1. Introduction
Hyperspectral images typically consist of hundreds of continuous spectral bands, usually ranging from visible to mid-infrared [
1,
2]. Due to the rich information contained in the high spectral dimension, hyperspectral images can sensitively distinguish different landforms and objects according to their materials [
3,
4]. Therefore, hyperspectral images are often used to discover anomalies in scenes, such as airplanes, tanks, or other objects in backgrounds like airports or forests [
5]. The task of identifying anomalous objects from hyperspectral backgrounds is called hyperspectral anomaly detection (HAD), which has a wide range of practical applications [
6,
7].
For HAD, a major challenge is that the prior information of anomalies is usually unknown, and therefore it is usually regarded as an unsupervised task [
8,
9]. Moreover, there are several characteristics between anomalies and the backgrounds in hyperspectral images [
10]. Anomalous targets are usually composed of materials such as metal, plastic, and paint, occupying a small proportion in remote sensing scenes, with spectral characteristics that differ significantly from the environment (soil, vegetation, cement, water, etc.). Based on these characteristics, many statistics-based methods were proposed in early research [
11,
12,
13]. The Reed–Xiaoli (RX) detector is one of the most classic methods [
14]. It assumes that the background follows a multivariate Gaussian distribution and detects anomalies by calculating the Mahalanobis distance between the central pixel and surrounding pixels. Subsequently, some improved RX detectors were proposed, such as the local RX [
15] and the kernel RX algorithm [
16].
However, for complex regions, the background may not be accurately estimated with statistical models. To remove such limitations, many other methods have been proposed, such as representation-based methods and tensor decomposition-based methods [
17,
18,
19,
20]. Collaborative representation detection (CRD) [
21] is a representation-based method that assumes a background pixel can be represented by its surrounding pixels while anomalous pixels cannot. Methods based on low-rank and sparse representation (LRASR) exploit the low-rank characteristics of the background [
22,
23]. In order to further model background and anomaly information, an HAD method based on potential anomaly and background dictionary construction (PAB-DC) was proposed [
24]. Shen et al. [
25] introduced the saliency prior and utilized framelet decomposition to maintain the sparsity and piecewise smoothness of background representation. Total variation regularization is also commonly used in tensor-based HAD methods due to its ability to maintain piecewise smoothness [
26,
27]. Feng et al. [
28] combined tensor ring decomposition with TV regularization, exploiting both the low-rank property and piecewise smoothness in the spatial and spectral dimensions. These methods achieve good detection performance through the representation and decomposition of hyperspectral images. However, for different hyperspectral images, different dictionaries and representations need to be constructed, making the parameters difficult to apply in unknown hyperspectral images.
In recent years, with the rapid development of deep neural networks, numerous deep learning-based HAD methods have been proposed, such as deep belief network (DBN) [
29], convolutional neural network (CNN) [
30,
31], generative adversarial network (GAN) [
10,
32], long short-term memory (LSTM) [
33], and autoencoder (AE) [
34,
35]. Many methods utilize AEs to reconstruct hyperspectral images and distinguish anomalies from the background through reconstruction errors. These methods are usually based on an assumption that the number of anomalous pixels is significantly smaller than the number of backgrounds. Therefore, the model tends to learn the reconstruction criterion of the background, while anomalies cannot be reconstructed well [
36,
37,
38]. By introducing a convolutional autoencoder, Wang et al. proposed Auto-AD [
39], reconstructing hyperspectral images from random noise. Gao et al. proposed a blind-spot architecture that uses surrounding pixels to reconstruct the central pixel, thereby suppressing the reconstruction of anomalies [
40,
41]. Liu et al. introduced enhanced separation training to address the identical mapping problem in the reconstruction process [
42,
43]. Cheng et al. [
9] introduced an alternating optimization strategy to reduce the effects of anomalies during optimization. Wu et al. [
44] proposed a Transformer-based autoencoder that enhances the representation of global spatial information. Liu et al. [
45] combined low-rank representation models with self-supervised learning, using deep neural networks to generate pseudo-anomalies. Chen et al. [
46] proposed a spectral diffusion model to further infer the potential background of the anomalous regions. Variational autoencoders (VAEs) have also been used in anomaly detection in recent years [
47]. The VAE implements regularization constraints on the encoded latent space features, so it can obtain latent space features with regular distribution, thereby reducing the overfitting of the model. Lei et al. [
5] introduced the VAE into HAD, leveraging the strong representation capability of the VAE to extract inherent spectral features from high-dimensional spectral vectors. Subsequently, some improved methods were introduced to the VAE to further enhance HAD performance, such as 3D convolution [
48], graph regularization [
49], manifold learning, and multi-head self-attention [
50]. Yu et al. [
51], combining the Chebyshev neighborhood, discriminated anomalies based on the latent layer probability distribution of pixels. Since the latent layer constraint can reduce the interference of anomalous samples on learning background reconstruction, the variational inference method was also introduced into a GAN to obtain hyperspectral image reconstruction in a generative strategy [
52].
These deep learning methods mostly learn from a single hyperspectral image in an unsupervised manner and detect anomalies in the current image. They require training a specific network for each hyperspectral image, and the knowledge learned from one hyperspectral image is difficult to extend to other images. Therefore, the detection efficiency is likely to be reduced. To address these issues, in recent years, many studies have begun exploring HAD across images. Li et al. used a CNN to learn the similarity between pixels and their surroundings through classification labels and discriminated if the central pixel is anomalous [
30]. Based on relation learning, Huyan et al. [
53] introduced VLAD pooling to project different image features into the same space. Li et al. [
54] first proposed an unsupervised cross-image HAD model that can directly generate an anomaly map in one step. Ma et al. [
55] proposed a statistical offset module that enables the model to adapt to hyperspectral images in different domains. To extract spatial context information, AETNet was proposed, which can learn reconstruction rules directly from a set of hyperspectral images [
56]. As shown in
Figure 1, these cross-image HAD methods do not need to be optimized for each unknown image. However, the current cross-image HAD methods still face the following issues.
- (1)
Knowledge transfer misalignment. During the model training process, additional supervised information may be required, such as classification labels. However, the background may contain various categories of land cover in HAD, which might be classified as negative samples in category classification, thereby affecting the performance of the model.
- (2)
Implicit modeling. The existing cross-image HAD methods mostly learn features of background and anomalies in an implicit manner, insufficiently considering the distribution differences between the background and anomalies for reconstruction or discrimination.
- (3)
High computational complexity. In order to maintain performance, most existing cross-image HAD methods require stacking of networks, such as CNNs or Transformers, resulting in extensive parameters and hardware requirements.
To address the above issues, a simple and lightweight cross-image HAD model is proposed in this paper. Like other cross-image HAD methods, once it is trained, for any new image, only one forward propagation is required to obtain the detection map without additional optimization. Based on the assumption that background pixels in hyperspectral images are much more than anomalies, we use artificially generated anomalies and original pixels to train a binary classification network to perform HAD without ground truth labels. After sampling from the central pixel and the surrounding pixels, through a model based on a siamese VAE, the VJDNet can combine global and local information to discriminate anomalies. From the global perspective, by learning the probability of pixels being reconstructed, the model can identify anomalies with low reconstruction probability from the whole image, which are difficult to be reconstructed. To prevent the model from overfitting to specific images, we use a relatively broad reconstruction probability rather than the precise spectral angle distances as the learning objective. From the local perspective, by encoding the distributions of pixels and their surroundings, the model can identify anomalies that are significantly different from the surrounding pixels based on local information. To integrate global and local information, we propose a probability distribution joint discrimination (PDJD) module, which can directly obtain the anomaly score of the input pixels. Furthermore, we propose generating methods for anomaly samples and surrounding background representations, respectively, considering the stability and cross-image generalization of the generated samples. For anomaly samples, we generate them through dynamic weights to ensure their diversity and difference from the original pixels. On the other hand, in the original image, the surrounding pixels might contain anomalous pixels. Therefore, we establish a distribution for the surrounding pixels and sample from it to obtain representations. Compared with the existing cross-image HAD methods, the proposed VJDNet can be implemented with just a few fully connected layers, making it highly lightweight while maintaining good detection performance and scalability. The main contributions of this paper can be summarized as follows.
- (1)
A lightweight cross-image HAD network based on a siamese VAE named VJDNet is proposed. The network is able to learning global and local distributions from samples of multiple hyperspectral images and detect anomalies in unknown hyperspectral images after one unsupervised training process. Compared with other advanced unsupervised cross-image HAD methods, our proposed method achieves comparable or even superior performance while utilizing a lightweight network structure.
- (2)
A probability distribution joint discriminant (PDJD) module is proposed, which can simultaneously consider reconstruction probabilities and distribution differences to distinguish anomalies. The PDJD module can combine the information of the pixel itself and the information of the surroundings to achieve more accurate anomaly detection.
- (3)
We propose a dynamic sample pair generation strategy. This generative module balances the stability and randomness of training samples, allowing the model to learn more diverse representations and better adapt to unknown hyperspectral images.
The remainder of this paper is organized as follows.
Section 2 provides a brief overview of the related works covered in this paper, specifically introducing VAEs and cross-image HAD.
Section 3 provides a detailed explanation of the proposed method.
Section 4 presents the experimental results and analysis, validating the effectiveness of the proposed method. Finally, a conclusion is given in
Section 5.
3. Methodology
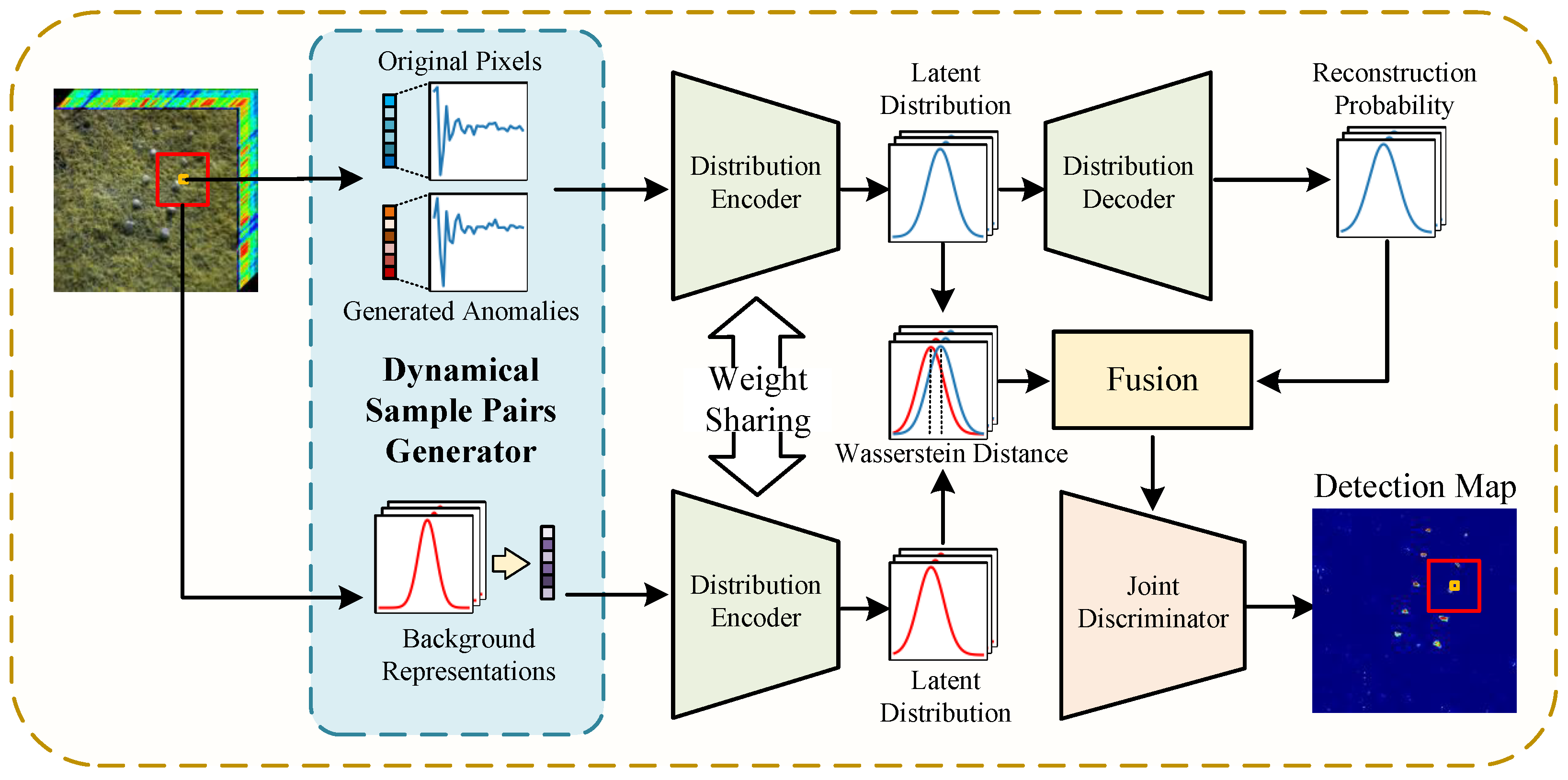
In this paper, we propose a siamese variational autoencoder (VAE)-based cross-image hyperspectral anomaly detection model, named Variational Joint Discrimination Network (VJDNet). After training with multiple hyperspectral images, the VJDNet can perform anomaly detection on other hyperspectral images not involved in the training process. The overall structure of the VJDNet is shown in
Figure 2. It mainly consists of three parts: sample pair generation module, siamese VAE module, and probability-distribution joint discrimination (PDJD) module. First, the VJDNet dynamically constructs a series of background–center pixel sample pairs. The background representation is extracted by dual windows and resampled according to the distribution model, while the central pixel mutates into an anomaly according to a preset probability. After obtaining such sample pairs, we use two weight-shared VAEs to represent their latent distribution and the reconstruction probability of the central pixel. Finally, the PDJD module combines the reconstruction probability of the central pixel and the difference in latent distribution between the background and central pixels to determine whether the central pixel is an anomaly.
3.1. Dynamical Generation of Sample Pairs
In the sample pair generation module, we first divide the input hyperspectral image into image patches according to the dual window sizes and . For the model to learn discriminative features between anomalies and non-anomalies, we need to mutate the central pixel to an anomaly based on a preset probability . Then, we model the distribution of surrounding pixels between the inner and outer windows and sample representative surrounding background pixels from the modeled distribution.
Given
N image patches,
, which may come from different hyperspectral images, where
c is the spectral dimension after dimensionality reduction. In this work, we use principal component analysis (PCA) to reduce the dimension of hyperspectral images and achieve dimensional unification between images. Each image patch
contains two elements, the central pixel
and the surrounding pixel set
.
represents the number of surrounding pixels, which can be calculated from the double window size as follows:
For the central pixel
, we generate anomalies based on the probability
. That is, in one anomaly generation process, each central pixel has a
probability of being selected as an anomaly. Anomalies can be generated by shuffling the spectral order of the original pixels [
54]. However, for samples after PCA dimension reduction, shuffling the dimensions may destroy the data structure at the level of feature space. Therefore, we have designed an anomaly generation method by generating weight vectors. Once a pixel is selected, a random weight array
is generated according to Gaussian distribution
, in which the negative value is fixed to 1. Then, the selected center pixel is multiplied by
. As a result, the values in some dimensions of generated anomalies remain unchanged, while the values in the remaining dimensions are randomly enlarged or reduced, resulting in features different from the original pixels. This approach is able to generate anomalies similar to the original pixels in some dimensions, thus constraining the decision boundary by similar but not identical samples rather than significantly different samples, enhancing the discriminability of the model. After we obtain the center pixel
, the corresponding binary label
y is also generated. When
, it means that the corresponding center pixel
is selected as the generated anomaly. On the contrary, when
, the center pixel
remains unchanged, and it is regarded as a normal sample.
For the surrounding pixel set
, we first model its distribution. Many previous works have assumed that the background of hyperspectral images can be represented by a multivariate Gaussian distribution. Due to the double window, the surrounding pixels are limited to a smaller scope, so their distribution is generally closer than that of the global image. Therefore, we model
as a univariate Gaussian distribution
on each reduced spectral dimension, where
We perform sampling in the distribution to obtain the sampled background pixels and then take their mean as the background representation of the image patch. This approach makes representative and close to the mean value of surrounding pixels while also introducing some randomness to enhance the network’s generalization and resistance to interference. To make the trained model more adaptable for transfer between images, we use a dynamic approach where anomaly and background generation are performed once per training epoch. This approach enriches the diversity of samples and reduces the overfitting of the model on training hyperspectral images.
During the inference stage, we use the mean of the surrounding pixels as the background representation. This is because the inference process is only performed once, so, compared to the training process, it is necessary to reduce randomness to ensure the stability of the detection results. Since most of the background representations generated during training are close to the mean , the model can achieve good detection performance during the inference process as well.
3.2. Model Architecture
The network structure consists of three parts: distribution encoder, distribution decoder, and probability-distribution joint discriminator. The encoder and decoder together form a VAE structure. To keep the model as lightweight as possible, we use several fully connected structures to build the network. We use Leaky ReLU as the activation layer in the model to ensure non-zero output of neurons, avoid gradient vanishing, and enhance the generalization capability of the network. It is worth noting that, during the encoding and decoding process of background representation, we fixed the parameters of the network. That is, the encoder and decoder only learn the distribution representation and reconstruction probability of the central pixel and share the weights for the forward-propagation process of the background representation. The reason is that the background representation is obtained by resampling from the background distribution, and we hope that the VAE part can maximize the reconstruction probability of real pixels as much as possible.
3.2.1. Distribution Encoder
The distribution encoder
consists of three fully connected layers, with a Batch Normalization layer and an activation layer between every two layers. We use a siamese structure to construct the encoder, which can encode the input sample pairs into latent distribution representations separately. Therefore, the input layer size of the encoder is the same as the sample spectral size. The last layer size is twice the latent size, which is used to represent the mean value
and standard deviation
of the latent distribution, where
is the latent-layer size. The encoding process can be represented as
where
and
are the weight and bias of the encoder
, respectively. Then, the latent layer distribution
of the center pixel and the latent layer distribution
of the background representation can be represented as
For the latent distribution representation, we refer to the latent layer constraint of the VAE and use KL divergence as the loss function to make it close to the standard normal distribution; that is,
3.2.2. Distribution Decoder
Similar to the encoder, the distribution decoder
also consists of three fully connected layers, with a Batch Normalization layer and an activation layer between every two fully connected layers. Before decoding, the VAE performs
M sampling from the latent distribution to obtain latent sample representations
. Then, the decoder reconstructs the latent sample representations into corresponding reconstruction distributions. Therefore, the input size of the decoder is the same as the latent size, while the output size is twice the sample spectral size, used to represent the mean
and the standard deviation
of the reconstruction distribution. For each latent-layer sample representation
, similar to the encoding process, the reconstruction process can be represented as
where
and
are the weight and bias of the decoder
, respectively. Since we only use the center pixels to optimize the weights of the VAE module, the background representation does not participate in the reconstruction decoding process. Then, the reconstruction distribution
of the central pixel can be represented as
We use the logarithmic probability of the center pixel
in the reconstruction distribution as the reconstruction probability and take the average over the number of latent samples. The final reconstruction probability
can be represented as
The objective of the VAE is to maximize the reconstruction probability; thus, the reconstruction loss can be represented as
3.2.3. Probability-Distribution Joint Discriminator
To jointly utilize the relationship between pixels with global hyperspectral images and with local surrounding pixels, we propose a probability-distribution joint discriminator (PDJD) module. First, we calculate the distance between the latent distributions of the central pixel
and of the background representation
to measure the difference between the central pixel and its surroundings. In this work, we use Wasserstein distance to measure the distance between latent layer distributions. Wasserstein distance measures the minimum cost of transforming one distribution into another, effectively reflecting their distance regardless of whether there is overlap between distributions. Since the dimensions are independent of each other, the distribution distance
can be expressed as
Then, the distribution distance
d and the reconstruction probability
are concatenated to obtain the joint measurement representation
r. We use a classification network
to discriminate whether the represented central pixel
belongs to an anomaly based on the joint measurement representation. The classification network
consists of three fully connected layers, with an activation layer between each two layers. Finally, we use a softmax layer to obtain the probability of
being classified as background or anomaly, where the probability of being classified as anomaly can serve as the output anomaly score. We use cross-entropy loss as the classification loss
, which can be represented as
where
is the binary classification label, indicating that the
i-th sample is a background sample or a generated anomaly sample.
is the joint measurement representation of the
i-th sample. Finally, introducing a balancing parameter
, the overall loss function of the model is
After the discriminator, we apply an n-th power operation to the output. In this work, the exponent n is set to 3 to suppress the background while keeping the integrity of the anomalous regions.
4. Experiments
4.1. Dataset Description
To verify the cross-image anomaly detection capabilities of the VJDNet, six different datasets are used in this work. Their specific details are as follows.
- (1)
San Diego Dataset [
22]: This dataset was collected by the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS, Jet Propulsion Laboratory, Pasadena, CA, USA) sensor in San Diego, CA, USA. The original data size is
, with a resolution of 3.5 m per pixel, containing 224 spectral bands ranging from 400–2500 nm. For anomaly detection, 35 bands with low quality are removed, and a subset of
is selected, containing 143 anomalous pixels.
- (2)
Cri Dataset [
58]: This dataset was collected by the Nuance Cri (PerkinElmer, Waltham, MA, USA) hyperspectral sensor, containing 46 bands ranging from 650–1100 nm. The image size is
, containing 1254 anomalous pixels.
- (3)
HYDICE Dataset [
21]: This dataset was collected by the Hyperspectral Digital Imagery Collection Experiment (HYDICE, Naval Research Laboratory, Washington, DC, USA) sensor, containing 175 bands after removing water vapor absorption bands. The image size is
, with 1 m per pixel as the spatial resolution. There are 21 anomalous pixels representing cars and roofs in the image.
- (4)
WHU-Hi-River Dataset [
59]: This dataset was collected by the Nano-Hyperspec (Headwall Photonics, Bolton, MA, USA) visible and near-infrared UAV-borne hyperspectral sensor, containing 135 bands ranging from 400 to 1000 nm. The image size is
, with 6 cm per pixel as the spatial resolution. There are 21 anomalous pixels representing plastic plates in the image.
- (5)
Airport–Beach–Urban (ABU) Dataset [
60]: This dataset contains 13 hyperspectral scenes, including airport, beach, and urban. They were collected by the AVIRIS sensor and the Reflective Optics System Imaging Spectrometer (ROSIS-03, Deutsches Zentrum für Luft- und Raumfahrt, Oberpfaffenhofen, Germany) sensor. The images are
or
in size, with different spatial resolutions and numbers of the spectral bands.
- (6)
HAD-100 Dataset [
56]: This is a large-scale hyperspectral dataset containing 260 training images and 100 test images, collected by the AVIRIS-NG sensor. The test images are
in size, with spatial resolutions ranging from 1.9 m to 8.4 m.
The pseudo-color images and ground truths of the four individual datasets used for testing are shown in
Figure 3, and some detailed information is listed in
Table 1.
4.2. Implementation Details
In this work, the input hyperspectral images are normalized and scaled to the range [0, 1]. Then, to keep the input sample size consistent, we use principal component analysis (PCA) to reduce the spectral size to 30. In the sample pair generation module, the inner window size is set to , while the outer window size is . For cross-image detection, the anomaly generation probability is set to 0.2; for single-image detection, is set to 0.5. The number of background representation samples is 10 each time, and the number of latent-layer samples M is also set to 10. In the network, the latent size is set as 20. The balancing parameter is set to 1. The whole model is trained by the Adam optimizer with a learning rate of , and the batch size is set to 64.
For cross-image anomaly detection, we first train the VJDNet on 13 images of the ABU dataset, and then verify the detection performance on the remaining four individual datasets. To reduce the computational cost, we randomly select 3500 pixels and their surroundings from each image as training samples. Afterward, these samples are randomly shuffled and sent to the network for learning. In this way, the VJDNet achieves simultaneous training on multiple hyperspectral images. For the HAD-100 dataset, we randomly select 1000 pixels and their surroundings from each training image. After training the network, detection is performed on all images in the test set.
4.3. Comparative Methods and Evaluation Metrics
In the comparative experiment, we compared the VJDNet with 11 methods: RX [
14], CRD [
21], LRASR [
22], 2S-GLRT [
61], Auto-AD [
39], GT-HAD [
62], MSNet [
43], CNND [
30], AUD-Net [
53], AET-Net [
56], and BSDM [
55]. Among them, RX and 2S-GLRT are statistics-based methods, while CRD and LRASR are representation-based methods. In deep learning methods, Auto-AD, MSNet, and CNND are CNN-based methods, GT-HAD and AUD-Net are Transformer-based methods, AET-Net is a method combining CNN and Transformer, and BSDM is a method based on Denoising Diffusion Probabilistic Models (DDPMs).
For Auto-AD, the experiment is conducted only on single-image detection. For cross-image detection by GT-HAD, we concatenate the training images into a large image to train the network and then perform inference on the four test images. For CNND and AUD-Net, since they require classification labels for supervised training, the experiment is conducted only for cross-image detection. We use the pre-trained weights on their default hyperspectral classification dataset for testing. For other methods, similarly to the proposed VJDNet, the hyperspectral image is first normalized, and the spectral dimension is reduced to 30 by PCA. For CRD and 2S-GLRT, the settings of the dual-window size are the same as those of the proposed VJDNet. Other experimental settings are consistent with those in the original paper.
To evaluate the performance of the model, the receiver operating characteristic (ROC) curves are plotted based on the relationship between the true positive rate , the false positive rate , and the threshold . Then, their areas under the curve (AUCs) are calculated as the quantitative metric. Moreover, we also compare the number of parameters, FLOPs, and inference times of the methods to verify the lightweightness of the VJDNet.
4.4. Comparative Results on Single-Image Detection
We first verified the anomaly detection performance of the VJDNet by training and testing on the same hyperspectral images. The experimental results are shown in
Table 2, in which River is the abbreviation of the WHU-Hi-River dataset. As can be seen from the table, the proposed VJDNet does not achieve the best performance on a single dataset but shows overall balance and thus achieves the highest mean score of AUROC.
As shown in the table, CRD exhibits significant performance on the HYDICE datasets but does not perform as well on the Cri dataset. Similarly, LRASR and 2S-GLRT also perform poorly on the Cri dataset. This may be because the spectral range and dimension size of the Cri dataset are significantly different from others. On the other hand, Auto-AD achieves the best performance on the San Diego dataset but experiences a large performance drop on the WHU-Hi-River dataset. The proposed VJDNet demonstrates good detection performance on these four datasets, which have varying sensors, resolutions, and data sizes, thus showing its universality.
4.5. Comparative Results on Cross-Image Detection
4.5.1. Comparison on Four Individual Datasets
To verify the performance of the VJDNet on cross-image HAD, we compared it with different methods for cross-image detection. Among these, traditional methods such as RX, CRD, LRASR, and 2S-GLRT do not perform cross-image detection, so they have the same results as single-image detection. The CNND and AUD-Net are cross-image HAD methods based on classification labels, so they are first trained on their default classification datasets and then perform anomaly detection on the four test datasets. The remaining methods are first trained on 13 images from the ABU dataset and then tested on the four datasets. The AUC scores for each method are shown in
Table 3. Similar to the results of single-image detection, the VJDNet shows balanced performance on various datasets and achieves the highest mean AUC(
,
) score. In addition, the VJDNet also achieves the best detection performance on the San Diego dataset. From the results of AUC(
,
) and AUC(
,
), although the VJDNet does not show significant advantages in background suppression, it has excellent sensitivity to anomalies, thereby achieving the highest AUC(
,
) scores in most datasets. This enables the VJDNet to ensure the ability to distinguish between anomalies and background.
Compared with
Table 2, we find that, on most datasets, the cross-image detection performs better than single-image detection. This may be because overfitting problems are more likely to occur in single-image detection, while, in cross-image detection, the network can learn richer information about anomalies and backgrounds by training on multiple images, thereby improving detection performance.
The ROC curves of different methods on various datasets are shown in
Figure 4. It can be seen that, on the San Diego dataset, the VJDNet can quickly achieve a high true positive rate. On other datasets, the performance of the VJDNet can reach a similar level to other methods. We present the detection maps of cross-image detection for different methods in
Figure 5,
Figure 6,
Figure 7 and
Figure 8. It can be seen from the detection map that, compared to other methods, the VJDNet can greatly enhance the activation of anomalies.
4.5.2. Comparison on HAD-100 Dataset
To further validate the cross-image detection performance and efficiency of the VJDNet, we conducted comparative experiments on the large-scale dataset HAD-100. Similar to the experiments on individual datasets, we first trained on all images in the training set, then performed detection on the 100 test images. We compared the AUC scores and efficiency metrics of different methods, as shown in
Table 4. The FLOPs were calculated on a
image, while the inference time represents the average time taken for detection on one image.
The experimental results show that the proposed VJDNet achieves the best detection performance on large-scale datasets compared to non-deep-learning methods and other cross-image methods. Although CNND has higher sensitivity to anomalies than the VJDNet, it also has the highest mAUC (, ) score, resulting in weaker discrimination between background and anomalies. In terms of model lightweightness and detection efficiency, while the VJDNet’s inference time is slightly higher than RX and AET-Net, it achieves the lowest number of parameters and FLOPs. In general, the VJDNet exhibits remarkable generalization and stability while also featuring a lightweight network structure.
4.6. Ablation Studies
4.6.1. Effectiveness of the PDJD Module
In this section, we validate the effectiveness of the proposed PDJD module. The PDJD module combines the global reconstruction probability and the local distribution difference to jointly discriminate anomalies. Therefore, we compare the detection results of the PDJD module with methods using single discriminative information. Each method is first trained on the ABU dataset and then tested on the remaining four datasets. The detection results on the four datasets are shown in
Table 5. In the table, the “Probability” method uses pixel reconstruction probability as the anomaly score, which can be regarded as the basic VAE method. The “Distribution” method uses the Wasserstein distance between the latent distribution of the central pixel and the background representation as the anomaly score. To further demonstrate the performance of the VJDNet visually, we use the San Diego dataset as an example and compare the detection map after exponentiation of different methods.
The results in
Table 5 show that, on the three datasets and the mean score, the proposed method using the PDJD module achieved the best performance and was only slightly inferior to the distribution-discriminant method on the WHU-Hi-River dataset. The visualization results on the San Diego dataset are shown in
Figure 9. It can be observed that, compared to the method using only global reconstruction probability information, the PDJD module suppresses background activation by measuring differences with surroundings. Compared to the method using only local distribution difference information, the PDJD module significantly enhances the anomaly activation. Therefore, the proposed VJDNet can balance background suppression and anomaly enhancement and achieve good detection results on different datasets.
4.6.2. Effectiveness of the Dynamical Sample Pair Generator
To verify the effectiveness of the dynamic generation procedure, we compare four combinations of training sample pairs: static anomalies with static surroundings, static anomalies with dynamic surroundings, dynamic anomalies with static surroundings, and dynamic anomalies with dynamic surroundings. For static anomalies, we converted 20 percent of samples into anomalies as preprocessing rather than doing so every iteration. For static surroundings, we used the mean of surrounding pixels instead of the sampling process. The experimental results of the four combinations are shown in
Table 6. The WHU-Hi-River dataset is abbreviated as River.
As seen from the results, although the static generation procedure can already perform effective detection, using the dynamic generation approach further improves the overall detection performance. Especially on San Diego and WHU-Hi-River datasets, the dynamic generation of anomalies and surroundings both significantly improve the detection results. For the HYDICE dataset, the dynamic generation of anomalies does not improve the detection performance significantly. This may be because the HYDICE dataset has relatively complex backgrounds while dynamic anomalies enhance the discriminability of the network, thus slightly increasing the probability of classifying the backgrounds as anomalies.
4.7. Parameter Analysis
In this section, we conduct experiments on the hyperparameter settings in the VJDNet, including the number of background representation samples
, the anomaly generation probability
, and the balance parameter
in (
17). When a certain hyperparameter is evaluated, the remaining hyperparameters are consistent with the settings in
Section 4.2.
- (1)
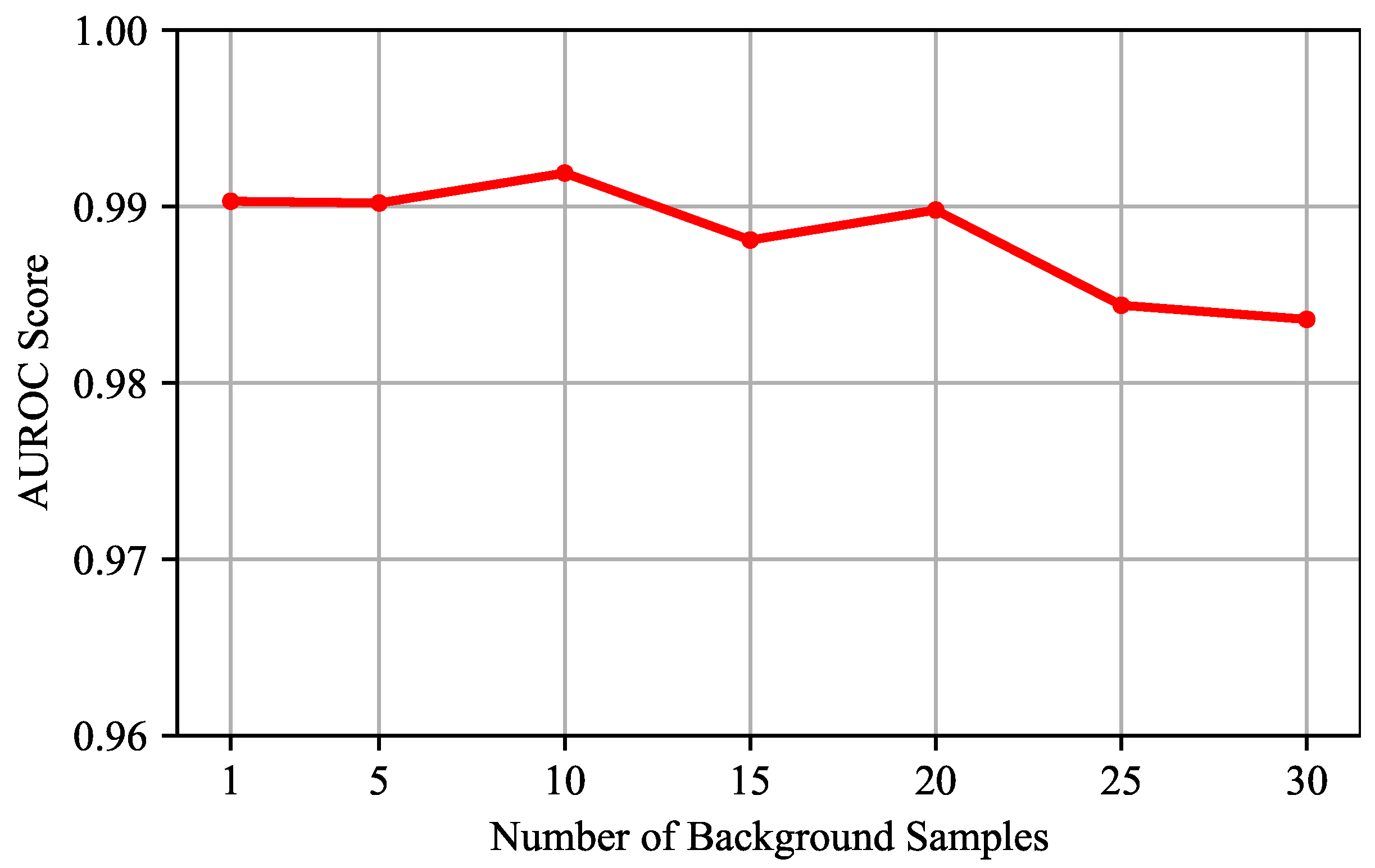
Evaluation of the Number of Background Representation Samples: We conduct experiments on different numbers of background representation samples
, which is set as [1, 5, 10, 15, 20, 25, 30]. The averages of the results on the four datasets are shown in
Figure 10. The results show that, when
is less than 20, the detection performance remains relatively stable. However, as
becomes larger, the AUROC score gradually decreases. This may be because, with a larger
, the background representation is more likely to be close to the mean of surrounding pixels, thereby reducing diversity and weakening the generalization of the network. When
is set to 10, the detection performance reaches the best, and the generalization and stability of the network have reached a balance.
- (2)
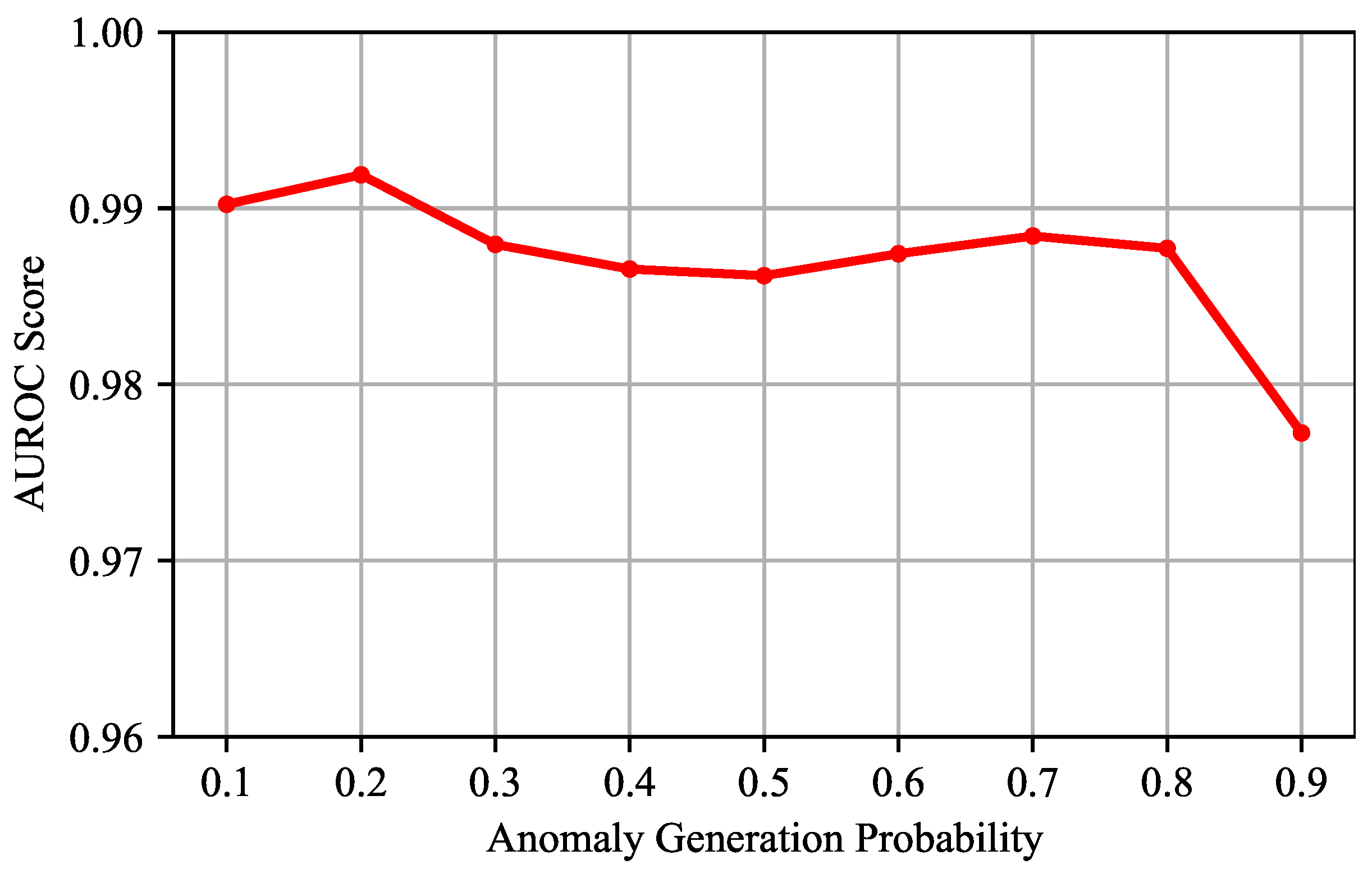
Evaluation of the Anomaly Generation Probability: We conduct experiments on different values of the anomaly generation probability
in the range of [0.1, 0.9]. The averages of the results on the four datasets are shown in
Figure 11. The results show that, when
is 0.2, the detection performance reaches the best. When
is set to different values, the VJDNet can achieve good results within a certain range. But, when
reaches 0.9, the detection performance declines. It is worth noting that, when
is large, network training may become unstable. In this case, as the number of training epochs increases, the detection performance may drop significantly. This is another reason why we have chosen a small anomaly generation probability.
- (3)
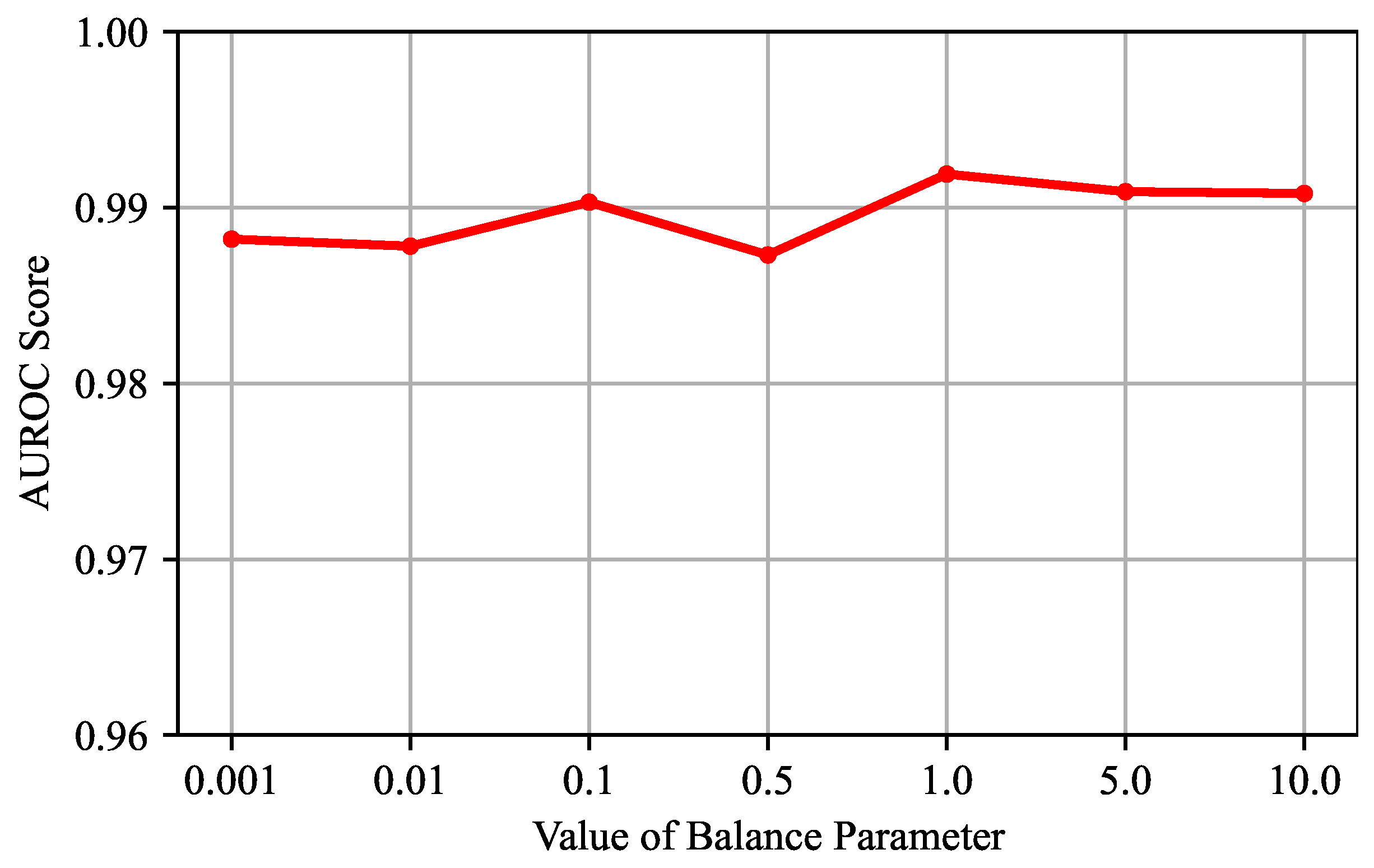
Evaluation of the Balance Parameter: We conduct experiments on different values of the balance parameter
, which is set as [0.001, 0.01, 0.1, 0.5, 1, 5, 10]. The averages of the results on the four datasets are shown in
Figure 12. The results show that the performance of the VJDNet is not sensitive to the value of
. When
is set to 1, the detection performance reaches the best. Therefore, we set
as 1 in the experiments.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}