1. Introduction
Lunar craters, formed by the high-velocity impacts of meteorites, constitute a fundamental class of surface topographic features on the Moon. These widely distributed craters can offer invaluable geological insights. The morphology, spatial distribution, and scale characteristics of lunar craters provide rich geological data critical for various scientific endeavors, including lunar dating [
1], stratigraphy [
2], and planetary evolution research [
3]. In recent years, with the advancement of lunar exploration activities, the precise topographic mapping of the lunar surface has become increasingly important for scientific research and mission planning. Specifically, the targeted mapping of medium- and small-scale craters (cratered regions larger than 8 ∗ 8 pixels) has become indispensable for the accurate selection and hazard assessment of safe landing and exploration sites on the Moon [
4].
The acquisition of high-resolution lunar remote sensing imagery provides a rich data foundation for crater detection while also presenting significant challenges. On one hand, lunar craters are inherently sparse in features, and a significant portion of them exhibit challenging visual characteristics such as small size, blurred boundaries, and low grayscale contrast. These factors lead to incomplete semantic representation during feature extraction, causing significant difficulties to accurately identify crater regions [
5]. Due to the sparsity of visual features, the model must rely on learning highly abstract and essential representations to achieve accurate detection. This increases the need for deeper and more complex network structures, which may compromise computational efficiency, especially in real-time applications. These challenges necessitate the need for effective feature enhancement strategy to mitigate the negative effect of down-sampled resolution on semantic representation and detection accuracy [
6]. On the other hand, the inherent complexity of the lunar surface, with features such as ravines, faults, and debris that visually resemble craters, can lead to significant background confusion in detection regions [
7,
8,
9]. Constructing global semantic associations in both spatial and channel dimensions to guide the model to focus on target areas while suppressing redundant responses is another key issue in improving crater detection performance.
To address the aforementioned challenges, it is imperative to develop more effective feature enhancement strategies that can improve the model’s capacity for semantic representation of lunar craters and enhance its stability and accuracy under complex background interference. In recent years, the rapid development of artificial intelligence, particularly data-driven methods based on deep learning, has led to transformative advances in various computer vision tasks such as image classification [
10], semantic segmentation [
11], and object detection [
12]. These methods leverage end-to-end learning mechanisms to automatically extract multi-level and multi-scale features from large datasets, significantly improving model adaptability to complex scenes and diverse targets. With the powerful feature representation capabilities of deep neural networks, researchers have increasingly applied these techniques to lunar and planetary surface analysis. In particular, deep learning-based approaches have demonstrated remarkable performance in automatic crater recognition, offering more efficient and intelligent solutions to support lunar geological studies and mission planning [
13].
However, degraded crater morphologies characterized by overlapping rims, partial erosion, or burial under regolith remain a primary source of false positives and missed detections. Existing approaches, ranging from morphological template fitting based on mathematical morphology [
14], texture-based segmentation using local binary patterns (LBPs) [
15] and Gabor filters [
9] to hybrid deep learning frameworks that jointly detect and reconstruct incomplete rims, demonstrate promising results on controlled benchmarks but often falter under realistic lunar imaging conditions due to variable illumination, resolution constraints, and heterogeneous terrain. This issue highlights the urgent need for enhanced feature representation.
Regarding the crater feature enhancement, early-stage two-stage models including Fast R-CNN [
16] and Faster R-CNN [
12] have reached high precision by refining region proposals and extracting features at multiple levels through RoI pooling and cascaded classifiers. These designs are particularly effective for craters with clear boundaries. However, their complex pipelines and slower inference speed limit their applicability to large-scale or real-time crater detection tasks. In contrast, recent single-stage detectors, especially the YOLO family of algorithms [
17], have become the mainstream architectures for crater detection owing to a fine balance between speed and accuracy. Various YOLO-based models, including YOLOv7-DCN [
18], YOLOv8-LCNet [
19], and YOLOv9-GELAN [
20], have been proposed by integrating different YOLO versions, yielding significant improvements in feature representation capabilities as well as global detection accuracy. Furthermore, the incorporation of attention mechanisms and multi-scale feature fusion has greatly enhanced the model’s capability of crater feature representation. For instance, HRFPNet [
21] employs a feature aggregation module (FAM) to strengthen contextual awareness, and the EfficientDet series [
22] introduces a BiFPN structure for efficient information integration. SE-Net [
23] boosts detection precision by introducing the CBAM attention module. Additionally, multi-branch convolutions [
24] and Transformer structures [
25] have also exhibited promising results in feature enhancement.
Building on feature enhancement, the integration of global modeling mechanisms enables the model to further focus on target regions and suppress background interference. CAD-Net [
26] introduced global context attention mechanisms to achieve comprehensive semantic understanding of the entire image. Following this, LBA-MCNet [
27] proposed the GDAL module to simulate pixel-level spatial dependencies, enhancing edge feature expression. GCNet [
28] and SCPNet [
29] effectively improved region focusing by combining spatial and channel attention mechanisms. Furthermore, a recently proposed GLGCNet [
30], adopted a “global–local–global” three-stage structure to address the issue of varying crater scales, showing superior robustness.
Despite the previous progress in strengthening the target representation and mitigating background interference, two major challenges persist: Firstly, to enhance the global crater detection performance, the local feature representation must be emphasized, especially for the craters with indistinct structural features. Most models deeply rely on the backbone network for shallow local modeling, causing difficulties to fully exploit contextual information for craters, further resulting in insufficient feature expression. Secondly, the visual similarity between craters and surrounding features, such as ridges or faults, often frustrate the correct detection of targeted craters. This problem is especially prominent when crater boundaries are blurred or degraded. Without sufficient contextual reasoning, models may misclassify these ambiguous regions, leading to false positives and missed detections. To address these issues, this paper proposes an improved YOLO11 series model—Spatial Channel Fusion and Context-Aware YOLO—that integrates context-aware modeling with spatial–channel information enhancement, aiming to systematically enhance lunar crater detection performance.
The main contributions of this paper are summarized as follows:
(1) The feature sparsity of lunar craters, caused by their small size and low contrast, often leads to incomplete semantic representation, which makes it difficult for conventional detectors to accurately localize the targets. To address this issue, we develop a Context- Aware Module (CAM) that enhances local contextual information through a multi-scale dilated convolution structure, thereby improving detection robustness. Simultaneously, Channel Attention Concatenation (CAC) is proposed to adaptively adjust the weight of each channel, leading to emphasized weights of important channels.
(2) A Joint Spatial and Channel Fusion Module (SCFM) is constructed to tackle the detection accuracy issue caused by the blurred boundaries and background interference. The cross-dimensional semantic associations employed by the SCFM contributes to advanced capability to focus on crater regions and suppress background interference.
(3) The feasibility of our model is validated using the self-constructed Chang’e 6 dataset. Comparing with mainstream detection models, our model achieves comprehensive results for precision, recall, , and . Experiments are conducted including model comparisons, ablation studies, and module replacements for the SCFM.
2. Methodology
2.1. Framework of SCCA-YOLO
YOLO11 was adopted as the baseline framework for the proposed model, based on a trade-off between detection performance and the expandability of new modules. Specifically, YOLO11 offers greater flexibility in module integration under the PyTorch framework, making it more suitable for model embedding. To enhance both context awareness and global perceptual capability, two specially designed modules were integrated into the head of YOLO11, alongside an improved feature concatenation strategy.
Initially, the CAM was introduced to enrich the network’s ability to perceive local contextual dependencies. Following this, a CAC strategy was applied to selectively emphasize the important channels. Subsequently, the SCFM was designed to strengthen the global representation by effectively extracting cross-spatial and cross-channel features. Detailed descriptions of the CAM, CAC, and SCFM are provided in
Section 2.2 and
Section 2.3, respectively.
The input remote sensing images were initially processed through the backbone to extract multi-scale features. These features were further enhanced and fused in the improved SCCA-YOLO head. Eventually, feature maps with three different sizes were utilized for the multi-scale target detection.
The architecture of the proposed SCCA-YOLO model is illustrated in
Figure 1.
2.2. Context-Aware Module (CAM)
In lunar crater detection, the challenge often arises from the inherent sparse features, leading to frequent misidentification of the target. However, the backbone network suffers from limited feature extraction ability, resulting from relatively insufficient context information and a shallow perception field, which causes difficulties in the accurate detection of the craters. Worse still, as the network deepens, the spatial resolution decreases, which exacerbates difficulties in detecting small craters.
To enhance the local feature perception of our model, we propose the CAM to optimize feature representation in two key aspects. First, to increase the richness of features, we utilize a multi-branch convolution structure that extracts semantic information from multiple perspectives to better differentiate planetary craters. Second, we expand the receptive field by employing dilated convolutions, which aggregate contextual information at varying scales without adding redundant computation cost. The detailed architecture of the CAM is illustrated in
Figure 2.
As shown in
Figure 2, the three branches of CAM initially pass through a
convolution to adjust the number of channels, thereby reducing computational complexity while preserving essential feature information. The second and third branches then apply
convolutions to extract basic features. Subsequently, dilated convolutions with dilation rates of
,
, and
are established to represent receptive fields of different sizes. The mathematical representation of the three branches of the CAM is as follows:
where
and
represent the standard convolutions with kernel sizes of
and
, respectively;
,
, and
represent the dilated convolution with a kernel size of
and dilation rates of 1, 3, and 5, respectively;
is the input feature map, and
,
, and
represent the output feature maps of the three branches.
After being processed by the three branches, the outputs are concatenated and passed through a final
convolution to refine the feature map into the output channel. Finally, a residual structure is introduced to pass the input feature map through a
convolution, which retains the key features of the crater. This residual map is then fused with the previously extracted features containing local contextual information. The concatenation and residual connection are expressed as:
where
denotes the feature map concatenation operation; ⊕ denotes the element-wise addition of the feature maps;
denotes using the rectified linear unit as the activation function;
M represents the feature map of local feature awareness; and
represents the output feature map.
In particular, the choice of dilated convolution was based on the relationship between crater size and receptive field. The input images were sized at 512 × 512 pixels, and we defined a valid crater as having a diameter greater than 8 pixels. However, in the YOLO11 framework, even the deepest feature map (P5) only offers a receptive field of approximately 11 pixels, which is insufficient to cover and characterize larger craters entirely. This limitation restricts the network’s ability to incorporate contextual information around the craters. Therefore, by employing dilated convolutions, we effectively enlarged the receptive field without increasing the model’s depth, strengthening its capability to integrate neighboring features into the crater representation. This strategy is refereed to as context-aware modeling in this study.
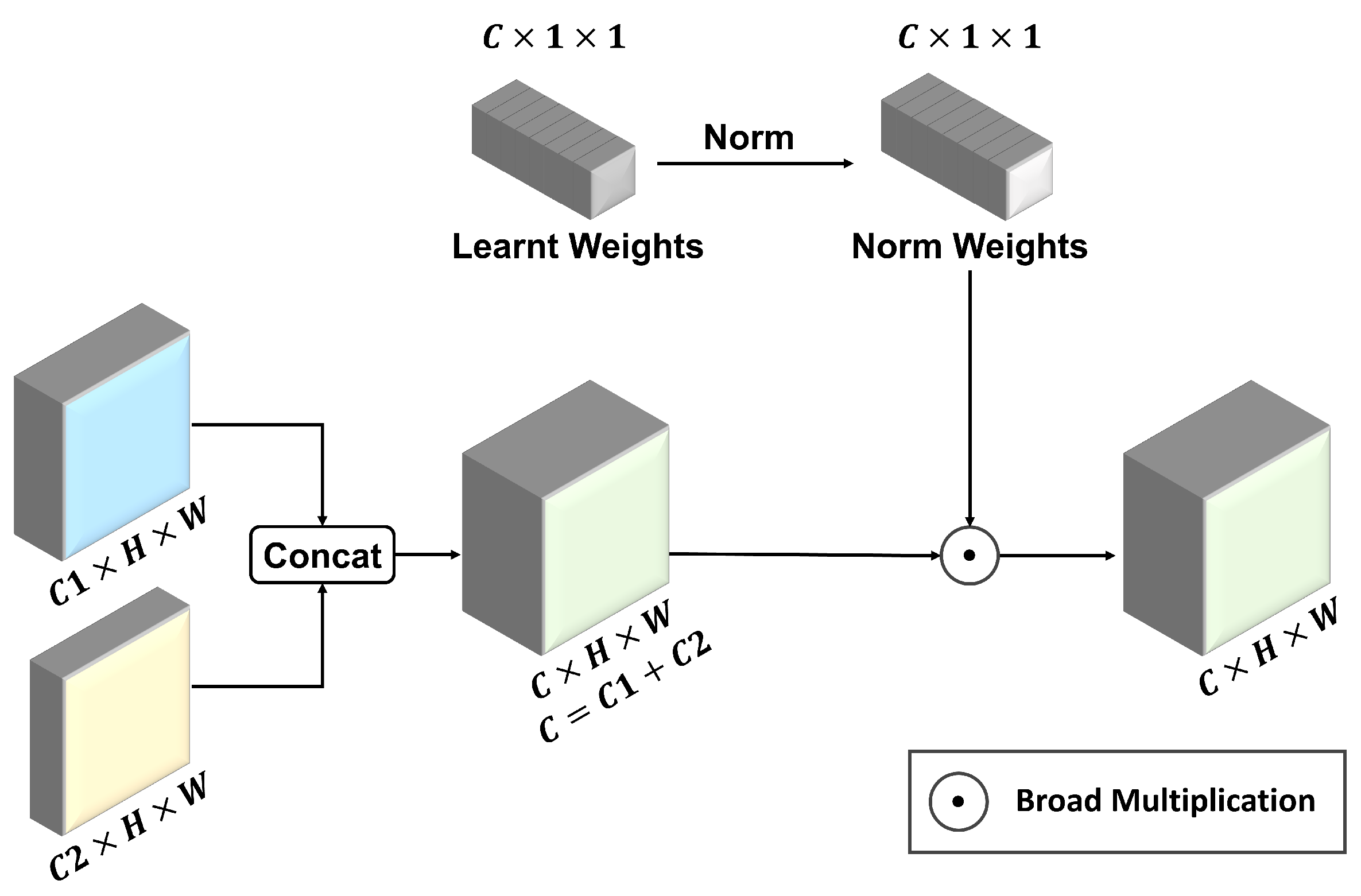
Furthermore, the original splicing strategy of the YOLO11 model simply stacks two feature maps without distinguishing the importance of their semantic content. To optimize the information fusion process of impact craters, we propose a Channel Attention Concatenation (CAC) strategy. By assigning attention weights to channel information, the concatenated features pay more attention to channels with more semantic information, providing more effective feature maps for subsequent global information modeling.
As shown in
Figure 3, CAC introduces a learnable weight for each input feature map. These adaptive weights are automatically updated during training like convolution parameters, allowing the model to adaptively weight each feature map according to its importance, thus achieving more effective and discriminative feature fusion. Our attention weighting strategy first concatenates the input feature maps, then normalizes the trained weights, multiplies them with the original input features, and finally obtains the reconstructed features in the channel dimension. The mathematical expression of CAC is as follows:
where
denotes the feature map concatenation operation, ⊙ denotes the broad multiply operation of feature maps.
,
represent the input feature maps, and
M is the concatenated feature map.
W represents the adaptive weight vector, and
represents the
ith value of
W,
is the normalized weight vector, and
represents the
jth value of
.
represents the output feature map.
Different from the original splicing strategy of YOLO11, which treats all feature maps equally, the proposed CAC strategy introduces an adaptive weighting mechanism in the channel dimension. It assigns different weights according to the importance of each channel for impact crater feature expression. This enables the model to better focus on channels highly relevant to the semantics of impact craters, thereby enhancing the ability to extract key information.
2.3. Joint Spatial and Channel Fusion Module (SCFM)
After the CAM and CAC, the feature maps have captured abundant local contextual information, enhancing the representation of crater features. At this stage, modeling the global relationship between craters and the background allows the model to focus attention more effectively on the target craters. Therefore, we designed the SCFM before the detection head instead of the backbone network. The SCFM integrates global spatial and channel information, representing the relationships across both space and channels between pixels. This helps suppress irrelevant background features and improves the distinction between craters and the background.
As illustrated in
Figure 4, the SCFM consists of four branches. The first and second branches, respectively, utilize global max pooling (GMP) and global average pooling (GAP) to integrate global spatial information, representing it as channel weights. The third branch applies a
convolution to map the input feature map. The fourth branch uses a
convolution to adjust the feature map channels to 1, integrating global channel information into spatial position weights. Following this, the third branch performs matrix multiplication with the first and second branches to apply channel-wise weighting to the mapped feature map, emphasizing the more important feature channels. The two multiplication results are subsequently concatenated and processed through a
convolution, yielding a spatial location weight. This spatial attention mechanism based on dual pooling layers contributes to a more concentrated attention on the test-related regions. Simultaneously, the third branch performs matrix multiplication with the fourth branch to selectively focus on the spatial locations in the feature map, obtaining a channel weight. This matrix multiplication result is enhanced by a
convolution, further yielding a channel-aware feature map, which strengthens the model’s ability to focus on the most salient features of craters. The mathematical representations of the operations above are listed as follows:
where
and
represent the standard convolution with the output channel of
and 1, respectively.
and
denote global average pooling and global max pooling, respectively. ⊗ denotes the matrix multiply operation of feature maps.
denotes the feature map concatenation operation.
and
represent the feature maps of the first and second branches, respectively.
and
represents the spatial-aware and channel-aware feature maps, respectively.
At this stage, both spatial-aware and channel-aware feature maps are prepared. Through a board multiplication of these two feature maps, a feature representation with global spatial and channel information can be obtained. Eventually, a residual net connecting the original feature map is applied to retain the shallow features and avoid issues including gradient vanishing. It is also notable that a learnable residual scaling factor is included in this residual structure. This factor adjusts the weight of global fused information in the SCFM, allowing the model to selectively focus on the original key crater features and the fused cross-channel and cross-space information.
The final-stage pixel-level global information in the SCFM can be represented as follows:
where ⊙ denotes the broad multiply operation of feature maps, ⊕ denotes element-wise addition of the feature maps,
M is the spatial-aware and channel-aware feature map,
W is the residual scaling factor, and
represents the output feature map.
In short, according to
Figure 4, the SCFM enhances and fuses channel and spatial information twice, making it highly effective in global perception. This approach allows the model to adopt a holistic view and direct attention toward the target craters, ultimately improving crater detection performance.
3. Experiment Results and Discussions
3.1. Experiment Configurations
3.1.1. Datasets Provenance and Segmentation
The dataset employed in this study originated from the Chang’e-6 landing site and its surrounding areas. The native ground sampling distance of the original images was approximately 0.85 m per pixel. From these original images, we carefully selected representative regions and extracted grayscale patches, resulting in a curated dataset consisting of 216 images. Each image covered approximately 200,000 square meters of the lunar surface, and the 216 images together spanned over 40 million square meters. The dataset exhibited strong diversity by covering a wide range of typical detection scenarios.
During the dataset preparing process, all of the reference lunar craters were labeled manually to ensure an optimal dataset quality. A significant portion of these images contained over 100 annotated craters each, with a total of 26,435 crater instances labeled across the dataset. To ensure annotation consistency, we adopted a unified filtering strategy: craters smaller than 8 × 8 pixels were excluded due to their high ambiguity, and for partially truncated craters at the image boundaries, only those with more than half of the structure preserved were annotated. These annotated craters spanned a broad spectrum of scales and morphological variations, ranging from small-scale, well-defined rims to large, heavily degraded structures. Specifically, small craters with diameters less than 50 m account for approximately 92% of all labeled instances in the dataset. The diversity and richness of this dataset provided a robust foundation for evaluating detection performance under challenging conditions including small-object recognition, ambiguous boundaries, and cluttered backgrounds.
Regarding the dataset partitioning, the dataset was split into training, validation, and testing subsets in a ratio of 8:1:1. All performance metrics reported in this study were computed on the testing subset to comprehensively and objectively assess the effectiveness and generalizability of the model.
It is also notable that no redundant cropping was applied during the image pre-processing stage. While overlapping cropping could increase sample diversity and allow some partially cut craters to appear fully in other patches, it may also introduce data leakage and lead to overfitting. The fundamental reason is that the overlapping clipping would cause the same crater to reappear in different data subsets, resulting in advanced exposure of key characteristics. This negative consequence can further lead to falsely high results for the evaluation metrics.
3.1.2. Model Implementation
All experiments in this study were conducted on a workstation equipped with an NVIDIA GeForce RTX 4090 GPU (24,111 MiB memory) (NVIDIA, Santa Clara, CA, USA). The software environment included Python 3.10.8, PyTorch 2.5.1, and the Ultralytics YOLO version 8.3.25 framework.
Among the five different-size YOLO11 variants, YOLO11s was selected as a trade-off between computational efficiency and detection accuracy. The AdamW optimizer was employed for model training, and hyperparameters were empirically selected and fine-tuned based on the validation set performance to ensure both stable convergence and optimal accuracy. The training pipeline was configured for 300 epochs with a batch size of 32. The initial learning rate was set to 0.002, and the momentum coefficient was fixed at 0.9. This implementation setup ensured a robust and reproducible training process that balanced computational efficiency with convergence stability.
3.1.3. Evaluation Metrics
To comprehensively evaluate the proposed model’s detection performance and computational efficiency, we adopted six widely used metrics. Detection performance was assessed using precision (P), recall (R), , and . For computational efficiency, GFLOPs and Params were utilized as evaluation metrics.
Regarding the detection performance evaluation, precision (P) quantifies the proportion of correctly predicted positive instances among all predicted positives. It is calculated as
where
and
denote true positives and false positives, respectively.
Recall (R) measures the model’s ability to detect actual positive instances. It is defined as
where
refers to false negatives.
mAP provides an overall measure of detection accuracy across various confidence thresholds. It is one of the most widely accepted metrics in object detection tasks and includes two commonly reported forms
and
. mAP is calculated as the area under the precision–recall (PR) curve, averaged over all object classes:
where
N denotes the number of object classes, and
is the average precision for class
i.
With regard to the computational efficiency performance, GFLOPs measure the model’s computational complexity. A lower number of GFLOPs reflects lower computational demands, making the model more suitable for deployment in resource-constrained environments.
Params assesses the model’s size and storage requirement. Smaller models with fewer parameters are easier to store, transfer, and deploy, particularly in embedded or mobile systems.
By jointly considering these multidimensional metrics, we established a systematic and holistic evaluation of the model’s overall performance, encompassing detection accuracy, computational efficiency, and resource consumption.
3.2. Results and Comparisons
3.2.1. Performance Comparison with Mainstream Detection Models
To comprehensively validate the detection performance and application potential of the proposed SCCA-YOLO model, we conducted comparative experiments against a range of representative baseline algorithms. These included the two-stage detector Faster R-CNN, single-stage detectors RetinaNet and CenterNet, and the mainstream YOLO series including YOLOv5, YOLOv6 [
31], YOLOv8, YOLOv9 [
32], YOLOv10 [
33], and YOLO11.
Faster R-CNN, a canonical two-stage detection framework, incorporates a Region Proposal Network (RPN), making it a high-precision model suitable as an accuracy benchmark. RetinaNet addresses class imbalance using the Focal Loss function, offering notable advantages in small-object detection. CenterNet, as a keypoint-based one-stage detector, yields a fine balance between speed and accuracy by directly predicting object centers.
The YOLO family of algorithms have gained wide adoption in practical applications due to their remarkable real-time performance and detection accuracy. Notably, with iterative improvements from YOLOv5 to YOLO11, the architectures have progressively optimized the trade-off between detection accuracy and the interference speed, leading to incrementally robust and efficient models. Consequently, benchmarking against multiple YOLO versions enabled a comprehensive evaluation of SCCA-YOLO’s comprehensive capabilities in terms of detection precision, computational complexity, and real-time applicability within the same algorithm family. The overall comparison experiment results are illustrated in
Table 1.
Experimental results indicated that traditional detectors including Faster R-CNN, RetinaNet, and CenterNet fell short in the task of lunar crater detection, largely because their design philosophies are misaligned with the unique characteristics of crater imagery. Firstly, Faster R-CNN’s two-stage pipeline relies on an RPN to generate candidate regions, followed by region-wise pooling that inherently diminishes spatial resolution. Such an approach proves ill-suited for isolating small, densely clustered craters with faint rims, as RPNs are highly sensitive to edge ambiguity, and the pooling layers further erode the already subtle features of degraded crater boundaries. Moreover, the model’s computationally heavy backbone and multi-stage processing significantly hamper throughput, rendering it impractical for large-scale inference on high-resolution planetary datasets.
RetinaNet addresses class imbalance by introducing Focal Loss, which indeed elevates detection metrics—pushing precision to 40.3% and recall to 50.4%—yet it still lacks the architectural innovations necessary for robust multi-scale feature extraction and holistic context reasoning. In lunar surface scenes, many non-crater structures (such as ridges, shadows, and geological faults) exhibit textures and shapes that closely resemble true craters. Without an explicit mechanism for aggregating fine-grained details across scales or for modeling long-range dependencies, RetinaNet frequently confused these terrain artifacts with genuine impact features, capping its mAP at 60.8% (IoU = 0.5) and 36.5% (IoU = 0.5:0.95).
CenterNet reframes detection as keypoint estimation, predicting object centers and regressing object dimensions in a single stage. While this yields commendable inference speed, it rests on implicit assumptions of object centrality and approximate symmetry—assumptions that lunar craters often violate. Craters on planetary surfaces can overlap, erode unevenly, or be partially obscured by ejecta and shadows, disrupting the notion of a well-defined centroid. Consequently, CenterNet’s reliance on a single-point representation led to missed detections and spurious false positives, limiting its precision to 40.6% and recall to 45.2%.
In contrast, the YOLO family generally outperformed these models due to their dense prediction structure, robust feature fusion capabilities, and high-resolution output maps, which are more compatible with the demands of crater detection. For instance, YOLOv5 yielded a precision of 90.7% and a recall of 86.8%, which showcased a great advancement comparing with non-YOLO algorithms. Subsequent versions incorporate attention mechanisms and various feature fusion strategies, leading to similarly acceptable results with minor advancement. By YOLO11, most metrics illustrated an ascent despite the compromise on precision at 88.7%. The recall reached 87.6%, and and improved to 95.9% and 80.8%, respectively. However, challenges persisted, particularly under high IoU thresholds, where the model exhibited localization inaccuracies reflected in stagnant precision, especially for small-scale craters in complex terrain.
In comparison of all models, the proposed SCCA-YOLO surpassed all baselines across all detection performance. It achieved a precision of 90.8%, recall of 88.5%, of 96.5%, and of 81.5%, representing respective gains of 2.1%, 0.9%, 0.6%, and 0.7% over YOLO11. Regarding computational efficiency, YOLO11 achieved the best GFLOPs (21.5) while YOLOv9 excelled in Params (7.288M). Although SCCA-YOLO was slightly inferior in these metrics compared with some mainstream models, its computational efficiency had an acceptable tolerance. In short summary, SCCA-YOLO, despite an acceptable sacrifice in computational efficiency, yielded stronger robustness and generalization in lunar crater detection, which is especially critical for representing subtle crater features, extracting semantic information, and suppressing interference from complex backgrounds.
3.2.2. Visual Evaluation of Classic YOLO Algorithms
To further provide an intuitive assessment of model performance under complex and challenging conditions, four representative test images were selected for visual analysis. These samples encompassed typical difficulties encountered in lunar crater detection tasks, including blurred crater boundaries, overlapping crater clusters, large-scale variations, and high-exposure interference. We compared the detection results of the proposed SCCA-YOLO model with those of three mainstream models, including YOLOv5, YOLOv8, and the baseline YOLO11, to evaluate their robustness and adaptability in practical application scenarios. The comparison results are illustrated in
Figure 5.
From an overall perspective, YOLOv5 and YOLOv8 demonstrated moderate capability in target boundary localization. However, they frequently suffered from missed detections and false positives when dealing with craters that exhibited weak visual features or were embedded in complex spatial structures. For instance, in the second and third rows of
Figure 5, where unclear boundaries, crater overlap, and scale diversity are prominent, both YOLOv5 and YOLOv8 exhibit noticeable performance degradation, failing to accurately detect several targets.
YOLO11, in comparison, demonstrated a marked improvement in detecting craters with weak or subtle features, highlighting its enhanced feature extraction capability. Nonetheless, it still struggled with target omission and misclassification in challenging settings such as high-exposure regions (first row) and complex background interference (fourth row). In these cases, YOLO11 exhibited similar issues such as boundary ambiguity, incomplete crater localization, and spurious detections, necessitating further improvements for robust performance in adverse conditions.
In contrast, the proposed SCCA-YOLO consistently delivered more stable and accurate detection results across all four challenging scenarios. It effectively identified craters with low contrast, ambiguous morphology, or overlapping spatial arrangements, and demonstrates strong resistance to illumination noise and background clutter. These results validate the effectiveness and practicality of SCCA-YOLO in real-world lunar crater detection tasks, especially under conditions that traditionally degrade detection robustness.
The superior performance of SCCA-YOLO stems from comprehensive enhancements in feature extraction and information fusion strategies. On one hand, the model reinforces local contextual understanding and multi-scale feature awareness, enabling the more sensitive detection of small-scale craters. On the other hand, its optimized fusion architecture strengthens salient feature representation and attenuates background noise, improving the model’s ability to discriminate between craters and surrounding terrain. This synergy between local feature enhancement and global semantic modeling significantly improves both detection accuracy and localization precision, thereby ensuring the model’s adaptability and stability in various real-world scenarios.
Notably, as shown in
Figure 5, medium- and small-scale craters constitute the vast majority of our annotated population. Because these smaller features also exhibit the greatest degree of degradation, the aggregate recall and precision scores we report predominantly reflect our model’s ability to detect such challenging instances. Consequently, the overall performance metrics can be regarded as a robust proxy for small-crater detection accuracy, thereby guiding targeted improvements in future work.
3.3. Ablation Experimental Result
To further validate the effectiveness of the individual modules in SCCA-YOLO, a series of ablation experiments were designed. These experiments were conducted on the same dataset by selectively removing key modules, including the CAM, CAC, and SCFM. Notably, we did not evaluate the CAC strategy independently (i.e., baseline + CAC or baseline + CAC + SCFM), as CAC was specifically designed to complement the CAM module. As detailed in
Section 2.2, CAC performs channel-wise reweighting on the multi-branch outputs produced by CAM. Without the CAM providing enriched feature representations, CAC cannot operate as intended, and its independent evaluation would deviate from the original module design. The results of the ablation experiments are presented in
Table 2. To further illustrate the effectiveness of the proposed modules,
Figure 6 visualizes the intermediate feature maps across different configurations.
From these results, it can be observed that the baseline model achieved a precision of 88.7% and a recall of 87.6%. The corresponding values of and were 95.9% and 80.8%, respectively. These results indicate that the baseline model, despite the absence of any added modules, demonstrated moderate detection capability.
After introducing the CAM (Case b) into the baseline model, the precision and recall increased to 90.5% and 87.8%, respectively, while
slightly improved to 96.0%. These findings suggest that the CAM, through multi-branch dilated convolution, effectively enhances the model’s local contextual awareness and improves its sensitivity to craters with indistinct visual features. To intuitively demonstrate the effectiveness of the CAM, we conducted a visualization of the feature map after processing through the CAM, as illustrated in the third column of
Figure 6. According to these feature maps, the CAM contributes to the initial feature enhancement of our model based on the local context information. This partially mitigates the challenge of weak feature representation. However, due to the insufficient fusion of high-level semantic information,
did not show a substantial improvement.
Upon further integration of the CAC strategy (Case c), the precision and recall remained largely unchanged, whereas increased to 81.3%. This demonstrates that the CAC strategy optimizes the feature fusion process through adaptive channel-wise weighting, strengthening semantic associations across multi-scale features and improving overall recognition performance under varying crater scales and background complexities.
When the SCFM was incorporated (Case d), the model’s performance improved comprehensively, with both precision and recall reaching 90.0%. Meanwhile,
and
further increased to 96.3% and 81.4%, respectively. The SCFM, by performing global feature fusion along both spatial and channel dimensions, effectively suppresses complex background noise and further enhances the model’s ability to differentiate craters from clutter. The corresponding feature maps (the fourth column of
Figure 6) corroborate this improvement: After the SCFM, the model further concentrates on the target craters owing to the module’s superior global modeling capability. Therefore, the craters can be more effectively distinguished with the background interference.
Finally, with all three modules integrated (Case f), the model achieved optimal performance across three of the four metrics: precision improved to 90.8%, recall to 88.5%, to 96.5%, and to 81.5%. These results validate the effectiveness of the proposed progressive optimization strategy across three stages—feature enhancement, semantic fusion, and global modeling. In particular, the combined application of the CAM, CAC strategy, and SCFM exhibits strong complementarity and synergistic benefits, significantly improving the model’s robustness and generalization capability in detecting small-scale craters and suppressing complex background interference.
3.4. SCFM Replacement
Finally, we conducted comparative experiments against several representative global context modeling methods, including NLBlock, SCPBlock, and GCBlock. The experimental results are summarized in
Table 3.
The NLBlock, which models long-range dependencies via non-local operations, improves global contextual awareness by directly computing interactions across all spatial positions. However, its high computational complexity and lack of specialization for small object features or complex backgrounds limit its performance in crater detection tasks. Specifically, it yielded a precision of 83.3%, recall of 84.6%, and a relatively low of 69.3%, falling short of practical deployment requirements in high-density, high-noise environments.
The SCPBlock achieved a recall of 90.1%, slightly higher than the SCFM, but its precision dropped to 88.2%, lower than the 90.0% attained by the SCFM. This trade-off suggests that while SCPBlock improves detection coverage, it sacrifices accuracy, likely introducing more false positives. This drawback arises from SCPBlock’s emphasis on enhancing spatial features while lacking adequate channel-wise feature representation. As a result, the model struggles to accurately delineate craters from background textures in complex terrains, ultimately impairing detection precision.
In contrast, GCBlock performed well in terms of precision (91.4%) but exhibited a lower recall of 87.5% compared to the SCFM. This indicates a reduced capacity to detect all craters, especially in challenging scenarios. The GCBlock primarily leverages channel attention for global feature modeling but does not sufficiently utilize spatial information, making it less effective for detecting irregular or edge-degraded crater instances. Consequently, the model is prone to missed detections in regions with ambiguous boundaries, leading to a higher type II error.
The proposed SCFM addresses the limitations of the above approaches by jointly modeling global context across both spatial and channel dimensions. This dual-domain interaction significantly enhances the model’s ability to capture salient features while suppressing background noise. As a result, SCFM achieved balanced and superior performance, with both precision and recall reaching 90.0%. Furthermore, it delivered the best results across two evaluation metrics, attaining of 96.3% and of 81.4%. On the other two metrics, P and R, it obtained the second-best result among the four modules, yielding 90.0% for both. While our SCFM did not achieve the highest scores on every metric, it nevertheless attained an optimal trade-off between precision and recall.
These findings clearly demonstrate the robustness and generalization capability of the SCFM, particularly in detecting craters amidst complex background conditions. The module’s effectiveness makes it especially suitable for scenarios involving dense crater distributions and topographically heterogeneous surfaces, where conventional global modeling methods fall short.
4. Conclusions
This paper presented SCCA-YOLO, a novel lunar crater detection framework tailored for high-resolution CCD imagery. To address the limitations of traditional methods, particularly the insufficient feature representation and background interference, SCCA-YOLO incorporates two key innovation modules: CAM and SCFM. The CAM utilizes a multi-branch dilated convolution structure to capture diverse semantic information and enhances local contextual perception through diffusion convolutions, effectively detecting craters across various scales. Additionally, an adaptive CAC mechanism was introduced to strengthen critical information pathways during feature fusion, further enhancing feature representation quality. On this basis, the SCFM performs feature fusion along both the global spatial and channel dimensions, directing the model’s attention towards target craters and significantly improving detection capability.
Extensive experiments conducted on the Chang’e-6 dataset demonstrated that SCCA-YOLO consistently outperformed other mainstream detection models in terms of precision, recall, and mAP.
In particular, SCCA-YOLO exhibited a marked advantage in crater detection tasks, especially under challenging scenarios of blurred features and complex background interference. This incremental advancement notably improved detection accuracy and enhanced robustness against complex illumination and topographic variations. Compared to traditional YOLO-based methods, SCCA-YOLO achieved superior stability and resilience.
In conclusion, lunar craters are fundamental geomorphological features of the Moon and are crucial for understanding lunar surface evolution. The efficient and accurate detection of these craters holds significant scientific importance and practical value. Given the diversity in crater sizes, detection results not only affect recognition performance but also directly impact lunar age estimation, where large craters are typically used as statistical indicators. Ensuring accurate detection across scales helps improve the scientific reliability of geological interpretation. In particular, crater statistics derived from high-precision detection results can serve as a key basis for crater-based lunar dating methods, helping to reduce age estimation errors and improve the reliability of geological evolutionary analysis. Future research will focus on further compressing the model architecture and enhancing real-time detection capabilities. In addition, the generalizability and scalability of the proposed method will be explored in surface feature extraction and geological structure recognition tasks on other planetary bodies.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}