



Hybrid GIS-Transformer Approach for Forecasting Sentinel-1 Displacement Time Series

 ,
,  and
and
Abstract
1. Introduction
2. InSAR Time Series Generation and Preprocessing Strategy
2.1. The Geohazard Thematic Exploitation Platform (G-TEP)
2.2. Parallel Small BAseline Subset (P-SBAS) Processing
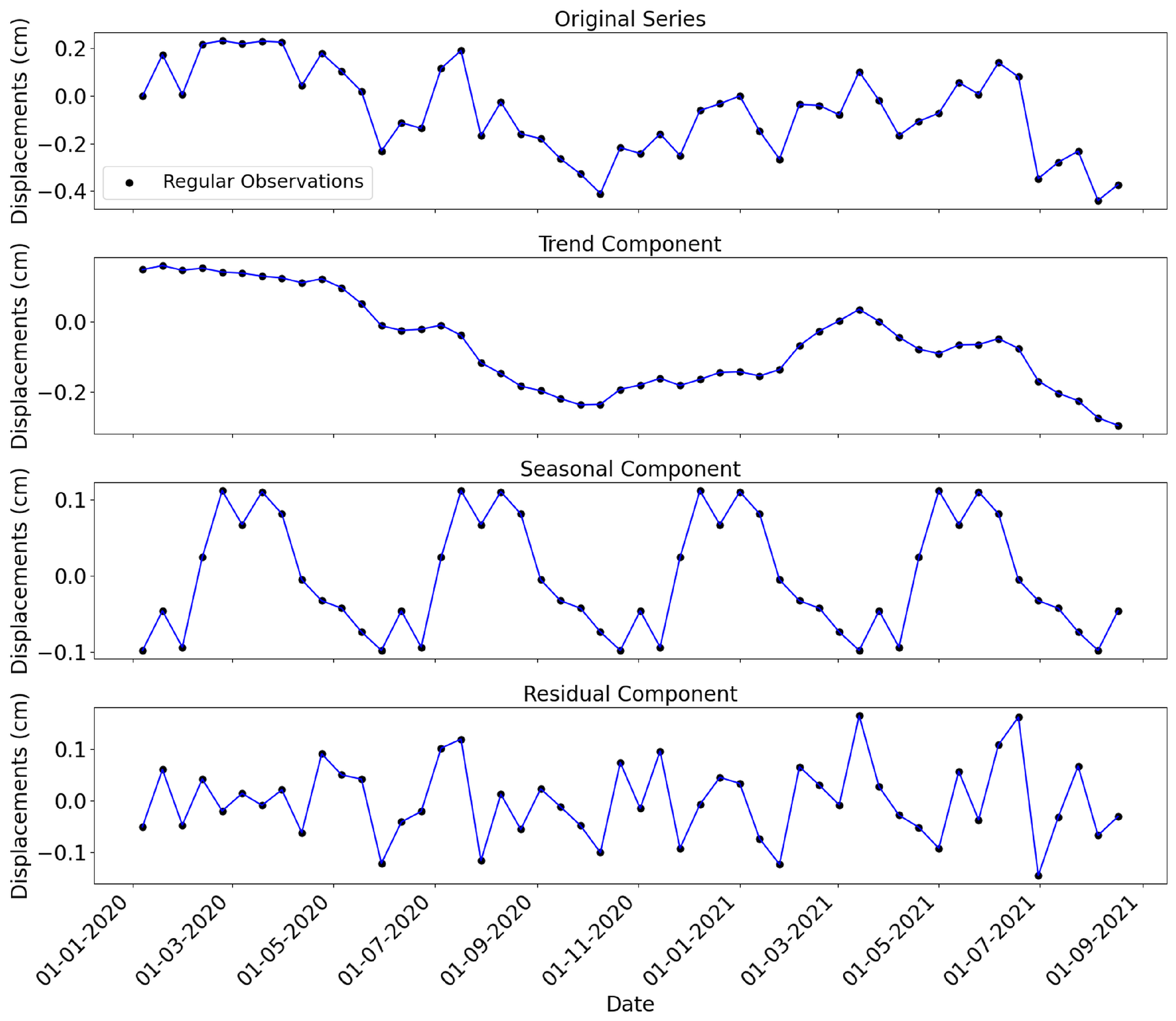
2.3. Preprocessing and Datasets
- Missing Values Imputation (Backward Filling): This method replaces a missing value at time t with the observation at time . It is effective for short gaps or when later values are more representative. Figure 4 illustrates the application of this method on synthetic displacement data with 15% missing values. This imputation technique regularizes the time series by filling gaps, allowing it to be used as input for models that require uniform time intervals, such as standard LSTMs. It should be noted that missing values were imputed on the basis of the minimum observed temporal interval in the dataset to maintain temporal consistency.
- Feature Engineering (Embedding Time Intervals): Intervals between observations were embedded as a second feature. Instead of using a univariate displacement sequence, the input was structured as a multivariate time series (sequence length, 2) consisting of displacement and time interval. This structure enhances the model’s awareness of irregular measurement spacing and improves its ability to capture dynamics influenced by temporal gaps [39].
2.3.1. Lombardy Dataset
2.3.2. Lisbon Dataset
2.3.3. Washington Dataset
3. Methodology
3.1. Basic Structure and Training of LSTM and Motivation
3.1.1. Gating Mechanism in LSTM
3.1.2. Forward and Backward Propagation
3.2. From Standard LSTM to Time-Gated LSTM: Handling Irregular Time Series
3.3. Implementing the Temporal Fusion Transformer (TFT) Model
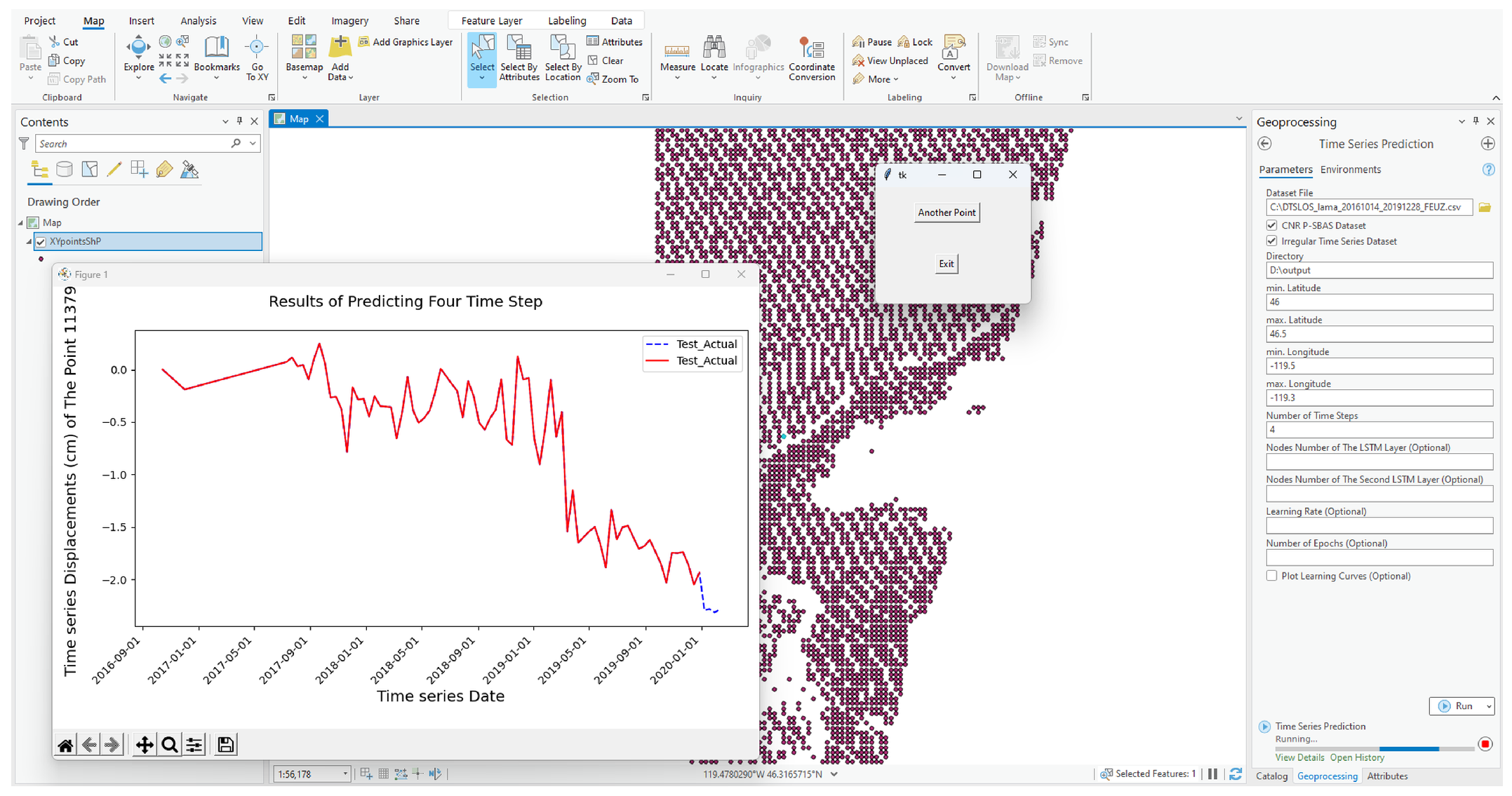
3.4. Integration of LSTM, TG-LSTM and TFT Models into ArcGIS Pro Toolbox
4. Results
4.1. Models Evaluation and Validation
4.1.1. Outcomes of Time Series Forcasting for Regular Displacement Patterns
- One Time Step PredictionAll hyperparameters for predicting one time step are listed in Table 5. The model used a custom loss function that combines L1 (Mean Absolute Error) and L2 (Mean Squared Error) components. These were weighted using the parameters alpha and beta. By setting alpha to 0.3 and beta to 0.7, we placed more weight on L2 loss. This helped reduce larger errors while still being robust to outliers. Reference [67] contains detailed descriptions of the basic and advanced definitions of DL model parameters and hyperparameters.The displacement values in the dataset ranged from −4.1 cm to 3.2 cm, with a standard deviation of 0.4 cm. Based on this distribution, the model’s average RMSE, evaluated on a split of the dataset (80% for training and validation, 20% for testing, consistently applied across all datasets), was recorded at 0.08 cm. This relatively low RMSE, when compared to the overall range and variability of the displacement values, indicates that the model is capable of reliably approximating the underlying patterns in the data. The small difference between the predicted and observed values shows that the model captures detailed displacement trends effectively.
- Multiple Time Step PredictionFor multi-step forecasting, we used an enhanced LSTM model based on the single-step version. This updated model demonstrated strong performance. The corresponding hyperparameters are listed in Table 5.To assess the model’s reliability in predicting a sequence of up to fourteen time steps within a 50-step time series, two critical diagnostic checks were performed: plotting the ACF (autocorrelation function) and evaluating homoscedasticity.
- –
- ACF: The Autocorrelation Function (ACF) measures the linear relationship between observations separated by time lags in the sequence [68]. Plotting the ACF is essential as it reveals any remaining correlation in the residuals of the model’s predictions. Significant autocorrelation at any lag suggests that the model has not fully captured the predictive structure within the data, indicating room for improvement. Conversely, the absence of such correlation would affirm that the model’s predictions are not systematically biased by overlooked temporal dependencies.
- –
- Homoscedasticity: Homoscedasticity indicates that prediction errors have a consistent variance across all input values. This is an important condition for statistical validity. Heteroscedasticity may indicate that the model is missing important features, contains misspecifications, or requires variable transformations. This condition is foundational for the validity of various statistical inferences made based on the model, as described in [69].
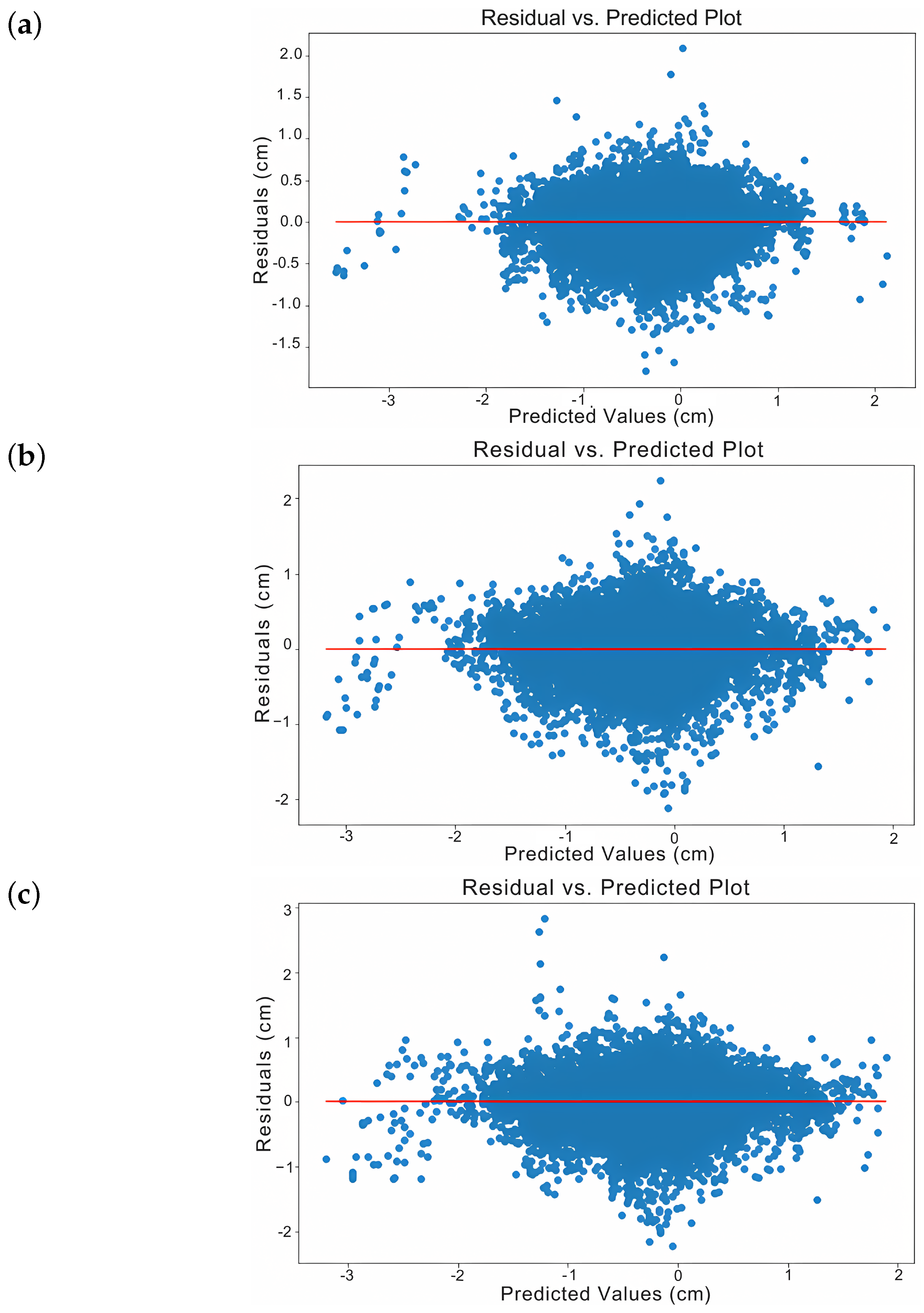
The training results showed consistent improvement in both loss and RMSE over six, ten, and fourteen prediction steps. The validation results followed a similar trend. There was no sign of overfitting. The model balanced bias and variance well and generalized effectively to unseen data. As shown in Figure 6, Figure 6a displays a more homoscedastic error pattern than Figure 6b,c.This is demonstrated by the reduced number of outliers and tighter error containment around zero, indicating stable variance in prediction errors across different predicted values. The residuals are also symmetrically distributed above and below the zero line without a funnel shape, reinforcing the presence of homoscedasticity. Figure 7 shows that as the prediction range increases—from six to fourteen steps—outlier errors become more frequent. This suggests higher uncertainty in longer-term forecasts.Figure 8 shows the ACF for predicting fourteen time steps. It reveals that autocorrelation remains minimal and stable up to five steps but increases significantly beyond this point. This pattern suggests that autocorrelation grows as predictions extend further. This is expected in physical systems where each time step continues the same process. Such systems often show correlation between successive stages.Consequently, forecasts beyond five steps may compromise accuracy, while predictions within this range maintain reliability. Thus, to ensure accuracy while maintaining temporal coverage, we used 10% of the series length as a benchmark. This was applied to the Lisbon (48 steps) and Washington (75 steps) datasets. Figure 9 shows examples of six, ten, and fourteen predicted time steps for the time series number 4395 of the dataset.
4.1.2. Outcomes of Time Series Forecasting for Irregular Displacement Patterns
- One-Time-Step Prediction
- -
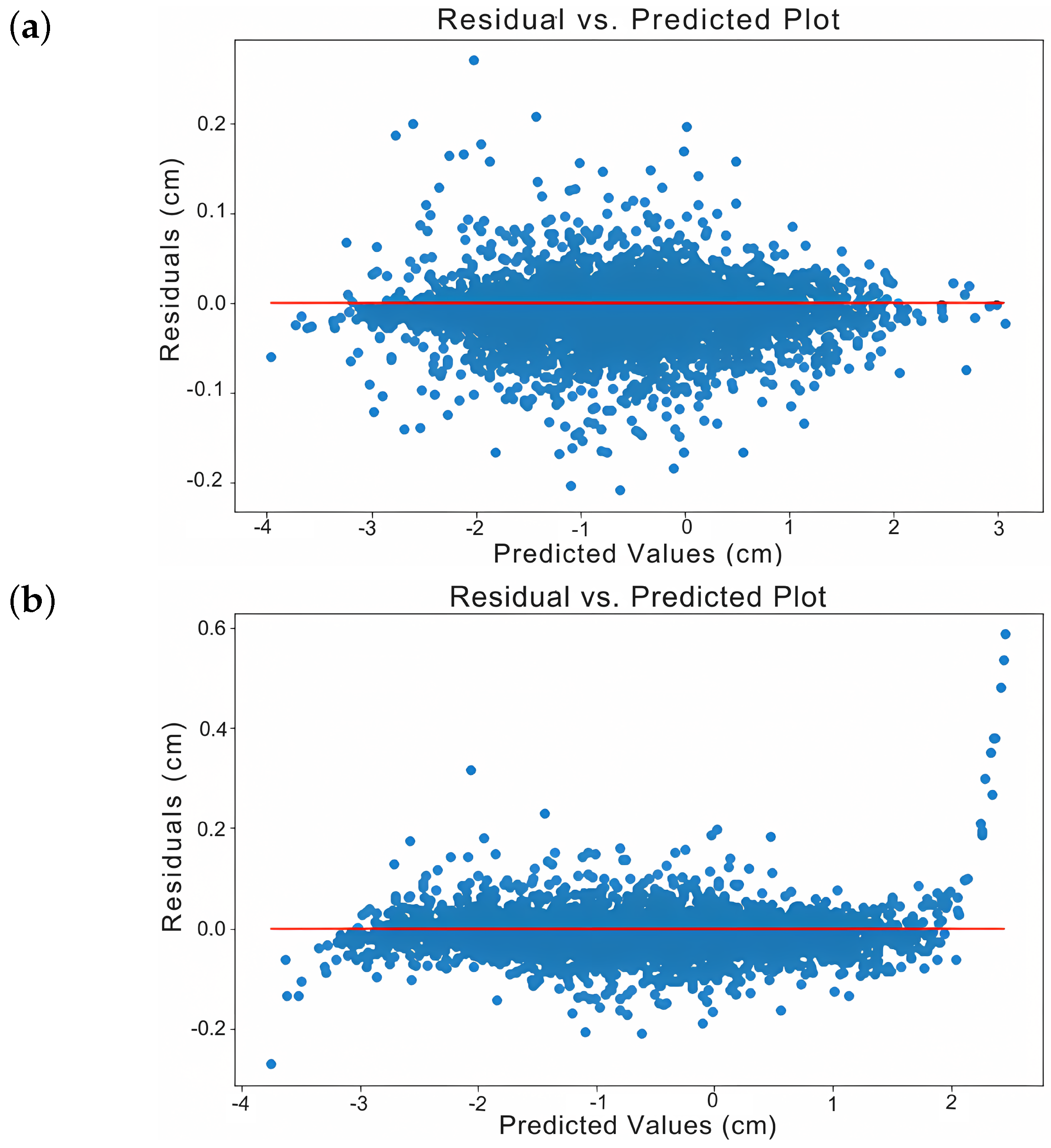
- Lisbon Dataset Results:We applied the LSTM model to the Lisbon dataset using the same architecture as for the Lombardy dataset. However, we increased the number of epochs from 15 to 35 and expanded the dataset to 109,962 samples, with displacement values ranging from −6.5 cm to 3.8 cm.We excluded the ACF analysis because it works well when time is used as a feature but not when missing values are imputed, where artificial correlations may be introduced. Therefore, it was deemed more appropriate to exclude it from this comparison.After training, we observed the learning curves of both models—one incorporating missing value imputation and the other embedding time intervals as a second feature. Both models learned rapidly, with loss and RMSE values converging within the first few epochs. The key difference was in the initial loss and RMSE values. The model with time intervals started with higher errors but eventually reached similar low levels. This is likely due to its dual input of displacements and time intervals, unlike the other model. The validation and training results were closely aligned, suggesting minimal overfitting and strong generalization.On average, the RMSE was 0.0004 cm when implementing missing data imputation. The low RMSE with imputation may result from the smoothing effect of filled-in values and the larger dataset. When embedding time intervals as a second feature, the RMSE was 0.055 cm. To draw a more detailed conclusion, Figure 10 presents a comparative analysis of the homoscedasticity associated with the aforementioned data preprocessing techniques. Figure 10a (missing value imputation) shows better homoscedasticity, making it preferable, as it indicates that model errors are evenly distributed and stable across predictions. Figure 10b (time interval embedding) shows greater residual variability, especially as predictions move away from zero. This indicates heteroscedasticity, where error magnitude depends on the predicted value. The homoscedasticity plots in this paper represent only displacement residuals.
- -
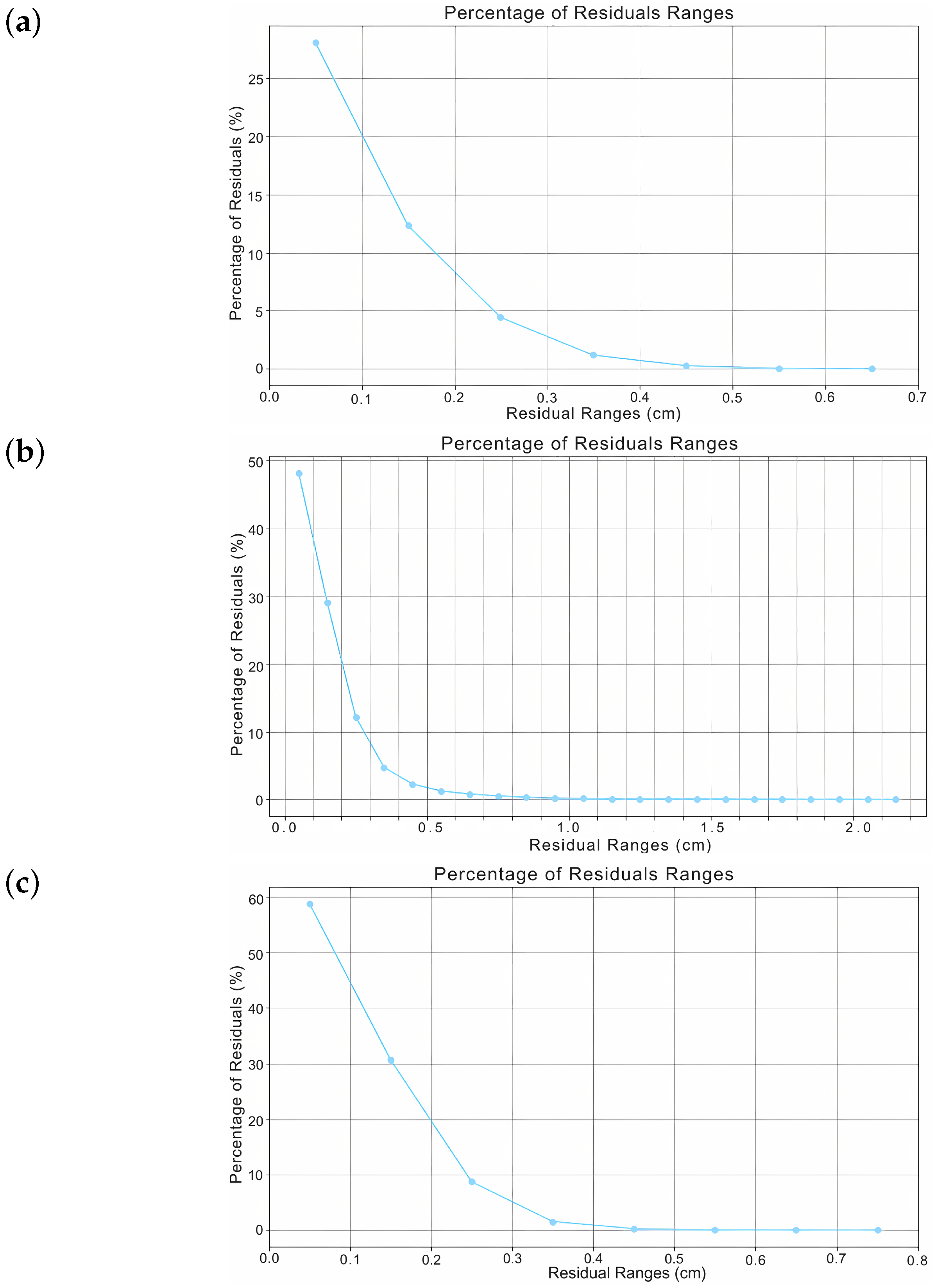
- Washington Dataset Results:We trained the Washington dataset using the same hyperparameters as for the Lisbon dataset. The only difference was a smaller sample size—21,471 records, ranging from −5.1 cm to 4.1 cm. Learning curves showed rapid improvement, with sharp drops in both loss and RMSE. This trend was similar to what was observed in the Lisbon single-step forecast. Initially higher errors were caused by the added complexity of using time interval embeddings. Despite this, both models generalized well. The validation metrics stayed close to the training results, reducing concerns about overfitting. The consistently lower loss and RMSE values suggested effective model performance across datasets. On average, the RMSE was 0.036 cm with missing data imputation and 0.03 cm with time interval integration.Figure 11 presents a comparative analysis of the homoscedasticity associated with missing data imputation and embedding time intervals as a second feature. Figure 11a (missing value imputation) exhibits better homoscedasticity, with residuals evenly distributed around zero across the predicted values. This consistency is desirable, as it indicates a uniform distribution of errors. In contrast, Figure 11b (time interval embedding) displays a "fan-shaped" spread of residuals. This indicates that errors increase with higher predicted values, suggesting variability in accuracy.Furthermore, the residual distribution plots in Figure 12 support the previous observations. In Figure 12a (missing value imputation), nearly all residuals fall within a narrow range, indicating consistent, low error, and better homoscedasticity. Figure 12b (embedding time intervals) shows residuals distributed over a broader range, reflecting greater variability and heteroscedasticity. All residual plots in this paper show absolute displacement errors. We excluded time interval errors due to their negligible magnitude.Overall, the model using missing data imputation generally performed better than the one using time interval embedding.
- Multiple-Time-Step PredictionBecause some heteroscedasticity persisted, we tested the TG-LSTM model, which is designed to handle irregular time intervals. While TG-LSTM mitigated some of these issues, it was computationally expensive and still exhibited outliers.Consequently, we transitioned to the TFT model for improved performance. The LSTM model used in this task was configured with hyperparameters comparable to those applied in Lombardy’s multi-step time series forecasting. Unlike the LSTM, the TG-LSTM model incorporated time as a second feature and utilized a dual-layer architecture, as described in Section 3.2.The TFT model architecture in this study is specifically tailored to predict both displacement and time intervals in multi-step time series. Its architecture begins with an LSTM encoder layer (eight units), followed by a multi-head attention layer with two heads and a key size of eight. The attention output passes through a Gated Residual Network (GRN), implemented as a dense layer with eight nodes and ReLU activation. This setup includes a residual connection and layer normalization for training stability.
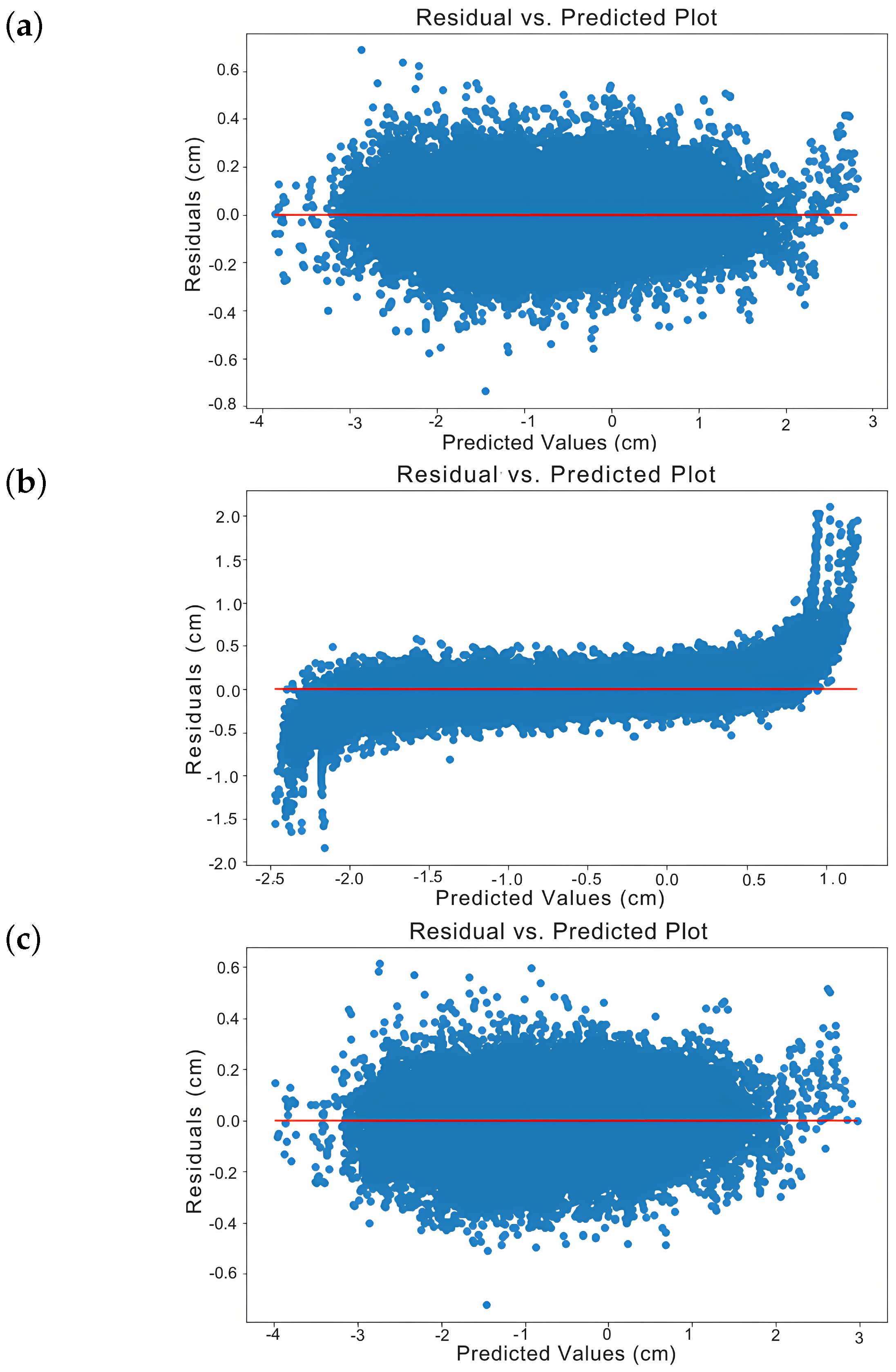
- -
- Lisbon Dataset ResultsAll three models showed good convergence, with training and validation curves aligning quickly. Table 6 reports the RMSE, Mean Absolute Error (MAE), and computation time. The TFT model achieved both low error and the shortest run time. Since the computational time depends on the system’s processor and memory, we note that the experiments were conducted on a machine equipped with an AMD Ryzen 7 5700U processor (8 cores, 16 threads, 1801 MHz) and 16 GB of RAM.Figure 13 illustrates the influence of homoscedasticity on the standard LSTM, TG-LSTM, and TFT models. The standard LSTM model (Figure 13a) exhibited scattered residuals with variable spread, indicating some heteroscedasticity and leading to inconsistent error distribution across predictions. Figure 13b (TG-LSTM) showed a better residual concentration around zero compared to LSTM, but still displayed variability at extreme values and remained sensitive to outliers. In contrast, the TFT model (Figure 13c) showed the most consistent residual spread around zero, demonstrating the most favorable homoscedasticity. Its strength in capturing dependencies and handling irregular time steps made TFT the most reliable model.In addition to the residual-based evaluation, we also report the MAE to provide a complementary view of average prediction accuracy. For the Lisbon dataset, the LSTM model achieved the lowest MAE, followed by TG-LSTM and TFT. Although LSTM achieves better average performance, the residual plots indicate that this comes at the cost of increased variance and reduced error stability—particularly at the edges of the prediction range. In contrast, TFT’s slightly higher MAE is compensated for by its more homoscedastic and symmetric residual distribution.Furthermore, the residual distribution plots (Figure 14) support the earlier conclusions. Figure 14c shows the narrowest error range and the highest residual concentration, aligning with TFT’s strong stability and homoscedasticity. Figure 14b (TG-LSTM) has broader residuals than TFT but they are still slightly narrower than in the standard LSTM. The standard LSTM model (Figure 14a) presents the widest spread of residuals, confirming higher error variability. These observations further highlight that the TFT model manages residuals more effectively, providing better stability and generalization in predictions.Figure 15 presents an example of multi-step predictions using the three models for time series index 11,840. The difference in the number of time steps is due to missing value imputation in the dataset. Originally consisting of 48 displacement data points, the dataset expanded to 138 points after imputation. Consequently, 10% of the time series now corresponds to 5 time steps in the original dataset and 14 time steps in the imputed dataset. Another example of multi-step forecasting results for time series number 9691 is presented in Appendix B, reinforcing the comparative evaluation of the three models.
- -
- Washington Dataset Results:The same three models were subsequently applied to the Washington dataset, with the training epoch count adjusted to 50. They were assessed on 10% of the time series length, corresponding to eight steps. Overall, the models appeared to learn effectively without overfitting, as evidenced by the convergence and parallel behavior of the training and validation loss/RMSE curves.Table 7 presents the RMSE, MAE, and computation time values for each model. The results indicate that the TFT model outperformed the TG-LSTM in both predictive accuracy and computational efficiency. Compared to standard LSTM, TFT required more computational time and achieved a slightly lower RMSE; however, the difference between the two was minimal. The MAE results followed a similar trend, with TFT and LSTM showing comparable performance and TG-LSTM exhibiting the highest average error. While LSTM achieved the lowest MAE, the difference from TFT was small, and, as shown in the residual plots, TFT maintained superior stability and consistency, which are essential in irregular, multi-step forecasting. Despite the higher computational cost, TFT remains the most robust option. Its dual input of displacement and time intervals allows for a higher-dimensional data representation. Unlike standard LSTM, which excluded the first two time steps to avoid bias from large gaps, the TFT model retained all data, better capturing time-based variation. Therefore, its higher cost is justified by improved accuracy and handling of continuous time series.Figure 16 illustrates the homoscedasticity for the three models. The TFT model (Figure 16c) demonstrates the best homoscedasticity, with residuals most evenly distributed around zero and no discernible pattern. The standard LSTM model (Figure 16a) follows closely, though it shows slightly denser clusters at certain predicted values, suggesting minor issues with variance consistency. Figure 16b (TG-LSTM) shows a funnel-shaped residual pattern, with growing error variance at higher prediction values, confirming heteroscedasticity.The residual distribution plots in Figure 17 confirm that the TFT model offers the best consistency in error distribution, followed by the standard LSTM. The TG-LSTM model shows the greatest variability, with a broader spread and residuals extending to larger ranges.Figure 18 shows an example of predicting multiple time steps using the three models for the time series number 1904. A second example illustrating multi-step predictions for time series number 828 is provided in Appendix B, further supporting the comparative analysis across models.
- Overall SummaryAccording to the results, the learning curves from the Lisbon and Washington datasets did not provide definitive evidence to identify a single best-performing model overall. However, the Lisbon multi-step analysis showed that the TFT model performed best in terms of homoscedasticity, residual distribution, and computational cost.While the TFT had a slightly higher RMSE than the standard LSTM—mainly due to a few large residuals—this metric should be interpreted with caution. Residual plots show that the TFT model produced more predictions with residuals below 0.1 cm than the others. This indicates that, despite a few extreme values, the TFT model consistently delivered high-accuracy predictions for the majority of the dataset. This is important in practical applications, where consistent accuracy matters more than rare large errors.Comparable results were observed for the Washington dataset, further supporting the superior performance of the TFT model. Qualitative examples further show that the TFT model accurately captured subtle displacement changes over time.
4.2. The Developed Toolbox Workflow in ArcGIS Pro
- A shapefile containing the spatial coordinates (latitudes and longitudes) of the points specified by the user and referenced to the time series dataset.
- A notification displaying the RMSE obtained from training the predictive model.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Displacement Velocity Maps of the Studied Datasets



Appendix B. Additional Multi-Step Forecasting Examples



References
- Crosetto, M.; Monserrat, O.; Cuevas-González, M.; Devanthéry, N.; Crippa, B. Persistent scatterer interferometry: A review. ISPRS J. Photogramm. Remote Sens. 2016, 115, 78–89. [Google Scholar] [CrossRef]
- Macchiarulo, V.; Milillo, P.; Blenkinsopp, C.; Reale, C.; Giardina, G. Multi-temporal InSAR for transport infrastructure monitoring: Recent trends and challenges. In Proceedings of the Institution of Civil Engineers-Bridge Engineering; Thomas Telford Ltd.: London, UK, 2021; Volume 176, pp. 92–117. [Google Scholar] [CrossRef]
- Gama, F.F.; Mura, J.C.; Paradella, W.R.; de Oliveira, C.G. Deformations prior to the Brumadinho dam collapse revealed by Sentinel-1 InSAR data using SBAS and PSI techniques. Remote Sens. 2020, 12, 3664. [Google Scholar] [CrossRef]
- Romanuke, V. Arima Model Optimal Selection for Time Series Forecasting. Marit. Tech. J. 2022, 224, 28–40. [Google Scholar] [CrossRef]
- Jiang, W.; Ling, L.; Zhang, D.; Lin, R.; Zeng, L. A time series forecasting model selection framework using CNN and data augmentation for small sample data. Neural Process. Lett. 2023, 55, 5783–5810. [Google Scholar] [CrossRef]
- Zhang, G.P.; Qi, M. Neural network forecasting for seasonal and trend time series. Eur. J. Oper. Res. 2005, 160, 501–514. [Google Scholar] [CrossRef]
- Liu, Q.; Li, Z.; Ji, Y.; Martinez, L.; Zia, U.H.; Javaid, A.; Lu, W.; Wang, J. Forecasting the Seasonality and Trend of Pulmonary Tuberculosis in Jiangsu Province of China Using Advanced Statistical Time-Series Analyses. Infect. Drug Resist. 2019, 12, 2311–2322. [Google Scholar] [CrossRef]
- Song, L.; Ding, L.; Wen, T.; Yin, M.; Zeng, Z. Time series change detection using reservoir computing networks for remote sensing data. Int. J. Intell. Syst. 2022, 37, 10845–10860. [Google Scholar] [CrossRef]
- Ji, X.; Zhang, H.; Li, J.; Zhao, X.; Li, S.; Chen, R. Multivariate time series prediction of high dimensional data based on deep reinforcement learning. In Proceedings of the International Conference on Power System and Energy Internet (PoSEI2021), Chengdu, China, 16–18 April 2021; Volume 256, p. 02038. [Google Scholar] [CrossRef]
- Lai, K.H.; Zha, D.; Xu, J.; Zhao, Y.; Wang, G.; Hu, X. Revisiting Time Series Outlier Detection: Definitions and Benchmarks. In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1), Online, 6–14 December 2021. [Google Scholar]
- Bauer, A. Automated Hybrid Time Series Forecasting: Design, Benchmarking, and Use Cases. Ph.D. Thesis, Universitat Würzburg, Würzburg, Germany, 2021. [Google Scholar]
- Weerakody, P.B.; Wong, K.W.; Wang, G.; Ela, W. A review of irregular time series data handling with gated recurrent neural networks. Neurocomputing 2021, 441, 161–178. [Google Scholar] [CrossRef]
- Rehfeld, K.; Marwan, N.; Heitzig, J.; Kurths, J. Comparison of correlation analysis techniques for irregularly sampled time series. Nonlinear Process. Geophys. 2011, 18, 389–404. [Google Scholar] [CrossRef]
- Zhang, K.; Ng, C.T.; Na, M.H. Real time prediction of irregular periodic time series data. J. Forecast. 2020, 39, 501–511. [Google Scholar] [CrossRef]
- Tan, Q.; Ye, M.; Yang, B.; Liu, S.; Ma, A.J.; Yip, T.C.F.; Wong, G.L.H.; Yuen, P. Data-gru: Dual-attention time-aware gated recurrent unit for irregular multivariate time series. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 930–937. [Google Scholar] [CrossRef]
- Kidger, P.; Morrill, J.; Foster, J.; Lyons, T. Neural controlled differential equations for irregular time series. Adv. Neural Inf. Process. Syst. 2020, 33, 6696–6707. [Google Scholar] [CrossRef]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. A comparison of ARIMA and LSTM in forecasting time series. In Proceedings of the 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 1394–1401. [Google Scholar]
- Colak, I.; Sagiroglu, S.; Yesilbudak, M.; Kabalci, E.; Bulbul, H.I. Multi-time series and -time scale modeling for wind speed and wind power forecasting part I: Statistical methods, very short-term and short-term applications. In Proceedings of the International Conference on Renewable Energy Research and Applications (ICRERA), Palermo, Italy, 22–25 November 2015; pp. 209–214. [Google Scholar] [CrossRef]
- Dilling, S.; MacVicar, B. Cleaning high-frequency velocity profile data with autoregressive moving average (ARMA) models. Flow Meas. Instrum. 2017, 54, 68–81. [Google Scholar] [CrossRef]
- Dubey, A.K.; Kumar, A.; García-Díaz, V.; Sharma, A.K.; Kanhaiya, K. Study and analysis of SARIMA and LSTM in forecasting time series data. Sustain. Energy Technol. Assess. 2021, 47, 101474. [Google Scholar] [CrossRef]
- Alharbi, F.R.; Csala, D. A seasonal autoregressive integrated moving average with exogenous factors (SARIMAX) forecasting model-based time series approach. Inventions 2022, 7, 94. [Google Scholar] [CrossRef]
- Connolly, E. The Suitability of Sarimax Time Series and LSTM Neural Networks for Predicting Electricity Consumption in Ireland. Ph.D. Thesis, National College of Ireland, Dublin, Ireland, 2021. [Google Scholar]
- Gelper, S.; Fried, R.; Croux, C. Robust forecasting with exponential and Holt–Winters smoothing. J. Forecast. 2010, 29, 285–300. [Google Scholar] [CrossRef]
- Hill, P.; Biggs, J.; Ponce-López, V.; Bull, D. Time-Series Prediction Approaches to Forecasting Deformation in Sentinel-1 InSAR Data. J. Geophys. Res. Solid Earth 2021, 126, e2020JB020176. [Google Scholar] [CrossRef]
- Fiorentini, N.; Maboudi, M.; Leandri, P.; Losa, M. Can Machine Learning and PS-InSAR Reliably Stand in for Road Profilometric Surveys? Sensors 2021, 21, 3377. [Google Scholar] [CrossRef]
- Radman, A.; Akhoondzadeh, M.; Hosseiny, B. Integrating InSAR and Deep-Learning for Modeling and Predicting Subsidence over the Adjacent Area of Lake Urmia, Iran. GISci. Remote Sens. 2021, 58, 1413–1433. [Google Scholar] [CrossRef]
- Abdikan, S.; Coskun, S.; Narin, O.G.; Bayik, C.; Calò, F.; Pepe, A.; Balik Sanli, F. Prediction of Long-Term SENTINEL-1 InSAR Time Series Analysis. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2023, 48, 3–8. [Google Scholar] [CrossRef]
- Mirmazloumi, S.M.; Wassie, Y.; Nava, L.; Cuevas-González, M.; Crosetto, M.; Monserrat, O. InSAR Time Series and LSTM Model to Support Early Warning Detection Tools of Ground Instabilities: Mining Site Case Studies. Bull. Eng. Geol. Environ. 2023, 82, 374. [Google Scholar] [CrossRef]
- Lattari, F.; Rucci, A.; Matteucci, M. A Deep Learning Approach for Change Points Detection in InSAR Time Series. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5223916. [Google Scholar] [CrossRef]
- Wang, J.; Li, C.; Li, L.; Huang, Z.; Wang, C.; Zhang, H.; Zhang, Z. InSAR Time-Series Deformation Forecasting Surrounding Salt Lake Using Deep Transformer Models. Sci. Total Environ. 2023, 858, 159744. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Fan, X.; Zhang, Z.; Zhang, X.; Nie, W.; Qi, Y.; Zhang, N. Spatiotemporal Mechanism-Based Spacetimeformer Network for InSAR Deformation Prediction and Identification of Retrogressive Thaw Slumps in the Chumar River Basin. Remote Sens. 2024, 16, 1891. [Google Scholar] [CrossRef]
- Gualandi, A.; Liu, Z. Variational Bayesian Independent Component Analysis for InSAR Displacement Time-Series with Application to Central California, USA. J. Geophys. Res. Solid Earth 2021, 126, e2020JB020845. [Google Scholar] [CrossRef]
- Geohazards-TEP. Geohazard Exploitation Platform. Available online: https://geohazards-tep.eu/#! (accessed on 21 September 2021).
- Manunta, M.; De Luca, C.; Zinno, I.; Casu, F.; Manzo, M.; Bonano, M.; Fusco, A.; Pepe, A.; Onorato, G.; Berardino, P.; et al. The Parallel SBAS Approach for Sentinel-1 Interferometric Wide Swath Deformation Time-Series Generation: Algorithm Description and Products Quality Assessment. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6259–6281. [Google Scholar] [CrossRef]
- Cuervas-Mons, J.; Zêzere, J.L.; Domínguez-Cuesta, M.J.; Barra, A.; Reyes-Carmona, C.; Monserrat, O.; Oliveira, S.C.; Melo, R. Assessment of Urban Subsidence in the Lisbon Metropolitan Area (Central-West of Portugal) Applying Sentinel-1 SAR Dataset and Active Deformation Areas Procedure. Remote Sens. 2022, 14, 4084. [Google Scholar] [CrossRef]
- Seabold, S.; Perktold, J. Statsmodels: Econometric and statistical modeling with python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; Volume 57, p. 61. [Google Scholar] [CrossRef]
- Harvey, A.C. Forecasting, Structural Time Series Models and the Kalman Filter; Cambridge University Press: Cambridge, UK, 1990. [Google Scholar] [CrossRef]
- Pelagatti, M.M. Time Series Modelling with Unobserved Components; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- Costa, P.; Cerqueira, V.; Vinagre, J. AutoFITS: Automatic Feature Engineering for Irregular Time Series. arXiv 2021, arXiv:2112.14806. [Google Scholar] [CrossRef]
- Viganò, A.; Rossato, S.; Martin, S.; Ivy-Ochs, S.; Zampieri, D.; Rigo, M.; Monegato, G. Large Landslides in the Alpine Valleys of the Giudicarie and Schio-Vicenza Tectonic Domains (NE Italy). J. Maps 2021, 17, 197–208. [Google Scholar] [CrossRef]
- Guzzetti, F. Landslide fatalities and the evaluation of landslide risk in Italy. Eng. Geol. 2000, 58, 89–107. [Google Scholar] [CrossRef]
- ISPRA. Rapporto Dissesto Idrogeologico Italia Ispra 356_2021; ISPRA: Rome, Italy, 2021; p. 183. [Google Scholar]
- Pereira, S.; Santos, P.P.; Zêzere, J.L.; Tavares, A.O.; Garcia, R.A.C.; Oliveira, S.C. A Landslide Risk Index for Municipal Land Use Planning in Portugal. Sci. Total Environ. 2020, 735, 139463. [Google Scholar] [CrossRef]
- Terrinha, P.; Duarte, H.; Brito, P.; Noiva, J.; Ribeiro, C.; Omira, R.; Baptista, M.A.; Miranda, M.; Magalhães, V.; Roque, C.; et al. The Tagus River Delta Landslide, off Lisbon, Portugal. Implications for Marine Geo-Hazards. Mar. Geol. 2019, 416, 105983. [Google Scholar] [CrossRef]
- Xu, Y.; Schulz, W.H.; Lu, Z.; Kim, J.; Baxstrom, K. Geologic Controls of Slow-Moving Landslides Near the US West Coast. Landslides 2021, 18, 3353–3365. [Google Scholar] [CrossRef]
- Moualla, L.; Rucci, A.; Naletto, G.; Anantrasirichai, N. Learning Ground Displacement Signals Directly from InSAR-Wrapped Interferograms. Sensors 2024, 24, 2637. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, H.; Dong, J.; Zhong, G.; Sun, X. Prediction of Sea Surface Temperature Using Long Short-Term Memory. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1745–1749. [Google Scholar] [CrossRef]
- Wang, J.; Jin, L.; Li, X.; He, S.; Huang, M.; Wang, H. A Hybrid Air Quality Index Prediction Model Based on CNN and Attention Gate Unit. IEEE Access 2022, 10, 113343–113354. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A Search Space Odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef]
- Wu, Z.; King, S. Investigating Gated Recurrent Neural Networks for Speech Synthesis. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5140–5144. [Google Scholar] [CrossRef]
- Fanta, H.; Shao, Z.; Ma, L. Forget the Forget Gate: Estimating Anomalies in Videos Using Self-contained Long Short-Term Memory Networks. In Proceedings of the Advances in Computer Graphics: 37th Computer Graphics International Conference, CGI 2020, Geneva, Switzerland, 20–23 October 2020; Springer: Cham, Switzerland, 2020; pp. 169–181. [Google Scholar] [CrossRef]
- Can, T.; Krishnamurthy, K.; Schwab, D.J. Gating Creates Slow Modes and Controls Phase-Space Complexity in GRUs and LSTMs. In Proceedings of the First Mathematical and Scientific Machine Learning Conference, Princeton, NJ, USA, 20–24 July 2020; pp. 476–511. [Google Scholar]
- Yao, L.; Guan, Y. An improved LSTM structure for natural language processing. In Proceedings of the IEEE International Conference of Safety Produce Informatization (IICSPI), Chongqing, China, 10–12 December 2018; pp. 565–569. [Google Scholar] [CrossRef]
- Wang, J.; Xue, M.; Culhane, R.; Diao, E.; Ding, J.; Tarokh, V. Speech Emotion Recognition with Dual-Sequence LSTM Architecture. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6474–6478. [Google Scholar] [CrossRef]
- Sulistyo, S.; Danang, A.W.; Aji Prasetya, P.; Didik, D.A.; Almu’iini, F. LSTM-Based Machine Translation for Madurese-Indonesian. J. Appl. Data Sci. 2023, 4, 189–199. [Google Scholar] [CrossRef]
- Salman, A.G.; Heryadi, Y.; Abdurahman, E.; Suparta, W. Single Layer & Multi-layer Long Short-Term Memory (LSTM) Model with Intermediate Variables for Weather Forecasting. Procedia Comput. Sci. 2018, 135, 89–98. [Google Scholar] [CrossRef]
- Werbos, P.J. Backpropagation through time: What it does and how to do it. Proc. IEEE 1990, 78, 1550–1560. [Google Scholar] [CrossRef]
- Sahin, S.O.; Kozat, S.S. Nonuniformly Sampled Data Processing Using LSTM Networks. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 1452–1461. [Google Scholar] [CrossRef] [PubMed]
- Lim, B.; Arık, S.; Loeff, N.; Pfister, T. Temporal Fusion Transformers for Interpretable Multi-Horizon Time Series Forecasting. Int. J. Forecast. 2021, 37, 1748–1764. [Google Scholar] [CrossRef]
- Koya, S.R.; Roy, T. Temporal Fusion Transformers for Streamflow Prediction: Value of Combining Attention with Recurrence. J. Hydrol. 2024, 637, 131301. [Google Scholar] [CrossRef]
- López Santos, M.; García-Santiago, X.; Echevarría Camarero, F.; Blázquez Gil, G.; Carrasco Ortega, P. Application of Temporal Fusion Transformer for Day-Ahead PV Power Forecasting. Energies 2022, 15, 5232. [Google Scholar] [CrossRef]
- Liao, X.; Wong, M.S.; Zhu, R.; Zhe, W. A Temporal Fusion Transformer augmented GeoAI framework for estimating hourly land surface solar irradiation. Energy AI 2025, 21, 100529. [Google Scholar] [CrossRef]
- Li, X.; Xu, Y.; Law, R.; Wang, S. Enhancing Tourism Demand Forecasting with a Transformer-Based Framework. Ann. Tour. Res. 2024, 107, 103791. [Google Scholar] [CrossRef]
- Wu, B.; Wang, L.; Zeng, Y.R. Interpretable Wind Speed Prediction with Multivariate Time Series and Temporal Fusion Transformers. Energy 2022, 252, 123990. [Google Scholar] [CrossRef]
- Laborda, J.; Ruano, S.; Zamanillo, I. Multi-Country and Multi-Horizon GDP Forecasting Using Temporal Fusion Transformers. Mathematics 2023, 11, 2625. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Atique, A.; Sharif, N.; Subrina, R.; Vishwajit, S.; Vinitha, B.; Macfie, S.J. Forecasting of total daily solar energy generation using ARIMA: A Case Study. In Proceedings of the 2019 IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 8–10 January 2019; pp. 114–119. [Google Scholar]
- Corbin, N.; Oliveira, R.; Raynaud, Q.; Di Domenicantonio, G.; Draganski, B.; Kherif, F.; Callaghan, M.F.; Lutti, A. Statistical analyses of motion-corrupted MRI relaxometry data. bioRxiv 2023. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Start Date | End Date | NoI | DEM | Coh. | BBX | Orb. |
|---|---|---|---|---|---|---|---|
| Lombardy (Italy) | 7 January 2020 | 17 August 2021 | 50 | SRTM1 arcsec | 0.85 | 44.943°, 8.693° 46.884°, 12.231° | Desc. |
| Dataset | Start Date | End Date | NoI | DEM | Coh. | BBX | Orb. |
|---|---|---|---|---|---|---|---|
| Lisbon (Portugal) | 26 January 2018 | 27 April 2020 | 50 | SRTM1 arcsec | 0.6 | 38.088°, −11.124° 39.800°, −7.945° | Asc. |
| Dataset | Start Date | End Date | NoI | DEM | Coh. | BBX | Orb. |
|---|---|---|---|---|---|---|---|
| Washington (USA) | 14 October 2016 | 28 December 2019 | 75 | SRTM1 arcsec | 0.7 | −121.426°, 46.358° −120.042°, 47.167° | Asc. |
| ID | Lat | Lon | 26 January 2018 | 7 February 2018 | 19 February 2018 | 3 March 2018 | 15 March 2018 |
|---|---|---|---|---|---|---|---|
| 0 | 38.7079 | −9.4854 | 0 | 0.0004 | 0.1624 | 0.1624 | 0.3414 |
| 1 | 38.7088 | −9.4863 | 0 | 0.0016 | 0.0385 | 0.0385 | 0.3324 |
| 2 | 38.7096 | −9.4863 | 0 | 0.0031 | 0.1335 | 0.1335 | 0.2479 |
| 3 | 38.7096 | −9.4863 | 0 | 0.0052 | 0.4813 | 0.4813 | 0.5352 |
| 4 | 38.7104 | −9.4863 | 0 | 0.0071 | 0.3348 | 0.3348 | 0.4225 |
| 5 | 38.7071 | −9.4846 | 0 | 0.0831 | −0.0141 | −0.0141 | 0.2588 |
| 6 | 38.7079 | −9.4846 | 0 | −0.0023 | 0.1143 | 0.1143 | 0.2320 |
| 7 | 38.7079 | −9.4846 | 0 | −0.1181 | 0.0620 | 0.0620 | 0.1224 |
| 8 | 38.7088 | −9.4854 | 0 | −0.2369 | 0.4562 | 0.4562 | 0.2081 |
| 9 | 38.7096 | −9.4854 | 0 | 0.0018 | 0.2273 | 0.2273 | 0.2738 |
| Hyperparameter | One Time Step | Multiple Time Steps |
|---|---|---|
| Num. of LSTM Layers | 1 | 2 |
| Num. of Nodes | 50 | 100, 50 |
| Num. of Epochs | 15 | 35 |
| Learning Rate | 0.001 | 0.0001 |
| Optimizer | Adam | Adam |
| Loss Function | custom L1-L2 | custom L1-L2 |
| Accuracy Metric | RMSE | RMSE |
| Batch Size | 128 | 128 |
| Cross-Fold Validation | 5 folds | 5 folds |
| Model | RMSE (cm) | MAE (cm) | Computation Cost (min) |
|---|---|---|---|
| Standard LSTM | 0.124 | 0.085 | 287 |
| TG-LSTM | 0.169 | 0.125 | 288 |
| TFT | 0.167 | 0.128 | 84 |
| Model | RMSE (cm) | MAE (cm) | Computation Cost (min) |
|---|---|---|---|
| Standard LSTM | 0.127 | 0.099 | 55 |
| TG-LSTM | 0.224 | 0.134 | 115 |
| TFT | 0.125 | 0.11 | 85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moualla, L.; Rucci, A.; Naletto, G.; Anantrasirichai, N.; Da Deppo, V. Hybrid GIS-Transformer Approach for Forecasting Sentinel-1 Displacement Time Series. Remote Sens. 2025, 17, 2382. https://doi.org/10.3390/rs17142382
Moualla L, Rucci A, Naletto G, Anantrasirichai N, Da Deppo V. Hybrid GIS-Transformer Approach for Forecasting Sentinel-1 Displacement Time Series. Remote Sensing. 2025; 17(14):2382. https://doi.org/10.3390/rs17142382
Chicago/Turabian StyleMoualla, Lama, Alessio Rucci, Giampiero Naletto, Nantheera Anantrasirichai, and Vania Da Deppo. 2025. "Hybrid GIS-Transformer Approach for Forecasting Sentinel-1 Displacement Time Series" Remote Sensing 17, no. 14: 2382. https://doi.org/10.3390/rs17142382
APA StyleMoualla, L., Rucci, A., Naletto, G., Anantrasirichai, N., & Da Deppo, V. (2025). Hybrid GIS-Transformer Approach for Forecasting Sentinel-1 Displacement Time Series. Remote Sensing, 17(14), 2382. https://doi.org/10.3390/rs17142382