1. Introduction
Cross-view geo-localization is a task that achieves target localization through multi-source image matching, commonly involving perspectives such as UAV imagery, satellite imagery, and ground-level imagery. It finds applications in autonomous driving [
1], event detection, 3D reconstruction, and other fields. Typically, this process involves using an image from one perspective (query image) to search for the most similar image within a large dataset (gallery) captured from another perspective. The gallery images are usually pre-annotated with geographic coordinates, enabling the derivation of the query image’s location through successful matching. This localization approach functions as an image retrieval method and serves as a robust supplementary positioning solution when GNSS signals are weak or unavailable [
2,
3].
Early research on cross-view image matching predominantly focused on single ground-level views [
4,
5]. However, ground-level imagery suffers from limitations such as small spatiotemporal coverage, incomplete geolocation metadata, and high manual annotation costs. Satellite imagery, with its inherent advantages of broad spatial coverage and geotagged metadata, has positioned multi-view cross-view matching as a prominent research focus. A seminal advancement in this field is the cross-view feature translation method proposed by Lin et al. [
6], which represents a critical milestone in cross-view matching research. Traditional methods relied on handcrafted feature descriptors for matching. Castealdó et al. designed descriptors to robustly capture semantic concepts and spatial layouts [
7], yet manually engineered features demonstrated limited robustness and matching accuracy. Subsequently, Support Vector Machine (SVM)-based image classification methods emerged. With the rapid advancements in deep learning, Convolutional Neural Networks (CNNs) have shown superior performance in feature representation and are now widely adopted in cross-view image matching. Zhai et al. proposed a semantic feature extraction strategy for satellite views based on the VGG16 architecture, which projects satellite image features onto ground-view perspectives for direct comparison with ground-level image features, enabling cross-view image matching and localization [
8]. Pan et al. proposed a CNN-based visual navigation method for UAVs, designing a fully convolutional network model integrated with saliency features and a neighborhood saliency reference localization strategy to achieve multi-scale aerial image localization [
9].
The advancement of cross-view image matching has necessitated the creation of specialized datasets. Workman et al. introduced the large-scale CVUSA (Cross-View USA) dataset to support training and developed a CNN-based framework for transforming ground-level image features into aerial representations [
10]; Liu and Li proposed the CVACT dataset and incorporated orientation-aware modeling into their framework, enhancing matching accuracy between satellite and ground-level views [
11]. In recent years, with the widespread adoption of UAVs, researchers have leveraged drones as critical platforms for data collection. Building on this, Zheng et al. introduced the University-1652 tri-view dataset, utilizing dual-branch and triple-branch CNNs with category labels for cross-view image matching and localization by incorporating UAVs as auxiliary platforms [
12]. In the University-1652 dataset, UAV images capture fewer obstructions compared to ground-level imagery, providing a broader field-of-view (FOV). Additionally, each platform offers multi-view imagery, with an average of 71 images per location, which enhances the model’s ability to comprehend target structures and learn viewpoint-invariant features. Therefore, this dataset is selected to investigate UAV-to-satellite image matching and localization [
13], offering a robust foundation for cross-view geo-localization research.
Most existing cross-view image matching studies adopt viewpoint-agnostic processing, where end-to-end learning extracts highly discriminative features from different views and distinguishes similar images based on inter-class variations. Ding et al. improved Zheng’s baseline model by reframing image retrieval as a classification problem, proposing the LCM (Location Classification Method) [
14]. Zhuang et al. designed the MSBA (Multiscale Block Attention) model using a self-attention mechanism, partitioning images into multiscale blocks for feature extraction to achieve more effective metric learning [
15]. Inspired by human visual observation patterns, Wang et al. introduced the LPN (Local Pattern Network) based on square-ring partitioning [
16]. This strategy captures geographic target information and contextual details, enhancing matching performance and robustness to image rotation. However, as building distributions in images are irregular, fixed square-ring partitions may introduce noise from varying UAV flight heights and angles. Equal weighting of all four partitions amplifies such noise.
To address this limitation, we revisit human observation habits; humans typically focus first on central structures in images. If the central region lacks informative content or lacks a dominant structure, attention shifts to surrounding salient features. Therefore, images can be partitioned into central subjects and peripheral environments, aligning with human observation patterns while reducing noise interference. In addition, given the variability in the position and size of the central subject across different images, we propose incorporating heatmaps to achieve precise localization of the central subject while dynamically optimizing the weighting of the central region through hyperparameter adaptation. This approach effectively enhances the accuracy of image partitioning.
Beyond enhancing feature discriminability and maximizing inter-class differences, reducing intra-class distances offers another pathway to improve matching accuracy. By treating multi-view images of the same building as a single class, minimizing feature discrepancies between views effectively reduces intra-class variance. To address large cross-view perspective gaps, Huang et al. proposed a Conditional Generative Adversarial Network (CGAN)-based prediction module, generating auxiliary ground-level information from satellite images for feature alignment [
17]. Tian et al. integrated spatial correspondences between satellite images and surrounding areas, first transforming UAV oblique views to nadir perspectives via perspective projection, then using CGANs to adapt UAV images to satellite-like views [
18]. Shao et al. introduced a Style Alignment Strategy (SAS) to harmonize UAV image RGB distributions with satellite imagery, mimicking their stylistic properties [
19].
Observations reveal significant stylistic discrepancies between UAV and satellite views due to differences in capture time and angles. Satellite images exhibit uniform coloration owing to long-distance imaging, while UAV images display vivid colors and inconsistent lighting due to variable flight heights and angles. Therefore, to reduce intra-class variance, we align UAV image brightness with satellite references, harmonizing stylistic discrepancies between the two views to enhance matching accuracy.
Deep learning-based drone geo-localization algorithms fundamentally rely on constructing cross-modal aerial-satellite matching models, which necessitate large-scale training data. To address this, researchers have begun integrating traditional methodologies with deep learning frameworks to compensate for inherent limitations and enhance robustness in complex environments. Nassar et al. [
20,
21] developed a hybrid framework combining conventional computer vision techniques with CNNs; initial registration is achieved through SIFT and ORB feature matching, followed by U-Net semantic segmentation to extract precise building and road masks. Kenvin et al. [
22] proposed a hybrid-feature non-rigid correspondence estimation method for multi-perspective remote sensing imagery, where SIFT point features initially characterize images before resolving terrain undulations and viewpoint variations via mixed-feature correspondence estimation.
While prior studies typically employed traditional methods for preliminary registration, such approaches often introduce false correspondences and incur high computational costs. To overcome these limitations, our method implements a CNN-based coarse matching stage to identify candidate satellite images, followed by geometric verification for fine-grained alignment. This hierarchical strategy significantly improves matching accuracy.
In summary, the primary contributions of this paper are as follows:
We propose an adaptive threshold-guided ring partitioning framework that divides images into central subjects and peripheral environments. By dynamically selecting the central subject’s position via heatmaps and optimizing its size as a learnable hyperparameter, this method resolves noise issues introduced by fixed four-layer partitioning, achieving more accurate and flexible feature division.
During testing, we introduce a keypoint matching-based re-ranking mechanism for the top 5 candidate images. By refining rankings based on matched keypoint counts, this approach addresses the low accuracy of top 1 correct matches, significantly improving retrieval precision.
By adjusting the brightness of UAV images to align with satellite references, we address the challenge of significant stylistic discrepancies between cross-view images of the same target, harmonizing their visual styles and thereby reducing the complexity of cross-view matching. Simultaneously, we propose integrating an additive angular margin loss (ArcFace Loss) with the cross-entropy loss, which enhances the discriminability of visual features by enforcing intra-class compactness and inter-class separation in angular space, effectively overcoming the difficulty of extracting salient features.
We rigorously evaluate our method on the University-1652 dataset. Both qualitative analysis and quantitative evaluations demonstrate that the proposed algorithm achieves competitive performance, confirming its effectiveness in cross-view geo-localization tasks.
3. Proposed Method
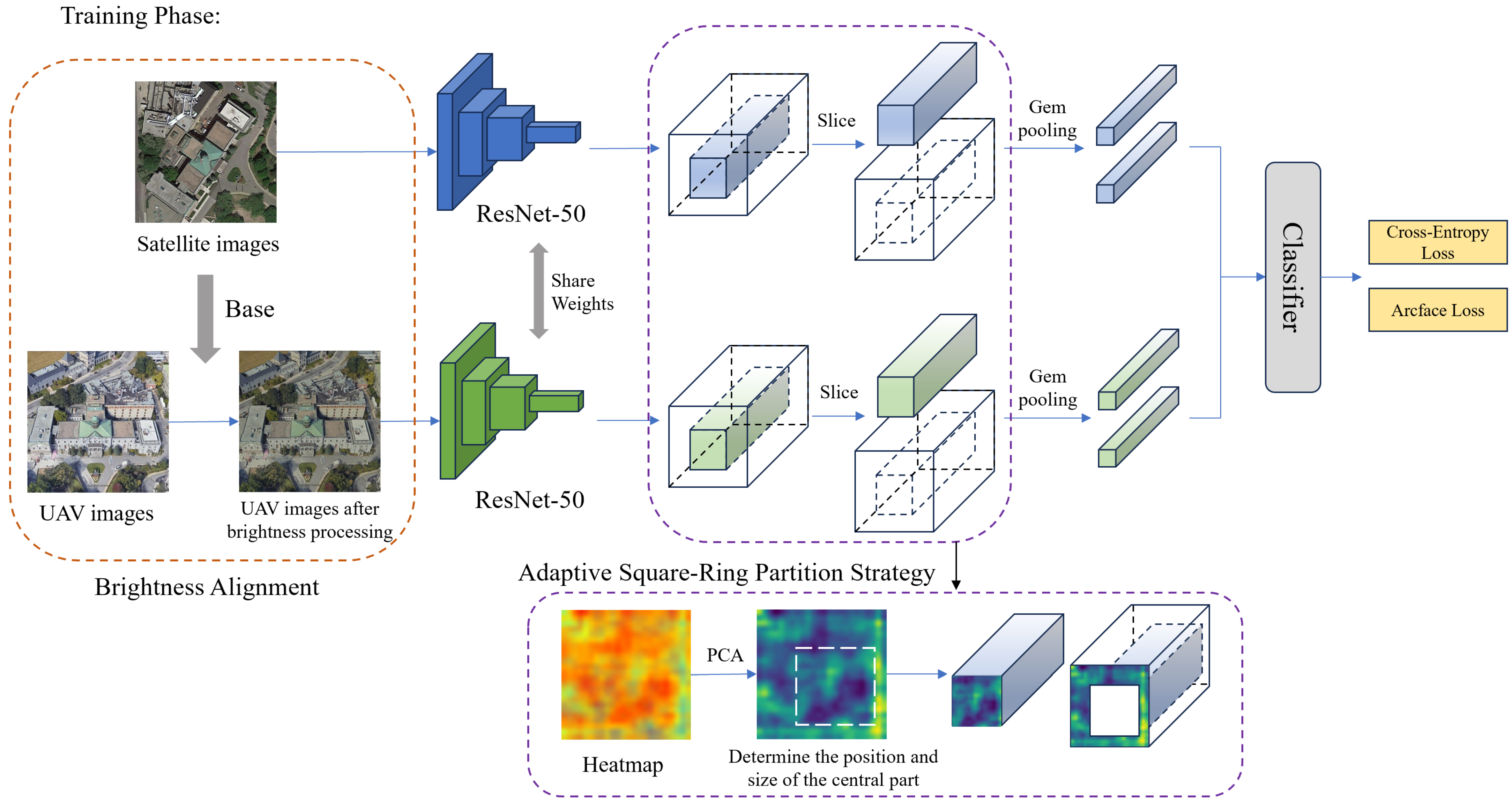
The architecture of the proposed adaptive threshold-guided partition-based matching algorithm is illustrated in
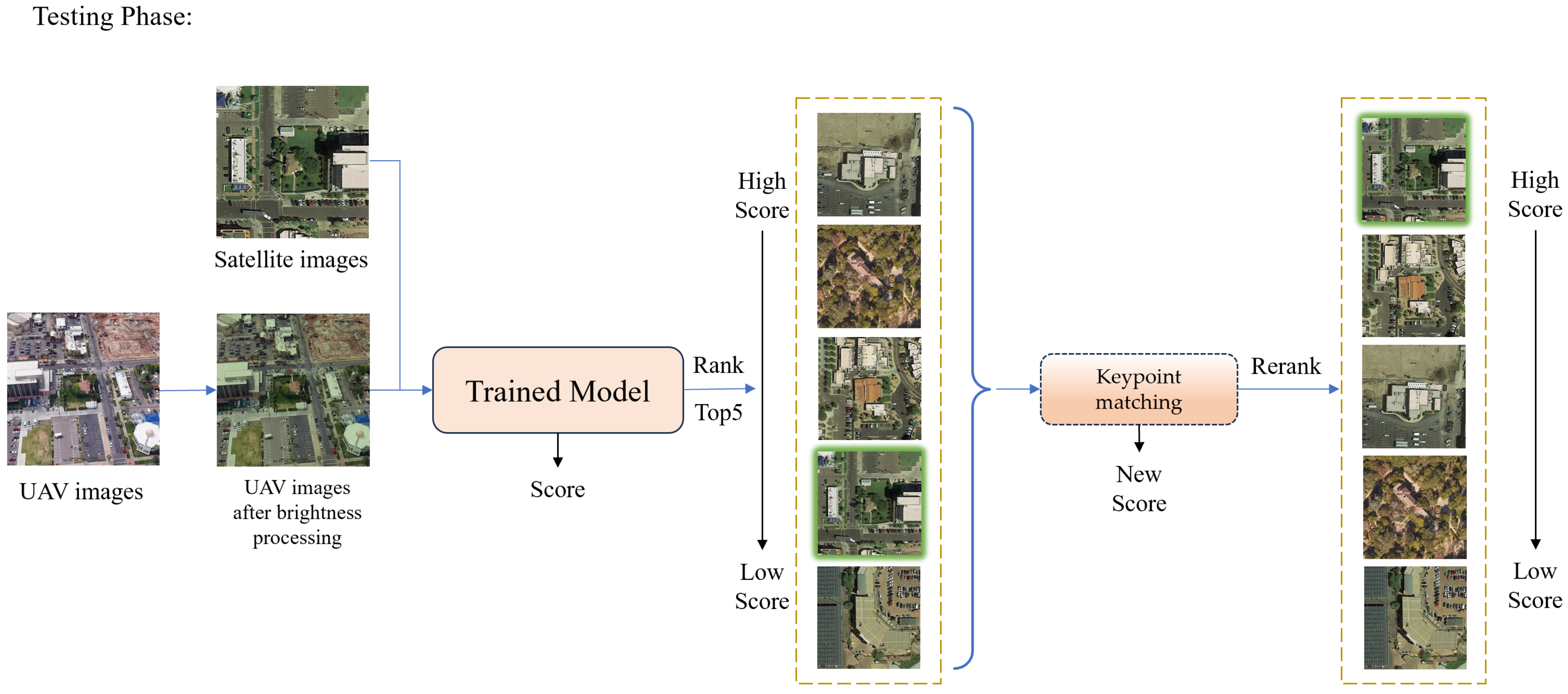
Figure 1 and
Figure 2.
During the training phase, the dataset is first preprocessed with brightness alignment to reduce matching complexity. A dual-branch CNN serves as the baseline model for feature extraction from UAV and satellite images. For feature extraction, Squeeze-and-Excitation (SE) attention modules are integrated after each convolutional layer in the ResNet-50 backbone. Building on the square-ring partition strategy proposed by Wang et al., we enhance the partitioning reliability and contextual information utilization by incorporating heatmap-guided adaptive positioning to dynamically determine region boundaries. The extracted features are then fed into a Generalized Mean (GeM) pooling layer, and the model is optimized using a combined loss function of cross-entropy loss and ArcFace loss to ensure robust convergence.
During the testing phase, images undergo brightness-aligned preprocessing before visual features are extracted using the trained model for both query and gallery images. Retrieval is then performed by ranking candidates based on feature similarity scores, with each query image returning the top 5 most similar matches. To further enhance accuracy, keypoint matching is applied to the top 5 candidates, refining their rankings based on the count of geometrically consistent keypoints. This re-ranking strategy enables rapid and precise cross-view geo-localization, effectively bridging the domain gap between UAV and satellite perspectives.
The following sections elaborate on the technical details of the algorithm.
3.1. Brightness Alignment
Analysis of the University-1652 dataset reveals substantial cross-view appearance discrepancies between satellite and drone imagery due to divergent acquisition platforms, capture times, and illumination conditions. These variations significantly increase the difficulty of cross-view image retrieval. To address this, Shao et al.’s SAS first computes cumulative distributions across RGB channels in satellite images to generate transformation mappings. Drone images are subsequently transformed using these mappings to align their visual style with satellite references. Inspired by this principle, we propose a streamlined solution in HSV color space that minimizes appearance gaps by adjusting only the brightness component. This single-parameter alignment achieves comparable style normalization with substantially reduced computational complexity compared to RGB-based transformations.
Therefore, we implement brightness normalization as a preprocessing step. Drone image brightness values are normalized to match corresponding satellite reference targets. As demonstrated in
Figure 3, which shows the satellite image, original UAV image, and processed UAV image, this simple yet effective adjustment harmonizes luminance between cross-view images and achieves approximate style alignment. This preprocessing step significantly reduces intra-class variance caused by illumination differences, thereby substantially improving the model’s matching accuracy.
The brightness alignment strategy is implemented in two steps. First, each satellite image
I is converted to a grayscale image
G, and the mean brightness value
B(
I) of the satellite image is calculated as defined in Equation (
1):
where
W and
H are the width and height of the image, and
G(
x,
y) represents the pixel value at position (
x,
y) in the grayscale image. In Equation (
2), the brightness values of all
N satellite images are averaged, where
denotes the mean brightness value of the
i-th satellite image.
Finally, the brightness of each UAV image
J is adjusted to this global mean
. The brightness of UAV image
J, calculated using the same method as for satellite images in Equation (
1), is denoted as
B(
J). The adjustment process is expressed in Equation (
3):
where
J(
x,
y) denotes the pixel value at position (
x,
y) in the original UAV image, and
J’(
x,
y) denotes the adjusted pixel value after brightness alignment.
3.2. Adaptive Threshold-Guided Ring Partition Framework (ATRPF)
Unlike the four-layer square-ring partition strategy proposed by Wang et al., Shao et al.’s dual-layer approach proves more effective for datasets featuring prominent architectural structures. As illustrated in
Figure 4, the four-layer segmentation results in excessively fragmented regions where primary buildings and surrounding environments are divided into disproportionately sized patches, compromising spatial coherence. Conversely, the dual-layer configuration optimally preserves structural integrity by minimizing building fragmentation while maintaining contextual relationships. Additionally, this methodology facilitates subsequent adaptive zoning operations. Consequently, we adopt the dual-ring partitioning strategy as our preferred approach for architectural feature extraction.
After establishing the dual-layer square-ring partitioning strategy, we optimize the partitioning scheme. In the conventional four-layer approach, the positions and sizes of square rings are fixed (uniform distribution), assigning equal computational weights to all partitions. This rigid uniformity amplifies noise interference from peripheral regions. To address this, our adaptive dual-layer square-ring partition strategy dynamically adjusts the size and position of the central square box, as depicted in
Figure 5.
Firstly, the size ratio between the central box (Wc) and the original image (W), defined as Wc/W, is initialized as a trainable hyperparameter. This transforms fixed partitions into an automatically learnable mechanism, allowing distinct computational weights for each partition. Furthermore, heatmap visualization highlights regions of high attention (e.g., building locations) within the image. The central box is dynamically positioned over these high-attention regions, enabling instance-specific adaptive partitioning for precise localization. This dual mechanism optimizes both partition geometry and semantic focus, enhancing robustness against environmental noise.
3.3. Loss Functions
In the dual-branch network, discriminative feature learning is achieved by jointly employing cross-entropy loss and ArcFace Loss.
The cross-entropy loss focuses on the predicted probability of the ground-truth class, commonly used in image classification tasks. It is defined as:
where
p represents the true probability distribution of known classes in the training dataset. When the sample image belongs to the
i-th class,
, and 0 otherwise.
q denotes the predicted probability distribution from the classifier.
ArcFace loss, an angular margin-based loss function, enhances feature discriminability by introducing an additive angular margin constraint in the angular space. It compacts intra-class features while separating inter-class features in angular space. The loss is formulated as:
where
represents the deep feature of the
i-th sample, which belongs to the
-th class, and the total number of classes is
N.
denotes the
j-th column of the weight matrix.
is the angle between the weight
and the feature
, while
represents the angle between the feature
and the true center
.
m is the angular margin, and
s is the feature scale.
3.4. Feature Re-Matching
To address the issue of low accuracy in top 1 image matching, we introduce feature point matching as a secondary criterion for ranking during the testing phase, where the number of matched points serves as the sorting metric. This approach reorders the initial top 5 images selected by the network, significantly enhancing the accuracy of top 1 image matching and enabling precise localization of UAV imagery.
Feature matching between two images can generally be categorized into traditional matching methods (SIFT, ORB, etc.) and deep learning-based approaches. SIFT matching identifies stable keypoints through scale-space extrema detection, generates descriptors using gradient orientation information from keypoint neighborhoods, and finally establishes point-to-point correspondences based on descriptor similarity. ORB feature matching combines FAST corner detection with BRIEF binary descriptors, achieving faster matching speeds than SIFT through scale pyramid construction and rotation-invariant feature descriptors. The LoFTR (Local Feature Transformer) method employs a Transformer architecture to enhance feature descriptor matching capabilities by learning long-range dependencies among feature points through self-attention mechanisms [
40]. SuperPoint [
41] extracts keypoints and descriptors from images, while SuperGlue [
42] establishes contextual relationships between features through graph neural networks (GNNs) and attention mechanisms to achieve robust optimal matching. Notably, LoFTR emphasizes precise local feature matching, whereas the SuperPoint+SuperGlue (SP+SG) framework prioritizes global-view feature matching optimization, demonstrating particular efficacy in complex scenes.
Figure 6 illustrates point-to-point matching results between UAV and satellite images using the four aforementioned methods. After applying Random Sample Consensus (RANSAC) to eliminate outliers, SIFT yielded five valid matching pairs, whereas ORB produced fifteen pairs with noticeable mismatches. Transformer-based methods demonstrated superior performance, generating significantly more accurate matches. Notably, SP+SG achieved finer image detail matching and higher reliability compared to LoFTR.
By integrating feature point matching, this strategy not only improves top 1 matching precision but also enables cross-view image registration. The established spatial transformation model between UAV and satellite imagery lays a critical foundation for subsequent high-accuracy localization of small targets in UAV images. This advancement ensures robust geolocation capabilities in challenging environments, aligning with the demands of remote sensing applications.
4. Experiments
4.1. Datasets and Evaluation Protocol
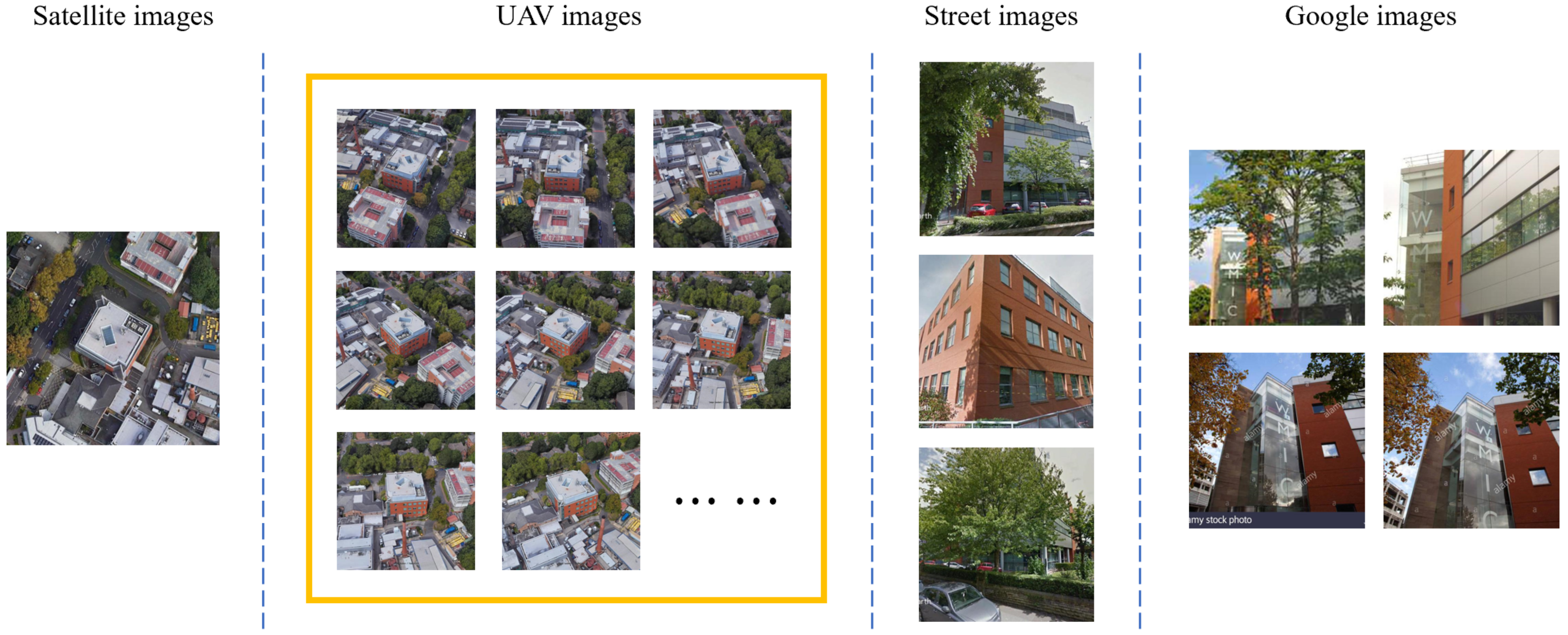
The experiments utilize the multi-source, multi-view University-1652 dataset, which comprises 1652 buildings across 72 universities worldwide, distributed across diverse geographical locations and climatic zones. Significant variations exist in architectural styles and surrounding environments—for instance, universities in urban centers feature densely clustered buildings with busy road networks, while those in suburban areas exhibit more dispersed structures. This diverse data distribution provides robust support for evaluating algorithm performance across heterogeneous real-world scenarios. The training set includes 701 buildings, while the test set comprises the remaining 951 buildings, with no overlapping buildings between the two sets. Each building is represented by three perspectives: one satellite image, fifty-four UAV images captured at varying heights and angles, and multiple ground-level images. UAV images are synthetically generated from 3D models provided by Google Earth, simulated as video recordings at 30 frames per second along spiral trajectories. The dataset also incorporates 21,099 co-view images collected from Google Images as an additional training set.
Figure 7 illustrates representative cross-view image samples of a specific building within the dataset, demonstrating its multi-perspective coverage. For this study, we focus exclusively on cross-view geo-localization between satellite and UAV images.
Proposed by Zheng et al., this dataset supports two UAV-centric tasks:
UAV Target Geo-Localization (UAV → Satellite): Retrieving the geographic location of a UAV-captured query image from a satellite gallery.
UAV Navigation (Satellite → UAV): Guiding a UAV to a target area using a satellite query image.
The experiments employ Recall@K and Average Precision (AP) as metrics to evaluate matching model performance. After the model generates a ranked list of candidate images for a query, Recall@K is assigned a value of 1 if the ground-truth match appears within the top K + 1 ranked results; otherwise, it is 0. Common values for K include 1, 5, and 10. Higher Recall@K values indicate superior retrieval performance. However, Recall@K is highly sensitive to the position of the first true match in the ranked list. For UAV navigation tasks, where multiple valid matches may exist for a query target, AP—calculated as the area under the Precision–Recall (P-R) curve—is adopted as an additional metric. AP comprehensively reflects both precision and recall, ensuring a more accurate and holistic assessment of retrieval performance.
4.2. Implementation Details
The experiments were conducted on an Ubuntu 16.04 operating system using the PyTorch 1.7.0 framework with Python 3.6. The hardware configuration featured an Intel(R) Core(TM) i9-10900K CPU operating at 3.70 GHz base frequency. The backbone network, ResNet-50, was pre-trained on the ImageNet dataset and modified for our task; the stride of the second convolutional layer was reduced from 2 to 1, the original classification layer was removed, and a new fully connected (FC) layer followed by a classification layer was inserted after the pooling layer. Input images were resized to 384 × 384 pixels and augmented through random cropping, affine transformations, and horizontal flipping. The initial learning rate was set to 0.001 for the backbone network and 0.01 for the newly added layers. Training spanned 120 epochs, with the learning rate decaying by a factor of 0.1 every 80 epochs, and a dropout rate of 0.5 was applied. The model was optimized using Stochastic Gradient Descent (SGD) with a momentum of 0.9, weight decay of 0.0005, and parameters updated iteratively to ensure convergence.
During the testing phase, the similarity between cross-view images was computed using cosine distance, and the retrieval process ranked candidates based on these similarity scores. Given the absence of ground-level images as auxiliary data in UAV geo-localization applications, this experiment employed the dual-branch baseline model, where weights were updated and shared across branches after each training epoch.
4.3. Comparison with Other Methods
Table 1 presents the evaluation metrics of existing methods and the proposed algorithm on the University-1652 dataset. Zheng et al. introduced a baseline model using ResNet50 for this dataset. The LCM augments satellite data to enhance robustness. The LPN employs square-ring partitioning on extracted features to fully leverage contextual information. The SAFA (Spatial-Aware Feature Aggregation) [
43] utilizes a two-step prior-informed approach: first, applying polar coordinate transformation to warp aerial images to approximate ground-level perspectives, and second, incorporating a spatial attention mechanism to align deep features in the embedding space. The USAM (Unit Subtraction Attention Module) [
44] combines representation learning with keypoint detection, automatically identifying representative keypoints from feature maps and directing attention to salient regions; Tian et al.’s PCL methodology executes a three-stage workflow: Perspective Projection Transformation (PPT) converts oblique UAV imagery to nadir views, CGAN-based synthesis enhances satellite-style realism, and LPN facilitates discriminative feature extraction for classification; FSRA framework integrates Transformer architectures to partition images according to attention heatmaps, establishes cross-view correspondences through region-wise paired alignment, and ultimately consolidates localized features into unified representations; Wang et al. [
45] developed Dynamic Weighted Decorrelation Regularization (DWDR) to address feature redundancy in cross-view image geo-localization.
The proposed algorithm is based on a dual-branch architecture tailored for UAV and ground-view perspectives, and does not employ common-view images collected from Google Image during training. As shown in
Table 1, our method outperforms most existing approaches. Specifically, it achieves Recall@1 of 82.50% and AP of 84.28% for UAV→Satellite geo-localization, and Recall@1 of 90.87% with AP of 80.25% for Satellite→UAV navigation. The proposed algorithm achieves the highest recall rates in both drone geo-localization and navigation tasks, though its AP is marginally lower than the FSRA method. Nevertheless, holistic evaluation demonstrates the overall superiority of our approach.
Since the UAV images in the University-1652 dataset are synthesized from 3D models, their results exhibit inherent limitations; hence, we validate the effectiveness of our algorithm on real-world imagery. In this experiment, we employ the SUES-200 dataset captured at varying altitudes and conduct comparative studies with multiple algorithms on these authentic drone images. As shown in
Table 2, we compare LCM, SUES-200 Baseline, LPN, and our proposed method. The results demonstrate that our algorithm achieves 73.72% Recall@1 and 76.93% AP in drone geolocation tasks, where the Recall@1 outperforms all four methods; however, its AP slightly trails LPN, which might be attributed to LPN’s superior capability in capturing global image features.
During training, the model converged in approximately 38 min when trained on the 701-category dataset. For inference, the UAV-to-satellite task took 10 min when processing the 700-category test set, while the satellite-to-UAV task required 13 min.
4.4. Ablation Studies
In the ablation study, we first established a baseline model as the control group. The baseline employs a ResNet-50 backbone with a SE attention mechanism appended after each convolutional layer. GeM pooling was adopted for feature aggregation, and the loss function solely utilized cross-entropy loss. As shown in
Table 3, the baseline achieved Recall@1 and MAP scores of 66.17% and 70.33%, respectively, for the UAV geolocation task, and Recall@1 and AP scores of 77.43% and 64.79% for the UAV navigation task.
When matching a single UAV image against a satellite gallery, only limited angular information is available. To address this, we implement the multi-query strategy proposed by Zheng et al., utilizing multiple drone images captured from diverse perspectives. This approach enriches feature representation by averaging descriptors across multi-angle drone captures before cross-view retrieval against the satellite database. As presented in
Table 3, the multi-query method substantially outperforms single-query baselines in the UAV-to-satellite task, achieving 76.71% Recall@1 and 79.95% AP. These results represent improvements of 10.54% in Recall@1 and 9.62% in AP over conventional single-image matching approaches. Notably, this strategy is applicable only to UAV→Satellite geo-localization tasks (not UAV navigation), due to the inherent diversity of satellite perspectives.
The proposed adaptive double-layer square-ring partition strategy dynamically adjusts the position of the central subject based on heatmap predictions and optimizes its size through hyperparameter iteration to maximize contextual information utilization. To validate the necessity of this strategy, we integrated it into the baseline multi-query framework.
Table 3 demonstrates that this integration improved Recall@1 to 81.31% (geolocation) and 82.71% (navigation), with MAP/AP increasing to 83.94% and 70.93%, respectively. Compared to the baseline, this corresponds to absolute gains of 4.60% and 5.28% in Recall@1, and 3.99% and 6.14% in AP, highlighting its effectiveness.
To enhance feature discriminability, we augmented the original cross-entropy loss with ArcFace loss. As evidenced in
Table 3, the addition of ArcFace loss further boosted Recall@1 by 3.40% and MAP by 3.03% for the UAV-to-satellite geolocation task. For the satellite-to-UAV navigation task, Recall@1 and AP improved by 2.43% and 2.12%, respectively, confirming the efficacy of ArcFace loss in refining feature separability.
An illumination alignment strategy was applied during dataset preprocessing to mitigate style discrepancies between cross-view images. Building upon previous experiments, its inclusion elevated Recall@1 by 2.74% and MAP by 2.47% for UAV-to-satellite geolocation, while Recall@1 and AP for satellite-to-UAV navigation increased by 5.73% and 5.20%, respectively. These results validate that illumination alignment effectively reduces intra-class variations and enhances matching precision.
To improve top 1 recall, we introduced an additional SP+SG feature point matching step during testing, which re-ranks the top 5 candidates based on the number of matched keypoints. Due to computational constraints, this method was only applied to the UAV geolocation task. As shown in
Table 3, this refinement increased Recall@1 by 2.76% and MAP by 1.82% for multi-image matching in geolocation.
This ablation study quantitatively validates the effectiveness of each proposed strategy in improving matching accuracy on the University-1652 dataset. After integrating the adaptive double-layer square-ring partition strategy, the Recall@1 metric exhibits a significant improvement, primarily attributed to the strategy’s ability to precisely localize the target subject within the image and extract more representative features. Furthermore, when combined with complementary strategies such as ArcFace loss, these components synergistically enhance feature expressiveness and discriminability, thereby achieving higher matching accuracy. Notably, the illumination alignment strategy serves as a foundational preprocessing step, which collaborates synergistically with other feature extraction and learning frameworks to collectively elevate the algorithm’s overall performance.
4.5. Impact of Square Ring Proportion on Matching Accuracy
In the proposed adaptive double-layer square-ring partition strategy, the size of the central main body is controlled through a proportional relationship with the original image, where this ratio is defined as a hyperparameter with an initial value. To investigate the impact of this initial ratio (denoted as ratio: Wc/W, where Wc represents the side length of the central region and W the original image dimension) on matching accuracy, we conducted experiments with three distinct initial ratio values: 0.25, 0.5, and 0.75. Additional control groups without feature partitioning (ratio = 0 or 1) were included for comparison. As shown in
Table 4, the highest matching accuracy for both tasks was achieved when the initial ratio was set to 0.5, yielding Recall@1 scores of 77.99% and 90.87%, along with AP values of 81.22% and 80.25%, respectively. Compared to the control groups without feature partitioning, these results demonstrate performance improvements of 0.79% and 2.3% in Recall@1, as well as 0.82% and 2.99% in AP for the respective tasks.
4.6. Impact of Different Feature Point Matching Methods on Accuracy
In the feature re-matching strategy, feature point matching methods were applied to re-evaluate the top 5 images, with the number of matched points serving as the criterion for re-ranking. To investigate the influence of different feature point matching methods on matching accuracy, we employed four approaches: SIFT, ORB, LoFTR, and SP+SG, while experiments without feature point matching served as the control group. As shown in
Table 5, all methods except ORB improved the Recall@1 and AP, with SP+SG achieving the most significant enhancement. For UAV geo-localization, the single-image and multi-image matching Recall@1 values using SP+SG reached 82.50% and 90.21%, respectively, while AP values were 90.21% and 96.15%. Compared to the control group, these results represent improvements of 4.51% and 2.76% in Recall@1, and 3.06% and 1.82% in AP for the two tasks. The inferior performance of ORB may stem from its higher rate of mismatched points, whereas SP+SG exhibited superior accuracy and finer detail matching capabilities compared to other methods.
4.7. Qualitative Results
Figure 8 and
Figure 9 present the retrieval results of our proposed algorithm on the University-1652 dataset, showcasing performance for both UAV→Satellite geo-localization and Satellite→UAV navigation tasks, with LPN-based matching provided as a baseline. In
Figure 8, for UAV geo-localization, our algorithm significantly outperforms LPN in ranking ground-truth matches higher. For instance, in rows 1 and 3, the true matches ascend from third to first position. Notably, our method retrieves previously undetected true matches (e.g., row 2, where LPN failed to rank the true match within the top 5, while our algorithm places it second).
Figure 9 highlights the multi-match nature of the dataset, where one satellite image corresponds to fifty-four UAV images from varying altitudes and angles. For UAV navigation tasks, our algorithm retrieves more true matches within the top 5 compared to LPN. In rows 1, 3, 4, and 5, all top 5 candidates are correct matches. However, in row 2, only the top 1 result is correct, likely due to high similarity among white-roofed buildings causing mismatches.
Figure 10 demonstrates the robustness of our algorithm under diverse challenging conditions. In rows 1–2, despite significant seasonal appearance discrepancies—vegetation variations in row 1 and distinct bare-soil exposure in row 2—between query drone images and satellite references, our architecture maintains consistent localization precision by prioritizing architecturally stable features unaffected by seasonal land cover changes, confirming season-invariant performance. Row 3 exhibits partial occlusion of the primary structure due to oblique drone acquisition angles, while rows 4–5 feature off-center principal buildings. The adaptive dual-layer partitioning strategy preserves matching accuracy through dynamic bounding box repositioning that compensates for compositional shifts. The final row demonstrates successful multi-target localization, where the algorithm proactively identifies high-attention regions corresponding to semantically significant features—effectively navigating complex scenes through saliency-guided feature weighting to achieve accurate retrieval despite target multiplicity.
Figure 8 (rows 2 and 4) reveals instances where our algorithm fails to retrieve ground-truth matches at the top 1 position. Consequently,
Figure 11 documents representative top 1 failure scenarios. Rows 1–2 exhibit significant structural modifications (notably complete building replacement in row 1) that compromise recognition; row 3 demonstrates severe occlusion hindering architectural feature extraction; row 4 features dominant vegetation obscuring primary structures. The final row presents high-confusion failures where ground-truth matches display striking spectral–spatial similarity to competing candidates in structural and chromatic characteristics, compounded by spatial duplication of targets across satellite imagery—the predominant failure mechanism in cross-view geo-localization systems.
This qualitative analysis robustly validates that our algorithm effectively extracts discriminative features, achieving accurate cross-view image matching even under significant viewpoint and illumination variations.
5. Discussion
As demonstrated by the ablation studies in
Section 3 and qualitative results in
Section 4, our proposed method achieves robust matching performance, validating its effectiveness. First, the brightness alignment of UAV images based on satellite references harmonizes stylistic differences between the two views, significantly reducing intra-class variance and thereby lowering matching complexity while improving accuracy. Second, after feature extraction, the heatmaps of features clearly highlight the spatial distribution of key structures (e.g., buildings), enabling dynamic square-ring partitioning and adaptive learning of the central region size (via learnable hyperparameters), which enhances local feature discriminability. Furthermore, during testing, the keypoint matching step leverages the number of geometrically consistent keypoints as a re-ranking criterion, refining the top 1 accuracy by revisiting initially mismatched candidates. Finally, in ablation experiments, the integration of ArcFace loss amplifies inter-class feature separability, substantially boosting matching precision for both UAV geo-localization and navigation tasks.
However, in practical applications, the algorithm may underperform in certain datasets (e.g., desert/Gobi regions with sparse structural features or suburban areas lacking dominant buildings) compared to ideal retrieval results reported. This limitation potentially stems from the adaptive ring partitioning strategy’s reduced efficacy in feature extraction from data-scarce environments. Future work will incorporate more diverse and complex imagery for algorithmic refinement through comprehensive characteristic analysis.
To address the performance degradation of current algorithms under scenarios with significant illumination variations, future research could focus on leveraging advanced illumination compensation algorithms or deep learning-based image enhancement techniques to further enhance the robustness of cross-view image matching. Additionally, the integration of prior geospatial information—such as topographic maps, building height data, and 3D urban models—into cross-view geolocation frameworks presents a critical direction for exploration. For instance, one promising approach involves incorporating topographic map information into the feature extraction pipeline of CNNs, or utilizing building height data to facilitate 3D reconstruction and matching of targets in imagery. Such strategies could enable sub-meter-level geolocation accuracy by synergizing multi-modal geospatial data with advanced computational models.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}