1. Introduction
Global climate change has emerged as one of the most pressing environmental and economic challenges facing humanity in the 21st century. According to the Intergovernmental Panel on Climate Change (IPCC) Sixth Assessment Report (AR6) released in 2023, the global average temperature has increased by 1.1 °C compared to pre-industrial levels, with greenhouse gas emissions from human activities identified as the dominant driver of global warming [
1]. As the world’s largest carbon emitter [
2], China accounted for 9.89 Gt of CO
2 emissions in 2019, representing 30.7% of the global total [
3]. The effectiveness of China’s emission reduction policies plays a pivotal role in the achievement of global climate governance targets. In response to its “dual carbon” pledge, the Chinese government has implemented a range of stringent mitigation measures, including the establishment of a national carbon trading system, the promotion of green finance, the expansion of renewable energy industries, and deep adjustments to industrial structures [
4]. However, the accurate implementation of these policies at the county level requires high-precision carbon emission forecasting models as critical support. Carbon emission forecasting efforts have primarily focused on national [
5,
6,
7], provincial [
8,
9], and city-level scales [
10,
11], with comparatively limited attention given to the county level. Moreover, existing studies often analyze either temporal trends or spatial distributions in isolation, lacking an integrated spatiotemporal approach necessary to fully capture the dynamic evolution of county-level emissions. Thus, developing forecasting models that incorporate both spatial and temporal dimensions at the county scale has become a key scientific challenge in enhancing the accuracy and resolution of carbon emission simulations and in advancing China’s dual-carbon goals.
The choice of forecasting model directly influences the reliability of carbon emission predictions. Traditional regression models, especially linear regression [
11], are widely used due to their simplicity and interpretability. However, these models are inherently limited in capturing nonlinear relationships, making them less suitable for complex, high-dimensional forecasting tasks and inadequate in modeling the interaction effects of multiple driving factors [
12]. Gray forecasting models (GMs), while adaptable to small-sample scenarios [
13], heavily rely on initial assumptions and expert knowledge during model construction [
14], restricting their generalizability. In contrast, machine learning models—known for their robust nonlinear fitting capabilities—have opened new avenues for carbon emission prediction. Among them, shallow learning models such as support vector machines (SVMs) have demonstrated significant advantages in small-sample, high-dimensional contexts [
15]. For instance, Agbulut successfully employed SVMs to predict CO
2 emissions in Turkey’s transportation sector [
16], while Sun et al. developed a particle swarm optimization (PSO)-LSSVM model that achieved low error rates (0.663) in forecasting carbon emissions in Hebei Province [
17]. These models can effectively map complex nonlinear relationships between emissions and their drivers and are particularly suited to data-constrained environments due to their global optimization and computational efficiency [
18].
The advent of deep learning has further expanded the application scope of machine learning in this domain. Wen et al. employed a PSO-enhanced backpropagation neural network (BPNN) combined with random forest (RF) to accurately predict CO
2 emissions in China’s commercial sector. Similarly, Zhou et al. applied a PSO-optimized BPNN to forecast emissions from the thermal power industry in the Beijing–Tianjin–Hebei region, achieving error rates within 6%. Long short-term memory (LSTM) networks have also improved prediction accuracy through their ability to model time series data—Bismark et al., for example, successfully applied BiLSTM networks to forecast emissions in African countries such as Ghana and Nigeria [
19]. In addition, convolutional neural networks (CNNs), with their automatic feature learning mechanisms, have proven effective in handling multivariable inputs, as demonstrated by Hien and Kor in their high-accuracy, high-stability CNN-based prediction model [
20]. Nevertheless, the “black-box” nature of deep learning models poses challenges for interpretability [
21], limiting their applicability in policy-making contexts where transparency and mechanism insight are critical.
While deep learning models offer strong capabilities in modeling complex spatiotemporal and nonlinear dependencies, their “black-box” nature and computational demands often limit their practicality for structured tabular datasets commonly used in regional carbon emission studies. This is particularly challenging in policy-making contexts, where interpretability and transparency are essential. Given these constraints, gradient boosting algorithms—such as GBDT, XGBoost, and LightGBM—have gained increasing attention as effective alternatives. These models strike a balance between predictive accuracy, computational efficiency, and interpretability, making them well-suited for carbon emission forecasting tasks that involve structured and high-dimensional socioeconomic and environmental datasets at the county scale. GBDT models, leveraging tree-based nonlinear fitting, have shown superior prediction performance compared to support vector machines (SVMs) and random forests in many scenarios [
22], while maintaining computational advantages [
23,
24]. XGBoost improves generalization by introducing regularization, and LightGBM accelerates training through histogram-based algorithms [
25,
26]. These innovations have facilitated wide adoption of boosting algorithms across various domains, including air pollution forecasting [
27], natural disaster prediction [
28], electricity load modeling [
29], and energy demand analysis [
30]. In the field of carbon emission forecasting, XGBoost has achieved high accuracy in megacity-scale modeling in China, with RMSE as low as 0.036 [
31]. LightGBM, when combined with the SHAP interpretability framework, has enhanced transparency and feature attribution in building-level carbon modeling [
32]. Despite their proven success at larger spatial scales, systematic assessments of these algorithms at the county level remain limited. Their potential to model fine-grained carbon emissions across diverse regions and uncover underlying drivers has yet to be fully explored. To address these gaps, this study conducts a comparative analysis of GBDT, XGBoost, and LightGBM, focusing on both predictive effectiveness and interpretability in the context of county-level carbon emissions in China. Their potential to model fine-grained carbon emissions across diverse regions and uncover underlying drivers has yet to be fully explored. To address these gaps, this study conducts a comparative analysis of GBDT, XGBoost, and LightGBM, focusing on both predictive effectiveness and interpretability in the context of county-level carbon emissions in China.
Equally important is the rational selection of emission-driving variables, which plays a critical role in building accurate forecasting models [
33]. Prior research has established that factors such as economic growth, energy consumption, industrial structure, population size, urbanization, and natural conditions significantly influence regional carbon emissions [
34]. For example, Lukman et al. employed an ARDL cointegration model to analyze Nigeria’s data from 1981 to 2015, finding that population size, per capita GDP, urbanization level, and energy consumption all had significant long-term positive effects on carbon emissions [
35]. Singh’s work also revealed a strong influence of climate change on greenhouse gas emissions [
11]. Nonetheless, current studies often suffer from redundant variable inclusion, which increases model complexity and may reduce both prediction accuracy and interpretability [
36]. Therefore, scientifically grounded feature selection is essential to eliminate redundant inputs, streamline model complexity, and significantly enhance both performance and explainability in carbon emission forecasting.
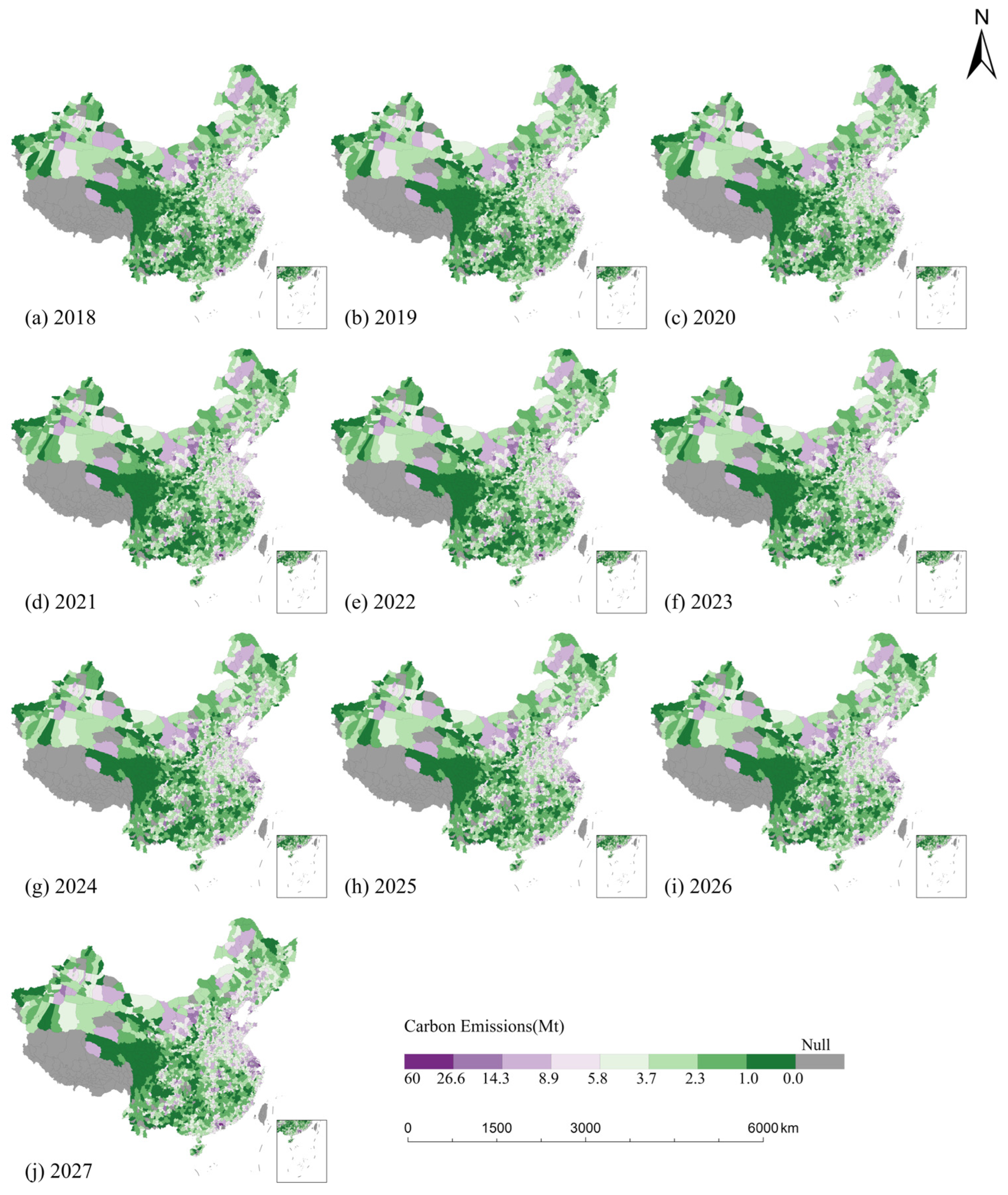
This study aims to address the following three key scientific questions: (1) How can high-precision carbon emission forecasting models be effectively constructed at the county level to accurately quantify the contributions of different driving factors? (2) How can gradient boosting algorithms (GBDT, XGBoost, LightGBM) be optimized based on the characteristics of county-level data to further improve prediction accuracy and generalizability? (3) How can the underlying driving mechanisms of county-level carbon emissions in China be revealed, and how can the spatial evolution of future emissions be reliably predicted? To tackle these issues, this study develops a county-scale carbon emission forecasting framework based on gradient boosting algorithms, aiming to explore high-precision modeling techniques suitable for fine-grained analysis. Coupled with feature importance analysis, the study identifies key driving forces behind emissions. Using data from 2008 to 2017 on county-level emissions and related factors, the research first conducts correlation analysis for initial feature screening and applies interpolation methods to address missing values, ensuring data completeness and consistency. Then, GBDT, XGBoost, and LightGBM models are constructed and optimized through grid search and cross-validation techniques to enhance predictive performance. Finally, the best-performing model is used to forecast emission trends from 2018 to 2027, thereby revealing the spatiotemporal dynamics of future county-level emissions and providing crucial support for policy formulation aimed at achieving emission reductions at the county scale in China.


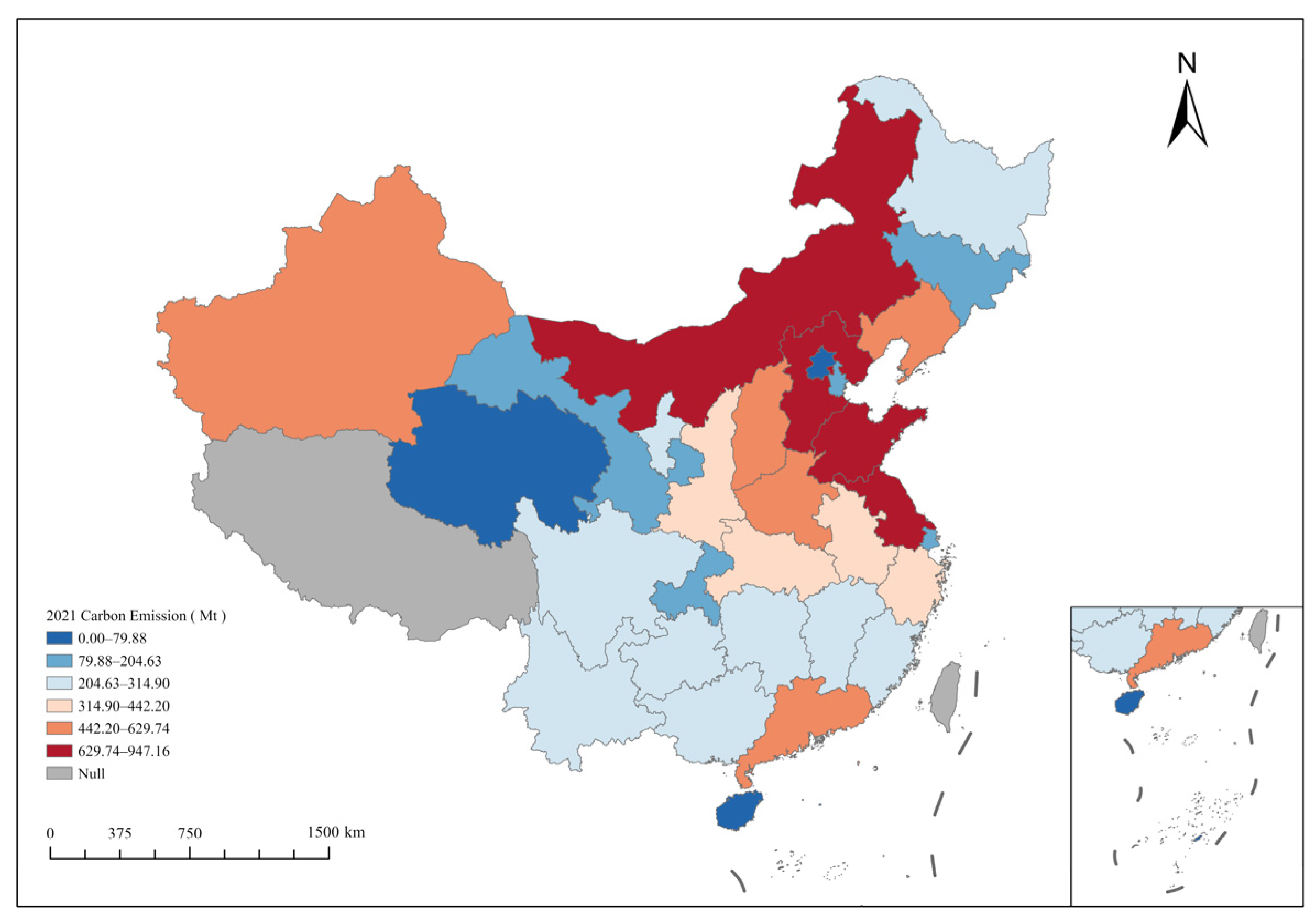
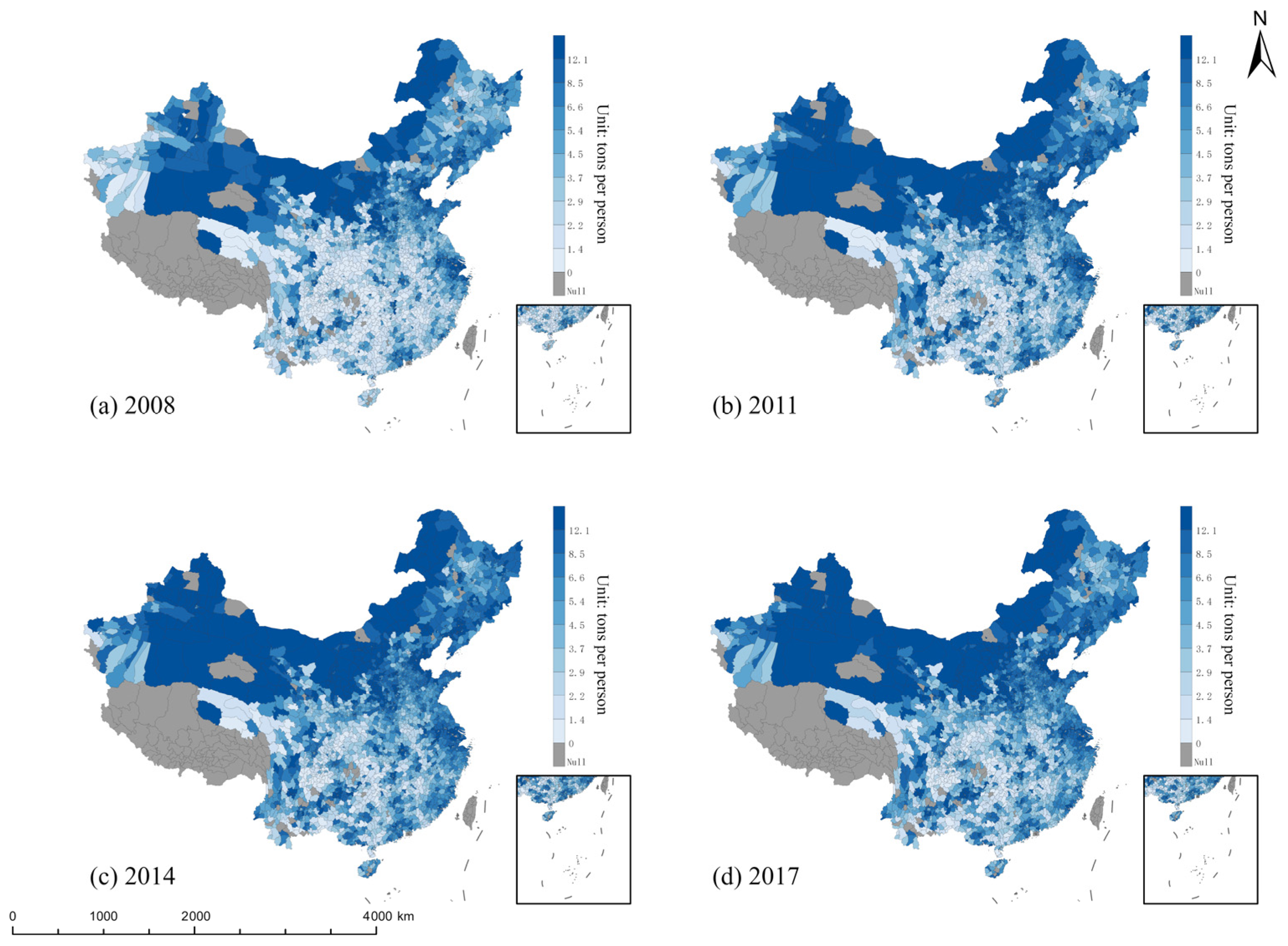
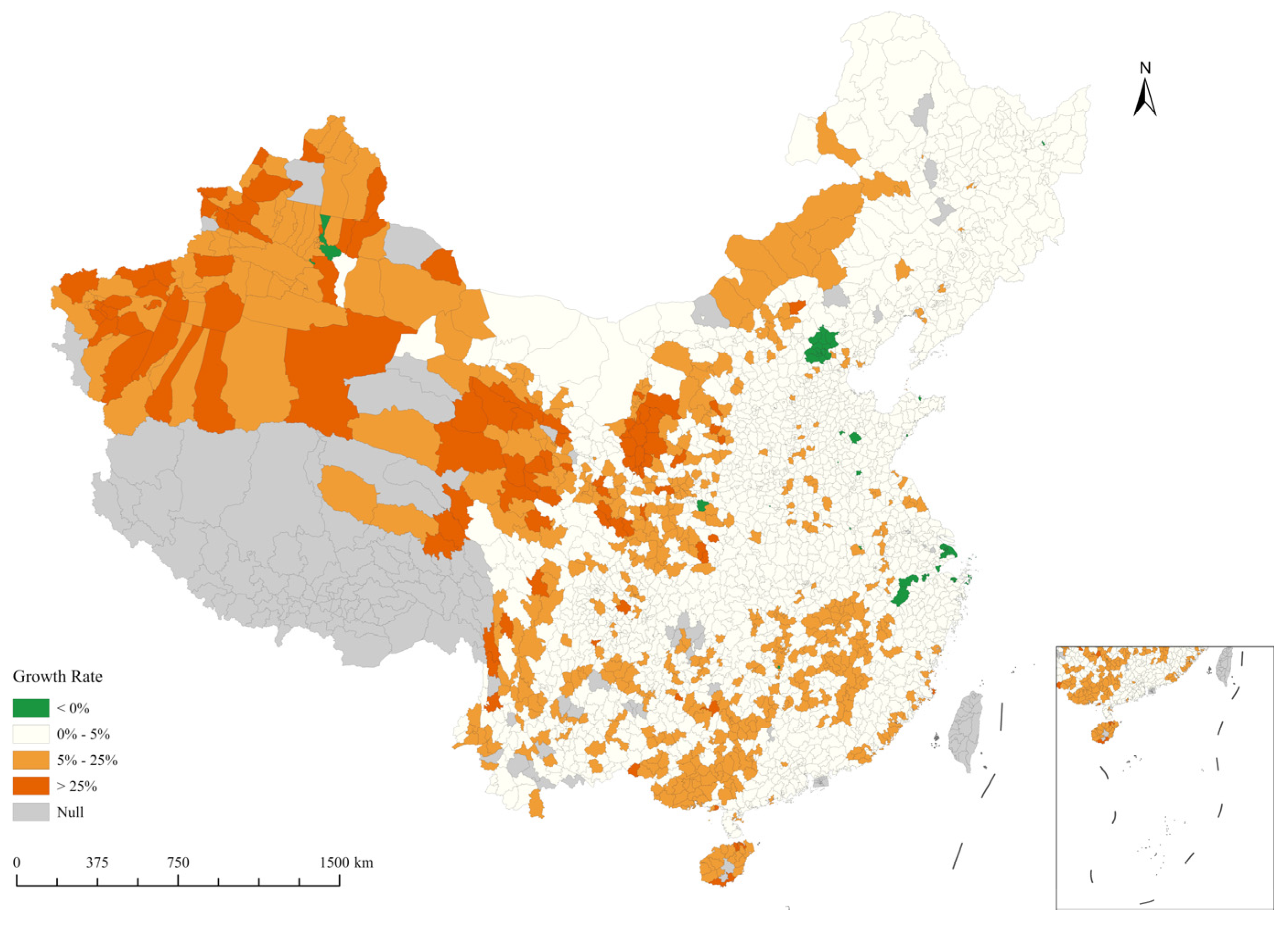
 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}