1. Introduction
Building polygon (footprint/roof) datasets and their inventories enhance the management of the urban environment and improve societal aspects of urban living with applications such as mapping, urban planning, disaster management, sprawl and green space management, urban heat monitoring, change detection, and humanitarian efforts [
1,
2,
3]. Additionally, building data aids in tracking housing development, managing zoning regulations, and ensuring equitable land use, enabling planners to monitor urban expansion, assess population densities, and identify infrastructure needs [
4]. Furthermore, it enhances disaster preparedness by mapping vulnerable areas, planning evacuation routes, and improving urban resilience. This paper aims to improve the development of urban building datasets by addressing a major problem in remote sensing-based extraction within complex urban environments.
Urban buildings are extracted from high-resolution remote sensing (RS) images using deep learning-based semantic segmentation models [
5,
6]. These models classify each image pixel into ‘building’ and ‘non-building’ categories. Most segmentation models follow an encoder–decoder network (EDN) architecture, with U-Net [
7] being a widely used example. Global building datasets such as Microsoft’s Building Footprints [
8], Google’s Open Buildings [
9], and ESRI (See:
https://www.arcgis.com/home/item.html?id=4e38dec1577b4b7da5365294d8a66534 (accessed on 30 March 2025), ESRI’s Deep Learning Model to Extract Buildings) are produced using EDN-based segmentation models.
Global data providers face a major problem in building extraction due to label displacement error, where annotated building labels fail to align accurately with true building footprints in remote sensing imagery. This misalignment arises from the off-nadir angle of aerial and satellite sensors, which may be primarily caused by central projection errors and push-broom scanning approaches of high-resolution satellite sensors [
10]. A potential solution in photogrammetry is true orthophotos, but their high computational cost, limited global availability, and processing complexity hinder large-scale adoption. Instead, data providers like Microsoft and Google rely on deep learning techniques, stereo imagery, and post-processing corrections to minimize the effects of off-nadir distortions [
8,
9]. Without true orthophotos, displacements can only be reduced rather than eliminated. As a result, extracting true building footprints is a challenge, and most building extraction studies assume the extracted roof polygons are the footprints. The label displacement error can increase the number of pixels for taller building heights and higher spatial resolution of off-nadir images. As illustrated in
Figure 1, when spatial resolution rises from 120 cm/px (cm/px = centimeter per pixel, a unit of ground sample distance) to 60 cm/px, each original pixel is replaced by four smaller pixels, effectively quadrupling the displacement error. This label displacement error results in inaccurate training datasets, ultimately compromising the accuracy of building extraction models trained on these misaligned labels. Given its impact on large-scale data products, this problem has gained increasing attention, including research efforts such as the SpaceNet 4 Challenge [
11]).
Tackling the misalignment problem is ongoing research, and the problem has recently devised many methods. Relief displacement correction [
12], multitask learning [
13], multilabel learning [
14], and learning from depth [
15] are studied as potential solutions. The segmented outputs in these methods are improved with several post-processing steps, including morphological operations that limit their robustness and end-to-end usage. Apart from addressing the misalignment problem, some studies distinguish between the facade and roof in a multi-view oblique image [
16,
17,
18]. Wang et al. [
19] developed the BONAI building dataset with labels for the roof, footprints, and the offset between them and employed a learning offset vector (LOFT) method with CNN that learned from the offset. The accuracy of the BONAI dataset was further improved recently by [
14] using multilabel learning of footprint, roof, and additional ‘shape’ labels. These methods have provided remarkable achievements in tackling the misalignment problem, given that the annotations (labels) are available for multiple features of oblique-view buildings. However, developing a dataset that constitutes these features (footprint, roof, facade, and offset) is an additional challenge to the already difficult process of labeling footprints alone on the limited remote sensing images. While these methods require multiple post-processing steps or additional annotations for other building features over oblique-view images, other studies focus on knowledge distillation with a teacher–student learning approach.
Knowledge distillation (KD) [
20] is a technique where a teacher model, trained on a large dataset, transfers its knowledge to a student model, which is typically smaller and more efficient. KD has been widely applied in learning from noisy labels (aka. supervision from label noise) [
21,
22] and has shown potential in remote sensing applications [
23]. Xu et al. [
24] adopted this KD-based teacher–student learning approach to address the label displacement problem. Their approach involved training a teacher on a large but noisy dataset (with misaligned labels) and distilling its knowledge into a student that learns from a smaller, cleaner dataset (without misalignment), making the student more robust to label noise. They compare their results to deep mutual learning (DML) [
25], where multiple student models collaborate and teach each other while distilling knowledge from the teacher. Expanding on their work, Ref. [
26] introduced fine-tuning learning (FTL), where models trained on noisy off-nadir images are adapted to true orthophotos, demonstrating that FTL was more effective than KD for training misalignment-tolerant students. Originally, KD was designed to transfer knowledge from large, high-performing models to smaller, deployable students [
20], but this process inherently limits the student’s ability to surpass the teacher’s performance since smaller models retain less information. This constraint reduces accuracy in segmenting complex urban buildings, whereas FTL, unlike KD and DML, allows re-training beyond the pre-trained teacher’s limitations, enabling the student to develop greater noise tolerance and adapt more effectively to new datasets.
FTL adopts a pre-trained model on a source domain by further training it on a target domain using labeled target data while retaining knowledge from the source. FTL can also be called supervised domain adaptation if it explicitly addresses domain shifts between the source and target. Given that our datasets contain labels in both domains, FTL is more suitable than unsupervised domain adaptation (UDA) to adapt a student model to the target dataset. Studies have shown that FTL enhances building extraction accuracy [
27,
28] and is effective in fine-tuning models trained on large–noisy datasets for improved performance on small–clean datasets [
29,
30,
31].
With FTL showing promising results in training misalignment-tolerant students compared with other teacher–student learning methods like KD, several research questions remain unanswered. These methods are introduced to address the misalignment problem, yet their experimentation in varied settings remains minimal. From the available studies of [
24,
26], two knowledge gaps are identified: (i) the teacher–student learning methods have not yet been studied for different building types of varying heights and images of different spatial resolutions; (ii) the available CNNs and EDNs are not benchmarked to identify the optimal teachers (large immovable networks) and students (lightweight and deployable) for the three methods.
To develop accurate building extraction models that are more tolerant to misalignment in off-nadir images and to investigate the two identified knowledge gaps, this study makes the following contributions:
FTL is introduced to mitigate misalignment between building image–label pairs caused by off-nadir angles. FTL is implemented within a teacher–student learning framework, where a large teacher model is pre-trained on a misaligned dataset (source domain) and subsequently fine-tuned on a smaller, error-free student dataset (target domain) to improve segmentation accuracy.
A structured experimental setup is designed to systematically compare FTL against KD, DML, and the models without FTL. Three new urban building datasets, including high-rise and skyscraper buildings, are developed with “large–noisy” and “small–clean” image–label pairs. The datasets and codes are openly released for reproducibility (see the data availability statement).
The methods are evaluated across four building types (low-rise, mid-rise, high-rise, and skyscrapers) and three spatial resolutions, ensuring a comprehensive performance analysis.
A comparative analysis of 43 representative lightweight CNNs, five optimizers, nine loss functions, and seven EDNs is conducted to identify the optimal trade-off between lightweight efficiency and high-performance models. The CNNs include state-of-the-art lightweight architectures from Google, Apple, Meta, Amazon, and Huawei. To the best of our knowledge, such a comprehensive benchmark of lightweight CNNs and their integration into an EDN is novel for building extraction.
2. Materials and Methods
The proposed method of FTL between large-noisy and small–clean datasets to achieve misalignment-tolerant models is carried out in a four-step workflow: (i) data preparation, (ii) selection of teacher and student network architectures, (iii) fine-tuning-based transfer learning, and (iv) evaluation of the fine-tuned students against the students distilled from KD and DML. The workflow is illustrated in
Figure 2 and is detailed stepwise in this section.
2.1. Data Preparation
This study uses four datasets: one benchmark dataset for benchmarking the hyperparameters, CNNs, and EDNs for our experimental setup of FTL and three newly developed datasets for training, fine-tuning/distillation, and evaluation of EDNs. The benchmark dataset helps identify optimal configurations for setting up the teacher (pre-trained network) and students (fine-tuned/distilled networks) in FTL. Once configured, the teacher model is trained and evaluated on the teacher’s dataset (T), while the student models undergo fine-tuning/distillation and are evaluated using the student’s dataset (S) and Evaluation dataset (). The effectiveness of the student models in reducing misalignment is assessed based on their performance on these two datasets.
The benchmark dataset is derived from the widely used Massachusetts Building dataset [
32]. A smaller subset of the dataset, as provided in [
5], is used for experimental consistency and lower memory usage to benchmark the lightweight models. This subset crops the original 1500 × 1500 px (px = number of pixels) tiles to 256 × 256 px, and the training and test images are reduced by 4× and 2×. The number of validation images is kept the same as in the original dataset.
The teacher’s dataset (
T) is developed by masking and tiling the building roof polygons provided by the City of Melbourne. See
https://data.melbourne.vic.gov.au/explore/dataset/2020-building-footprints/information/ (accessed on 15 April 2024), 2020 Building Footprints from the City of Melbourne. Multi-resolution image tiles of 30, 60, and 120 cm/px spatial resolution are collected from the
Nearmap Tile API. The vector labels are rasterized with reference to the image using Algorithm 1. The misalignment between these image–label pairs is not accounted for, making it the “large–noisy” teacher’s dataset.
| Algorithm 1 Building Dataset Preparation from Nearmap API Service |
Require: Building Geodatabase (GDB), API key, zoom level
Ensure: Geospatial tiles and rasterised building polygons
- 1:
function FetchAndRasteriseTiles() - 2:
- 3:
for all do - 4:
CalculateCentroid() - 5:
ConvertToTile(, ) - 6:
if then - 7:
FetchTile(, ) - 8:
SaveTile() - 9:
- 10:
end if - 11:
end for - 12:
end function - 13:
procedure DatasetPreparation() - 14:
LoadShapefile() - 15:
FetchAndRasteriseTiles() - 16:
end procedure - 17:
DatasetPreparation()
|
Student’s dataset (S) is developed for fine-tuning/distillation purposes by collecting images over the central business district (CBD) of Melbourne. The CBD consists mostly of high-rise and skyscraper buildings with complex structures, providing challenging urban environments. For the images, both off-nadir images and true orthophotos are collected from Nearmap. The orthophoto is separately downloaded and tiled, and the off-nadir image tiles are collected from the API service. City of Melbourne’s building roof polygons are overlaid over the true orthophoto image, and for the off-nadir image tiles, the buildings are manually annotated (by hand). Therefore, unlike T, this dataset provides ’clean’ image–label pairs.
The evaluation dataset (
) is curated as a dataset to evaluate the fine-tuned/distilled networks on the manually annotated labels for image scenes of the four building types. This dataset does not have training samples (only validation). A subset of 55 image tiles of
T is taken and manually annotated (by hand). The building types are separated according to their heights as defined by the Australian Bureau of Statistics (ABS). See:
https://www.abs.gov.au/ausstats/abs@.nsf/Lookup/8752.0Feature+Article1Dec%202018 (accessed on 15 April 2024), Characteristics of Apartment Building Heights by ABS.
Table 1 summarizes the datasets, where (i)
T contains misaligned image–label pairs for training and validation, (ii)
S includes both off-nadir and true orthophoto images with clean labels, and (iii)
features off-nadir images from
T with clean labels. “Clean labels” refer to overlaying labels without misalignment. Both
S and
consist of complex high-rise buildings from the CBD, making them valuable for evaluating segmentation performance under challenging conditions. All datasets have an image size of 256 × 256 px.
Figure 3 presents the study area and dataset samples.
2.2. Selection of Representative Teacher and Student Networks
EDNs enable flexible integration of backbone CNNs (encoders) for multi-scale feature extraction in semantic segmentation, with U-Net being a widely used architecture for building segmentation [
5]. The encoder processes input images, while the decoder upsamples learned features to generate the segmented output, with skip connections preserving spatial details. An illustrative example of a U-Net EDN and two CNN examples—EfficientNetv2 and MobileViT—are provided in
Figure 4.
EfficientNetv2 [
33] is a lightweight CNN from Google Brain. It uses Fused-MBConv convolutional blocks alongside the NAS component, and like its predecessor v1, it offers multiple scaled versions. The network uses different variations of Mobile Inverted Bottleneck Convolution (MBConv) blocks: MBConv1, MBConv4, and MBConv6. These blocks are a type of inverted residual block central to the network architecture, providing efficient and flexible building blocks for CNNs. The blocks consist of the EdgeResidual layer to improve the flow of gradients during backpropagation, the non-linear activation function SiLU to introduce non-linearity, and the Squeeze-and-Excitation layer to improve the representational power of a network by explicitly modeling the interdependencies between the channels of convolutional features.
MobileViT [
34] is a compact vision transformer developed for mobile devices. These models use MobileNetv2 (MV2) blocks to leverage their efficiency and lightweight nature for mobile and edge devices. MV2 blocks consist of an expansion layer, depthwise convolution, ReLU6 activation for non-linearity, pointwise convolution to project features back to the desired output dimension, and residual connection between input and output. It uses an additional MobileViT block, which is specialized to integrate the strengths of CNNs and transformers. It consists of the convolutional layer that extracts local features, the Transformer layer to capture global context and long-range dependencies, and the Reconstruction layer that reshapes and passes the output of the Transformer layer through another convolutional layer (to combine the local and global information). MobileViT is available in several smaller versions (s, xs, and xxs).
Optimal performance in EDNs is achieved by tuning hyperparameters, including the loss function (
), which quantifies prediction errors (e.g., dice loss, Jaccard loss), the optimizer (e.g., Adam, SGD) for weight updates, the learning rate (
) controlling step size during training, and the batch size, affecting memory use and convergence stability. The best-performing model is selected by systematically searching for hyperparameter configurations, training until validation loss stabilizes, and evaluating metrics like IoU and F1 score to ensure high segmentation accuracy and generalization. Therefore, before applying the proposed FTL and comparing it to other transfer learning methods, we carry out a systematic search of the (i) hyperparameters, (ii) EDNs, (iii) student models, and (iv) teacher models with an extensive benchmark study. The detailed benchmark is provided in
Appendix A; however, its summary can be categorized into four steps:
- Step 1.
Hyperparameter search: A CNN encoder (MobileOne-s1) is randomly chosen and integrated into a U-Net EDN to explore various hyperparameters, including learning rate, converging epoch, loss functions, and optimizers. Five optimizers and nine loss functions are tested, with learning rate scheduling and early stopping at the converging epoch. A combination of the RMSProp optimizer, dice loss, and 0.0001 learning rate provided the highest scores in most experiments.
- Step 2.
EDN Comparison: The best hyperparameters from Step 1 are applied to eight state-of-the-art EDNs—U-Net, U-Net++ [
35], U-Net3+ [
36], LinkNet [
37], PSPNet [
38], FPN [
39], DeepLabv3+ [
40], and MANet [
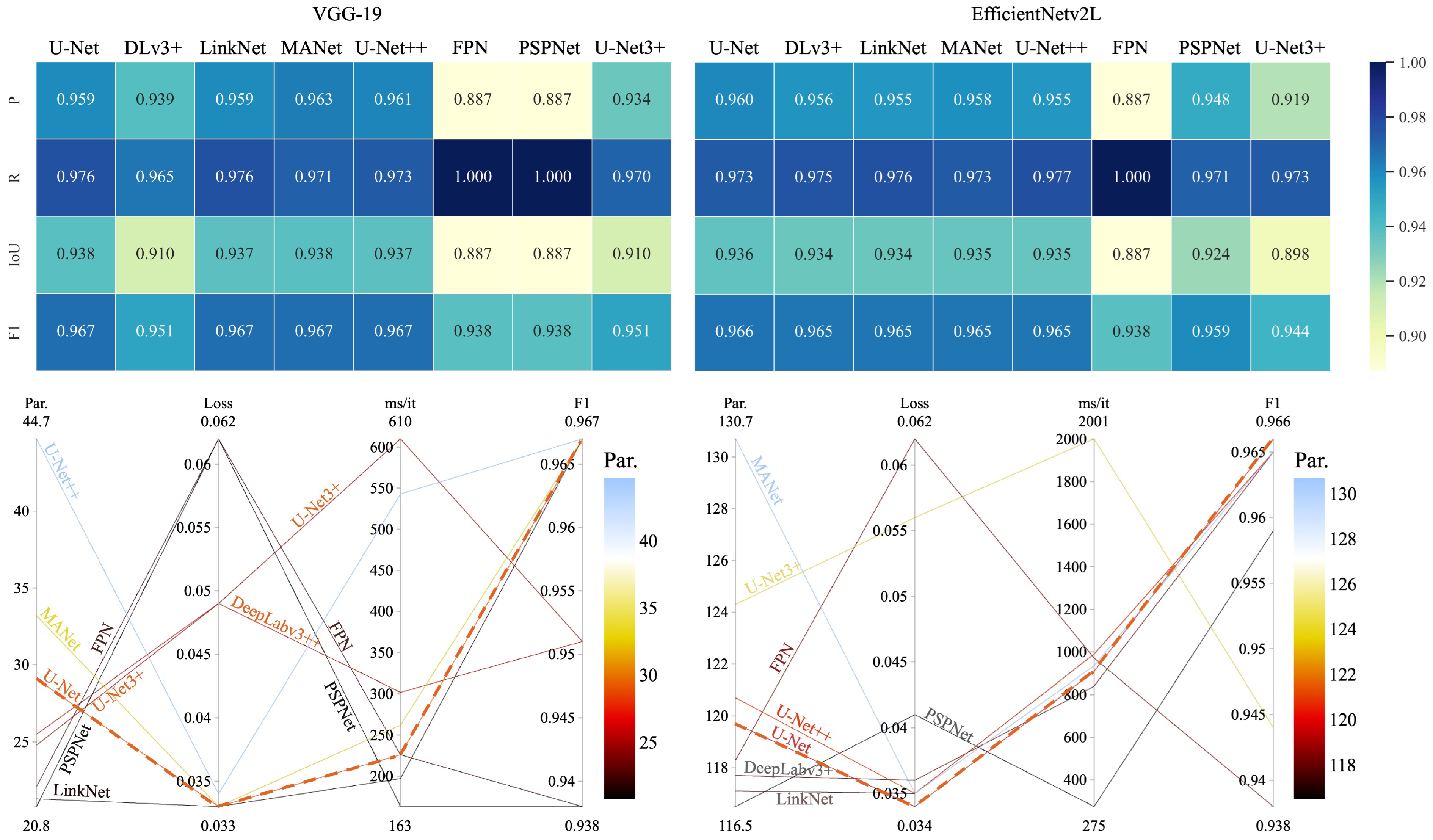
41]—to identify an architecture that balances model size and performance for the teacher and student networks. From the benchmarks, U-Net provided the best trade-off between the number of parameters, network complexity, and evaluation scores. It is therefore the best EDN to configure student and teacher models for the proposed FTL.
- Step 3.
Student search: 43 lightweight CNNs (e.g., ResNeSt, GERNet, MobileOne, TinyNet, MobileViT, MobileNet, EfficientNet) (The explanation of the CNN along with their references is provided at
https://github.com/bipulneupane/TeacherStudentBuildingExtractor (accessed on 30 March 2025)). They are benchmarked as potential students. These CNNs are integrated into the EDN from Step 2 (U-Net) and trained with the hyperparameters from Step 1. For the integration, we remove their final layers of 1x1 convolution and fully connected layers. The remaining layers are then connected to the decoder that comprises 2D convolution, batch normalization (BN), ReLU, and attention layers. The top five best student models are selected based on a trade-off between network parameters, loss, training time, and evaluation scores. The top five student models were U-EfficientNetv2B3 (high scorer), U-EfficientNet-lite0 (best trade-off between evaluation scores and network parameters), U-MNASNet-s, U-TinyNet-e, and U-MobileViT-xxs (with the smallest size, suitable to configure student models).
- Step 4.
Teacher search: For FTL, the teacher and student share the same EDN. However, to facilitate KD and DML for comparison, the teacher is a larger, static model distilling knowledge to smaller students. We evaluate a larger version of the student’s CNN and U-VGG19, given its strong benchmark performance [
5]. U-VGG19 was identified as the best teacher with the highest F1 score and lower network parameters when compared with U-EfficientNetv2L (the largest version of the high-scorer EfficientNetv2B3 from Step 3).
2.3. Proposed Fine-Tuning-Based Transfer Learning (FTL)
The proposed FTL fine-tunes a model pre-trained on a source dataset by updating all layers on a target dataset. The process begins with pre-training an EDN on a large–noisy dataset, T (source domain = teacher’s dataset), containing misaligned labels. The model, denoted as , learns broad feature representations. The pre-trained model (teacher) is then fine-tuned on a clean dataset S (target domain = student’s dataset). The goal is to adapt the model beyond the constraints of the teacher while retaining generalizable features learned from T. Fine-tuning consists of two key phases:
2.3.1. Pre-Training on Noisy Labels
The EDN, parameterised by
is trained on the noisy
T dataset:
where
represents the input image of height
H, width
W, and number of channels
C. Similarly,
is the corresponding noisy building label, and
is the number of samples in
T. The training minimizes a segmentation loss, such as dice loss:
where
is the predicted segmentation mask,
y is the input label mask, and
prevents division by zero. The pre-training loss across
T is
After minimizing , we obtain the pre-trained model parameters, .
2.3.2. Fine-Tuning on Clean Labels
The pre-trained model is fine-tuned on the student dataset:
where
is the clean input image,
is its input label, and
is the number of samples in
S. Fine-tuning minimizes dice loss over
S:
The model parameters are updated using gradient descent:
where
are the fine-tuned parameters,
is the learning rate, and
is the gradient of the loss. Since all layers are fine-tuned, the encoder and decoder adapt to
S, improving segmentation precision.
2.4. Comparison Methods
The proposed FTL method is compared with existing teacher–student learning methods: knowledge distillation (KD) and deep mutual learning (DML). KD [
20] distills a student on a small–clean dataset while being supervised by a teacher trained on a large–noisy set. DML [
25] extends this by enabling multiple students to collaboratively learn from each other under teacher supervision. The two methods are established for the other applications of supervision from label noise [
21,
22,
42,
43]. Xu et al. [
24] applied both methods to the label displacement problem we address, though with limited accuracy and unresolved knowledge gaps mentioned before. As KD and DML are the only teacher–student approaches introduced for this problem, we adopt them in our experimental setup with their respective loss functions for a fair, state-of-the-art comparison with FTL.
2.4.1. Knowledge Distillation
KD transfers knowledge from a large teacher model trained on noisy data (
T) to a smaller student model trained on clean data (
S) while minimizing performance loss. The student is optimized using a total loss:
where
balances segmentation accuracy (
) and feature alignment (
). The distillation loss aligns multi-scale feature maps:
where
and
are the predictions from the teacher and student for pixel
j,
is the sigmoid activation, and
controls the softness of the predictions. The Mean Squared Error (MSE) loss is
where
and
are the GT and prediction for pixel
j, and
normalises the loss.
By optimizing , KD ensures that the student retains the teacher’s knowledge while refining its segmentation accuracy. However, the student model is inherently constrained by the teacher’s performance, limiting its potential.
2.4.2. Deep Mutual Learning
DML enables multiple models to learn collaboratively rather than through a one-way teacher-to-student transfer. In this setup, one teacher and two students train jointly, benefiting from label supervision and mutual distillation. This encourages knowledge exchange, likely enhancing generalization and robustness, particularly in data-scarce settings like S.
Each model
(teacher or student) is trained with a segmentation loss and a mutual distillation loss:
where
is the segmentation loss for
,
is the mutual distillation loss between
and
, and
balances segmentation accuracy and mutual learning.
The mutual distillation loss encourages agreement between models:
where
and
are the predictions for pixel
j from models
and
,
is the sigmoid activation function, and
controls distribution softening.
By aligning their predictions, students develop a consensus on segmentation accuracy, improving generalization. DML is particularly effective when labeled data in S is limited, as models benefit from mutual knowledge exchange.
2.5. Experimental Setup
The experimental setup with training details, accuracy metrics, train-val settings, and baseline scores for comparison is provided below.
2.5.1. Training Details and Accuracy Metrics
All networks are wrapped in the PyTorch (version 2.2.2) using the Segmentation Models Pytorch library (version 0.3.4) [
44] and trained on an Nvidia A100 GPU (Nvidia, Santa Clara, CA, USA) (with 80 GB RAM). The teacher and students are trained up to 50 and 200 epochs, respectively. The learning rate is reduced upon a plateau of intersection over union (IoU) metric by a factor of 0.1 with a patience of 10 epochs. A sigmoid function classifies the final binary outputs. Four accuracy metrics are used for evaluation: precision (P), recall (R), IoU, and F1 score. The mathematical notation of the metrics is from [
5].
2.5.2. Train-Val Settings
The experiments are performed in different experimental settings for FTL, KD, and DML. Depending on the training (train) and validation (val) subsets of T, S, and Ev datasets, five experimental settings are used for the comparison:
T–T: training/fine-tuning/distilling on T; validation on T.
S–S: training/fine-tuning/distilling on S; validation on S.
T–S: training/fine-tuning/distilling on T; validation on S.
T–Ev: training/fine-tuning/distilling on T; validation on Ev.
S–Ev: training/fine-tuning/distilling on S; validation on Ev.
2.5.3. Baseline Scores for Comparison
With the teacher and students identified from the benchmarks, we trained them on the T and S datasets alone. The trained models were evaluated on Ev to produce the baseline scores for the comparison of the transfer learning methods.
Teacher’s baseline scores were produced in T–T, T–S, and T–Ev settings, as reported in
Table 2. From the difference in T–T and T–S settings, it was found that the teacher’s ability to generalize the validation samples from S was influenced by the domain shift between T and S. This domain shift can be attributed to two primary factors: the presence of unfamiliar, complex urban high-rise buildings in S and the contrast between the precision of ortho-rectification between the samples of T and S. However, in the T–Ev setting, the teacher demonstrated its capacity to generalize complex high-rise buildings in Ev, even though it was trained on misaligned labels in T. The complexity of the clean data S and Ev was prominent in the experimental results.
Student’s baseline scores (without transfer learning) were studied in S–S and S–Ev settings.
Table 3 reports their baseline scores along with the performance of the three knowledge transfer methods. U-VGG19 (0.893 F1) and U-EfficientNetv2B3 (0.819 F1) score the highest when validated on S and Ev, respectively. The performance of students after FTL and other knowledge transfer methods will be evaluated against these baseline scores.
Having thus established our experimental setup, we now present the comparative evaluation of FTL against KD and DML across different types of urban buildings.
5. Conclusions
This study proposed fine-tuning-based transfer learning as an effective method for building extraction from remote sensing imagery, specifically addressing the misalignment problem (label displacement errors) caused by off-nadir images. Unlike the existing methods of KD and DML, which primarily focus on model compression, FTL leverages the teacher–student learning framework to fine-tune a pre-trained model on a smaller, high-quality dataset. This approach allows better adaptation to the target domain without compromising segmentation accuracy, making it a more robust alternative to the previous transfer learning methods.
A structured experimental framework was designed with three new urban building datasets that incorporate both large–noisy (misaligned) and small–clean (manually annotated) image–label pairs. This setup enabled a controlled evaluation of FTL, KD, and DML across different building types and spatial resolutions. Additionally, an extensive benchmark study was conducted, evaluating 43 representative lightweight CNNs, five optimizers, nine loss functions, and seven encoder–decoder networks (EDNs) to identify the optimal balance between lightweight efficiency and high segmentation accuracy. The benchmark found that U-VGG19 and U-EfficientNetv2B3 are the best (in terms of accuracy, training time, and model size) teacher and student models.
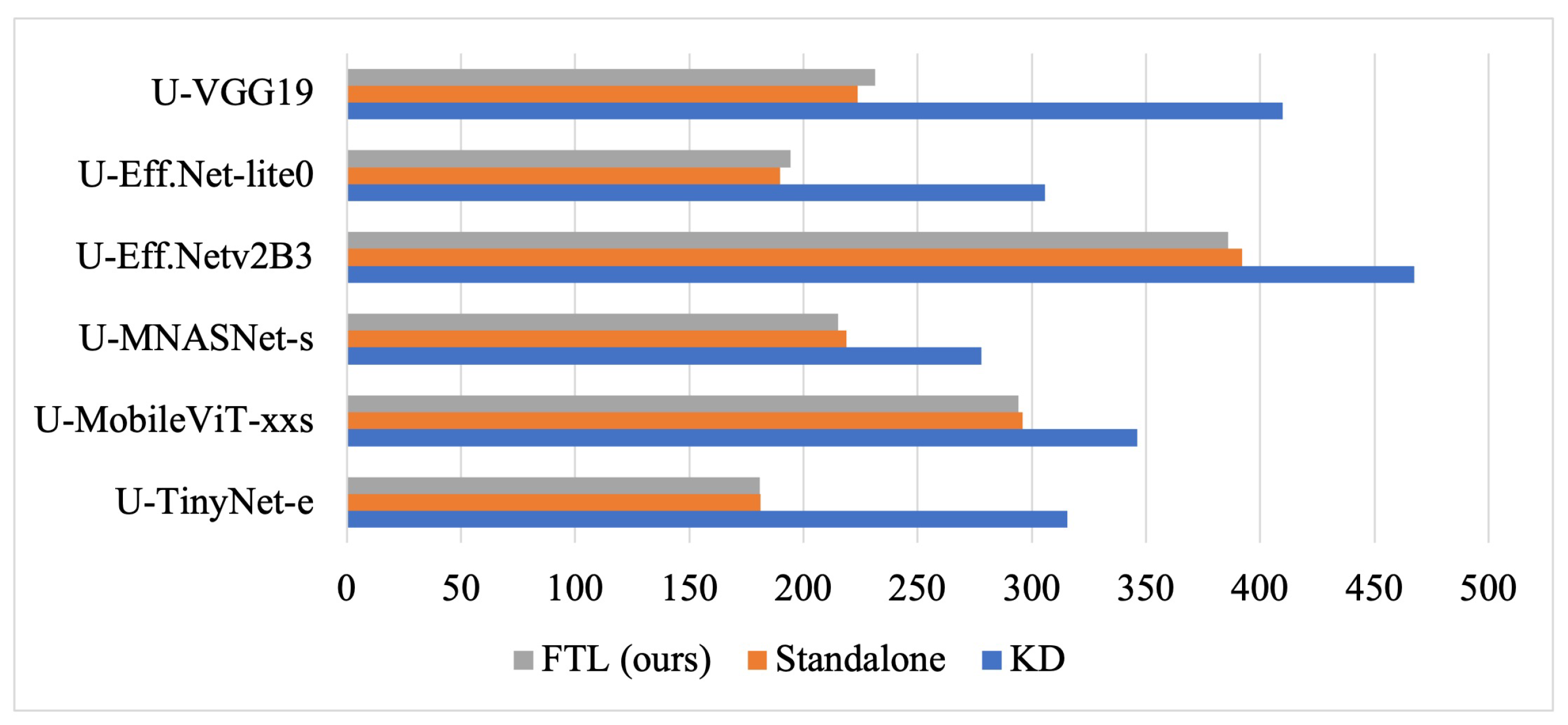
The results demonstrated that FTL consistently outperformed standalone training (baseline), KD, and DML, achieving higher F1 and IoU scores across different building types and spatial resolutions. Among the student models, U-VGG19 achieved the highest F1 (0.903) in the S–S setting, while U-EfficientNetv2B3 performed best in the S–Ev setting (0.847 F1), suggesting its suitability for generalizing to unseen datasets. KD and DML provided some improvements in model efficiency but at the cost of reduced segmentation accuracy. Additionally, FTL proved computationally efficient, introducing minimal overhead compared with standalone training, while KD incurred significant computational costs, and DML was the least efficient due to its quadratic increase in complexity when distilling multiple students.
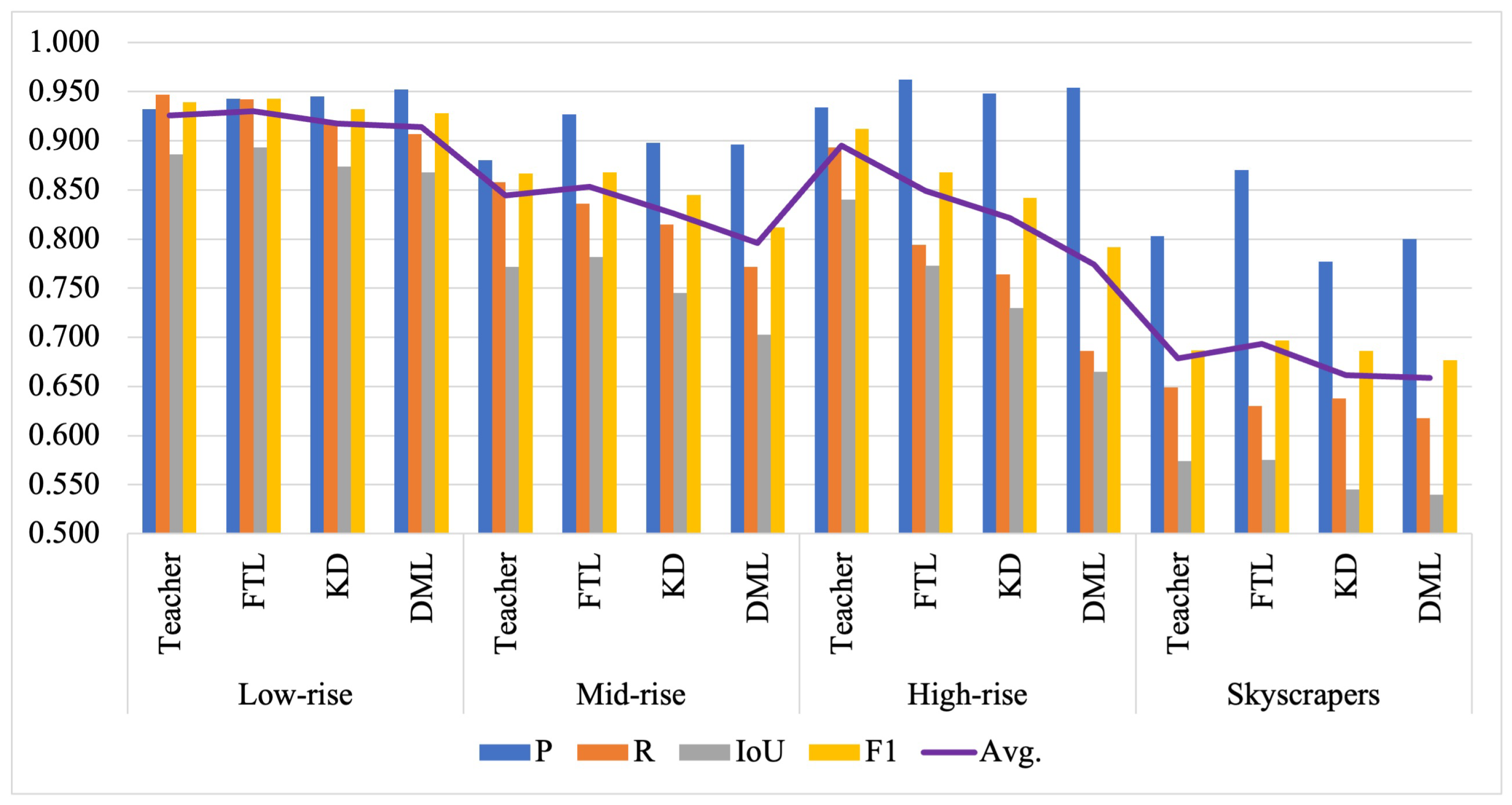
Further investigations revealed that FTL was particularly effective in complex urban environments, especially for skyscrapers, where it significantly outperformed KD and DML in handling off-nadir distortions and misaligned building labels. However, high-rise buildings remained challenging, with the teacher sometimes performing better than fine-tuned models. The analysis of spatial resolution further highlighted that 60 cm/px imagery provided the best balance for building extraction, and 120 cm/px images were more suitable for skyscrapers. The 30 cm/px images introduced intricate noise (over-segmentation and outliers) for small buildings as they were too small for accurate segmentation, and the high-rises and skyscrapers were too large to fit in a single image tile.
These findings highlight the potential of FTL as a robust method for accurate building extraction, particularly in off-nadir images of urban environments. The approach can be extended to other remote sensing applications, such as flood damage assessment, post-disaster building extraction, and large-scale urban monitoring, where accurate segmentation under variable conditions is needed. Future research could explore self-supervised learning to reduce reliance on clean labels, test FTL across diverse geographic regions, and investigate multi-feature learning for enhanced segmentation of oblique-view images.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}