
Classical vs. Machine Learning-Based Inpainting for Enhanced Classification of Remote Sensing Image

Abstract
1. Introduction
2. Related Works
3. Data
4. Experiment and Results
4.1. Inpainting
4.1.1. Methodology of Inpainting
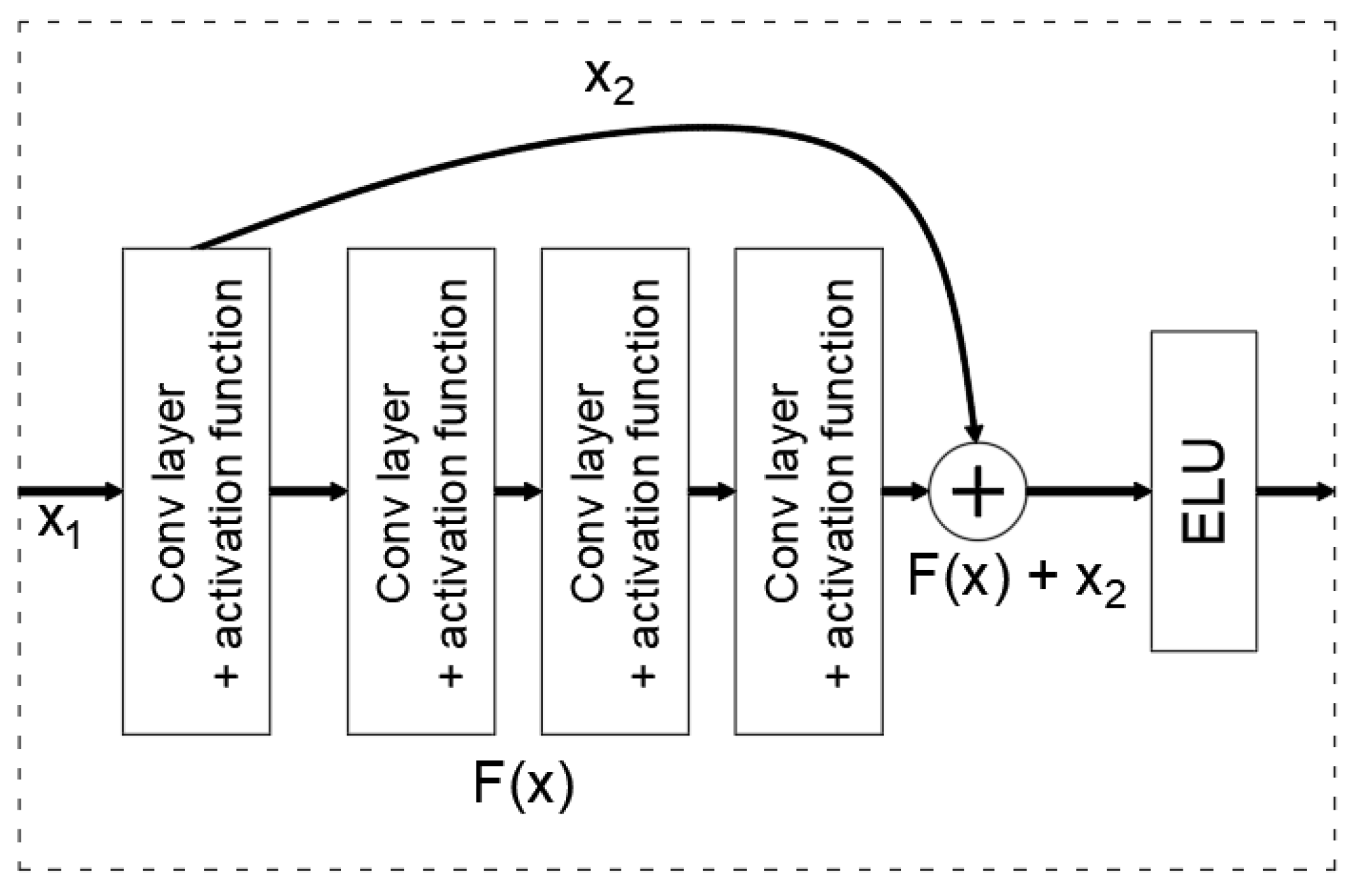
Removing Erroneous Lines from the Image—ResGMCNN Algorithm
Removing Area Objects from Images
- Computing patch priorities.
- Propagating texture and structure information.
- Updating confidence values.
4.1.2. Results of the Inpainting
Results of the ResGMCNN Algorithm
Results of Removing Cars from Images
4.1.3. Conclusions of the Inpainting
4.2. Classification
4.2.1. Methods of Classification
4.2.2. Results of Classification
Metrics to Assess Classification Quality
Results of the Classification After the Removal of Cars
4.2.3. Conclusions of Clasification
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A


References
- Sun, Y.; Lei, L.; Li, Z.; Kuang, G. Similarity and Dissimilarity Relationships Based Graphs for Multimodal Change Detection. ISPRS J. Photogramm. Remote Sens. 2024, 208, 70–88. [Google Scholar] [CrossRef]
- Zheng, Z.; Ermon, S.; Kim, D.; Zhang, L.; Zhong, Y. Changen2: Multi-Temporal Remote Sensing Generative Change Foundation Model. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 725–741. [Google Scholar] [CrossRef] [PubMed]
- Jiang, W.; Sun, Y.; Lei, L.; Kuang, G.; Ji, K. Change Detection of Multisource Remote Sensing Images: A Review. Int. J. Digit. Earth 2024, 17, 2398051. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27. [Google Scholar]
- Zhang, X.; Zhai, D.; Li, T.; Zhou, Y.; Lin, Y. Image Inpainting Based on Deep Learning: A Review. Inf. Fusion 2023, 90, 74–94. [Google Scholar] [CrossRef]
- Agostinelli, F.; Anderson, M.R.; Lee, H. Adaptive Multi-Column Deep Neural Networks with Application to Robust Image Denoising. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; Curran Associates, Inc.: Red Hook, NY, USA, 2013; Volume 26. [Google Scholar]
- Ciregan, D.; Meier, U.; Schmidhuber, J. Multi-Column Deep Neural Networks for Image Classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Hongkong, China, 16–21 June 2012; pp. 3642–3649. [Google Scholar]
- Elharrouss, O.; Almaadeed, N.; Al-Maadeed, S.; Akbari, Y. Image Inpainting: A Review. Neural Process. Lett. 2020, 51, 2007–2028. [Google Scholar] [CrossRef]
- Criminisi, A.; Perez, P.; Toyama, K. Region Filling and Object Removal by Exemplar-Based Image Inpainting. IEEE Trans. Image Process. 2004, 13, 1200–1212. [Google Scholar] [CrossRef] [PubMed]
- Qin, Z.; Zeng, Q.; Zong, Y.; Xu, F. Image Inpainting Based on Deep Learning: A Review. Displays 2021, 69, 102028. [Google Scholar] [CrossRef]
- Shen, H.; Li, X.; Cheng, Q.; Zeng, C.; Yang, G.; Li, H.; Zhang, L. Missing Information Reconstruction of Remote Sensing Data: A Technical Review. IEEE Geosci. Remote Sens. Mag. 2015, 3, 61–85. [Google Scholar] [CrossRef]
- Harrison, P. A Non-Hierarchical Procedure for Re-Synthesis of Complex Textures. Monash University: Melbourne, Australia, 2000; p. 16. [Google Scholar]
- Jia, J.; Tang, C.-K. Image Repairing: Robust Image Synthesis by Adaptive ND Tensor Voting. In Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003; Volume 1, p. I-I. [Google Scholar]
- Zalesny, A.; Ferrari, V.; Caenen, G.; Gool, L.V. Parallel Composite Texture Synthesis. In Proceedings of the Texture 2002 Workshop-ECCV, Copenhagen, Denmark, June 2002; pp. 151–155. [Google Scholar]
- Jin, K.H.; Ye, J.C. Annihilating Filter-Based Low-Rank Hankel Matrix Approach for Image Inpainting. IEEE Trans. Image Process. 2015, 24, 3498–3511. [Google Scholar] [CrossRef]
- Guo, Q.; Gao, S.; Zhang, X.; Yin, Y.; Zhang, C. Patch-Based Image Inpainting via Two-Stage Low Rank Approximation. IEEE Trans. Vis. Comput. Graph. 2018, 24, 2023–2036. [Google Scholar] [CrossRef]
- Lu, H.; Liu, Q.; Zhang, M.; Wang, Y.; Deng, X. Gradient-Based Low Rank Method and Its Application in Image Inpainting. Multimed. Tools Appl. 2018, 77, 5969–5993. [Google Scholar] [CrossRef]
- Fan, Q.; Zhang, L. A Novel Patch Matching Algorithm for Exemplar-Based Image Inpainting. Multimed. Tools Appl. 2018, 77, 10807–10821. [Google Scholar] [CrossRef]
- Liu, J.; Yang, S.; Fang, Y.; Guo, Z. Structure-Guided Image Inpainting Using Homography Transformation. IEEE Trans. Multimed. 2018, 20, 3252–3265. [Google Scholar] [CrossRef]
- Zeng, J.; Fu, X.; Leng, L.; Wang, C. Image Inpainting Algorithm Based on Saliency Map and Gray Entropy. Arab. J. Sci. Eng. 2019, 44, 3549–3558. [Google Scholar] [CrossRef]
- Zhang, D.; Liang, Z.; Yang, G.; Li, Q.; Li, L.; Sun, X. A Robust Forgery Detection Algorithm for Object Removal by Exemplar-Based Image Inpainting. Multimed. Tools Appl. 2018, 77, 11823–11842. [Google Scholar] [CrossRef]
- Shen, H.; Zhang, L. A MAP-Based Algorithm for Destriping and Inpainting of Remotely Sensed Images. IEEE Trans. Geosci. Remote Sens. 2009, 47, 1492–1502. [Google Scholar] [CrossRef]
- Maalouf, A.; Carre, P.; Augereau, B.; Fernandez-Maloigne, C. A Bandelet-Based Inpainting Technique for Clouds Removal From Remotely Sensed Images. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2363–2371. [Google Scholar] [CrossRef]
- Zhang, Q.; Lin, J. Exemplar-Based Image Inpainting Using Color Distribution Analysis. J. Inf. Sci. Eng. 2012, 28, 641–654. [Google Scholar]
- Wali, S.; Zhang, H.; Chang, H.; Wu, C. A New Adaptive Boosting Total Generalized Variation (TGV) Technique for Image Denoising and Inpainting. J. Vis. Commun. Image Represent. 2019, 59, 39–51. [Google Scholar] [CrossRef]
- Zhang, T.; Gelman, A.; Laronga, R. Structure-and Texture-Based Fullbore Image Reconstruction. Math. Geosci. 2017, 49, 195–215. [Google Scholar] [CrossRef]
- Hays, J.; Efros, A.A. Scene Completion Using Millions of Photographs. ACM Trans. Graph. 2007, 26, 4. [Google Scholar] [CrossRef]
- Li, H.; Luo, W.; Huang, J. Localization of Diffusion-Based Inpainting in Digital Images. IEEE Trans. Inf. Forensics Secur. 2017, 12, 3050–3064. [Google Scholar] [CrossRef]
- Sridevi, G.; Srinivas Kumar, S. Image Inpainting Based on Fractional-Order Nonlinear Diffusion for Image Reconstruction. Circuits Syst. Signal Process. 2019, 38, 3802–3817. [Google Scholar] [CrossRef]
- Telea, A. An Image Inpainting Technique Based on the Fast Marching Method. J. Graph. Tools 2004, 9, 23–34. [Google Scholar] [CrossRef]
- Bertalmio, M.; Bertozzi, A.L.; Sapiro, G. Navier-stokes, Fluid Dynamics, and Image and Video Inpainting. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I-I. [Google Scholar]
- Bertalmio, M.; Sapiro, G.; Caselles, V.; Ballester, C. Image Inpainting. In Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 23–28 July 2000; ACM Press/Addison-Wesley Publishing Co.: Boston, MA, USA, 2000; pp. 417–424. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context Encoders: Feature Learning by Inpainting. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Liu, G.; Reda, F.A.; Shih, K.J.; Wang, T.-C.; Tao, A.; Catanzaro, B. Image Inpainting for Irregular Holes Using Partial Convolutions. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Free-Form Image Inpainting With Gated Convolution. In Proceedings of the International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4471–4480. [Google Scholar]
- Nazeri, K.; Ng, E.; Joseph, T.; Qureshi, F.; Ebrahimi, M. EdgeConnect: Structure Guided Image Inpainting using Edge Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019; Available online: https://openaccess.thecvf.com/content_ICCVW_2019/html/AIM/Nazeri_EdgeConnect_Structure_Guided_Image_Inpainting_using_Edge_Prediction_ICCVW_2019_paper.html (accessed on 3 April 2025).
- Liu, Y.; Liu, C.; Zou, H.; Zhou, S.; Shen, Q.; Chen, T. A Novel Exemplar-Based Image Inpainting Algorithm. In Proceedings of the 2015 International Conference on Intelligent Networking and Collaborative Systems, Taipei, Taiwan, 2–4 September 2015; pp. 86–90. [Google Scholar]
- Yang, S.; Liang, H.; Wang, Y.; Cai, H.; Chen, X. Image Inpainting Based on Multi-Patch Match with Adaptive Size. Appl. Sci. 2020, 10, 4921. [Google Scholar] [CrossRef]
- Pu, C.; Song, R.; Tylecek, R.; Li, N.; Fisher, R.B. SDF-MAN: Semi-Supervised Disparity Fusion with Multi-Scale Adversarial Networks. Remote Sens. 2019, 11, 487. [Google Scholar] [CrossRef]
- Li, C.; He, K.; Liu, K.; Ma, X. Image Inpainting Using Two-Stage Loss Function and Global and Local Markovian Discriminators. Sensors 2020, 20, 6193. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Tao, X.; Qi, X.; Shen, X.; Jia, J. Image Inpainting via Generative Multi-Column Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Kuznetsov, A.; Gashnikov, M. Remote Sensing Image Inpainting with Generative Adversarial Networks. In Proceedings of the 2020 8th International Symposium on Digital Forensics and Security (ISDFS), Beirut, Lebanon, 1–2 June 2020; pp. 1–6. [Google Scholar]
- Zaytar, M.A.; El Amrani, C. Satellite Image Inpainting with Deep Generative Adversarial Neural Networks. IAES Int. J. Artif. Intell. IJ-AI 2021, 10, 121. [Google Scholar] [CrossRef]
- Czerkawski, M.; Upadhyay, P.; Davison, C.; Werkmeister, A.; Cardona, J.; Atkinson, R.; Michie, C.; Andonovic, I.; Macdonald, M.; Tachtatzis, C. Deep Internal Learning for Inpainting of Cloud-Affected Regions in Satellite Imagery. Remote Sens. 2022, 14, 1342. [Google Scholar] [CrossRef]
- Saxena, J.; Jain, A.; Krishna, P.R.; Bothale, R.V. Cloud Removal and Satellite Image Reconstruction Using Deep Learning Based Image Inpainting Approaches. In Proceedings of the Rising Threats in Expert Applications and Solutions; Rathore, V.S., Sharma, S.C., Tavares, J.M.R.S., Moreira, C., Surendiran, B., Eds.; Springer Nature: Berlin, Germany, 2022; pp. 113–121. [Google Scholar]
- Zhang, X.; Qiu, Z.; Peng, C.; Ye, P. Removing Cloud Cover Interference from Sentinel-2 Imagery in Google Earth Engine by Fusing Sentinel-1 SAR Data with a CNN Model. Int. J. Remote Sens. 2022, 43, 132–147. [Google Scholar] [CrossRef]
- Ma, X.; Huang, Y.; Zhang, X.; Pun, M.-O.; Huang, B. Cloud-EGAN: Rethinking CycleGAN From a Feature Enhancement Perspective for Cloud Removal by Combining CNN and Transformer. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 4999–5012. [Google Scholar] [CrossRef]
- Li, J.; Lv, Y.; Xu, Y.; Weng, H.; Li, D.; Shi, N. Automatic Cloud Detection and Removal in Satellite Imagery Using Deep Learning Techniques. Trait. Signal 2024, 41, 857–865. [Google Scholar] [CrossRef]
- Zhou, H.; Wang, Y.; Liu, W.; Tao, D.; Ma, W.; Liu, B. MSC-GAN: A Multistream Complementary Generative Adversarial Network With Grouping Learning for Multitemporal Cloud Removal. IEEE Trans. Geosci. Remote Sens. 2025, 63, 1–17. [Google Scholar] [CrossRef]
- Jin, M.; Wang, P.; Li, Y. HyA-GAN: Remote Sensing Image Cloud Removal Based on Hybrid Attention Generation Adversarial Network. Int. J. Remote Sens. 2024, 45, 1755–1773. [Google Scholar] [CrossRef]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Mundhenk, T.N.; Konjevod, G.; Sakla, W.A.; Boakye, K. A Large Contextual Dataset for Classification, Detection and Counting of Cars with Deep Learning. In Proceedings of the Computer Vision–ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 785–800. [Google Scholar]
- Central Statistical Office Area and Population by Territory in 2022. Table 21 Area, Population and Locations by Commune. s.l. Central Statistical Office. Available online: https://stat.gov.pl/obszary-tematyczne/ludnosc/ludnosc/powierzchnia-i-ludnosc-w-przekroju-terytorialnym-w-2022-roku,7,19.html (accessed on 14 February 2025).
- Geoportal 2. Available online: https://polska.geoportal2.pl/map/www/mapa.php?mapa=polska (accessed on 30 January 2025).
- Drone for Fast and Accurate Survey Data Every Time. Available online: https://wingtra.com/ (accessed on 29 January 2025).
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; ISBN 978-0-262-03561-3. [Google Scholar]
- Tkalcic, M.; Tasic, J.F. Colour Spaces: Perceptual, Historical and Applicational Background. In Proceedings of the IEEE Region 8 EUROCON 2003. Computer As a Tool., Ljubljana, Slovenia, 22–24 September 2003; Volume 1, pp. 304–308. [Google Scholar]
- Keelan, B. Handbook of Image Quality: Characterization and Prediction; CRC Press: Boca Raton, FL, USA, 2002; ISBN 978-0-429-22280-1. [Google Scholar]
- Sekrecka, A. Application of the XBoost Regressor for an A Priori Prediction of UAV Image Quality. Remote Sens. 2021, 13, 4757. [Google Scholar] [CrossRef]
- Venkatanath, N.; Praneeth, D.; Bh, M.C.; Channappayya, S.S.; Medasani, S.S. Blind Image Quality Evaluation Using Perception Based Features. In Proceedings of the 2015 Twenty First National Conference on Communications (NCC), Mumbai, India, 27 February–1 March 2015; pp. 1–6. [Google Scholar]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “Completely Blind” Image Quality Analyzer. IEEE Signal Process. Lett. 2013, 20, 209–212. [Google Scholar] [CrossRef]
- Crete, F.; Dolmiere, T.; Ladret, P.; Nicolas, M. The blur effect: Perception and Estimation with a New No-Reference Perceptual Blur Metric. In Proceedings of the Human Vision and Electronic Imaging XII, San Jose, CA, USA, 29 January–1 February 2007; SPIE: Bellingham, WA, USA, 2007; Volume 6492, pp. 196–206. [Google Scholar]
- Fix, E.; Hodges, J.L. Discriminatory Analysis. Nonparametric Discrimination: Consistency Properties. Int. Stat. Rev. Rev. Int. Stat. 1989, 57, 238–247. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Support Vector Method. In Proceedings of the Artificial Neural Networks—ICANN’97; Gerstner, W., Germond, A., Hasler, M., Nicoud, J.-D., Eds.; Springer: Berlin, Heidelberg, 1997; pp. 261–271. [Google Scholar]
- Ho, T.K. Random Decision Forests. In Proceedings of the Proceedings of 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–15 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Friedman, J.H. Stochastic Gradient Boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Bayes, T. An Essay towards Solving a Problem in the Doctrine of Chances. By the Late Rev. Mr. Bayes, F.R.S. Communicated by Mr. Price, in a Letter to John Canton, A.M.F.R.S. Philos. Trans. R. Soc. Lond. 1997, 53, 370–418. [Google Scholar] [CrossRef]
- Baracchi, D.; Boato, G.; De Natale, F.; Iuliani, M.; Montibeller, A.; Pasquini, C.; Piva, A.; Shullani, D. Toward Open-World Multimedia Forensics Through Media Signature Encoding. IEEE Access 2024, 12, 59930–59952. [Google Scholar] [CrossRef]
- Zhang, X.; Zheng, Z.; Gao, D.; Zhang, B.; Yang, Y.; Chua, T.-S. Multi-View Consistent Generative Adversarial Networks for Compositional 3D-Aware Image Synthesis. Int. J. Comput. Vis. 2023, 131, 2219–2242. [Google Scholar] [CrossRef]
- Rot, P.; Grm, K.; Peer, P.; Štruc, V. PrivacyProber: Assessment and Detection of Soft–Biometric Privacy–Enhancing Techniques. IEEE Trans. Dependable Secure Comput. 2024, 21, 2869–2887. [Google Scholar] [CrossRef]
- Cira, C.-I.; Kada, M.; Manso-Callejo, M.-Á.; Alcarria, R.; Bordel Sanchez, B. Improving Road Surface Area Extraction via Semantic Segmentation with Conditional Generative Learning for Deep Inpainting Operations. ISPRS Int. J. Geo-Inf. 2022, 11, 43. [Google Scholar] [CrossRef]
- Akshatha, K.R.; Biswas, S.; Karunakar, A.K.; Satish Shenoy, B. Anchored versus Anchorless Detector for Car Detection in Aerial Imagery. In Proceedings of the 2021 2nd Global Conference for Advancement in Technology (GCAT), Bangalore, India, 1–3 October 2021; pp. 1–6. [Google Scholar]
- Katar, O.; Duman, E. U-Net Based Car Detection Method For Unmanned Aerial Vehicles. Mühendis. Bilim. Ve Tasar. Derg. 2022, 10, 1141–1154. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | GMCNN | ResGMCNN |
|---|---|---|
| Architecture | Multi-branch encoder–decoder architecture | Multi-branch encoder–decoder architecture with skip connections in each branch. |
| Residual Connections | None | Includes residual connections in each branch, allowing for better gradient propagation and retention of essential input features during the reconstruction process. |
| Activation | ELU | LeakyReLU |
| Feature Branch Merging | Results from different columns are combined to obtain the final image reconstruction. | Feature maps from each of the three branches are merged into a single tensor, which is then transformed into image space using a common decoder module consisting of two convolutional layers. |
| Navier–Stokes | Telea | Criminisi | GMCNN | GMCNN with Leaky ReLU | ResGMCNN (our) | |
|---|---|---|---|---|---|---|
| DOTA | 0.803 | 0.804 | 0.982 | 0.675 | 0.708 | 0.905 |
| WV2 | 0.929 | 0.815 | 0.988 | 0.769 | 0.719 | 0.931 |
| COWC | 0.913 | 0.911 | 0.994 | 0.864 | 0.846 | 0.925 |
| Radom | ||||
| Metric/image | original | Criminisi | Navier–Stokes | Telea |
| PIQE | 30.282 | 25.538 | 27.917 | 27.310 |
| NIQE | 1.876 | 2.504 | 2.506 | 2.502 |
| NRPBM | 0.267 | 0.257 | 0.262 | 0.262 |
| Entropy | 7.677 | 7.665 | 7.658 | 7.657 |
| Warsaw | ||||
| Metric/image | original | Criminisi | Navier–Stokes | Telea |
| PIQE | 26.005 | 25.264 | 27.073 | 26.743 |
| NIQE | 1.988 | 1.987 | 2.023 | 1.998 |
| NRPBM | 0.263 | 0.262 | 0.264 | 0.263 |
| Entropy | 7.517 | 7.515 | 7.512 | 7.513 |
| Model | Parameter | Image 1 | Image 2 | Image 3 | Image 4 |
|---|---|---|---|---|---|
| kNN | neighbours | 7 | 5 | 5 | |
| weights | distance * | Distance * | distance * | Distance * | |
| SVM | kernel | RBF ** | RBF ** | RBF ** | RBF ** |
| C | 1.5 | 2.0 | 4.5 | 2.0 | |
| RF | max depth | 20 | 20 | 20 | None *** |
| number of trees | 200 | 50 | 200 | ||
| GBC | learning rate | 0.2 | 0.2 | 0.2 | 0.2 |
| max depth | 7 | 7 | 7 | 5 | |
| estimators | 200 | 200 | 200 | 200 | |
| GNB | variance | 1 × 10−9 | 1 × 10−9 | 1 × 10−9 | 1 × 10−9 |
| MLP | activation | tanh | tanh | tanh | tanh |
| layer sizes | (50,50) | (50,50) | (50,50) | (50,50) | |
| optimiser (solver) | Adam | Adam | Adam | Adam | |
| learning rate (init) | 0.001 | 0.001 | 0.001 | 0.001 |
| Metric | Description | Goal |
|---|---|---|
| Accuracy | Accuracy is the ratio of the number of correctly classified samples to the total number of samples. It expresses the overall effectiveness of the classification algorithm. In the case of unbalanced datasets, where one class dominates, accuracy alone can be misleading. | 1 |
| Precision | Precision is a measure that indicates how many of the predicted positive examples are actually positive. High precision means that the model rarely misclassifies negative examples as positive. | 1 |
| Recall | Recall measures how many actual positive examples were correctly detected by the model. High recall indicates that the model rarely misses positive cases. | 1 |
| F1-score | The F1-score is the harmonic mean of precision and recall. It is particularly useful in cases of imbalanced data (i.e., when one class occurs significantly more frequently than the other). | 1 (perfect agreement) 0.8–1 (good agreement) |
| Indeks Jaccarda (Intersection over Union—IoU) | The Jaccard Index is a measure of the overlap between two sets, in this case, the classified image and the reference image. It is the ratio of the intersection of two areas to their union. is the number of pixels classified as object or background in at least one of the images. A high IoU value indicates that the model’s classification closely matches the reference image. | 1 |
| Cohen’s Kappa | Cohen’s kappa measures the agreement between two classifications, accounting for the possibility of random agreement. It is a useful metric when a classifier may accidentally classify images in agreement with the reference. | 1 (perfect agreement) 0.8–1 (good agreement) |
| Advantages | Disadvantages | |
|---|---|---|
| Inpainting using deep learning (based on GMCNN and ResGMCNN) |
|
|
| Classical inpainting methods |
|
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sekrecka, A.; Karwowska, K. Classical vs. Machine Learning-Based Inpainting for Enhanced Classification of Remote Sensing Image. Remote Sens. 2025, 17, 1305. https://doi.org/10.3390/rs17071305
Sekrecka A, Karwowska K. Classical vs. Machine Learning-Based Inpainting for Enhanced Classification of Remote Sensing Image. Remote Sensing. 2025; 17(7):1305. https://doi.org/10.3390/rs17071305
Chicago/Turabian StyleSekrecka, Aleksandra, and Kinga Karwowska. 2025. "Classical vs. Machine Learning-Based Inpainting for Enhanced Classification of Remote Sensing Image" Remote Sensing 17, no. 7: 1305. https://doi.org/10.3390/rs17071305
APA StyleSekrecka, A., & Karwowska, K. (2025). Classical vs. Machine Learning-Based Inpainting for Enhanced Classification of Remote Sensing Image. Remote Sensing, 17(7), 1305. https://doi.org/10.3390/rs17071305