1. Introduction
The frequency of forest fires has increased significantly in recent years, and extreme forest fire events have had a major impact on societies and ecosystems globally [
1]. With the advantages of flexible mobility and multi-scale observation, UAV has become an important equipment for forest fire detection. In the daily inspection of forest fires, the composite strategy of long-term rapid inspection and close-range fine detection requires the detection algorithm to have both lightweight and generalization characteristics.
As shown in
Figure 1, in the process of forest fire detection, UAVs face two different application scenarios: remote shooting and close shooting. This brings about the difficulty of multi-scale target detection and matching for forest fires. At the same time, the aerial image is affected by the change in flight attitude and vegetation occlusion. The target presents significant multi-scale features, deformation characteristics and edge blurring effect. The traditional fixed shape detection model has the defects of feature matching deviation and scale sensitivity. Therefore, RGB-Thermal fusion detection can give full play to the advantages of visible light image (RGB) and thermal infrared image (T), and make up for the deficiency of single mode [
2]. The visible light image contains rich texture and color information, which can accurately identify the color characteristics of the flame and provide the basis for the detailed analysis of the fire target. The thermal infrared image is not limited by light conditions and vegetation occlusion, and can keenly capture high-temperature heat sources. Even in the presence of heavy smoke or in nighttime conditions, it can accurately pinpoint the locations of fire points. In the remote shooting scene, the initial fire point is small, and the combination of the high temperature signal in the thermal infrared image and the smoke texture feature of the visible light image can also detect the potential fire source in time. In the close shooting scene, RGB-Thermal fusion detection can quickly adapt to the scale change and shape distortion of the target in the face of complex vegetation environment and fire scene with dramatic perspective change.
In the existing forest fire detection research, most of the publicly available forest fire image datasets are limited to visible light images and lack real fire data. Furthermore, there is a paucity of publicly available RGB-Thermal image datasets, and there is a lack of more accurate image alignment work. The majority of these datasets are focused on fire classification and segmentation tasks, and there is still a gap in fire detection work [
3]. The FLAME1 [
4] and FLAME2 [
5] datasets utilise the overhead view, which is incapable of reflecting the multi-angle characteristics of UAVs during daily forest fire inspections. The well-labelled Corsican Fire Dataset [
6] and the RGB-T wildfire dataset [
2] contain a limited amount of data and are all images of a single experimental scenario, which lacks data generalization. The FireMan-UAV-RGBT dataset [
3] has captured multi-scene forest fire images from multiple viewpoints, but only supports the classification task and does not provide more refined information for forest fire detection. The dataset in this paper is comprehensive, considering the diversity of viewpoints in aerial photography, the diversity of forest fire scenes, and the precision of the data that has been annotated. The RGBT-3M has been constructed in order to provide reliable data support for the detection of forest fires using RGB-Thermal imaging.
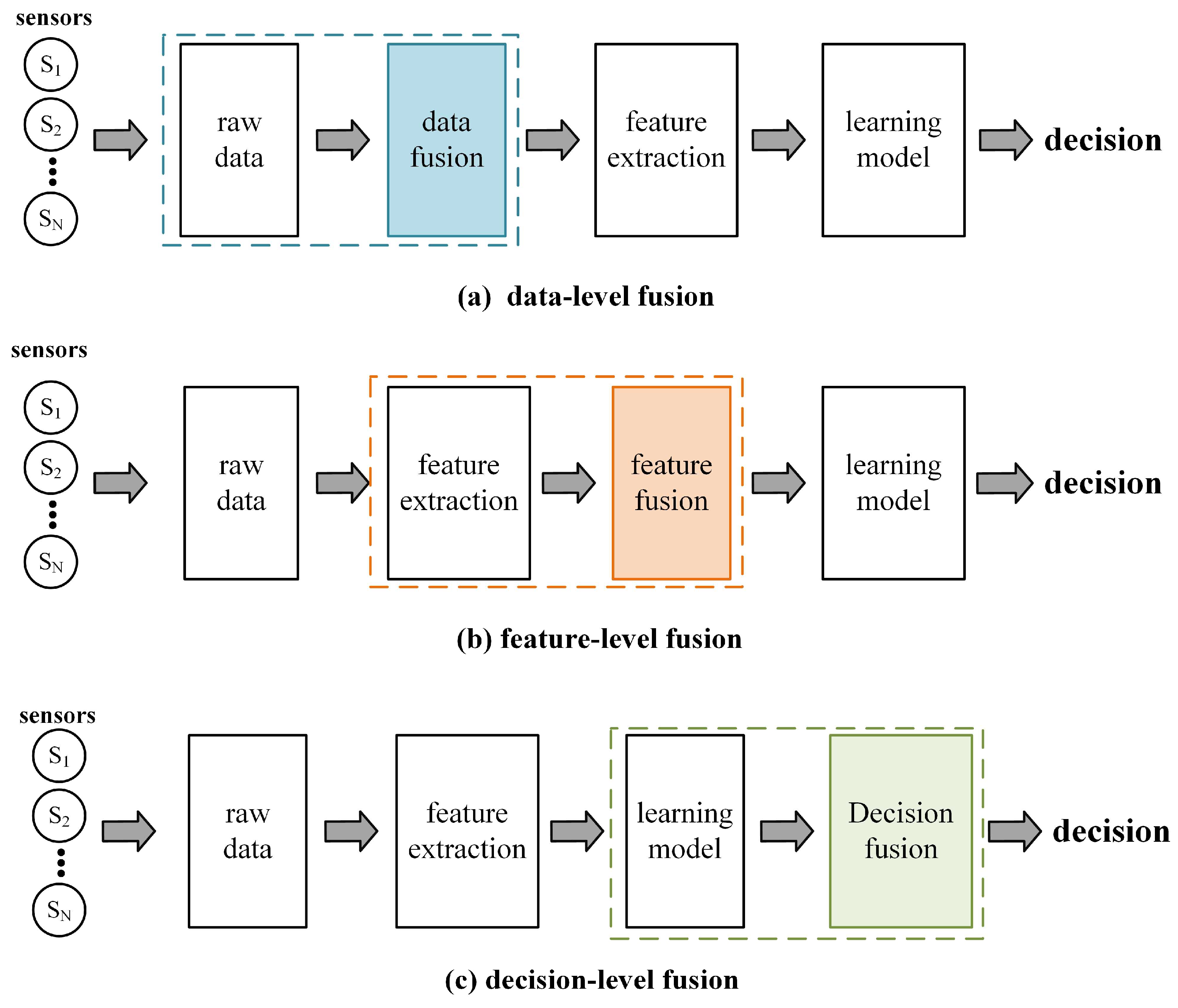
At the methodological level, the multimodal fusion strategies can be mainly categorized into three types: data-level fusion, feature-level fusion and decision-level fusion. They correspond to different stages of the algorithmic model inference process, as shown in
Figure 2.
In the field of multimodal detection methods, deep learning networks mostly use intermediate fusion strategies [
7,
8], and researchers have developed a number of multimodal interaction and fusion strategies, which have proved to be effective in enhancing the design of modal interactions in the feature extraction phase [
9,
10]. CACFNet [
11] mines complementary information from two modalities by designing cross-modal attention fusion modules, and uses cascaded fusion modules to decode multilevel features in an up–down manner; SICFNet [
12] constructs a shared information interaction and complementary feature fusion network, which consists of three phases: feature extraction, information interaction, and feature calibration refinement; and the Thermal-induced Modality-interaction Multi-stage Attention Network (TMMANet [
13]) leverages thermal-induced attention mechanisms in both the encoder and decoder stages to effectively integrate RGB and thermal modalities.
At present, preliminary progress has been made in forest fire identification based on the RGB-Thermal fusion method [
2,
3,
5,
6]. Although existing work applies deep learning frameworks such as LeNet [
14], MobileViT [
15], ResNet [
16], YOLO [
17], etc., to forest fire detection, which improves the efficiency of forest fire recognition [
5], the design of algorithms based on RGB-Thermal correlation is still very limited. Chen et al. [
5] explored RGB-Thermal based early fusion and late fusion methods for classification and detection of forest fire images. Rui et al. [
2] proposed an adaptive learning RGB-T bimodal image recognition framework for forest fires. Guo et al. [
18] designed the SkipInception feature extraction module and SFSeg sandwich structure to fuse visible and thermal infrared images for flame segmentation task. Overall, the above algorithms do not deeply consider the information interaction and propagation of cross-modal features, and lack the ability to simultaneously achieve the calibration of shallow texture features and the localization of high-level semantic information at all scales, and thus remain deficient in analyzing diverse and challenging forest fire scenarios.
We propose a new forest fire detection framework. It employs a parallel backbone network to extract RGB and TIR features. A feature cross-fertilization structure is established in multi-scale feature extraction to enhance information interaction and propagation between modalities. The channel and spatial attention mechanisms, along with a feature branching selection strategy, are introduced to suppress noise from heterogeneous inter-modal features. Finally, it achieves effective combination of complementary relationships between modalities.
In summary, this paper will explore how to effectively fuse the features of visible and thermal infrared images on existing deep learning models to improve the efficiency and effectiveness of forest fire target detection in complex environments. Based on the above background, the main contributions of this paper are as follows:
(1) A novel forest fire dataset is introduced, containing time-synchronized RGB-thermal video data from real fires and outdoor experiments in multiple Chinese forest areas. It provides high-quality, reliable data for classification and detection tasks via manual frame-splitting, image alignment, and annotation, supporting subsequent deep learning model training and testing. To the best of our knowledge, this is the first RGB-Thermal image detection dataset for forest fires.
(2) A fire detection method was carried out by combining multimodal fusion techniques and computer vision methods. We choose the well-known deep learning architecture YOLOv11, and add cross-modal feature fusion structure and attention mechanism under the dual backbone structure of RGB and TIR to guide the gradual fusion of modal heterogeneous information and improve the adaptability of the method in forest fire target detection.
(3) Our constructed model is evaluated in several challenging forest fire scenarios, effectively demonstrating the usability and robustness of our proposed dataset and deep learning approach in forest fire detection scenarios.
2. Dataset
2.1. Data Collection
The experimental equipment used for RGB-T image data collection is the DJI M300 RTK UAV (DJI Technology Co., Ltd., Shenzhen, China) equipped with the H20T, and the DJI MAVIC 2 (DJI Technology Co., Ltd., Shenzhen, China) Enterprise with integrated camera, as shown in
Figure 3.
In the process of data collection, the specific shooting specifications are shown in
Table 1.
In order to collect forest fire images covering a wide range of scenarios, the study carried out large-scale field environmental data collection in Anhui, Yunnan, and Inner Mongolia, including real fires or outdoor experimental data. In the data collection process, multiple UAV devices were used, and all devices were time-synchronized to simultaneously acquire visible and thermal infrared videos to ensure the consistency of the acquired data. Finally, from the large number of videos collected, we filtered out the videos with high representativeness of forest fire scenes, and the relevant information is shown in
Table 2.
2.2. Data Pre-Processing
In the pre-processing stage, the video is extracted at 5 frames per second to reduce similarity between image frame pairs. Images are divided into fire and non-fire frame pairs to facilitate image classification tasks. Considering the similarity of scenes, additional frame-skipping strategies are adopted to optimize the processing workflow. Finally, 17,862 frame pairs of images are obtained, of which the non-fire frames are 6642 pairs and the fire frames are 11,220 pairs.
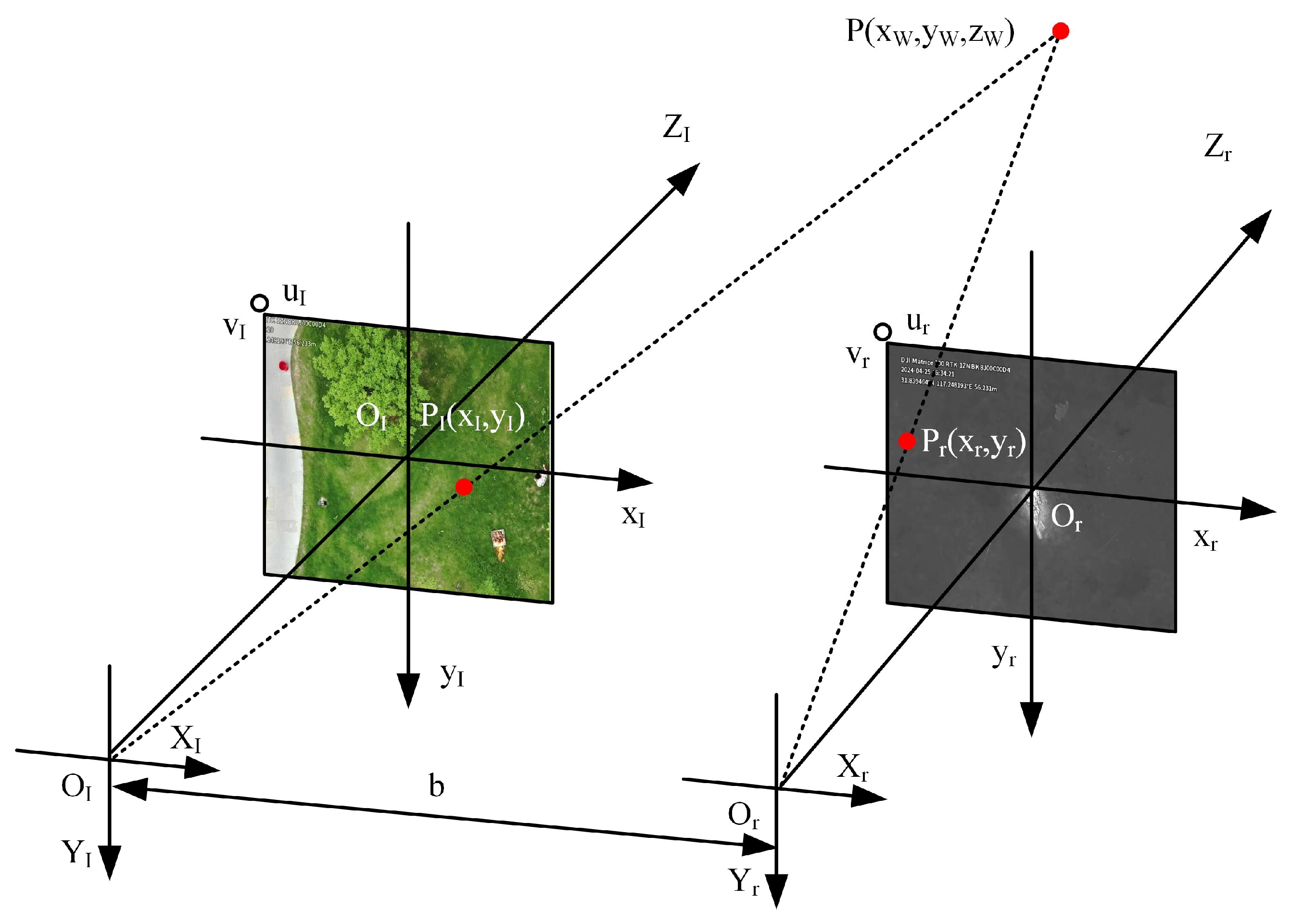
The visible and thermal infrared images are usually captured by different sensors, and the modality gaps caused by different imaging systems or styles pose a great challenge to the matching task [
19]. Although complementary information is provided in different imaging modalities, multimodal images obtained directly from the camera are not aligned for direct fusion, as shown in
Figure 4. This figure depicts a stereo vision system framework. Two cameras, each associated with independent coordinate systems (left and right), are included.
Image alignment refers to the establishment of pixel-level correspondences between images of two viewpoints, through a series of pre-processing and alignment steps, transforming them into a common reference frame or coordinate system through spatial mapping relationships, i.e., converting them into a common representation that makes them spatially aligned, and allows them to be compared and analyzed on the same spatial scale. Image alignment is used to merge the strengths of different modalities, resulting in a more comprehensive, accurate, and robust characterization.
At the device hardware level, the temporal acquisition frame rates of visible and thermal infrared images are kept synchronized, i.e., they are already aligned in the temporal dimension. In the spatial dimension, the alignment between the visible and thermal infrared images can be realized by solving the homography matrix of the visible images and the thermal infrared images and performing affine transformations, i.e.,
is the univariate responsivity matrix, and denotes the rotation and translation matrices between the two coordinate systems. The coordinates of a point on the plane in the world coordinate system in the two coordinate systems are and , the normal vector of the plane is , and the distance to the origin of the camera coordinate system is .
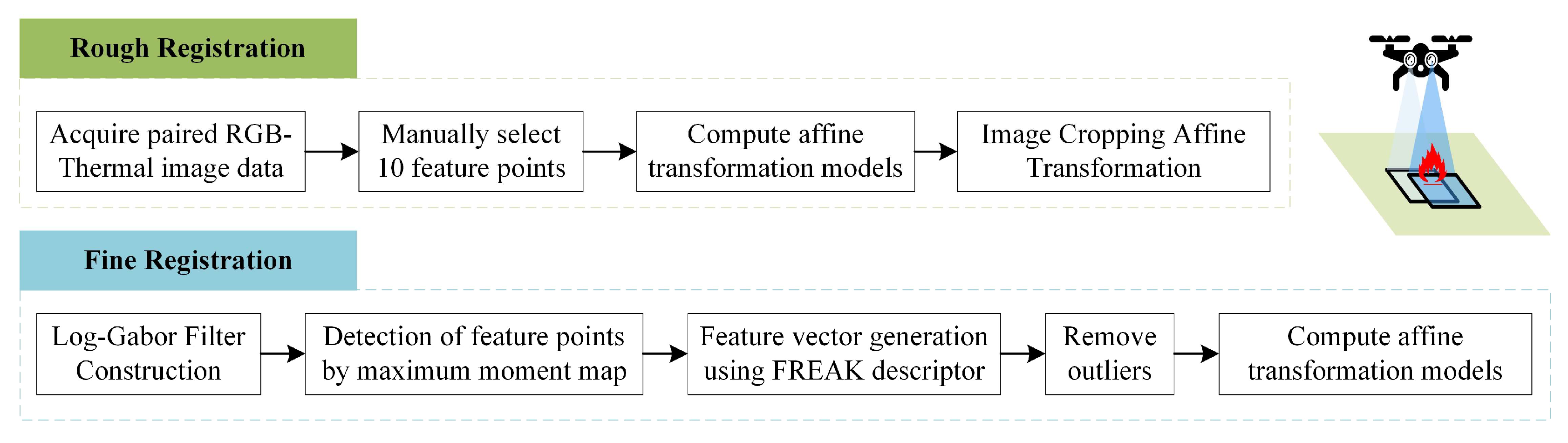
During the construction of most forest fire RGB-T data sets, the image registration process is usually carried out by manually selecting feature points, or by using general feature point matching methods such as ORB [
20] or SIFT [
21]. We propose a two-stage bimodal image alignment framework, termed M-RIFT, to improve the accuracy and robustness of matching heterogeneous image data, as shown in
Figure 5. In the rough alignment stage, manually selected feature points are used as the coarse alignment step for image resizing to quickly overcome the initial geometric distortion. In the fine alignment stage, we adopt the RIFT multimodal image matching method [
22]. First, feature points in the image are detected via the maximum moment map. Then, the maximum value index in each direction is searched to construct the maximum index map. Next, the FREAK descriptor is used to generate the feature vector, and homonymous point pairs are obtained based on the nearest-neighbor strategy. After removing outliers, the affine transform model between images is derived. This approach enables the rapid and accurate establishment of feature correspondences and optimization of matching results.
Through the above method, the homography matrix can be computed, and for each match point
and
, a system of equations is constructed based on the mathematical model of the perspective transformation. The mathematical model of perspective transformation is as follows:
is the homography matrix. Two equations can be obtained after expansion:
denotes the elements of the homography matrix expanded into a vector. The vector is obtained by solving the chi-square equation system via singular value decomposition (SVD), from which the homography matrix is then derived.
Traditional feature point matching methods cannot effectively handle the modal differences between cross-modal images, making it difficult to match heterogeneous information.
Figure 6 demonstrates a comparative analysis of the feature point matching results between our approach and other methodologies. The green line connects the matching points corresponding to the visible light image and the thermal infrared image.
The traditional methods are only capable of identifying a limited number of matching points, frequently accompanied by issues of incorrect alignment. By contrast, the approach proposed in this paper successfully detects a substantial number of accurate matching points, thereby demonstrating the superiority of the proposed method.
2.3. Statistical Analysis of the Dataset
The multi-scene, multi-target and multimodal forest fire aerial photography dataset (RGBT-3M dataset) contains 22,440 images (i.e., 11,220 pairs of images) of fire frames, which were annotated using LabelImg (version: 1.8.6), and the labeled targets were smoke, fire, and person, with the numbers of 13,574, 11,315, and 5888. Infrared images lacked obvious smoke features, so we provided labels excluding smoke targets. The dataset is divided according to the ratio of 7:3 to form the training set and validation set, some representative scenes are shown in
Figure 7, and the specific data are shown in
Table 3. The dataset will be updated to the website:
https://complex.ustc.edu.cn/.
4. Experiment
4.1. Experimental Settings
The algorithmic model was experimented in the Ubuntu 18.04 operating system with NVIDIA GeForce RTX 3090 graphics card, CUDA version number 11.1, and Python version number 3.9.19. The principle of consistency was followed during the training of all the networks, keeping the same core optimizer parameters, optimization algorithm, and number of training parameters. The detailed settings of each specific training parameter are shown in
Table 4.
4.2. Evaluation Criteria
Metrics such as precision (P), detection recall (R), and average precision (AP) are used to evaluate the model performance.
The detection threshold set is 0.5, which is adopted as mAP50. Meanwhile, the evaluation index mAP50-95 is defined as the average value of detection thresholds ranging from 0.5 to 0.95 (excluding 0.5, with a step size of 0.05).
4.3. Comparative Experiment
In this section, a comparative study is carried out for the above single-modal detection model as well as the RGB-Thermal detection framework. It is worth noting that smoke is visible on visible images and difficult to recognize on thermal infrared images. This is due to the low sensitivity of the thermal infrared camera carried by the UAV and, for the remote observation, the UAV is far away from the forest fire target and cannot effectively capture the smoke information. Meanwhile, in order to focus more on the RGB-T bimodal fusion detection in small target detection, the subsequent comparison experiments are carried out with the smoke label removed, and only the flame and person are targeted for analysis.
Table 5 gives a comparison of the effect of different number of target categories for visible light detection.
For single-modal comparison, we selected RTMdet [
27], a single-stage target detection algorithm with similar model complexity to YOLOv11, and FasterRCNN [
28], a well-known two-stage target detection algorithm, for comparison experiments.
Table 6 presents a comparison of the effect of single-modal detection methods.
Compared to the single-stage target detection model with similar complexity, the YOLOv11 model reflects a more prominent performance advantage, which is significantly higher than the RTMdet model in all metrics. Compared to the complex two-stage target detection model, the YOLOv11 model is not much different from the FasterRCNN model in all the indicators, but YOLOv11 is slightly higher in recall, which reflects that the YOLOv11 model performs well in reducing the leakage of detection, which is needed for the early detection task of forest fires.
4.4. Ablation Experiment
In order to verify the effect of each improvement module on the model detection capability, we compare the effects of different improvements on the model detection performance. Ablation test results of the algorithm model are shown in
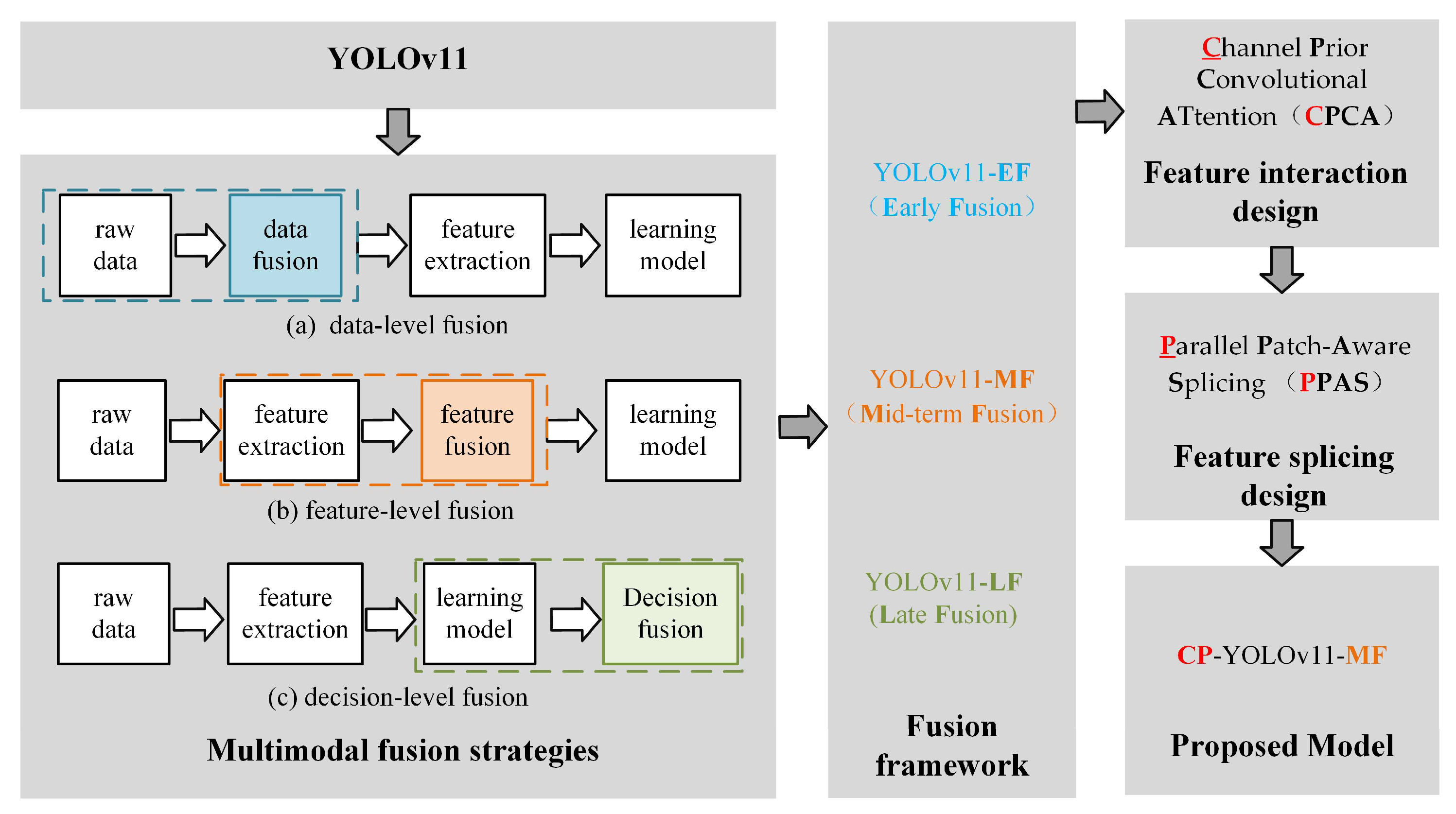
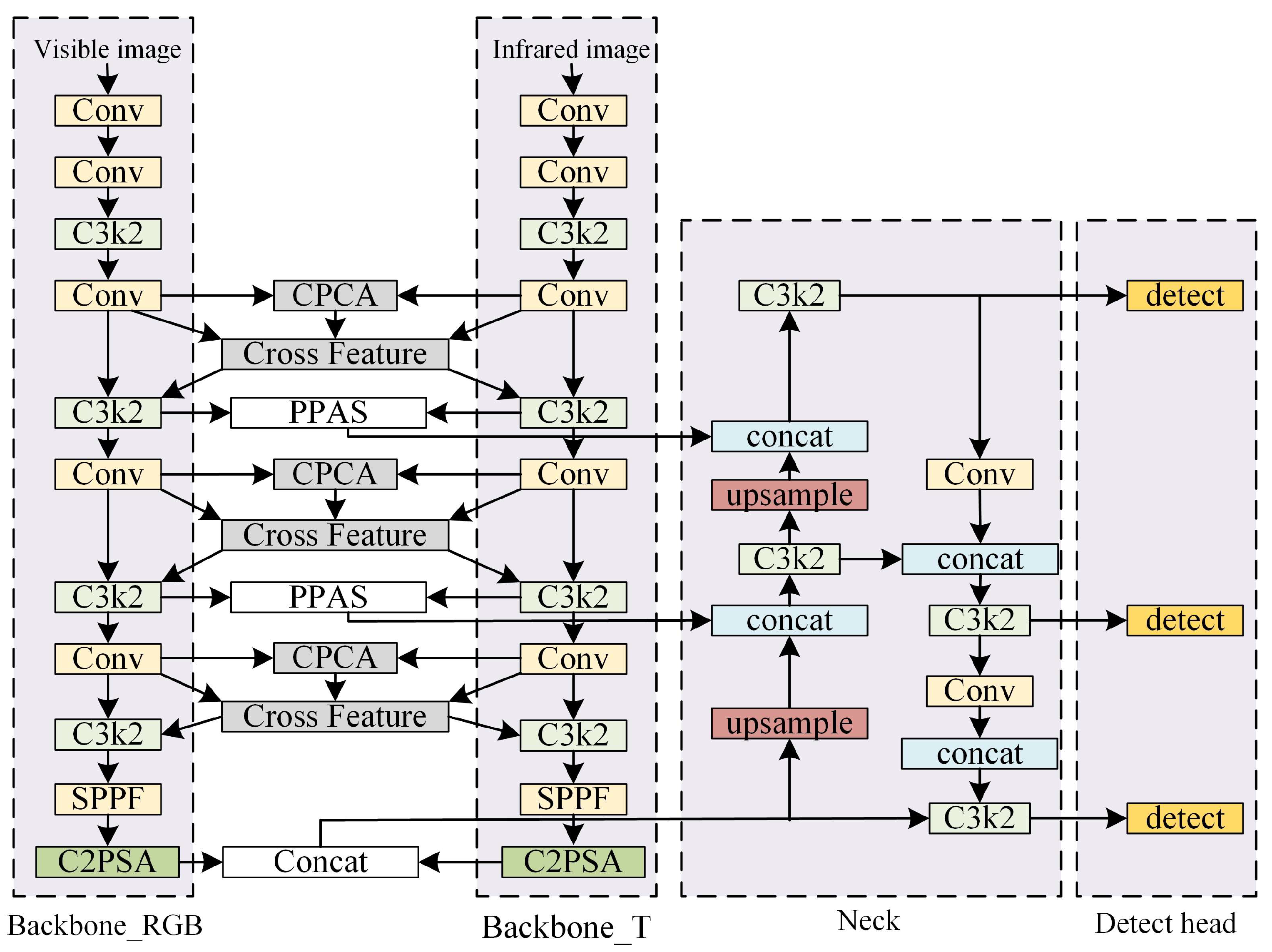
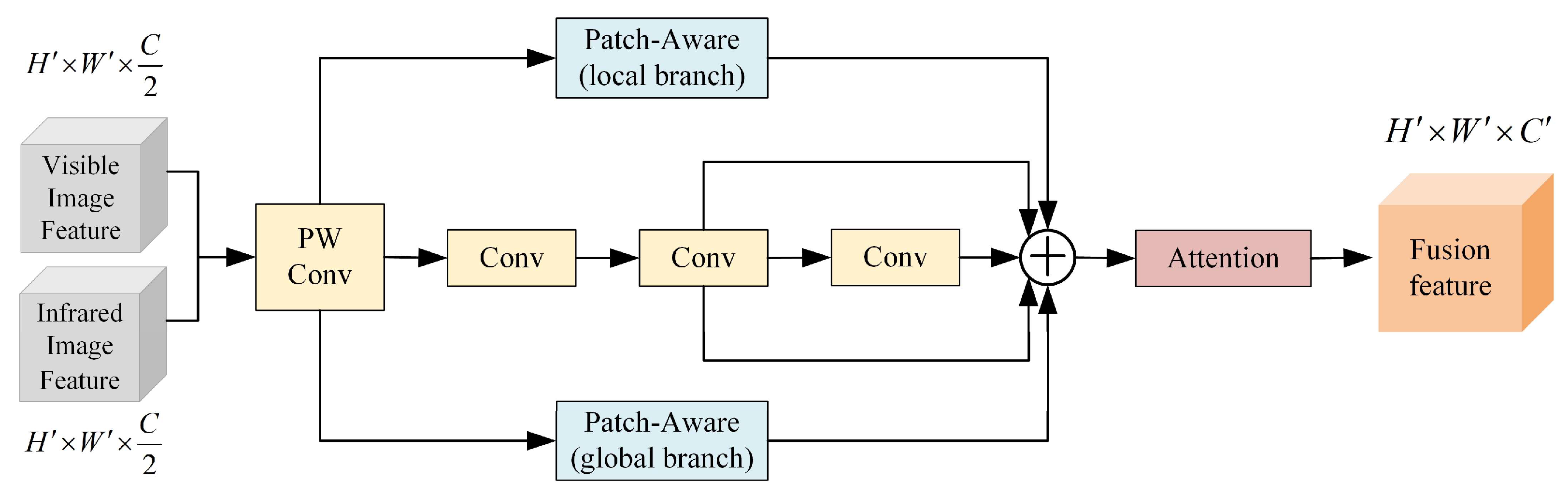
Table 7. The experiments adopt YOLOv11 as the baseline model for unimodal detection in visible and infrared images. Based on this, the mid-term fusion framework “YOLOv11-MF” is designed. Adding a cross-modal feature interaction design based on CPCA to YOLOv11-MF yields “YOLOv11-MF+ feature interaction structure”. Finally, integrating the PPAS feature splicing module results in “CP-YOLOv11-MF”.
As shown in
Table 7, early, mid, and late RGB-Thermal bimodal fusion frameworks are constructed via multimodal strategies. According to different multimodal fusion strategies, a simple Concat function is used for modal splicing, and the early fusion framework (YOLOv11-EF), the mid-term fusion framework (YOLOv11-MF), and the late fusion framework (YOLOv11-LF) are constructed on the basis of the YOLOv11 model. Simple bimodal feature splicing slightly improves algorithm performance, while designing a cross-modal feature interaction module and optimizing modal splicing modules enhances intermodal interactions, enabling deep feature and information complementarity across modalities. After a series of targeted improvements, the algorithm model (CP-YOLOv11-MF) constructed finally reaches 92.5%, 93.5%, 96.3%, and 62.9%, which reflects the effectiveness of the various improvement methods for model performance improvement.
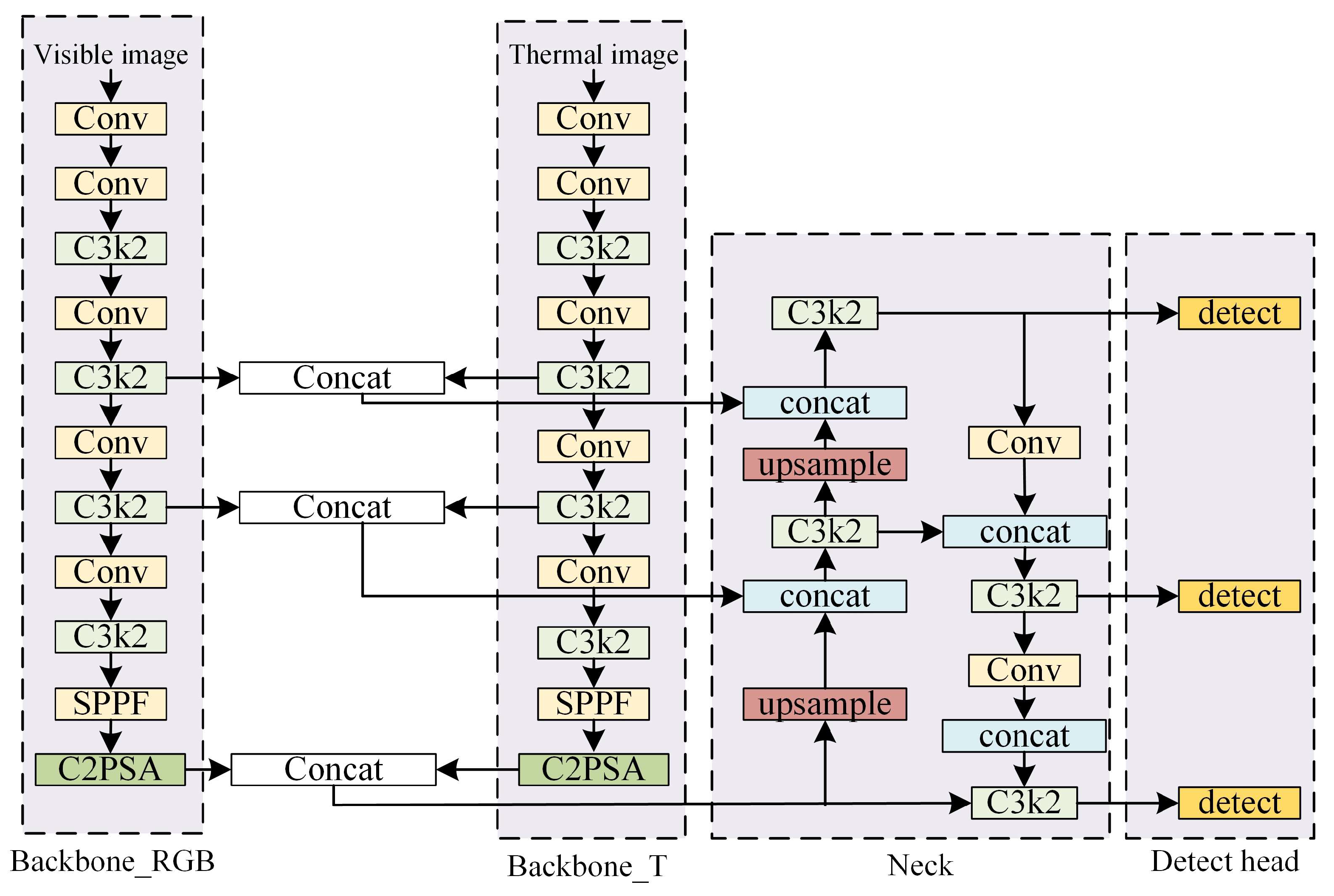
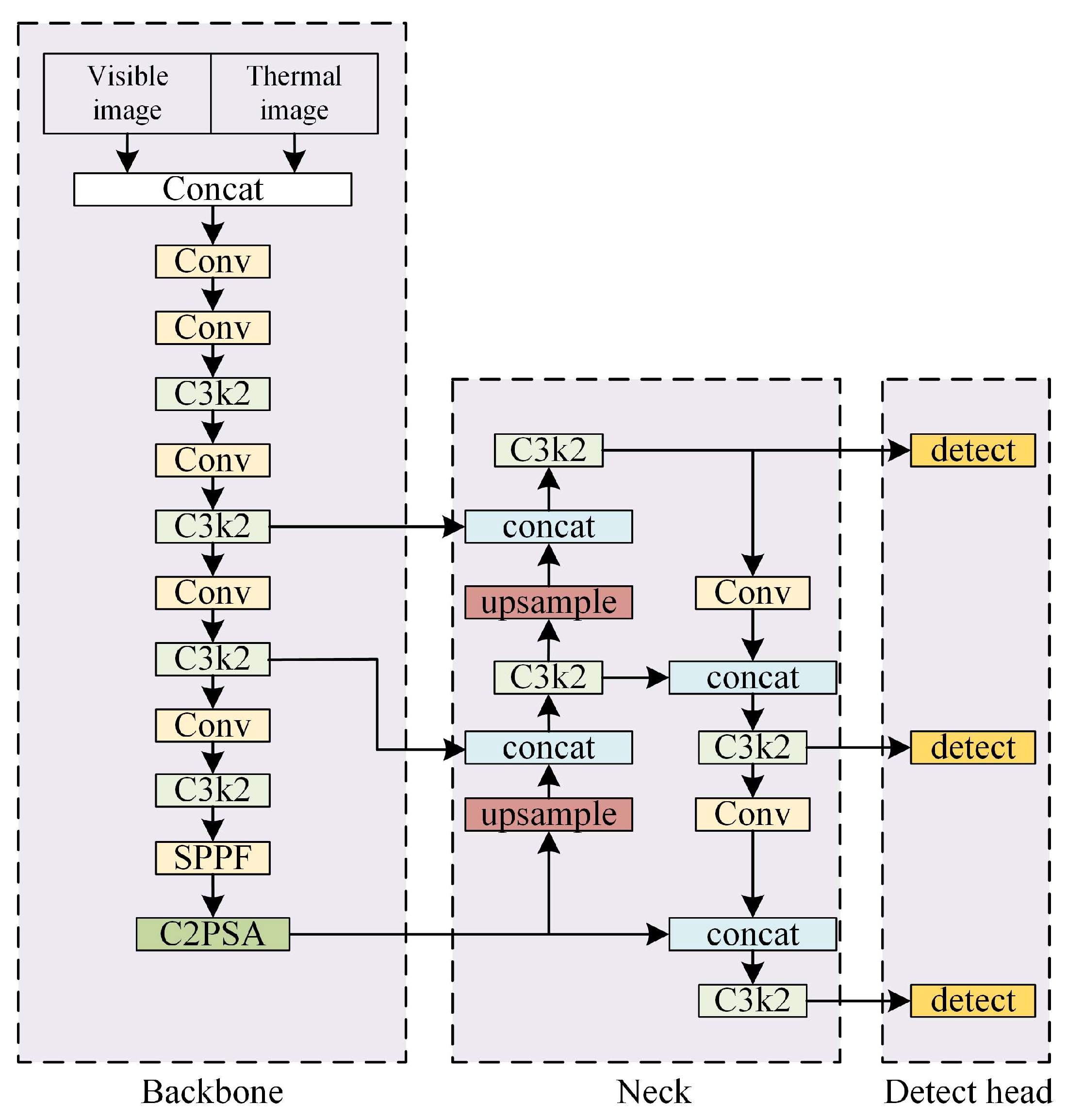
In the detection framework based on early fusion Strategies (YOLOv11-EF), the input layer is improved by adding two new input channels and introducing the Concat function for early bimodal feature splicing. First, the infrared image and the visible image are used as input data, and the feature splicing operation is performed on the images of two different modalities to generate the bimodal fusion feature map. Subsequently, the generated bimodal fusion feature map is input to the backbone network layer and the neck network layer. The detection layer performs target detection operations from the previous layers and outputs the detection results. The network structure of YOLOv11-EF is shown in
Figure 14.
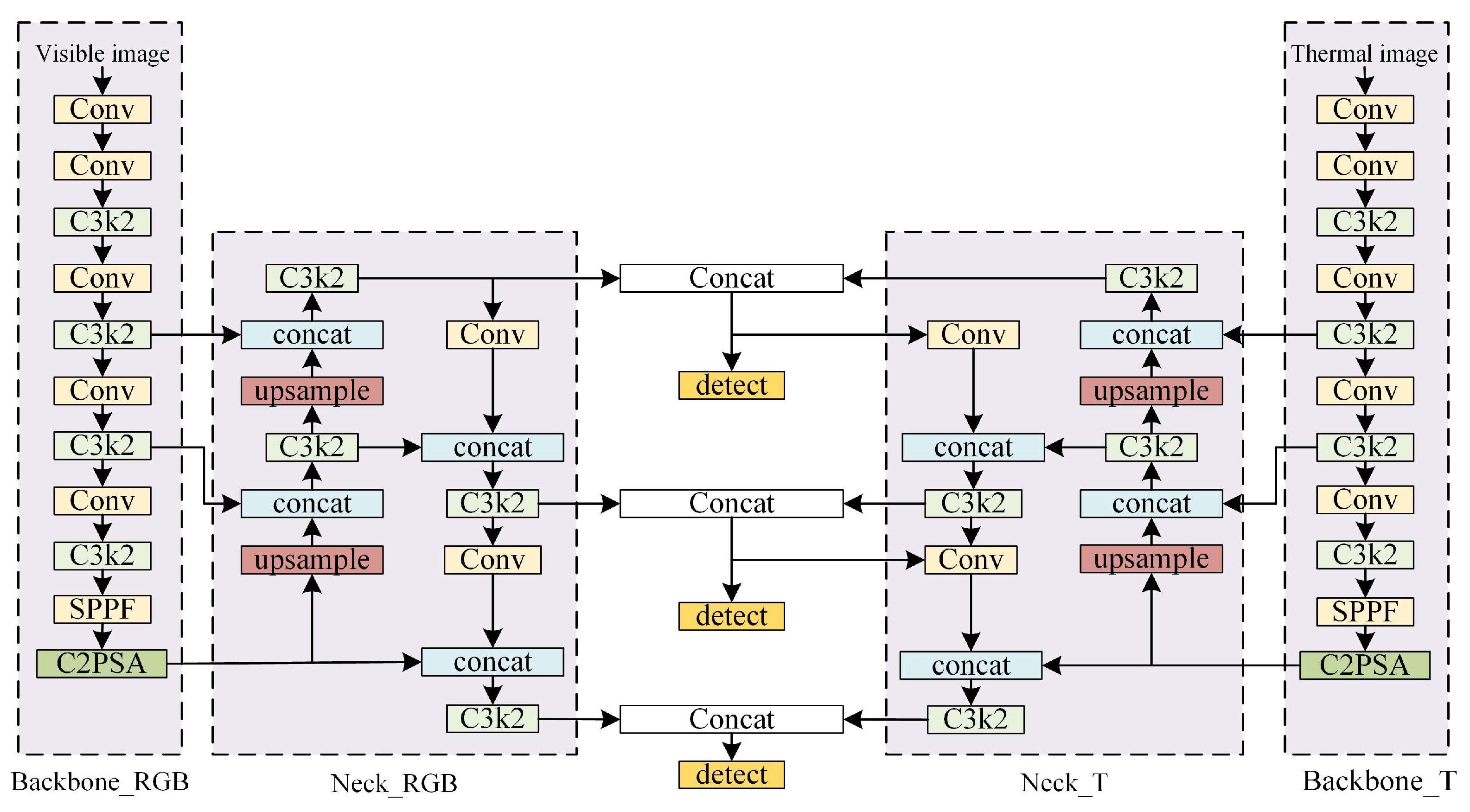
The detection framework based on late fusion strategies (YOLOv11-LF) consists of a dual-input layer, a dual-channel backbone network layer, a dual-channel neck network layer, and a detection layer. The visible channel backbone network and the thermal infrared channel backbone network perform feature extraction for the visible and thermal infrared images, and output the extracted features to the neck network layer. The features are enhanced in the neck network layer. A feature splicing module is embedded at the output position of the neck network layer to input the generated bimodal image fusion features to the detection layer. The network structure is shown in
Figure 15.
In order to verify the effectiveness of the RGB-Thermal bimodal target detection algorithm model, in this section, the YOLOv11 model is utilized to train the infrared and visible images separately to obtain the detection results in a single modality, i.e., the YOLOv11 network model processes the two types of images, visible and thermal infrared, and directly outputs the detection results without any fusion. As shown in
Table 8, the performance of each model under single-modal detection and different detection fusion frameworks is compared.
A comparison of visible and infrared image detection results in a single modality shows that visible images, despite richer information, contain more interference. Evaluation of detection performance reveals similar mAP50 values for both modalities. However, infrared images exhibit a significant advantage in flame detection under the stricter mAP50-95 metric, outperforming visible images by 5.4%. In contrast, detection accuracy of person with infrared is slightly lower than that with visible light.
In terms of the comparative analysis of the detection effect of single-modal and dual-modal, the RGB-T dual-modal image detection method is significantly better than the single-modal image detection results in the three types of evaluation indexes (Precision, Recall, mAP), which proves the effectiveness of the image fusion technology in improving the performance of target detection. In-depth analysis of the characteristics of different stages of fusion methods within each RGB-Thermal bimodal fusion framework reveals that later fusion shows certain advantages. In the early fusion stage, because the original data has not been processed in depth, a large amount of redundant information and potential noise are not effectively eliminated, and these interfering factors are likely to have a negative impact on the subsequent model analysis process. Mid-term fusion also suffers from a similar problematic potential, in which a certain degree of noise interference inevitably exists in the data processing process. In this case, relying only on simple splicing operations to integrate multi-source data, it is not possible to fully explore the intrinsic correlation between the data, and it is difficult to realize the efficient fusion and utilization of information. In contrast, the fusion in the later stages of the information processing process, the data underwent multiple rounds of rigorous screening, effectively reducing noise impact. Subsequently, the information is integrated, which enables the model to more accurately refine the key features, thus presenting a better performance than the mid-term fusion framework on this dataset.
Under the multiple RGB-Thermal bimodal fusion frameworks mentioned above, only the Concat function is used for modal splicing operations and, in order to better perform modal fusion interactions, a cross-modal feature interaction structure is designed. Since only a single backbone network exists in the early fusion framework (YOLOv11-EF), the cross-modal feature interaction structure is applied in this section to the mid-term fusion framework (YOLOv11-MF) and late fusion framework (YOLOv11-LF) for experiments, as shown in
Table 9. After adding the cross-modal feature interaction structure, the improved mid-term fusion framework performs optimally.
The experimental results show that, after the addition of cross-modal structures, all indicators under the late integration framework decreased to a certain extent while, for the mid-term integration framework, all indicators were significantly improved. Since the cross-modal structure introduced in the late fusion framework at the late stage of data processing does not have effective feature interaction with the late integration, it makes it difficult for the model to quickly adapt to and effectively integrate this cross-modal information. In the mid-term fusion stage, the data is initially processed and not yet fully solidified with feature patterns, and the introduction of cross-modal structures at this time can timely capture the rich complementary information between different modal data. From the network architecture, modal splicing and interactions are cross-cutting, enabling inter-modal feature mapping, enhancing information flow, and improving characterization of complex scenarios and diversified targets. This significantly improves model performance, especially in mAP50-95, where obvious advantages are observed.
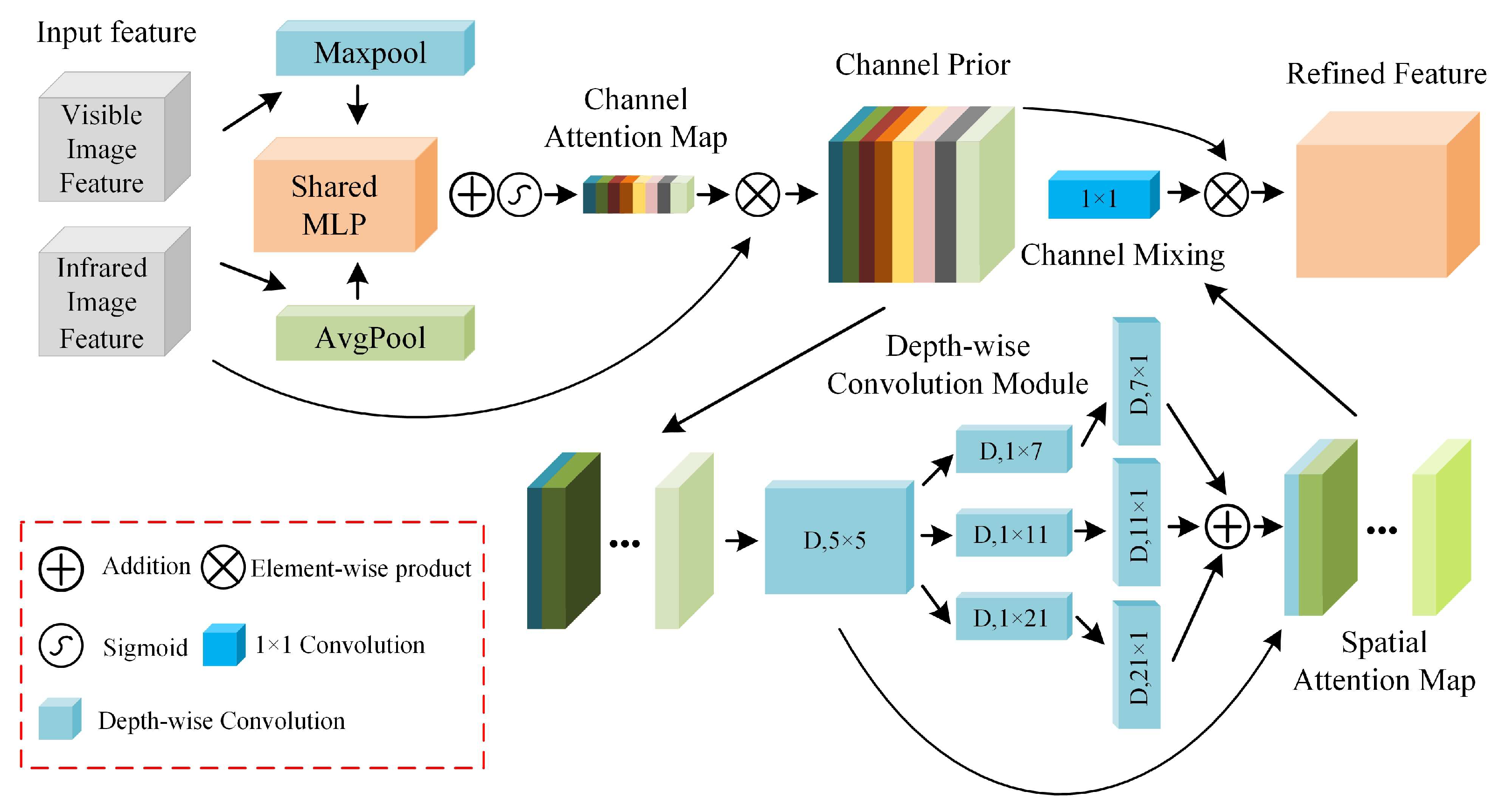
In the feature splicing module, we test the effectiveness of different attentions in the optimization of the feature splicing module. Various attentional mechanisms (SimAM [
29], GAM [
30], NAM [
31], LCA [
32], and our method) are adopted to improve the modal splicing approach, which are applied in the feature splicing module after the C3k2 feature extraction module of the backbone network, and the related results are shown in
Table 10.
As shown in
Table 10, our designed PPAS, enabled by its multi-branching structure, effectively filters noisy information, complements cross-modal information, and outperforms in all metrics. The GAM attention mechanism ranks second in several metrics. Similar to our approach, it leverages channel-spatial attention interaction to enhance feature extraction accuracy.
4.5. Lightweight Design
In the experimental process, during the modal splicing function design, the overall complexity of the model is increased greatly after all modal splicing modules are replaced with PPAS. Considering that the algorithmic model is mainly used for UAVs to perform forest fire detection tasks (especially small targets), the lightweight approach is designed in this section. The original modal splicing function (Concat) is retained in the third modal splicing module corresponding to the third detection layer (which is mainly used for the detection of large targets).
This section presents comparative experiments to assess the detection performance of different modal splicing methods and model complexity. All schemes are evaluated within the medium-term fusion framework of the enhanced modal fusion structure (YOLOv11—MF+ feature interaction structure). As detailed in
Table 11, Scheme 1 replaces all modal splicing modules with PPAS; Scheme 2 substitutes only the first two modules with PPAS; and Scheme 3 replaces only the first module with PPAS.
As shown in
Table 11, simplified modal splicing Scheme 2 (replacing only the first two modal splicing modules with PPAS) reduces model parameters and size by nearly 50% compared to full replacement. Notably, indicators show no significant decline, with slight improvements in accuracy and mAP50-95, verifying the effectiveness of the simplified design.
In order to further verify the balance between the detection effect and model complexity of the algorithmic models, the comparison of detection performance and complexity of the single-modal and RGB-T bimodal algorithmic models is shown in
Table 12.
From
Table 12, the model, designed to handle RGB-T bi-modal data, with a dual backbone for cross-modal feature extraction, incorporates lightweight designs in data input and algorithmic improvements. Although its parameter count and model size are slightly larger than the original single-modal detector, it achieves improved performance at lower complexity.
4.6. Visual Analysis
In order to visualize the performance of the algorithmic model established in the forest fire target detection task,
Figure 16 shows the partial detection results of the algorithmic model CP-YOLOv11-MF, which demonstrates the detection effect of the UAV from different viewpoints and in different scenes.
The blue box labeled “fire 0.8” indicates that the model predicts that the target is “fire” with 80% confidence. From the above figure, it can be seen that the CP-YOLOv11-MF algorithm model can fulfill the forest fire target detection task well.
At the same time, in order to further analyze the performance differences between different algorithm models, representative forest fire image detection samples (night environment, tree cover, smoke cover) are selected for visual analysis in this section, as shown in
Figure 17,
Figure 18 and
Figure 19, to visualize the improvement effect of different algorithm models.
Figure 17 illustrates the detection performance of each model under nighttime conditions. While each model demonstrates proficiency in detecting fires with distinct characteristics, person detection may incur pixel-level displacement. This is because humans lack rich texture in thermal infrared images, leading to blurred detection box borders that hinder accurate localization. In the mid-term fusion framework (YOLOv11-MF), multiple detection boxes initially appear, but the final model—incorporating cross-modal feature fusion and splicing—achieves precise person detection with the highest confidence among all models.
The performance of visible images in flame detection under tree occlusion conditions is limited, as shown in
Figure 18. For some fire objects, the detection confidence is only 30%, and the detection boxes have localization bias. Thermal infrared images can effectively recognize high-temperature target regions that stand out from the surrounding environment by virtue of their ability to perceive high-temperature areas in the scene. In the early fusion framework (YOLOv11-EF), the poor fusion of bimodal information initially generates multiple detection boxes. After model improvement, the confidence level of all target detections increases to 80%, demonstrating that the adopted algorithm model effectively enhances the accuracy and stability of forest fire target detection under tree occlusion conditions. This provides a more reliable solution for forest fire target detection in complex environments.
There is a false alarm problem with thermal infrared images in smoke occlusion environments, as shown in
Figure 19. Due to the existence of areas around the fire point with temperatures close to the human body temperature, thermal infrared images incorrectly identify these areas as personnel targets. Although visible light images have rich texture information and are still able to detect flames and smoke under low visibility, they are deficient in the localization accuracy of the detection framework. In addition, in the application scenarios of the early fusion framework and the middle fusion framework, the visible light image has under-reporting phenomenon and fails to successfully detect some of the actual targets. When the proposed method is used for detection, the detection confidence is increased to 80% for both critical targets, namely, flames and people, which improves the accuracy and reliability of detection.
In summary, the algorithm model CP-YOLOv11-MF constructed is able to perform the target detection task more accurately in complex forest fire scenarios. Compared with single-modal detection methods, the model significantly reduces the false alarm rate and missed alarm rate, effectively overcoming the limitations of single-modal detection. Meanwhile, by designing the modal interaction structure and optimizing the modal splicing module, the model’s ability to detect targets in complex environments is enhanced significantly.
5. Conclusions
In this paper, a multi-target and multi-scene forest fire aerial photography dataset is constructed by collecting data in multiple locations with a UAV equipped with a dual-optical camera head, which provides a more comprehensive visual dataset for subsequent forest fire prevention and management research. Meanwhile, the early fusion detection framework (YOLOv11-EF), the middle fusion detection framework (YOLOv11-MF) and the late fusion detection framework (YOLOv11-LF) are constructed for the multimodal fusion strategy on the basis of the YOLOv11 target detection model, which proves the advancement of the RGB-T bimodal target detection network model compared with the single-modal one. Based on this, a modal interaction structure is designed and a modal splicing module is optimized to enhance deep cross-modal interaction and fusion for RGB-Thermal bimodal target detection. Lightweight design is also incorporated during algorithm model improvement. Finally, the RGB-T dual-modal detection model CP-YOLOv11-MF constructed achieves 92.5%, 93.5%, 96.3%, and 62.9% in terms of precision, recall, mAP50, and mAP50-95. Compared with the metrics of visible light detection in a single mode, there are 1.8%, 3.2%, 2.7%, and 7.9% improvement and, with the metrics of thermal infrared detection in a single mode, the improvement is 1.3%, 4.9%, 2.7%, and 4.7%.
This paper presents an optimized AI-driven framework for RGB-thermal fusion in wildfire detection, which significantly improves the accuracy and response efficiency of monitoring systems. In the context of the growing trend of multi-source data fusion for forest fire detection, this study provides novel insights into the integration of diverse data modalities. Future work will focus on further enhancing the scale and diversity of the multi-scenario fire dataset by continuing to collect data in more forested areas with different geographic environments and climatic conditions, covering a wide range of terrains such as mountains, hills, and plains, as well as forested scenarios with different seasons and day/night time slots, in order to increase the dataset’s level of coverage of complex real-world scenarios. At the algorithmic research level, we continue to study the cross-modal fusion mechanism in depth, explore more potential modal interaction features, and improve the efficiency of the model in utilizing the bimodal data, so as to achieve more stable and accurate detection in the complex and changing forest fire scenarios.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}