



SonarNet: Global Feature-Based Hybrid Attention Network for Side-Scan Sonar Image Segmentation

Abstract

1. Introduction
- We propose a novel dual-encoder structure incorporating self-attention for global feature extraction. This architecture enables simultaneous extraction of spatial features and global location information, effectively mitigating the decay of global correlations caused by continuous convolution and downsampling.
- We design an adaptive hybrid attention module that dynamically emphasizes or suppresses information based on input data. By jointly focusing on spatial and channel-wise features, this module enhances the model’s ability to accurately identify and localize target regions, improving generalization and robustness against complex underwater environments.
- We introduce a global information enhancement module between the dual encoder and decoder. This module integrates global and spatial features from both encoding paths, providing the decoder with multi-scale global information and significantly improving segmentation accuracy.
2. Related Works
2.1. Traditional and CNNs-Based Sonar Image Segmentation
2.2. Global Context and Attention Mechanisms
3. Methodlogy
- The input underwater sonar image is first processed by a global feature extractor to obtain a global feature map. Subsequently, a dual encoder is employed to generate high-level feature representations of size .
- An adaptive hybrid attention network is applied to assign higher weights to channels containing important features, thereby emphasizing key regions within the features.
- The decoder reconstructs these high-level features to restore the original input resolution, yielding the final segmentation result.
- The global feature enhancement module is integrated into the skip connections between the dual encoder and the decoder. This module provides additional complementary information to the decoder, which further improves the accuracy and robustness of underwater sonar image segmentation.
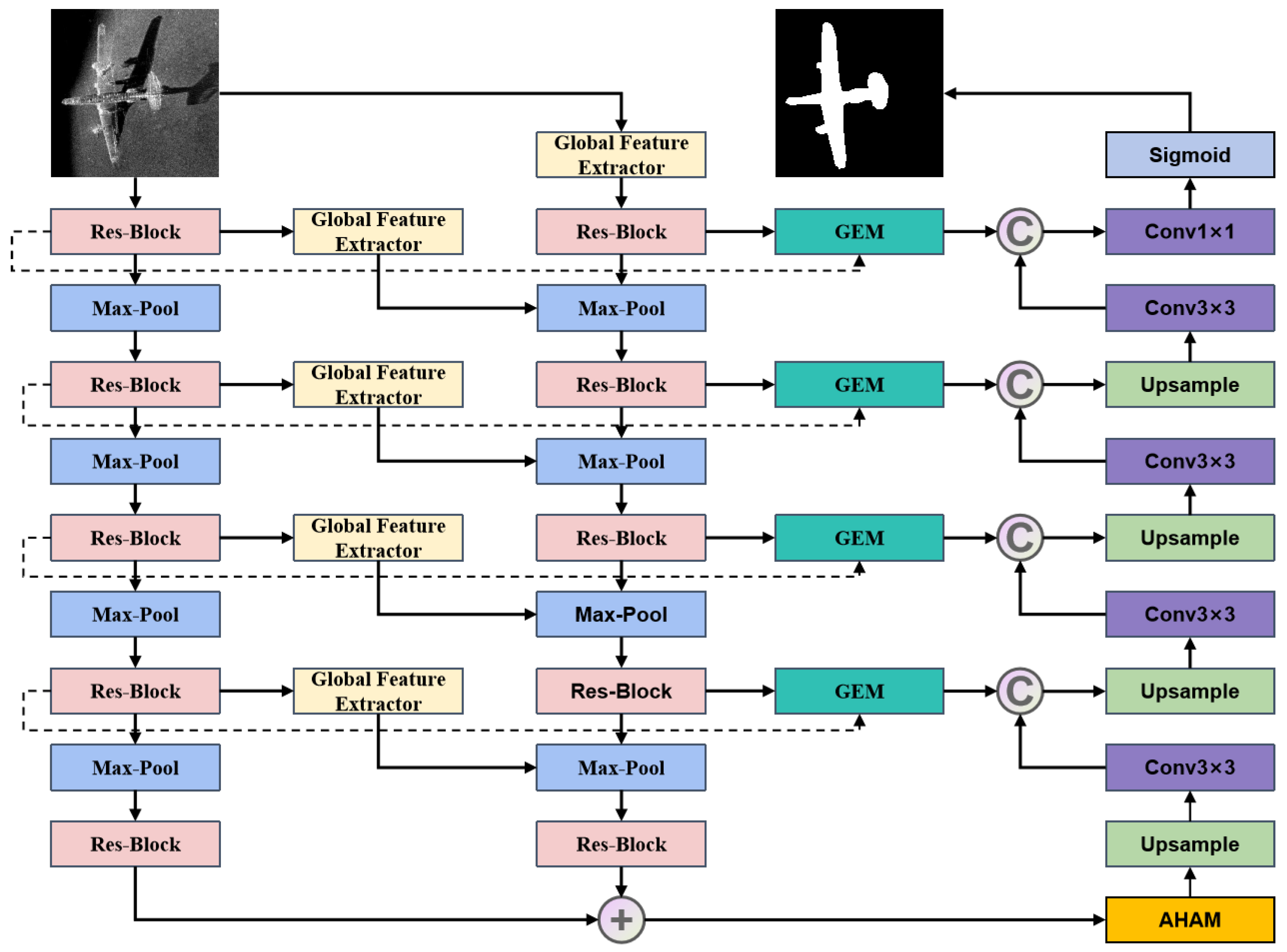
3.1. Dual Encoder Based on Global Feature Extraction
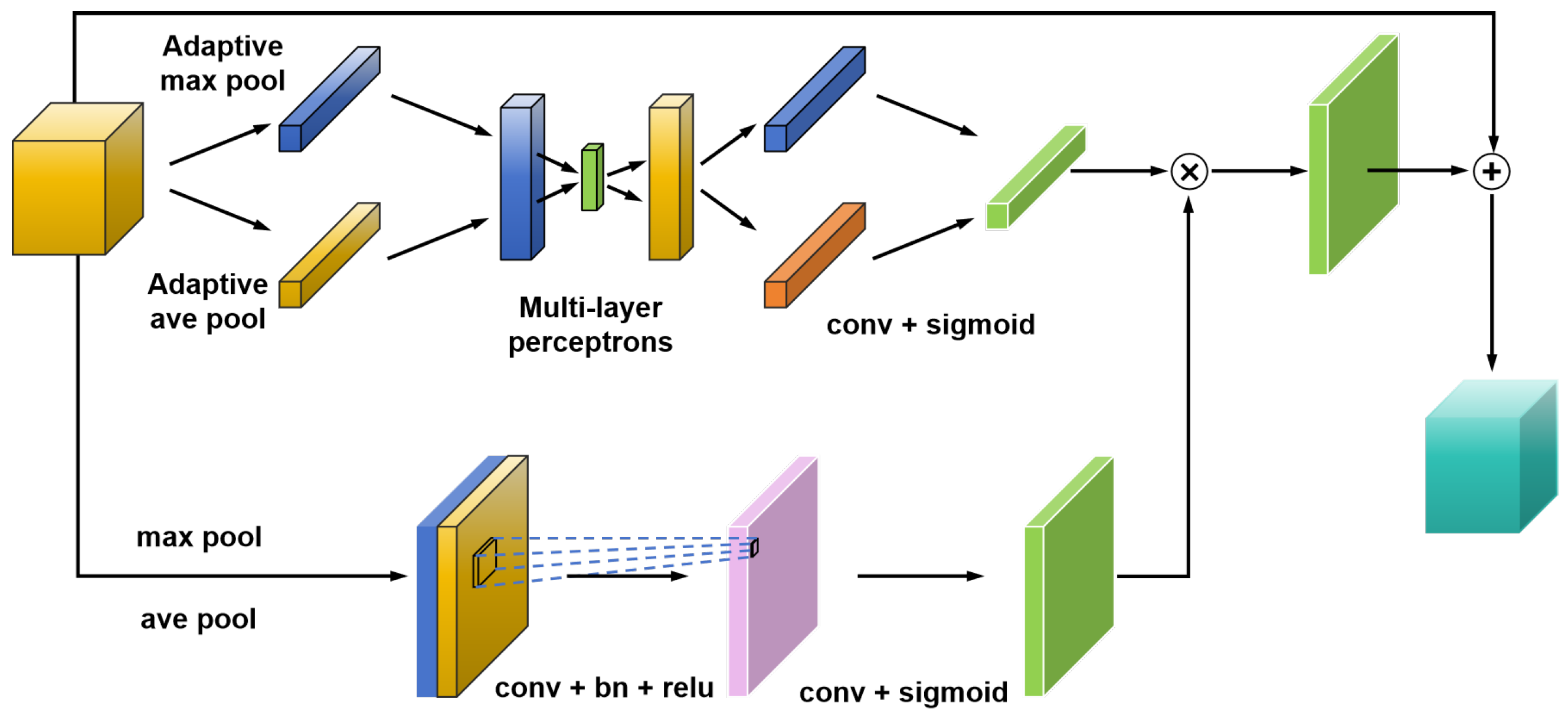
3.2. Adaptive Hybrid Attention Mechanism
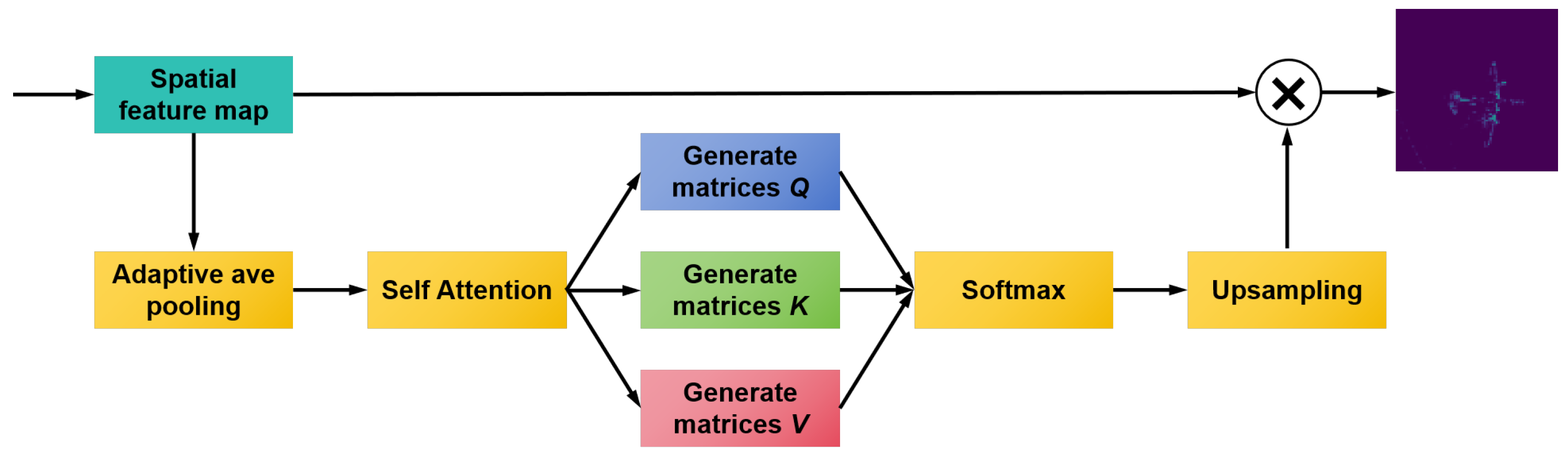
3.3. Global Feature Enhancement Module
4. Experiments and Results
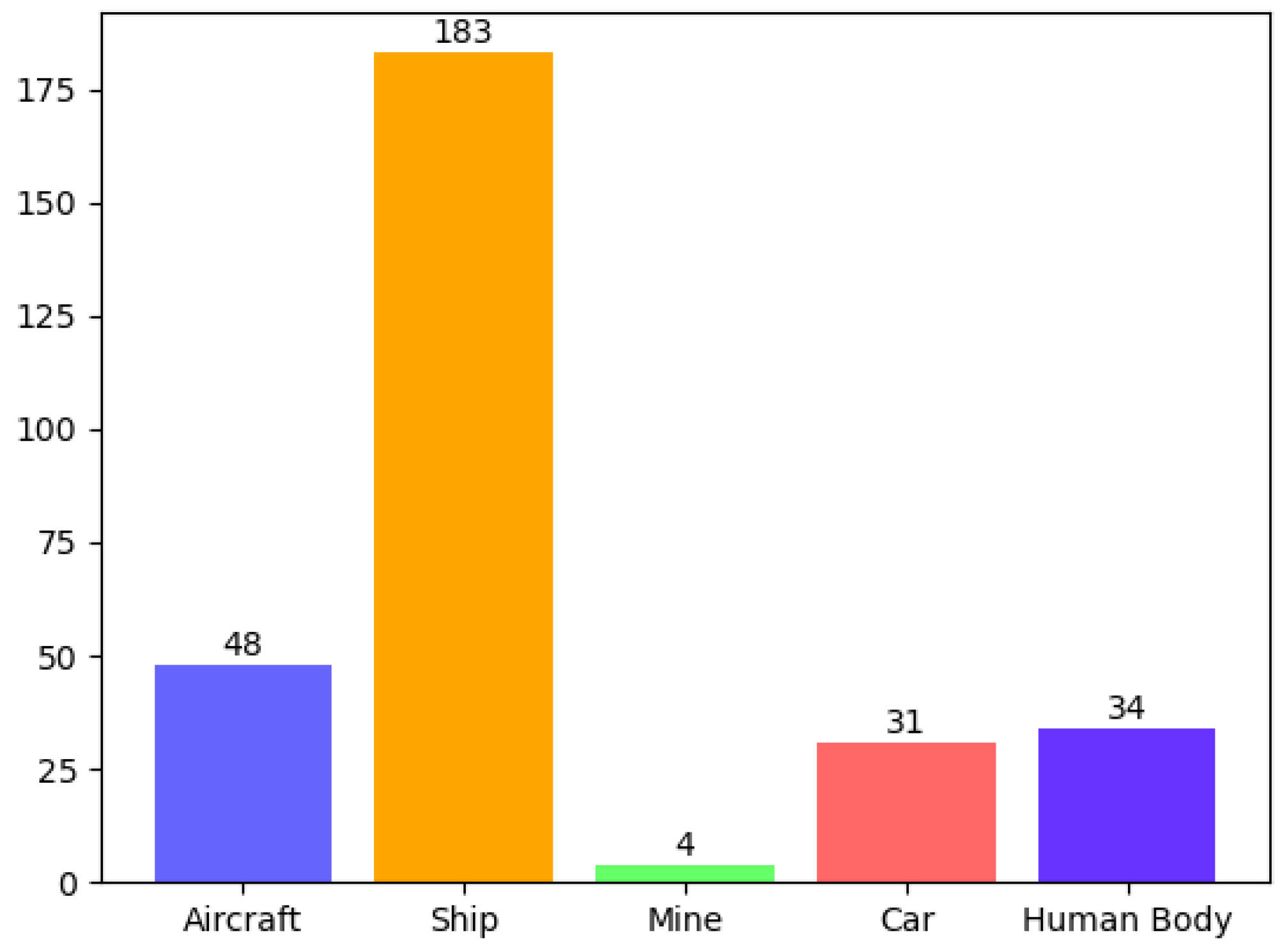
4.1. Dataset
4.2. Parameter Settings and Implementation Details
4.3. Evaluation Metrics
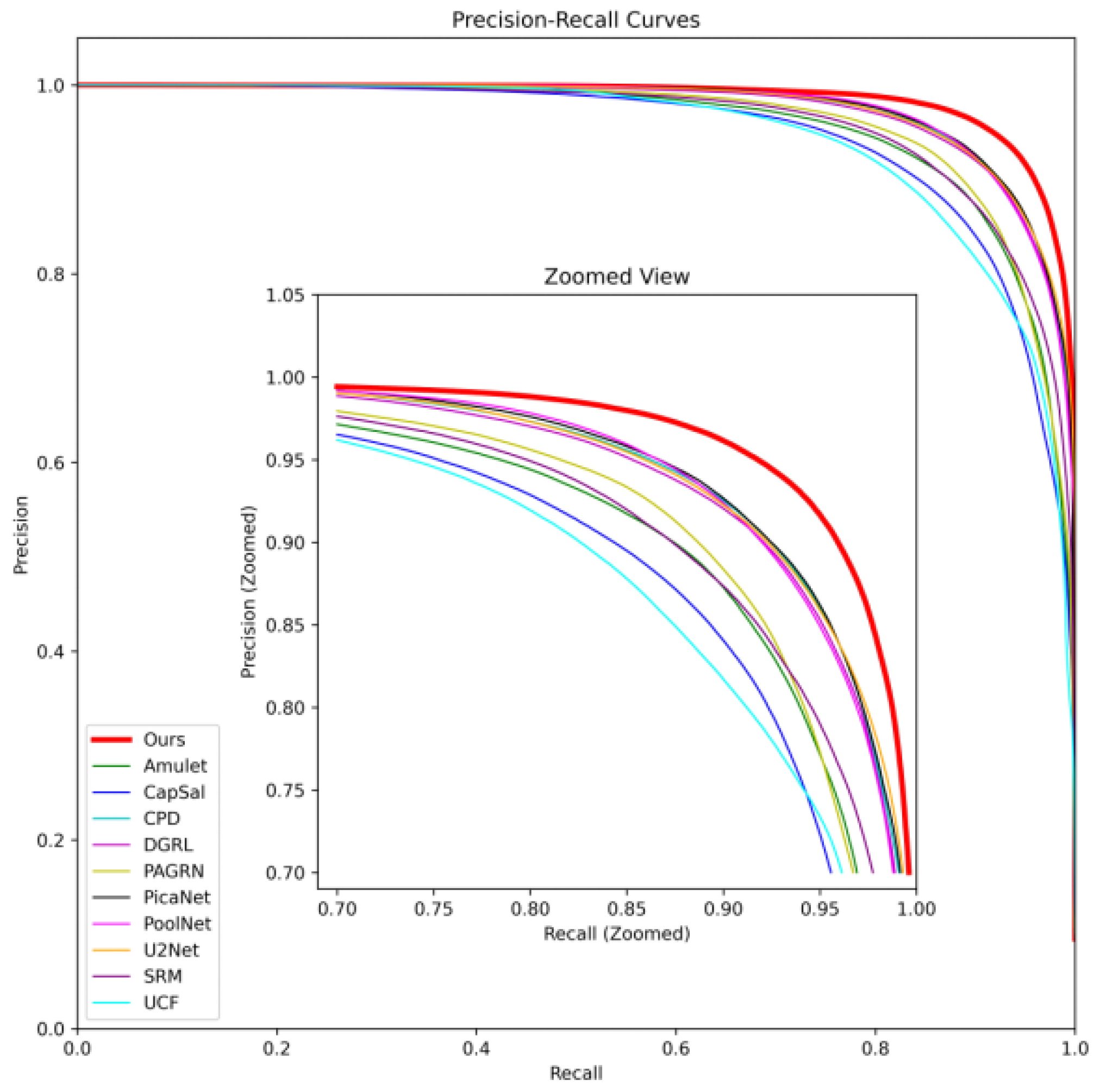
4.4. Comparative Experiments
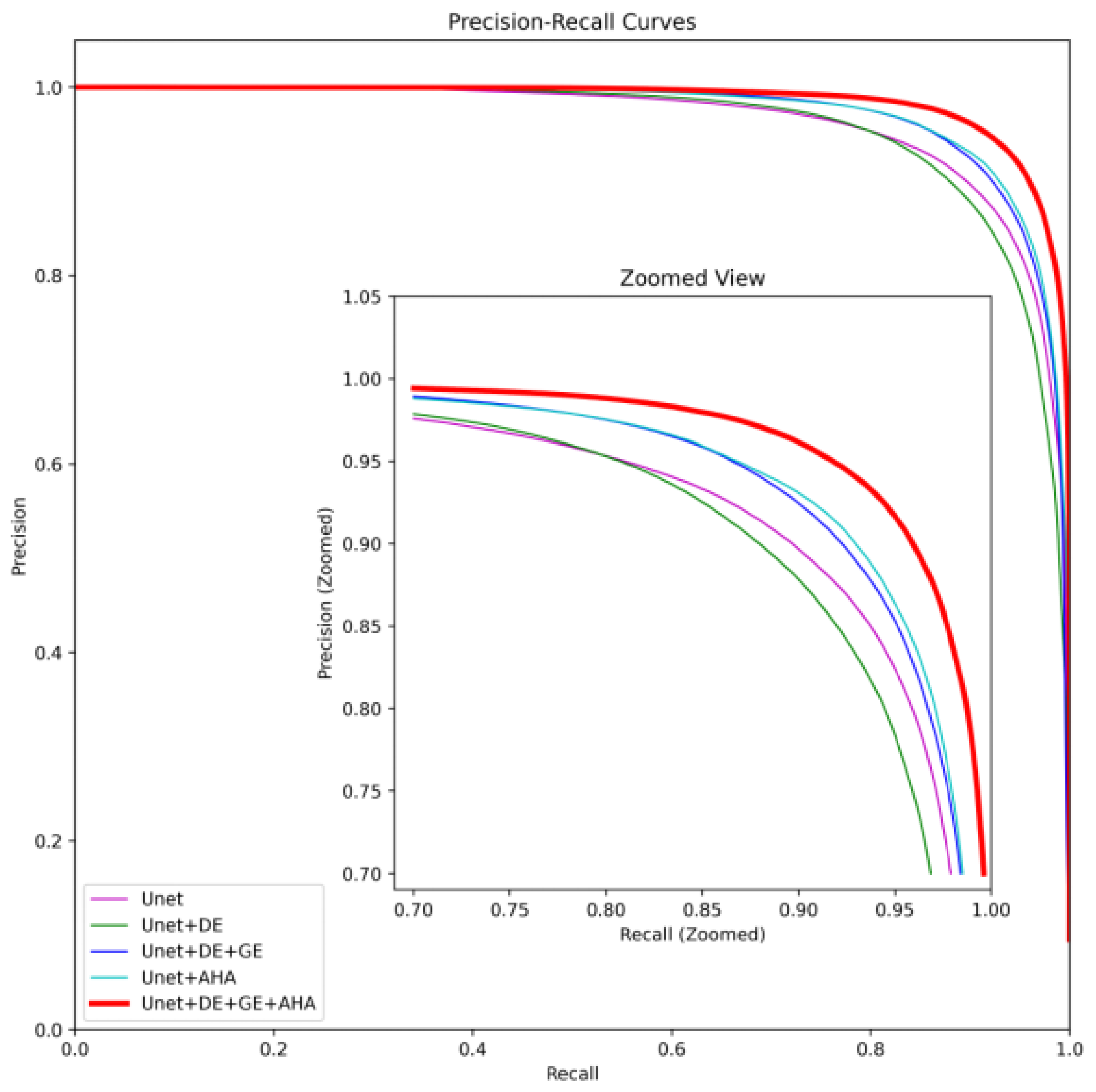
4.5. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, X.; Yang, P.; Dai, X. Focusing multireceiver SAS data based on the fourth order Legendre expansion. Circuits Syst. Signal Process. 2019, 38, 2607–2629. [Google Scholar] [CrossRef]
- Zhang, X.; Yang, P. Imaging algorithm for multireceiver synthetic aperture sonar. J. Electr. Eng. Technol. 2019, 14, 471–478. [Google Scholar] [CrossRef]
- Miller, K.A.; Singh, H.; Caiti, A. An overview of seabed mining including the current state of development, environmental impacts, and knowledge gaps. Front. Mar. Sci. 2018, 4, 312755. [Google Scholar] [CrossRef]
- Singh, H.; Adams, R.; White, L. Imaging underwater for archaeology. J. Field Archaeol. 2000, 27, 319–328. [Google Scholar] [CrossRef]
- Caiti, A.; Brown, T.; Lee, S. Innovative technologies in underwater archaeology: Field experience, open problems, and research lines. Chem. Ecol. 2006, 22 (Suppl. S1), S383–S396. [Google Scholar] [CrossRef]
- Shortis, M.; Harvey, E.; Abdo, D. A review of underwater stereo-image measurement for marine biology and ecology applications. Oceanogr. Mar. Biol. 2016, 269–304. [Google Scholar]
- Lamarche, G.; Smith, J.; Brown, T. Quantitative characterisation of seafloor substrate and bedforms using advanced processing of multibeam backscatter—Application to Cook Strait, New Zealand. Cont. Shelf Res. 2011, 31, S93–S109. [Google Scholar] [CrossRef]
- Hu, K.; Wang, L.; Zhang, P. Overview of underwater 3D reconstruction technology based on optical images. J. Mar. Sci. Eng. 2023, 11, 949. [Google Scholar] [CrossRef]
- Reggiannini, M.; Moroni, D. The use of saliency in underwater computer vision: A review. Remote Sens. 2020, 13, 22. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K. R-FCN: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 379–387. [Google Scholar]
- Wang, L.; Zhang, X.; Liu, N. Saliency detection with recurrent fully convolutional networks. Lect. Notes Comput. Sci. 2016, 9907, 825–841. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. Med. Image Comput. Comput.-Assist. Interv. 2015, 9351, 234–241. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Zhang, X.; Yang, P.; Sun, M. Progressive attention guided recurrent network for salient object detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 714–722. [Google Scholar]
- Wang, T.; Zhang, P.; Liu, J. A stagewise refinement model for detecting salient objects in images. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4039–4048. [Google Scholar]
- Zhang, P.; Wang, T.; Liu, J. Learning uncertain convolutional features for accurate saliency detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2123–2132. [Google Scholar]
- Wu, Z.; Su, L.; Huang, Q. Cascaded partial decoder for fast and accurate salient object detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 3907–3916. [Google Scholar]
- Zhang, P.; Wang, T.; Liu, J. AMulet: Aggregating multi-level convolutional features for salient object detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 202–211. [Google Scholar]
- Liu, N.; Han, J.; Yang, M.-H. PiCANet: Learning pixel-wise contextual attention for saliency detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3089–3098. [Google Scholar]
- Wang, T.; Zhang, P.; Liu, J. Detect globally, refine locally: A novel approach to saliency detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3127–3135. [Google Scholar]
- Liu, J.-J.; Hou, Q.; Cheng, M.-M. A simple pooling-based design for real-time salient object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3917–3926. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Cheng, M.-M.; Mitra, N.J.; Huang, X. Global contrast based salient region detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 569–582. [Google Scholar] [CrossRef] [PubMed]
- Jiang, H.; Wang, J.; Yuan, Z. Salient object detection: A discriminative regional feature integration approach. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2083–2090. [Google Scholar]
- Li, X.; Lu, H.; Xu, X. Saliency detection via dense and sparse reconstruction. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2976–2983. [Google Scholar]
- Perazzi, F.; Krahenbuhl, P.; Pritch, Y. Saliency filters: Contrast based filtering for salient region detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 733–740. [Google Scholar]
- Zhang, X.; Cao, D. Synthetic aperture image enhancement with near-coinciding Nonuniform sampling case. Comput. Electr. Eng. 2024, 120, 109818. [Google Scholar] [CrossRef]
- Zhang, X. An efficient method for the simulation of multireceiver SAS raw signal. Multimed. Tools Appl. 2024, 83, 37351–37368. [Google Scholar] [CrossRef]
- Li, G.; Yu, Y. Visual saliency based on multiscale deep features. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5455–5463. [Google Scholar]
- Wang, L.; Lu, H.; Ruan, X. Deep networks for saliency detection via local estimation and global search. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3183–3192. [Google Scholar]
- Zhao, R.; Ouyang, W.; Li, H. Saliency detection by multi-context deep learning. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1265–1274. [Google Scholar]
- Lee, G.; Tai, Y.-W.; Kim, J. Deep saliency with encoded low level distance map and high level features. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 660–668. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Liu, N.; Han, J. DHSNet: Deep hierarchical saliency network for salient object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 678–686. [Google Scholar]
- Hou, Q.; Cheng, M.-M.; Hu, X. Deeply supervised salient object detection with short connections. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5300–5309. [Google Scholar]
- Luo, Z.; Mishra, A.; Achkar, A. Non-local deep features for salient object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6593–6601. [Google Scholar]
- Zhang, L.; Dai, J.; Lu, H. A bi-directional message passing model for salient object detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1741–1750. [Google Scholar]
- Xiao, H.; Feng, J.; Wei, Y. Deep salient object detection with dense connections and distraction diagnosis. IEEE Trans. Multimed. 2018, 20, 3239–3251. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Zhang, L.; Wang, T.; Liu, J. CapSal: Leveraging captioning to boost semantics for salient object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6024–6033. [Google Scholar]
- Zeng, Y.; Zhuge, Y.; Lu, H. Multi-source weak supervision for saliency detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6067–6076. [Google Scholar]
- Feng, M.; Lu, H.; Ding, E. Attentive feedback network for boundary-aware salient object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1623–1632. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C. BASNet: Boundary-aware salient object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7479–7489. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y. CBAM: Convolutional block attention module. Lect. Notes Comput. Sci. 2018, 11211, 3–19. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Li, Y.; Zhang, Z.; Liu, J. Dual encoder-based dynamic-channel graph convolutional network with edge enhancement for retinal vessel segmentation. IEEE Trans. Med. Imaging 2022, 41, 1975–1989. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Yang, P.; Feng, X.; Sun, H. Efficient imaging method for multireceiver SAS. IET Radar Sonar Navig. 2022, 16, 1470–1483. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Zhang, X.; Yang, P.; Sun, M. Experiment results of a novel sub-bottom profiler using synthetic aperture technique. Curr. Sci. 2022, 122, 461–464. [Google Scholar] [CrossRef]
- Wu, H.; Chen, S.; Wang, G. SCS-Net: A scale and context sensitive network for retinal vessel segmentation. Med. Image Anal. 2021, 70, 102025. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Acc (%) | Precision (%) | Recall (%) | MaxF (%) | SM (%) | MIoU (%) | F1 (%) | MAE (%) | AUPR (%) |
|---|---|---|---|---|---|---|---|---|---|
| Amulet | 97.87 | 85.57 | 84.45 | 83.56 | 71.14 | 74.89 | 83.21 | 3.70 | 95.62 |
| CapSal | 97.59 | 80.65 | 87.13 | 81.20 | 70.12 | 73.57 | 82.23 | 3.99 | 94.71 |
| CPD | 98.35 | 89.41 | 86.43 | 88.31 | 73.16 | 80.21 | 87.42 | 2.95 | 97.59 |
| DGRL | 98.31 | 88.45 | 87.32 | 87.95 | 73.16 | 80.33 | 87.57 | 3.04 | 97.38 |
| PAGRN | 98.02 | 90.31 | 84.89 | 88.12 | 71.79 | 77.34 | 86.32 | 4.26 | 96.01 |
| PiCANet | 98.18 | 92.52 | 80.41 | 89.07 | 73.01 | 77.38 | 85.65 | 3.07 | 97.62 |
| PoolNet | 98.34 | 89.55 | 90.05 | 89.14 | 73.63 | 81.25 | 88.99 | 2.47 | 97.57 |
| SRM | 97.72 | 81.03 | 88.65 | 81.75 | 71.66 | 74.27 | 83.46 | 3.76 | 95.98 |
| U2-Net | 98.31 | 90.10 | 84.15 | 88.43 | 73.53 | 78.93 | 86.74 | 2.52 | 97.63 |
| UCF | 96.52 | 94.14 | 66.83 | 84.77 | 69.02 | 65.25 | 76.94 | 4.77 | 94.54 |
| Ours | 98.77 | 93.59 | 91.85 | 93.06 | 74.25 | 86.37 | 92.55 | 2.35 | 98.51 |
| Method | Acc (%) | Precision (%) | Recall (%) | MaxF (%) | SM (%) | MIoU (%) | F1 (%) | MAE (%) | AUPR (%) |
|---|---|---|---|---|---|---|---|---|---|
| UNet | 98.07 | 83.39 | 83.61 | 83.06 | 71.24 | 75.02 | 82.97 | 3.84 | 96.37 |
| UNet+DE | 97.91 | 88.18 | 86.90 | 86.51 | 72.37 | 77.30 | 86.07 | 3.51 | 95.88 |
| UNet+DE+GE | 98.32 | 90.30 | 84.96 | 88.61 | 72.34 | 79.66 | 87.08 | 3.16 | 97.18 |
| UNet+AHA | 98.42 | 90.82 | 89.46 | 90.39 | 72.54 | 82.51 | 89.99 | 3.42 | 97.46 |
| UNet+DE+AHA+GE | 98.77 | 93.59 | 91.85 | 93.06 | 74.25 | 86.37 | 92.55 | 2.35 | 98.51 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, J.; Wang, H.; Fan, L.; Gu, Q.; Rong, S.; Zhang, H. SonarNet: Global Feature-Based Hybrid Attention Network for Side-Scan Sonar Image Segmentation. Remote Sens. 2025, 17, 2450. https://doi.org/10.3390/rs17142450
Lei J, Wang H, Fan L, Gu Q, Rong S, Zhang H. SonarNet: Global Feature-Based Hybrid Attention Network for Side-Scan Sonar Image Segmentation. Remote Sensing. 2025; 17(14):2450. https://doi.org/10.3390/rs17142450
Chicago/Turabian StyleLei, Juan, Huigang Wang, Liming Fan, Qingyue Gu, Shaowei Rong, and Huaxia Zhang. 2025. "SonarNet: Global Feature-Based Hybrid Attention Network for Side-Scan Sonar Image Segmentation" Remote Sensing 17, no. 14: 2450. https://doi.org/10.3390/rs17142450
APA StyleLei, J., Wang, H., Fan, L., Gu, Q., Rong, S., & Zhang, H. (2025). SonarNet: Global Feature-Based Hybrid Attention Network for Side-Scan Sonar Image Segmentation. Remote Sensing, 17(14), 2450. https://doi.org/10.3390/rs17142450