
Enhancing DeepLabv3+ Convolutional Neural Network Model for Precise Apple Orchard Identification Using GF-6 Remote Sensing Images and PIE-Engine Cloud Platform



Abstract
1. Introduction
2. Study Area and Data Source
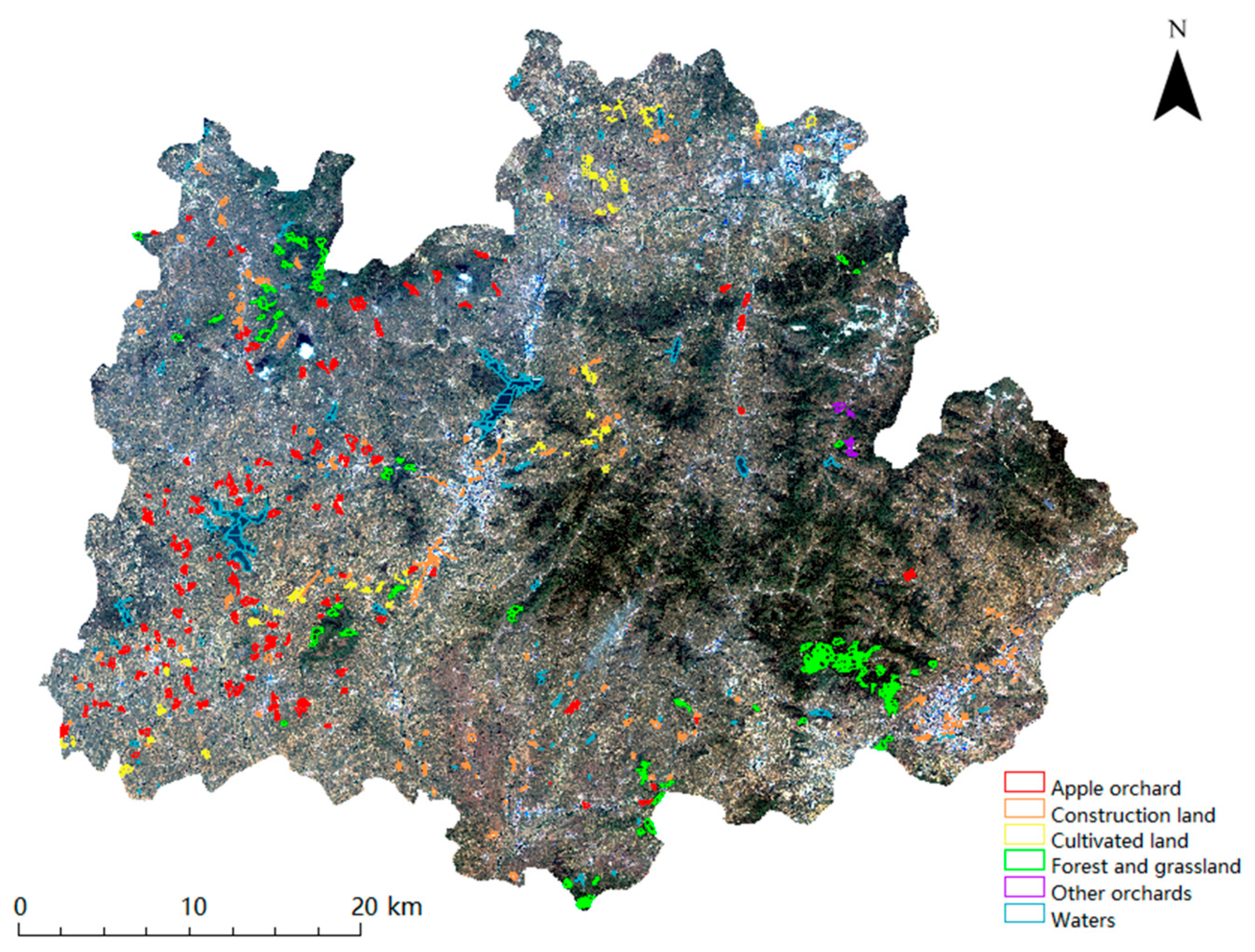
2.1. Case Study Area
2.2. Data Source and Preprocessing
2.2.1. Field Survey
2.2.2. GF-6 Image
2.2.3. Data Preprocessing
2.3. Research Processing Tools
3. Methods
3.1. Overview
3.2. Construction of Apple Orchard Data Sample Set
3.2.1. Image Preliminary Classification
- Multiscale Image Segmentation
- 2.
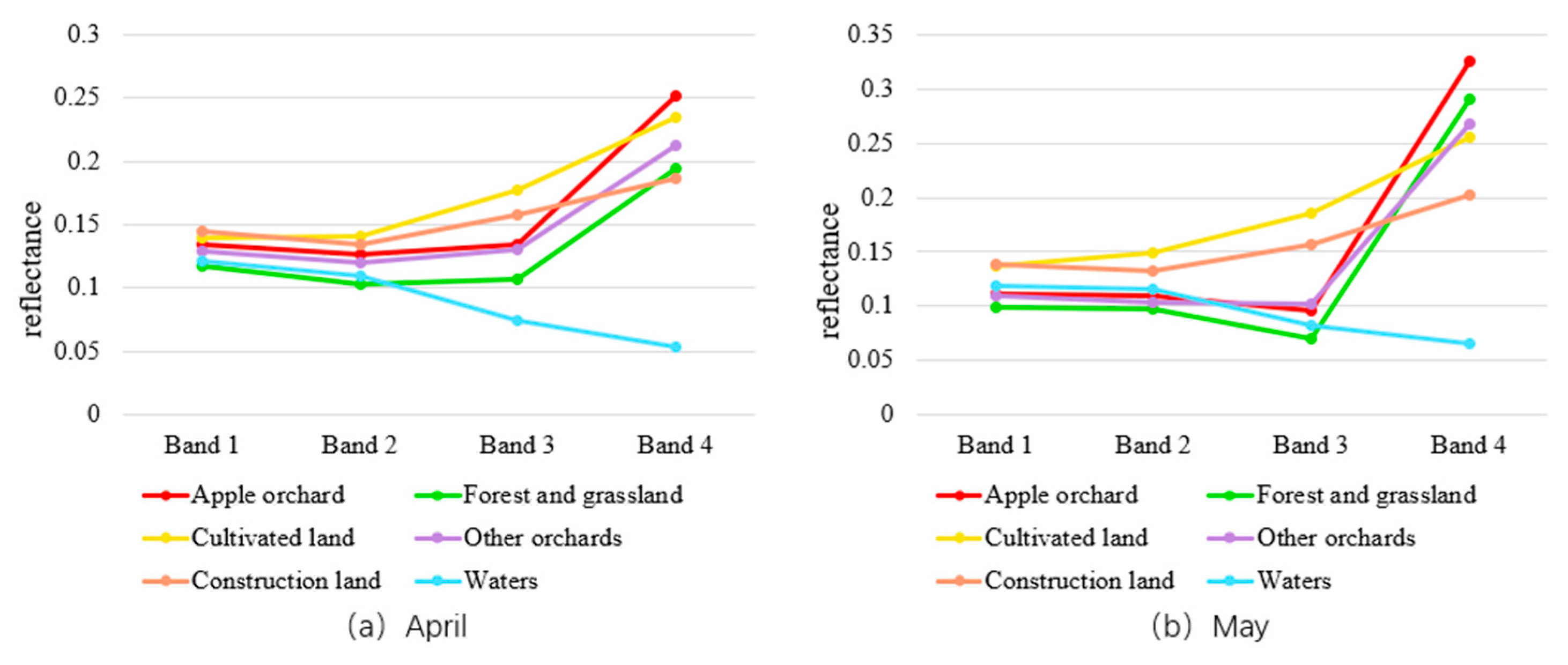
- Feature Parameter Selection
- 3.
- Machine Learning Classifier
3.2.2. Manual Annotation Data Sample Set
3.3. Enhancing of DeepLabv3+ Model
3.3.1. ResNet
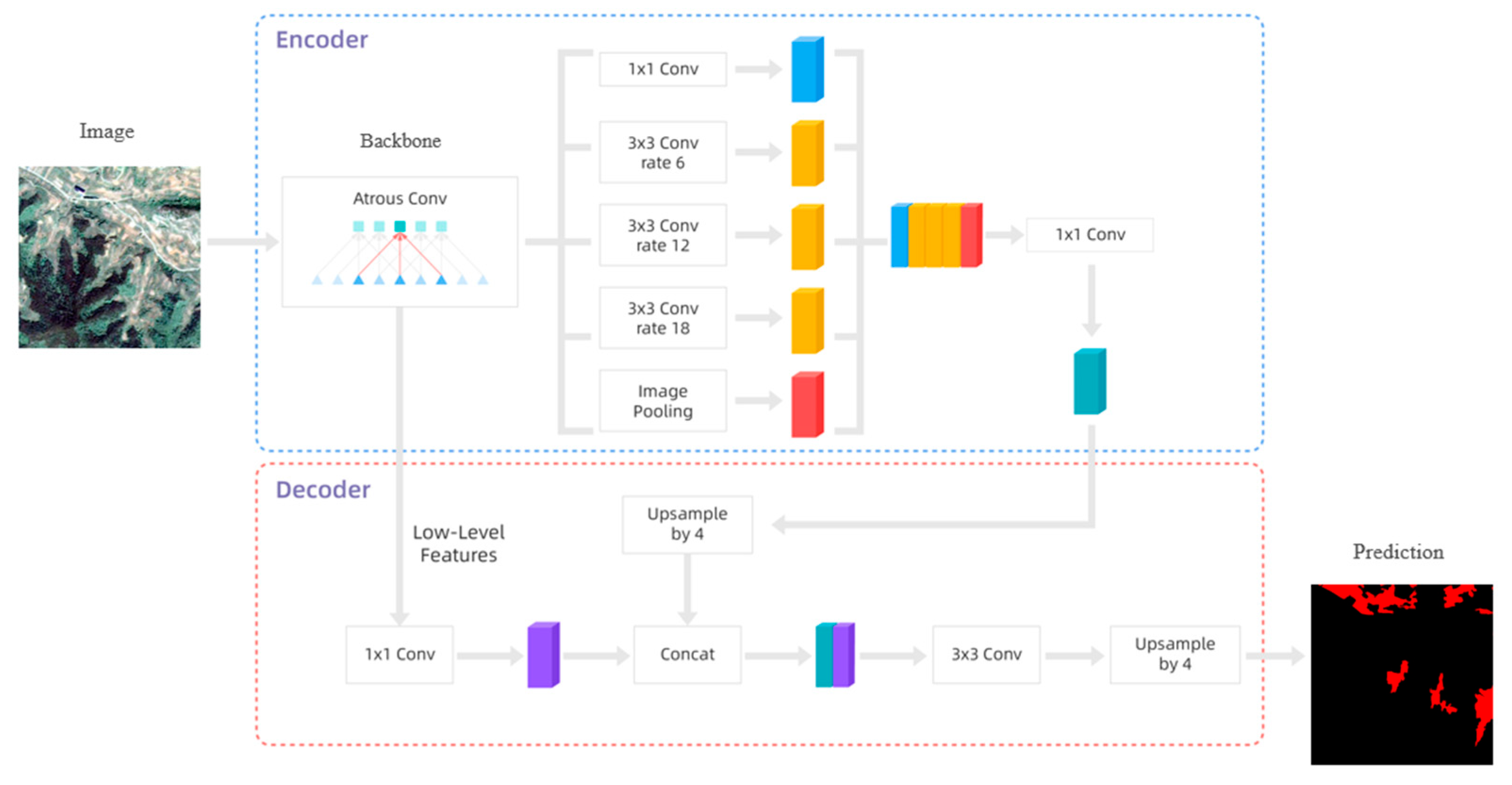
3.3.2. Construction of DeepLabv3+ Model
3.3.3. Model Enhancement
- (1)
- Cross-Entropy: The minimum cross-entropy is equivalent to minimizing the relative entropy between the actual output and the expected output, which can be measured by calculating the KL divergence of probability distributions and . Formula 1 presents the definition of cross-entropy when considering two discrete probability distributions.
- (2)
- Dice Loss: It is utilized for quantifying the similarity between the predicted outcome and the actual label, exhibiting a high sensitivity towards object boundary accuracy.
3.3.4. Hyperparameter Configuration
3.4. Model Performance Evaluation
- (1)
- Precision:
- (2)
- Recall:
- (3)
- Intersection over Union (IoU):
- (4)
- Mean Intersection over Union (mIoU):
4. Results
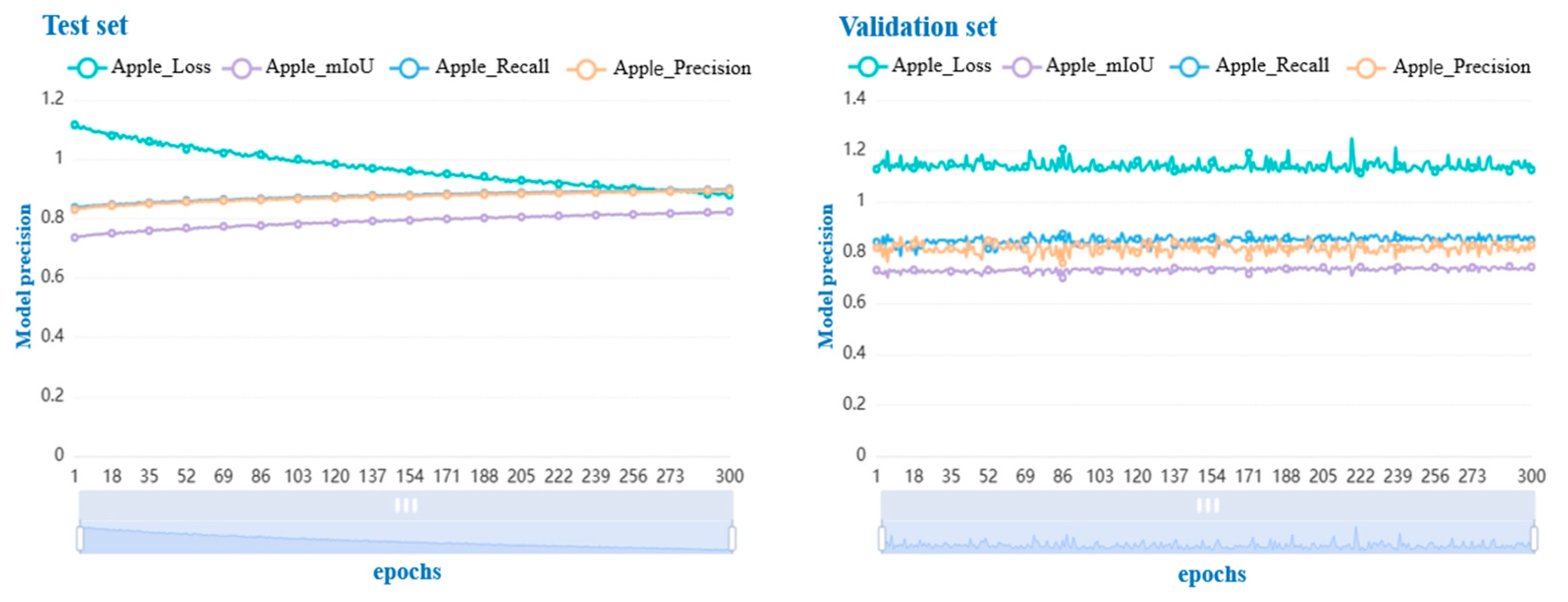
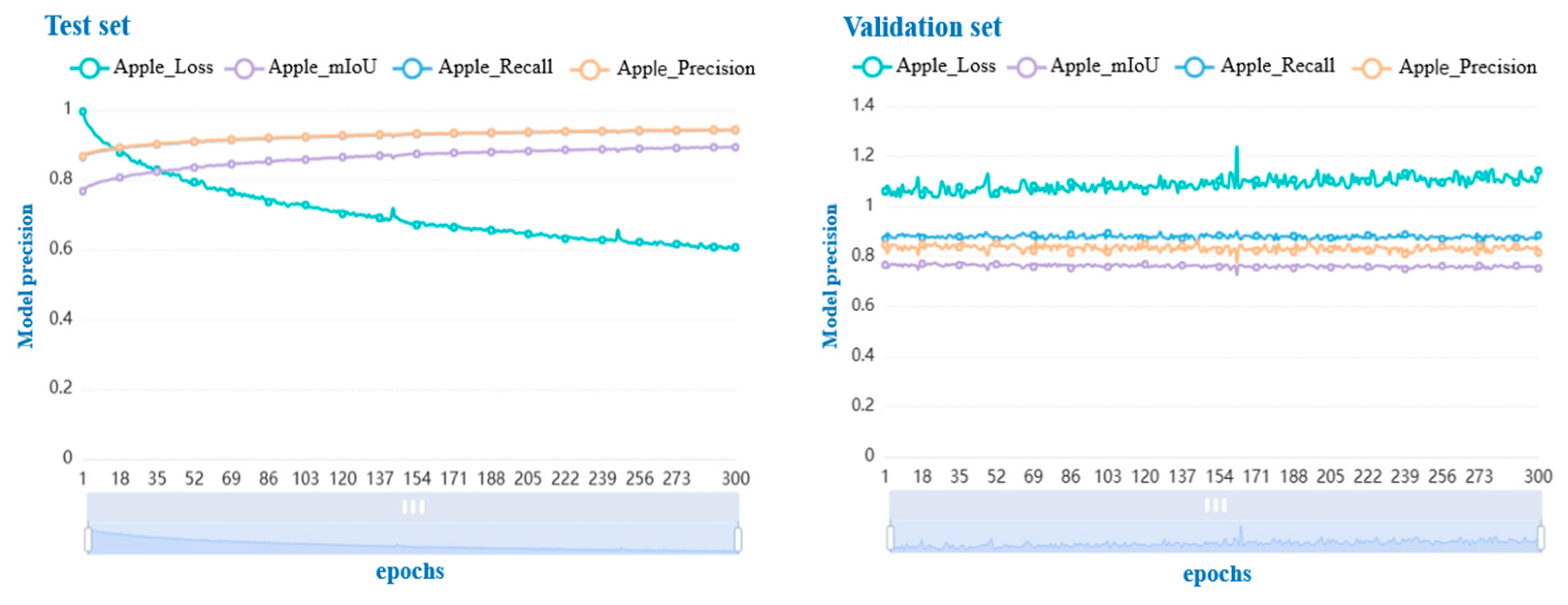
4.1. Enhanced Model Training Results
4.2. Analysis of the Ablation Experiment Results
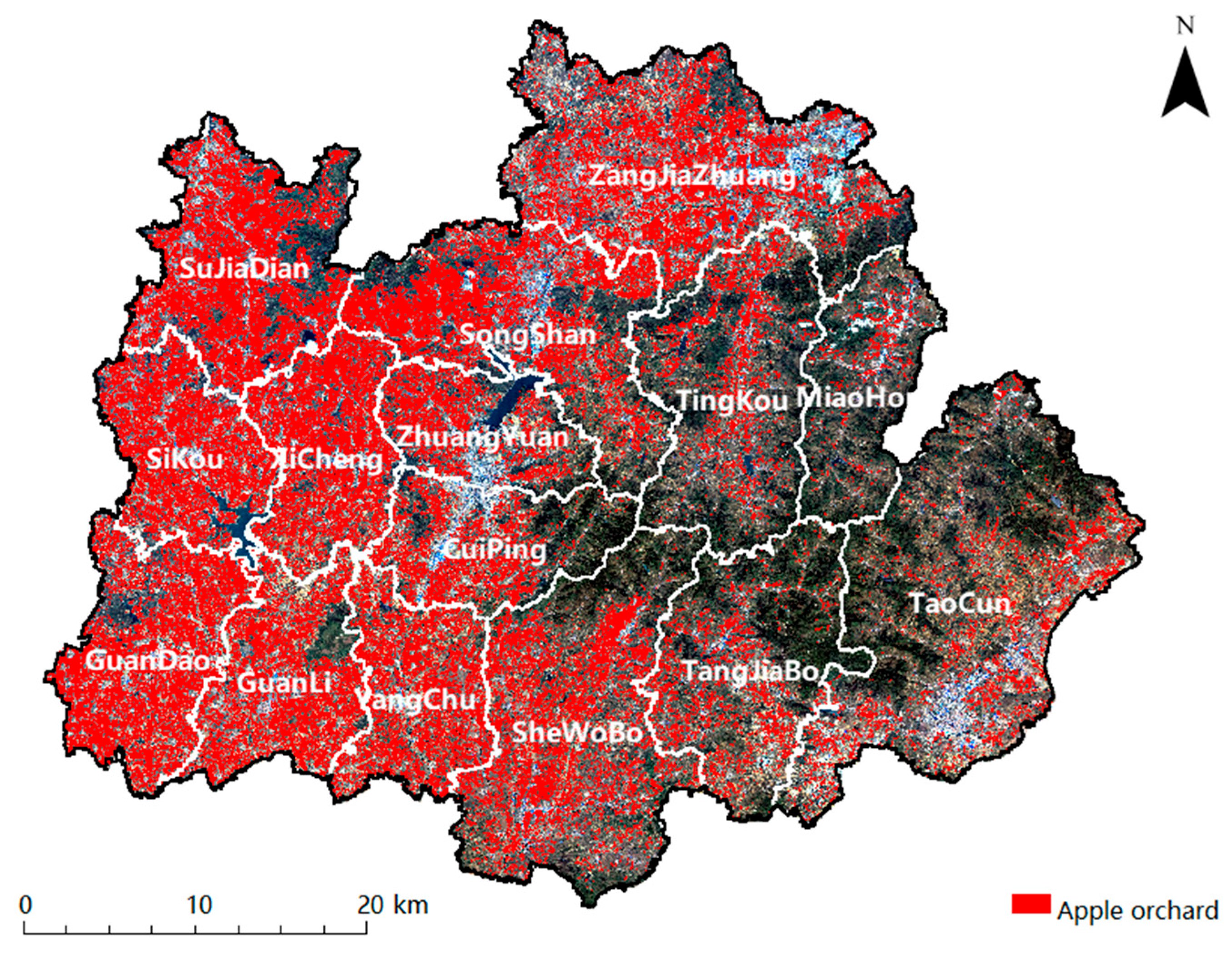
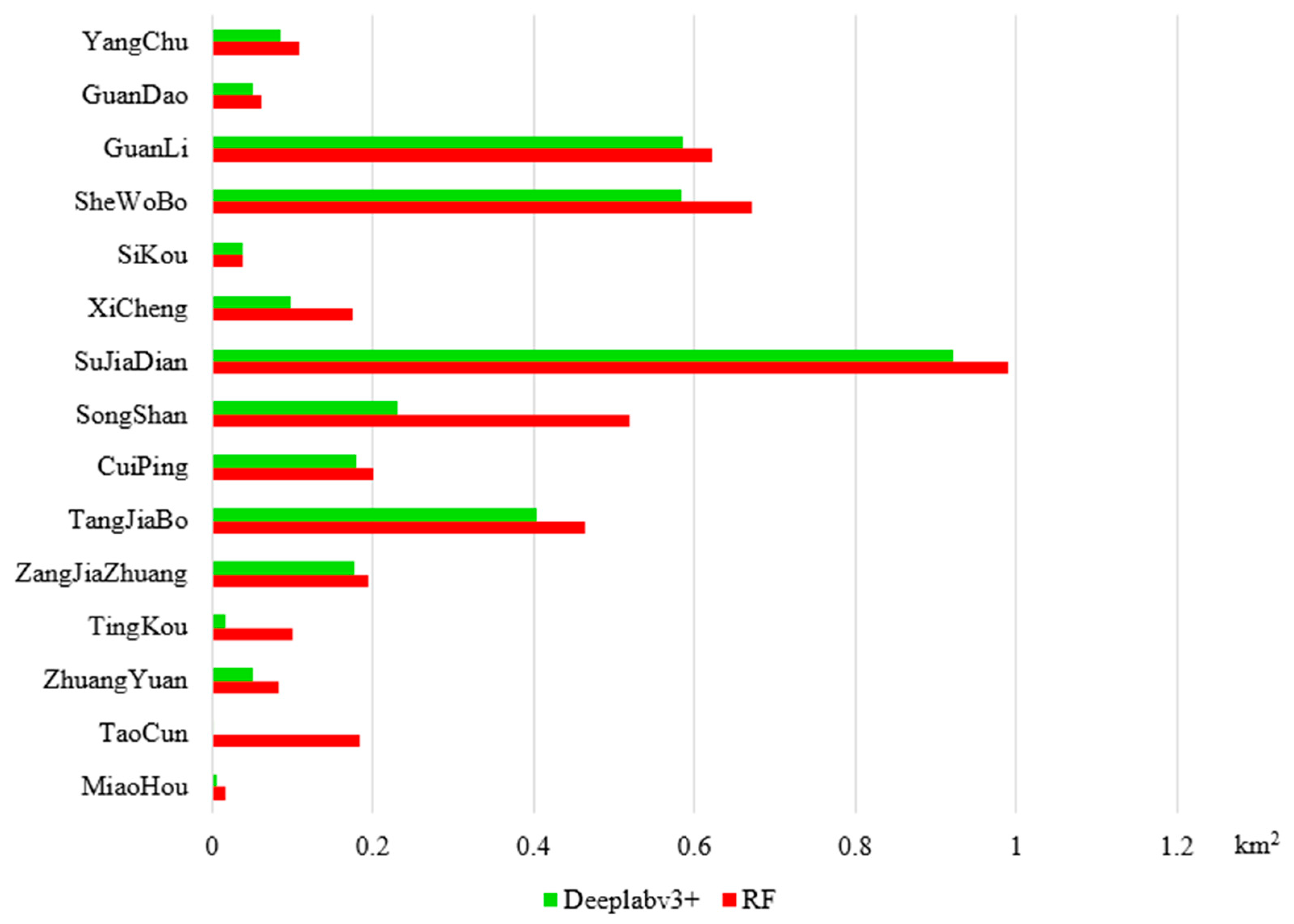
4.3. Comparison of Identification Results
5. Discussions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional neural network |
| PSPNet | Pyramid Scene Parsing Network |
| GNSS | Global Navigation Satellite System |
| BIE | Band enhancement |
| KNN | K-nearest neighbor |
| SVM | Support vector machine |
| RF | Random forest |
| ASPP | Atrous Spatial Pyramid Pooling |
| PMS | panchromatic/8 m multispectral high-resolution camera |
| WFV | Wide-format camera |
| NDVI | Normalized vegetation index |
| NDWI | Normalized water body index |
| DVI | Difference vegetation index |
| RVI | Ratio vegetation index |
| GLCM | Gray-level co-occurrence matrix |
| PA | Producer accuracy |
| OA | Overall classification accuracy |
References
- Na, W.; Wolf, J.; Zhang, F.S. Towards sustainable intensification of apple production in China—Yield gaps and nutrient use efficiency in apple farming systems. J. Integr. Agric. 2016, 15, 716–725. [Google Scholar]
- Zhou, H.; Niu, X.; Yan, H.; Zhao, N.; Zhang, F.; Wu, L.; Yin, D.; Kjelgren, R. Interactive effects of water and fertilizer on yield, soil water and nitrate dynamics of young apple tree in semiarid region of northwest China. Agronomy 2019, 9, 360. [Google Scholar] [CrossRef]
- Frolking, S.; Qiu, J.; Boles, S.; Xiao, X.; Liu, J.; Zhuang, Y.; Li, C.; Qin, X. Combining remote sensing and ground census data to develop new maps of the distribution of rice agriculture in China. Glob. Biogeochem. Cycles 2002, 16, 38-1–38-10. [Google Scholar] [CrossRef]
- Zhang, C.; Valente, J.; Kooistra, L.; Guo, L.; Wang, W. Orchard management with small unmanned aerial vehicles: A survey of sensing and analysis approaches. Precis. Agric. 2021, 22, 2007–2052. [Google Scholar] [CrossRef]
- Ballesteros, R.; Ortega, J.F.; Hernandez, D.; Del Campo, A.; Moreno, M.A. Combined use of agro-climatic and very high-resolution remote sensing information for crop monitoring. Int. J. Appl. Earth Obs. 2018, 72, 66–75. [Google Scholar] [CrossRef]
- Berni, J.A.; Zarco-Tejada, P.J.; Suárez, L.; Fereres, E. Thermal and narrowband multispectral remote sensing for vegetation monitoring from an unmanned aerial vehicle. IEEE Trans. Geosci. Remote 2009, 47, 722–738. [Google Scholar] [CrossRef]
- Xia, T.; He, Z.; Cai, Z.; Wang, C.; Wang, W.; Wang, J.; Hu, Q.; Song, Q. Exploring the potential of Chinese GF-6 images for crop mapping in regions with complex agricultural landscapes. Int. J. Appl. Earth Obs. 2022, 107, 102702. [Google Scholar] [CrossRef]
- Chen, K.; Chen, B.; Liu, C.; Li, W.; Zou, Z.; Shi, Z. Rsmamba: Remote sensing image classification with state space model. IEEE Geosci. Remote Sens. Lett. 2024, 21, 8002605. [Google Scholar] [CrossRef]
- Coulibaly, S.; Kamsu-Foguem, B.; Kamissoko, D.; Traore, D. Deep learning for precision agriculture: A bibliometric analysis. Intell. Syst. Appl. 2022, 16, 200102. [Google Scholar] [CrossRef]
- Zhang, D.; Pan, Y.; Zhang, J.; Hu, T.; Zhao, J.; Li, N.; Chen, Q. A generalized approach based on convolutional neural networks for large area cropland mapping at very high resolution. Remote Sens. Environ. 2020, 247, 111912. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Comba, L.; Gay, P.; Primicerio, J.; Aimonino, D.R. Vineyard detection from unmanned aerial systems images. Comput. Electron. Agric. 2015, 114, 78–87. [Google Scholar] [CrossRef]
- Sun, Z.; Zhu, S.; Gao, Z.; Gu, M.; Zhang, G.; Zhang, H. Recognition of grape growing areas in multispectral images based on band enhanced DeepLabv3+. Trans. CSAE 2022, 38, 229–236. [Google Scholar]
- Chen, R.; Zhang, C.; Xu, B.; Zhu, Y.; Zhao, F.; Han, S.; Yang, G.; Yang, H. Predicting individual apple tree yield using UAV multi-source remote sensing data and ensemble learning. Comput. Electron. Agric. 2022, 201, 107275. [Google Scholar] [CrossRef]
- Hung, C.; Xu, Z.; Sukkarieh, S. Feature learning based approach for weed classification using high resolution aerial images from a digital camera mounted on a UAV. Remote Sens. 2014, 6, 12037–12054. [Google Scholar] [CrossRef]
- Karen, S. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 1–9. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Hu, F.; Xia, G.-S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Chaurasia, A.; Culurciello, E. Linknet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chen, L.-C. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zeng, J.; Dai, X.; Li, W.; Xu, J.; Li, W.; Liu, D. Quantifying the impact and importance of natural, economic, and mining activities on environmental quality using the PIE-engine cloud platform: A case study of seven typical mining cities in China. Sustainability 2024, 16, 1447. [Google Scholar] [CrossRef]
- Penatti, O.A.; Nogueira, K.; Dos Santos, J.A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 8–10 June 2015; pp. 44–51. [Google Scholar]
- Ma, L.; Fu, T.; Blaschke, T.; Li, M.; Tiede, D.; Zhou, Z.; Ma, X.; Chen, D. Evaluation of feature selection methods for object-based land cover mapping of unmanned aerial vehicle imagery using random forest and support vector machine classifiers. ISPRS Int. J. Geo-Inf. 2017, 6, 51. [Google Scholar] [CrossRef]
- Wang, D.; Wan, B.; Qiu, P.; Su, Y.; Guo, Q.; Wu, X. Artificial mangrove species mapping using pléiades-1: An evaluation of pixel-based and object-based classifications with selected machine learning algorithms. Remote Sens. 2018, 10, 294. [Google Scholar] [CrossRef]
- Feng, S.; Fan, F. A hierarchical extraction method of impervious surface based on NDVI thresholding integrated with multispectral and high-resolution remote sensing imageries. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1461–1470. [Google Scholar] [CrossRef]
- Xue, J.; Su, B. Significant remote sensing vegetation indices: A review of developments and applications. J. Sens. 2017, 2017, 1353691. [Google Scholar] [CrossRef]
- Song, Q.; Hu, Q.; Zhou, Q.; Hovis, C.; Xiang, M.; Tang, H.; Wu, W. In-season crop mapping with GF-1/WFV data by combining object-based image analysis and random forest. Remote Sens. 2017, 9, 1184. [Google Scholar] [CrossRef]
- Weinberger, K.Q.; Saul, L.K. Distance metric learning for large margin nearest neighbor classification. J. Mach. Learn. Res. 2009, 10, 207–224. [Google Scholar]
- He, T.; Xie, C.; Liu, Q.; Guan, S.; Liu, G. Evaluation and comparison of random forest and A-LSTM networks for large-scale winter wheat identification. Remote Sens. 2019, 11, 1665. [Google Scholar] [CrossRef]
- Papandreou, G.; Chen, L.-C.; Murphy, K.P.; Yuille, A.L. Weakly-and semi-supervised learning of a deep convolutional network for semantic image segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1742–1750. [Google Scholar]
- Taylor, L.; Nitschke, G. Improving deep learning with generic data augmentation. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 1542–1547. [Google Scholar]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 630–645. [Google Scholar]
- Xu, H.; Xiao, X.; Qin, Y.; Qiao, Z.; Long, S.; Tang, X.; Liu, L. Annual Maps of Built-Up Land in Guangdong from 1991 to 2020 Based on Landsat Images, Phenology, Deep Learning Algorithms, and Google Earth Engine. Remote Sens. 2022, 14, 3562. [Google Scholar] [CrossRef]
- Jha, D.; Smedsrud, P.H.; Riegler, M.A.; Johansen, D.; De Lange, T.; Halvorsen, P.; Johansen, H.D. Resunet++: An advanced architecture for medical image segmentation. In Proceedings of the 2019 IEEE International Symposium on Multimedia (ISM), San Diego, CA, USA, 9–11 December 2019; pp. 225–2255. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. Adv. Neur. Inf. Proc. Syst. 2016, 29. [Google Scholar]
- Yu, F. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Zhao, S.; Zhang, T.; Hu, M.; Chang, W.; You, F. AP-BERT: Enhanced pre-trained model through average pooling. Appl. Intell. 2022, 52, 15929–15937. [Google Scholar] [CrossRef]
- Yang, Q.; Shi, L.; Han, J.; Zha, Y.; Zhu, P. Deep convolutional neural networks for rice grain yield estimation at the ripening stage using UAV-based remotely sensed images. Field Crops Res. 2019, 235, 142–153. [Google Scholar] [CrossRef]
- Xu, J.; Li, Z.; Du, B.; Zhang, M.; Liu, J. Reluplex made more practical: Leaky ReLU. In Proceedings of the 2020 IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020; pp. 1–7. [Google Scholar]
- Hasimoto-Beltran, R.; Canul-Ku, M.; Méndez, G.M.D.; Ocampo-Torres, F.J.; Esquivel-Trava, B. Ocean oil spill detection from SAR images based on multi-channel deep learning semantic segmentation. Mar. Pollut. Bull. 2023, 188, 114651. [Google Scholar] [CrossRef] [PubMed]
- Han, J.; Zheng, L.; Huang, H.; Xu, Y.; Philip, S.Y.; Zuo, W. Deep latent factor model with hierarchical similarity measure for recommender systems. Inform. Sci. 2019, 503, 521–532. [Google Scholar] [CrossRef]
- Mo, Y.; Wu, Y.; Yang, X.; Liu, F.; Liao, Y. Review the state-of-the-art technologies of semantic segmentation based on deep learning. Neurocomputing 2022, 493, 626–646. [Google Scholar] [CrossRef]
- Vali, A.; Comai, S.; Matteucci, M. Deep learning for land use and land cover classification based on hyperspectral and multispectral earth observation data: A review. Remote Sens. 2020, 12, 2495. [Google Scholar] [CrossRef]
- Yan, Y.; Tang, X.; Zhu, X.; Yu, X. Optimal time phase identification for apple orchard land recognition and spatial analysis using multitemporal sentinel-2 images and random forest classification. Sustainability 2023, 15, 4695. [Google Scholar] [CrossRef]
- Mpakairi, K.S.; Dube, T.; Sibanda, M.; Mutanga, O. Fine-scale characterization of irrigated and rainfed croplands at national scale using multi-source data, random forest, and deep learning algorithms. ISPRS J. Photogramm. 2023, 204, 117–130. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhao, X.; Gao, X.; Zhang, L.; Yang, M. Accurate Extraction of Apple Orchard on the Loess Plateau Based on Improved Linknet Network. Smart Agric. 2022, 4, 95. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor | Band | Wave Length | Spatial Resolution | Width |
|---|---|---|---|---|
| PMS | Panchromatic | 2 m | 90 km | |
| B1 (Blue) | ||||
| B2 (Green) | 8 m | |||
| B3 (Red) | ||||
| B4 (Near-infrared) |
| Characteristic Exponent | Calculation Formula |
|---|---|
| NDVI | |
| NDWI | |
| DVI | |
| RVI | |
| Mean | |
| Variance | |
| Homogeneity | |
| Contrast | |
| Dissimilarity | |
| Entropy | |
| Angular Second Moment | |
| Correlation |
| Preliminary Classification Algorithm | UA | PA | Kappa | OA |
|---|---|---|---|---|
| KNN | 86.08% | 86.00% | 0.88 | 87.88% |
| SVM | 89.06% | 87.86% | 0.90 | 91.05% |
| RF | 91.14% | 90.00% | 0.92 | 93.33% |
| Component | ResNet34 | ResNet50 | ResNet101 |
|---|---|---|---|
| Total Layers | 34 | 50 | 101 |
| Parameters | ~21.8 M | ~25.5 M | ~44.5 M |
| Key Building Block | Basic Block (2 conv layers) | Bottleneck Block (3 conv layers) | Bottleneck Block (3 conv layers) |
| Structure Details | - 3 × 3 conv ×2 per block - No 1 × 1 conv in shortcuts | - 1 × 1 + 3 × 3 + 1 × 1 conv per block - 1 × 1 conv in shortcuts | Same as ResNet50, but with more stacked blocks |
| FLOPs | ~3.6 GFLOPs | ~4.1 GFLOPs | ~7.8 GFLOPs |
| Model | Precision/% | Recall/% | mIoU/% |
|---|---|---|---|
| ResU-Net34 | 86.55% | 86.98% | 80.87% |
| ResU-Net50 | 89.48% | 89.82% | 82.20% |
| ResU-Net101 | 90.82% | 90.69% | 83.23% |
| LinkNet34 | 88.46% | 88.13% | 82.96% |
| LinkNet50 | 92.48% | 91.87% | 86.71% |
| LinkNet101 | 92.52% | 92.19% | 85.92% |
| DeepLabv3+_34 | 91.17% | 91.40% | 84.67% |
| DeepLabv3+_50 | 92.55% | 92.70% | 86.79% |
| DeepLabv3+_101 | 94.37% | 94.27% | 89.33% |
| Township | Area of Apple Orchard (km2) | Township Area (km2) | Apple Orchard Area Proportion (%) |
|---|---|---|---|
| YangChu | 47.58 | 86.76 | 54.84 |
| GuanDao | 55.95 | 113.47 | 49.31 |
| GuanLi | 46.92 | 97.44 | 48.15 |
| SheWoBo | 92.03 | 201.69 | 45.63 |
| SiKou | 40.82 | 91.60 | 44.56 |
| XiCheng | 44.75 | 91.27 | 49.03 |
| SuJiaDian | 48.36 | 136.43 | 35.45 |
| SongShan | 45.34 | 158.50 | 28.61 |
| CuiPing | 23.97 | 89.74 | 26.71 |
| TangJiaBo | 28.83 | 138.69 | 20.79 |
| ZangJiaZhuang | 55.96 | 223.14 | 25.08 |
| TingKou | 32.39 | 151.30 | 21.41 |
| ZhuangYuan | 20.63 | 73.80 | 27.95 |
| TaoCun | 35.12 | 277.56 | 12.65 |
| MiaoHou | 10.67 | 85.27 | 12.51 |
| Total | 629.32 | 2016.66 | 31.21 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, G.; Chen, Z.; Wei, Y.; Zhu, X.; Yu, X. Enhancing DeepLabv3+ Convolutional Neural Network Model for Precise Apple Orchard Identification Using GF-6 Remote Sensing Images and PIE-Engine Cloud Platform. Remote Sens. 2025, 17, 1923. https://doi.org/10.3390/rs17111923
Gao G, Chen Z, Wei Y, Zhu X, Yu X. Enhancing DeepLabv3+ Convolutional Neural Network Model for Precise Apple Orchard Identification Using GF-6 Remote Sensing Images and PIE-Engine Cloud Platform. Remote Sensing. 2025; 17(11):1923. https://doi.org/10.3390/rs17111923
Chicago/Turabian StyleGao, Guining, Zhihan Chen, Yicheng Wei, Xicun Zhu, and Xinyang Yu. 2025. "Enhancing DeepLabv3+ Convolutional Neural Network Model for Precise Apple Orchard Identification Using GF-6 Remote Sensing Images and PIE-Engine Cloud Platform" Remote Sensing 17, no. 11: 1923. https://doi.org/10.3390/rs17111923
APA StyleGao, G., Chen, Z., Wei, Y., Zhu, X., & Yu, X. (2025). Enhancing DeepLabv3+ Convolutional Neural Network Model for Precise Apple Orchard Identification Using GF-6 Remote Sensing Images and PIE-Engine Cloud Platform. Remote Sensing, 17(11), 1923. https://doi.org/10.3390/rs17111923