


HiGoReg: A Hierarchical Grouping Strategy for Point Cloud Registration

Abstract
1. Introduction
- 1.
- The random errors present in all measurements are taken into account in the functional model, resulting in a more rigorous treatment of the observations with higher robustness.
- 2.
- Compared with the batch solution, the proposed PCR method based on the hierarchical grouping strategy substantially improves the efficiency of parameter estimation while ensuring consistent parameter estimation results.
- 3.
- The effects of two commonly used stochastic models on parameter estimation accuracy and computational efficiency are explored.
- 4.
- We introduce the concept of optimal grouping, and give the value of the number of groups under the minimum computation time through plentiful experiments.
2. Methodology
2.1. Batch Solution
2.2. Hierarchical Grouping Solution
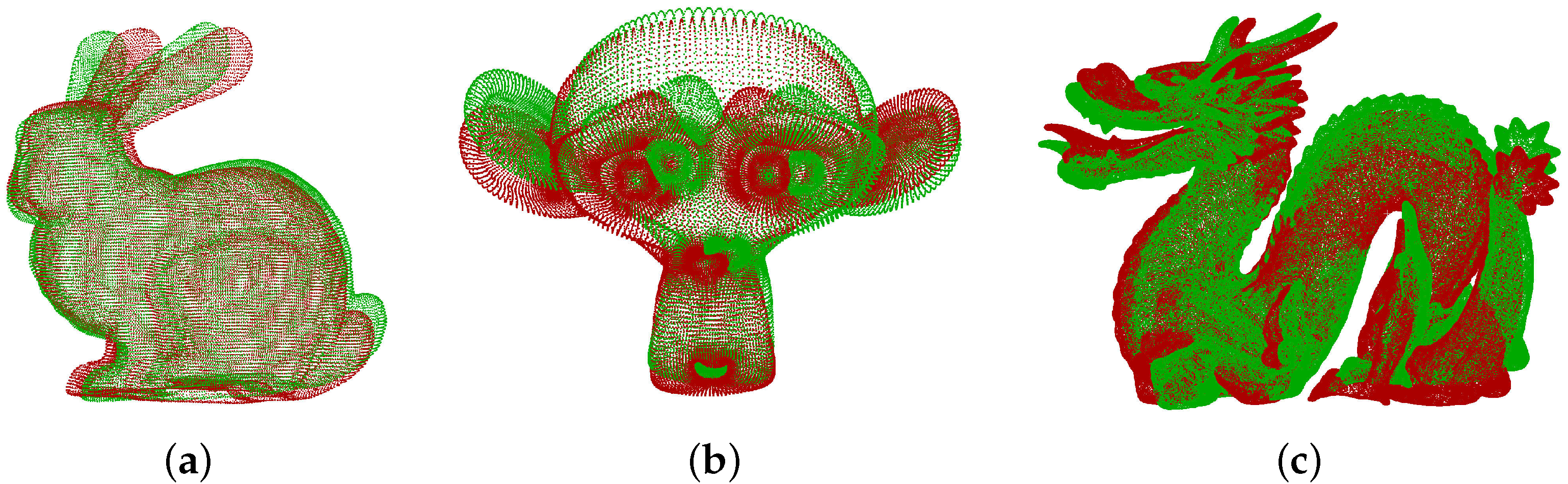
3. Experiments
3.1. Simulation Experiment
- Batch solution.
- HiGoReg method.
3.2. Real-World Data Experiment
4. Results
4.1. Simulated Datasets
4.1.1. Registration Accuracy Metrics
4.1.2. Computational Efficiency
4.2. Real-World Datasets
4.2.1. Registration Accuracy Metrics
4.2.2. Computational Efficiency
5. Discussions
5.1. Impact of Grouping Strategy
5.2. Effect of Dataset Characteristics
5.3. Weighting Schemes in Stochastic Models
5.4. Scalability and Real-World Performance
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Derivation of the Woodbury Matrix Identity
Appendix B. Algorithm of Hierarchical Grouping Strategy
| Algorithm A1: HiGoReg |
 |
References
- Wu, D.; Han, W.; Liu, Y.; Wang, T.; Xu, C.Z.; Zhang, X.; Shen, J. Language prompt for autonomous driving. In Proceedings of the 39th AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 25 February–4 March 2025; Volume 9, pp. 8359–8367. [Google Scholar] [CrossRef]
- Hao, D.; Li, Y.; Liu, H.; Xu, Z.; Zhang, J.; Ren, J.; Wu, J. Deformation monitoring of large steel structure based on terrestrial laser scanning technology. Measurement 2025, 116962. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, C.; Dong, X.; Ning, J. Point Cloud-Based Deep Learning in Industrial Production: A Survey. ACM Comput. Surv. 2025, 57, 1–36. [Google Scholar] [CrossRef]
- Zhou, Y.; Ye, D.; Zhang, H.; Xu, X.; Sun, H.; Xu, Y.; Liu, X.; Zhou, Y. Recurrent diffusion for 3d point cloud generation from a single image. IEEE Trans. Image Process. 2025, 34, 1753–1765. [Google Scholar] [CrossRef] [PubMed]
- Huang, T.; Li, H.; Peng, L.; Liu, Y.; Liu, Y.H. Efficient and robust point cloud registration via heuristics-guided parameter search. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 6966–6984. [Google Scholar] [CrossRef]
- Li, R.; Yuan, X.; Gan, S.; Bi, R.; Gao, S.; Luo, W.; Chen, C. An effective point cloud registration method based on robust removal of outliers. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5701316. [Google Scholar] [CrossRef]
- Jia, S.; Liu, C.; Wu, H.; Huan, W.; Wang, S. Incremental registration towards large-scale heterogeneous point clouds by hierarchical graph matching. ISPRS J. Photogramm. Remote Sens. 2024, 213, 87–106. [Google Scholar] [CrossRef]
- Tang, Z.; Meng, K. Efficient multi-scale 3D point cloud registration. Computing 2025, 107, 48. [Google Scholar] [CrossRef]
- Zhao, Z.; Li, Z.; Wang, B.; Wang, Y.; Shao, K. A Novel 3-D Point Cloud Registration Method with Quaternions Optimization and Data Snooping. IEEE Trans. Instrum. Meas. 2025, 74, 1005215. [Google Scholar] [CrossRef]
- Li, B.L.; Fan, J.S.; Li, J.H.; Liu, Y.F. Semirigid optimal step iterative algorithm for point cloud registration and segmentation in grid structure deformation detection. Autom. Constr. 2025, 171, 105981. [Google Scholar] [CrossRef]
- Lyu, M.; Yang, J.; Qi, Z.; Xu, R.; Liu, J. Rigid pairwise 3D point cloud registration: A survey. Pattern Recognit. 2024, 110408. [Google Scholar] [CrossRef]
- Xu, Y.; Ma, S.; Yao, X.; Zhang, Z.; Yan, Q.; Chen, J. Tunnel full-space deformation measurement based on improved downsampling and registration approach by point clouds. Measurement 2025, 242, 116026. [Google Scholar] [CrossRef]
- Lyu, W.; Ke, W.; Sheng, H.; Ma, X.; Zhang, H. Dynamic Downsampling Algorithm for 3D Point Cloud Map Based on Voxel Filtering. Appl. Sci. 2024, 14, 3160. [Google Scholar] [CrossRef]
- Tao, W.; Xiao, Y.; Wang, R.; Lu, T.; Xu, S. A Fast Registration Method for Building Point Clouds Obtained by Terrestrial Laser Scanner via 2-D Feature Points. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 9324–9336. [Google Scholar] [CrossRef]
- Yang, L.; Xu, S.; Yang, Z.; He, J.; Gong, L.; Wang, W.; Li, Y.; Wang, L.; Chen, Z. Fast Registration Algorithm for Laser Point Cloud Based on 3D-SIFT Features. Sensors 2025, 25, 628. [Google Scholar] [CrossRef]
- Dong, Z.; Yang, B.; Liu, Y.; Liang, F.; Li, B.; Zang, Y. A novel binary shape context for 3D local surface description. ISPRS J. Photogramm. Remote Sens. 2017, 130, 431–452. [Google Scholar] [CrossRef]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast point feature histograms (FPFH) for 3D registration. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 3212–3217. [Google Scholar] [CrossRef]
- Lim, H.; Kim, D.; Shin, G.; Shi, J.; Vizzo, I.; Myung, H.; Park, J.; Carlone, L. KISS-Matcher: Fast and Robust Point Cloud Registration Revisited. arXiv 2024, arXiv:2409.15615. [Google Scholar]
- Yan, L.; Wei, P.; Xie, H.; Dai, J.; Wu, H.; Huang, M. A new outlier removal strategy based on reliability of correspondence graph for fast point cloud registration. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 7986–8002. [Google Scholar] [CrossRef]
- Chang, Q.; Wang, W.; Miyazaki, J. Accelerating Nearest Neighbor Search in 3D Point Cloud Registration on GPUs. ACM Trans. Archit. Code Optim. 2025, 22, 1–24. [Google Scholar] [CrossRef]
- Besl, P.J.; McKay, N.D. A method for registration of 3-D shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Lan, F.; Castellani, M.; Zheng, S.; Wang, Y. The SVD-enhanced bees algorithm, a novel procedure for point cloud registration. Swarm Evol. Comput. 2024, 88, 101590. [Google Scholar] [CrossRef]
- Fu, S.; Ma, C.; Li, K.; Xie, C.; Fan, Q.; Huang, H.; Xie, J.; Zhang, G.; Yu, M. Modified LSHADE-SPACMA with new mutation strategy and external archive mechanism for numerical optimization and point cloud registration. Artif. Intell. Rev. 2025, 58, 72. [Google Scholar] [CrossRef]
- Koide, K. small_gicp: Efficient and parallel algorithms for point cloud registration. J. Open Source Softw. 2024, 9, 6948. [Google Scholar] [CrossRef]
- Vizzo, I.; Guadagnino, T.; Mersch, B.; Wiesmann, L.; Behley, J.; Stachniss, C. Kiss-icp: In defense of point-to-point icp–simple, accurate, and robust registration if done the right way. IEEE Robot. Autom. Lett. 2023, 8, 1029–1036. [Google Scholar] [CrossRef]
- Lyu, F.; Song, X.; Shi, Y.; Li, G.; Wang, H. Different-scale dense point cloud registration algorithm for drone based on VCDEI-SCHO-ICP. Surv. Rev. 2025, 1–13. [Google Scholar] [CrossRef]
- Gruen, A. Adaptive least squares correlation: A powerful image matching technique. S. Afr. J. Photogramm. Remote Sens. Cartogr. 1985, 14, 175–187. [Google Scholar]
- Brockett, R.W. Least squares matching problems. Linear Algebra Its Appl. 1989, 122, 761–777. [Google Scholar] [CrossRef]
- Bethmann, F.; Luhmann, T. Least-squares matching with advanced geometric transformation models. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2010, 38, 86–91. [Google Scholar]
- Gruen, A.; Akca, D. Least squares 3D surface and curve matching. ISPRS J. Photogramm. Remote Sens. 2005, 59, 151–174. [Google Scholar] [CrossRef]
- Akca, D. Co-registration of surfaces by 3D least squares matching. Photogramm. Eng. Remote Sens. 2010, 76, 307–318. [Google Scholar] [CrossRef]
- Guo, F.; Liu, K.; Huang, B. Laplace Distribution Based Robust Identification of Errors-in-Variables Systems with Outliers. IEEE Trans. Ind. Electron. 2025, 1–10. [Google Scholar] [CrossRef]
- Hu, Y.; Fang, X. Linear estimation under the Gauss–Helmert model: Geometrical interpretation and general solution. J. Geod. 2023, 97, 44. [Google Scholar] [CrossRef]
- Wang, B.; Zhao, Z.; Wang, S.; Yu, J.; Chen, Y. Robust LS-VCE for the nonlinear Gauss-Helmert model: Case studies for point cloud fitting and geodetic symmetric transformation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4701413. [Google Scholar] [CrossRef]
- Wang, B.; Zhao, Z.; Chen, Y.; Yu, J. A novel robust point cloud fitting algorithm based on nonlinear Gauss-Helmert model. IEEE Trans. Instrum. Meas. 2023, 72, 1002012. [Google Scholar] [CrossRef]
- Vogel, S.; Ernst, D.; Neumann, I.; Alkhatib, H. Recursive Gauss-Helmert model with equality constraints applied to the efficient system calibration of a 3D laser scanner. J. Appl. Geod. 2022, 16, 37–57. [Google Scholar] [CrossRef]
- Ge, X.M.; Wunderlich, T. Surface-based matching of 3D point clouds with variable coordinates in source and target system. ISPRS J. Photogramm. Remote Sens. 2016, 111, 1–12. [Google Scholar] [CrossRef]
- Hu, Y.; Fang, X.; Zeng, W. Nonlinear least-squares solutions to the TLS multi-station registration adjustment problem. ISPRS J. Photogramm. Remote Sens. 2024, 218, 220–231. [Google Scholar] [CrossRef]
- Lee, E.; Kwon, Y.; Kim, C.; Choi, W.; Sohn, H.G. Multi-source point cloud registration for urban areas using a coarse-to-fine approach. Giscience Remote Sens. 2024, 61, 2341557. [Google Scholar] [CrossRef]
- Ghorbani, F.; Chen, Y.C.; Hollaus, M.; Pfeifer, N. A Robust and Automatic Algorithm for TLS–ALS Point Cloud Registration in Forest Environments Based on Tree Locations. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 4015–4035. [Google Scholar] [CrossRef]
- Wu, Y.; Sheng, J.; Ding, H.; Gong, P.; Li, H.; Gong, M.; Ma, W.; Miao, Q. Evolutionary Multitasking Descriptor Optimization for Point Cloud Registration. IEEE Trans. Evol. Comput. 2024, 2024, 1. [Google Scholar] [CrossRef]
- Wang, Z.; Li, P.; Zhang, Q.; Zhu, L.; Tian, W. A LiDAR-depth camera information fusion method for human robot collaboration environment. Inf. Fusion 2025, 114, 102717. [Google Scholar] [CrossRef]
- Wimmer, T.; Wonka, P.; Ovsjanikov, M. Back to 3D: Few-Shot 3D Keypoint Detection with Back-Projected 2D Features. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 4154–4164. [Google Scholar] [CrossRef]
- Liu, Q.; Zhu, H.; Wang, Z.; Zhou, Y.; Chang, S.; Guo, M. Extend your own correspondences: Unsupervised distant point cloud registration by progressive distance extension. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 20816–20826. [Google Scholar]
- Xing, X.; Lu, Z.; Wang, Y.; Xiao, J. Efficient Single Correspondence Voting for Point Cloud Registration. IEEE Trans. Image Process. 2024, 33, 2116–2130. [Google Scholar] [CrossRef] [PubMed]
- Mu, J.; Bie, L.; Du, S.; Gao, Y. Colorpcr: Color point cloud registration with multi-stage geometric-color fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 21061–21070. [Google Scholar]
- Zhou, W.; Ren, L.; Yu, J.; Qu, N.; Dai, G. Boosting RGB-D Point Cloud Registration via Explicit Position-Aware Geometric Embedding. IEEE Robot. Autom. Lett. 2024, 9, 5839–5846. [Google Scholar] [CrossRef]
- Brockmann, J.M.; Schuh, W.D. Computational Aspects of High-resolution Global Gravity Field Determination–Numbering Schemes and Reordering. In Proceedings of the NIC Symposium 2016, Jülich, Germany, 1–12 February 2016; John von Neumann-Institut für Computing: Jülich, Germany, 2016; pp. 309–317. [Google Scholar]
- Klees, R.; Ditmar, P.; Kusche, J. Numerical techniques for large least-squares problems with applications to GOCE. In Proceedings of the V Hotine-Marussi Symposium on Mathematical Geodesy, Matera, Italy, 17–21 June 2003; Springer: Berlin/Heidelberg, Germany, 2004; pp. 12–21. [Google Scholar] [CrossRef]
- Zhang, Z. Iterative point matching for registration of free-form curves and surfaces. Int. J. Comput. Vis. 1994, 13, 119–152. [Google Scholar] [CrossRef]
- Rusinkiewicz, S.; Levoy, M. Efficient variants of the ICP algorithm. In Proceedings of the 3rd International Conference on 3-D Digital Imaging and Modeling, Quebec City, QC, Canada, 28 May–1 June 2001; pp. 145–152. [Google Scholar] [CrossRef]
- Mahboub, V.; Saadatseresht, M.; Ardalan, A.A. A solution to dynamic errors-in-variables within system equations. Acta Geod. Geophys. 2018, 53, 31–44. [Google Scholar] [CrossRef]
- Zeng, W.; Liu, J.; Yao, Y. On partial errors-in-variables models with inequality constraints of parameters and variables. J. Geod. 2015, 89, 111–119. [Google Scholar] [CrossRef]
- Xu, P.; Liu, J.; Shi, C. Total least squares adjustment in partial errors-in-variables models: Algorithm and statistical analysis. J. Geod. 2012, 86, 661–675. [Google Scholar] [CrossRef]
- Wang, J.; Lu, X.; Bennamoun, M.; Sheng, B. Non-rigid Point Cloud Registration via Anisotropic Hybrid Field Harmonization. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 1–18. [Google Scholar] [CrossRef]
- Zhang, Y.X.; Gui, J.; Cong, X.; Gong, X.; Tao, W. A comprehensive survey and taxonomy on point cloud registration based on deep learning. arXiv 2024, arXiv:2404.13830. [Google Scholar]
- Zhao, Y.; Zhang, J.; Xu, S.; Ma, J. Deep learning-based low overlap point cloud registration for complex scenario: The review. Inf. Fusion 2024, 107, 102305. [Google Scholar] [CrossRef]
- Hou, P.; Zhang, B. A generalized least-squares filter designed for GNSS data processing. J. Geod. 2025, 99, 3. [Google Scholar] [CrossRef]
- Teunissen, P.J. Dynamic Data Processing: Recursive Least-Squares; TU Delft OPEN Publishing: Delft, The Netherlands, 2024. [Google Scholar] [CrossRef]
- Zhao, J.; Qian, X.; Jiang, B. Lithium battery state of charge estimation based on improved variable forgetting factor recursive least squares method and adaptive Kalman filter joint algorithm. J. Energy Storage 2024, 100, 113392. [Google Scholar] [CrossRef]
- Koide, H.; Vayssettes, J.; Mercère, G. A Robust and Regularized Algorithm for Recursive Total Least Squares Estimation. IEEE Control. Syst. Lett. 2024, 8, 1006–1011. [Google Scholar] [CrossRef]
- Zhou, T.; Lin, P.; Zhang, S.; Zhang, J.; Fang, J. A novel sequential solution for multi-period observations based on the Gauss-Helmert model. Measurement 2022, 193, 110916. [Google Scholar] [CrossRef]
- Shen, Y.; Li, B.; Chen, Y. An iterative solution of weighted total least-squares adjustment. J. Geod. 2011, 85, 229–238. [Google Scholar] [CrossRef]
- Hager, W.W. Updating the inverse of a matrix. SIAM Rev. 1989, 31, 221–239. [Google Scholar] [CrossRef]
- Lu, T.; Wu, G.; Zhou, S. Ridge estimation algorithm to ill-posed uncertainty adjustment model. Acta Geod. Cartogr. Sin. 2019, 48, 403. [Google Scholar] [CrossRef]
- Golub, G.H.; Hansen, P.C.; O’Leary, D.P. Tikhonov regularization and total least squares. SIAM J. Matrix Anal. Appl. 1999, 21, 185–194. [Google Scholar] [CrossRef]
- Wang, H.; Zeng, Q.; Jiao, J.; Chen, J. InSAR Time Series Analysis Technique Combined with Sequential Adjustment Method for Monitoring of Surface Deformation. Acta Sci. Nat. Univ. Pekin. 2021, 57, 241–249. [Google Scholar] [CrossRef]
- Liu, Y.; Yan, X.; Xia, Y.; Zhao, Z. Monitoring and Analysis of Surface Deformation in Beijing Plain Using Progressive SBAS-InSAR. J. Geod. Geodyn. 2023, 43, 239–245. [Google Scholar] [CrossRef]
- Zhong, Y. Intrinsic shape signatures: A shape descriptor for 3D object recognition. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 689–696. [Google Scholar] [CrossRef]
- Zinßer, T.; Schmidt, J.; Niemann, H. A refined ICP algorithm for robust 3-D correspondence estimation. In Proceedings of the 2003 International Conference on Image Processing (Cat. No. 03CH37429), Barcelona, Spain, 14–17 September 2003; Volume 2, p. II-695. [Google Scholar] [CrossRef]
- Wang, X.; Yang, Z.; Cheng, X.; Stoter, J.; Xu, W.; Wu, Z.; Nan, L. GlobalMatch: Registration of forest terrestrial point clouds by global matching of relative stem positions. ISPRS J. Photogramm. Remote Sens. 2023, 197, 71–86. [Google Scholar] [CrossRef]
- Dong, Z.; Liang, F.; Yang, B.; Xu, Y.; Zang, Y.; Li, J.; Wang, Y.; Dai, W.; Fan, H.; Hyyppä, J.; et al. Registration of large-scale terrestrial laser scanner point clouds: A review and benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 163, 327–342. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Model | Time Complexity | Data Assumptions and Constraints |
|---|---|---|---|
| ICP [21,50,51] | Requires significant overlap and good initial transformation; sensitive to outliers; may fall into local minima. | ||
| LS3D [30,31] | Assumes Gaussian noise only in target cloud; source cloud is noise-free; may lead to biased, asymmetric estimation. | ||
| EIV [52,53,54] | Total Least Squares; Gaussian noise in both point clouds; risk of singular or unstable coefficient matrix. | ||
| GH-LS3D [34,35,37] | Symmetric error modeling; multivariate Gaussian noise; nonlinear model; needs iterative linearization; sensitive to initial values; high-dimensional computational matrices. | ||
| RGH [36] | Assumes independent Gaussian process and measurement noise; requires well-set process noise to avoid divergence; complex computation steps. | ||
| HiGoReg (ours) | Group-based recursive estimation; assumes Gaussian noise; high computational efficiency; optimal grouping with around 100 points in each group. |
| Datasets | Schemes | Voxel Grid (m) | RMSE (m) | (m) | Errors | |
|---|---|---|---|---|---|---|
| Bunny | Batch | 0.001 | 0 | |||
| HiGoReg | 0.001 | 0 | ||||
| Monkey | Batch | 0.001 | 0 | |||
| HiGoReg | 0.001 | 0 | ||||
| Dragon | Batch | 0.001 | 0 | |||
| HiGoReg | 0.001 | 0 | ||||
| Large-scale | Batch | 0 | 0 | |||
| HiGoReg | 0 | 0 | ||||
| Datasets | Batch (s) | HiGoReg (s) | Improvement (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Min 1 | Max 2 | Ave 3 | Min | Max | Ave | Min | Max | Ave | |
| Bunny | 1.3763 | 1.4649 | 1.4151 | 0.8537 | 0.9144 | 0.8748 | 37.86 | 37.58 | 38.18 |
| Monkey | 4.7757 | 5.0573 | 4.9710 | 1.2902 | 1.4239 | 1.3517 | 72.98 | 71.84 | 72.81 |
| Dragon | 20.2370 | 21.8469 | 20.8628 | 3.5107 | 3.7435 | 3.6131 | 82.65 | 82.86 | 82.68 |
| Large-scale | 2079.8988 | 2082.2567 | 2081.1157 | 4.3026 | 4.4598 | 4.3611 | 99.79 | 99.79 | 99.79 |
| Schemes | Voxel Grid (m) | RMSE (m) | (m) | Iteration | Time (s) | Errors | |
|---|---|---|---|---|---|---|---|
| (rad) | (m) | ||||||
| Batch | 0.03 | 0.0240 | 0.0078 | 5 | 454.6589 | 0.0041 | |
| 0.05 | 0.0243 | 0.0082 | 6 | 71.9290 | 0.0044 | ||
| HiGoReg | 0.03 | 0.0240 | 0.0078 | 5 | 19.0796 | 0.0041 | |
| 0.05 | 0.0243 | 0.0082 | 6 | 6.6133 | 0.0044 | ||
| Schemes | Stochastic Model | Voxel Grid (m) | RMSE (m) | (m) | Iterations | Ave Time (s) |
|---|---|---|---|---|---|---|
| Batch | Equal weight | 0.001 | 0.0102 | 5 | 2.1177 | |
| Nominal weight | 0.001 | 0.0021 | 5 | 3.9096 | ||
| HiGoReg | Equal weight | 0.001 | 0.0102 | 5 | 1.8276 | |
| Nominal weight | 0.001 | 0.0021 | 5 | 2.7503 |
| Metrics | Bunny | Monkey | Dragon | Large-Scale | Subway (0.03 m) | Subway (0.05 m) | Statue |
|---|---|---|---|---|---|---|---|
| ISS points | 330 | 223 | 936 | 7000 | 3698 | 1665 | 244 |
| Stochastic model | E | E | E | E | E | E | E/N |
| Optimal groups | 3 | 3 | 9 | 70 | 20 | 10 | 3/2 |
| Points per group | 110 | 74 | 104 | 100 | 185 | 166 | 81/122 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, T.; Gu, J.; Dong, Z. HiGoReg: A Hierarchical Grouping Strategy for Point Cloud Registration. Remote Sens. 2025, 17, 2433. https://doi.org/10.3390/rs17142433
Zhou T, Gu J, Dong Z. HiGoReg: A Hierarchical Grouping Strategy for Point Cloud Registration. Remote Sensing. 2025; 17(14):2433. https://doi.org/10.3390/rs17142433
Chicago/Turabian StyleZhou, Tengfei, Jianxiang Gu, and Zhen Dong. 2025. "HiGoReg: A Hierarchical Grouping Strategy for Point Cloud Registration" Remote Sensing 17, no. 14: 2433. https://doi.org/10.3390/rs17142433
APA StyleZhou, T., Gu, J., & Dong, Z. (2025). HiGoReg: A Hierarchical Grouping Strategy for Point Cloud Registration. Remote Sensing, 17(14), 2433. https://doi.org/10.3390/rs17142433