1. Introduction
Sea level anomaly (SLA) is a crucial parameter for monitoring the dynamic marine environment and is used in various applications such as understanding ocean circulation variability, predicting extreme climate events like El Ni no, and assessing global sea level rise trends [
1,
2,
3]. However, the spatial resolution of SLA data derived from satellite altimeters is typically 1/4° (approximately 25 km), which is insufficient for high-precision oceanographic research [
4]. For example, Copernicus/AVISO now provides gridded SLA products at 1/8° resolution in historical and near-real-time datasets, offering improved spatial detail; nonetheless, even these may not fully capture finer mesoscale processes. Applications such as fine-scale modeling of nearshore waters and precise detection of mesoscale eddies (10–100 km), therefore, require even higher-resolution SLA products (e.g., 1/16°) [
5]. Mesoscale eddies contribute over 90% of the global ocean kinetic energy flux, but their spatial scales (typically below 100 km) mean that 1/4° data cannot accurately resolve their boundary geometries and three-dimensional structures [
6]. Increasing SLA resolution to 1/16° has been shown to improve eddy identification accuracy by approximately 30%, significantly enhancing the quantification of oceanic material transport, including heat and salinity [
7]. Moreover, high-resolution SLA data are essential for analyzing air–sea interactions, such as the upper-ocean response to typhoons, and for initializing nearshore circulation models [
8].
However, conventional approaches to enhancing SLA resolution exhibit notable limitations. Traditional interpolation techniques (e.g., bilinear interpolation) fail to preserve high-frequency details of the physical field, resulting in over-smoothed reconstructions [
9]. Likewise, dynamic downscaling using regional ocean models (e.g., ROMS) can capture small-scale processes but incur high computational cost and require complex parameterizations [
10]. For example, gridded SLA at 1/4° produced from multiple altimeters still misses many mesoscale eddies, highlighting the shortcomings of simple interpolation. These challenges motivate data-driven downscaling: statistical methods establish empirical relationships between large-scale predictors and local variables to generate fine-scale fields. In practice, statistical downscaling has been widely used in climate impact studies [
11], but its accuracy depends on the quality of training data and predictors. With the rapid expansion of big Earth datasets and improvements in computational capabilities, deep learning has shown great potential to advance statistical downscaling [
12]. In particular, convolutional neural networks (CNNs), with their ability to automatically extract spatial features, have become a cornerstone of downscaling approaches [
13]. CNNs’ multi-layer architectures can capture complex nonlinear mappings from coarse to fine scales, often outperforming traditional statistical techniques [
14]. However, even with these advances, developing efficient and physically consistent downscaling methods remains a priority in ocean remote sensing [
15].
Recent advancements in deep learning have provided innovative solutions to the challenges of statistical downscaling [
16]. For instance, the DeepSD framework [
17] couples low-resolution climate model outputs with high-resolution topography to improve precipitation downscaling. In the oceanographic context, Generative Adversarial Networks (GANs) have been used to downscale 1° sea surface temperature (SST) fields to 0.25°, thereby improving the timeliness of El Ni no index predictions [
18]. Similarly, Martin et al. [
19] employed a ConvLSTM model to integrate multi-temporal satellite altimeter data, achieving dynamic reconstruction of submesoscale (less than 10 km) sea surface height with high fidelity (correlation 0.90 compared to Argo float data). These examples demonstrate that deep neural networks can enhance the spatial resolution of ocean surface fields beyond traditional methods.
Despite these advances, most current deep learning approaches rely on single-modality inputs and face significant limitations. Conventional CNN models often neglect the spatial heterogeneity between land and ocean regions when processing marine data, leading to suboptimal feature representation for variables such as SLA [
9]. They also involve high computational complexity, which can be a bottleneck for large-scale applications [
20]. In addition, the spatiotemporal distribution of SLA is synergistically regulated by multiple oceanographic factors—such as sea surface wind fields, currents, and temperature. For example, seasonal and interannual SLA variations in the South China Sea are coupled with wind stress curl, the Kuroshio Current, and ENSO-related heat content changes [
21]. Integrating multi-source remote sensing data (e.g., along-track altimetry, scatterometry, and infrared SST) can effectively capture these coupled processes [
22]. Indeed, combining altimetry with high-resolution SST imagery has been shown to produce more accurate, higher-resolution SLA maps, reducing the root-mean-square error (RMSE) by 20% while doubling spatial resolution compared to traditional methods [
19]. Similarly, interpolating sea surface height fields from simulated multi-variable satellite observations (including SSH and SST) achieved a 25% RMSE reduction in regions with complex dynamics [
23]. These findings indicate that multi-modal data fusion can significantly improve downscaling performance and physical interpretability.
Nevertheless, current network architectures still encounter challenges when processing multi-modal, high-dimensional data. Standard convolutional layers often suffer from parameter redundancy, leading to inefficient training [
24]. Moreover, the mean squared error (MSE) loss function commonly used in super-resolution tasks ensures pixel-level consistency but fails to preserve important spatial structures in SLA fields [
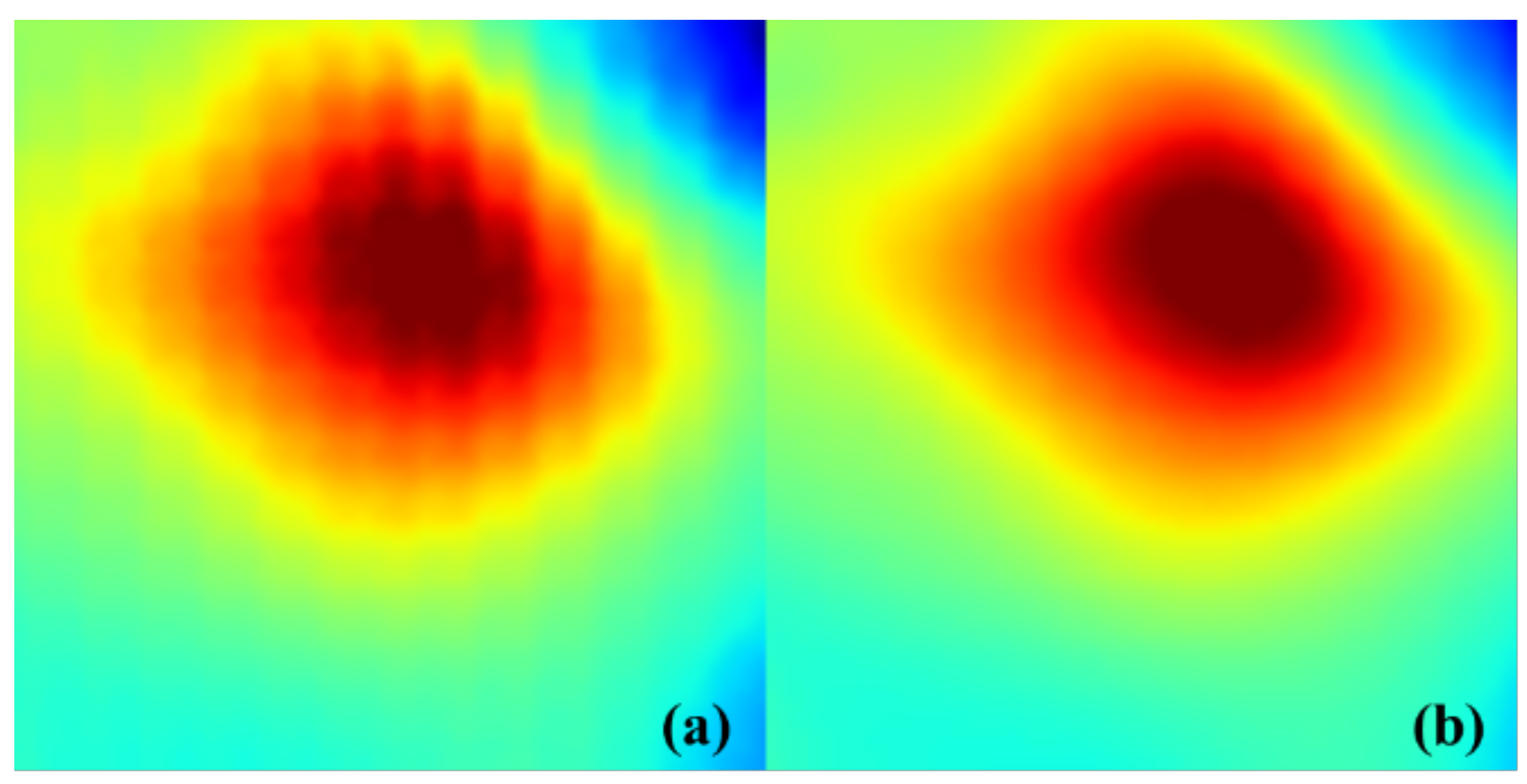
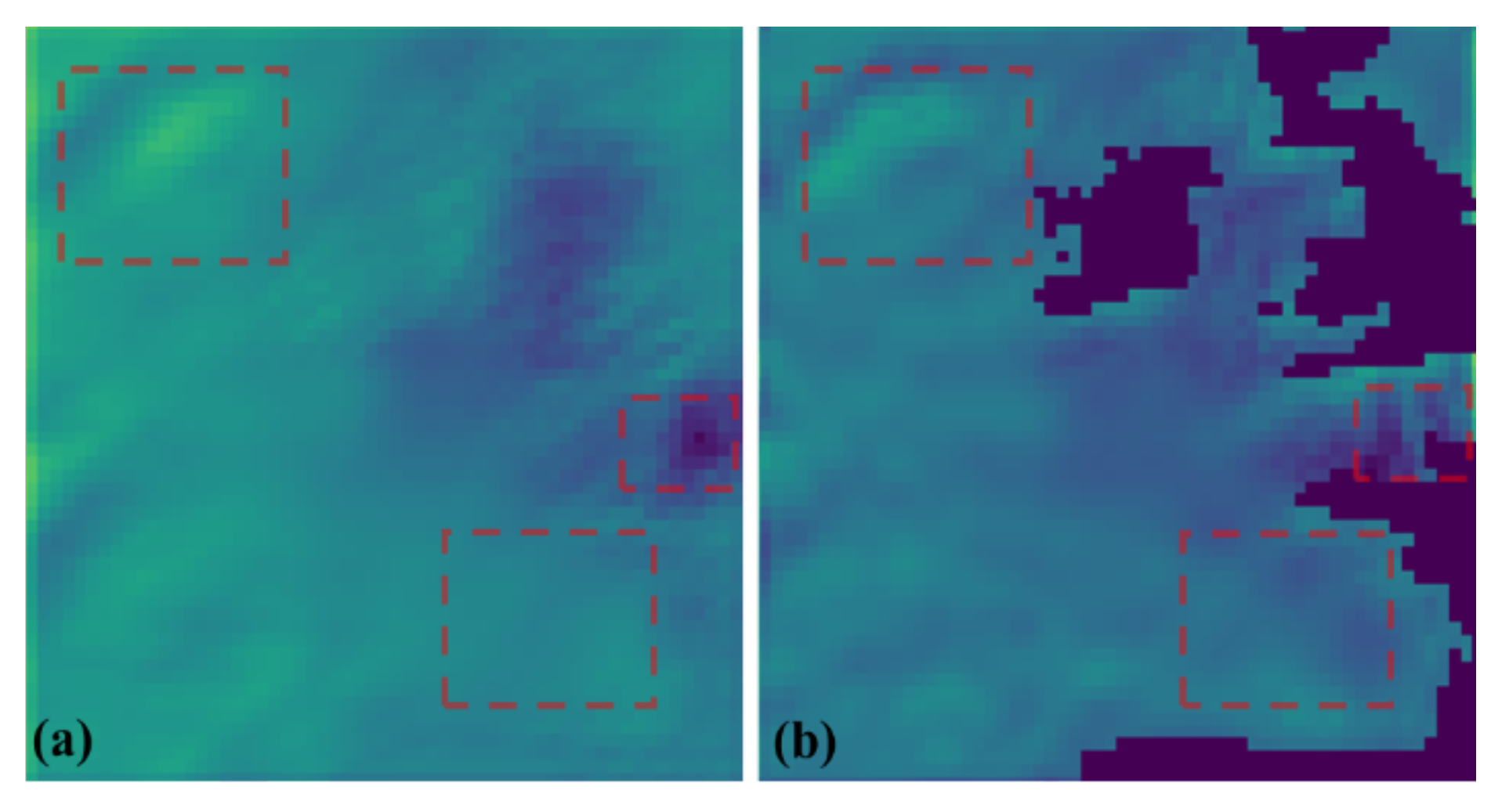
25]. This can result in over-smoothed reconstructions where the closed-contour features of mesoscale eddies are lost, as illustrated in
Figure 1a. Such smoothing reduces the reliability of downstream applications like eddy identification and tracking [
26].
To address these challenges, this study proposes a novel multi-modal fusion framework based on the Deep Separable Distillation Network (DSDN) and introduces an innovative Pixel-Structure Loss function (PSLoss). The framework achieves significant advancements through the following core components:
Depthwise Separable Convolution Module: The standard convolution operations are replaced with depthwise separable convolutions, reducing the parameter count by 50% while retaining the nonlinear expression capability for multi-modal features.
Landmask Contextual Attention Mechanism: The M_CAMB uses land masks to direct attention, enhancing the model’s focus on relevant ocean areas and ensuring that the network prioritizes ocean pixels, which are crucial for SLA data.
Pixel-Structure Loss Function: Building upon the traditional MSELoss, the PSLoss incorporates a structural similarity (SSIM) constraint term. The SSIM component optimizes vortex closure morphology by mimicking human visual perception of structural characteristics (as shown in
Figure 1b). Theoretical and experimental analyses demonstrate that PSLoss effectively suppresses smoothing effects, reducing the area error of vortex closure in downscaling results.
2. Materials and Methods
2.1. Study Area and Data
2.1.1. Study Area
This study aims to obtain the downscaling of SLA data in two representative marine regions, as shown in
Figure 2. The first region, shown in
Figure 2a, is the Bay of Biscay–Irish Seas (BIA) in the Atlantic, spanning latitudes 42°N to 58°N and longitudes 16°W to 0°W. This region is characterized by its complex ocean dynamics, influenced by the North Atlantic Current and frequent mid-latitude storm systems, resulting in highly variable SLA [
1,
27]. The second region, shown in
Figure 2b, is the South China Sea (SCS), covering latitudes 6°N to 22°N and longitudes 106°E to 122°E. As a semi-enclosed marginal sea, the SCS features a unique marine environment with a complex basin-shelf topography, including numerous islands and coral reefs [
28]. Seasonal variations in wind stress, precipitation, and river runoff, driven by the East Asian monsoon, contribute to pronounced seasonal fluctuations in sea level [
29].
2.1.2. SLA Data
In this study, we utilized three datasets of SLA from the Copernicus Marine Environment Monitoring Service (CMEMS), a leading platform for high-quality oceanographic datasets. These datasets include: (1) the Global Ocean Gridded L4 Sea Surface Heights and Derived Variables Reprocessed Copernicus Climate Service SEALEVEL_GLO_PHY_CLIMATE_L4_MY_008_057, which provides monthly SLA data at a
resolution for climate studies [
30]; (2) the Global Ocean Gridded L4 Sea Surface Heights and Derived Variables Reprocessed 1993 Ongoing SEALEVEL_GLO_PHY_L4_MY_008_047, which offers daily SLA data at a
resolution [
31]; and (3) the European Seas Gridded L4 Sea Surface Heights and Derived Variables Reprocessed 1993 Ongoing SEALEVEL_EUR_PHY_L4_MY_008_068, which provides daily and monthly SLA data at a finer
resolution specifically tailored to European seas [
32]. More detailed information on each dataset can be found in
Table 1.
This study investigates two marine regions, the BIA and SCS, utilizing daily SLA datasets with varying spatial resolutions. For the BIA region, SLA datasets with resolutions of 0.25°, 0.125°, and 0.0625° were employed to construct two different downscaling datasets ( and ). In contrast, the SCS region utilized a downscaling dataset. The datasets encompass a temporal span of 18 to 23 years, with daily observations ensuring both temporal continuity and sufficient sample size.
To evaluate and validate the model performance, the dataset was divided into three parts: the data from 18 to 22 years was allocated for model training and validation, while the data from 23 years served as an independent test set. This data partitioning strategy not only supports effective model training but also provides a scientific basis for assessing the model’s downscaling performance across different marine regions, enabling a direct comparison of model performance in various areas.
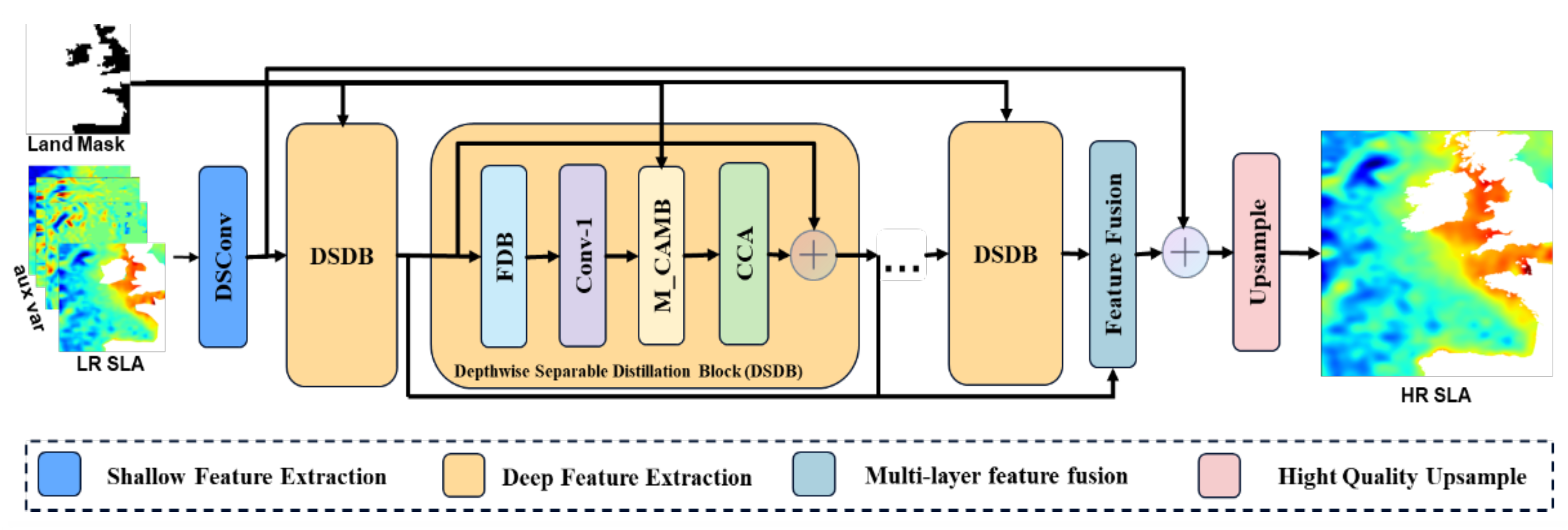
2.2. Deep Separable Distillation Network
2.2.1. Network Architecture
The overall architecture of our method, DSDN, is shown in
Figure 3. It is inherited from the structure of RFDN [
33], which is the champion solution of AIM 2020 Challenge on Efficient Super-Resolution. It consists of four stages: shallow feature extraction, deep feature extraction, multi-layer feature fusion, and reconstruction. Let us denote
and
as the input and output data. In pre-processing, the input data is first replicated n times. Then we concatenate these data together as:
In this context, the symbol
is employed to denote the concatenation operation along the channel dimension, with
n signifying the number of
to be concatenated. The subsequent shallow feature extraction process maps the input image to a higher-dimensional feature space as follows:
In this study, we utilize the notation
to represent the module of shallow feature extraction. Specifically, a DSConv [
24] is employed to facilitate shallow feature extraction. The architecture of DSConv is illustrated in
Figure 4e, comprising a depth-wise convolution and a 1 × 1 convolution. Subsequently,
is employed for the purpose of deep feature extraction by a stack of DSDBs, which gradually refine the extracted features. The aforementioned process can be formulated as follows:
where
denotes the
k-th DSDB.
and
represent the input feature and output feature of the
k-th DSDB, respectively. To fully utilize features from all depths, features generated at different depths are fused and mapped by a 1 × 1 convolution and a GELU [
34] activation. Then, a DSConv is used to refine features. The multi-layer feature fusion is formulated as:
where
represents the fusion module and
is the aggregated feature. To take advantage of residual [
35] learning, a long skip connection is involved. The reconstruction stage is formulated as:
where
denotes the reconstruction module, which consists of a standard convolution layer and a pixelshuffle operation [
36].
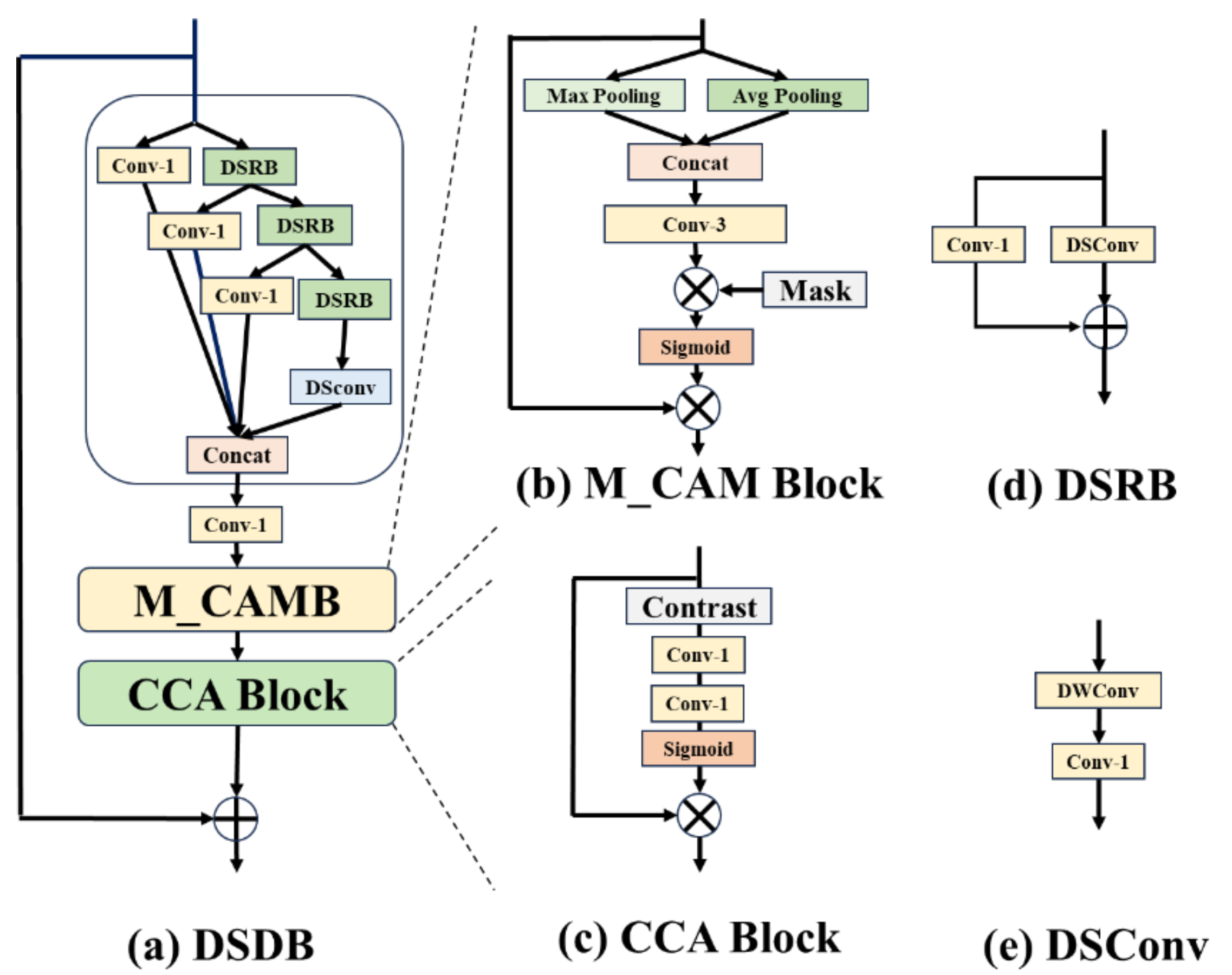
2.2.2. Depthwise Separable Distillation Block
Inspired by the Residual Feature Distillation Block (RFDB) in RFDN [
33], we propose an efficient Depthwise Separable Distillation Block (DSDB) that retains a similar structure to RFDB but is optimized for both efficiency and performance (Experimentally validated in
Section 4.3.3). The overall architecture of DSDB is illustrated in
Figure 4a, comprising three primary stages: feature distillation, feature condensation, and feature enhancement. In the feature distillation stage, given an input feature
, we progressively extract and refine features through a series of distillation and refinement layers. This process can be formulated as:
where
denotes the distillation layer that generates distilled features, and
represents the refinement layer that further refines coarse features step by step. In the feature condensation stage, the distilled features
are concatenated along the channel dimension and condensed using a
convolution layer, expressed as:
where
denotes the
convolution layer, and
is the condensed feature. In the feature enhancement stage, to boost the model’s representational capacity while maintaining efficiency, we propose a novel LandMask Contextual Attention Mechanism (M_CAMB) alongside the Contrast-aware Channel Attention (CCA) to enhance the spatial downscaling of sea level anomaly (SLA) fields, as depicted in
Figure 4c. M_CBAM incorporates landmask information to not only enhance the network’s focus on spatial features but also guide the network to prioritize the spatial characteristics of marine data, particularly excelling in handling sea level anomaly data with complex spatial structures. The feature enhancement process is formulated as:
where
and
represent the M_CBAM and CCA modules, respectively, and
is the final enhanced feature. M_CBAM dynamically generates masks to emphasize critical spatial features in marine regions, thereby improving the model’s ability to capture fine details. Meanwhile, CCA further refines feature representations by exploiting contrast information across channels. Experimental results demonstrate that the combination of M_CAMB and CCA significantly enhances the model’s performance in spatial downscaling tasks.
2.2.3. Landmask Contextual Attention Mechanism (M_CAMB)
To enhance the model’s capability in modeling spatial features of marine data, such as sea level anomaly data, we propose the Landmask Contextual Attention Mechanism (M_CAMB), the structure of M_CAMB is shown in
Figure 4b, built upon the Convolutional Block Attention Module (CBAM) [
37]. CBAM integrates channel and spatial attention to effectively capture global and local feature information. By incorporating a landmask derived from geographic information into CBAM’s spatial attention module, M_CAMB strengthens the model’s focus on complex spatial structures in marine regions, leading to superior performance in spatial downscaling tasks. The design of M_CAMB consists of two core steps: first, defining the landmask to distinguish between land and marine regions, and then integrating the mask into CBAM’s spatial attention computation to generate an enhanced attention map.
Landmask Definition: The landmask
is a binary spatial matrix derived directly from geographic information, used to distinguish land and marine regions in the input feature
. It is defined as:
where
denotes the spatial position in the feature map. The mask is sourced from external geographic data, such as satellite mapping or map databases, and aligned with the spatial resolution of the input feature to accurately reflect real-world surface distributions. This mask provides a clear regional delineation for the subsequent spatial attention computation, enabling the model to prioritize marine regions.
Improved Spatial Attention Mechanism: In CBAM’s original spatial attention module, the spatial attention map is generated through the following steps: the input feature
is first processed by max pooling and average pooling operations to produce two
feature maps; these feature maps are then concatenated along the channel dimension and passed through a 3 × 3 convolutional layer to extract spatial contextual information; finally, a Softmax function is applied for normalization to obtain the spatial attention map. To enhance the model’s focus on marine regions, we introduce the landmask
after generating the preliminary spatial attention map, adjusting the attention weights through element-wise multiplication to amplify the weights in marine regions. This process is formulated as:
where MaxPool and AvgPool denote max pooling and average pooling, respectively, Concat represents concatenation along the channel dimension,
is a 3 × 3 convolutional layer, and ⊙ indicates element-wise multiplication. Through this operation, the landmask
ensures that attention weights in land regions (
) are set to zero, while weights in marine regions (
) are preserved and enhanced, thereby guiding the model to focus on the complex spatial structures in marine regions.
The final output of M_CAMB is the enhanced feature . By incorporating a geographically-informed landmask into CBAM’s spatial attention mechanism, M_CAMB significantly improves the model’s ability to model spatial structures in marine data, particularly excelling in handling sea level anomaly data with intricate spatial distributions. Subsequent experimental analysis will validate the effectiveness of this improved approach, demonstrating M_CAMB’s superior performance in spatial downscaling tasks.
2.3. Pixel-Structure Loss Function
In the context of dimensionality reduction for Sea Level Anomaly (SLA) data spaces, achieving a balance between pixel-level accuracy and structural fidelity remains a critical challenge. Traditional loss functions, such as the Mean Squared Error (MSE) [
38], defined as:
where
and
represent the ground truth and predicted values, respectively, and
N is the total number of pixels, effectively capturing pixel-wise discrepancies. However, MSE often fails to preserve the spatial structures inherent in SLA data, such as oceanic currents and eddies, which are essential for downstream geophysical analyses. To address this limitation, prior works have incorporated perceptual loss terms, such as the Structural Similarity Index (SSIM) [
39], to enhance structural preservation in image reconstruction tasks. Inspired by these advancements, we propose an improved loss function, termed Pixel-Structure Loss (PSLoss), which integrates both pixel-level accuracy and structural awareness tailored to SLA data.
The SSIM is a widely adopted metric for assessing the perceptual similarity between two images by evaluating their luminance, contrast, and structural components. For two image patches
x and
y the SSIM index is mathematically defined as:
where
and
represent the mean intensities of patches
x and
y, respectively;
and
denote their variances;
is the covariance between
x and
y, and
and
are small constants included to ensure numerical stability when the denominators approach zero. The SSIM value ranges from
to 1, with 1 indicating perfect structural similarity.
Building on this, our proposed PSLoss combines MSE with a modified SSIM-based term:
where
and
are adjustable hyperparameters that balance the contributions of pixel-level error and structural perception loss. Unlike the conventional
formulation used in prior studies [
40], we introduce the squared term
to amplify the sensitivity of the loss function in regions where SSIM approaches 1. This modification is motivated by the observation that SLA data often exhibit high structural similarity between reconstructed and ground-truth fields; yet, subtle differences in spatial patterns (e.g., eddy boundaries) are critical for accurate representation.
To elucidate the advantage of this design, consider the gradient of the SSIM term with respect to the model parameters
. For the traditional
, the gradient is:
In contrast, for our proposed
, the gradient becomes:
When SSIM is close to 1, the factor amplifies the gradient magnitude compared to the linear form, thereby enhancing the model’s optimization sensitivity to fine structural details. This is particularly beneficial for SLA data, where preserving high-frequency spatial features is paramount. PSLoss achieves a superior trade-off between pixel fidelity and structural integrity, as validated in our experiments.
2.4. Evaluation Metrics
To quantitatively assess the performance of the spatial downscaling model for SLA, we employed four evaluation metrics: Root Mean Square Error (RMSE) [
41], Peak Signal-to-Noise Ratio (PSNR) [
42], Structural Similarity Index (SSIM), and Temporal Correlation Coefficient (TCC) [
43]. During the computation of these metrics, a mask was applied to exclude land values, ensuring that only ocean grid points were considered. Below, we present the mathematical formulations and interpretations of each metric.
Root Mean Square Error (RMSE): The RMSE quantifies the square root of the average squared differences between downscaled and actual SLA values, emphasizing larger errors due to the squaring operation. It is expressed as:
where
is the SLA value at the
i-th grid point in the reference dataset,
is the corresponding value in the downscaled dataset,
N is the total number of grid points. RMSE is sensitive to outliers, and smaller values reflect higher accuracy in the downscaled SLA.
Peak Signal-to-Noise Ratio (PSNR): The PSNR is a standard metric for evaluating the quality of spatially downscaled Sea Level Anomaly (SLA) data against high-resolution reference data. Expressed in decibels (dB), PSNR quantifies the fidelity of the downscaled SLA field by comparing it to the original. The PSNR is defined as:
Here, , , and N are defined as above. The denotes the maximum SLA value across the reference dataset. The denominator represents the average squared difference between the reference and downscaled SLA fields, indicating error power.
In SLA applications, PSNR assesses the accuracy of downscaling methods, such as those enhancing satellite altimetry data resolution. Higher PSNR values, typically ranging from 20 to 50 dB, indicate better preservation of SLA features like eddies or coastal variations. However, PSNR may not capture spatially correlated errors critical to oceanographic contexts, necessitating complementary metrics like the Structural Similarity Index (SSIM) for a comprehensive evaluation.
Structural Similarity Index (SSIM): The SSIM assesses the structural similarity between the downscaled and ground-truth SLA fields, considering luminance, contrast, and structure. It is given by:
where
and
are the means of the ground-truth and downscaled SLA,
and
are their variances,
is the covariance, and
and
are small constants to stabilize the division. SSIM ranges from −1 to 1, with values closer to 1 indicating greater similarity. The computation is performed over ocean grid points only.
While both PSNR and SSIM assess the similarity between downscaled and ground-truth SLA fields, they emphasize different aspects of quality. PSNR focuses on pixel-level accuracy by measuring the logarithmic ratio of the maximum possible signal power to the mean squared error, making it sensitive to large pixel-wise errors and effective for evaluating overall intensity fidelity. In contrast, SSIM prioritizes perceptual similarity by evaluating luminance, contrast, and structural components, capturing the spatial patterns and morphological features critical for SLA data, such as eddy boundaries. Thus, PSNR is more suited for detecting numerical discrepancies, whereas SSIM excels in assessing structural integrity.
Temporal Correlation Coefficient (TCC): The TCC measures the temporal consistency of the downscaled SLA against the ground-truth over the entire test period (2023) at each ocean grid point. It is defined as:
where
and
are the ground-truth and downscaled SLA values at grid point
i and time
t,
and
are their temporal means over the test period, and
T is the total number of time steps in the test set. TCC is computed for each ocean grid point individually (with land masked out) and then averaged across all points, with values closer to 1 indicating stronger temporal correlation.
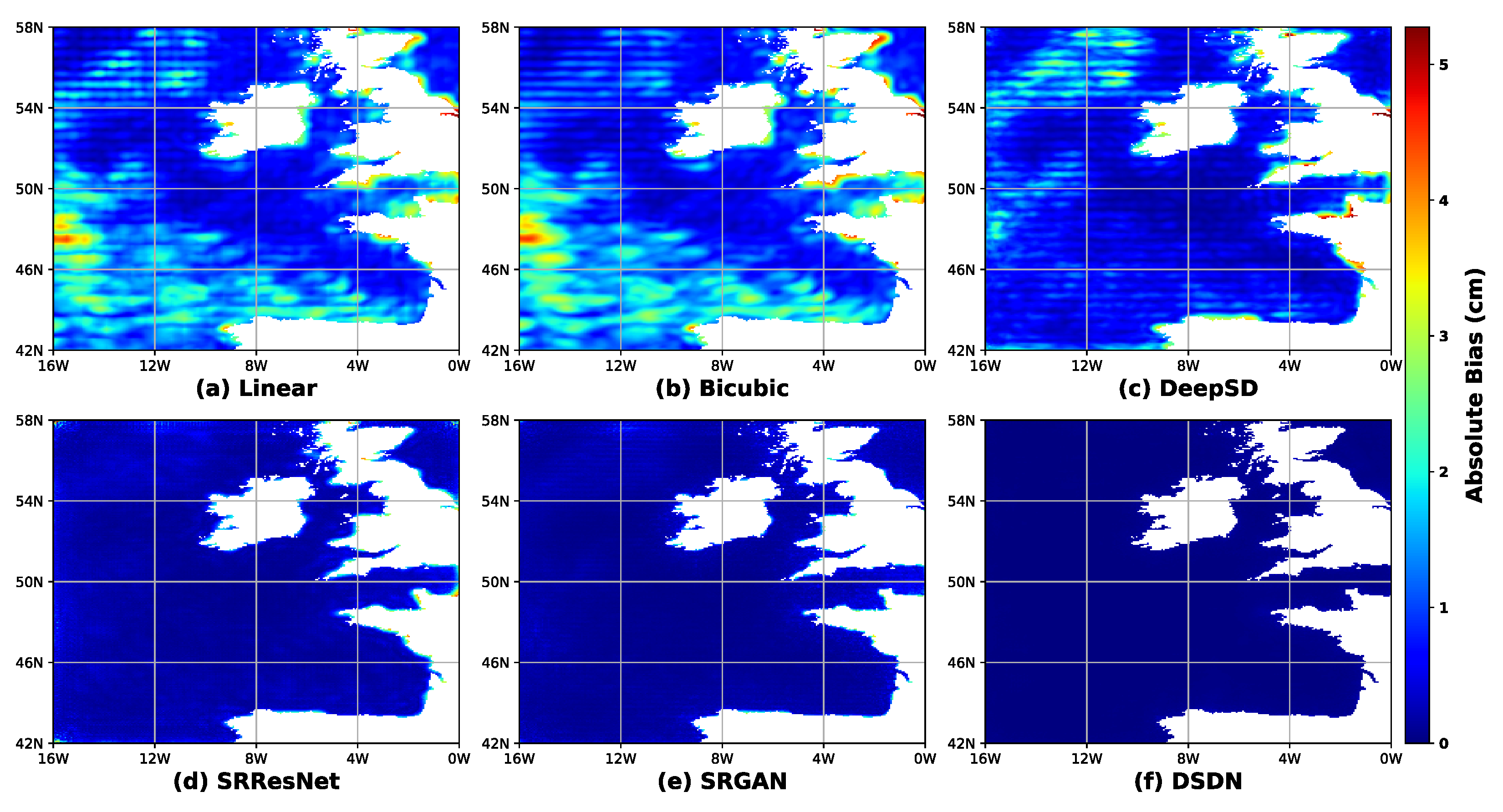
5. Conclusions
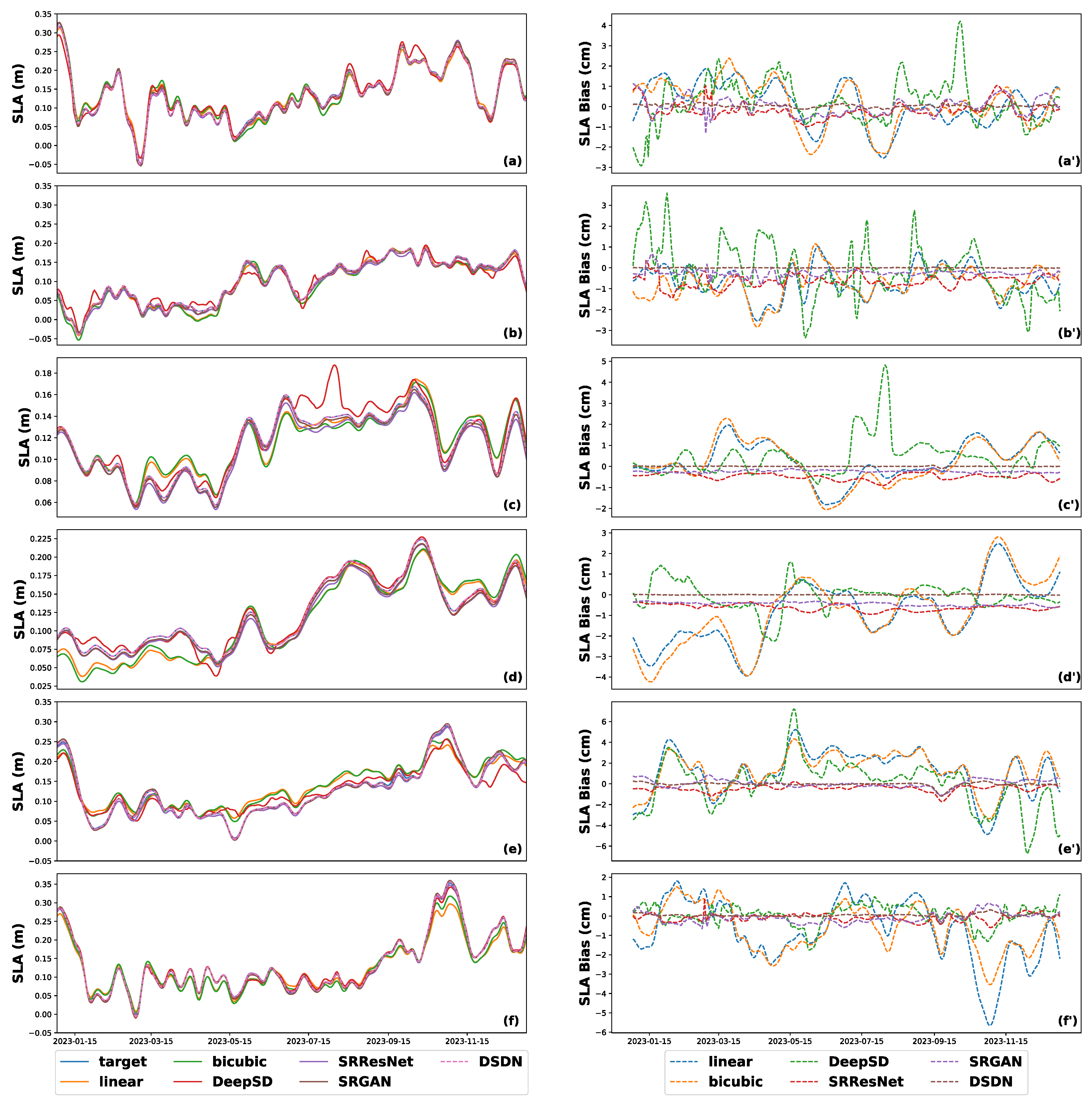
In this study, an innovative network, called DSDN, is proposed for SLA downscaling. The DSDN leverages depthwise separable convolutions by employing the DSDB and M_CAMB modules. The DSDB optimizes feature representation through iterative feature distillation and compression, while the M_CAMB, by incorporating a landmask, significantly enhances the model’s ability to capture spatial features in marine regions. Experimental results highlight DSDN’s superior performance in the SLA downscaling, with an approximately 87% reduction in RMSE to 0.047 cm. Additionally, by incorporating the PSLoss, the SSIM improves by approximately 5% to 0.976, demonstrating the model’s advantages in accuracy and structural consistency.
In terms of computational efficiency, DSDN demonstrates notable improvements. By utilizing depthwise separable convolutions, DSDN reduces the computational cost (measured in FLOPs) by approximately 50% compared to standard convolutional neural networks. Meanwhile, the performance degradation is minimal, with the PSNR decreasing by only about 0.3 dB, indicating that DSDN maintains high downscaling performance while significantly reducing computational demands. This efficiency makes DSDN particularly suitable for processing large-scale marine datasets, offering a practical tool for efficient spatial downscaling tasks.
Future research can extend this work in several directions. First, exploring more sophisticated attention mechanisms, such as multi-scale attention, could further improve the model’s adaptability to varying spatial scales. Second, applying DSDN to other marine variables, such as sea surface temperature or ocean currents, could validate its generalizability. Finally, integrating physical constraints or hybrid models (e.g., combining deep learning with numerical models) may enhance the physical consistency of downscaled results, providing more reliable support for climate change studies.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}