This section outlines the methodological framework adopted for dataset creation, including image collection and pre-processing, semantic attribute category design, annotation protocol, and dataset characteristics. We also describe the strategy used to split the dataset to support standardised training and evaluation procedures.
3.1. Image Collection and Pre-Processing
To build the WHU-RS19 ABZSL dataset, we use the well-established WHU-RS19 dataset [
15], which was originally designed for scene classification in RS applications. The images in WHU-RS19 were collected using Google Earth, ensuring access to high-resolution, globally distributed aerial scenes covering a wide range of geographical and infrastructural environments. Each image in the dataset is standardised to a resolution of
pixels and belongs to 1 of 19 scene categories, including natural environments (e.g., forest, river, and mountain), urban infrastructure (e.g., residential, commercial, and parking) and transport hubs (e.g., airport, port, and railway station). We carefully construct the dataset to minimise intra-class variance and maximise inter-class diversity, ensuring a balanced and representative sample for classification tasks.
Table 2 summarises the distribution of images per class in the WHU-RS19 dataset. Although the original images are already of high quality, several pre-processing steps are applied to ensure consistency and to prepare them for semantic attribute annotation and deep learning experiments. First, all images are converted to a uniform RGB format and checked for artefacts, distortions, or irrelevant overlays. The original authors removed images with poor visual quality, such as those affected by excessive cloud cover or compression noise, during the initial dataset creation process. Therefore we focus our annotation efforts only on clean, interpretable examples. To improve visual consistency and model compatibility, we resize all images to the appropriate input dimensions required by each deep learning architecture (e.g.,
for ResNet, VGG16, EfficientNet, and ViT;
for InceptionV3). Images are converted to RGB format (if not already in RGB), and normalised using the standard ImageNet pre-processing scheme: pixel values are scaled to [0, 1], then normalised using mean = [0.485, 0.456, 0.406] and standard deviation = [0.229, 0.224, 0.225] per channel. These standardisation parameters ensure compatibility with models pretrained on ImageNet and are critical for effective transfer learning. No other spectral enhancements or data augmentations are applied prior to training. No further geometric or spectral enhancement is applied prior to annotation in order to preserve the semantic fidelity of the scenes as perceived by human annotators.
3.2. Category Design
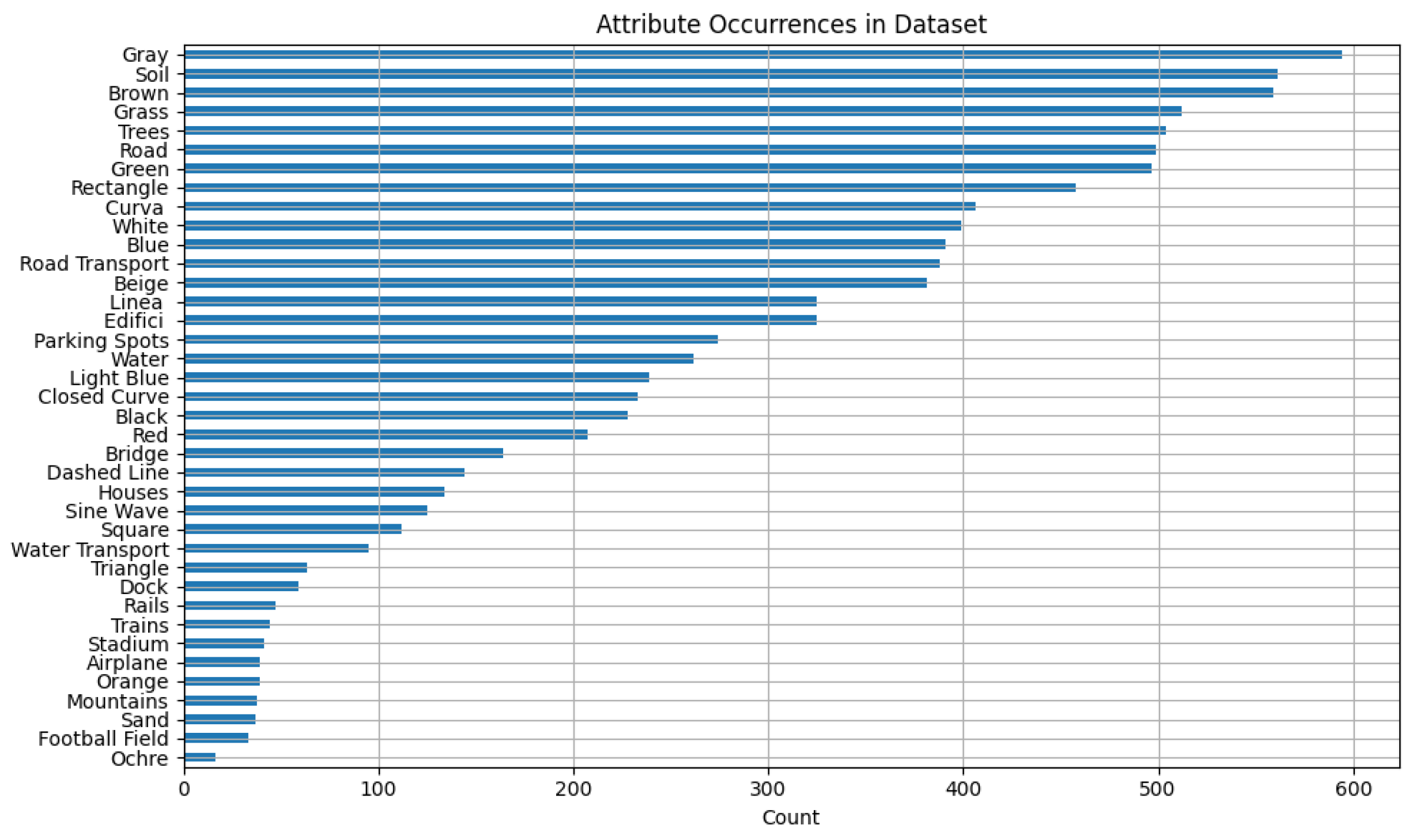
Most existing RS datasets emphasise broad scene-level categories or static object types (e.g., bridges, parks, or buildings), without providing detailed semantic breakdowns within individual images. Such coarse-grained labels fail to capture the complexity and variability typical of aerial scenes, especially when aiming at tasks such as attribute-based ZSL, interpretability, or multimodal analysis. In WHU-RS19 ABZSL, we address this gap by introducing a comprehensive set of 38 image-level attributes grouped into three semantically meaningful categories: Objects, Geometric Patterns, and Dominant Colours.
The Objects category contains 19 attributes and covers both natural and man-made elements commonly observed in aerial scenes. These include typically found infrastructure (e.g., roads, bridges, and buildings), transportation elements (e.g., aircraft, road vehicles, water vehicles, and trains), and landscape features (e.g., trees, terrain, meadow, mountains, water, and sand). The selection of object types is driven by their recurrence across the 19 classes in the original WHU-RS19 dataset and their visual discriminability from a top–down perspective. These object-level annotations are critical for supporting interpretable model decisions and enabling fine-grained scene understanding.
The Geometric Pattern category includes 11 attributes representing abstract visual structures found in aerial imagery, such as rectangles, triangles, lines, curves, and closed curves. These geometric features are particularly valuable for interpreting the structural layout of scenes and understanding how man-made and natural elements are arranged spatially. For example, straight lines and rectangles often indicate man-made structures, while organic curves may correspond to rivers, terrain or forest boundaries. Such features are very useful in XAI environments, where the semantic justification of model predictions is required.
Finally, the Dominant Colour category includes eight key colours that are commonly found in aerial scenes: red, orange, ochre, beige, green, light blue, blue, brown, grey, white, and black. These colours are selected based on visual surveys of the dataset and are useful not only for improving zero-shot generalisation through semantic embedding but also for scene characterisation (e.g., distinguishing vegetation from urban areas, or identifying seasonal cues such as autumn foliage). In contrast to RGB pixel distributions, dominant colour annotations reflect human-perceived scene composition and are useful for vision language alignment. Overall, our attribute set is designed to be compact yet expressive, allowing for the detailed yet manageable annotation of the 1005 images in WHU-RS19. These categories are selected in collaboration with RS experts and refined through iterative pilot annotations. Each image in WHU-RS19 ABZSL is annotated with a binary presence/absence vector across the 38 attributes, resulting in a highly structured and interpretable representation of the scene content. This attribute taxonomy lays the foundation for novel experimental scenarios in RS, particularly attribute-based ZSL, where unseen scene classes need to be predicted based on semantic descriptions. In contrast to the existing class-level attribute datasets (e.g., AwA2 or SUN), our fine-grained image-level annotations allow intra-class variability analysis and support a wide range of tasks, including semantic embedding learning, content-based retrieval, and explainable classification.
The selection of the 38 semantic attributes is the result of a hybrid strategy combining expert elicitation, domain-specific literature review, and visual inspection of the dataset. Initially, a broad set of candidate attributes was proposed by domain experts in remote sensing from the University of Macerata and the Polytechnic University of Marche, based on their relevance in aerial scene interpretation and their visual distinguishability at the given resolution. This list was further refined through an iterative process that included pilot annotations, internal feedback rounds, and removal of ambiguous or redundant terms. Particular emphasis was placed on selecting attributes that are (i) semantically meaningful across multiple scene categories, (ii) interpretable by both humans and machine learning models, and (iii) useful for tasks such as XAI, ZSL, and visual–semantic alignment. By grounding attribute selection in both expert knowledge and empirical image analysis, we can ensure that the final set is both representative and practically useful for downstream applications.
The grouping of attributes into Objects, Geometric Patterns, and Dominant Colours is designed to balance visual discriminability, human annotator consistency, and semantic relevance for downstream tasks. These categories reflect three core types of visual information typically used in human scene interpretation: what is present (objects), how it is arranged (geometry), and what it looks like (colour). Other potential categories, such as texture, vegetation index (NDVI), or elevation, are not considered due to limitations in the input data. WHU-RS19 provides only 2D RGB imagery, and thus lacks the spectral or topographic information needed to derive vegetation indices or elevation models. Additionally, texture is a low-level visual pattern that is difficult to annotate consistently by humans and is better handled through learned feature extraction. Our taxonomy is therefore intentionally aligned with perceptually accessible features, enabling reliable, interpretable, and reproducible human annotation across the entire dataset.
3.3. Image Annotation
The annotation process produces a comprehensive, structured, semantic representation of each image in the WHU-RS19 ABZSL dataset. By combining object-level, geometric, and colour-based attributes, the dataset enables learning scenarios that go beyond traditional scene classification. Below, we describe the dataset’s overall characteristics, emphasising its diversity, semantic richness, and potential to support a wide range of AI tasks in RS.
3.3.1. Annotation Format
The WHU-RS19 ABZSL dataset uses an attribute-based, image-level annotation strategy. Each of the 1005 images in the WHU-RS19 dataset is annotated with a binary vector of 38 descriptors, which are grouped into three main categories: Objects, Geometric Patterns, and Dominant Colours. These annotations offer a simplified yet semantically rich description of scene content, facilitating interpretable and explainable ZSL experiments. Each attribute is marked as
1 if it is visibly present in the image, or
0 otherwise. The initial design of the attribute space includes 40 labels, which are later reduced to 26, and finally consolidated into 8 grouped macro-attributes for more robust and interpretable classification performance. These 8 macro-attributes are Transportation, Infrastructure, Buildings, Sports Structures, Water Elements, Land Elements, Polygons, and Curved Shapes. This grouping is guided by semantic affinity and practical observations during annotation. Attributes that exhibit high variability or ambiguity, such as fine-grained colours and complex shapes, are excluded during refinement.
Figure 1 shows an example of this evolution, displaying three sample images from the
Port class alongside their attribute annotations. These illustrate the level of detail and challenge involved in attribute classification, especially under varying lighting, resolution, and scene complexity conditions.
During the annotation process, particular attention is paid to reduce mislabelling and semantic ambiguity. Duplicate or corrupted images are removed to minimise potential misclassification due to redundancy. After cleaning, the dataset consists of 1005 unique, high-quality annotated samples.
3.3.2. Annotation Quality
A rigorous multi-stage quality control process is established to ensure the high quality and reliability of the annotations. After collecting the initial annotations, we design a three-stage verification and correction pipeline to ensure their consistency and accuracy. In the first stage, annotators are randomly paired, and each annotator is tasked with independently re-annotating the images assigned to the other. Following this cross-validation step, the paired annotators collaborate to merge their respective annotations, resolving discrepancies to produce a more accurate and reliable result. In the second step, a dedicated supervisor conducts an in-depth review of the merged annotations. The supervisor systematically examines key annotation attributes, including exact locations, category labels, and bounding box orientation, to ensure they meet the predefined standards and guidelines. Finally, in the third stage, domain experts specialising in RS imagery perform a final quality assessment. These experts conduct a comprehensive review of the dataset, validating both individual annotations and the overall dataset consistency. This multi-stage quality assurance process is critical in achieving a high-quality dataset suitable for robust downstream applications.
3.3.3. Attribute Refinement and Grouping
During the initial design phase, we define a set of 40 image-level attributes spanning various semantic concepts. Through iterative annotation trials and expert feedback, we refine this list to 26 by eliminating ambiguous or infrequently occurring attributes. Finally, to facilitate interpretable classification and multi-task evaluation, we group the remaining attributes into eight macro-attributes based on semantic similarity and co-occurrence patterns.
Table 3 presents the full list of original attributes, indicates their final status (retained, removed, or merged), and provides the reasons behind each decision.
3.7. Algorithm Analysis
In this study, we evaluate several CNNs and Transformer-based architectures to perform multi-label attribute classification on the WHU-RS19 ABZSL dataset. The selected models are as follows:
ResNet-18 [
16]—a residual network with 18 layers, known for its efficient skip connections.
VGG-16 [
17]—a deep convolutional network using sequential small convolutional kernels.
InceptionV3 [
18]—a network based on inception modules designed for computational efficiency.
EfficientNet-B0 [
19]—a lightweight and scalable CNN that balances network depth, width, and resolution through compound scaling, achieving high accuracy with fewer parameters.
Vision Transformer (ViT) [
20]—a Transformer-based architecture that processes images as sequences of patches.
We initialize all models using pretrained weights from ImageNet [
60] to take advantage of transfer learning. The fully connected classification layers are modified to match the number of target attributes (multi-label setup), using a final sigmoid activation function to predict multiple labels simultaneously. The training procedure is kept homogeneous across the models to ensure a fair comparison. The main hyperparameters used for training are summarised in
Table 4.
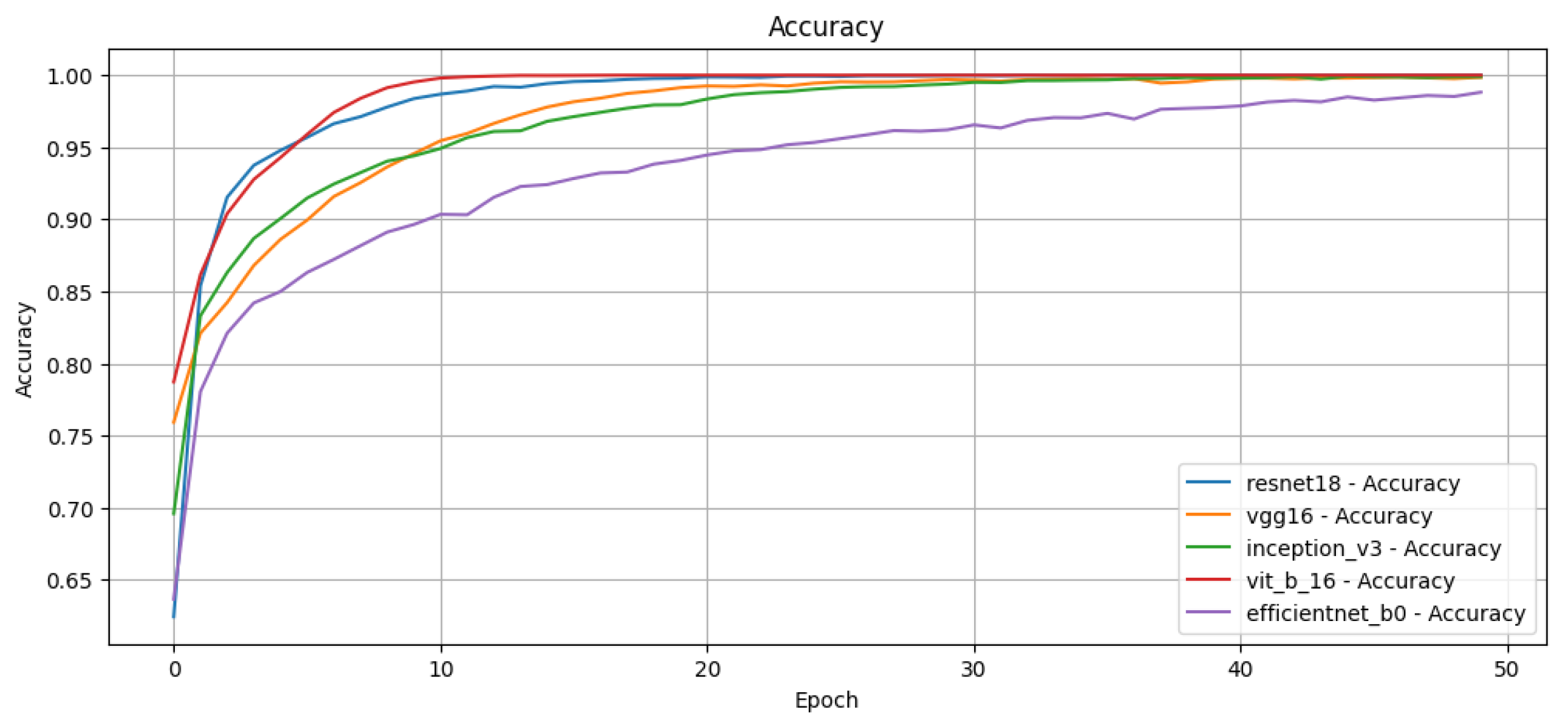
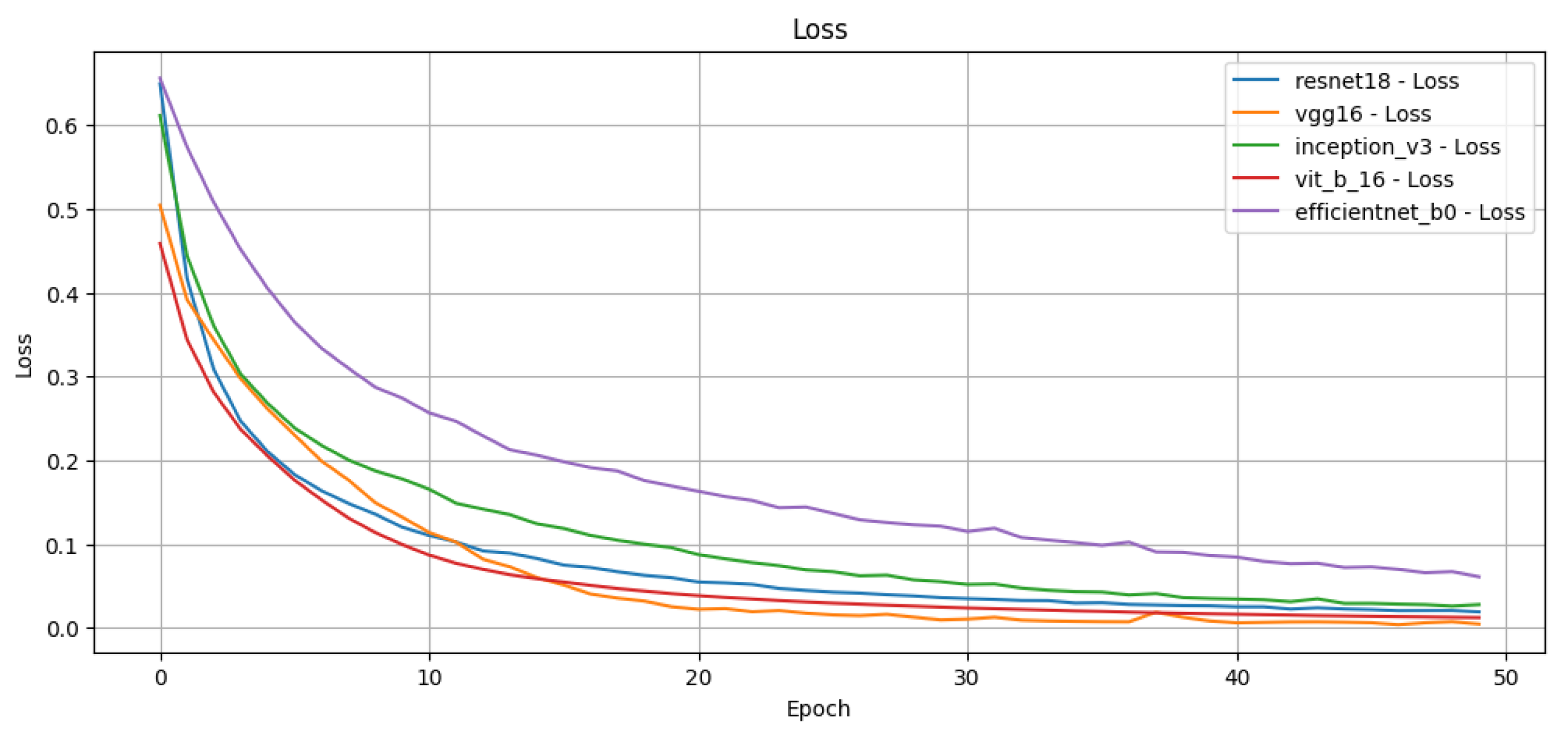
We train each model for 50 epochs using binary cross-entropy loss to optimise multi-label predictions. We apply a resize transformation to the input images to match the required input dimensions for each network. In addition, we normalise the images for ViT to match the range expected by the pretrained model.
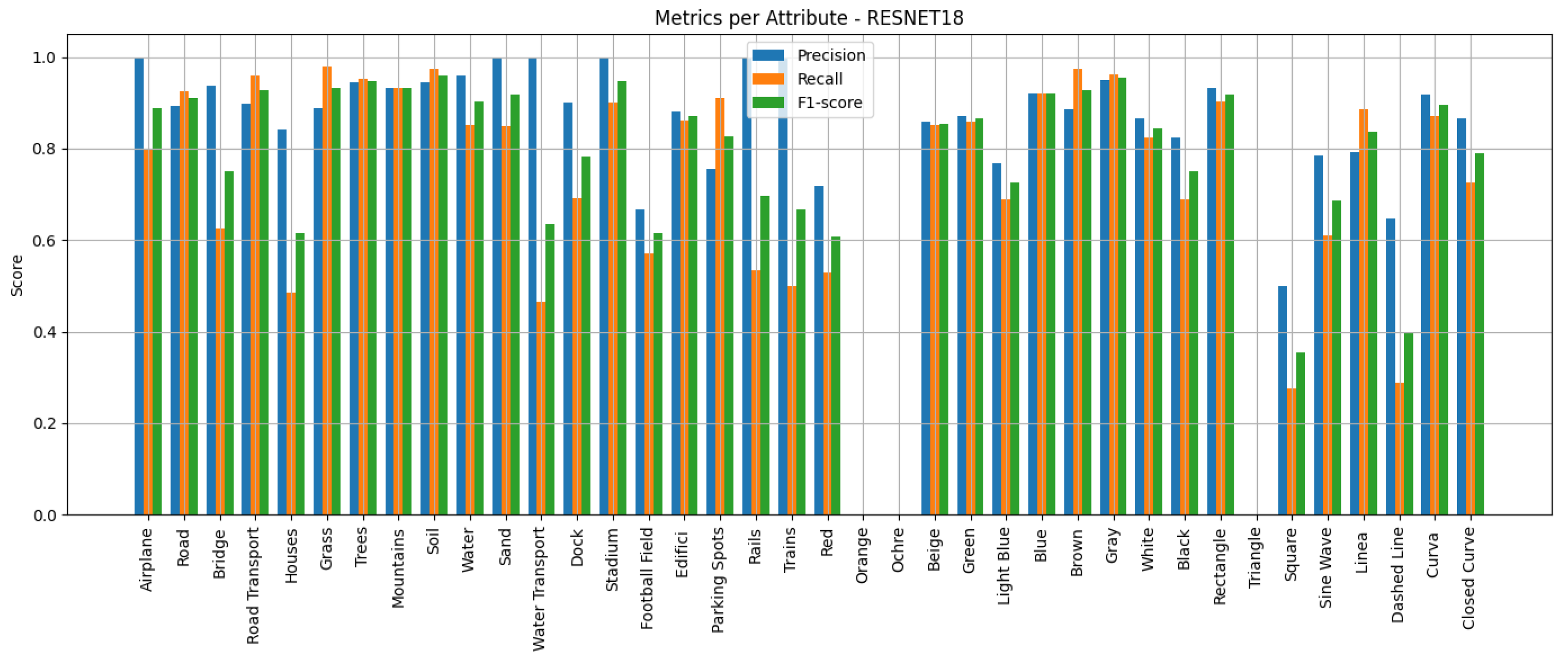
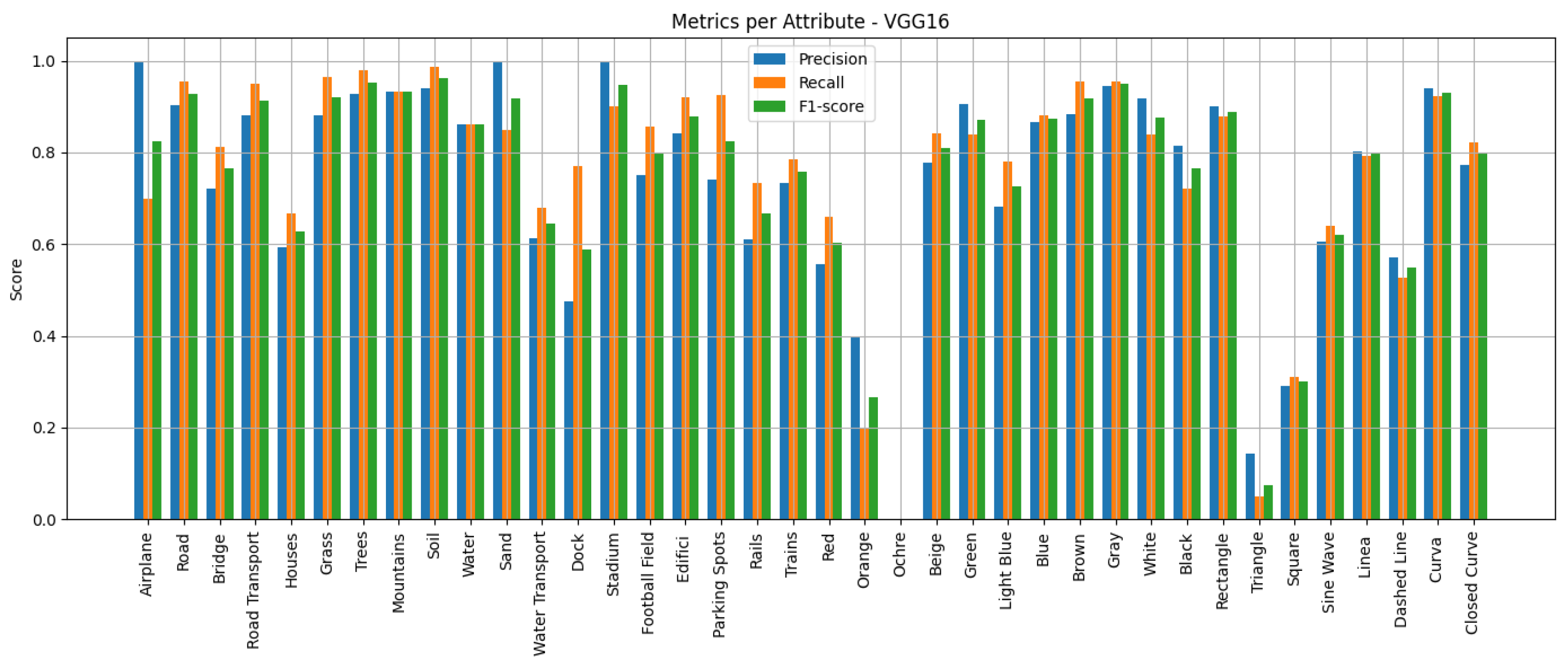
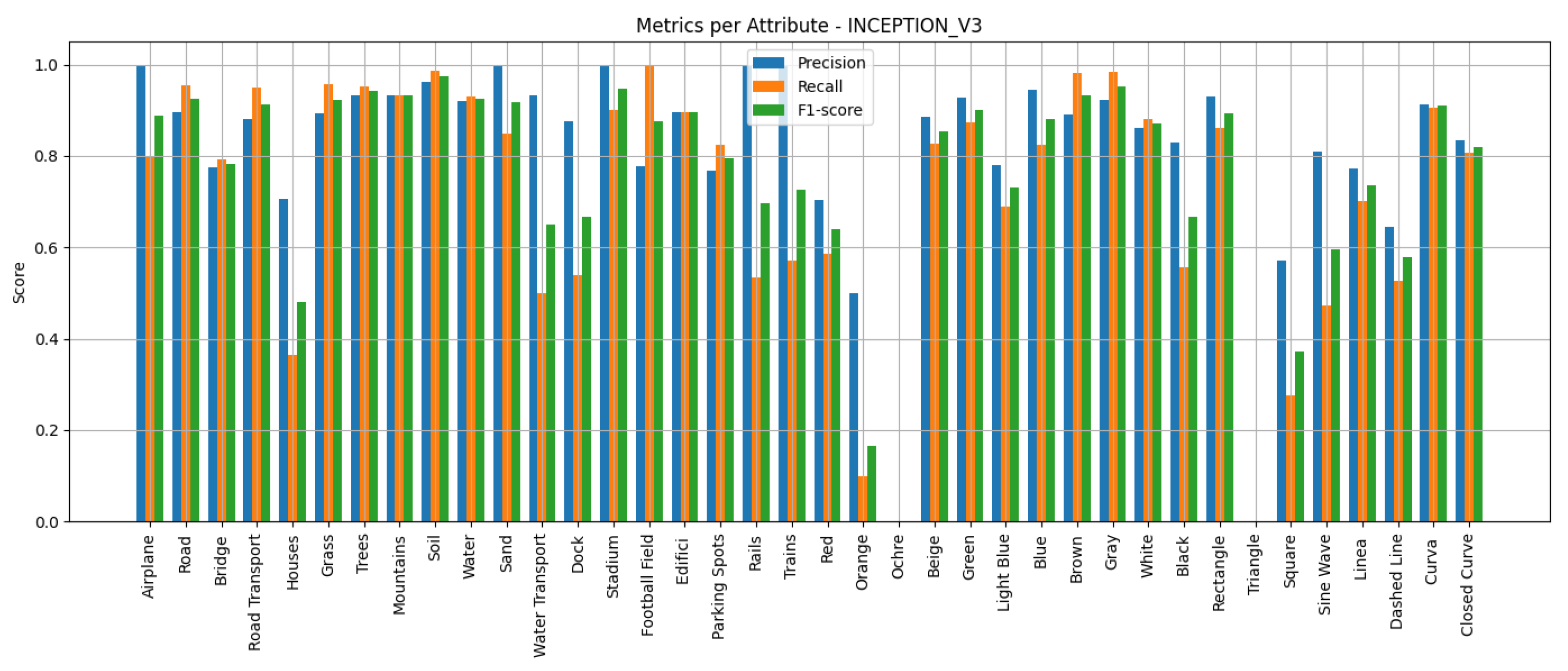
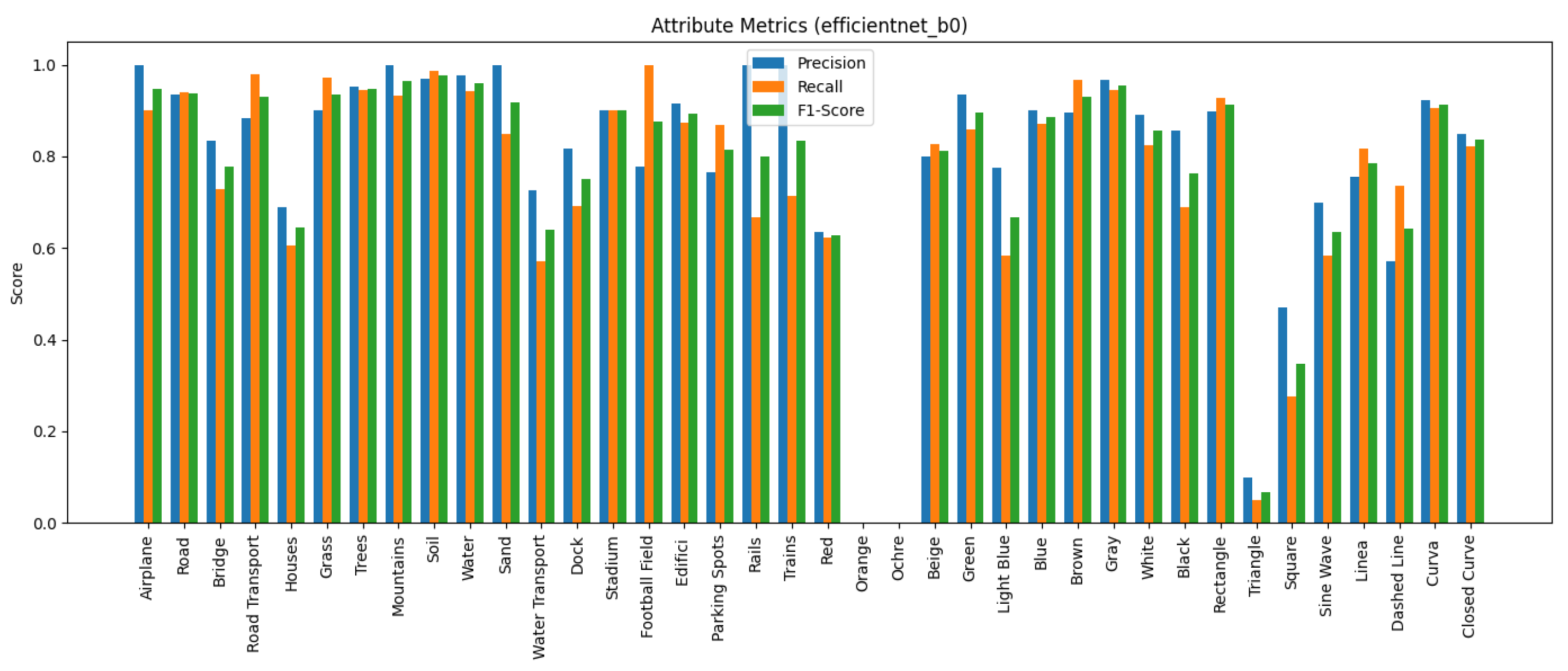
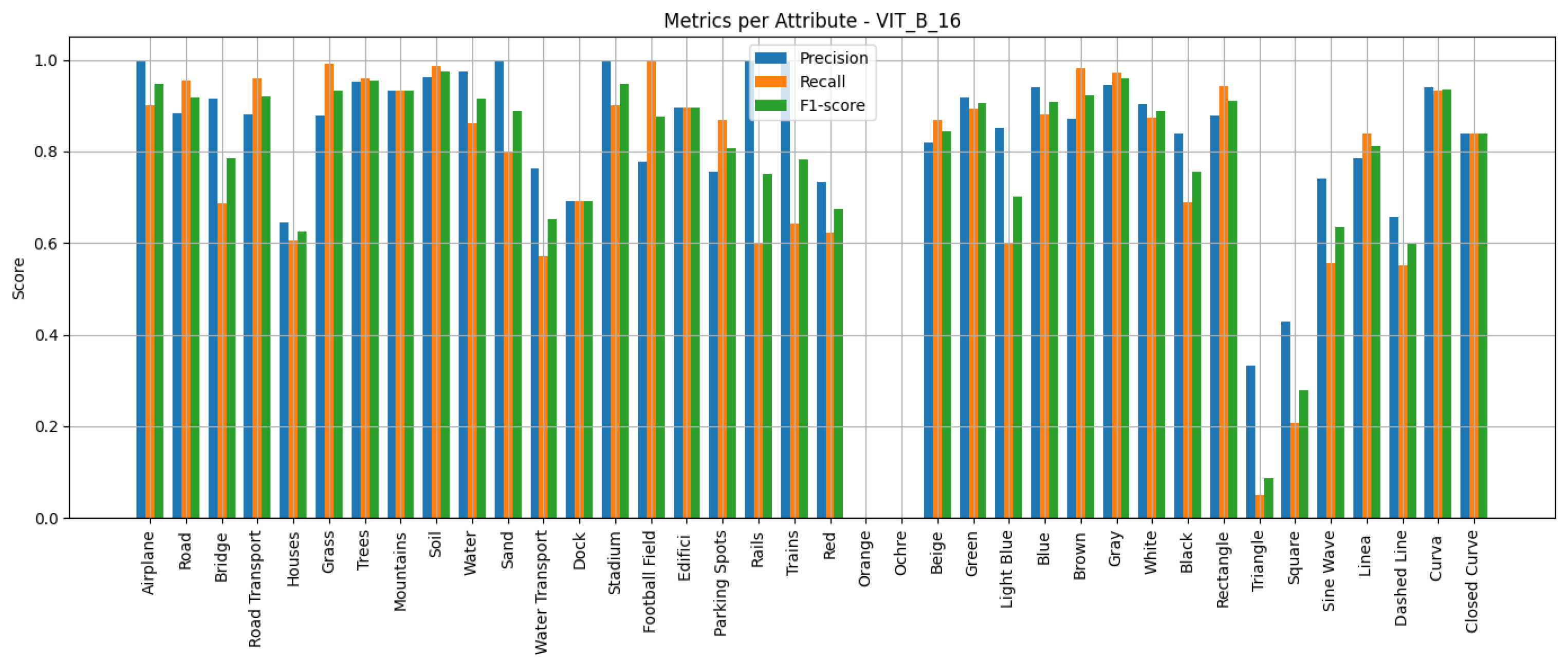
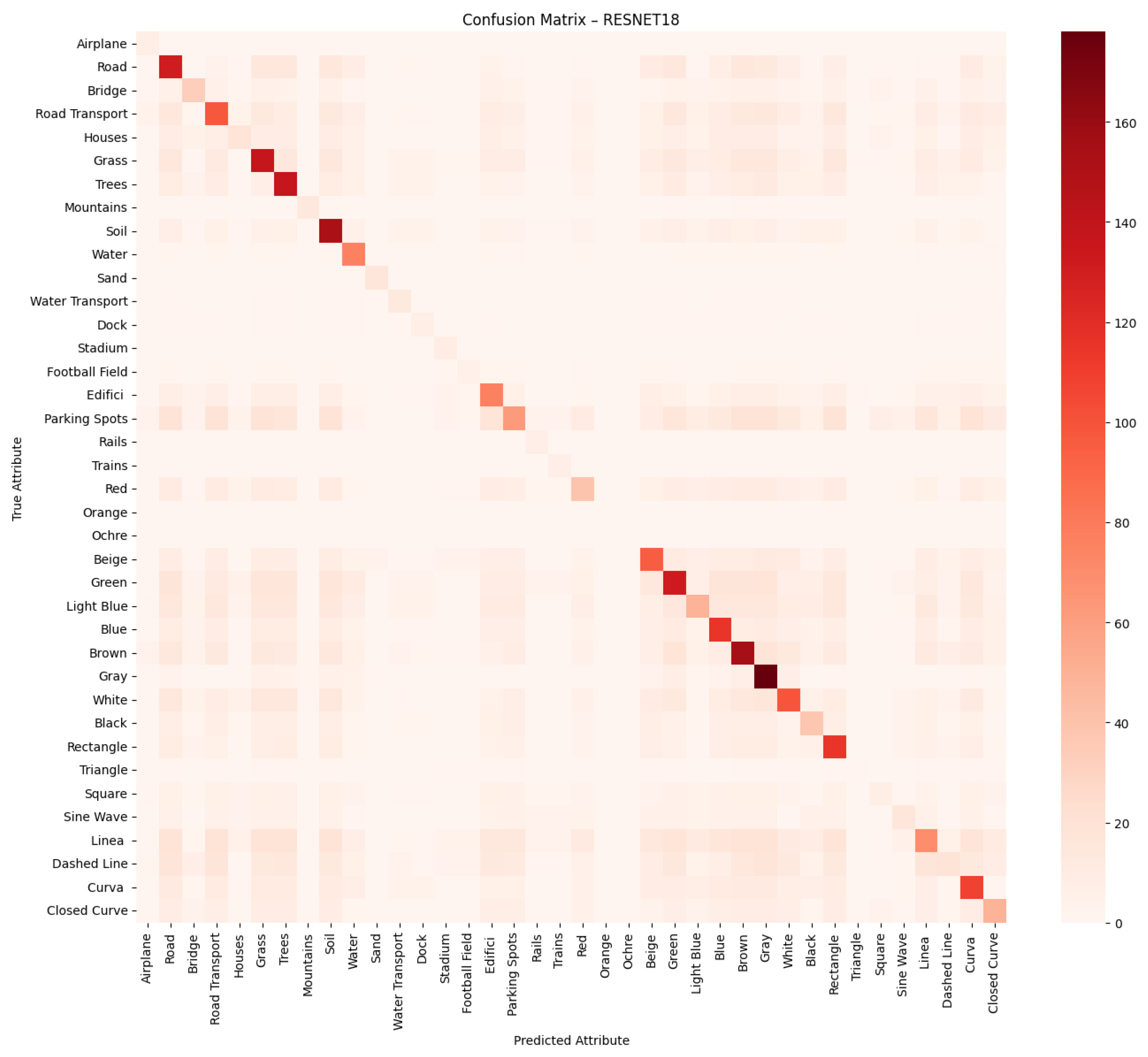
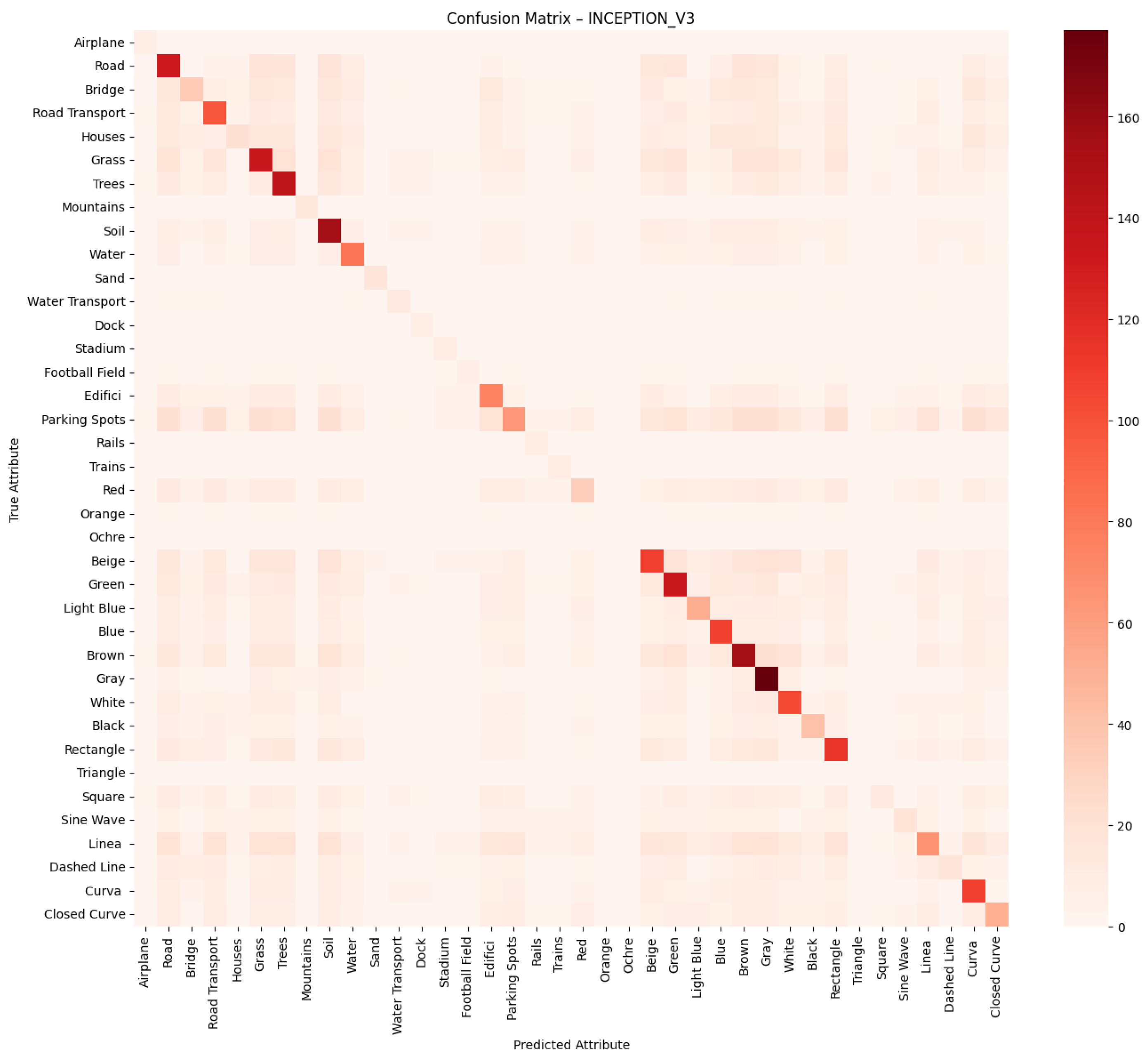
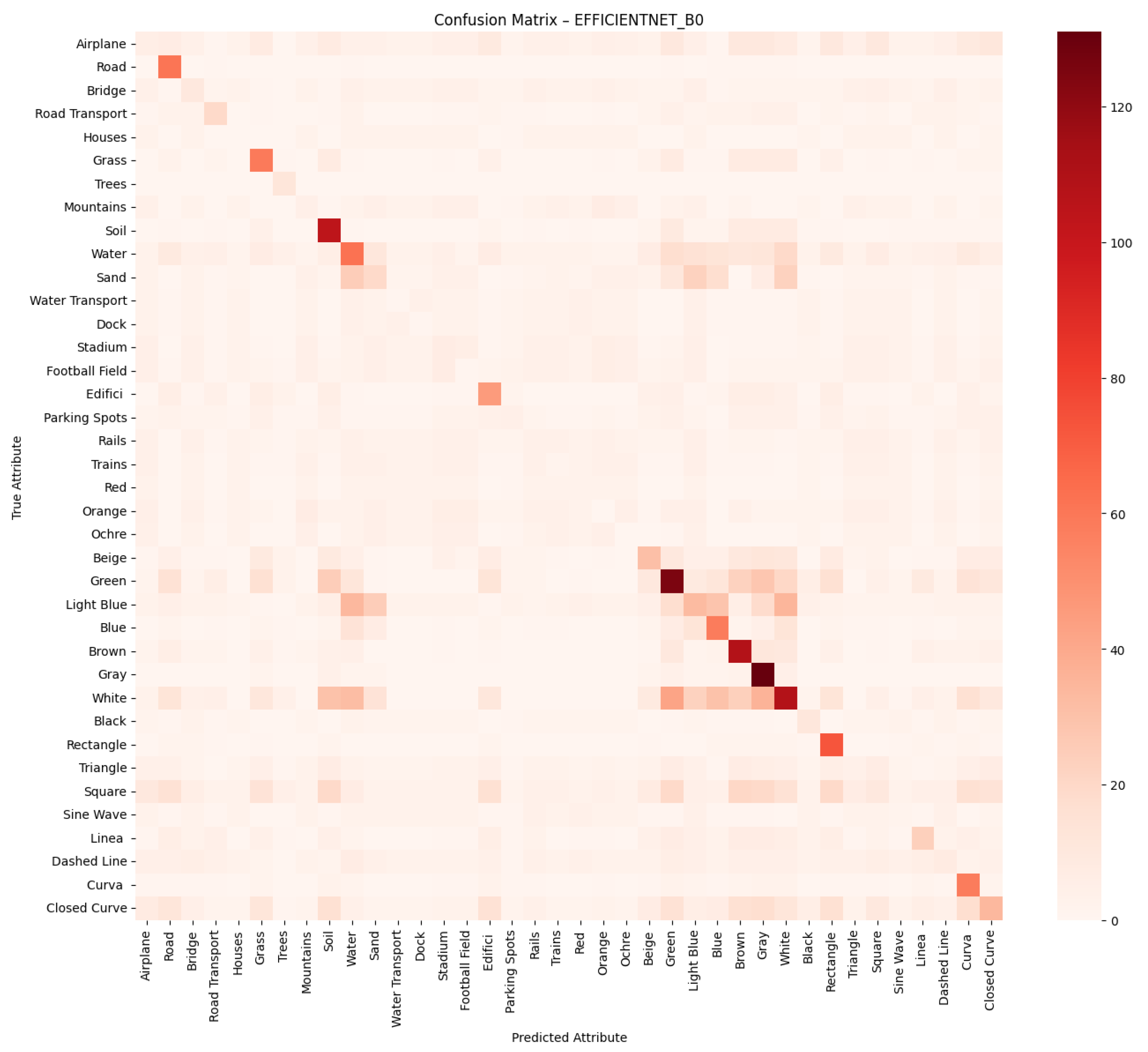
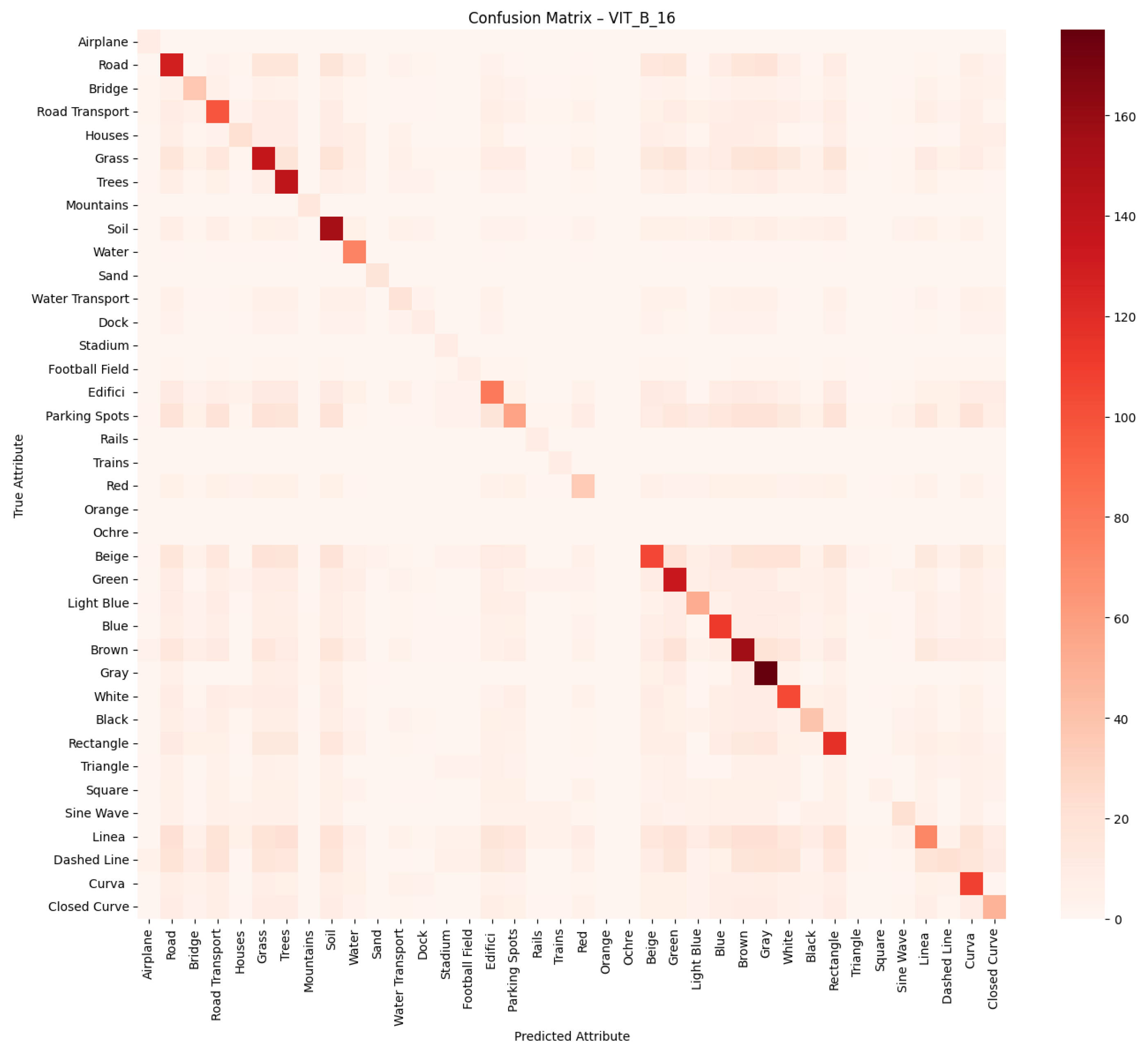
We employ standard multi-label classification metrics to evaluate the performance of the proposed models, including precision, recall, F1-score, and macro F1-score. These metrics are widely used in the literature to assess multi-label classification performance, particularly in tasks involving attribute prediction across multiple semantic categories. In addition, we generate confusion matrices for each network to visualise the distribution of true positives, false positives, true negatives and false negatives, providing a deeper insight into the classification errors per attribute.
Predicting attributes rather than scene classes enables a more granular and interpretable understanding of remote sensing images, especially when multiple objects or features exist within the same image. Lampert et al. [
13] supported this idea when they introduced attribute-based recognition for ZSL, demonstrating that attributes can serve as a meaningful intermediate representation for recognising novel categories. Xian et al. [
14] also demonstrated that semantic features facilitate knowledge transfer between familiar and unfamiliar classes, which is crucial in scenarios with limited labelled data. While this paper does not include a full zero-shot experiment, our attribute-based predictions lay the groundwork for future zero-shot or interpretable classification tasks where traditional class labels are inadequate for nuanced scene analysis.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




