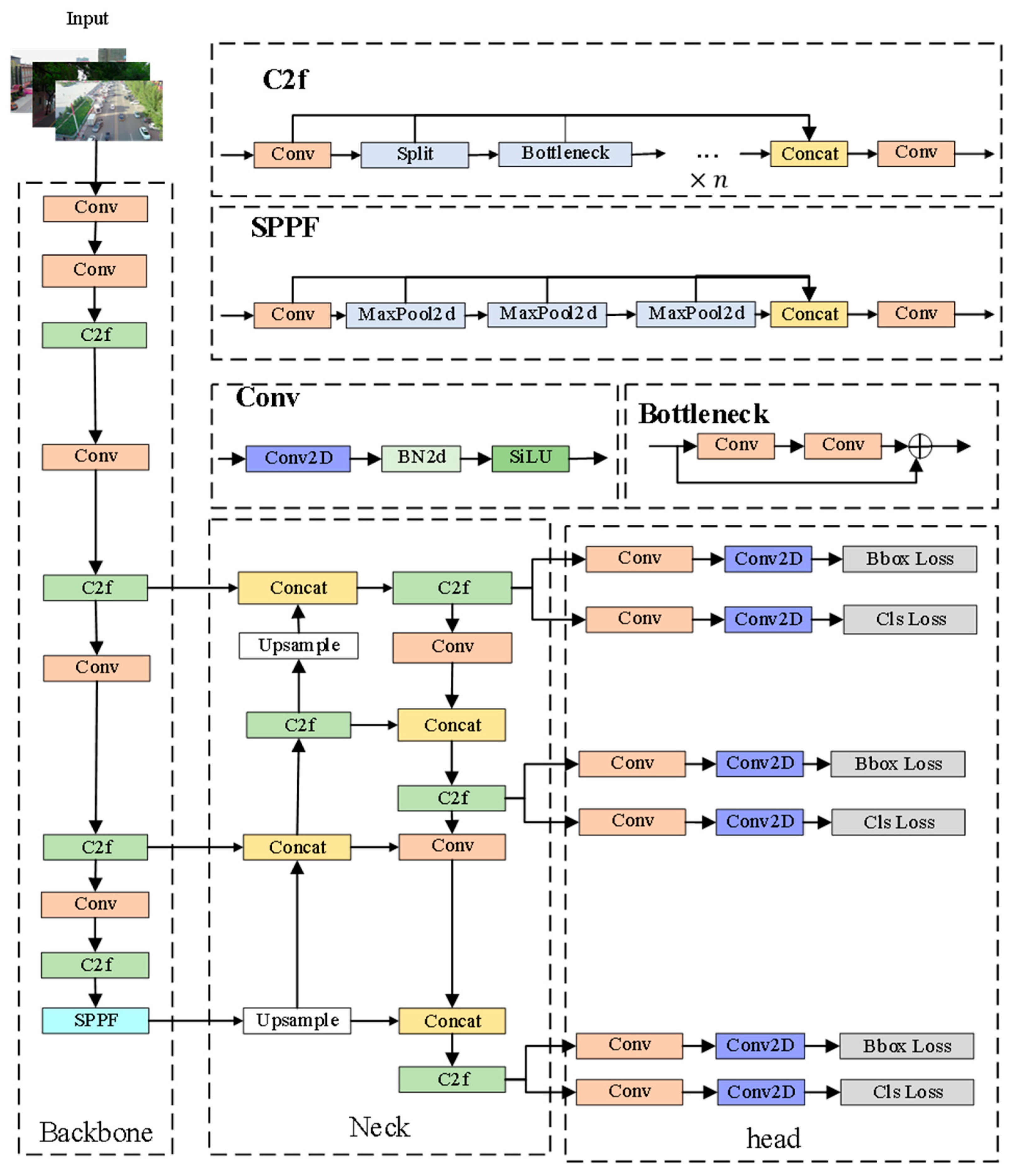
4.4.1. Loss Function Experiments
To verify the effect of various weighting parameters within the NWD-CIoU loss function on the detection performance of small targets in YOLOv8s, as illustrated in Equation (6), comparative experiments were conducted on the VisDrone2019 dataset by adjusting different values of
. To evaluate the detection efficacy, the metrics of mAP@0.5, mAP@0.5:0.95, and F1 were chosen, aiming to identify the optimal weighting coefficients. The detailed experimental outcomes are listed in
Table 3. It can be seen that the setting value of
plays a key role in the detection performance of the model. Specifically, as the value of
increases, the proportion of the NWD function rises, leading to a decrease in detection accuracy. When
, the loss function of the model is CIoU, whereas when
is set to 1.0, the loss function becomes NWD. At
, the improved model achieves the highest values for mAP@0.5, mAP@0.5:0.95, and F1. This indicates that setting
to 0.2 optimizes the detection performance of the improved model. Experimental results suggest that, compared to the CIoU loss function, the NWD loss function more effectively balances the variability among samples. Consequently, combining NWD with CIoU enhances the detection performance of the mode for small targets. Hence, in subsequent experiments,
was set to 0.2.
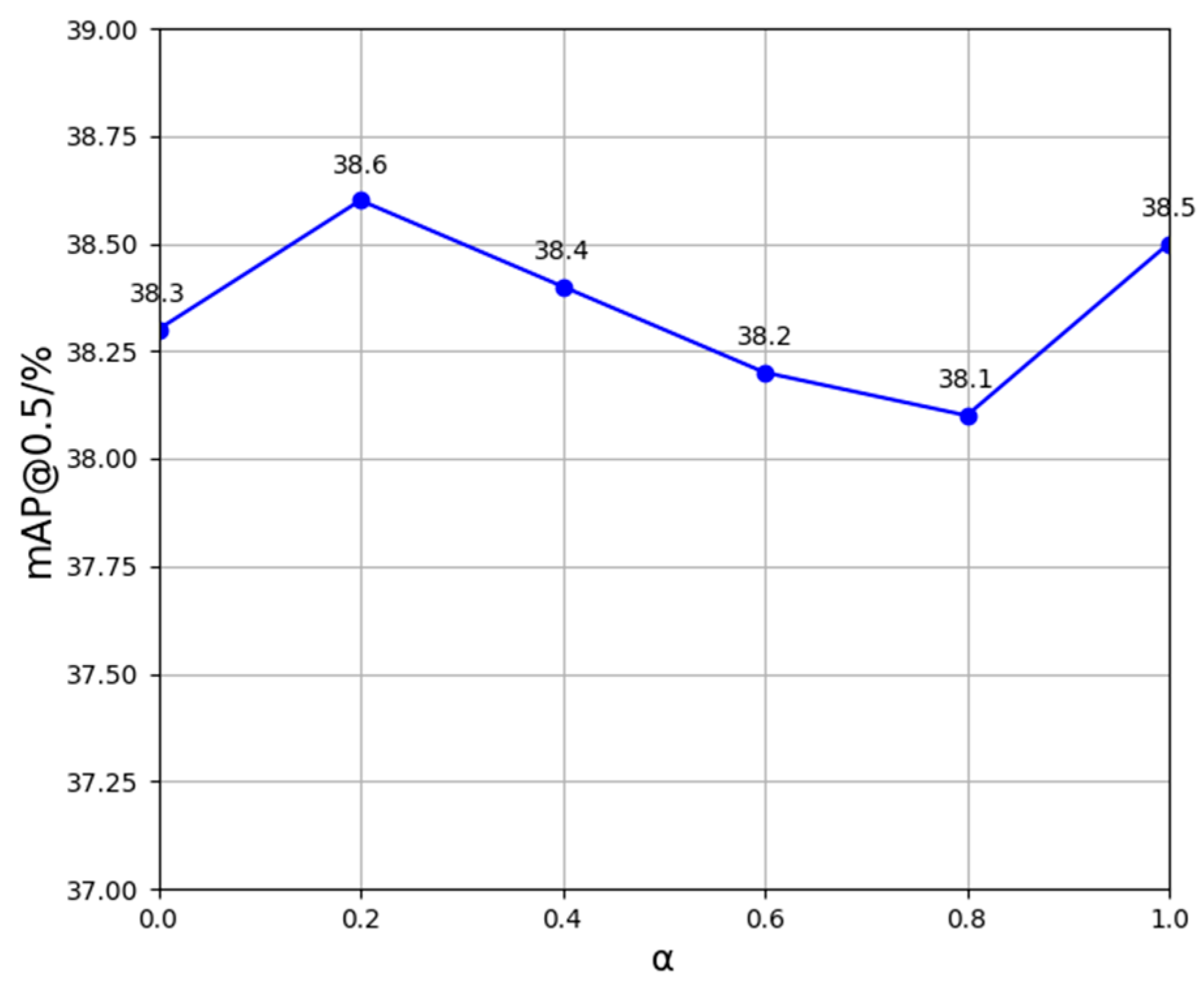
To more intuitively discover the impact of various weighting parameters used in the NWD-CIoU loss function on the small target detection capabilities of YOLOv8s, a line graph illustrating the effect of different α values on mAP@0.5 is presented in
Figure 11. As depicted in
Figure 11, detection accuracy diminishes with an increase in the value of
, indicating a higher proportion of the NWD function. When
equals 0.2, YOLOv8s achieves its optimal detection performance, thereby confirming the influence of varying
values on the detection capabilities of the model.
To verify the superiority of the combined method of NWD and CIoU for small target detection, experiments were conducted on the VisDrone2019 dataset. The NWD-CIoU approach was compared against several contemporary loss functions, including CIoU, SIoU, GIoU, WIoU, and EIoU, using YOLOv8s. Three key metrics, mAP@0.5, mAP@0.5:0.95, and F1 score, were selected to evaluate detection performance. The comparative results of these loss functions are presented in
Table 4. It reveals that the detection performance of the model is influenced to varying extents by substituting different loss functions for the original YOLOv8s loss function. Notably, by combining the NWD loss function with the CIoU loss function to form a new loss function for the model, the highest values of mAP@0.5, mAP@0.5:0.95, and F1 score were achieved. This indicates that the model exhibits the best detection performance when the loss function is improved using the NWD-CIoU method, thereby further validating the effectiveness of the NWD-CIoU loss function for small target detection.
4.4.2. Ablation Experiments
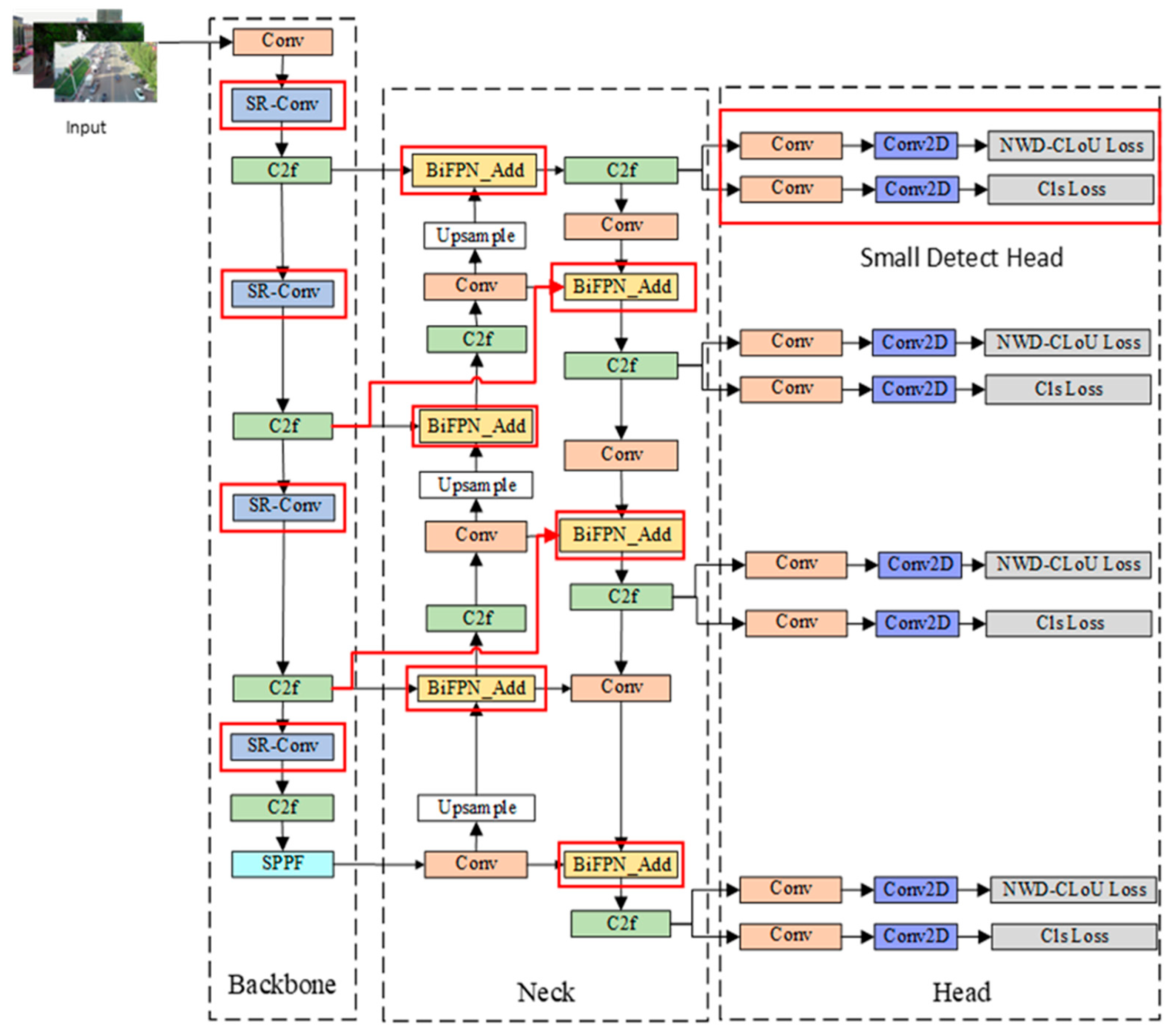
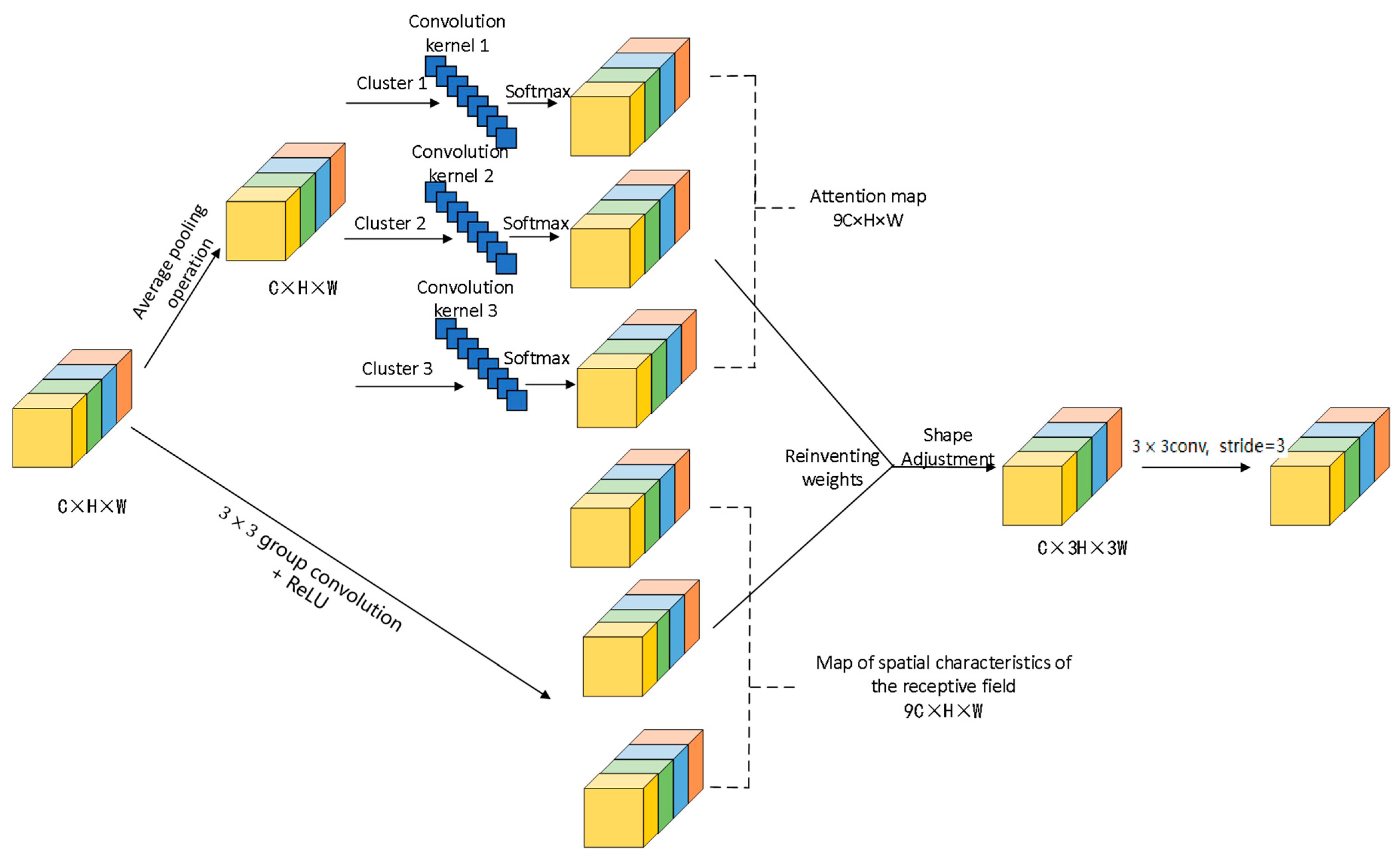
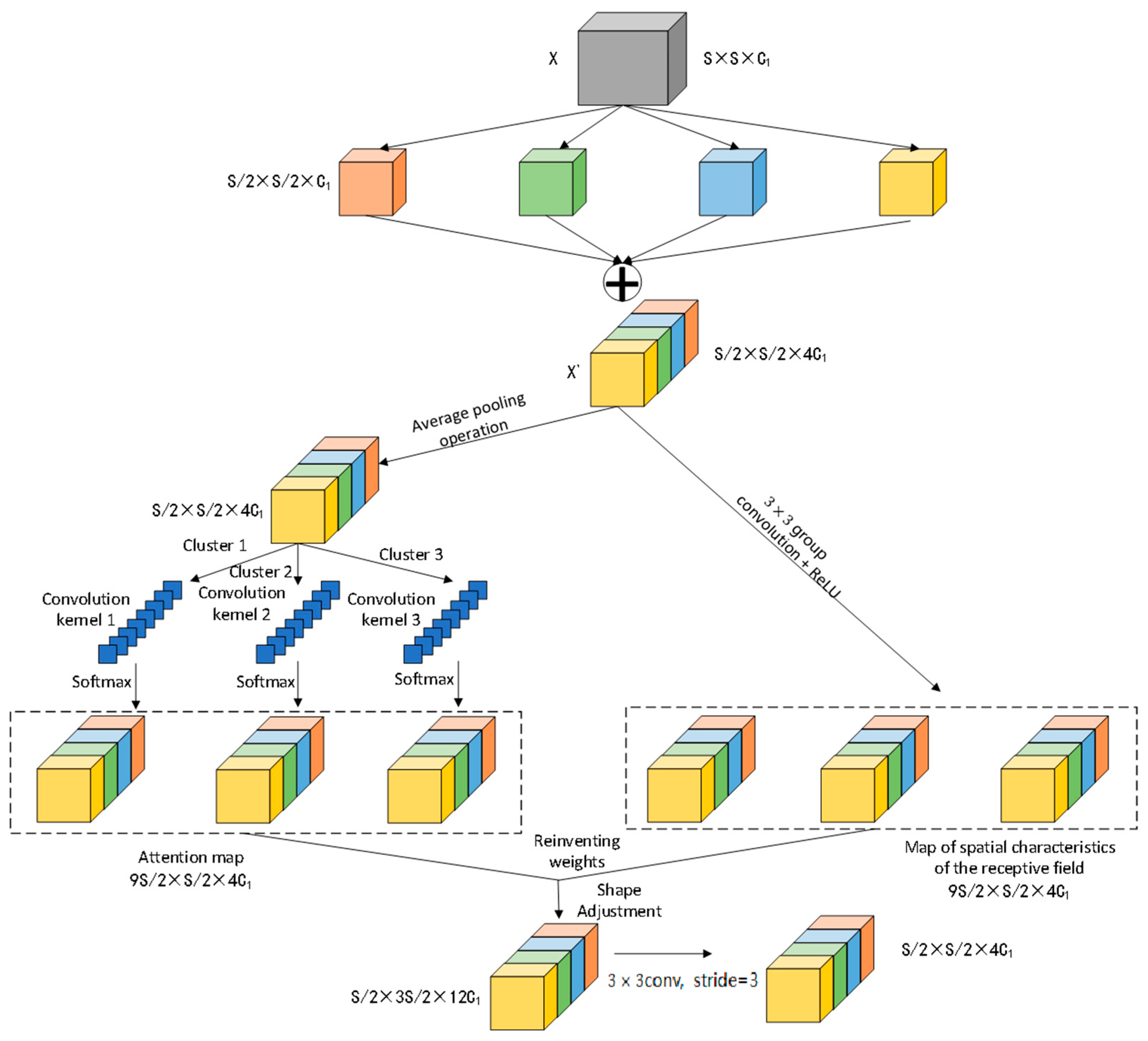
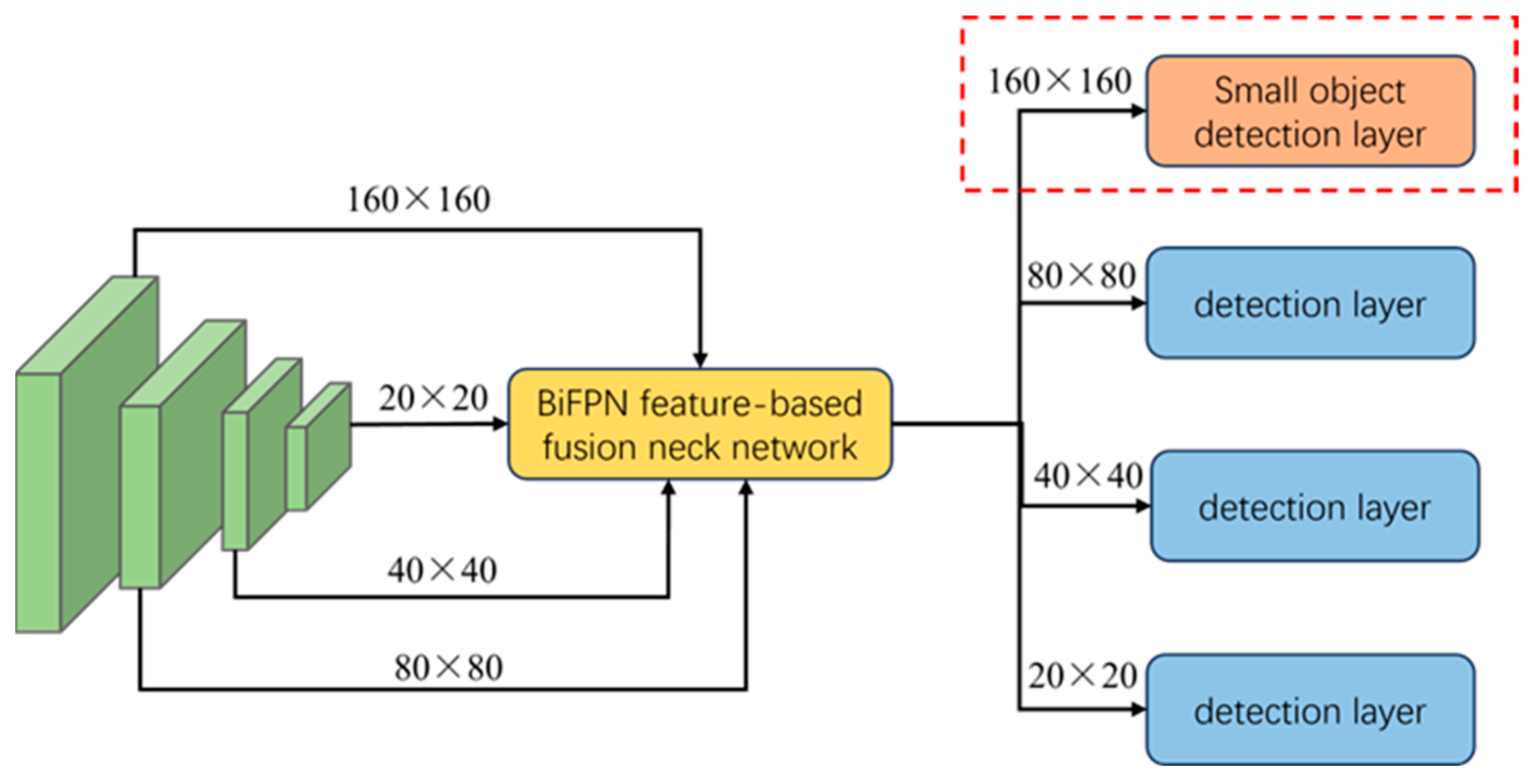
To validate the effectiveness of the improved method proposed in this paper for small target detection, YOLOv8s is employed as the baseline model. Metrics, such as mAP, precision, and recall, are selected for the ablation experiments. Eight sets of experiments are conducted on the public dataset VisDrone2019 to assess the detection efficacy of each enhanced method. The experimental results are detailed in
Table 5.
As evident from
Table 5, the baseline model is YOLOv8s. Initially, the improvement of YOLOv8s was made through a single module. In the first step, the loss function combining NWD and CIoU was used instead of the original loss function. This resulted in slight improvements to mAP@0.5, mAP@0.5:0.95, as well as recall, while precision experienced a minor decrease. This indicates that the combined loss function of NWD and CIoU can enhance the detection performance of the model for small targets, albeit to a limited extent. In the second step, the SR-Conv module was designed to replace the standard convolutional module in the original backbone network. Consequently, the mAP@0.5, mAP@0.5:0.95, and recall of the model were improved by 1%, 0.5%, and 1%, respectively. The detection performance of the model has been optimized. This suggests that the SR-Conv module enhances the model’s ability to extract target features. In the third step, BiFPN and a small target detection layer were introduced into the neck network, leading to significant increases in mAP, precision, and recall. This demonstrates that BiFPN effectively boosts the feature fusion capability of the model, and the introduction of the small target detection layer compensates for the model’s previous oversight of small target features. Secondly, the multi-module combination was improved for YOLOv8s, resulting in significant enhancements to mAP@0.5, mAP@0.5:0.95, precision, and recall compared to the improvements from using a single module. Finally, SR-Conv, BiFPN, the small target detection layer, and the NWD-CIoU loss function were simultaneously introduced to improve the baseline model, resulting in SR-YOLO. This model achieved 44.6%, 26.6%, 55.2%, and 43.3% for mAP@0.5, mAP@0.5:0.95, precision, and recall, respectively, which is significantly higher than YOLOv8s’ corresponding metrics by 6.3%, 3.8%, 3.2%, and 5.1%, respectively.
In summary, SR-YOLO, along with the simultaneous introduction of SR-Conv, BiFPN, the small target detection layer, and the NWD-CIoU loss function, achieves the best detection results. This further confirms that SR-YOLO enhances the detection accuracy of small targets in aerial images and reduces misdetections and missed detections of small targets compared to YOLOv8s.
To make a more intuitive comparison of the detection performance between YOLOv8s and the improved model, the variations in the four metrics—mAP@0.5, mAP@0.5:0.95, precision, and recall—on the VisDrone2019 dataset are depicted in
Figure 12. It is evident that the improved model, SR-YOLO, significantly enhances the values of mAP@0.5, mAP@0.5:0.95, precision, and recall metrics compared to YOLOv8s. Consequently, SR-YOLO demonstrates superior small target detection capabilities compared to YOLOv8s.
For the purpose of demonstrating the enhanced detection capability of the improved module, we conducted eight experimental trials on the publicly available RSOD dataset using four evaluation metrics: mAP@0.5, mAP@0.5:0.95, Params, and GFLOPs, with the comprehensive results documented in
Table 6.
Table 6 presents the performance change of YOLOv8s through module optimization. The initial modification employs the NWD-CIoU loss function, which demonstrates significant improvements in both mAP@0.5 and mAP@0.5:0.95 metrics while maintaining identical parameter counts and computational requirements. These results confirm the effectiveness of NWD-CIoU for small target detection. The subsequent integration of the SR-Conv module into the backbone network results in increased Params and GFLOPs, while achieving performance improvements of 1.3% in mAP@0.5 and 1.6% in mAP@0.5:0.95. This enhancement validates the module’s capability for improved feature extraction, particularly for small targets. Implementation of the BiFPN architecture with dedicated small-target detection layers in the neck network achieves a parameter reduction of 1.2 M with only a marginal computational increase of 0.7 GFLOPs, while demonstrating statistically significant enhancements in detection accuracy, with mAP@0.5 increasing by 2.4%. These findings indicate superior multi-scale feature fusion capabilities. Subsequently, we implemented a multi-module optimization approach for YOLOv8s, which resulted in modest increases in both Params and GFLOPs, while achieving significantly greater improvements in mAP@0.5 and mAP@0.5:0.95 compared to single-module enhancements. The proposed SR-YOLO architecture integrates four key components: SR-Conv modules, BiFPN feature pyramid network, a specialized small target detection layer, and NWD-CIoU loss function. Compared to the baseline YOLOv8s model, SR-YOLO demonstrates a Params increase of 2.2 M and computational overhead of 7.4 GFLOPs, while achieving significant performance gains of 3.3% in mAP@0.5 and 2.3% in mAP@0.5:0.95. Consequently, although the number of parameters and the computation amount are increased, the detection accuracy of SR-YOLO is improved. It indicates that the algorithm can effectively reduce the misdetection and omission of small targets in aerial images.
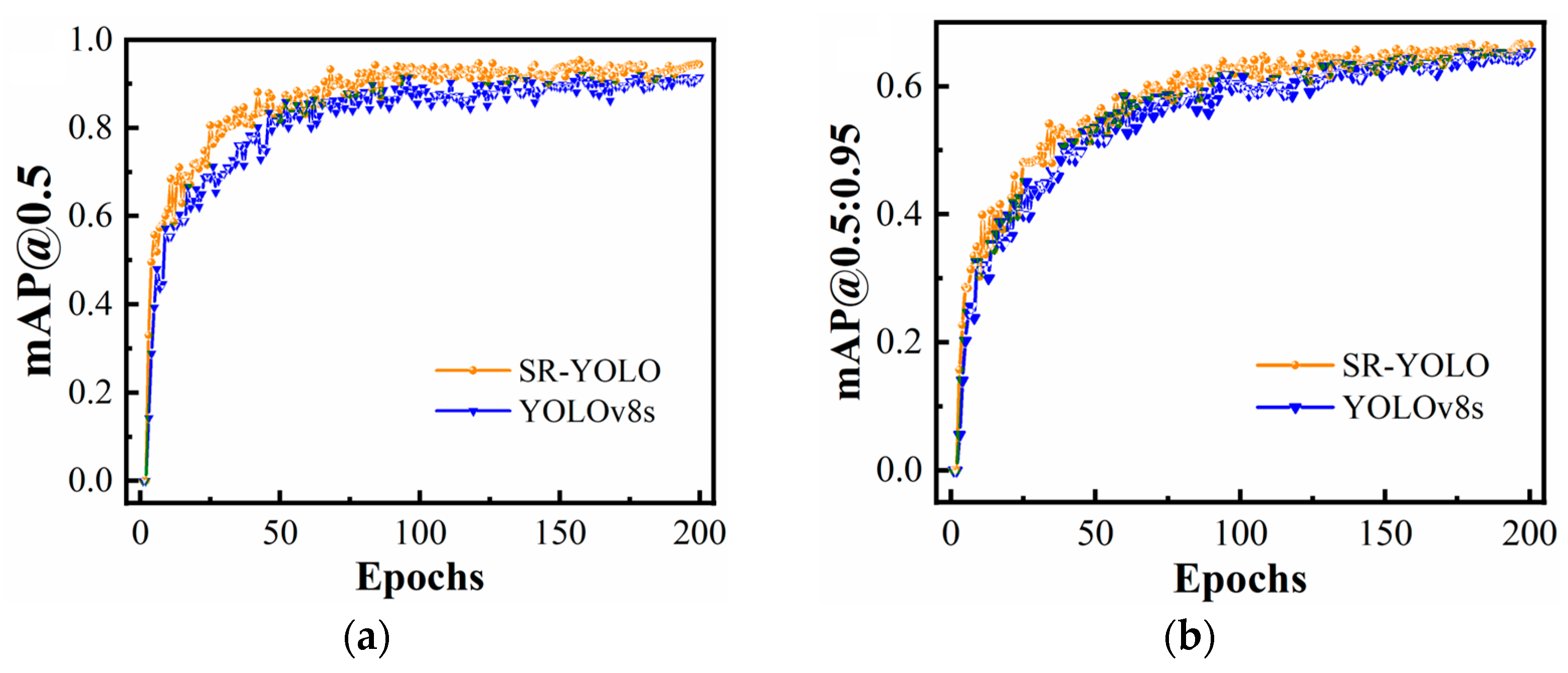
Figure 13 illustrates the evolution of mAP@0.5 and mAP@0.5:0.95 throughout the training epochs on the publicly available RSOD dataset for both YOLOv8s and SR-YOLO. The comparative results in
Figure 13 reveal that SR-YOLO exhibits enhanced performance across both evaluation metrics when compared to YOLOv8s. Owing to the prevalence of small-scale targets within the RSOD dataset, these findings substantiate the superior detection performance of the SR-YOLO algorithm for small object identification.
4.4.3. Comparative Experiments
To evaluate the performance improvements of the proposed SR-YOLO algorithm, we conducted comparative experiments using the VisDrone2019 benchmark dataset. The assessment employed four standard evaluation metrics: mAP@0.5, F1 score, Params, FPS, and GFLOPs. The analysis compared SR-YOLO against twelve state-of-the-art object detection architectures, including Faster R-CNN, SSD, RT-DETR [
44], YOLOv3s, YOLOv5s, YOLOv6s, YOLOv7, YOLOv8s, YOLOv8m, YOLOv8l, YOLOv9s, YOLOv12s [
45], and SOD-YOLO [
32], with detailed performance comparisons presented in
Table 7.
As demonstrated in
Table 7, the proposed SR-YOLO algorithm achieves superior performance on key detection metrics, attaining 44.6% mAP@0.5 and 48.5% F1 score. These results represent significant improvements over current state-of-the-art object detection methods. Compared to YOLOv5s, YOLOv8s, SOD-YOLO, YOLOv9s, and YOLOv12s, SR-YOLO achieves higher detection accuracy despite moderate increases in parameter count and computational requirements. Relative to Faster-RCNN, SSD, RT-DETR, YOLOv3s, YOLOv6s, YOLOv7, YOLOv8m, YOLOv10m, and YOLOv11m, SR-YOLO achieves superior detection accuracy while maintaining computational efficiency. Regarding real-time capability, SR-YOLO achieves significantly higher FPS while maintaining superior detection accuracy compared to Faster-RCNN, YOLOv3s, YOLOv5s, YOLOv6s, and YOLOv7. This demonstrates that the SR-YOLO model delivers both high precision and excellent real-time performance, making it well-suited for time-sensitive applications, such as UAV-based detection. In summary, comparative evaluations demonstrate that SR-YOLO achieves superior inference speed while maintaining competitive detection accuracy. This balance of computational efficiency and precision makes the proposed architecture particularly well-suited for small object detection tasks in aerial imagery applications.
For rigorous assessment of the detection performance improvements in the SR-YOLO framework, we evaluated SR-YOLO against seven contemporary object detection algorithms YOLOv5s, YOLOv5m, YOLOv5l, YOLOv7, YOLOv8n, YOLOv8s, and YOLOv11s on the RSOD benchmark dataset, employing three principal evaluation metrics: mAP@0.5, precision, and recall, with detailed performance comparisons presented in
Table 8.
Experimental results presented in
Table 8 demonstrate that SR-YOLO attains a mAP@0.5 of 95.4% on the RSOD dataset, representing a statistically significant improvement over existing YOLO-series architecture. Furthermore, SR-YOLO exhibits superior performance in both precision and recall metrics compared to baseline YOLO variants. These findings substantiate the algorithm’s enhanced capability to mitigate both false negatives and false positives in aerial image target detection applications.
To conclude, relative to the baseline YOLOv8s model, the proposed SR-YOLO algorithm exhibits a modest increment in both parameter count and computational load, while remaining within practical operational limits. Furthermore, comparative evaluations on two publicly available datasets demonstrate SR-YOLO’s superior performance in small target detection compared to state-of-the-art detection methods, confirming its enhanced suitability for aerial image target detection applications.
4.4.4. Visualization Analysis
To validate the effectiveness of the SR-YOLO algorithm in real-world conditions, we conducted comprehensive evaluations using the VisDrone2019 dataset, systematically sampling images across three challenging scenarios: intense scene, sparse scene, and low-light scene.
Figure 14 presents a comparative visualization of detection results from YOLOv8s, YOLOv9s, and SR-YOLO under identical training conditions and parameter configurations.
As illustrated in
Figure 14, the SR-YOLO algorithm achieves robust detection performance for small targets in aerial imagery. Specifically, the model demonstrates reliable identification capabilities for both dense urban scenarios and sparse environments. Under low-light conditions, SR-YOLO maintains effective detection of distant vehicles on highways. Comparative evaluations with YOLOv8s and YOLOv9s confirm that the proposed SR-YOLO architecture significantly reduces both false negatives and false positives across diverse imaging scenarios.
To comprehensively evaluate SR-YOLO’s effectiveness in real-world applications, we randomly selected small target images from aircraft and oil tank scenarios in the RSOD dataset for detection tasks.
Figure 15 presents a comparative visualization of the detection results obtained by YOLOv5s, YOLOv8s, and SR-YOLO algorithms under identical training conditions and parameter configurations.
Figure 15 demonstrates the enhanced small-target detection capability of SR-YOLO across diverse scenarios. In aerial imagery applications, the proposed model achieves accurate localization of small aircraft targets. For industrial inspection tasks, SR-YOLO effectively identifies small oil tank objects, showing superior performance compared to baseline approaches. Comparative evaluations with YOLOv5s and YOLOv8s confirm that SR-YOLO reduces both false negatives and false positives in aerial image analysis, demonstrating improved detection performance for small targets.
To summarize, the enhanced SR-YOLO architecture demonstrates improved small-target detection performance across diverse scenarios, effectively reducing both false positives and false negatives in aerial imagery analysis.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}