

Enhancing Urban Understanding Through Fine-Grained Segmentation of Very-High-Resolution Aerial Imagery



Abstract
1. Introduction
2. Background and Related Works
2.1. Advances with Airborne Platforms
2.2. VHR Imagery for Predicting Roof Properties
2.3. Roof Type Classification
2.4. Roof Material Segmentation
2.5. Building Delineation
3. Materials and Methods
3.1. Dataset
3.2. Methodology
3.2.1. Multi-Head CNN
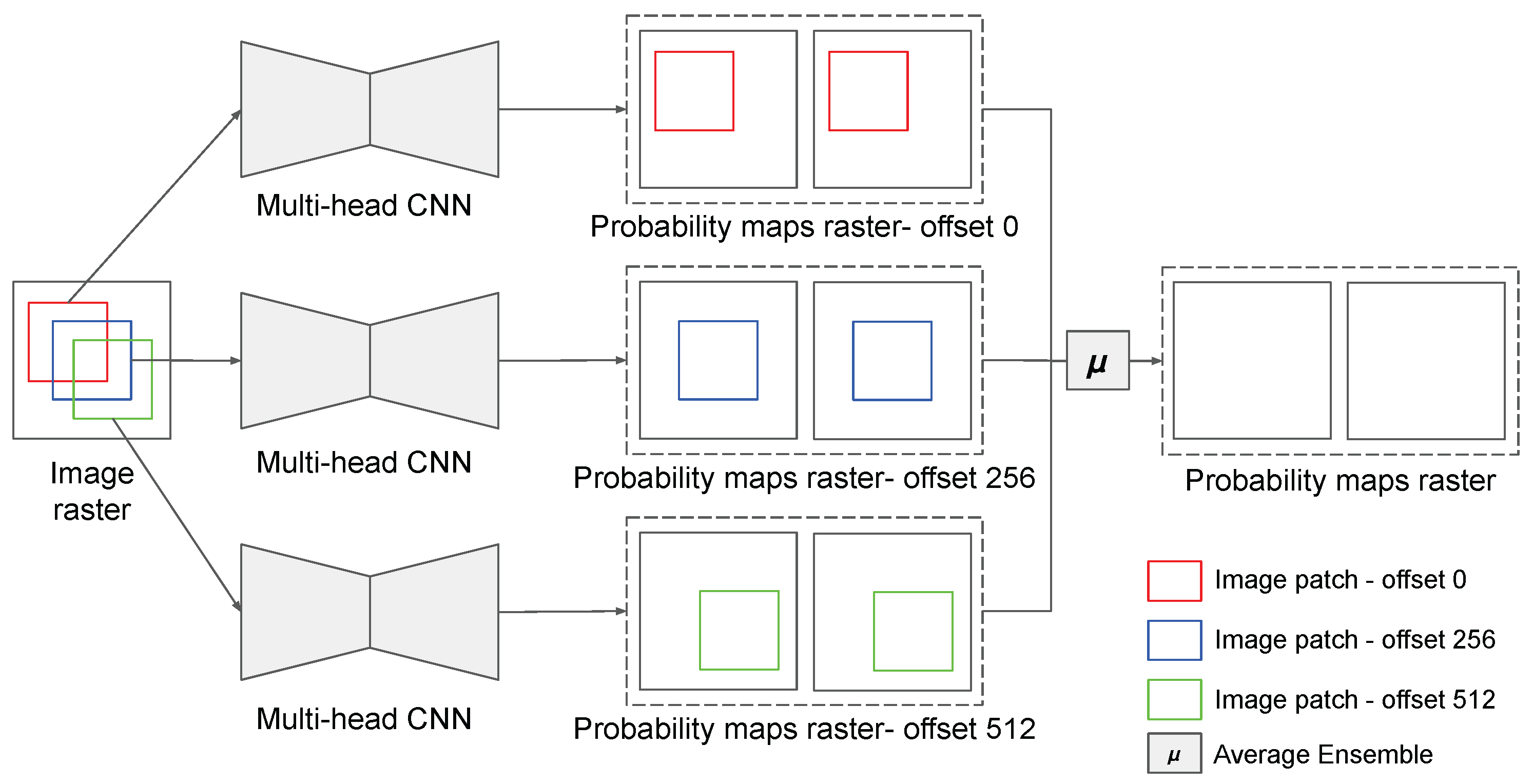
3.2.2. Multi-Offset Self-Ensemble Inference
3.2.3. DEM-Based Filter
3.2.4. Clustering Roof Parts and Vectorization
| Algorithm 1 Clustering and Vectorization of Roof Parts for GIS Integration |
| Require: Binary roof edge segmentation (0 for non-edges, 1 for roof part edges) and material raster Ensure: Polygons representing individual roof parts with associated materials, in GeoJSON format
|
4. Results
4.1. Evaluation Metrics
4.1.1. Metric for Segmentation
4.1.2. Panoptic Quality Metric for Roof Part Vectorization
4.2. Performance Optimization on Validation Data
4.2.1. Single-Head Segmentation Experiments
4.2.2. Multi-Head Segmentation Experiments
4.2.3. Vectorization Experiments
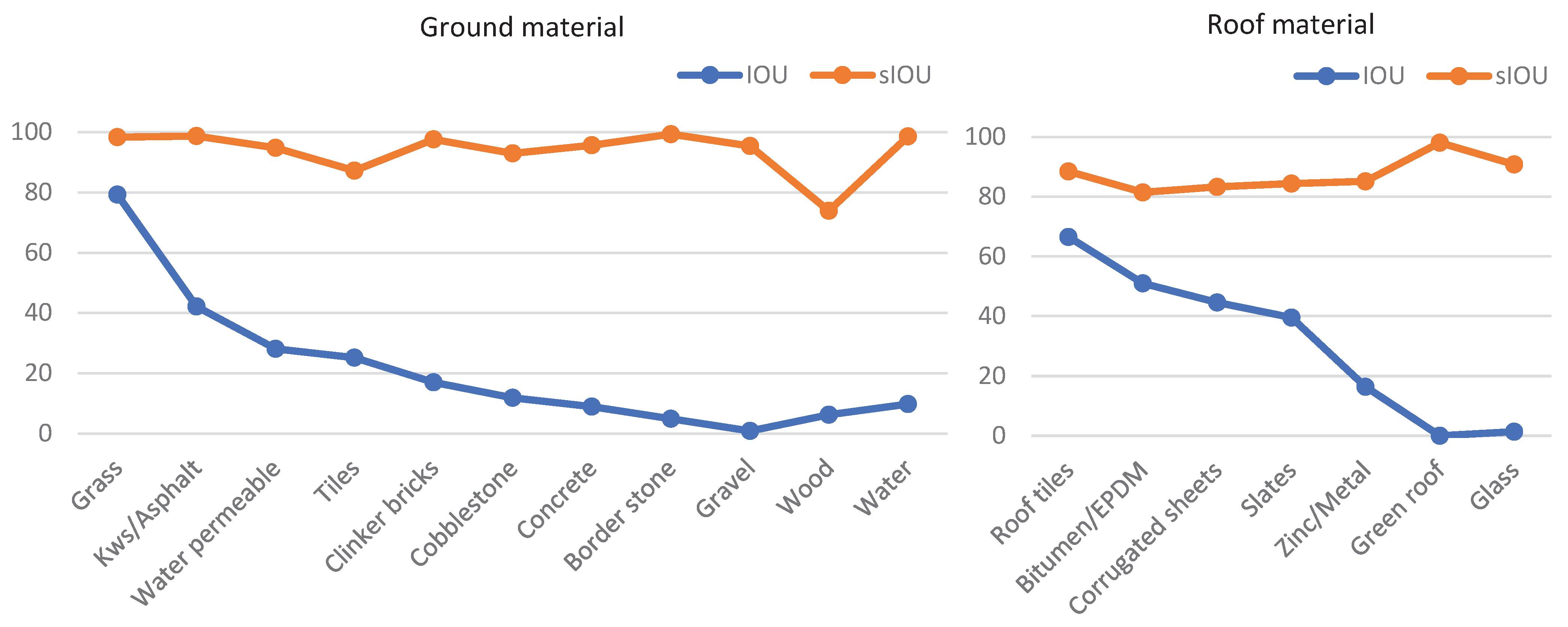
4.3. Performance Evaluation on Test Data
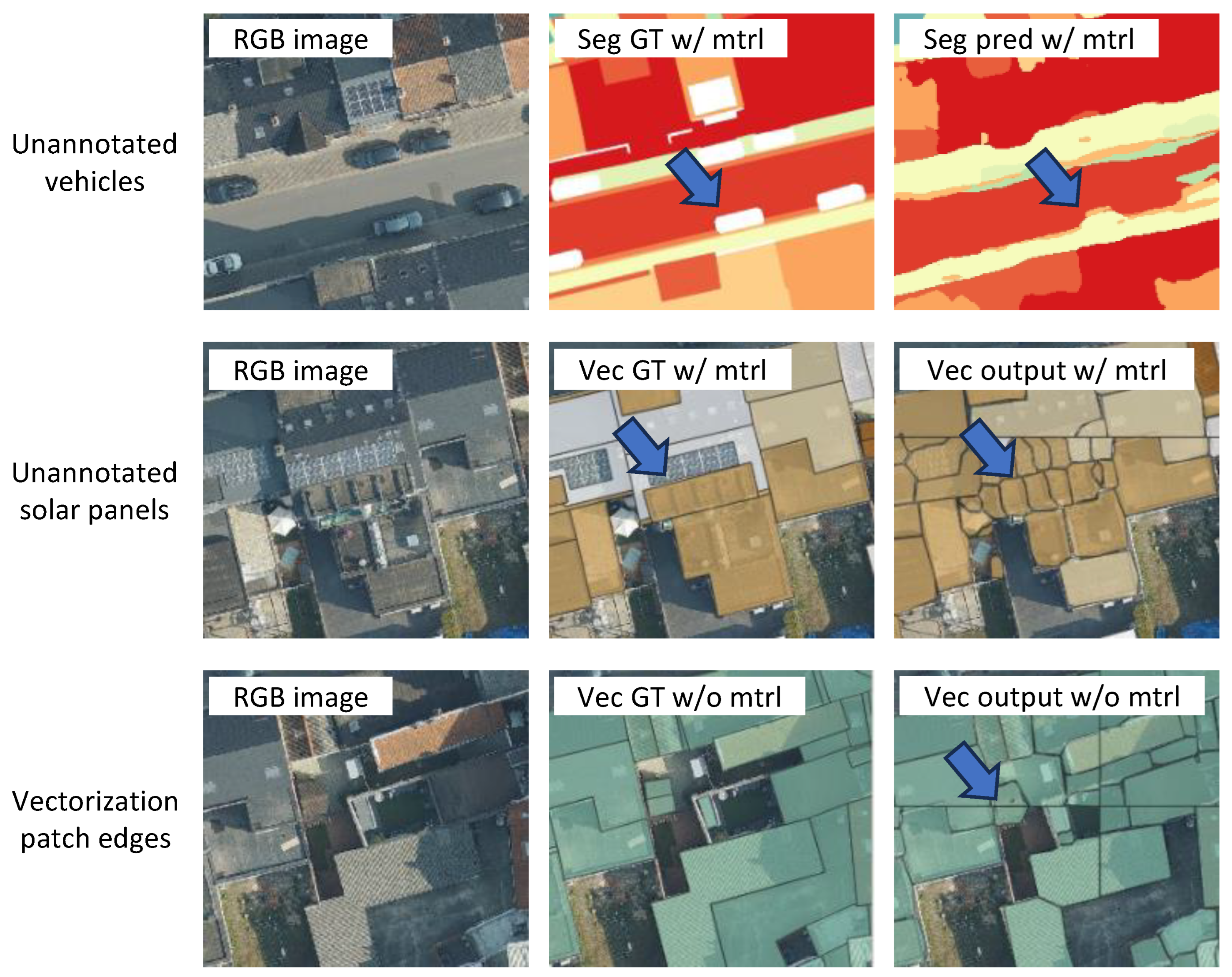
5. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CCE | Categorical Cross Entropy |
| CNN | Convolutional Neural Network |
| DEM | Digital Elevation Model |
| DTM | Digital Terrain Model |
| EPDM | Ethylene Propylene Diene Monomer |
| GIS | Geographic Information System |
| FCN | Fully Convolutional Network |
| GSD | Ground Sampling Distance |
| IOU | Intersection Over Union |
| LOD | Level of Detail |
| LULC | Land Use/Land Cover |
| PAN | Pyramid Attention Network |
| PQ | Panoptic Quality |
| RQ | Recognition Quality |
| SQ | Segmentation Quality |
| UAV | Unmanned Aerial Vehicle |
| VHR | Very High Resolution |
References
- Landsat Missions. Available online: https://www.usgs.gov/landsat-missions (accessed on 1 November 2024).
- Sentinel Online. Available online: https://sentinels.copernicus.eu/web/sentinel/home (accessed on 1 November 2024).
- Worldview. Available online: https://www.earthdata.nasa.gov/data/tools/worldview (accessed on 1 November 2024).
- Statistics Flanders. Available online: https://www.vlaanderen.be/statistiek-vlaanderen (accessed on 1 November 2024).
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Krähenbühl, P.; Koltun, V. Efficient inference in fully connected crfs with Gaussian edge potentials. Adv. Neural Inf. Process. Syst. 2011, 24, 109–117. [Google Scholar]
- Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- ISPRS. 2D Semantic Labeling-Vaihingen Data. Available online: https://www.isprs.org/resources/datasets/benchmarks/UrbanSemLab/2d-sem-label-vaihingen.aspx (accessed on 15 May 2025).
- ISPRS. 2D Semantic Labeling Contest-Potsdam. Available online: https://www.isprs.org/resources/datasets/benchmarks/UrbanSemLab/2d-sem-label-potsdam.aspx (accessed on 15 May 2025).
- Pandey, A.; Jain, K. An intelligent system for crop identification and classification from UAV images using conjugated dense convolutional neural network. Comput. Electron. Agric. 2022, 192, 106543. [Google Scholar] [CrossRef]
- Reedha, R.; Dericquebourg, E.; Canals, R.; Hafiane, A. Transformer neural network for weed and crop classification of high resolution UAV images. Remote Sens. 2022, 14, 592. [Google Scholar] [CrossRef]
- Hu, X.; Wang, X.; Zhong, Y.; Zhang, L. S3ANet: Spectral-spatial-scale attention network for end-to-end precise crop classification based on UAV-borne H2 imagery. ISPRS J. Photogramm. Remote Sens. 2022, 183, 147–163. [Google Scholar] [CrossRef]
- Stewart, E.L.; Wiesner-Hanks, T.; Kaczmar, N.; DeChant, C.; Wu, H.; Lipson, H.; Nelson, R.J.; Gore, M.A. Quantitative phenotyping of northern leaf blight in UAV images using deep learning. Remote Sens. 2019, 11, 2209. [Google Scholar] [CrossRef]
- Görlich, F.; Marks, E.; Mahlein, A.K.; König, K.; Lottes, P.; Stachniss, C. UAV-based classification of cercospora leaf spot using RGB images. Drones 2021, 5, 34. [Google Scholar] [CrossRef]
- Pan, Q.; Gao, M.; Wu, P.; Yan, J.; Li, S. A deep-learning-based approach for wheat yellow rust disease recognition from unmanned aerial vehicle images. Sensors 2021, 21, 6540. [Google Scholar] [CrossRef]
- Deng, J.; Zhou, H.; Lv, X.; Yang, L.; Shang, J.; Sun, Q.; Zheng, X.; Zhou, C.; Zhao, B.; Wu, J.; et al. Applying convolutional neural networks for detecting wheat stripe rust transmission centers under complex field conditions using RGB-based high spatial resolution images from UAVs. Comput. Electron. Agric. 2022, 200, 107211. [Google Scholar] [CrossRef]
- Sugiura, R.; Tsuda, S.; Tsuji, H.; Murakami, N. Virus-infected plant detection in potato seed production field by UAV imagery. In Proceedings of the 2018 ASABE Annual International Meeting, Detroit, MI, USA, 29 July–1 August 2018; American Society of Agricultural and Biological Engineers: St. Joseph, MI, USA, 2018; p. 1. [Google Scholar]
- Tetila, E.C.; Machado, B.B.; Menezes, G.K.; Oliveira, A.D.; Alvarez, M.; Amorim, W.P.; Belete, N.A.; Da Silva, G.G.; Pistori, H. Automatic recognition of soybean leaf diseases using UAV images and deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2019, 17, 903–907. [Google Scholar] [CrossRef]
- Bah, M.D.; Hafiane, A.; Canals, R. CRowNet: Deep network for crop row detection in UAV images. IEEE Access 2019, 8, 5189–5200. [Google Scholar] [CrossRef]
- Pang, Y.; Shi, Y.; Gao, S.; Jiang, F.; Veeranampalayam-Sivakumar, A.N.; Thompson, L.; Luck, J.; Liu, C. Improved crop row detection with deep neural network for early-season maize stand count in UAV imagery. Comput. Electron. Agric. 2020, 178, 105766. [Google Scholar] [CrossRef]
- Ribeiro, J.B.; da Silva, R.R.; Dias, J.D.; Escarpinati, M.C.; Backes, A.R. Automated detection of sugarcane crop lines from UAV images using deep learning. Inf. Process. Agric. 2024, 11, 385–396. [Google Scholar] [CrossRef]
- Osco, L.P.; de Arruda, M.D.; Gonçalves, D.N.; Dias, A.; Batistoti, J.; de Souza, M.; Gomes, F.D.; Ramos, A.P.; de Castro Jorge, L.A.; Liesenberg, V.; et al. A CNN approach to simultaneously count plants and detect plantation-rows from UAV imagery. ISPRS J. Photogramm. Remote Sens. 2021, 174, 1–7. [Google Scholar] [CrossRef]
- Ecke, S.; Dempewolf, J.; Frey, J.; Schwaller, A.; Endres, E.; Klemmt, H.J.; Tiede, D.; Seifert, T. UAV-based forest health monitoring: A systematic review. Remote Sens. 2022, 14, 3205. [Google Scholar] [CrossRef]
- Diez, Y.; Kentsch, S.; Fukuda, M.; Caceres, M.L.; Moritake, K.; Cabezas, M. Deep learning in forestry using UAV-acquired RGB data: A practical review. Remote Sens. 2021, 13, 2837. [Google Scholar] [CrossRef]
- Fraser, B.T.; Congalton, R.G. Monitoring fine-scale forest health using unmanned aerial systems (UAS) multispectral models. Remote Sens. 2021, 13, 4873. [Google Scholar] [CrossRef]
- Zheng, J.Y.; Hao, Y.Y.; Wang, Y.C.; Zhou, S.Q.; Wu, W.B.; Yuan, Q.; Gao, Y.; Guo, H.Q.; Cai, X.X.; Zhao, B. Coastal wetland vegetation classification using pixel-based, object-based and deep learning methods based on RGB-UAV. Land 2022, 11, 2039. [Google Scholar] [CrossRef]
- Kentsch, S.; Cabezas, M.; Tomhave, L.; Groß, J.; Burkhard, B.; Lopez Caceres, M.L.; Waki, K.; Diez, Y. Analysis of UAV-acquired wetland orthomosaics using GIS, computer vision, computational topology and deep learning. Sensors 2021, 21, 471. [Google Scholar] [CrossRef]
- Bak, S.H.; Hwang, D.H.; Kim, H.M.; Yoon, H.J. Detection and monitoring of beach litter using UAV image and deep neural network. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2019, 42, 55–58. [Google Scholar] [CrossRef]
- Wu, J.; Li, R.; Li, J.; Zou, M.; Huang, Z. Cooperative unmanned surface vehicles and unmanned aerial vehicles platform as a tool for coastal monitoring activities. Ocean Coast. Manag. 2023, 232, 106421. [Google Scholar] [CrossRef]
- Zhu, J.; Sun, K.; Jia, S.; Li, Q.; Hou, X.; Lin, W.; Liu, B.; Qiu, G. Urban traffic density estimation based on ultrahigh-resolution UAV video and deep neural network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4968–4981. [Google Scholar] [CrossRef]
- Gupta, H.; Verma, O.P. Monitoring and surveillance of urban road traffic using low altitude drone images: A deep learning approach. Multimed. Tools Appl. 2022, 81, 19683–19703. [Google Scholar] [CrossRef]
- Song, A. Deep Learning-Based Semantic Segmentation of Urban Areas Using Heterogeneous Unmanned Aerial Vehicle Datasets. Aerospace 2023, 10, 880. [Google Scholar] [CrossRef]
- Shukla, A.; Jain, K. Automatic extraction of urban land information from unmanned aerial vehicle (UAV) data. Earth Sci. Inform. 2020, 13, 1225–1236. [Google Scholar] [CrossRef]
- Moreno-Armendáriz, M.A.; Calvo, H.; Duchanoy, C.A.; López-Juárez, A.P.; Vargas-Monroy, I.A.; Suarez-Castañon, M.S. Deep green diagnostics: Urban green space analysis using deep learning and drone images. Sensors 2019, 19, 5287. [Google Scholar] [CrossRef] [PubMed]
- Hartling, S.; Sagan, V.; Maimaitijiang, M. Urban tree species classification using UAV-based multi-sensor data fusion and machine learning. GISci. Remote Sens. 2021, 58, 1250–1275. [Google Scholar] [CrossRef]
- Cho, Y.I.; Yoon, D.; Lee, M.J. Comparative Analysis of Urban Heat Island Cooling Strategies According to Spatial and Temporal Conditions Using Unmanned Aerial Vehicles (UAV) Observation. Appl. Sci. 2023, 13, 10052. [Google Scholar] [CrossRef]
- Fuentes, J.E.; Moya, F.D.; Montoya, O.D. Method for estimating solar energy potential based on photogrammetry from unmanned aerial vehicles. Electronics 2020, 9, 2144. [Google Scholar] [CrossRef]
- Shao, H.; Song, P.; Mu, B.; Tian, G.; Chen, Q.; He, R.; Kim, G. Assessing city-scale green roof development potential using Unmanned Aerial Vehicle (UAV) imagery. Urban For. Urban Green. 2021, 57, 126954. [Google Scholar] [CrossRef]
- Solla, M.; Gonçalves, L.M.; Gonçalves, G.; Francisco, C.; Puente, I.; Providência, P.; Gaspar, F.; Rodrigues, H. A building information modeling approach to integrate geomatic data for the documentation and preservation of cultural heritage. Remote Sens. 2020, 12, 4028. [Google Scholar] [CrossRef]
- Murtiyoso, A.; Veriandi, M.; Suwardhi, D.; Soeksmantono, B.; Harto, A.B. Automatic workflow for roof extraction and generation of 3D citygml models from low-cost UAV image-derived point clouds. ISPRS Int. J. Geo-Inf. 2020, 9, 743. [Google Scholar] [CrossRef]
- Partovi, T.; Fraundorfer, F.; Azimi, S.; Marmanis, D.; Reinartz, P. Roof type selection based on patch-based classification using deep learning for high resolution satellite imagery. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2017, 42, 653–657. [Google Scholar] [CrossRef]
- Castagno, J.; Atkins, E. Roof shape classification from LiDAR and satellite image data fusion using supervised learning. Sensors 2018, 18, 3960. [Google Scholar] [CrossRef]
- Buyukdemircioglu, M.; Can, R.; Kocaman, S. Deep learning based roof type classification using very high resolution aerial imagery. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2021, 43, 55–60. [Google Scholar] [CrossRef]
- Ölçer, N.; Ölçer, D.; Sümer, E. Roof type classification with innovative machine learning approaches. PeerJ Comput. Sci. 2023, 9, e1217. [Google Scholar] [CrossRef]
- Cimpoi, M.; Maji, S.; Kokkinos, I.; Mohamed, S.; Vedaldi, A. Describing textures in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3606–3613. [Google Scholar]
- Bell, S.; Upchurch, P.; Snavely, N.; Bala, K. Material recognition in the wild with the materials in context database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3479–3487. [Google Scholar]
- Xue, J.; Zhang, H.; Dana, K. Deep texture manifold for ground terrain recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 558–567. [Google Scholar]
- Cai, S.; Wakaki, R.; Nobuhara, S.; Nishino, K. RGB road scene material segmentation. In Proceedings of the Asian Conference on Computer Vision, Macao, China, 4–8 December 2022; pp. 3051–3067. [Google Scholar]
- Jayasinghe, M.T.; Attalage, R.A.; Jayawardena, A.I. Roof orientation, roofing materials and roof surface colour: Their influence on indoor thermal comfort in warm humid climates. Energy Sustain. Dev. 2003, 7, 16–27. [Google Scholar] [CrossRef]
- Prado, R.T.; Ferreira, F.L. Measurement of albedo and analysis of its influence the surface temperature of building roof materials. Energy Build. 2005, 37, 295–300. [Google Scholar] [CrossRef]
- Mendez, C.B.; Klenzendorf, J.B.; Afshar, B.R.; Simmons, M.T.; Barrett, M.E.; Kinney, K.A.; Kirisits, M.J. The effect of roofing material on the quality of harvested rainwater. Water Res. 2011, 45, 2049–2059. [Google Scholar] [CrossRef]
- Lemp, D.; Weidner, U. Segment-based characterization of roof surfaces using hyperspectral and laser scanning data. In Proceedings of the 2005 IEEE International Geoscience and Remote Sensing Symposium, Seoul, Republic of Korea, 25–29 July 2005; IGARSS’05. IEEE: Piscataway, NJ, USA, 2005; Volume 7, pp. 4942–4945. [Google Scholar]
- Ilehag, R.; Bulatov, D.; Helmholz, P.; Belton, D. Classification and representation of commonly used roofing material using multisensorial aerial data. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2018, 42, 217–224. [Google Scholar] [CrossRef]
- Trevisiol, F.; Lambertini, A.; Franci, F.; Mandanici, E. An object-oriented approach to the classification of roofing materials using very high-resolution satellite stereo-pairs. Remote Sens. 2022, 14, 849. [Google Scholar] [CrossRef]
- Kim, J.; Bae, H.; Kang, H.; Lee, S.G. CNN algorithm for roof detection and material classification in satellite images. Electronics 2021, 10, 1592. [Google Scholar] [CrossRef]
- Boonpook, W.; Tan, Y.; Xu, B. Deep learning-based multi-feature semantic segmentation in building extraction from images of UAV photogrammetry. Int. J. Remote Sens. 2021, 42, 1–9. [Google Scholar] [CrossRef]
- Farajzadeh, Z.; Saadatseresht, M.; Alidoost, F. Automatic building extraction from UAV-based images and DSMs using deep learning. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2023, 10, 171–177. [Google Scholar] [CrossRef]
- Pilinja Subrahmanya, P.; Haridas Aithal, B.; Mitra, S. Automatic extraction of buildings from UAV-based imagery using Artificial Neural Networks. J. Indian Soc. Remote Sens. 2021, 49, 681–687. [Google Scholar] [CrossRef]
- Djenaliev, A.; Chymyrov, A.; Kada, M.; Hellwich, O.; Akmatov, T.; Golev, O.; Chymyrova, S. Unmanned Aerial Systems for Building Footprint Extraction in Urban Area. Int. J. Geoinform. 2024, 20, 64–81. [Google Scholar]
- Zhao, W.; Persello, C.; Lv, X.; Stein, A.; Vergauwen, M. Vectorizing planar roof structure from very high resolution remote sensing images using transformers. Int. J. Digit. Earth 2024, 17, 1–5. [Google Scholar] [CrossRef]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Zhang, T.Y.; Suen, C.Y. A fast parallel algorithm for thinning digital patterns. Commun. ACM 1984, 27, 236–239. [Google Scholar] [CrossRef]
- Kumar, U.R.; Vandewalle, P. Similarity-Weighted IoU (sIOU): A Comprehensive Metric for Evaluating Model Performance Through Similarity-Weighted Class Overlaps. In Proceedings of the 2024 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 27–30 October 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 936–942. [Google Scholar]
- Kirillov, A.; He, K.; Girshick, R.; Rother, C.; Dollár, P. Panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9404–9413. [Google Scholar]
- Zhao, B.; Yu, S.; Ma, W.; Yu, M.; Mei, S.; Wang, A.; He, J.; Yuille, A.; Kortylewski, A. Ood-cv: A benchmark for robustness to out-of-distribution shifts of individual nuisances in natural images. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022; pp. 163–180. [Google Scholar]
- Kumar, U.R.; Fayjie, A.R.; Hannaert, J.; Vandewalle, P. BelHouse3D: A Benchmark Dataset for Assessing Occlusion Robustness in 3D Point Cloud Semantic Segmentation. arXiv 2024, arXiv:2411.13251. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Loss Function | Architecture | Backbone | w/o Material msIOU(%) | w/ Material mIOU(%) |
|---|---|---|---|---|
| CCE | UNet | ResNet18 | 75.66 | 19.85 |
| ResNet34 | 78.09 | 19.28 | ||
| ResNet50 | 70.73 | 15.98 | ||
| EfficientNet-b4 | 77.29 | 22.45 | ||
| EfficientNet-b5 | 76.42 | 21.60 | ||
| EfficientNet-b6 | 76.92 | 20.31 | ||
| CCE | UNet | EfficientNet-b4 | 77.29 | 22.45 |
| FPN | 71.49 | 18.54 | ||
| PAN | 77.70 | 23.00 | ||
| PSPNet | 68.28 | 15.86 | ||
| CCE | PAN | EfficientNet-b4 | 77.70 | 23.00 |
| Soft dice | 75.49 | 18.42 | ||
| Combo | 77.44 | 22.89 |
| Head 1 (Bldg. & Ground) | Head 2 (Bldg.) | |||
|---|---|---|---|---|
| w/o Material msIOU (%) | w/ Material mIOU (%) | Bldg. Edge mIOU (%) | ||
| Baseline | 76.55 | 22.65 | 50.19 | |
| + Edge Weight | 1 | 76.55 | 22.65 | 50.19 |
| 10 | 78.91 | 25.87 | 55.14 | |
| 25 | 81.21 | 25.54 | 57.47 | |
| + Edge Dilation | 1 px. | 81.21 | 25.54 | 57.47 |
| 5 px. | 80.90 | 24.60 | 58.31 | |
| 11 px. | 84.60 | 25.54 | 63.83 | |
| 15 px. | 82.22 | 22.89 | 66.63 | |
| + Input Size | 1024 × 1024 | 84.60 | 25.54 | 63.83 |
| 2048 × 2048 | 86.30 | 26.38 | 63.69 | |
| 4096 × 4096 | 86.12 | 26.35 | 63.57 | |
| + Multi-offset | (0) | 86.30 | 26.38 | 63.69 |
| (0, 256) | 86.83 | 26.85 | 63.61 | |
| (0, 256, 512) | 86.64 | 26.88 | 63.70 | |
| (0, 256, 512, 1024) | 86.98 | 26.98 | 63.85 | |
| + DEM Threshold | 0.2 m | 87.21 | 27.01 | 63.70 |
| 0.5 m | 87.67 | 27.08 | 63.70 | |
| 1 m | 87.97 | 27.09 | 63.70 | |
| 2 m | 87.92 | 26.80 | 63.70 | |
| w/o Material | w/ Material | |||||
|---|---|---|---|---|---|---|
| SQ (%) | RQ (%) | PQ (%) | SQ (%) | RQ (%) | PQ (%) | |
| Baseline | 20.19 | 1.59 | 0.32 | 9.97 | 0.71 | 0.16 |
| + Edge Weight & Dilation | 66.90 | 54.88 | 36.72 | 68.19 | 35.27 | 23.84 |
| + Input Size | 69.95 | 53.57 | 37.47 | 71.01 | 35.06 | 24.71 |
| + Multi-offset | 69.92 | 53.15 | 37.16 | 71.31 | 34.63 | 24.51 |
| + DEM Threshold | 69.67 | 54.52 | 37.99 | 71.23 | 35.03 | 24.77 |
| Segmentation (Bldg. & Gnd.) | Vectorization (Bldg.) | |||
|---|---|---|---|---|
|
w/o Mtrl msIOU (%) |
w/ Mtrl mIOU (%) |
w/o Mtrl PQ (%) |
w/ Mtrl PQ (%) | |
| Baseline | 69.68 | 22.06 | 0.32 | 0.17 |
| + Edge Weight & Dilation | 82.03 | 25.72 | 36.93 | 26.27 |
| + Input Size | 82.58 | 28.04 | 37.05 | 28.50 |
| + Multi-offset | 83.34 | 28.53 | 38.37 | 28.50 |
| + DEM Threshold | 89.19 | 28.60 | 38.93 | 28.70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Raman Kumar, U.; Goedemé, T.; Vandewalle, P. Enhancing Urban Understanding Through Fine-Grained Segmentation of Very-High-Resolution Aerial Imagery. Remote Sens. 2025, 17, 1771. https://doi.org/10.3390/rs17101771
Raman Kumar U, Goedemé T, Vandewalle P. Enhancing Urban Understanding Through Fine-Grained Segmentation of Very-High-Resolution Aerial Imagery. Remote Sensing. 2025; 17(10):1771. https://doi.org/10.3390/rs17101771
Chicago/Turabian StyleRaman Kumar, Umamaheswaran, Toon Goedemé, and Patrick Vandewalle. 2025. "Enhancing Urban Understanding Through Fine-Grained Segmentation of Very-High-Resolution Aerial Imagery" Remote Sensing 17, no. 10: 1771. https://doi.org/10.3390/rs17101771
APA StyleRaman Kumar, U., Goedemé, T., & Vandewalle, P. (2025). Enhancing Urban Understanding Through Fine-Grained Segmentation of Very-High-Resolution Aerial Imagery. Remote Sensing, 17(10), 1771. https://doi.org/10.3390/rs17101771