 | 90.25 | 93.74 | 85.33 | 95.67 |
| Class | Super-RF [14] | CNN [18] | CV-CNN [20] | 3D-CNN [57] | PolMPCNN [58] | CEGCN [59] | SGCN-CNN [60] | MLDnet |
|---|---|---|---|---|---|---|---|---|
| Bare ground | 91.76 | 85.95 | 68.86 | 91.76 | 86.92 | 93.14 | 92.94 | 96.97 |
| Forest | 85.26 | 83.22 | 81.16 | 84.59 | 82.51 | 90.13 | 81.96 | 96.17 |
| Building | 59.55 | 83.50 | 87.52 | 83.91 | 85.82 | 94.46 | 87.60 | 95.77 |
| Farmland | 57.28 | 53.44 | 70.49 | 65.33 | 65.65 | 80.70 | 32.02 | 95.50 |
| Road | 49.19 | 67.41 | 76.20 | 50.34 | 10.38 | 66.14 | 14.67 | 93.78 |
| OA | 78.40 | 80.87 | 74.88 | 82.82 | 75.82 | 88.93 | 77.29 | 96.19 |
| AA | 68.59 | 74.70 | 76.85 | 75.19 | 66.26 | 84.91 | 61.84 | 95.64 |
| Kappa | 67.42 | 72.03 | 65.73 | 74.28 | 63.46 | 83.66 | 64.76 | 94.44 |
| Class | Super-RF [14] | CNN [18] | CV-CNN [20] | 3D-CNN [57] | PolMPCNN [58] | CEGCN [59] | SGCN-CNN [60] | MLDnet |
|---|---|---|---|---|---|---|---|---|
| Ocean | 99.98 | 99.59 | 99.99 | 100 | 99.58 | 99.99 | 100 | 100 |
| Vegetation | 93.89 | 93.51 | 96.42 | 94.80 | 95.63 | 97.87 | 97.40 | 99.89 |
| LD urban | 97.31 | 94.47 | 94.51 | 97.96 | 99.39 | 99.58 | 99.48 | 99.97 |
| HD urban | 77.76 | 92.57 | 96.37 | 97.61 | 98.57 | 99.49 | 99.48 | 99.98 |
| Developed | 81.00 | 90.31 | 95.92 | 96.25 | 96.81 | 99.88 | 99.95 | 100 |
| OA | 94.33 | 96.28 | 97.71 | 98.38 | 98.93 | 99.55 | 99.47 | 99.97 |
| AA | 89.99 | 94.09 | 96.64 | 97.32 | 98.08 | 99.36 | 99.26 | 99.97 |
| Kappa | 91.81 | 94.65 | 96.70 | 97.66 | 98.46 | 99.35 | 99.24 | 99.96 |
| Class | Super-RF [14] | CNN [18] | CV-CNN [20] | 3D-CNN [57] | PolMPCNN [58] | CEGCN [59] | SGCN-CNN [60] | MLDnet |
|---|---|---|---|---|---|---|---|---|
| Urban | 81.84 | 88.87 | 96.26 | 94.74 | 96.29 | 99.45 | 99.73 | 99.98 |
| Water | 98.69 | 99.68 | 99.85 | 98.87 | 99.14 | 99.65 | 99.77 | 99.99 |
| Woodland | 94.92 | 95.59 | 96.48 | 96.03 | 98.77 | 98.96 | 99.58 | 99.89 |
| Cropland | 94.16 | 93.16 | 93.94 | 96.75 | 98.66 | 99.47 | 99.63 | 99.92 |
| OA | 93.88 | 95.01 | 96.57 | 96.84 | 98.49 | 99.37 | 99.67 | 99.94 |
| AA | 92.40 | 94.33 | 96.63 | 96.60 | 98.21 | 99.38 | 99.68 | 99.95 |
| Kappa | 91.61 | 93.18 | 95.33 | 95.69 | 97.94 | 99.14 | 99.55 | 99.92 |
| Class | Super-RF [14] | CNN [18] | CV-CNN [20] | 3D-CNN [57] | PolMPCNN [58] | CEGCN [59] | SGCN-CNN [60] | MLDnet |
|---|---|---|---|---|---|---|---|---|
| Stem beans | 96.77 | 99.58 | 99.72 | 88.45 | 99.79 | 98.54 | 95.41 | 99.96 |
| Peas | 98.64 | 97.95 | 99.99 | 85.90 | 99.00 | 85.70 | 99.63 | 100 |
| Forest | 95.88 | 97.36 | 99.82 | 99.85 | 99.97 | 99.95 | 99.89 | 99.98 |
| Lucerne | 96.63 | 88.95 | 98.17 | 96.26 | 98.45 | 100 | 99.84 | 99.98 |
| Beets | 99.05 | 93.86 | 98.66 | 99.21 | 95.52 | 99.49 | 98.91 | 99.97 |
| Wheat | 95.70 | 97.43 | 99.22 | 98.57 | 98.00 | 98.54 | 97.60 | 99.69 |
| Potatoes | 96.04 | 94.98 | 99.14 | 98.14 | 98.76 | 99.40 | 99.56 | 99.96 |
| Bare soil | 94.57 | 99.09 | 100 | 99.71 | 99.84 | 100 | 100 | 99.89 |
| Grasses | 84.03 | 76.51 | 99.94 | 76.50 | 95.71 | 88.32 | 90.96 | 99.68 |
| Rapeseed | 53.13 | 83.90 | 94.18 | 94.83 | 93.55 | 99.30 | 97.79 | 99.98 |
| Barley | 100 | 81.75 | 99.58 | 75.36 | 40.25 | 100 | 91.74 | 100 |
| Wheat2 | 79.93 | 95.26 | 99.41 | 97.04 | 95.97 | 99.95 | 99.85 | 100 |
| Wheat3 | 99.39 | 98.47 | 99.37 | 99.77 | 93.88 | 99.97 | 99.78 | 99.97 |
| Water | 100 | 99.81 | 99.99 | 100 | 91.27 | 100 | 99.96 | 100 |
| Buildings | 0 | 86.01 | 100 | 50.63 | 96.01 | 80.88 | 96.22 | 100 |
| OA | 92.18 | 93.96 | 98.96 | 95.28 | 93.82 | 98.32 | 98.50 | 99.95 |
| AA | 85.98 | 92.73 | 99.15 | 90.68 | 93.06 | 96.67 | 97.81 | 99.94 |
| Kappa | 91.44 | 93.40 | 98.87 | 94.84 | 93.27 | 98.16 | 98.36 | 99.95 |
| Data Set | Xi’an | Oberpfaffenhofen | Flevoland1 | Flevoland2 | San Francisco | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | OA | Kappa | OA | Kappa | OA | Kappa | OA | Kappa | OA | Kappa |
| wihtout MF | 96.86 | 94.83 | 93.82 | 91.04 | 99.19 | 98.89 | 98.92 | 98.82 | 99.80 | 99.72 |
| without L-deeplabV3+ | 96.73 | 94.62 | 95.50 | 93.47 | 99.83 | 99.78 | 99.77 | 99.75 | 99.96 | 99.95 |
| without Attention | 96.29 | 93.93 | 96.52 | 94.93 | 99.86 | 99.81 | 99.55 | 99.50 | 99.75 | 99.64 |
| MLDnet | 97.38 | 95.67 | 96.76 | 95.29 | 99.94 | 99.92 | 99.95 | 99.95 | 99.97 | 99.96 |
| Class | DeeplabV3+ [31] | L-DeeplabV3+ |
|---|---|---|
| Stem beans | 95.61 | 99.96 |
| Peas | 70.36 | 100 |
| Forest | 89.49 | 99.97 |
| Lucerne | 97.51 | 99.87 |
| Beets | 94.72 | 100 |
| Wheat | 84.74 | 99.25 |
| Potatoes | 92.93 | 99.40 |
| Bare soil | 97.23 | 100 |
| Grasses | 96.04 | 99.96 |
| Rapeseed | 95.84 | 99.38 |
| Barley | 96.71 | 100 |
| Wheat2 | 92.58 | 96.52 |
| Wheat3 | 84.41 | 99.84 |
| Water | 90.43 | 100 |
| Buildings | 98.40 | 90.90 |
| OA | 97.59 | 99.55 |
| Kappa | 92.87 | 99.50 |
| Class | Feature 1 | Feature 2 | Feature 3 | Multi-Features |
|---|---|---|---|---|
| Water | 91.25 | 93.79 | 89.24 | 94.10 |
| Grass | 95.31 | 89.57 | 97.15 | 97.72 |
| Building | 95.31 | 89.57 | 97.15 | 98.28 |
| OA | 91.39 | 93.25 | 95.98 | 97.38 |
| AA | 90.83 | 93.85 | 94.53 | 96.70 |
| Kappa | 85.69 | 89.00 | 93.33 | 95.67 |
| Class | Front1 | Front2 | Front3 | Behind1 | Behind2 | Behind3 |
|---|---|---|---|---|---|---|
| Water | 86.95 | 77.91 | 79.65 | 94.10 | 80.48 | 79.99 |
| Grass | 92.27 | 96.00 | 94.06 | 97.72 | 97.57 | 92.03 |
| Building | 94.90 | 92.34 | 93.90 | 98.28 | 88.78 | 94.43 |
| OA | 92.40 | 91.99 | 91.85 | 97.38 | 91.91 | 91.07 |
| AA | 91.37 | 88.75 | 89.20 | 96.70 | 88.94 | 88.82 |
| Kappa | 87.50 | 86.58 | 86.40 | 95.67 | 86.38 | 85.20 |
| Super-RF | CNN | CV-CNN | 3D-CNN | PolMPCNN | CEGCN | SGCN-CNN | DeeplabV3+ | MLDnet | |
|---|---|---|---|---|---|---|---|---|---|
| Training | 59.22 | 150.59 | 3463.20 | 121.84 | 21,600.35 | 129.43 | 30.59 | 1543.21 | 511.10 |
| Testing | 1.85 | 10.56 | 38.43 | 22.80 | 327.53 | 4.45 | 3.00 | 53.50 | 23.48 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, J.; Ji, S.; Jin, H.; Zhang, Y.; Gong, M.; Lin, W. Multi-Feature Lightweight DeeplabV3+ Network for Polarimetric SAR Image Classification with Attention Mechanism. Remote Sens. 2025, 17, 1422. https://doi.org/10.3390/rs17081422
Shi J, Ji S, Jin H, Zhang Y, Gong M, Lin W. Multi-Feature Lightweight DeeplabV3+ Network for Polarimetric SAR Image Classification with Attention Mechanism. Remote Sensing. 2025; 17(8):1422. https://doi.org/10.3390/rs17081422
Chicago/Turabian StyleShi, Junfei, Shanshan Ji, Haiyan Jin, Yuanlin Zhang, Maoguo Gong, and Weisi Lin. 2025. "Multi-Feature Lightweight DeeplabV3+ Network for Polarimetric SAR Image Classification with Attention Mechanism" Remote Sensing 17, no. 8: 1422. https://doi.org/10.3390/rs17081422
APA StyleShi, J., Ji, S., Jin, H., Zhang, Y., Gong, M., & Lin, W. (2025). Multi-Feature Lightweight DeeplabV3+ Network for Polarimetric SAR Image Classification with Attention Mechanism. Remote Sensing, 17(8), 1422. https://doi.org/10.3390/rs17081422