


Assessment of Landslide Susceptibility Based on the Two-Layer Stacking Model—A Case Study of Jiacha County, China


Abstract
1. Introduction
2. Region Background and Data Sources
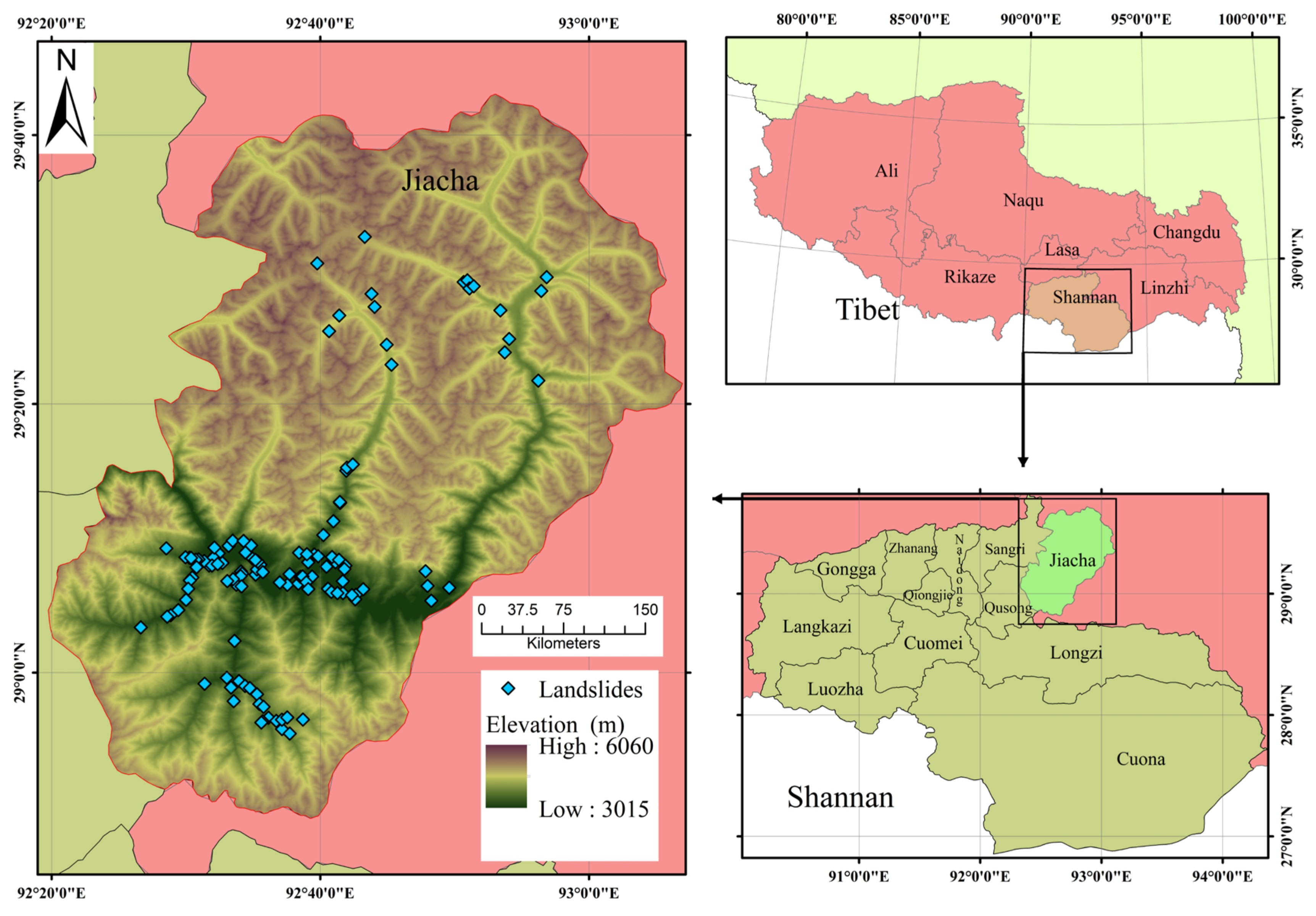
2.1. Study Area
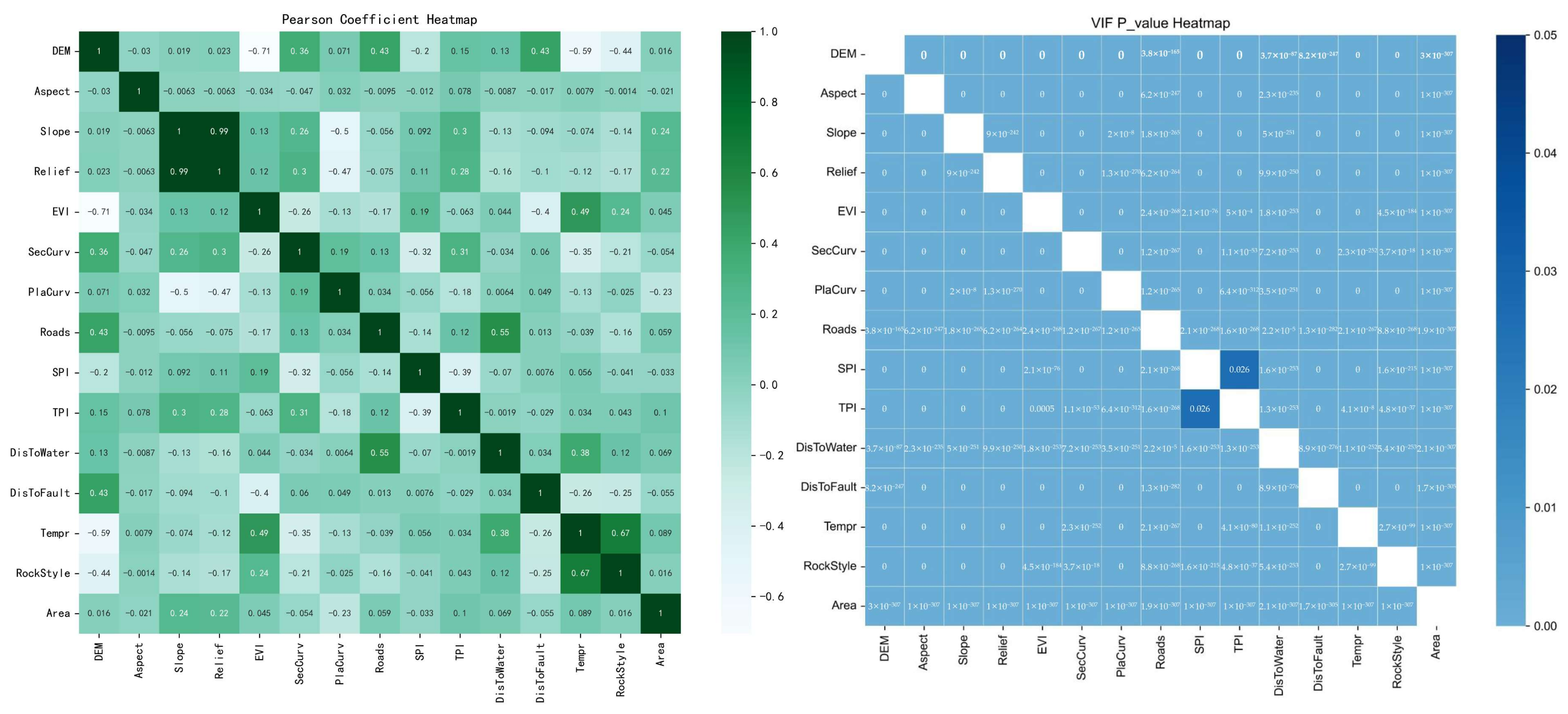
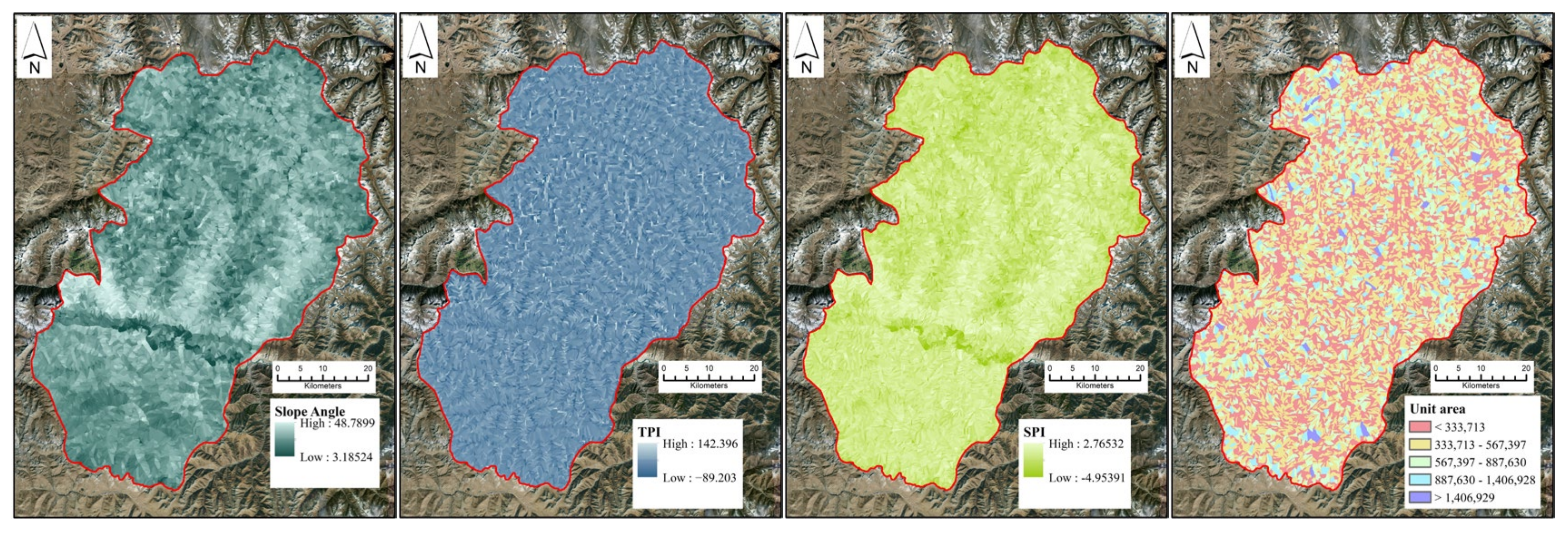
2.2. Predisposing Factors
2.3. Division of Evaluation Units
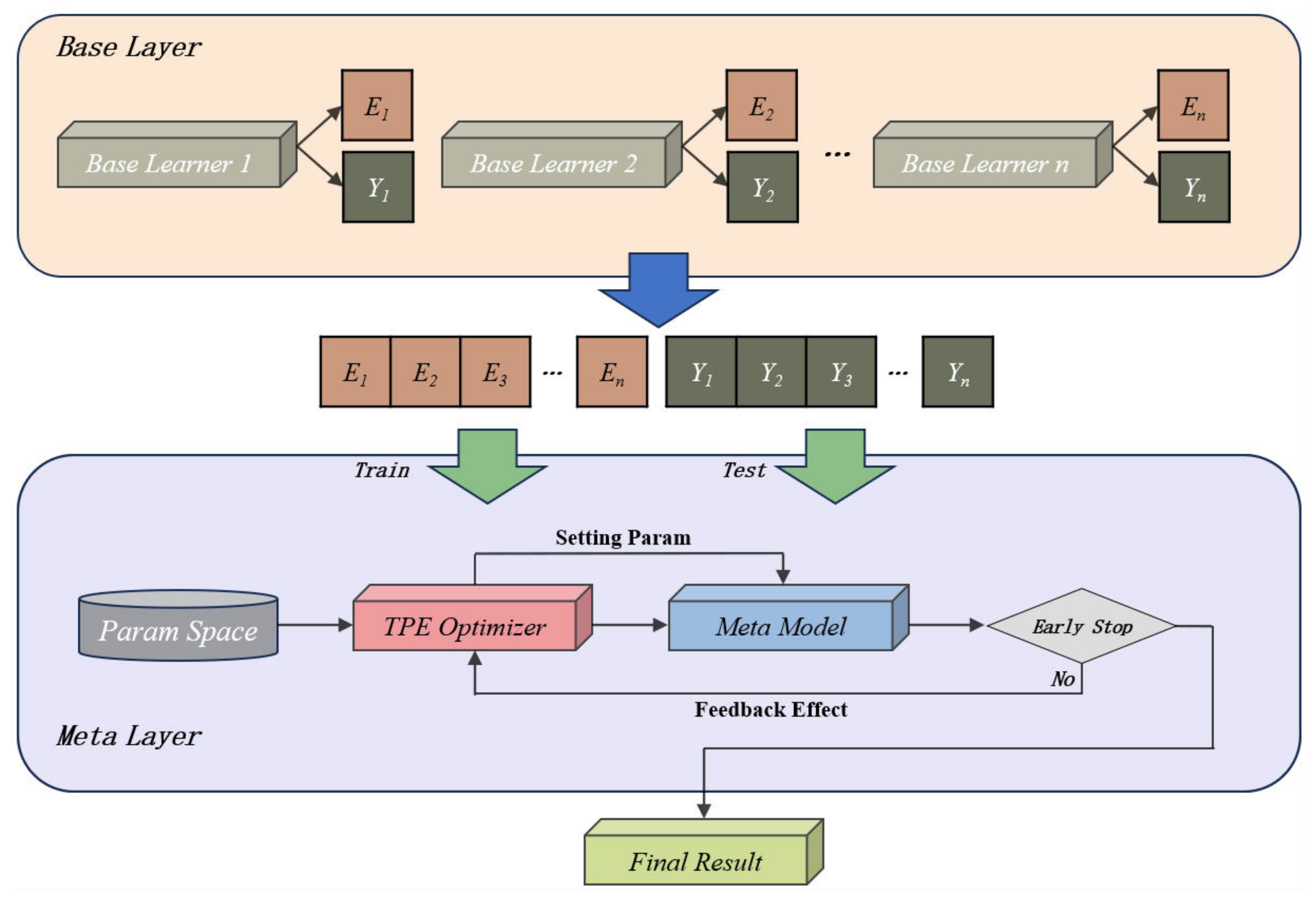
3. Methodology
3.1. Hyperparameter Optimization and Base Model
3.2. Stacking
4. Results
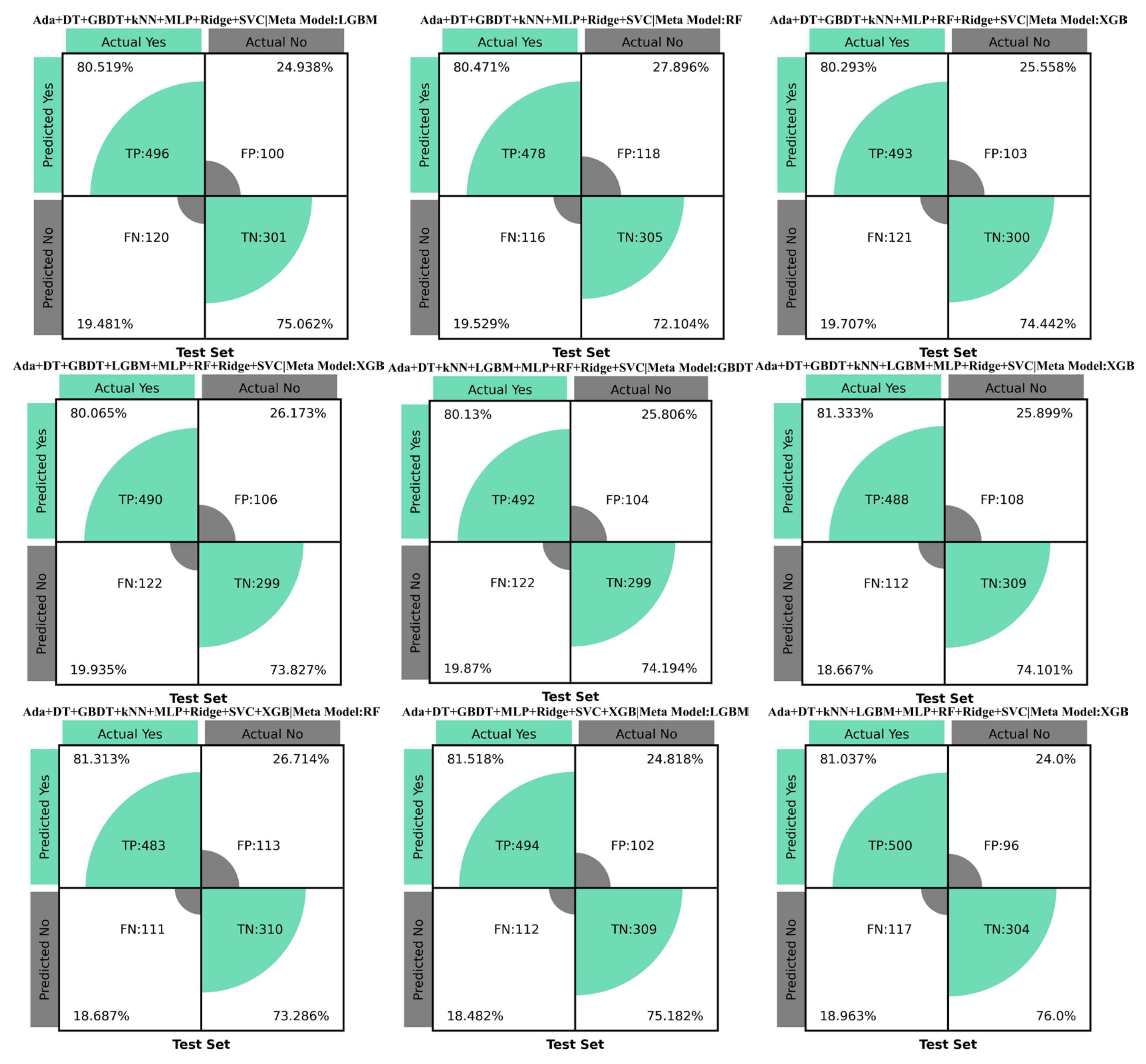
4.1. Confusion Matrix Evaluation
4.2. Static Derivation Indicator Evaluation
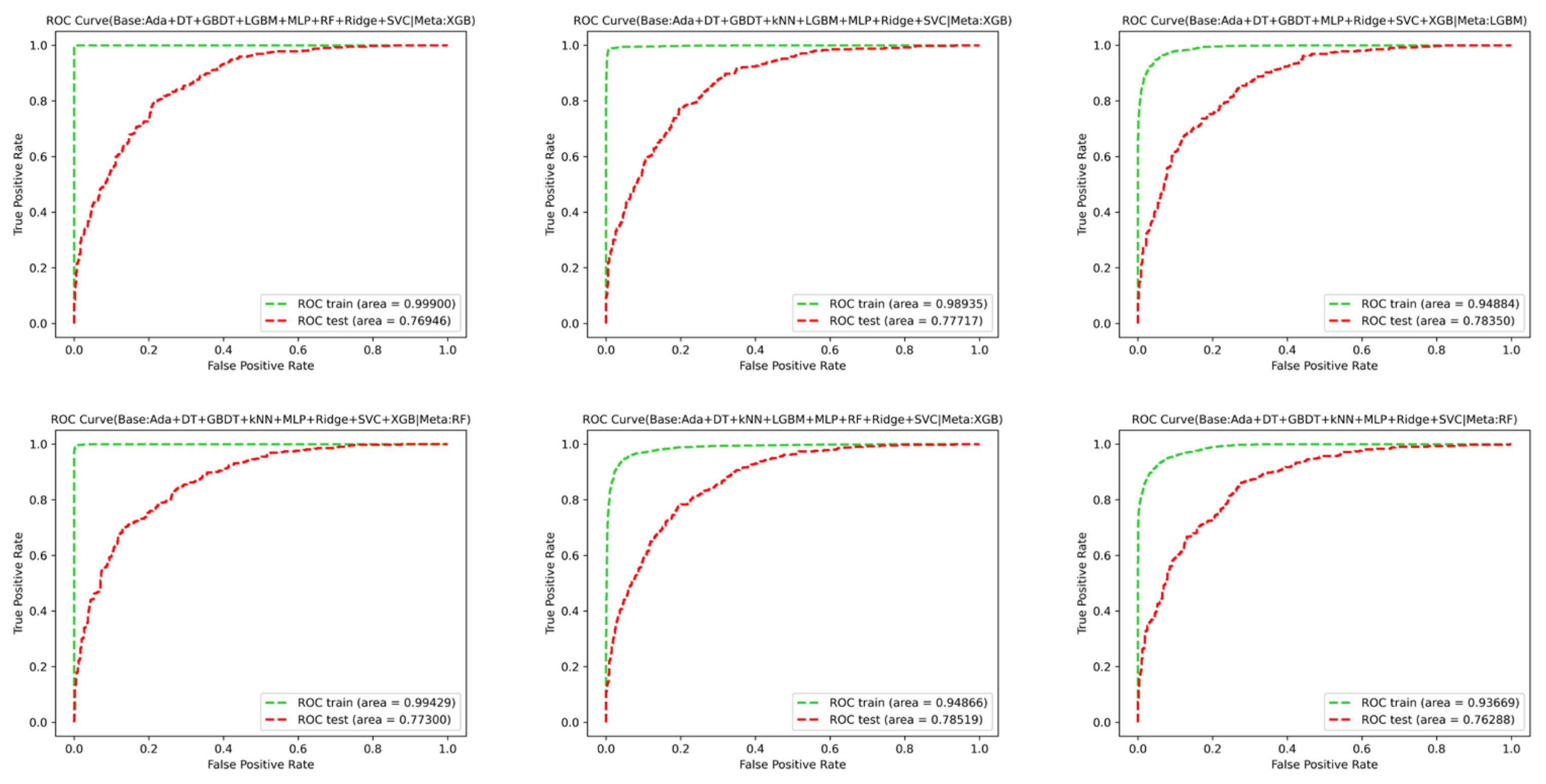
4.3. ROC Evaluation
4.4. Landslide Susceptibility Mapping
5. Discussion
6. Conclusions
- In Jiacha County, high susceptibility and very high susceptibility areas account for 14.1% and 8.2% of the total area of the study area. These areas are primarily located in regions characterized by significant topographic relief, complex geological structures, and relative low altitudes, such as the Yarlung Zangbo River and its derivative rivers. In contrast, moderate and less susceptibility areas are predominantly situated in high-altitude regions across most models. These areas are distinguished by their remote locations, sparse populations, and distinctive geological structures, which to a certain extent, mitigate the risk of landslide disasters.
- The application of disparate numbers of algorithms, encompassing different types, within the two-layer structure of the Stacking ensemble method, results in a total of 4660 model combinations. These models exhibit variability in performance at the data level. Consequently, these various combinations generate disparate predicted values and evaluation results. The efficacy of models derived from multiple sources performs at an optimal level. Among the 9 models identified as excellent in this study, the static test index demonstrates an accuracy of up to 0.998 and 0.789 on the training set and test set. The area under the ROC curve for the dynamic test index reaches 0.99 and 0.78 on the training set and test set, indicating that these models possess superior data fitting and prediction capabilities.
- The established model was utilized for landslide susceptibility mapping, and the model’s result was field validated in two cases: the No.1 Hydropower Station Landslide and the Reduicun Landslide. The model’s predicted results were found to be consistent with the actual situation to a certain extent, indicating that the susceptibility evaluation results obtained through this method have a degree of applicability and credibility. The integration of predicted results from multiple models can enhance the accuracy of susceptibility evaluation and provide a scientific foundation for disaster prevention and mitigation strategies in local contexts.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Assilzadeh, H.; Levy, J.K.; Wang, X. Landslide catastrophes and disaster risk reduction: A GIS framework for landslide prevention and management. Remote Sens. 2010, 2, 2259–2273. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, X.; Wen, T.; Wang, L. Step-like displacement prediction of reservoir landslides based on a metaheuristic-optimized KELM: A comparative study. Bull. Eng. Geol. Environ. 2024, 83, 322. [Google Scholar]
- Wang, Y.; Jin, J.; Yuan, R. Analysis on Spatial Distribution and Influencing Factors of Geological Disasters in Southeast Tibet. J. Seismol. Res. 2019, 42, 428–437. [Google Scholar]
- Qi, T.; Meng, X.; Qing, F.; Zhao, Y.; Shi, W.; Chen, G.; Zhang, Y.; Li, Y.; Yue, D.; Su, X. Distribution and characteristics of large landslides in a fault zone: A case study of the NE Qinghai-Tibet Plateau. Geomorphology 2021, 379, 107592. [Google Scholar]
- Ye, T.; Shi, P.; Cui, P. Integrated Disaster Risk Research of the Qinghai-Tibet Plateau Under Climate Change. Int. J. Disaster Risk Sci. 2023, 14, 507–509. [Google Scholar]
- Wang, F.; Wen, Z.; Gao, Q.; Yu, Q.; Li, D.; Chen, L. Thermokarst landslides susceptibility evaluation across the permafrost region of the central Qinghai-Tibet Plateau: Integrating a machine learning model with InSAR technology. J. Hydrol. 2024, 642, 131800. [Google Scholar] [CrossRef]
- Huang, F.; Cao, Y.; Li, W.; Catani, F.; Song, G.; Huang, J.; Yu, C. Uncertainties of landslide susceptibility prediction: Influences of different study area scales and mapping unit scales. Int. J. Coal Sci. Technol. 2024, 11, 143–172. [Google Scholar]
- Fang, K.; Tang, H.; Li, C.; Su, X.; An, P.; Sun, S. Centrifuge modelling of landslides and landslide hazard mitigation: A review. Geosci. Front. 2023, 14, 101493. [Google Scholar]
- Sethi, S.S.; Ewers, R.M.; Jones, N.S.; Orme, C.D.L.; Picinali, L. Robust, real-time and autonomous monitoring of ecosystems with an open, low-cost, networked device. Methods Ecol. Evol. 2018, 9, 2383–2387. [Google Scholar]
- Huang, F.; Liu, K.; Li, Z.; Zhou, X.; Zeng, Z.; Li, W.; Huang, J.; Catani, F.; Chang, Z. Single landslide risk assessment considering rainfall-induced landslide hazard and the vulnerability of disaster-bearing body. Geol. J. 2024, 59, 2549–2565. [Google Scholar]
- Zhang, J.; Lin, C.; Tang, H.; Wen, T.; Tannant, D.D.; Zhang, B. Input-parameter Optimization Using a SVR Based Ensemble Model to Predict Landslide Displacements in a Reservoir Area—A Comparative Study. Appl. Soft Comput. 2024, 150, 111107. [Google Scholar] [CrossRef]
- Lv, L.; Chen, T.; Dou, J.; Plaza, A. A hybrid ensemble-based deep-learning framework for landslide susceptibility mapping. Int. J. Appl. Earth Obs. Geoinf. 2022, 108, 102713. [Google Scholar] [CrossRef]
- Ullah, I.; Aslam, B.; Shah, S.H.I.A.; Tariq, A.; Qin, S.; Majeed, M.; Havenith, H.-B. An integrated approach of machine learning, remote sensing, and GIS data for the landslide susceptibility mapping. Land 2022, 11, 1265. [Google Scholar] [CrossRef]
- Tripathi, A.; Tiwari, R.K.; Tiwari, S.P. A deep learning multi-layer perceptron and remote sensing approach for soil health based crop yield estimation. Int. J. Appl. Earth Obs. Geoinf. 2022, 113, 102959. [Google Scholar] [CrossRef]
- Gao, D.; Li, K.; Cai, Y.; Wen, T. Landslide Displacement Prediction Based on Time Series and PSO-BP Model in Three Georges Reservoir, China. J. Earth Sci. 2024, 35, 1079–1082. [Google Scholar] [CrossRef]
- Huang, F.; Liu, K.; Jiang, S.; Catani, F.; Liu, W.; Fan, X.; Huang, J. Optimization method of conditioning factors selection and combination for landslide susceptibility prediction. J. Rock Mech. Geotech. Eng. 2025, 17, 722–746. [Google Scholar] [CrossRef]
- Cheng, H.; Zheng, Y.; Wu, S.; Lin, Y.; Gao, F.; Lin, D.; Wei, J.; Wang, S.; Shu, D.; Wei, S. GIS-based mineral prospectivity mapping using machine learning methods: A case study from Zhuonuo ore district, Tibet. Ore Geol. Rev. 2023, 161, 105627. [Google Scholar] [CrossRef]
- Huang, F.; Mao, D.; Jiang, S.; Zhou, C.; Fan, X.; Zeng, Z.; Catani, F.; Yu, C.; Chang, Z.; Huang, J.; et al. Uncertainties in landslide susceptibility prediction modeling: A review on the incompleteness of landslide inventory and its influence rules. Geosci. Front. 2024, 15, 101886. [Google Scholar] [CrossRef]
- Yang, Z.; Guo, C.; Wu, R.; Zhong, N.; Ren, S. Predicting seismic landslide hazard in the Batang fault zone of the Qinghai-Tibet Plateau. Hydrogeol. Eng. Geol. 2021, 48, 91–101. [Google Scholar] [CrossRef]
- Yin, G.; Luo, J.; Niu, F.; Lin, Z.; Liu, M. Machine learning-based thermokarst landslide susceptibility modeling across the permafrost region on the Qinghai-Tibet Plateau. Landslides 2021, 18, 2639–2649. [Google Scholar] [CrossRef]
- Lin, Q.; Steger, S.; Pittore, M.; Zhang, J.; Wang, L.; Jiang, T.; Wang, Y. Evaluation of potential changes in landslide susceptibility and landslide occurrence frequency in China under climate change. Sci. Total Environ. 2022, 850, 158049. [Google Scholar] [PubMed]
- Zou, Z.; Luo, T.; Zhang, S.; Duan, H.; Li, S.; Wang, J.; Deng, Y.; Wang, J. A novel method to evaluate the time-dependent stability of reservoir landslides: Exemplified by Outang landslide in the Three Gorges Reservoir. Landslides 2023, 20, 1731–1746. [Google Scholar] [CrossRef]
- Xie, Y.; Sun, W.; Ren, M.; Chen, S.; Huang, Z.; Pan, X. Stacking ensemble learning models for daily runoff prediction using 1D and 2D CNNs. Expert Syst. Appl. 2023, 217, 119469. [Google Scholar]
- Divina, F.; Gilson, A.; Goméz-Vela, F.; García Torres, M.; Torres, J.F. Stacking ensemble learning for short-term electricity consumption forecasting. Energies 2018, 11, 949. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, D.; Geng, N.; Wang, Y.; Yin, Y.; Jin, Y. Stacking-based ensemble learning of decision trees for interpretable prostate cancer detection. Appl. Soft Comput. 2019, 77, 188–204. [Google Scholar]
- Chen, J.; Zeb, A.; Nanehkaran, Y.A.; Zhang, D. Stacking ensemble model of deep learning for plant disease recognition. J. Ambient Intell. Humaniz. Comput. 2023, 14, 12359–12372. [Google Scholar] [CrossRef]
- Duan, Z.; Zhang, L.; Xue, Y.; He, M.; Chen, J. Analysis of the development characteristics and influencing factors of landslide disasters in Hunan Province based on big data theory. China Min. Mag. 2024, 1–11. [Google Scholar]
- Yan, G.; Liang, S.; Zhao, H. An Approach to Improving Slope Unit Division Using GIS Technique. Sci. Geogr. Sin. 2017, 37, 1764–1770. [Google Scholar] [CrossRef]
- Nguyen, H.-P.; Liu, J.; Zio, E. A long-term prediction approach based on long short-term memory neural networks with automatic parameter optimization by Tree-structured Parzen Estimator and applied to time-series data of NPP steam generators. Appl. Soft Comput. 2020, 89, 106116. [Google Scholar]
- Wei, L.; Cheng, N. Research on Web Log Abnormal Traffic Detection Based on the SVM-DT-MLP Model. Mod. Inf. Technol. 2024, 8, 171–174+179. [Google Scholar] [CrossRef]
- Zhang, T.; Huang, Y.; Liao, H.; Liang, Y. A hybrid electric vehicle load classification and forecasting approach based on GBDT algorithm and temporal convolutional network. Appl. Energy 2023, 351, 121768. [Google Scholar]
- Wan, M.; Zou, S. Adolescent mental health state assessment framework by combining YOLO with random forest. Appl. Soft Comput. 2024, 168, 112497. [Google Scholar]
- Li, J.; Gao, L.; Li, P.; Zhang, X.; Yang, J.; Su, S. Detection of Imbalanced Multi-class False Data Injection Attacks in Cyber-physical Systems Based on DDPM-Light GBM. J. Kunming Univ. Sci. Technol. (Nat. Sci.) 2024, 1–12. [Google Scholar] [CrossRef]
- Li, X.; Wang, L.; Sung, E. AdaBoost with SVM-based component classifiers. Eng. Appl. Artif. Intell. 2008, 21, 785–795. [Google Scholar]
- Tian, R.; Li, S.; Liu, T.; Jing, Y. vP/vS prediction based on XGBoost algorithm and itsapplication in reservoir detection. Oil Geophys. Prospect. 2024, 59, 653–663. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, J. Wind Power Load Combination Forecasting Based on Improved SOA and Ridge Regression Weighting. J. North China Electr. Power Univ. 2024, 51, 1–10. [Google Scholar]
- Hajihosseinlou, M.; Maghsoudi, A.; Ghezelbash, R. Stacking: A novel data-driven ensemble machine learning strategy for prediction and mapping of Pb-Zn prospectivity in Varcheh district, west Iran. Expert Syst. Appl. 2024, 237, 121668. [Google Scholar] [CrossRef]
- Wu, X.; Ren, F.; Niu, R.; Peng, L. Landslide Spatial Prediction Based on Slope Units and Support Vector Machines. Geomat. Inf. Sci. Wuhan Univ. 2013, 38, 1499–1503. [Google Scholar]
- Liu, T.; Xu, L.; Yuan, K.; Yan, W. Constant Volume Method of Shared Bicycle Parking Area Based on Natural Breakpoint Method. J. Wuhan Univ. Technol. (Transp. Sci. Eng.) 2023, 47, 992–997. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factor Type | Factor Name | Scale | Sources |
|---|---|---|---|
| Terrain Factor | DEM | 30 m | Geospatial Data Cloud (https://www.gscloud.cn) |
| Slope aspect | 30 m | Generated from DEM by ArcGIS | |
| Slope angle | 30 m | Generated from DEM by ArcGIS | |
| Surface relief (QFD) | 30 m | Generated from DEM by ArcGIS | |
| Surface curvature (SecCurv) | 30 m | Generated from DEM by ArcGIS | |
| Profile curvature (PlaCurv) | 30 m | Generated from DEM by ArcGIS | |
| TPI | 30 m | Generated from DEM by ArcGIS | |
| Environmental and Hydrological Factor | Distance to Roads | 30 m | OpenStreetMap (https://www.openstreetmap.org) |
| Distance to Water | 30 m | OpenStreetMap (https://www.openstreetmap.org) | |
| Annual average temperature | 1000 m | Geospatial Data Cloud (https://www.gscloud.cn) | |
| EVI | 250 m | Geospatial Data Cloud (https://www.gscloud.cn) | |
| SPI | 30 m | Generated from DEM by ArcGIS | |
| Fundamental Geological Factor | Distance to fault | 30 m | OpenStreetMap (https://www.openstreetmap.org) |
| Lithology (RockStyle) | 1:250,000-scale Regional Geological Map | ||
| Other | Area of evaluation unit | 1 m2 | Generated from DEM by ArcGIS |
| Landslide locations | Field survey |
| Index | Accuracy | Recall | Precision | F1-Score |
|---|---|---|---|---|
| Model1 | 0.769912 | 0.724466 | 0.802013 | 0.7227488 |
| Model2 | 0.783677 | 0.714964 | 0.832215 | 0.7323601 |
| Model3 | 0.779744 | 0.712589 | 0.827181 | 0.7281553 |
| Model4 | 0.777778 | 0.710214 | 0.825503 | 0.7257282 |
| Model5 | 0.775811 | 0.710214 | 0.822148 | 0.7239709 |
| Model6 | 0.783677 | 0.733967 | 0.818792 | 0.7374702 |
| Model7 | 0.789577 | 0.733967 | 0.828859 | 0.7427885 |
| Model8 | 0.779744 | 0.736342 | 0.810403 | 0.7345972 |
| Model9 | 0.790560 | 0.722090 | 0.838926 | 0.7405603 |
| Naïve Bayes | 0.714847 | 0.631828 | 0.663341 | 0.647201 |
| Logis Reg. | 0.733529 | 0.610451 | 0.706043 | 0.654777 |
| SVM | 0.752212 | 0.627791 | 0.712676 | 0.667546 |
| Index | Accuracy | Recall | Precision | F1-Score |
|---|---|---|---|---|
| Model1 | 0.938225 | 0.921905 | 0.949715 | 0.9249881 |
| Model2 | 0.96026 | 0.948095 | 0.968823 | 0.9517208 |
| Model3 | 0.939996 | 0.918095 | 0.955414 | 0.9267003 |
| Model4 | 0.926421 | 0.89381 | 0.949380 | 0.9093992 |
| Model5 | 0.99882 | 0.997143 | 0.999990 | 0.9985694 |
| Model6 | 0.988983 | 0.981905 | 0.993966 | 0.9866029 |
| Model7 | 0.948849 | 0.92619 | 0.964801 | 0.9373494 |
| Model8 | 0.994295 | 0.991905 | 0.995977 | 0.993087 |
| Model9 | 0.949636 | 0.934286 | 0.960443 | 0.938756 |
| Naïve Bayes | 0.713969 | 0.656343 | 0.652843 | 0.654588 |
| Logis Reg. | 0.741023 | 0.632519 | 0.708945 | 0.668555 |
| SVM | 0.737825 | 0.624042 | 0.712172 | 0.665201 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Wen, T.; Chen, N.; Tang, R. Assessment of Landslide Susceptibility Based on the Two-Layer Stacking Model—A Case Study of Jiacha County, China. Remote Sens. 2025, 17, 1177. https://doi.org/10.3390/rs17071177
Wang Z, Wen T, Chen N, Tang R. Assessment of Landslide Susceptibility Based on the Two-Layer Stacking Model—A Case Study of Jiacha County, China. Remote Sensing. 2025; 17(7):1177. https://doi.org/10.3390/rs17071177
Chicago/Turabian StyleWang, Zhihan, Tao Wen, Ningsheng Chen, and Ruixuan Tang. 2025. "Assessment of Landslide Susceptibility Based on the Two-Layer Stacking Model—A Case Study of Jiacha County, China" Remote Sensing 17, no. 7: 1177. https://doi.org/10.3390/rs17071177
APA StyleWang, Z., Wen, T., Chen, N., & Tang, R. (2025). Assessment of Landslide Susceptibility Based on the Two-Layer Stacking Model—A Case Study of Jiacha County, China. Remote Sensing, 17(7), 1177. https://doi.org/10.3390/rs17071177