
A Dual-Branch Spatial-Frequency Domain Fusion Method with Cross Attention for SAR Image Target Recognition


Abstract
1. Introduction
- We propose a spatial-frequency domain fusion recognition method with cross attention, which solves the limitations of single-domain feature extraction, increases the amount of cross-domain feature information and achieves efficient cross-domain fusion recognition.
- We propose an EMFE module and an HFDT module. The EMFE module employs a multi-branch parallel convolution structure to extract multi-scale local features in the spatial domain. To enhance key regional features, the HFDT module provides a frequency-domain attention weight, improving the distinguishability of spatial features. Furthermore, the HFDT module extracts global structural features in the frequency domain, compensating for the limited receptive field of spatial-domain feature extraction. To align with the spatial domain features, the EMFE provides a spatial-domain attention weight, reducing the problem of feature inconsistency across domains.
- We propose a cross-domain feature fusion (CDFF) module that employs a cross-attention mechanism, bilinear projection, and adaptive fusion. Through bidirectional cross-domain attention interaction, the CDFF module achieves complementary fusion of spatial-domain detail features and frequency-domain global features. This further enhances feature distinguishability and spatial-frequency domain alignment, significantly improving the model’s feature representation capability and achieving optimal cross-domain feature fusion.
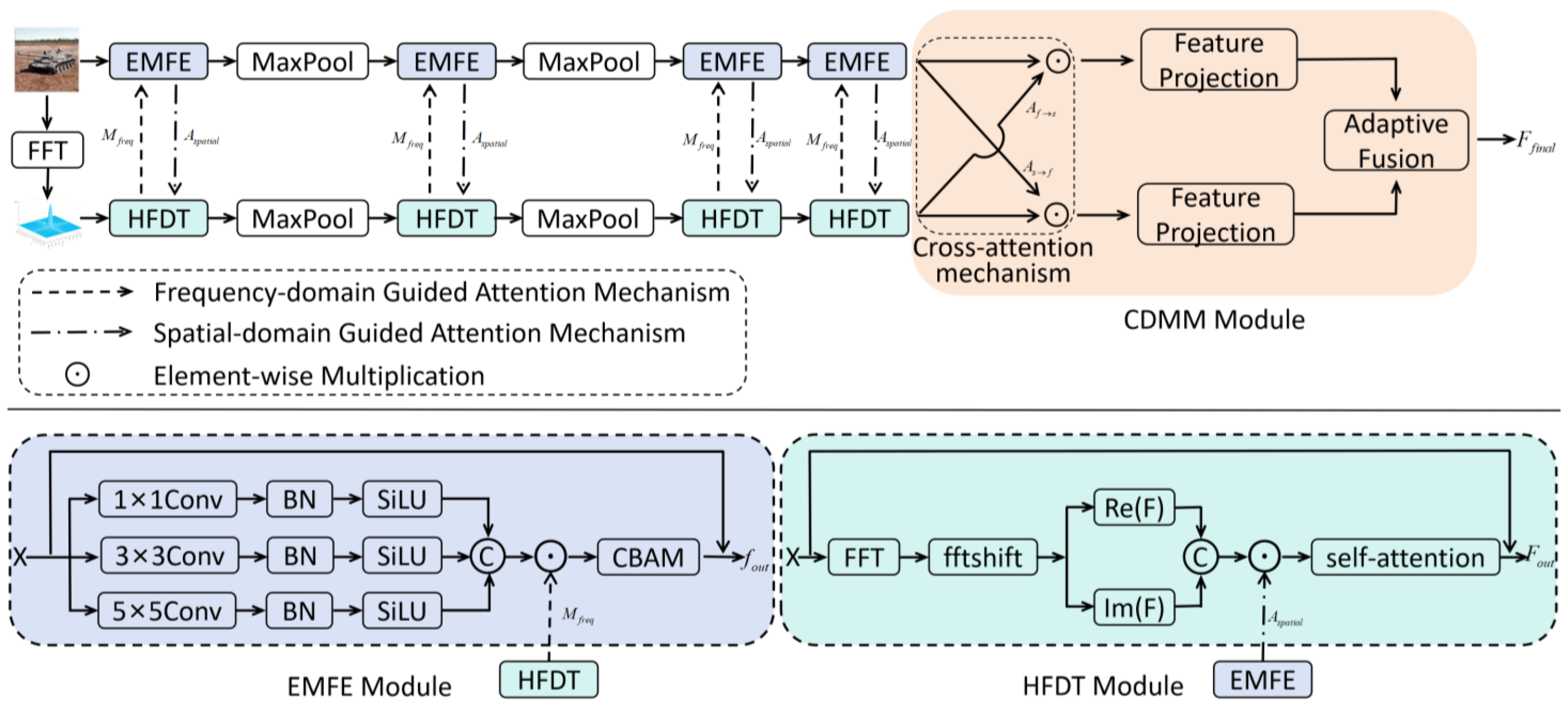
2. Proposed Method
2.1. Spatial Domain Feature Extraction
2.1.1. Multi-Scale Feature Extraction
- Local detail feature extraction. It uses 1 × 1 convolution kernels to capture pixel-level local features, achieving fine-grained feature extraction and preserving local detail information of the target.
- 2.
- Medium scale feature extraction. It employs 3 × 3 depthwise separable convolution to extract region-level features, constructing feature representations with medium receptive fields [25]. This balances local details with contextual information while reducing computational complexity, effectively capturing the spatial correlations between target components. As shown in Figure 2.
- 3.
- Global contextual feature extraction. It uses 5 × 5 standard convolutions to construct a feature extraction path with large receptive fields, capturing the overall geometric morphology and spatial layout features of the target. This approach establishes global contextual relationships, suppresses local interference from speckle noise, and reduces the computational complexity of large convolution kernels.
2.1.2. Frequency Domain Guided Attention
2.1.3. Convolutional Block Attention Module (CBAM) and Residual Connection
2.2. Frequency Domain Feature Extraction
2.2.1. Frequency Domain Feature Transformation
2.2.2. Spatial Domain Guided Attention
2.2.3. Frequency Domain Self-Attention and Residual Connection
2.3. Cross Domain Feature Fusion Module
2.3.1. Cross Attention Mechanisms
2.3.2. Dual Domain Feature Projection
2.3.3. Adaptive Feature Fusion
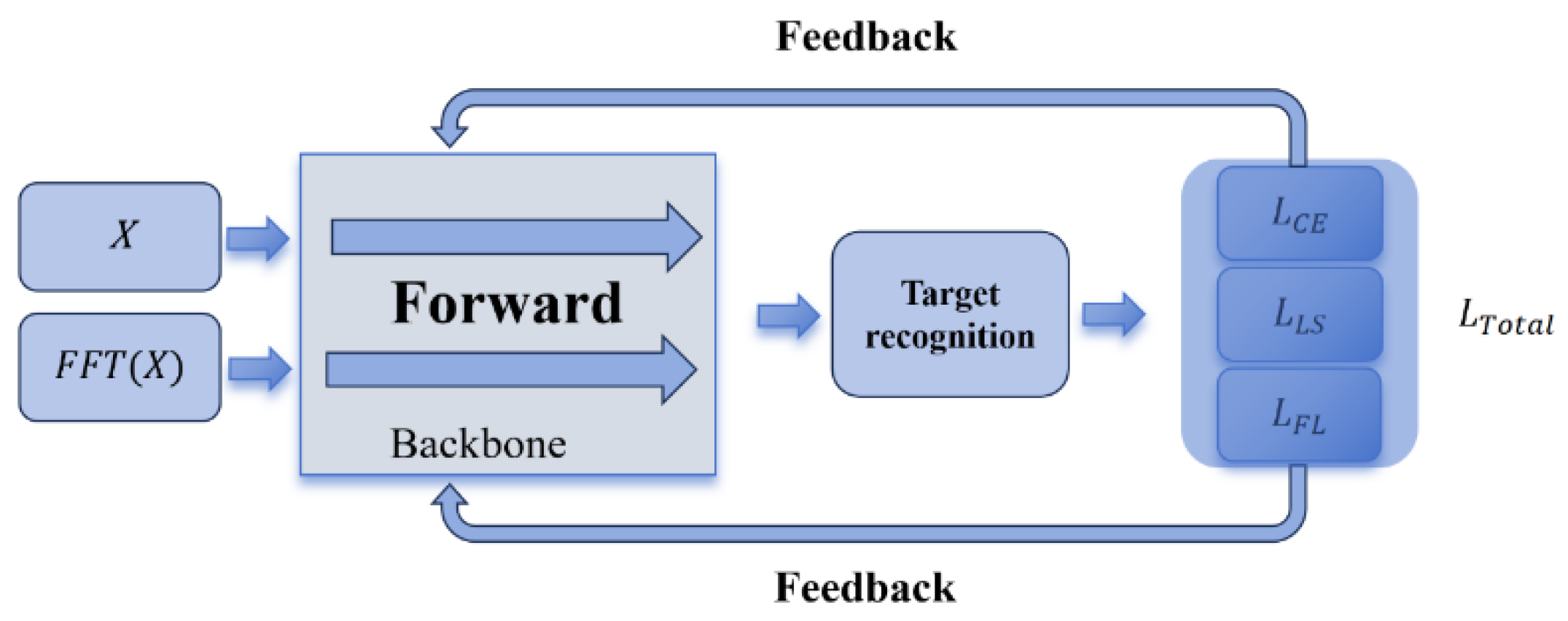
2.4. Joint Loss Function
- 1.
- Cross entropy loss (). It is used to measure the difference between the predicted probability distribution and the true label distribution.
- 2.
- Label smoothing cross entropy loss (). Label smoothing is a regularization technique that prevents the model from overfitting by adding some noise to the true labels. Specifically, when calculating the cross-entropy loss, the label smoothing cross entropy loss replaces the true label with a smoothed label
- 3.
- Focal loss (). It reduces the loss contribution of easy-to-classify samples by introducing an adjustable focusing parameter, thereby enhancing the model’s attention to difficult-to-classify samples.
3. Experiment and Discussion
3.1. Dataset Introduction
3.2. Comparison Experiment
3.3. Ablation Experiment
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- He, D.; Guo, W.; Zhang, T.; Zhang, Z.; Yu, W. Occluded target recognition in SAR imagery with scattering excitation learning and channel dropout. IEEE Geosci. Remote Sens. Lett. 2023, 20, 4005005. [Google Scholar] [CrossRef]
- Dong, Z.; Liu, M.; Chen, S.; Tao, M.; Wei, J.; Xing, M. Occluded SAR target recognition based on center local constraint shadow residual network. IEEE Geosci. Remote Sens. Lett. 2025, 22, 3532763. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, F.; Ma, L.; Ma, F. Long-tailed SAR target recognition based on expert network and intraclass resampling. IEEE Geosci. Remote Sens. Lett. 2023, 20, 4010405. [Google Scholar] [CrossRef]
- Chen, Z.; Zhao, L.; He, Q.; Kuang, G. Pixel-level and feature-level domain adaptation for heterogeneous SAR target recognition. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4515205. [Google Scholar] [CrossRef]
- Sun, S.K.; He, Z.; Fan, Z.H.; Ding, D.Z. SAR Image target recognition using diffusion model and scattering information. IEEE Geosci. Remote Sens. Lett. 2024, 21, 4017505. [Google Scholar] [CrossRef]
- Li, Y.; Wan, C.; Zhou, X.; Tang, T. Small-sample SAR target recognition using a multimodal views contrastive learning method. IEEE Geosci. Remote Sens. Lett. 2025, 22, 4007905. [Google Scholar] [CrossRef]
- Chen, H.; Du, C.; Zhu, J.; Guo, D. Target-aspect domain continual learning for SAR target recognition. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5205514. [Google Scholar] [CrossRef]
- Guo, S.; Chen, T.; Wang, P.; Yan, J.; Liu, H. TSMAL: Target-shadow mask assistance learning network for SAR target recognition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 18247–18263. [Google Scholar] [CrossRef]
- Yu, X.; Dong, F.; Ren, H.; Zhang, C.; Zou, L.; Zhou, Y. Multilevel adaptive knowledge distillation network for incremental sar target recognition. IEEE Geosci. Remote Sens. Lett. 2023, 20, 4004405. [Google Scholar] [CrossRef]
- Ren, H.; Dong, F.; Zhou, R.; Yu, X.; Zou, L.; Zhou, Y. Dynamic embedding relation distillation network for incremental SAR automatic target recognition. IEEE Geosci. Remote Sens. Lett. 2024, 21, 4002105. [Google Scholar] [CrossRef]
- Hou, J.J.; Bian, Z.D.; Yao, G.J.; Lin, H.; Zhang, Y.H.; He, S.Y. Attribute scattering center-assisted SAR ATR based on GNN-FiLM. IEEE Geosci. Remote Sens. Lett. 2024, 21, 4009205. [Google Scholar] [CrossRef]
- Zhang, B.; Kannan, R.; Prasanna, V.; Busart, C. Accelerating GNN-Based SAR automatic target recognition on HBM-enabled FPGA. In Proceedings of the 2023 IEEE High Performance Extreme Computing Conference (HPEC), Boston, MA, USA, 25–29 September 2023; pp. 1–7. [Google Scholar]
- Wu, Y.; Wu, L.; Hu, T.; Xiao, Z.; Xiao, M.; Li, L. An efficient radar-based gesture recognition method using enhanced GMM and hybrid SNN. IEEE Sens. J. 2025, 25, 12511–12524. [Google Scholar] [CrossRef]
- Zhu, N.; Xi, Z.; Wu, C.; Zhong, F.; Qi, R.; Chen, H. Inductive conformal prediction enhanced LSTM-SNN network: Applications to birds and UAVs recognition. IEEE Geosci. Remote Sens. Lett. 2024, 21, 3502705. [Google Scholar] [CrossRef]
- Liu, S.; Yi, Y. Knowledge distillation between DNN and SNN for intelligent sensing systems on loihi chip. In Proceedings of the 2023 24th International Symposium on Quality Electronic Design (ISQED), San Francisco, CA, USA, 5–7 April 2023; pp. 1–8. [Google Scholar]
- Sun, Z.; Leng, X.; Lei, Y.; Xiong, B.; Ji, K.; Kuang, G. BiFA-YOLO: A novel YOLO-based method for arbitrary-oriented ship detection in high-resolution SAR images. Remote Sens. 2021, 13, 4209. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, S.; Sun, Z.; Liu, C.; Sun, Y.; Ji, K. Cross-sensor SAR image target detection based on dynamic feature discrimination and center-aware calibration. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5209417. [Google Scholar] [CrossRef]
- Jia, L.; Ma, T.; Rong, H.; Al-Nabhan, N. Affective region recognition and fusion network for target-level multimodal sentiment classification. IEEE Trans. Emerg. Top. Comput. 2024, 12, 688–699. [Google Scholar] [CrossRef]
- Su, X. SAR Target recognition method based on adaptive weighted decision fusion of deep features. Recent Adv. Electr. Electron. Eng. 2024, 8, 803–810. [Google Scholar] [CrossRef]
- He, S.; Hua, M.; Zhang, Y.; Du, X.; Zhang, F. Forward modeling of scattering centers from coated target on rough ground for remote sensing target recognition applications. IEEE Trans. Geosci. Remote Sens. 2024, 62, 2000617. [Google Scholar] [CrossRef]
- Lin, H.; Wang, H.; Xu, F.; Jin, Y.Q. Target recognition for SAR images enhanced by polarimetric information. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5204516. [Google Scholar] [CrossRef]
- Ding, B.; Zhang, A.; Li, R. A 3-D scattering centre model-based SAR target recognition method using multi-level region matching. Remote Sens. Lett. 2024, 15, 215–223. [Google Scholar] [CrossRef]
- Guan, T.; Chang, S.; Wang, C.; Jia, X. SAR small ship detection based on enhanced YOLO network. Remote Sens. 2025, 17, 839. [Google Scholar] [CrossRef]
- Qu, X.; Gao, F.; Dong, J.; Du, Q.; Li, H. Change detection in synthetic aperture radar images using a dual-domain network. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4013405. [Google Scholar] [CrossRef]
- Xu, C.; Wang, Q.; Wang, X.; Chao, X.; Pan, B. Wake2Wake: Feature-guided self-supervised wave suppression method for SAR ship wake detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5108114. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, Y.; Luo, Y.; Kang, Y.; Wang, H. Dynamically self-training open set domain adaptation classification method for heterogeneous SAR image. IEEE Geosci. Remote Sens. Lett. 2024, 21, 4003705. [Google Scholar] [CrossRef]
- Xu, C.; Wang, X. OpenSARWake: A large-scale SAR dataset for ship wake recognition with a feature refinement oriented detector. IEEE Geosci. Remote Sens. Lett. 2024, 21, 4010105. [Google Scholar] [CrossRef]
- Zhang, T.; Tong, X.; Wang, Y. Semantics-assisted multiview fusion for SAR automatic target recognition. IEEE Geosci. Remote Sens. Lett. 2024, 21, 4007005. [Google Scholar] [CrossRef]
- Lin, Q.; Sun, H.; Xu, Y.; Wang, J.; Ji, K.; Kuang, G. Combining local electromagnetic scattering and global structure features for SAR open set recognition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 12572–12587. [Google Scholar] [CrossRef]
- Sun, Z.; Leng, X.; Zhang, X.; Zhou, Z.; Xiong, B.; Ji, K. Arbitrary-direction SAR ship detection method for multiscale imbalance. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5208921. [Google Scholar]
- Zhao, X.; Zhao, S.; Luo, Y.; Lv, B.; Zhang, Z. Generalizing SAR object detection: A unified framework for cross-source scenarios. IEEE Geosci. Remote Sens. Lett. 2025, 22, 4009105. [Google Scholar] [CrossRef]
- Saret, A.; Choudhury, T.; Aich, S.; Joshi, P.; Pant, B.; Choudhury, T. Butterfly image classification using modification and fine-tuning of ResNet18. In Proceedings of the 2024 OPJU International Technology Conference (OTCON) on Smart Computing for Innovation and Advancement in Industry 4.0, Raigarh, India, 5 June 2024; pp. 1–6. [Google Scholar]
- Wang, Z.; Xin, Z.; Liao, G. Land-sea target detection and recognition in SAR image based on non-local channel attention network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5237316. [Google Scholar] [CrossRef]
- Lv, B.; Ni, J.; Lu, Y.; Zhao, S.; Liang, J.; Yuan, H.; Zhang, Q. A multiview inter-class dissimilarity feature fusion SAR images recognition network within limited sample condition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 17820–17836. [Google Scholar] [CrossRef]
- Sun, Z.; Leng, X.; Zhang, X.; Xiong, B.; Ji, K.; Kuang, G. Ship recognition for complex SAR images via dual-branch transformer fusion network. IEEE Geosci. Remote Sens. Lett. 2024, 21, 4009905. [Google Scholar] [CrossRef]
- Wen, Z.; Yu, Y.; Wu, Q. Multimodal discriminative feature learning for SAR ATR: A fusion framework of phase history, scattering topology, and image. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5200414. [Google Scholar] [CrossRef]
- Zhang, L.; Leng, X.; Feng, S.; Ma, X.; Ji, K.; Kuang, G.; Liu, L. Domain knowledge powered two-stream deep network for few-shot SAR vehicle recognition. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5215315. [Google Scholar] [CrossRef]
- Wang, C.; Luo, S.; Huang, Y.; Pei, J.; Zhang, Y.; Yang, J. SAR ATR method with limited training data via an embedded feature augmenter and dynamic hierarchical-feature refiner. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5216215. [Google Scholar] [CrossRef]
- Wang, C.; Huang, Y.; Liu, X.; Pei, J.; Zhang, Y.; Yang, J. Global in local: A convolutional transformer for SAR ATR FSL. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4509605. [Google Scholar] [CrossRef]
- Lv, B.; Luo, Y.; Ni, J.; Zhao, S.; Liang, J.; Zhang, Q. Multiview and multi-level feature fusion method within limited sample conditions for SAR image target recognition. ISPRS J. Photogramm. Remote Sens. 2025, 224, 302–316. [Google Scholar] [CrossRef]
- Choi, J.H.; Lee, M.J.; Jeong, N.H.; Lee, G.; Kim, K.T. Fusion of target and shadow regions for improved SAR ATR. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5226217. [Google Scholar] [CrossRef]
- Xiao, Z.; Zhang, G.; Dai, Q. Multiview features centers sample expansion for SAR image classification. IEEE Geosci. Remote Sens. Lett. 2024, 21, 4001905. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target Type | BMP2 | BTR70 | T72 | 2S1 | BRDM2 | D7 | BTR60 | T62 | ZIL131 | ZSU234 |
|---|---|---|---|---|---|---|---|---|---|---|
| Training(15°) | 218 | 220 | 220 | 221 | 220 | 224 | 217 | 224 | 224 | 222 |
| Testing(17°) | 38 | 42 | 42 | 40 | 37 | 41 | 37 | 39 | 40 | 41 |
| Operating Condition | Training | Testing | ||||
|---|---|---|---|---|---|---|
| EOC-D | Types | Number | Depression Angle | Types | Number | Depression Angle |
| 2S1 | 299 | 17° | 2S1 | 288 | 30° | |
| BRDM2 | 298 | BRDM2 | 287 | |||
| T72 | 232 | T72 | 288 | |||
| ZSU234 | 299 | ZSU234 | 288 | |||
| EOC-V | Types | Number | Depression Angle | Types | Number | Depression Angle |
| BMP2 | 233 | 17° | T72-SN812 | 426 | 17°, 15° | |
| T72-A04 | 573 | |||||
| BRDM2 | 298 | T72-A05 | 573 | |||
| T72-A07 | 573 | |||||
| BTR70 | 233 | T72-A10 | 567 | |||
| BMP2-9566 | 428 | |||||
| T72 | 232 | BMP2-C21 | 429 | |||
| EOC-C | Types | Number | Depression Angle | Types | Number | Depression Angle |
| BMP2 | 233 | 17° | T72-S7 | 419 | 17°, 15° | |
| BRDM2 | 298 | T72-A32 | 572 | |||
| BTR70 | 233 | T72-A62 | 573 | |||
| T72 | 232 | T72-A63 | 573 | |||
| T72-A64 | 573 | |||||
| Method | Recall | Precision | F1 | Accuracy |
|---|---|---|---|---|
| VGG16 | 91.19 | 93.43 | 93.43 | 91.66 |
| GoogLeNet | 99.40 | 99.12 | 99.12 | 99.16 |
| ResNet18 | 99.15 | 98.92 | 99.01 | 99.09 |
| NLCANet | 99.75 | 99.57 | 99.58 | 99.72 |
| MIDFF | 99.54 | 99.53 | 99.54 | 99.58 |
| DDNet | 99.65 | 99.61 | 99.61 | 99.63 |
| DBTF | 99.16 | 99.10 | 99.11 | 99.14 |
| Ours | 99.92 | 99.88 | 99.88 | 99.90 |
| Class | BMP2 | BTR70 | T72 | 2S1 | BRDM2 | Average |
|---|---|---|---|---|---|---|
| Accuracy | 99 | 100 | 100 | 100 | 100 | 99.90 |
| Class | ZIL131 | BTR60 | T62 | D7 | ZSU234 | |
| Accuracy | 100 | 100 | 100 | 100 | 100 |
| EOC-D | Type | Accuracy | Average |
| 2S1 | 99.12 | 97.68 | |
| BRDM2 | 94.38 | ||
| T72 | 99.65 | ||
| ZSU234 | 97.57 | ||
| EOC-V | Type | Accuracy | Average |
| T72-SN812 | 98.59 | 98.11 | |
| T72-A04 | 98.25 | ||
| T72-A05 | 99.21 | ||
| T72-A07 | 97.73 | ||
| T72-A10 | 99.65 | ||
| BMP2-9566 | 97.79 | ||
| BMP2-C21 | 95.54 | ||
| EOC-C | Type | Accuracy | Average |
| T72-S7 | 98.33 | 99.11 | |
| T72-A32 | 98.60 | ||
| T72-A62 | 100 | ||
| T72-A63 | 98.95 | ||
| T72-A64 | 99.65 |
| Method | EOC-D | EOC-V | EOC-C |
|---|---|---|---|
| MoFFL [36] | 73.99 | 66.80 | 86.27 |
| DKTS-N [37] | 71.09 | 70.18 | 68.41 |
| EFA-DHFR [38] | 78.52 | 79.15 | 87.01 |
| ConvT [39] | 74.80 | 83.55 | 89.74 |
| MMFF [40] | 81.83 | 91.62 | 92.40 |
| IFTS [41] | 96.87 | 98.23 | 95.52 |
| EFAS [42] | 95.30 | 96.75 | 96.76 |
| Ours | 97.68 | 98.11 | 99.11 |
| Method | 1 | 2 | 3 | BMP2 | BTR70 | T72 | 2S1 | BRDM2 | D7 | BTR60 | T62 | ZIL131 | ZSU234 | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| V1 | √ | 95.83 | 100 | 100 | 91.67 | 100 | 100 | 95.45 | 91.30 | 100 | 100 | 97.36 | ||
| V2 | √ | 95.83 | 95.45 | 100 | 91.67 | 100 | 100 | 90.91 | 95.65 | 100 | 100 | 95.15 | ||
| V3 | √ | √ | 91.67 | 100 | 100 | 95.83 | 100 | 100 | 100 | 100 | 100 | 100 | 98.68 | |
| V4 | √ | √ | √ | 99.00 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 99.90 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Ni, J.; Luo, Y.; Wang, D.; Zhang, Q. A Dual-Branch Spatial-Frequency Domain Fusion Method with Cross Attention for SAR Image Target Recognition. Remote Sens. 2025, 17, 2378. https://doi.org/10.3390/rs17142378
Li C, Ni J, Luo Y, Wang D, Zhang Q. A Dual-Branch Spatial-Frequency Domain Fusion Method with Cross Attention for SAR Image Target Recognition. Remote Sensing. 2025; 17(14):2378. https://doi.org/10.3390/rs17142378
Chicago/Turabian StyleLi, Chao, Jiacheng Ni, Ying Luo, Dan Wang, and Qun Zhang. 2025. "A Dual-Branch Spatial-Frequency Domain Fusion Method with Cross Attention for SAR Image Target Recognition" Remote Sensing 17, no. 14: 2378. https://doi.org/10.3390/rs17142378
APA StyleLi, C., Ni, J., Luo, Y., Wang, D., & Zhang, Q. (2025). A Dual-Branch Spatial-Frequency Domain Fusion Method with Cross Attention for SAR Image Target Recognition. Remote Sensing, 17(14), 2378. https://doi.org/10.3390/rs17142378